mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-24 18:42:25 +08:00
修改中文符号为英文
This commit is contained in:
@@ -12,15 +12,15 @@
|
||||
|
||||
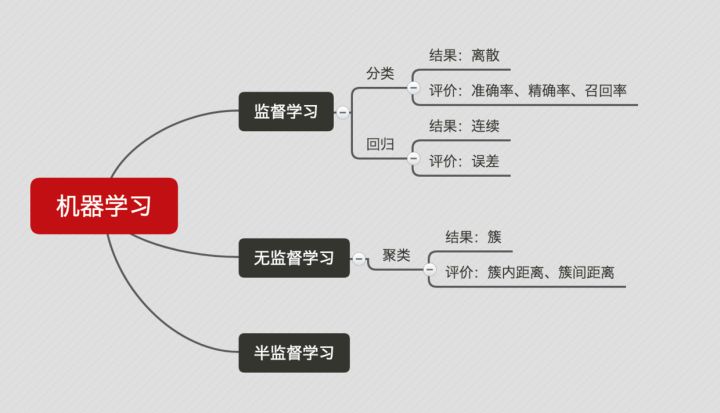
## 机器学习 研究意义
|
||||
|
||||
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
|
||||
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是: A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
|
||||
|
||||
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
|
||||
机器学习已经有了十分广泛的应用,例如: 数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
|
||||
## 机器学习 场景
|
||||
|
||||
* 例如:识别动物猫
|
||||
* 模式识别(官方标准):人们通过大量的经验,得到结论,从而判断它就是猫。
|
||||
* 机器学习(数据学习):人们通过阅读进行学习,观察它会叫、小眼睛、两只耳朵、四条腿、一条尾巴,得到结论,从而判断它就是猫。
|
||||
* 深度学习(深入数据):人们通过深入了解它,发现它会'喵喵'的叫、与同类的猫科动物很类似,得到结论,从而判断它就是猫。(深度学习常用领域:语音识别、图像识别)
|
||||
* 例如: 识别动物猫
|
||||
* 模式识别(官方标准): 人们通过大量的经验,得到结论,从而判断它就是猫。
|
||||
* 机器学习(数据学习): 人们通过阅读进行学习,观察它会叫、小眼睛、两只耳朵、四条腿、一条尾巴,得到结论,从而判断它就是猫。
|
||||
* 深度学习(深入数据): 人们通过深入了解它,发现它会'喵喵'的叫、与同类的猫科动物很类似,得到结论,从而判断它就是猫。(深度学习常用领域: 语音识别、图像识别)
|
||||
|
||||
* 模式识别(pattern recognition): 模式识别是最古老的(作为一个术语而言,可以说是很过时的)。
|
||||
* 我们把环境与客体统称为“模式”,识别是对模式的一种认知,是如何让一个计算机程序去做一些看起来很“智能”的事情。
|
||||
@@ -32,12 +32,12 @@
|
||||
* 深度学习(deep learning): 深度学习是非常崭新和有影响力的前沿领域,我们甚至不会去思考-后深度学习时代。
|
||||
* 深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
|
||||
|
||||
* 参考地址:
|
||||
* 参考地址:
|
||||
* [深度学习 vs 机器学习 vs 模式识别](http://www.csdn.net/article/2015-03-24/2824301)
|
||||
* [深度学习 百科资料](http://baike.baidu.com/link?url=76P-uA4EBrC3G-I__P1tqeO7eoDS709Kp4wYuHxc7GNkz_xn0NxuAtEohbpey7LUa2zUQLJxvIKUx4bnrEfOmsWLKbDmvG1PCoRkJisMTQka6-QReTrIxdYY3v93f55q)
|
||||
|
||||
|
||||
> 机器学习已应用于多个领域,远远超出大多数人的想象,横跨:计算机科学、工程技术和统计学等多个学科。
|
||||
> 机器学习已应用于多个领域,远远超出大多数人的想象,横跨: 计算机科学、工程技术和统计学等多个学科。
|
||||
|
||||
* 搜索引擎: 根据你的搜索点击,优化你下次的搜索结果,是机器学习来帮助搜索引擎判断哪个结果更适合你(也判断哪个广告更适合你)。
|
||||
* 垃圾邮件: 会自动的过滤垃圾广告邮件到垃圾箱内。
|
||||
@@ -50,37 +50,37 @@
|
||||
|
||||
### 主要任务
|
||||
|
||||
* 分类(classification):将实例数据划分到合适的类别中。
|
||||
* 应用实例:判断网站是否被黑客入侵(二分类 ),手写数字的自动识别(多分类)
|
||||
* 回归(regression):主要用于预测数值型数据。
|
||||
* 应用实例:股票价格波动的预测,房屋价格的预测等。
|
||||
* 分类(classification): 将实例数据划分到合适的类别中。
|
||||
* 应用实例: 判断网站是否被黑客入侵(二分类 ),手写数字的自动识别(多分类)
|
||||
* 回归(regression): 主要用于预测数值型数据。
|
||||
* 应用实例: 股票价格波动的预测,房屋价格的预测等。
|
||||
|
||||
### 监督学习(supervised learning)
|
||||
|
||||
* 必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括:分类和回归)
|
||||
* 样本集:训练数据 + 测试数据
|
||||
* 必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括: 分类和回归)
|
||||
* 样本集: 训练数据 + 测试数据
|
||||
* 训练样本 = 特征(feature) + 目标变量(label: 分类-离散值/回归-连续值)
|
||||
* 特征通常是训练样本集的列,它们是独立测量得到的。
|
||||
* 目标变量: 目标变量是机器学习预测算法的测试结果。
|
||||
* 在分类算法中目标变量的类型通常是标称型(如:真与假),而在回归算法中通常是连续型(如:1~100)。
|
||||
* 监督学习需要注意的问题:
|
||||
* 在分类算法中目标变量的类型通常是标称型(如: 真与假),而在回归算法中通常是连续型(如: 1~100)。
|
||||
* 监督学习需要注意的问题:
|
||||
* 偏置方差权衡
|
||||
* 功能的复杂性和数量的训练数据
|
||||
* 输入空间的维数
|
||||
* 噪声中的输出值
|
||||
* `知识表示`:
|
||||
* 可以采用规则集的形式【例如:数学成绩大于90分为优秀】
|
||||
* 可以采用概率分布的形式【例如:通过统计分布发现,90%的同学数学成绩,在70分以下,那么大于70分定为优秀】
|
||||
* 可以使用训练样本集中的一个实例【例如:通过样本集合,我们训练出一个模型实例,得出 年轻,数学成绩中高等,谈吐优雅,我们认为是优秀】
|
||||
* `知识表示`:
|
||||
* 可以采用规则集的形式【例如: 数学成绩大于90分为优秀】
|
||||
* 可以采用概率分布的形式【例如: 通过统计分布发现,90%的同学数学成绩,在70分以下,那么大于70分定为优秀】
|
||||
* 可以使用训练样本集中的一个实例【例如: 通过样本集合,我们训练出一个模型实例,得出 年轻,数学成绩中高等,谈吐优雅,我们认为是优秀】
|
||||
|
||||
### 非监督学习(unsupervised learing)
|
||||
|
||||
* 在机器学习,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。
|
||||
* 无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。
|
||||
* 数据没有类别信息,也不会给定目标值。
|
||||
* 非监督学习包括的类型:
|
||||
* 聚类:在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。
|
||||
* 密度估计:通过样本分布的紧密程度,来估计与分组的相似性。
|
||||
* 非监督学习包括的类型:
|
||||
* 聚类: 在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。
|
||||
* 密度估计: 通过样本分布的紧密程度,来估计与分组的相似性。
|
||||
* 此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据信息。
|
||||
### 强化学习
|
||||
这个算法可以训练程序做出某一决定。程序在某一情况下尝试所有的可能行动,记录不同行动的结果并试着找出最好的一次尝试来做决定。 属于这一类算法的有马尔可夫决策过程。
|
||||
@@ -127,54 +127,54 @@
|
||||
### Python语言
|
||||
|
||||
1. 可执行伪代码
|
||||
2. Python比较流行:使用广泛、代码范例多、丰富模块库,开发周期短
|
||||
3. Python语言的特色:清晰简练、易于理解
|
||||
4. Python语言的缺点:唯一不足的是性能问题
|
||||
2. Python比较流行: 使用广泛、代码范例多、丰富模块库,开发周期短
|
||||
3. Python语言的特色: 清晰简练、易于理解
|
||||
4. Python语言的缺点: 唯一不足的是性能问题
|
||||
5. Python相关的库
|
||||
* 科学函数库:`SciPy`、`NumPy`(底层语言:C和Fortran)
|
||||
* 绘图工具库:`Matplotlib`
|
||||
* 科学函数库: `SciPy`、`NumPy`(底层语言: C和Fortran)
|
||||
* 绘图工具库: `Matplotlib`
|
||||
* 数据分析库 `Pandas`
|
||||
### 数学工具
|
||||
* Matlab
|
||||
## 附:机器学习专业术语
|
||||
* 模型(model):计算机层面的认知
|
||||
## 附: 机器学习专业术语
|
||||
* 模型(model): 计算机层面的认知
|
||||
* 学习算法(learning algorithm),从数据中产生模型的方法
|
||||
* 数据集(data set):一组记录的合集
|
||||
* 示例(instance):对于某个对象的描述
|
||||
* 样本(sample):也叫示例
|
||||
* 属性(attribute):对象的某方面表现或特征
|
||||
* 特征(feature):同属性
|
||||
* 属性值(attribute value):属性上的取值
|
||||
* 属性空间(attribute space):属性张成的空间
|
||||
* 样本空间/输入空间(samplespace):同属性空间
|
||||
* 特征向量(feature vector):在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
|
||||
* 维数(dimensionality):描述样本参数的个数(也就是空间是几维的)
|
||||
* 学习(learning)/训练(training):从数据中学得模型
|
||||
* 训练数据(training data):训练过程中用到的数据
|
||||
* 数据集(data set): 一组记录的合集
|
||||
* 示例(instance): 对于某个对象的描述
|
||||
* 样本(sample): 也叫示例
|
||||
* 属性(attribute): 对象的某方面表现或特征
|
||||
* 特征(feature): 同属性
|
||||
* 属性值(attribute value): 属性上的取值
|
||||
* 属性空间(attribute space): 属性张成的空间
|
||||
* 样本空间/输入空间(samplespace): 同属性空间
|
||||
* 特征向量(feature vector): 在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
|
||||
* 维数(dimensionality): 描述样本参数的个数(也就是空间是几维的)
|
||||
* 学习(learning)/训练(training): 从数据中学得模型
|
||||
* 训练数据(training data): 训练过程中用到的数据
|
||||
* 训练样本(training sample):训练用到的每个样本
|
||||
* 训练集(training set):训练样本组成的集合
|
||||
* 假设(hypothesis):学习模型对应了关于数据的某种潜在规则
|
||||
* 训练集(training set): 训练样本组成的集合
|
||||
* 假设(hypothesis): 学习模型对应了关于数据的某种潜在规则
|
||||
* 真相(ground-truth):真正存在的潜在规律
|
||||
* 学习器(learner):模型的另一种叫法,把学习算法在给定数据和参数空间的实例化
|
||||
* 预测(prediction):判断一个东西的属性
|
||||
* 标记(label):关于示例的结果信息,比如我是一个“好人”。
|
||||
* 样例(example):拥有标记的示例
|
||||
* 标记空间/输出空间(label space):所有标记的集合
|
||||
* 分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务
|
||||
* 回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
|
||||
* 二分类(binary classification):只涉及两个类别的分类任务
|
||||
* 正类(positive class):二分类里的一个
|
||||
* 反类(negative class):二分类里的另外一个
|
||||
* 多分类(multi-class classification):涉及多个类别的分类
|
||||
* 测试(testing):学习到模型之后对样本进行预测的过程
|
||||
* 测试样本(testing sample):被预测的样本
|
||||
* 聚类(clustering):把训练集中的对象分为若干组
|
||||
* 簇(cluster):每一个组叫簇
|
||||
* 监督学习(supervised learning):典范--分类和回归
|
||||
* 无监督学习(unsupervised learning):典范--聚类
|
||||
* 未见示例(unseen instance):“新样本“,没训练过的样本
|
||||
* 泛化(generalization)能力:学得的模型适用于新样本的能力
|
||||
* 分布(distribution):样本空间的全体样本服从的一种规律
|
||||
* 学习器(learner): 模型的另一种叫法,把学习算法在给定数据和参数空间的实例化
|
||||
* 预测(prediction): 判断一个东西的属性
|
||||
* 标记(label): 关于示例的结果信息,比如我是一个“好人”。
|
||||
* 样例(example): 拥有标记的示例
|
||||
* 标记空间/输出空间(label space): 所有标记的集合
|
||||
* 分类(classification): 预测是离散值,比如把人分为好人和坏人之类的学习任务
|
||||
* 回归(regression): 预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
|
||||
* 二分类(binary classification): 只涉及两个类别的分类任务
|
||||
* 正类(positive class): 二分类里的一个
|
||||
* 反类(negative class): 二分类里的另外一个
|
||||
* 多分类(multi-class classification): 涉及多个类别的分类
|
||||
* 测试(testing): 学习到模型之后对样本进行预测的过程
|
||||
* 测试样本(testing sample): 被预测的样本
|
||||
* 聚类(clustering): 把训练集中的对象分为若干组
|
||||
* 簇(cluster): 每一个组叫簇
|
||||
* 监督学习(supervised learning): 典范--分类和回归
|
||||
* 无监督学习(unsupervised learning): 典范--聚类
|
||||
* 未见示例(unseen instance): “新样本“,没训练过的样本
|
||||
* 泛化(generalization)能力: 学得的模型适用于新样本的能力
|
||||
* 分布(distribution): 样本空间的全体样本服从的一种规律
|
||||
* 独立同分布(independent and identically distributed,简称i,i,d.):获得的每个样本都是独立地从这个分布上采样获得的。
|
||||
|
||||
## 机器学习基础补充
|
||||
@@ -187,10 +187,10 @@
|
||||
|
||||
### 模型拟合程度
|
||||
|
||||
* 欠拟合(Underfitting):模型没有很好地捕捉到数据特征,不能够很好地拟合数据,对训练样本的一般性质尚未学好。类比,光看书不做题觉得自己什么都会了,上了考场才知道自己啥都不会。
|
||||
* 过拟合(Overfitting):模型把训练样本学习“太好了”,可能把一些训练样本自身的特性当做了所有潜在样本都有的一般性质,导致泛化能力下降。类比,做课后题全都做对了,超纲题也都认为是考试必考题目,上了考场还是啥都不会。
|
||||
* 欠拟合(Underfitting): 模型没有很好地捕捉到数据特征,不能够很好地拟合数据,对训练样本的一般性质尚未学好。类比,光看书不做题觉得自己什么都会了,上了考场才知道自己啥都不会。
|
||||
* 过拟合(Overfitting): 模型把训练样本学习“太好了”,可能把一些训练样本自身的特性当做了所有潜在样本都有的一般性质,导致泛化能力下降。类比,做课后题全都做对了,超纲题也都认为是考试必考题目,上了考场还是啥都不会。
|
||||
|
||||
通俗来说,欠拟合和过拟合都可以用一句话来说,欠拟合就是:“你太天真了!”,过拟合就是:“你想太多了!”。
|
||||
通俗来说,欠拟合和过拟合都可以用一句话来说,欠拟合就是: “你太天真了!”,过拟合就是: “你想太多了!”。
|
||||
|
||||
### 常见的模型指标
|
||||
|
||||
@@ -198,22 +198,22 @@
|
||||
* 召回率 —— 提取出的正确信息条数 / 样本中的信息条数
|
||||
* F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值)
|
||||
|
||||
举个例子如下:
|
||||
举个例子如下:
|
||||
|
||||
举个例子如下:
|
||||
举个例子如下:
|
||||
某池塘有 1400 条鲤鱼,300 只虾,300 只乌龟。现在以捕鲤鱼为目的。撒了一张网,逮住了 700 条鲤鱼,200 只
|
||||
虾, 100 只乌龟。那么这些指标分别如下:
|
||||
虾, 100 只乌龟。那么这些指标分别如下:
|
||||
正确率 = 700 / (700 + 200 + 100) = 70%
|
||||
召回率 = 700 / 1400 = 50%
|
||||
F 值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
|
||||
|
||||
### 模型
|
||||
|
||||
* 分类问题 —— 说白了就是将一些未知类别的数据分到现在已知的类别中去。比如,根据你的一些信息,判断你是高富帅,还是穷屌丝。评判分类效果好坏的三个指标就是上面介绍的三个指标:正确率,召回率,F值。
|
||||
* 分类问题 —— 说白了就是将一些未知类别的数据分到现在已知的类别中去。比如,根据你的一些信息,判断你是高富帅,还是穷屌丝。评判分类效果好坏的三个指标就是上面介绍的三个指标: 正确率,召回率,F值。
|
||||
* 回归问题 —— 对数值型连续随机变量进行预测和建模的监督学习算法。回归往往会通过计算 误差(Error)来确定模型的精确性。
|
||||
* 聚类问题 —— 聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
|
||||
* 聚类问题 —— 聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类问题的标准一般基于距离: 簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
|
||||
|
||||
下面这个图可以比较直观地展示出来:
|
||||
下面这个图可以比较直观地展示出来:
|
||||
|
||||
|
||||
|
||||
@@ -223,17 +223,17 @@ F 值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
|
||||
|
||||
* 特征提取 —— 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点,连续的曲线或者连续的区域。
|
||||
|
||||
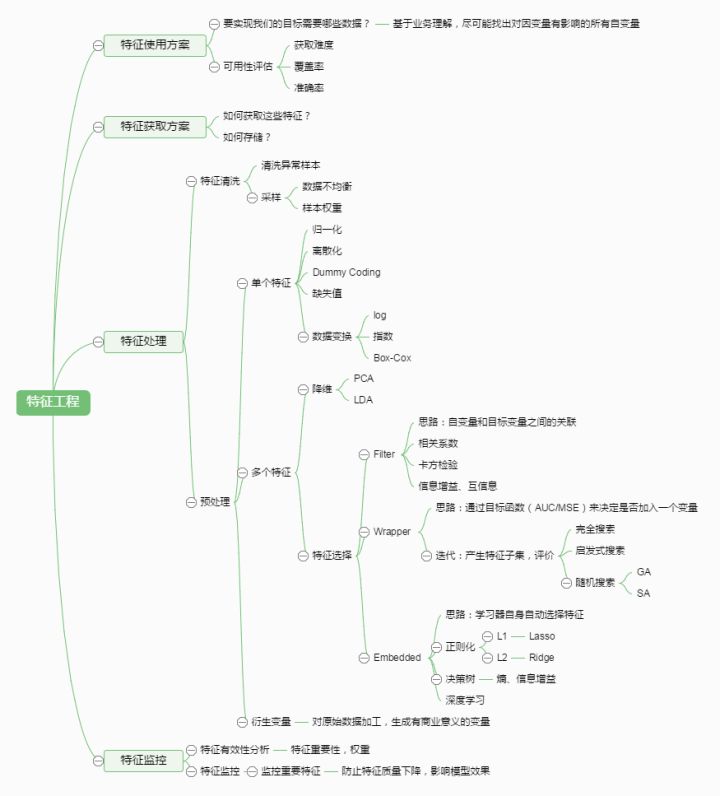
下面给出一个特征工程的图:
|
||||
下面给出一个特征工程的图:
|
||||
|
||||
|
||||
|
||||
### 其他
|
||||
|
||||
* Learning rate —— 学习率,通俗地理解,可以理解为步长,步子大了,很容易错过最佳结果。就是本来目标尽在咫尺,可是因为我迈的步子很大,却一下子走过了。步子小了呢,就是同样的距离,我却要走很多很多步,这样导致训练的耗时费力还不讨好。
|
||||
* 一个总结的知识点很棒的链接 :https://zhuanlan.zhihu.com/p/25197792
|
||||
* 一个总结的知识点很棒的链接 : https://zhuanlan.zhihu.com/p/25197792
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* **作者: [片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -1,15 +1,26 @@
|
||||
|
||||
# 第 10 章 K-Means(K-均值)聚类算法
|
||||
|
||||

|
||||
|
||||
## 聚类
|
||||
|
||||
聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来说,你并不清楚这个数据集内部有多少种类的动物,你能做的只是利用聚类方法将它自动按照特征分为多类,然后人为给出这个聚类结果的定义(即簇识别)。例如,你将一个动物集分为了三簇(类),然后通过观察这三类动物的特征,你为每一个簇起一个名字,如大象、狗、猫等,这就是聚类的基本思想。
|
||||
|
||||
至于“相似”这一概念,是利用距离这个评价标准来衡量的,我们通过计算对象与对象之间的距离远近来判断它们是否属于同一类别,即是否是同一个簇。至于距离如何计算,科学家们提出了许多种距离的计算方法,其中欧式距离是最为简单和常用的,除此之外还有曼哈顿距离和余弦相似性距离等。
|
||||
|
||||
欧式距离,我想大家再熟悉不过了,但为免有一些基础薄弱的同学,在此再说明一下,它的定义为:
|
||||
对于x点(坐标为(x1,x2,x3,...,xn))和 y点(坐标为(y1,y2,y3,...,yn)),两者的欧式距离为
|
||||

|
||||
欧式距离,我想大家再熟悉不过了,但为免有一些基础薄弱的同学,在此再说明一下,它的定义为:
|
||||
对于x点坐标为(x1,x2,x3,...,xn)和 y点坐标为(y1,y2,y3,...,yn),两者的欧式距离为:
|
||||
|
||||
$$
|
||||
d(x,y)
|
||||
={\sqrt{
|
||||
(x_{1}-y_{1})^{2}+(x_{2}-y_{2})^{2} + \cdots +(x_{n}-y_{n})^{2}
|
||||
}}
|
||||
={\sqrt{
|
||||
\sum_{ {i=1} }^{n}(x_{i}-y_{i})^{2}
|
||||
}}
|
||||
$$
|
||||
|
||||
在二维平面,它就是我们初中时就学过的两点距离公式
|
||||
|
||||
## K-Means 算法
|
||||
@@ -68,12 +79,12 @@ kmeans,如前所述,用于数据集内种类属性不明晰,希望能够
|
||||
### K-Means 开发流程
|
||||
|
||||
```
|
||||
收集数据:使用任意方法
|
||||
准备数据:需要数值型数据类计算距离, 也可以将标称型数据映射为二值型数据再用于距离计算
|
||||
分析数据:使用任意方法
|
||||
训练算法:不适用于无监督学习,即无监督学习不需要训练步骤
|
||||
测试算法:应用聚类算法、观察结果.可以使用量化的误差指标如误差平方和(后面会介绍)来评价算法的结果.
|
||||
使用算法:可以用于所希望的任何应用.通常情况下, 簇质心可以代表整个簇的数据来做出决策.
|
||||
收集数据: 使用任意方法
|
||||
准备数据: 需要数值型数据类计算距离, 也可以将标称型数据映射为二值型数据再用于距离计算
|
||||
分析数据: 使用任意方法
|
||||
训练算法: 不适用于无监督学习,即无监督学习不需要训练步骤
|
||||
测试算法: 应用聚类算法、观察结果.可以使用量化的误差指标如误差平方和(后面会介绍)来评价算法的结果.
|
||||
使用算法: 可以用于所希望的任何应用.通常情况下, 簇质心可以代表整个簇的数据来做出决策.
|
||||
```
|
||||
### K-Means 的评价标准
|
||||
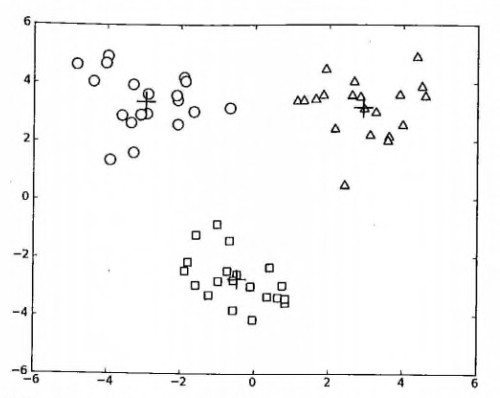
k-means算法因为手动选取k值和初始化随机质心的缘故,每一次的结果不会完全一样,而且由于手动选取k值,我们需要知道我们选取的k值是否合理,聚类效果好不好,那么如何来评价某一次的聚类效果呢?也许将它们画在图上直接观察是最好的办法,但现实是,我们的数据不会仅仅只有两个特征,一般来说都有十几个特征,而观察十几维的空间对我们来说是一个无法完成的任务。因此,我们需要一个公式来帮助我们判断聚类的性能,这个公式就是**SSE** (Sum of Squared Error, 误差平方和 ),它其实就是每一个点到其簇内质心的距离的平方值的总和,这个数值对应kmeans函数中**clusterAssment**矩阵的第一列之和。 **SSE**值越小表示数据点越接近于它们的质心,聚类效果也越好。 因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低**SSE**值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
|
||||
@@ -166,7 +177,7 @@ def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
|
||||
|
||||
为了保持簇总数不变,可以将某两个簇进行合并。从上图中很明显就可以看出,应该将上图下部两个出错的簇质心进行合并。那么问题来了,我们可以很容易对二维数据上的聚类进行可视化, 但是如果遇到40维的数据应该如何去做?
|
||||
|
||||
有两种可以量化的办法:合并最近的质心,或者合并两个使得**SSE**增幅最小的质心。 第一种思路通过计算所有质心之间的距离, 然后合并距离最近的两个点来实现。第二种方法需要合并两个簇然后计算总**SSE**值。必须在所有可能的两个簇上重复上述处理过程,直到找到合并最佳的两个簇为止。
|
||||
有两种可以量化的办法: 合并最近的质心,或者合并两个使得**SSE**增幅最小的质心。 第一种思路通过计算所有质心之间的距离, 然后合并距离最近的两个点来实现。第二种方法需要合并两个簇然后计算总**SSE**值。必须在所有可能的两个簇上重复上述处理过程,直到找到合并最佳的两个簇为止。
|
||||
|
||||
因为上述后处理过程实在是有些繁琐,所以有更厉害的大佬提出了另一个称之为二分K-均值(bisecting K-Means)的算法.
|
||||
|
||||
@@ -206,7 +217,7 @@ def biKMeans(dataSet, k, distMeas=distEclud):
|
||||
sseSplit = sum(splitClustAss[:,1]) # 将二分 kMeans 结果中的平方和的距离进行求和
|
||||
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) # 将未参与二分 kMeans 分配结果中的平方和的距离进行求和
|
||||
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
|
||||
if (sseSplit + sseNotSplit) < lowestSSE: # 总的(未拆分和已拆分)误差和越小,越相似,效果越优化,划分的结果更好(注意:这里的理解很重要,不明白的地方可以和我们一起讨论)
|
||||
if (sseSplit + sseNotSplit) < lowestSSE: # 总的(未拆分和已拆分)误差和越小,越相似,效果越优化,划分的结果更好(注意: 这里的理解很重要,不明白的地方可以和我们一起讨论)
|
||||
bestCentToSplit = i
|
||||
bestNewCents = centroidMat
|
||||
bestClustAss = splitClustAss.copy()
|
||||
@@ -230,6 +241,6 @@ def biKMeans(dataSet, k, distMeas=distEclud):
|
||||
运行参考结果如下:
|
||||
|
||||
|
||||
* **作者:[那伊抹微笑](http://cwiki.apachecn.org/display/~xuxin), [清都江水郎](http://cwiki.apachecn.org/display/~xuzhaoqing)**
|
||||
* **作者: [那伊抹微笑](http://cwiki.apachecn.org/display/~xuxin), [清都江水郎](http://cwiki.apachecn.org/display/~xuzhaoqing)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
@@ -47,20 +47,20 @@
|
||||
Apriori 算法优缺点
|
||||
|
||||
```
|
||||
* 优点:易编码实现
|
||||
* 缺点:在大数据集上可能较慢
|
||||
* 适用数据类型:数值型 或者 标称型数据。
|
||||
* 优点: 易编码实现
|
||||
* 缺点: 在大数据集上可能较慢
|
||||
* 适用数据类型: 数值型 或者 标称型数据。
|
||||
```
|
||||
|
||||
Apriori 算法流程步骤:
|
||||
Apriori 算法流程步骤:
|
||||
|
||||
```
|
||||
* 收集数据:使用任意方法。
|
||||
* 准备数据:任何数据类型都可以,因为我们只保存集合。
|
||||
* 分析数据:使用任意方法。
|
||||
* 训练数据:使用Apiori算法来找到频繁项集。
|
||||
* 测试算法:不需要测试过程。
|
||||
* 使用算法:用于发现频繁项集以及物品之间的关联规则。
|
||||
* 收集数据: 使用任意方法。
|
||||
* 准备数据: 任何数据类型都可以,因为我们只保存集合。
|
||||
* 分析数据: 使用任意方法。
|
||||
* 训练数据: 使用Apiori算法来找到频繁项集。
|
||||
* 测试算法: 不需要测试过程。
|
||||
* 使用算法: 用于发现频繁项集以及物品之间的关联规则。
|
||||
```
|
||||
|
||||
## Apriori 算法的使用
|
||||
@@ -288,7 +288,7 @@ def apriori(dataSet, minSupport=0.5):
|
||||
# 计算可信度(confidence)
|
||||
def calcConf(freqSet, H
|
||||
, supportData, brl, minConf=0.7):
|
||||
"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
|
||||
"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
|
||||
|
||||
Args:
|
||||
freqSet 频繁项集中的元素,例如: frozenset([1, 3])
|
||||
@@ -369,7 +369,7 @@ def generateRules(L, supportData, minConf=0.7):
|
||||
for i in range(1, len(L)):
|
||||
# 获取频繁项集中每个组合的所有元素
|
||||
for freqSet in L[i]:
|
||||
# 假设:freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]
|
||||
# 假设: freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]
|
||||
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
|
||||
H1 = [frozenset([item]) for item in freqSet]
|
||||
# 2 个的组合,走 else, 2 个以上的组合,走 if
|
||||
@@ -382,15 +382,15 @@ def generateRules(L, supportData, minConf=0.7):
|
||||
|
||||
到这里为止,通过调用 generateRules 函数即可得出我们所需的 `关联规则`。
|
||||
|
||||
* 分级法: 频繁项集->关联规则
|
||||
* 分级法: 频繁项集->关联规则
|
||||
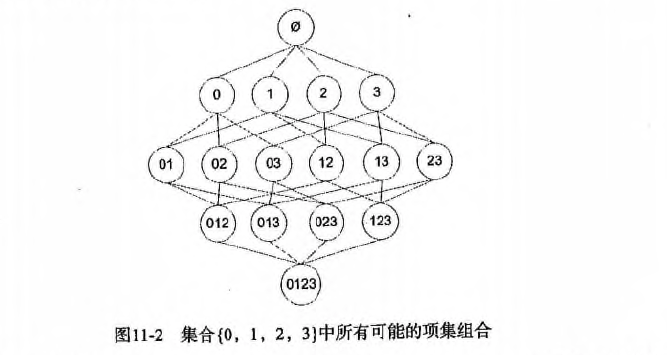
* 1.首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
|
||||
* 2.接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
|
||||
* 如下图:
|
||||
* 如下图:
|
||||
* 
|
||||
* 最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢? 下一章:FP-growth算法等着你的到来
|
||||
* 最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢? 下一章: FP-growth算法等着你的到来
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* **作者: [片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -69,13 +69,13 @@ class treeNode:
|
||||
FP-growth 算法优缺点:
|
||||
|
||||
```
|
||||
* 优点: 1. 因为 FP-growth 算法只需要对数据集遍历两次,所以速度更快。
|
||||
* 优点: 1. 因为 FP-growth 算法只需要对数据集遍历两次,所以速度更快。
|
||||
2. FP树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。
|
||||
3. 不需要生成候选集。
|
||||
4. 比Apriori更快。
|
||||
* 缺点: 1. FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
|
||||
* 缺点: 1. FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
|
||||
2. 构建FP-Tree是比较昂贵的。
|
||||
* 适用数据类型:标称型数据(离散型数据)。
|
||||
* 适用数据类型: 标称型数据(离散型数据)。
|
||||
```
|
||||
|
||||
|
||||
@@ -97,6 +97,6 @@ if __name__ == "__main__":
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[mikechengwei](https://github.com/mikechengwei)**
|
||||
* **作者: [mikechengwei](https://github.com/mikechengwei)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -11,7 +11,7 @@
|
||||
* 人们实时的将显示器上的百万像素转换成为一个三维图像,该图像就给出运动场上球的位置。
|
||||
* 在这个过程中,人们已经将百万像素点的数据,降至为三维。这个过程就称为`降维(dimensionality reduction)`
|
||||
|
||||
> 数据显示 并非大规模特征下的唯一难题,对数据进行简化还有如下一系列的原因:
|
||||
> 数据显示 并非大规模特征下的唯一难题,对数据进行简化还有如下一系列的原因:
|
||||
|
||||
* 1) 使得数据集更容易使用
|
||||
* 2) 降低很多算法的计算开销
|
||||
@@ -26,19 +26,19 @@
|
||||
> 在以下3种降维技术中, PCA的应用目前最为广泛,因此本章主要关注PCA。
|
||||
|
||||
* 1) 主成分分析(Principal Component Analysis, PCA)
|
||||
* `通俗理解:就是找出一个最主要的特征,然后进行分析。`
|
||||
* `例如: 考察一个人的智力情况,就直接看数学成绩就行(存在:数学、语文、英语成绩)`
|
||||
* `通俗理解: 就是找出一个最主要的特征,然后进行分析。`
|
||||
* `例如: 考察一个人的智力情况,就直接看数学成绩就行(存在: 数学、语文、英语成绩)`
|
||||
* 2) 因子分析(Factor Analysis)
|
||||
* `通俗理解:将多个实测变量转换为少数几个综合指标。它反映一种降维的思想,通过降维将相关性高的变量聚在一起,从而减少需要分析的变量的数量,而减少问题分析的复杂性`
|
||||
* `例如: 考察一个人的整体情况,就直接组合3样成绩(隐变量),看平均成绩就行(存在:数学、语文、英语成绩)`
|
||||
* 应用的领域:社会科学、金融和其他领域
|
||||
* `通俗理解: 将多个实测变量转换为少数几个综合指标。它反映一种降维的思想,通过降维将相关性高的变量聚在一起,从而减少需要分析的变量的数量,而减少问题分析的复杂性`
|
||||
* `例如: 考察一个人的整体情况,就直接组合3样成绩(隐变量),看平均成绩就行(存在: 数学、语文、英语成绩)`
|
||||
* 应用的领域: 社会科学、金融和其他领域
|
||||
* 在因子分析中,我们
|
||||
* 假设观察数据的成分中有一些观察不到的隐变量(latent variable)。
|
||||
* 假设观察数据是这些隐变量和某些噪音的线性组合。
|
||||
* 那么隐变量的数据可能比观察数据的数目少,也就说通过找到隐变量就可以实现数据的降维。
|
||||
* 3) 独立成分分析(Independ Component Analysis, ICA)
|
||||
* `通俗理解:ICA 认为观测信号是若干个独立信号的线性组合,ICA 要做的是一个解混过程。`
|
||||
* `例如:我们去ktv唱歌,想辨别唱的是什么歌曲?ICA 是观察发现是原唱唱的一首歌【2个独立的声音(原唱/主唱)】。`
|
||||
* `通俗理解: ICA 认为观测信号是若干个独立信号的线性组合,ICA 要做的是一个解混过程。`
|
||||
* `例如: 我们去ktv唱歌,想辨别唱的是什么歌曲?ICA 是观察发现是原唱唱的一首歌【2个独立的声音(原唱/主唱)】。`
|
||||
* ICA 是假设数据是从 N 个数据源混合组成的,这一点和因子分析有些类似,这些数据源之间在统计上是相互独立的,而在 PCA 中只假设数据是不 相关(线性关系)的。
|
||||
* 同因子分析一样,如果数据源的数目少于观察数据的数目,则可以实现降维过程。
|
||||
|
||||
@@ -47,11 +47,11 @@
|
||||
|
||||
### PCA 概述
|
||||
|
||||
主成分分析(Principal Component Analysis, PCA):`通俗理解:就是找出一个最主要的特征,然后进行分析。`
|
||||
主成分分析(Principal Component Analysis, PCA): `通俗理解: 就是找出一个最主要的特征,然后进行分析。`
|
||||
|
||||
### PCA 场景
|
||||
|
||||
`例如: 考察一个人的智力情况,就直接看数学成绩就行(存在:数学、语文、英语成绩)`
|
||||
`例如: 考察一个人的智力情况,就直接看数学成绩就行(存在: 数学、语文、英语成绩)`
|
||||
|
||||
### PCA 原理
|
||||
|
||||
@@ -68,16 +68,16 @@
|
||||
1. 正交是为了数据有效性损失最小
|
||||
2. 正交的一个原因是特征值的特征向量是正交的
|
||||
|
||||
例如下图:
|
||||
例如下图:
|
||||
|
||||
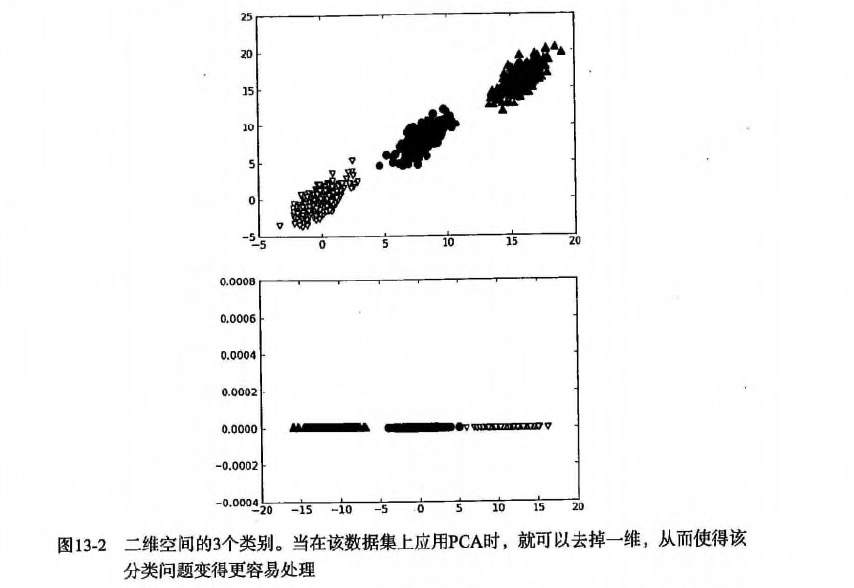
|
||||
|
||||
> PCA 优缺点
|
||||
|
||||
```
|
||||
优点:降低数据的复杂性,识别最重要的多个特征。
|
||||
缺点:不一定需要,且可能损失有用信息。
|
||||
适用数据类型:数值型数据。
|
||||
优点: 降低数据的复杂性,识别最重要的多个特征。
|
||||
缺点: 不一定需要,且可能损失有用信息。
|
||||
适用数据类型: 数值型数据。
|
||||
```
|
||||
|
||||
### 项目案例: 对半导体数据进行降维处理
|
||||
@@ -92,16 +92,16 @@
|
||||
具体来讲,它拥有590个特征。我们看看能否对这些特征进行降维处理。
|
||||
|
||||
对于数据的缺失值的问题,我们有一些处理方法(参考第5章)
|
||||
目前该章节处理的方案是:将缺失值NaN(Not a Number缩写),全部用平均值来替代(如果用0来处理的策略就太差劲了)。
|
||||
目前该章节处理的方案是: 将缺失值NaN(Not a Number缩写),全部用平均值来替代(如果用0来处理的策略就太差劲了)。
|
||||
```
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集数据:提供文本文件
|
||||
> 收集数据: 提供文本文件
|
||||
|
||||
文件名:secom.data
|
||||
文件名: secom.data
|
||||
|
||||
文本文件数据格式如下:
|
||||
文本文件数据格式如下:
|
||||
|
||||
```
|
||||
3030.93 2564 2187.7333 1411.1265 1.3602 100 97.6133 0.1242 1.5005 0.0162 -0.0034 0.9455 202.4396 0 7.9558 414.871 10.0433 0.968 192.3963 12.519 1.4026 -5419 2916.5 -4043.75 751 0.8955 1.773 3.049 64.2333 2.0222 0.1632 3.5191 83.3971 9.5126 50.617 64.2588 49.383 66.3141 86.9555 117.5132 61.29 4.515 70 352.7173 10.1841 130.3691 723.3092 1.3072 141.2282 1 624.3145 218.3174 0 4.592 4.841 2834 0.9317 0.9484 4.7057 -1.7264 350.9264 10.6231 108.6427 16.1445 21.7264 29.5367 693.7724 0.9226 148.6009 1 608.17 84.0793 NaN NaN 0 0.0126 -0.0206 0.0141 -0.0307 -0.0083 -0.0026 -0.0567 -0.0044 7.2163 0.132 NaN 2.3895 0.969 1747.6049 0.1841 8671.9301 -0.3274 -0.0055 -0.0001 0.0001 0.0003 -0.2786 0 0.3974 -0.0251 0.0002 0.0002 0.135 -0.0042 0.0003 0.0056 0 -0.2468 0.3196 NaN NaN NaN NaN 0.946 0 748.6115 0.9908 58.4306 0.6002 0.9804 6.3788 15.88 2.639 15.94 15.93 0.8656 3.353 0.4098 3.188 -0.0473 0.7243 0.996 2.2967 1000.7263 39.2373 123 111.3 75.2 46.2 350.671 0.3948 0 6.78 0.0034 0.0898 0.085 0.0358 0.0328 12.2566 0 4.271 10.284 0.4734 0.0167 11.8901 0.41 0.0506 NaN NaN 1017 967 1066 368 0.09 0.048 0.095 2 0.9 0.069 0.046 0.725 0.1139 0.3183 0.5888 0.3184 0.9499 0.3979 0.16 0 0 20.95 0.333 12.49 16.713 0.0803 5.72 0 11.19 65.363 0 0 0 0 0 0 0.292 5.38 20.1 0.296 10.62 10.3 5.38 4.04 16.23 0.2951 8.64 0 10.3 97.314 0 0.0772 0.0599 0.07 0.0547 0.0704 0.052 0.0301 0.1135 3.4789 0.001 NaN 0.0707 0.0211 175.2173 0.0315 1940.3994 0 0.0744 0.0546 0 0 0 0 0 0 0 0 0 0.0027 0.004 0 0 0 0 NaN NaN NaN NaN 0.0188 0 219.9453 0.0011 2.8374 0.0189 0.005 0.4269 0 0 0 0 0 0 0 0 0 0 0 0.0472 40.855 4.5152 30.9815 33.9606 22.9057 15.9525 110.2144 0.131 0 2.5883 0.001 0.0319 0.0197 0.012 0.0109 3.9321 0 1.5123 3.5811 0.1337 0.0055 3.8447 0.1077 0.0167 NaN NaN 418.1363 398.3185 496.1582 158.333 0.0373 0.0202 0.0462 0.6083 0.3032 0.02 0.0174 0.2827 0.0434 0.1342 0.2419 0.1343 0.367 0.1431 0.061 0 0 0 6.2698 0.1181 3.8208 5.3737 0.0254 1.6252 0 3.2461 18.0118 0 0 0 0 0 0 0.0752 1.5989 6.5893 0.0913 3.0911 8.4654 1.5989 1.2293 5.3406 0.0867 2.8551 0 2.9971 31.8843 NaN NaN 0 0.0215 0.0274 0.0315 0.0238 0.0206 0.0238 0.0144 0.0491 1.2708 0.0004 NaN 0.0229 0.0065 55.2039 0.0105 560.2658 0 0.017 0.0148 0.0124 0.0114 0 0 0 0 0 0 0 0.001 0.0013 0 0 0 0 NaN NaN NaN NaN 0.0055 0 61.5932 0.0003 0.9967 0.0082 0.0017 0.1437 0 0 0 0 0 0 0 0 0 0 0 0.0151 14.2396 1.4392 5.6188 3.6721 2.9329 2.1118 24.8504 29.0271 0 6.9458 2.738 5.9846 525.0965 0 3.4641 6.0544 0 53.684 2.4788 4.7141 1.7275 6.18 3.275 3.6084 18.7673 33.1562 26.3617 49.0013 10.0503 2.7073 3.1158 3.1136 44.5055 42.2737 1.3071 0.8693 1.1975 0.6288 0.9163 0.6448 1.4324 0.4576 0.1362 0 0 0 5.9396 3.2698 9.5805 2.3106 6.1463 4.0502 0 1.7924 29.9394 0 0 0 0 0 0 6.2052 311.6377 5.7277 2.7864 9.7752 63.7987 24.7625 13.6778 2.3394 31.9893 5.8142 0 1.6936 115.7408 0 613.3069 291.4842 494.6996 178.1759 843.1138 0 53.1098 0 48.2091 0.7578 NaN 2.957 2.1739 10.0261 17.1202 22.3756 0 0 0 0 0 0 0 0 0 0 0 0 64.6707 0 0 0 0 0 NaN NaN NaN NaN 1.9864 0 29.3804 0.1094 4.856 3.1406 0.5064 6.6926 0 0 0 0 0 0 0 0 0 0 0 2.057 4.0825 11.5074 0.1096 0.0078 0.0026 7.116 1.0616 395.57 75.752 0.4234 12.93 0.78 0.1827 5.7349 0.3363 39.8842 3.2687 1.0297 1.0344 0.4385 0.1039 42.3877 NaN NaN NaN NaN NaN NaN NaN NaN 533.85 2.1113 8.95 0.3157 3.0624 0.1026 1.6765 14.9509 NaN NaN NaN NaN 0.5005 0.0118 0.0035 2.363 NaN NaN NaN NaN
|
||||
@@ -111,7 +111,7 @@
|
||||
3032.24 2502.87 2233.3667 1326.52 1.5334 100 100.3967 0.1235 1.5031 -0.0031 -0.0072 0.9569 201.9424 0 10.5661 420.5925 10.3387 0.9735 191.6037 12.4735 1.3888 -5476.25 2635.25 -3987.5 117 1.2887 1.9912 7.2748 62.8333 3.1556 0.2696 3.2728 86.3269 8.7677 50.248 64.1511 49.752 66.1542 86.1468 121.4364 76.39 2.209 70 353.34 10.4091 176.3136 789.7523 1.0341 138.0882 1 667.7418 233.5491 0 4.624 4.894 2865 0.9298 0.9449 4.6414 -12.2945 355.0809 9.7948 144.0191 21.9782 32.2945 44.1498 745.6025 0.9256 146.6636 1 645.7636 65.8417 NaN NaN 0 -0.0534 0.0183 -0.0167 -0.0449 0.0034 -0.0178 -0.0123 -0.0048 7.5017 0.1342 NaN 2.453 0.9902 1828.3846 0.1829 9014.46 0.0448 -0.0077 -0.0001 -0.0001 -0.0001 0.2189 0 -0.6704 -0.0167 0.0004 -0.0003 0.0696 -0.0045 0.0002 0.0078 0 -0.0799 -0.2038 NaN NaN NaN NaN 0.9424 0 796.595 0.9908 58.3858 0.5913 0.9628 6.3551 15.75 3.148 15.73 15.71 0.946 3.027 0.5328 3.299 -0.5677 0.778 1.001 2.3715 993.1274 38.1448 119 143.2 123.1 48.8 296.303 0.3744 0 3.64 0.0041 0.0634 0.0451 0.0623 0.024 14.2354 0 9.005 12.506 0.4434 0.0126 13.9047 0.43 0.0538 NaN NaN 699 283 1747 1443 0.147 0.04 0.113 3.9 0.8 0.101 0.499 0.576 0.0631 0.3053 0.583 0.3053 0.8285 0.1308 0.922 0 0 15.24 0.282 10.85 37.715 0.1189 3.98 0 25.54 72.149 0 0 0 0 0 0 0.25 5.52 15.76 0.519 10.71 19.77 5.52 8.446 33.832 0.3951 9.09 0 19.77 92.307 0 0.0915 0.0506 0.0769 0.1079 0.0797 0.1047 0.0924 0.1015 4.1338 0.003 NaN 0.0802 0.0004 69.151 0.197 1406.4004 0 0.0227 0.0272 0 0 0 0 0 0 0 0 0 0.0067 0.0031 0 0 0 0 NaN NaN NaN NaN 0.024 0 149.2172 0.0006 2.5775 0.0177 0.0214 0.4051 0 0 0 0 0 0 0 0 0 0 0 0.0488 19.862 3.6163 34.125 55.9626 53.0876 17.4864 88.7672 0.1092 0 1.0929 0.0013 0.0257 0.0116 0.0163 0.008 4.4239 0 3.2376 3.6536 0.1293 0.004 4.3474 0.1275 0.0181 NaN NaN 319.1252 128.0296 799.5884 628.3083 0.0755 0.0181 0.0476 1.35 0.2698 0.032 0.1541 0.2155 0.031 0.1354 0.2194 0.1354 0.3072 0.0582 0.3574 0 0 0 4.8956 0.0766 2.913 11.0583 0.0327 1.1229 0 7.3296 23.116 0 0 0 0 0 0 0.0822 1.6216 4.7279 0.1773 3.155 9.7777 1.6216 2.5923 10.5352 0.1301 3.0939 0 6.3767 32.0537 NaN NaN 0 0.0246 0.0221 0.0329 0.0522 0.0256 0.0545 0.0476 0.0463 1.553 0.001 NaN 0.0286 0.0001 21.0312 0.0573 494.7368 0 0.0063 0.0077 0.0052 0.0027 0 0 0 0 0 0 0 0.0025 0.0012 0 0 0 0 NaN NaN NaN NaN 0.0089 0 57.2692 0.0002 0.8495 0.0065 0.0077 0.1356 0 0 0 0 0 0 0 0 0 0 0 0.0165 7.1493 1.1704 5.3823 4.7226 4.9184 2.185 22.3369 24.4142 0 3.6256 3.3208 4.2178 0 866.0295 2.5046 7.0492 0 85.2255 2.9734 4.2892 1.2943 7.257 3.4473 3.8754 12.7642 10.739 43.8119 0 11.4064 2.0088 1.5533 6.2069 25.3521 37.4691 15.247 0.6672 0.7198 0.6076 0.9088 0.6136 1.2524 0.1518 0.7592 0 0 0 4.3131 2.7092 6.1538 4.7756 11.4945 2.8822 0 3.8248 30.8924 0 0 0 0 0 0 5.3863 44.898 4.4384 5.2987 7.4365 89.9529 17.0927 19.1303 4.5375 42.6838 6.1979 0 3.0615 140.1953 0 171.4486 276.881 461.8619 240.1781 0 587.3773 748.1781 0 55.1057 2.2358 NaN 3.2712 0.0372 3.7821 107.6905 15.6016 0 293.1396 0 0 0 0 0 0 0 0 0 0 148.0663 0 0 0 0 0 NaN NaN NaN NaN 2.5512 0 18.7319 0.0616 4.4146 2.9954 2.2181 6.3745 0 0 0 0 0 0 0 0 0 0 0 2.0579 1.9999 9.4805 0.1096 0.0078 0.0026 7.116 1.4636 399.914 79.156 1.0388 19.63 1.98 0.4287 9.7608 0.8311 70.9706 4.9086 2.5014 0.9778 0.2156 0.0461 22.05 NaN NaN NaN NaN NaN NaN NaN NaN 532.0155 2.0275 8.83 0.2224 3.1776 0.0706 1.6597 10.9698 NaN NaN NaN NaN 0.48 0.4766 0.1045 99.3032 0.0202 0.0149 0.0044 73.8432
|
||||
```
|
||||
|
||||
> 准备数据:将value为NaN的替换为均值
|
||||
> 准备数据: 将value为NaN的替换为均值
|
||||
|
||||
```python
|
||||
def replaceNanWithMean():
|
||||
@@ -126,7 +126,7 @@ def replaceNanWithMean():
|
||||
return datMat
|
||||
```
|
||||
|
||||
> 分析数据:统计分析 N 的阈值
|
||||
> 分析数据: 统计分析 N 的阈值
|
||||
|
||||

|
||||
|
||||
@@ -134,7 +134,7 @@ def replaceNanWithMean():
|
||||
|
||||
在等式 Av=入v 中,v 是特征向量, 入是特征值。<br/>
|
||||
表示 如果特征向量 v 被某个矩阵 A 左乘,那么它就等于某个标量 入 乘以 v.<br/>
|
||||
幸运的是: Numpy 中有寻找特征向量和特征值的模块 linalg,它有 eig() 方法,该方法用于求解特征向量和特征值。
|
||||
幸运的是: Numpy 中有寻找特征向量和特征值的模块 linalg,它有 eig() 方法,该方法用于求解特征向量和特征值。
|
||||
|
||||
```python
|
||||
def pca(dataMat, topNfeat=9999999):
|
||||
@@ -158,9 +158,9 @@ def pca(dataMat, topNfeat=9999999):
|
||||
|
||||
# cov协方差=[(x1-x均值)*(y1-y均值)+(x2-x均值)*(y2-y均值)+...+(xn-x均值)*(yn-y均值)+]/(n-1)
|
||||
'''
|
||||
方差:(一维)度量两个随机变量关系的统计量
|
||||
协方差: (二维)度量各个维度偏离其均值的程度
|
||||
协方差矩阵:(多维)度量各个维度偏离其均值的程度
|
||||
方差: (一维)度量两个随机变量关系的统计量
|
||||
协方差: (二维)度量各个维度偏离其均值的程度
|
||||
协方差矩阵: (多维)度量各个维度偏离其均值的程度
|
||||
|
||||
当 cov(X, Y)>0时,表明X与Y正相关;(X越大,Y也越大;X越小Y,也越小。这种情况,我们称为“正相关”。)
|
||||
当 cov(X, Y)<0时,表明X与Y负相关;
|
||||
@@ -212,7 +212,7 @@ def pca(dataMat, topNfeat=9999999):
|
||||
```
|
||||
降维技术使得数据变的更易使用,并且它们往往能够去除数据中的噪音,使得其他机器学习任务更加精确。
|
||||
降维往往作为预处理步骤,在数据应用到其他算法之前清洗数据。
|
||||
比较流行的降维技术: 独立成分分析、因子分析 和 主成分分析, 其中又以主成分分析应用最广泛。
|
||||
比较流行的降维技术: 独立成分分析、因子分析 和 主成分分析, 其中又以主成分分析应用最广泛。
|
||||
|
||||
本章中的PCA将所有的数据集都调入了内存,如果无法做到,就需要其他的方法来寻找其特征值。
|
||||
如果使用在线PCA分析的方法,你可以参考一篇优秀的论文 "Incremental Eigenanalysis for Classification"。
|
||||
@@ -221,6 +221,6 @@ def pca(dataMat, topNfeat=9999999):
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* **作者: [片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
|
||||
> 信息检索-隐性语义检索(Latent Semantic Indexing, LSI)或 隐形语义分析(Latent Semantic Analysis, LSA)
|
||||
|
||||
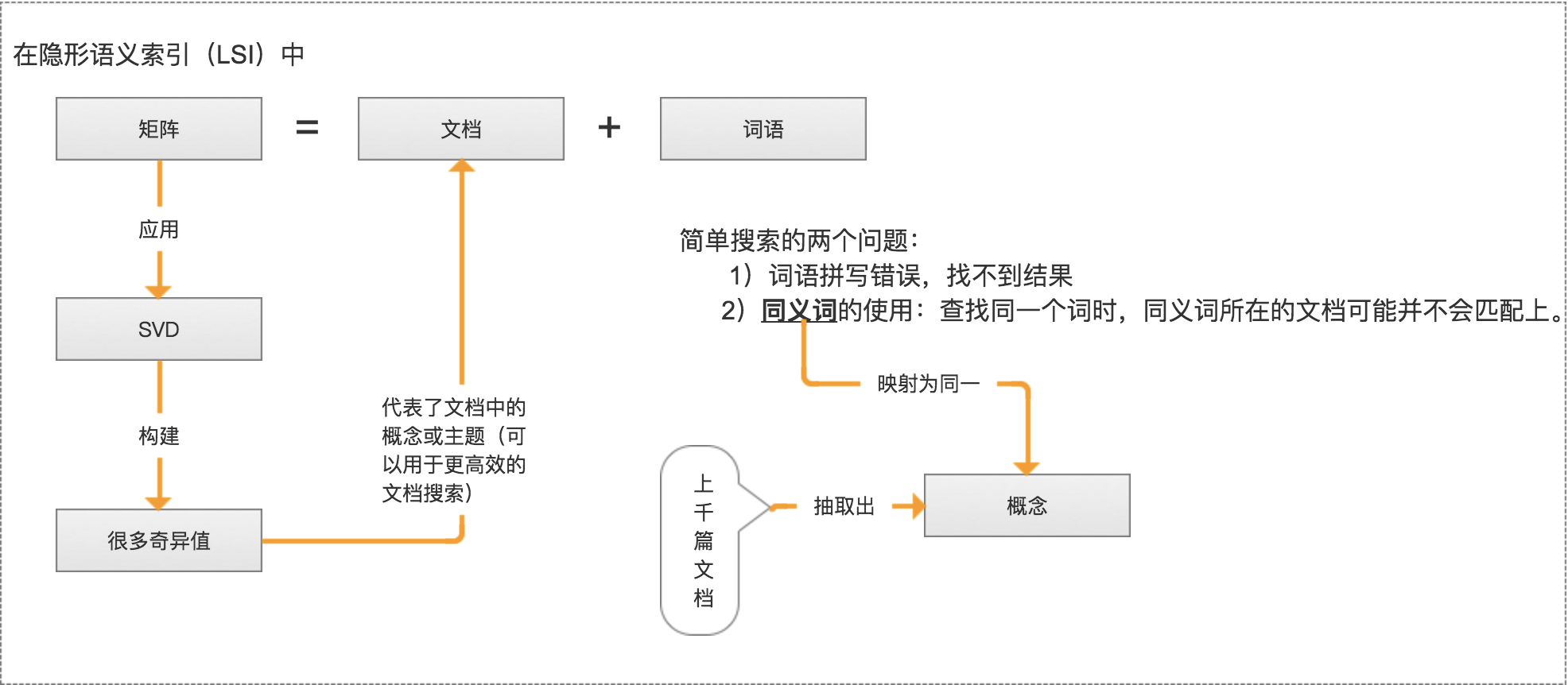
隐性语义索引:矩阵 = 文档 + 词语
|
||||
隐性语义索引: 矩阵 = 文档 + 词语
|
||||
* 是最早的 SVD 应用之一,我们称利用 SVD 的方法为隐性语义索引(LSI)或隐性语义分析(LSA)。
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@
|
||||
|
||||
> 图像压缩
|
||||
|
||||
例如:`32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
例如: `32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
|
||||
|
||||
|
||||
@@ -42,12 +42,12 @@
|
||||
|
||||
* 矩阵分解是将数据矩阵分解为多个独立部分的过程。
|
||||
* 矩阵分解可以将原始矩阵表示成新的易于处理的形式,这种新形式是两个或多个矩阵的乘积。(类似代数中的因数分解)
|
||||
* 举例:如何将12分解成两个数的乘积?(1,12)、(2,6)、(3,4)都是合理的答案。
|
||||
* 举例: 如何将12分解成两个数的乘积?(1,12)、(2,6)、(3,4)都是合理的答案。
|
||||
|
||||
> SVD 是矩阵分解的一种类型,也是矩阵分解最常见的技术
|
||||
|
||||
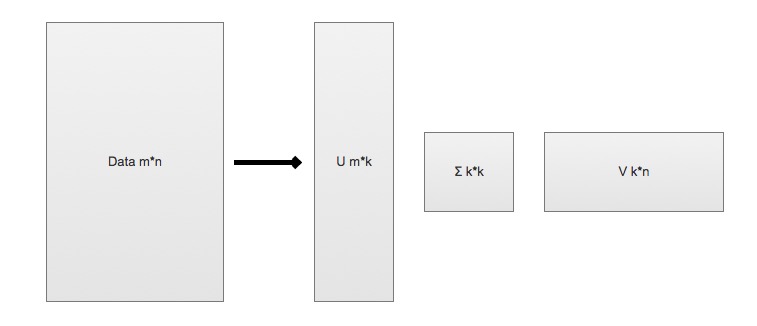
* SVD 将原始的数据集矩阵 Data 分解成三个矩阵 U、∑、V
|
||||
* 举例:如果原始矩阵 \\(Data_{m*n}\\) 是m行n列,
|
||||
* 举例: 如果原始矩阵 \\(Data_{m*n}\\) 是m行n列,
|
||||
* \\(U_{m * k}\\) 表示m行k列
|
||||
* \\(∑_{k * k}\\) 表示k行k列
|
||||
* \\(V_{k * n}\\) 表示k行n列。
|
||||
@@ -56,20 +56,20 @@
|
||||
|
||||

|
||||
|
||||
具体的案例:(大家可以试着推导一下:https://wenku.baidu.com/view/b7641217866fb84ae45c8d17.html )
|
||||
具体的案例: (大家可以试着推导一下: https://wenku.baidu.com/view/b7641217866fb84ae45c8d17.html )
|
||||
|
||||

|
||||
|
||||
* 上述分解中会构建出一个矩阵∑,该矩阵只有对角元素,其他元素均为0(近似于0)。另一个惯例就是,∑的对角元素是从大到小排列的。这些对角元素称为奇异值。
|
||||
* 奇异值与特征值(PCA 数据中重要特征)是有关系的。这里的奇异值就是矩阵 \\(Data * Data^T\\) 特征值的平方根。
|
||||
* 普遍的事实:在某个奇异值的数目(r 个=>奇异值的平方和累加到总值的90%以上)之后,其他的奇异值都置为0(近似于0)。这意味着数据集中仅有 r 个重要特征,而其余特征则都是噪声或冗余特征。
|
||||
* 普遍的事实: 在某个奇异值的数目(r 个=>奇异值的平方和累加到总值的90%以上)之后,其他的奇异值都置为0(近似于0)。这意味着数据集中仅有 r 个重要特征,而其余特征则都是噪声或冗余特征。
|
||||
|
||||
### SVD 算法特点
|
||||
|
||||
```
|
||||
优点:简化数据,去除噪声,优化算法的结果
|
||||
缺点:数据的转换可能难以理解
|
||||
使用的数据类型:数值型数据
|
||||
优点: 简化数据,去除噪声,优化算法的结果
|
||||
缺点: 数据的转换可能难以理解
|
||||
使用的数据类型: 数值型数据
|
||||
```
|
||||
|
||||
## 推荐系统
|
||||
@@ -89,17 +89,17 @@
|
||||
> 基于协同过滤(collaborative filtering) 的推荐引擎
|
||||
|
||||
* 利用Python 实现 SVD(Numpy 有一个称为 linalg 的线性代数工具箱)
|
||||
* 协同过滤:是通过将用户和其他用户的数据进行对比来实现推荐的。
|
||||
* 协同过滤: 是通过将用户和其他用户的数据进行对比来实现推荐的。
|
||||
* 当知道了两个用户或两个物品之间的相似度,我们就可以利用已有的数据来预测未知用户的喜好。
|
||||
|
||||
> 基于物品的相似度和基于用户的相似度:物品比较少则选择物品相似度,用户比较少则选择用户相似度。【矩阵还是小一点好计算】
|
||||
> 基于物品的相似度和基于用户的相似度: 物品比较少则选择物品相似度,用户比较少则选择用户相似度。【矩阵还是小一点好计算】
|
||||
|
||||
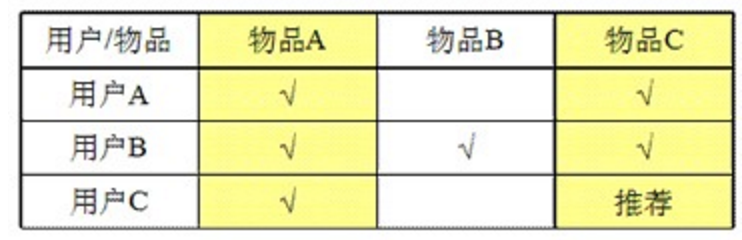
* 基于物品的相似度:计算物品之间的距离。【耗时会随物品数量的增加而增加】
|
||||
* 基于物品的相似度: 计算物品之间的距离。【耗时会随物品数量的增加而增加】
|
||||
* 由于物品A和物品C 相似度(相关度)很高,所以给买A的人推荐C。
|
||||
|
||||
|
||||
|
||||
* 基于用户的相似度:计算用户之间的距离。【耗时会随用户数量的增加而增加】
|
||||
* 基于用户的相似度: 计算用户之间的距离。【耗时会随用户数量的增加而增加】
|
||||
* 由于用户A和用户C 相似度(相关度)很高,所以A和C是兴趣相投的人,对于C买的物品就会推荐给A。
|
||||
|
||||
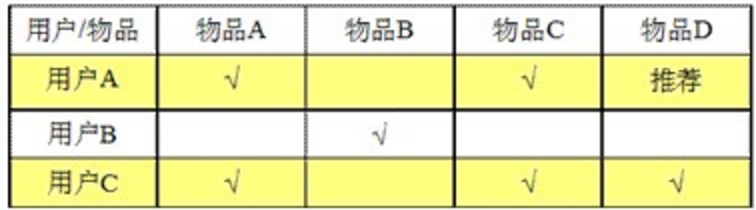
|
||||
@@ -107,15 +107,15 @@
|
||||
> 相似度计算
|
||||
|
||||
* inA, inB 对应的是 列向量
|
||||
1. 欧氏距离:指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。二维或三维中的欧氏距离就是两点之间的实际距离。
|
||||
1. 欧氏距离: 指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。二维或三维中的欧氏距离就是两点之间的实际距离。
|
||||
* 相似度= 1/(1+欧式距离)
|
||||
* `相似度= 1.0/(1.0 + la.norm(inA - inB))`
|
||||
* 物品对越相似,它们的相似度值就越大。
|
||||
2. 皮尔逊相关系数:度量的是两个向量之间的相似度。
|
||||
2. 皮尔逊相关系数: 度量的是两个向量之间的相似度。
|
||||
* 相似度= 0.5 + 0.5*corrcoef() 【皮尔逊相关系数的取值范围从 -1 到 +1,通过函数0.5 + 0.5\*corrcoef()这个函数计算,把值归一化到0到1之间】
|
||||
* `相似度= 0.5 + 0.5 * corrcoef(inA, inB, rowvar = 0)[0][1]`
|
||||
* 相对欧氏距离的优势:它对用户评级的量级并不敏感。
|
||||
3. 余弦相似度:计算的是两个向量夹角的余弦值。
|
||||
* 相对欧氏距离的优势: 它对用户评级的量级并不敏感。
|
||||
3. 余弦相似度: 计算的是两个向量夹角的余弦值。
|
||||
* 余弦值 = (A·B)/(||A||·||B||) 【余弦值的取值范围也在-1到+1之间】
|
||||
* 相似度= 0.5 + 0.5*余弦值
|
||||
* `相似度= 0.5 + 0.5*( float(inA.T*inB) / la.norm(inA)*la.norm(inB))`
|
||||
@@ -124,15 +124,15 @@
|
||||
> 推荐系统的评价
|
||||
|
||||
* 采用交叉测试的方法。【拆分数据为训练集和测试集】
|
||||
* 推荐引擎评价的指标: 最小均方根误差(Root mean squared error, RMSE),也称标准误差(Standard error),就是计算均方误差的平均值然后取其平方根。
|
||||
* 推荐引擎评价的指标: 最小均方根误差(Root mean squared error, RMSE),也称标准误差(Standard error),就是计算均方误差的平均值然后取其平方根。
|
||||
* 如果RMSE=1, 表示相差1个星级;如果RMSE=2.5, 表示相差2.5个星级。
|
||||
|
||||
### 推荐系统 原理
|
||||
|
||||
* 推荐系统的工作过程:给定一个用户,系统会为此用户返回N个最好的推荐菜。
|
||||
* 实现流程大致如下:
|
||||
* 推荐系统的工作过程: 给定一个用户,系统会为此用户返回N个最好的推荐菜。
|
||||
* 实现流程大致如下:
|
||||
1. 寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值。
|
||||
2. 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说:我们认为用户可能会对物品的打分(这就是相似度计算的初衷)。
|
||||
2. 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说: 我们认为用户可能会对物品的打分(这就是相似度计算的初衷)。
|
||||
3. 对这些物品的评分从高到低进行排序,返回前N个物品。
|
||||
|
||||
|
||||
@@ -152,9 +152,9 @@
|
||||
def loadExData3():
|
||||
# 利用SVD提高推荐效果,菜肴矩阵
|
||||
"""
|
||||
行:代表人
|
||||
列:代表菜肴名词
|
||||
值:代表人对菜肴的评分,0表示未评分
|
||||
行: 代表人
|
||||
列: 代表菜肴名词
|
||||
值: 代表人对菜肴的评分,0表示未评分
|
||||
"""
|
||||
return[[2, 0, 0, 4, 4, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
|
||||
@@ -227,7 +227,7 @@ def standEst(dataMat, user, simMeas, item):
|
||||
return ratSimTotal/simTotal
|
||||
```
|
||||
|
||||
* 2.基于SVD(参考地址:http://www.codeweblog.com/svd-%E7%AC%94%E8%AE%B0/)
|
||||
* 2.基于SVD(参考地址: http://www.codeweblog.com/svd-%E7%AC%94%E8%AE%B0/)
|
||||
|
||||
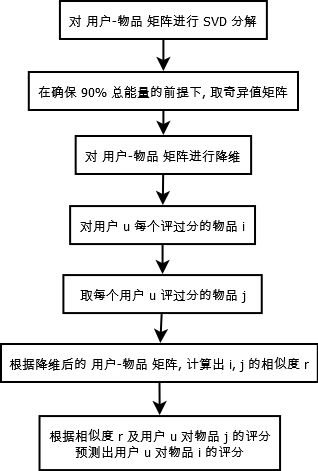
|
||||
|
||||
@@ -315,14 +315,14 @@ def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
|
||||
|
||||
1. 通过各种标签来标记菜肴
|
||||
2. 将这些属性作为相似度计算所需要的数据
|
||||
3. 这就是:基于内容的推荐。
|
||||
3. 这就是: 基于内容的推荐。
|
||||
|
||||
> 构建推荐引擎面临的挑战
|
||||
|
||||
问题
|
||||
* 1)在大规模的数据集上,SVD分解会降低程序的速度
|
||||
* 2)存在其他很多规模扩展性的挑战性问题,比如矩阵的表示方法和计算相似度得分消耗资源。
|
||||
* 3)如何在缺乏数据时给出好的推荐-称为冷启动【简单说:用户不会喜欢一个无效的物品,而用户不喜欢的物品又无效】
|
||||
* 3)如何在缺乏数据时给出好的推荐-称为冷启动【简单说: 用户不会喜欢一个无效的物品,而用户不喜欢的物品又无效】
|
||||
|
||||
建议
|
||||
* 1)在大型系统中,SVD分解(可以在程序调入时运行一次)每天运行一次或者其频率更低,并且还要离线运行。
|
||||
@@ -372,13 +372,13 @@ def analyse_data(Sigma, loopNum=20):
|
||||
|
||||
通常保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并取出噪声。
|
||||
'''
|
||||
print '主成分:%s, 方差占比:%s%%' % (format(i+1, '2.0f'), format(SigmaI/SigmaSum*100, '4.2f'))
|
||||
print '主成分: %s, 方差占比: %s%%' % (format(i+1, '2.0f'), format(SigmaI/SigmaSum*100, '4.2f'))
|
||||
```
|
||||
|
||||
> 使用算法: 对比使用 SVD 前后的数据差异对比,对于存储大家可以试着写写
|
||||
|
||||
|
||||
例如:`32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
例如: `32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
|
||||
```python
|
||||
# 打印矩阵
|
||||
@@ -428,6 +428,6 @@ def imgCompress(numSV=3, thresh=0.8):
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* **作者: [片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。
|
||||
对于你来说,可能很想识别那些有购物意愿的用户。
|
||||
那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。
|
||||
接下来:我们讲讲 MapRedece 如何来解决这样的问题
|
||||
接下来: 我们讲讲 MapRedece 如何来解决这样的问题
|
||||
```
|
||||
|
||||
|
||||
@@ -79,17 +79,17 @@ cat data/15.BigData_MapReduce/inputFile.txt | python src/python/15.BigData_MapRe
|
||||
|
||||
#### Mahout in Action
|
||||
|
||||
1. 简单贝叶斯:它属于为数不多的可以很自然的使用MapReduce的算法。通过统计在某个类别下某特征的概率。
|
||||
2. k-近邻算法:高维数据下(如文本、图像和视频)流行的近邻查找方法是局部敏感哈希算法。
|
||||
3. 支持向量机(SVM):使用随机梯度下降算法求解,如Pegasos算法。
|
||||
4. 奇异值分解:Lanczos算法是一个有效的求解近似特征值的算法。
|
||||
5. k-均值聚类:canopy算法初始化k个簇,然后再运行K-均值求解结果。
|
||||
1. 简单贝叶斯: 它属于为数不多的可以很自然的使用MapReduce的算法。通过统计在某个类别下某特征的概率。
|
||||
2. k-近邻算法: 高维数据下(如文本、图像和视频)流行的近邻查找方法是局部敏感哈希算法。
|
||||
3. 支持向量机(SVM): 使用随机梯度下降算法求解,如Pegasos算法。
|
||||
4. 奇异值分解: Lanczos算法是一个有效的求解近似特征值的算法。
|
||||
5. k-均值聚类: canopy算法初始化k个簇,然后再运行K-均值求解结果。
|
||||
|
||||
### 使用 mrjob 库将 MapReduce 自动化
|
||||
|
||||
> 理论简介
|
||||
|
||||
* MapReduce 作业流自动化的框架:Cascading 和 Oozie.
|
||||
* MapReduce 作业流自动化的框架: Cascading 和 Oozie.
|
||||
* mrjob 是一个不错的学习工具,与2010年底实现了开源,来之于 Yelp(一个餐厅点评网站).
|
||||
|
||||
```Shell
|
||||
@@ -106,7 +106,7 @@ python src/python/15.BigData_MapReduce/mrMean.py < data/15.BigData_MapReduce/inp
|
||||
python src/python/15.BigData_MapReduce/mrMean.py < data/15.BigData_MapReduce/inputFile.txt
|
||||
```
|
||||
|
||||
### 项目案例:分布式 SVM 的 Pegasos 算法
|
||||
### 项目案例: 分布式 SVM 的 Pegasos 算法
|
||||
|
||||
Pegasos是指原始估计梯度求解器(Peimal Estimated sub-GrAdient Solver)
|
||||
|
||||
@@ -118,14 +118,14 @@ Pegasos是指原始估计梯度求解器(Peimal Estimated sub-GrAdient Solver)
|
||||
* 如果不是则将其加入到待更新集合。
|
||||
3. 批处理完毕后,权重向量按照这些错分的样本进行更新。
|
||||
|
||||
上述算法伪代码如下:
|
||||
上述算法伪代码如下:
|
||||
|
||||
```
|
||||
将 回归系数w 初始化为0
|
||||
对每次批处理
|
||||
随机选择 k 个样本点(向量)
|
||||
对每个向量
|
||||
如果该向量被错分:
|
||||
如果该向量被错分:
|
||||
更新权重向量 w
|
||||
累加对 w 的更新
|
||||
```
|
||||
@@ -133,17 +133,17 @@ Pegasos是指原始估计梯度求解器(Peimal Estimated sub-GrAdient Solver)
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:数据按文本格式存放。
|
||||
准备数据:输入数据已经是可用的格式,所以不需任何准备工作。如果你需要解析一个大规模的数据集,建议使用 map 作业来完成,从而达到并行处理的目的。
|
||||
分析数据:无。
|
||||
训练算法:与普通的 SVM 一样,在分类器训练上仍需花费大量的时间。
|
||||
测试算法:在二维空间上可视化之后,观察超平面,判断算法是否有效。
|
||||
使用算法:本例不会展示一个完整的应用,但会展示如何在大数据集上训练SVM。该算法其中一个应用场景就是本文分类,通常在文本分类里可能有大量的文档和成千上万的特征。
|
||||
收集数据: 数据按文本格式存放。
|
||||
准备数据: 输入数据已经是可用的格式,所以不需任何准备工作。如果你需要解析一个大规模的数据集,建议使用 map 作业来完成,从而达到并行处理的目的。
|
||||
分析数据: 无。
|
||||
训练算法: 与普通的 SVM 一样,在分类器训练上仍需花费大量的时间。
|
||||
测试算法: 在二维空间上可视化之后,观察超平面,判断算法是否有效。
|
||||
使用算法: 本例不会展示一个完整的应用,但会展示如何在大数据集上训练SVM。该算法其中一个应用场景就是本文分类,通常在文本分类里可能有大量的文档和成千上万的特征。
|
||||
```
|
||||
|
||||
> 收集数据
|
||||
|
||||
文本文件数据格式如下:
|
||||
文本文件数据格式如下:
|
||||
|
||||
```python
|
||||
0.365032 2.465645 -1
|
||||
@@ -213,11 +213,11 @@ def batchPegasos(dataSet, labels, lam, T, k):
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/pegasos.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/pegasos.py>
|
||||
|
||||
运行方式:`python /opt/git/MachineLearning/src/python/15.BigData_MapReduce/mrSVM.py < data/15.BigData_MapReduce/inputFile.txt`
|
||||
运行方式: `python /opt/git/MachineLearning/src/python/15.BigData_MapReduce/mrSVM.py < data/15.BigData_MapReduce/inputFile.txt`
|
||||
[MR版本的代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/mrSVM.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/mrSVM.py>
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -2,9 +2,9 @@
|
||||
|
||||
## 背景与挖掘目标
|
||||
|
||||
随着互联网的快速发展,用户很难快速从海量信息中寻找到自己感兴趣的信息。因此诞生了:搜索引擎+推荐系统
|
||||
随着互联网的快速发展,用户很难快速从海量信息中寻找到自己感兴趣的信息。因此诞生了: 搜索引擎+推荐系统
|
||||
|
||||
本章节-推荐系统:
|
||||
本章节-推荐系统:
|
||||
|
||||
1. 帮助用户发现其感兴趣和可能感兴趣的信息。
|
||||
2. 让网站价值信息脱颖而出,得到广大用户的认可。
|
||||
@@ -23,9 +23,9 @@
|
||||
|
||||
正常的情况下,需要对用户的兴趣爱好以及需求进行分类。
|
||||
因为在用户访问记录中,没有记录用户访问页面时间的长短,因此不容易判断用户兴趣爱好。
|
||||
因此,本文根据用户浏览的网页信息进行分析处理,主要采用以下方法处理:以用户浏览网页的类型进行分类,然后对每个类型中的内容进行推荐。
|
||||
因此,本文根据用户浏览的网页信息进行分析处理,主要采用以下方法处理: 以用户浏览网页的类型进行分类,然后对每个类型中的内容进行推荐。
|
||||
|
||||
分析过程如下:
|
||||
分析过程如下:
|
||||
|
||||
* 从系统中获取用户访问网站的原始记录。
|
||||
* 对数据进行多维分析,包括用户访问内容,流失用户分析以及用户分类等分析。
|
||||
@@ -65,21 +65,21 @@
|
||||
* 矩阵分解通过把原始的评分矩阵R分解为两个矩阵相乘,并且只考虑有评分的值,训练时不考虑missing项的值。R矩阵分解成为U与V两个矩阵后,评分矩阵R中missing的值就可以通过U矩阵中的某列和V矩阵的某行相乘得到
|
||||
* 矩阵分解的目标函数: U矩阵与V矩阵的可以通过梯度下降(gradient descent)算法求得,通过交替更新u与v多次迭代收敛之后可求出U与V。
|
||||
* 矩阵分解背后的核心思想,找到两个矩阵,它们相乘之后得到的那个矩阵的值,与评分矩阵R中有值的位置中的值尽可能接近。这样一来,分解出来的两个矩阵相乘就尽可能还原了评分矩阵R,因为有值的地方,值都相差得尽可能地小,那么missing的值通过这样的方式计算得到,比较符合趋势。
|
||||
* 协同过滤中主要存在如下两个问题:稀疏性与冷启动问题。已有的方案通常会通过引入多个不同的数据源或者辅助信息(Side information)来解决这些问题,用户的Side information可以是用户的基本个人信息、用户画像信息等,而Item的Side information可以是物品的content信息等。
|
||||
* 协同过滤中主要存在如下两个问题: 稀疏性与冷启动问题。已有的方案通常会通过引入多个不同的数据源或者辅助信息(Side information)来解决这些问题,用户的Side information可以是用户的基本个人信息、用户画像信息等,而Item的Side information可以是物品的content信息等。
|
||||
|
||||
## 效果评估
|
||||
|
||||
1. 召回率和准确率 【人为统计分析】
|
||||
2. F值(P-R曲线) 【偏重:非均衡问题】
|
||||
3. ROC和AUC 【偏重:不同结果的对比】
|
||||
2. F值(P-R曲线) 【偏重: 非均衡问题】
|
||||
3. ROC和AUC 【偏重: 不同结果的对比】
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* **作者: [片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
> 摘录的原文地址:
|
||||
> 摘录的原文地址:
|
||||
|
||||
* [推荐系统中常用算法 以及优点缺点对比](http://www.36dsj.com/archives/9519)
|
||||
* [推荐算法的基于知识推荐](https://zhidao.baidu.com/question/2013524494179442228.html)
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
|
||||
`k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。`
|
||||
|
||||
**一句话总结:近朱者赤近墨者黑!**
|
||||
**一句话总结: 近朱者赤近墨者黑!**
|
||||
|
||||
`k 近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k 近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。`
|
||||
|
||||
@@ -16,8 +16,8 @@
|
||||
## KNN 场景
|
||||
|
||||
电影可以按照题材分类,那么如何区分 `动作片` 和 `爱情片` 呢?<br/>
|
||||
1. 动作片:打斗次数更多
|
||||
2. 爱情片:亲吻次数更多
|
||||
1. 动作片: 打斗次数更多
|
||||
2. 爱情片: 亲吻次数更多
|
||||
|
||||
基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。
|
||||
|
||||
@@ -47,20 +47,20 @@ knn 算法按照距离最近的三部电影的类型,决定未知电影的类
|
||||
> KNN 开发流程
|
||||
|
||||
```
|
||||
收集数据:任何方法
|
||||
准备数据:距离计算所需要的数值,最好是结构化的数据格式
|
||||
分析数据:任何方法
|
||||
训练算法:此步骤不适用于 k-近邻算法
|
||||
测试算法:计算错误率
|
||||
使用算法:输入样本数据和结构化的输出结果,然后运行 k-近邻算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
收集数据: 任何方法
|
||||
准备数据: 距离计算所需要的数值,最好是结构化的数据格式
|
||||
分析数据: 任何方法
|
||||
训练算法: 此步骤不适用于 k-近邻算法
|
||||
测试算法: 计算错误率
|
||||
使用算法: 输入样本数据和结构化的输出结果,然后运行 k-近邻算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
```
|
||||
|
||||
> KNN 算法特点
|
||||
|
||||
```
|
||||
优点:精度高、对异常值不敏感、无数据输入假定
|
||||
缺点:计算复杂度高、空间复杂度高
|
||||
适用数据范围:数值型和标称型
|
||||
优点: 精度高、对异常值不敏感、无数据输入假定
|
||||
缺点: 计算复杂度高、空间复杂度高
|
||||
适用数据范围: 数值型和标称型
|
||||
```
|
||||
|
||||
## KNN 项目案例
|
||||
@@ -76,7 +76,7 @@ knn 算法按照距离最近的三部电影的类型,决定未知电影的类
|
||||
* 魅力一般的人
|
||||
* 极具魅力的人
|
||||
|
||||
她希望:
|
||||
她希望:
|
||||
1. 工作日与魅力一般的人约会
|
||||
2. 周末与极具魅力的人约会
|
||||
3. 不喜欢的人则直接排除掉
|
||||
@@ -86,25 +86,25 @@ knn 算法按照距离最近的三部电影的类型,决定未知电影的类
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供文本文件
|
||||
准备数据:使用 Python 解析文本文件
|
||||
分析数据:使用 Matplotlib 画二维散点图
|
||||
训练算法:此步骤不适用于 k-近邻算法
|
||||
测试算法:使用海伦提供的部分数据作为测试样本。
|
||||
测试样本和非测试样本的区别在于:
|
||||
收集数据: 提供文本文件
|
||||
准备数据: 使用 Python 解析文本文件
|
||||
分析数据: 使用 Matplotlib 画二维散点图
|
||||
训练算法: 此步骤不适用于 k-近邻算法
|
||||
测试算法: 使用海伦提供的部分数据作为测试样本。
|
||||
测试样本和非测试样本的区别在于:
|
||||
测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
|
||||
使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
使用算法: 产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
```
|
||||
|
||||
> 收集数据:提供文本文件
|
||||
> 收集数据: 提供文本文件
|
||||
|
||||
海伦把这些约会对象的数据存放在文本文件 [datingTestSet2.txt](/data/2.KNN/datingTestSet2.txt) 中,总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
|
||||
海伦把这些约会对象的数据存放在文本文件 [datingTestSet2.txt](/data/2.KNN/datingTestSet2.txt) 中,总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
|
||||
|
||||
* 每年获得的飞行常客里程数
|
||||
* 玩视频游戏所耗时间百分比
|
||||
* 每周消费的冰淇淋公升数
|
||||
|
||||
文本文件数据格式如下:
|
||||
文本文件数据格式如下:
|
||||
```
|
||||
40920 8.326976 0.953952 3
|
||||
14488 7.153469 1.673904 2
|
||||
@@ -112,7 +112,7 @@ knn 算法按照距离最近的三部电影的类型,决定未知电影的类
|
||||
75136 13.147394 0.428964 1
|
||||
38344 1.669788 0.134296 1
|
||||
```
|
||||
> 准备数据:使用 Python 解析文本文件
|
||||
> 准备数据: 使用 Python 解析文本文件
|
||||
|
||||
将文本记录转换为 NumPy 的解析程序
|
||||
|
||||
@@ -130,7 +130,7 @@ def file2matrix(filename):
|
||||
# 获得文件中的数据行的行数
|
||||
numberOfLines = len(fr.readlines())
|
||||
# 生成对应的空矩阵
|
||||
# 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
|
||||
# 例如: zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
|
||||
returnMat = zeros((numberOfLines, 3)) # prepare matrix to return
|
||||
classLabelVector = [] # prepare labels return
|
||||
fr = open(filename)
|
||||
@@ -149,7 +149,7 @@ def file2matrix(filename):
|
||||
return returnMat, classLabelVector
|
||||
```
|
||||
|
||||
> 分析数据:使用 Matplotlib 画二维散点图
|
||||
> 分析数据: 使用 Matplotlib 画二维散点图
|
||||
|
||||
```python
|
||||
import matplotlib
|
||||
@@ -164,7 +164,7 @@ plt.show()
|
||||
|
||||
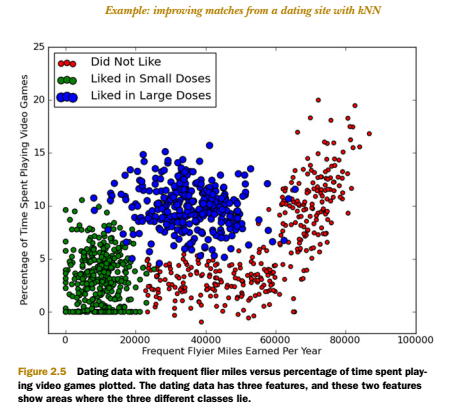
|
||||
|
||||
* 归一化数据 (归一化是一个让权重变为统一的过程,更多细节请参考: https://www.zhihu.com/question/19951858 )
|
||||
* 归一化数据 (归一化是一个让权重变为统一的过程,更多细节请参考: https://www.zhihu.com/question/19951858 )
|
||||
|
||||
| 序号 | 玩视频游戏所耗时间百分比 | 每年获得的飞行常客里程数 | 每周消费的冰淇淋公升数 | 样本分类 |
|
||||
| ------------- |:-------------:| -----:| -----:| -----:|
|
||||
@@ -173,34 +173,34 @@ plt.show()
|
||||
| 3 | 0 | 20 000 | 1.1 | 2 |
|
||||
| 4 | 67 | 32 000 | 0.1 | 2 |
|
||||
|
||||
样本3和样本4的距离:
|
||||
样本3和样本4的距离:
|
||||
$$\sqrt{(0-67)^2 + (20000-32000)^2 + (1.1-0.1)^2 }$$
|
||||
|
||||
归一化特征值,消除特征之间量级不同导致的影响
|
||||
|
||||
**归一化定义:** 我是这样认为的,归一化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。 方法有如下:
|
||||
**归一化定义: ** 我是这样认为的,归一化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。 方法有如下:
|
||||
|
||||
1) 线性函数转换,表达式如下:
|
||||
1) 线性函数转换,表达式如下:
|
||||
|
||||
y=(x-MinValue)/(MaxValue-MinValue)
|
||||
|
||||
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
|
||||
说明: x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
|
||||
|
||||
2) 对数函数转换,表达式如下:
|
||||
2) 对数函数转换,表达式如下:
|
||||
|
||||
y=log10(x)
|
||||
|
||||
说明:以10为底的对数函数转换。
|
||||
说明: 以10为底的对数函数转换。
|
||||
|
||||
如图:
|
||||
如图:
|
||||
|
||||
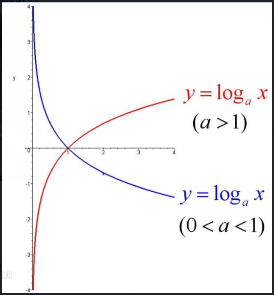
|
||||
|
||||
3) 反余切函数转换,表达式如下:
|
||||
3) 反余切函数转换,表达式如下:
|
||||
|
||||
y=arctan(x)*2/PI
|
||||
|
||||
如图:
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
@@ -220,7 +220,7 @@ def autoNorm(dataSet):
|
||||
return:
|
||||
归一化后的数据集 normDataSet. ranges和minVals即最小值与范围,并没有用到
|
||||
|
||||
归一化公式:
|
||||
归一化公式:
|
||||
Y = (X-Xmin)/(Xmax-Xmin)
|
||||
其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。
|
||||
"""
|
||||
@@ -238,15 +238,15 @@ def autoNorm(dataSet):
|
||||
return normDataSet, ranges, minVals
|
||||
```
|
||||
|
||||
> 训练算法:此步骤不适用于 k-近邻算法
|
||||
> 训练算法: 此步骤不适用于 k-近邻算法
|
||||
|
||||
因为测试数据每一次都要与全量的训练数据进行比较,所以这个过程是没有必要的。
|
||||
|
||||
kNN 算法伪代码:
|
||||
kNN 算法伪代码:
|
||||
|
||||
对于每一个在数据集中的数据点:
|
||||
对于每一个在数据集中的数据点:
|
||||
计算目标的数据点(需要分类的数据点)与该数据点的距离
|
||||
将距离排序:从小到大
|
||||
将距离排序: 从小到大
|
||||
选取前K个最短距离
|
||||
选取这K个中最多的分类类别
|
||||
返回该类别来作为目标数据点的预测值
|
||||
@@ -259,11 +259,11 @@ def classify0(inX, dataSet, labels, k):
|
||||
sqDistances = sqDiffMat.sum(axis=1)
|
||||
distances = sqDistances**0.5
|
||||
|
||||
#将距离排序:从小到大
|
||||
#将距离排序: 从小到大
|
||||
sortedDistIndicies = distances.argsort()
|
||||
#选取前K个最短距离, 选取这K个中最多的分类类别
|
||||
classCount={}
|
||||
for i in range(k):
|
||||
for i in range(k):
|
||||
voteIlabel = labels[sortedDistIndicies[i]]
|
||||
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
|
||||
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
|
||||
@@ -271,7 +271,7 @@ def classify0(inX, dataSet, labels, k):
|
||||
```
|
||||
|
||||
|
||||
> 测试算法:使用海伦提供的部分数据作为测试样本。如果预测分类与实际类别不同,则标记为一个错误。
|
||||
> 测试算法: 使用海伦提供的部分数据作为测试样本。如果预测分类与实际类别不同,则标记为一个错误。
|
||||
|
||||
kNN 分类器针对约会网站的测试代码
|
||||
|
||||
@@ -306,7 +306,7 @@ def datingClassTest():
|
||||
print errorCount
|
||||
```
|
||||
|
||||
> 使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
> 使用算法: 产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
|
||||
约会网站预测函数
|
||||
|
||||
@@ -343,19 +343,19 @@ You will probably like this person: in small doses
|
||||
|
||||
构造一个能识别数字 0 到 9 的基于 KNN 分类器的手写数字识别系统。
|
||||
|
||||
需要识别的数字是存储在文本文件中的具有相同的色彩和大小:宽高是 32 像素 * 32 像素的黑白图像。
|
||||
需要识别的数字是存储在文本文件中的具有相同的色彩和大小: 宽高是 32 像素 * 32 像素的黑白图像。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供文本文件。
|
||||
准备数据:编写函数 img2vector(), 将图像格式转换为分类器使用的向量格式
|
||||
分析数据:在 Python 命令提示符中检查数据,确保它符合要求
|
||||
训练算法:此步骤不适用于 KNN
|
||||
测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的
|
||||
收集数据: 提供文本文件。
|
||||
准备数据: 编写函数 img2vector(), 将图像格式转换为分类器使用的向量格式
|
||||
分析数据: 在 Python 命令提示符中检查数据,确保它符合要求
|
||||
训练算法: 此步骤不适用于 KNN
|
||||
测试算法: 编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的
|
||||
区别在于测试样本是已经完成分类的数据,如果预测分类与实际类别不同,
|
||||
则标记为一个错误
|
||||
使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取
|
||||
使用算法: 本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取
|
||||
数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统
|
||||
```
|
||||
|
||||
@@ -380,7 +380,7 @@ def img2vector(filename):
|
||||
return returnVect
|
||||
```
|
||||
|
||||
> 分析数据:在 Python 命令提示符中检查数据,确保它符合要求
|
||||
> 分析数据: 在 Python 命令提示符中检查数据,确保它符合要求
|
||||
|
||||
在 Python 命令行中输入下列命令测试 img2vector 函数,然后与文本编辑器打开的文件进行比较:
|
||||
|
||||
@@ -392,11 +392,11 @@ array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0
|
||||
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
|
||||
```
|
||||
|
||||
> 训练算法:此步骤不适用于 KNN
|
||||
> 训练算法: 此步骤不适用于 KNN
|
||||
|
||||
因为测试数据每一次都要与全量的训练数据进行比较,所以这个过程是没有必要的。
|
||||
|
||||
> 测试算法:编写函数使用提供的部分数据集作为测试样本,如果预测分类与实际类别不同,则标记为一个错误
|
||||
> 测试算法: 编写函数使用提供的部分数据集作为测试样本,如果预测分类与实际类别不同,则标记为一个错误
|
||||
|
||||
```python
|
||||
def handwritingClassTest():
|
||||
@@ -430,17 +430,17 @@ def handwritingClassTest():
|
||||
print "\nthe total error rate is: %f" % (errorCount / float(mTest))
|
||||
```
|
||||
|
||||
> 使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统。
|
||||
> 使用算法: 本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统。
|
||||
|
||||
## KNN 小结
|
||||
|
||||
KNN 是什么?定义: 监督学习? 非监督学习?
|
||||
KNN 是什么?定义: 监督学习? 非监督学习?
|
||||
|
||||
KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模型。在分类和回归中均有应用。
|
||||
|
||||
### 基本原理
|
||||
|
||||
简单来说: 通过距离度量来计算查询点(query point)与每个训练数据点的距离,然后选出与查询点(query point)相近的K个最邻点(K nearest neighbors),使用分类决策来选出对应的标签来作为该查询点的标签。
|
||||
简单来说: 通过距离度量来计算查询点(query point)与每个训练数据点的距离,然后选出与查询点(query point)相近的K个最邻点(K nearest neighbors),使用分类决策来选出对应的标签来作为该查询点的标签。
|
||||
|
||||
### KNN 三要素
|
||||
|
||||
@@ -454,7 +454,7 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>>>>太大太小都不太好,可以用交叉验证(cross validation)来选取适合的k值。
|
||||
|
||||
>>>>近似误差和估计误差,请看这里:https://www.zhihu.com/question/60793482
|
||||
>>>>近似误差和估计误差,请看这里: https://www.zhihu.com/question/60793482
|
||||
|
||||
>距离度量 Metric/Distance Measure
|
||||
|
||||
@@ -464,7 +464,7 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>>>>分类决策 在 分类问题中 通常为通过少数服从多数 来选取票数最多的标签,在回归问题中通常为 K个最邻点的标签的平均值。
|
||||
|
||||
### 算法:(sklearn 上有三种)
|
||||
### 算法: (sklearn 上有三种)
|
||||
|
||||
>Brute Force 暴力计算/线性扫描
|
||||
|
||||
@@ -474,27 +474,27 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>树结构的算法都有建树和查询两个过程。Brute Force 没有建树的过程。
|
||||
|
||||
>算法特点:
|
||||
>算法特点:
|
||||
|
||||
>>>>优点: High Accuracy, No Assumption on data, not sensitive to outliers
|
||||
>>>>优点: High Accuracy, No Assumption on data, not sensitive to outliers
|
||||
|
||||
>>>>缺点:时间和空间复杂度 高
|
||||
>>>>缺点: 时间和空间复杂度 高
|
||||
|
||||
>>>>适用范围: continuous values and nominal values
|
||||
>>>>适用范围: continuous values and nominal values
|
||||
|
||||
>相似同源产物:
|
||||
>相似同源产物:
|
||||
|
||||
>>>>radius neighbors 根据制定的半径来找寻邻点
|
||||
|
||||
>影响算法因素:
|
||||
>影响算法因素:
|
||||
|
||||
>>>>N 数据集样本数量(number of samples), D 数据维度 (number of features)
|
||||
|
||||
>总消耗:
|
||||
>总消耗:
|
||||
|
||||
>>>>Brute Force: O[DN^2]
|
||||
|
||||
>>>>此处考虑的是最蠢的方法:把所有训练的点之间的距离都算一遍。当然有更快的实现方式, 比如 O(ND + kN) 和 O(NDK) , 最快的是 O[DN] 。感兴趣的可以阅读这个链接: [k-NN computational complexity](https://stats.stackexchange.com/questions/219655/k-nn-computational-complexity)
|
||||
>>>>此处考虑的是最蠢的方法: 把所有训练的点之间的距离都算一遍。当然有更快的实现方式, 比如 O(ND + kN) 和 O(NDK) , 最快的是 O[DN] 。感兴趣的可以阅读这个链接: [k-NN computational complexity](https://stats.stackexchange.com/questions/219655/k-nn-computational-complexity)
|
||||
|
||||
>>>>KD Tree: O[DN log(N)]
|
||||
|
||||
@@ -530,7 +530,7 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>>>>查询点较少的时候用Brute Force。查询点较多的时候可以使用树结构算法。
|
||||
|
||||
>关于 sklearn 中模型的一些额外干货:
|
||||
>关于 sklearn 中模型的一些额外干货:
|
||||
|
||||
>>>>如果KD Tree,Ball Tree 和Brute Force 应用场景傻傻分不清楚,可以直接使用 含有algorithm='auto'的模组。 algorithm='auto' 自动为您选择最优算法。
|
||||
>>>>有 regressor 和 classifier 可以来选择。
|
||||
@@ -539,11 +539,11 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>leaf size 对KD Tree 和 Ball Tree 的影响
|
||||
|
||||
>>>>建树时间:leaf size 比较大的时候,建树时间也就快点。
|
||||
>>>>建树时间: leaf size 比较大的时候,建树时间也就快点。
|
||||
|
||||
>>>>查询时间: leaf size 太大太小都不太好。如果leaf size 趋向于 N(训练数据的样本数量),算法其实就是 brute force了。如果leaf size 太小了,趋向于1,那查询的时候 遍历树的时间就会大大增加。leaf size 建议的数值是 30,也就是默认值。
|
||||
>>>>查询时间: leaf size 太大太小都不太好。如果leaf size 趋向于 N(训练数据的样本数量),算法其实就是 brute force了。如果leaf size 太小了,趋向于1,那查询的时候 遍历树的时间就会大大增加。leaf size 建议的数值是 30,也就是默认值。
|
||||
|
||||
>>>>内存: leaf size 变大,存树结构的内存变小。
|
||||
>>>>内存: leaf size 变大,存树结构的内存变小。
|
||||
|
||||
>Nearest Centroid Classifier
|
||||
|
||||
@@ -551,17 +551,17 @@ KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模
|
||||
|
||||
>>>>该模型假设在所有维度中方差相同。 是一个很好的base line。
|
||||
|
||||
>进阶版: Nearest Shrunken Centroid
|
||||
>进阶版: Nearest Shrunken Centroid
|
||||
|
||||
>>>>可以通过shrink_threshold来设置。
|
||||
|
||||
>>>>作用: 可以移除某些影响分类的特征,例如移除噪音特征的影响
|
||||
>>>>作用: 可以移除某些影响分类的特征,例如移除噪音特征的影响
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
102
docs/ml/3.决策树.md
102
docs/ml/3.决策树.md
@@ -10,13 +10,13 @@
|
||||
|
||||
`决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。`
|
||||
|
||||
`决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。`
|
||||
`决策树学习通常包括 3 个步骤: 特征选择、决策树的生成和决策树的修剪。`
|
||||
|
||||
## 决策树 场景
|
||||
|
||||
一个叫做 "二十个问题" 的游戏,游戏的规则很简单:参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。
|
||||
一个叫做 "二十个问题" 的游戏,游戏的规则很简单: 参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。
|
||||
|
||||
一个邮件分类系统,大致工作流程如下:
|
||||
一个邮件分类系统,大致工作流程如下:
|
||||
|
||||

|
||||
|
||||
@@ -26,11 +26,11 @@
|
||||
如果不包含则将邮件归类到 "无需阅读的垃圾邮件" 。
|
||||
```
|
||||
|
||||
决策树的定义:
|
||||
决策树的定义:
|
||||
|
||||
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
|
||||
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型: 内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
|
||||
|
||||
用决策树对需要测试的实例进行分类:从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。
|
||||
用决策树对需要测试的实例进行分类: 从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。
|
||||
|
||||
## 决策树 原理
|
||||
|
||||
@@ -38,19 +38,19 @@
|
||||
|
||||
#### 信息熵 & 信息增益
|
||||
|
||||
熵(entropy):
|
||||
熵(entropy):
|
||||
熵指的是体系的混乱的程度,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。
|
||||
|
||||
信息论(information theory)中的熵(香农熵):
|
||||
是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。
|
||||
信息论(information theory)中的熵(香农熵):
|
||||
是一种信息的度量方式,表示信息的混乱程度,也就是说: 信息越有序,信息熵越低。例如: 火柴有序放在火柴盒里,熵值很低,相反,熵值很高。
|
||||
|
||||
信息增益(information gain):
|
||||
信息增益(information gain):
|
||||
在划分数据集前后信息发生的变化称为信息增益。
|
||||
|
||||
### 决策树 工作原理
|
||||
|
||||
如何构造一个决策树?<br/>
|
||||
我们使用 createBranch() 方法,如下所示:
|
||||
我们使用 createBranch() 方法,如下所示:
|
||||
|
||||
```
|
||||
def createBranch():
|
||||
@@ -71,20 +71,20 @@ def createBranch():
|
||||
### 决策树 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任何方法。
|
||||
准备数据:树构造算法 (这里使用的是ID3算法,只适用于标称型数据,这就是为什么数值型数据必须离散化。 还有其他的树构造算法,比如CART)
|
||||
分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
|
||||
训练算法:构造树的数据结构。
|
||||
测试算法:使用训练好的树计算错误率。
|
||||
使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
收集数据: 可以使用任何方法。
|
||||
准备数据: 树构造算法 (这里使用的是ID3算法,只适用于标称型数据,这就是为什么数值型数据必须离散化。 还有其他的树构造算法,比如CART)
|
||||
分析数据: 可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
|
||||
训练算法: 构造树的数据结构。
|
||||
测试算法: 使用训练好的树计算错误率。
|
||||
使用算法: 此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
```
|
||||
|
||||
### 决策树 算法特点
|
||||
|
||||
```
|
||||
优点:计算复杂度不高,输出结果易于理解,数据有缺失也能跑,可以处理不相关特征。
|
||||
缺点:容易过拟合。
|
||||
适用数据类型:数值型和标称型。
|
||||
优点: 计算复杂度不高,输出结果易于理解,数据有缺失也能跑,可以处理不相关特征。
|
||||
缺点: 容易过拟合。
|
||||
适用数据类型: 数值型和标称型。
|
||||
```
|
||||
|
||||
## 决策树 项目案例
|
||||
@@ -93,9 +93,9 @@ def createBranch():
|
||||
|
||||
#### 项目概述
|
||||
|
||||
根据以下 2 个特征,将动物分成两类:鱼类和非鱼类。
|
||||
根据以下 2 个特征,将动物分成两类: 鱼类和非鱼类。
|
||||
|
||||
特征:
|
||||
特征:
|
||||
1. 不浮出水面是否可以生存
|
||||
2. 是否有脚蹼
|
||||
|
||||
@@ -104,15 +104,15 @@ def createBranch():
|
||||
[完整代码地址](/src/py2.x/ml/3.DecisionTree/DecisionTree.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/3.DecisionTree/DecisionTree.py>
|
||||
|
||||
```
|
||||
收集数据:可以使用任何方法
|
||||
准备数据:树构造算法(这里使用的是ID3算法,因此数值型数据必须离散化。)
|
||||
分析数据:可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
训练算法:构造树结构
|
||||
测试算法:使用习得的决策树执行分类
|
||||
使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义
|
||||
收集数据: 可以使用任何方法
|
||||
准备数据: 树构造算法(这里使用的是ID3算法,因此数值型数据必须离散化。)
|
||||
分析数据: 可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
训练算法: 构造树结构
|
||||
测试算法: 使用习得的决策树执行分类
|
||||
使用算法: 此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义
|
||||
```
|
||||
|
||||
> 收集数据:可以使用任何方法
|
||||
> 收集数据: 可以使用任何方法
|
||||
|
||||

|
||||
|
||||
@@ -128,11 +128,11 @@ def createDataSet():
|
||||
labels = ['no surfacing', 'flippers']
|
||||
return dataSet, labels
|
||||
```
|
||||
> 准备数据:树构造算法
|
||||
> 准备数据: 树构造算法
|
||||
|
||||
此处,由于我们输入的数据本身就是离散化数据,所以这一步就省略了。
|
||||
|
||||
> 分析数据:可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
> 分析数据: 可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
|
||||

|
||||
|
||||
@@ -187,7 +187,7 @@ def splitDataSet(dataSet, index, value):
|
||||
# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行
|
||||
reducedFeatVec = featVec[:index]
|
||||
'''
|
||||
请百度查询一下: extend和append的区别
|
||||
请百度查询一下: extend和append的区别
|
||||
music_media.append(object) 向列表中添加一个对象object
|
||||
music_media.extend(sequence) 把一个序列seq的内容添加到列表中 (跟 += 在list运用类似, music_media += sequence)
|
||||
1、使用append的时候,是将object看作一个对象,整体打包添加到music_media对象中。
|
||||
@@ -195,17 +195,17 @@ def splitDataSet(dataSet, index, value):
|
||||
music_media = []
|
||||
music_media.extend([1,2,3])
|
||||
print music_media
|
||||
#结果:
|
||||
#结果:
|
||||
#[1, 2, 3]
|
||||
|
||||
music_media.append([4,5,6])
|
||||
print music_media
|
||||
#结果:
|
||||
#结果:
|
||||
#[1, 2, 3, [4, 5, 6]]
|
||||
|
||||
music_media.extend([7,8,9])
|
||||
print music_media
|
||||
#结果:
|
||||
#结果:
|
||||
#[1, 2, 3, [4, 5, 6], 7, 8, 9]
|
||||
'''
|
||||
reducedFeatVec.extend(featVec[index+1:])
|
||||
@@ -261,25 +261,25 @@ def chooseBestFeatureToSplit(dataSet):
|
||||
```
|
||||
|
||||
```
|
||||
问:上面的 newEntropy 为什么是根据子集计算的呢?
|
||||
答:因为我们在根据一个特征计算香农熵的时候,该特征的分类值是相同,这个特征这个分类的香农熵为 0;
|
||||
问: 上面的 newEntropy 为什么是根据子集计算的呢?
|
||||
答: 因为我们在根据一个特征计算香农熵的时候,该特征的分类值是相同,这个特征这个分类的香农熵为 0;
|
||||
这就是为什么计算新的香农熵的时候使用的是子集。
|
||||
```
|
||||
|
||||
> 训练算法:构造树的数据结构
|
||||
> 训练算法: 构造树的数据结构
|
||||
|
||||
创建树的函数代码如下:
|
||||
创建树的函数代码如下:
|
||||
|
||||
```python
|
||||
def createTree(dataSet, labels):
|
||||
classList = [example[-1] for example in dataSet]
|
||||
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
|
||||
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
|
||||
# 第一个停止条件: 所有的类标签完全相同,则直接返回该类标签。
|
||||
# count() 函数是统计括号中的值在list中出现的次数
|
||||
if classList.count(classList[0]) == len(classList):
|
||||
return classList[0]
|
||||
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
|
||||
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
|
||||
# 第二个停止条件: 使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
|
||||
if len(dataSet[0]) == 1:
|
||||
return majorityCnt(classList)
|
||||
|
||||
@@ -289,7 +289,7 @@ def createTree(dataSet, labels):
|
||||
bestFeatLabel = labels[bestFeat]
|
||||
# 初始化myTree
|
||||
myTree = {bestFeatLabel: {}}
|
||||
# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
|
||||
# 注: labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
|
||||
# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list
|
||||
del(labels[bestFeat])
|
||||
# 取出最优列,然后它的branch做分类
|
||||
@@ -304,7 +304,7 @@ def createTree(dataSet, labels):
|
||||
return myTree
|
||||
```
|
||||
|
||||
> 测试算法:使用决策树执行分类
|
||||
> 测试算法: 使用决策树执行分类
|
||||
|
||||
```python
|
||||
def classify(inputTree, featLabels, testVec):
|
||||
@@ -335,7 +335,7 @@ def classify(inputTree, featLabels, testVec):
|
||||
return classLabel
|
||||
```
|
||||
|
||||
> 使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
> 使用算法: 此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
|
||||
|
||||
### 项目案例2: 使用决策树预测隐形眼镜类型
|
||||
@@ -355,9 +355,9 @@ def classify(inputTree, featLabels, testVec):
|
||||
5. 测试算法: 编写测试函数验证决策树可以正确分类给定的数据实例。
|
||||
6. 使用算法: 存储树的数据结构,以便下次使用时无需重新构造树。
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
> 收集数据: 提供的文本文件
|
||||
|
||||
文本文件数据格式如下:
|
||||
文本文件数据格式如下:
|
||||
|
||||
```
|
||||
young myope no reduced no lenses
|
||||
@@ -365,20 +365,20 @@ pre myope no reduced no lenses
|
||||
presbyopic myope no reduced no lenses
|
||||
```
|
||||
|
||||
> 解析数据:解析 tab 键分隔的数据行
|
||||
> 解析数据: 解析 tab 键分隔的数据行
|
||||
|
||||
```python
|
||||
lecses = [inst.strip().split('\t') for inst in fr.readlines()]
|
||||
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
|
||||
```
|
||||
|
||||
> 分析数据:快速检查数据,确保正确地解析数据内容,使用 createPlot() 函数绘制最终的树形图。
|
||||
> 分析数据: 快速检查数据,确保正确地解析数据内容,使用 createPlot() 函数绘制最终的树形图。
|
||||
|
||||
```python
|
||||
>>> treePlotter.createPlot(lensesTree)
|
||||
```
|
||||
|
||||
> 训练算法:使用 createTree() 函数
|
||||
> 训练算法: 使用 createTree() 函数
|
||||
|
||||
```python
|
||||
>>> lensesTree = trees.createTree(lenses, lensesLabels)
|
||||
@@ -412,6 +412,6 @@ def grabTree(filename):
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
# 第4章 基于概率论的分类方法:朴素贝叶斯
|
||||
# 第4章 基于概率论的分类方法: 朴素贝叶斯
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
@@ -12,11 +12,11 @@
|
||||
|
||||
### 贝叶斯理论
|
||||
|
||||
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
|
||||
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
|
||||
|
||||

|
||||
|
||||
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
|
||||
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
|
||||
* 如果 p1(x,y) > p2(x,y) ,那么类别为1
|
||||
* 如果 p2(x,y) > p1(x,y) ,那么类别为2
|
||||
|
||||
@@ -36,13 +36,13 @@
|
||||
|
||||
计算 P(white) 或者 P(black) ,如果事先我们知道石头所在桶的信息是会改变结果的。这就是所谓的条件概率(conditional probablity)。假定计算的是从 B 桶取到白色石头的概率,这个概率可以记作 P(white|bucketB) ,我们称之为“在已知石头出自 B 桶的条件下,取出白色石头的概率”。很容易得到,P(white|bucketA) 值为 2/4 ,P(white|bucketB) 的值为 1/3 。
|
||||
|
||||
条件概率的计算公式如下:
|
||||
条件概率的计算公式如下:
|
||||
|
||||
P(white|bucketB) = P(white and bucketB) / P(bucketB)
|
||||
|
||||
首先,我们用 B 桶中白色石头的个数除以两个桶中总的石头数,得到 P(white and bucketB) = 1/7 .其次,由于 B 桶中有 3 块石头,而总石头数为 7 ,于是 P(bucketB) 就等于 3/7 。于是又 P(white|bucketB) = P(white and bucketB) / P(bucketB) = (1/7) / (3/7) = 1/3 。
|
||||
|
||||
另外一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知 P(x|c),要求 P(c|x),那么可以使用下面的计算方法:
|
||||
另外一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知 P(x|c),要求 P(c|x),那么可以使用下面的计算方法:
|
||||
|
||||
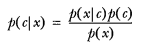
|
||||
|
||||
@@ -199,7 +199,7 @@ def setOfWords2Vec(vocabList, inputSet):
|
||||
'stupid', 'so', 'take', 'mr', 'steak', 'my']
|
||||
```
|
||||
|
||||
检查函数有效性。例如:myVocabList 中索引为 2 的元素是什么单词?应该是是 help 。该单词在第一篇文档中出现了,现在检查一下看看它是否出现在第四篇文档中。
|
||||
检查函数有效性。例如: myVocabList 中索引为 2 的元素是什么单词?应该是是 help 。该单词在第一篇文档中出现了,现在检查一下看看它是否出现在第四篇文档中。
|
||||
|
||||
```python
|
||||
>>> bayes.setOfWords2Vec(myVocabList, listOPosts[0])
|
||||
@@ -219,7 +219,7 @@ def setOfWords2Vec(vocabList, inputSet):
|
||||
|
||||
问: 上述代码实现中,为什么没有计算P(w)?
|
||||
|
||||
答:根据上述公式可知,我们右边的式子等同于左边的式子,由于对于每个ci,P(w)是固定的。并且我们只需要比较左边式子值的大小来决策分类,那么我们就可以简化为通过比较右边分子值得大小来做决策分类。
|
||||
答: 根据上述公式可知,我们右边的式子等同于左边的式子,由于对于每个ci,P(w)是固定的。并且我们只需要比较左边式子值的大小来决策分类,那么我们就可以简化为通过比较右边分子值得大小来做决策分类。
|
||||
|
||||
首先可以通过类别 i (侮辱性留言或者非侮辱性留言)中的文档数除以总的文档数来计算概率 p(ci) 。接下来计算 p(<b>w</b> | ci) ,这里就要用到朴素贝叶斯假设。如果将 w 展开为一个个独立特征,那么就可以将上述概率写作 p(w0, w1, w2...wn | ci) 。这里假设所有词都互相独立,该假设也称作条件独立性假设(例如 A 和 B 两个人抛骰子,概率是互不影响的,也就是相互独立的,A 抛 2点的同时 B 抛 3 点的概率就是 1/6 * 1/6),它意味着可以使用 p(w0 | ci)p(w1 | ci)p(w2 | ci)...p(wn | ci) 来计算上述概率,这样就极大地简化了计算的过程。
|
||||
|
||||
@@ -326,10 +326,10 @@ def trainNB0(trainMatrix, trainCategory):
|
||||
```python
|
||||
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
|
||||
"""
|
||||
使用算法:
|
||||
使用算法:
|
||||
# 将乘法转换为加法
|
||||
乘法:P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
|
||||
加法:P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
乘法: P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
|
||||
加法: P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
:param vec2Classify: 待测数据[0,1,1,1,1...],即要分类的向量
|
||||
:param p0Vec: 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
:param p1Vec: 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
@@ -340,7 +340,7 @@ def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
|
||||
# 大家可能会发现,上面的计算公式,没有除以贝叶斯准则的公式的分母,也就是 P(w) (P(w) 指的是此文档在所有的文档中出现的概率)就进行概率大小的比较了,
|
||||
# 因为 P(w) 针对的是包含侮辱和非侮辱的全部文档,所以 P(w) 是相同的。
|
||||
# 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。
|
||||
# 我的理解是:这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来
|
||||
# 我的理解是: 这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来
|
||||
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # P(w|c1) * P(c1) ,即贝叶斯准则的分子
|
||||
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) # P(w|c0) * P(c0) ,即贝叶斯准则的分子·
|
||||
if p1 > p0:
|
||||
@@ -562,7 +562,7 @@ def spamTest():
|
||||
|
||||
> 收集数据: 从 RSS 源收集内容,这里需要对 RSS 源构建一个接口
|
||||
|
||||
也就是导入 RSS 源,我们使用 python 下载文本,在http://code.google.com/p/feedparser/ 下浏览相关文档,安装 feedparse,首先解压下载的包,并将当前目录切换到解压文件所在的文件夹,然后在 python 提示符下输入:
|
||||
也就是导入 RSS 源,我们使用 python 下载文本,在http://code.google.com/p/feedparser/ 下浏览相关文档,安装 feedparse,首先解压下载的包,并将当前目录切换到解压文件所在的文件夹,然后在 python 提示符下输入:
|
||||
|
||||
```python
|
||||
>>> python setup.py install
|
||||
@@ -729,7 +729,7 @@ the error rate is: 0.55
|
||||
|
||||
接下来,我们要分析一下数据,显示地域相关的用词
|
||||
|
||||
可以先对向量pSF与pNY进行排序,然后按照顺序打印出来,将下面的代码添加到文件中:
|
||||
可以先对向量pSF与pNY进行排序,然后按照顺序打印出来,将下面的代码添加到文件中:
|
||||
|
||||
```python
|
||||
#最具表征性的词汇显示函数
|
||||
@@ -752,7 +752,7 @@ def getTopWords(ny,sf):
|
||||
|
||||
函数 getTopWords() 使用两个 RSS 源作为输入,然后训练并测试朴素贝叶斯分类器,返回使用的概率值。然后创建两个列表用于元组的存储,与之前返回排名最高的 X 个单词不同,这里可以返回大于某个阈值的所有词,这些元组会按照它们的条件概率进行排序。
|
||||
|
||||
保存 bayes.py 文件,在python提示符下输入:
|
||||
保存 bayes.py 文件,在python提示符下输入:
|
||||
|
||||
```python
|
||||
>>> reload(bayes)
|
||||
@@ -788,7 +788,7 @@ strings
|
||||
|
||||
***
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
|
||||
@@ -64,19 +64,19 @@ Sigmoid 函数的输入记为 z ,由下面公式得到:
|
||||
|
||||
该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或者算法达到某个可以允许的误差范围。
|
||||
|
||||
介绍一下几个相关的概念:
|
||||
介绍一下几个相关的概念:
|
||||
```
|
||||
例如:y = w0 + w1x1 + w2x2 + ... + wnxn
|
||||
梯度:参考上图的例子,二维图像,x方向代表第一个系数,也就是 w1,y方向代表第二个系数也就是 w2,这样的向量就是梯度。
|
||||
α:上面的梯度算法的迭代公式中的阿尔法,这个代表的是移动步长(step length)。移动步长会影响最终结果的拟合程度,最好的方法就是随着迭代次数更改移动步长。
|
||||
例如: y = w0 + w1x1 + w2x2 + ... + wnxn
|
||||
梯度: 参考上图的例子,二维图像,x方向代表第一个系数,也就是 w1,y方向代表第二个系数也就是 w2,这样的向量就是梯度。
|
||||
α: 上面的梯度算法的迭代公式中的阿尔法,这个代表的是移动步长(step length)。移动步长会影响最终结果的拟合程度,最好的方法就是随着迭代次数更改移动步长。
|
||||
步长通俗的理解,100米,如果我一步走10米,我需要走10步;如果一步走20米,我只需要走5步。这里的一步走多少米就是步长的意思。
|
||||
▽f(w):代表沿着梯度变化的方向。
|
||||
▽f(w): 代表沿着梯度变化的方向。
|
||||
```
|
||||
|
||||
|
||||
问:有人会好奇为什么有些书籍上说的是梯度下降法(Gradient Decent)?
|
||||
问: 有人会好奇为什么有些书籍上说的是梯度下降法(Gradient Decent)?
|
||||
|
||||
答: 其实这个两个方法在此情况下本质上是相同的。关键在于代价函数(cost function)或者叫目标函数(objective function)。如果目标函数是损失函数,那就是最小化损失函数来求函数的最小值,就用梯度下降。 如果目标函数是似然函数(Likelihood function),就是要最大化似然函数来求函数的最大值,那就用梯度上升。在逻辑回归中, 损失函数和似然函数无非就是互为正负关系。
|
||||
答: 其实这个两个方法在此情况下本质上是相同的。关键在于代价函数(cost function)或者叫目标函数(objective function)。如果目标函数是损失函数,那就是最小化损失函数来求函数的最小值,就用梯度下降。 如果目标函数是似然函数(Likelihood function),就是要最大化似然函数来求函数的最大值,那就用梯度上升。在逻辑回归中, 损失函数和似然函数无非就是互为正负关系。
|
||||
|
||||
只需要在迭代公式中的加法变成减法。因此,对应的公式可以写成
|
||||
|
||||
@@ -210,7 +210,7 @@ Logistic 回归梯度上升优化算法
|
||||
|
||||
```python
|
||||
# 正常的处理方案
|
||||
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 两个参数: 第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
# 转化为矩阵[[1,1,2],[1,1,2]....]
|
||||
@@ -231,8 +231,8 @@ def gradAscent(dataMatIn, classLabels):
|
||||
weights = ones((n,1))
|
||||
for k in range(maxCycles): #heavy on matrix operations
|
||||
# m*3 的矩阵 * 3*1 的矩阵 = m*1的矩阵
|
||||
# 那么乘上矩阵的意义,就代表:通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# 那么乘上矩阵的意义,就代表: 通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# print 'dataMatrix====', dataMatrix
|
||||
# print 'weights====', weights
|
||||
# n*3 * 3*1 = n*1
|
||||
@@ -284,7 +284,7 @@ def plotBestFit(dataArr, labelMat, weights):
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
w0*x0+w1*x1+w2*x2=f(x)
|
||||
x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
|
||||
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
|
||||
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
|
||||
"""
|
||||
y = (-weights[0]-weights[1]*x)/weights[2]
|
||||
ax.plot(x, y)
|
||||
@@ -433,7 +433,7 @@ def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
假设有100个样本和20个特征,这些数据都是机器收集回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?此时是否要扔掉整个数据?这种情况下,另外19个特征怎么办?
|
||||
它们是否还可以用?答案是肯定的。因为有时候数据相当昂贵,扔掉和重新获取都是不可取的,所以必须采用一些方法来解决这个问题。
|
||||
|
||||
下面给出了一些可选的做法:
|
||||
下面给出了一些可选的做法:
|
||||
* 使用可用特征的均值来填补缺失值;
|
||||
* 使用特殊值来填补缺失值,如 -1;
|
||||
* 忽略有缺失值的样本;
|
||||
@@ -465,7 +465,7 @@ def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
|
||||
```python
|
||||
# 正常的处理方案
|
||||
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 两个参数: 第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
# 转化为矩阵[[1,1,2],[1,1,2]....]
|
||||
@@ -486,8 +486,8 @@ def gradAscent(dataMatIn, classLabels):
|
||||
weights = ones((n,1))
|
||||
for k in range(maxCycles): #heavy on matrix operations
|
||||
# m*3 的矩阵 * 3*1 的单位矩阵 = m*1的矩阵
|
||||
# 那么乘上单位矩阵的意义,就代表:通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# 那么乘上单位矩阵的意义,就代表: 通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# print 'dataMatrix====', dataMatrix
|
||||
# print 'weights====', weights
|
||||
# n*3 * 3*1 = n*1
|
||||
@@ -634,11 +634,11 @@ Logistic回归和最大熵模型 都属于对数线性模型 (log linear model
|
||||
|
||||
## 多标签分类
|
||||
|
||||
逻辑回归也可以用作于多标签分类。 思路如下:
|
||||
逻辑回归也可以用作于多标签分类。 思路如下:
|
||||
|
||||
假设我们标签A中有a0,a1,a2....an个标签,对于每个标签 ai (ai 是标签A之一),我们训练一个逻辑回归分类器。
|
||||
|
||||
即,训练该标签的逻辑回归分类器的时候,将ai看作一类标签,非ai的所有标签看作一类标签。那么相当于整个数据集里面只有两类标签:ai 和其他。
|
||||
即,训练该标签的逻辑回归分类器的时候,将ai看作一类标签,非ai的所有标签看作一类标签。那么相当于整个数据集里面只有两类标签: ai 和其他。
|
||||
|
||||
剩下步骤就跟我们训练正常的逻辑回归分类器一样了。
|
||||
|
||||
@@ -646,6 +646,6 @@ Logistic回归和最大熵模型 都属于对数线性模型 (log linear model
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -38,11 +38,11 @@ Classification Machine,是分类器,这个没什么好说的。也可以理
|
||||
|
||||
### “支持向量” 又是什么?
|
||||
|
||||
<b>通俗理解</b>:
|
||||
<b>通俗理解</b>:
|
||||
support vector (支持向量)的意思就是 <b>数据集中的某些点</b>,位置比较特殊。比如 x+y-2=0 这条直线,直线上面区域 x+y-2>0 的全是 A 类,下面的 x+y-2<0 的全是 B 类,我们找这条直线的时候,一般就看聚集在一起的两类数据,他们各自的 <b>最边缘</b> 位置的点,也就是最靠近划分直线的那几个点,而其他点对这条直线的最终位置的确定起不了作用,所以我姑且叫这些点叫 “支持点”(意思就是有用的点),但是在数学上,没这种说法,数学里的点,又可以叫向量,比如 二维点 (x,y) 就是二维向量,三维度的就是三维向量 (x,y,z)。所以 “<b>支持点</b>” 改叫 “<b>支持向量</b>” ,听起来比较专业,而且又装逼,何乐而不为呢?是吧...
|
||||
|
||||
<b>不通俗的理解</b>:
|
||||
在 maximum margin (最大间隔)上的这些点就叫 “支持向量”,我想补充的是为啥这些点就叫 “支持向量” ,因为最后的 classification machine (分类器)的表达式里只含有这些 “支持向量” 的信息,而与其他数据点无关:
|
||||
<b>不通俗的理解</b>:
|
||||
在 maximum margin (最大间隔)上的这些点就叫 “支持向量”,我想补充的是为啥这些点就叫 “支持向量” ,因为最后的 classification machine (分类器)的表达式里只含有这些 “支持向量” 的信息,而与其他数据点无关:
|
||||
|
||||

|
||||
|
||||
@@ -79,13 +79,13 @@ support vector (支持向量)的意思就是 <b>数据集中的某些点</b>
|
||||
|
||||
## How does it work? (SVM 原理)
|
||||
|
||||
### 1、引用知乎上 [@简之](https://www.zhihu.com/people/wangjianzhi/answers) 大佬的回答:
|
||||
### 1、引用知乎上 [@简之](https://www.zhihu.com/people/wangjianzhi/answers) 大佬的回答:
|
||||
|
||||
首先我们讲个故事:
|
||||
|
||||
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
|
||||
|
||||
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
|
||||
魔鬼在桌子上似乎有规律放了两种颜色的球,说: “你用一根棍分开它们?要求: 尽量在放更多球之后,仍然适用。”
|
||||
|
||||

|
||||
|
||||
@@ -119,12 +119,12 @@ SVM 就是试图把棍放在最佳位置,好让在棍的两边有尽可能大
|
||||
|
||||
再之后,无聊的大人们,把这些球叫做 <b>「data」</b>,把棍子叫做 <b>「classifier」</b>, 最大间隙 trick 叫做<b>「optimization」</b>, 拍桌子叫做<b>「kernelling」</b>, 那张纸叫做<b>「hyperplane」</b> 。
|
||||
|
||||
有梯子的童鞋,可以看一下这个地方,看视频来更直观的感受:
|
||||
有梯子的童鞋,可以看一下这个地方,看视频来更直观的感受:
|
||||
|
||||
https://www.youtube.com/watch?v=3liCbRZPrZA
|
||||
|
||||
|
||||
### 2、引用知乎 [@开膛手水货](https://www.zhihu.com/people/kai-tang-shou-xin/answers) 大佬的回答,我认为是超级通俗的一个版本:
|
||||
### 2、引用知乎 [@开膛手水货](https://www.zhihu.com/people/kai-tang-shou-xin/answers) 大佬的回答,我认为是超级通俗的一个版本:
|
||||
|
||||
支持向量机是用来解决分类问题的。
|
||||
|
||||
@@ -150,15 +150,15 @@ d<D,米粒
|
||||
|
||||
以此类推,还有三维的,四维的,N维的 属性的分类,这样构造的也许就不是直线,而是平面,超平面。
|
||||
|
||||
一个三维的函数分类 :x+y+z-2=0,这就是个分类的平面了。
|
||||
一个三维的函数分类 : x+y+z-2=0,这就是个分类的平面了。
|
||||
|
||||
有时候,分类的那条线不一定是直线,还有可能是曲线,我们通过某些函数来转换,就可以转化成刚才的哪种多维的分类问题,这个就是核函数的思想。
|
||||
|
||||
例如:分类的函数是个圆形 x^2+y^2-4=0 。这个时候令 x^2=a ; y^2=b ,还不就变成了a+b-4=0 这种直线问题了。
|
||||
例如: 分类的函数是个圆形 x^2+y^2-4=0 。这个时候令 x^2=a ; y^2=b ,还不就变成了a+b-4=0 这种直线问题了。
|
||||
|
||||
这就是支持向量机的思想。
|
||||
|
||||
### 3、引用 [@胡KF](https://www.zhihu.com/people/hu-kf/answers) 大佬的回答(这个需要一些数学知识):
|
||||
### 3、引用 [@胡KF](https://www.zhihu.com/people/hu-kf/answers) 大佬的回答(这个需要一些数学知识):
|
||||
|
||||
如图的例子,(训练集)红色点是我们已知的分类1,(训练集)蓝色点是已知的分类2,我们想寻找一个分隔超平面(图中绿线)(因为示例是二维数据点,所以只是一条线,如果数据是三维的就是平面,如果是三维以上就是超平面)把这两类完全分开,这样的话再来一个样本点需要我们预测的话,我们就可以根据这个分界超平面预测出分类结果。
|
||||
|
||||
@@ -172,7 +172,7 @@ d<D,米粒
|
||||
|
||||
不同于传统的最小二乘策略的思想,我们采用一种新的思路,这个分界面有什么样的特征呢?
|
||||
|
||||
第一,它 “夹” 在两类样本点之间;第二,它离两类样本点中所有 “离它最近的点” ,都离它尽可能的远。如图所示:
|
||||
第一,它 “夹” 在两类样本点之间;第二,它离两类样本点中所有 “离它最近的点” ,都离它尽可能的远。如图所示:
|
||||
|
||||

|
||||
|
||||
@@ -182,7 +182,7 @@ d<D,米粒
|
||||
|
||||
介绍完 SVM 的基本思想,我们来探讨一下如何用数学的方法进行 SVM 分类。
|
||||
|
||||
首先我们需要把刚刚说的最大间隔分类器的思想用数学公式表达出来。先定义几何间隔的概念,几何间隔就是在多维空间中一个多维点到一个超平面的距离,根据向量的知识可以算出来:
|
||||
首先我们需要把刚刚说的最大间隔分类器的思想用数学公式表达出来。先定义几何间隔的概念,几何间隔就是在多维空间中一个多维点到一个超平面的距离,根据向量的知识可以算出来:
|
||||
|
||||

|
||||
|
||||
@@ -196,9 +196,9 @@ d<D,米粒
|
||||
|
||||
总之,在计算的过程中,我们不需要了解支持向量以外的其他样本点,只需要利用相对于所有样本点来说为数不多的支持向量,就可以求出分类超平面,计算复杂度大为降低。
|
||||
|
||||
### 4、引用知乎 [@靠靠靠谱](https://www.zhihu.com/people/kao-kao-kao-pu/answers) 大佬的理解(这个需要的数学知识更加厉害一点):
|
||||
### 4、引用知乎 [@靠靠靠谱](https://www.zhihu.com/people/kao-kao-kao-pu/answers) 大佬的理解(这个需要的数学知识更加厉害一点):
|
||||
|
||||
先看思维导图:
|
||||
先看思维导图:
|
||||
|
||||
* 左边是求解基本的SVM问题
|
||||
* 右边是相关扩展
|
||||
@@ -225,7 +225,7 @@ Support Vector Machine, 一个普通的 SVM 就是一条直线罢了,用来完
|
||||
|
||||

|
||||
|
||||
(可以把 margin 看作是 boundary 的函数,并且想要找到使得是使得 margin 最大化的boundary,而 margin(*) 这个函数是:输入一个 boundary ,计算(正确分类的)所有苹果和香蕉中,到 boundary 的最小距离。)
|
||||
(可以把 margin 看作是 boundary 的函数,并且想要找到使得是使得 margin 最大化的boundary,而 margin(*) 这个函数是: 输入一个 boundary ,计算(正确分类的)所有苹果和香蕉中,到 boundary 的最小距离。)
|
||||
|
||||
又有最大又有最小看起来好矛盾。实际上『最大』是对这个整体使用不同 boundary 层面的最大,『最小』是在比较『点』的层面上的最小。外层在比较 boundary 找最大的 margin ,内层在比较点点找最小的距离。
|
||||
|
||||
@@ -243,11 +243,11 @@ Support Vector Machine, 一个普通的 SVM 就是一条直线罢了,用来完
|
||||
|
||||

|
||||
|
||||
稍微借用刚刚数学表达里面的内容看个有趣的东西:
|
||||
稍微借用刚刚数学表达里面的内容看个有趣的东西:
|
||||
|
||||
还记得我们怎么预测一个新的水果是苹果还是香蕉吗?我们代入到分界的直线里,然后通过符号来判断。
|
||||
|
||||
刚刚w已经被表达出来了也就是说这个直线现在变成了: 
|
||||
刚刚w已经被表达出来了也就是说这个直线现在变成了: 
|
||||
|
||||
看似仿佛用到了所有的训练水果,但是其中  的水果都没有起到作用,剩下的就是小部分靠边边的 Support vectors 呀。
|
||||
|
||||
@@ -277,13 +277,13 @@ Kernel trick.
|
||||
|
||||

|
||||
|
||||
可以每个类别做一次 SVM:是苹果还是不是苹果?是香蕉还是不是香蕉?是梨子还是不是梨子?从中选出可能性最大的。这是 one-versus-the-rest approach。
|
||||
可以每个类别做一次 SVM: 是苹果还是不是苹果?是香蕉还是不是香蕉?是梨子还是不是梨子?从中选出可能性最大的。这是 one-versus-the-rest approach。
|
||||
|
||||
也可以两两做一次 SVM:是苹果还是香蕉?是香蕉还是梨子?是梨子还是苹果?最后三个分类器投票决定。这是 one-versus-one approace。
|
||||
也可以两两做一次 SVM: 是苹果还是香蕉?是香蕉还是梨子?是梨子还是苹果?最后三个分类器投票决定。这是 one-versus-one approace。
|
||||
|
||||
但这其实都多多少少有问题,比如苹果特别多,香蕉特别少,我就无脑判断为苹果也不会错太多;多个分类器要放到一个台面上,万一他们的 scale 没有在一个台面上也未可知。
|
||||
|
||||
课后题:
|
||||
课后题:
|
||||
1、vector 不愿意 support 怎么办?
|
||||
2、苹果好吃还是香蕉好吃?
|
||||
|
||||
|
||||
@@ -5,14 +5,14 @@
|
||||
|
||||
## 支持向量机 概述
|
||||
|
||||
支持向量机(Support Vector Machines, SVM):是一种监督学习算法。
|
||||
支持向量机(Support Vector Machines, SVM): 是一种监督学习算法。
|
||||
* 支持向量(Support Vector)就是离分隔超平面最近的那些点。
|
||||
* 机(Machine)就是表示一种算法,而不是表示机器。
|
||||
|
||||
## 支持向量机 场景
|
||||
|
||||
* 要给左右两边的点进行分类
|
||||
* 明显发现:选择D会比B、C分隔的效果要好很多。
|
||||
* 明显发现: 选择D会比B、C分隔的效果要好很多。
|
||||
|
||||
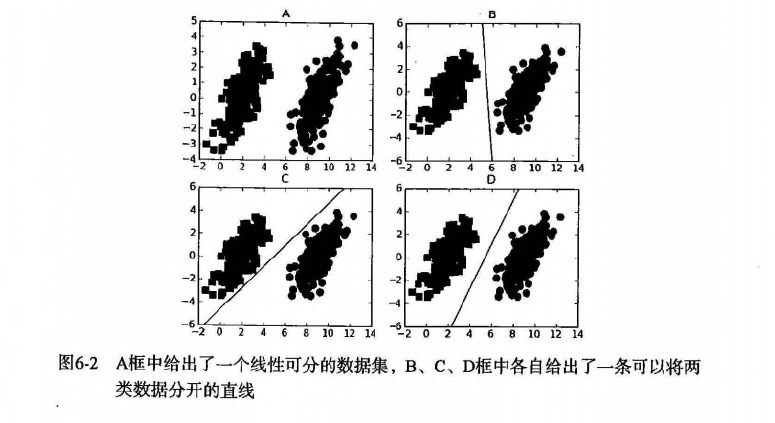
|
||||
|
||||
@@ -39,7 +39,7 @@
|
||||
#### 为什么寻找最大间隔
|
||||
|
||||
```
|
||||
摘录地址:http://slideplayer.com/slide/8610144 (第12条信息)
|
||||
摘录地址: http://slideplayer.com/slide/8610144 (第12条信息)
|
||||
Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why Maximum Margin?
|
||||
|
||||
1.Intuitively this feels safest.
|
||||
@@ -62,7 +62,7 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
> 点到超平面的距离
|
||||
|
||||
* 分隔超平面`函数间距`: \\(y(x)=w^Tx+b\\)
|
||||
* 分类的结果: \\(f(x)=sign(w^Tx+b)\\) (sign表示>0为1,<0为-1,=0为0)
|
||||
* 分类的结果: \\(f(x)=sign(w^Tx+b)\\) (sign表示>0为1,<0为-1,=0为0)
|
||||
* 点到超平面的`几何间距`: \\(d(x)=(w^Tx+b)/||w||\\) (||w||表示w矩阵的二范数=> \\(\sqrt{w^T*w}\\), 点到超平面的距离也是类似的)
|
||||
|
||||

|
||||
@@ -71,12 +71,12 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
|
||||
* 类别标签用-1、1,是为了后期方便 \\(label*(w^Tx+b)\\) 的标识和距离计算;如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,否则预测错误。
|
||||
* 现在目标很明确,就是要找到`w`和`b`,因此我们必须要找到最小间隔的数据点,也就是前面所说的`支持向量`。
|
||||
* 也就说,让最小的距离取最大.(最小的距离:就是最小间隔的数据点;最大:就是最大间距,为了找出最优超平面--最终就是支持向量)
|
||||
* 目标函数:\\(arg: max_{关于w, b} \left( min[label*(w^Tx+b)]*\frac{1}{||w||} \right) \\)
|
||||
* 也就说,让最小的距离取最大.(最小的距离: 就是最小间隔的数据点;最大: 就是最大间距,为了找出最优超平面--最终就是支持向量)
|
||||
* 目标函数: \\(arg: max_{关于w, b} \left( min[label*(w^Tx+b)]*\frac{1}{||w||} \right) \\)
|
||||
1. 如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,也称`函数间隔`,\\(||w||\\) 可以理解为归一化,也称`几何间隔`。
|
||||
2. 令 \\(label*(w^Tx+b)>=1\\), 因为0~1之间,得到的点是存在误判的可能性,所以要保障 \\(min[label*(w^Tx+b)]=1\\),才能更好降低噪音数据影响。
|
||||
3. 所以本质上是求 \\(arg: max_{关于w, b} \frac{1}{||w||} \\);也就说,我们约束(前提)条件是: \\(label*(w^Tx+b)=1\\)
|
||||
* 新的目标函数求解: \\(arg: max_{关于w, b} \frac{1}{||w||} \\)
|
||||
* 新的目标函数求解: \\(arg: max_{关于w, b} \frac{1}{||w||} \\)
|
||||
* => 就是求: \\(arg: min_{关于w, b} ||w|| \\) (求矩阵会比较麻烦,如果x只是 \\(\frac{1}{2}*x^2\\) 的偏导数,那么。。同样是求最小值)
|
||||
* => 就是求: \\(arg: min_{关于w, b} (\frac{1}{2}*||w||^2)\\) (二次函数求导,求极值,平方也方便计算)
|
||||
* 本质上就是求线性不等式的二次优化问题(求分隔超平面,等价于求解相应的凸二次规划问题)
|
||||
@@ -85,66 +85,66 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
* 设g(x,y)=M-φ(x,y) # 临时φ(x,y)表示下文中 \\(label*(w^Tx+b)\\)
|
||||
* 定义一个新函数: F(x,y,λ)=f(x,y)+λg(x,y)
|
||||
* a为λ(a>=0),代表要引入的拉格朗日乘子(Lagrange multiplier)
|
||||
* 那么: \\(L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 因为:\\(label*(w^Tx+b)>=1, \alpha>=0\\) , 所以 \\(\alpha*[1-label*(w^Tx+b)]<=0\\) , \\(\sum_{i=1}^{n} \alpha_i * [1-label*(w^Tx+b)]<=0\\)
|
||||
* 那么: \\(L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 因为: \\(label*(w^Tx+b)>=1, \alpha>=0\\) , 所以 \\(\alpha*[1-label*(w^Tx+b)]<=0\\) , \\(\sum_{i=1}^{n} \alpha_i * [1-label*(w^Tx+b)]<=0\\)
|
||||
* 当 \\(label*(w^Tx+b)>1\\) 则 \\(\alpha=0\\) ,表示该点为<font color=red>非支持向量</font>
|
||||
* 相当于求解: \\(max_{关于\alpha} L(w,b,\alpha) = \frac{1}{2} *||w||^2\\)
|
||||
* 如果求: \\(min_{关于w, b} \frac{1}{2} *||w||^2\\) , 也就是要求: \\(min_{关于w, b} \left( max_{关于\alpha} L(w,b,\alpha)\right)\\)
|
||||
* 相当于求解: \\(max_{关于\alpha} L(w,b,\alpha) = \frac{1}{2} *||w||^2\\)
|
||||
* 如果求: \\(min_{关于w, b} \frac{1}{2} *||w||^2\\) , 也就是要求: \\(min_{关于w, b} \left( max_{关于\alpha} L(w,b,\alpha)\right)\\)
|
||||
* 现在转化到对偶问题的求解
|
||||
* \\(min_{关于w, b} \left(max_{关于\alpha} L(w,b,\alpha) \right) \\) >= \\(max_{关于\alpha} \left(min_{关于w, b}\ L(w,b,\alpha) \right) \\)
|
||||
* 现在分2步
|
||||
* 先求: \\(min_{关于w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 就是求`L(w,b,a)`关于[w, b]的偏导数, 得到`w和b的值`,并化简为:`L和a的方程`。
|
||||
* 参考: 如果公式推导还是不懂,也可以参考《统计学习方法》李航-P103<学习的对偶算法>
|
||||
* 先求: \\(min_{关于w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 就是求`L(w,b,a)`关于[w, b]的偏导数, 得到`w和b的值`,并化简为: `L和a的方程`。
|
||||
* 参考: 如果公式推导还是不懂,也可以参考《统计学习方法》李航-P103<学习的对偶算法>
|
||||

|
||||
* 终于得到课本上的公式: \\(max_{关于\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i·label_j·\alpha_i·\alpha_j·<x_i, x_j> \right) \\)
|
||||
* 约束条件: \\(a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 终于得到课本上的公式: \\(max_{关于\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i·label_j·\alpha_i·\alpha_j·<x_i, x_j> \right) \\)
|
||||
* 约束条件: \\(a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
|
||||
> 松弛变量(slack variable)
|
||||
|
||||
参考地址:http://blog.csdn.net/wusecaiyun/article/details/49659183
|
||||
参考地址: http://blog.csdn.net/wusecaiyun/article/details/49659183
|
||||
|
||||
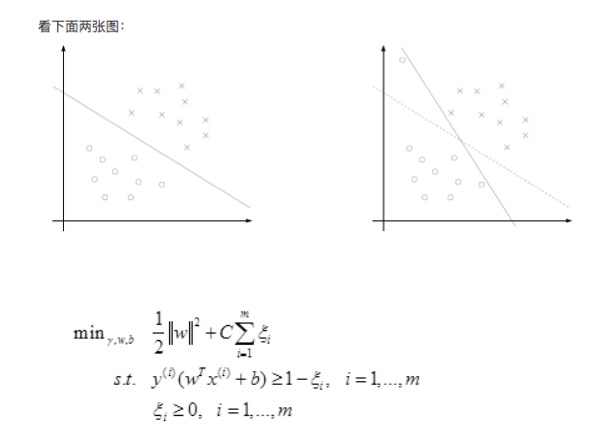
|
||||
|
||||
* 我们知道几乎所有的数据都不那么干净, 通过引入松弛变量来 `允许数据点可以处于分隔面错误的一侧`。
|
||||
* 约束条件: \\(C>=a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 总的来说:
|
||||
* 约束条件: \\(C>=a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 总的来说:
|
||||
* 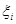 表示 `松弛变量`
|
||||
* 常量C是 `惩罚因子`, 表示离群点的权重(用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0” )
|
||||
* \\(label*(w^Tx+b) > 1\\) and alpha = 0 (在边界外,就是非支持向量)
|
||||
* \\(label*(w^Tx+b) = 1\\) and 0< alpha < C (在分割超平面上,就支持向量)
|
||||
* \\(label*(w^Tx+b) < 1\\) and alpha = C (在分割超平面内,是误差点 -> C表示它该受到的惩罚因子程度)
|
||||
* 参考地址:https://www.zhihu.com/question/48351234/answer/110486455
|
||||
* 参考地址: https://www.zhihu.com/question/48351234/answer/110486455
|
||||
* C值越大,表示离群点影响越大,就越容易过度拟合;反之有可能欠拟合。
|
||||
* 我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件。
|
||||
* 例如:正类有10000个样本,而负类只给了100个(C越大表示100个负样本的影响越大,就会出现过度拟合,所以C决定了负样本对模型拟合程度的影响!,C就是一个非常关键的优化点!)
|
||||
* 例如: 正类有10000个样本,而负类只给了100个(C越大表示100个负样本的影响越大,就会出现过度拟合,所以C决定了负样本对模型拟合程度的影响!,C就是一个非常关键的优化点!)
|
||||
* 这一结论十分直接,SVM中的主要工作就是要求解 alpha.
|
||||
|
||||
### SMO 高效优化算法
|
||||
|
||||
* SVM有很多种实现,最流行的一种实现是: `序列最小优化(Sequential Minimal Optimization, SMO)算法`。
|
||||
* SVM有很多种实现,最流行的一种实现是: `序列最小优化(Sequential Minimal Optimization, SMO)算法`。
|
||||
* 下面还会介绍一种称为 `核函数(kernel)` 的方式将SVM扩展到更多数据集上。
|
||||
* 注意:`SVM几何含义比较直观,但其算法实现较复杂,牵扯大量数学公式的推导。`
|
||||
* 注意: `SVM几何含义比较直观,但其算法实现较复杂,牵扯大量数学公式的推导。`
|
||||
|
||||
> 序列最小优化(Sequential Minimal Optimization, SMO)
|
||||
|
||||
* 创建作者:John Platt
|
||||
* 创建时间:1996年
|
||||
* SMO用途:用于训练 SVM
|
||||
* SMO目标:求出一系列 alpha 和 b,一旦求出 alpha,就很容易计算出权重向量 w 并得到分隔超平面。
|
||||
* SMO思想:是将大优化问题分解为多个小优化问题来求解的。
|
||||
* SMO原理:每次循环选择两个 alpha 进行优化处理,一旦找出一对合适的 alpha,那么就增大一个同时减少一个。
|
||||
* 创建作者: John Platt
|
||||
* 创建时间: 1996年
|
||||
* SMO用途: 用于训练 SVM
|
||||
* SMO目标: 求出一系列 alpha 和 b,一旦求出 alpha,就很容易计算出权重向量 w 并得到分隔超平面。
|
||||
* SMO思想: 是将大优化问题分解为多个小优化问题来求解的。
|
||||
* SMO原理: 每次循环选择两个 alpha 进行优化处理,一旦找出一对合适的 alpha,那么就增大一个同时减少一个。
|
||||
* 这里指的合适必须要符合一定的条件
|
||||
1. 这两个 alpha 必须要在间隔边界之外
|
||||
2. 这两个 alpha 还没有进行过区间化处理或者不在边界上。
|
||||
* 之所以要同时改变2个 alpha;原因是我们有一个约束条件: \\(\sum_{i=1}^{m} a_i·label_i=0\\);如果只是修改一个 alpha,很可能导致约束条件失效。
|
||||
* 之所以要同时改变2个 alpha;原因是我们有一个约束条件: \\(\sum_{i=1}^{m} a_i·label_i=0\\);如果只是修改一个 alpha,很可能导致约束条件失效。
|
||||
|
||||
> SMO 伪代码大致如下:
|
||||
> SMO 伪代码大致如下:
|
||||
|
||||
```
|
||||
创建一个 alpha 向量并将其初始化为0向量
|
||||
当迭代次数小于最大迭代次数时(外循环)
|
||||
对数据集中的每个数据向量(内循环):
|
||||
对数据集中的每个数据向量(内循环):
|
||||
如果该数据向量可以被优化
|
||||
随机选择另外一个数据向量
|
||||
同时优化这两个向量
|
||||
@@ -155,20 +155,20 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
### SVM 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任意方法。
|
||||
准备数据:需要数值型数据。
|
||||
分析数据:有助于可视化分隔超平面。
|
||||
训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优。
|
||||
测试算法:十分简单的计算过程就可以实现。
|
||||
使用算法:几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二类分类器,对多类问题应用SVM需要对代码做一些修改。
|
||||
收集数据: 可以使用任意方法。
|
||||
准备数据: 需要数值型数据。
|
||||
分析数据: 有助于可视化分隔超平面。
|
||||
训练算法: SVM的大部分时间都源自训练,该过程主要实现两个参数的调优。
|
||||
测试算法: 十分简单的计算过程就可以实现。
|
||||
使用算法: 几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二类分类器,对多类问题应用SVM需要对代码做一些修改。
|
||||
```
|
||||
|
||||
### SVM 算法特点
|
||||
|
||||
```
|
||||
优点:泛化(由具体的、个别的扩大为一般的,就是说:模型训练完后的新样本)错误率低,计算开销不大,结果易理解。
|
||||
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适合于处理二分类问题。
|
||||
使用数据类型:数值型和标称型数据。
|
||||
优点: 泛化(由具体的、个别的扩大为一般的,就是说: 模型训练完后的新样本)错误率低,计算开销不大,结果易理解。
|
||||
缺点: 对参数调节和核函数的选择敏感,原始分类器不加修改仅适合于处理二分类问题。
|
||||
使用数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 课本案例(无核函数)
|
||||
@@ -181,7 +181,7 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
|
||||
> 收集数据
|
||||
|
||||
文本文件格式:
|
||||
文本文件格式:
|
||||
|
||||
```python
|
||||
3.542485 1.977398 -1
|
||||
@@ -261,7 +261,7 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
|
||||
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
|
||||
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
|
||||
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
# 表示发生错误的概率: labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
'''
|
||||
# 检验训练样本(xi, yi)是否满足KKT条件
|
||||
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
|
||||
@@ -310,7 +310,7 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
|
||||
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
|
||||
# w= Σ[1~n] ai*yi*xi => b = yj- Σ[1~n] ai*yi(xi*xj)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
|
||||
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[i, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i, :]*dataMatrix[j, :].T
|
||||
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[j, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j, :]*dataMatrix[j, :].T
|
||||
@@ -332,9 +332,9 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
return b, alphas
|
||||
```
|
||||
|
||||
[完整代码地址:SVM简化版,应用简化版SMO算法处理小规模数据集](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py>
|
||||
[完整代码地址: SVM简化版,应用简化版SMO算法处理小规模数据集](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py>
|
||||
|
||||
[完整代码地址:SVM完整版,使用完整 Platt SMO算法加速优化,优化点:选择alpha的方式不同](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py>
|
||||
[完整代码地址: SVM完整版,使用完整 Platt SMO算法加速优化,优化点: 选择alpha的方式不同](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py>
|
||||
|
||||
## 核函数(kernel) 使用
|
||||
|
||||
@@ -343,13 +343,13 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
|
||||
> 利用核函数将数据映射到高维空间
|
||||
|
||||
* 使用核函数:可以将数据从某个特征空间到另一个特征空间的映射。(通常情况下:这种映射会将低维特征空间映射到高维空间。)
|
||||
* 使用核函数: 可以将数据从某个特征空间到另一个特征空间的映射。(通常情况下: 这种映射会将低维特征空间映射到高维空间。)
|
||||
* 如果觉得特征空间很装逼、很难理解。
|
||||
* 可以把核函数想象成一个包装器(wrapper)或者是接口(interface),它能将数据从某个很难处理的形式转换成为另一个较容易处理的形式。
|
||||
* 经过空间转换后:低维需要解决的非线性问题,就变成了高维需要解决的线性问题。
|
||||
* 经过空间转换后: 低维需要解决的非线性问题,就变成了高维需要解决的线性问题。
|
||||
* SVM 优化特别好的地方,在于所有的运算都可以写成内积(inner product: 是指2个向量相乘,得到单个标量 或者 数值);内积替换成核函数的方式被称为`核技巧(kernel trick)`或者`核"变电"(kernel substation)`
|
||||
* 核函数并不仅仅应用于支持向量机,很多其他的机器学习算法也都用到核函数。最流行的核函数:径向基函数(radial basis function)
|
||||
* 径向基函数的高斯版本,其具体的公式为:
|
||||
* 核函数并不仅仅应用于支持向量机,很多其他的机器学习算法也都用到核函数。最流行的核函数: 径向基函数(radial basis function)
|
||||
* 径向基函数的高斯版本,其具体的公式为:
|
||||
|
||||

|
||||
|
||||
@@ -358,13 +358,13 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
#### 项目概述
|
||||
|
||||
```python
|
||||
你的老板要求:你写的那个手写识别程序非常好,但是它占用内存太大。顾客无法通过无线的方式下载我们的应用。
|
||||
所以:我们可以考虑使用支持向量机,保留支持向量就行(knn需要保留所有的向量),就可以获得非常好的效果。
|
||||
你的老板要求: 你写的那个手写识别程序非常好,但是它占用内存太大。顾客无法通过无线的方式下载我们的应用。
|
||||
所以: 我们可以考虑使用支持向量机,保留支持向量就行(knn需要保留所有的向量),就可以获得非常好的效果。
|
||||
```
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
> 收集数据: 提供的文本文件
|
||||
|
||||
```python
|
||||
00000000000000001111000000000000
|
||||
@@ -402,7 +402,7 @@ def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
|
||||
```
|
||||
|
||||
> 准备数据:基于二值图像构造向量
|
||||
> 准备数据: 基于二值图像构造向量
|
||||
|
||||
`将 32*32的文本转化为 1*1024的矩阵`
|
||||
|
||||
@@ -435,9 +435,9 @@ def loadImages(dirName):
|
||||
return trainingMat, hwLabels
|
||||
```
|
||||
|
||||
> 分析数据:对图像向量进行目测
|
||||
> 分析数据: 对图像向量进行目测
|
||||
|
||||
> 训练算法:采用两种不同的核函数,并对径向基核函数采用不同的设置来运行SMO算法
|
||||
> 训练算法: 采用两种不同的核函数,并对径向基核函数采用不同的设置来运行SMO算法
|
||||
|
||||
```python
|
||||
def kernelTrans(X, A, kTup): # calc the kernel or transform data to a higher dimensional space
|
||||
@@ -489,7 +489,7 @@ def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
|
||||
entireSet = True
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 循环遍历:循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
|
||||
# 循环遍历: 循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
|
||||
alphaPairsChanged = 0
|
||||
|
||||
@@ -520,7 +520,7 @@ def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
|
||||
return oS.b, oS.alphas
|
||||
```
|
||||
|
||||
> 测试算法:便携一个函数来测试不同的和函数并计算错误率
|
||||
> 测试算法: 便携一个函数来测试不同的和函数并计算错误率
|
||||
|
||||
```python
|
||||
def testDigits(kTup=('rbf', 10)):
|
||||
@@ -557,12 +557,12 @@ def testDigits(kTup=('rbf', 10)):
|
||||
print("the test error rate is: %f" % (float(errorCount) / m))
|
||||
```
|
||||
|
||||
> 使用算法:一个图像识别的完整应用还需要一些图像处理的知识,这里并不打算深入介绍
|
||||
> 使用算法: 一个图像识别的完整应用还需要一些图像处理的知识,这里并不打算深入介绍
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete.py>
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [geekidentity](http://cwiki.apachecn.org/display/~houfachao)**
|
||||
* **作者: [片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [geekidentity](http://cwiki.apachecn.org/display/~houfachao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -4,11 +4,11 @@
|
||||
|
||||
## 集成方法: ensemble method(元算法: meta algorithm) 概述
|
||||
|
||||
* 概念:是对其他算法进行组合的一种形式。
|
||||
* 通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。
|
||||
* 概念: 是对其他算法进行组合的一种形式。
|
||||
* 通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。
|
||||
机器学习处理问题时又何尝不是如此? 这就是集成方法背后的思想。
|
||||
|
||||
* 集成方法:
|
||||
* 集成方法:
|
||||
1. 投票选举(bagging: 自举汇聚法 bootstrap aggregating): 是基于数据随机重抽样分类器构造的方法
|
||||
2. 再学习(boosting): 是基于所有分类器的加权求和的方法
|
||||
|
||||
@@ -16,10 +16,10 @@
|
||||
## 集成方法 场景
|
||||
|
||||
目前 bagging 方法最流行的版本是: 随机森林(random forest)<br/>
|
||||
选男友:美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友
|
||||
选男友: 美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友
|
||||
|
||||
目前 boosting 方法最流行的版本是: AdaBoost<br/>
|
||||
追女友:3个帅哥追同一个美女,第1个帅哥失败->(传授经验:姓名、家庭情况) 第2个帅哥失败->(传授经验:兴趣爱好、性格特点) 第3个帅哥成功
|
||||
追女友: 3个帅哥追同一个美女,第1个帅哥失败->(传授经验: 姓名、家庭情况) 第2个帅哥失败->(传授经验: 兴趣爱好、性格特点) 第3个帅哥成功
|
||||
|
||||
> bagging 和 boosting 区别是什么?
|
||||
|
||||
@@ -38,15 +38,15 @@
|
||||
### 随机森林 原理
|
||||
|
||||
那随机森林具体如何构建呢?<br/>
|
||||
有两个方面:<br/>
|
||||
有两个方面: <br/>
|
||||
1. 数据的随机性化<br/>
|
||||
2. 待选特征的随机化<br/>
|
||||
|
||||
使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
|
||||
|
||||
> 数据的随机化:使得随机森林中的决策树更普遍化一点,适合更多的场景。
|
||||
> 数据的随机化: 使得随机森林中的决策树更普遍化一点,适合更多的场景。
|
||||
|
||||
(有放回的准确率在:70% 以上, 无放回的准确率在:60% 以上)
|
||||
(有放回的准确率在: 70% 以上, 无放回的准确率在: 60% 以上)
|
||||
1. 采取有放回的抽样方式 构造子数据集,保证不同子集之间的数量级一样(不同子集/同一子集 之间的元素可以重复)
|
||||
2. 利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。
|
||||
3. 然后统计子决策树的投票结果,得到最终的分类 就是 随机森林的输出结果。
|
||||
@@ -68,20 +68,20 @@
|
||||
> 随机森林 开发流程
|
||||
|
||||
```
|
||||
收集数据:任何方法
|
||||
准备数据:转换样本集
|
||||
分析数据:任何方法
|
||||
训练算法:通过数据随机化和特征随机化,进行多实例的分类评估
|
||||
测试算法:计算错误率
|
||||
使用算法:输入样本数据,然后运行 随机森林 算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
收集数据: 任何方法
|
||||
准备数据: 转换样本集
|
||||
分析数据: 任何方法
|
||||
训练算法: 通过数据随机化和特征随机化,进行多实例的分类评估
|
||||
测试算法: 计算错误率
|
||||
使用算法: 输入样本数据,然后运行 随机森林 算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
```
|
||||
|
||||
> 随机森林 算法特点
|
||||
|
||||
```
|
||||
优点:几乎不需要输入准备、可实现隐式特征选择、训练速度非常快、其他模型很难超越、很难建立一个糟糕的随机森林模型、大量优秀、免费以及开源的实现。
|
||||
缺点:劣势在于模型大小、是个很难去解释的黑盒子。
|
||||
适用数据范围:数值型和标称型
|
||||
优点: 几乎不需要输入准备、可实现隐式特征选择、训练速度非常快、其他模型很难超越、很难建立一个糟糕的随机森林模型、大量优秀、免费以及开源的实现。
|
||||
缺点: 劣势在于模型大小、是个很难去解释的黑盒子。
|
||||
适用数据范围: 数值型和标称型
|
||||
```
|
||||
|
||||
### 项目案例: 声纳信号分类
|
||||
@@ -93,17 +93,17 @@
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供的文本文件
|
||||
准备数据:转换样本集
|
||||
分析数据:手工检查数据
|
||||
训练算法:在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
测试算法:在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分
|
||||
使用算法:若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
收集数据: 提供的文本文件
|
||||
准备数据: 转换样本集
|
||||
分析数据: 手工检查数据
|
||||
训练算法: 在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
测试算法: 在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分
|
||||
使用算法: 若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
```
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
> 收集数据: 提供的文本文件
|
||||
|
||||
样本数据:sonar-all-data.txt
|
||||
样本数据: sonar-all-data.txt
|
||||
|
||||
```
|
||||
0.02,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.066,0.2273,0.31,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.555,0.6711,0.6415,0.7104,0.808,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.051,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.018,0.0084,0.009,0.0032,R
|
||||
@@ -111,7 +111,7 @@
|
||||
0.0262,0.0582,0.1099,0.1083,0.0974,0.228,0.2431,0.3771,0.5598,0.6194,0.6333,0.706,0.5544,0.532,0.6479,0.6931,0.6759,0.7551,0.8929,0.8619,0.7974,0.6737,0.4293,0.3648,0.5331,0.2413,0.507,0.8533,0.6036,0.8514,0.8512,0.5045,0.1862,0.2709,0.4232,0.3043,0.6116,0.6756,0.5375,0.4719,0.4647,0.2587,0.2129,0.2222,0.2111,0.0176,0.1348,0.0744,0.013,0.0106,0.0033,0.0232,0.0166,0.0095,0.018,0.0244,0.0316,0.0164,0.0095,0.0078,R
|
||||
```
|
||||
|
||||
> 准备数据:转换样本集
|
||||
> 准备数据: 转换样本集
|
||||
|
||||
```python
|
||||
# 导入csv文件
|
||||
@@ -135,9 +135,9 @@ def loadDataSet(filename):
|
||||
return dataset
|
||||
```
|
||||
|
||||
> 分析数据:手工检查数据
|
||||
> 分析数据: 手工检查数据
|
||||
|
||||
> 训练算法:在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
> 训练算法: 在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
|
||||
* 样本数据随机无放回抽样-用于交叉验证
|
||||
|
||||
@@ -149,7 +149,7 @@ def cross_validation_split(dataset, n_folds):
|
||||
dataset 原始数据集
|
||||
n_folds 数据集dataset分成n_flods份
|
||||
Returns:
|
||||
dataset_split list集合,存放的是:将数据集进行抽重抽样 n_folds 份,数据可以重复抽取
|
||||
dataset_split list集合,存放的是: 将数据集进行抽重抽样 n_folds 份,数据可以重复抽取
|
||||
"""
|
||||
dataset_split = list()
|
||||
dataset_copy = list(dataset) # 复制一份 dataset,防止 dataset 的内容改变
|
||||
@@ -249,7 +249,7 @@ def random_forest(train, test, max_depth, min_size, sample_size, n_trees, n_feat
|
||||
return predictions
|
||||
```
|
||||
|
||||
> 测试算法:在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分。
|
||||
> 测试算法: 在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分。
|
||||
|
||||
* 计算随机森林的预测结果的正确率
|
||||
|
||||
@@ -302,7 +302,7 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
return scores
|
||||
```
|
||||
|
||||
> 使用算法:若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
> 使用算法: 若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.RandomForest/randomForest.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.RandomForest/randomForest.py>
|
||||
|
||||
@@ -322,22 +322,22 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
> AdaBoost 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任意方法
|
||||
准备数据:依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以处理任何数据类型。
|
||||
收集数据: 可以使用任意方法
|
||||
准备数据: 依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以处理任何数据类型。
|
||||
当然也可以使用任意分类器作为弱分类器,第2章到第6章中的任一分类器都可以充当弱分类器。
|
||||
作为弱分类器,简单分类器的效果更好。
|
||||
分析数据:可以使用任意方法。
|
||||
训练算法:AdaBoost 的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器。
|
||||
测试算法:计算分类的错误率。
|
||||
使用算法:通SVM一样,AdaBoost 预测两个类别中的一个。如果想把它应用到多个类别的场景,那么就要像多类 SVM 中的做法一样对 AdaBoost 进行修改。
|
||||
分析数据: 可以使用任意方法。
|
||||
训练算法: AdaBoost 的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器。
|
||||
测试算法: 计算分类的错误率。
|
||||
使用算法: 通SVM一样,AdaBoost 预测两个类别中的一个。如果想把它应用到多个类别的场景,那么就要像多类 SVM 中的做法一样对 AdaBoost 进行修改。
|
||||
```
|
||||
|
||||
> AdaBoost 算法特点
|
||||
|
||||
```
|
||||
* 优点:泛化(由具体的、个别的扩大为一般的)错误率低,易编码,可以应用在大部分分类器上,无参数调节。
|
||||
* 缺点:对离群点敏感。
|
||||
* 适用数据类型:数值型和标称型数据。
|
||||
* 优点: 泛化(由具体的、个别的扩大为一般的)错误率低,易编码,可以应用在大部分分类器上,无参数调节。
|
||||
* 缺点: 对离群点敏感。
|
||||
* 适用数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 项目案例: 马疝病的预测
|
||||
@@ -356,18 +356,18 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供的文本文件
|
||||
准备数据:确保类别标签是+1和-1,而非1和0
|
||||
分析数据:统计分析
|
||||
训练算法:在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
测试算法:我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较
|
||||
使用算法:观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去
|
||||
收集数据: 提供的文本文件
|
||||
准备数据: 确保类别标签是+1和-1,而非1和0
|
||||
分析数据: 统计分析
|
||||
训练算法: 在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
测试算法: 我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较
|
||||
使用算法: 观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去
|
||||
```
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
> 收集数据: 提供的文本文件
|
||||
|
||||
训练数据:horseColicTraining.txt<br/>
|
||||
测试数据:horseColicTest.txt
|
||||
训练数据: horseColicTraining.txt<br/>
|
||||
测试数据: horseColicTest.txt
|
||||
|
||||
```
|
||||
2.000000 1.000000 38.500000 66.000000 28.000000 3.000000 3.000000 0.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 3.000000 5.000000 45.000000 8.400000 0.000000 0.000000 -1.000000
|
||||
@@ -375,7 +375,7 @@ def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
2.000000 1.000000 38.300000 40.000000 24.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 33.000000 6.700000 0.000000 0.000000 1.000000
|
||||
```
|
||||
|
||||
> 准备数据:确保类别标签是+1和-1,而非1和0
|
||||
> 准备数据: 确保类别标签是+1和-1,而非1和0
|
||||
|
||||
```python
|
||||
def loadDataSet(fileName):
|
||||
@@ -394,18 +394,18 @@ def loadDataSet(fileName):
|
||||
return dataArr, labelArr
|
||||
```
|
||||
|
||||
> 分析数据:统计分析
|
||||
> 分析数据: 统计分析
|
||||
|
||||
过拟合(overfitting, 也称为过学习)
|
||||
* 发现测试错误率在达到一个最小值之后有开始上升,这种现象称为过拟合。
|
||||
|
||||
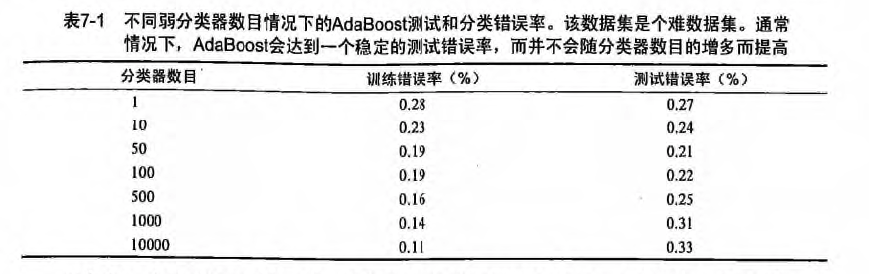
|
||||
|
||||
* 通俗来说:就是把一些噪音数据也拟合进去的,如下图。
|
||||
* 通俗来说: 就是把一些噪音数据也拟合进去的,如下图。
|
||||
|
||||
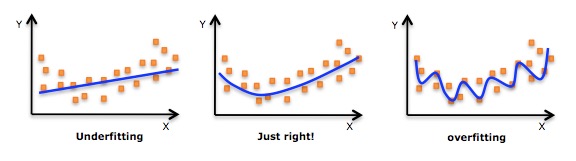
|
||||
|
||||
> 训练算法:在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
> 训练算法: 在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
|
||||
```python
|
||||
def adaBoostTrainDS(dataArr, labelArr, numIt=40):
|
||||
@@ -435,21 +435,21 @@ def adaBoostTrainDS(dataArr, labelArr, numIt=40):
|
||||
weakClassArr.append(bestStump)
|
||||
|
||||
print "alpha=%s, classEst=%s, bestStump=%s, error=%s " % (alpha, classEst.T, bestStump, error)
|
||||
# 分类正确:乘积为1,不会影响结果,-1主要是下面求e的-alpha次方
|
||||
# 分类错误:乘积为 -1,结果会受影响,所以也乘以 -1
|
||||
# 分类正确: 乘积为1,不会影响结果,-1主要是下面求e的-alpha次方
|
||||
# 分类错误: 乘积为 -1,结果会受影响,所以也乘以 -1
|
||||
expon = multiply(-1*alpha*mat(labelArr).T, classEst)
|
||||
print '(-1取反)预测值expon=', expon.T
|
||||
# 计算e的expon次方,然后计算得到一个综合的概率的值
|
||||
# 结果发现: 判断错误的样本,D中相对应的样本权重值会变大。
|
||||
# 结果发现: 判断错误的样本,D中相对应的样本权重值会变大。
|
||||
D = multiply(D, exp(expon))
|
||||
D = D/D.sum()
|
||||
|
||||
# 预测的分类结果值,在上一轮结果的基础上,进行加和操作
|
||||
print '当前的分类结果:', alpha*classEst.T
|
||||
print '当前的分类结果: ', alpha*classEst.T
|
||||
aggClassEst += alpha*classEst
|
||||
print "叠加后的分类结果aggClassEst: ", aggClassEst.T
|
||||
# sign 判断正为1, 0为0, 负为-1,通过最终加和的权重值,判断符号。
|
||||
# 结果为:错误的样本标签集合,因为是 !=,那么结果就是0 正, 1 负
|
||||
# 结果为: 错误的样本标签集合,因为是 !=,那么结果就是0 正, 1 负
|
||||
aggErrors = multiply(sign(aggClassEst) != mat(labelArr).T, ones((m, 1)))
|
||||
errorRate = aggErrors.sum()/m
|
||||
# print "total error=%s " % (errorRate)
|
||||
@@ -459,16 +459,16 @@ def adaBoostTrainDS(dataArr, labelArr, numIt=40):
|
||||
```
|
||||
|
||||
```
|
||||
发现:
|
||||
发现:
|
||||
alpha (模型权重)目的主要是计算每一个分类器实例的权重(加和就是分类结果)
|
||||
分类的权重值:最大的值= alpha 的加和,最小值=-最大值
|
||||
D (样本权重)的目的是为了计算错误概率: weightedError = D.T*errArr,求最佳分类器
|
||||
样本的权重值:如果一个值误判的几率越小,那么 D 的样本权重越小
|
||||
分类的权重值: 最大的值= alpha 的加和,最小值=-最大值
|
||||
D (样本权重)的目的是为了计算错误概率: weightedError = D.T*errArr,求最佳分类器
|
||||
样本的权重值: 如果一个值误判的几率越小,那么 D 的样本权重越小
|
||||
```
|
||||
|
||||

|
||||
|
||||
> 测试算法:我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较。
|
||||
> 测试算法: 我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较。
|
||||
|
||||
```python
|
||||
def adaClassify(datToClass, classifierArr):
|
||||
@@ -486,14 +486,14 @@ def adaClassify(datToClass, classifierArr):
|
||||
|
||||
# 循环 多个分类器
|
||||
for i in range(len(classifierArr)):
|
||||
# 前提: 我们已经知道了最佳的分类器的实例
|
||||
# 前提: 我们已经知道了最佳的分类器的实例
|
||||
# 通过分类器来核算每一次的分类结果,然后通过alpha*每一次的结果 得到最后的权重加和的值。
|
||||
classEst = stumpClassify(dataMat, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
|
||||
aggClassEst += classifierArr[i]['alpha']*classEst
|
||||
return sign(aggClassEst)
|
||||
```
|
||||
|
||||
> 使用算法:观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去。
|
||||
> 使用算法: 观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去。
|
||||
|
||||
```python
|
||||
# 马疝病数据集
|
||||
@@ -508,7 +508,7 @@ dataArrTest, labelArrTest = loadDataSet("data/7.AdaBoost/horseColicTest2.txt")
|
||||
m = shape(dataArrTest)[0]
|
||||
predicting10 = adaClassify(dataArrTest, weakClassArr)
|
||||
errArr = mat(ones((m, 1)))
|
||||
# 测试:计算总样本数,错误样本数,错误率
|
||||
# 测试: 计算总样本数,错误样本数,错误率
|
||||
print m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10 != mat(labelArrTest).T].sum()/m
|
||||
```
|
||||
|
||||
@@ -516,7 +516,7 @@ print m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10
|
||||
|
||||
#### 要点补充
|
||||
|
||||
> 非均衡现象:
|
||||
> 非均衡现象:
|
||||
|
||||
`在分类器训练时,正例数目和反例数目不相等(相差很大)。或者发生在正负例分类错误的成本不同的时候。`
|
||||
|
||||
@@ -525,9 +525,9 @@ print m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10
|
||||
* 不能放过传染病的人
|
||||
* 不能随便认为别人犯罪
|
||||
|
||||
我们有多种方法来处理这个问题: 具体可参考[此链接](https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/)
|
||||
我们有多种方法来处理这个问题: 具体可参考[此链接](https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/)
|
||||
|
||||
再结合书中的方法,可以归为八大类:
|
||||
再结合书中的方法,可以归为八大类:
|
||||
|
||||
##### 1.能否收集到更多的数据?
|
||||
|
||||
@@ -538,13 +538,13 @@ print m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10
|
||||
|
||||
Accuracy 或者error rate 不能用于非均衡的数据集。这会误导人。这时候可以尝试其他的评价指标。
|
||||
|
||||
Confusion Matrix 混淆矩阵:使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。
|
||||
Confusion Matrix 混淆矩阵: 使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为: TP、FN、FP与TN。
|
||||
|
||||
Precision:精确度
|
||||
Precision: 精确度
|
||||
|
||||
Recall: 召回率
|
||||
Recall: 召回率
|
||||
|
||||
F1 Score (or F-Score): 精确度和召回率的加权平均
|
||||
F1 Score (or F-Score): 精确度和召回率的加权平均
|
||||
|
||||
或者使用
|
||||
|
||||
@@ -577,7 +577,7 @@ ROC Curves
|
||||
|
||||
或者结合上述两种方法进行抽样
|
||||
|
||||
一些经验法则:
|
||||
一些经验法则:
|
||||
|
||||
* 考虑样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
|
||||
|
||||
@@ -609,11 +609,11 @@ python实现可以查阅[UnbalancedDataset](https://github.com/scikit-learn-cont
|
||||
|
||||
惩罚的模型就是对于不同的分类错误给予不同的代价(惩罚)。比如对于错分的小类给予更高的代价。这种方式会使模型偏差,更加关注小类。
|
||||
|
||||
通常来说这种代价/惩罚或者比重在学习中算法是特定的。比如使用代价函数来实现:
|
||||
通常来说这种代价/惩罚或者比重在学习中算法是特定的。比如使用代价函数来实现:
|
||||
|
||||
> 代价函数
|
||||
|
||||
* 基于代价函数的分类器决策控制:`TP*(-5)+FN*1+FP*50+TN*0`
|
||||
* 基于代价函数的分类器决策控制: `TP*(-5)+FN*1+FP*50+TN*0`
|
||||
|
||||
|
||||
|
||||
@@ -627,7 +627,7 @@ python实现可以查阅[UnbalancedDataset](https://github.com/scikit-learn-cont
|
||||
|
||||
从它们的角度看看你的问题,思考你的问题,说不定会有新的想法。
|
||||
|
||||
两个领域您可以考虑: anomaly detection(异常值检测) 和 change detection(变化趋势检测)。
|
||||
两个领域您可以考虑: anomaly detection(异常值检测) 和 change detection(变化趋势检测)。
|
||||
|
||||
Anomaly dectection 就是检测稀有事件。 比如通过机器震动来识别机器谷中或者根据一系列系统的调用来检测恶意操作。与常规操作相比,这些事件是罕见的。
|
||||
|
||||
@@ -641,7 +641,7 @@ change detection 变化趋势检测类似于异常值检测。但是他不是寻
|
||||
|
||||
仔细思考你的问题然后想想看如何将这问题细分为几个更切实际的小问题。
|
||||
|
||||
比如:
|
||||
比如:
|
||||
|
||||
将你的大类分解成多个较小的类;
|
||||
|
||||
@@ -655,6 +655,6 @@ change detection 变化趋势检测类似于异常值检测。但是他不是寻
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* **作者: [片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
124
docs/ml/8.回归.md
124
docs/ml/8.回归.md
@@ -1,4 +1,4 @@
|
||||
# 第8章 预测数值型数据:回归
|
||||
# 第8章 预测数值型数据: 回归
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
@@ -19,7 +19,7 @@ HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
|
||||
说到回归,一般都是指 `线性回归(linear regression)`。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。
|
||||
|
||||
补充:
|
||||
补充:
|
||||
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以由前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
|
||||
|
||||
## 回归 原理
|
||||
@@ -75,9 +75,9 @@ HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
#### 1.4、线性回归 算法特点
|
||||
|
||||
```
|
||||
优点:结果易于理解,计算上不复杂。
|
||||
缺点:对非线性的数据拟合不好。
|
||||
适用于数据类型:数值型和标称型数据。
|
||||
优点: 结果易于理解,计算上不复杂。
|
||||
缺点: 对非线性的数据拟合不好。
|
||||
适用于数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
#### 1.5、线性回归 项目案例
|
||||
@@ -106,9 +106,9 @@ x0 x1 y
|
||||
def loadDataSet(fileName):
|
||||
""" 加载数据
|
||||
解析以tab键分隔的文件中的浮点数
|
||||
Returns:
|
||||
dataMat : feature 对应的数据集
|
||||
labelMat : feature 对应的分类标签,即类别标签
|
||||
Returns:
|
||||
dataMat : feature 对应的数据集
|
||||
labelMat : feature 对应的分类标签,即类别标签
|
||||
|
||||
"""
|
||||
# 获取样本特征的总数,不算最后的目标变量
|
||||
@@ -134,13 +134,13 @@ def loadDataSet(fileName):
|
||||
|
||||
def standRegres(xArr,yArr):
|
||||
'''
|
||||
Description:
|
||||
Description:
|
||||
线性回归
|
||||
Args:
|
||||
xArr :输入的样本数据,包含每个样本数据的 feature
|
||||
yArr :对应于输入数据的类别标签,也就是每个样本对应的目标变量
|
||||
xArr : 输入的样本数据,包含每个样本数据的 feature
|
||||
yArr : 对应于输入数据的类别标签,也就是每个样本对应的目标变量
|
||||
Returns:
|
||||
ws:回归系数
|
||||
ws: 回归系数
|
||||
'''
|
||||
|
||||
# mat()函数将xArr,yArr转换为矩阵 mat().T 代表的是对矩阵进行转置操作
|
||||
@@ -239,20 +239,20 @@ LWLR 使用 “核”(与支持向量机中的核类似)来对附近的点
|
||||
# 局部加权线性回归
|
||||
def lwlr(testPoint,xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
Description:
|
||||
局部加权线性回归,在待预测点附近的每个点赋予一定的权重,在子集上基于最小均方差来进行普通的回归。
|
||||
Args:
|
||||
testPoint:样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
Args:
|
||||
testPoint: 样本点
|
||||
xArr: 样本的特征数据,即 feature
|
||||
yArr: 每个样本对应的类别标签,即目标变量
|
||||
k:关于赋予权重矩阵的核的一个参数,与权重的衰减速率有关
|
||||
Returns:
|
||||
testPoint * ws:数据点与具有权重的系数相乘得到的预测点
|
||||
testPoint * ws: 数据点与具有权重的系数相乘得到的预测点
|
||||
Notes:
|
||||
这其中会用到计算权重的公式,w = e^((x^((i))-x) / -2k^2)
|
||||
理解:x为某个预测点,x^((i))为样本点,样本点距离预测点越近,贡献的误差越大(权值越大),越远则贡献的误差越小(权值越小)。
|
||||
理解: x为某个预测点,x^((i))为样本点,样本点距离预测点越近,贡献的误差越大(权值越大),越远则贡献的误差越小(权值越小)。
|
||||
关于预测点的选取,在我的代码中取的是样本点。其中k是带宽参数,控制w(钟形函数)的宽窄程度,类似于高斯函数的标准差。
|
||||
算法思路:假设预测点取样本点中的第i个样本点(共m个样本点),遍历1到m个样本点(含第i个),算出每一个样本点与预测点的距离,
|
||||
算法思路: 假设预测点取样本点中的第i个样本点(共m个样本点),遍历1到m个样本点(含第i个),算出每一个样本点与预测点的距离,
|
||||
也就可以计算出每个样本贡献误差的权值,可以看出w是一个有m个元素的向量(写成对角阵形式)。
|
||||
'''
|
||||
# mat() 函数是将array转换为矩阵的函数, mat().T 是转换为矩阵之后,再进行转置操作
|
||||
@@ -279,15 +279,15 @@ def lwlr(testPoint,xArr,yArr,k=1.0):
|
||||
|
||||
def lwlrTest(testArr,xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
Description:
|
||||
测试局部加权线性回归,对数据集中每个点调用 lwlr() 函数
|
||||
Args:
|
||||
testArr:测试所用的所有样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
k:控制核函数的衰减速率
|
||||
Returns:
|
||||
yHat:预测点的估计值
|
||||
Args:
|
||||
testArr: 测试所用的所有样本点
|
||||
xArr: 样本的特征数据,即 feature
|
||||
yArr: 每个样本对应的类别标签,即目标变量
|
||||
k: 控制核函数的衰减速率
|
||||
Returns:
|
||||
yHat: 预测点的估计值
|
||||
'''
|
||||
# 得到样本点的总数
|
||||
m = shape(testArr)[0]
|
||||
@@ -303,13 +303,13 @@ def lwlrTestPlot(xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
首先将 X 排序,其余的都与lwlrTest相同,这样更容易绘图
|
||||
Args:
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量,实际值
|
||||
k:控制核函数的衰减速率的有关参数,这里设定的是常量值 1
|
||||
Return:
|
||||
yHat:样本点的估计值
|
||||
xCopy:xArr的复制
|
||||
Args:
|
||||
xArr: 样本的特征数据,即 feature
|
||||
yArr: 每个样本对应的类别标签,即目标变量,实际值
|
||||
k: 控制核函数的衰减速率的有关参数,这里设定的是常量值 1
|
||||
Return:
|
||||
yHat: 样本点的估计值
|
||||
xCopy: xArr的复制
|
||||
'''
|
||||
# 生成一个与目标变量数目相同的 0 向量
|
||||
yHat = zeros(shape(yArr))
|
||||
@@ -397,9 +397,9 @@ def rssError(yArr,yHatArr):
|
||||
'''
|
||||
Desc:
|
||||
返回真实值与预测值误差大小
|
||||
Args:
|
||||
yArr:样本的真实值
|
||||
yHatArr:样本的预测值
|
||||
Args:
|
||||
yArr: 样本的真实值
|
||||
yHatArr: 样本的预测值
|
||||
Returns:
|
||||
一个数字,代表误差
|
||||
'''
|
||||
@@ -461,7 +461,7 @@ def abaloneTest():
|
||||
#### 4.1、岭回归
|
||||
|
||||
简单来说,岭回归就是在矩阵 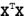 上加一个 λI 从而使得矩阵非奇异,进而能对 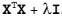 求逆。其中矩阵I是一个 n * n (等于列数) 的单位矩阵,
|
||||
对角线上元素全为1,其他元素全为0。而λ是一个用户定义的数值,后面会做介绍。在这种情况下,回归系数的计算公式将变成:
|
||||
对角线上元素全为1,其他元素全为0。而λ是一个用户定义的数值,后面会做介绍。在这种情况下,回归系数的计算公式将变成:
|
||||
|
||||
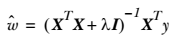
|
||||
|
||||
@@ -480,16 +480,16 @@ def abaloneTest():
|
||||
```python
|
||||
def ridgeRegres(xMat,yMat,lam=0.2):
|
||||
'''
|
||||
Desc:
|
||||
Desc:
|
||||
这个函数实现了给定 lambda 下的岭回归求解。
|
||||
如果数据的特征比样本点还多,就不能再使用上面介绍的的线性回归和局部线性回归了,因为计算 (xTx)^(-1)会出现错误。
|
||||
如果特征比样本点还多(n > m),也就是说,输入数据的矩阵x不是满秩矩阵。非满秩矩阵在求逆时会出现问题。
|
||||
为了解决这个问题,我们下边讲一下:岭回归,这是我们要讲的第一种缩减方法。
|
||||
Args:
|
||||
xMat:样本的特征数据,即 feature
|
||||
yMat:每个样本对应的类别标签,即目标变量,实际值
|
||||
lam:引入的一个λ值,使得矩阵非奇异
|
||||
Returns:
|
||||
为了解决这个问题,我们下边讲一下: 岭回归,这是我们要讲的第一种缩减方法。
|
||||
Args:
|
||||
xMat: 样本的特征数据,即 feature
|
||||
yMat: 每个样本对应的类别标签,即目标变量,实际值
|
||||
lam: 引入的一个λ值,使得矩阵非奇异
|
||||
Returns:
|
||||
经过岭回归公式计算得到的回归系数
|
||||
'''
|
||||
|
||||
@@ -506,13 +506,13 @@ def ridgeRegres(xMat,yMat,lam=0.2):
|
||||
|
||||
def ridgeTest(xArr,yArr):
|
||||
'''
|
||||
Desc:
|
||||
Desc:
|
||||
函数 ridgeTest() 用于在一组 λ 上测试结果
|
||||
Args:
|
||||
xArr:样本数据的特征,即 feature
|
||||
yArr:样本数据的类别标签,即真实数据
|
||||
Returns:
|
||||
wMat:将所有的回归系数输出到一个矩阵并返回
|
||||
Args:
|
||||
xArr: 样本数据的特征,即 feature
|
||||
yArr: 样本数据的类别标签,即真实数据
|
||||
Returns:
|
||||
wMat: 将所有的回归系数输出到一个矩阵并返回
|
||||
'''
|
||||
|
||||
xMat = mat(xArr)
|
||||
@@ -674,12 +674,12 @@ Dangler 喜欢为乐高套装估价,我们用回归技术来帮助他建立一
|
||||
##### 开发流程
|
||||
|
||||
```
|
||||
(1) 收集数据:用 Google Shopping 的API收集数据。
|
||||
(2) 准备数据:从返回的JSON数据中抽取价格。
|
||||
(3) 分析数据:可视化并观察数据。
|
||||
(4) 训练算法:构建不同的模型,采用逐步线性回归和直接的线性回归模型。
|
||||
(5) 测试算法:使用交叉验证来测试不同的模型,分析哪个效果最好。
|
||||
(6) 使用算法:这次练习的目标就是生成数据模型。
|
||||
(1) 收集数据: 用 Google Shopping 的API收集数据。
|
||||
(2) 准备数据: 从返回的JSON数据中抽取价格。
|
||||
(3) 分析数据: 可视化并观察数据。
|
||||
(4) 训练算法: 构建不同的模型,采用逐步线性回归和直接的线性回归模型。
|
||||
(5) 测试算法: 使用交叉验证来测试不同的模型,分析哪个效果最好。
|
||||
(6) 使用算法: 这次练习的目标就是生成数据模型。
|
||||
```
|
||||
|
||||
> 收集数据: 使用 Google 购物的 API
|
||||
@@ -753,7 +753,7 @@ def setDataCollect(retX, retY):
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10196.html', 2009, 3263, 249.99)
|
||||
```
|
||||
|
||||
> 测试算法:使用交叉验证来测试不同的模型,分析哪个效果最好
|
||||
> 测试算法: 使用交叉验证来测试不同的模型,分析哪个效果最好
|
||||
|
||||
```python
|
||||
# 交叉验证测试岭回归
|
||||
@@ -823,7 +823,7 @@ def regression5():
|
||||
crossValidation(lgX, lgY, 10)
|
||||
```
|
||||
|
||||
> 使用算法:这次练习的目标就是生成数据模型
|
||||
> 使用算法: 这次练习的目标就是生成数据模型
|
||||
|
||||
## 7、选读内容
|
||||
|
||||
@@ -843,6 +843,6 @@ def regression5():
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[小瑶](http://cwiki.apachecn.org/display/~chenyao) [片刻](https://github.com/jiangzhonglian)**
|
||||
* **作者: [小瑶](http://cwiki.apachecn.org/display/~chenyao) [片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
@@ -74,20 +74,20 @@ CART 和 C4.5 之间主要差异在于分类结果上,CART 可以回归分析
|
||||
### 1.4、树回归 开发流程
|
||||
|
||||
```
|
||||
(1) 收集数据:采用任意方法收集数据。
|
||||
(2) 准备数据:需要数值型数据,标称型数据应该映射成二值型数据。
|
||||
(3) 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树。
|
||||
(4) 训练算法:大部分时间都花费在叶节点树模型的构建上。
|
||||
(5) 测试算法:使用测试数据上的R^2值来分析模型的效果。
|
||||
(6) 使用算法:使用训练处的树做预测,预测结果还可以用来做很多事情。
|
||||
(1) 收集数据: 采用任意方法收集数据。
|
||||
(2) 准备数据: 需要数值型数据,标称型数据应该映射成二值型数据。
|
||||
(3) 分析数据: 绘出数据的二维可视化显示结果,以字典方式生成树。
|
||||
(4) 训练算法: 大部分时间都花费在叶节点树模型的构建上。
|
||||
(5) 测试算法: 使用测试数据上的R^2值来分析模型的效果。
|
||||
(6) 使用算法: 使用训练处的树做预测,预测结果还可以用来做很多事情。
|
||||
```
|
||||
|
||||
### 1.5、树回归 算法特点
|
||||
|
||||
```
|
||||
优点:可以对复杂和非线性的数据建模。
|
||||
缺点:结果不易理解。
|
||||
适用数据类型:数值型和标称型数据。
|
||||
优点: 可以对复杂和非线性的数据建模。
|
||||
缺点: 结果不易理解。
|
||||
适用数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 1.6、回归树 项目案例
|
||||
@@ -99,15 +99,15 @@ CART 和 C4.5 之间主要差异在于分类结果上,CART 可以回归分析
|
||||
#### 1.6.2、开发流程
|
||||
|
||||
```
|
||||
收集数据:采用任意方法收集数据
|
||||
准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法:大部分时间都花费在叶节点树模型的构建上
|
||||
测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
收集数据: 采用任意方法收集数据
|
||||
准备数据: 需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据: 绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法: 大部分时间都花费在叶节点树模型的构建上
|
||||
测试算法: 使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法: 使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
```
|
||||
|
||||
> 收集数据:采用任意方法收集数据
|
||||
> 收集数据: 采用任意方法收集数据
|
||||
|
||||
data1.txt 文件中存储的数据格式如下:
|
||||
|
||||
@@ -119,9 +119,9 @@ data1.txt 文件中存储的数据格式如下:
|
||||
0.343554 -0.371700
|
||||
0.098016 -0.332760
|
||||
```
|
||||
> 准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
> 准备数据: 需要数值型数据,标称型数据应该映射成二值型数据
|
||||
|
||||
> 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
> 分析数据: 绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
|
||||
基于 CART 算法构建回归树的简单数据集
|
||||
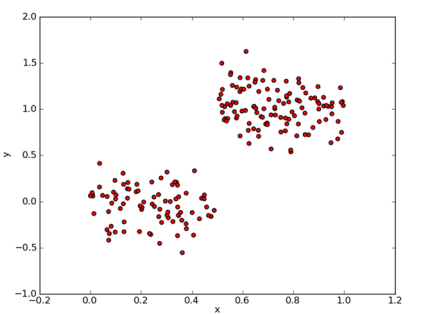
|
||||
@@ -135,7 +135,7 @@ data1.txt 文件中存储的数据格式如下:
|
||||
```python
|
||||
def binSplitDataSet(dataSet, feature, value):
|
||||
"""binSplitDataSet(将数据集,按照feature列的value进行 二元切分)
|
||||
Description:在给定特征和特征值的情况下,该函数通过数组过滤方式将上述数据集合切分得到两个子集并返回。
|
||||
Description: 在给定特征和特征值的情况下,该函数通过数组过滤方式将上述数据集合切分得到两个子集并返回。
|
||||
Args:
|
||||
dataMat 数据集
|
||||
feature 待切分的特征列
|
||||
@@ -224,7 +224,7 @@ def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
# 假设 dataSet 是 NumPy Mat 类型的,那么我们可以进行 array 过滤
|
||||
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
"""createTree(获取回归树)
|
||||
Description:递归函数:如果构建的是回归树,该模型是一个常数,如果是模型树,其模型师一个线性方程。
|
||||
Description: 递归函数: 如果构建的是回归树,该模型是一个常数,如果是模型树,其模型师一个线性方程。
|
||||
Args:
|
||||
dataSet 加载的原始数据集
|
||||
leafType 建立叶子点的函数
|
||||
@@ -233,7 +233,7 @@ def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
Returns:
|
||||
retTree 决策树最后的结果
|
||||
"""
|
||||
# 选择最好的切分方式: feature索引值,最优切分值
|
||||
# 选择最好的切分方式: feature索引值,最优切分值
|
||||
# choose the best split
|
||||
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
|
||||
# if the splitting hit a stop condition return val
|
||||
@@ -252,9 +252,9 @@ def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
> 测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
> 测试算法: 使用测试数据上的R^2值来分析模型的效果
|
||||
|
||||
> 使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
> 使用算法: 使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
|
||||
## 2、树剪枝
|
||||
|
||||
@@ -349,7 +349,7 @@ def prune(tree, testData):
|
||||
# 1. 如果正确
|
||||
# * 那么计算一下总方差 和 该结果集的本身不分枝的总方差比较
|
||||
# * 如果 合并的总方差 < 不合并的总方差,那么就进行合并
|
||||
# 注意返回的结果: 如果可以合并,原来的dict就变为了 数值
|
||||
# 注意返回的结果: 如果可以合并,原来的dict就变为了 数值
|
||||
if not isTree(tree['left']) and not isTree(tree['right']):
|
||||
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
|
||||
# power(x, y)表示x的y次方
|
||||
@@ -387,7 +387,7 @@ def prune(tree, testData):
|
||||
模型树的叶节点生成函数
|
||||
|
||||
```python
|
||||
# 得到模型的ws系数:f(x) = x0 + x1*featrue1+ x3*featrue2 ...
|
||||
# 得到模型的ws系数: f(x) = x0 + x1*featrue1+ x3*featrue2 ...
|
||||
# create linear model and return coeficients
|
||||
def modelLeaf(dataSet):
|
||||
"""
|
||||
@@ -467,17 +467,17 @@ def linearSolve(dataSet):
|
||||
#### 4.1.2、开发流程
|
||||
|
||||
```
|
||||
收集数据:采用任意方法收集数据
|
||||
准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法:模型树的构建
|
||||
测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
收集数据: 采用任意方法收集数据
|
||||
准备数据: 需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据: 绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法: 模型树的构建
|
||||
测试算法: 使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法: 使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
```
|
||||
|
||||
> 收集数据: 采用任意方法收集数据
|
||||
|
||||
> 准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
> 准备数据: 需要数值型数据,标称型数据应该映射成二值型数据
|
||||
|
||||
数据存储格式:
|
||||
```
|
||||
@@ -488,11 +488,11 @@ def linearSolve(dataSet):
|
||||
15.000000 139.737693
|
||||
```
|
||||
|
||||
> 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
> 分析数据: 绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
|
||||
|
||||
|
||||
> 训练算法:模型树的构建
|
||||
> 训练算法: 模型树的构建
|
||||
|
||||
用树回归进行预测的代码
|
||||
```python
|
||||
@@ -583,13 +583,13 @@ def createForeCast(tree, testData, modelEval=regTreeEval):
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
> 测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
> 测试算法: 使用测试数据上的R^2值来分析模型的效果
|
||||
|
||||
R^2 判定系数就是拟合优度判定系数,它体现了回归模型中自变量的变异在因变量的变异中所占的比例。如 R^2=0.99999 表示在因变量 y 的变异中有 99.999% 是由于变量 x 引起。当 R^2=1 时表示,所有观测点都落在拟合的直线或曲线上;当 R^2=0 时,表示自变量与因变量不存在直线或曲线关系。
|
||||
|
||||
所以我们看出, R^2 的值越接近 1.0 越好。
|
||||
|
||||
> 使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
> 使用算法: 使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
|
||||
|
||||
## 5、附加 Python 中 GUI 的使用
|
||||
@@ -628,6 +628,6 @@ Tkinter 是 Python 的一个 GUI 工具包。虽然并不是唯一的包,但
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* **作者: [片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
* **版权声明: 欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
Reference in New Issue
Block a user