mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-27 12:03:29 +08:00
2020-10-19 21:18:53
This commit is contained in:
16
docs/ml/4.md
16
docs/ml/4.md
@@ -2,7 +2,7 @@
|
||||
# 第4章 基于概率论的分类方法: 朴素贝叶斯
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||

|
||||
|
||||
## 朴素贝叶斯 概述
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
|
||||
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
|
||||
* 如果 p1(x,y) > p2(x,y) ,那么类别为1
|
||||
@@ -28,11 +28,11 @@
|
||||
|
||||
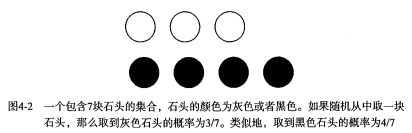
有一个装了 7 块石头的罐子,其中 3 块是白色的,4 块是黑色的。如果从罐子中随机取出一块石头,那么是白色石头的可能性是多少?由于取石头有 7 种可能,其中 3 种为白色,所以取出白色石头的概率为 3/7 。那么取到黑色石头的概率又是多少呢?很显然,是 4/7 。我们使用 P(white) 来表示取到白色石头的概率,其概率值可以通过白色石头数目除以总的石头数目来得到。
|
||||
|
||||
|
||||

|
||||
|
||||
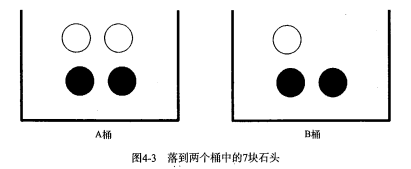
如果这 7 块石头如下图所示,放在两个桶中,那么上述概率应该如何计算?
|
||||
|
||||
|
||||

|
||||
|
||||
计算 P(white) 或者 P(black) ,如果事先我们知道石头所在桶的信息是会改变结果的。这就是所谓的条件概率(conditional probablity)。假定计算的是从 B 桶取到白色石头的概率,这个概率可以记作 P(white|bucketB) ,我们称之为“在已知石头出自 B 桶的条件下,取出白色石头的概率”。很容易得到,P(white|bucketA) 值为 2/4 ,P(white|bucketB) 的值为 1/3 。
|
||||
|
||||
@@ -44,7 +44,7 @@ P(white|bucketB) = P(white and bucketB) / P(bucketB)
|
||||
|
||||
另外一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知 P(x|c),要求 P(c|x),那么可以使用下面的计算方法:
|
||||
|
||||
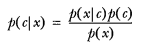
|
||||

|
||||
|
||||
### 使用条件概率来分类
|
||||
|
||||
@@ -54,7 +54,7 @@ P(white|bucketB) = P(white and bucketB) / P(bucketB)
|
||||
|
||||
这并不是贝叶斯决策理论的所有内容。使用 p1() 和 p2() 只是为了尽可能简化描述,而真正需要计算和比较的是 p(c1|x, y) 和 p(c2|x, y) .这些符号所代表的具体意义是: 给定某个由 x、y 表示的数据点,那么该数据点来自类别 c1 的概率是多少?数据点来自类别 c2 的概率又是多少?注意这些概率与概率 p(x, y|c1) 并不一样,不过可以使用贝叶斯准则来交换概率中条件与结果。具体地,应用贝叶斯准则得到:
|
||||
|
||||
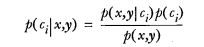
|
||||

|
||||
|
||||
使用上面这些定义,可以定义贝叶斯分类准则为:
|
||||
* 如果 P(c1|x, y) > P(c2|x, y), 那么属于类别 c1;
|
||||
@@ -213,7 +213,7 @@ def setOfWords2Vec(vocabList, inputSet):
|
||||
|
||||
现在已经知道了一个词是否出现在一篇文档中,也知道该文档所属的类别。接下来我们重写贝叶斯准则,将之前的 x, y 替换为 <b>w</b>. 粗体的 <b>w</b> 表示这是一个向量,即它由多个值组成。在这个例子中,数值个数与词汇表中的词个数相同。
|
||||
|
||||
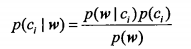
|
||||

|
||||
|
||||
我们使用上述公式,对每个类计算该值,然后比较这两个概率值的大小。
|
||||
|
||||
@@ -274,7 +274,7 @@ def _trainNB0(trainMatrix, trainCategory):
|
||||
|
||||
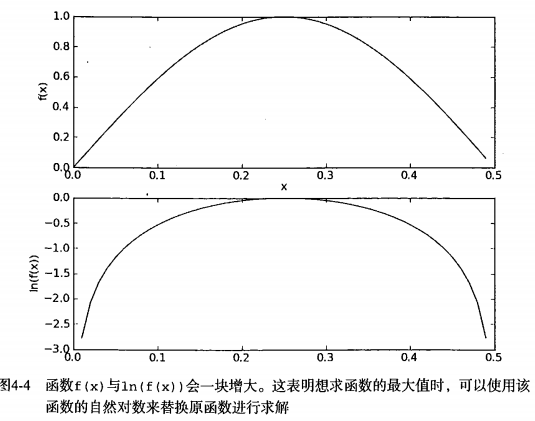
下图给出了函数 f(x) 与 ln(f(x)) 的曲线。可以看出,它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
|
||||
|
||||
|
||||

|
||||
|
||||
```python
|
||||
def trainNB0(trainMatrix, trainCategory):
|
||||
|
||||
Reference in New Issue
Block a user