mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-24 02:23:45 +08:00
2020-10-19 21:18:53
This commit is contained in:
20
docs/ml/7.md
20
docs/ml/7.md
@@ -1,6 +1,6 @@
|
||||
# 第7章 集成方法 ensemble method
|
||||
|
||||

|
||||

|
||||
|
||||
## 集成方法: ensemble method(元算法: meta algorithm) 概述
|
||||
|
||||
@@ -52,7 +52,7 @@
|
||||
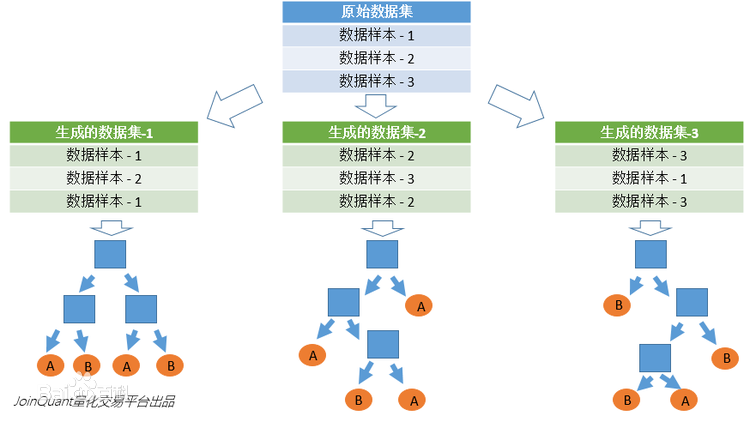
3. 然后统计子决策树的投票结果,得到最终的分类 就是 随机森林的输出结果。
|
||||
4. 如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
|
||||
|
||||
|
||||

|
||||
|
||||
> 待选特征的随机化
|
||||
|
||||
@@ -63,7 +63,7 @@
|
||||
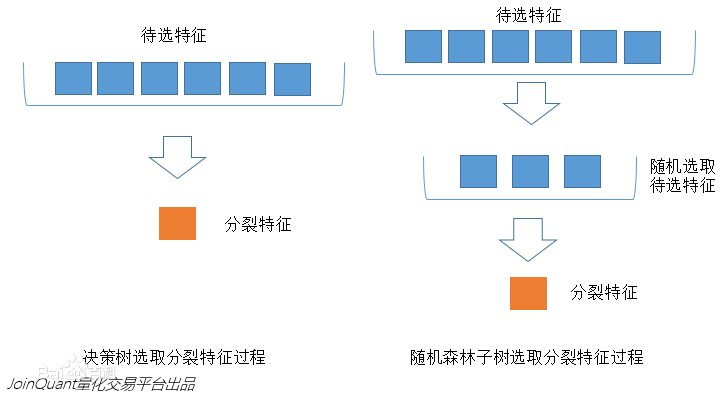
左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(别忘了前文提到的ID3算法,C4.5算法,CART算法等等),完成分裂。<br/>
|
||||
右边是一个随机森林中的子树的特征选取过程。<br/>
|
||||
|
||||
|
||||

|
||||
|
||||
> 随机森林 开发流程
|
||||
|
||||
@@ -317,7 +317,7 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
|
||||
> AdaBoost 工作原理
|
||||
|
||||

|
||||

|
||||
|
||||
> AdaBoost 开发流程
|
||||
|
||||
@@ -344,7 +344,7 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
|
||||
> 项目流程图
|
||||
|
||||

|
||||

|
||||
|
||||
基于单层决策树构建弱分类器
|
||||
* 单层决策树(decision stump, 也称决策树桩)是一种简单的决策树。
|
||||
@@ -399,11 +399,11 @@ def loadDataSet(fileName):
|
||||
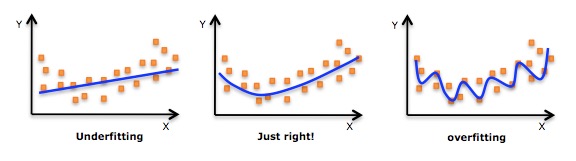
过拟合(overfitting, 也称为过学习)
|
||||
* 发现测试错误率在达到一个最小值之后有开始上升,这种现象称为过拟合。
|
||||
|
||||
|
||||

|
||||
|
||||
* 通俗来说: 就是把一些噪音数据也拟合进去的,如下图。
|
||||
|
||||
|
||||

|
||||
|
||||
> 训练算法: 在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
|
||||
@@ -466,7 +466,7 @@ D (样本权重)的目的是为了计算错误概率: weightedError = D.T*e
|
||||
样本的权重值: 如果一个值误判的几率越小,那么 D 的样本权重越小
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
> 测试算法: 我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较。
|
||||
|
||||
@@ -556,7 +556,7 @@ ROC Curves
|
||||
|
||||
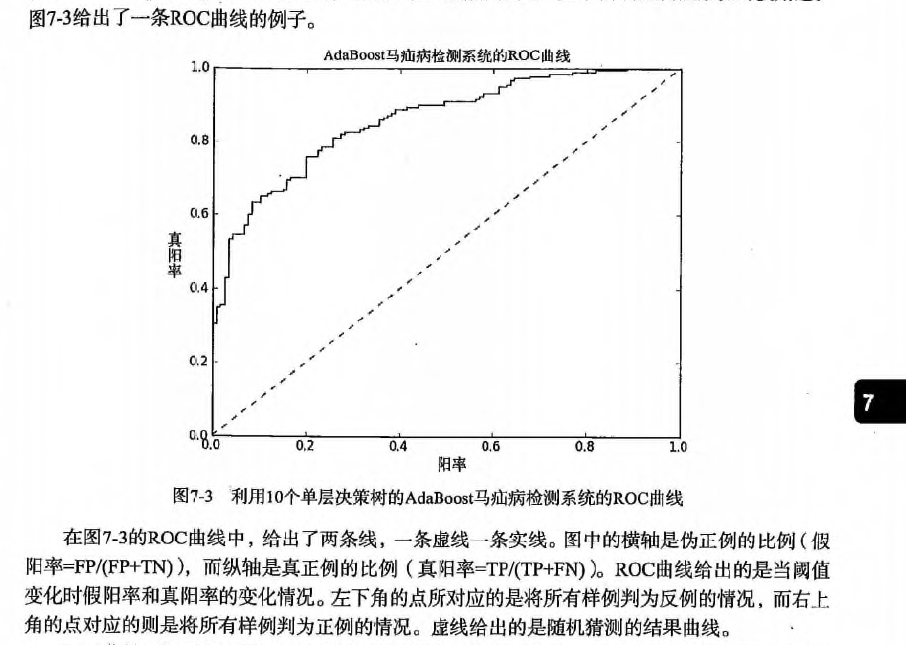
* ROC 曲线: 最佳的分类器应该尽可能地处于左上角
|
||||
|
||||
|
||||

|
||||
|
||||
* 对不同的 ROC 曲线进行比较的一个指标是曲线下的面积(Area Unser the Curve, AUC).
|
||||
|
||||
@@ -615,7 +615,7 @@ python实现可以查阅[UnbalancedDataset](https://github.com/scikit-learn-cont
|
||||
|
||||
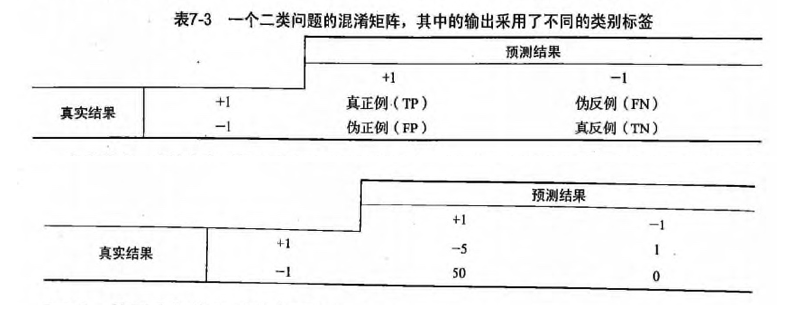
* 基于代价函数的分类器决策控制: `TP*(-5)+FN*1+FP*50+TN*0`
|
||||
|
||||
|
||||

|
||||
|
||||
这种方式叫做 cost sensitive learning,Weka 中相应的框架可以实现叫[CostSensitiveClassifier](http://weka.sourceforge.net/doc.dev/weka/classifiers/meta/CostSensitiveClassifier.html)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user