2020-10-19 21:26:11
BIN
docs/TensorFlow2.x/img/output_23_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
docs/TensorFlow2.x/img/output_45_0.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.5 KiB |
BIN
docs/TensorFlow2.x/img/output_45_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.9 KiB |
BIN
docs/TensorFlow2.x/img/output_47_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.2 KiB |
BIN
docs/TensorFlow2.x/img/output_47_2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.4 KiB |
BIN
docs/TensorFlow2.x/img/output_51_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.3 KiB |
BIN
docs/TensorFlow2.x/img/output_53_0.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.2 KiB |
BIN
docs/TensorFlow2.x/img/overfit_and_underfit__1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.1 KiB |
BIN
docs/TensorFlow2.x/img/overfit_and_underfit__2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.0 KiB |
BIN
docs/TensorFlow2.x/img/overfit_and_underfit__3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.7 KiB |
BIN
docs/TensorFlow2.x/img/overfit_and_underfit__4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.1 KiB |
@@ -333,7 +333,7 @@ sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
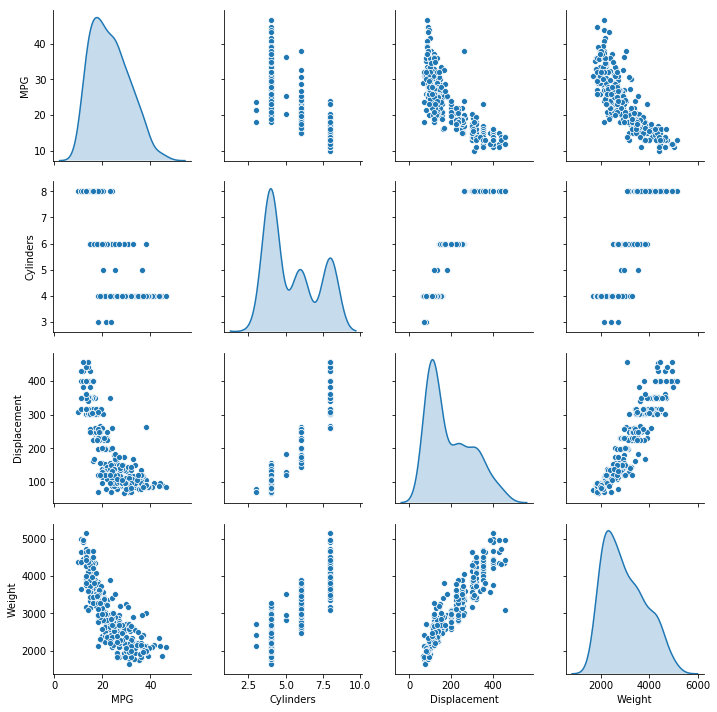
也可以查看总体的数据统计:
|
||||
@@ -728,11 +728,11 @@ plot_history(history)
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
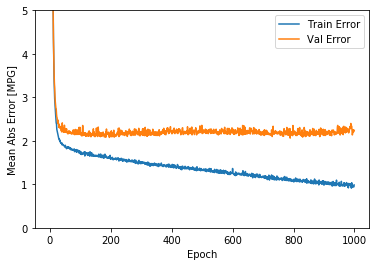
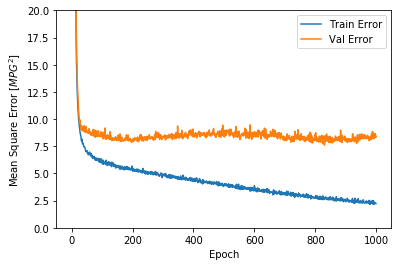
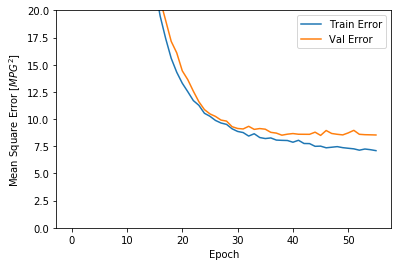
该图表显示在约100个 epochs 之后误差非但没有改进,反而出现恶化。 让我们更新 `model.fit` 调用,当验证值没有提高上是自动停止训练。
|
||||
@@ -758,11 +758,11 @@ plot_history(history)
|
||||
........................................................
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
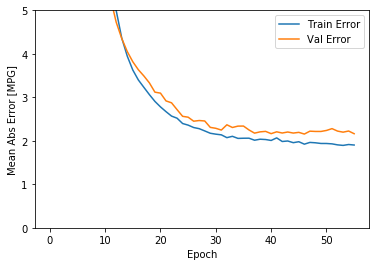
如图所示,验证集中的平均的误差通常在 +/- 2 MPG左右。 这个结果好么? 我们将决定权留给你。
|
||||
@@ -804,7 +804,7 @@ _ = plt.plot([-100, 100], [-100, 100])
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
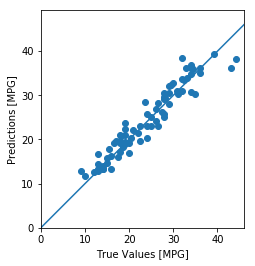
这看起来我们的模型预测得相当好。我们来看下误差分布。
|
||||
@@ -818,7 +818,7 @@ _ = plt.ylabel("Count")
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
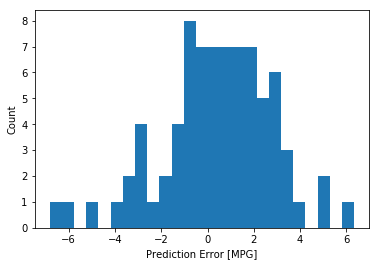
它不是完全的高斯分布,但我们可以推断出,这是因为样本的数量很小所导致的。
|
||||
|
||||
@@ -61,7 +61,7 @@ test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
|
||||
plt.plot(train_data[0])
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
## 证明过拟合
|
||||
|
||||
@@ -327,7 +327,7 @@ plot_history([('baseline', baseline_history),
|
||||
('bigger', bigger_history)])
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
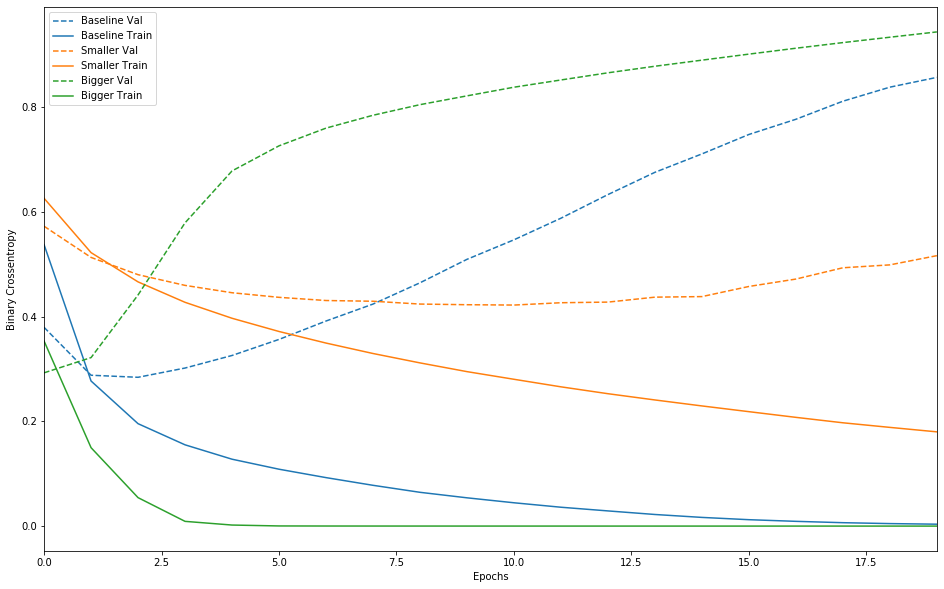
请注意,较大的网络仅在一个时期后就开始过拟合,而且过拟合严重。网络的容量越多,将能够更快地对训练数据进行建模(导致较低的训练损失),但网络越容易过拟合(导致训练和验证损失之间存在较大差异)。
|
||||
|
||||
@@ -421,7 +421,7 @@ plot_history([('baseline', baseline_history),
|
||||
('l2', l2_model_history)])
|
||||
```
|
||||
|
||||
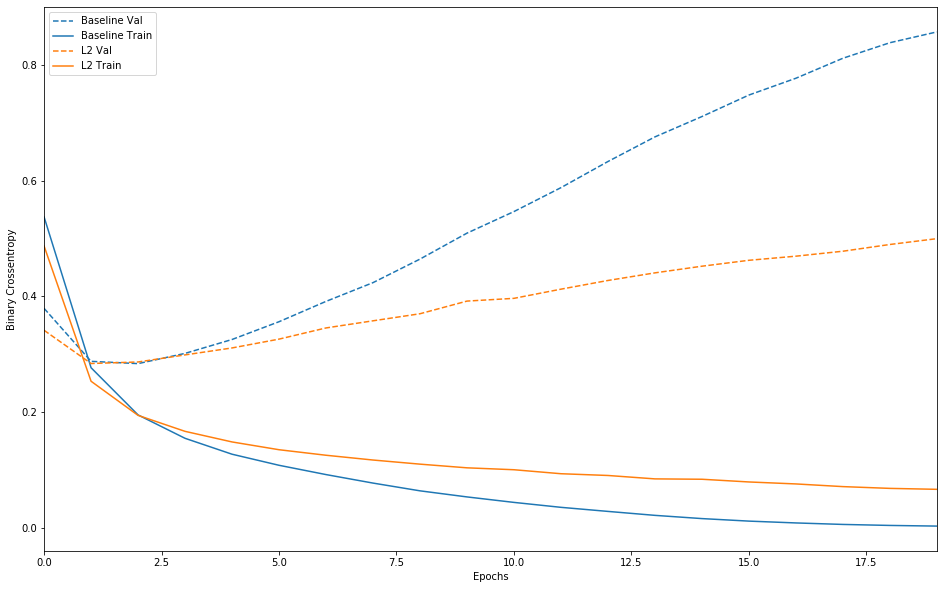
|
||||

|
||||
|
||||
如您所见,即使两个模型具有相同数量的参数,L2正则化模型也比基线模型具有更高的抗过度拟合能力。
|
||||
|
||||
@@ -504,7 +504,7 @@ plot_history([('baseline', baseline_history),
|
||||
('dropout', dpt_model_history)])
|
||||
```
|
||||
|
||||
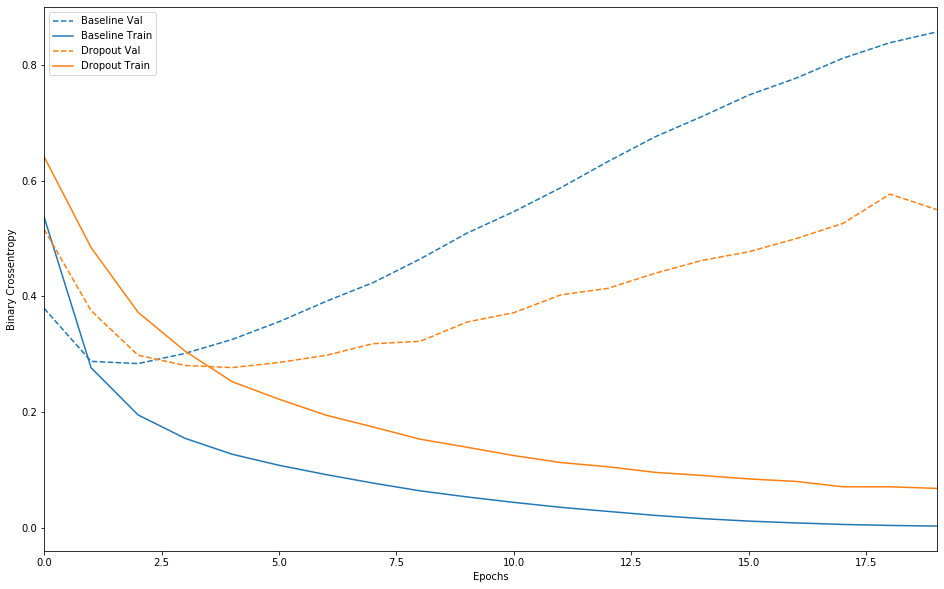
|
||||

|
||||
|
||||
添加 dropout 是对基线模型的明显改进。
|
||||
|
||||
|
||||