mirror of
https://github.com/apachecn/ailearning.git
synced 2026-05-02 06:22:04 +08:00
2020-10-19 21:18:53
This commit is contained in:
@@ -1,7 +1,7 @@
|
||||
|
||||
# 第 11 章 使用 Apriori 算法进行关联分析
|
||||
|
||||

|
||||

|
||||
|
||||
## 关联分析
|
||||
关联分析是一种在大规模数据集中寻找有趣关系的任务。
|
||||
@@ -12,7 +12,7 @@
|
||||
## 相关术语
|
||||
* 关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 `关联分析(associati analysis)` 或者 `关联规则学习(association rule learning)` 。
|
||||
下面是用一个 `杂货店` 例子来说明这两个概念,如下图所示:
|
||||

|
||||

|
||||
|
||||
* 频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
|
||||
* 关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。
|
||||
@@ -31,14 +31,14 @@
|
||||
|
||||
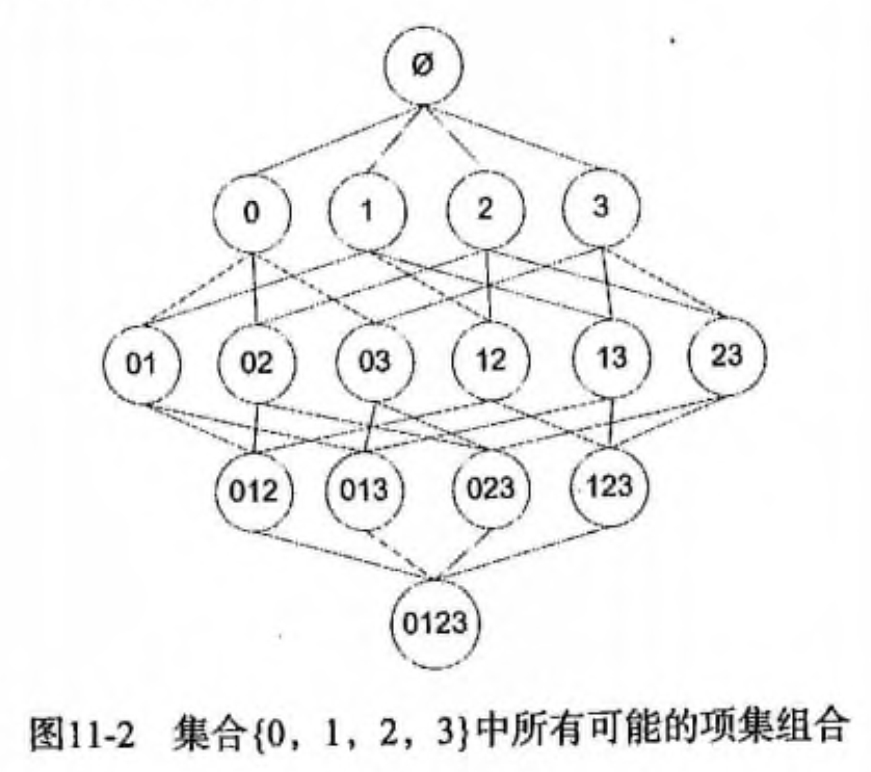
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。
|
||||
所有可能的情况如下:
|
||||
|
||||

|
||||
如果我们计算所有组合的支持度,也需要计算 15 次。即 2^N - 1 = 2^4 - 1 = 15。
|
||||
随着物品的增加,计算的次数呈指数的形式增长 ...
|
||||
为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。
|
||||
例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。
|
||||
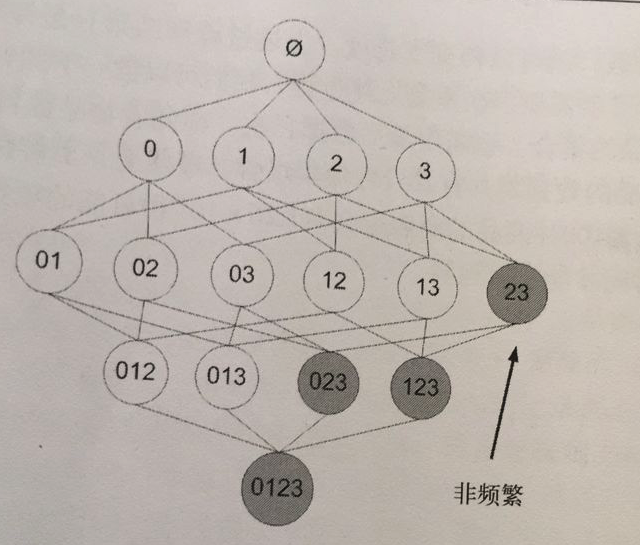
该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 `非频繁项集`,那么它的所有超集也是非频繁项集,如下图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
在图中我们可以看到,已知灰色部分 {2,3} 是 `非频繁项集`,那么利用上面的知识,我们就可以知道 {0,2,3} {1,2,3} {0,1,2,3} 都是 `非频繁的`。
|
||||
也就是说,计算出 {2,3} 的支持度,知道它是 `非频繁` 的之后,就不需要再计算 {0,2,3} {1,2,3} {0,1,2,3} 的支持度,因为我们知道这些集合不会满足我们的要求。
|
||||
@@ -272,7 +272,7 @@ def apriori(dataSet, minSupport=0.5):
|
||||
|
||||
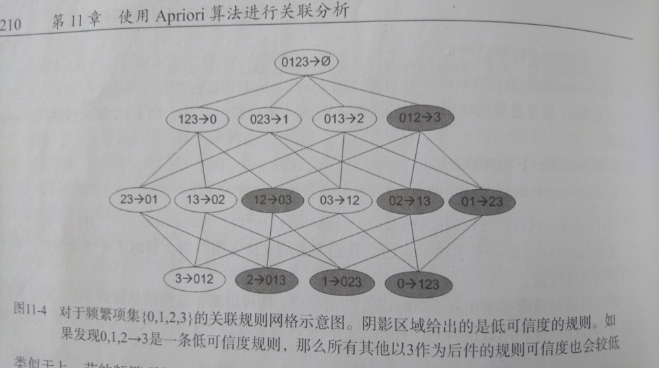
### 一个频繁项集可以产生多少条关联规则呢?
|
||||
如下图所示,给出的是项集 {0,1,2,3} 产生的所有关联规则:
|
||||
|
||||

|
||||
与我们前面的 `频繁项集` 生成一样,我们可以为每个频繁项集产生许多关联规则。
|
||||
如果能减少规则的数目来确保问题的可解析,那么计算起来就会好很多。
|
||||
通过观察,我们可以知道,如果某条规则并不满足 `最小可信度` 要求,那么该规则的所有子集也不会满足 `最小可信度` 的要求。
|
||||
@@ -386,7 +386,7 @@ def generateRules(L, supportData, minConf=0.7):
|
||||
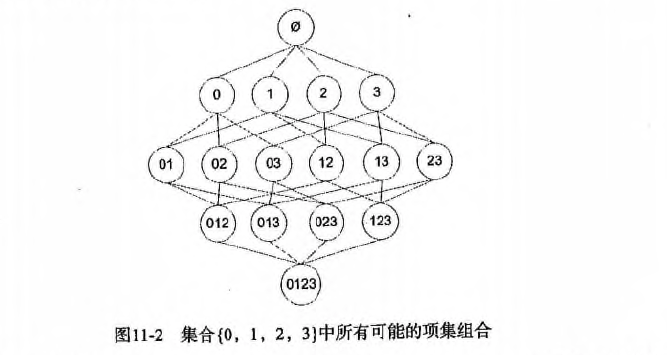
* 1.首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
|
||||
* 2.接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
|
||||
* 如下图:
|
||||
* 
|
||||
* 
|
||||
* 最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢? 下一章: FP-growth算法等着你的到来
|
||||
|
||||
* * *
|
||||
|
||||
Reference in New Issue
Block a user