mirror of
https://github.com/apachecn/ailearning.git
synced 2026-05-03 10:01:56 +08:00
2020-10-19 21:18:53
This commit is contained in:
@@ -1,7 +1,7 @@
|
||||
|
||||
# 第12章 使用FP-growth算法来高效发现频繁项集
|
||||
|
||||

|
||||

|
||||
|
||||
## 前言
|
||||
在 [第11章]() 时我们已经介绍了用 `Apriori` 算法发现 `频繁项集` 与 `关联规则`。
|
||||
@@ -37,16 +37,16 @@ class treeNode:
|
||||
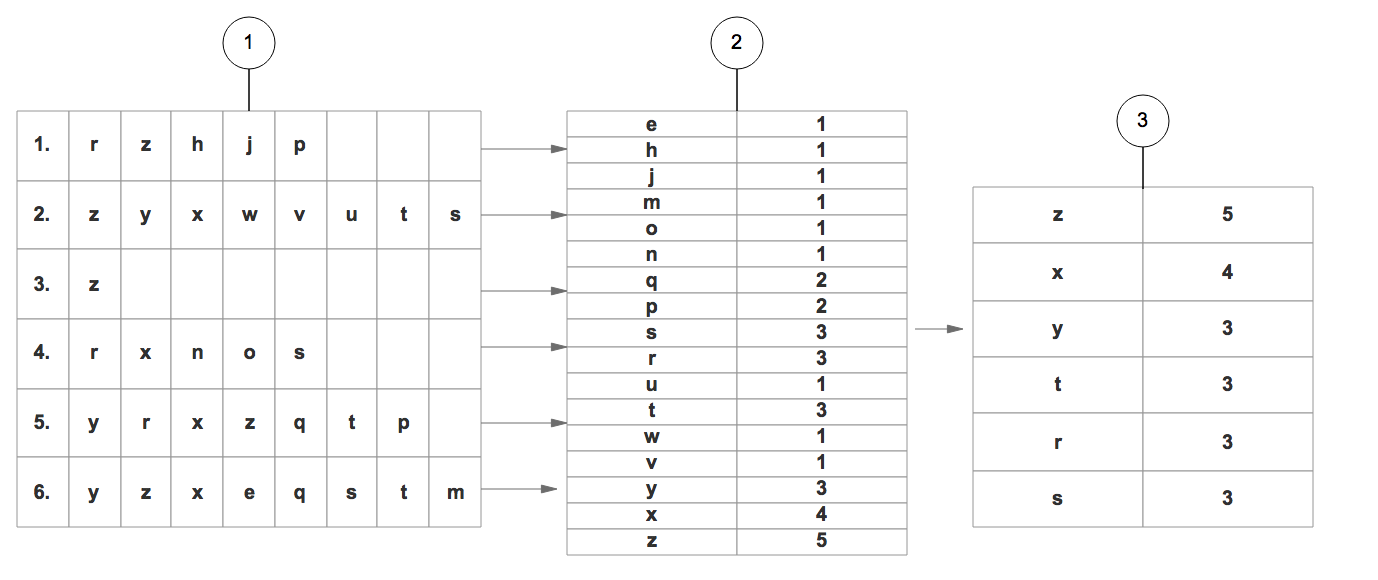
1. 遍历所有的数据集合,计算所有项的支持度。
|
||||
2. 丢弃非频繁的项。
|
||||
3. 基于 支持度 降序排序所有的项。
|
||||
|
||||

|
||||
4. 所有数据集合按照得到的顺序重新整理。
|
||||
5. 重新整理完成后,丢弃每个集合末尾非频繁的项。
|
||||
|
||||

|
||||
|
||||
步骤2:
|
||||
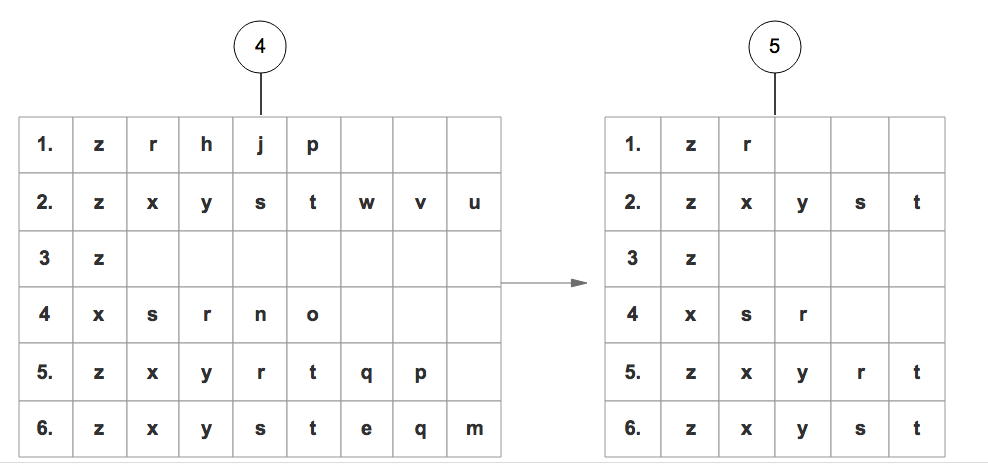
6. 读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项。
|
||||
|
||||

|
||||
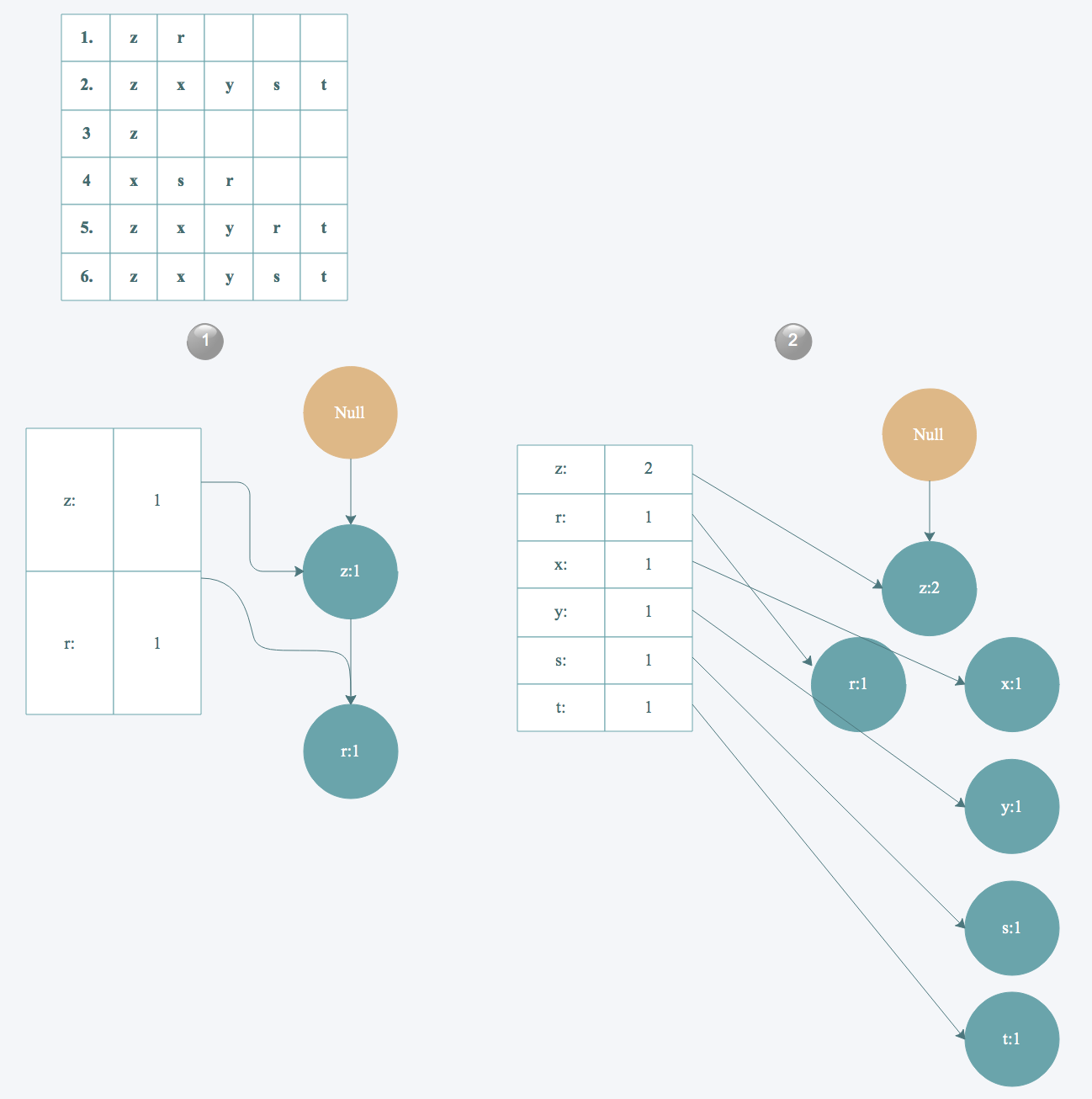
最终得到下面这样一棵FP树
|
||||
|
||||

|
||||
|
||||
|
||||
从FP树中挖掘出频繁项集
|
||||
@@ -54,14 +54,14 @@ class treeNode:
|
||||
步骤3:
|
||||
1. 对头部链表进行降序排序
|
||||
2. 对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集。
|
||||

|
||||

|
||||
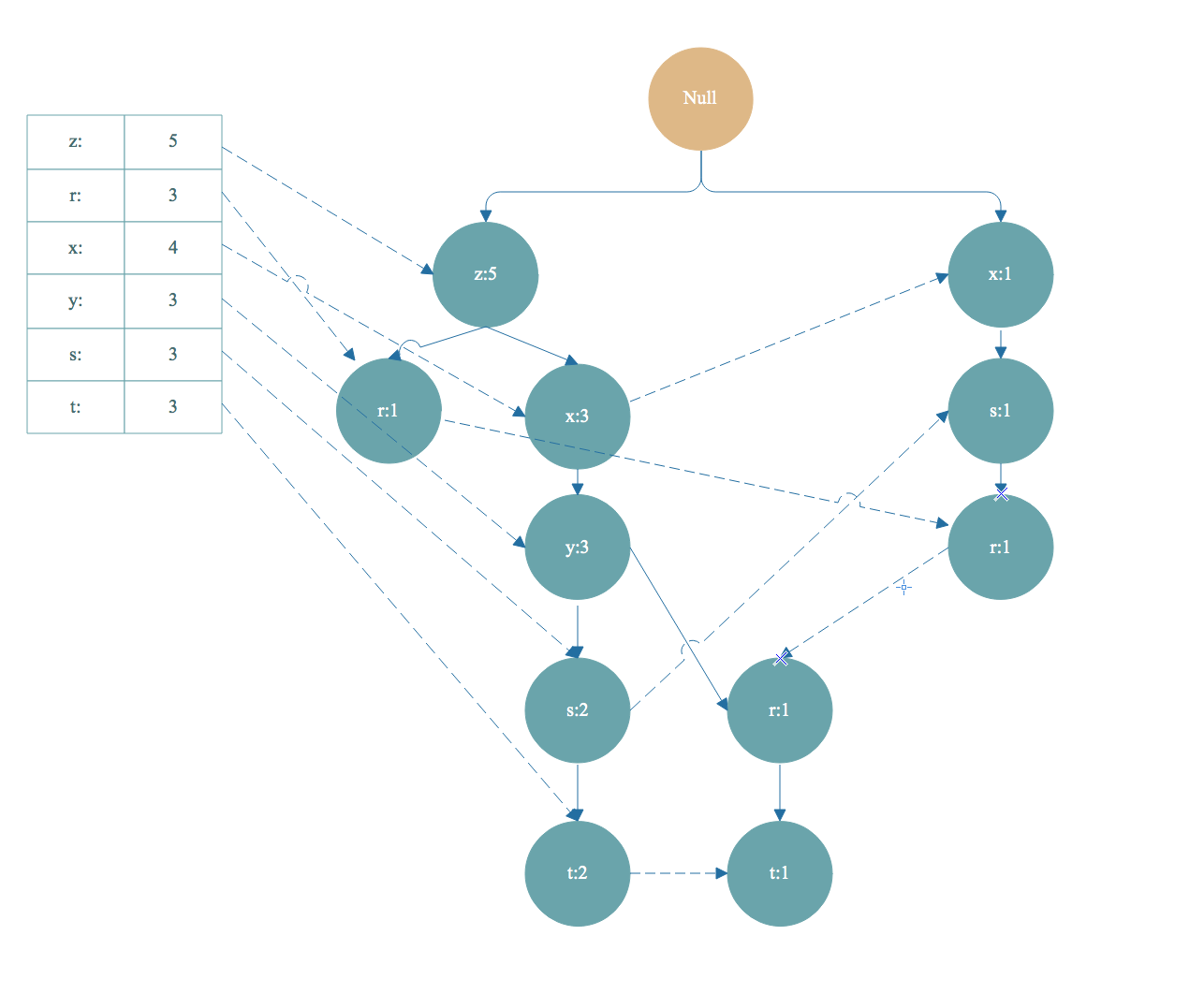
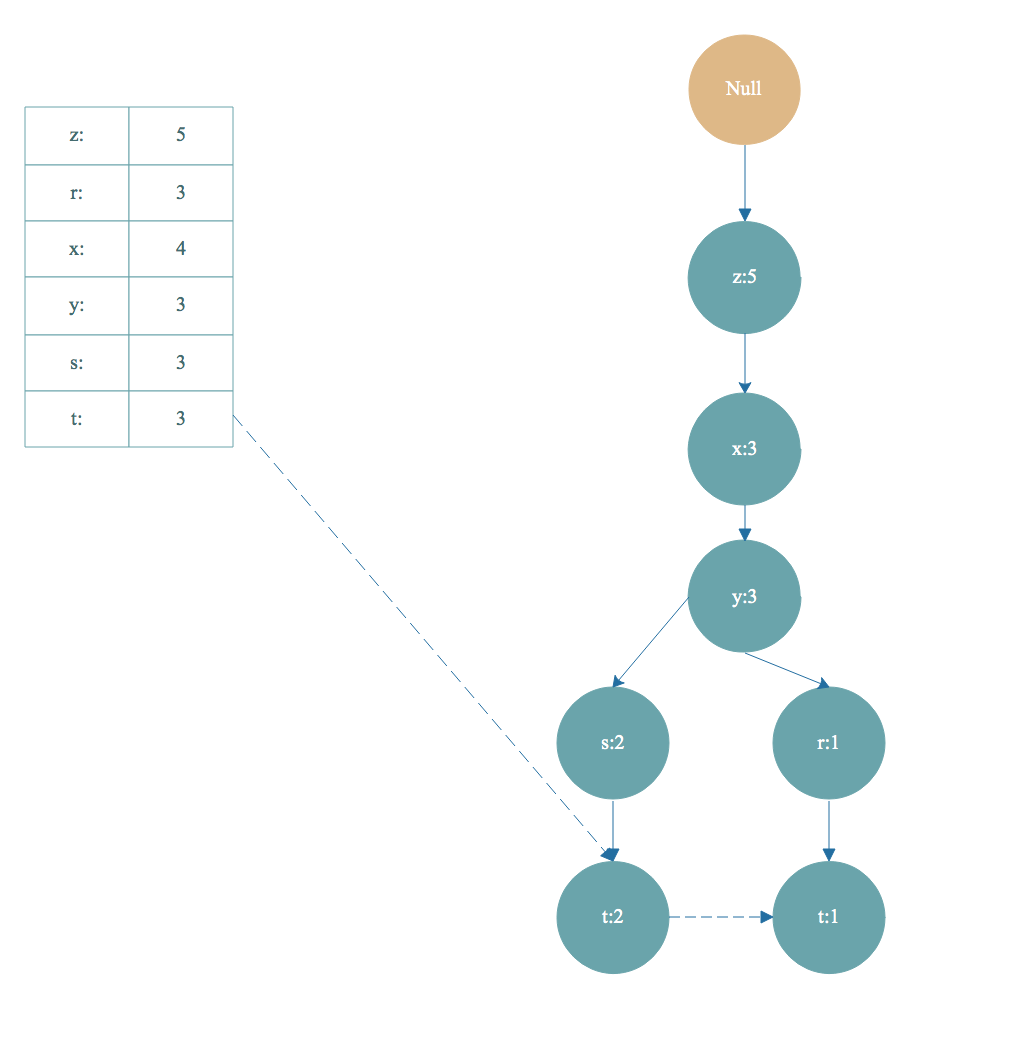
如上图,从头部链表 t 节点开始遍历,t 节点加入到频繁项集。找到以 t 节点为结尾的路径如下:
|
||||
|
||||

|
||||
去掉FP树中的t节点,得到条件模式基<左边路径, 右边是值>[z,x,y,s,t]:2,[z,x,y,r,t]:1 。条件模式基的值取决于末尾节点 t ,因为 t 的出现次数最小,一个频繁项集的支持度由支持度最小的项决定。所以 t 节点的条件模式基的值可以理解为对于以 t 节点为末尾的前缀路径出现次数。
|
||||
|
||||
3. 条件模式基继续构造条件 FP树, 得到频繁项集,和之前的频繁项组合起来,这是一个递归遍历头部链表生成FP树的过程,递归截止条件是生成的FP树的头部链表为空。
|
||||
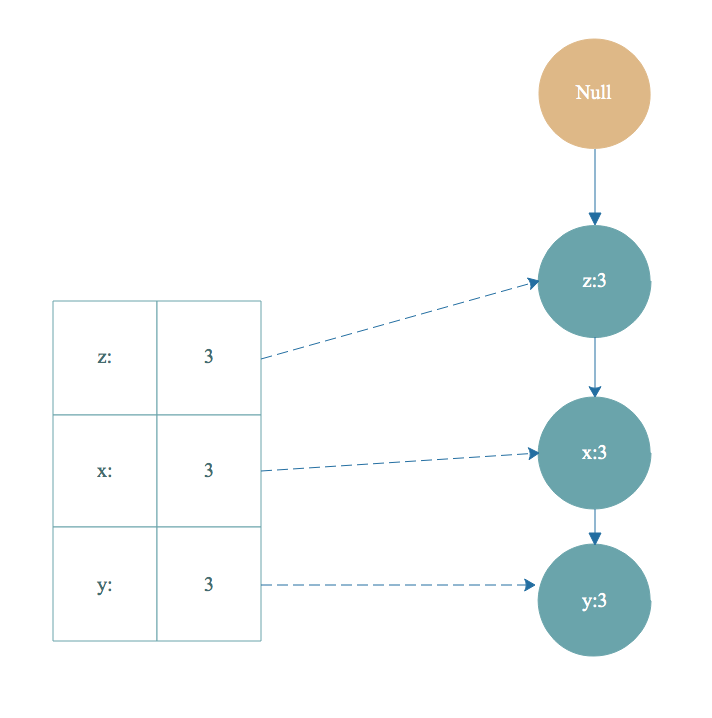
根据步骤 2 得到的条件模式基 [z,x,y,s,t]:2,[z,x,y,r,t]:1 作为数据集继续构造出一棵FP树,计算支持度,去除非频繁项,集合按照支持度降序排序,重复上面构造FP树的步骤。最后得到下面 t-条件FP树 :
|
||||
|
||||

|
||||
然后根据 t-条件FP树 的头部链表进行遍历,从 y 开始。得到频繁项集 ty 。然后又得到 y 的条件模式基,构造出 ty的条件FP树,即 ty-条件FP树。继续遍历ty-条件FP树的头部链表,得到频繁项集 tyx,然后又得到频繁项集 tyxz. 然后得到构造tyxz-条件FP树的头部链表是空的,终止遍历。我们得到的频繁项集有 t->ty->tyz->tyzx,这只是一小部分。
|
||||
* 条件模式基:头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。
|
||||
* 条件FP树:以条件模式基为数据集构造的FP树叫做条件FP树。
|
||||
|
||||
Reference in New Issue
Block a user