diff --git a/units/en/unit1/conclusion.mdx b/units/en/unit1/conclusion.mdx
index b501e20..de31951 100644
--- a/units/en/unit1/conclusion.mdx
+++ b/units/en/unit1/conclusion.mdx
@@ -1,14 +1,14 @@
# Conclusion [[conclusion]]
-Congrats on finishing this chapter! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared it on the Hub 🥳.
+Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared it with the community! 🥳
-That’s **normal if you still feel confused with all these elements**. This was the same for me and for all people who studied RL.
+It's **normal if you still feel confused with some of these elements**. This was the same for me and for all people who studied RL.
**Take time to really grasp the material** before continuing. It’s important to master these elements and having a solid foundations before entering the fun part.
-Naturally, during the course, we’re going to use and explain these terms again, but it’s better to understand them before diving into the next chapters.
+Naturally, during the course, we’re going to use and explain these terms again, but it’s better to understand them before diving into the next units.
-In the next chapter, we’re going to reinforce what we just learn by **training Huggy the Dog to fetch the stick**.
+In the next (bonus) unit, we’re going to reinforce what we just learned by **training Huggy the Dog to fetch the stick**.
You will be able then to play with him 🤗.
diff --git a/units/en/unit1/deep-rl.mdx b/units/en/unit1/deep-rl.mdx
index fab6091..c0c2247 100644
--- a/units/en/unit1/deep-rl.mdx
+++ b/units/en/unit1/deep-rl.mdx
@@ -6,11 +6,11 @@ What we've talked about so far is Reinforcement Learning. But where does the "De
Deep Reinforcement Learning introduces **deep neural networks to solve Reinforcement Learning problems** — hence the name “deep”.
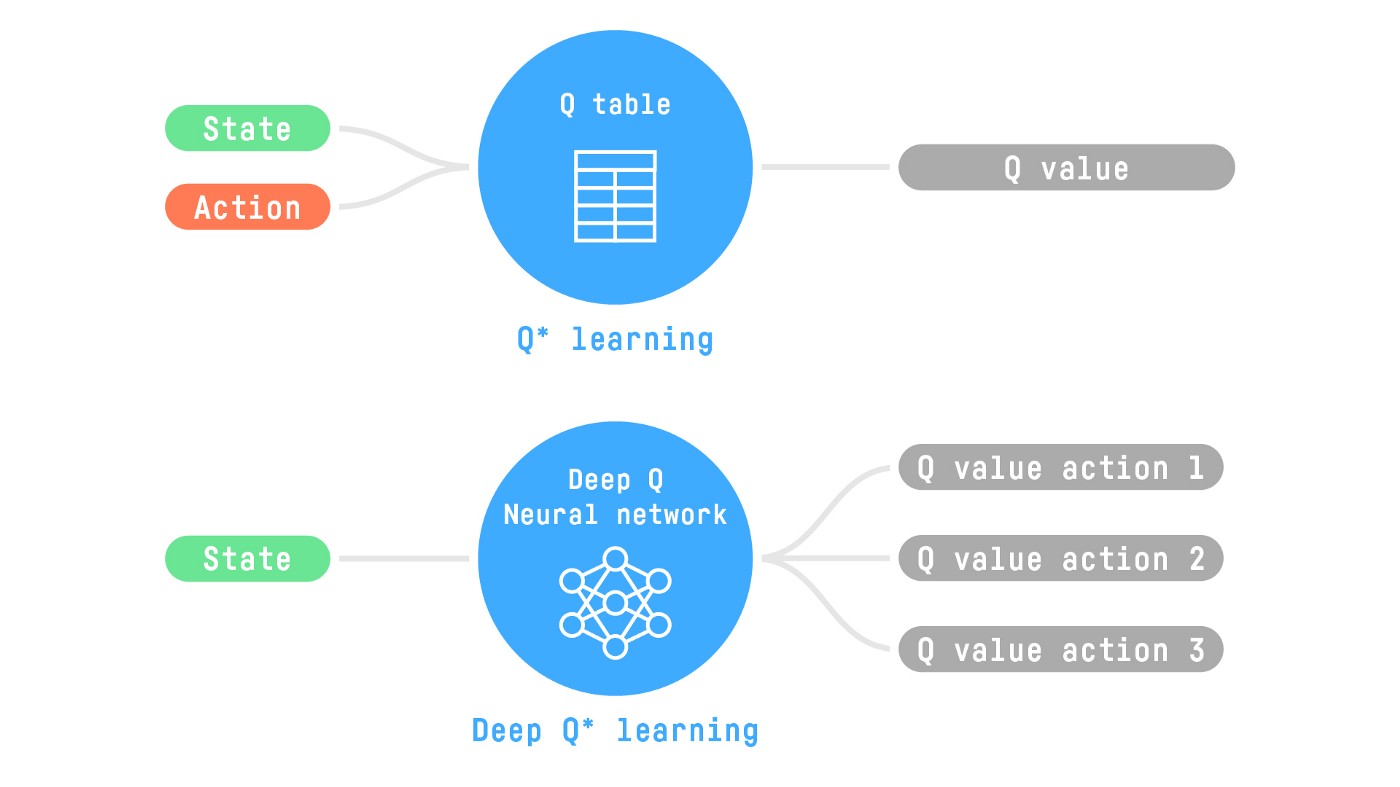
-For instance, in the next article, we’ll work on Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning both are value-based RL algorithms.
+For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
You’ll see the difference is that in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
-In the second approach, **we will use a Neural Network** (to approximate the q value).
+In the second approach, **we will use a Neural Network** (to approximate the Q value).
@@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the q
-If you are not familiar with Deep Learning you definitely should watch the fastai Practical Deep Learning for Coders (Free)
+If you are not familiar with Deep Learning you definitely should watch [the FastAI Practical Deep Learning for Coders](https://course.fast.a) (Free).
diff --git a/units/en/unit1/exp-exp-tradeoff.mdx b/units/en/unit1/exp-exp-tradeoff.mdx
index 65682b5..10798d8 100644
--- a/units/en/unit1/exp-exp-tradeoff.mdx
+++ b/units/en/unit1/exp-exp-tradeoff.mdx
@@ -1,4 +1,4 @@
-# The Exploration/ Exploitation tradeoff [[exp-exp-tradeoff]]
+# The Exploration/Exploitation trade-off [[exp-exp-tradeoff]]
Finally, before looking at the different methods to solve Reinforcement Learning problems, we must cover one more very important topic: *the exploration/exploitation trade-off.*
@@ -19,9 +19,10 @@ But if our agent does a little bit of exploration, it can **discover the big re
This is what we call the exploration/exploitation trade-off. We need to balance how much we **explore the environment** and how much we **exploit what we know about the environment.**
-Therefore, we must **define a rule that helps to handle this trade-off**. We’ll see the different ways to handle it in the future chapters.
+Therefore, we must **define a rule that helps to handle this trade-off**. We’ll see the different ways to handle it in the future units.
+
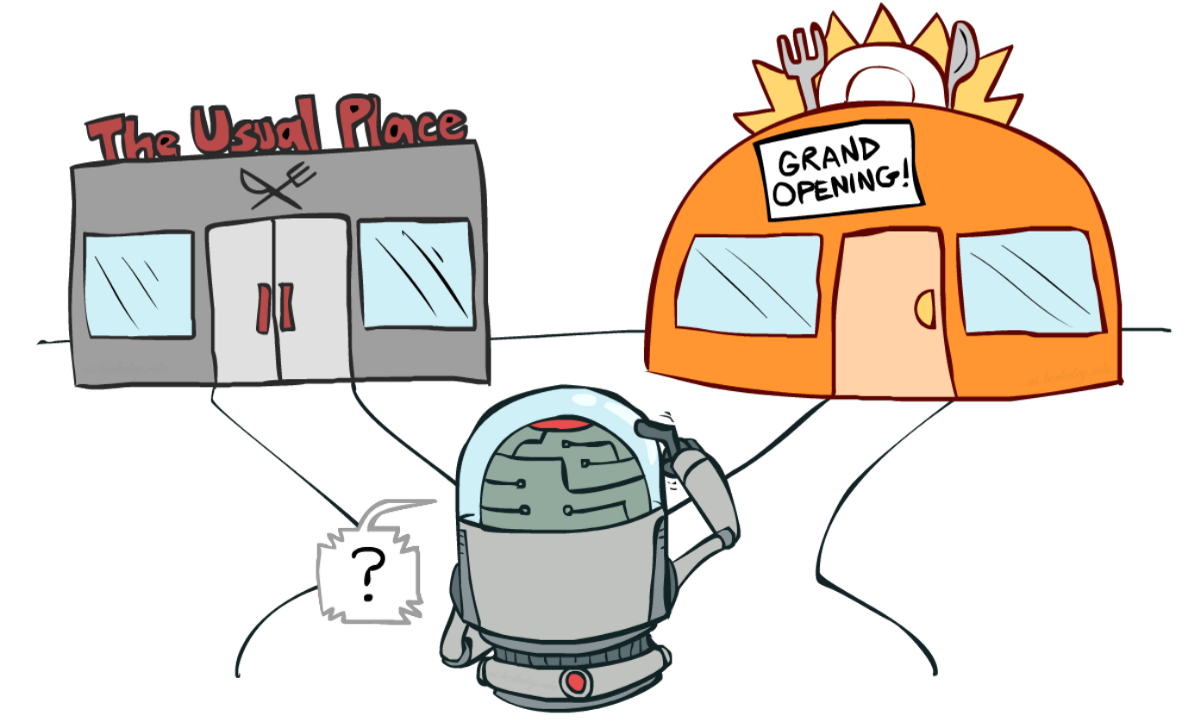
+If it’s still confusing, **think of a real problem: the choice of picking a restaurant:**
-If it’s still confusing, **think of a real problem: the choice of a restaurant:**
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 40e9c0f..506f858 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -8,6 +8,6 @@ A Lunar Lander agent that will learn to land correctly on the Moon 🌕
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
-Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 1 🏆?
+Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index a891204..660ec20 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -7,9 +7,11 @@ Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinfo
Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
-So in this first chapter, **you'll learn the foundations of Deep Reinforcement Learning.**
+In this first unit, **you'll learn the foundations of Deep Reinforcement Learning.**
+
+
+Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 , a Deep Reinforcement Learning library.
-Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 a Deep Reinforcement Learning library.
diff --git a/units/en/unit1/quiz.mdx b/units/en/unit1/quiz.mdx
index b29b41f..e89379f 100644
--- a/units/en/unit1/quiz.mdx
+++ b/units/en/unit1/quiz.mdx
@@ -132,7 +132,7 @@ In Reinforcement Learning, we need to **balance how much we explore the environm
Solution
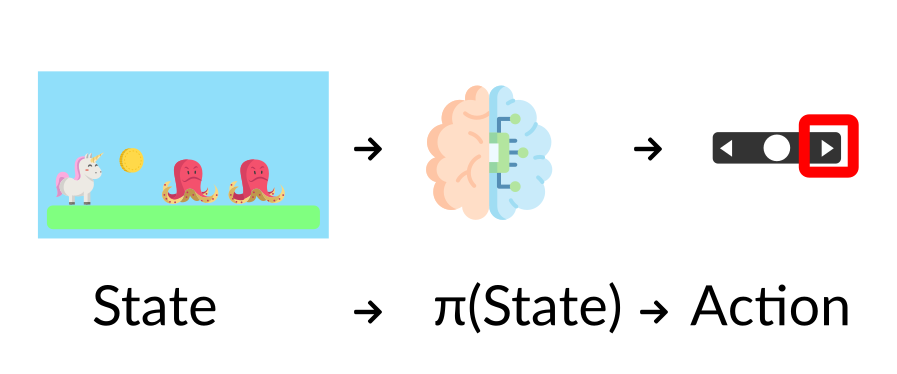
-- The Policy π **is the brain of our Agent**, it’s the function that tell us what action to take given the state we are. So it defines the agent’s behavior at a given time.
+- The Policy π **is the brain of our Agent**. It’s the function that tells us what action to take given the state we are in. So it defines the agent’s behavior at a given time.
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d26811c..51a136a 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
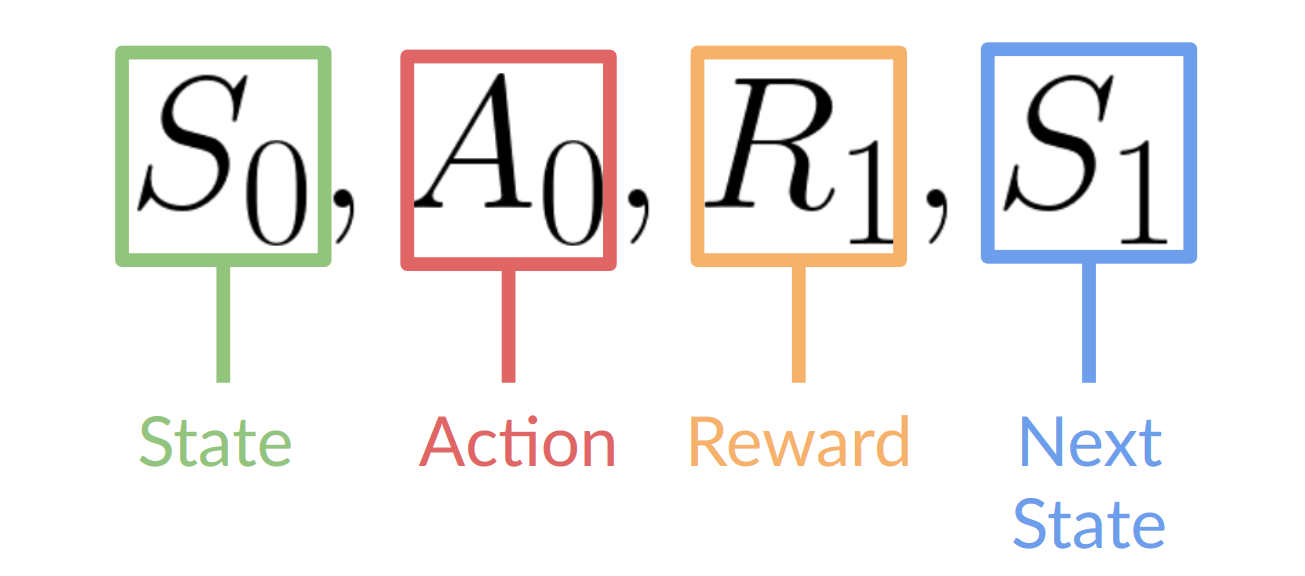
@@ -23,7 +23,7 @@ This RL loop outputs a sequence of **state, action, reward and next state.**
-The agent's goal is to maximize its cumulative reward, **called the expected return.**
+The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
@@ -31,19 +31,20 @@ The agent's goal is to maximize its cumulative reward, **called the expected re
Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-That’s why in Reinforcement Learning, **to have the best behavior,** we need to **maximize the expected cumulative reward.**
+That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+
## Markov Property [[markov-property]]
In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states** **and actions** they took before.
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
## Observations/States Space [[obs-space]]
Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-There is a differentiation to make between *observation* and *state*:
+There is a differentiation to make between *observation* and *state*, however:
- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
@@ -53,9 +54,7 @@ There is a differentiation to make between *observation* and *state*:
In chess game, we receive a state from the environment since we have access to the whole check board information.
-In chess game, we receive a state from the environment since we have access to the whole check board information.
-
-With a chess game, we are in a fully observed environment, since we have access to the whole check board information.
+In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
- *Observation o*: is a **partial description of the state.** In a partially observed environment.
@@ -69,7 +68,7 @@ In Super Mario Bros, we only see a part of the level close to the player, so we
In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
-In reality, we use the term state in this course but we will make the distinction in implementations.
+In this course, we use the term "state" to denote both state and observation, but we will make the distinction in implementations.
To recap:
@@ -86,7 +85,8 @@ The actions can come from a *discrete* or *continuous space*:
-Again, in Super Mario Bros, we have only 4 directions and jump possible
+Again, in Super Mario Bros, we have only 5 possible actions: 4 directions and jumping
+
In Super Mario Bros, we have a finite set of actions since we have only 4 directions and jump.
 @@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the q
@@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the q
 diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 40e9c0f..506f858 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -8,6 +8,6 @@ A Lunar Lander agent that will learn to land correctly on the Moon 🌕
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
-Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 1 🏆?
+Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index a891204..660ec20 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -7,9 +7,11 @@ Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinfo
Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
-So in this first chapter, **you'll learn the foundations of Deep Reinforcement Learning.**
+In this first unit, **you'll learn the foundations of Deep Reinforcement Learning.**
+
+
+Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 , a Deep Reinforcement Learning library.
-Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 a Deep Reinforcement Learning library.
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 40e9c0f..506f858 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -8,6 +8,6 @@ A Lunar Lander agent that will learn to land correctly on the Moon 🌕
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
-Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 1 🏆?
+Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index a891204..660ec20 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -7,9 +7,11 @@ Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinfo
Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
-So in this first chapter, **you'll learn the foundations of Deep Reinforcement Learning.**
+In this first unit, **you'll learn the foundations of Deep Reinforcement Learning.**
+
+
+Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 , a Deep Reinforcement Learning library.
-Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using Stable-Baselines3 a Deep Reinforcement Learning library.
 diff --git a/units/en/unit1/quiz.mdx b/units/en/unit1/quiz.mdx
index b29b41f..e89379f 100644
--- a/units/en/unit1/quiz.mdx
+++ b/units/en/unit1/quiz.mdx
@@ -132,7 +132,7 @@ In Reinforcement Learning, we need to **balance how much we explore the environm
diff --git a/units/en/unit1/quiz.mdx b/units/en/unit1/quiz.mdx
index b29b41f..e89379f 100644
--- a/units/en/unit1/quiz.mdx
+++ b/units/en/unit1/quiz.mdx
@@ -132,7 +132,7 @@ In Reinforcement Learning, we need to **balance how much we explore the environm
 diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d26811c..51a136a 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -23,7 +23,7 @@ This RL loop outputs a sequence of **state, action, reward and next state.**
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d26811c..51a136a 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -23,7 +23,7 @@ This RL loop outputs a sequence of **state, action, reward and next state.**
 -The agent's goal is to maximize its cumulative reward, **called the expected return.**
+The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
@@ -31,19 +31,20 @@ The agent's goal is to maximize its cumulative reward, **called the expected re
Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-That’s why in Reinforcement Learning, **to have the best behavior,** we need to **maximize the expected cumulative reward.**
+That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+
## Markov Property [[markov-property]]
In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states** **and actions** they took before.
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
## Observations/States Space [[obs-space]]
Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-There is a differentiation to make between *observation* and *state*:
+There is a differentiation to make between *observation* and *state*, however:
- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
@@ -53,9 +54,7 @@ There is a differentiation to make between *observation* and *state*:
-The agent's goal is to maximize its cumulative reward, **called the expected return.**
+The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
@@ -31,19 +31,20 @@ The agent's goal is to maximize its cumulative reward, **called the expected re
Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-That’s why in Reinforcement Learning, **to have the best behavior,** we need to **maximize the expected cumulative reward.**
+That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+
## Markov Property [[markov-property]]
In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states** **and actions** they took before.
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
## Observations/States Space [[obs-space]]
Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-There is a differentiation to make between *observation* and *state*:
+There is a differentiation to make between *observation* and *state*, however:
- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
@@ -53,9 +54,7 @@ There is a differentiation to make between *observation* and *state*:
 -
-