mirror of
https://github.com/apachecn/ailearning.git
synced 2026-07-27 17:00:48 +08:00
修改中文符号为英文
This commit is contained in:
@@ -1,6 +1,6 @@
|
||||
# CNN原理
|
||||
|
||||
> 建议:看懂原理就行
|
||||
> 建议: 看懂原理就行
|
||||
|
||||
# [【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理](https://www.cnblogs.com/charlotte77/p/7759802.html)
|
||||
|
||||
@@ -16,7 +16,7 @@
|
||||
|
||||
大家可能会疑惑,对于同一个分类任务,我们可以用机器学习的算法来做,为什么要用神经网络呢?大家回顾一下,一个分类任务,我们在用机器学习算法来做时,首先要明确feature和label,然后把这个数据"灌"到算法里去训练,最后保存模型,再来预测分类的准确性。但是这就有个问题,即我们需要实现确定好特征,每一个特征即为一个维度,特征数目过少,我们可能无法精确的分类出来,即我们所说的欠拟合,如果特征数目过多,可能会导致我们在分类过程中过于注重某个特征导致分类错误,即过拟合。
|
||||
|
||||
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征:形状和颜色,可能没法分区来;如果特征的维度有:形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是:形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
|
||||
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征: 形状和颜色,可能没法分区来;如果特征的维度有: 形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是: 形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
|
||||
|
||||
* 数据格式的简易性
|
||||
|
||||
@@ -48,7 +48,7 @@
|
||||
|
||||
** 传统神经网络的劣势**
|
||||
|
||||
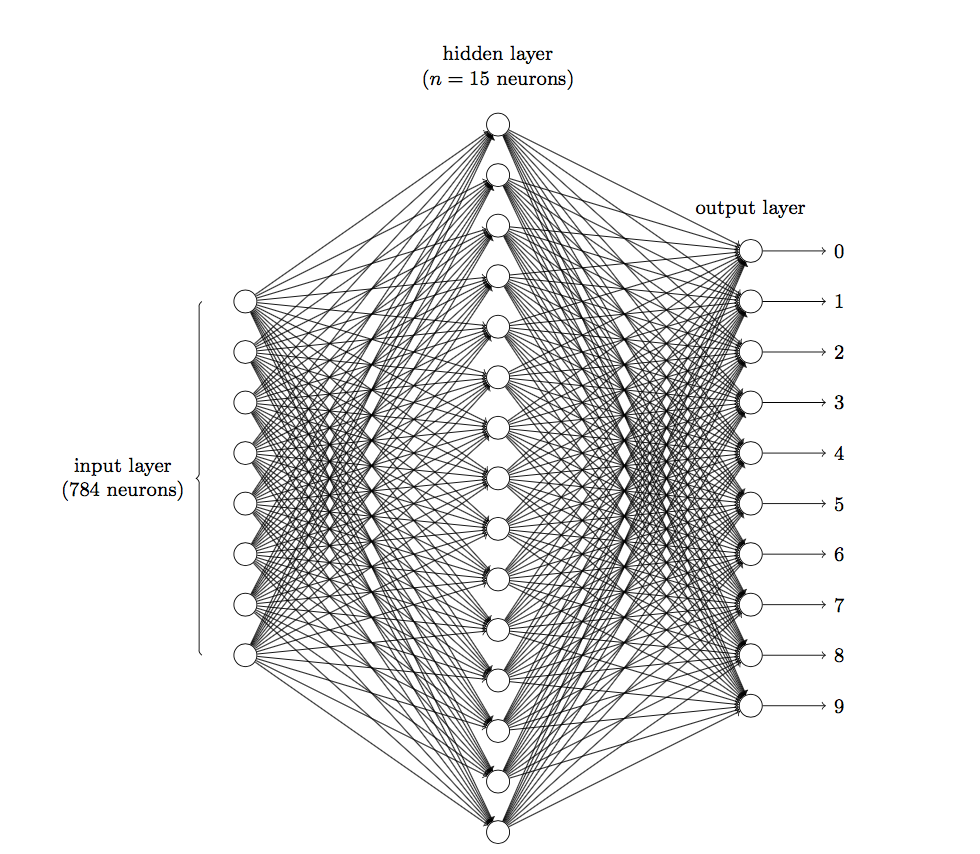
前面说到在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有 `28 * 28 =784` 个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有: `784*15*10+15+10=117625` 个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。(评论中有同学对这个参数计算不太理解,我简单说一下:图片是由像素点组成的,用矩阵表示的, `28*28` 的矩阵,肯定是没法直接放到神经元里的,我们得把它“拍平”,变成一个`28*28=784` 的一列向量,这一列向量和隐含层的15个神经元连接,就有 `784*15=11760` 个权重w,隐含层和最后的输出层的10个神经元连接,就有 `11760*10=117600` 个权重w,再加上隐含层的偏置项15个和输出层的偏置项10个,就是:117625个参数了)
|
||||
前面说到在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有 `28 * 28 =784` 个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有: `784*15*10+15+10=117625` 个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。(评论中有同学对这个参数计算不太理解,我简单说一下: 图片是由像素点组成的,用矩阵表示的, `28*28` 的矩阵,肯定是没法直接放到神经元里的,我们得把它“拍平”,变成一个`28*28=784` 的一列向量,这一列向量和隐含层的15个神经元连接,就有 `784*15=11760` 个权重w,隐含层和最后的输出层的10个神经元连接,就有 `11760*10=117600` 个权重w,再加上隐含层的偏置项15个和输出层的偏置项10个,就是: 117625个参数了)
|
||||
|
||||
|
||||
|
||||
@@ -66,7 +66,7 @@
|
||||
|
||||
图2 4*4 image与两个2*2的卷积核操作结果
|
||||
|
||||
由上图可以看到,原始图片是一张灰度图片,每个位置表示的是像素值,0表示白色,1表示黑色,(0,1)区间的数值表示灰色。对于这个4*4的图像,我们采用两个2*2的卷积核来计算。设定步长为1,即每次以2*2的固定窗口往右滑动一个单位。以第一个卷积核filter1为例,计算过程如下:
|
||||
由上图可以看到,原始图片是一张灰度图片,每个位置表示的是像素值,0表示白色,1表示黑色,(0,1)区间的数值表示灰色。对于这个4*4的图像,我们采用两个2*2的卷积核来计算。设定步长为1,即每次以2*2的固定窗口往右滑动一个单位。以第一个卷积核filter1为例,计算过程如下:
|
||||
|
||||
```python
|
||||
feature_map1(1,1) = 1*1 + 0*(-1) + 1*1 + 1*(-1) = 1
|
||||
@@ -75,7 +75,7 @@ feature_map1(1,2) = 0*1 + 1*(-1) + 1*1 + 1*(-1) = -1
|
||||
feature_map1(3,3) = 1*1 + 0*(-1) + 1*1 + 0*(-1) = 2
|
||||
```
|
||||
|
||||
可以看到这就是最简单的内积公式。feature_map1(1,1)表示在通过第一个卷积核计算完后得到的feature_map的第一行第一列的值,随着卷积核的窗口不断的滑动,我们可以计算出一个3\*3的feature_map1;同理可以计算通过第二个卷积核进行卷积运算后的feature_map2,那么这一层卷积操作就完成了。feature_map尺寸计算公式:[ (原图片尺寸 -卷积核尺寸)/ 步长 ] + 1。这一层我们设定了两个2\*2的卷积核,在paddlepaddle里是这样定义的:
|
||||
可以看到这就是最简单的内积公式。feature_map1(1,1)表示在通过第一个卷积核计算完后得到的feature_map的第一行第一列的值,随着卷积核的窗口不断的滑动,我们可以计算出一个3\*3的feature_map1;同理可以计算通过第二个卷积核进行卷积运算后的feature_map2,那么这一层卷积操作就完成了。feature_map尺寸计算公式: [ (原图片尺寸 -卷积核尺寸)/ 步长 ] + 1。这一层我们设定了两个2\*2的卷积核,在paddlepaddle里是这样定义的:
|
||||
|
||||
|
||||
```python
|
||||
@@ -89,7 +89,7 @@ conv_pool_1 = paddle.networks.simple_img_conv_pool(
|
||||
```
|
||||
|
||||
|
||||
这里调用了networks里simple_img_conv_pool函数,激活函数是Relu(修正线性单元),我们来看一看源码里外层接口是如何定义的:
|
||||
这里调用了networks里simple_img_conv_pool函数,激活函数是Relu(修正线性单元),我们来看一看源码里外层接口是如何定义的:
|
||||
|
||||
|
||||
```python
|
||||
@@ -177,7 +177,7 @@ def simple_img_conv_pool(input,
|
||||
layer_attr=pool_layer_attr)
|
||||
```
|
||||
|
||||
我们在 [Paddle/python/paddle/v2/framework/nets.py](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/framework/nets.py) 里可以看到simple_img_conv_pool这个函数的定义:
|
||||
我们在 [Paddle/python/paddle/v2/framework/nets.py](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/framework/nets.py) 里可以看到simple_img_conv_pool这个函数的定义:
|
||||
|
||||
```python
|
||||
def simple_img_conv_pool(input,
|
||||
@@ -207,7 +207,7 @@ def simple_img_conv_pool(input,
|
||||
return pool_out
|
||||
```
|
||||
|
||||
可以看到这里面有两个输出,conv_out是卷积输出值,pool_out是池化输出值,最后只返回池化输出的值。conv_out和pool_out分别又调用了layers.py的conv2d和pool2d,去layers.py里我们可以看到conv2d和pool2d是如何实现的:
|
||||
可以看到这里面有两个输出,conv_out是卷积输出值,pool_out是池化输出值,最后只返回池化输出的值。conv_out和pool_out分别又调用了layers.py的conv2d和pool2d,去layers.py里我们可以看到conv2d和pool2d是如何实现的:
|
||||
|
||||
conv2d:
|
||||
|
||||
@@ -521,7 +521,7 @@ class LayerHelper(object):
|
||||
|
||||
仔细思考一下,这个时候,我们设计的两个卷积核分别能够提取,或者说检测出原始图片的特定的特征。此时我们其实就可以把卷积核就理解为特征提取器啊!现在就明白了,为什么我们只需要把图片数据灌进去,设计好卷积核的尺寸、数量和滑动的步长就可以让自动提取出图片的某些特征,从而达到分类的效果啊!
|
||||
|
||||
**注**:1.此处的卷积运算是两个卷积核大小的矩阵的内积运算,不是矩阵乘法。即相同位置的数字相乘再相加求和。不要弄混淆了。
|
||||
**注**: 1.此处的卷积运算是两个卷积核大小的矩阵的内积运算,不是矩阵乘法。即相同位置的数字相乘再相加求和。不要弄混淆了。
|
||||
|
||||
2.卷积核的公式有很多,这只是最简单的一种。我们所说的卷积核在数字信号处理里也叫滤波器,那滤波器的种类就多了,均值滤波器,高斯滤波器,拉普拉斯滤波器等等,不过,不管是什么滤波器,都只是一种数学运算,无非就是计算更复杂一点。
|
||||
|
||||
@@ -529,17 +529,17 @@ class LayerHelper(object):
|
||||
|
||||
* **池化层(Pooling Layer)**
|
||||
|
||||
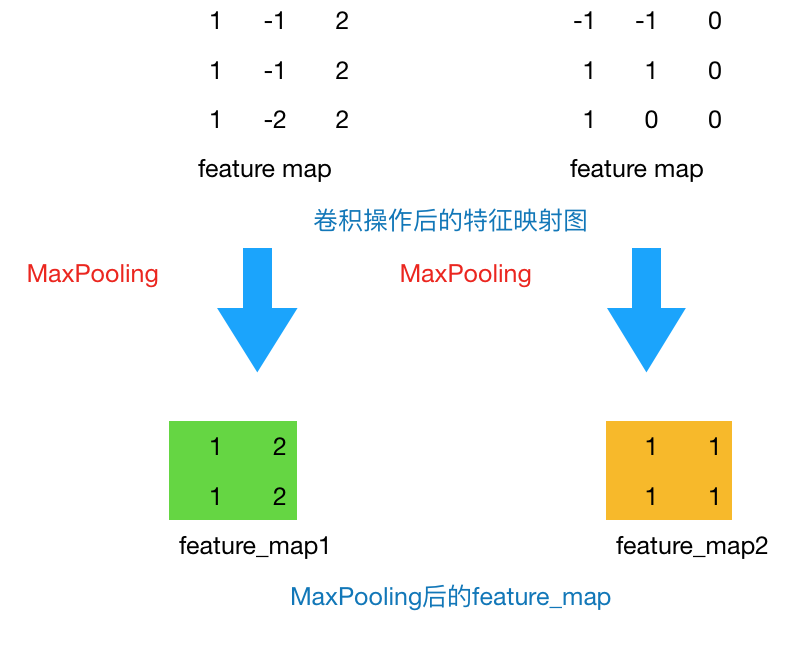
通过上一层2*2的卷积核操作后,我们将原始图像由4*4的尺寸变为了3*3的一个新的图片。池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2*2,步长为1,取每个窗口最大的数值重新,那么图片的尺寸就会由3*3变为2*2:(3-2)+1=2。从上例来看,会有如下变换:
|
||||
通过上一层2*2的卷积核操作后,我们将原始图像由4*4的尺寸变为了3*3的一个新的图片。池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2*2,步长为1,取每个窗口最大的数值重新,那么图片的尺寸就会由3*3变为2*2: (3-2)+1=2。从上例来看,会有如下变换:
|
||||
|
||||
|
||||
|
||||
|
||||
图3 Max Pooling结果
|
||||
|
||||
通常来说,池化方法一般有一下两种:
|
||||
通常来说,池化方法一般有一下两种:
|
||||
|
||||
* MaxPooling:取滑动窗口里最大的值
|
||||
* AveragePooling:取滑动窗口内所有值的平均值
|
||||
* MaxPooling: 取滑动窗口里最大的值
|
||||
* AveragePooling: 取滑动窗口内所有值的平均值
|
||||
|
||||
为什么采用Max Pooling?
|
||||
|
||||
@@ -551,7 +551,7 @@ class LayerHelper(object):
|
||||
|
||||
Zero Padding
|
||||
|
||||
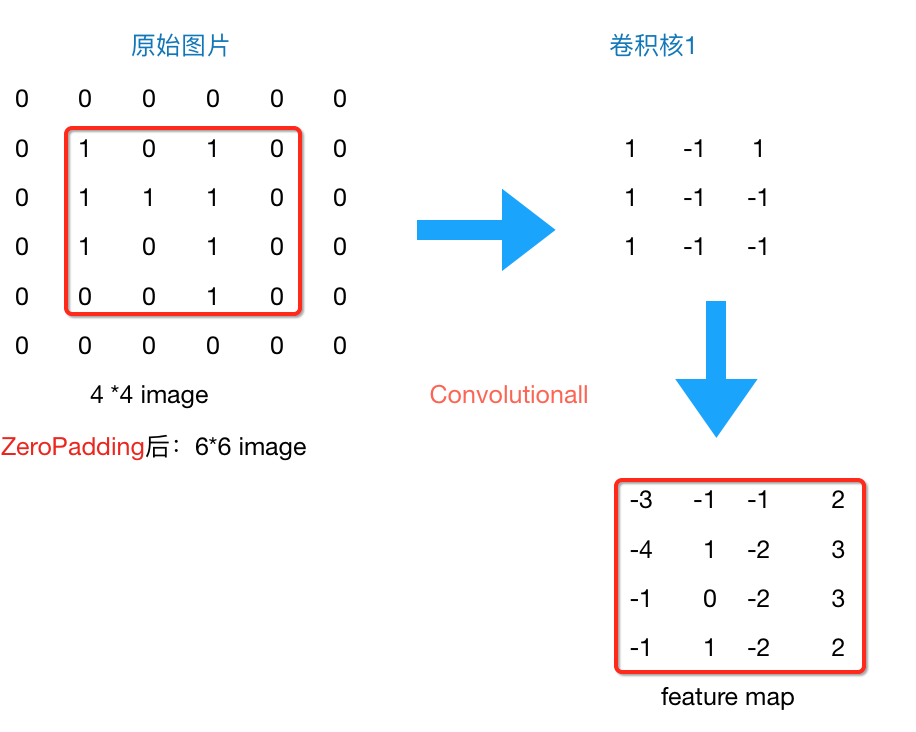
所以到现在为止,我们的图片由4*4,通过卷积层变为3*3,再通过池化层变化2*2,如果我们再添加层,那么图片岂不是会越变越小?这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用3*3的卷积核,那么变换后的图片尺寸与原图片尺寸相同,如下图所示:
|
||||
所以到现在为止,我们的图片由4*4,通过卷积层变为3*3,再通过池化层变化2*2,如果我们再添加层,那么图片岂不是会越变越小?这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用3*3的卷积核,那么变换后的图片尺寸与原图片尺寸相同,如下图所示:
|
||||
|
||||
|
||||
|
||||
@@ -559,7 +559,7 @@ class LayerHelper(object):
|
||||
|
||||
通常情况下,我们希望图片做完卷积操作后保持图片大小不变,所以我们一般会选择尺寸为3*3的卷积核和1的zero padding,或者5*5的卷积核与2的zero padding,这样通过计算后,可以保留图片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1
|
||||
|
||||
注:这里的width也可换成height,此处是默认正方形的卷积核,weight = height,如果两者不相等,可以分开计算,分别补零。
|
||||
注: 这里的width也可换成height,此处是默认正方形的卷积核,weight = height,如果两者不相等,可以分开计算,分别补零。
|
||||
|
||||
* **Flatten层 & Fully Connected Layer**
|
||||
|
||||
@@ -573,7 +573,7 @@ class LayerHelper(object):
|
||||
|
||||
* **小结**
|
||||
|
||||
这一节我们介绍了最基本的卷积神经网络的基本层的定义,计算方式和起的作用。有几个小问题可以供大家思考一下:
|
||||
这一节我们介绍了最基本的卷积神经网络的基本层的定义,计算方式和起的作用。有几个小问题可以供大家思考一下:
|
||||
|
||||
1.卷积核的尺寸必须为正方形吗?可以为长方形吗?如果是长方形应该怎么计算?
|
||||
|
||||
@@ -581,9 +581,9 @@ class LayerHelper(object):
|
||||
|
||||
3.步长的向右和向下移动的幅度必须是一样的吗?
|
||||
|
||||
如果对上面的讲解真的弄懂了的话,其实这几个问题并不难回答。下面给出我的想法,可以作为参考:
|
||||
如果对上面的讲解真的弄懂了的话,其实这几个问题并不难回答。下面给出我的想法,可以作为参考:
|
||||
|
||||
1.卷积核的尺寸不一定非得为正方形。长方形也可以,只不过通常情况下为正方形。如果要设置为长方形,那么首先得保证这层的输出形状是整数,不能是小数。如果你的图像是边长为 28 的正方形。那么卷积层的输出就满足 [ (28 - kernel_size)/ stride ] + 1 ,这个数值得是整数才行,否则没有物理意义。譬如,你算得一个边长为 3.6 的 feature map 是没有物理意义的。 pooling 层同理。FC 层的输出形状总是满足整数,其唯一的要求就是整个训练过程中 FC 层的输入得是定长的。如果你的图像不是正方形。那么在制作数据时,可以缩放到统一大小(非正方形),再使用非正方形的 kernel_size 来使得卷积层的输出依然是整数。总之,撇开网络结果设定的好坏不谈,其本质上就是在做算术应用题:如何使得各层的输出是整数。
|
||||
1.卷积核的尺寸不一定非得为正方形。长方形也可以,只不过通常情况下为正方形。如果要设置为长方形,那么首先得保证这层的输出形状是整数,不能是小数。如果你的图像是边长为 28 的正方形。那么卷积层的输出就满足 [ (28 - kernel_size)/ stride ] + 1 ,这个数值得是整数才行,否则没有物理意义。譬如,你算得一个边长为 3.6 的 feature map 是没有物理意义的。 pooling 层同理。FC 层的输出形状总是满足整数,其唯一的要求就是整个训练过程中 FC 层的输入得是定长的。如果你的图像不是正方形。那么在制作数据时,可以缩放到统一大小(非正方形),再使用非正方形的 kernel_size 来使得卷积层的输出依然是整数。总之,撇开网络结果设定的好坏不谈,其本质上就是在做算术应用题: 如何使得各层的输出是整数。
|
||||
|
||||
|
||||
2.由经验确定。通常情况下,靠近输入的卷积层,譬如第一层卷积层,会找出一些共性的特征,如手写数字识别中第一层我们设定卷积核个数为5个,一般是找出诸如"横线"、“竖线”、“斜线”等共性特征,我们称之为basic feature,经过max pooling后,在第二层卷积层,设定卷积核个数为20个,可以找出一些相对复杂的特征,如“横折”、“左半圆”、“右半圆”等特征,越往后,卷积核设定的数目越多,越能体现label的特征就越细致,就越容易分类出来,打个比方,如果你想分类出“0”的数字,你看到这个特征,能推测是什么数字呢?只有越往后,检测识别的特征越多,试过能识别这几个特征,那么我就能够确定这个数字是“0”。
|
||||
@@ -624,22 +624,22 @@ def convolutional_neural_network_org(img):
|
||||
return predict
|
||||
```
|
||||
|
||||
那么它的网络结构是:
|
||||
那么它的网络结构是:
|
||||
|
||||
conv1----> conv2---->fully Connected layer
|
||||
|
||||
非常简单的网络结构。第一层我们采取的是 `3*3` 的正方形卷积核,个数为20个,深度为1,stride为2,pooling尺寸为 `2*2`,激活函数采取的为RELU;第二层只对卷积核的尺寸、个数和深度做了些变化,分别为 `5*5` ,50个和20;最后链接一层全连接,设定10个label作为输出,采用Softmax函数作为分类器,输出每个label的概率。
|
||||
|
||||
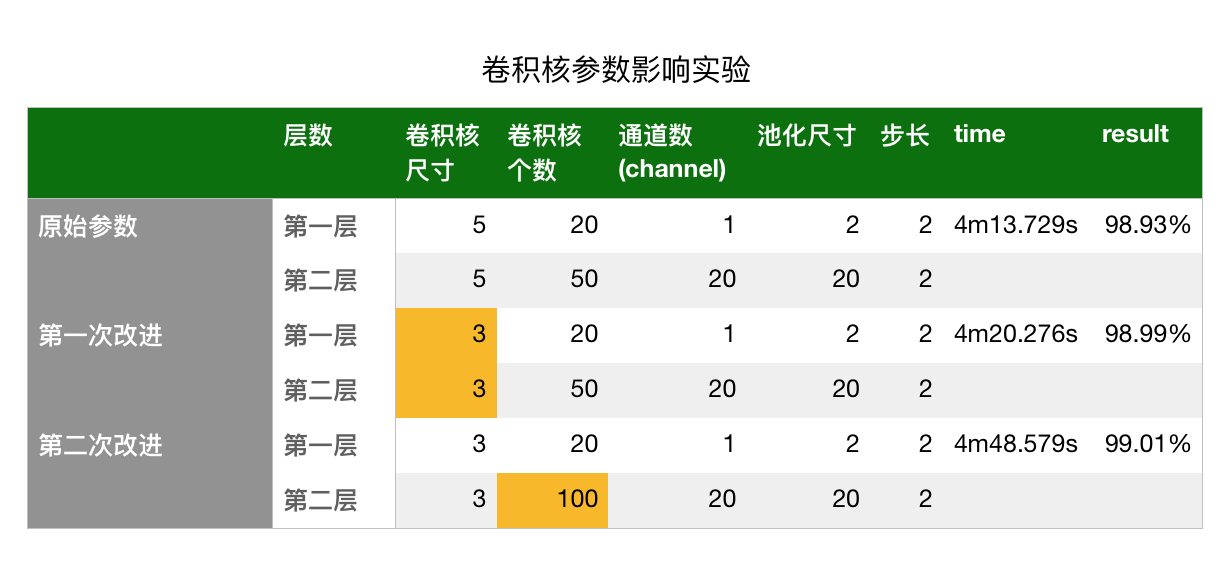
那么这个时候我考虑的问题是,既然上面我们已经了解了卷积核,改变卷积核的大小是否会对我的结果造成影响?增多卷积核的数目能够提高准确率?于是我做了个实验:
|
||||
那么这个时候我考虑的问题是,既然上面我们已经了解了卷积核,改变卷积核的大小是否会对我的结果造成影响?增多卷积核的数目能够提高准确率?于是我做了个实验:
|
||||
|
||||
|
||||
|
||||
* 第一次改进:仅改变第一层与第二层的卷积核数目的大小,其他保持不变。可以看到结果提升了0.06%
|
||||
* 第二次改进:保持3*3的卷积核大小,仅改变第二层的卷积核数目,其他保持不变,可以看到结果相较于原始参数提升了0.08%
|
||||
* 第一次改进: 仅改变第一层与第二层的卷积核数目的大小,其他保持不变。可以看到结果提升了0.06%
|
||||
* 第二次改进: 保持3*3的卷积核大小,仅改变第二层的卷积核数目,其他保持不变,可以看到结果相较于原始参数提升了0.08%
|
||||
|
||||
由以上结果可以看出,改变卷积核的大小与卷积核的数目会对结果产生一定影响,在目前手写数字识别的项目中,缩小卷积核尺寸,增加卷积核数目都会提高准确率。不过以上实验只是一个小测试,有兴趣的同学可以多做几次实验,看看参数带来的具体影响,下篇文章我们会着重分析参数的影响。
|
||||
|
||||
这篇文章主要介绍了神经网络的预备知识,卷积神经网络的常见的层及基本的计算过程,看完后希望大家明白以下几个知识点:
|
||||
这篇文章主要介绍了神经网络的预备知识,卷积神经网络的常见的层及基本的计算过程,看完后希望大家明白以下几个知识点:
|
||||
|
||||
> * 为什么卷积神经网络更适合于图像分类?相比于传统的神经网络优势在哪里?
|
||||
> * 卷积层中的卷积过程是如何计算的?为什么卷积核是有效的?
|
||||
@@ -648,7 +648,7 @@ def convolutional_neural_network_org(img):
|
||||
> * 为什么要采用池化层,Max Pooling有什么好处?
|
||||
> * Zero Padding有什么作用?如果已知一个feature map的尺寸,如何确定zero padding的数目?
|
||||
|
||||
上面的问题,有些在文章中已经详细讲过,有些大家可以根据文章的内容多思考一下。最后给大家留几个问题思考一下:
|
||||
上面的问题,有些在文章中已经详细讲过,有些大家可以根据文章的内容多思考一下。最后给大家留几个问题思考一下:
|
||||
|
||||
> * 为什么改变卷积核的大小能够提高结果的准确率?卷积核大小对于分类结果是如何影响的?
|
||||
> * 卷积核的参数是怎么求的?一开始随机定义一个,那么后来是如何训练才能使这个卷积核识别某些特定的特征呢?
|
||||
@@ -656,7 +656,7 @@ def convolutional_neural_network_org(img):
|
||||
|
||||
|
||||
|
||||
下篇文章我们会着重讲解以下几点:
|
||||
下篇文章我们会着重讲解以下几点:
|
||||
|
||||
> * 卷积核的参数如何确定?随机初始化一个数值后,是如何训练得到一个能够识别某些特征的卷积核的?
|
||||
> * CNN是如何进行反向传播的?
|
||||
@@ -664,10 +664,10 @@ def convolutional_neural_network_org(img):
|
||||
> * 如何设计最适合的CNN网络结构?
|
||||
> * 能够不用调用框架的api,手写一个CNN,并和paddlepaddle里的实现过程做对比,看看有哪些可以改进的?
|
||||
|
||||
ps:本篇文章是基于个人对CNN的理解来写的,本人能力有限,有些地方可能写的不是很严谨,如有错误或疏漏之处,请留言给我,我一定会仔细核实并修改的^_^!不接受无脑喷哦~此外,文中的图表结构均为自己所做,希望不要被人随意抄袭,可以进行非商业性质的转载,需要转载留言或发邮件即可,希望能够尊重劳动成果,谢谢!有不懂的也请留言给我,我会尽力解答的哈~
|
||||
ps: 本篇文章是基于个人对CNN的理解来写的,本人能力有限,有些地方可能写的不是很严谨,如有错误或疏漏之处,请留言给我,我一定会仔细核实并修改的^_^!不接受无脑喷哦~此外,文中的图表结构均为自己所做,希望不要被人随意抄袭,可以进行非商业性质的转载,需要转载留言或发邮件即可,希望能够尊重劳动成果,谢谢!有不懂的也请留言给我,我会尽力解答的哈~
|
||||
|
||||
---
|
||||
|
||||
* 作者:Charlotte77
|
||||
* 出处:http://www.cnblogs.com/charlotte77/
|
||||
* 作者: Charlotte77
|
||||
* 出处: http://www.cnblogs.com/charlotte77/
|
||||
* 本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
# 长短期记忆网络(Long Short-Term Memory,LSTM)及其变体双向LSTM和GRU
|
||||
|
||||
**LSTM**(Long Short-Term Memory)长短期记忆网络,是一种时间递归神经网络,**适合于处理和预测时间序列中间隔和延迟相对较长的重要事件**。LSTM是解决循环神经网络RNN结构中存在的“梯度消失”问题而提出的,是一种特殊的循环神经网络。最常见的一个例子就是:当我们要预测“the clouds are in the (...)"的时候, 这种情况下,相关的信息和预测的词位置之间的间隔很小,RNN会使用先前的信息预测出词是”sky“。但是如果想要预测”I grew up in France ... I speak fluent (...)”,语言模型推测下一个词可能是一种语言的名字,但是具体是什么语言,需要用到间隔很长的前文中France,在这种情况下,RNN因为“梯度消失”的问题,并不能利用间隔很长的信息,然而,LSTM在设计上明确避免了长期依赖的问题,这主要归功于LSTM精心设计的“门”结构(输入门、遗忘门和输出门)消除或者增加信息到细胞状态的能力,使得LSTM能够记住长期的信息。
|
||||
**LSTM**(Long Short-Term Memory)长短期记忆网络,是一种时间递归神经网络,**适合于处理和预测时间序列中间隔和延迟相对较长的重要事件**。LSTM是解决循环神经网络RNN结构中存在的“梯度消失”问题而提出的,是一种特殊的循环神经网络。最常见的一个例子就是: 当我们要预测“the clouds are in the (...)"的时候, 这种情况下,相关的信息和预测的词位置之间的间隔很小,RNN会使用先前的信息预测出词是”sky“。但是如果想要预测”I grew up in France ... I speak fluent (...)”,语言模型推测下一个词可能是一种语言的名字,但是具体是什么语言,需要用到间隔很长的前文中France,在这种情况下,RNN因为“梯度消失”的问题,并不能利用间隔很长的信息,然而,LSTM在设计上明确避免了长期依赖的问题,这主要归功于LSTM精心设计的“门”结构(输入门、遗忘门和输出门)消除或者增加信息到细胞状态的能力,使得LSTM能够记住长期的信息。
|
||||
|
||||
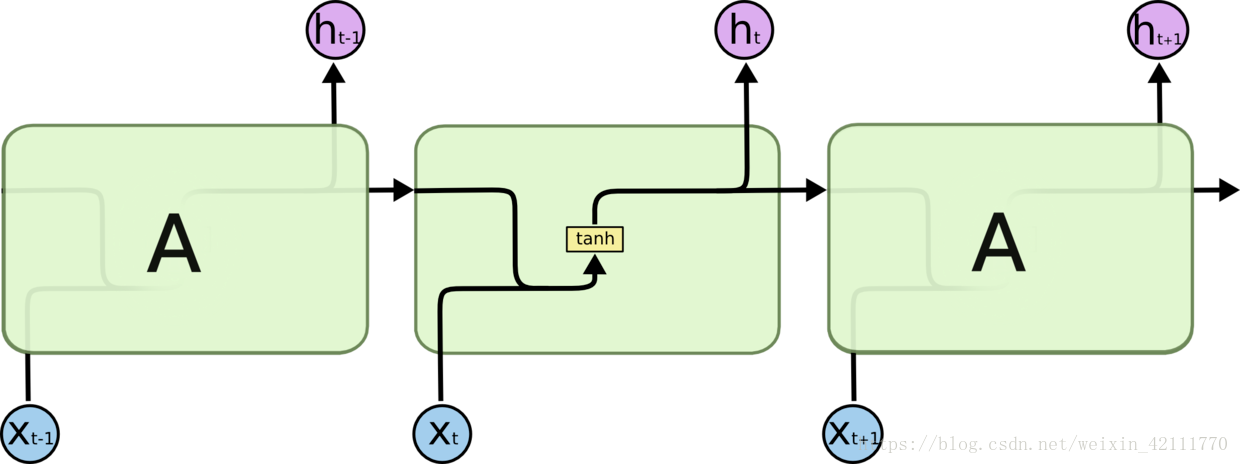 vs 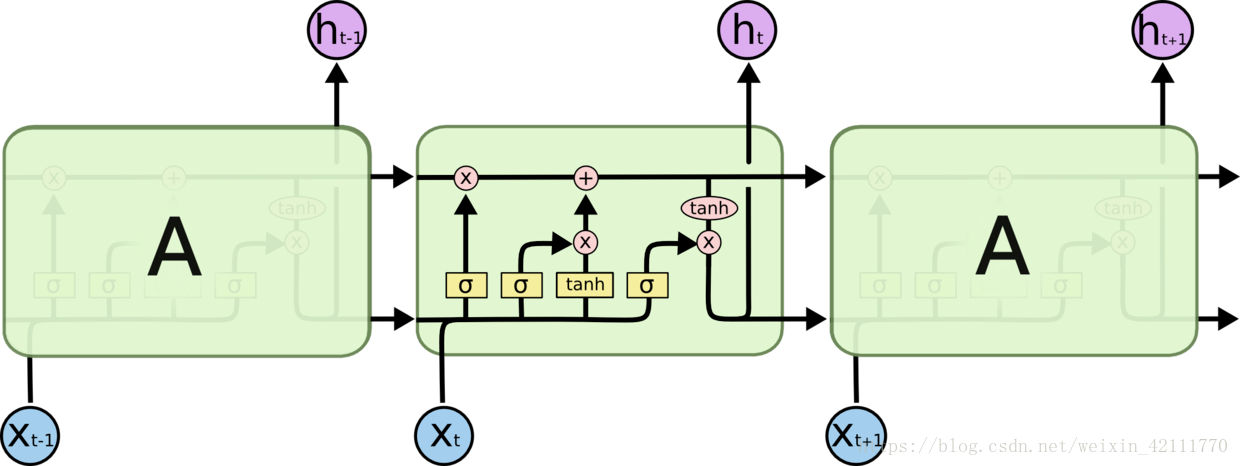
|
||||
|
||||
@@ -15,12 +15,12 @@
|
||||
|
||||
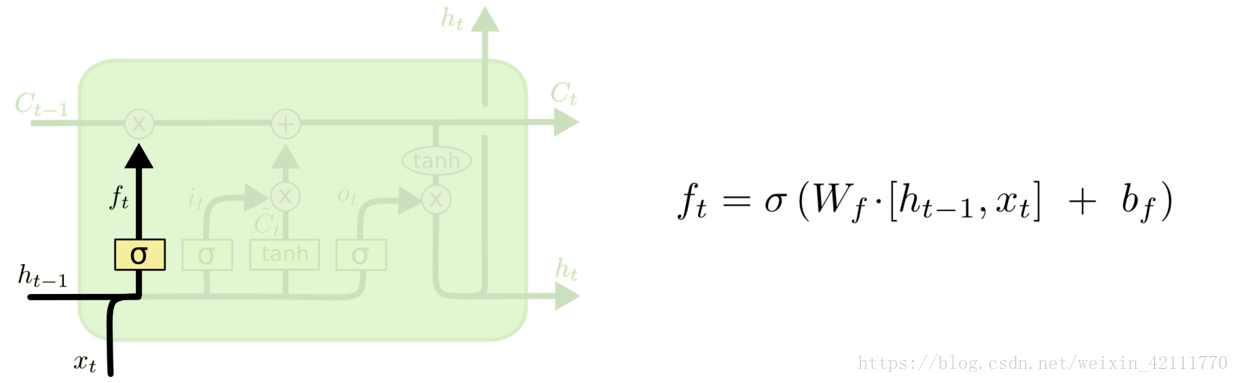
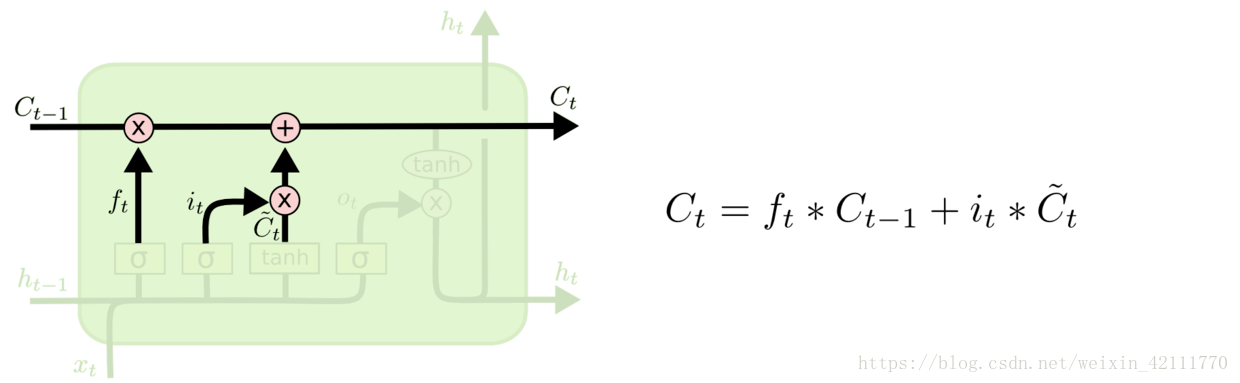
**在LSTM中,第一阶段是遗忘门,遗忘层决定哪些信息需要从细胞状态中被遗忘,下一阶段是输入门,输入门确定哪些新信息能够被存放到细胞状态中,最后一个阶段是输出门,输出门确定输出什么值**。下面我们把LSTM就着各个门的子结构和数学表达式进行分析。
|
||||
|
||||
* 遗忘门:遗忘门是以上一层的输出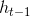和本层要输入的序列数据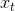作为输入,通过一个激活函数sigmoid,得到输出为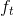。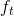的输出取值在[0,1]区间,表示上一层细胞状态被遗忘的概率,1是“完全保留”,0是“完全舍弃”
|
||||
* 遗忘门: 遗忘门是以上一层的输出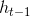和本层要输入的序列数据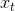作为输入,通过一个激活函数sigmoid,得到输出为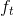。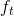的输出取值在[0,1]区间,表示上一层细胞状态被遗忘的概率,1是“完全保留”,0是“完全舍弃”
|
||||
|
||||
|
||||
|
||||
|
||||
* 输入门:输入门包含两个部分,第一部分使用sigmoid激活函数,输出为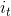,第二部分使用tanh激活函数,输出为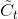。**【个人通俗理解: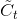在RNN网络中就是本层的输出,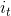是在[0,1]区间取值,表示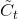中的信息被保留的程度,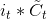表示该层被保留的新信息】**
|
||||
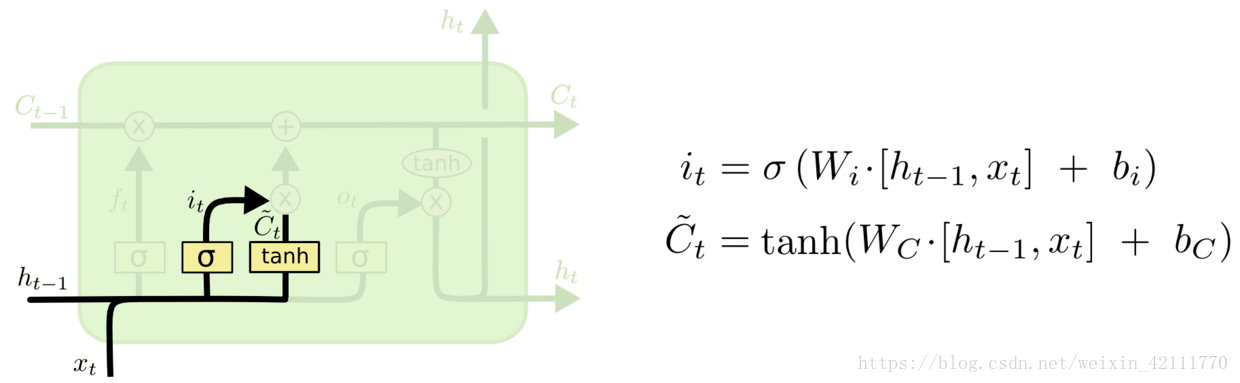
* 输入门: 输入门包含两个部分,第一部分使用sigmoid激活函数,输出为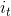,第二部分使用tanh激活函数,输出为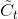。**【个人通俗理解: 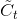在RNN网络中就是本层的输出,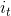是在[0,1]区间取值,表示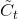中的信息被保留的程度,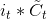表示该层被保留的新信息】**
|
||||
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@
|
||||
|
||||
|
||||
|
||||
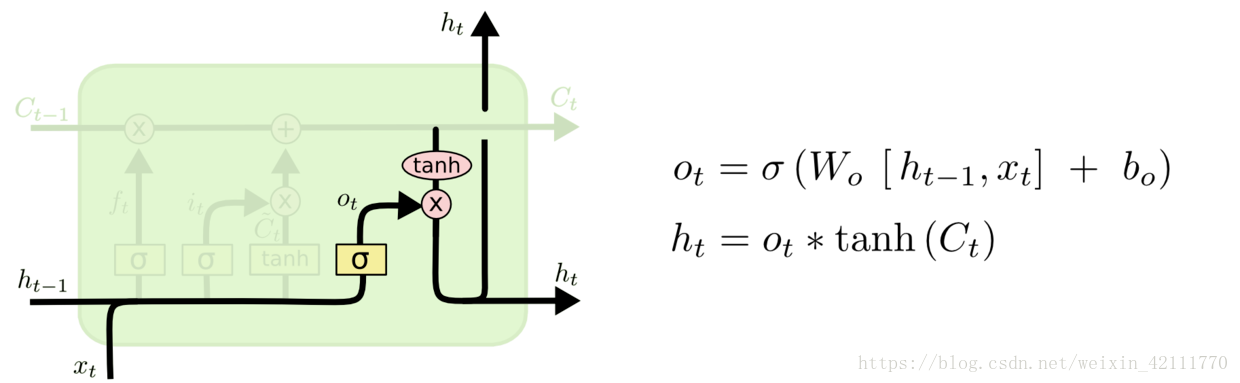
* 输出门:输出门用来控制该层的细胞状态有多少被过滤。首先使用sigmoid激活函数得到一个[0,1]区间取值的,接着将细胞状态通过tanh激活函数处理后与相乘,即是本层的输出。
|
||||
* 输出门: 输出门用来控制该层的细胞状态有多少被过滤。首先使用sigmoid激活函数得到一个[0,1]区间取值的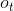,接着将细胞状态通过tanh激活函数处理后与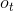相乘,即是本层的输出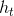。
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -6,26 +6,26 @@
|
||||
|
||||
循环神经网络的应用场景比较多,比如暂时能写论文,写程序,写诗,但是,(总是会有但是的),但是他们现在还不能正常使用,学习出来的东西没有逻辑,所以要想真正让它更有用,路还很远。
|
||||
|
||||
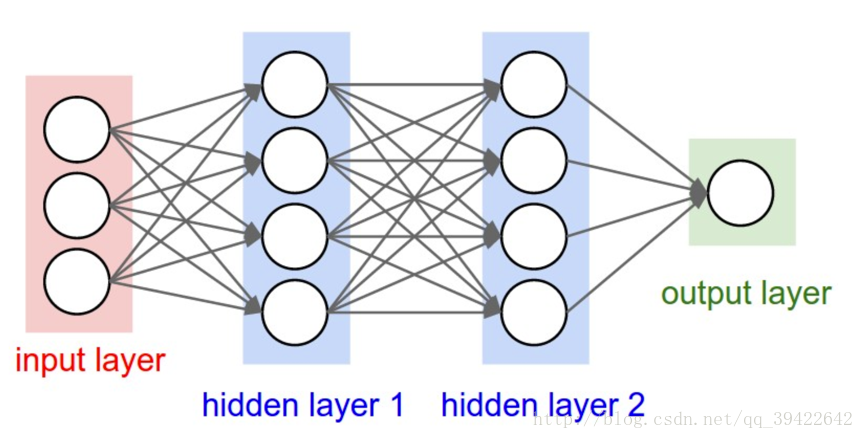
这是一般的神经网络应该有的结构:
|
||||
这是一般的神经网络应该有的结构:
|
||||
|
||||
|
||||
既然我们已经有了人工神经网络和卷积神经网络,为什么还要循环神经网络?
|
||||
原因很简单,无论是卷积神经网络,还是人工神经网络,他们的前提假设都是:元素之间是相互独立的,**输入与输出也是独立的**,比如猫和狗。
|
||||
但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,一个人说了:我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去___这里填空,人应该都知道是填“云南“。因为我们是根据上下文的内容推断出来的,但机会要做到这一步就相当得难了。因此,就有了现在的循环神经网络,他的本质是**:像人一样拥有记忆的能力。**因此,他的输出就依赖于当前的输入和记忆。
|
||||
原因很简单,无论是卷积神经网络,还是人工神经网络,他们的前提假设都是: 元素之间是相互独立的,**输入与输出也是独立的**,比如猫和狗。
|
||||
但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,一个人说了: 我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去___这里填空,人应该都知道是填“云南“。因为我们是根据上下文的内容推断出来的,但机会要做到这一步就相当得难了。因此,就有了现在的循环神经网络,他的本质是**: 像人一样拥有记忆的能力。**因此,他的输出就依赖于当前的输入和记忆。
|
||||
|
||||
## 2.RNN的网络结构及原理
|
||||
|
||||
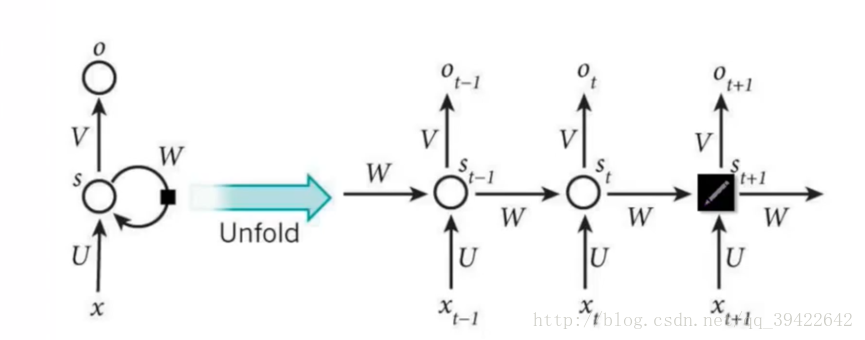
它的网络结构如下:
|
||||
它的网络结构如下:
|
||||
|
||||
其中每个圆圈可以看作是一个单元,而且每个单元做的事情也是一样的,因此可以折叠呈左半图的样子。用一句话解释RNN,就是**一个单元结构重复使用**。
|
||||
|
||||
RNN是一个序列到序列的模型,假设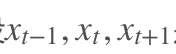是一个输入:“我是中国“,那么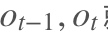就应该对应”是”,”中国”这两个,预测下一个词最有可能是什么?就是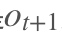应该是”人”的概率比较大。
|
||||
RNN是一个序列到序列的模型,假设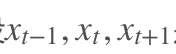是一个输入: “我是中国“,那么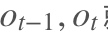就应该对应”是”,”中国”这两个,预测下一个词最有可能是什么?就是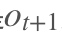应该是”人”的概率比较大。
|
||||
|
||||
因此,我们可以做这样的定义:
|
||||
因此,我们可以做这样的定义:
|
||||
|
||||

|
||||
|
||||
。因为我们当前时刻的输出是由记忆和当前时刻的输入决定的,就像你现在大四,你的知识是由大四学到的知识(当前输入)和大三以及大三以前学到的东西的(记忆)的结合,RNN在这点上也类似,神经网络最擅长做的就是通过一系列参数把很多内容整合到一起,然后学习这个参数,因此就定义了RNN的基础:
|
||||
。因为我们当前时刻的输出是由记忆和当前时刻的输入决定的,就像你现在大四,你的知识是由大四学到的知识(当前输入)和大三以及大三以前学到的东西的(记忆)的结合,RNN在这点上也类似,神经网络最擅长做的就是通过一系列参数把很多内容整合到一起,然后学习这个参数,因此就定义了RNN的基础:
|
||||
|
||||
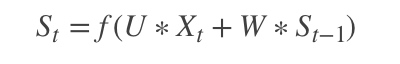
|
||||
|
||||
@@ -40,16 +40,16 @@ RNN是一个序列到序列的模型,假设就表示时刻t的输出。
|
||||
|
||||
RNN中的结构细节:
|
||||
RNN中的结构细节:
|
||||
1.可以把St当作隐状态,捕捉了之前时间点上的信息。就像你去考研一样,考的时候记住了你能记住的所有信息。
|
||||
2.Ot是由当前时间以及之前所有的记忆得到的。就是你考研之后做的考试卷子,是用你的记忆得到的。
|
||||
3.很可惜的是,St并不能捕捉之前所有时间点的信息。就像你考研不能记住所有的英语单词一样。
|
||||
4.和卷积神经网络一样,这里的网络中每个cell都共享了一组参数(U,V,W),这样就能极大的降低计算量了。
|
||||
5.Ot在很多情况下都是不存在的,因为很多任务,比如文本情感分析,都是只关注最后的结果的。就像考研之后选择学校,学校不会管你到底怎么努力,怎么心酸的准备考研,而只关注你最后考了多少分。
|
||||
|
||||
## 3.RNN的改进1:双向RNN
|
||||
## 3.RNN的改进1: 双向RNN
|
||||
|
||||
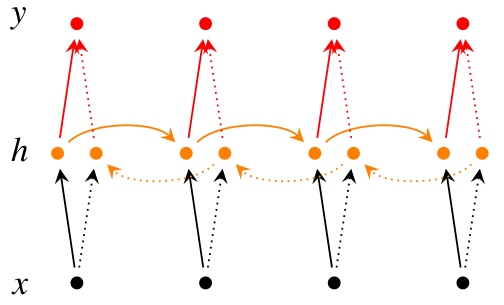
在有些情况,比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法。如图是双向RNN的图解:
|
||||
在有些情况,比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法。如图是双向RNN的图解:
|
||||
|
||||
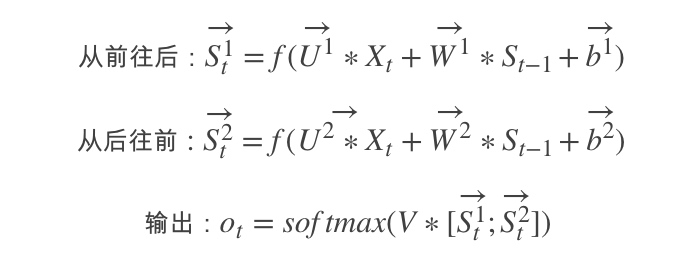
|
||||
|
||||
@@ -57,7 +57,7 @@ RNN中的结构细节:
|
||||
|
||||
双向RNN需要的内存是单向RNN的两倍,因为在同一时间点,双向RNN需要保存两个方向上的权重参数,在分类的时候,需要同时输入两个隐藏层输出的信息。
|
||||
|
||||
## 4.RNN的改进2:深层双向RNN
|
||||
## 4.RNN的改进2: 深层双向RNN
|
||||
|
||||
深层双向RNN 与双向RNN相比,多了几个隐藏层,因为他的想法是很多信息记一次记不下来,比如你去考研,复习考研英语的时候,背英语单词一定不会就看一次就记住了所有要考的考研单词吧,你应该也是带着先前几次背过的单词,然后选择那些背过,但不熟的内容,或者没背过的单词来背吧。
|
||||
|
||||
@@ -66,12 +66,12 @@ RNN中的结构细节:
|
||||
|
||||
我们用公式来表示是这样的:
|
||||
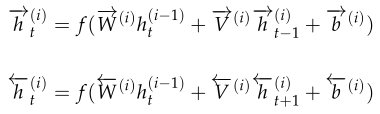
|
||||
然后再利用最后一层来进行分类,分类公式如下:
|
||||
然后再利用最后一层来进行分类,分类公式如下:
|
||||
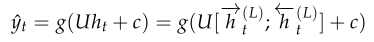
|
||||
|
||||
### 4.1 Pyramidal RNN
|
||||
|
||||
其他类似的网络还有Pyramidal RNN:
|
||||
其他类似的网络还有Pyramidal RNN:
|
||||
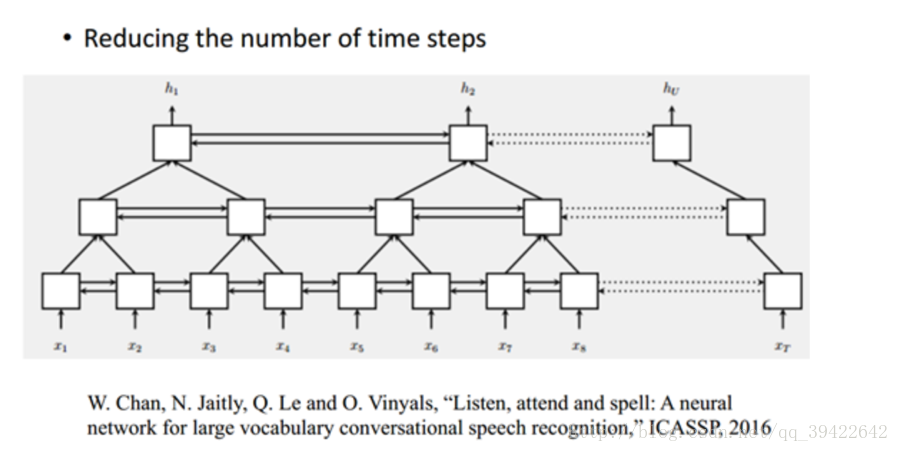
|
||||
我们现在有一个很长的输入序列,可以看到这是一个双向的RNN,上图是谷歌的W.Chan做的一个测试,它原先要做的是语音识别,他要用序列到序列的模型做语音识别,序列到序列就是说,输入一个序列然后就输出一个序列。
|
||||
|
||||
@@ -82,61 +82,61 @@ RNN中的结构细节:
|
||||
|
||||
## 5.RNN的训练-BPTT
|
||||
|
||||
如前面我们讲的,如果要预测t时刻的输出,我们必须先利用上一时刻(t-1)的记忆和当前时刻的输入,得到t时刻的记忆:
|
||||
如前面我们讲的,如果要预测t时刻的输出,我们必须先利用上一时刻(t-1)的记忆和当前时刻的输入,得到t时刻的记忆:
|
||||
|
||||
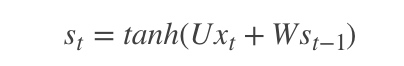
|
||||
|
||||
然后利用当前时刻的记忆,通过softmax分类器输出每个词出现的概率:
|
||||
然后利用当前时刻的记忆,通过softmax分类器输出每个词出现的概率:
|
||||
|
||||
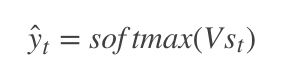
|
||||
|
||||
为了找出模型最好的参数,U,W,V,我们就要知道当前参数得到的结果怎么样,因此就要定义我们的损失函数,用交叉熵损失函数:
|
||||
为了找出模型最好的参数,U,W,V,我们就要知道当前参数得到的结果怎么样,因此就要定义我们的损失函数,用交叉熵损失函数:
|
||||
|
||||
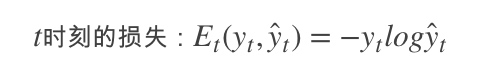
|
||||
|
||||
其中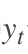
|
||||
t时刻的标准答案,是一个只有一个是1,其他都是0的向量; 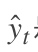是我们预测出来的结果,与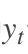
|
||||
的维度一样,但它是一个概率向量,里面是每个词出现的概率。因为对结果的影响,肯定不止一个时刻,因此需要把所有时刻的造成的损失都加起来:
|
||||
的维度一样,但它是一个概率向量,里面是每个词出现的概率。因为对结果的影响,肯定不止一个时刻,因此需要把所有时刻的造成的损失都加起来:
|
||||
|
||||
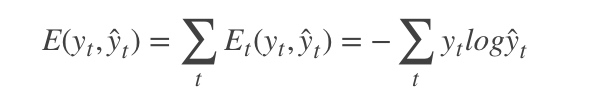
|
||||
|
||||
|
||||
|
||||
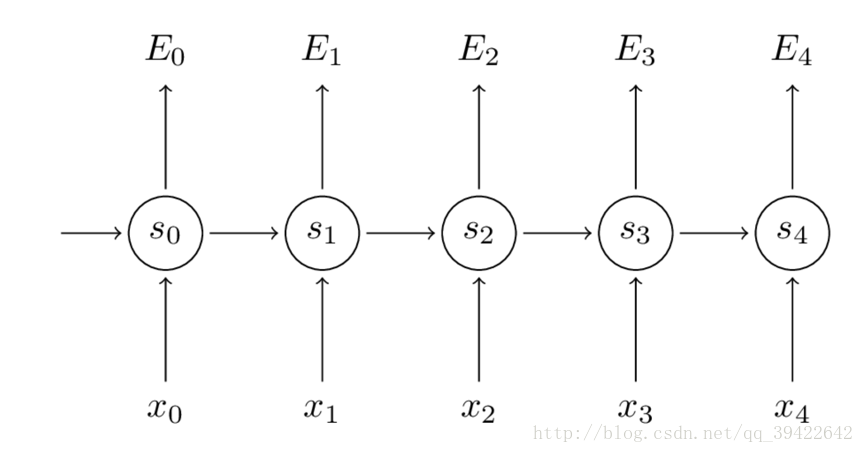
如图所示,你会发现每个cell都会有一个损失,我们已经定义好了损失函数,接下来就是熟悉的一步了,那就是根据损失函数利用SGD来求解最优参数,在CNN中使用反向传播BP算法来求解最优参数,但在RNN就要用到BPTT,它和BP算法的本质区别,也是CNN和RNN的本质区别:CNN没有记忆功能,它的输出仅依赖与输入,但RNN有记忆功能,它的输出不仅依赖与当前输入,还依赖与当前的记忆。这个记忆是序列到序列的,也就是当前时刻收到上一时刻的影响,比如股市的变化。
|
||||
如图所示,你会发现每个cell都会有一个损失,我们已经定义好了损失函数,接下来就是熟悉的一步了,那就是根据损失函数利用SGD来求解最优参数,在CNN中使用反向传播BP算法来求解最优参数,但在RNN就要用到BPTT,它和BP算法的本质区别,也是CNN和RNN的本质区别: CNN没有记忆功能,它的输出仅依赖与输入,但RNN有记忆功能,它的输出不仅依赖与当前输入,还依赖与当前的记忆。这个记忆是序列到序列的,也就是当前时刻收到上一时刻的影响,比如股市的变化。
|
||||
|
||||
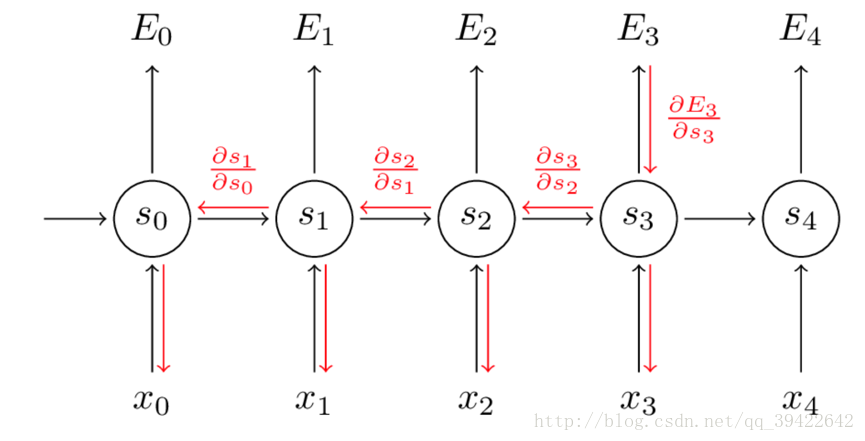
因此,在对参数求偏导的时候,对当前时刻求偏导,一定会涉及前一时刻,我们用例子看一下:
|
||||
因此,在对参数求偏导的时候,对当前时刻求偏导,一定会涉及前一时刻,我们用例子看一下:
|
||||
|
||||
|
||||
|
||||
假设我们对E3的W求偏导:它的损失首先来源于预测的输出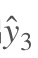
|
||||
,预测的输出又是来源于当前时刻的记忆s3,当前的记忆又是来源于当前的输出和截止到上一时刻的记忆: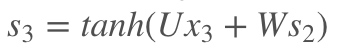
|
||||
假设我们对E3的W求偏导: 它的损失首先来源于预测的输出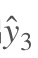
|
||||
,预测的输出又是来源于当前时刻的记忆s3,当前的记忆又是来源于当前的输出和截止到上一时刻的记忆: 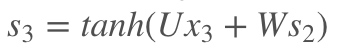
|
||||
因此,根据链式法则可以有:
|
||||
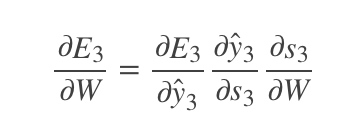
|
||||
|
||||
但是,你会发现,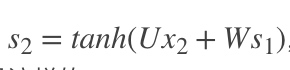
|
||||
,也就是s2里面的函数还包含了W,因此,这个链式法则还没到底,就像图上画的那样,所以真正的链式法则是这样的:
|
||||
,也就是s2里面的函数还包含了W,因此,这个链式法则还没到底,就像图上画的那样,所以真正的链式法则是这样的:
|
||||
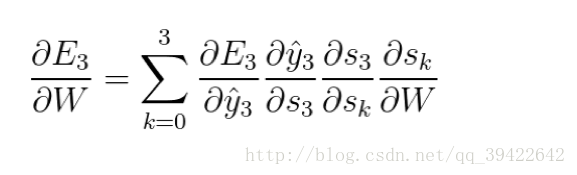
|
||||
我们要把当前时刻造成的损失,和以往每个时刻造成的损失加起来,因为我们每一个时刻都用到了权重参数W。和以往的网络不同,一般的网络,比如人工神经网络,参数是不同享的,但在循环神经网络,和CNN一样,设立了参数共享机制,来降低模型的计算量。
|
||||
|
||||
## 6.RNN与CNN的结合应用:看图说话
|
||||
## 6.RNN与CNN的结合应用: 看图说话
|
||||
|
||||
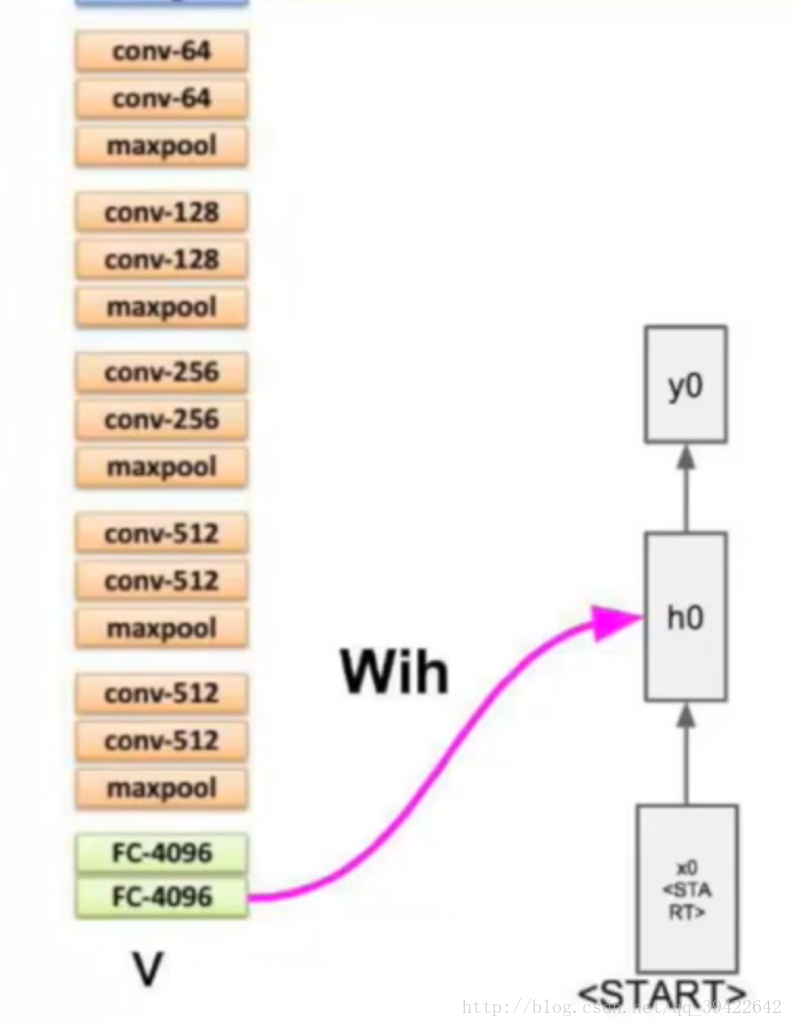
在图像处理中,目前做的最好的是CNN,而自然语言处理中,表现比较好的是RNN,因此,我们能否把他们结合起来,一起用呢?那就是看图说话了,这个原理也比较简单,举个小栗子:假设我们有CNN的模型训练了一个网络结构,比如是这个
|
||||
在图像处理中,目前做的最好的是CNN,而自然语言处理中,表现比较好的是RNN,因此,我们能否把他们结合起来,一起用呢?那就是看图说话了,这个原理也比较简单,举个小栗子: 假设我们有CNN的模型训练了一个网络结构,比如是这个
|
||||
|
||||
|
||||
|
||||
最后我们不是要分类嘛,那在分类前,是不是已经拿到了图像的特征呀,那我们能不能把图像的特征拿出来,放到RNN的输入里,让他学习呢?
|
||||
|
||||
之前的RNN是这样的:
|
||||
之前的RNN是这样的:
|
||||
|
||||
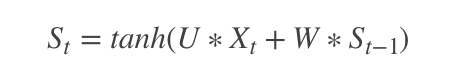
|
||||
|
||||
我们把图像的特征加在里面,可以得到:
|
||||
我们把图像的特征加在里面,可以得到:
|
||||
|
||||
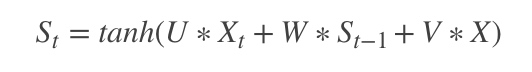
|
||||
|
||||
其中的X就是图像的特征。如果用的是上面的CNN网络,X应该是一个4096X1的向量。
|
||||
|
||||
注:这个公式只在第一步做,后面每次更新就没有V了,因为给RNN数据只在第一次迭代的时候给。
|
||||
注: 这个公式只在第一步做,后面每次更新就没有V了,因为给RNN数据只在第一次迭代的时候给。
|
||||
|
||||
## 7.RNN项目练手
|
||||
|
||||
|
||||
@@ -1,26 +1,26 @@
|
||||
# 反向传递
|
||||
|
||||
> 建议:一定要看懂推导过程
|
||||
> 建议: 一定要看懂推导过程
|
||||
|
||||
# [一文弄懂神经网络中的反向传播法——BackPropagation](https://www.cnblogs.com/charlotte77/p/5629865.html)
|
||||
|
||||
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
|
||||
|
||||
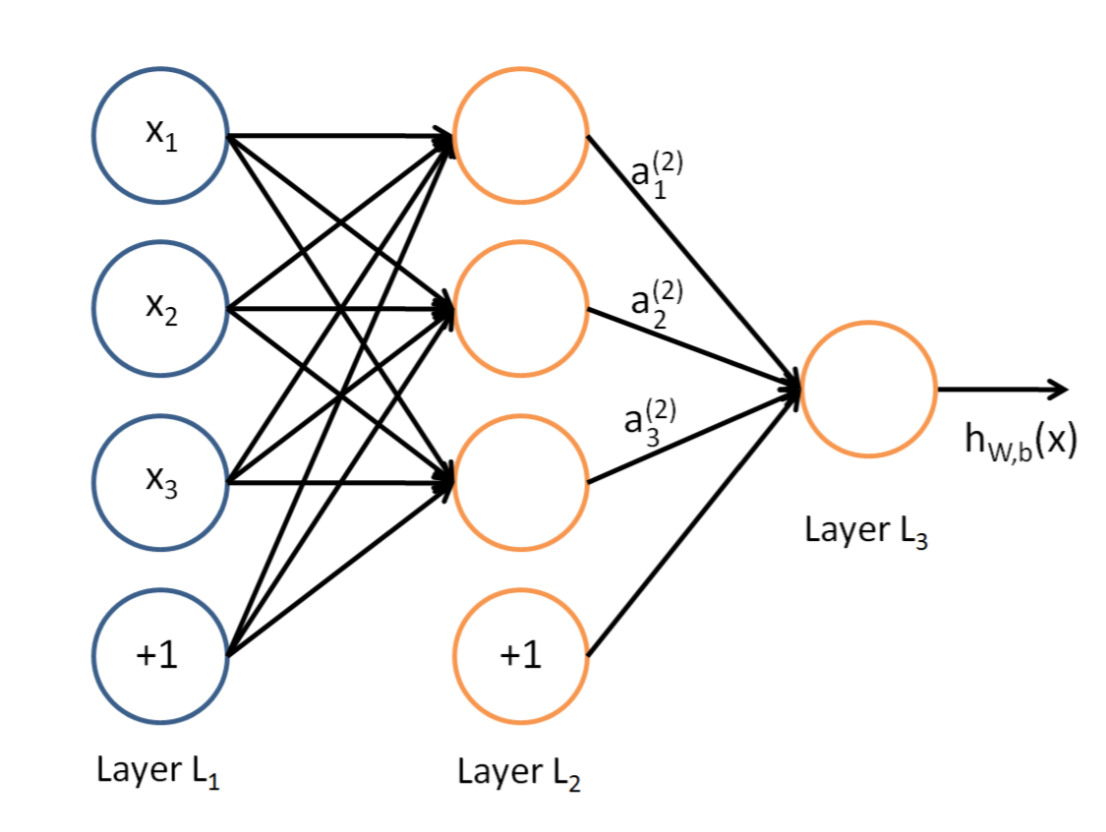
说到神经网络,大家看到这个图应该不陌生:
|
||||
说到神经网络,大家看到这个图应该不陌生:
|
||||
|
||||
|
||||
|
||||
这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
|
||||
|
||||
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:[[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html))
|
||||
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试: )(注: 本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记: [[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html))
|
||||
|
||||
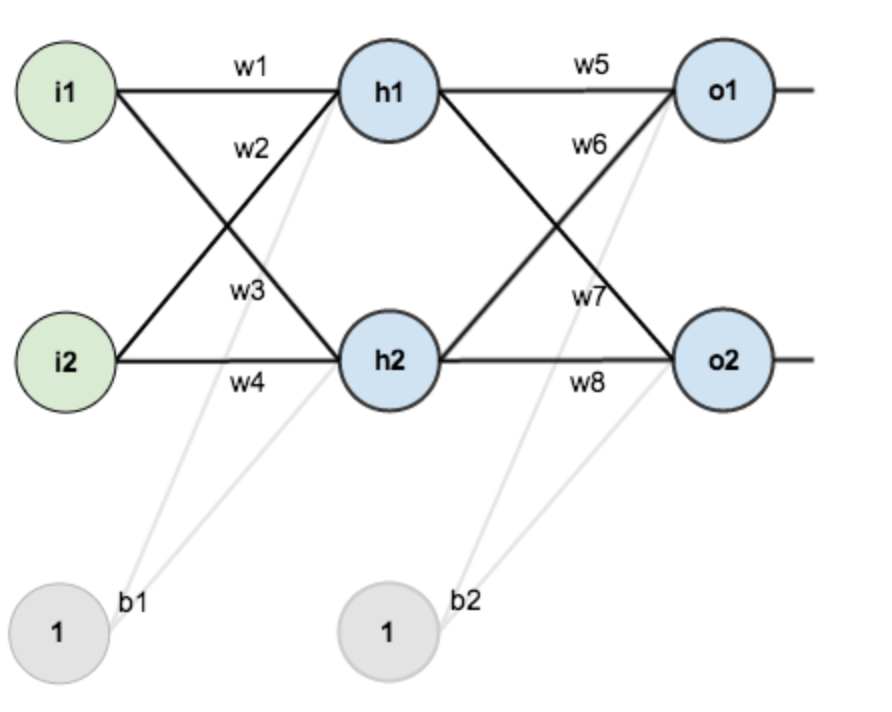
假设,你有这样一个网络层:
|
||||
假设,你有这样一个网络层:
|
||||
|
||||
|
||||
|
||||
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
|
||||
|
||||
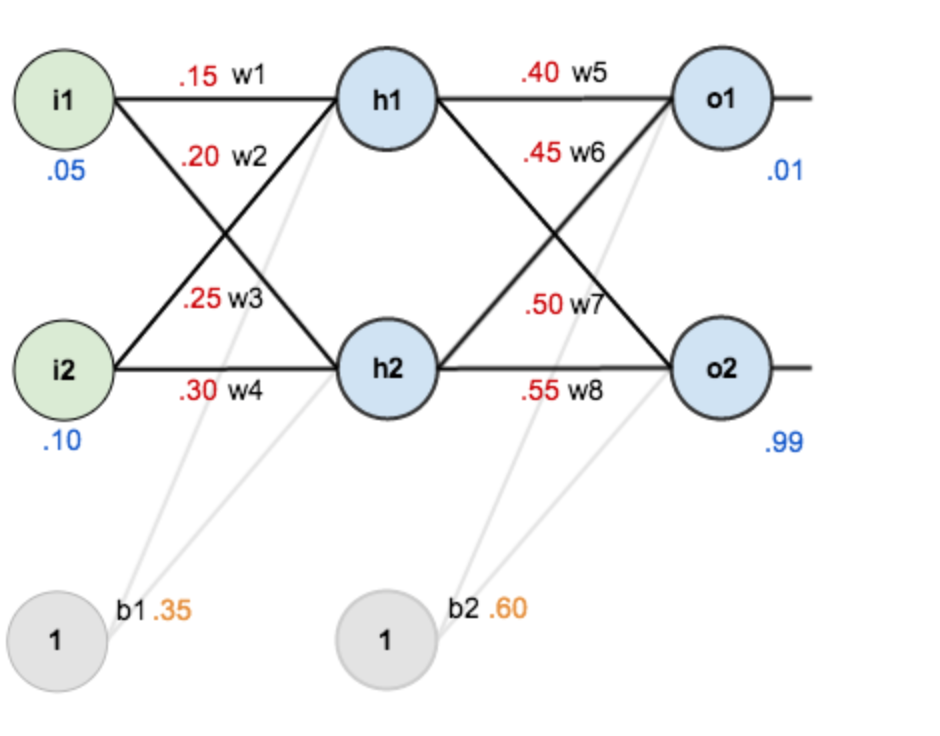
现在对他们赋上初值,如下图:
|
||||
现在对他们赋上初值,如下图:
|
||||
|
||||
|
||||
|
||||
@@ -32,27 +32,27 @@
|
||||
|
||||
w5=0.40,w6=0.45,w7=0.50,w8=0.55
|
||||
|
||||
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
|
||||
目标: 给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
|
||||
|
||||
**Step 1 前向传播**
|
||||
|
||||
1.输入层---->隐含层:
|
||||
1.输入层---->隐含层:
|
||||
|
||||
计算神经元h1的输入加权和:
|
||||
计算神经元h1的输入加权和:
|
||||
|
||||
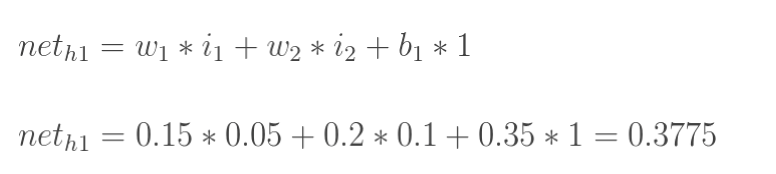
|
||||
|
||||
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
|
||||
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
|
||||
|
||||
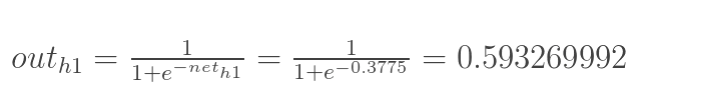
|
||||
|
||||
同理,可计算出神经元h2的输出o2:
|
||||
同理,可计算出神经元h2的输出o2:
|
||||
|
||||
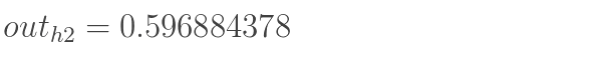
|
||||
|
||||
2.隐含层---->输出层:
|
||||
2.隐含层---->输出层:
|
||||
|
||||
计算输出层神经元o1和o2的值:
|
||||
计算输出层神经元o1和o2的值:
|
||||
|
||||
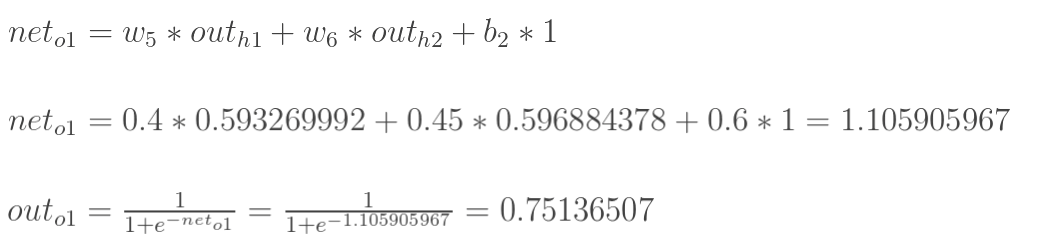
|
||||
|
||||
@@ -64,11 +64,11 @@
|
||||
|
||||
1.计算总误差
|
||||
|
||||
总误差:(square error)
|
||||
总误差: (square error)
|
||||
|
||||
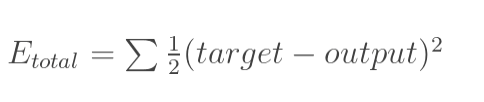
|
||||
|
||||
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
|
||||
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
|
||||
|
||||
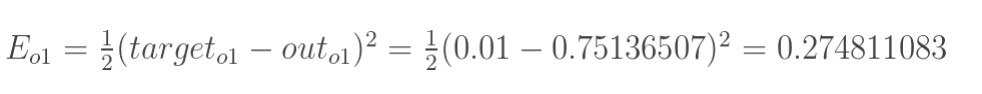
|
||||
|
||||
@@ -76,55 +76,55 @@
|
||||
|
||||
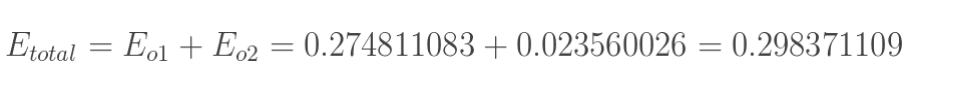
|
||||
|
||||
2.隐含层---->输出层的权值更新:
|
||||
2.隐含层---->输出层的权值更新:
|
||||
|
||||
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
|
||||
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出: (链式法则)
|
||||
|
||||
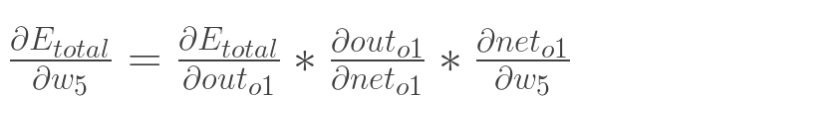
|
||||
|
||||
下面的图可以更直观的看清楚误差是怎样反向传播的:
|
||||
下面的图可以更直观的看清楚误差是怎样反向传播的:
|
||||
|
||||
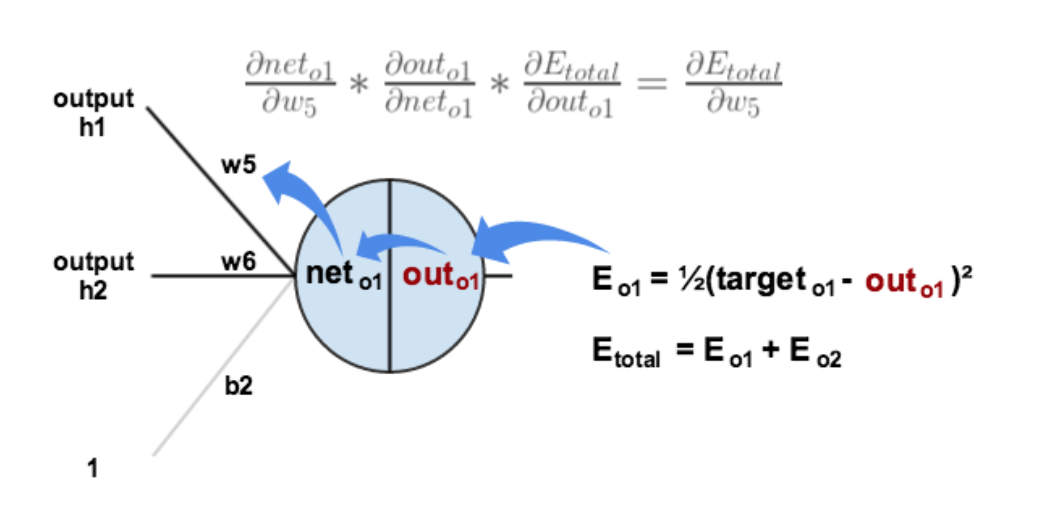
|
||||
|
||||
现在我们来分别计算每个式子的值:
|
||||
现在我们来分别计算每个式子的值:
|
||||
|
||||
计算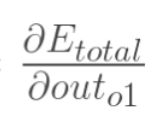:
|
||||
计算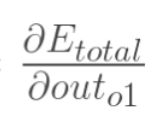:
|
||||
|
||||
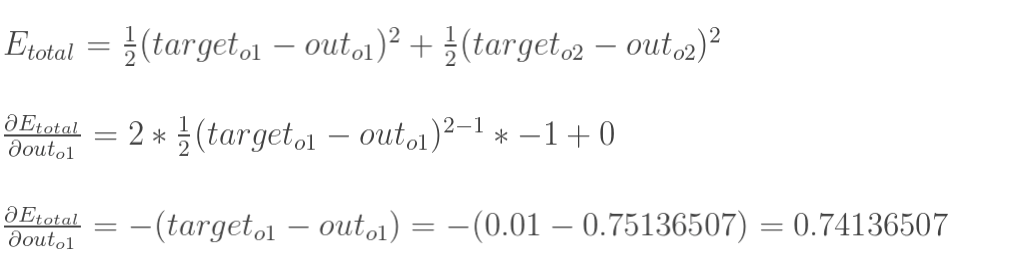
|
||||
|
||||
计算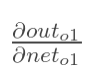:
|
||||
计算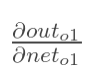:
|
||||
|
||||

|
||||
|
||||
(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
|
||||
|
||||
计算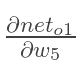:
|
||||
计算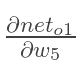:
|
||||
|
||||
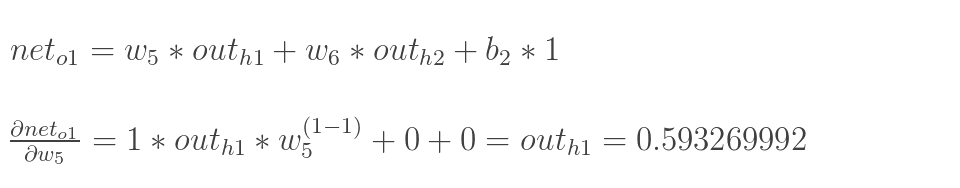
|
||||
|
||||
最后三者相乘:
|
||||
最后三者相乘:
|
||||
|
||||

|
||||
|
||||
这样我们就计算出整体误差E(total)对w5的偏导值。
|
||||
|
||||
回过头来再看看上面的公式,我们发现:
|
||||
回过头来再看看上面的公式,我们发现:
|
||||
|
||||
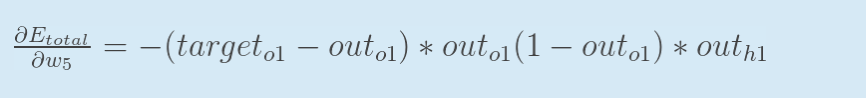
|
||||
|
||||
为了表达方便,用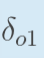来表示输出层的误差:
|
||||
为了表达方便,用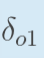来表示输出层的误差:
|
||||
|
||||
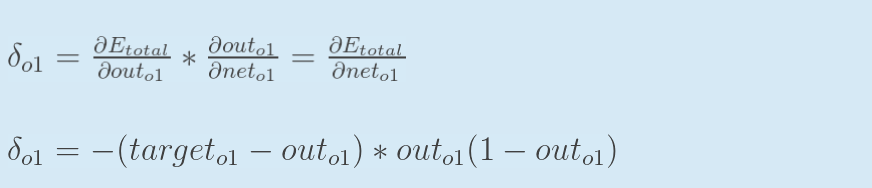
|
||||
|
||||
因此,整体误差E(total)对w5的偏导公式可以写成:
|
||||
因此,整体误差E(total)对w5的偏导公式可以写成:
|
||||
|
||||

|
||||
|
||||
如果输出层误差计为负的话,也可以写成:
|
||||
如果输出层误差计为负的话,也可以写成:
|
||||
|
||||

|
||||
|
||||
最后我们来更新w5的值:
|
||||
最后我们来更新w5的值:
|
||||
|
||||
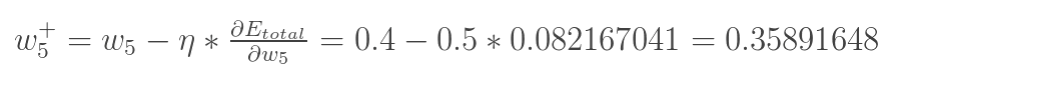
|
||||
|
||||
@@ -134,17 +134,17 @@
|
||||
|
||||

|
||||
|
||||
3.隐含层---->隐含层的权值更新:
|
||||
3.隐含层---->隐含层的权值更新:
|
||||
|
||||
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
|
||||
|
||||
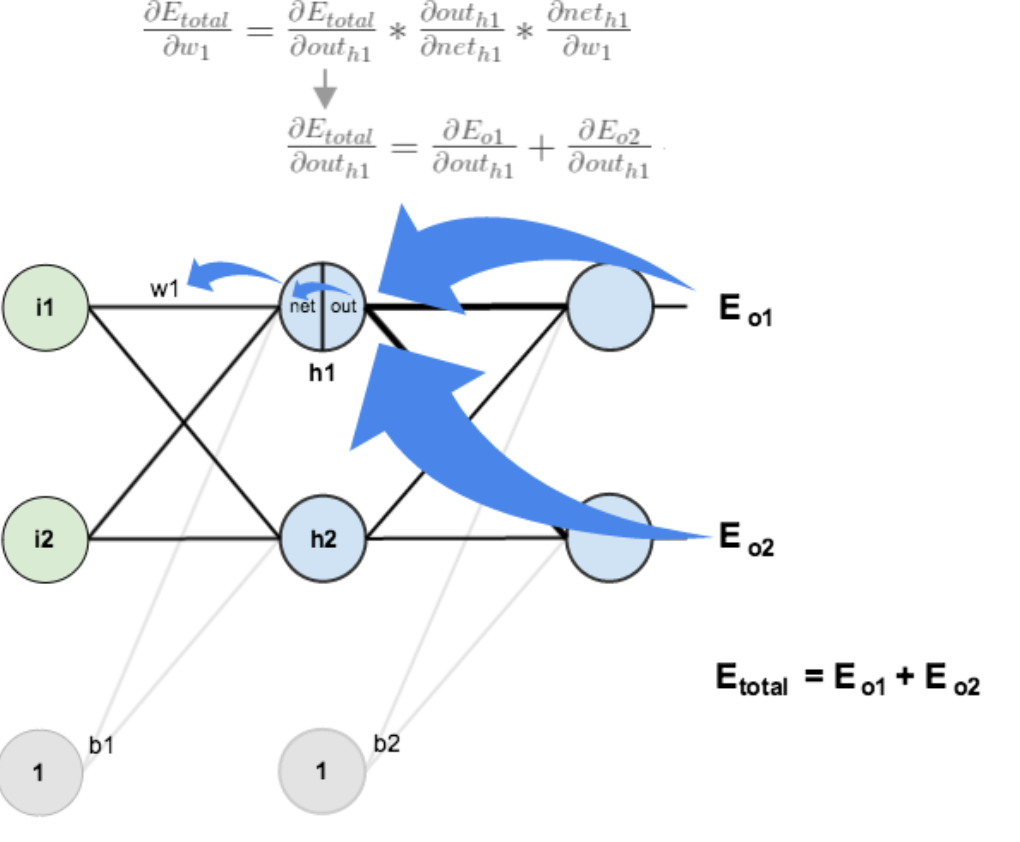
|
||||
|
||||
计算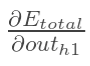:
|
||||
计算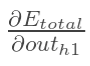:
|
||||
|
||||

|
||||
|
||||
先计算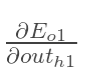:
|
||||
先计算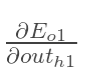:
|
||||
|
||||
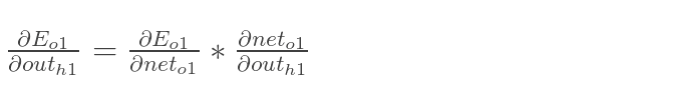
|
||||
|
||||
@@ -154,35 +154,35 @@
|
||||
|
||||
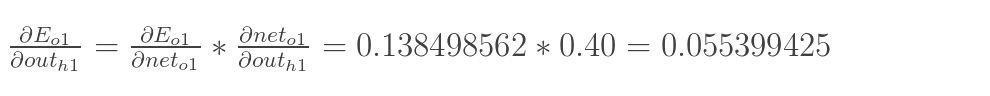
|
||||
|
||||
同理,计算出:
|
||||
同理,计算出:
|
||||
|
||||
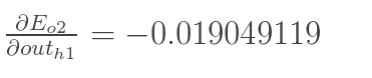
|
||||
|
||||
两者相加得到总值:
|
||||
两者相加得到总值:
|
||||
|
||||
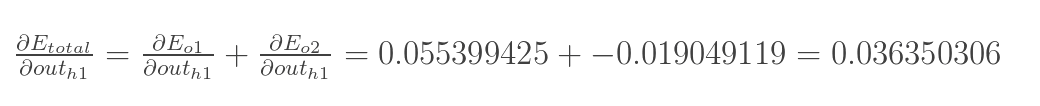
|
||||
|
||||
再计算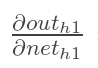:
|
||||
再计算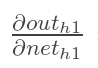:
|
||||
|
||||

|
||||
|
||||
再计算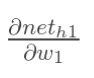:
|
||||
再计算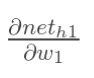:
|
||||
|
||||
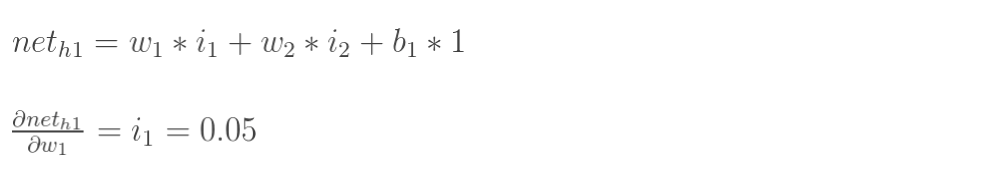
|
||||
|
||||
最后,三者相乘:
|
||||
最后,三者相乘:
|
||||
|
||||

|
||||
|
||||
为了简化公式,用sigma(h1)表示隐含层单元h1的误差:
|
||||
为了简化公式,用sigma(h1)表示隐含层单元h1的误差:
|
||||
|
||||

|
||||
|
||||
最后,更新w1的权值:
|
||||
最后,更新w1的权值:
|
||||
|
||||

|
||||
|
||||
同理,额可更新w2,w3,w4的权值:
|
||||
同理,额可更新w2,w3,w4的权值:
|
||||
|
||||

|
||||
|
||||
@@ -197,11 +197,11 @@ import random
|
||||
import math
|
||||
|
||||
#
|
||||
# 参数解释:
|
||||
# "pd_" :偏导的前缀
|
||||
# "d_" :导数的前缀
|
||||
# "w_ho" :隐含层到输出层的权重系数索引
|
||||
# "w_ih" :输入层到隐含层的权重系数的索引
|
||||
# 参数解释:
|
||||
# "pd_" : 偏导的前缀
|
||||
# "d_" : 导数的前缀
|
||||
# "w_ho" : 隐含层到输出层的权重系数索引
|
||||
# "w_ih" : 输入层到隐含层的权重系数的索引
|
||||
|
||||
class NeuralNetwork:
|
||||
LEARNING_RATE = 0.5
|
||||
@@ -396,17 +396,17 @@ for i in range(10000):
|
||||
# print(i, nn.calculate_total_error(training_sets))
|
||||
```
|
||||
|
||||
最后写到这里就结束了,现在还不会用latex编辑数学公式,本来都直接想写在草稿纸上然后扫描了传上来,但是觉得太影响阅读体验了。以后会用公式编辑器后再重把公式重新编辑一遍。稳重使用的是sigmoid激活函数,实际还有几种不同的激活函数可以选择,具体的可以参考文献[3],最后推荐一个在线演示神经网络变化的网址:http://www.emergentmind.com/neural-network,可以自己填输入输出,然后观看每一次迭代权值的变化,很好玩~如果有错误的或者不懂的欢迎留言:)
|
||||
最后写到这里就结束了,现在还不会用latex编辑数学公式,本来都直接想写在草稿纸上然后扫描了传上来,但是觉得太影响阅读体验了。以后会用公式编辑器后再重把公式重新编辑一遍。稳重使用的是sigmoid激活函数,实际还有几种不同的激活函数可以选择,具体的可以参考文献[3],最后推荐一个在线演示神经网络变化的网址: http://www.emergentmind.com/neural-network,可以自己填输入输出,然后观看每一次迭代权值的变化,很好玩~如果有错误的或者不懂的欢迎留言: )
|
||||
|
||||
参考文献:
|
||||
参考文献:
|
||||
|
||||
1. Poll的笔记:[[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html)(http://www.cnblogs.com/maybe2030/p/5597716.html#3457159 )
|
||||
1. Poll的笔记: [[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html)(http://www.cnblogs.com/maybe2030/p/5597716.html#3457159 )
|
||||
2. Rachel_Zhang:http://blog.csdn.net/abcjennifer/article/details/7758797
|
||||
3. http://www.cedar.buffalo.edu/%7Esrihari/CSE574/Chap5/Chap5.3-BackProp.pdf
|
||||
4. https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
|
||||
|
||||
---
|
||||
|
||||
* 作者:Charlotte77
|
||||
* 出处:http://www.cnblogs.com/charlotte77/
|
||||
* 作者: Charlotte77
|
||||
* 出处: http://www.cnblogs.com/charlotte77/
|
||||
* 本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
|
||||
|
||||
Reference in New Issue
Block a user