diff --git a/工作日志/2020年9月6日-ML.md b/工作日志/2020年9月6日-ML.md
index 6031cc37..153ff1af 100644
--- a/工作日志/2020年9月6日-ML.md
+++ b/工作日志/2020年9月6日-ML.md
@@ -58,6 +58,13 @@ python3-numpy-scipy-matplotlib-pandas√
> 变更说明
> * 经过仔细思考,感觉李宏毅的机器学习+深度学习与吴恩达的机器学习+深度学习,重叠的部分太多,入门阶段进行混合学习代价较大。所以,入门阶段都是以吴恩达的课程为主,编程也是以吴恩达的课程为主。总共包括五个模块,可以适当地学习三到四个模块,然后进行下一阶段。
+> * 等所有部分完成了,以李宏毅的课程作为基础知识的回顾和强化。
+
+
+> 学习路径说明
+> * 视频教程-基础知识构建,以知识的角度,逐渐构建机器学习体系,跟随课程理解。
+> * 读书整理-机器学习算法,从算法的角度,独立理解算法的原理,深刻理解每个算法的原理。
+> * 算法实践,从工程的角度,考虑如何设计算法,实现算法,优化算法和进行算法可视化
### 联邦学习系列(三周)
@@ -68,7 +75,12 @@ fate
### 相关资料说明
* 吴恩达的机器学习
* 吴恩达的深度学习五套课程
-* 西瓜书
+* 李宏毅《机器学习+深度学习》课程
+* ~~林轩田《机器学习基石》课程~~
+* 李航《统计学习方法》
+* 周志华《西瓜书》
+* 《机器学习实战》
+* 《Python机器学习》
### 选择
框架选择:
diff --git a/机器学习/ApacheCN/readme.md b/机器学习/ApacheCN/readme.md
deleted file mode 100644
index a176c1d8..00000000
--- a/机器学习/ApacheCN/readme.md
+++ /dev/null
@@ -1 +0,0 @@
-> 这里主要以各种算法的理论知识为主进行说明。
\ No newline at end of file
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1D-3D-Convolution.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1D-3D-Convolution.png
new file mode 100644
index 00000000..7f9ff369
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1D-3D-Convolution.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-1.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-1.png
new file mode 100644
index 00000000..ef24153d
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-1.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-2.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-2.png
new file mode 100644
index 00000000..a42dcef2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/1x1-Conv-2.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/AlexNet.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/AlexNet.png
new file mode 100644
index 00000000..9e9653f6
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/AlexNet.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Another-Convolutional-operation-example.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Another-Convolutional-operation-example.jpg
new file mode 100644
index 00000000..9c7c818c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Another-Convolutional-operation-example.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Average-Pooling.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Average-Pooling.png
new file mode 100644
index 00000000..4dc253aa
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Average-Pooling.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Bounding-Box-Predictions.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Bounding-Box-Predictions.png
new file mode 100644
index 00000000..f72fd113
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Bounding-Box-Predictions.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/CNN-Example.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/CNN-Example.jpg
new file mode 100644
index 00000000..7a2a8e7a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/CNN-Example.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolution-implementation-of-sliding-windows.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolution-implementation-of-sliding-windows.png
new file mode 100644
index 00000000..71bccaf3
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolution-implementation-of-sliding-windows.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation-example.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation-example.jpg
new file mode 100644
index 00000000..30e61ad9
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation-example.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation.jpg
new file mode 100644
index 00000000..d8c73dce
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutional-operation.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutions-on-RGB-image.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutions-on-RGB-image.png
new file mode 100644
index 00000000..1e7768ab
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Convolutions-on-RGB-image.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Different-edges.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Different-edges.png
new file mode 100644
index 00000000..2d69ecac
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Different-edges.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-module.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-module.jpg
new file mode 100644
index 00000000..24765c12
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-module.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-network.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-network.jpg
new file mode 100644
index 00000000..c550ebc1
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Inception-network.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Intuition-about-style-of-an-image.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Intuition-about-style-of-an-image.png
new file mode 100644
index 00000000..cbf4b9cc
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Intuition-about-style-of-an-image.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/LeNet-5.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/LeNet-5.png
new file mode 100644
index 00000000..5a0aa010
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/LeNet-5.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Max-Pooling.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Max-Pooling.png
new file mode 100644
index 00000000..b2f12ffc
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Max-Pooling.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/More-Filters.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/More-Filters.jpg
new file mode 100644
index 00000000..f1a52898
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/More-Filters.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Motivation-for-inception-network.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Motivation-for-inception-network.jpg
new file mode 100644
index 00000000..69a9f9c5
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Motivation-for-inception-network.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Neural-style-transfer.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Neural-style-transfer.png
new file mode 100644
index 00000000..04a04652
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Neural-style-transfer.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/One-Layer-of-a-Convolutional-Network.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/One-Layer-of-a-Convolutional-Network.jpg
new file mode 100644
index 00000000..183fa505
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/One-Layer-of-a-Convolutional-Network.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Overlapping-objects.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Overlapping-objects.png
new file mode 100644
index 00000000..8f8f58b7
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Overlapping-objects.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Padding.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Padding.jpg
new file mode 100644
index 00000000..e524eff7
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Padding.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/R-CNN.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/R-CNN.png
new file mode 100644
index 00000000..55c83521
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/R-CNN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Paper.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Paper.png
new file mode 100644
index 00000000..1bedade9
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Paper.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Training-Error.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Training-Error.jpg
new file mode 100644
index 00000000..37ec3ba6
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/ResNet-Training-Error.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-Network.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-Network.jpg
new file mode 100644
index 00000000..b153aa93
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-Network.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-block.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-block.jpg
new file mode 100644
index 00000000..ac27bf92
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Residual-block.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Siamese.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Siamese.png
new file mode 100644
index 00000000..2a565861
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Siamese.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Simple-Convolutional-Network-Example.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Simple-Convolutional-Network-Example.jpg
new file mode 100644
index 00000000..c2bee84e
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Simple-Convolutional-Network-Example.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sliding-windows-detection.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sliding-windows-detection.png
new file mode 100644
index 00000000..f14be51e
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sliding-windows-detection.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sobel-Filter-and-Scharr-Filter.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sobel-Filter-and-Scharr-Filter.png
new file mode 100644
index 00000000..ee8ef85c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Sobel-Filter-and-Scharr-Filter.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Stride.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Stride.jpg
new file mode 100644
index 00000000..214502e6
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Stride.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/The-problem-of-computational-cost.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/The-problem-of-computational-cost.png
new file mode 100644
index 00000000..45680c25
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/The-problem-of-computational-cost.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Training-set-using-triplet-loss.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Training-set-using-triplet-loss.png
new file mode 100644
index 00000000..76ebd1d2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Training-set-using-triplet-loss.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Using-1x1-convolution.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Using-1x1-convolution.png
new file mode 100644
index 00000000..553da67d
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Using-1x1-convolution.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/VGG.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/VGG.png
new file mode 100644
index 00000000..05c5f905
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/VGG.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-Edge-Detection.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-Edge-Detection.jpg
new file mode 100644
index 00000000..09265a5c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-Edge-Detection.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-and-Horizontal-Filter.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-and-Horizontal-Filter.png
new file mode 100644
index 00000000..59694832
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Vertical-and-Horizontal-Filter.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Visualizing-deep-layers.png b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Visualizing-deep-layers.png
new file mode 100644
index 00000000..8e8c75a0
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Visualizing-deep-layers.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Why-do-residual-networks-work.jpg b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Why-do-residual-networks-work.jpg
new file mode 100644
index 00000000..63d0f2aa
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/Why-do-residual-networks-work.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/卷积神经网络.md b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/卷积神经网络.md
new file mode 100644
index 00000000..3d985a64
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/卷积神经网络.md
@@ -0,0 +1,222 @@
+卷积神经网络
+
+## 计算机视觉
+
+**计算机视觉(Computer Vision)**的高速发展标志着新型应用产生的可能,例如自动驾驶、人脸识别、创造新的艺术风格。人们对于计算机视觉的研究也催生了很多机算机视觉与其他领域的交叉成果。一般的计算机视觉问题包括以下几类:
+
+* 图片分类(Image Classification);
+* 目标检测(Object detection);
+* 神经风格转换(Neural Style Transfer)。
+
+应用计算机视觉时要面临的一个挑战是数据的输入可能会非常大。例如一张 1000x1000x3 的图片,神经网络输入层的维度将高达三百万,使得网络权重 W 非常庞大。这样会造成两个后果:
+
+1. 神经网络结构复杂,数据量相对较少,容易出现过拟合;
+2. 所需内存和计算量巨大。
+
+因此,一般的神经网络很难处理蕴含着大量数据的图像。解决这一问题的方法就是使用**卷积神经网络(Convolutional Neural Network, CNN)**。
+
+## 卷积运算
+
+我们之前提到过,神经网络由浅层到深层,分别可以检测出图片的边缘特征、局部特征(例如眼睛、鼻子等),到最后面的一层就可以根据前面检测的特征来识别整体面部轮廓。这些工作都是依托卷积神经网络来实现的。
+
+**卷积运算(Convolutional Operation)**是卷积神经网络最基本的组成部分。我们以边缘检测为例,来解释卷积是怎样运算的。
+
+### 边缘检测
+
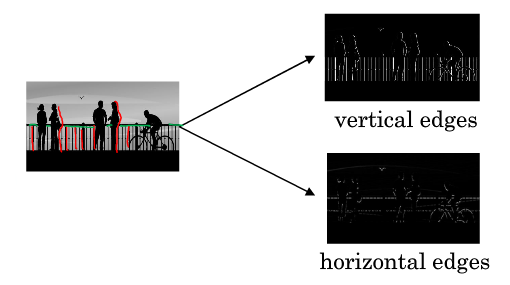
+图片最常做的边缘检测有两类:**垂直边缘(Vertical Edges)检测**和**水平边缘(Horizontal Edges)检测**。
+
+
+
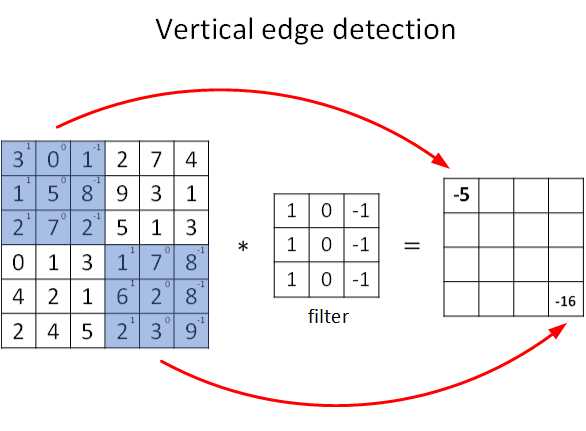
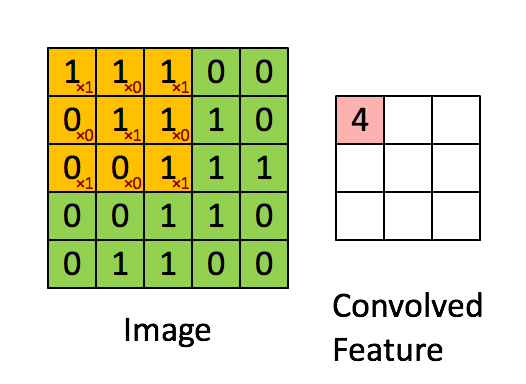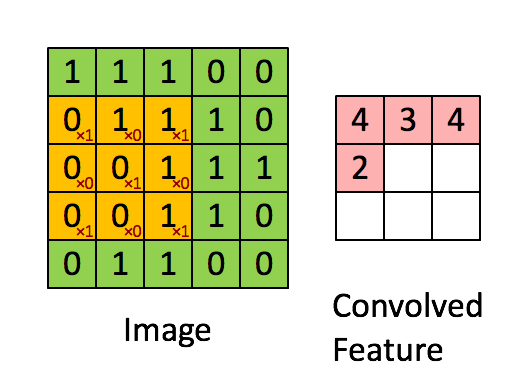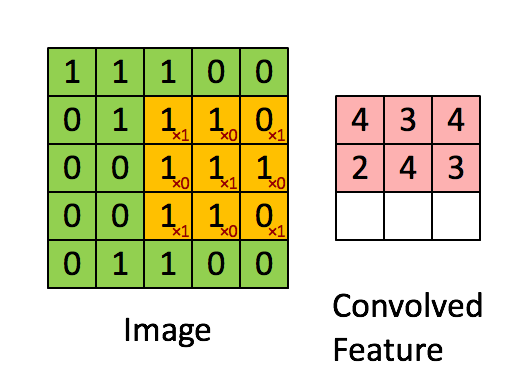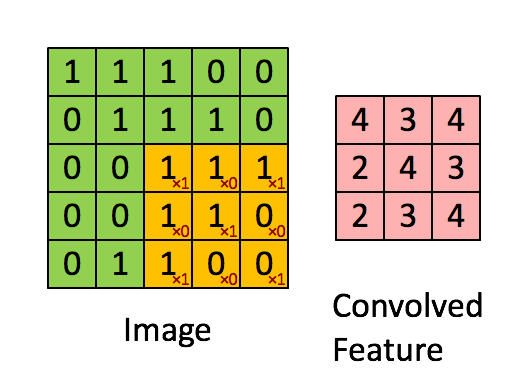
+图片的边缘检测可以通过与相应滤波器进行卷积来实现。以垂直边缘检测为例,原始图片尺寸为 6x6,中间的矩阵被称作**滤波器(filter)**,尺寸为 3x3,卷积后得到的图片尺寸为 4x4,得到结果如下(数值表示灰度,以左上角和右下角的值为例):
+
+
+
+可以看到,卷积运算的求解过程是从左到右,由上到下,每次在原始图片矩阵中取与滤波器同等大小的一部分,每一部分中的值与滤波器中的值对应相乘后求和,将结果组成一个矩阵。
+
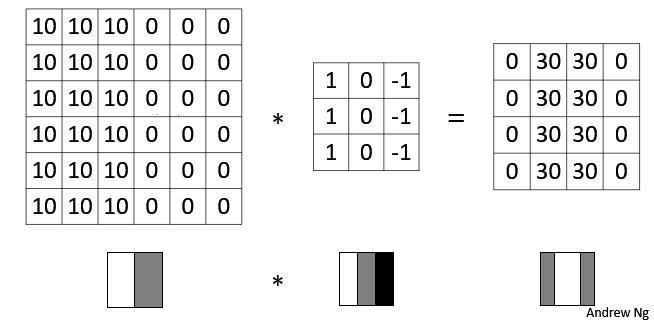
+下图对应一个垂直边缘检测的例子:
+
+
+
+如果将最右边的矩阵当作图像,那么中间一段亮一些的区域对应最左边的图像中间的垂直边缘。
+
+这里有另一个卷积运算的动态的例子,方便理解:
+
+
+
+图中的`*`表示卷积运算符号。在计算机中这个符号表示一般的乘法,而在不同的深度学习框架中,卷积操作的 API 定义可能不同:
+
+* 在 Python 中,卷积用`conv_forward()`表示;
+* 在 Tensorflow 中,卷积用`tf.nn.conv2d()`表示;
+* 在 keras 中,卷积用`Conv2D()`表示。
+
+### 更多边缘检测的例子
+
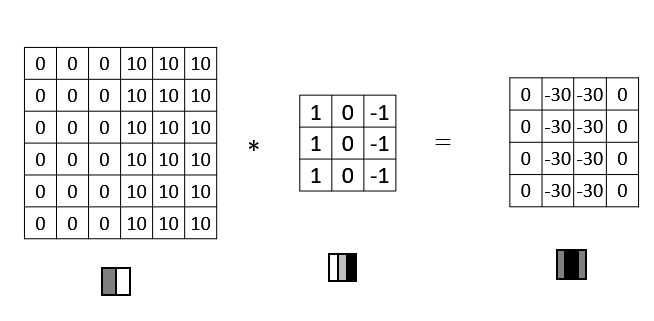
+如果将灰度图左右的颜色进行翻转,再与之前的滤波器进行卷积,得到的结果也有区别。实际应用中,这反映了由明变暗和由暗变明的两种渐变方式。可以对输出图片取绝对值操作,以得到同样的结果。
+
+
+
+垂直边缘检测和水平边缘检测的滤波器如下所示:
+
+
+
+其他常用的滤波器还有 Sobel 滤波器和 Scharr 滤波器。它们增加了中间行的权重,以提高结果的稳健性。
+
+
+
+滤波器中的值还可以设置为**参数**,通过模型训练来得到。这样,神经网络使用反向传播算法可以学习到一些低级特征,从而实现对图片所有边缘特征的检测,而不仅限于垂直边缘和水平边缘。
+
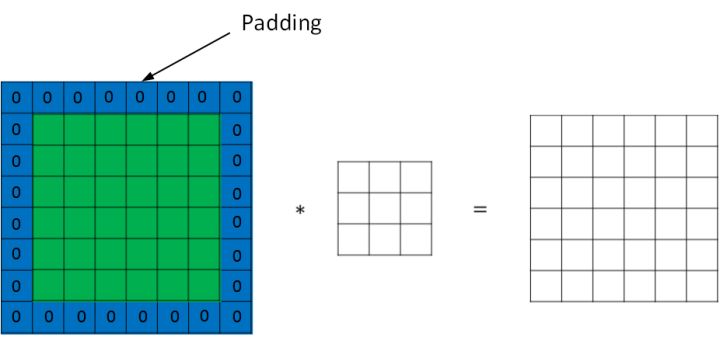
+## 填充
+
+假设输入图片的大小为 $n \times n$,而滤波器的大小为 $f \times f$,则卷积后的输出图片大小为 $(n-f+1) \times (n-f+1)$。
+
+这样就有两个问题:
+
+* 每次卷积运算后,输出图片的尺寸缩小;
+* 原始图片的角落、边缘区像素点在输出中采用较少,输出图片丢失边缘位置的很多信息。
+
+为了解决这些问题,可以在进行卷积操作前,对原始图片在边界上进行**填充(Padding)**,以增加矩阵的大小。通常将 0 作为填充值。
+
+
+
+设每个方向扩展像素点数量为 $p$,则填充后原始图片的大小为 $(n+2p) \times (n+2p)$,滤波器大小保持 $f \times f$不变,则输出图片大小为 $(n+2p-f+1) \times (n+2p-f+1)$。
+
+因此,在进行卷积运算时,我们有两种选择:
+
+* **Valid 卷积**:不填充,直接卷积。结果大小为 $(n-f+1) \times (n-f+1)$;
+* **Same 卷积**:进行填充,并使得卷积后结果大小与输入一致,这样 $p = \frac{f-1}{2}$。
+
+在计算机视觉领域,$f$通常为奇数。原因包括 Same 卷积中 $p = \frac{f-1}{2}$能得到自然数结果,并且滤波器有一个便于表示其所在位置的中心点。
+
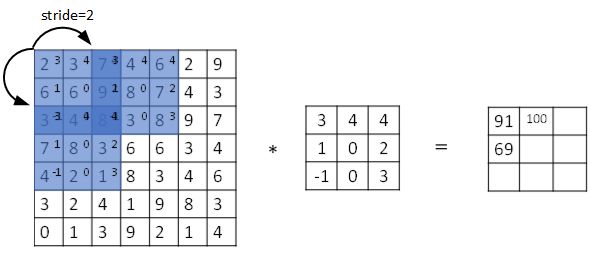
+## 卷积步长
+
+卷积过程中,有时需要通过填充来避免信息损失,有时也需要通过设置**步长(Stride)**来压缩一部分信息。
+
+步长表示滤波器在原始图片的水平方向和垂直方向上每次移动的距离。之前,步长被默认为 1。而如果我们设置步长为 2,则卷积过程如下图所示:
+
+
+
+设步长为 $s$,填充长度为 $p$,输入图片大小为 $n \times n$,滤波器大小为 $f \times f$,则卷积后图片的尺寸为:
+
+$$\biggl\lfloor \frac{n+2p-f}{s}+1 \biggr\rfloor \times \biggl\lfloor \frac{n+2p-f}{s}+1 \biggr\rfloor$$
+
+注意公式中有一个向下取整的符号,用于处理商不为整数的情况。向下取整反映着当取原始矩阵的图示蓝框完全包括在图像内部时,才对它进行运算。
+
+目前为止我们学习的“卷积”实际上被称为**互相关(cross-correlation)**,而非数学意义上的卷积。真正的卷积操作在做元素乘积求和之前,要将滤波器沿水平和垂直轴翻转(相当于旋转 180 度)。因为这种翻转对一般为水平或垂直对称的滤波器影响不大,按照机器学习的惯例,我们通常不进行翻转操作,在简化代码的同时使神经网络能够正常工作。
+
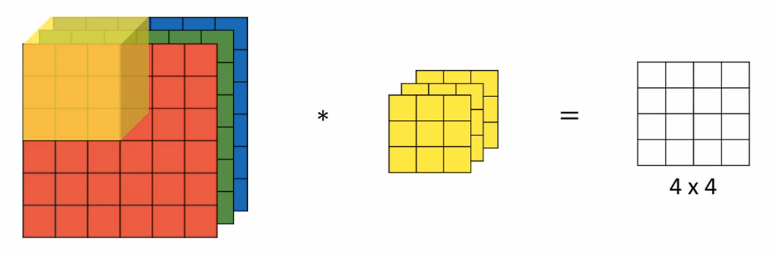
+## 高维卷积
+
+如果我们想要对三通道的 RGB 图片进行卷积运算,那么其对应的滤波器组也同样是三通道的。过程是将每个单通道(R,G,B)与对应的滤波器进行卷积运算求和,然后再将三个通道的和相加,将 27 个乘积的和作为输出图片的一个像素值。
+
+
+
+不同通道的滤波器可以不相同。例如只检测 R 通道的垂直边缘,G 通道和 B 通道不进行边缘检测,则 G 通道和 B 通道的滤波器全部置零。当输入有特定的高、宽和通道数时,滤波器可以有不同的高和宽,但通道数必须和输入一致。
+
+如果想同时检测垂直和水平边缘,或者更多的边缘检测,可以增加更多的滤波器组。例如设置第一个滤波器组实现垂直边缘检测,第二个滤波器组实现水平边缘检测。设输入图片的尺寸为 $n \times n \times n\_c$($n\_c$为通道数),滤波器尺寸为 $f \times f \times n\_c$,则卷积后的输出图片尺寸为 $(n-f+1) \times (n-f+1) \times n'\_c$,$n'\_c$为滤波器组的个数。
+
+
+
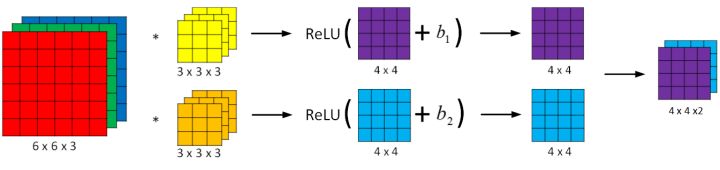
+## 单层卷积网络
+
+
+
+与之前的卷积过程相比较,卷积神经网络的单层结构多了激活函数和偏移量;而与标准神经网络:
+
+$$Z^{[l]} = W^{[l]}A^{[l-1]}+b$$
+$$A^{[l]} = g^{[l]}(Z^{[l]})$$
+
+相比,滤波器的数值对应着权重 $W^{[l]}$,卷积运算对应着 $W^{[l]}$与 $A^{[l-1]}$的乘积运算,所选的激活函数变为 ReLU。
+
+对于一个 3x3x3 的滤波器,包括偏移量 $b$在内共有 28 个参数。不论输入的图片有多大,用这一个滤波器来提取特征时,参数始终都是 28 个,固定不变。即**选定滤波器组后,参数的数目与输入图片的尺寸无关**。因此,卷积神经网络的参数相较于标准神经网络来说要少得多。这是 CNN 的优点之一。
+
+### 符号总结
+
+设 $l$ 层为卷积层:
+
+* $f^{[l]}$:**滤波器的高(或宽)**
+* $p^{[l]}$:**填充长度**
+* $s^{[l]}$:**步长**
+* $n^{[l]}\_c$:**滤波器组的数量**
+
+* **输入维度**:$n^{[l-1]}\_H \times n^{[l-1]}\_W \times n^{[l-1]}\_c$ 。其中 $n^{[l-1]}\_H$表示输入图片的高,$n^{[l-1]}\_W$表示输入图片的宽。之前的示例中输入图片的高和宽都相同,但是实际中也可能不同,因此加上下标予以区分。
+
+* **输出维度**:$n^{[l]}\_H \times n^{[l]}\_W \times n^{[l]}\_c$ 。其中
+
+$$n^{[l]}\_H = \biggl\lfloor \frac{n^{[l-1]}\_H+2p^{[l]}-f^{[l]}}{s^{[l]}}+1 \biggr\rfloor$$
+
+$$n^{[l]}\_W = \biggl\lfloor \frac{n^{[l-1]}\_W+2p^{[l]}-f^{[l]}}{s^{[l]}}+1 \biggr\rfloor$$
+
+* **每个滤波器组的维度**:$f^{[l]} \times f^{[l]} \times n^{[l-1]}\_c$ 。其中$n^{[l-1]}\_c$ 为输入图片通道数(也称深度)。
+* **权重维度**:$f^{[l]} \times f^{[l]} \times n^{[l-1]}\_c \times n^{[l]}\_c$
+* **偏置维度**:$1 \times 1 \times 1 \times n^{[l]}\_c$
+
+由于深度学习的相关文献并未对卷积标示法达成一致,因此不同的资料关于高度、宽度和通道数的顺序可能不同。有些作者会将通道数放在首位,需要根据标示自行分辨。
+
+## 简单卷积网络示例
+
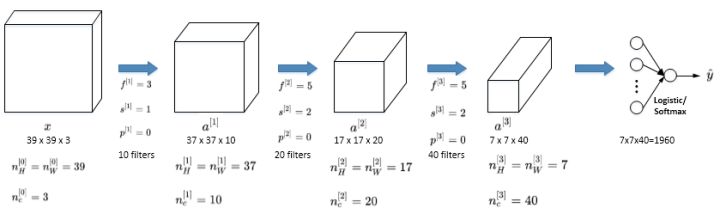
+一个简单的 CNN 模型如下图所示:
+
+
+
+其中,$a^{[3]}$的维度为 7x7x40,将 1960 个特征平滑展开成 1960 个单元的一列,然后连接最后一级的输出层。输出层可以是一个神经元,即二元分类(logistic);也可以是多个神经元,即多元分类(softmax)。最后得到预测输出 $\hat y$。
+
+随着神经网络计算深度不断加深,图片的高度和宽度 $n^{[l]}\_H $、$n^{[l]}\_W$一般逐渐减小,而 $n^{[l]}\_c$在增加。
+
+一个典型的卷积神经网络通常包含有三种层:**卷积层(Convolution layer)**、**池化层(Pooling layer)**、**全连接层(Fully Connected layer)**。仅用卷积层也有可能构建出很好的神经网络,但大部分神经网络还是会添加池化层和全连接层,它们更容易设计。
+
+## 池化层
+
+**池化层**的作用是缩减模型的大小,提高计算速度,同时减小噪声提高所提取特征的稳健性。
+
+采用较多的一种池化过程叫做**最大池化(Max Pooling)**。将输入拆分成不同的区域,输出的每个元素都是对应区域中元素的最大值,如下图所示:
+
+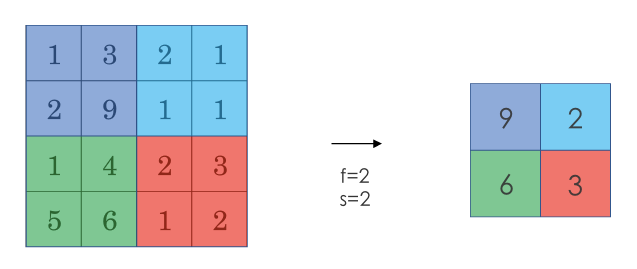
+
+池化过程类似于卷积过程,上图所示的池化过程中相当于使用了一个大小 $f=2$的滤波器,且池化步长 $s=2$。卷积过程中的几个计算大小的公式也都适用于池化过程。如果有多个通道,那么就对每个通道分别执行计算过程。
+
+对最大池化的一种直观解释是,元素值较大可能意味着池化过程之前的卷积过程提取到了某些特定的特征,池化过程中的最大化操作使得只要在一个区域内提取到某个特征,它都会保留在最大池化的输出中。但是,没有足够的证据证明这种直观解释的正确性,而最大池化被使用的主要原因是它在很多实验中的效果都很好。
+
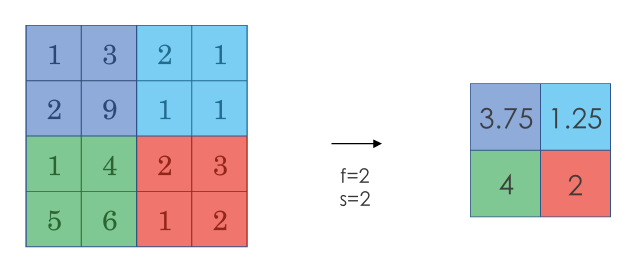
+另一种池化过程是**平均池化(Average Pooling)**,就是从取某个区域的最大值改为求这个区域的平均值:
+
+
+
+池化过程的特点之一是,它有一组超参数,但是并**没有参数需要学习**。池化过程的超参数包括滤波器的大小 $f$、步长 $s$,以及选用最大池化还是平均池化。而填充 $p$则很少用到。
+
+池化过程的输入维度为:
+
+$$n\_H \times n\_W \times n\_c$$
+
+输出维度为:
+
+$$\biggl\lfloor \frac{n\_H-f}{s}+1 \biggr\rfloor \times \biggl\lfloor \frac{n\_W-f}{s}+1 \biggr\rfloor \times n\_c$$
+
+## 卷积神经网络示例
+
+
+
+在计算神经网络的层数时,通常只统计具有权重和参数的层,因此池化层通常和之前的卷积层共同计为一层。
+
+图中的 FC3 和 FC4 为全连接层,与标准的神经网络结构一致。整个神经网络各层的尺寸与参数如下表所示:
+
+ | Activation shape | Activation Size | #parameters
+:-: | :-: | :-: | :-:
+**Input:** | (32, 32, 3) | 3072 | 0
+**CONV1(f=5, s=1)** | (28, 28, 6) | 4704 | 158
+**POOL1** | (14, 14, 6) | 1176 | 0
+**CONV2(f=5, s=1)** | (10, 10, 16) | 1600 | 416
+**POOL2** | (5, 5, 16) | 400 | 0
+**FC3** | (120, 1) | 120 | 48120
+**FC4** | (84, 1) | 84 | 10164
+**Softmax** | (10, 1) | 10 | 850
+
+个人推荐[一个直观感受卷积神经网络的网站](http://scs.ryerson.ca/~aharley/vis/conv/)。
+
+## 使用卷积的原因
+
+相比标准神经网络,对于大量的输入数据,卷积过程有效地减少了 CNN 的参数数量,原因有以下两点:
+
+* **参数共享(Parameter sharing)**:特征检测如果适用于图片的某个区域,那么它也可能适用于图片的其他区域。即在卷积过程中,不管输入有多大,一个特征探测器(滤波器)就能对整个输入的某一特征进行探测。
+* **稀疏连接(Sparsity of connections)**:在每一层中,由于滤波器的尺寸限制,输入和输出之间的连接是稀疏的,每个输出值只取决于输入在局部的一小部分值。
+
+池化过程则在卷积后很好地聚合了特征,通过降维来减少运算量。
+
+由于 CNN 参数数量较小,所需的训练样本就相对较少,因此在一定程度上不容易发生过拟合现象。并且 CNN 比较擅长捕捉区域位置偏移。即进行物体检测时,不太受物体在图片中位置的影响,增加检测的准确性和系统的健壮性。
\ No newline at end of file
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/深度卷积网络:实例探究.md b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/深度卷积网络:实例探究.md
new file mode 100644
index 00000000..f8233a65
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/深度卷积网络:实例探究.md
@@ -0,0 +1,199 @@
+深度卷积网络:实例探究
+
+讲到的经典 CNN 模型包括:
+
+* LeNet-5
+* AlexNet
+* VGG
+
+此外还有 ResNet(Residual Network,残差网络),以及 Inception Neural Network。
+
+## 经典卷积网络
+
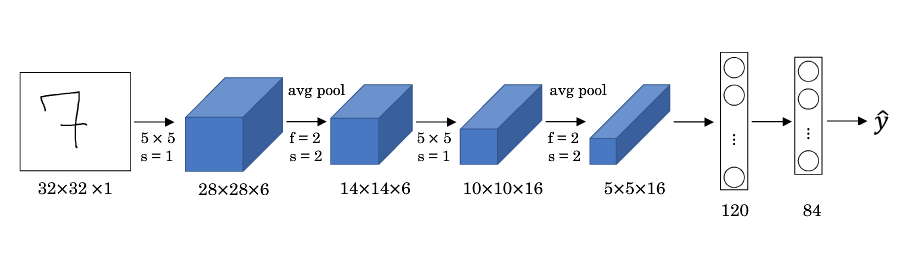
+### LeNet-5
+
+
+
+特点:
+
+* LeNet-5 针对灰度图像而训练,因此输入图片的通道数为 1。
+* 该模型总共包含了约 6 万个参数,远少于标准神经网络所需。
+* 典型的 LeNet-5 结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为 CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。
+* 当 LeNet-5模型被提出时,其池化层使用的是平均池化,而且各层激活函数一般选用 Sigmoid 和 tanh。现在,我们可以根据需要,做出改进,使用最大池化并选用 ReLU 作为激活函数。
+
+相关论文:[LeCun et.al., 1998. Gradient-based learning applied to document recognition](http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=726791&tag=1)。吴恩达老师建议精读第二段,泛读第三段。
+
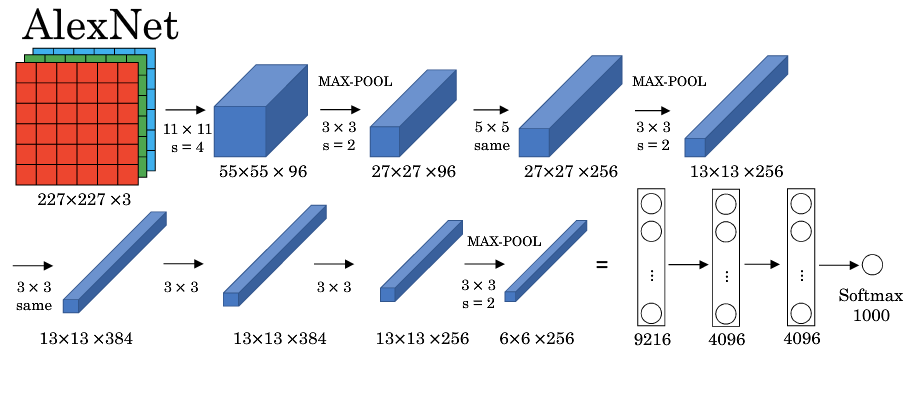
+### AlexNet
+
+
+
+特点:
+
+* AlexNet 模型与 LeNet-5 模型类似,但是更复杂,包含约 6000 万个参数。另外,AlexNet 模型使用了 ReLU 函数。
+* 当用于训练图像和数据集时,AlexNet 能够处理非常相似的基本构造模块,这些模块往往包含大量的隐藏单元或数据。
+
+相关论文:[Krizhevsky et al.,2012. ImageNet classification with deep convolutional neural networks](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)。这是一篇易于理解并且影响巨大的论文,计算机视觉群体自此开始重视深度学习。
+
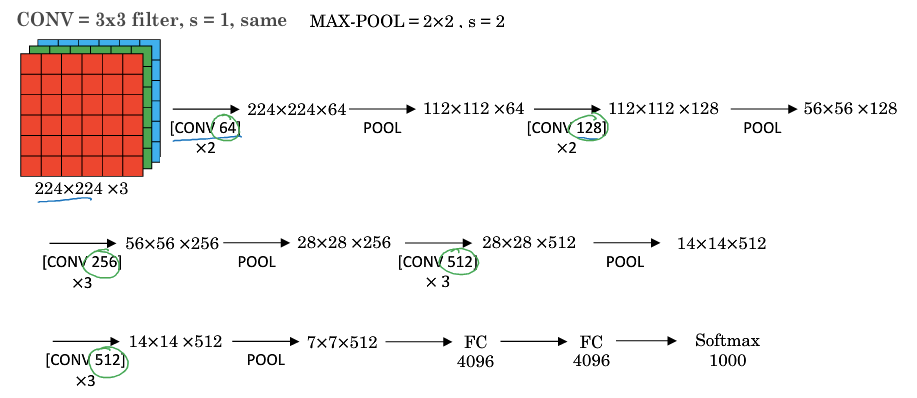
+### VGG
+
+
+
+特点:
+
+* VGG 又称 VGG-16 网络,“16”指网络中包含 16 个卷积层和全连接层。
+* 超参数较少,只需要专注于构建卷积层。
+* 结构不复杂且规整,在每一组卷积层进行滤波器翻倍操作。
+* VGG 需要训练的特征数量巨大,包含多达约 1.38 亿个参数。
+
+相关论文:[Simonvan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition](https://arxiv.org/pdf/1409.1556.pdf)。
+
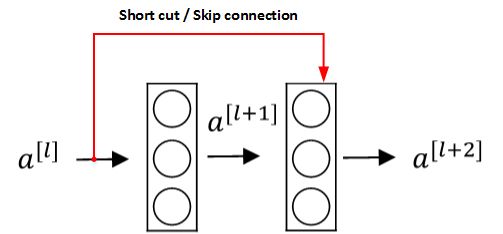
+## 残差网络
+
+因为存在梯度消失和梯度爆炸问题,网络越深,就越难以训练成功。**残差网络(Residual Networks,简称为 ResNets)**可以有效解决这个问题。
+
+
+
+上图的结构被称为**残差块(Residual block)**。通过**捷径(Short cut,或者称跳远连接,Skip connections)**可以将 $a^{[l]}$添加到第二个 ReLU 过程中,直接建立 $a^{[l]}$与 $a^{[l+2]}$之间的隔层联系。表达式如下:
+
+$$z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l+1]}$$
+
+$$a^{[l+1]} = g(z^{[l+1]})$$
+
+$$z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+2]}$$
+
+$$a^{[l+2]} = g(z^{[l+2]} + a^{[l]})$$
+
+构建一个残差网络就是将许多残差块堆积在一起,形成一个深度网络。
+
+
+
+为了便于区分,在 ResNets 的论文[He et al., 2015. Deep residual networks for image recognition](https://arxiv.org/pdf/1512.03385.pdf)中,非残差网络被称为**普通网络(Plain Network)**。将它变为残差网络的方法是加上所有的跳远连接。
+
+在理论上,随着网络深度的增加,性能应该越来越好。但实际上,对于一个普通网络,随着神经网络层数增加,训练错误会先减少,然后开始增多。但残差网络的训练效果显示,即使网络再深,其在训练集上的表现也会越来越好。
+
+
+
+残差网络有助于解决梯度消失和梯度爆炸问题,使得在训练更深的网络的同时,又能保证良好的性能。
+
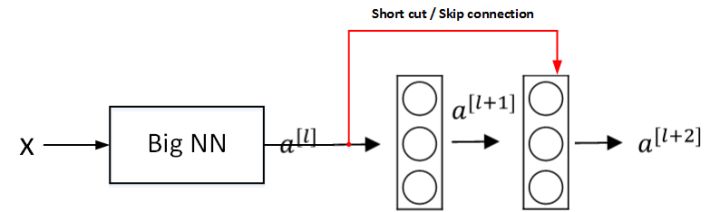
+### 残差网络有效的原因
+
+假设有一个大型神经网络,其输入为 $X$,输出为 $a^{[l]}$。给这个神经网络额外增加两层,输出为 $a^{[l+2]}$。将这两层看作一个具有跳远连接的残差块。为了方便说明,假设整个网络中都选用 ReLU 作为激活函数,因此输出的所有激活值都大于等于 0。
+
+
+
+则有:
+
+$$
+\begin{equation}
+\begin{split}
+ a^{[l+2]} &= g(z^{[l+2]}+a^{[l]})
+ \\\ &= g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})
+\end{split}
+\end{equation}
+$$
+
+当发生梯度消失时,$W^{[l+2]}\approx0$,$b^{[l+2]}\approx0$,则有:
+
+$$a^{[l+2]} = g(a^{[l]}) = ReLU(a^{[l]}) = a^{[l]}$$
+
+因此,这两层额外的残差块不会降低网络性能。而如果没有发生梯度消失时,训练得到的非线性关系会使得表现效果进一步提高。
+
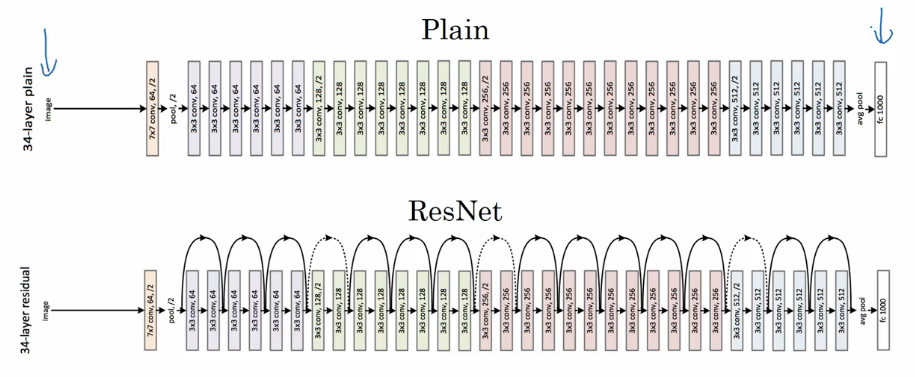
+注意,如果 $a^{[l]}$与 $a^{[l+2]}$的维度不同,需要引入矩阵 $W\_s$与 $a^{[l]}$相乘,使得二者的维度相匹配。参数矩阵 $W\_s$既可以通过模型训练得到,也可以作为固定值,仅使 $a^{[l]}$截断或者补零。
+
+
+
+上图是论文提供的 CNN 中 ResNet 的一个典型结构。卷积层通常使用 Same 卷积以保持维度相同,而不同类型层之间的连接(例如卷积层和池化层),如果维度不同,则需要引入矩阵 $W\_s$。
+
+## 1x1 卷积
+
+1x1 卷积(1x1 convolution,或称为 Network in Network)指滤波器的尺寸为 1。当通道数为 1 时,1x1 卷积意味着卷积操作等同于乘积操作。
+
+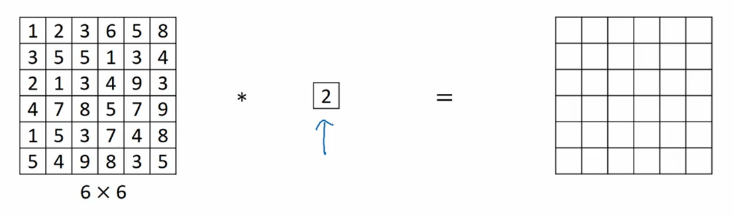
+
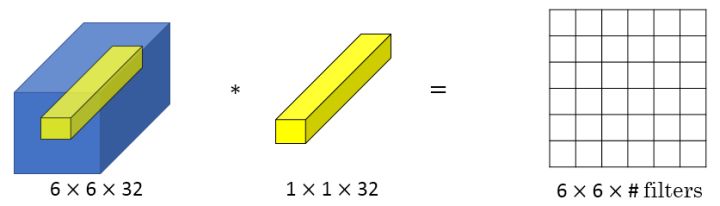
+而当通道数更多时,1x1 卷积的作用实际上类似全连接层的神经网络结构,从而降低(或升高,取决于滤波器组数)数据的维度。
+
+池化能压缩数据的高度($n\_H$)及宽度($n\_W$),而 1×1 卷积能压缩数据的通道数($n\_C$)。在如下图所示的例子中,用 32 个大小为 1×1×192 的滤波器进行卷积,就能使原先数据包含的 192 个通道压缩为 32 个。
+
+
+
+虽然论文[Lin et al., 2013. Network in network](https://arxiv.org/pdf/1312.4400.pdf)中关于架构的详细内容并没有得到广泛应用,但是 1x1 卷积的理念十分有影响力,许多神经网络架构(包括 Inception 网络)都受到它的影响。
+
+## Inception 网络
+
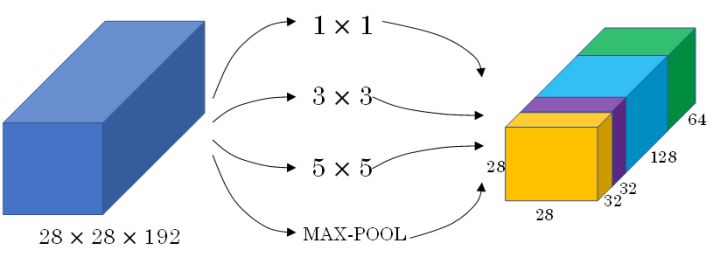
+在之前的卷积网络中,我们只能选择单一尺寸和类型的滤波器。而 **Inception 网络的作用**即是代替人工来确定卷积层中的滤波器尺寸与类型,或者确定是否需要创建卷积层或池化层。
+
+
+
+如图,Inception 网络选用不同尺寸的滤波器进行 Same 卷积,并将卷积和池化得到的输出组合拼接起来,最终让网络自己去学习需要的参数和采用的滤波器组合。
+
+相关论文:[Szegedy et al., 2014, Going Deeper with Convolutions](https://arxiv.org/pdf/1409.4842.pdf)
+
+### 计算成本问题
+
+在提升性能的同时,Inception 网络有着较大的计算成本。下图是一个例子:
+
+
+
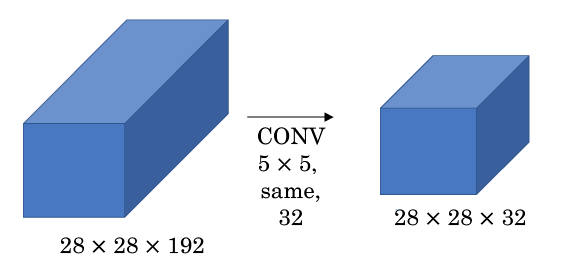
+图中有 32 个滤波器,每个滤波器的大小为 5x5x192。输出大小为 28x28x32,所以需要计算 28x28x32 个数字,对于每个数,都要执行 5x5x192 次乘法运算。加法运算次数与乘法运算次数近似相等。因此,可以看作这一层的计算量为 28x28x32x5x5x192 = 1.2亿。
+
+为了解决计算量大的问题,可以引入 1x1 卷积来减少其计算量。
+
+
+
+对于同一个例子,我们使用 1x1 卷积把输入数据从 192 个通道减少到 16 个通道,然后对这个较小层运行 5x5 卷积,得到最终输出。这个 1x1 的卷积层通常被称作**瓶颈层(Bottleneck layer)**。
+
+改进后的计算量为 28x28x192x16 + 28x28x32x5x5x15 = 1.24 千万,减少了约 90%。
+
+只要合理构建瓶颈层,就可以既显著缩小计算规模,又不会降低网络性能。
+
+### 完整的 Inception 网络
+
+
+
+上图是引入 1x1 卷积后的 Inception 模块。值得注意的是,为了将所有的输出组合起来,红色的池化层使用 Same 类型的填充(padding)来池化使得输出的宽高不变,通道数也不变。
+
+多个 Inception 模块组成一个完整的 Inception 网络(被称为 GoogLeNet,以向 LeNet 致敬),如下图所示:
+
+
+
+注意黑色椭圆圈出的隐藏层,这些分支都是 Softmax 的输出层,可以用来参与特征的计算及结果预测,起到调整并防止发生过拟合的效果。
+
+经过研究者们的不断发展,Inception 模型的 V2、V3、V4 以及引入残差网络的版本被提出,这些变体都基于 Inception V1 版本的基础思想上。顺便一提,Inception 模型的名字来自电影《盗梦空间》。
+
+## 使用开源的实现方案
+
+很多神经网络复杂细致,并充斥着参数调节的细节问题,因而很难仅通过阅读论文来重现他人的成果。想要搭建一个同样的神经网络,查看开源的实现方案会快很多。
+
+## 迁移学习
+
+在“搭建机器学习项目”课程中,[迁移学习](http://kyonhuang.top/Andrew-Ng-Deep-Learning-notes/#/Structuring_Machine_Learning_Projects/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88ML%EF%BC%89%E7%AD%96%E7%95%A5%EF%BC%882%EF%BC%89?id=%e8%bf%81%e7%a7%bb%e5%ad%a6%e4%b9%a0)已经被提到过。计算机视觉是一个经常用到迁移学习的领域。在搭建计算机视觉的应用时,相比于从头训练权重,下载别人已经训练好的网络结构的权重,用其做**预训练**,然后转换到自己感兴趣的任务上,有助于加速开发。
+
+对于已训练好的卷积神经网络,可以将所有层都看作是**冻结的**,只需要训练与你的 Softmax 层有关的参数即可。大多数深度学习框架都允许用户指定是否训练特定层的权重。
+
+而冻结的层由于不需要改变和训练,可以看作一个固定函数。可以将这个固定函数存入硬盘,以便后续使用,而不必每次再使用训练集进行训练了。
+
+上述的做法适用于你只有一个较小的数据集。如果你有一个更大的数据集,应该冻结更少的层,然后训练后面的层。越多的数据意味着冻结越少的层,训练更多的层。如果有一个极大的数据集,你可以将开源的网络和它的权重整个当作初始化(代替随机初始化),然后训练整个网络。
+
+## 数据扩增
+
+计算机视觉领域的应用都需要大量的数据。当数据不够时,**数据扩增(Data Augmentation)**就有帮助。常用的数据扩增包括镜像翻转、随机裁剪、色彩转换。
+
+其中,色彩转换是对图片的 RGB 通道数值进行随意增加或者减少,改变图片色调。另外,**PCA 颜色增强**指更有针对性地对图片的 RGB 通道进行主成分分析(Principles Components Analysis,PCA),对主要的通道颜色进行增加或减少,可以采用高斯扰动做法来增加有效的样本数量。具体的 PCA 颜色增强做法可以查阅 AlexNet 的相关论文或者开源代码。
+
+在构建大型神经网络的时候,数据扩增和模型训练可以由两个或多个不同的线程并行来实现。
+
+## 计算机视觉现状
+
+通常,学习算法有两种知识来源:
+
+* 被标记的数据
+* 手工工程
+
+**手工工程(Hand-engineering,又称 hacks)**指精心设计的特性、网络体系结构或是系统的其他组件。手工工程是一项非常重要也比较困难的工作。在数据量不多的情况下,手工工程是获得良好表现的最佳方式。正因为数据量不能满足需要,历史上计算机视觉领域更多地依赖于手工工程。近几年数据量急剧增加,因此手工工程量大幅减少。
+
+另外,在模型研究或者竞赛方面,有一些方法能够有助于提升神经网络模型的性能:
+
+* 集成(Ensembling):独立地训练几个神经网络,并平均输出它们的输出
+* Multi-crop at test time:将数据扩增应用到测试集,对结果进行平均
+
+但是由于这些方法计算和内存成本较大,一般不适用于构建实际的生产项目。
\ No newline at end of file
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/特殊应用:人脸识别和神经风格迁移.md b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/特殊应用:人脸识别和神经风格迁移.md
new file mode 100644
index 00000000..461d1bf5
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/特殊应用:人脸识别和神经风格迁移.md
@@ -0,0 +1,168 @@
+特殊应用:人脸识别和神经风格转换
+
+## 人脸识别
+
+**人脸验证(Face Verification)**和**人脸识别(Face Recognition)**的区别:
+
+* 人脸验证:一般指一个一对一问题,只需要验证输入的人脸图像是否与某个已知的身份信息对应;
+* 人脸识别:一个更为复杂的一对多问题,需要验证输入的人脸图像是否与多个已知身份信息中的某一个匹配。
+
+一般来说,由于需要匹配的身份信息更多导致错误率增加,人脸识别比人脸验证更难一些。
+
+### One-Shot 学习
+
+人脸识别所面临的一个挑战是要求系统只采集某人的一个面部样本,就能快速准确地识别出这个人,即只用一个训练样本来获得准确的预测结果。这被称为**One-Shot 学习**。
+
+有一种方法是假设数据库中存有 N 个人的身份信息,对于每张输入图像,用 Softmax 输出 N+1 种标签,分别对应每个人以及都不是。然而这种方法的实际效果很差,因为过小的训练集不足以训练出一个稳健的神经网络;并且如果有新的身份信息入库,需要重新训练神经网络,不够灵活。
+
+因此,我们通过学习一个 Similarity 函数来实现 One-Shot 学习过程。Similarity 函数定义了输入的两幅图像的差异度,其公式如下:
+
+$$Similarity = d(img1, img2)$$
+
+可以设置一个超参数 $τ$ 作为阈值,作为判断两幅图片是否为同一个人的依据。
+
+### Siamese 网络
+
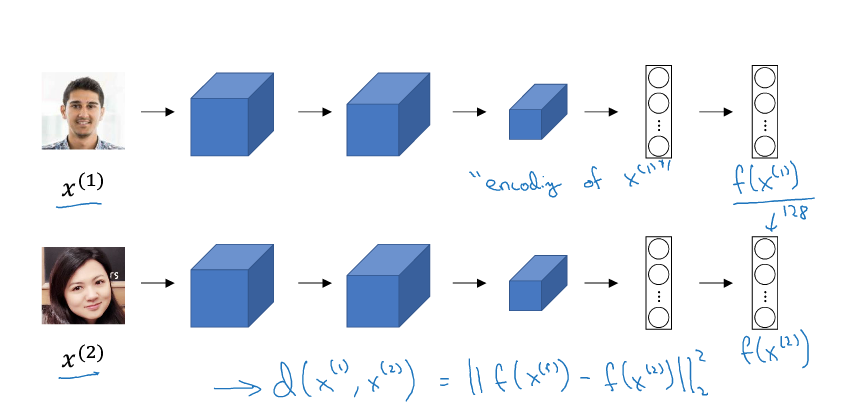
+实现 Similarity 函数的一种方式是使用**Siamese 网络**,它是一种对两个不同输入运行相同的卷积网络,然后对它们的结果进行比较的神经网络。
+
+
+
+如上图示例,将图片 $x^{(1)}$、$x^{(2)}$ 分别输入两个相同的卷积网络中,经过全连接层后不再进行 Softmax,而是得到特征向量 $f(x^{(1)})$、$f(x^{(2)})$。这时,Similarity 函数就被定义为两个特征向量之差的 L2 范数:
+
+$$d(x^{(1)}, x^{(2)}) = ||f(x^{(1)}) - f(x^{(2)})||^2\_2$$
+
+相关论文:[Taigman et al., 2014, DeepFace closing the gap to human level performance](http://www.cs.wayne.edu/~mdong/taigman_cvpr14.pdf)
+
+### Triplet 损失
+
+**Triplet 损失函数**用于训练出合适的参数,以获得高质量的人脸图像编码。“Triplet”一词来源于训练这个神经网络需要大量包含 Anchor(靶目标)、Positive(正例)、Negative(反例)的图片组,其中 Anchor 和 Positive 需要是同一个人的人脸图像。
+
+
+
+对于这三张图片,应该有:
+
+$$||f(A) - f(P)||^2\_2 + \alpha \le ||f(A) - f(N)||^2\_2$$
+
+其中,$\alpha$ 被称为**间隔(margin)**,用于确保 $f()$ 不会总是输出零向量(或者一个恒定的值)。
+
+Triplet 损失函数的定义:
+
+$$L(A, P, N) = max(||f(A) - f(P)||^2\_2 - ||f(A) - f(N)||^2\_2 + \alpha, 0)$$
+
+其中,因为 $||f(A) - f(P)||^2\_2 - ||f(A) - f(N)||^2\_2 + \alpha$ 的值需要小于等于 0,因此取它和 0 的更大值。
+
+对于大小为 $m$ 的训练集,代价函数为:
+
+$$J = \sum^m\_{i=1}L(A^{(i)}, P^{(i)}, N^{(i)})$$
+
+通过梯度下降最小化代价函数。
+
+在选择训练样本时,随机选择容易使 Anchor 和 Positive 极为接近,而 Anchor 和 Negative 相差较大,以致训练出来的模型容易抓不到关键的区别。因此,最好的做法是人为增加 Anchor 和 Positive 的区别,缩小 Anchor 和 Negative 的区别,促使模型去学习不同人脸之间的关键差异。
+
+相关论文:[Schroff et al., 2015, FaceNet: A unified embedding for face recognition and clustering](https://arxiv.org/pdf/1503.03832.pdf)
+
+### 二分类结构
+
+除了 Triplet 损失函数,二分类结构也可用于学习参数以解决人脸识别问题。其做法是输入一对图片,将两个 Siamese 网络产生的特征向量输入至同一个 Sigmoid 单元,输出 1 则表示是识别为同一人,输出 0 则表示识别为不同的人。
+
+Sigmoid 单元对应的表达式为:
+
+$$\hat y = \sigma (\sum^K\_{k=1}w\_k|f(x^{(i)})\_{k} - x^{(j)})\_{k}| + b)$$
+
+其中,$w\_k$ 和 $b$ 都是通过梯度下降算法迭代训练得到的参数。上述计算表达式也可以用另一种表达式代替:
+
+$$\hat y = \sigma (\sum^K\_{k=1}w\_k
+\frac{(f(x^{(i)})\_k - f(x^{(j)})\_k)^2}{f(x^{(i)})\_k + f(x^{(j)})\_k} + b)$$
+
+其中,$\frac{(f(x^{(i)})\_k - f(x^{(j)})\_k)^2}{f(x^{(i)})\_k + f(x^{(j)})\_k}$ 被称为 $\chi$ 方相似度。
+
+无论是对于使用 Triplet 损失函数的网络,还是二分类结构,为了减少计算量,可以提前计算好编码输出 $f(x)$ 并保存。这样就不必存储原始图片,并且每次进行人脸识别时只需要计算测试图片的编码输出。
+
+## 神经风格迁移
+
+**神经风格迁移(Neural style transfer)**将参考风格图像的风格“迁移”到另外一张内容图像中,生成具有其特色的图像。
+
+
+
+### 深度卷积网络在学什么?
+
+想要理解如何实现神经风格转换,首先要理解在输入图像数据后,一个深度卷积网络从中都学到了些什么。我们借助可视化来做到这一点。
+
+
+
+我们通过遍历所有的训练样本,找出使该层激活函数输出最大的 9 块图像区域。可以看出,浅层的隐藏层通常检测出的是原始图像的边缘、颜色、阴影等简单信息。随着层数的增加,隐藏单元能捕捉的区域更大,学习到的特征也由从边缘到纹理再到具体物体,变得更加复杂。
+
+相关论文:[Zeiler and Fergus., 2013, Visualizing and understanding convolutional networks](https://arxiv.org/pdf/1311.2901.pdf)
+
+### 代价函数
+
+神经风格迁移生成图片 G 的代价函数如下:
+
+$$J(G) = \alpha \cdot J\_{content}(C, G) + \beta \cdot J\_{style}(S, G)$$
+
+其中,$\alpha$、$\beta$ 是用于控制相似度比重的超参数。
+
+神经风格迁移的算法步骤如下:
+
+1. 随机生成图片 G 的所有像素点;
+2. 使用梯度下降算法使代价函数最小化,以不断修正 G 的所有像素点。
+
+相关论文:[Gatys al., 2015. A neural algorithm of artistic style](https://arxiv.org/pdf/1508.06576v2.pdf)
+
+#### 内容代价函数
+
+上述代价函数包含一个内容代价部分和风格代价部分。我们先来讨论内容代价函数 $J\_{content}(C, G)$,它表示内容图片 C 和生成图片 G 之间的相似度。
+
+$J\_{content}(C, G)$ 的计算过程如下:
+
+* 使用一个预训练好的 CNN(例如 VGG);
+* 选择一个隐藏层 $l$ 来计算内容代价。$l$ 太小则内容图片和生成图片像素级别相似,$l$ 太大则可能只有具体物体级别的相似。因此,$l$ 一般选一个中间层;
+* 设 $a^{(C)[l]}$、$a^{(G)[l]}$ 为 C 和 G 在 $l$ 层的激活,则有:
+
+$$J\_{content}(C, G) = \frac{1}{2}||(a^{(C)[l]} - a^{(G)[l]})||^2$$
+
+$a^{(C)[l]}$ 和 $a^{(G)[l]}$ 越相似,则 $J\_{content}(C, G)$ 越小。
+
+#### 风格代价函数
+
+
+
+每个通道提取图片的特征不同,比如标为红色的通道提取的是图片的垂直纹理特征,标为黄色的通道提取的是图片的橙色背景特征。那么计算这两个通道的相关性,相关性的大小,即表示原始图片既包含了垂直纹理也包含了该橙色背景的可能性大小。通过 CNN,“风格”被定义为同一个隐藏层不同通道之间激活值的相关系数,因其反映了原始图片特征间的相互关系。
+
+对于风格图像 S,选定网络中的第 $l$ 层,则相关系数以一个 gram 矩阵的形式表示:
+
+$$G^{\[l](S)}\_{kk'} = \sum^{n^{[l]}\_H}\_{i=1} \sum^{n^{[l]}\_W}\_{j=1} a^{\[l](S)}\_{ijk} a^{\[l](S)}\_{ijk'}$$
+
+其中,$i$ 和 $j$ 为第 $l$ 层的高度和宽度;$k$ 和 $k'$ 为选定的通道,其范围为 $1$ 到 $n\_C^{[l]}$;$a^{\[l](S)}\_{ijk}$ 为激活。
+
+同理,对于生成图像 G,有:
+
+$$G^{\[l](G)}\_{kk'} = \sum^{n^{[l]}\_H}\_{i=1} \sum^{n^{[l]}\_W}\_{j=1} a^{\[l](G)}\_{ijk} a^{\[l](G)}\_{ijk'}$$
+
+因此,第 $l$ 层的风格代价函数为:
+
+$$J^{[l]}\_{style}(S, G) = \frac{1}{(2n^{[l]}\_Hn^{[l]}\_Wn^{[l]}\_C)^2} \sum\_k \sum\_{k'}(G^{\[l](S)}\_{kk'} - G^{\[l](G)}\_{kk'})^2$$
+
+如果对各层都使用风格代价函数,效果会更好。因此有:
+
+$$J\_{style}(S, G) = \sum\_l \lambda^{[l]} J^{[l]}\_{style}(S, G)$$
+
+其中,$lambda$ 是用于设置不同层所占权重的超参数。
+
+### 推广至一维和三维
+
+之前我们处理的都是二维图片,实际上卷积也可以延伸到一维和三维数据。我们举两个示例来说明。
+
+
+
+EKG 数据(心电图)是由时间序列对应的每个瞬间的电压组成,是一维数据。一般来说我们会用 RNN(循环神经网络)来处理,不过如果用卷积处理,则有:
+
+* 输入时间序列维度:14 x 1
+* 滤波器尺寸:5 x 1,滤波器个数:16
+* 输出时间序列维度:10 x 16
+
+而对于三维图片的示例,有
+
+* 输入 3D 图片维度:14 x 14 x 14 x 1
+* 滤波器尺寸:5 x 5 x 5 x 1,滤波器个数:16
+* 输出 3D 图片维度:10 x 10 x 10 x 16
diff --git a/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/目标检测.md b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/目标检测.md
new file mode 100644
index 00000000..30246f17
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Convolutional_Neural_Networks/目标检测.md
@@ -0,0 +1,145 @@
+目标检测
+
+目标检测是计算机视觉领域中一个新兴的应用方向,其任务是对输入图像进行分类的同时,检测图像中是否包含某些目标,并对他们准确定位并标识。
+
+## 目标定位
+
+定位分类问题不仅要求判断出图片中物体的种类,还要在图片中标记出它的具体位置,用**边框(Bounding Box,或者称包围盒)**把物体圈起来。一般来说,定位分类问题通常只有一个较大的对象位于图片中间位置;而在目标检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。
+
+为了定位图片中汽车的位置,可以让神经网络多输出 4 个数字,标记为 $b\_x$、$b\_y$、$b\_h$、$b\_w$。将图片左上角标记为 (0, 0),右下角标记为 (1, 1),则有:
+
+* 红色方框的中心点:($b\_x$,$b\_y$)
+* 边界框的高度:$b\_h$
+* 边界框的宽度:$b\_w$
+
+因此,训练集不仅包含对象分类标签,还包含表示边界框的四个数字。定义目标标签 Y 如下:
+
+$$\left[\begin{matrix}P\_c\\\ b\_x\\\ b\_y\\\ b\_h\\\ b\_w\\\ c\_1\\\ c\_2\\\ c\_3\end{matrix}\right]$$
+
+则有:
+
+$$P\_c=1, Y = \left[\begin{matrix}1\\\ b\_x\\\ b\_y\\\ b\_h\\\ b\_w\\\ c\_1\\\ c\_2\\\ c\_3\end{matrix}\right]
+$$
+
+其中,$c\_n$表示存在第 $n$个种类的概率;如果 $P\_c=0$,表示没有检测到目标,则输出标签后面的 7 个参数都是无效的,可以忽略(用 ? 来表示)。
+
+$$P\_c=0, Y = \left[\begin{matrix}0\\\ ?\\\ ?\\\ ?\\\ ?\\\ ?\\\ ?\\\ ?\end{matrix}\right]$$
+
+损失函数可以表示为 $L(\hat y, y)$,如果使用平方误差形式,对于不同的 $P\_c$有不同的损失函数(注意下标 $i$指标签的第 $i$个值):
+
+1. $P\_c=1$,即$y\_1=1$:
+
+ $L(\hat y,y)=(\hat y\_1-y\_1)^2+(\hat y\_2-y\_2)^2+\cdots+(\hat y\_8-y\_8)^2$
+
+2. $P\_c=0$,即$y\_1=0$:
+
+ $L(\hat y,y)=(\hat y\_1-y\_1)^2$
+
+除了使用平方误差,也可以使用逻辑回归损失函数,类标签 $c\_1,c\_2,c\_3$ 也可以通过 softmax 输出。相比较而言,平方误差已经能够取得比较好的效果。
+
+## 特征点检测
+
+神经网络可以像标识目标的中心点位置那样,通过输出图片上的特征点,来实现对目标特征的识别。在标签中,这些特征点以多个二维坐标的形式表示。
+
+通过检测人脸特征点可以进行情绪分类与判断,或者应用于 AR 领域等等。也可以透过检测姿态特征点来进行人体姿态检测。
+
+## 目标检测
+
+想要实现目标检测,可以采用**基于滑动窗口的目标检测(Sliding Windows Detection)**算法。该算法的步骤如下:
+
+1. 训练集上搜集相应的各种目标图片和非目标图片,样本图片要求尺寸较小,相应目标居于图片中心位置并基本占据整张图片。
+2. 使用训练集构建 CNN 模型,使得模型有较高的识别率。
+3. 选择大小适宜的窗口与合适的固定步幅,对测试图片进行从左到右、从上倒下的滑动遍历。每个窗口区域使用已经训练好的 CNN 模型进行识别判断。
+4. 可以选择更大的窗口,然后重复第三步的操作。
+
+
+
+滑动窗口目标检测的**优点**是原理简单,且不需要人为选定目标区域;**缺点**是需要人为直观设定滑动窗口的大小和步幅。滑动窗口过小或过大,步幅过大均会降低目标检测的正确率。另外,每次滑动都要进行一次 CNN 网络计算,如果滑动窗口和步幅较小,计算成本往往很大。
+
+所以,滑动窗口目标检测算法虽然简单,但是性能不佳,效率较低。
+
+## 基于卷积的滑动窗口实现
+
+相比从较大图片多次截取,在卷积层上应用滑动窗口目标检测算法可以提高运行速度。所要做的仅是将全连接层换成卷积层,即使用与上一层尺寸一致的滤波器进行卷积运算。
+
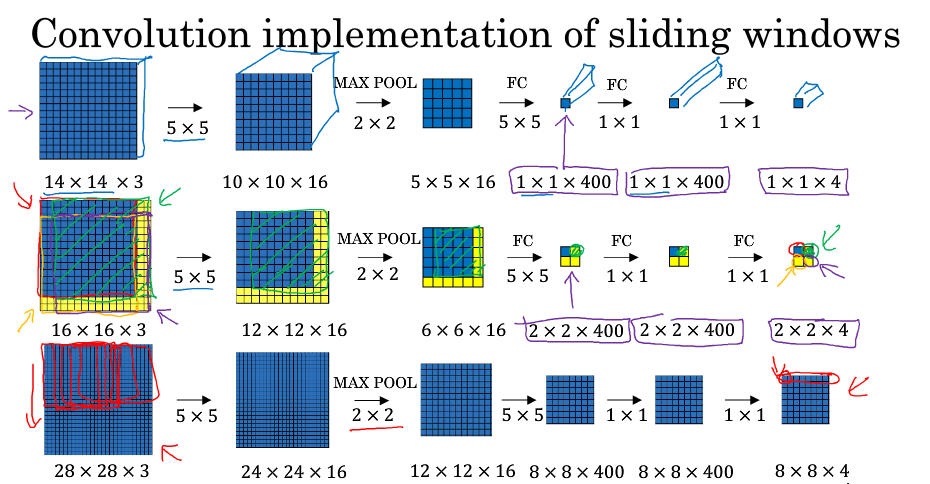
+
+
+如图,对于 16x16x3 的图片,步长为 2,CNN 网络得到的输出层为 2x2x4。其中,2x2 表示共有 4 个窗口结果。对于更复杂的 28x28x3 的图片,得到的输出层为 8x8x4,共 64 个窗口结果。最大池化层的宽高和步长相等。
+
+运行速度提高的原理:在滑动窗口的过程中,需要重复进行 CNN 正向计算。因此,不需要将输入图片分割成多个子集,分别执行向前传播,而是将它们作为一张图片输入给卷积网络进行一次 CNN 正向计算。这样,公共区域的计算可以共享,以降低运算成本。
+
+相关论文:[Sermanet et al., 2014. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks](https://arxiv.org/pdf/1312.6229.pdf)
+
+## 边框预测
+
+在上述算法中,边框的位置可能无法完美覆盖目标,或者大小不合适,或者最准确的边框并非正方形,而是长方形。
+
+**YOLO(You Only Look Once)算法**可以用于得到更精确的边框。YOLO 算法将原始图片划分为 n×n 网格,并将[目标定位](http://kyonhuang.top/Andrew-Ng-Deep-Learning-notes/#/Convolutional_Neural_Networks/%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B?id=%e7%9b%ae%e6%a0%87%e5%ae%9a%e4%bd%8d)一节中提到的图像分类和目标定位算法,逐一应用在每个网格中,每个网格都有标签如:
+
+$$\left[\begin{matrix}P\_c\\\ b\_x\\\ b\_y\\\ b\_h\\\ b\_w\\\ c\_1\\\ c\_2\\\ c\_3\end{matrix}\right]$$
+
+若某个目标的中点落在某个网格,则该网格负责检测该对象。
+
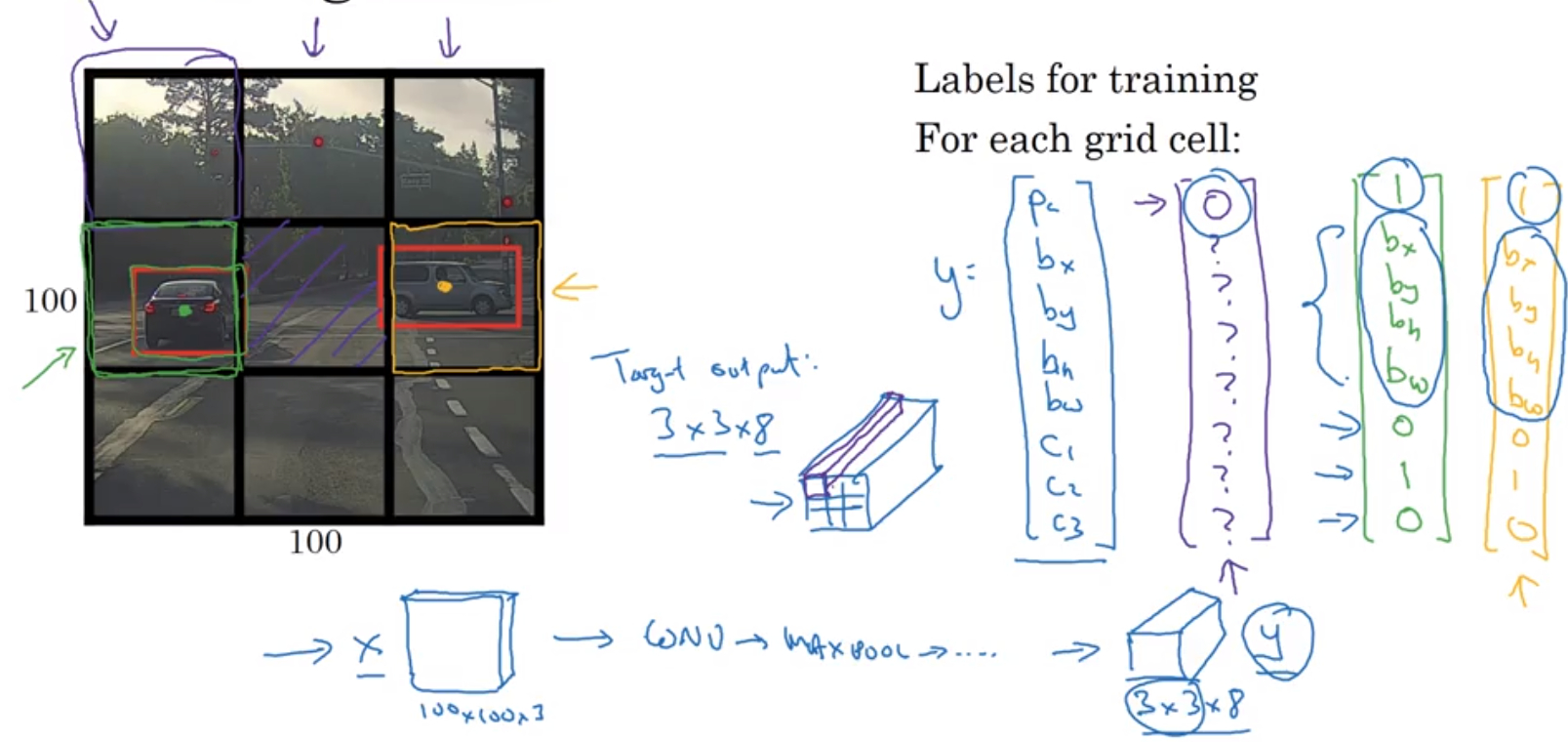
+
+
+如上面的示例中,如果将输入的图片划分为 3×3 的网格、需要检测的目标有 3 类,则每一网格部分图片的标签会是一个 8 维的列矩阵,最终输出的就是大小为 3×3×8 的结果。要得到这个结果,就要训练一个输入大小为 100×100×3,输出大小为 3×3×8 的 CNN。在实践中,可能使用更为精细的 19×19 网格,则两个目标的中点在同一个网格的概率更小。
+
+YOLO 算法的优点:
+
+1. 和图像分类和目标定位算法类似,显式输出边框坐标和大小,不会受到滑窗分类器的步长大小限制。
+2. 仍然只进行一次 CNN 正向计算,效率很高,甚至可以达到实时识别。
+
+如何编码边框 $b\_x$、$b\_y$、$b\_h$、$b\_w$?YOLO 算法设 $b\_x$、$b\_y$、$b\_h$、$b\_w$ 的值是相对于网格长的比例。则 $b\_x$、$b\_y$ 在 0 到 1 之间,而 $b\_h$、$b\_w$ 可以大于 1。当然,也有其他参数化的形式,且效果可能更好。这里只是给出一个通用的表示方法。
+
+相关论文:[Redmon et al., 2015. You Only Look Once: Unified, Real-Time Object Detection](https://arxiv.org/pdf/1506.02640.pdf)。Ng 认为该论文较难理解。
+
+## 交互比
+
+**交互比(IoU, Intersection Over Union)**函数用于评价对象检测算法,它计算预测边框和实际边框交集(I)与并集(U)之比:
+
+$$IoU = \frac{I}{U}$$
+
+IoU 的值在 0~1 之间,且越接近 1 表示目标的定位越准确。IoU 大于等于 0.5 时,一般可以认为预测边框是正确的,当然也可以更加严格地要求一个更高的阈值。
+
+## 非极大值抑制
+
+YOLO 算法中,可能有很多网格检测到同一目标。**非极大值抑制(Non-max Suppression)**会通过清理检测结果,找到每个目标中点所位于的网格,确保算法对每个目标只检测一次。
+
+进行非极大值抑制的步骤如下:
+
+1. 将包含目标中心坐标的可信度 $P\_c$ 小于阈值(例如 0.6)的网格丢弃;
+2. 选取拥有最大 $P\_c$ 的网格;
+3. 分别计算该网格和其他所有网格的 IoU,将 IoU 超过预设阈值的网格丢弃;
+4. 重复第 2~3 步,直到不存在未处理的网格。
+
+上述步骤适用于单类别目标检测。进行多个类别目标检测时,对于每个类别,应该单独做一次非极大值抑制。
+
+## Anchor Boxes
+
+到目前为止,我们讨论的情况都是一个网格只检测一个对象。如果要将算法运用在多目标检测上,需要用到 Anchor Boxes。一个网格的标签中将包含多个 Anchor Box,相当于存在多个用以标识不同目标的边框。
+
+
+
+在上图示例中,我们希望同时检测人和汽车。因此,每个网格的的标签中含有两个 Anchor Box。输出的标签结果大小从 3×3×8 变为 3×3×16。若两个 $P\_c$ 都大于预设阈值,则说明检测到了两个目标。
+
+在单目标检测中,图像中的目标被分配给了包含该目标中点的那个网格;引入 Anchor Box 进行多目标检测时,图像中的目标则被分配到了包含该目标中点的那个网格以及具有最高 IoU 值的该网格的 Anchor Box。
+
+Anchor Boxes 也有局限性,对于同一网格有三个及以上目标,或者两个目标的 Anchor Box 高度重合的情况处理不好。
+
+Anchor Box 的形状一般通过人工选取。高级一点的方法是用 k-means 将两类对象形状聚类,选择最具代表性的 Anchor Box。
+
+如果对以上内容不是很理解,在“3.9 YOLO 算法”一节中视频的第 5 分钟,有一个更为直观的示例。
+
+## R-CNN
+
+前面介绍的滑动窗口目标检测算法对一些明显没有目标的区域也进行了扫描,这降低了算法的运行效率。为了解决这个问题,**R-CNN(Region CNN,带区域的 CNN)**被提出。通过对输入图片运行**图像分割算法**,在不同的色块上找出**候选区域(Region Proposal)**,就只需要在这些区域上运行分类器。
+
+
+
+R-CNN 的缺点是运行速度很慢,所以有一系列后续研究工作改进。例如 Fast R-CNN(与基于卷积的滑动窗口实现相似,但得到候选区域的聚类步骤依然很慢)、Faster R-CNN(使用卷积对图片进行分割)。不过大多数时候还是比 YOLO 算法慢。
+
+相关论文:
+
+* R-CNN:[Girshik et al., 2013. Rich feature hierarchies for accurate object detection and semantic segmentation](https://arxiv.org/pdf/1311.2524.pdf)
+* Fast R-CNN:[Girshik, 2015. Fast R-CNN](https://arxiv.org/pdf/1504.08083.pdf)
+* Faster R-CNN:[Ren et al., 2016. Faster R-CNN: Towards real-time object detection with region proposal networks](https://arxiv.org/pdf/1506.01497v3.pdf)
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/BN.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/BN.png
new file mode 100644
index 00000000..fdc24098
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/BN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Exponentially-weight-average.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Exponentially-weight-average.png
new file mode 100644
index 00000000..b2c33d7c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Exponentially-weight-average.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Gradient-Descent-with-Momentum.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Gradient-Descent-with-Momentum.png
new file mode 100644
index 00000000..69713a90
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/Gradient-Descent-with-Momentum.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/RMSProp.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/RMSProp.png
new file mode 100644
index 00000000..38f7d5a4
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/RMSProp.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/choosing-mini-batch-size.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/choosing-mini-batch-size.png
new file mode 100644
index 00000000..fb1ad377
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/choosing-mini-batch-size.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dictionary_to_vector.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dictionary_to_vector.png
new file mode 100644
index 00000000..2949cae8
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dictionary_to_vector.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dropout_regularization.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dropout_regularization.png
new file mode 100644
index 00000000..55dc31d9
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/dropout_regularization.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/one-sided-difference.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/one-sided-difference.png
new file mode 100644
index 00000000..ac256d1c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/one-sided-difference.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/regularization_prevent_overfitting.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/regularization_prevent_overfitting.png
new file mode 100644
index 00000000..0589ecac
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/regularization_prevent_overfitting.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/saddle.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/saddle.png
new file mode 100644
index 00000000..f867f8a9
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/saddle.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/training-with-mini-batch-gradient-descent.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/training-with-mini-batch-gradient-descent.png
new file mode 100644
index 00000000..f03a11bb
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/training-with-mini-batch-gradient-descent.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/two-sided-difference.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/two-sided-difference.png
new file mode 100644
index 00000000..19b8f002
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/two-sided-difference.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/understanding-softmax.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/understanding-softmax.png
new file mode 100644
index 00000000..26d1634c
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/understanding-softmax.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/why_normalize.png b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/why_normalize.png
new file mode 100644
index 00000000..59a73fd7
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/why_normalize.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/优化算法.md b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/优化算法.md
new file mode 100644
index 00000000..3a62cbcb
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/优化算法.md
@@ -0,0 +1,278 @@
+优化算法
+
+深度学习难以在大数据领域发挥最大效果的一个原因是,在巨大的数据集基础上进行训练速度很慢。而优化算法能够帮助快速训练模型,大大提高效率。
+
+## batch 梯度下降法
+
+**batch 梯度下降法**(批梯度下降法,我们之前一直使用的梯度下降法)是最常用的梯度下降形式,即同时处理整个训练集。其在更新参数时使用所有的样本来进行更新。
+
+对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。
+
+但是如果每次处理训练数据的一部分即进行梯度下降法,则我们的算法速度会执行的更快。而处理的这些一小部分训练子集即称为 **mini-batch**。
+
+## Mini-Batch 梯度下降法
+
+**Mini-Batch 梯度下降法**(小批量梯度下降法)每次同时处理单个的 mini-batch,其他与 batch 梯度下降法一致。
+
+使用 batch 梯度下降法,对整个训练集的一次遍历只能做一个梯度下降;而使用 Mini-Batch 梯度下降法,对整个训练集的一次遍历(称为一个 epoch)能做 mini-batch 个数个梯度下降。之后,可以一直遍历训练集,直到最后收敛到一个合适的精度。
+
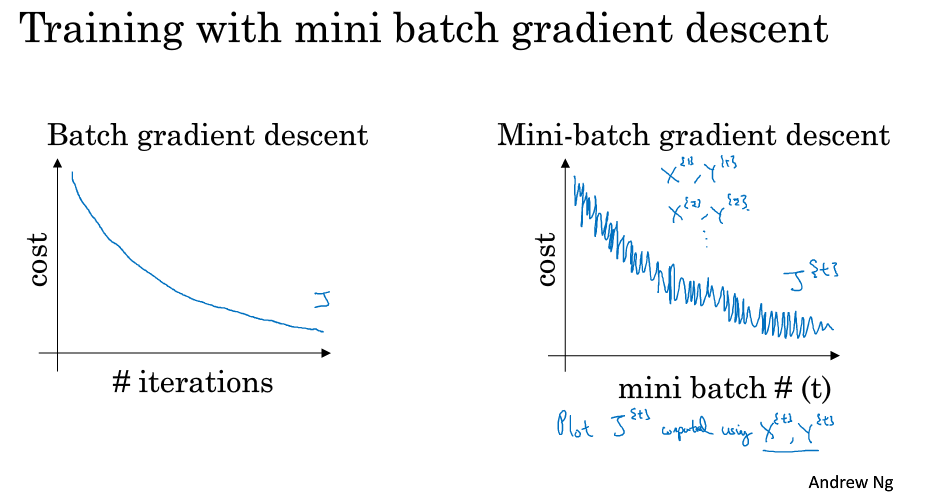
+batch 梯度下降法和 Mini-batch 梯度下降法代价函数的变化趋势如下:
+
+
+
+### batch 的不同大小(size)带来的影响
+
+* mini-batch 的大小为 1,即是**随机梯度下降法(stochastic gradient descent)**,每个样本都是独立的 mini-batch;
+* mini-batch 的大小为 m(数据集大小),即是 batch 梯度下降法;
+
+
+
+* batch 梯度下降法:
+ * 对所有 m 个训练样本执行一次梯度下降,**每一次迭代时间较长,训练过程慢**;
+ * 相对噪声低一些,幅度也大一些;
+ * 成本函数总是向减小的方向下降。
+
+* 随机梯度下降法:
+ * 对每一个训练样本执行一次梯度下降,训练速度快,但**丢失了向量化带来的计算加速**;
+ * 有很多噪声,减小学习率可以适当;
+ * 成本函数总体趋势向全局最小值靠近,但永远不会收敛,而是一直在最小值附近波动。
+
+因此,选择一个`1 < size < m`的合适的大小进行 Mini-batch 梯度下降,可以实现快速学习,也应用了向量化带来的好处,且成本函数的下降处于前两者之间。
+
+### mini-batch 大小的选择
+
+* 如果训练样本的大小比较小,如 m ⩽ 2000 时,选择 batch 梯度下降法;
+* 如果训练样本的大小比较大,选择 Mini-Batch 梯度下降法。为了和计算机的信息存储方式相适应,代码在 mini-batch 大小为 2 的幂次时运行要快一些。典型的大小为 $2^6$、$2^7$、...、$2^9$;
+* mini-batch 的大小要符合 CPU/GPU 内存。
+
+mini-batch 的大小也是一个重要的超变量,需要根据经验快速尝试,找到能够最有效地减少成本函数的值。
+
+### 获得 mini-batch 的步骤
+
+1. 将数据集打乱;
+2. 按照既定的大小分割数据集;
+
+其中打乱数据集的代码:
+
+```py
+m = X.shape[1]
+permutation = list(np.random.permutation(m))
+shuffled_X = X[:, permutation]
+shuffled_Y = Y[:, permutation].reshape((1,m))
+```
+
+`np.random.permutation`与`np.random.shuffle`有两处不同:
+
+1. 如果传给`permutation`一个矩阵,它会返回一个洗牌后的矩阵副本;而`shuffle`只是对一个矩阵进行洗牌,没有返回值。
+2. 如果传入一个整数,它会返回一个洗牌后的`arange`。
+
+### 符号表示
+
+* 使用上角小括号 i 表示训练集里的值,$x^{(i)}$ 是第 i 个训练样本;
+* 使用上角中括号 l 表示神经网络的层数,$z^{[l]}$ 表示神经网络中第 l 层的 z 值;
+* 现在引入大括号 t 来代表不同的 mini-batch,因此有 $X^{t}$、$Y^{t}$。
+
+## 指数平均加权
+
+**指数加权平均(Exponentially Weight Average)**是一种常用的序列数据处理方式,计算公式为:
+
+$$
+S\_t =
+\begin{cases}
+Y\_1, &t = 1 \\\\
+\beta S\_{t-1} + (1-\beta)Y_t, &t > 1
+\end{cases}
+$$
+
+其中 $Y\_t$ 为 t 下的实际值,$S\_t$ 为 t 下加权平均后的值,β 为权重值。
+
+指数加权平均数在统计学中被称为“指数加权移动平均值”。
+
+
+
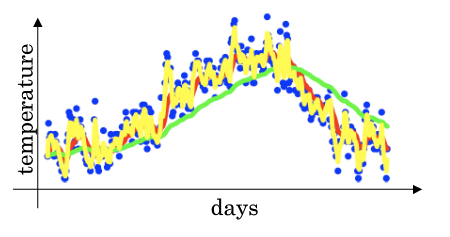
+给定一个时间序列,例如伦敦一年每天的气温值,图中蓝色的点代表真实数据。对于一个即时的气温值,取权重值 β 为 0.9,根据求得的值可以得到图中的红色曲线,它反映了气温变化的大致趋势。
+
+当取权重值 β=0.98 时,可以得到图中更为平滑的绿色曲线。而当取权重值 β=0.5 时,得到图中噪点更多的黄色曲线。**β 越大相当于求取平均利用的天数越多**,曲线自然就会越平滑而且越滞后。
+
+### 理解指数平均加权
+
+当 β 为 0.9 时,
+
+$$v\_{100} = 0.9v\_{99} + 0.1 \theta\_{100}$$
+
+$$v\_{99} = 0.9v\_{98} + 0.1 \theta\_{99}$$
+
+$$v\_{98} = 0.9v\_{97} + 0.1 \theta\_{98}$$
+$$...$$
+
+展开:
+
+$$v\_{100} = 0.1 \theta\_{100} + 0.1 \* 0.9 \theta\_{99} + 0.1 \* {(0.9)}^2 \theta\_{98} + ...$$
+
+其中 θi 指第 i 天的实际数据。所有 θ 前面的系数(不包括 0.1)相加起来为 1 或者接近于 1,这些系数被称作**偏差修正(Bias Correction)**。
+
+根据函数极限的一条定理:
+
+$${\lim\_{\beta\to 0}}(1 - \beta)^{\frac{1}{\beta}} = \frac{1}{e} \approx 0.368$$
+
+当 β 为 0.9 时,可以当作把过去 10 天的气温指数加权平均作为当日的气温,因为 10 天后权重已经下降到了当天的 1/3 左右。同理,当 β 为 0.98 时,可以把过去 50 天的气温指数加权平均作为当日的气温。
+
+因此,在计算当前时刻的平均值时,只需要前一天的平均值和当前时刻的值。
+
+$$v\_t = \beta v\_{t-1} + (1 - \beta)\theta_t$$
+
+考虑到代码,只需要不断更新 v 即可:
+
+$$v := \beta v + (1 - \beta)\theta_t$$
+
+
+指数平均加权并**不是最精准**的计算平均数的方法,你可以直接计算过去 10 天或 50 天的平均值来得到更好的估计,但缺点是保存数据需要占用更多内存,执行更加复杂,计算成本更加高昂。
+
+指数加权平均数公式的好处之一在于它只需要一行代码,且占用极少内存,因此**效率极高,且节省成本**。
+
+### 指数平均加权的偏差修正
+
+我们通常有
+
+$$v\_0 = 0$$
+$$v\_1 = 0.98v\_0 + 0.02\theta\_1$$
+
+因此,$v\_1$ 仅为第一个数据的 0.02(或者说 1-β),显然不准确。往后递推同理。
+
+因此,我们修改公式为
+
+$$v\_t = \frac{\beta v\_{t-1} + (1 - \beta)\theta_t}{{1-\beta^t}}$$
+
+随着 t 的增大,β 的 t 次方趋近于 0。因此当 t 很大的时候,偏差修正几乎没有作用,但是在前期学习可以帮助更好的预测数据。在实际过程中,一般会忽略前期偏差的影响。
+
+## 动量梯度下降法
+
+**动量梯度下降(Gradient Descent with Momentum)**是计算梯度的指数加权平均数,并利用该值来更新参数值。具体过程为:
+
+for l = 1, .. , L:
+
+$$v\_{dW^{[l]}} = \beta v\_{dW^{[l]}} + (1 - \beta) dW^{[l]}$$
+$$v\_{db^{[l]}} = \beta v\_{db^{[l]}} + (1 - \beta) db^{[l]}$$
+$$W^{[l]} := W^{[l]} - \alpha v\_{dW^{[l]}}$$
+$$b^{[l]} := b^{[l]} - \alpha v\_{db^{[l]}}$$
+
+其中,将动量衰减参数 β 设置为 0.9 是超参数的一个常见且效果不错的选择。当 β 被设置为 0 时,显然就成了 batch 梯度下降法。
+
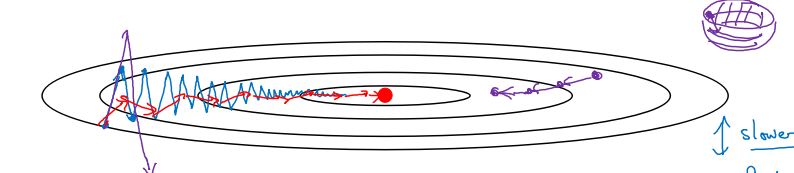
+
+
+进行一般的梯度下降将会得到图中的蓝色曲线,由于存在上下波动,减缓了梯度下降的速度,因此只能使用一个较小的学习率进行迭代。如果用较大的学习率,结果可能会像紫色曲线一样偏离函数的范围。
+
+而使用动量梯度下降时,通过累加过去的梯度值来减少抵达最小值路径上的波动,加速了收敛,因此在横轴方向下降得更快,从而得到图中红色的曲线。
+
+当前后梯度方向一致时,动量梯度下降能够加速学习;而前后梯度方向不一致时,动量梯度下降能够抑制震荡。
+
+另外,在 10 次迭代之后,移动平均已经不再是一个具有偏差的预测。因此实际在使用梯度下降法或者动量梯度下降法时,不会同时进行偏差修正。
+
+### 动量梯度下降法的形象解释
+
+将成本函数想象为一个碗状,从顶部开始运动的小球向下滚,其中 dw,db 想象成球的加速度;而 $v\_{dw}$、$v\_{db}$ 相当于速度。
+
+小球在向下滚动的过程中,因为加速度的存在速度会变快,但是由于 β 的存在,其值小于 1,可以认为是摩擦力,所以球不会无限加速下去。
+
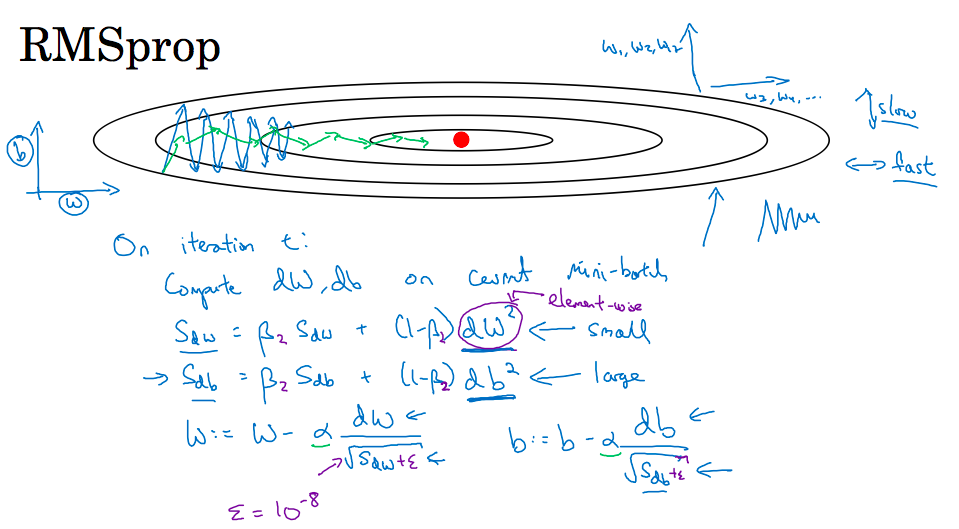
+## RMSProp 算法
+
+**RMSProp(Root Mean Square Propagation,均方根传播)**算法是在对梯度进行指数加权平均的基础上,引入平方和平方根。具体过程为(省略了 l):
+
+$$s\_{dw} = \beta s\_{dw} + (1 - \beta)(dw)^2$$
+$$s\_{db} = \beta s\_{db} + (1 - \beta)(db)^2$$
+$$w := w - \alpha \frac{dw}{\sqrt{s\_{dw} + \epsilon}}$$
+$$b := b - \alpha \frac{db}{\sqrt{s\_{db} + \epsilon}}$$
+
+其中,ϵ 是一个实际操作时加上的较小数(例如10^-8),为了防止分母太小而导致的数值不稳定。
+
+当 dw 或 db 较大时,$(dw)^2$、$(db)^2$会较大,进而 $s\_{dw}$、$s\_{db}$也会较大,最终使得
+
+$$\frac{dw}{\sqrt{s\_{dw} + \epsilon}}$$
+
+和
+
+$$\frac{db}{\sqrt{s\_{db} + \epsilon}}$$
+
+较小,从而减小某些维度梯度更新波动较大的情况,使下降速度变得更快。
+
+
+
+RMSProp 有助于减少抵达最小值路径上的摆动,并允许使用一个更大的学习率 α,从而加快算法学习速度。并且,它和 Adam 优化算法已被证明适用于不同的深度学习网络结构。
+
+注意,β 也是一个超参数。
+
+## Adam 优化算法
+
+**Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)**基本上就是将 Momentum 和 RMSProp 算法结合在一起,通常有超越二者单独时的效果。具体过程如下(省略了 l):
+
+首先进行初始化:
+
+$$v\_{dW} = 0, s\_{dW} = 0, v\_{db} = 0, s\_{db} = 0$$
+
+用每一个 mini-batch 计算 dW、db,第 t 次迭代时:
+
+$$v\_{dW} = \beta\_1 v\_{dW} + (1 - \beta\_1) dW$$
+$$v\_{db} = \beta\_1 v\_{db} + (1 - \beta\_1) db$$
+$$s\_{dW} = \beta\_2 s\_{dW} + (1 - \beta\_2) {(dW)}^2$$
+$$s\_{db} = \beta\_2 s\_{db} + (1 - \beta\_2) {(db)}^2$$
+
+一般使用 Adam 算法时需要计算偏差修正:
+
+$$v^{corrected}\_{dW} = \frac{v\_{dW}}{1-{\beta\_1}^t}$$
+$$v^{corrected}\_{db} = \frac{v\_{db}}{1-{\beta\_1}^t}$$
+$$s^{corrected}\_{dW} = \frac{s\_{dW}}{1-{\beta\_2}^t}$$
+$$s^{corrected}\_{db} = \frac{s\_{db}}{1-{\beta\_2}^t}$$
+
+所以,更新 W、b 时有:
+
+$$W := W - \alpha \frac{v^{corrected}\_{dW}}{{\sqrt{s^{corrected}\_{dW}} + \epsilon}}$$
+
+$$b := b - \alpha \frac{v^{corrected}\_{db}}{{\sqrt{s^{corrected}\_{db}} + \epsilon}}$$
+
+(可以看到 Andrew 在这里 ϵ 没有写到平方根里去,和他在 RMSProp 中写的不太一样。考虑到 ϵ 所起的作用,我感觉影响不大)
+
+### 超参数的选择
+
+Adam 优化算法有很多的超参数,其中
+
+* 学习率 α:需要尝试一系列的值,来寻找比较合适的;
+* β1:常用的缺省值为 0.9;
+* β2:Adam 算法的作者建议为 0.999;
+* ϵ:不重要,不会影响算法表现,Adam 算法的作者建议为 $10^{-8}$;
+
+β1、β2、ϵ 通常不需要调试。
+
+## 学习率衰减
+
+如果设置一个固定的学习率 α,在最小值点附近,由于不同的 batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
+
+而如果随着时间慢慢减少学习率 α 的大小,在初期 α 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 α 的值,即减小步长,有助于算法的收敛,更容易接近最优解。
+
+最常用的学习率衰减方法:
+
+$$\alpha = \frac{1}{1 + decay\\\_rate \* epoch\\\_num} \* \alpha\_0$$
+
+其中,`decay_rate`为衰减率(超参数),`epoch_num`为将所有的训练样本完整过一遍的次数。
+
+* 指数衰减:
+
+$$\alpha = 0.95^{epoch\\\_num} \* \alpha\_0$$
+
+* 其他:
+
+$$\alpha = \frac{k}{\sqrt{epoch\\\_num}} \* \alpha\_0$$
+
+* 离散下降
+
+对于较小的模型,也有人会在训练时根据进度手动调小学习率。
+
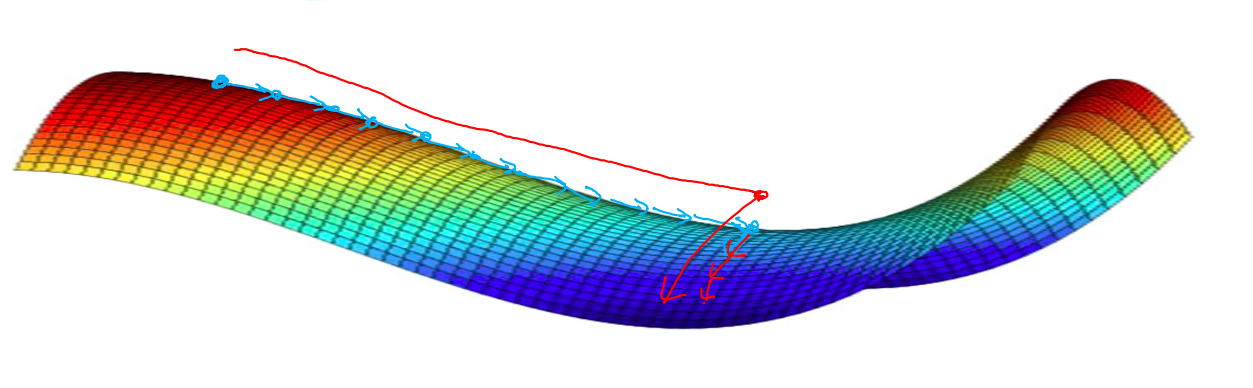
+## 局部最优问题
+
+
+
+**鞍点(saddle)**是函数上的导数为零,但不是轴上局部极值的点。当我们建立一个神经网络时,通常梯度为零的点是上图所示的鞍点,而非局部最小值。减少损失的难度也来自误差曲面中的鞍点,而不是局部最低点。因为在一个具有高维度空间的成本函数中,如果梯度为 0,那么在每个方向,成本函数或是凸函数,或是凹函数。而所有维度均需要是凹函数的概率极小,因此在低维度的局部最优点的情况并不适用于高维度。
+
+结论:
+
+* 在训练较大的神经网络、存在大量参数,并且成本函数被定义在较高的维度空间时,困在极差的局部最优中是不大可能的;
+* 鞍点附近的平稳段会使得学习非常缓慢,而这也是动量梯度下降法、RMSProp 以及 Adam 优化算法能够加速学习的原因,它们能帮助尽早走出平稳段。
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/深度学习的实用层面.md b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/深度学习的实用层面.md
new file mode 100644
index 00000000..10699112
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/深度学习的实用层面.md
@@ -0,0 +1,318 @@
+深度学习的实用层面
+
+## 数据划分:训练 / 验证 / 测试集
+
+应用深度学习是一个典型的迭代过程。
+
+对于一个需要解决的问题的样本数据,在建立模型的过程中,数据会被划分为以下几个部分:
+
+* 训练集(train set):用训练集对算法或模型进行**训练**过程;
+* 验证集(development set):利用验证集(又称为简单交叉验证集,hold-out cross validation set)进行**交叉验证**,**选择出最好的模型**;
+* 测试集(test set):最后利用测试集对模型进行测试,**获取模型运行的无偏估计**(对学习方法进行评估)。
+
+在**小数据量**的时代,如 100、1000、10000 的数据量大小,可以将数据集按照以下比例进行划分:
+
+* 无验证集的情况:70% / 30%;
+* 有验证集的情况:60% / 20% / 20%;
+
+而在如今的**大数据时代**,对于一个问题,我们拥有的数据集的规模可能是百万级别的,所以验证集和测试集所占的比重会趋向于变得更小。
+
+验证集的目的是为了验证不同的算法哪种更加有效,所以验证集只要足够大到能够验证大约 2-10 种算法哪种更好,而不需要使用 20% 的数据作为验证集。如百万数据中抽取 1 万的数据作为验证集就可以了。
+
+测试集的主要目的是评估模型的效果,如在单个分类器中,往往在百万级别的数据中,我们选择其中 1000 条数据足以评估单个模型的效果。
+
+* 100 万数据量:98% / 1% / 1%;
+* 超百万数据量:99.5% / 0.25% / 0.25%(或者99.5% / 0.4% / 0.1%)
+
+### 建议
+
+建议**验证集要和训练集来自于同一个分布**(数据来源一致),可以使得机器学习算法变得更快并获得更好的效果。
+
+如果不需要用**无偏估计**来评估模型的性能,则可以不需要测试集。
+
+### 补充:交叉验证(cross validation)
+
+交叉验证的基本思想是重复地使用数据;把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
+
+### 参考资料
+
+[无偏估计_百度百科](https://baike.baidu.com/item/%E6%97%A0%E5%81%8F%E4%BC%B0%E8%AE%A1/3370664?fr=aladdin)
+
+## 模型估计:偏差 / 方差
+
+**“偏差-方差分解”(bias-variance decomposition)**是解释学习算法泛化性能的一种重要工具。
+
+泛化误差可分解为偏差、方差与噪声之和:
+
+* **偏差**:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了**学习算法本身的拟合能力**;
+* **方差**:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了**数据扰动所造成的影响**;
+* **噪声**:表达了在当前任务上任何学习算法所能够达到的期望泛化误差的下界,即刻画了**学习问题本身的难度**。
+
+偏差-方差分解说明,**泛化性能**是由**学习算法的能力**、**数据的充分性**以及**学习任务本身的难度**所共同决定的。给定学习任务,为了取得好的泛化性能,则需要使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
+
+
+
+在**欠拟合(underfitting)**的情况下,出现**高偏差(high bias)**的情况,即不能很好地对数据进行分类。
+
+当模型设置的太复杂时,训练集中的一些噪声没有被排除,使得模型出现**过拟合(overfitting)**的情况,在验证集上出现**高方差(high variance)**的现象。
+
+当训练出一个模型以后,如果:
+
+* 训练集的错误率较小,而验证集的错误率却较大,说明模型存在较大方差,可能出现了过拟合;
+* 训练集和开发集的错误率都较大,且两者相当,说明模型存在较大偏差,可能出现了欠拟合;
+* 训练集错误率较大,且开发集的错误率远较训练集大,说明方差和偏差都较大,模型很差;
+* 训练集和开发集的错误率都较小,且两者的相差也较小,说明方差和偏差都较小,这个模型效果比较好。
+
+偏差和方差的权衡问题对于模型来说十分重要。
+
+最优误差通常也称为“贝叶斯误差”。
+
+### 应对方法
+
+存在高偏差:
+
+* 扩大网络规模,如添加隐藏层或隐藏单元数目;
+* 寻找合适的网络架构,使用更大的 NN 结构;
+* 花费更长时间训练。
+
+存在高方差:
+
+* 获取更多的数据;
+* 正则化(regularization);
+* 寻找更合适的网络结构。
+
+不断尝试,直到找到低偏差、低方差的框架。
+
+在深度学习的早期阶段,没有太多方法能做到只减少偏差或方差而不影响到另外一方。而在大数据时代,深度学习对监督式学习大有裨益,使得我们不用像以前一样太过关注如何平衡偏差和方差的权衡问题,通过以上方法可以在不增加某一方的前提下减少另一方的值。
+
+## 正则化(regularization)
+
+**正则化**是在成本函数中加入一个正则化项,惩罚模型的复杂度。正则化可以用于解决高方差的问题。
+
+### Logistic 回归中的正则化
+
+对于 Logistic 回归,加入 L2 正则化(也称“L2 范数”)的成本函数:
+
+$$J(w,b) = \frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})+\frac{\lambda}{2m}{||w||}^2\_2$$
+
+* L2 正则化:$$\frac{\lambda}{2m}{||w||}^2\_2 = \frac{\lambda}{2m}\sum_{j=1}^{n\_x}w^2\_j = \frac{\lambda}{2m}w^Tw$$
+* L1 正则化:$$\frac{\lambda}{2m}{||w||}\_1 = \frac{\lambda}{2m}\sum_{j=1}^{n\_x}{|w\_j|}$$
+
+其中,λ 为**正则化因子**,是**超参数**。
+
+由于 L1 正则化最后得到 w 向量中将存在大量的 0,使模型变得稀疏化,因此 L2 正则化更加常用。
+
+**注意**,`lambda`在 Python 中属于保留字,所以在编程的时候,用`lambd`代替这里的正则化因子。
+
+### 神经网络中的正则化
+
+对于神经网络,加入正则化的成本函数:
+
+$$J(w^{[1]}, b^{[1]}, ..., w^{[L]}, b^{[L]}) = \frac{1}{m}\sum\_{i=1}^mL(\hat{y}^{(i)},y^{(i)})+\frac{\lambda}{2m}\sum\_{l=1}^L{{||w^{[l]}||}}^2\_F$$
+
+因为 w 的大小为 ($n^{[l−1]}$, $n^{[l]}$),因此
+
+$${{||w^{[l]}||}}^2\_F = \sum^{n^{[l-1]}}\_{i=1}\sum^{n^{[l]}}\_{j=1}(w^{[l]}\_{ij})^2$$
+
+该矩阵范数被称为**弗罗贝尼乌斯范数(Frobenius Norm)**,所以神经网络中的正则化项被称为弗罗贝尼乌斯范数矩阵。
+
+#### 权重衰减(Weight decay)
+
+**在加入正则化项后,梯度变为**(反向传播要按这个计算):
+
+$$dW^{[l]}= \frac{\partial L}{\partial w^{[l]}} +\frac{\lambda}{m}W^{[l]}$$
+
+代入梯度更新公式:
+
+$$W^{[l]} := W^{[l]}-\alpha dW^{[l]}$$
+
+可得:
+
+$$W^{[l]} := W^{[l]} - \alpha [\frac{\partial L}{\partial w^{[l]}} + \frac{\lambda}{m}W^{[l]}]$$
+
+$$= W^{[l]} - \alpha \frac{\lambda}{m}W^{[l]} - \alpha \frac{\partial L}{\partial w^{[l]}}$$
+
+$$= (1 - \frac{\alpha\lambda}{m})W^{[l]} - \alpha \frac{\partial L}{\partial w^{[l]}}$$
+
+其中,因为 $1 - \frac{\alpha\lambda}{m}<1$,会给原来的 $W^{[l]}$一个衰减的参数,因此 L2 正则化项也被称为**权重衰减(Weight Decay)**。
+
+### 正则化可以减小过拟合的原因
+
+#### 直观解释
+
+正则化因子设置的足够大的情况下,为了使成本函数最小化,权重矩阵 W 就会被设置为接近于 0 的值,**直观上**相当于消除了很多神经元的影响,那么大的神经网络就会变成一个较小的网络。当然,实际上隐藏层的神经元依然存在,但是其影响减弱了,便不会导致过拟合。
+
+#### 数学解释
+
+假设神经元中使用的激活函数为`g(z) = tanh(z)`(sigmoid 同理)。
+
+
+
+在加入正则化项后,当 λ 增大,导致 $W^{[l]}$减小,$Z^{[l]} = W^{[l]}a^{[l-1]} + b^{[l]}$便会减小。由上图可知,在 z 较小(接近于 0)的区域里,`tanh(z)`函数近似线性,所以每层的函数就近似线性函数,整个网络就成为一个简单的近似线性的网络,因此不会发生过拟合。
+
+#### 其他解释
+
+在权值 $w^{[L]}$变小之下,输入样本 X 随机的变化不会对神经网络模造成过大的影响,神经网络受局部噪音的影响的可能性变小。这就是正则化能够降低模型方差的原因。
+
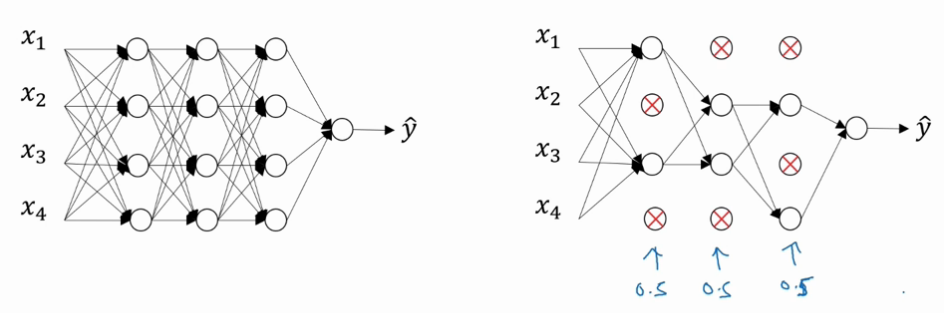
+## dropout 正则化
+
+**dropout(随机失活)**是在神经网络的隐藏层为每个神经元结点设置一个随机消除的概率,保留下来的神经元形成一个结点较少、规模较小的网络用于训练。dropout 正则化较多地被使用在**计算机视觉(Computer Vision)**领域。
+
+
+
+### 反向随机失活(Inverted dropout)
+
+反向随机失活是实现 dropout 的方法。对第`l`层进行 dropout:
+
+```py
+keep_prob = 0.8 # 设置神经元保留概率
+dl = np.random.rand(al.shape[0], al.shape[1]) < keep_prob
+al = np.multiply(al, dl)
+al /= keep_prob
+```
+
+最后一步`al /= keep_prob`是因为 $a^{[l]}$中的一部分元素失活(相当于被归零),为了在下一层计算时不影响 $Z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l+1]}$的期望值,因此除以一个`keep_prob`。
+
+**注意**,在**测试阶段不要使用 dropout**,因为那样会使得预测结果变得随机。
+
+### 理解 dropout
+
+对于单个神经元,其工作是接收输入并产生一些有意义的输出。但是加入了 dropout 后,输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,即不会给任何一个输入特征设置太大的权重。
+
+因此,通过传播过程,dropout 将产生和 L2 正则化相同的**收缩权重**的效果。
+
+对于不同的层,设置的`keep_prob`也不同。一般来说,神经元较少的层,会设`keep_prob`为 1.0,而神经元多的层则会设置比较小的`keep_prob`。
+
+dropout 的一大**缺点**是成本函数无法被明确定义。因为每次迭代都会随机消除一些神经元结点的影响,因此无法确保成本函数单调递减。因此,使用 dropout 时,先将`keep_prob`全部设置为 1.0 后运行代码,确保 $J(w, b)$函数单调递减,再打开 dropout。
+
+## 其他正则化方法
+
+* 数据扩增(Data Augmentation):通过图片的一些变换(翻转,局部放大后切割等),得到更多的训练集和验证集。
+* 早停止法(Early Stopping):将训练集和验证集进行梯度下降时的成本变化曲线画在同一个坐标轴内,当训练集误差降低但验证集误差升高,两者开始发生较大偏差时及时停止迭代,并返回具有最小验证集误差的连接权和阈值,以避免过拟合。这种方法的缺点是无法同时达成偏差和方差的最优。
+
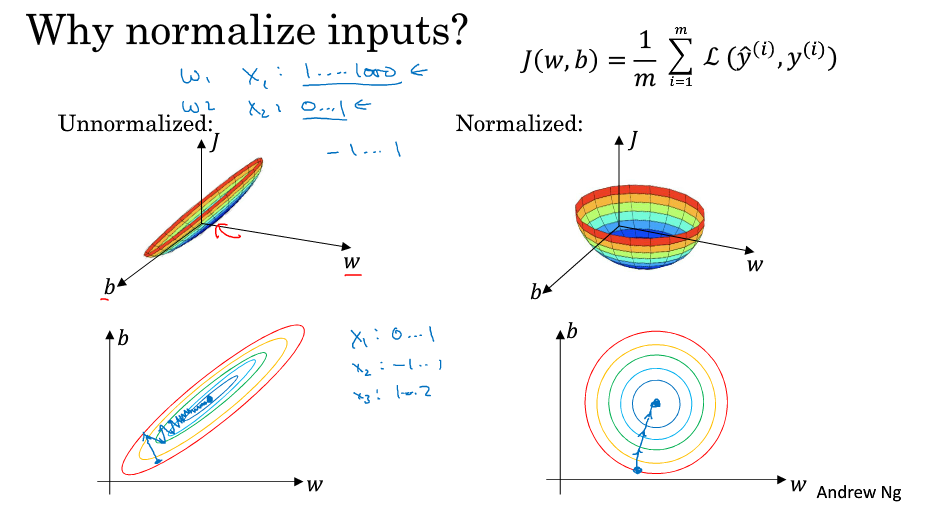
+## 标准化输入
+
+使用标准化处理输入 X 能够有效加速收敛。
+
+### 标准化公式
+
+$$x = \frac{x - \mu}{\sigma}$$
+
+其中,
+
+$$\mu = \frac{1}{m}\sum^m\_{i=1}x^{(i)}$$
+
+$$\sigma = \sqrt{\frac{1}{m}\sum^m\_{i=1}x^{{(i)}^2}}$$
+
+(注意,课程上对应内容中的标准化公式疑似有误,将标准差写成了方差,此处进行修正)
+
+### 使用标准化的原因
+
+
+
+有图可知,使用标准化前后,成本函数的形状有较大差别。
+
+在不使用标准化的成本函数中,如果设置一个较小的学习率,可能需要很多次迭代才能到达全局最优解;而如果使用了标准化,那么无论从哪个位置开始迭代,都能以相对较少的迭代次数找到全局最优解。
+
+## 梯度消失和梯度爆炸
+
+在梯度函数上出现的以指数级递增或者递减的情况分别称为**梯度爆炸**或者**梯度消失**。
+
+假定 $g(z) = z, b^{[l]} = 0$,对于目标输出有:
+
+$$\hat{y} = W^{[L]}W^{[L-1]}...W^{[2]}W^{[1]}X$$
+
+* 对于 $W^{[l]}$的值大于 1 的情况,激活函数的值将以指数级递增;
+* 对于 $W^{[l]}$的值小于 1 的情况,激活函数的值将以指数级递减。
+
+对于导数同理。因此,在计算梯度时,根据不同情况梯度函数会以指数级递增或递减,导致训练导数难度上升,梯度下降算法的步长会变得非常小,需要训练的时间将会非常长。
+
+### 利用初始化缓解梯度消失和爆炸
+
+根据
+
+$$z={w}_1{x}\_1+{w}\_2{x}\_2 + ... + {w}\_n{x}\_n + b$$
+
+可知,当输入的数量 n 较大时,我们希望每个 wi 的值都小一些,这样它们的和得到的 z 也较小。
+
+为了得到较小的 wi,设置`Var(wi)=1/n`,这里称为 **Xavier initialization**。
+
+```py
+WL = np.random.randn(WL.shape[0], WL.shape[1]) * np.sqrt(1/n)
+```
+
+其中 n 是输入的神经元个数,即`WL.shape[1]`。
+
+这样,激活函数的输入 x 近似设置成均值为 0,标准方差为 1,神经元输出 z 的方差就正则化到 1 了。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
+
+同理,也有 **He Initialization**。它和 Xavier initialization 唯一的区别是`Var(wi)=2/n`,适用于 **ReLU** 作为激活函数时。
+
+当激活函数使用 ReLU 时,`Var(wi)=2/n`;当激活函数使用 tanh 时,`Var(wi)=1/n`。
+
+## 梯度检验(Gradient checking)
+
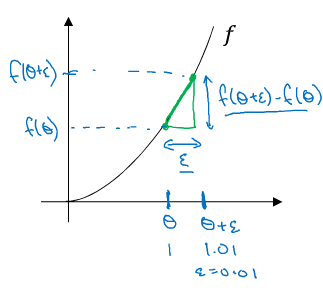
+### 梯度的数值逼近
+
+使用双边误差的方法去逼近导数,精度要高于单边误差。
+
+* 单边误差:
+
+
+
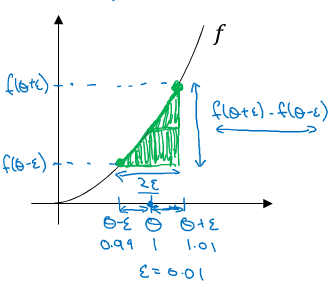
+$$f'(\theta) = {\lim\_{\varepsilon\to 0}} = \frac{f(\theta + \varepsilon) - (\theta)}{\varepsilon}$$
+
+误差:$O(\varepsilon)$
+
+* 双边误差求导(即导数的定义):
+
+
+
+$$f'(\theta) = {\lim\_{\varepsilon\to 0}} = \frac{f(\theta + \varepsilon) - (\theta - \varepsilon)}{2\varepsilon}$$
+
+误差:$O(\varepsilon^2)$
+
+当 ε 越小时,结果越接近真实的导数,也就是梯度值。可以使用这种方法来判断反向传播进行梯度下降时,是否出现了错误。
+
+### 梯度检验的实施
+
+#### 连接参数
+
+将 $W^{[1]}$,$b^{[1]}$,...,$W^{[L]}$,$b^{[L]}$全部连接出来,成为一个巨型向量 θ。这样,
+
+$$J(W^{[1]}, b^{[1]}, ..., W^{[L]},b^{[L]}) = J(\theta)$$
+
+同时,对 $dW^{[1]}$,$db^{[1]}$,...,$dW^{[L]}$,$db^{[L]}$执行同样的操作得到巨型向量 dθ,它和 θ 有同样的维度。
+
+
+
+现在,我们需要找到 dθ 和代价函数 J 的梯度的关系。
+
+#### 进行梯度检验
+
+求得一个梯度逼近值
+
+$$d\theta_{approx}[i] = \frac{J(\theta\_1, \theta\_2, ..., \theta\_i+\varepsilon, ...) - J(\theta\_1, \theta\_2, ..., \theta\_i-\varepsilon, ...)}{2\varepsilon}$$
+
+应该
+
+$$\approx{d\theta[i]} = \frac{\partial J}{\partial \theta_i}$$
+
+因此,我们用梯度检验值
+
+$$\frac{{||d\theta\_{approx} - d\theta||}\_2}{{||d\theta\_{approx}||}\_2+{||d\theta||}\_2}$$
+
+检验反向传播的实施是否正确。其中,
+
+$${||x||}\_2 = \sum^N\_{i=1}{|x_i|}^2$$
+
+表示向量 x 的 2-范数(也称“欧几里德范数”)。
+
+如果梯度检验值和 ε 的值相近,说明神经网络的实施是正确的,否则要去检查代码是否存在 bug。
+
+### 在神经网络实施梯度检验的实用技巧和注意事项
+
+1. 不要在训练中使用梯度检验,它只用于调试(debug)。使用完毕关闭梯度检验的功能;
+2. 如果算法的梯度检验失败,要检查所有项,并试着找出 bug,即确定哪个 dθapprox[i] 与 dθ 的值相差比较大;
+3. 当成本函数包含正则项时,也需要带上正则项进行检验;
+4. 梯度检验不能与 dropout 同时使用。因为每次迭代过程中,dropout 会随机消除隐藏层单元的不同子集,难以计算 dropout 在梯度下降上的成本函数 J。建议关闭 dropout,用梯度检验进行双重检查,确定在没有 dropout 的情况下算法正确,然后打开 dropout;
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/超参数调试、Batch正则化和程序框架.md b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/超参数调试、Batch正则化和程序框架.md
new file mode 100644
index 00000000..6390d59a
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Improving_Deep_Neural_Networks/超参数调试、Batch正则化和程序框架.md
@@ -0,0 +1,223 @@
+超参数调试、Batch 正则化和程序框架
+
+## 超参数调试处理
+
+### 重要程度排序
+
+目前已经讲到过的超参数中,重要程度依次是(仅供参考):
+
+* **最重要**:
+ * 学习率 α;
+
+* **其次重要**:
+ * β:动量衰减参数,常设置为 0.9;
+ * #hidden units:各隐藏层神经元个数;
+ * mini-batch 的大小;
+
+* **再次重要**:
+ * β1,β2,ϵ:Adam 优化算法的超参数,常设为 0.9、0.999、$10^{-8}$;
+ * #layers:神经网络层数;
+ * decay_rate:学习衰减率;
+
+### 调参技巧
+
+系统地组织超参调试过程的技巧:
+
+* **随机选择**点(而非均匀选取),用这些点实验超参数的效果。这样做的原因是我们提前很难知道超参数的重要程度,可以通过选择更多值来进行更多实验;
+* 由粗糙到精细:聚焦效果不错的点组成的小区域,在其中更密集地取值,以此类推;
+
+### 选择合适的范围
+
+* 对于学习率 α,用**对数标尺**而非线性轴更加合理:0.0001、0.001、0.01、0.1 等,然后在这些刻度之间再随机均匀取值;
+* 对于 β,取 0.9 就相当于在 10 个值中计算平均值,而取 0.999 就相当于在 1000 个值中计算平均值。可以考虑给 1-β 取值,这样就和取学习率类似了。
+
+上述操作的原因是当 β 接近 1 时,即使 β 只有微小的改变,所得结果的灵敏度会有较大的变化。例如,β 从 0.9 增加到 0.9005 对结果(1/(1-β))几乎没有影响,而 β 从 0.999 到 0.9995 对结果的影响巨大(从 1000 个值中计算平均值变为 2000 个值中计算平均值)。
+
+### 一些建议
+
+* 深度学习如今已经应用到许多不同的领域。不同的应用出现相互交融的现象,某个应用领域的超参数设定有可能通用于另一领域。不同应用领域的人也应该更多地阅读其他研究领域的 paper,跨领域地寻找灵感;
+* 考虑到数据的变化或者服务器的变更等因素,建议每隔几个月至少一次,重新测试或评估超参数,来获得实时的最佳模型;
+* 根据你所拥有的计算资源来决定你训练模型的方式:
+ * Panda(熊猫方式):在在线广告设置或者在计算机视觉应用领域有大量的数据,但受计算能力所限,同时试验大量模型比较困难。可以采用这种方式:试验一个或一小批模型,初始化,试着让其工作运转,观察它的表现,不断调整参数;
+ * Caviar(鱼子酱方式):拥有足够的计算机去平行试验很多模型,尝试很多不同的超参数,选取效果最好的模型;
+
+## Batch Normalization
+
+**批标准化(Batch Normalization,经常简称为 BN)**会使参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更庞大,工作效果也很好,也会使训练更容易。
+
+之前,我们对输入特征 X 使用了标准化处理。我们也可以用同样的思路处理**隐藏层**的激活值 $a^{[l]}$,以加速 $W^{[l+1]}$和 $b^{[l+1]}$的训练。在**实践**中,经常选择标准化 $Z^{[l]}$:
+
+$$\mu = \frac{1}{m} \sum\_i z^{(i)}$$
+$$\sigma^2 = \frac{1}{m} \sum\_i {(z\_i - \mu)}^2$$
+$$z\_{norm}^{(i)} = \frac{z^{(i)} - \mu}{\sqrt{\sigma^2 + \epsilon}}$$
+
+其中,m 是单个 mini-batch 所包含的样本个数,ϵ 是为了防止分母为零,通常取 $10^{-8}$。
+
+这样,我们使得所有的输入 $z^{(i)}$均值为 0,方差为 1。但我们不想让隐藏层单元总是含有平均值 0 和方差 1,也许隐藏层单元有了不同的分布会更有意义。因此,我们计算
+
+$$\tilde z^{(i)} = \gamma z^{(i)}\_{norm} + \beta$$
+
+其中,γ 和 β 都是模型的学习参数,所以可以用各种梯度下降算法来更新 γ 和 β 的值,如同更新神经网络的权重一样。
+
+通过对 γ 和 β 的合理设置,可以让 $\tilde z^{(i)}$的均值和方差为任意值。这样,我们对隐藏层的 $z^{(i)}$进行标准化处理,用得到的 $\tilde z^{(i)}$替代 $z^{(i)}$。
+
+**设置 γ 和 β 的原因**是,如果各隐藏层的输入均值在靠近 0 的区域,即处于激活函数的线性区域,不利于训练非线性神经网络,从而得到效果较差的模型。因此,需要用 γ 和 β 对标准化后的结果做进一步处理。
+
+### 将 BN 应用于神经网络
+
+对于 L 层神经网络,经过 Batch Normalization 的作用,整体流程如下:
+
+
+
+实际上,Batch Normalization 经常使用在 mini-batch 上,这也是其名称的由来。
+
+使用 Batch Normalization 时,因为标准化处理中包含减去均值的一步,因此 b 实际上没有起到作用,其数值效果交由 β 来实现。因此,在 Batch Normalization 中,可以省略 b 或者暂时设置为 0。
+
+在使用梯度下降算法时,分别对 $W^{[l]}$,$β^{[l]}$和 $γ^{[l]}$进行迭代更新。除了传统的梯度下降算法之外,还可以使用之前学过的动量梯度下降、RMSProp 或者 Adam 等优化算法。
+
+### BN 有效的原因
+
+Batch Normalization 效果很好的原因有以下两点:
+
+1. 通过对隐藏层各神经元的输入做类似的标准化处理,提高神经网络训练速度;
+2. 可以使前面层的权重变化对后面层造成的影响减小,整体网络更加健壮。
+
+关于第二点,如果实际应用样本和训练样本的数据分布不同(例如,橘猫图片和黑猫图片),我们称发生了“**Covariate Shift**”。这种情况下,一般要对模型进行重新训练。Batch Normalization 的作用就是减小 Covariate Shift 所带来的影响,让模型变得更加健壮,鲁棒性(Robustness)更强。
+
+即使输入的值改变了,由于 Batch Normalization 的作用,使得均值和方差保持不变(由 γ 和 β 决定),限制了在前层的参数更新对数值分布的影响程度,因此后层的学习变得更容易一些。Batch Normalization 减少了各层 W 和 b 之间的耦合性,让各层更加独立,实现自我训练学习的效果。
+
+另外,Batch Normalization 也**起到微弱的正则化**(regularization)效果。因为在每个 mini-batch 而非整个数据集上计算均值和方差,只由这一小部分数据估计得出的均值和方差会有一些噪声,因此最终计算出的 $\tilde z^{(i)}$也有一定噪声。类似于 dropout,这种噪声会使得神经元不会再特别依赖于任何一个输入特征。
+
+因为 Batch Normalization 只有微弱的正则化效果,因此可以和 dropout 一起使用,以获得更强大的正则化效果。通过应用更大的 mini-batch 大小,可以减少噪声,从而减少这种正则化效果。
+
+最后,不要将 Batch Normalization 作为正则化的手段,而是当作加速学习的方式。正则化只是一种非期望的副作用,Batch Normalization 解决的还是反向传播过程中的梯度问题(梯度消失和爆炸)。
+
+### 测试时的 Batch Normalization
+
+Batch Normalization 将数据以 mini-batch 的形式逐一处理,但在测试时,可能需要对每一个样本逐一处理,这样无法得到 μ 和 $σ^2$。
+
+理论上,我们可以将所有训练集放入最终的神经网络模型中,然后将每个隐藏层计算得到的 $μ^{[l]}$和 $σ^{2[l]}$直接作为测试过程的 μ 和 σ 来使用。但是,实际应用中一般不使用这种方法,而是使用之前学习过的指数加权平均的方法来预测测试过程单个样本的 μ 和 $σ^2$。
+
+对于第 l 层隐藏层,考虑所有 mini-batch 在该隐藏层下的 $μ^{[l]}$和 $σ^{2[l]}$,然后用指数加权平均的方式来预测得到当前单个样本的 $μ^{[l]}$和 $σ^{2[l]}$。这样就实现了对测试过程单个样本的均值和方差估计。
+
+## Softmax 回归
+
+目前为止,介绍的分类例子都是二分类问题:神经网络输出层只有一个神经元,表示预测输出 $\hat y$是正类的概率 P(y = 1|x),$\hat y$ > 0.5 则判断为正类,反之判断为负类。
+
+对于**多分类问题**,用 C 表示种类个数,则神经网络输出层,也就是第 L 层的单元数量 $n^{[L]} = C$。每个神经元的输出依次对应属于该类的概率,即 $P(y = c|x), c = 0, 1, .., C-1$。有一种 Logistic 回归的一般形式,叫做 **Softmax 回归**,可以处理多分类问题。
+
+对于 Softmax 回归模型的输出层,即第 L 层,有:
+
+$$Z^{[L]} = W^{[L]}a^{[L-1]} + b^{[L]}$$
+
+for i in range(L),有:
+
+$$a^{[L]}\_i = \frac{e^{Z^{[L]}\_i}}{\sum^C\_{i=1}e^{Z^{[L]}\_i}}$$
+
+为输出层每个神经元的输出,对应属于该类的概率,满足:
+
+$$\sum^C\_{i=1}a^{[L]}\_i = 1$$
+
+一个直观的计算例子如下:
+
+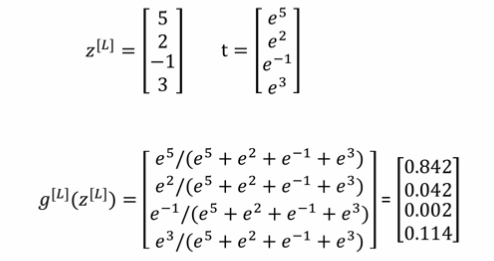
+
+### 损失函数和成本函数
+
+定义**损失函数**为:
+
+$$L(\hat y, y) = -\sum^C\_{j=1}y\_jlog\hat y\_j$$
+
+当 i 为样本真实类别,则有:
+
+$$y\_j = 0, j \ne i$$
+
+因此,损失函数可以简化为:
+
+$$L(\hat y, y) = -y\_ilog\hat y\_i = log \hat y\_i$$
+
+所有 m 个样本的**成本函数**为:
+
+$$J = \frac{1}{m}\sum^m\_{i=1}L(\hat y, y)$$
+
+### 梯度下降法
+
+多分类的 Softmax 回归模型与二分类的 Logistic 回归模型只有输出层上有一点区别。经过不太一样的推导过程,仍有
+
+$$dZ^{[L]} = A^{[L]} - Y$$
+
+反向传播过程的其他步骤也和 Logistic 回归的一致。
+
+### 参考资料
+
+* [Softmax回归 - Ufldl](http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92)
+
+## 深度学习框架
+
+### 比较著名的框架
+
+* Caffe / Caffe 2
+* CNTK
+* DL4J
+* Keras
+* Lasagne
+* mxnet
+* PaddlePaddle
+* TensorFlow
+* Theano
+* Torch
+
+### 选择框架的标准
+
+* 便于编程:包括神经网络的开发和迭代、配置产品;
+* 运行速度:特别是训练大型数据集时;
+* 是否真正开放:不仅需要开源,而且需要良好的管理,能够持续开放所有功能。
+
+## Tensorflow
+
+目前最火的深度学习框架大概是 Tensorflow 了。这里简单的介绍一下。
+
+Tensorflow 框架内可以直接调用梯度下降算法,极大地降低了编程人员的工作量。例如以下代码:
+
+```py
+import numpy as np
+import tensorflow as tf
+
+cofficients = np.array([[1.],[-10.],[25.]])
+
+w = tf.Variable(0,dtype=tf.float32)
+x = tf.placeholder(tf.float32,[3,1])
+# Tensorflow 重载了加减乘除符号
+cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
+# 改变下面这行代码,可以换用更好的优化算法
+train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
+
+init = tf.global_variables_initializer()
+session = tf.Session()
+session.run(init)
+for i in range(1000):
+ session.run(train, feed_dict=(x:coefficients))
+print(session.run(w))
+```
+
+打印为 4.99999,基本可以认为是我们需要的结果。更改 cofficients 的值可以得到不同的结果 w。
+
+上述代码中:
+
+```py
+session = tf.Session()
+session.run(init)
+print(session.run(w))
+```
+
+也可以写作:
+
+```py
+with tf.Session() as session:
+ session.run(init)
+ print(session.run(w))
+```
+
+with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
+
+想了解更多 Tensorflow 有关知识,请参考[官方文档](https://www.tensorflow.org)。
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/00神经网络简介.md b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/00神经网络简介.md
new file mode 100644
index 00000000..2e77f552
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/00神经网络简介.md
@@ -0,0 +1,44 @@
+# 神经网络简介
+
+> 必须得明白,吴恩达在通过什么角度,构建神经网络的基础知识。
+
+
+## 什么是神经网络
+
+
+
+* 输入层----隐藏层----输出层
+
+* **向量化** 实现一个神经网络时,如果需要遍历整个训练集,并不需要直接使用 for 循环。采用向量化的方法代替for 循环
+* **计算过程**
+ * 正向过程(forward pass)或者叫**正向传播步骤(forward propagation step)**
+ * 反向过程(backward pass)或者叫**反向传播步骤(backward propagation step)**。
+
+## 用神经网络进行监督学习
+
+### 应用领域
+
+* 房屋价格预测-ANN普通神经网络,多维度特征
+* 图像-CNN卷积神经网络,二维像素
+* 声音-RNN循环神经网络,一维实践序列
+* 翻译-RNNs循环神经网络
+
+### 不同的神经网络
+
+
+
+### 监督学习
+
+* 结构化数据:数据库中的结构化数据。
+* 非结构化数据:声音、图像、文本。
+
+## 深度学习的历史
+
+### 原因
+* 更多的数据data
+* 更高的算力compute
+* 更复杂的算法algorithm
+
+### 流程
+
+idea--code--experiment---back to idea
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/01神经网络基础.md b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/01神经网络基础.md
new file mode 100644
index 00000000..cf8c0372
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/01神经网络基础.md
@@ -0,0 +1,153 @@
+# 神经网络基础
+
+
+
+
+## Logistic 回归
+
+Logistic 回归是一个用于二分分类的算法。
+
+Logistic 回归中使用的参数如下:
+
+* 输入的特征向量:$x \in R^{n\_x}$,其中 ${n\_x}$是特征数量;
+* 用于训练的标签:$y \in 0,1$
+* 权重:$w \in R^{n\_x}$
+* 偏置: $b \in R$
+* 输出:$\hat{y} = \sigma(w^Tx+b)$
+* Sigmoid 函数:$$s = \sigma(w^Tx+b) = \sigma(z) = \frac{1}{1+e^{-z}}$$
+
+为将 $w^Tx+b$ 约束在 [0, 1] 间,引入 Sigmoid 函数。从下图可看出,Sigmoid 函数的值域为 [0, 1]。
+
+
+
+Logistic 回归可以看作是一个非常小的神经网络。下图是一个典型例子:
+
+
+
+### 损失函数
+
+**损失函数(loss function)**用于衡量预测结果与真实值之间的误差。
+
+最简单的损失函数定义方式为平方差损失:$$L(\hat{y},y) = \frac{1}{2}(\hat{y}-y)^2$$
+
+但 Logistic 回归中我们并不倾向于使用这样的损失函数,因为之后讨论的优化问题会变成非凸的,最后会得到很多个局部最优解,梯度下降法可能找不到全局最优值。
+
+一般使用$$L(\hat{y},y) = -(y\log\hat{y})-(1-y)\log(1-\hat{y})$$
+
+损失函数是在单个训练样本中定义的,它衡量了在**单个**训练样本上的表现。而**代价函数(cost function,或者称作成本函数)**衡量的是在**全体**训练样本上的表现,即衡量参数 w 和 b 的效果。
+
+$$J(w,b) = \frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})$$
+
+## 梯度下降法(Gradient Descent)
+
+函数的**梯度(gradient)**指出了函数的最陡增长方向。即是说,按梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。
+
+模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。简单起见我们先假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:
+
+
+
+可以看到,成本函数 J 是一个**凸函数**,与非凸函数的区别在于其不含有多个局部最低点;选择这样的代价函数就保证了无论我们初始化模型参数如何,都能够寻找到合适的最优解。
+
+参数 w 的更新公式为:
+
+$$w := w - \alpha\frac{dJ(w, b)}{dw}$$
+
+其中 α 表示学习速率,即每次更新的 w 的步伐长度。
+
+当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
+
+在成本函数 J(w, b) 中还存在参数 b,因此也有:
+
+$$b := b - \alpha\frac{dJ(w, b)}{db}$$
+
+## 计算图(Computation Graph)
+
+神经网络中的计算即是由多个计算网络输出的前向传播与计算梯度的后向传播构成。所谓的 **反向传播(Back Propagation)** 即是当我们需要计算最终值相对于某个特征变量的导数时,我们需要利用计算图中上一步的结点定义。
+
+## Logistic 回归中的梯度下降法
+
+假设输入的特征向量维度为 2,即输入参数共有 x1, w1, x2, w2, b 这五个。可以推导出如下的计算图:
+
+
+
+首先反向求出 L 对于 a 的导数:
+
+$$da=\frac{dL(a,y)}{da}=−\frac{y}{a}+\frac{1−y}{1−a}$$
+
+然后继续反向求出 L 对于 z 的导数:
+
+$$dz=\frac{dL}{dz}=\frac{dL(a,y)}{dz}=\frac{dL}{da}\frac{da}{dz}=a−y$$
+
+依此类推求出最终的损失函数相较于原始参数的导数之后,根据如下公式进行参数更新:
+
+$$w _1:=w _1−\alpha dw _1$$
+
+$$w _2:=w _2−\alpha dw _2$$
+
+$$b:=b−\alpha db$$
+
+接下来我们需要将对于单个用例的损失函数扩展到整个训练集的代价函数:
+
+$$J(w,b)=\frac{1}{m}\sum^m_{i=1}L(a^{(i)},y^{(i)})$$
+
+$$a^{(i)}=\hat{y}^{(i)}=\sigma(z^{(i)})=\sigma(w^Tx^{(i)}+b)$$
+
+我们可以对于某个权重参数 w1,其导数计算为:
+
+$$\frac{\partial J(w,b)}{\partial{w\_1}}=\frac{1}{m}\sum^m_{i=1}\frac{\partial L(a^{(i)},y^{(i)})}{\partial{w\_1}}$$
+
+
+完整的 Logistic 回归中某次训练的流程如下,这里仅假设特征向量的维度为 2:
+
+
+
+然后对 w1、w2、b 进行迭代。
+
+上述过程在计算时有一个缺点:你需要编写两个 for 循环。第一个 for 循环遍历 m 个样本,而第二个 for 循环遍历所有特征。如果有大量特征,在代码中显式使用 for 循环会使算法很低效。**向量化**可以用于解决显式使用 for 循环的问题。
+
+## 向量化(Vectorization)
+
+在 Logistic 回归中,需要计算 $$z=w^Tx+b$$如果是非向量化的循环方式操作,代码可能如下:
+
+```py
+z = 0;
+for i in range(n_x):
+ z += w[i] * x[i]
+z += b
+```
+
+而如果是向量化的操作,代码则会简洁很多,并带来近百倍的性能提升(并行指令):
+
+```py
+z = np.dot(w, x) + b
+```
+
+不用显式 for 循环,实现 Logistic 回归的梯度下降一次迭代(对应之前蓝色代码的 for 循环部分。这里公式和 NumPy 的代码混杂,注意分辨):
+
+$$Z=w^TX+b=np.dot(w.T, x) + b$$
+$$A=\sigma(Z)$$
+$$dZ=A-Y$$
+$$dw=\frac{1}{m}XdZ^T$$
+$$db=\frac{1}{m}np.sum(dZ)$$
+$$w:=w-\sigma dw$$
+$$b:=b-\sigma db$$
+
+正向和反向传播尽管如此,多次迭代的梯度下降依然需要 for 循环。
+
+## 广播(broadcasting)
+
+Numpy 的 Universal functions 中要求输入的数组 shape 是一致的。当数组的 shape 不相等的时候,则会使用广播机制,调整数组使得 shape 一样,满足规则,则可以运算,否则就出错。
+
+四条规则:
+
+1. 让所有输入数组都向其中 shape 最长的数组看齐,shape 中不足的部分都通过在前面加 1 补齐;
+2. 输出数组的 shape 是输入数组 shape 的各个轴上的最大值;
+3. 如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错;
+4. 当输入数组的某个轴的长度为 1 时,沿着此轴运算时都用此轴上的第一组值。
+
+## NumPy 使用技巧
+
+转置对秩为 1 的数组无效。因此,应该避免使用秩为 1 的数组,用 n * 1 的矩阵代替。例如,用`np.random.randn(5,1)`代替`np.random.randn(5)`。
+
+如果得到了一个秩为 1 的数组,可以使用`reshape`进行转换。
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/02浅层神经网络.md b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/02浅层神经网络.md
new file mode 100644
index 00000000..fca081b3
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/02浅层神经网络.md
@@ -0,0 +1,135 @@
+# 浅层神经网络
+
+## 神经网络表示
+
+* ReLU,recfied linear unit修正线性单元
+
+竖向堆叠起来的输入特征被称作神经网络的**输入层(the input layer)**。
+
+神经网络的 **隐藏层(a hidden layer)** 。“隐藏”的含义是 **在训练集中** ,这些中间节点的真正数值是无法看到的。
+
+**输出层(the output layer)** 负责输出预测值。
+
+
+
+如图是一个**双层神经网络**,也称作**单隐层神经网络(a single hidden layer neural network)**。当我们计算网络的层数时,通常不考虑输入层,因此图中隐藏层是第一层,输出层是第二层。
+
+约定俗成的符号表示是:
+
+* 输入层的激活值为 $a^{[0]}$;
+* 同样,隐藏层也会产生一些激活值,记作 $a^{[1]}$
+隐藏层的第一个单元(或者说节点)就记作 $a^{[1]}_1$输出层同理。
+* 另外,隐藏层和输出层都是带有参数 W 和 b 的。它们都使用上标`[1]`来表示是和第一个隐藏层有关,或者上标`[2]`来表示是和输出层有关。
+
+## 计算神经网络的输出
+
+
+
+实际上,神经网络只不过将 Logistic 回归的计算步骤重复很多次。对于隐藏层的第一个节点,有
+
+$$z _1^{[1]} = (W _1^{[1]})^TX+b _1^{[1]}$$
+
+$$a _1^{[1]} = \sigma(z _1^{[1]})$$
+
+我们可以类推得到,对于第一个隐藏层有下列公式:
+
+$$z^{[1]} = (W^{[1]})^Ta^{[0]}+b^{[1]}$$
+
+$$a^{[1]} = \sigma(z^{[1]})$$
+
+其中,$a^{[0]}$可以是一个列向量,也可以将多个列向量堆叠起来得到矩阵。如果是后者的话,得到的 $z^{[1]}$和 $a^{[1]}$也是一个矩阵。
+
+同理,对于输出层有:
+
+$$z^{[2]} = (W^{[2]})^Ta^{[1]}+b^{[2]}$$
+
+$$\hat{y} = a^{[2]} = \sigma(z^{[2]})$$
+
+值得注意的是层与层之间参数矩阵的规格大小。
+
+* 输入层和隐藏层之间:${(W^{[1]})}^T$的 shape 为`(4,3)`,前面的 4 是隐藏层神经元的个数,后面的 3 是输入层神经元的个数;$b^{[1]}$的 shape 为`(4,1)`,和隐藏层的神经元个数相同。
+* 隐藏层和输出层之间:${(W^{[2]})}^T$的 shape 为`(1,4)`,前面的 1 是输出层神经元的个数,后面的 4 是隐藏层神经元的个数;$b^{[2]}$的 shape 为`(1,1)`,和输出层的神经元个数相同。
+
+## 激活函数
+
+有一个问题是神经网络的隐藏层和输出单元用什么激活函数。之前我们都是选用 sigmoid 函数,但有时其他函数的效果会好得多。
+
+可供选用的激活函数有:
+
+* tanh 函数(the hyperbolic tangent function,双曲正切函数):
+
+$$a = \frac{e^z - e^{-z}}{e^z + e^{-z}}$$
+
+效果几乎总比 sigmoid 函数好(除开**二元分类的输出层**,因为我们希望输出的结果介于 0 到 1 之间),因为函数输出介于 -1 和 1 之间,激活函数的平均值就更接近 0,有类似数据中心化的效果。
+
+然而,tanh 函数存在和 sigmoid 函数一样的缺点:当 z 趋紧无穷大(或无穷小),导数的梯度(即函数的斜率)就趋紧于 0,这使得梯度算法的速度大大减缓。
+
+* **ReLU 函数(the rectified linear unit,修正线性单元)**:
+
+$$a=max(0,z)$$
+
+当 z > 0 时,梯度始终为 1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于 sigmoid 和 tanh。然而当 z < 0 时,梯度一直为 0,但是实际的运用中,该缺陷的影响不是很大。
+
+* Leaky ReLU(带泄漏的 ReLU):
+
+$$a=max(0.01z,z)$$
+
+Leaky ReLU 保证在 z < 0 的时候,梯度仍然不为 0。理论上来说,Leaky ReLU 有 ReLU 的所有优点,但在实际操作中没有证明总是好于 ReLU,因此不常用。
+
+
+
+在选择激活函数的时候,如果在不知道该选什么的时候就选择 ReLU,当然也没有固定答案,要依据实际问题在交叉验证集合中进行验证分析。当然,我们可以在不同层选用不同的激活函数。
+
+### 使用非线性激活函数的原因
+
+使用线性激活函数和不使用激活函数、直接使用 Logistic 回归没有区别,那么无论神经网络有多少层,输出都是输入的线性组合,与**没有隐藏层**效果相当,就成了最原始的感知器了。
+
+### 激活函数的导数
+
+* sigmoid 函数:
+
+$$g(z) = \frac{1}{1+e^{-z}}$$
+
+$$g\prime(z)=\frac{dg(z)}{dz} = \frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})=g(z)(1-g(z))$$
+
+* tanh 函数:
+
+$$g(z) = tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}$$
+
+$$g\prime(z)=\frac{dg(z)}{dz} = 1-(tanh(z))^2=1-(g(z))^2$$
+
+## 神经网络的梯度下降法
+
+### 正向梯度下降
+
+$$Z^{[1]}={(W^{[1]})}^TX+b^{[1]}$$
+
+$$A^{[1]}=g^{[1]}(Z^{[1]})$$
+
+$$Z^{[2]}={(W^{[2]})}^TA^{[1]}+b^{[2]}$$
+
+$$A^{[2]}=g^{[2]}(Z^{[2]})=\sigma(Z^{[2]})$$
+
+### 反向梯度下降
+
+神经网络反向梯度下降公式(左)和其代码向量化(右):
+
+
+
+## 随机初始化
+
+如果在初始时将两个隐藏神经元的参数设置为相同的大小,那么两个隐藏神经元对输出单元的影响也是相同的,通过反向梯度下降去进行计算的时候,会得到同样的梯度大小,所以在经过多次迭代后,两个隐藏层单位仍然是对称的。无论设置多少个隐藏单元,其最终的影响都是相同的,那么多个隐藏神经元就没有了意义。
+
+在初始化的时候,W 参数要进行随机初始化,不可以设置为 0。而 b 因为不存在对称性的问题,可以设置为 0。
+
+以 2 个输入,2 个隐藏神经元为例:
+
+```py
+W = np.random.rand(2,2)* 0.01
+b = np.zeros((2,1))
+```
+
+这里将 W 的值乘以 0.01(或者其他的常数值)的原因是为了使得权重 W 初始化为较小的值,这是因为使用 sigmoid 函数或者 tanh 函数作为激活函数时,W 比较小,则 Z=WX+b 所得的值趋近于 0,梯度较大,能够提高算法的更新速度。而如果 W 设置的太大的话,得到的梯度较小,训练过程因此会变得很慢。
+
+ReLU 和 Leaky ReLU 作为激活函数时不存在这种问题,因为在大于 0 的时候,梯度均为 1。
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/03深层神经网络.md b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/03深层神经网络.md
new file mode 100644
index 00000000..293ecf23
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/03深层神经网络.md
@@ -0,0 +1,85 @@
+深层神经网络
+
+## 深层网络中的前向和反向传播
+
+### 前向传播
+
+**输入**:$a^{[l−1]}$
+
+**输出**:$a^{[l]}$,cache($z^{[l]}$)
+
+**公式**:
+
+$$Z^{[l]}=W^{[l]}\cdot a^{[l-1]}+b^{[l]}$$
+
+$$a^{[l]}=g^{[l]}(Z^{[l]})$$
+
+### 反向传播
+
+**输入**:$da^{[l]}$
+
+**输出**:$da^{[l-1]}$,$dW^{[l]}$,$db^{[l]}$
+
+**公式**:
+
+$$dZ^{[l]}=da^{[l]}*g^{[l]}{'}(Z^{[l]})$$
+
+$$dW^{[l]}=dZ^{[l]}\cdot a^{[l-1]}$$
+
+$$db^{[l]}=dZ^{[l]}$$
+
+$$da^{[l-1]}=W^{[l]T}\cdot dZ^{[l]}$$
+
+### 搭建深层神经网络块
+
+
+
+神经网络的一步训练(一个梯度下降循环),包含了从 $a^{[0]}$(即 x)经过一系列正向传播计算得到 $\hat y$ (即 $a^{[l]}$)。然后再计算 $da^{[l]}$,开始实现反向传播,用**链式法则**得到所有的导数项,W 和 b 也会在每一层被更新。
+
+在代码实现时,可以将正向传播过程中计算出来的 z 值缓存下来,待到反向传播计算时使用。
+
+补充一张从 [Hinton、LeCun 和 Bengio 写的深度学习综述](https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf)中摘下来的图,有助于理解整个过程:
+
+
+
+## 矩阵的维度
+
+$$W^{[l]}: (n^{[l]}, n^{[l-1]})$$
+
+$$b^{[l]}: (n^{[l]}, 1)$$
+
+$$dW^{[l]}: (n^{[l]}, n^{[l-1]})$$
+
+$$db^{[l]}: (n^{[l]}, 1)$$
+
+对于 Z、a,向量化之前有:
+
+$$Z^{[l]}, a^{[l]}: (n^{[l]}, 1)$$
+
+而在向量化之后,则有:
+
+$$Z^{[l]}, A^{[l]}: (n^{[l]}, m)$$
+
+在计算反向传播时,dZ、dA 的维度和 Z、A 是一样的。
+
+## 使用深层表示的原因
+
+对于人脸识别,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
+
+同样的,对于语音识别,第一层神经网络可以学习到语言发音的一些音调,后面更深层次的网络可以检测到基本的音素,再到单词信息,逐渐加深可以学到短语、句子。
+
+通过例子可以看到,随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
+
+## 参数和超参数
+
+**参数**即是我们在过程中想要模型学习到的信息(**模型自己能计算出来的**),例如 $W^{[l]}$,$b^{[l]}$。而**超参数(hyper parameters)**即为控制参数的输出值的一些网络信息(**需要人经验判断**)。超参数的改变会导致最终得到的参数 $W^{[l]}$,$b^{[l]}$ 的改变。
+
+典型的超参数有:
+
+* 学习速率:α
+* 迭代次数:N
+* 隐藏层的层数:L
+* 每一层的神经元个数:$n^{[1]}$,$n^{[2]}$,...
+* 激活函数 g(z) 的选择
+
+当开发新应用时,预先很难准确知道超参数的最优值应该是什么。因此,通常需要尝试很多不同的值。应用深度学习领域是一个很大程度基于经验的过程。
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-11-48-42.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-11-48-42.png
new file mode 100644
index 00000000..7ec2639a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-11-48-42.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-12-31-27.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-12-31-27.png
new file mode 100644
index 00000000..01bb7861
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/2020-10-14-12-31-27.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/LogReg_kiank.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/LogReg_kiank.png
new file mode 100644
index 00000000..404ae5af
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/LogReg_kiank.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/Logistic-Computation-Graph.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/Logistic-Computation-Graph.png
new file mode 100644
index 00000000..dd188ede
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/Logistic-Computation-Graph.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/The_activation_function.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/The_activation_function.png
new file mode 100644
index 00000000..fb0389db
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/The_activation_function.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/cost-function.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/cost-function.png
new file mode 100644
index 00000000..d0de726d
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/cost-function.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-example.jpg b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-example.jpg
new file mode 100644
index 00000000..22ca6415
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-example.jpg differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-functions.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-functions.png
new file mode 100644
index 00000000..b333acfe
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/forward-and-backward-functions.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/neural_network_like_logistic.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/neural_network_like_logistic.png
new file mode 100644
index 00000000..35dd0cec
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/neural_network_like_logistic.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/sigmoid-function.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/sigmoid-function.png
new file mode 100644
index 00000000..8a726e61
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/sigmoid-function.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/single_hidden_layer_neural_network.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/single_hidden_layer_neural_network.png
new file mode 100644
index 00000000..dd55af0a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/single_hidden_layer_neural_network.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/summary-of-gradient-descent.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/summary-of-gradient-descent.png
new file mode 100644
index 00000000..145334d4
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/summary-of-gradient-descent.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/whole-logistic-training-update.png b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/whole-logistic-training-update.png
new file mode 100644
index 00000000..abb3f41e
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Neural_Networks_and_Deep_Learning/whole-logistic-training-update.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-Model.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-Model.png
new file mode 100644
index 00000000..a4c707e8
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-Model.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-model-for-speech-recognition.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-model-for-speech-recognition.png
new file mode 100644
index 00000000..39f15265
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Attention-model-for-speech-recognition.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/BRNN.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/BRNN.png
new file mode 100644
index 00000000..49b62ade
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/BRNN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Beam-search.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Beam-search.png
new file mode 100644
index 00000000..54e147d5
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Beam-search.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Bleu-score-on-unigram.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Bleu-score-on-unigram.png
new file mode 100644
index 00000000..9617d957
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Bleu-score-on-unigram.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CBOW.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CBOW.png
new file mode 100644
index 00000000..f6e51b5a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CBOW.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CTC-for-speech-recognition.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CTC-for-speech-recognition.png
new file mode 100644
index 00000000..1d6984a2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/CTC-for-speech-recognition.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Computing-attention.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Computing-attention.png
new file mode 100644
index 00000000..4b49e146
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Computing-attention.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/DRNN.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/DRNN.png
new file mode 100644
index 00000000..08b51e55
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/DRNN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Defining-a-learning-problem.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Defining-a-learning-problem.png
new file mode 100644
index 00000000..2790d6c2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Defining-a-learning-problem.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Embedding-matrix.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Embedding-matrix.png
new file mode 100644
index 00000000..8a78b700
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Embedding-matrix.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Equalization.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Equalization.png
new file mode 100644
index 00000000..ea9395d6
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Equalization.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Error-analysis-process.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Error-analysis-process.png
new file mode 100644
index 00000000..331535be
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Error-analysis-process.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-RNN-architectures.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-RNN-architectures.png
new file mode 100644
index 00000000..8264cce2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-RNN-architectures.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-Sequence-Model.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-Sequence-Model.png
new file mode 100644
index 00000000..fd9b79b2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Examples-of-Sequence-Model.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Image-captioning.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Image-captioning.png
new file mode 100644
index 00000000..af6f27ca
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Image-captioning.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/LSTM.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/LSTM.png
new file mode 100644
index 00000000..c2e333db
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/LSTM.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neural-language-model.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neural-language-model.png
new file mode 100644
index 00000000..53b375c8
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neural-language-model.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neutralize.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neutralize.png
new file mode 100644
index 00000000..3a25da56
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Neutralize.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-cell.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-cell.png
new file mode 100644
index 00000000..260db600
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-cell.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-sentiment-classification.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-sentiment-classification.png
new file mode 100644
index 00000000..f302cd9a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/RNN-sentiment-classification.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Recurrent-Neural-Network.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Recurrent-Neural-Network.png
new file mode 100644
index 00000000..072cdbf2
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Recurrent-Neural-Network.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling-a-sequence-from-a-trained-RNN.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling-a-sequence-from-a-trained-RNN.png
new file mode 100644
index 00000000..5ca2ea83
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling-a-sequence-from-a-trained-RNN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling.png
new file mode 100644
index 00000000..9d2ca9b9
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Sampling.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Seq2Seq.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Seq2Seq.png
new file mode 100644
index 00000000..1768c465
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Seq2Seq.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Simple-sentiment-classification-model.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Simple-sentiment-classification-model.png
new file mode 100644
index 00000000..cb147ee7
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Simple-sentiment-classification-model.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Trigger-word-detection-algorithm.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Trigger-word-detection-algorithm.png
new file mode 100644
index 00000000..5d5ba15a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/Trigger-word-detection-algorithm.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/formula-of-RNN.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/formula-of-RNN.png
new file mode 100644
index 00000000..1ab1a21d
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/formula-of-RNN.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/language-model-RNN-example.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/language-model-RNN-example.png
new file mode 100644
index 00000000..59121d2a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/language-model-RNN-example.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/new-Skip-Gram.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/new-Skip-Gram.png
new file mode 100644
index 00000000..9cd1fe53
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/new-Skip-Gram.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/old-Skip-gram.png b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/old-Skip-gram.png
new file mode 100644
index 00000000..231a0e78
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/old-Skip-gram.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/序列模型和注意力机制.md b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/序列模型和注意力机制.md
new file mode 100644
index 00000000..a3729cee
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/序列模型和注意力机制.md
@@ -0,0 +1,182 @@
+序列模型和注意力机制
+
+## Seq2Seq 模型
+
+**Seq2Seq(Sequence-to-Sequence)**模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含**编码器(Encoder)**和**解码器(Decoder)**两部分,它们通常是两个不同的 RNN。如下图所示,将编码器的输出作为解码器的输入,由解码器负责输出正确的翻译结果。
+
+
+
+提出 Seq2Seq 模型的相关论文:
+
+* [Sutskever et al., 2014. Sequence to sequence learning with neural networks](https://arxiv.org/pdf/1409.3215.pdf)
+* [Cho et al., 2014. Learning phrase representaions using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)
+
+这种编码器-解码器的结构也可以用于图像描述(Image captioning)。将 AlexNet 作为编码器,最后一层的 Softmax 换成一个 RNN 作为解码器,网络的输出序列就是对图像的一个描述。
+
+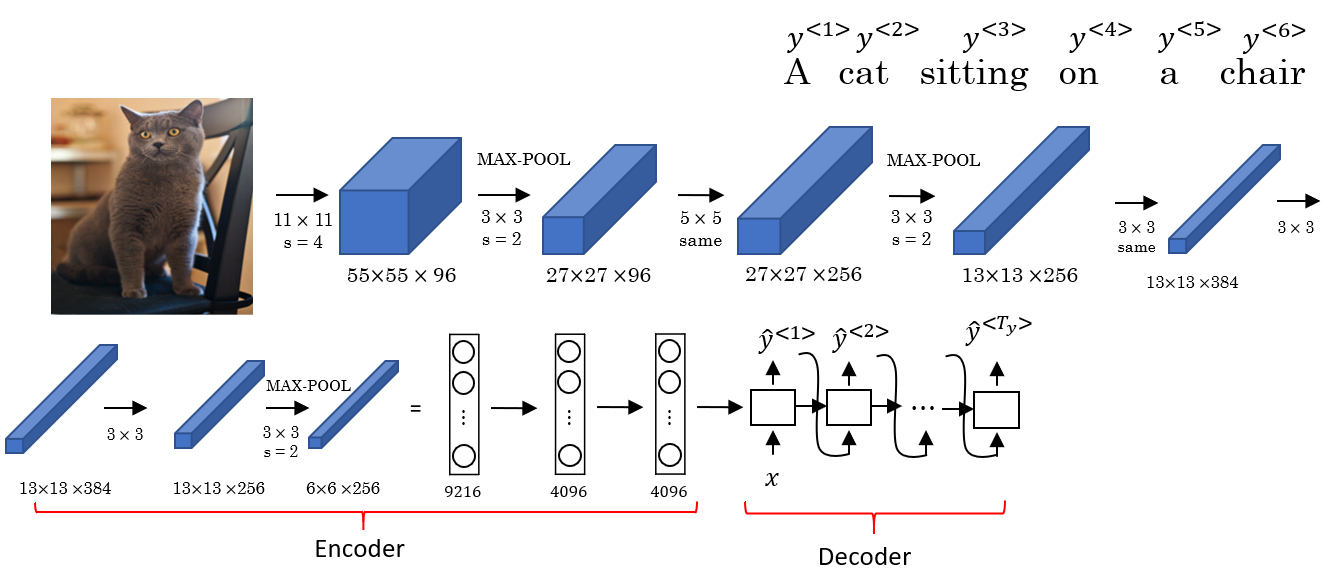
+
+图像描述的相关论文:
+
+* [Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks](https://arxiv.org/pdf/1412.6632.pdf)
+* [Vinyals et. al., 2014. Show and tell: Neural image caption generator](https://arxiv.org/pdf/1411.4555.pdf)
+* [Karpathy and Fei Fei, 2015. Deep visual-semantic alignments for generating image descriptions](https://arxiv.org/pdf/1412.2306.pdf)
+
+### 选择最可能的句子
+
+机器翻译用到的模型与语言模型相似,只是用编码器的输出作为解码器第一个时间步的输入(而非 0)。因此机器翻译的过程其实相当于建立一个条件语言模型。
+
+由于解码器进行随机采样过程,输出的翻译结果可能有好有坏。因此需要找到能使条件概率最大化的翻译,即
+
+$$arg \ max\_{y^{⟨1⟩}, ..., y^{⟨T\_y⟩}}P(y^{⟨1⟩}, ..., y^{⟨T\_y⟩} | x)$$
+
+鉴于贪心搜索算法得到的结果显然难以不符合上述要求,解决此问题最常使用的算法是**集束搜索(Beam Search)**。
+
+## 集束搜索
+
+**集束搜索(Beam Search)**会考虑每个时间步多个可能的选择。设定一个**集束宽(Beam Width)**$B$,代表了解码器中每个时间步的预选单词数量。例如 $B=3$,则将第一个时间步最可能的三个预选单词及其概率值 $P(\hat y^{⟨1⟩}|x)$ 保存到计算机内存,以待后续使用。
+
+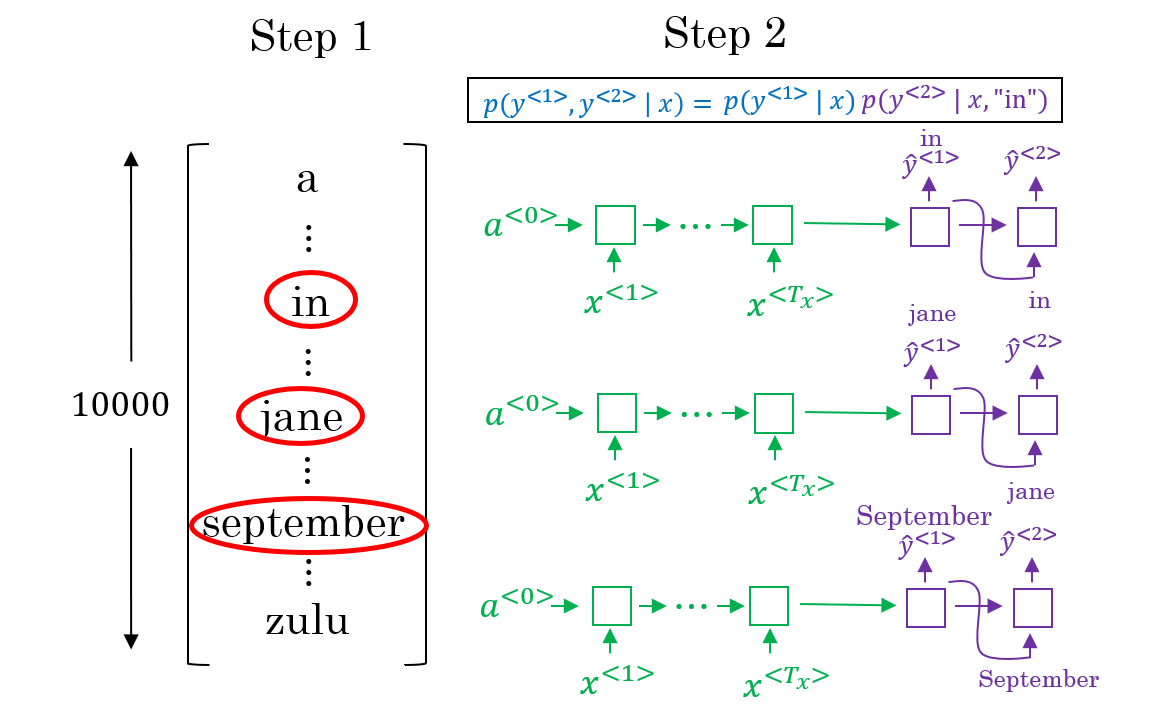
+
+第二步中,分别将三个预选词作为第二个时间步的输入,得到 $P(\hat y^{⟨2⟩}|x, \hat y^{⟨1⟩})$。
+
+因为我们需要的其实是第一个和第二个单词对(而非只有第二个单词)有着最大概率,因此根据条件概率公式,有:
+
+$$P(\hat y^{⟨1⟩}, \hat y^{⟨2⟩}|x) = P(\hat y^{⟨1⟩}|x) P(\hat y^{⟨2⟩}|x, \hat y^{⟨1⟩})$$
+
+设词典中有 $N$ 个词,则当 $B=3$ 时,有 $3*N$ 个 $P(\hat y^{⟨1⟩}, \hat y^{⟨2⟩}|x)$。仍然取其中概率值最大的 3 个,作为对应第一个词条件下的第二个词的预选词。以此类推,最后输出一个最优的结果,即结果符合公式:
+
+$$arg \ max \prod^{T\_y}\_{t=1} P(\hat y^{⟨t⟩} | x, \hat y^{⟨1⟩}, ..., \hat y^{⟨t-1⟩})$$
+
+可以看到,当 $B=1$ 时,集束搜索就变为贪心搜索。
+
+### 优化:长度标准化
+
+**长度标准化(Length Normalization)**是对集束搜索算法的优化方式。对于公式
+
+$$arg \ max \prod^{T\_y}\_{t=1} P(\hat y^{⟨t⟩} | x, \hat y^{⟨1⟩}, ..., \hat y^{⟨t-1⟩})$$
+
+当多个小于 1 的概率值相乘后,会造成**数值下溢(Numerical Underflow)**,即得到的结果将会是一个电脑不能精确表示的极小浮点数。因此,我们会取 $log$ 值,并进行标准化:
+
+$$arg \ max \frac{1}{T\_y^{\alpha}} \sum^{T\_y}\_{t=1} logP(\hat y^{⟨t⟩} | x, \hat y^{⟨1⟩}, ..., \hat y^{⟨t-1⟩})$$
+
+其中,$T\_y$ 是翻译结果的单词数量,$\alpha$ 是一个需要根据实际情况进行调节的超参数。标准化用于减少对输出长的结果的惩罚(因为翻译结果一般没有长度限制)。
+
+关于集束宽 $B$ 的取值,较大的 $B$ 值意味着可能更好的结果和巨大的计算成本;而较小的 $B$ 值代表较小的计算成本和可能表现较差的结果。通常来说,$B$ 可以取一个 10 以下的值。
+
+和 BFS、DFS 等精确的查找算法相比,集束搜索算法运行速度更快,但是不能保证一定找到 $arg \ max$ 准确的最大值。
+
+### 误差分析
+
+集束搜索是一种启发式搜索算法,其输出结果不总为最优。当结合 Seq2Seq 模型和集束搜索算法所构建的系统出错(没有输出最佳翻译结果)时,我们通过误差分析来分析错误出现在 RNN 模型还是集束搜索算法中。
+
+例如,对于下述两个由人工和算法得到的翻译结果:
+
+$$Human:\ Jane\ visits\ Africa\ in\ September.\ (y^*)$$
+
+$$Algorithm:\ Jane\ visited\ Africa\ last\ September.\ (y^*)$$
+
+将翻译中没有太大差别的前三个单词作为解码器前三个时间步的输入,得到第四个时间步的条件概率 $P(y^* | x)$ 和 $P(\hat y | x)$,比较其大小并分析:
+
+* 如果 $P(y^* | x) > P(\hat y | x)$,说明是集束搜索算法出现错误,没有选择到概率最大的词;
+* 如果 $P(y^* | x) \le P(\hat y | x)$,说明是 RNN 模型的效果不佳,预测的第四个词为“in”的概率小于“last”。
+
+建立一个如下图所示的表格,记录对每一个错误的分析,有助于判断错误出现在 RNN 模型还是集束搜索算法中。如果错误出现在集束搜索算法中,可以考虑增大集束宽 $B$;否则,需要进一步分析,看是需要正则化、更多数据或是尝试一个不同的网络结构。
+
+
+
+## Bleu 得分
+
+**Bleu(Bilingual Evaluation Understudy)得分**用于评估机器翻译的质量,其思想是机器翻译的结果越接近于人工翻译,则评分越高。
+
+最原始的 Bleu 将机器翻译结果中每个单词在人工翻译中出现的次数作为分子,机器翻译结果总词数作为分母得到。但是容易出现错误,例如,机器翻译结果单纯为某个在人工翻译结果中出现的单词的重复,则按照上述方法得到的 Bleu 为 1,显然有误。改进的方法是将每个单词在人工翻译结果中出现的次数作为分子,在机器翻译结果中出现的次数作为分母。
+
+
+
+上述方法是以单个词为单位进行统计,以单个词为单位的集合称为**unigram(一元组)**。而以成对的词为单位的集合称为**bigram(二元组)**。对每个二元组,可以统计其在机器翻译结果($count$)和人工翻译结果($count\_{clip}$)出现的次数,计算 Bleu 得分。
+
+以此类推,以 n 个单词为单位的集合称为**n-gram(多元组)**,对应的 Blue(即翻译精确度)得分计算公式为:
+
+$$p\_n = \frac{\sum\_{\text{n-gram} \in \hat y}count\_{clip}(\text{n-gram})}{\sum\_{\text{n-gram} \in \hat y}count(\text{n-gram})}$$
+
+对 N 个 $p\_n$ 进行几何加权平均得到:
+
+$$p\_{ave} = exp(\frac{1}{N}\sum^N\_{i=1}log^{p\_n})$$
+
+有一个问题是,当机器翻译结果短于人工翻译结果时,比较容易能得到更大的精确度分值,因为输出的大部分词可能都出现在人工翻译结果中。改进的方法是设置一个**最佳匹配长度(Best Match Length)**,如果机器翻译的结果短于该最佳匹配长度,则需要接受**简短惩罚(Brevity Penalty,BP)**:
+
+$$
+BP =
+\begin{cases}
+1, &MT\\\_length \ge BM\\\_length \\\\
+exp(1 - \frac{MT\\\_length}{BM\\\_length}), &MT\\\_length \lt BM\\\_length
+\end{cases}
+$$
+
+因此,最后得到的 Bleu 得分为:
+
+$$Blue = BP \times exp(\frac{1}{N}\sum^N\_{i=1}log^{p\_n})$$
+
+Bleu 得分的贡献是提出了一个表现不错的**单一实数评估指标**,因此加快了整个机器翻译领域以及其他文本生成领域的进程。
+
+相关论文:[Papineni et. al., 2002. A method for automatic evaluation of machine translation](http://www.aclweb.org/anthology/P02-1040.pdf)
+
+## 注意力模型
+
+对于一大段文字,人工翻译一般每次阅读并翻译一小部分。因为难以记忆,很难每次将一大段文字一口气翻译完。同理,用 Seq2Seq 模型建立的翻译系统,对于长句子,Blue 得分会随着输入序列长度的增加而降低。
+
+实际上,我们也并不希望神经网络每次去“记忆”很长一段文字,而是想让它像人工翻译一样工作。因此,**注意力模型(Attention Model)**被提出。目前,其思想已经成为深度学习领域中最有影响力的思想之一。
+
+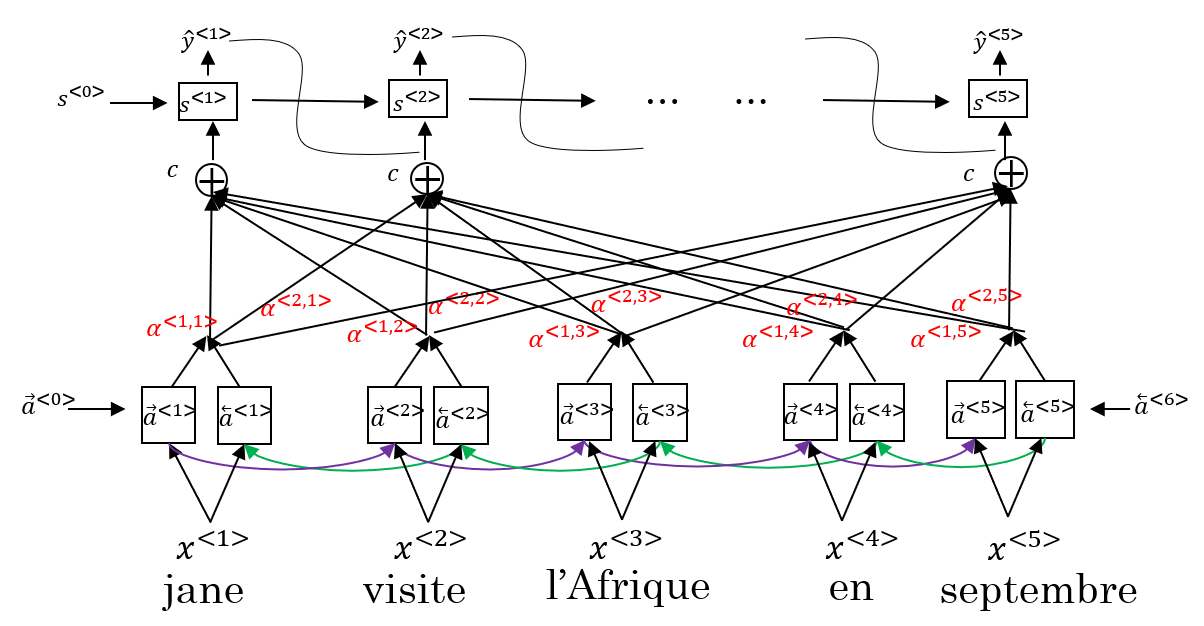
+
+注意力模型的一个示例网络结构如上图所示。其中,底层是一个双向循环神经网络(BRNN),该网络中每个时间步的激活都包含前向传播和反向传播产生的激活:
+
+$$a^{\langle t’ \rangle} = ({\overrightarrow a}^{\langle t’ \rangle}, {\overleftarrow a}^{\langle t’ \rangle})$$
+
+顶层是一个“多对多”结构的循环神经网络,第 $t$ 个时间步的输入包含该网络中前一个时间步的激活 $s^{\langle t-1 \rangle}$、输出 $y^{\langle t-1 \rangle}$ 以及底层的 BRNN 中多个时间步的激活 $c$,其中 $c$ 有(注意分辨 $\alpha$ 和 $a$):
+
+$$c^{\langle t \rangle} = \sum\_{t’}\alpha^{\langle t,t’ \rangle}a^{\langle t’ \rangle}$$
+
+其中,参数 $\alpha^{\langle t,t’ \rangle}$ 即代表着 $y^{\langle t \rangle}$ 对 $a^{\langle t' \rangle}$ 的“注意力”,总有:
+
+$$\sum\_{t’}\alpha^{\langle t,t’ \rangle} = 1$$
+
+我们使用 Softmax 来确保上式成立,因此有:
+
+$$\alpha^{\langle t,t’ \rangle} = \frac{exp(e^{\langle t,t’ \rangle})}{\sum^{T\_x}\_{t'=1}exp(e^{\langle t,t’ \rangle})}$$
+
+而对于 $e^{\langle t,t’ \rangle}$,我们通过神经网络学习得到。输入为 $s^{\langle t-1 \rangle}$ 和 $a^{\langle t’ \rangle}$,如下图所示:
+
+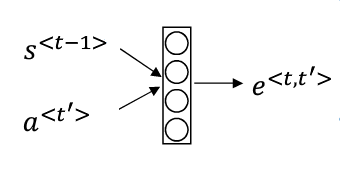
+
+注意力模型的一个缺点是时间复杂度为 $O(n^3)$。
+
+相关论文:
+
+* [Bahdanau et. al., 2014. Neural machine translation by jointly learning to align and translate](https://arxiv.org/pdf/1409.0473.pdf)
+* [Xu et. al., 2015. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/pdf/1502.03044.pdf):将注意力模型应用到图像标注中
+
+## 语音识别
+
+在语音识别任务中,输入是一段以时间为横轴的音频片段,输出是文本。
+
+音频数据的常见预处理步骤是运行音频片段来生成一个声谱图,并将其作为特征。以前的语音识别系统通过语言学家人工设计的**音素(Phonemes)**来构建,音素指的是一种语言中能区别两个词的最小语音单位。现在的端到端系统中,用深度学习就可以实现输入音频,直接输出文本。
+
+对于训练基于深度学习的语音识别系统,大规模的数据集是必要的。学术研究中通常使用 3000 小时长度的音频数据,而商业应用则需要超过一万小时的数据。
+
+语音识别系统可以用注意力模型来构建,一个简单的图例如下:
+
+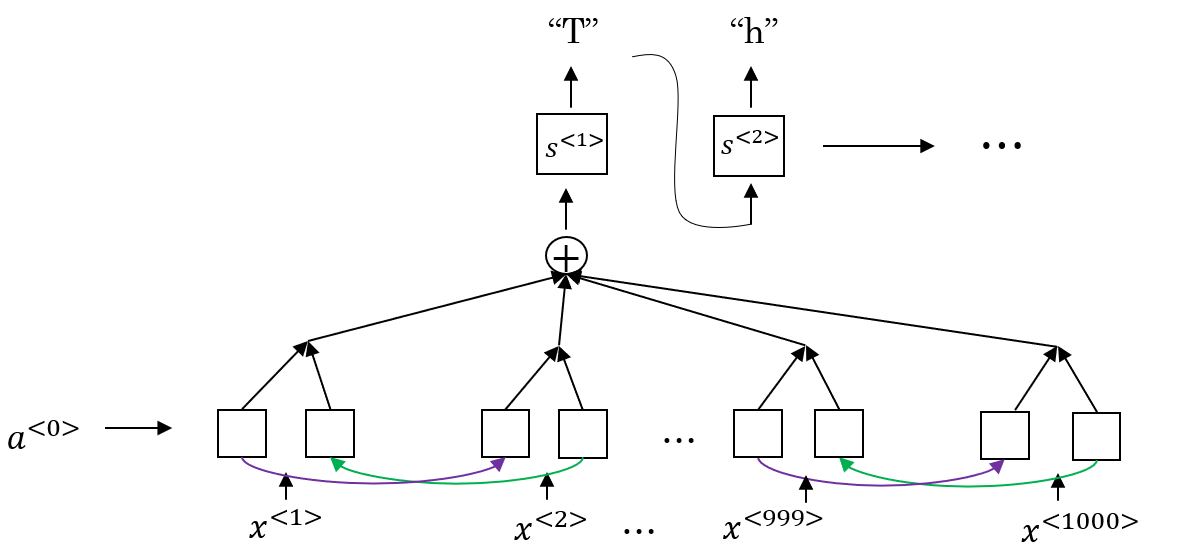
+
+用 **CTC(Connectionist Temporal Classification)**损失函数来做语音识别的效果也不错。由于输入是音频数据,使用 RNN 所建立的系统含有很多个时间步,且输出数量往往小于输入。因此,不是每一个时间步都有对应的输出。CTC 允许 RNN 生成下图红字所示的输出,并将两个空白符(blank)中重复的字符折叠起来,再将空白符去掉,得到最终的输出文本。
+
+
+
+相关论文:[Graves et al., 2006. Connectionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks](http://people.idsia.ch/~santiago/papers/icml2006.pdf)
+
+## 触发词检测
+
+**触发词检测(Trigger Word Detection)**常用于各种智能设备,通过约定的触发词可以语音唤醒设备。
+
+使用 RNN 来实现触发词检测时,可以将触发词对应的序列的标签设置为“1”,而将其他的标签设置为“0”。
+
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/循环序列模型.md b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/循环序列模型.md
new file mode 100644
index 00000000..f760ad49
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/循环序列模型.md
@@ -0,0 +1,210 @@
+循环序列模型
+
+自然语言和音频都是前后相互关联的数据,对于这些序列数据需要使用**循环神经网络(Recurrent Neural Network,RNN)**来进行处理。
+
+使用 RNN 实现的应用包括下图中所示:
+
+
+
+## 数学符号
+
+对于一个序列数据 $x$,用符号 $x^{⟨t⟩}$来表示这个数据中的第 $t$个元素,用 $y^{⟨t⟩}$来表示第 $t$个标签,用 $T\_x$ 和 $T\_y$来表示输入和输出的长度。对于一段音频,元素可能是其中的几帧;对于一句话,元素可能是一到多个单词。
+
+第 $i$ 个序列数据的第 $t$ 个元素用符号 $x^{(i)⟨t⟩}$,第 $t$ 个标签即为 $y^{(i)⟨t⟩}$。对应即有 $T^{(i)}\_x$ 和 $T^{(i)}\_y$。
+
+想要表示一个词语,需要先建立一个**词汇表(Vocabulary)**,或者叫**字典(Dictionary)**。将需要表示的所有词语变为一个列向量,可以根据字母顺序排列,然后根据单词在向量中的位置,用 **one-hot 向量(one-hot vector)**来表示该单词的标签:将每个单词编码成一个 $R^{|V| \times 1}$向量,其中 $|V|$是词汇表中单词的数量。一个单词在词汇表中的索引在该向量对应的元素为 1,其余元素均为 0。
+
+例如,'zebra'排在词汇表的最后一位,因此它的词向量表示为:
+
+$$w^{zebra} = \left [ 0, 0, 0, ..., 1\right ]^T$$
+
+**补充:**one-hot 向量是最简单的词向量。它的**缺点**是,由于每个单词被表示为完全独立的个体,因此单词间的相似度无法体现。例如单词 hotel 和 motel 意思相近,而与 cat 不相似,但是
+
+$$(w^{hotel})^Tw^{motel} = (w^{hotel})^Tw^{cat} = 0$$
+
+## 循环神经网络模型
+
+对于序列数据,使用标准神经网络存在以下问题:
+
+* 对于不同的示例,输入和输出可能有不同的长度,因此输入层和输出层的神经元数量无法固定。
+* 从输入文本的不同位置学到的同一特征无法共享。
+* 模型中的参数太多,计算量太大。
+
+为了解决这些问题,引入**循环神经网络(Recurrent Neural Network,RNN)**。一种循环神经网络的结构如下图所示:
+
+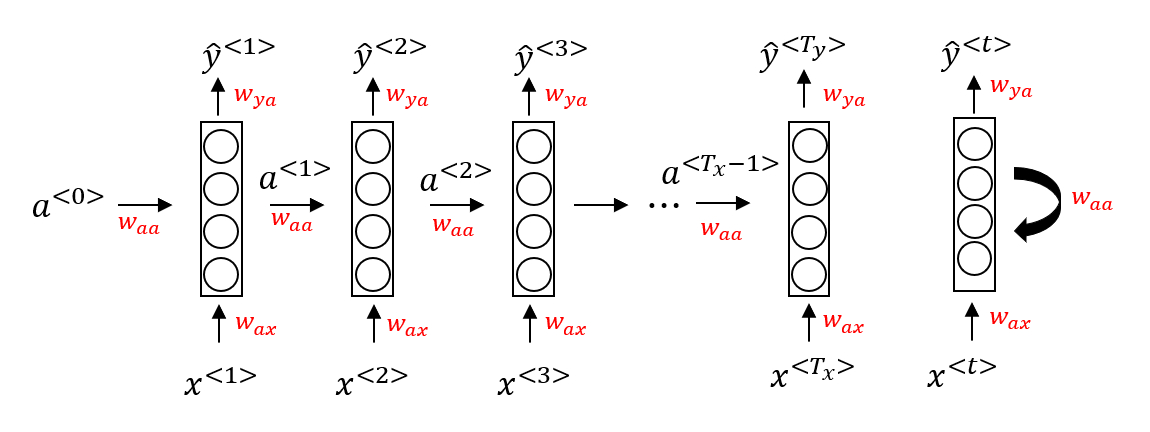
+
+当元素 $x^{⟨t⟩}$ 输入对应时间步(Time Step)的隐藏层的同时,该隐藏层也会接收来自上一时间步的隐藏层的激活值 $a^{⟨t-1⟩}$,其中 $a^{⟨0⟩}$ 一般直接初始化为零向量。一个时间步输出一个对应的预测结果 $\hat y^{⟨t⟩}$。
+
+循环神经网络从左向右扫描数据,同时每个时间步的参数也是共享的,输入、激活、输出的参数对应为 $W\_{ax}$、$W\_{aa}$、$W\_{ya}$。
+
+下图是一个 RNN 神经元的结构:
+
+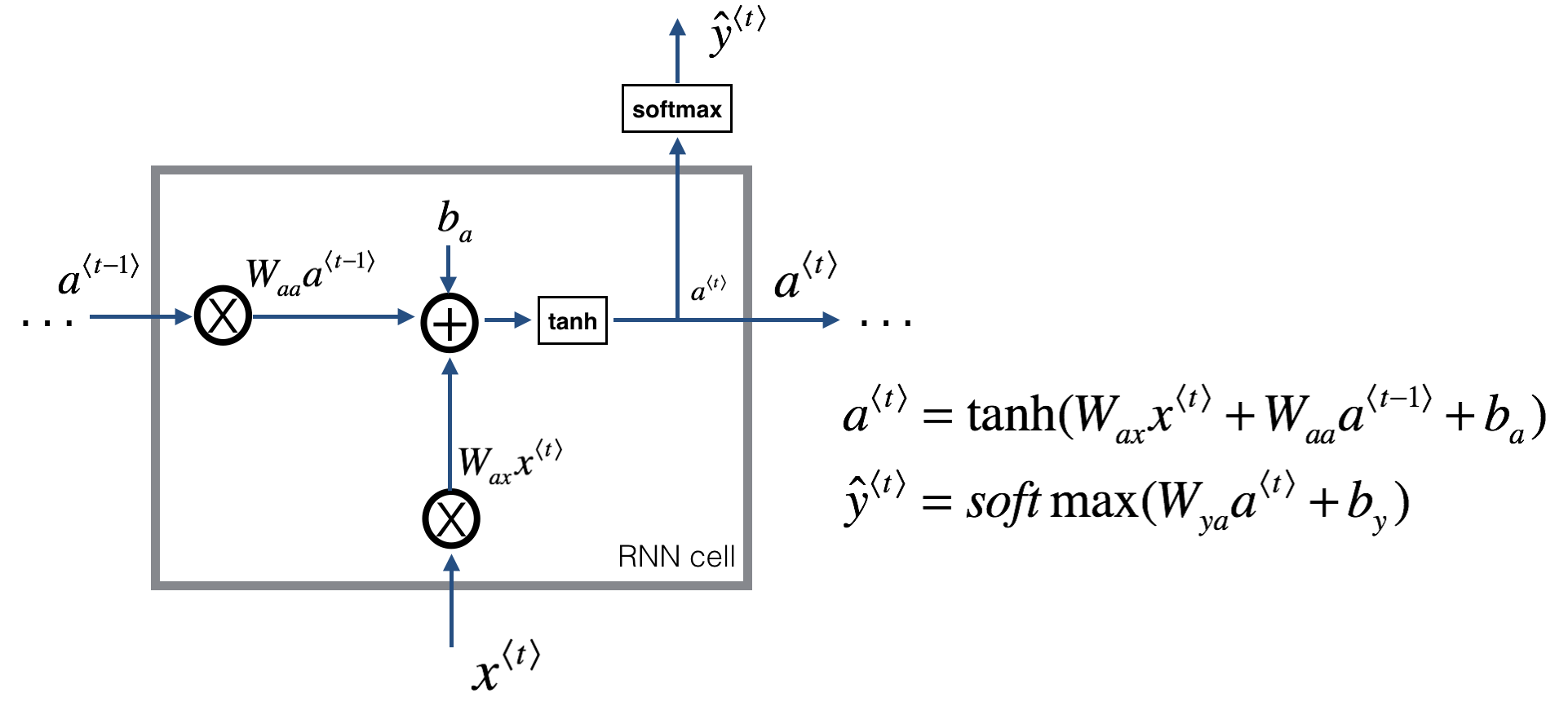
+
+前向传播过程的公式如下:
+
+$$a^{⟨0⟩} = \vec{0}$$
+
+$$a^{⟨t⟩} = g\_1(W\_{aa}a^{⟨t-1⟩} + W\_{ax}x^{⟨t⟩} + b\_a)$$
+
+$$\hat y^{⟨t⟩} = g\_2(W\_{ya}a^{⟨t⟩} + b\_y)$$
+
+激活函数 $g\_1$通常选择 tanh,有时也用 ReLU;$g\_2$可选 sigmoid 或 softmax,取决于需要的输出类型。
+
+为了进一步简化公式以方便运算,可以将 $W\_{aa}$、$W\_{ax}$ **水平并列**为一个矩阵 $W\_a$,同时 $a^{⟨t-1⟩}$和 $ x^{⟨t⟩}$ **堆叠**成一个矩阵。则有:
+
+$$W\_a = [W\_{aa}, W\_{ax}]$$
+
+$$a^{⟨t⟩} = g\_1(W\_a[a^{⟨t-1⟩}; x^{⟨t⟩}] + b\_a)$$
+
+$$\hat y^{⟨t⟩} = g\_2(W\_{ya}a^{⟨t⟩} + b\_y)$$
+
+### 反向传播
+
+为了计算反向传播过程,需要先定义一个损失函数。单个位置上(或者说单个时间步上)某个单词的预测值的损失函数采用**交叉熵损失函数**,如下所示:
+
+$$L^{⟨t⟩}(\hat y^{⟨t⟩}, y^{⟨t⟩}) = -y^{⟨t⟩}log\hat y^{⟨t⟩} - (1 - y^{⟨t⟩})log(1-\hat y^{⟨t⟩})$$
+
+将单个位置上的损失函数相加,得到整个序列的成本函数如下:
+
+$$J = L(\hat y, y) = \sum^{T\_x}\_{t=1} L^{⟨t⟩}(\hat y^{⟨t⟩}, y^{⟨t⟩})$$
+
+循环神经网络的反向传播被称为**通过时间反向传播(Backpropagation through time)**,因为从右向左计算的过程就像是时间倒流。
+
+更详细的计算公式如下:
+
+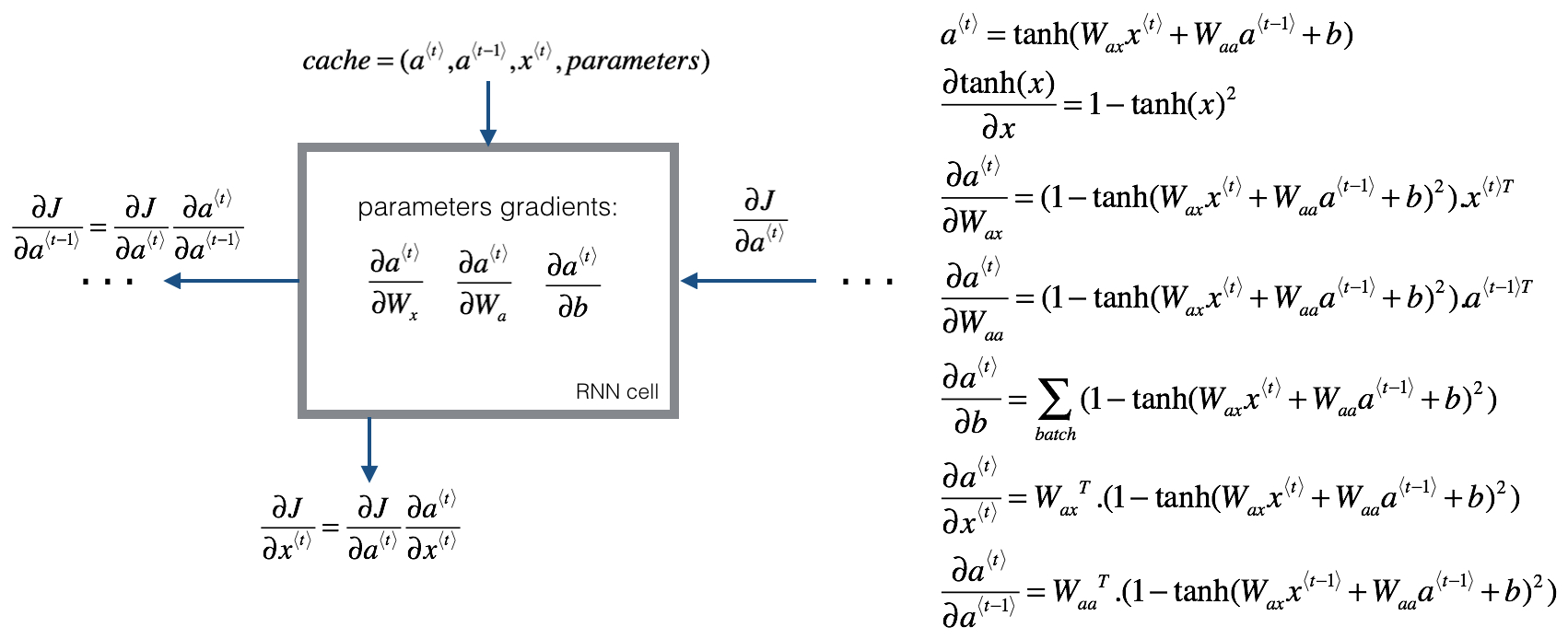
+
+### 不同结构
+
+某些情况下,输入长度和输出长度不一致。根据所需的输入及输出长度,循环神经网络可分为“一对一”、“多对一”、“多对多”等结构:
+
+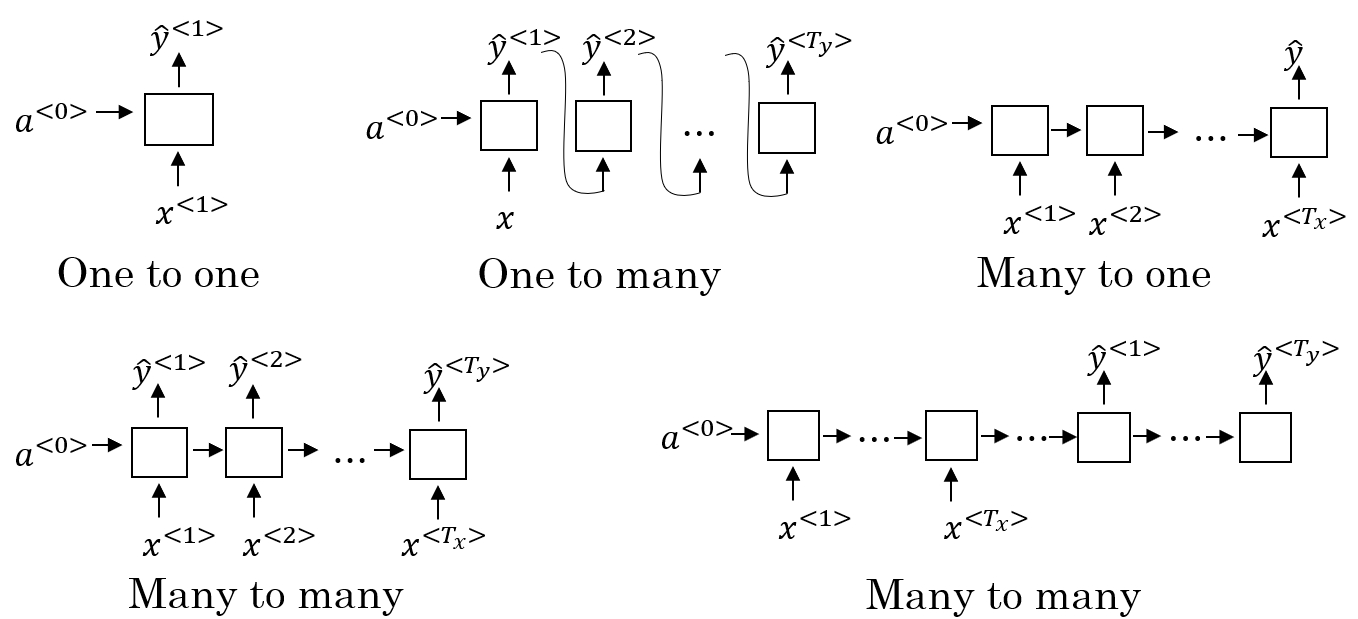
+
+目前我们看到的模型的问题是,只使用了这个序列中之前的信息来做出预测,即后文没有被使用。可以通过**双向循环神经网络(Bidirectional RNN,BRNN)**来解决这个问题。
+
+## 语言模型
+
+**语言模型(Language Model)**是根据语言客观事实而进行的语言抽象数学建模,能够估计某个序列中各元素出现的可能性。例如,在一个语音识别系统中,语言模型能够计算两个读音相近的句子为正确结果的概率,以此为依据作出准确判断。
+
+建立语言模型所采用的训练集是一个大型的**语料库(Corpus)**,指数量众多的句子组成的文本。建立过程的第一步是**标记化(Tokenize)**,即建立字典;然后将语料库中的每个词表示为对应的 one-hot 向量。另外,需要增加一个额外的标记 EOS(End of Sentence)来表示一个句子的结尾。标点符号可以忽略,也可以加入字典后用 one-hot 向量表示。
+
+对于语料库中部分特殊的、不包含在字典中的词汇,例如人名、地名,可以不必针对这些具体的词,而是在词典中加入一个 UNK(Unique Token)标记来表示。
+
+将标志化后的训练集用于训练 RNN,过程如下图所示:
+
+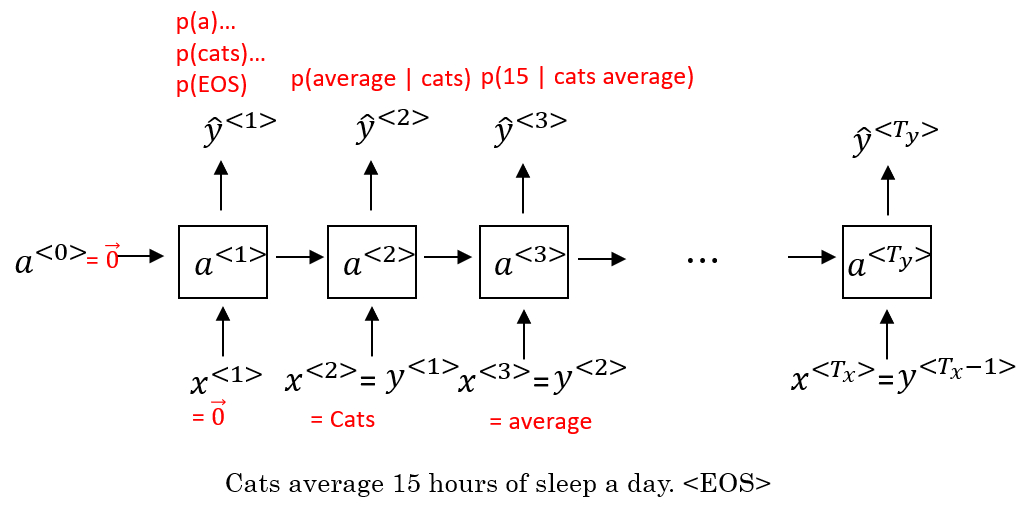
+
+在第一个时间步中,输入的 $a^{⟨0⟩}$和 $x^{⟨1⟩}$都是零向量,$\hat y^{⟨1⟩}$是通过 softmax 预测出的字典中每个词作为第一个词出现的概率;在第二个时间步中,输入的 $x^{⟨2⟩}$是训练样本的标签中的第一个单词 $y^{⟨1⟩}$(即“cats”)和上一层的激活项$a^{⟨1⟩}$,输出的 $y^{⟨2⟩}$表示的是通过 softmax 预测出的、单词“cats”后面出现字典中的其他每个词的条件概率。以此类推,最后就可以得到整个句子出现的概率。
+
+定义损失函数为:
+
+$$L(\hat y^{⟨t⟩}, y^{⟨t⟩}) = -\sum\_t y\_i^{⟨t⟩} log \hat y^{⟨t⟩}$$
+
+则成本函数为:
+
+$$J = \sum\_t L^{⟨t⟩}(\hat y^{⟨t⟩}, y^{⟨t⟩})$$
+
+## 采样
+
+在训练好一个语言模型后,可以通过**采样(Sample)**新的序列来了解这个模型中都学习到了一些什么。
+
+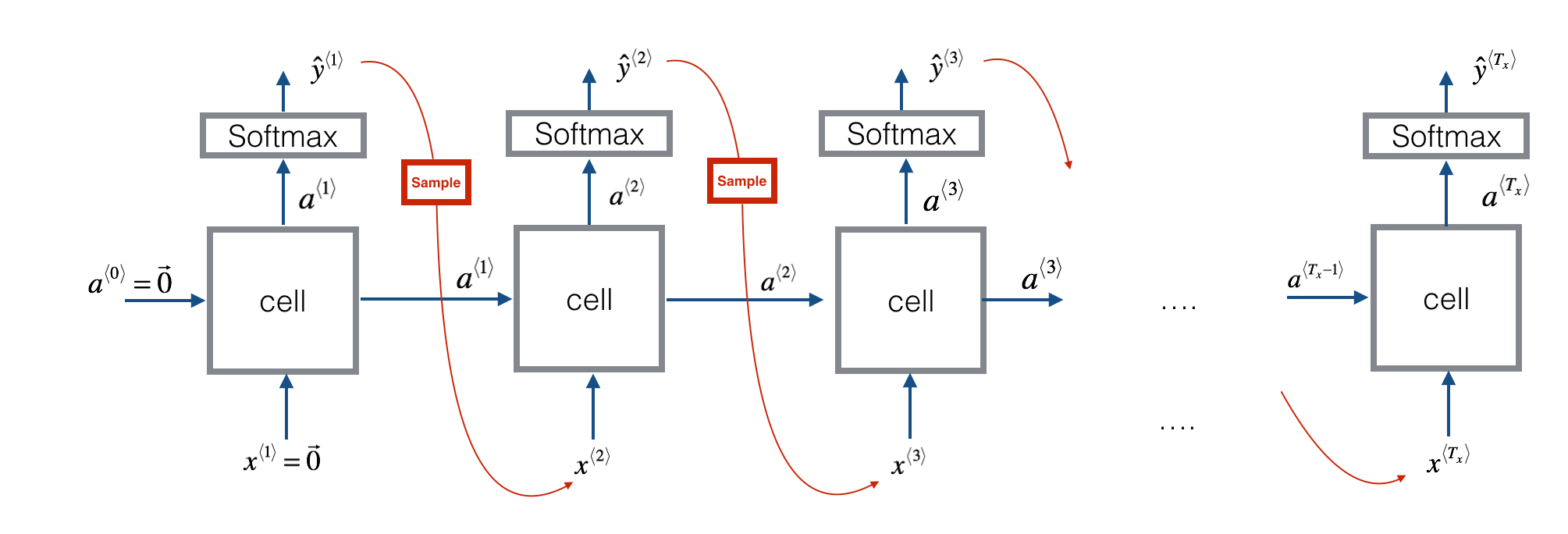
+
+在第一个时间步输入 $a^{⟨0⟩}$和 $x^{⟨1⟩}$为零向量,输出预测出的字典中每个词作为第一个词出现的概率,根据 softmax 的分布进行随机采样(`np.random.choice`),将采样得到的 $\hat y^{⟨1⟩}$作为第二个时间步的输入 $x^{⟨2⟩}$。以此类推,直到采样到 EOS,最后模型会自动生成一些句子,从这些句子中可以发现模型通过语料库学习到的知识。
+
+这里建立的是基于词汇构建的语言模型。根据需要也可以构建基于字符的语言模型,其优点是不必担心出现未知标识(UNK),其缺点是得到的序列过多过长,并且训练成本高昂。因此,基于词汇构建的语言模型更为常用。
+
+## RNN 的梯度消失
+
+$$The\ cat, which\ already\ ate\ a\ bunch\ of\ food,\ was\ full.$$
+
+$$The\ cats, which\ already\ ate\ a\ bunch\ of\ food,\ were\ full.$$
+
+对于以上两个句子,后面的动词单复数形式由前面的名词的单复数形式决定。但是**基本的 RNN 不擅长捕获这种长期依赖关系**。究其原因,由于梯度消失,在反向传播时,后面层的输出误差很难影响到较靠前层的计算,网络很难调整靠前的计算。
+
+在反向传播时,随着层数的增多,梯度不仅可能指数型下降,也有可能指数型上升,即梯度爆炸。不过梯度爆炸比较容易发现,因为参数会急剧膨胀到数值溢出(可能显示为 NaN)。这时可以采用**梯度修剪(Gradient Clipping)**来解决:观察梯度向量,如果它大于某个阈值,则缩放梯度向量以保证其不会太大。相比之下,梯度消失问题更难解决。**GRU 和 LSTM 都可以作为缓解梯度消失问题的方案**。
+
+## GRU(门控循环单元)
+
+**GRU(Gated Recurrent Units, 门控循环单元)**改善了 RNN 的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。
+
+$$The\ cat, which\ already\ ate\ a\ bunch\ of\ food,\ was\ full.$$
+
+当我们从左到右读上面这个句子时,GRU 单元有一个新的变量称为 $c$,代表**记忆细胞(Memory Cell)**,其作用是提供记忆的能力,记住例如前文主语是单数还是复数等信息。在时间 t,记忆细胞的值 $c^{⟨t⟩}$等于输出的激活值 $a^{⟨t⟩}$;$\tilde c^{⟨t⟩}$ 代表下一个 $c$ 的候选值。$Γ\_u$ 代表**更新门(Update Gate)**,用于决定什么时候更新记忆细胞的值。以上结构的具体公式为:
+
+$$\tilde c^{⟨t⟩} = tanh(W\_c[c^{⟨t-1⟩}, x^{⟨t⟩}] + b\_c)$$
+
+$$Γ\_u = \sigma(W\_u[c^{⟨t-1⟩}, x^{⟨t⟩}] + b\_u)$$
+
+$$c^{⟨t⟩} = Γ\_u \times \tilde c^{⟨t⟩} + (1 - Γ\_u) \times c^{⟨t-1⟩}$$
+
+$$a^{⟨t⟩} = c^{⟨t⟩}$$
+
+当使用 sigmoid 作为激活函数 $\sigma$ 来得到 $Γ\_u$时,$Γ\_u$ 的值在 0 到 1 的范围内,且大多数时间非常接近于 0 或 1。当 $Γ\_u = 1$时,$c^{⟨t⟩}$被更新为 $\tilde c^{⟨t⟩}$,否则保持为 $c^{⟨t-1⟩}$。因为 $Γ\_u$ 可以很接近 0,因此 $c^{⟨t⟩}$几乎就等于 $c^{⟨t-1⟩}$。在经过很长的序列后,$c$ 的值依然被维持,从而实现“记忆”的功能。
+
+以上实际上是简化过的 GRU 单元,但是蕴涵了 GRU 最重要的思想。完整的 GRU 单元添加了一个新的**相关门(Relevance Gate)** $Γ\_r$,表示 $\tilde c^{⟨t⟩}$和 $c^{⟨t⟩}$的相关性。因此,表达式改为如下所示:
+
+$$\tilde c^{⟨t⟩} = tanh(W\_c[Γ\_r \* c^{⟨t-1⟩}, x^{⟨t⟩}] + b\_c)$$
+
+$$Γ\_u = \sigma(W\_u[c^{⟨t-1⟩}, x^{⟨t⟩}] + b\_u)$$
+
+$$Γ\_r = \sigma(W\_r[c^{⟨t-1⟩}, x^{⟨t⟩}] + b\_r)$$
+
+$$c^{⟨t⟩} = Γ\_u \times \tilde c^{⟨t⟩} + (1 - Γ\_u) \times c^{⟨t-1⟩}$$
+
+$$a^{⟨t⟩} = c^{⟨t⟩}$$
+
+相关论文:
+
+1. [Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches](https://arxiv.org/pdf/1409.1259.pdf)
+2. [Chung et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling](https://arxiv.org/pdf/1412.3555.pdf)
+
+## LSTM(长短期记忆)
+
+**LSTM(Long Short Term Memory,长短期记忆)**网络比 GRU 更加灵活和强大,它额外引入了**遗忘门(Forget Gate)** $Γ\_f$和**输出门(Output Gate)** $Γ\_o$。其结构图和公式如下:
+
+
+
+
+
+将多个 LSTM 单元按时间次序连接起来,就得到一个 LSTM 网络。
+
+以上是简化版的 LSTM。在更为常用的版本中,几个门值不仅取决于 $a^{⟨t-1⟩}$和 $x^{⟨t⟩}$,有时也可以偷窥上一个记忆细胞输入的值 $c^{⟨t-1⟩}$,这被称为**窥视孔连接(Peephole Connection)**。这时,和 GRU 不同,$c^{⟨t-1⟩}$和门值是一对一的。
+
+$c^{0}$ 常被初始化为零向量。
+
+相关论文:[Hochreiter & Schmidhuber 1997. Long short-term memory](https://www.researchgate.net/publication/13853244_Long_Short-term_Memory)
+
+## 双向循环神经网络(BRNN)
+
+单向的循环神经网络在某一时刻的预测结果只能使用之前输入的序列信息。**双向循环神经网络(Bidirectional RNN,BRNN)**可以在序列的任意位置使用之前和之后的数据。其工作原理是增加一个反向循环层,结构如下图所示:
+
+
+
+因此,有
+
+$$y^{⟨t⟩} = g(W\_y[\overrightarrow a^{⟨t⟩}, \overleftarrow a^{⟨t⟩}] + b\_y)$$
+
+这个改进的方法不仅能用于基本的 RNN,也可以用于 GRU 或 LSTM。**缺点**是需要完整的序列数据,才能预测任意位置的结果。例如构建语音识别系统,需要等待用户说完并获取整个语音表达,才能处理这段语音并进一步做语音识别。因此,实际应用会有更加复杂的模块。
+
+## 深度循环神经网络(DRNN)
+
+循环神经网络的每个时间步上也可以包含多个隐藏层,形成**深度循环神经网络(Deep RNN)**。结构如下图所示:
+
+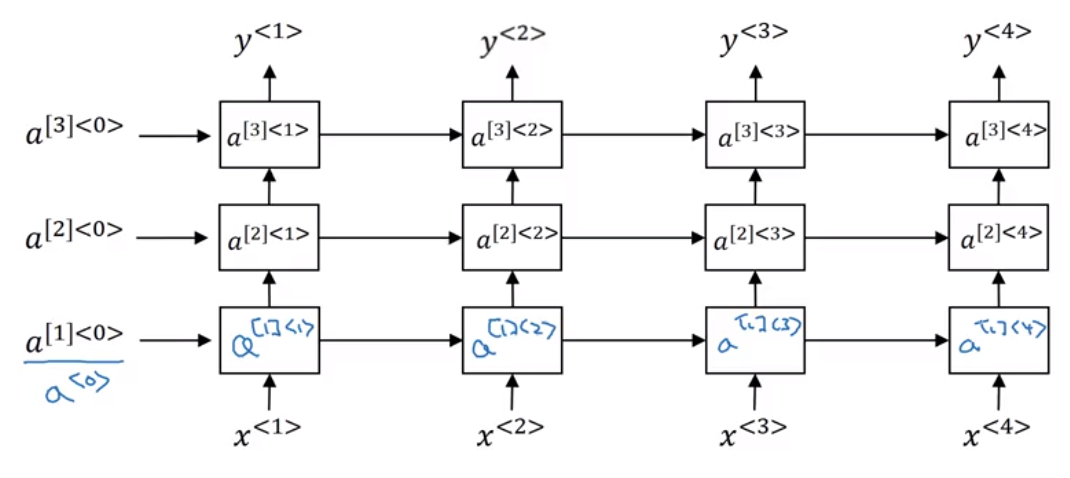
+
+以 $a^{[2]⟨3⟩}$为例,有 $a^{[2]⟨3⟩} = g(W\_a^{[2]}[a^{[2]⟨2⟩}, a^{[1]⟨3⟩}] + b\_a^{[2]})$。
+
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/自然语言处理与词嵌入.md b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/自然语言处理与词嵌入.md
new file mode 100644
index 00000000..3cf7e934
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Sequence_Models/自然语言处理与词嵌入.md
@@ -0,0 +1,187 @@
+自然语言处理与词嵌入
+
+## 词嵌入
+
+one-hot 向量将每个单词表示为完全独立的个体,不同词向量都是正交的,因此单词间的相似度无法体现。
+
+换用特征化表示方法能够解决这一问题。我们可以通过用语义特征作为维度来表示一个词,因此语义相近的词,其词向量也相近。
+
+将高维的词嵌入“嵌入”到一个二维空间里,就可以进行可视化。常用的一种可视化算法是 t-SNE 算法。在通过复杂而非线性的方法映射到二维空间后,每个词会根据语义和相关程度聚在一起。相关论文:[van der Maaten and Hinton., 2008. Visualizing Data using t-SNE](https://www.seas.harvard.edu/courses/cs281/papers/tsne.pdf)
+
+**词嵌入(Word Embedding)**是 NLP 中语言模型与表征学习技术的统称,概念上而言,它是指把一个维数为所有词的数量的高维空间(one-hot 形式表示的词)“嵌入”到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。对大量词汇进行词嵌入后获得的词向量,可用于完成**命名实体识别(Named Entity Recognition)**等任务。
+
+### 词嵌入与迁移学习
+
+用词嵌入做迁移学习可以降低学习成本,提高效率。其步骤如下:
+
+1. 从大量的文本集中学习词嵌入,或者下载网上开源的、预训练好的词嵌入模型;
+2. 将这些词嵌入模型迁移到新的、只有少量标注训练集的任务中;
+3. 可以选择是否微调词嵌入。当标记数据集不是很大时可以省下这一步。
+
+### 词嵌入与类比推理
+
+词嵌入可用于类比推理。例如,给定对应关系“男性(Man)”对“女性(Woman)”,想要类比出“国王(King)”对应的词汇。则可以有 $e\_{man} - e\_{woman} \approx e\_{king} - e\_? $ ,之后的目标就是找到词向量 $w$,来找到使相似度 $sim(e\_w, e\_{king} - e\_{man} + e\_{woman})$ 最大。
+
+一个最常用的相似度计算函数是**余弦相似度(cosine similarity)**。公式为:
+
+$$sim(u, v) = \frac{u^T v}{|| u ||\_2 || v ||\_2}$$
+
+相关论文:[Mikolov et. al., 2013, Linguistic regularities in continuous space word representations](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/rvecs.pdf)
+
+## 嵌入矩阵
+
+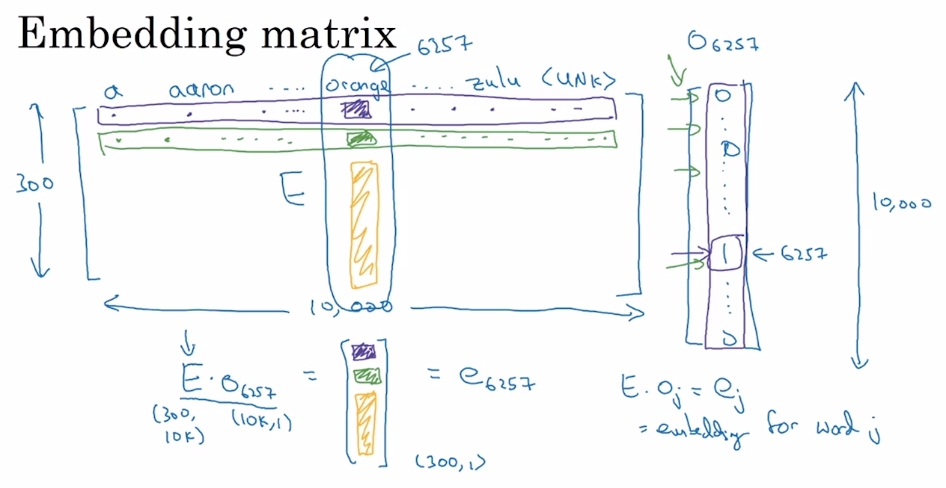
+
+不同的词嵌入方法能够用不同的方式学习到一个**嵌入矩阵(Embedding Matrix)** $E$。将字典中位置为 $i$ 的词的 one-hot 向量表示为 $o\_i$,词嵌入后生成的词向量用 $e\_i$表示,则有:
+
+$$E \cdot o\_i = e\_i$$
+
+但在实际情况下一般不这么做。因为 one-hot 向量维度很高,且几乎所有元素都是 0,这样做的效率太低。因此,实践中直接用专门的函数查找矩阵 $E$ 的特定列。
+
+## 学习词嵌入
+
+### 神经概率语言模型
+
+**神经概率语言模型(Neural Probabilistic Language Model)**构建了一个能够通过上下文来预测未知词的神经网络,在训练这个语言模型的同时学习词嵌入。
+
+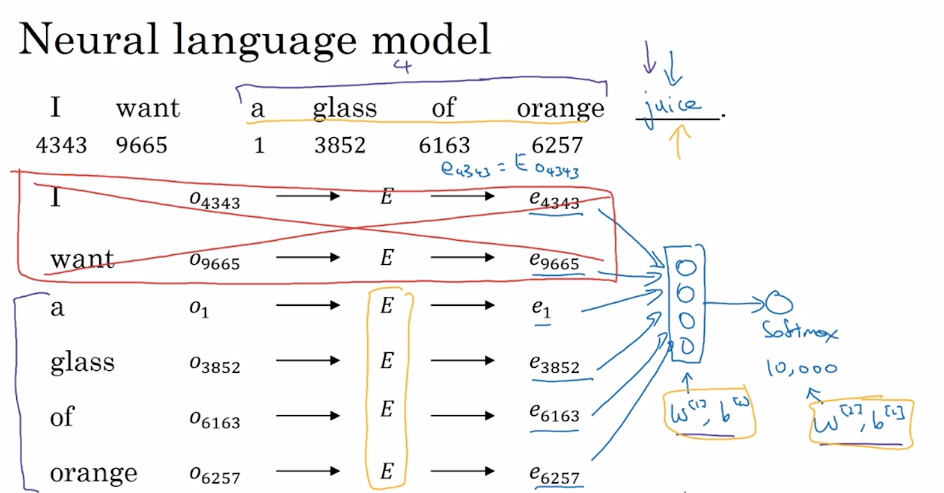
+
+训练过程中,将语料库中的某些词作为目标词,以目标词的部分上下文作为输入,Softmax 输出的预测结果为目标词。嵌入矩阵 $E$ 和 $w$、$b$ 为需要通过训练得到的参数。这样,在得到嵌入矩阵后,就可以得到词嵌入后生成的词向量。
+
+相关论文:[Bengio et. al., 2003, A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)
+
+### Word2Vec
+
+**Word2Vec** 是一种简单高效的词嵌入学习算法,包括 2 种模型:
+
+* **Skip-gram (SG)**:根据词预测目标上下文
+* **Continuous Bag of Words (CBOW)**:根据上下文预测目标词
+
+每种语言模型又包含**负采样(Negative Sampling)**和**分级的 Softmax(Hierarchical Softmax)**两种训练方法。
+
+训练神经网络时候的隐藏层参数即是学习到的词嵌入。
+
+相关论文:[Mikolov et. al., 2013. Efficient estimation of word representations in vector space.](https://arxiv.org/pdf/1301.3781.pdf)
+
+#### Skip-gram
+
+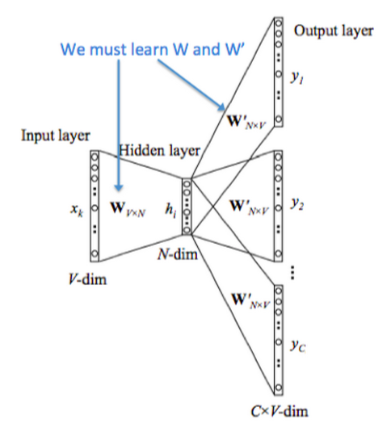
+
+从上图可以看到,从左到右是 One-hot 向量,乘以 center word 的矩阵 $W$ 于是找到词向量,乘以另一个 context word 的矩阵 $W'$ 得到对每个词语的“相似度”,对相似度取 Softmax 得到概率,与答案对比计算损失。
+
+设某个词为 $c$,该词的一定词距内选取一些配对的目标上下文 $t$,则该网路仅有的一个 Softmax 单元输出条件概率:
+
+$$p(t|c) = \frac{exp(\theta\_t^T e\_c)}{\sum^m\_{j=1}exp(\theta\_j^T e\_c)}$$
+
+$\theta\_t$ 是一个与输出 $t$ 有关的参数,其中省略了用以纠正偏差的参数。损失函数仍选用交叉熵:
+
+$$L(\hat y, y) = -\sum^m\_{i=1}y\_ilog\hat y\_i$$
+
+在此 Softmax 分类中,每次计算条件概率时,需要对词典中所有词做求和操作,因此计算量很大。解决方案之一是使用一个**分级的 Softmax 分类器(Hierarchical Softmax Classifier)**,形如二叉树。在实践中,一般采用霍夫曼树(Huffman Tree)而非平衡二叉树,常用词在顶部。
+
+如果在语料库中随机均匀采样得到选定的词 $c$,则 'the', 'of', 'a', 'and' 等出现频繁的词将影响到训练结果。因此,采用了一些策略来平衡选择。
+
+#### CBOW
+
+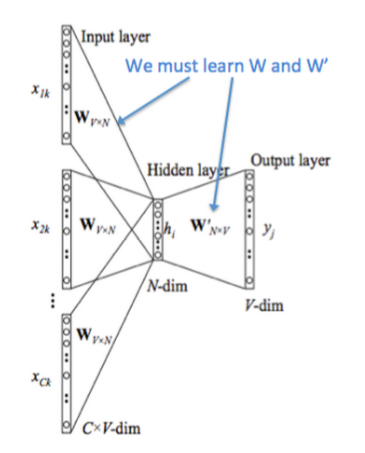
+
+CBOW 模型的工作方式与 Skip-gram 相反,通过采样上下文中的词来预测中间的词。
+
+吴恩达老师没有深入去讲 CBOW。想要更深入了解的话,推荐资料:
+
+* [[NLP] 秒懂词向量Word2vec的本质](https://zhuanlan.zhihu.com/p/26306795)(中文,简明原理)
+* [word2vec原理推导与代码分析-码农场](http://www.hankcs.com/nlp/word2vec.html)(中文,深入推导)
+* [课程 cs224n 的 notes1](https://github.com/stanfordnlp/cs224n-winter17-notes/blob/master/notes1.pdf)(英文)
+
+#### 负采样
+
+为了解决 Softmax 计算较慢的问题,Word2Vec 的作者后续提出了**负采样(Negative Sampling)**模型。对于监督学习问题中的分类任务,在训练时同时需要正例和负例。在分级的 Softmax 中,负例放在二叉树的根节点上;而对于负采样,负例是随机采样得到的。
+
+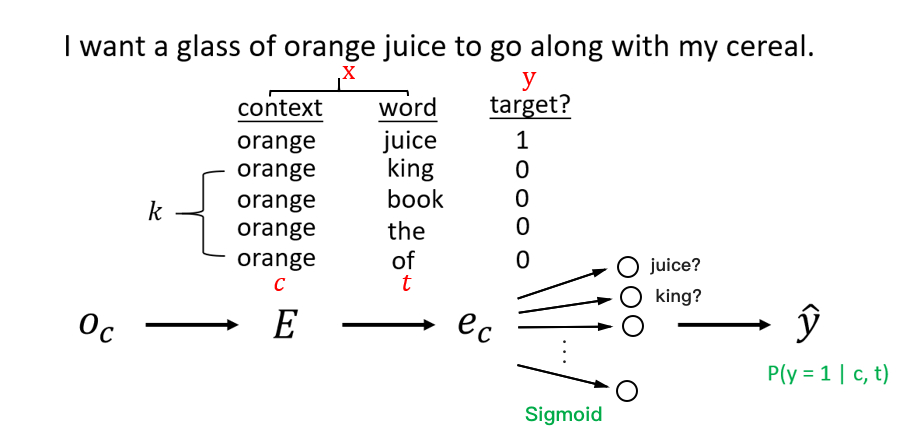
+
+如上图所示,当输入的词为一对上下文-目标词时,标签设置为 1(这里的上下文也是一个词)。另外任意取 k 对非上下文-目标词作为负样本,标签设置为 0。对于小数据集,k 取 5~20 较为合适;而当有大量数据时,k 可以取 2~5。
+
+改用多个 Sigmoid 输出上下文-目标词(c, t)为正样本的概率:
+
+$$P(y=1 | c, t) = \sigma(\theta\_t^Te\_c)$$
+
+其中,$\theta\_t$、$e\_c$ 分别代表目标词和上下文的词向量。
+
+之前训练中每次要更新 n 维的多分类 Softmax 单元(n 为词典中词的数量)。现在每次只需要更新 k+1 维的二分类 Sigmoid 单元,计算量大大降低。
+
+关于计算选择某个词作为负样本的概率,作者推荐采用以下公式(而非经验频率或均匀分布):
+
+$$p(w\_i) = \frac{f(w\_i)^{\frac{3}{4}}}{\sum^m\_{j=0}f(w\_j)^{\frac{3}{4}}}$$
+
+其中,$f(w\_i)$ 代表语料库中单词 $w\_i$ 出现的频率。上述公式更加平滑,能够增加低频词的选取可能。
+
+相关论文:[Mikolov et. al., 2013. Distributed representation of words and phrases and their compositionality](https://arxiv.org/pdf/1310.4546.pdf)
+
+### Glove
+
+**GloVe(Global Vectors)**是另一种流行的词嵌入算法。Glove 模型基于语料库统计了词的**共现矩阵**$X$,$X$中的元素 $X\_{ij}$ 表示单词 $i$ 和单词 $j$ “为上下文-目标词”的次数。之后,用梯度下降法最小化以下损失函数:
+
+$$J = \sum^N\_{i=1}\sum^N\_{j=1}f(X\_{ij})(\theta^t\_ie\_j + b\_i + b\_j - log(X\_{ij}))^2$$
+
+其中,$\theta\_i$、$e\_j$是单词 $i$ 和单词 $j$ 的词向量;$b\_i$、$b\_j$;$f()$ 是一个用来避免 $X\_{ij}=0$时$log(X\_{ij})$为负无穷大、并在其他情况下调整权重的函数。$X\_{ij}=0$时,$f(X\_{ij}) = 0$。
+
+“为上下文-目标词”可以代表两个词出现在同一个窗口。在这种情况下,$\theta\_i$ 和 $e\_j$ 是完全对称的。因此,在训练时可以一致地初始化二者,使用梯度下降法处理完以后取平均值作为二者共同的值。
+
+相关论文:[Pennington st. al., 2014. Glove: Global Vectors for Word Representation](https://nlp.stanford.edu/pubs/glove.pdf)
+
+最后,使用各种词嵌入算法学到的词向量实际上大多都超出了人类的理解范围,难以从某个值中看出与语义的相关程度。
+
+## 情感分类
+
+情感分类是指分析一段文本对某个对象的情感是正面的还是负面的,实际应用包括舆情分析、民意调查、产品意见调查等等。情感分类的问题之一是标记好的训练数据不足。但是有了词嵌入得到的词向量,中等规模的标记训练数据也能构建出一个效果不错的情感分类器。
+
+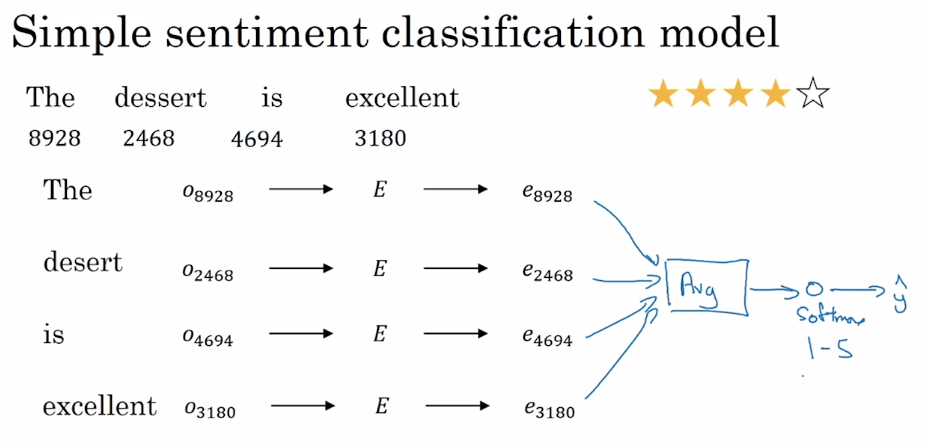
+
+如上图所示,用词嵌入方法获得嵌入矩阵 $E$ 后,计算出句中每个单词的词向量并取平均值,输入一个 Softmax 单元,输出预测结果。这种方法的优点是适用于任何长度的文本;缺点是没有考虑词的顺序,对于包含了多个正面评价词的负面评价,很容易预测到错误结果。
+
+使用 RNN 能够实现一个效果更好的情感分类器:
+
+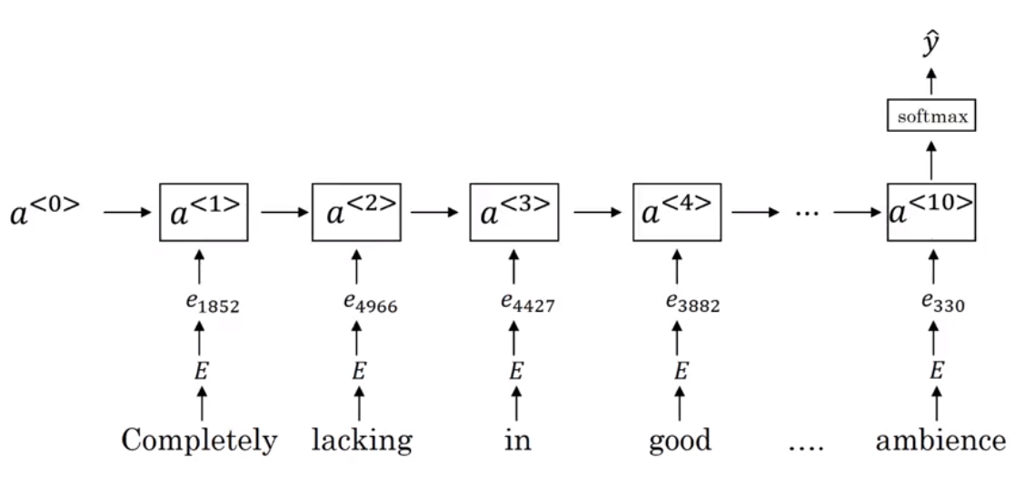
+
+## 词嵌入除偏
+
+语料库中可能存在性别歧视、种族歧视、性取向歧视等非预期形式偏见(Bias),这种偏见会直接反映到通过词嵌入获得的词向量。例如,使用未除偏的词嵌入结果进行类比推理时,"Man" 对 "Computer Programmer" 可能得到 "Woman" 对 "Housemaker" 等带有性别偏见的结果。词嵌入除偏的方法有以下几种:
+
+**1. 中和本身与性别无关词汇**
+
+对于“医生(doctor)”、“老师(teacher)”、“接待员(receptionist)”等本身与性别无关词汇,可以**中和(Neutralize)**其中的偏见。首先用“女性(woman)”的词向量减去“男性(man)”的词向量,得到的向量 $g=e\_{woman}−e\_{man}$ 就代表了“性别(gender)”。假设现有的词向量维数为 50,那么对某个词向量,将 50 维空间分成两个部分:与性别相关的方向 $g$ 和与 $g$ **正交**的其他 49 个维度 $g\_{\perp}$。如下左图:
+
+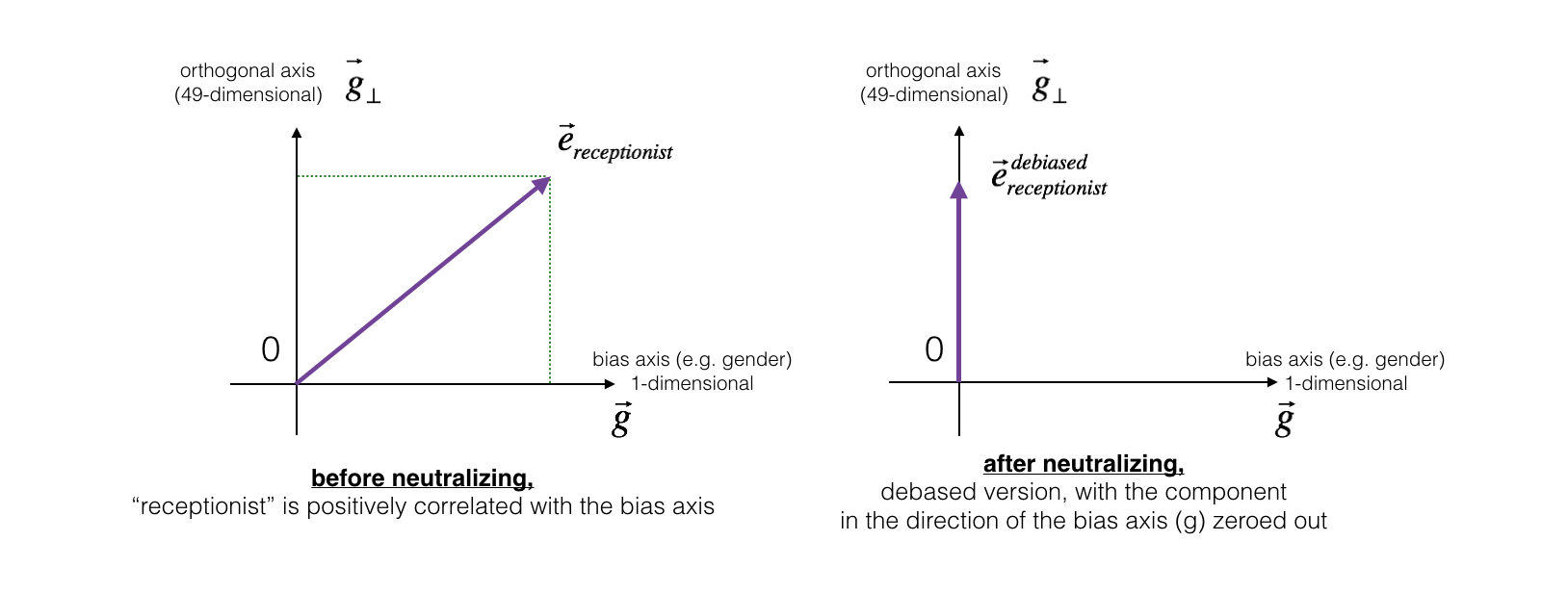
+
+而除偏的步骤,是将要除偏的词向量(左图中的 $e\_{receptionist}$)在向量 $g$ 方向上的值置为 0,变成右图所示的 $e^{debiased}\_{receptionist}$。
+
+公式如下:
+
+$$e^{bias\_component} = \frac{e*g}{||g||\_2^2} * g$$
+$$e^{debiased} = e - e^{bias\_component}$$
+
+**2. 均衡本身与性别有关词汇**
+
+对于“男演员(actor)”、“女演员(actress)”、“爷爷(grandfather)”等本身与性别有关词汇,中和“婴儿看护人(babysit)”中存在的性别偏见后,还是无法保证它到“女演员(actress)”与到“男演员(actor)”的距离相等。对这样一对性别有关的词,除偏的过程是**均衡(Equalization)**它们的性别属性。其核心思想是确保一对词(actor 和 actress)到 $g\_{\perp}$ 的距离相等。
+
+
+
+公式:
+
+$$ \mu = \frac{e\_{w1} + e\_{w2}}{2}$$
+
+
+$$\mu\_{B} = \frac {\mu * bias\\\_axis}{||bias\\\_axis||\_2} + ||bias\\\_axis||\_2 *bias\\\_axis$$
+
+$$\mu\_{\perp} = \mu - \mu\_{B}$$
+
+
+$$e\_{w1B} = \sqrt{ |{1 - ||\mu_{\perp} ||^2\_2} |} * \frac{(e\_{\text{w1}} - \mu\_{\perp}) - \mu\_B} {|(e\_{w1} - \mu\_{\perp}) - \mu\_B)|}$$
+
+
+$$e\_{w2B} = \sqrt{ |{1 - ||\mu\_{\perp} ||^2\_2} |} * \frac{(e\_{\text{w2}} - \mu\_{\perp}) - \mu\_B} {|(e\_{w2} - \mu\_{\perp}) - \mu\_B)|}$$
+
+$$e\_1 = e\_{w1B} + \mu\_{\perp}$$
+$$e\_2 = e\_{w2B} + \mu\_{\perp}$$
+
+相关论文:[Bolukbasi et. al., 2016. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings](https://arxiv.org/pdf/1607.06520.pdf)
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Analysis-With-Data-Mismatch.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Analysis-With-Data-Mismatch.png
new file mode 100644
index 00000000..e0406d0e
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Analysis-With-Data-Mismatch.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Bayes-Optimal-Error.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Bayes-Optimal-Error.png
new file mode 100644
index 00000000..71813fc4
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Bayes-Optimal-Error.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/End-to-end-Deep-Learning.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/End-to-end-Deep-Learning.png
new file mode 100644
index 00000000..c9af870a
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/End-to-end-Deep-Learning.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Error-analysis-table.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Error-analysis-table.png
new file mode 100644
index 00000000..1a78428e
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Error-analysis-table.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Human-level.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Human-level.png
new file mode 100644
index 00000000..e6d7e93f
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Human-level.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Multi-Task-Learning.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Multi-Task-Learning.png
new file mode 100644
index 00000000..e79b5fdb
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Multi-Task-Learning.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Shared-Representation.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Shared-Representation.png
new file mode 100644
index 00000000..076479b5
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Shared-Representation.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Tranfer-Learning.png b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Tranfer-Learning.png
new file mode 100644
index 00000000..cbd25735
Binary files /dev/null and b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/Tranfer-Learning.png differ
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(1).md b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(1).md
new file mode 100644
index 00000000..9b2073ce
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(1).md
@@ -0,0 +1,134 @@
+机器学习(ML)策略(1)
+
+对于一个已经被构建好且产生初步结果的机器学习系统,为了能使结果更令人满意,往往还要进行大量的改进。鉴于之前的课程介绍了多种改进的方法,例如收集更多数据、调试超参数、调整神经网络的大小或结构、采用不同的优化算法、进行正则化等等,我们有可能浪费大量时间在一条错误的改进路线上。
+
+想要找准改进的方向,使一个机器学习系统更快更有效地工作,就需要学习一些在构建机器学习系统时常用到的策略。
+
+## 正交化
+
+**正交化(Orthogonalization)**的核心在于每次调整只会影响模型某一方面的性能,而对其他功能没有影响。这种方法有助于更快更有效地进行机器学习模型的调试和优化。
+
+在机器学习(监督学习)系统中,可以划分四个“功能”:
+
+1. 建立的模型在训练集上表现良好;
+2. 建立的模型在验证集上表现良好;
+3. 建立的模型在测试集上表现良好;
+4. 建立的模型在实际应用中表现良好。
+
+其中,
+
+* 对于第一条,如果模型在训练集上表现不好,可以尝试训练更大的神经网络或者换一种更好的优化算法(例如 Adam);
+* 对于第二条,如果模型在验证集上表现不好,可以进行正则化处理或者加入更多训练数据;
+* 对于第三条,如果模型在测试集上表现不好,可以尝试使用更大的验证集进行验证;
+* 对于第四条,如果模型在实际应用中表现不好,可能是因为测试集没有设置正确或者成本函数评估指标有误,需要改变测试集或成本函数。
+
+面对遇到的各种问题,正交化能够帮助我们更为精准有效地解决问题。
+
+一个反例是[早停止法(Early Stopping)](http://kyonhuang.top/Andrew-Ng-Deep-Learning-notes/#/Improving_Deep_Neural_Networks/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%9A%84%E5%AE%9E%E7%94%A8%E5%B1%82%E9%9D%A2?id=%e5%85%b6%e4%bb%96%e6%ad%a3%e5%88%99%e5%8c%96%e6%96%b9%e6%b3%95)。如果早期停止,虽然可以改善验证集的拟合表现,但是对训练集的拟合就不太好。因为对两个不同的“功能”都有影响,所以早停止法不具有正交化。虽然也可以使用,但是用其他正交化控制手段来进行优化会更简单有效。
+
+## 单值评价指标
+
+构建机器学习系统时,通过设置一个量化的**单值评价指标**(single-number evaluation metric),可以使我们根据这一指标比较不同超参数对应的模型的优劣,从而选择最优的那个模型。
+
+例如,对于二分类问题,常用的评价指标是**精确率(Precision)**和**召回率(Recall)**。假设我们有 A 和 B 两个分类器,其两项指标分别如下:
+
+| 分类器 | 精确率 | 召回率 |
+| :---: | :---: | :---: |
+| A | 95% | 90% |
+| B | 98% | 85% |
+
+* 精确率:$\frac{预测为正类的正类数量}{预测为正类的数量} * 100\%$
+
+* 召回率:$\frac{预测为正类的正类数量}{正类数量} * 100\%$
+
+实际应用中,我们通常使用综合了精确率和召回率的单值评价指标 F1 Score 来评价模型的好坏。F1 Score 其实就是精准率和召回率的**调和平均数(Harmonic Mean)**,比单纯的平均数效果要好。
+
+$$F1 = \frac{2}{\frac{1}{P}+\frac{1}{R}} = \frac{2PR}{P+R}$$
+
+因此,我们计算出两个分类器的 F1 Score。可以看出 A 模型的效果要更好。
+
+| 分类器 | 精确率 | 召回率 | F1 Score |
+| :---: | :---: | :---: | :---: |
+| A | 95% | 90% | 92.4% |
+| B | 98% | 85% | 91.0% |
+
+通过引入单值评价指标,我们可以更方便快速地对不同模型进行比较。
+
+## 优化指标和满足指标
+
+如果我们还想要将分类器的运行时间也纳入考虑范围,将其和精确率、召回率组合成一个单值评价指标显然不那么合适。这时,我们可以将某些指标作为**优化指标(Optimizing Matric)**,寻求它们的最优值;而将某些指标作为**满足指标(Satisficing Matric)**,只要在一定阈值以内即可。
+
+在这个例子中,准确率就是一个优化指标,因为我们想要分类器尽可能做到正确分类;而运行时间就是一个满足指标,如果你想要分类器的运行时间不多于某个阈值,那最终选择的分类器就应该是以这个阈值为界里面准确率最高的那个。
+
+## 动态改变评价指标
+
+对于模型的评价标准优势需要根据实际情况进行动态调整,以让模型在实际应用中获得更好的效果。
+
+例如,有时我们不太能接受某些分类错误,于是改变单纯用错误率作为评价标准,给某些分类错误更高的权重,以从追求最小错误率转为追求最小风险。
+
+## 训练 / 验证 / 测试集划分
+
+我们一般将数据集分为训练集、验证集、测试集。构建机器学习系统时,我们采用不同的学习方法,在**训练集**上训练出不同的模型,然后使用**验证集**对模型的好坏进行评估,确信其中某个模型足够好时再用**测试集**对其进行测试。
+
+因此,训练集、验证集、测试集的设置对于机器学习模型非常重要,合理的设置能够大大提高模型训练效率和模型质量。
+
+### 验证集和测试集的分布
+
+验证集和测试集的数据来源应该相同(来自同一分布)、和机器学习系统将要在实际应用中面对的数据一致,且必须从所有数据中随机抽取。这样,系统才能做到尽可能不偏离目标。
+
+### 验证集和测试集的大小
+
+过去数据量较小(小于 1 万)时,通常将数据集按照以下比例进行划分:
+
+* 无验证集的情况:70% / 30%;
+* 有验证集的情况:60% / 20% / 20%;
+
+这是为了保证验证集和测试集有足够的数据。现在的机器学习时代数据集规模普遍较大,例如 100 万数据量,这时将相应比例设为 98% / 1% / 1% 或 99% / 1% 就已经能保证验证集和测试集的规模足够。
+
+测试集的大小应该设置得足够提高系统整体性能的可信度,验证集的大小也要设置得足够用于评估几个不同的模型。应该根据实际情况对数据集灵活地进行划分,而不是死板地遵循老旧的经验。
+
+## 比较人类表现水平
+
+很多机器学习模型的诞生是为了取代人类的工作,因此其表现也会跟人类表现水平作比较。
+
+
+
+上图展示了随着时间的推进,机器学习系统和人的表现水平的变化。一般的,当机器学习超过人的表现水平后,它的进步速度逐渐变得缓慢,最终性能无法超过某个理论上限,这个上限被称为**贝叶斯最优误差(Bayes Optimal Error)**。
+
+贝叶斯最优误差一般认为是理论上可能达到的最优误差,换句话说,其就是理论最优函数,任何从 x 到精确度 y 映射的函数都不可能超过这个值。例如,对于语音识别,某些音频片段嘈杂到基本不可能知道说的是什么,所以完美的识别率不可能达到 100%。
+
+因为人类对于一些自然感知问题的表现水平十分接近贝叶斯最优误差,所以当机器学习系统的表现超过人类后,就没有太多继续改善的空间了。
+
+也因此,只要建立的机器学习模型的表现还没达到人类的表现水平时,就可以通过各种手段来提升它。例如采用人工标记过的数据进行训练,通过人工误差分析了解为什么人能够正确识别,或者是进行偏差、方差分析。
+
+当模型的表现超过人类后,这些手段起的作用就微乎其微了。
+
+### 可避免偏差
+
+通过与贝叶斯最优误差,或者说,与人类表现水平的比较,可以表明一个机器学习模型表现的好坏程度,由此判断后续操作应该注重于减小偏差还是减小方差。
+
+模型在**训练集**上的误差与人类表现水平的差值被称作**可避免偏差(Avoidable Bias)**。可避免偏差低便意味着模型在训练集上的表现很好,而**训练集与验证集之间错误率的差值**越小,意味着模型在验证集与测试集上的表现和训练集同样好。
+
+如果**可避免偏差**大于**训练集与验证集之间错误率的差值**,之后的工作就应该专注于减小偏差;反之,就应该专注于减小方差。
+
+### 理解人类表现水平
+
+我们一般用**人类水平误差(Human-level Error)**来代表贝叶斯最优误差(或者简称贝叶斯误差)。对于不同领域的例子,不同人群由于其经验水平不一,错误率也不同。一般来说,**我们将表现最好的作为人类水平误差**。但是实际应用中,不同人选择人类水平误差的基准是不同的,这会带来一定的影响。
+
+例如,如果某模型在训练集上的错误率为 0.7%,验证集的错误率为 0.8%。如果选择的人类水平误差为 0.5%,那么偏差(bias)比方差(variance)更加突出;而如果选择的人类水平误差为 0.7%,则方差更加突出。也就是说,根据人类水平误差的不同选择,我们可能因此选择不同的优化操作。
+
+这种问题只会发生在模型表现很好,接近人类水平误差的时候才会出现。人类水平误差给了我们一种估计贝叶斯误差的方式,而不是像之前一样将训练的错误率直接对着 0% 的方向进行优化。
+
+当机器学习模型的表现超过了人类水平误差时,很难再通过人的直觉去判断模型还能够往什么方向优化以提高性能。
+
+## 总结
+
+想让一个监督学习算法达到使用程度,应该做到以下两点:
+
+1. 算法对训练集的拟合很好,可以看作可避免偏差很低;
+2. 推广到验证集和测试集效果也很好,即方差不是很大。
+
+
+
+根据正交化的思想,我们有一些措施可以独立地优化二者之一。
+
diff --git a/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(2).md b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(2).md
new file mode 100644
index 00000000..b6946c80
--- /dev/null
+++ b/机器学习/吴恩达深度学习/学习笔记/Structuring_Machine_Learning_Projects/机器学习(ML)策略(2).md
@@ -0,0 +1,144 @@
+机器学习(ML)策略(2)
+
+## 错误分析
+
+通过人工检查机器学习模型得出的结果中出现的一些错误,有助于深入了解下一步要进行的工作。这个过程被称作**错误分析(Error Analysis)**。
+
+例如,你可能会发现一个猫图片识别器错误地将一些看上去像猫的狗误识别为猫。这时,立即盲目地去研究一个能够精确识别出狗的算法不一定是最好的选择,因为我们不知道这样做会对提高分类器的准确率有多大的帮助。
+
+这时,我们可以从分类错误的样本中统计出狗的样本数量。根据狗样本所占的比重来判断这一问题的重要性。假如狗类样本所占比重仅为 5%,那么即使花费几个月的时间来提升模型对狗的识别率,改进后的模型错误率并没有显著改善;而如果错误样本中狗类所占比重为 50%,那么改进后的模型性能会有较大的提升。因此,花费更多的时间去研究能够精确识别出狗的算法是值得的。
+
+这种人工检查看似简单而愚笨,但却是十分必要的,因为这项工作能够有效避免花费大量的时间与精力去做一些对提高模型性能收效甚微的工作,让我们专注于解决影响模型准确率的主要问题。
+
+在对输出结果中分类错误的样本进行人工分析时,可以建立一个表格来记录每一个分类错误的具体信息,例如某些图像是模糊的,或者是把狗识别成了猫等,并统计属于不同错误类型的错误数量。这样,分类结果会更加清晰。
+
+
+
+总结一下,进行错误分析时,你应该观察错误标记的例子,看看假阳性和假阴性,统计属于不同错误类型的错误数量。在这个过程中,你可能会得到启发,归纳出新的错误类型。总之,通过统计不同错误标记类型占总数的百分比,有助于发现哪些问题亟待解决,或者提供构思新优化方向的灵感。
+
+## 修正错误标记
+
+我们用 mislabeled examples 来表示学习算法输出了错误的 Y 值。而在做误差分析时,有时会注意到数据集中有些样本被人为地错误标记(incorrectly labeled)了,这时该怎么做?
+
+如果是在训练集中,由于机器学习算法对于随机误差的**稳健性(Robust)**(也称作“鲁棒性”),只要这些出错的样本数量较小,且分布近似随机,就不必花费时间一一修正。
+
+而如果出现在验证集或者测试集,则可以在进行误差分析时,通过统计人为标记错误所占的百分比,来大致分析这种情况对模型的识别准确率的影响,并比较该比例的大小和其他错误类型的比例,以此判断是否值得去将错误的标记一一进行修正,还是可以忽略。
+
+当你决定在验证集和测试集上手动检查标签并进行修正时,有一些额外的方针和原则需要考虑:
+
+* 在验证集和测试集上**同时使用同样的修正手段**,以保证验证集和测试集来自相同的分布;
+* 同时检查判断正确和判断错误的例子(通常不用这么做);
+* 在修正验证集和测试集时,鉴于训练集的分布不必和验证/测试集完全相同,可以不去修正训练集。
+
+## 快速搭建系统并迭代
+
+对于每个可以改善模型的合理方向,如何选择一个方向集中精力处理成了问题。如果想搭建一个全新的机器学习系统,建议根据以下步骤快速搭建好第一个系统,然后开始迭代:
+
+1. 设置好训练、验证、测试集及衡量指标,确定目标;
+2. 快速训练出一个初步的系统,用训练集来拟合参数,用验证集调参,用测试集评估;
+3. 通过偏差/方差分析以及错误分析等方法,决定下一步优先处理的方向。
+
+## 在不同的分布上训练和测试
+
+有时,我们很难得到来自同一个分布的训练集和验证/测试集。还是以猫识别作为例子,我们的训练集可能由网络爬取得到,图片比较清晰,而且规模较大(例如 20 万);而验证/测试集可能来自用户手机拍摄,图片比较模糊,且数量较少(例如 1 万),难以满足作为训练集时的规模需要。
+
+虽然验证/测试集的质量不高,但是机器学习模型最终主要应用于识别这些用户上传的模糊图片。考虑到这一点,在划分数据集时,可以将 20 万张网络爬取的图片和 5000 张用户上传的图片作为训练集,而将剩下的 5000 张图片一半作验证集,一半作测试集。比起混合数据集所有样本再随机划分,这种分配方法虽然使训练集分布和验证/测试集的分布并不一样,但是能保证**验证/测试集更接近实际应用场景**,在长期能带来更好的系统性能。
+
+## 数据不匹配
+
+之前的学习中,我们通过比较人类水平误差、训练集错误率、验证集错误率的相对差值来判断进行偏差/方差分析。但在训练集和验证/测试集分布不一致的情况下,无法根据相对差值来进行偏差/方差分析。这是因为训练集错误率和验证集错误率的差值可能来自于算法本身(归为方差),也可能来自于样本分布不同,和模型关系不大。
+
+在可能存在训练集和验证/测试集分布不一致的情况下,为了解决这个问题,我们可以再定义一个**训练-验证集(Training-dev Set)**。训练-验证集和训练集的分布相同(或者是训练集分割出的子集),但是不参与训练过程。
+
+现在,我们有了*训练集*错误率、*训练-验证集*错误率,以及*验证集*错误率。其中,*训练集*错误率和*训练-验证集*错误率的差值反映了方差;而*训练-验证集*错误率和*验证集*错误率的差值反映了样本分布不一致的问题,从而说明**模型擅长处理的数据和我们关心的数据来自不同的分布**,我们称之为**数据不匹配(Data Mismatch)**问题。
+
+人类水平误差、*训练集*错误率、*训练-验证集*错误率、*验证集*错误率、*测试集*错误率之间的差值所反映的问题如下图所示:
+
+
+
+### 处理方法
+
+这里有两条关于如何解决数据不匹配问题的建议:
+
+* 做错误分析,尝试了解训练集和验证/测试集的具体差异(主要是人工查看训练集和验证集的样本);
+* 尝试将训练数据调整得更像验证集,或者收集更多类似于验证/测试集的数据。
+
+如果你打算将训练数据调整得更像验证集,可以使用的一种技术是**人工合成数据**。我们以语音识别问题为例,实际应用场合(验证/测试集)是包含背景噪声的,而作为训练样本的音频很可能是清晰而没有背景噪声的。为了让训练集与验证/测试集分布一致,我们可以给训练集人工添加背景噪声,合成类似实际场景的声音。
+
+人工合成数据能够使数据集匹配,从而提升模型的效果。但需要注意的是,不能给每段语音都增加同一段背景噪声,因为这样模型会对这段背景噪音出现过拟合现象,使得效果不佳。
+
+## 迁移学习
+
+**迁移学习(Tranfer Learning)**是通过将已训练好的神经网络模型的一部分网络结构应用到另一模型,将一个神经网络从某个任务中学到的知识和经验运用到另一个任务中,以显著提高学习任务的性能。
+
+例如,我们将为猫识别器构建的神经网络迁移应用到放射科诊断中。因为猫识别器的神经网络已经学习到了有关图像的结构和性质等方面的知识,所以只要先删除神经网络中原有的输出层,加入新的输出层并随机初始化权重系数($W^{[L]}$、$b^{[L]}$),随后用新的训练集进行训练,就完成了以上的迁移学习。
+
+如果新的数据集很小,可能只需要重新训练输出层前的最后一层的权重,即$W^{[L]}$、$b^{[L]}$,并保持其他参数不变;而如果有足够多的数据,可以只保留网络结构,重新训练神经网络中所有层的系数。这时初始权重由之前的模型训练得到,这个过程称为**预训练(Pre-Training)**,之后的权重更新过程称为**微调(Fine-Tuning)**。
+
+你也可以不止加入一个新的输出层,而是多向神经网络加几个新层。
+
+
+
+在下述场合进行迁移学习是有意义的:
+
+1. 两个任务有同样的输入(比如都是图像或者都是音频);
+2. **拥有更多数据的任务迁移到数据较少的任务**;
+3. 某一任务的低层次特征(底层神经网络的某些功能)对另一个任务的学习有帮助。
+
+## 多任务学习
+
+迁移学习中的步骤是串行的;而**多任务学习(Multi-Task Learning)**使用单个神经网络模型,利用共享表示采用并行训练同时学习多个任务。多任务学习的基本假设是**多个任务之间具有相关性**,并且任务之间可以利用相关性相互促进。例如,属性分类中,抹口红和戴耳环有一定的相关性,单独训练的时候是无法利用这些信息,多任务学习则可以利用任务相关性联合提高多个属性分类的精度。
+
+以汽车自动驾驶为例,需要实现的多任务是识别行人、车辆、交通标志和信号灯。如果在输入的图像中检测出车辆和交通标志,则输出的 y 为:
+
+$$y = \begin{bmatrix} 0 \\\ 1 \\\ 1 \\\ 0 \end{bmatrix}\quad$$
+
+
+
+多任务学习模型的成本函数为:
+
+$$\frac{1}{m} \sum^m\_{i=1} \sum^c\_{j=1} L(\hat y\_j^{(i)}, y\_j^{(i)})$$
+
+其中,j 代表任务下标,总有 c 个任务。对应的损失函数为:
+
+$$L(\hat y\_j^{(i)}, y\_j^{(i)}) = -y\_j^{(i)} log \hat y\_j^{(i)} - (1 -y\_j^{(i)})log(1 - \hat y\_j^{(i)})$$
+
+多任务学习是使用单个神经网络模型来实现多个任务。实际上,也可以分别构建多个神经网络来实现。多任务学习中可能存在训练样本 Y 某些标签空白的情况,这不会影响多任务学习模型的训练。
+
+多任务学习和 Softmax 回归看上去有些类似,容易混淆。它们的区别是,Softmax 回归的输出向量 y 中只有一个元素为 1;而多任务学习的输出向量 y 中可以有多个元素为 1。
+
+在下述场合进行多任务学习是有意义的:
+
+1. 训练的一组任务可以共用低层次特征;
+2. *通常*,每个任务的数据量接近;
+3. 能够训练一个足够大的神经网络,以同时做好所有的工作。多任务学习会降低性能的唯一情况(即和为每个任务训练单个神经网络相比性能更低的情况)是神经网络还不够大。
+
+
+
+在多任务深度网络中,低层次信息的共享有助于减少计算量,同时共享表示层可以使得几个有共性的任务更好的结合相关性信息,任务特定层则可以单独建模任务特定的信息,实现共享信息和任务特定信息的统一。
+
+在实践中,多任务学习的使用频率要远低于迁移学习。计算机视觉领域中的物体识别是一个多任务学习的例子。
+
+## 端到端学习
+
+在传统的机器学习分块模型中,每一个模块处理一种输入,然后其输出作为下一个模块的输入,构成一条流水线。而**端到端深度学习(End-to-end Deep Learning)**只用一个单一的神经网络模型来实现所有的功能。它将所有模块混合在一起,只关心输入和输出。
+
+如果数据量较少,传统机器学习分块模型所构成的流水线效果会很不错。但如果训练样本足够大,并且训练出的神经网络模型足够复杂,那么端到端深度学习模型的性能会比传统机器学习分块模型更好。
+
+而如果数据集规模适中,还是可以使用流水线方法,但是可以混合端到端深度学习,通过神经网络绕过某些模块,直接输出某些特征。
+
+
+
+### 优点与缺点
+
+应用端到端学习的优点:
+
+* 只要有足够多的数据,剩下的全部交给一个足够大的神经网络。比起传统的机器学习分块模型,可能更能捕获数据中的任何统计信息,而不需要用人类固有的认知(或者说,成见)来进行分析;
+* 所需手工设计的组件更少,简化设计工作流程;
+
+缺点:
+
+* 需要大量的数据;
+* 排除了可能有用的人工设计组件;
+
+根据以上分析,决定一个问题是否应用端到端学习的**关键点**是:是否有足够的数据,支持能够直接学习从 x 映射到 y 并且足够复杂的函数?
diff --git a/机器学习/吴恩达深度学习/编程作业/deeplearning-assignment b/机器学习/吴恩达深度学习/编程作业/deeplearning-assignment
new file mode 160000
index 00000000..f58e6d04
--- /dev/null
+++ b/机器学习/吴恩达深度学习/编程作业/deeplearning-assignment
@@ -0,0 +1 @@
+Subproject commit f58e6d042f5c1eecd11567362cf64b4a4db0e795
diff --git a/机器学习/殷康龙/readme.md b/机器学习/殷康龙/readme.md
new file mode 100644
index 00000000..0dfde5e8
--- /dev/null
+++ b/机器学习/殷康龙/readme.md
@@ -0,0 +1,7 @@
+> 这里主要以各种算法的理论知识为主进行说明。
+
+
+
+* 从算法的角度,进行说明。(算法角度的理论总结)
+
+* 算法相关的项目的实现。(机器学习实战)
\ No newline at end of file
diff --git a/机器学习/ApacheCN/机器学习笔记/1.机器学习基础.md b/机器学习/殷康龙/机器学习笔记/1.机器学习基础.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/1.机器学习基础.md
rename to 机器学习/殷康龙/机器学习笔记/1.机器学习基础.md
diff --git a/机器学习/ApacheCN/机器学习笔记/10.KMeans聚类.md b/机器学习/殷康龙/机器学习笔记/10.KMeans聚类.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/10.KMeans聚类.md
rename to 机器学习/殷康龙/机器学习笔记/10.KMeans聚类.md
diff --git a/机器学习/ApacheCN/机器学习笔记/11.使用Apriori算法进行关联分析.md b/机器学习/殷康龙/机器学习笔记/11.使用Apriori算法进行关联分析.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/11.使用Apriori算法进行关联分析.md
rename to 机器学习/殷康龙/机器学习笔记/11.使用Apriori算法进行关联分析.md
diff --git a/机器学习/ApacheCN/机器学习笔记/12.使用FP-growth算法来高效发现频繁项集.md b/机器学习/殷康龙/机器学习笔记/12.使用FP-growth算法来高效发现频繁项集.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/12.使用FP-growth算法来高效发现频繁项集.md
rename to 机器学习/殷康龙/机器学习笔记/12.使用FP-growth算法来高效发现频繁项集.md
diff --git a/机器学习/ApacheCN/机器学习笔记/13.利用PCA来简化数据.md b/机器学习/殷康龙/机器学习笔记/13.利用PCA来简化数据.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/13.利用PCA来简化数据.md
rename to 机器学习/殷康龙/机器学习笔记/13.利用PCA来简化数据.md
diff --git a/机器学习/ApacheCN/机器学习笔记/14.利用SVD简化数据.md b/机器学习/殷康龙/机器学习笔记/14.利用SVD简化数据.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/14.利用SVD简化数据.md
rename to 机器学习/殷康龙/机器学习笔记/14.利用SVD简化数据.md
diff --git a/机器学习/ApacheCN/机器学习笔记/15.大数据与MapReduce.md b/机器学习/殷康龙/机器学习笔记/15.大数据与MapReduce.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/15.大数据与MapReduce.md
rename to 机器学习/殷康龙/机器学习笔记/15.大数据与MapReduce.md
diff --git a/机器学习/ApacheCN/机器学习笔记/16.推荐系统.md b/机器学习/殷康龙/机器学习笔记/16.推荐系统.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/16.推荐系统.md
rename to 机器学习/殷康龙/机器学习笔记/16.推荐系统.md
diff --git a/机器学习/ApacheCN/机器学习笔记/2.k-近邻算法.md b/机器学习/殷康龙/机器学习笔记/2.k-近邻算法.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/2.k-近邻算法.md
rename to 机器学习/殷康龙/机器学习笔记/2.k-近邻算法.md
diff --git a/机器学习/ApacheCN/机器学习笔记/3.决策树.md b/机器学习/殷康龙/机器学习笔记/3.决策树.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/3.决策树.md
rename to 机器学习/殷康龙/机器学习笔记/3.决策树.md
diff --git a/机器学习/ApacheCN/机器学习笔记/4.朴素贝叶斯.md b/机器学习/殷康龙/机器学习笔记/4.朴素贝叶斯.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/4.朴素贝叶斯.md
rename to 机器学习/殷康龙/机器学习笔记/4.朴素贝叶斯.md
diff --git a/机器学习/ApacheCN/机器学习笔记/5.Logistic回归.md b/机器学习/殷康龙/机器学习笔记/5.Logistic回归.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/5.Logistic回归.md
rename to 机器学习/殷康龙/机器学习笔记/5.Logistic回归.md
diff --git a/机器学习/ApacheCN/机器学习笔记/6.1.支持向量机的几个通俗理解.md b/机器学习/殷康龙/机器学习笔记/6.1.支持向量机的几个通俗理解.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/6.1.支持向量机的几个通俗理解.md
rename to 机器学习/殷康龙/机器学习笔记/6.1.支持向量机的几个通俗理解.md
diff --git a/机器学习/ApacheCN/机器学习笔记/6.支持向量机.md b/机器学习/殷康龙/机器学习笔记/6.支持向量机.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/6.支持向量机.md
rename to 机器学习/殷康龙/机器学习笔记/6.支持向量机.md
diff --git a/机器学习/ApacheCN/机器学习笔记/7.集成方法-随机森林和AdaBoost.md b/机器学习/殷康龙/机器学习笔记/7.集成方法-随机森林和AdaBoost.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/7.集成方法-随机森林和AdaBoost.md
rename to 机器学习/殷康龙/机器学习笔记/7.集成方法-随机森林和AdaBoost.md
diff --git a/机器学习/ApacheCN/机器学习笔记/8.回归.md b/机器学习/殷康龙/机器学习笔记/8.回归.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/8.回归.md
rename to 机器学习/殷康龙/机器学习笔记/8.回归.md
diff --git a/机器学习/ApacheCN/机器学习笔记/9.树回归.md b/机器学习/殷康龙/机器学习笔记/9.树回归.md
similarity index 100%
rename from 机器学习/ApacheCN/机器学习笔记/9.树回归.md
rename to 机器学习/殷康龙/机器学习笔记/9.树回归.md