mirror of
https://github.com/apachecn/ailearning.git
synced 2026-05-01 05:51:01 +08:00
2020-10-19 21:18:53
This commit is contained in:
46
docs/ml/8.md
46
docs/ml/8.md
@@ -1,7 +1,7 @@
|
||||
# 第8章 预测数值型数据: 回归
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||

|
||||
|
||||
## 回归(Regression) 概述
|
||||
|
||||
@@ -30,11 +30,11 @@ HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
|
||||
平方误差可以写做(其实我们是使用这个函数作为 loss function):
|
||||
|
||||
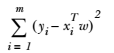
|
||||

|
||||
|
||||
用矩阵表示还可以写做 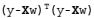 。如果对 w 求导,得到 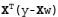 ,令其等于零,解出 w 如下(具体求导过程为: http://blog.csdn.net/nomadlx53/article/details/50849941 ):
|
||||
用矩阵表示还可以写做  。如果对 w 求导,得到  ,令其等于零,解出 w 如下(具体求导过程为: http://blog.csdn.net/nomadlx53/article/details/50849941 ):
|
||||
|
||||
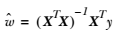
|
||||

|
||||
|
||||
#### 1.1、线性回归 须知概念
|
||||
|
||||
@@ -42,7 +42,7 @@ HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
|
||||
因为我们在计算回归方程的回归系数时,用到的计算公式如下:
|
||||
|
||||
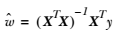
|
||||

|
||||
|
||||
需要对矩阵求逆,因此这个方程只在逆矩阵存在的时候适用,我们在程序代码中对此作出判断。
|
||||
判断矩阵是否可逆的一个可选方案是:
|
||||
@@ -88,7 +88,7 @@ HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
|
||||
根据下图中的点,找出该数据的最佳拟合直线。
|
||||
|
||||

|
||||

|
||||
|
||||
数据格式为:
|
||||
|
||||
@@ -178,7 +178,7 @@ def regression1():
|
||||
|
||||
##### 1.5.3、线性回归 拟合效果
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
### 2、局部加权线性回归
|
||||
@@ -187,21 +187,21 @@ def regression1():
|
||||
|
||||
一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在这个算法中,我们给预测点附近的每个点赋予一定的权重,然后与 线性回归 类似,在这个子集上基于最小均方误差来进行普通的回归。我们需要最小化的目标函数大致为:
|
||||
|
||||
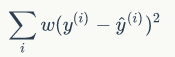
|
||||

|
||||
|
||||
目标函数中 w 为权重,不是回归系数。与 kNN 一样,这种算法每次预测均需要事先选取出对应的数据子集。该算法解出回归系数 w 的形式如下:
|
||||
|
||||
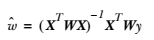
|
||||

|
||||
|
||||
其中 W 是一个矩阵,用来给每个数据点赋予权重。$\hat{w}$ 则为回归系数。 这两个是不同的概念,请勿混用。
|
||||
|
||||
LWLR 使用 “核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:
|
||||
|
||||
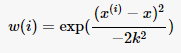
|
||||

|
||||
|
||||
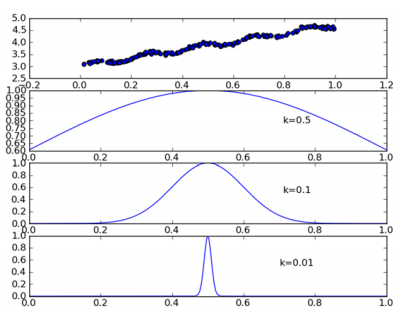
这样就构建了一个只含对角元素的权重矩阵 **w**,并且点 x 与 x(i) 越近,w(i) 将会越大。上述公式中包含一个需要用户指定的参数 k ,它决定了对附近的点赋予多大的权重,这也是使用 LWLR 时唯一需要考虑的参数,下面的图给出了参数 k 与权重的关系。
|
||||
|
||||
|
||||

|
||||
|
||||
上面的图是 每个点的权重图(假定我们正预测的点是 x = 0.5),最上面的图是原始数据集,第二个图显示了当 k = 0.5 时,大部分的数据都用于训练回归模型;而最下面的图显示当 k=0.01 时,仅有很少的局部点被用于训练回归模型。
|
||||
|
||||
@@ -222,7 +222,7 @@ LWLR 使用 “核”(与支持向量机中的核类似)来对附近的点
|
||||
|
||||
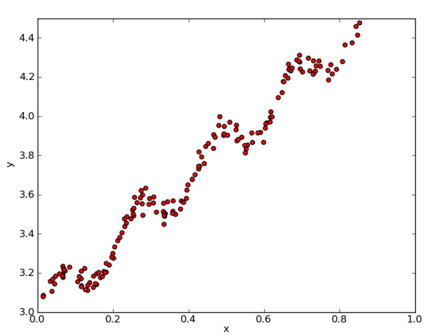
我们仍然使用上面 线性回归 的数据集,对这些点进行一个 局部加权线性回归 的拟合。
|
||||
|
||||
|
||||

|
||||
|
||||
数据格式为:
|
||||
|
||||
@@ -340,7 +340,7 @@ def regression2():
|
||||
|
||||
##### 2.2.3、局部加权线性回归 拟合效果
|
||||
|
||||
|
||||

|
||||
|
||||
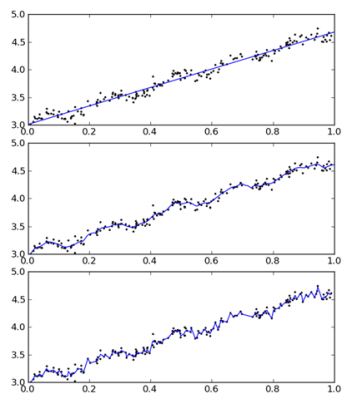
上图使用了 3 种不同平滑值绘出的局部加权线性回归的结果。上图中的平滑系数 k =1.0,中图 k = 0.01,下图 k = 0.003 。可以看到,k = 1.0 时的使所有数据等比重,其模型效果与基本的线性回归相同,k=0.01时该模型可以挖出数据的潜在规律,而 k=0.003时则考虑了太多的噪声,进而导致了过拟合现象。
|
||||
|
||||
@@ -452,7 +452,7 @@ def abaloneTest():
|
||||
|
||||
### 4、缩减系数来 “理解” 数据
|
||||
|
||||
如果数据的特征比样本点还多应该怎么办?是否还可以使用线性回归和之前的方法来做预测?答案是否定的,即我们不能再使用前面介绍的方法。这是因为在计算 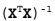 的时候会出错。
|
||||
如果数据的特征比样本点还多应该怎么办?是否还可以使用线性回归和之前的方法来做预测?答案是否定的,即我们不能再使用前面介绍的方法。这是因为在计算  的时候会出错。
|
||||
|
||||
如果特征比样本点还多(n > m),也就是说输入数据的矩阵 x 不是满秩矩阵。非满秩矩阵求逆时会出现问题。
|
||||
|
||||
@@ -460,14 +460,14 @@ def abaloneTest():
|
||||
|
||||
#### 4.1、岭回归
|
||||
|
||||
简单来说,岭回归就是在矩阵 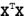 上加一个 λI 从而使得矩阵非奇异,进而能对 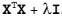 求逆。其中矩阵I是一个 n * n (等于列数) 的单位矩阵,
|
||||
简单来说,岭回归就是在矩阵  上加一个 λI 从而使得矩阵非奇异,进而能对  求逆。其中矩阵I是一个 n * n (等于列数) 的单位矩阵,
|
||||
对角线上元素全为1,其他元素全为0。而λ是一个用户定义的数值,后面会做介绍。在这种情况下,回归系数的计算公式将变成:
|
||||
|
||||
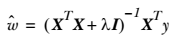
|
||||

|
||||
|
||||
岭回归最先用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里通过引入 λ 来限制了所有 w 之和,通过引入该惩罚项,能够减少不重要的参数,这个技术在统计学中也叫作 `缩减(shrinkage)`。
|
||||
|
||||

|
||||

|
||||
|
||||
缩减方法可以去掉不重要的参数,因此能更好地理解数据。此外,与简单的线性回归相比,缩减法能取得更好的预测效果。
|
||||
|
||||
@@ -551,7 +551,7 @@ def regression3():
|
||||
|
||||
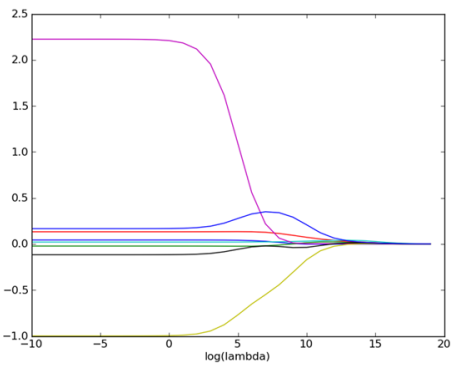
##### 4.1.2、岭回归在鲍鱼数据集上的运行效果
|
||||
|
||||
|
||||

|
||||
|
||||
上图绘制出了回归系数与 log(λ) 的关系。在最左边,即 λ 最小时,可以得到所有系数的原始值(与线性回归一致);而在右边,系数全部缩减为0;在中间部分的某值将可以取得最好的预测效果。为了定量地找到最佳参数值,还需要进行交叉验证。另外,要判断哪些变量对结果预测最具有影响力,在上图中观察它们对应的系数大小就可以了。
|
||||
|
||||
@@ -560,13 +560,13 @@ def regression3():
|
||||
|
||||
在增加如下约束时,普通的最小二乘法回归会得到与岭回归一样的公式:
|
||||
|
||||
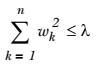
|
||||

|
||||
|
||||
上式限定了所有回归系数的平方和不能大于 λ 。使用普通的最小二乘法回归在当两个或更多的特征相关时,可能会得到一个很大的正系数和一个很大的负系数。正是因为上述限制条件的存在,使用岭回归可以避免这个问题。
|
||||
|
||||
与岭回归类似,另一个缩减方法lasso也对回归系数做了限定,对应的约束条件如下:
|
||||
|
||||
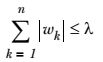
|
||||

|
||||
|
||||
唯一的不同点在于,这个约束条件使用绝对值取代了平方和。虽然约束形式只是稍作变化,结果却大相径庭: 在 λ 足够小的时候,一些系数会因此被迫缩减到 0.这个特性可以帮助我们更好地理解数据。
|
||||
|
||||
@@ -633,7 +633,7 @@ def regression4():
|
||||
|
||||
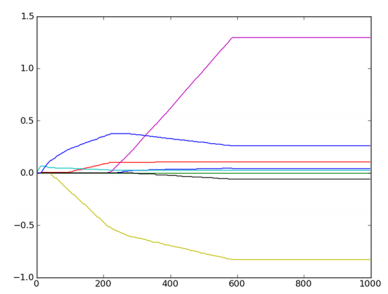
##### 4.3.2、逐步线性回归在鲍鱼数据集上的运行效果
|
||||
|
||||
|
||||

|
||||
|
||||
逐步线性回归算法的主要优点在于它可以帮助人们理解现有的模型并作出改进。当构建了一个模型后,可以运行该算法找出重要的特征,这样就有可能及时停止对那些不重要特征的收集。最后,如果用于测试,该算法每100次迭代后就可以构建出一个模型,可以使用类似于10折交叉验证的方法比较这些模型,最终选择使误差最小的模型。
|
||||
|
||||
@@ -646,13 +646,13 @@ def regression4():
|
||||
|
||||
任何时候,一旦发现模型和测量值之间存在差异,就说出现了误差。当考虑模型中的 “噪声” 或者说误差时,必须考虑其来源。你可能会对复杂的过程进行简化,这将导致在模型和测量值之间出现 “噪声” 或误差,若无法理解数据的真实生成过程,也会导致差异的产生。另外,测量过程本身也可能产生 “噪声” 或者问题。下面我们举一个例子,我们使用 `线性回归` 和 `局部加权线性回归` 处理过一个从文件导入的二维数据。
|
||||
|
||||

|
||||

|
||||
|
||||
其中的 N(0, 1) 是一个均值为 0、方差为 1 的正态分布。我们尝试过仅用一条直线来拟合上述数据。不难想到,直线所能得到的最佳拟合应该是 3.0+1.7x 这一部分。这样的话,误差部分就是 0.1sin(30x)+0.06N(0, 1) 。在上面,我们使用了局部加权线性回归来试图捕捉数据背后的结构。该结构拟合起来有一定的难度,因此我们测试了多组不同的局部权重来找到具有最小测试误差的解。
|
||||
|
||||
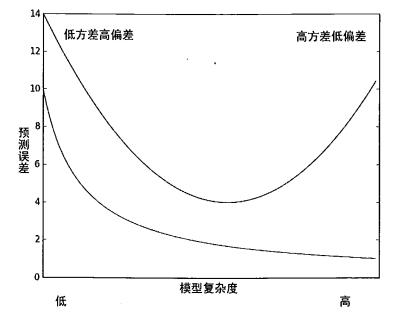
下图给出了训练误差和测试误差的曲线图,上面的曲面就是测试误差,下面的曲线是训练误差。我们根据 预测鲍鱼年龄 的实验知道: 如果降低核的大小,那么训练误差将变小。从下图开看,从左到右就表示了核逐渐减小的过程。
|
||||
|
||||
|
||||

|
||||
|
||||
一般认为,上述两种误差由三个部分组成: 偏差、测量误差和随机噪声。局部加权线性回归 和 预测鲍鱼年龄 中,我们通过引入了三个越来越小的核来不断增大模型的方差。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user