mirror of
https://github.com/apachecn/ailearning.git
synced 2026-05-03 10:01:56 +08:00
2020-10-19 21:18:53
This commit is contained in:
@@ -1,7 +1,7 @@
|
||||
# 第14章 利用SVD简化数据
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||

|
||||
|
||||
## SVD 概述
|
||||
|
||||
@@ -17,14 +17,14 @@
|
||||
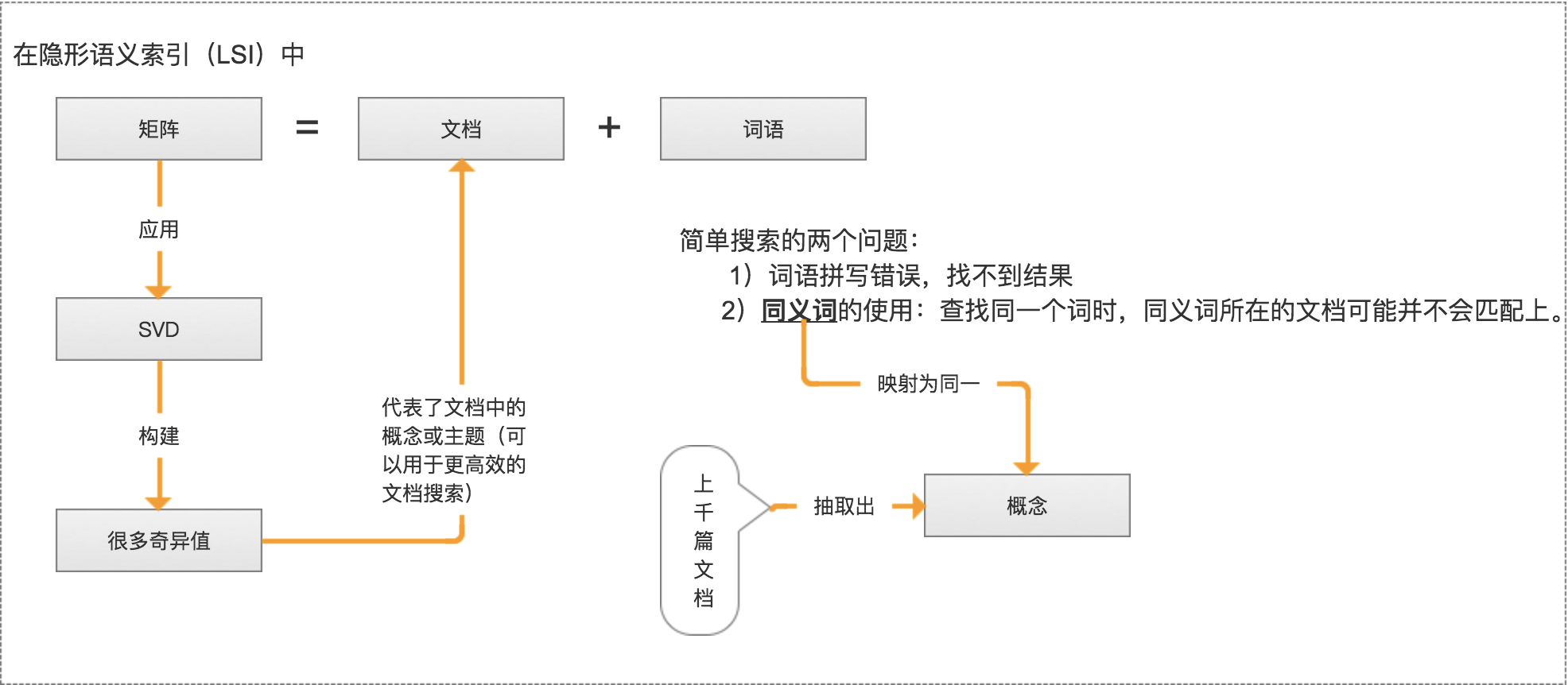
隐性语义索引: 矩阵 = 文档 + 词语
|
||||
* 是最早的 SVD 应用之一,我们称利用 SVD 的方法为隐性语义索引(LSI)或隐性语义分析(LSA)。
|
||||
|
||||
|
||||

|
||||
|
||||
> 推荐系统
|
||||
|
||||
1. 利用 SVD 从数据中构建一个主题空间。
|
||||
2. 再在该空间下计算其相似度。(从高维-低维空间的转化,在低维空间来计算相似度,SVD 提升了推荐系统的效率。)
|
||||
|
||||
|
||||

|
||||
|
||||
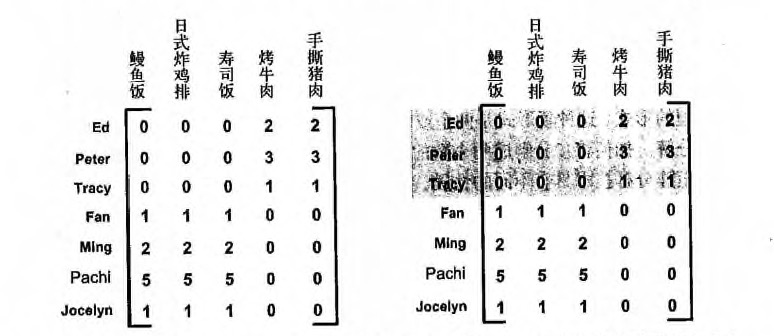
* 上图右边标注的为一组共同特征,表示美式 BBQ 空间;另一组在上图右边未标注的为日式食品 空间。
|
||||
|
||||
@@ -32,7 +32,7 @@
|
||||
|
||||
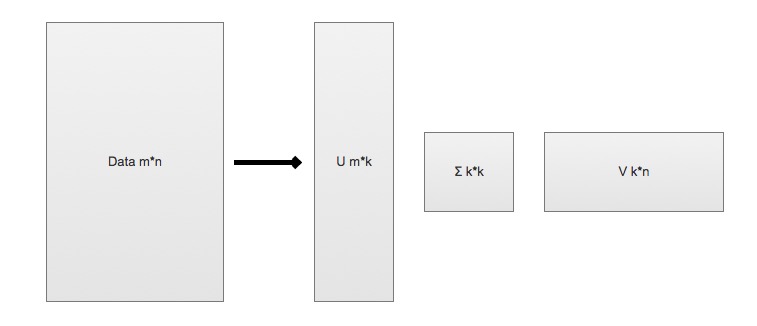
例如: `32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
|
||||
|
||||

|
||||
|
||||
## SVD 原理
|
||||
|
||||
@@ -54,11 +54,11 @@
|
||||
|
||||
$$Data_{m \ast n} = U_{m \ast k} \sum_{k \ast k} V_{k \ast n}$$
|
||||
|
||||

|
||||

|
||||
|
||||
具体的案例: (大家可以试着推导一下: https://wenku.baidu.com/view/b7641217866fb84ae45c8d17.html )
|
||||
|
||||

|
||||

|
||||
|
||||
* 上述分解中会构建出一个矩阵 $$\sum$$ ,该矩阵只有对角元素,其他元素均为0(近似于0)。另一个惯例就是,$$\sum$$ 的对角元素是从大到小排列的。这些对角元素称为奇异值。
|
||||
* 奇异值与特征值(PCA 数据中重要特征)是有关系的。这里的奇异值就是矩阵 $$Data \ast Data^T$$ 特征值的平方根。
|
||||
@@ -97,12 +97,12 @@ $$Data_{m \ast n} = U_{m \ast k} \sum_{k \ast k} V_{k \ast n}$$
|
||||
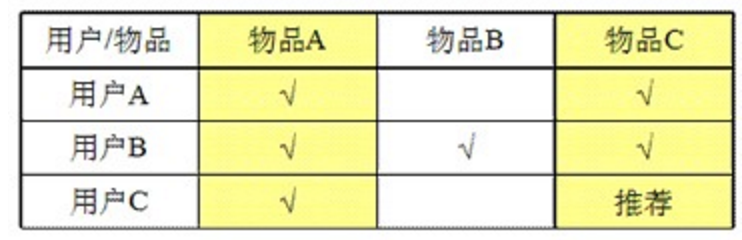
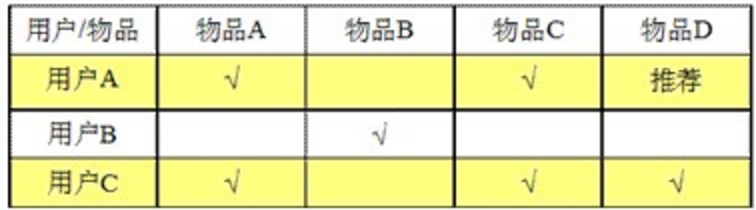
* 基于物品的相似度: 计算物品之间的距离。【耗时会随物品数量的增加而增加】
|
||||
* 由于物品A和物品C 相似度(相关度)很高,所以给买A的人推荐C。
|
||||
|
||||
|
||||

|
||||
|
||||
* 基于用户的相似度: 计算用户之间的距离。【耗时会随用户数量的增加而增加】
|
||||
* 由于用户A和用户C 相似度(相关度)很高,所以A和C是兴趣相投的人,对于C买的物品就会推荐给A。
|
||||
|
||||
|
||||

|
||||
|
||||
> 相似度计算
|
||||
|
||||
@@ -146,7 +146,7 @@ $$Data_{m \ast n} = U_{m \ast k} \sum_{k \ast k} V_{k \ast n}$$
|
||||
|
||||
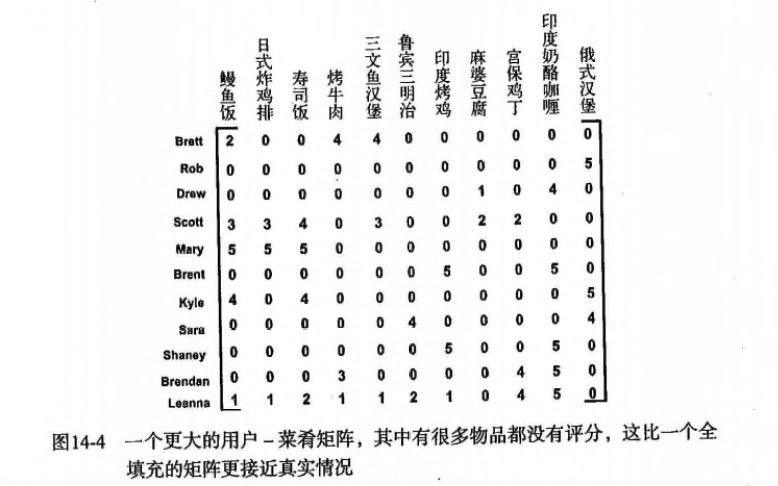
> 收集 并 准备数据
|
||||
|
||||
|
||||

|
||||
|
||||
```python
|
||||
def loadExData3():
|
||||
@@ -177,9 +177,9 @@ recommend() 会调用 基于物品相似度 或者是 基于SVD,得到推荐
|
||||
|
||||
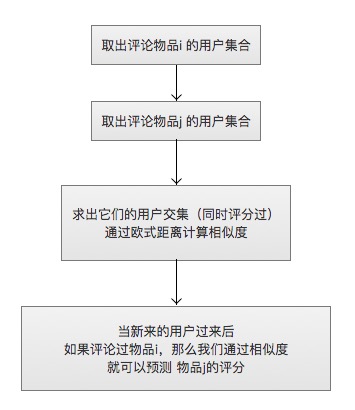
* 1.基于物品相似度
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
```python
|
||||
# 基于物品相似度的推荐引擎
|
||||
@@ -229,7 +229,7 @@ def standEst(dataMat, user, simMeas, item):
|
||||
|
||||
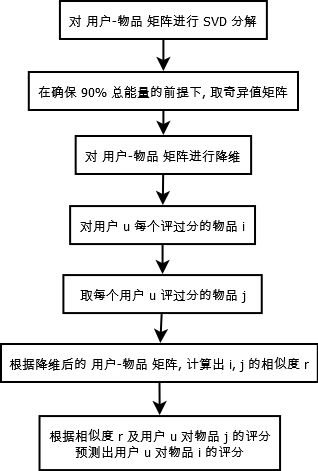
* 2.基于SVD(参考地址: http://www.codeweblog.com/svd-%E7%AC%94%E8%AE%B0/)
|
||||
|
||||
|
||||

|
||||
|
||||
```python
|
||||
# 基于SVD的评分估计
|
||||
|
||||
Reference in New Issue
Block a user