mirror of
https://github.com/apachecn/ailearning.git
synced 2026-05-03 10:01:56 +08:00
2020-10-19 21:18:53
This commit is contained in:
@@ -1,6 +1,6 @@
|
||||
# 第 10 章 K-Means(K-均值)聚类算法
|
||||
|
||||

|
||||

|
||||
|
||||
## 聚类
|
||||
|
||||
@@ -59,7 +59,7 @@ kmeans,如前所述,用于数据集内种类属性不明晰,希望能够
|
||||
|
||||
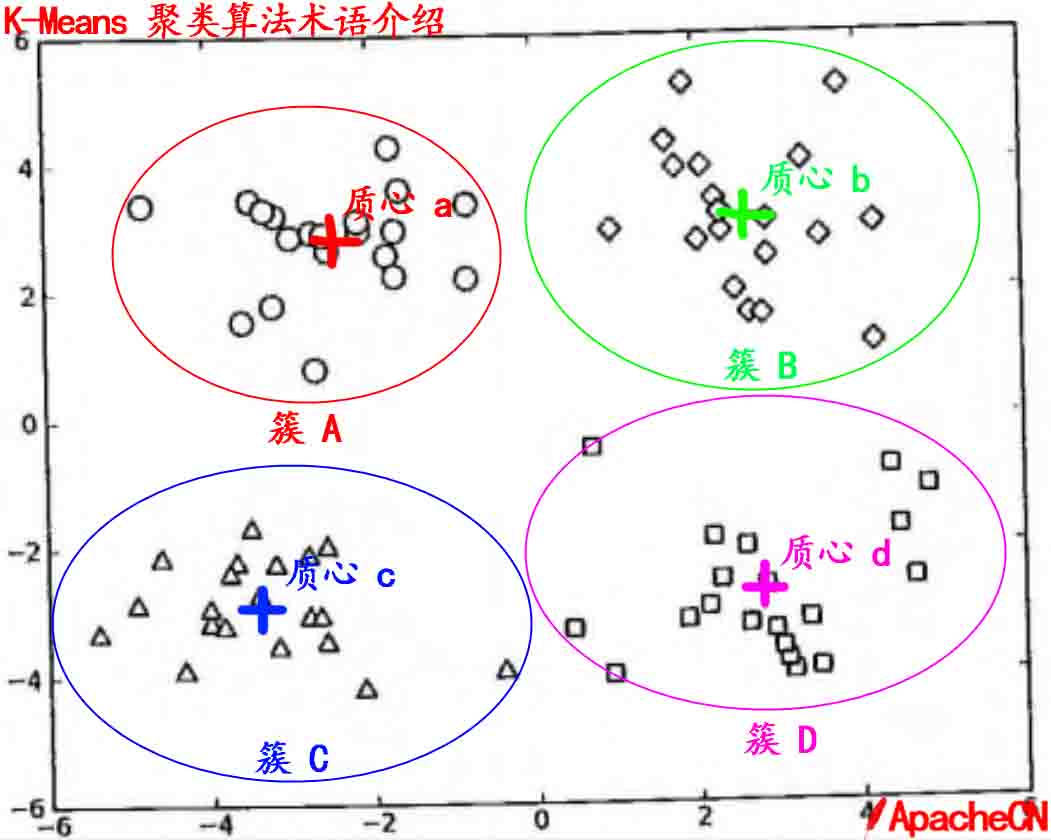
有关 `簇` 和 `质心` 术语更形象的介绍, 请参考下图:
|
||||
|
||||
|
||||

|
||||
|
||||
### K-Means 工作流程
|
||||
1. 首先, 随机确定 K 个初始点作为质心(**不必是数据中的点**)。
|
||||
@@ -162,7 +162,7 @@ def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
|
||||
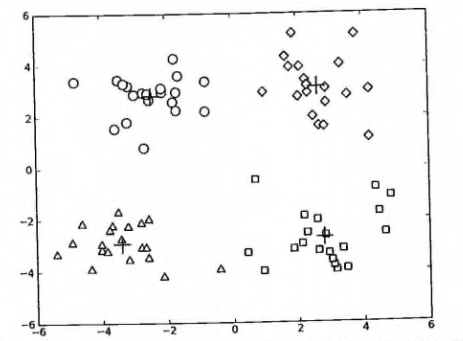
2. 测试一下 kMeans 函数是否可以如预期运行, 请看: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/10.kmeans/kMeans.py>
|
||||
|
||||
参考运行结果如下:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -170,7 +170,7 @@ def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
|
||||
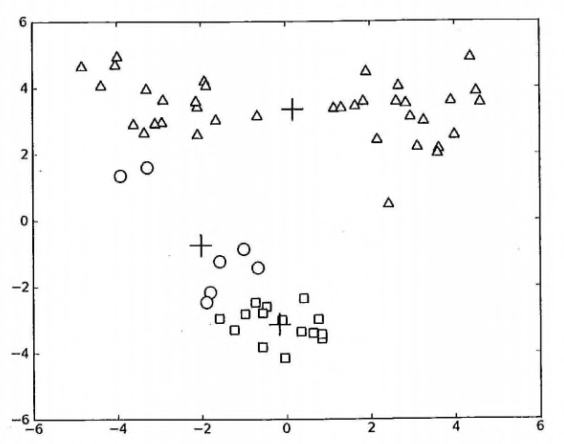
> 在 kMeans 的函数测试中,可能偶尔会陷入局部最小值(局部最优的结果,但不是全局最优的结果).
|
||||
|
||||
局部最小值的的情况如下:
|
||||
|
||||

|
||||
出现这个问题有很多原因,可能是k值取的不合适,可能是距离函数不合适,可能是最初随机选取的质心靠的太近,也可能是数据本身分布的问题。
|
||||
|
||||
为了解决这个问题,我们可以对生成的簇进行后处理,一种方法是将具有最大**SSE**值的簇划分成两个簇。具体实现时可以将最大簇包含的点过滤出来并在这些点上运行K-均值算法,令k设为2。
|
||||
@@ -239,7 +239,7 @@ def biKMeans(dataSet, k, distMeas=distEclud):
|
||||
|
||||
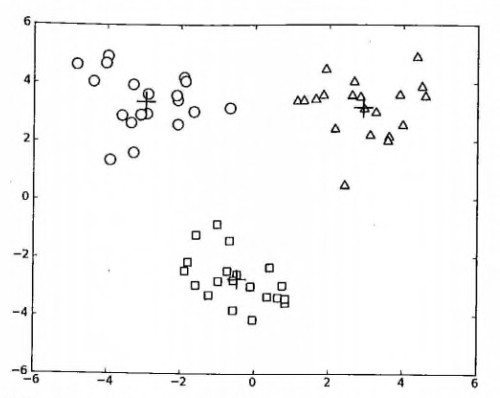
上述函数可以运行多次,聚类会收敛到全局最小值,而原始的 kMeans() 函数偶尔会陷入局部最小值。
|
||||
运行参考结果如下:
|
||||
|
||||

|
||||
|
||||
* **作者: [那伊抹微笑](http://cwiki.apachecn.org/display/~xuxin), [清都江水郎](http://cwiki.apachecn.org/display/~xuzhaoqing)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
|
||||
Reference in New Issue
Block a user