mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-29 04:51:49 +08:00
2020-10-19 21:18:53
This commit is contained in:
18
docs/ml/6.md
18
docs/ml/6.md
@@ -1,7 +1,7 @@
|
||||
# 第6章 支持向量机
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||

|
||||
|
||||
## 支持向量机 概述
|
||||
|
||||
@@ -14,14 +14,14 @@
|
||||
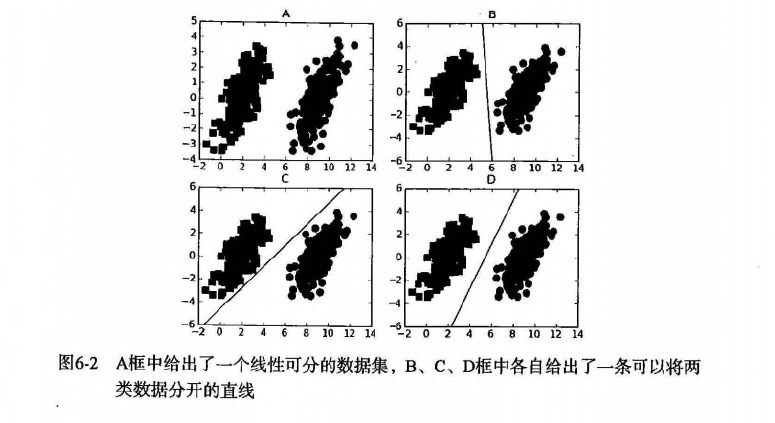
* 要给左右两边的点进行分类
|
||||
* 明显发现: 选择D会比B、C分隔的效果要好很多。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
## 支持向量机 原理
|
||||
|
||||
### SVM 工作原理
|
||||
|
||||

|
||||

|
||||
|
||||
对于上述的苹果和香蕉,我们想象为2种水果类型的炸弹。(保证距离最近的炸弹,距离它们最远)
|
||||
|
||||
@@ -32,7 +32,7 @@
|
||||
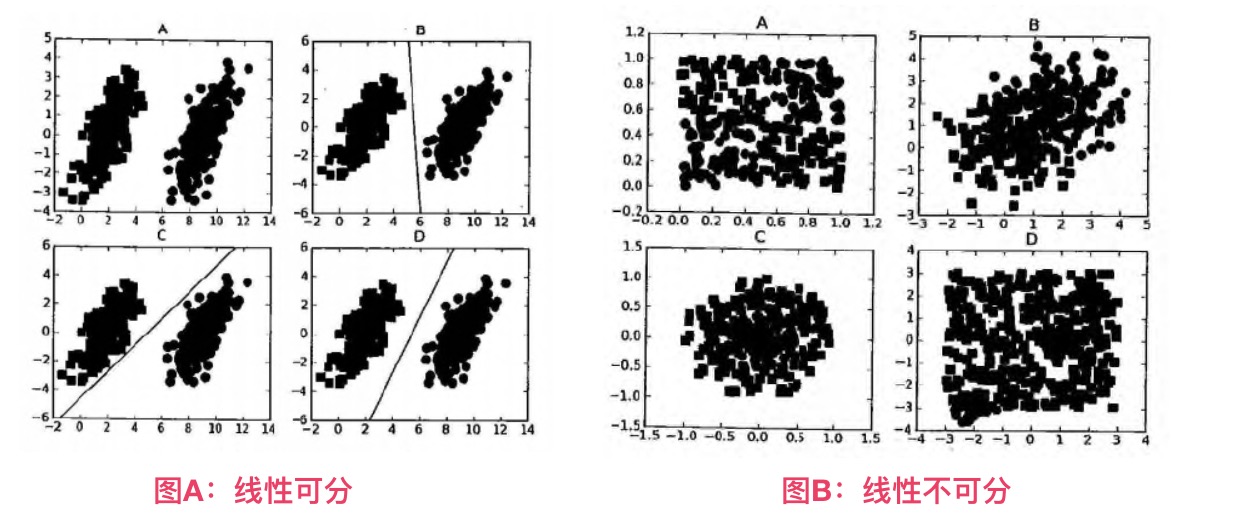
* 数据可以通过画一条直线就可以将它们完全分开,这组数据叫`线性可分(linearly separable)`数据,而这条分隔直线称为`分隔超平面(separating hyperplane)`。
|
||||
* 如果数据集上升到1024维呢?那么需要1023维来分隔数据集,也就说需要N-1维的对象来分隔,这个对象叫做`超平面(hyperlane)`,也就是分类的决策边界。
|
||||
|
||||
|
||||

|
||||
|
||||
### 寻找最大间隔
|
||||
|
||||
@@ -65,7 +65,7 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
* 分类的结果: $$f(x)=sign(w^Tx+b)$$ (sign表示>0为1,<0为-1,=0为0)
|
||||
* 点到超平面的`几何间距`: $$d(x)=(w^Tx+b)/||w||$$ (||w||表示w矩阵的二范数=> $$\sqrt{w^T*w}$$, 点到超平面的距离也是类似的)
|
||||
|
||||

|
||||

|
||||
|
||||
> 拉格朗日乘子法
|
||||
|
||||
@@ -96,7 +96,7 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
* 先求: $$min_{w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]$$
|
||||
* 就是求`L(w,b,a)`关于[w, b]的偏导数, 得到`w和b的值`,并化简为: `L和a的方程`。
|
||||
* 参考: 如果公式推导还是不懂,也可以参考《统计学习方法》李航-P103<学习的对偶算法>
|
||||

|
||||

|
||||
* 终于得到课本上的公式: $$max_{\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i \ast label_j \ast \alpha_i \ast \alpha_j \ast <x_i, x_j> \right) $$
|
||||
* 约束条件: $$a>=0$$ 并且 $$\sum_{i=1}^{m} a_i \ast label_i=0$$
|
||||
|
||||
@@ -104,12 +104,12 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
|
||||
参考地址: http://blog.csdn.net/wusecaiyun/article/details/49659183
|
||||
|
||||
|
||||

|
||||
|
||||
* 我们知道几乎所有的数据都不那么干净, 通过引入松弛变量来 `允许数据点可以处于分隔面错误的一侧`。
|
||||
* 约束条件: $$C>=a>=0$$ 并且 $$\sum_{i=1}^{m} a_i \ast label_i=0$$
|
||||
* 总的来说:
|
||||
* 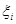 表示 `松弛变量`
|
||||
*  表示 `松弛变量`
|
||||
* 常量C是 `惩罚因子`, 表示离群点的权重(用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0” )
|
||||
* $$label*(w^Tx+b) > 1$$ and alpha = 0 (在边界外,就是非支持向量)
|
||||
* $$label*(w^Tx+b) = 1$$ and 0< alpha < C (在分割超平面上,就支持向量)
|
||||
@@ -351,7 +351,7 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
* 核函数并不仅仅应用于支持向量机,很多其他的机器学习算法也都用到核函数。最流行的核函数: 径向基函数(radial basis function)
|
||||
* 径向基函数的高斯版本,其具体的公式为:
|
||||
|
||||

|
||||

|
||||
|
||||
### 项目案例: 手写数字识别的优化(有核函数)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user