diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 6661341..7207c79 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -93,16 +93,16 @@ Before diving into the notebook, you need to:
*Q-Learning* **is the RL algorithm that**:
-- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
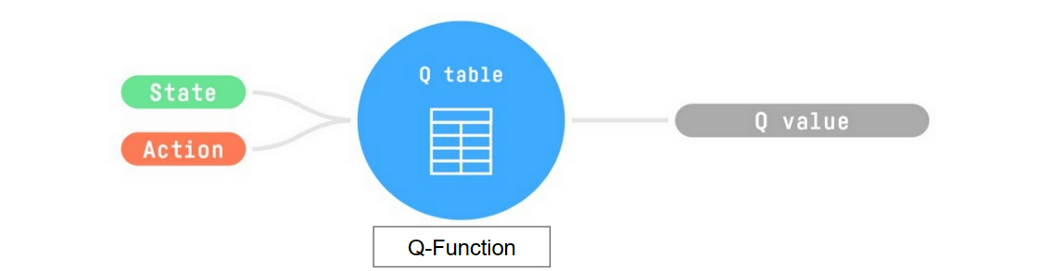 -- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
-- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
 diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec32172..5f46722 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -113,7 +113,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec32172..5f46722 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -113,7 +113,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**