mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-26 03:22:58 +08:00
2020-10-19 21:18:53
This commit is contained in:
12
docs/ml/2.md
12
docs/ml/2.md
@@ -1,7 +1,7 @@
|
||||
# 第2章 k-近邻算法
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||

|
||||
|
||||
## KNN 概述
|
||||
|
||||
@@ -21,7 +21,7 @@
|
||||
|
||||
基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。
|
||||
|
||||

|
||||

|
||||
|
||||
```
|
||||
现在根据上面我们得到的样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。
|
||||
@@ -162,7 +162,7 @@ plt.show()
|
||||
|
||||
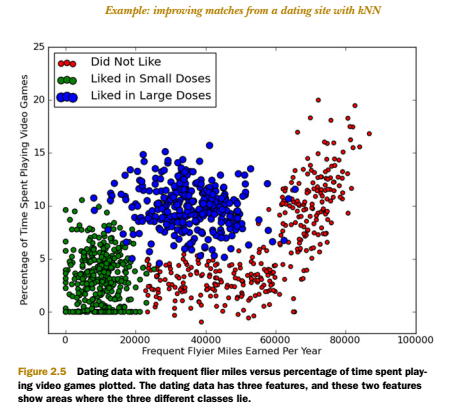
下图中采用矩阵的第一和第二列属性得到很好的展示效果,清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。
|
||||
|
||||
|
||||

|
||||
|
||||
* 归一化数据 (归一化是一个让权重变为统一的过程,更多细节请参考: https://www.zhihu.com/question/19951858 )
|
||||
|
||||
@@ -194,7 +194,7 @@ $$\sqrt{(0-67)^2 + (20000-32000)^2 + (1.1-0.1)^2 }$$
|
||||
|
||||
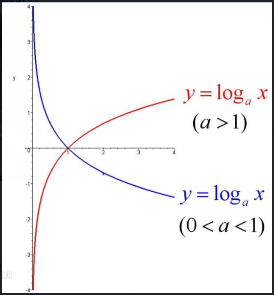
如图:
|
||||
|
||||
|
||||

|
||||
|
||||
3) 反余切函数转换,表达式如下:
|
||||
|
||||
@@ -202,7 +202,7 @@ $$\sqrt{(0-67)^2 + (20000-32000)^2 + (1.1-0.1)^2 }$$
|
||||
|
||||
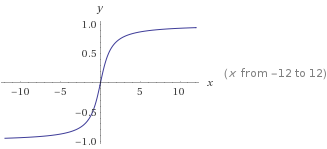
如图:
|
||||
|
||||
|
||||

|
||||
|
||||
4) 式(1)将输入值换算为[-1,1]区间的值,在输出层用式(2)换算回初始值,其中和分别表示训练样本集中负荷的最大值和最小值。
|
||||
|
||||
@@ -363,7 +363,7 @@ You will probably like this person: in small doses
|
||||
|
||||
目录 [trainingDigits](/data/2.KNN/trainingDigits) 中包含了大约 2000 个例子,每个例子内容如下图所示,每个数字大约有 200 个样本;目录 [testDigits](/data/2.KNN/testDigits) 中包含了大约 900 个测试数据。
|
||||
|
||||

|
||||

|
||||
|
||||
> 准备数据: 编写函数 img2vector(), 将图像文本数据转换为分类器使用的向量
|
||||
|
||||
|
||||
Reference in New Issue
Block a user