diff --git a/units/en/unit2/bellman-equation.mdx b/units/en/unit2/bellman-equation.mdx
index 6d224f0..b284c44 100644
--- a/units/en/unit2/bellman-equation.mdx
+++ b/units/en/unit2/bellman-equation.mdx
@@ -21,9 +21,9 @@ Then, to calculate the \\(V(S_{t+1})\\), we need to calculate the return startin
To calculate the value of State 2: the sum of rewards **if the agent started in that state, and then followed the **policy for all the time steps.
-So you see, that's a pretty tedious process if you need to do it for each state value or state-action value.
+So you may have noticed, we're repeating the computation of the value of different states, which can be tedious if you need to do it for each state value or state-action value.
-Instead of calculating the expected return for each state or each state-action pair, **we can use the Bellman equation.**
+Instead of calculating the expected return for each state or each state-action pair, **we can use the Bellman equation.** (hint: if you know what Dynamic Programming is, this is very similar! if you don't know what it is, no worries!)
The Bellman equation is a recursive equation that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as:
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
index 409f025..e465f45 100644
--- a/units/en/unit2/introduction.mdx
+++ b/units/en/unit2/introduction.mdx
@@ -19,8 +19,8 @@ Concretely, we will:
- Learn about **value-based methods**.
- Learn about the **differences between Monte Carlo and Temporal Difference Learning**.
-- Study and implement **our first RL algorithm**: Q-Learning.s
+- Study and implement **our first RL algorithm**: Q-Learning.
-This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that played Atari games and beat the human level on some of them (breakout, space invaders…).
+This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that played Atari games and beat the human level on some of them (breakout, space invaders, etc).
So let's get started! 🚀
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
index e78ee78..030ee62 100644
--- a/units/en/unit2/mc-vs-td.mdx
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -1,8 +1,8 @@
# Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
-The last thing we need to talk about before diving into Q-Learning is the two ways of learning.
+The last thing we need to discuss before diving into Q-Learning is the two learning strategies.
-Remember that an RL agent **learns by interacting with its environment.** The idea is that **using the experience taken**, given the reward it gets, will **update its value or policy.**
+Remember that an RL agent **learns by interacting with its environment.** The idea is that **given the experience and the received reward, the agent will update its value function or policy.**
Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
@@ -14,7 +14,7 @@ We'll explain both of them **using a value-based method example.**
Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
-So it requires a **complete entire episode of interaction before updating our value function.**
+So it requires a **complete episode of interaction before updating our value function.**
@@ -29,7 +29,7 @@ If we take an example:
- We get **the reward and the next state.**
- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
-- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States**
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
- It will then **update \\(V(s_t)\\) based on the formula**
@@ -74,12 +74,12 @@ For instance, if we train a state-value function using Monte Carlo:
## Temporal Difference Learning: learning at each step [[td-learning]]
-- **Temporal difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- **Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\(gamma * V(S_{t+1})\\).
The idea with **TD is to update the \\(V(S_t)\\) at each step.**
-But because we didn't play during an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
index 62e9be3..d6ccbda 100644
--- a/units/en/unit2/q-learning-example.mdx
+++ b/units/en/unit2/q-learning-example.mdx
@@ -68,7 +68,7 @@ I took action down. **Not a good action since it leads me to the poison.**
-## Step 3: Perform action At, gets \Rt+1 and St+1 [[step3-3]]
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3-3]]
Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index 8447e4c..d2e8aa4 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -3,7 +3,7 @@
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
-- *Off-policy*: we'll talk about that at the end of this chapter.
+- *Off-policy*: we'll talk about that at the end of this unit.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
@@ -18,7 +18,7 @@ The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action value pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
-If we take this maze example:
+Let's go through an example of a maze.
@@ -39,7 +39,7 @@ Therefore, Q-function contains a Q-table **that has the value of each-state act
If we recap, *Q-Learning* **is the RL algorithm that:**
-- Trains *Q-Function* (an **action-value function**) which internally is a *Q-table* **that contains all the state-action pair values.**
+- Trains a *Q-Function* (an **action-value function**), which internally is a *Q-table that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-Table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know for each state what is the best action to take.**
@@ -47,14 +47,14 @@ If we recap, *Q-Learning* **is the RL algorithm that:**
-But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0). As the agent **explores the environment and we update the Q-Table, it will give us better and better approximations** to the optimal policy.
We see here that with the training, our Q-Table is better since, thanks to it, we can know the value of each state-action pair.
-So now that we understand what Q-Learning, Q-Function, and Q-Table are, **let's dive deeper into the Q-Learning algorithm**.
+Now that we understand what Q-Learning, Q-Function, and Q-Table are, **let's dive deeper into the Q-Learning algorithm**.
## The Q-Learning algorithm [[q-learning-algo]]
@@ -112,15 +112,15 @@ How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
-Then when the update of this Q-value is done. We start in a new_state and select our action **using our epsilon-greedy policy again.**
+Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
-**It's why we say that this is an off-policy algorithm.**
+**This is why we say that Q Learning is an off-policy algorithm.**
## Off-policy vs On-policy [[off-vs-on]]
The difference is subtle:
-- *Off-policy*: using **a different policy for acting and updating.**
+- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
For instance, with Q-Learning, the Epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
@@ -140,7 +140,7 @@ Is different from the policy we use during the training part:
- *On-policy:* using the **same policy for acting and updating.**
-For instance, with Sarsa, another value-based algorithm, **the Epsilon-Greedy Policy selects the next_state-action pair, not a greedy policy.**
+For instance, with Sarsa, another value-based algorithm, **the Epsilon-Greedy Policy selects the next state-action pair, not a greedy policy.**
diff --git a/units/en/unit2/quiz1.mdx b/units/en/unit2/quiz1.mdx
index cc5692d..2372fdd 100644
--- a/units/en/unit2/quiz1.mdx
+++ b/units/en/unit2/quiz1.mdx
@@ -102,4 +102,4 @@ The immediate reward + the discounted value of the state that follows
-Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the previous sections to reinforce (😏) your knowledge.
diff --git a/units/en/unit2/summary1.mdx b/units/en/unit2/summary1.mdx
index 3a19d86..ee3c202 100644
--- a/units/en/unit2/summary1.mdx
+++ b/units/en/unit2/summary1.mdx
@@ -1,12 +1,12 @@
# Summary [[summary1]]
-Before diving on Q-Learning, let's summarize what we just learned.
+Before diving into Q-Learning, let's summarize what we just learned.
We have two types of value-based functions:
- State-Value function: outputs the expected return if **the agent starts at a given state and acts accordingly to the policy forever after.**
- Action-Value function: outputs the expected return if **the agent starts in a given state, takes a given action at that state** and then acts accordingly to the policy forever after.
-- In value-based methods, **we define the policy by hand** because we don't train it, we train a value function. The idea is that if we have an optimal value function, we **will have an optimal policy.**
+- In value-based methods, rather than learning the policy, **we define the policy by hand** and we learn a value function. If we have an optimal value function, we **will have an optimal policy.**
There are two types of methods to learn a policy for a value function:
diff --git a/units/en/unit2/two-types-value-based-methods.mdx b/units/en/unit2/two-types-value-based-methods.mdx
index 47da6ef..3ea7591 100644
--- a/units/en/unit2/two-types-value-based-methods.mdx
+++ b/units/en/unit2/two-types-value-based-methods.mdx
@@ -7,7 +7,7 @@ In value-based methods, **we learn a value function** that **maps a state to
The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
-But what does it mean to act according to our policy? After all, we don't have a policy in value-based methods, since we train a value function and not a policy.
+But what does it mean to act according to our policy? After all, we don't have a policy in value-based methods since we train a value function and not a policy.
Remember that the goal of an **RL agent is to have an optimal policy π.**
@@ -22,7 +22,7 @@ The policy takes a state as input and outputs what action to take at that state
And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
-- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take action.**
+- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take an action.**
Since the policy is not trained/learned, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
@@ -51,7 +51,7 @@ We write the state value function under a policy π like this:
-For each state, the state-value function outputs the expected return if the agent **starts at that state,** and then follows the policy forever afterwards (for all future timesteps, if you prefer).
+For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
@@ -79,7 +79,7 @@ We see that the difference is:
Note: We didn't fill all the state-action pairs for the example of Action-value function
-In either case, whatever value function we choose (state-value or action-value function), **the value is the expected return.**
+In either case, whatever value function we choose (state-value or action-value function), **the returned value is the expected return.**
However, the problem is that it implies that **to calculate EACH value of a state or a state-action pair, we need to sum all the rewards an agent can get if it starts at that state.**

 @@ -29,7 +29,7 @@ If we take an example:
- We get **the reward and the next state.**
- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
-- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States**
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
- It will then **update \\(V(s_t)\\) based on the formula**
@@ -74,12 +74,12 @@ For instance, if we train a state-value function using Monte Carlo:
## Temporal Difference Learning: learning at each step [[td-learning]]
-- **Temporal difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- **Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\(gamma * V(S_{t+1})\\).
The idea with **TD is to update the \\(V(S_t)\\) at each step.**
-But because we didn't play during an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
index 62e9be3..d6ccbda 100644
--- a/units/en/unit2/q-learning-example.mdx
+++ b/units/en/unit2/q-learning-example.mdx
@@ -68,7 +68,7 @@ I took action down. **Not a good action since it leads me to the poison.**
@@ -29,7 +29,7 @@ If we take an example:
- We get **the reward and the next state.**
- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
-- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States**
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
- It will then **update \\(V(s_t)\\) based on the formula**
@@ -74,12 +74,12 @@ For instance, if we train a state-value function using Monte Carlo:
## Temporal Difference Learning: learning at each step [[td-learning]]
-- **Temporal difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- **Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\(gamma * V(S_{t+1})\\).
The idea with **TD is to update the \\(V(S_t)\\) at each step.**
-But because we didn't play during an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
index 62e9be3..d6ccbda 100644
--- a/units/en/unit2/q-learning-example.mdx
+++ b/units/en/unit2/q-learning-example.mdx
@@ -68,7 +68,7 @@ I took action down. **Not a good action since it leads me to the poison.**
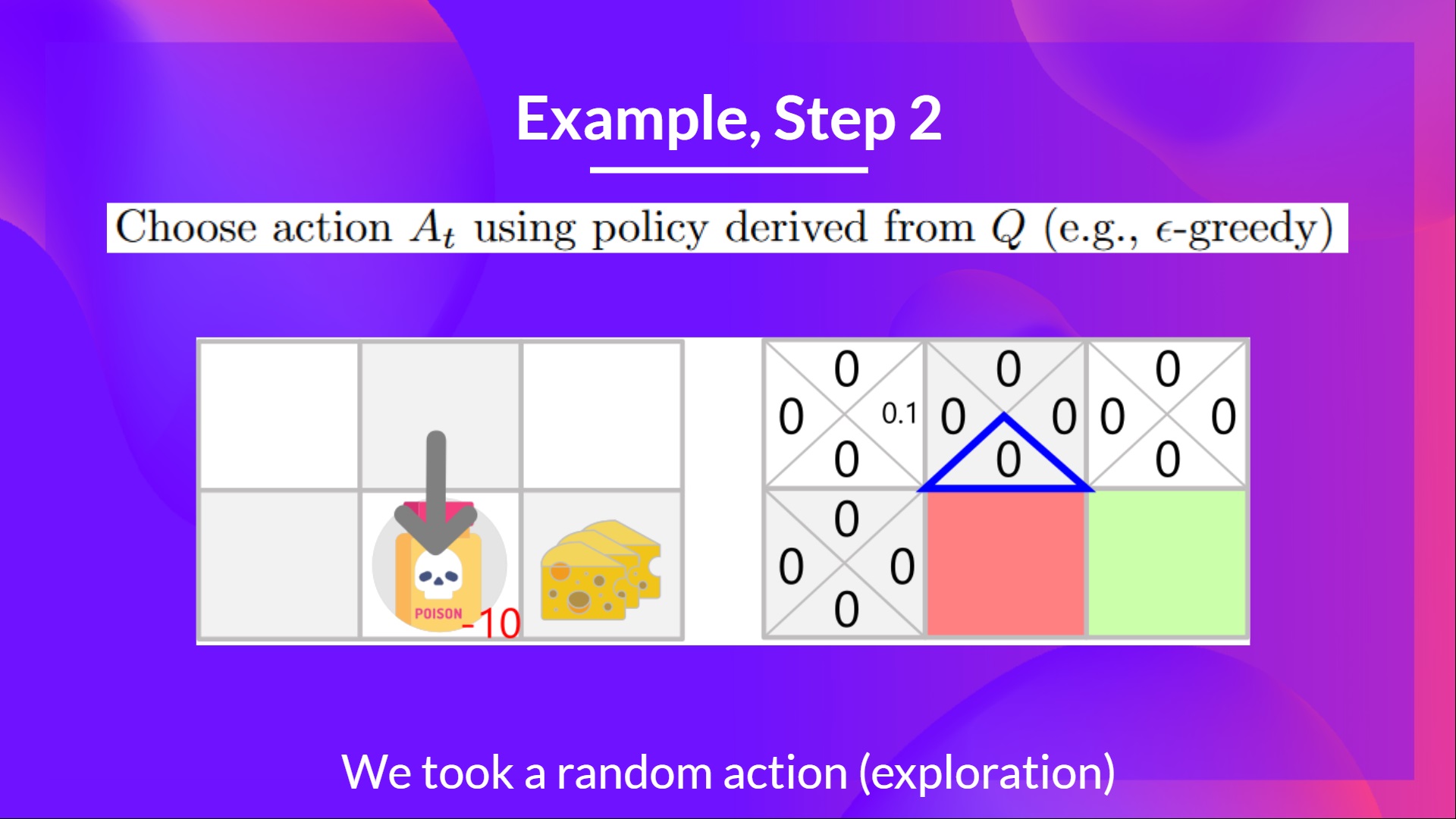 -## Step 3: Perform action At, gets \Rt+1 and St+1 [[step3-3]]
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3-3]]
Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index 8447e4c..d2e8aa4 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -3,7 +3,7 @@
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
-- *Off-policy*: we'll talk about that at the end of this chapter.
+- *Off-policy*: we'll talk about that at the end of this unit.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
@@ -18,7 +18,7 @@ The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action value pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
-If we take this maze example:
+Let's go through an example of a maze.
-## Step 3: Perform action At, gets \Rt+1 and St+1 [[step3-3]]
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3-3]]
Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index 8447e4c..d2e8aa4 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -3,7 +3,7 @@
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
-- *Off-policy*: we'll talk about that at the end of this chapter.
+- *Off-policy*: we'll talk about that at the end of this unit.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
@@ -18,7 +18,7 @@ The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action value pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
-If we take this maze example:
+Let's go through an example of a maze.
 @@ -39,7 +39,7 @@ Therefore, Q-function contains a Q-table **that has the value of each-state act
If we recap, *Q-Learning* **is the RL algorithm that:**
-- Trains *Q-Function* (an **action-value function**) which internally is a *Q-table* **that contains all the state-action pair values.**
+- Trains a *Q-Function* (an **action-value function**), which internally is a *Q-table that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-Table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know for each state what is the best action to take.**
@@ -47,14 +47,14 @@ If we recap, *Q-Learning* **is the RL algorithm that:**
@@ -39,7 +39,7 @@ Therefore, Q-function contains a Q-table **that has the value of each-state act
If we recap, *Q-Learning* **is the RL algorithm that:**
-- Trains *Q-Function* (an **action-value function**) which internally is a *Q-table* **that contains all the state-action pair values.**
+- Trains a *Q-Function* (an **action-value function**), which internally is a *Q-table that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-Table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know for each state what is the best action to take.**
@@ -47,14 +47,14 @@ If we recap, *Q-Learning* **is the RL algorithm that:**
 -But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0). As the agent **explores the environment and we update the Q-Table, it will give us better and better approximations** to the optimal policy.
-But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0). As the agent **explores the environment and we update the Q-Table, it will give us better and better approximations** to the optimal policy.
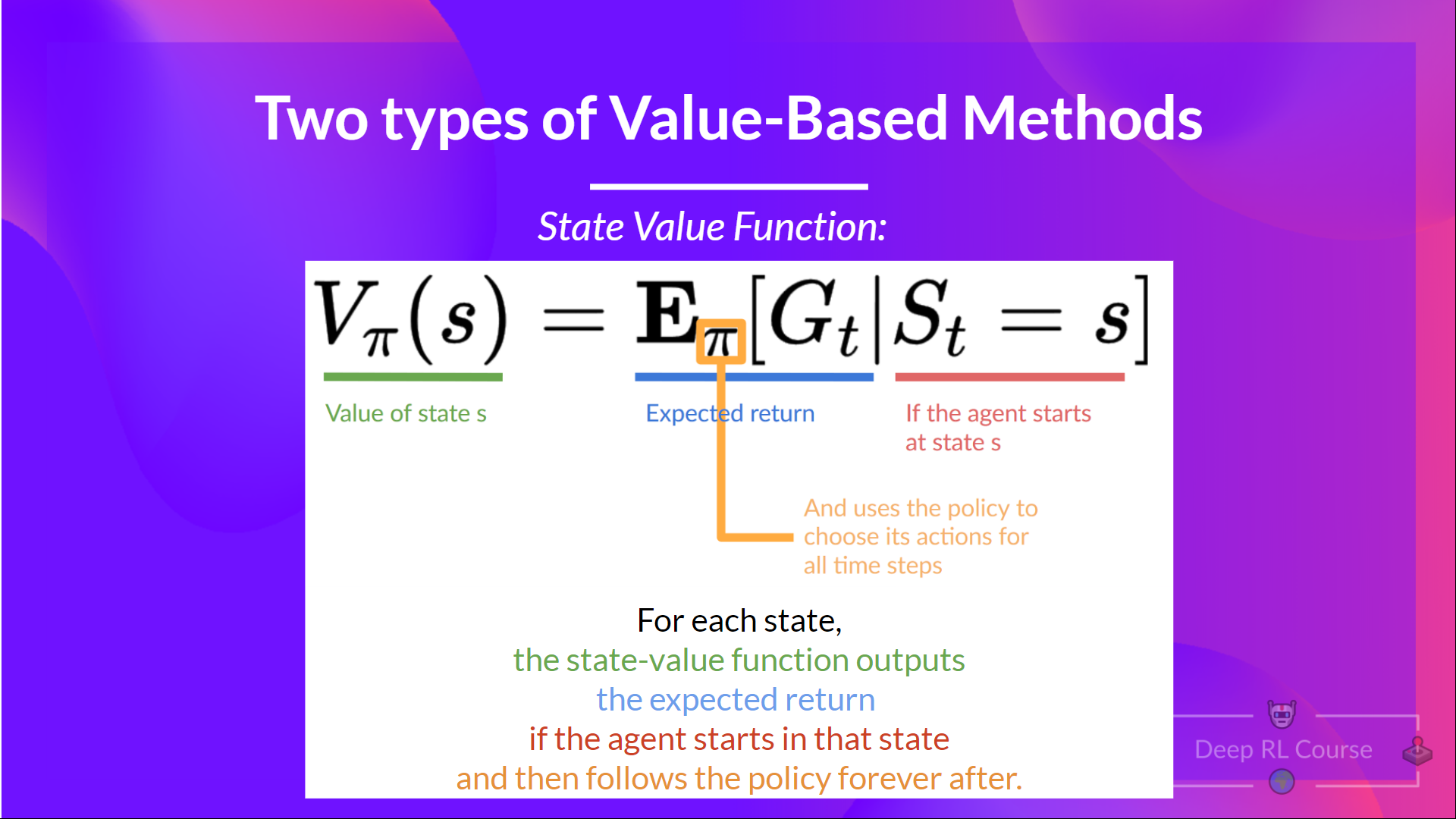 -For each state, the state-value function outputs the expected return if the agent **starts at that state,** and then follows the policy forever afterwards (for all future timesteps, if you prefer).
+For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
-For each state, the state-value function outputs the expected return if the agent **starts at that state,** and then follows the policy forever afterwards (for all future timesteps, if you prefer).
+For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
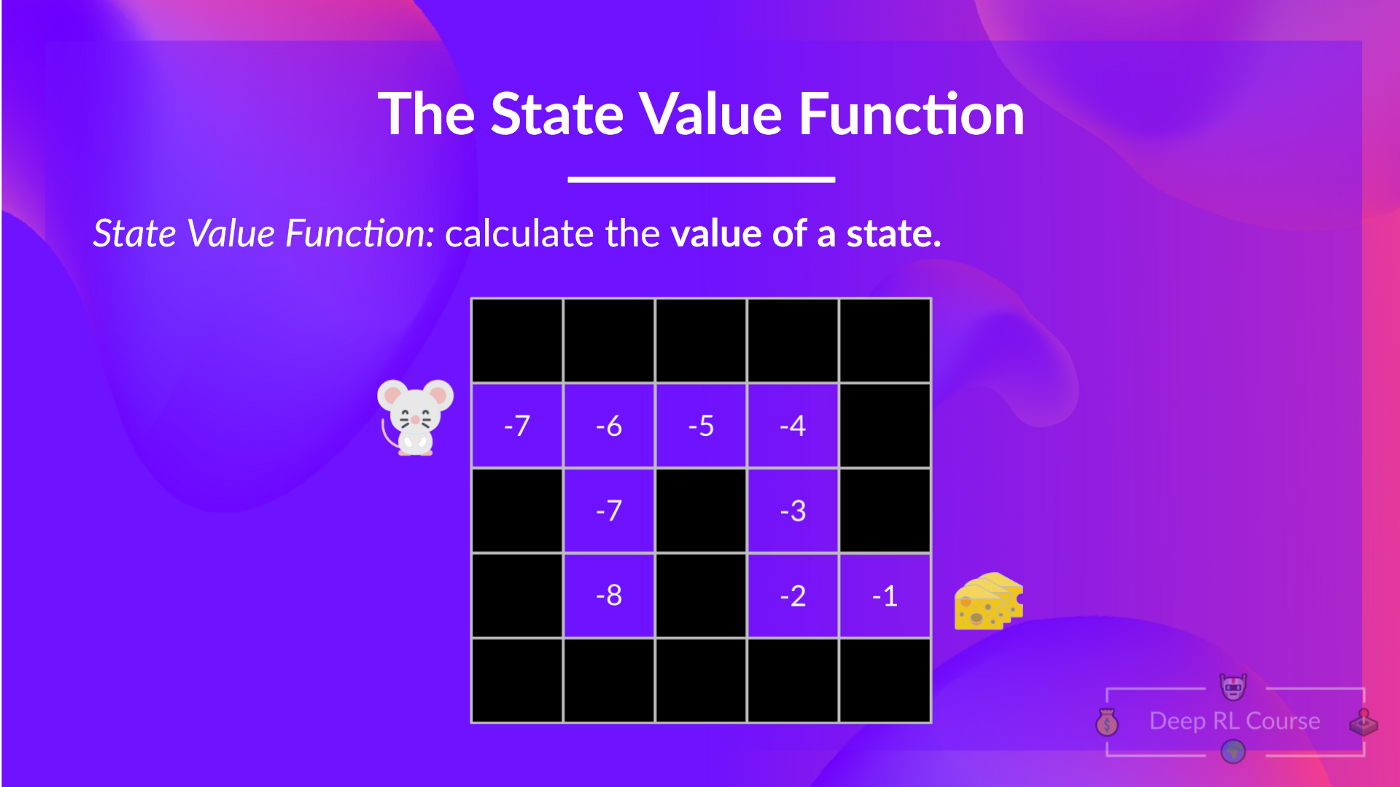 @@ -79,7 +79,7 @@ We see that the difference is:
Note: We didn't fill all the state-action pairs for the example of Action-value function
@@ -79,7 +79,7 @@ We see that the difference is:
Note: We didn't fill all the state-action pairs for the example of Action-value function