 +
+Welcome to the most fascinating topic in Artificial Intelligence: Deep Reinforcement Learning.
+
+This course will **teach you about Deep Reinforcement Learning from beginner to expert**. It’s completely free.
+
+In this unit you’ll:
+
+- Learn more about the **course content**.
+- **Define the path** you’re going to take (either self-audit or certification process)
+- Learn more about the **AI vs. AI challenges** you're going to participate to.
+- Learn more **about us**.
+- **Create your Hugging Face account** (it’s free).
+- **Sign-up our discord server**, the place where you can exchange with our classmates and us.
+
+Let’s get started!
+
+## What to expect? [[expect]]
+
+In this course, you will:
+
+- 📖 Study Deep Reinforcement Learning in **theory and practice.**
+- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, Sample Factory and CleanRL.
+- 🤖 **Train agents in unique environments** such as SnowballFight, Huggy the Doggo 🐶, MineRL (Minecraft ⛏️), VizDoom (Doom) and classical ones such as Space Invaders and PyBullet.
+- 💾 Publish your **trained agents in one line of code to the Hub**. But also download powerful agents from the community.
+- 🏆 Participate in challenges where you will **evaluate your agents against other teams. But also play against AI you'll train.**
+
+And more!
+
+At the end of this course, **you’ll get a solid foundation from the basics to the SOTA (state-of-the-art) methods**.
+
+You can find the syllabus on our website 👉 here
+
+Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
+
+Sign up 👉 here
+
+
+## What the course look like? [[course-look-like]]
+The course is composed of:
+
+- *A theory part*: where you learn a **concept in theory (article)**.
+- *A hands-on*: with a **weekly live hands-on session** in ADD DATE every week at ADD TIME. where you'll learn to use famous Deep RL libraries such as Stable Baselines3, RL Baselines3 Zoo, and RLlib to train your agents in unique environments such as SnowballFight, Huggy the Doggo dog, and classical ones such as Space Invaders and PyBullet.
+We strongly advise you to participate to the live so that you can ask questions but if you can't participate in the live, the sessions are recorded and will be posted.
+- *Challenges* such AI vs. AI and leaderboard.
+
+
+## Two paths: choose your own adventure [[two-paths]]
+
+
+
+Welcome to the most fascinating topic in Artificial Intelligence: Deep Reinforcement Learning.
+
+This course will **teach you about Deep Reinforcement Learning from beginner to expert**. It’s completely free.
+
+In this unit you’ll:
+
+- Learn more about the **course content**.
+- **Define the path** you’re going to take (either self-audit or certification process)
+- Learn more about the **AI vs. AI challenges** you're going to participate to.
+- Learn more **about us**.
+- **Create your Hugging Face account** (it’s free).
+- **Sign-up our discord server**, the place where you can exchange with our classmates and us.
+
+Let’s get started!
+
+## What to expect? [[expect]]
+
+In this course, you will:
+
+- 📖 Study Deep Reinforcement Learning in **theory and practice.**
+- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, Sample Factory and CleanRL.
+- 🤖 **Train agents in unique environments** such as SnowballFight, Huggy the Doggo 🐶, MineRL (Minecraft ⛏️), VizDoom (Doom) and classical ones such as Space Invaders and PyBullet.
+- 💾 Publish your **trained agents in one line of code to the Hub**. But also download powerful agents from the community.
+- 🏆 Participate in challenges where you will **evaluate your agents against other teams. But also play against AI you'll train.**
+
+And more!
+
+At the end of this course, **you’ll get a solid foundation from the basics to the SOTA (state-of-the-art) methods**.
+
+You can find the syllabus on our website 👉 here
+
+Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
+
+Sign up 👉 here
+
+
+## What the course look like? [[course-look-like]]
+The course is composed of:
+
+- *A theory part*: where you learn a **concept in theory (article)**.
+- *A hands-on*: with a **weekly live hands-on session** in ADD DATE every week at ADD TIME. where you'll learn to use famous Deep RL libraries such as Stable Baselines3, RL Baselines3 Zoo, and RLlib to train your agents in unique environments such as SnowballFight, Huggy the Doggo dog, and classical ones such as Space Invaders and PyBullet.
+We strongly advise you to participate to the live so that you can ask questions but if you can't participate in the live, the sessions are recorded and will be posted.
+- *Challenges* such AI vs. AI and leaderboard.
+
+
+## Two paths: choose your own adventure [[two-paths]]
+
+ +
+You can choose to follow this course either:
+
+- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of March 2023.
+- *As a simple audit*: you can participate in all challenges and do assignments if you want, but you have no deadlines.
+
+Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with the most classmates.**
+You don't need to tell us which path you choose. At the end of March, when we verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
+
+
+
+## How to get most of the course? [[advice]]
+
+To get most of the course, we have some advice:
+
+1. Join or create study groups in Discord : studying in groups is always easier. To do that, you need to join our discord server.
+2. **Do the quizzes and assignments**: the best way to learn is to do and test yourself.
+3. **Define a schedule to stay in sync: you can use our recommended pace schedule below or create yours.**
+
+
+
+You can choose to follow this course either:
+
+- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of March 2023.
+- *As a simple audit*: you can participate in all challenges and do assignments if you want, but you have no deadlines.
+
+Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with the most classmates.**
+You don't need to tell us which path you choose. At the end of March, when we verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
+
+
+
+## How to get most of the course? [[advice]]
+
+To get most of the course, we have some advice:
+
+1. Join or create study groups in Discord : studying in groups is always easier. To do that, you need to join our discord server.
+2. **Do the quizzes and assignments**: the best way to learn is to do and test yourself.
+3. **Define a schedule to stay in sync: you can use our recommended pace schedule below or create yours.**
+
+ +
+## What tools do I need? [[tools]]
+
+You need only 3 things:
+
+- A computer with an internet connection.
+- Google Colab (free version): most of our hands-on will use Google Colab, the **free version is enough.**
+- A Hugging Face Account: to push and load models. If you don’t have an account yet you can create one here (it’s free).
+
+
+
+## What tools do I need? [[tools]]
+
+You need only 3 things:
+
+- A computer with an internet connection.
+- Google Colab (free version): most of our hands-on will use Google Colab, the **free version is enough.**
+- A Hugging Face Account: to push and load models. If you don’t have an account yet you can create one here (it’s free).
+
+ +
+
+## What is the recommended pace? [[recommended-pace]]
+
+We defined a planning that you can follow to keep up the pace of the course.
+
+
+
+
+## What is the recommended pace? [[recommended-pace]]
+
+We defined a planning that you can follow to keep up the pace of the course.
+
+ +
+ +
+
+Each chapter in this course is designed **to be completed in 1 week, with approximately 3-4 hours of work per week**. However, you can take as much time as you need to complete the course.
+
+
+## Who are we [[who-are-we]]
+About the authors:
+
+Thomas Simonini is a Developer Advocate at Hugging Face 🤗 specializing in Deep Reinforcement Learning. He founded Deep Reinforcement Learning Course in 2018, which became one of the most used courses in Deep RL.
+
+ADD OMAR
+
+## When do the challenges start? [[challenges]]
+
+In this new version of the course, you have two types of challenges:
+- A leaderboard to compare your agent's performance to other classmates'.
+- AI vs. AI challenges where you can train your agent and compete against other classmates' agents.
+
+
+
+
+Each chapter in this course is designed **to be completed in 1 week, with approximately 3-4 hours of work per week**. However, you can take as much time as you need to complete the course.
+
+
+## Who are we [[who-are-we]]
+About the authors:
+
+Thomas Simonini is a Developer Advocate at Hugging Face 🤗 specializing in Deep Reinforcement Learning. He founded Deep Reinforcement Learning Course in 2018, which became one of the most used courses in Deep RL.
+
+ADD OMAR
+
+## When do the challenges start? [[challenges]]
+
+In this new version of the course, you have two types of challenges:
+- A leaderboard to compare your agent's performance to other classmates'.
+- AI vs. AI challenges where you can train your agent and compete against other classmates' agents.
+
+ +
+These AI vs.AI challenges will be announced **later in December**.
+
+
+## I found a bug, or I want to improve the course [[contribute]]
+
+Contributions are welcomed 🤗
+
+- If you *found a bug 🐛 in a notebook*, please open an issue and **describe the problem**.
+- If you *want to improve the course*, you can open a Pull Request.
+
+## I still have questions [[questions]]
+
+In that case, check our FAQ. And if the question is not in it, ask your question in our discord server #rl-discussions.
diff --git a/chapters/en/unit0/setup.mdx b/chapters/en/unit0/setup.mdx
new file mode 100644
index 0000000..0ad292c
--- /dev/null
+++ b/chapters/en/unit0/setup.mdx
@@ -0,0 +1,30 @@
+# Setup [[setup]]
+
+After all this information, it's time to get started. We're going to do two things:
+
+1. Create your Hugging Face account if it's not already done
+2. Sign up to Discord and introduce yourself (don't be shy 🤗)
+
+### Let's create my Hugging Face account
+
+(If it's not already done) create an account to HF
+
+These AI vs.AI challenges will be announced **later in December**.
+
+
+## I found a bug, or I want to improve the course [[contribute]]
+
+Contributions are welcomed 🤗
+
+- If you *found a bug 🐛 in a notebook*, please open an issue and **describe the problem**.
+- If you *want to improve the course*, you can open a Pull Request.
+
+## I still have questions [[questions]]
+
+In that case, check our FAQ. And if the question is not in it, ask your question in our discord server #rl-discussions.
diff --git a/chapters/en/unit0/setup.mdx b/chapters/en/unit0/setup.mdx
new file mode 100644
index 0000000..0ad292c
--- /dev/null
+++ b/chapters/en/unit0/setup.mdx
@@ -0,0 +1,30 @@
+# Setup [[setup]]
+
+After all this information, it's time to get started. We're going to do two things:
+
+1. Create your Hugging Face account if it's not already done
+2. Sign up to Discord and introduce yourself (don't be shy 🤗)
+
+### Let's create my Hugging Face account
+
+(If it's not already done) create an account to HF 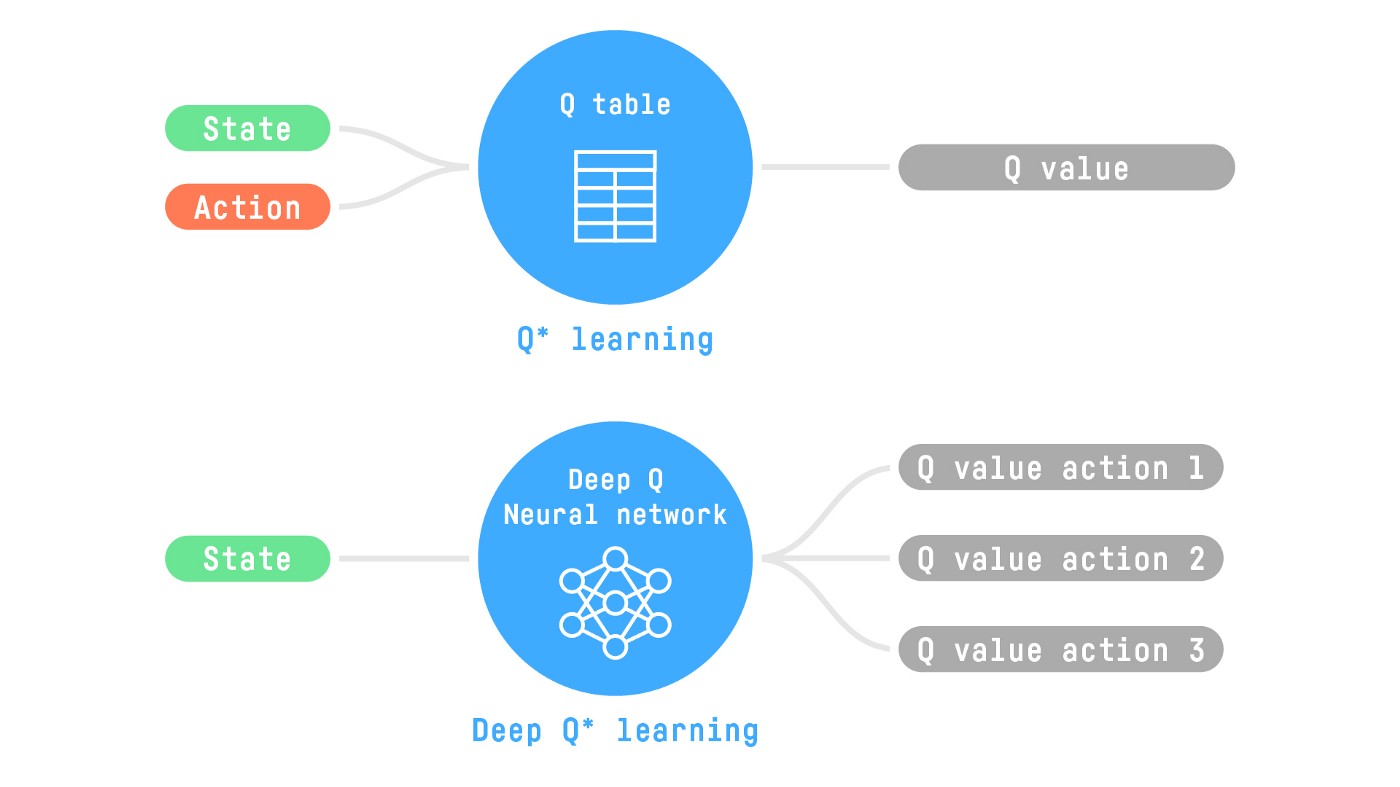 +
+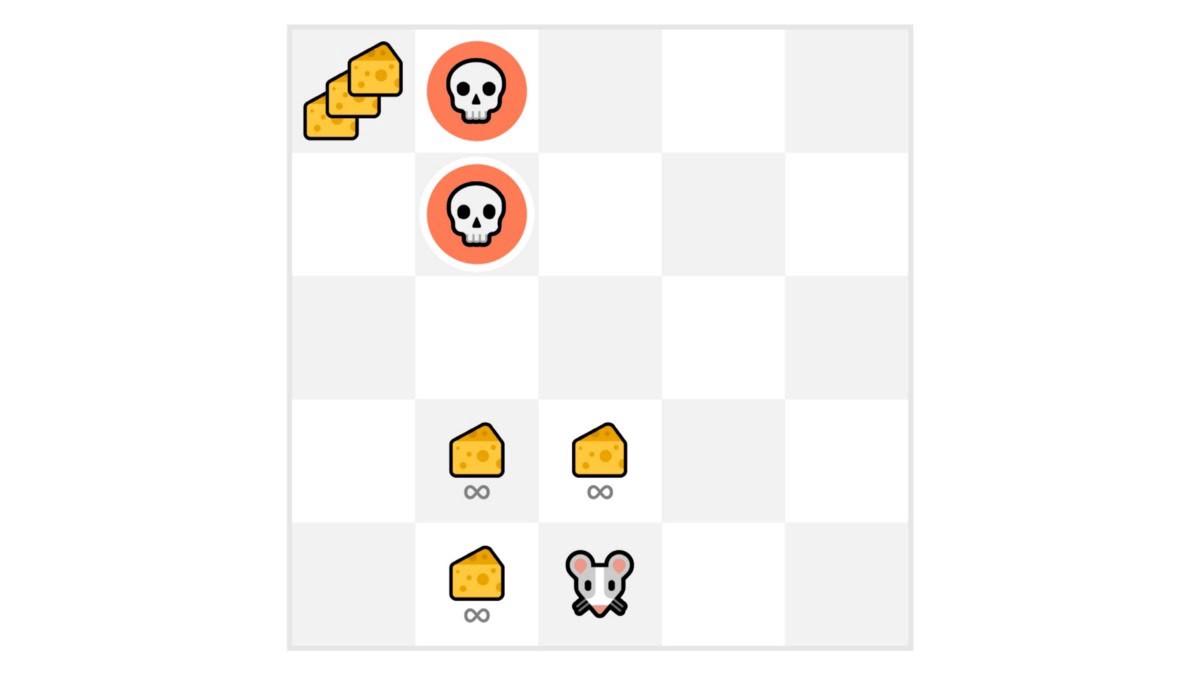 +
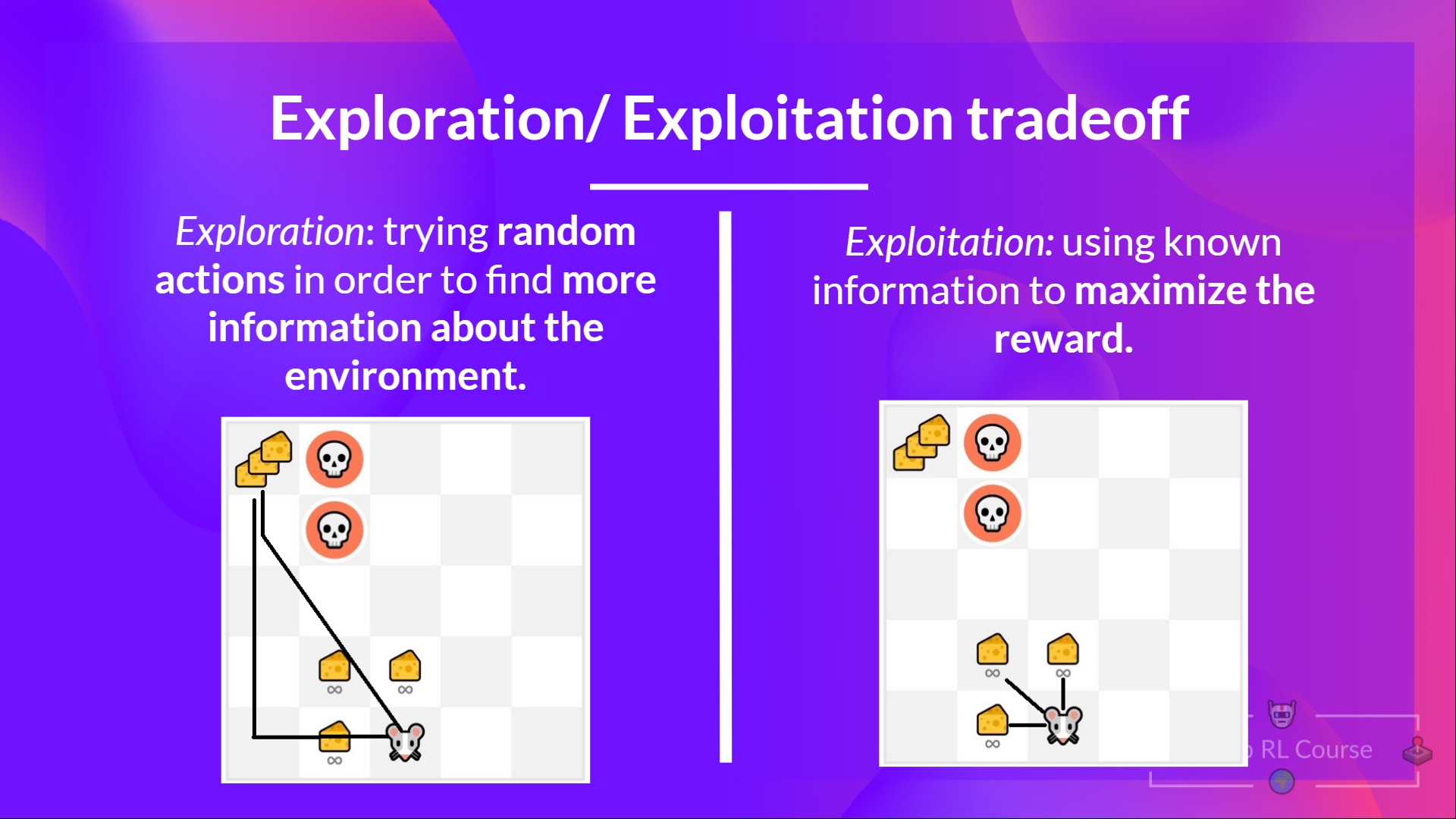
+In this game, our mouse can have an **infinite amount of small cheese** (+1 each). But at the top of the maze, there is a gigantic sum of cheese (+1000).
+
+However, if we only focus on exploitation, our agent will never reach the gigantic sum of cheese. Instead, it will only exploit **the nearest source of rewards,** even if this source is small (exploitation).
+
+But if our agent does a little bit of exploration, it can **discover the big reward** (the pile of big cheese).
+
+This is what we call the exploration/exploitation trade-off. We need to balance how much we **explore the environment** and how much we **exploit what we know about the environment.**
+
+Therefore, we must **define a rule that helps to handle this trade-off**. We’ll see in future chapters different ways to handle it.
+
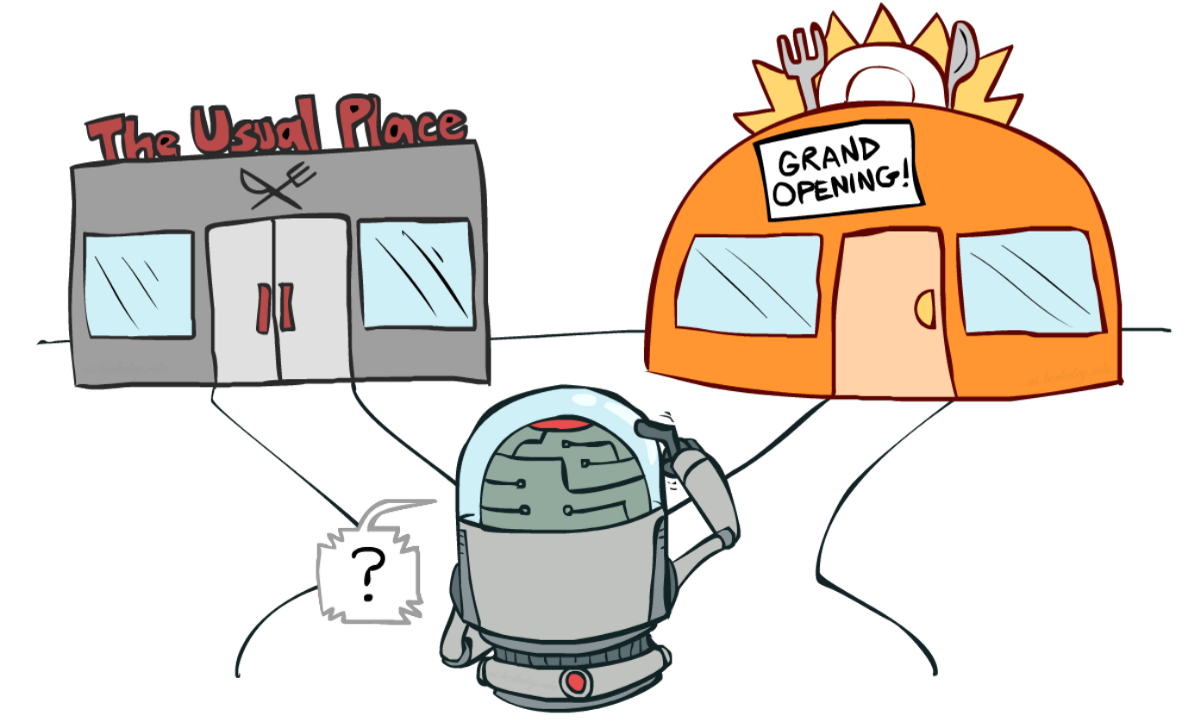
+If it’s still confusing, **think of a real problem: the choice of a restaurant:**
+
+
+
+In this game, our mouse can have an **infinite amount of small cheese** (+1 each). But at the top of the maze, there is a gigantic sum of cheese (+1000).
+
+However, if we only focus on exploitation, our agent will never reach the gigantic sum of cheese. Instead, it will only exploit **the nearest source of rewards,** even if this source is small (exploitation).
+
+But if our agent does a little bit of exploration, it can **discover the big reward** (the pile of big cheese).
+
+This is what we call the exploration/exploitation trade-off. We need to balance how much we **explore the environment** and how much we **exploit what we know about the environment.**
+
+Therefore, we must **define a rule that helps to handle this trade-off**. We’ll see in future chapters different ways to handle it.
+
+If it’s still confusing, **think of a real problem: the choice of a restaurant:**
+
+ +
+ diff --git a/chapters/en/unit1/hands-on.mdx b/chapters/en/unit1/hands-on.mdx
new file mode 100644
index 0000000..624e134
--- /dev/null
+++ b/chapters/en/unit1/hands-on.mdx
@@ -0,0 +1,13 @@
+# Hands on [[hands-on]]
+
+Now that you've studied the bases of Reinforcement Learning, you’re ready to train your first two agents and share it with the community through the Hub 🔥:
+
+- A Lunar Lander agent that will learn to land correctly on the Moon 🌕
+- A car that needs to reach the top of the mountain ⛰️ .
+
+TODO: Add illustration MountainCar and MoonLanding
+
+
+Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 1 🏆?
+
+So let's get started! 🚀
diff --git a/chapters/en/unit1/introduction.mdx b/chapters/en/unit1/introduction.mdx
new file mode 100644
index 0000000..7f9860e
--- /dev/null
+++ b/chapters/en/unit1/introduction.mdx
@@ -0,0 +1,26 @@
+# Introduction to Deep Reinforcement Learning [[introduction-to-deep-reinforcement-learning]]
+
+
+TODO: ADD IMAGE THUMBNAIL
+
+
+Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinforcement Learning.**
+
+Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
+
+So in this first chapter, **you'll learn the foundations of Deep Reinforcement Learning.**
+
+Then, you'll **train your first two Deep Reinforcement Learning agents** using Stable-Baselines3 a Deep Reinforcement Learning library.:
+
+1. A Lunar Lander agent that will learn to **land correctly on the Moon 🌕**
+2. A car that needs **to reach the top of the mountain ⛰️ **.
+
+TODO: Add illustration MountainCar and MoonLanding
+
+And finally, you'll **upload it to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
+
+TODO: ADD model card illustration
+
+It's essential **to master these elements** before diving into implementing Deep Reinforcement Learning agents. The goal of this chapter is to give you solid foundations.
+
+So let's get started! 🚀
diff --git a/chapters/en/unit1/quiz.mdx b/chapters/en/unit1/quiz.mdx
new file mode 100644
index 0000000..1f55843
--- /dev/null
+++ b/chapters/en/unit1/quiz.mdx
@@ -0,0 +1,168 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What is Reinforcement Learning?
+
+
diff --git a/chapters/en/unit1/hands-on.mdx b/chapters/en/unit1/hands-on.mdx
new file mode 100644
index 0000000..624e134
--- /dev/null
+++ b/chapters/en/unit1/hands-on.mdx
@@ -0,0 +1,13 @@
+# Hands on [[hands-on]]
+
+Now that you've studied the bases of Reinforcement Learning, you’re ready to train your first two agents and share it with the community through the Hub 🔥:
+
+- A Lunar Lander agent that will learn to land correctly on the Moon 🌕
+- A car that needs to reach the top of the mountain ⛰️ .
+
+TODO: Add illustration MountainCar and MoonLanding
+
+
+Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 1 🏆?
+
+So let's get started! 🚀
diff --git a/chapters/en/unit1/introduction.mdx b/chapters/en/unit1/introduction.mdx
new file mode 100644
index 0000000..7f9860e
--- /dev/null
+++ b/chapters/en/unit1/introduction.mdx
@@ -0,0 +1,26 @@
+# Introduction to Deep Reinforcement Learning [[introduction-to-deep-reinforcement-learning]]
+
+
+TODO: ADD IMAGE THUMBNAIL
+
+
+Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinforcement Learning.**
+
+Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
+
+So in this first chapter, **you'll learn the foundations of Deep Reinforcement Learning.**
+
+Then, you'll **train your first two Deep Reinforcement Learning agents** using Stable-Baselines3 a Deep Reinforcement Learning library.:
+
+1. A Lunar Lander agent that will learn to **land correctly on the Moon 🌕**
+2. A car that needs **to reach the top of the mountain ⛰️ **.
+
+TODO: Add illustration MountainCar and MoonLanding
+
+And finally, you'll **upload it to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
+
+TODO: ADD model card illustration
+
+It's essential **to master these elements** before diving into implementing Deep Reinforcement Learning agents. The goal of this chapter is to give you solid foundations.
+
+So let's get started! 🚀
diff --git a/chapters/en/unit1/quiz.mdx b/chapters/en/unit1/quiz.mdx
new file mode 100644
index 0000000..1f55843
--- /dev/null
+++ b/chapters/en/unit1/quiz.mdx
@@ -0,0 +1,168 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What is Reinforcement Learning?
+
+
+
+
+
+
+### Q2: Define the RL Loop
+
+Solution
+ +Reinforcement learning is a **framework for solving control tasks (also called decision problems)** by building agents that learn from the environment by interacting with it through trial and error and **receiving rewards (positive or negative) as unique feedback**. + +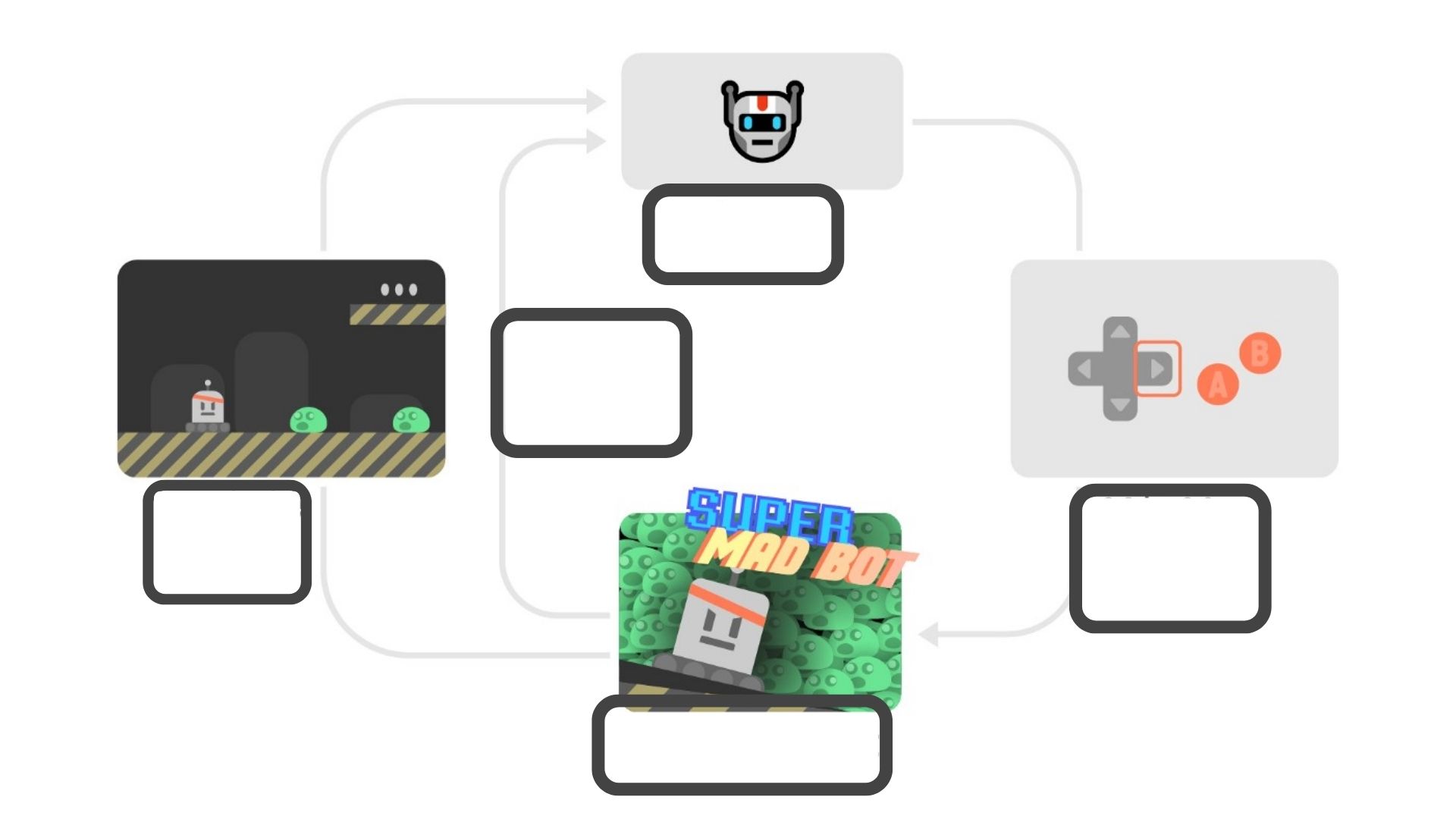 +
+At every step:
+- Our Agent receives ______ from the environment
+- Based on that ______ the Agent takes an ______
+- Our Agent will move to the right
+- The Environment goes to a ______
+- The Environment gives a ______ to the Agent
+
+
+
+
+At every step:
+- Our Agent receives ______ from the environment
+- Based on that ______ the Agent takes an ______
+- Our Agent will move to the right
+- The Environment goes to a ______
+- The Environment gives a ______ to the Agent
+
+
+
+
+
+
+
+
+### Q6: What is a policy?
+
+Solution
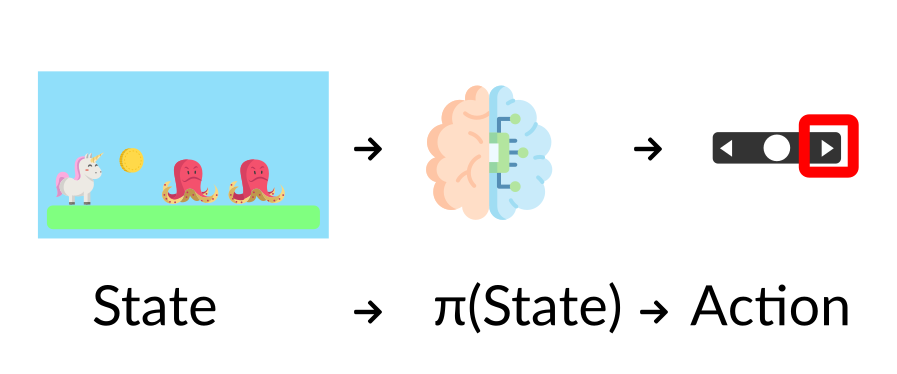
+ +In Reinforcement Learning, we need to **balance how much we explore the environment and how much we exploit what we know about the environment**. + +- *Exploration* is exploring the environment by **trying random actions in order to find more information about the environment**. + +- *Exploitation* is **exploiting known information to maximize the reward**. + +
+
+
+ +
+
+
+
+
+
+### Q7: What are value-based methods?
+
+Solution
+ +- The Policy π **is the brain of our Agent**, it’s the function that tell us what action to take given the state we are. So it defines the agent’s behavior at a given time. + +
+
+
+
+
+### Q8: What are policy-based methods?
+
+Solution
+ +- Value-based methods is one of the main approaches for solving RL problems. +- In Value-based methods, instead of training a policy function, **we train a value function that maps a state to the expected value of being at that state**. + + + +
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/chapters/en/unit1/rl-framework.mdx b/chapters/en/unit1/rl-framework.mdx
new file mode 100644
index 0000000..d26811c
--- /dev/null
+++ b/chapters/en/unit1/rl-framework.mdx
@@ -0,0 +1,146 @@
+# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
+
+## The RL Process [[the-rl-process]]
+
+Solution
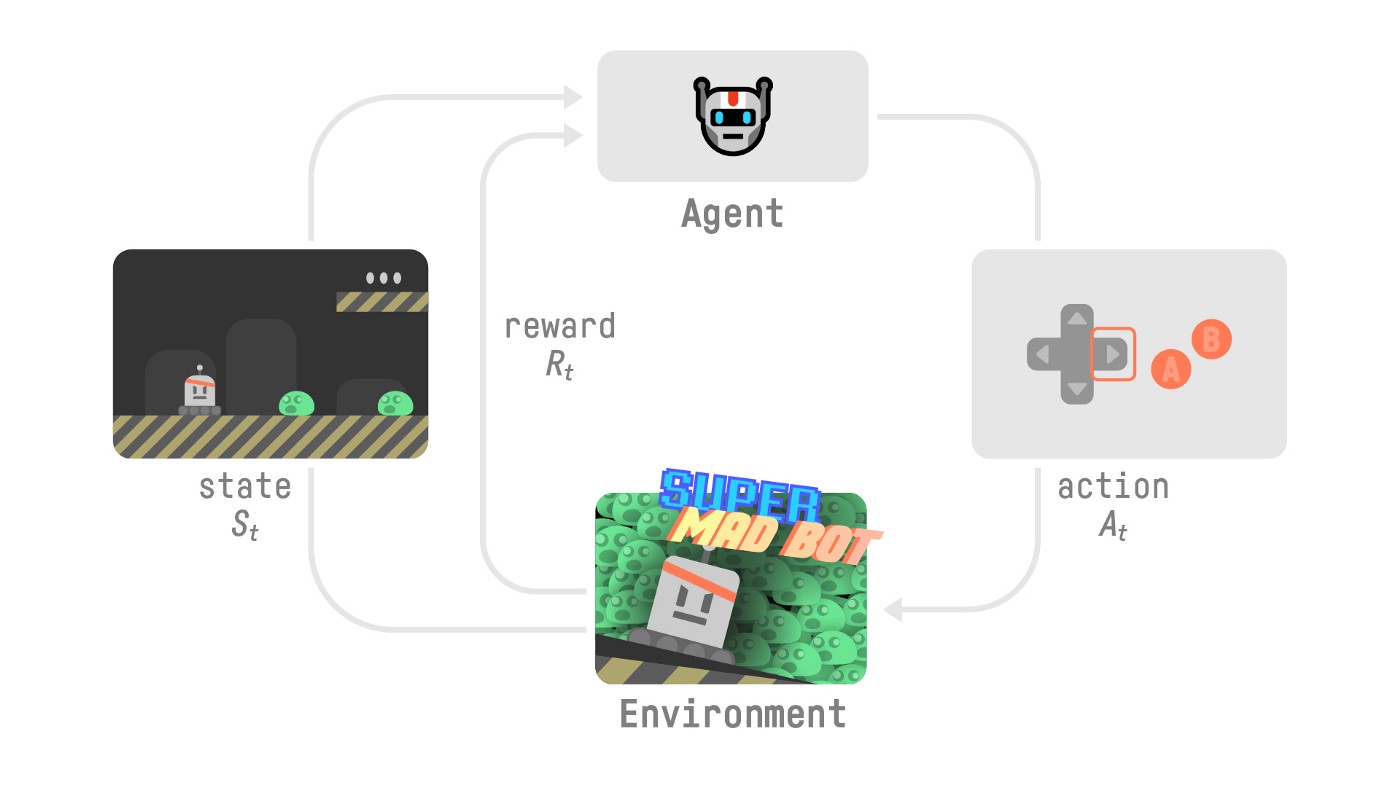
+ +- In *Policy-Based Methods*, we learn a **policy function directly**. +- This policy function will **map from each state to the best corresponding action at that state**. Or a **probability distribution over the set of possible actions at that state**. + + + + +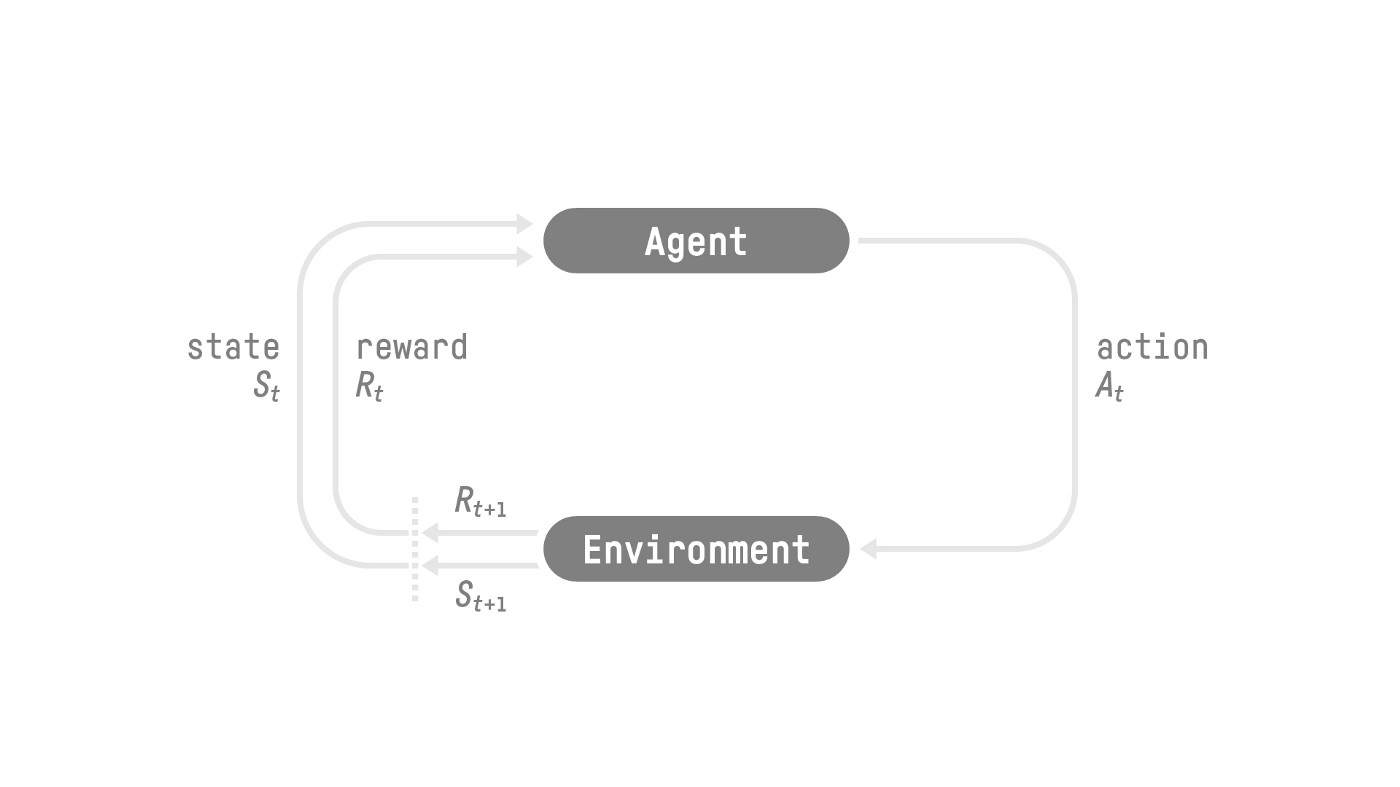 +
+ +
+\$\sqrt{2}\$
+
+- Our Agent receives **state $S_0$** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.**
+
+
+
+\$\sqrt{2}\$
+
+- Our Agent receives **state $S_0$** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.**
+
+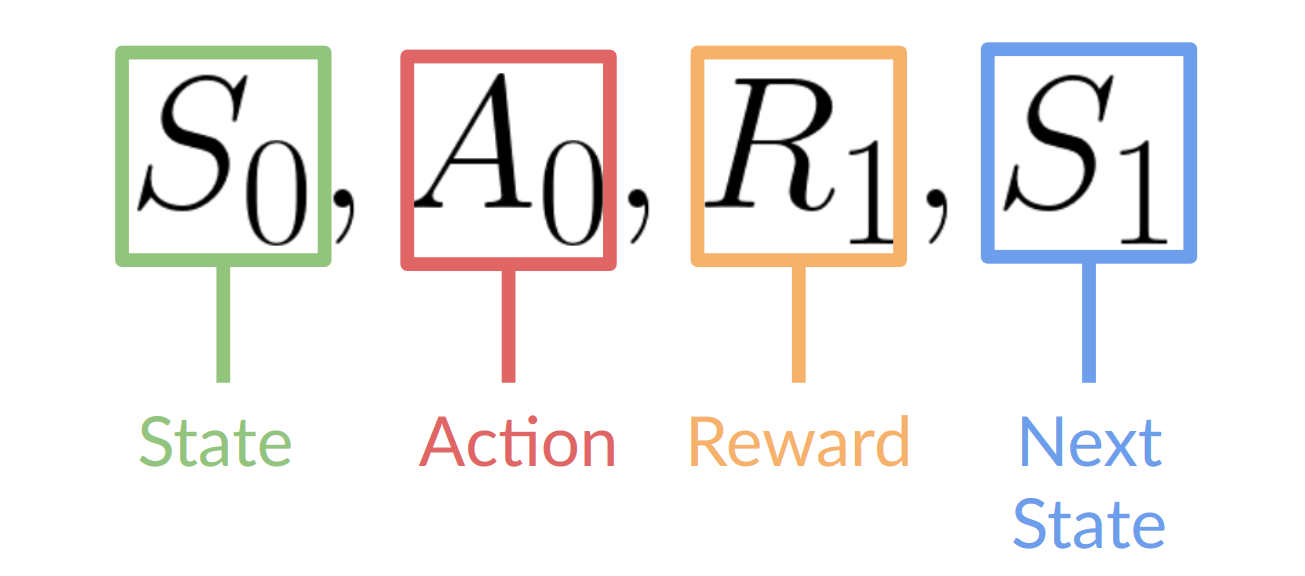 +
+The agent's goal is to maximize its cumulative reward, **called the expected return.**
+
+## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+
+⇒ Why is the goal of the agent to maximize the expected return?
+
+Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+
+That’s why in Reinforcement Learning, **to have the best behavior,** we need to **maximize the expected cumulative reward.**
+
+## Markov Property [[markov-property]]
+
+In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
+
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states** **and actions** they took before.
+
+## Observations/States Space [[obs-space]]
+
+Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
+
+There is a differentiation to make between *observation* and *state*:
+
+- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+
+
+
+
+The agent's goal is to maximize its cumulative reward, **called the expected return.**
+
+## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+
+⇒ Why is the goal of the agent to maximize the expected return?
+
+Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+
+That’s why in Reinforcement Learning, **to have the best behavior,** we need to **maximize the expected cumulative reward.**
+
+## Markov Property [[markov-property]]
+
+In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
+
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states** **and actions** they took before.
+
+## Observations/States Space [[obs-space]]
+
+Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
+
+There is a differentiation to make between *observation* and *state*:
+
+- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+
+
+ +
+ +
+ +
+
+## Action Space [[action-space]]
+
+The Action space is the set of **all possible actions in an environment.**
+
+The actions can come from a *discrete* or *continuous space*:
+
+- *Discrete space*: the number of possible actions is **finite**.
+
+
+
+
+
+## Action Space [[action-space]]
+
+The Action space is the set of **all possible actions in an environment.**
+
+The actions can come from a *discrete* or *continuous space*:
+
+- *Discrete space*: the number of possible actions is **finite**.
+
+
+ +
+ +
+Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+
+## Rewards and the discounting [[rewards]]
+
+The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
+
+The cumulative reward at each time step t can be written as:
+
+
+
+Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+
+## Rewards and the discounting [[rewards]]
+
+The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
+
+The cumulative reward at each time step t can be written as:
+
+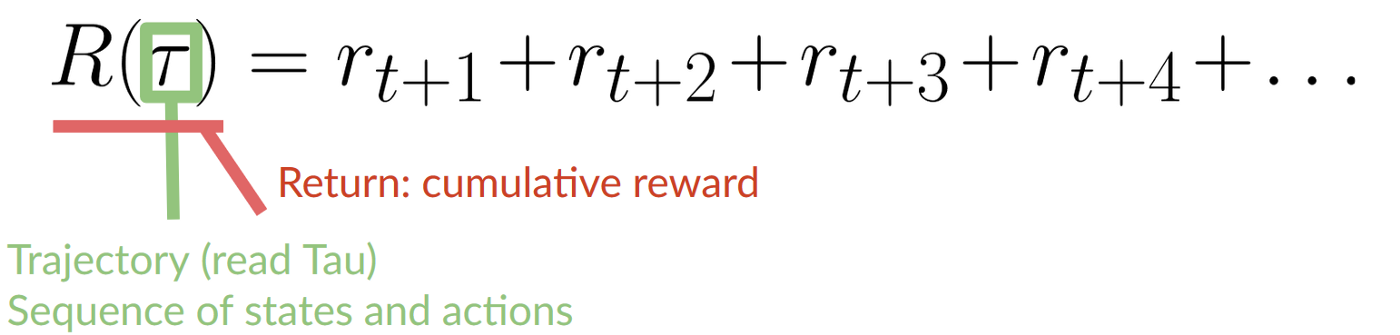 +
+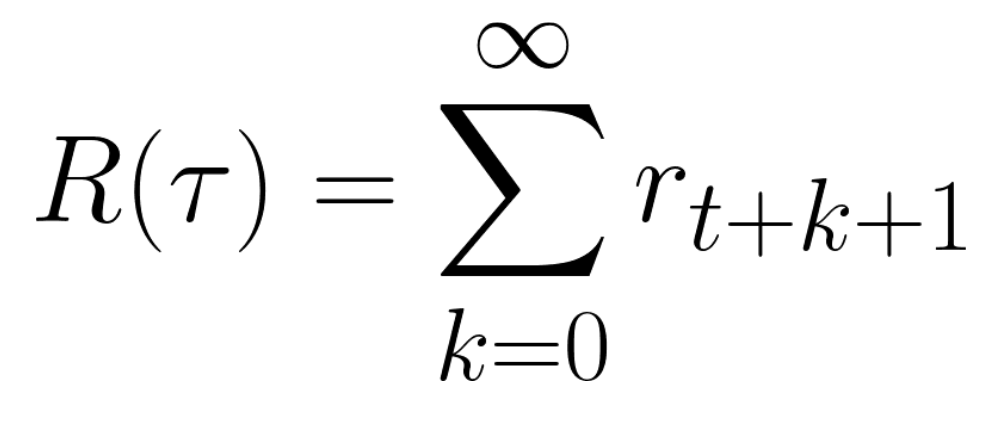 +
+ +
+As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+
+Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+
+To discount the rewards, we proceed like this:
+
+1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.99 and 0.95**.
+- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
+- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+
+2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+
+Our discounted cumulative expected rewards is:
+
+
+As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+
+Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+
+To discount the rewards, we proceed like this:
+
+1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.99 and 0.95**.
+- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
+- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+
+2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+
+Our discounted cumulative expected rewards is:
+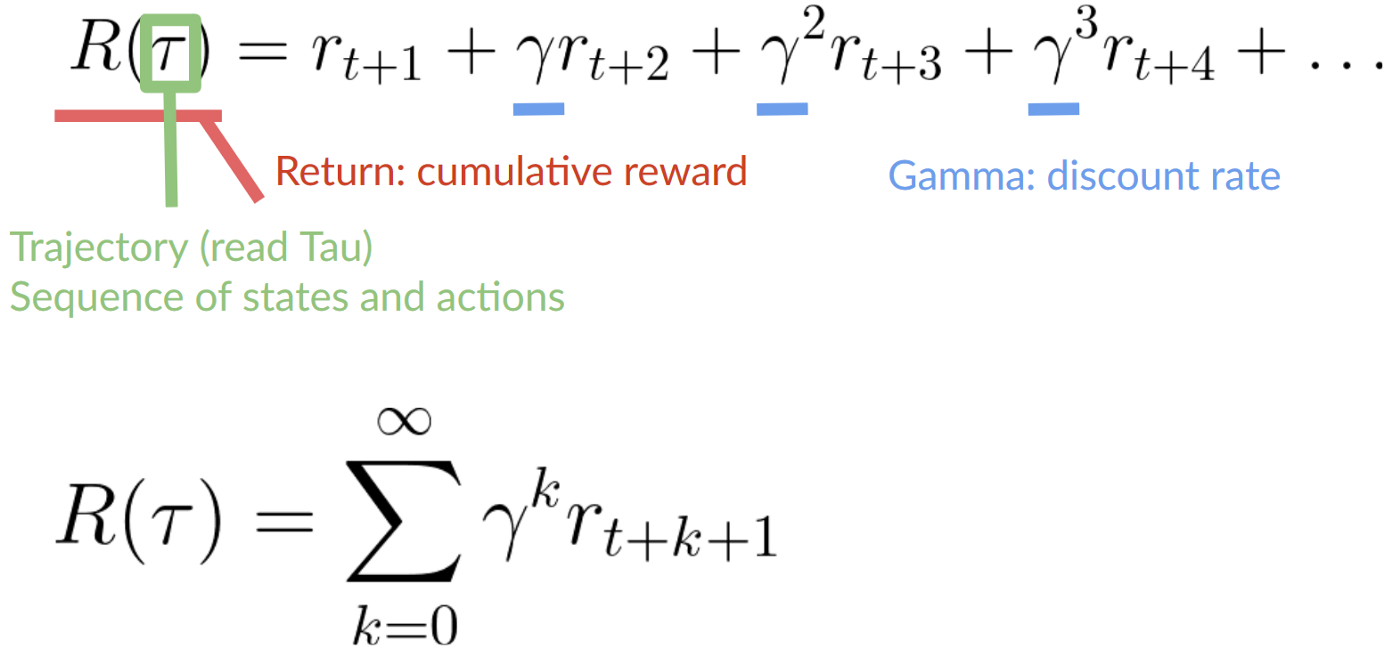 diff --git a/chapters/en/unit1/summary.mdx b/chapters/en/unit1/summary.mdx
new file mode 100644
index 0000000..eab64a9
--- /dev/null
+++ b/chapters/en/unit1/summary.mdx
@@ -0,0 +1,19 @@
+# Summary [[summary]]
+
+That was a lot of information, if we summarize:
+
+- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+
+- The goal of any RL agent is to maximize its expected cumulative reward (also called expected return) because RL is based on the **reward hypothesis**, which is that **all goals can be described as the maximization of the expected cumulative reward.**
+
+- The RL process is a loop that outputs a sequence of **state, action, reward and next state.**
+
+- To calculate the expected cumulative reward (expected return), we discount the rewards: the rewards that come sooner (at the beginning of the game) **are more probable to happen since they are more predictable than the long term future reward.**
+
+- To solve an RL problem, you want to **find an optimal policy**, the policy is the “brain” of your AI that will tell us **what action to take given a state.** The optimal one is the one who **gives you the actions that max the expected return.**
+
+- There are two ways to find your optimal policy:
+ 1. By training your policy directly: **policy-based methods.**
+ 2. By training a value function that tells us the expected return the agent will get at each state and use this function to define our policy: **value-based methods.**
+
+- Finally, we speak about Deep RL because we introduces **deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based)** hence the name “deep.”
diff --git a/chapters/en/unit1/tasks.mdx b/chapters/en/unit1/tasks.mdx
new file mode 100644
index 0000000..7eb393c
--- /dev/null
+++ b/chapters/en/unit1/tasks.mdx
@@ -0,0 +1,27 @@
+# Type of tasks [[tasks]]
+
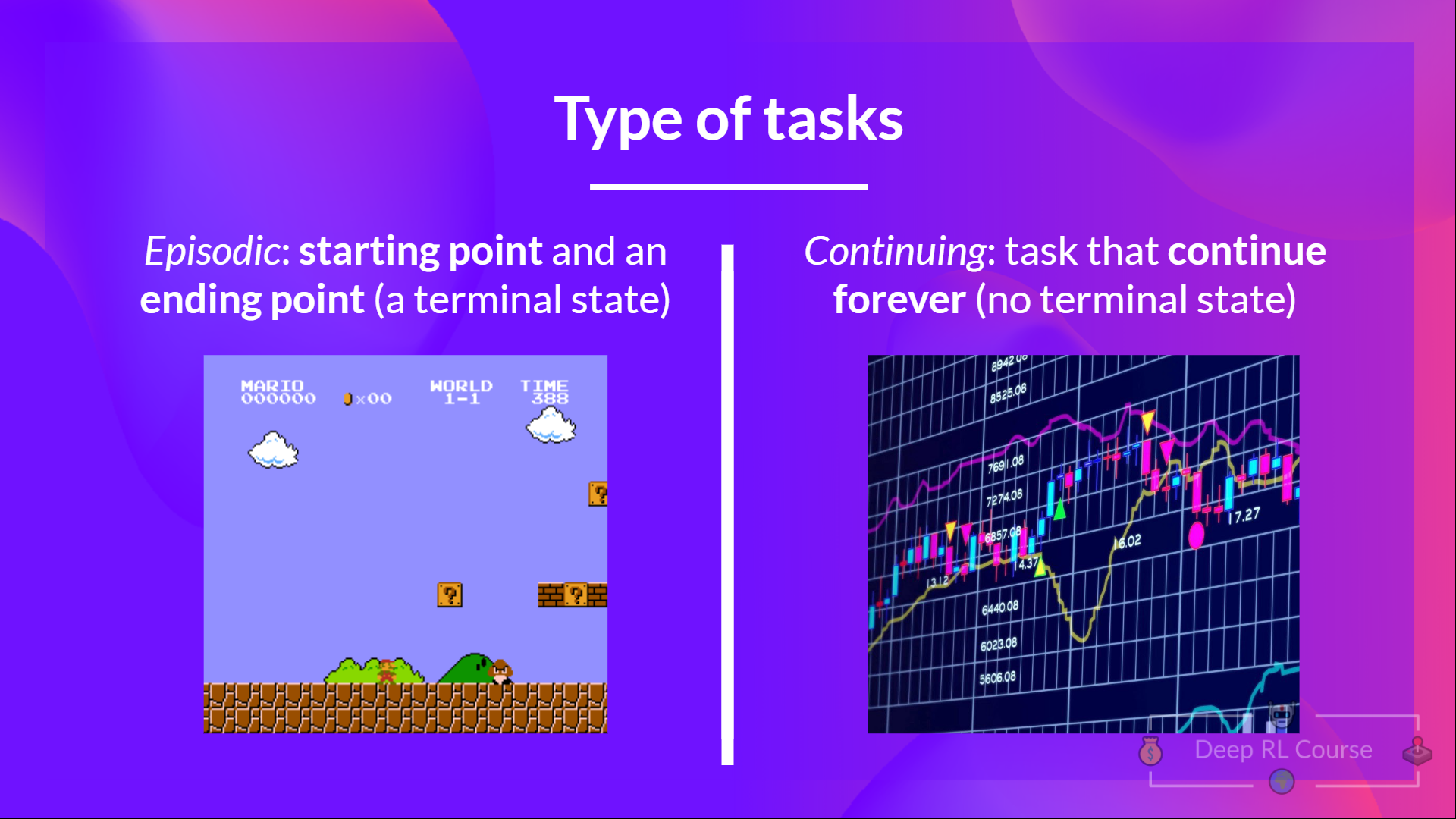
+A task is an **instance** of a Reinforcement Learning problem. We can have two types of tasks: episodic and continuing.
+
+## Episodic task [[episodic-task]]
+
+In this case, we have a starting point and an ending point **(a terminal state). This creates an episode**: a list of States, Actions, Rewards, and new States.
+
+For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ending **when you’re killed or you reached the end of the level.**
+
+
+
diff --git a/chapters/en/unit1/summary.mdx b/chapters/en/unit1/summary.mdx
new file mode 100644
index 0000000..eab64a9
--- /dev/null
+++ b/chapters/en/unit1/summary.mdx
@@ -0,0 +1,19 @@
+# Summary [[summary]]
+
+That was a lot of information, if we summarize:
+
+- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+
+- The goal of any RL agent is to maximize its expected cumulative reward (also called expected return) because RL is based on the **reward hypothesis**, which is that **all goals can be described as the maximization of the expected cumulative reward.**
+
+- The RL process is a loop that outputs a sequence of **state, action, reward and next state.**
+
+- To calculate the expected cumulative reward (expected return), we discount the rewards: the rewards that come sooner (at the beginning of the game) **are more probable to happen since they are more predictable than the long term future reward.**
+
+- To solve an RL problem, you want to **find an optimal policy**, the policy is the “brain” of your AI that will tell us **what action to take given a state.** The optimal one is the one who **gives you the actions that max the expected return.**
+
+- There are two ways to find your optimal policy:
+ 1. By training your policy directly: **policy-based methods.**
+ 2. By training a value function that tells us the expected return the agent will get at each state and use this function to define our policy: **value-based methods.**
+
+- Finally, we speak about Deep RL because we introduces **deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based)** hence the name “deep.”
diff --git a/chapters/en/unit1/tasks.mdx b/chapters/en/unit1/tasks.mdx
new file mode 100644
index 0000000..7eb393c
--- /dev/null
+++ b/chapters/en/unit1/tasks.mdx
@@ -0,0 +1,27 @@
+# Type of tasks [[tasks]]
+
+A task is an **instance** of a Reinforcement Learning problem. We can have two types of tasks: episodic and continuing.
+
+## Episodic task [[episodic-task]]
+
+In this case, we have a starting point and an ending point **(a terminal state). This creates an episode**: a list of States, Actions, Rewards, and new States.
+
+For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ending **when you’re killed or you reached the end of the level.**
+
+
+ +
+To recap:
+
+
+To recap:
+ diff --git a/chapters/en/unit1/two-methods.mdx b/chapters/en/unit1/two-methods.mdx
new file mode 100644
index 0000000..cd3600d
--- /dev/null
+++ b/chapters/en/unit1/two-methods.mdx
@@ -0,0 +1,97 @@
+# The two main approaches for solving RL problems [[two-methods]]
+
+
+
diff --git a/chapters/en/unit1/two-methods.mdx b/chapters/en/unit1/two-methods.mdx
new file mode 100644
index 0000000..cd3600d
--- /dev/null
+++ b/chapters/en/unit1/two-methods.mdx
@@ -0,0 +1,97 @@
+# The two main approaches for solving RL problems [[two-methods]]
+
+
+ +
+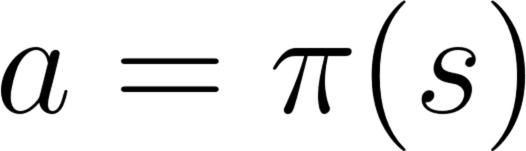 +
+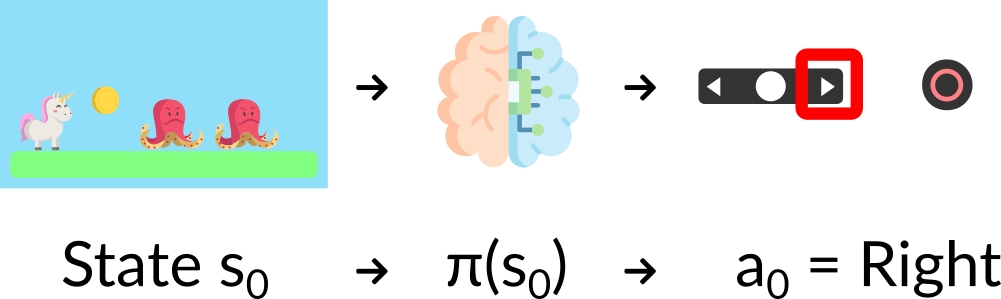 +
+- *Stochastic*: output **a probability distribution over actions.**
+
+
+
+- *Stochastic*: output **a probability distribution over actions.**
+
+ +
+
+
+ +
+ +
+
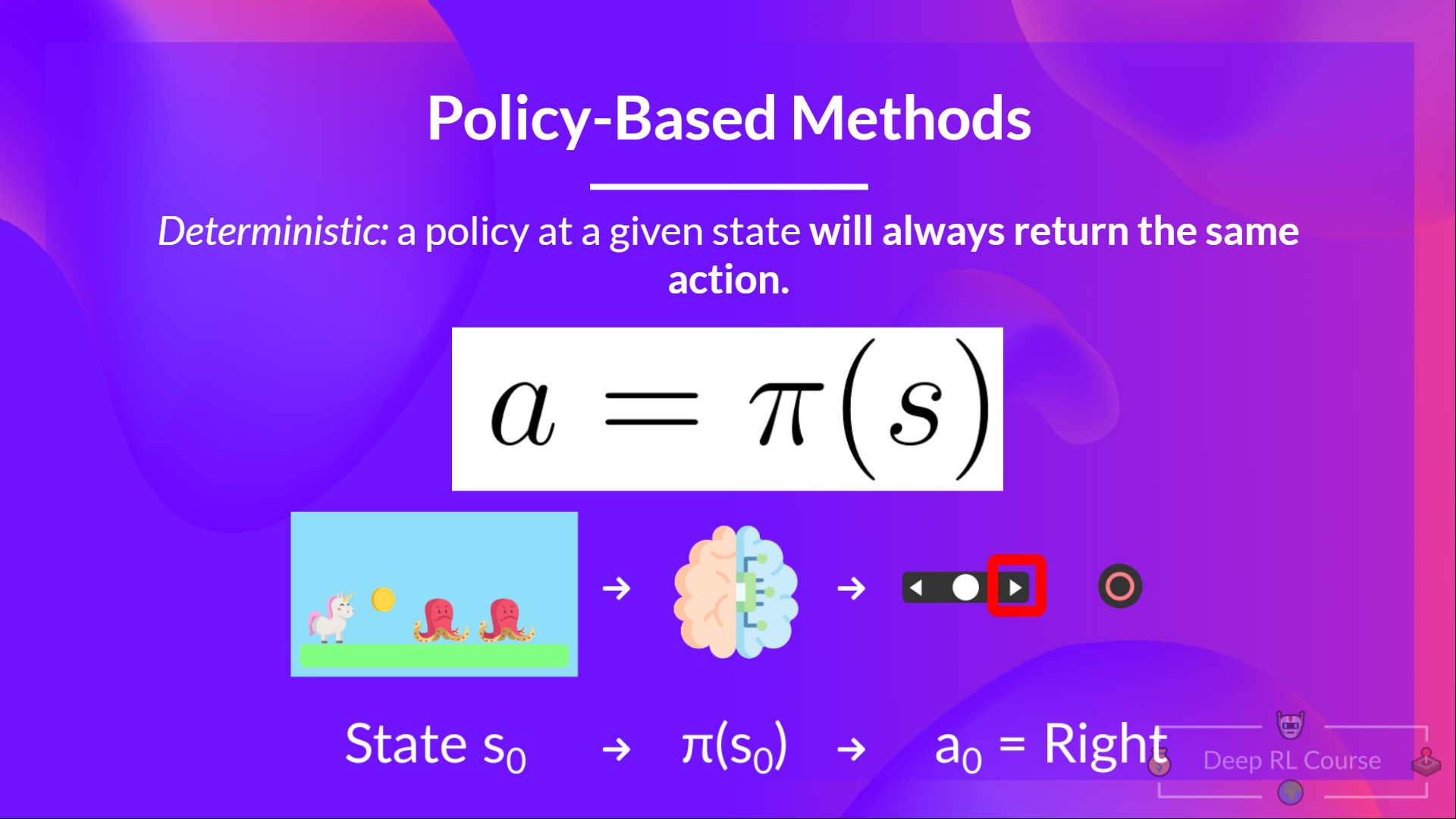
+## Value-based methods [[value-based]]
+
+In Value-based methods, instead of training a policy function, we **train a value function** that maps a state to the expected value **of being at that state.**
+
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
+
+“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
+
+
+
+
+## Value-based methods [[value-based]]
+
+In Value-based methods, instead of training a policy function, we **train a value function** that maps a state to the expected value **of being at that state.**
+
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
+
+“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
+
+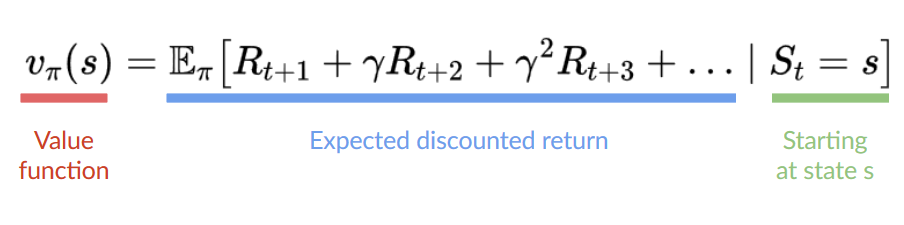 +
+Here we see that our value function **defined value for each possible state.**
+
+
+
+Here we see that our value function **defined value for each possible state.**
+
+ +
+ +
+ diff --git a/chapters/en/unit1/what-is-rl.mdx b/chapters/en/unit1/what-is-rl.mdx
new file mode 100644
index 0000000..cb1aa66
--- /dev/null
+++ b/chapters/en/unit1/what-is-rl.mdx
@@ -0,0 +1,37 @@
+# What is Reinforcement Learning? [[what-is-reinforcement-learning]]
+
+To understand Reinforcement Learning, let’s start with the big picture.
+
+## The big picture [[the-big-picture]]
+
+The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial and error) and **receiving rewards** (negative or positive) as feedback for performing actions.
+
+Learning from interaction with the environment **comes from our natural experiences.**
+
+For instance, imagine putting your little brother in front of a video game he never played, a controller in his hands, and letting him alone.
+
+
diff --git a/chapters/en/unit1/what-is-rl.mdx b/chapters/en/unit1/what-is-rl.mdx
new file mode 100644
index 0000000..cb1aa66
--- /dev/null
+++ b/chapters/en/unit1/what-is-rl.mdx
@@ -0,0 +1,37 @@
+# What is Reinforcement Learning? [[what-is-reinforcement-learning]]
+
+To understand Reinforcement Learning, let’s start with the big picture.
+
+## The big picture [[the-big-picture]]
+
+The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial and error) and **receiving rewards** (negative or positive) as feedback for performing actions.
+
+Learning from interaction with the environment **comes from our natural experiences.**
+
+For instance, imagine putting your little brother in front of a video game he never played, a controller in his hands, and letting him alone.
+
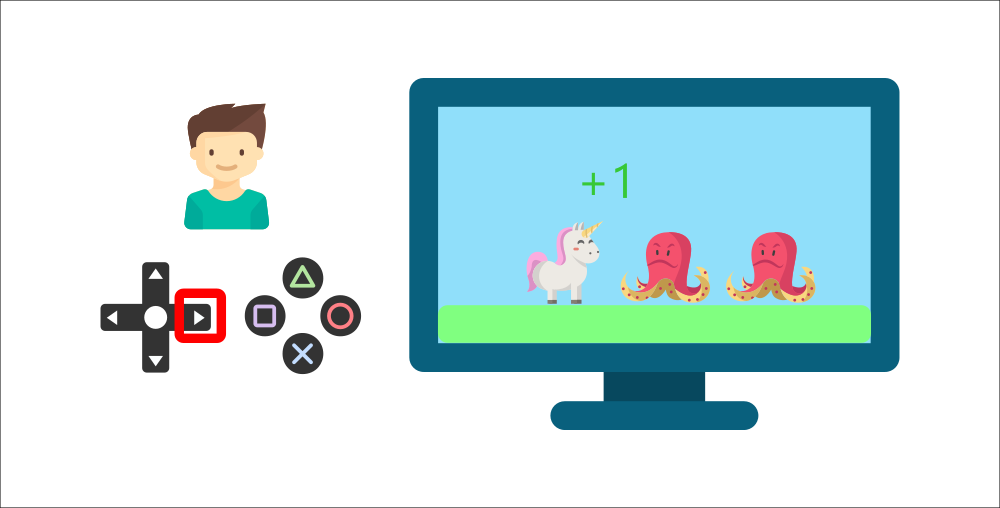
+ +
+Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
+
+
+
+Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
+
+ +
+But then, **he presses right again** and he touches an enemy, he just died -1 reward.
+
+
+
+But then, **he presses right again** and he touches an enemy, he just died -1 reward.
+
+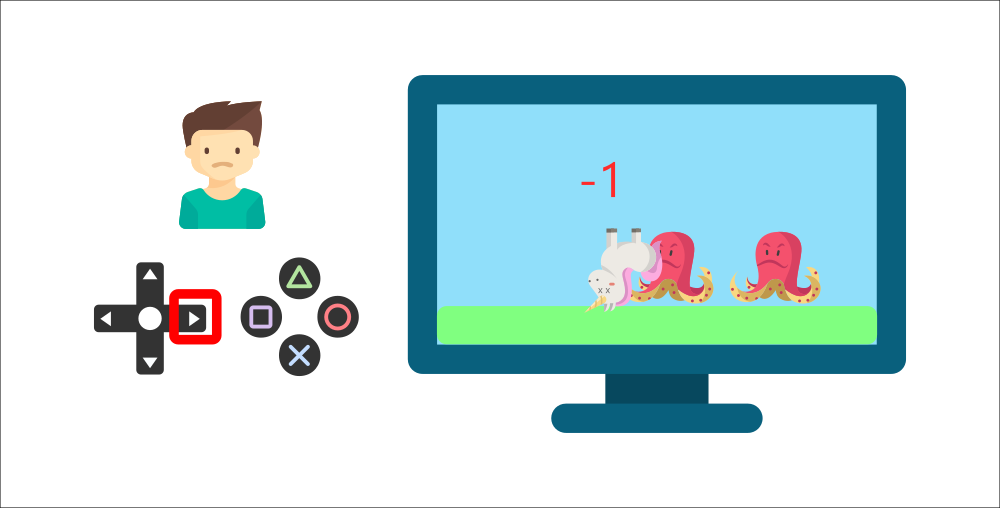 +
+By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
+
+**Without any supervision**, the child will get better and better at playing the game.
+
+That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from action.**
+
+### A formal definition [[a-formal-definition]]
+
+If we take now a formal definition:
+
+
+
+By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
+
+**Without any supervision**, the child will get better and better at playing the game.
+
+That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from action.**
+
+### A formal definition [[a-formal-definition]]
+
+If we take now a formal definition:
+
+ +
+With what we learned from now, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
+
+So to calculate \\(V(S_t)\\), we need to make the sum of the expected rewards. Hence:
+
+
+
+With what we learned from now, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
+
+So to calculate \\(V(S_t)\\), we need to make the sum of the expected rewards. Hence:
+
+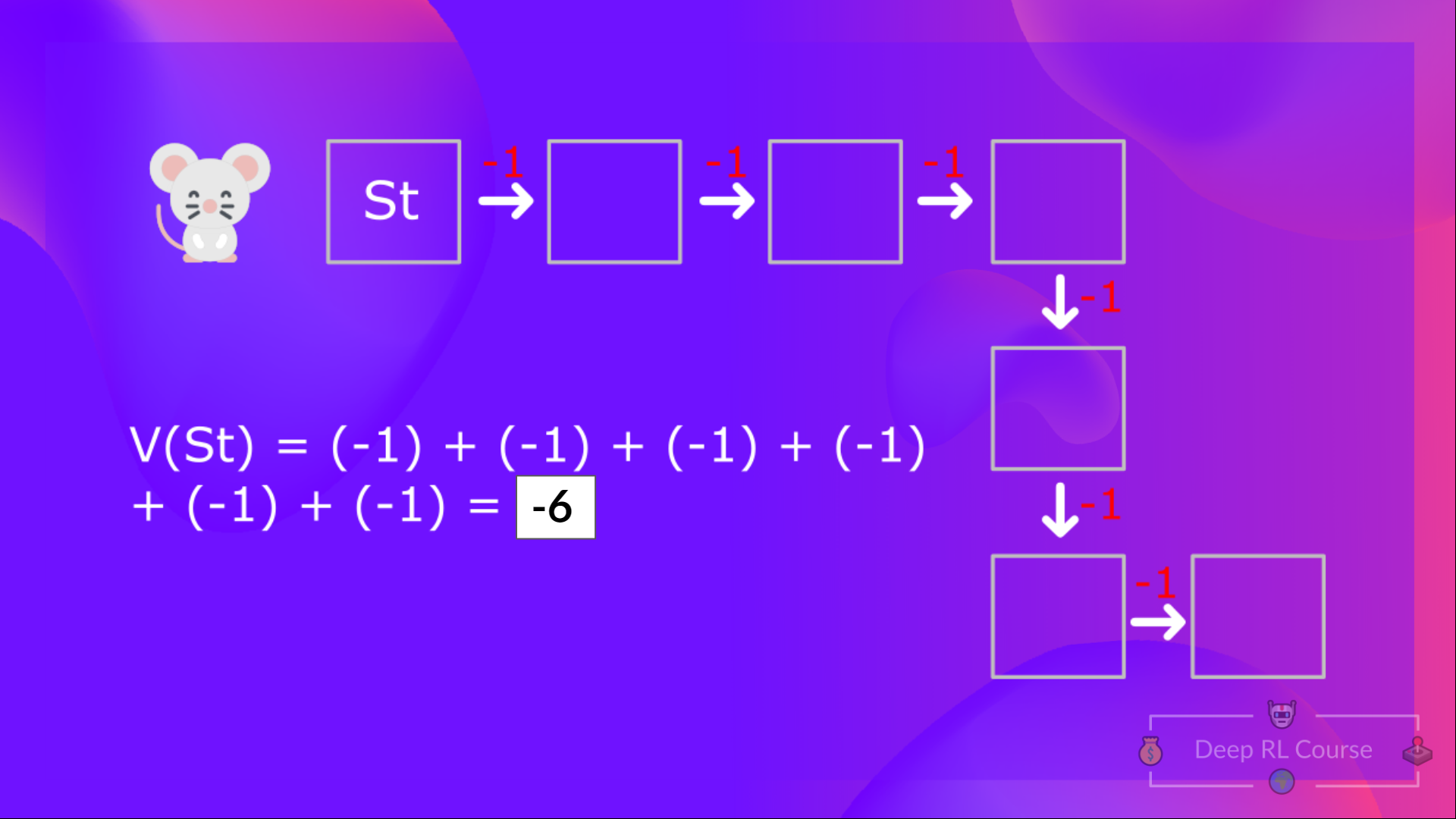 +
+  +
+  +
+
+
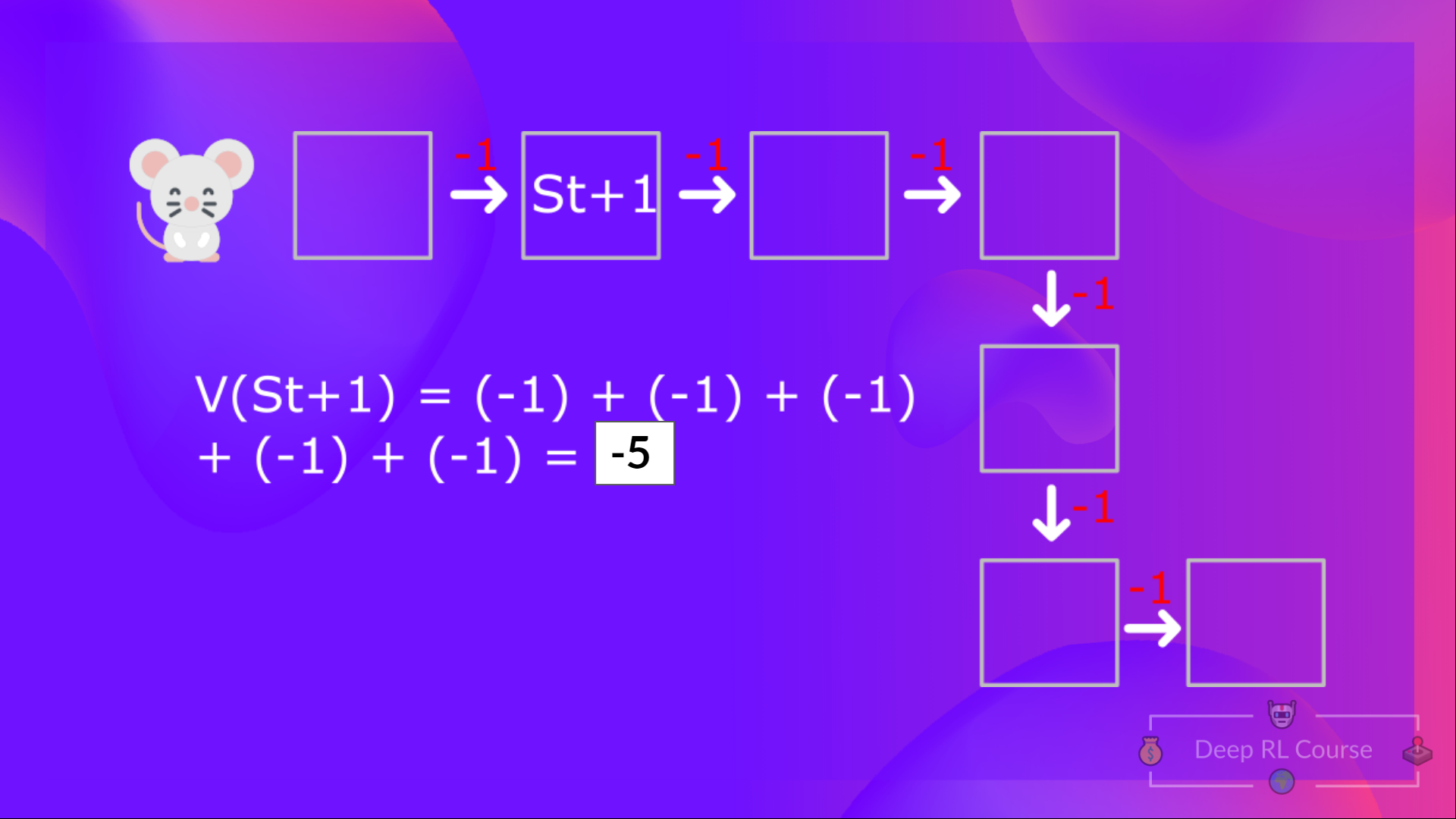
+To calculate the value of State 1: the sum of rewards **if the agent started in that state 1** and then followed the **policy for all the time steps.**
+
+Which is equivalent to \\(V(S_{t})\\) = Immediate reward \\(R_{t+1}\\) + Discounted value of the next state \\(gamma * V(S_{t+1})\\)
+
+
+
+
+
+To calculate the value of State 1: the sum of rewards **if the agent started in that state 1** and then followed the **policy for all the time steps.**
+
+Which is equivalent to \\(V(S_{t})\\) = Immediate reward \\(R_{t+1}\\) + Discounted value of the next state \\(gamma * V(S_{t+1})\\)
+
+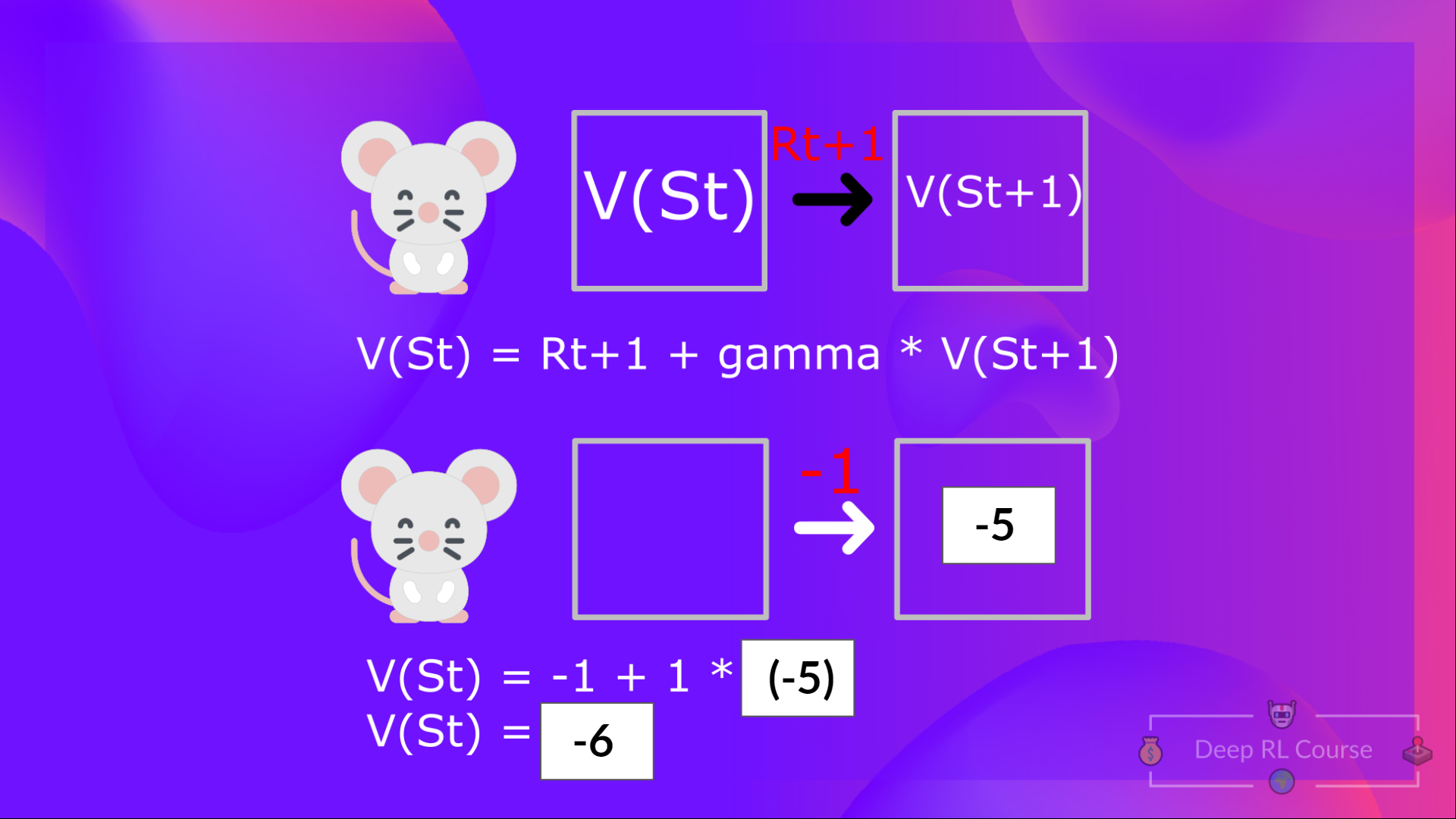 +
+
+For simplification, here we don't discount, so gamma = 1.
+
+- The value of \\(V(S_{t+1}) \\) = Immediate reward \\(R_{t+2}\\) + Discounted value of the next state ( \\(gamma * V(S_{t+2})\\) ).
+- And so on.
+
+To recap, the idea of the Bellman equation is that instead of calculating each value as the sum of the expected return, **which is a long process.** This is equivalent **to the sum of immediate reward + the discounted value of the state that follows.**
diff --git a/chapters/en/unit2/conclusion.mdx b/chapters/en/unit2/conclusion.mdx
new file mode 100644
index 0000000..f271ce0
--- /dev/null
+++ b/chapters/en/unit2/conclusion.mdx
@@ -0,0 +1,19 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorials. You’ve just implemented your first RL agent from scratch and shared it on the Hub 🥳.
+
+Implementing from scratch when you study a new architecture **is important to understand how it works.**
+
+That’s **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
+
+Take time to really grasp the material before continuing.
+
+
+In the next chapter, we’re going to dive deeper by studying our first Deep Reinforcement Learning algorithm based on Q-Learning: Deep Q-Learning. And you'll train a **DQN agent with RL-Baselines3 Zoo to play Atari Games**.
+
+
+
+
+
+For simplification, here we don't discount, so gamma = 1.
+
+- The value of \\(V(S_{t+1}) \\) = Immediate reward \\(R_{t+2}\\) + Discounted value of the next state ( \\(gamma * V(S_{t+2})\\) ).
+- And so on.
+
+To recap, the idea of the Bellman equation is that instead of calculating each value as the sum of the expected return, **which is a long process.** This is equivalent **to the sum of immediate reward + the discounted value of the state that follows.**
diff --git a/chapters/en/unit2/conclusion.mdx b/chapters/en/unit2/conclusion.mdx
new file mode 100644
index 0000000..f271ce0
--- /dev/null
+++ b/chapters/en/unit2/conclusion.mdx
@@ -0,0 +1,19 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorials. You’ve just implemented your first RL agent from scratch and shared it on the Hub 🥳.
+
+Implementing from scratch when you study a new architecture **is important to understand how it works.**
+
+That’s **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
+
+Take time to really grasp the material before continuing.
+
+
+In the next chapter, we’re going to dive deeper by studying our first Deep Reinforcement Learning algorithm based on Q-Learning: Deep Q-Learning. And you'll train a **DQN agent with RL-Baselines3 Zoo to play Atari Games**.
+
+
+ +
+
+
+### Keep Learning, stay awesome 🤗
diff --git a/chapters/en/unit2/hands-on.mdx b/chapters/en/unit2/hands-on.mdx
new file mode 100644
index 0000000..a9f9bb1
--- /dev/null
+++ b/chapters/en/unit2/hands-on.mdx
@@ -0,0 +1,2 @@
+# Hands-on [[hands-on]]
+n
diff --git a/chapters/en/unit2/introduction.mdx b/chapters/en/unit2/introduction.mdx
new file mode 100644
index 0000000..42e1e44
--- /dev/null
+++ b/chapters/en/unit2/introduction.mdx
@@ -0,0 +1,22 @@
+# Introduction to Q-Learning [[introduction-q-learning]]
+
+ADD THUMBNAIL
+
+In the first chapter of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
+
+In this chapter, we're going to **dive deeper into one of the Reinforcement Learning methods: value-based methods** and study our first RL algorithm: **Q-Learning.**
+
+We'll also **implement our first RL agent from scratch**: a Q-Learning agent and will train it in two environments:
+
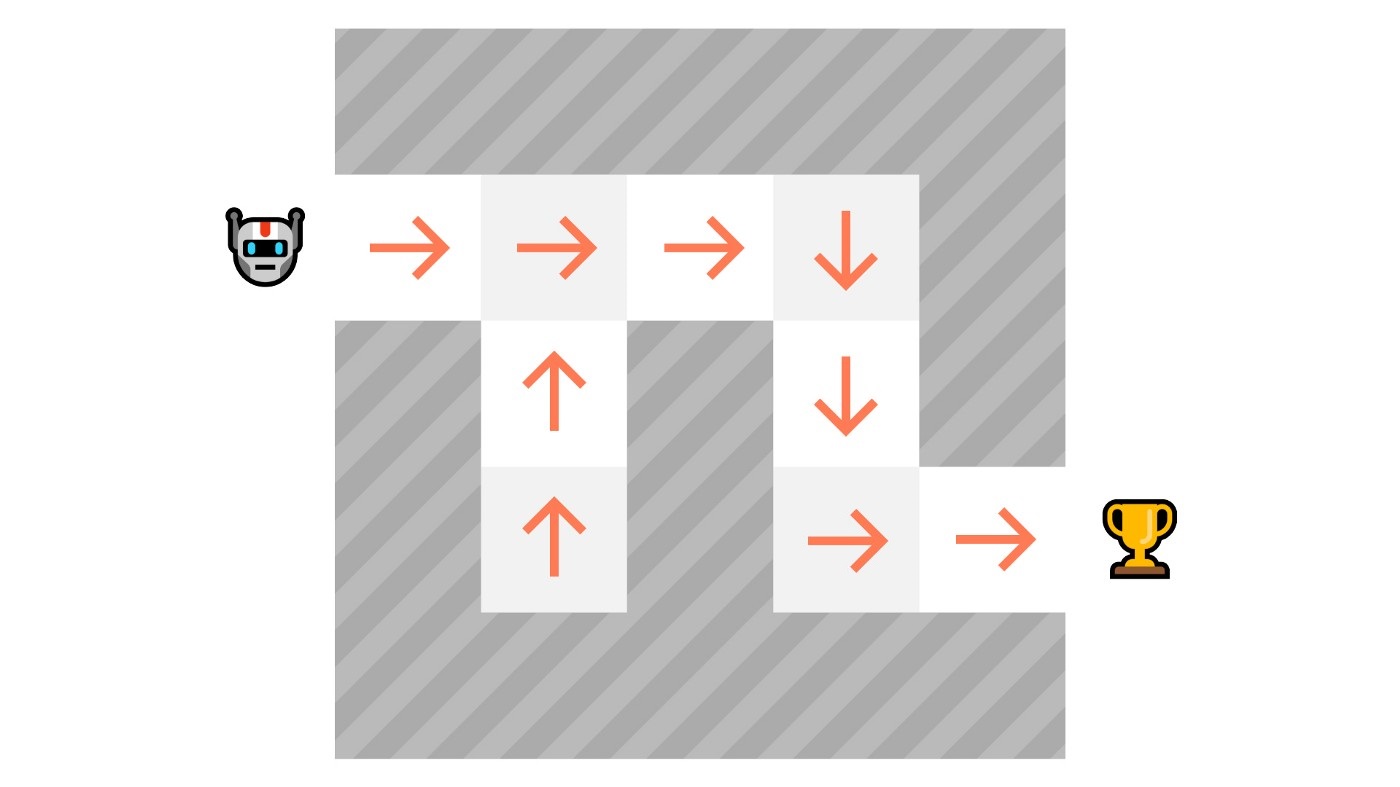
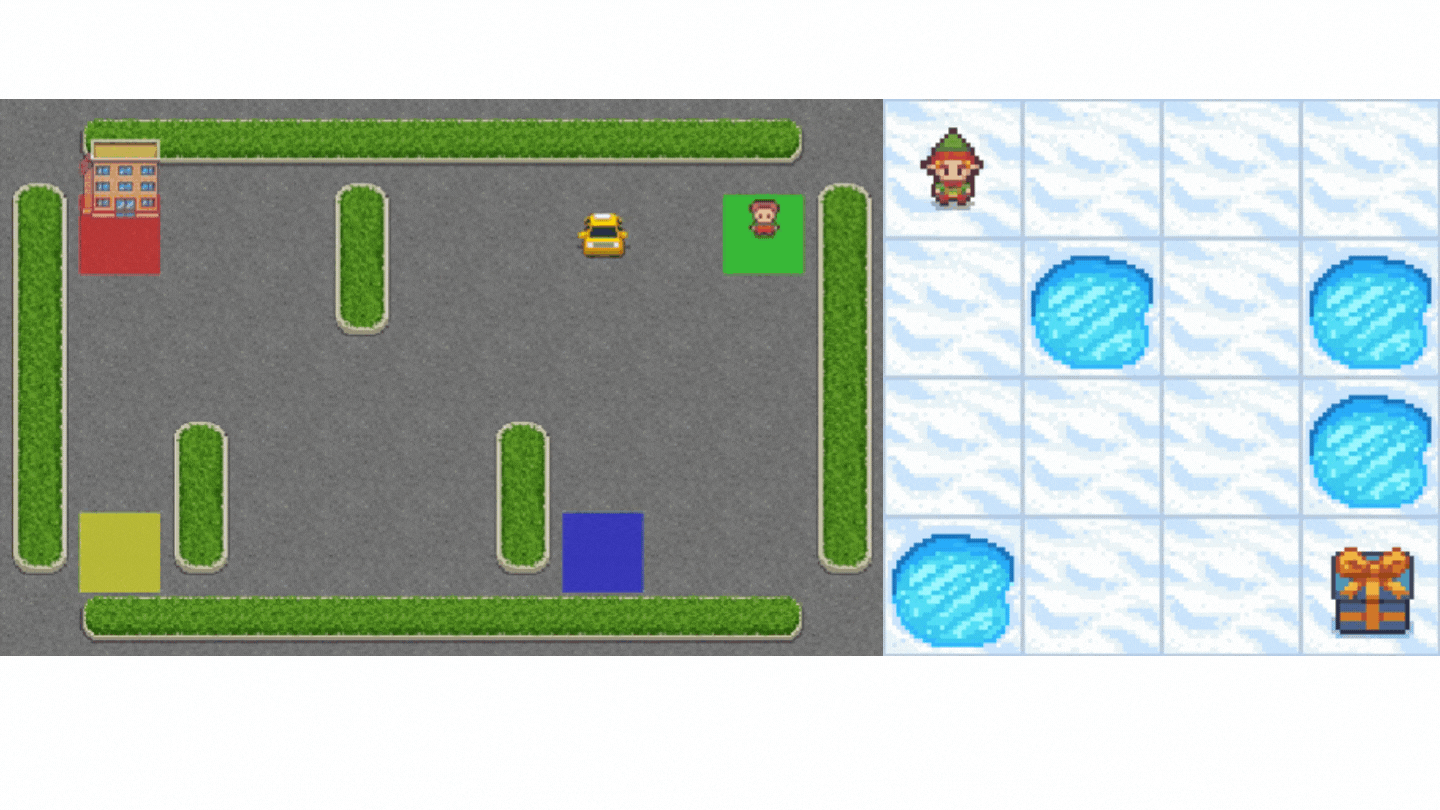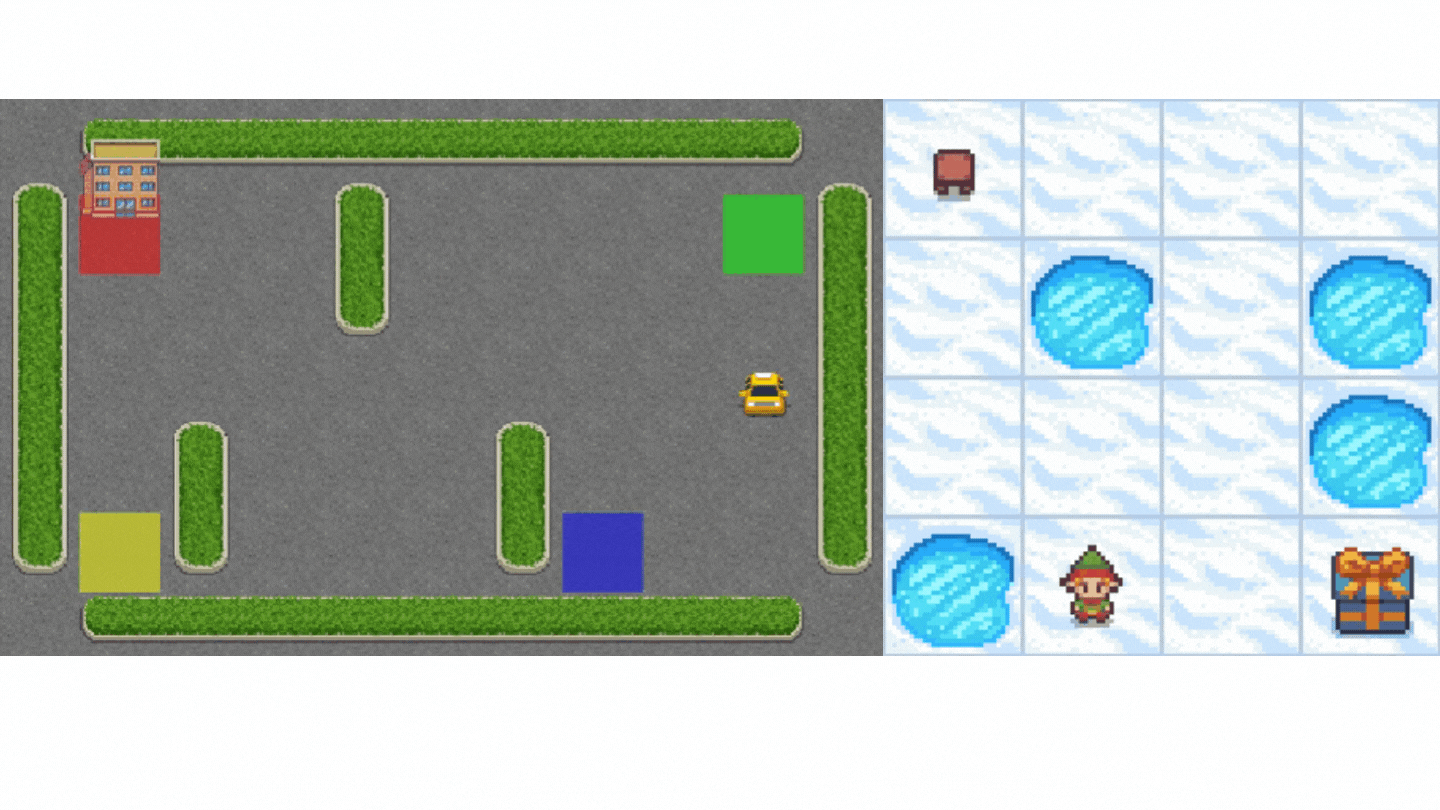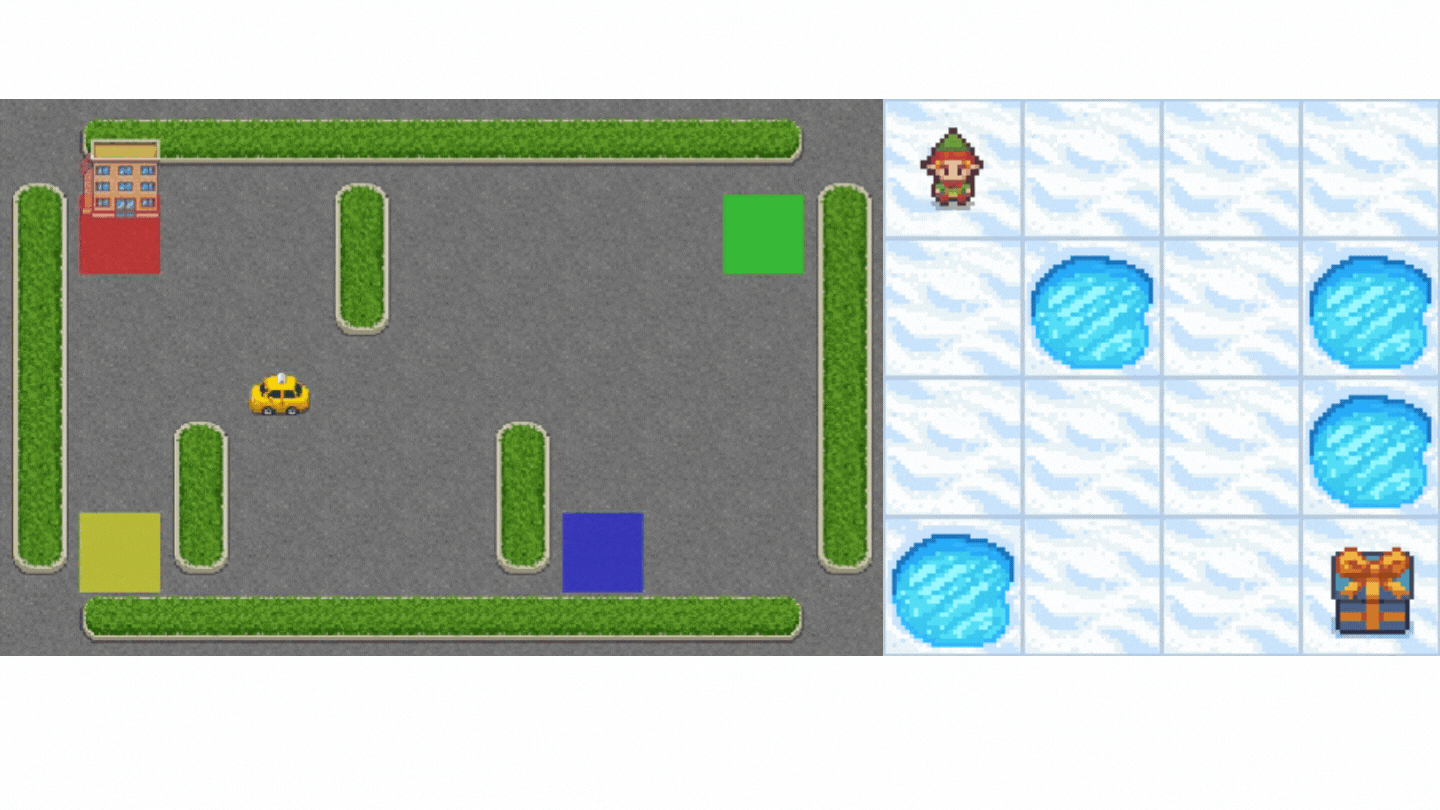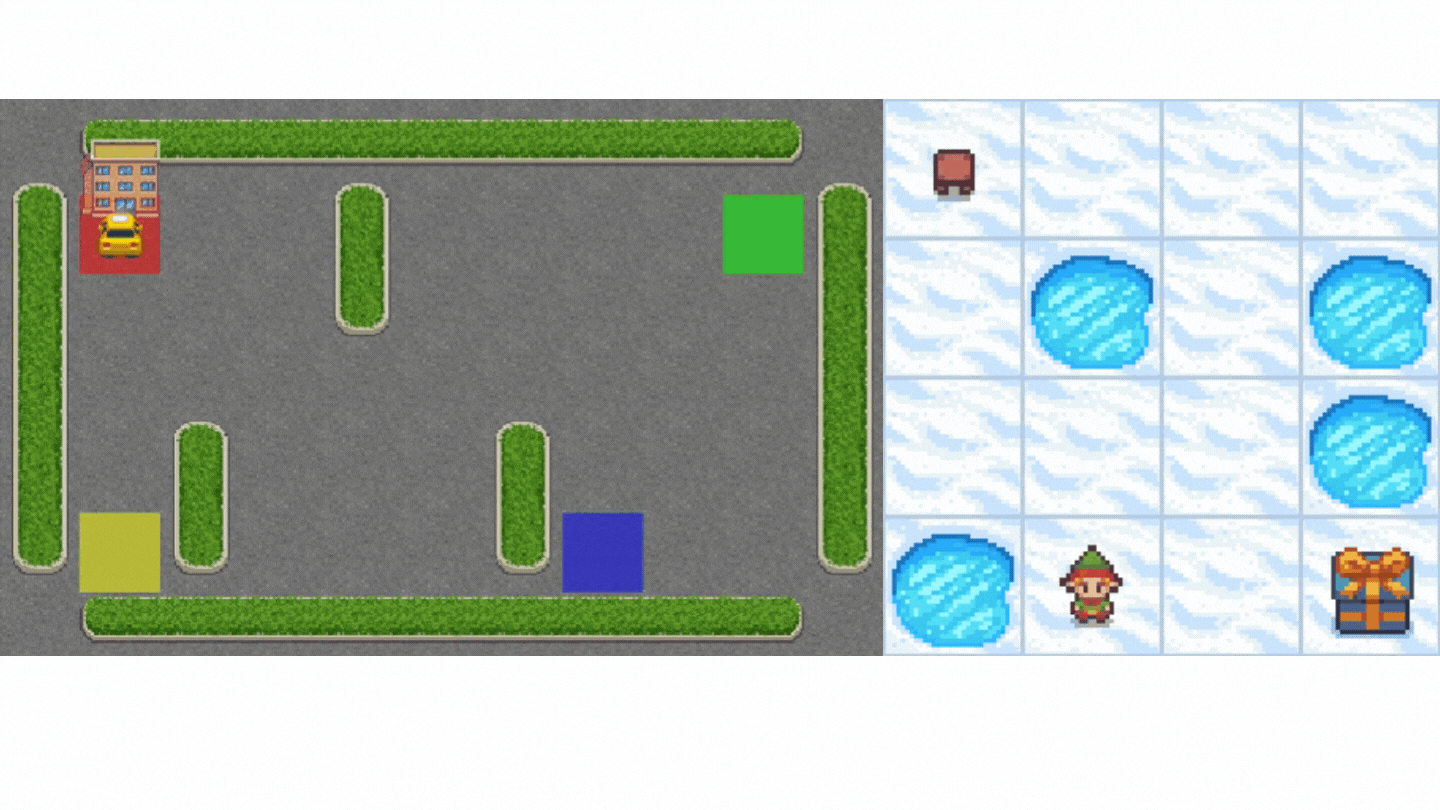
+1. Frozen-Lake-v1 (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. An autonomous taxi will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+
+
+
+
+### Keep Learning, stay awesome 🤗
diff --git a/chapters/en/unit2/hands-on.mdx b/chapters/en/unit2/hands-on.mdx
new file mode 100644
index 0000000..a9f9bb1
--- /dev/null
+++ b/chapters/en/unit2/hands-on.mdx
@@ -0,0 +1,2 @@
+# Hands-on [[hands-on]]
+n
diff --git a/chapters/en/unit2/introduction.mdx b/chapters/en/unit2/introduction.mdx
new file mode 100644
index 0000000..42e1e44
--- /dev/null
+++ b/chapters/en/unit2/introduction.mdx
@@ -0,0 +1,22 @@
+# Introduction to Q-Learning [[introduction-q-learning]]
+
+ADD THUMBNAIL
+
+In the first chapter of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
+
+In this chapter, we're going to **dive deeper into one of the Reinforcement Learning methods: value-based methods** and study our first RL algorithm: **Q-Learning.**
+
+We'll also **implement our first RL agent from scratch**: a Q-Learning agent and will train it in two environments:
+
+1. Frozen-Lake-v1 (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. An autonomous taxi will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+ +
+
+We'll learn about the value-based methods and the difference between Monte Carlo and Temporal Difference Learning. And then, **we'll study and code our first RL algorithm**: Q-Learning, and implement our first RL Agent.
+
+This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that was able to play Atari games and beat the human level on some of them (breakout, space invaders…).
+
+So let's get started! 🚀
diff --git a/chapters/en/unit2/mc-vs-td.mdx b/chapters/en/unit2/mc-vs-td.mdx
new file mode 100644
index 0000000..5410237
--- /dev/null
+++ b/chapters/en/unit2/mc-vs-td.mdx
@@ -0,0 +1,126 @@
+# Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
+
+The last thing we need to talk about before diving into Q-Learning is the two ways of learning.
+
+Remember that an RL agent **learns by interacting with its environment.** The idea is that **using the experience taken**, given the reward it gets, will **update its value or policy.**
+
+Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
+
+On one hand, Monte Carlo uses **an entire episode of experience before learning.** On the other hand, Temporal Difference uses **only a step ( \\(S_t, A_t, R_{t+1}, S_{t+1}\\) ) to learn.**
+
+We'll explain both of them **using a value-based method example.**
+
+## Monte Carlo: learning at the end of the episode [[monte-carlo]]
+
+Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
+
+So it requires a **complete entire episode of interaction before updating our value function.**
+
+
+
+
+We'll learn about the value-based methods and the difference between Monte Carlo and Temporal Difference Learning. And then, **we'll study and code our first RL algorithm**: Q-Learning, and implement our first RL Agent.
+
+This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that was able to play Atari games and beat the human level on some of them (breakout, space invaders…).
+
+So let's get started! 🚀
diff --git a/chapters/en/unit2/mc-vs-td.mdx b/chapters/en/unit2/mc-vs-td.mdx
new file mode 100644
index 0000000..5410237
--- /dev/null
+++ b/chapters/en/unit2/mc-vs-td.mdx
@@ -0,0 +1,126 @@
+# Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
+
+The last thing we need to talk about before diving into Q-Learning is the two ways of learning.
+
+Remember that an RL agent **learns by interacting with its environment.** The idea is that **using the experience taken**, given the reward it gets, will **update its value or policy.**
+
+Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
+
+On one hand, Monte Carlo uses **an entire episode of experience before learning.** On the other hand, Temporal Difference uses **only a step ( \\(S_t, A_t, R_{t+1}, S_{t+1}\\) ) to learn.**
+
+We'll explain both of them **using a value-based method example.**
+
+## Monte Carlo: learning at the end of the episode [[monte-carlo]]
+
+Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
+
+So it requires a **complete entire episode of interaction before updating our value function.**
+
+  +
+
+If we take an example:
+
+
+
+
+If we take an example:
+
+  +
+
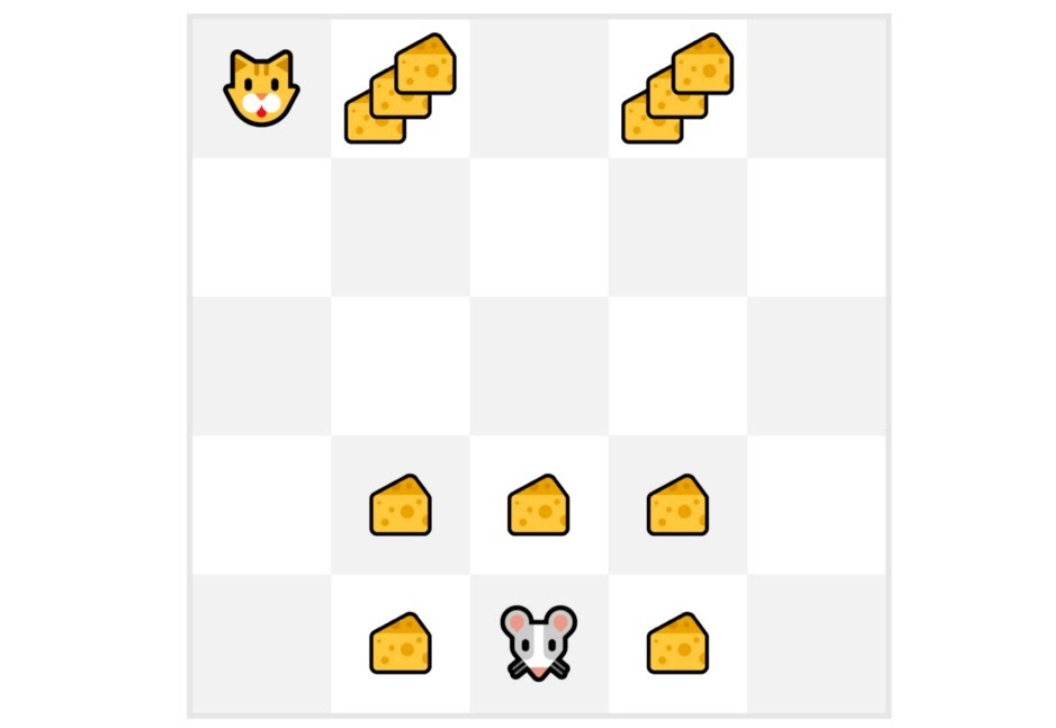
+- We always start the episode **at the same starting point.**
+- **The agent takes actions using the policy**. For instance, using an Epsilon Greedy Strategy, a policy that alternates between exploration (random actions) and exploitation.
+- We get **the reward and the next state.**
+- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
+
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States**
+- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
+- It will then **update \\(V(s_t)\\) based on the formula**
+
+
+
+
+- We always start the episode **at the same starting point.**
+- **The agent takes actions using the policy**. For instance, using an Epsilon Greedy Strategy, a policy that alternates between exploration (random actions) and exploitation.
+- We get **the reward and the next state.**
+- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
+
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States**
+- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
+- It will then **update \\(V(s_t)\\) based on the formula**
+
+  +
+- Then **start a new game with this new knowledge**
+
+By running more and more episodes, **the agent will learn to play better and better.**
+
+
+
+- Then **start a new game with this new knowledge**
+
+By running more and more episodes, **the agent will learn to play better and better.**
+
+  +
+For instance, if we train a state-value function using Monte Carlo:
+
+- We just started to train our Value function, **so it returns 0 value for each state**
+- Our learning rate (lr) is 0.1 and our discount rate is 1 (= no discount)
+- Our mouse **explores the environment and takes random actions**
+
+
+
+For instance, if we train a state-value function using Monte Carlo:
+
+- We just started to train our Value function, **so it returns 0 value for each state**
+- Our learning rate (lr) is 0.1 and our discount rate is 1 (= no discount)
+- Our mouse **explores the environment and takes random actions**
+
+ 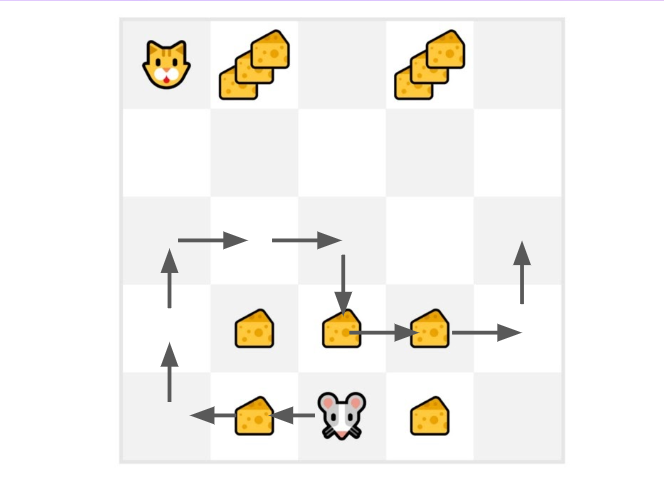 +
+
+- The mouse made more than 10 steps, so the episode ends .
+
+
+
+
+- The mouse made more than 10 steps, so the episode ends .
+
+ 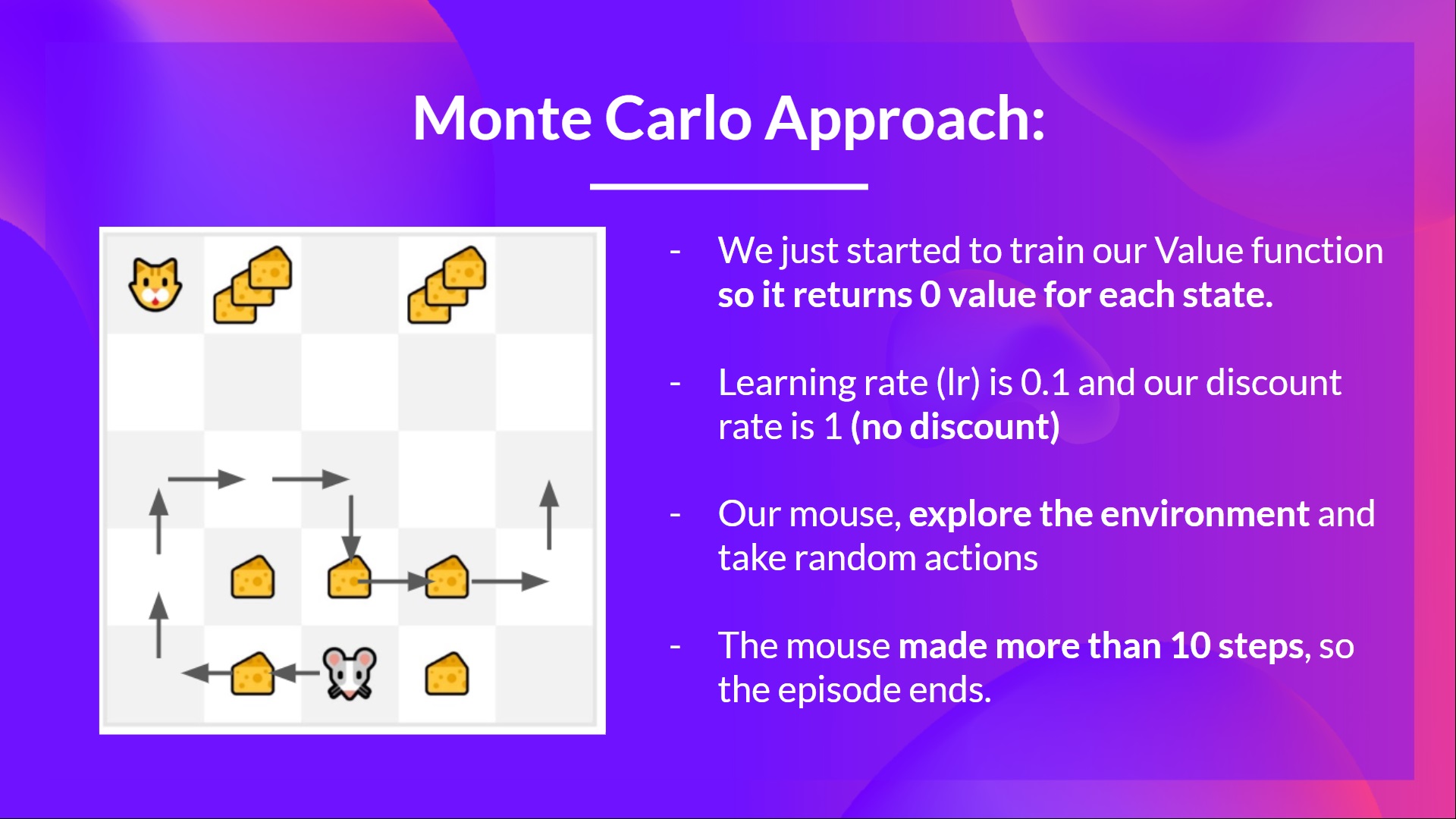 +
+
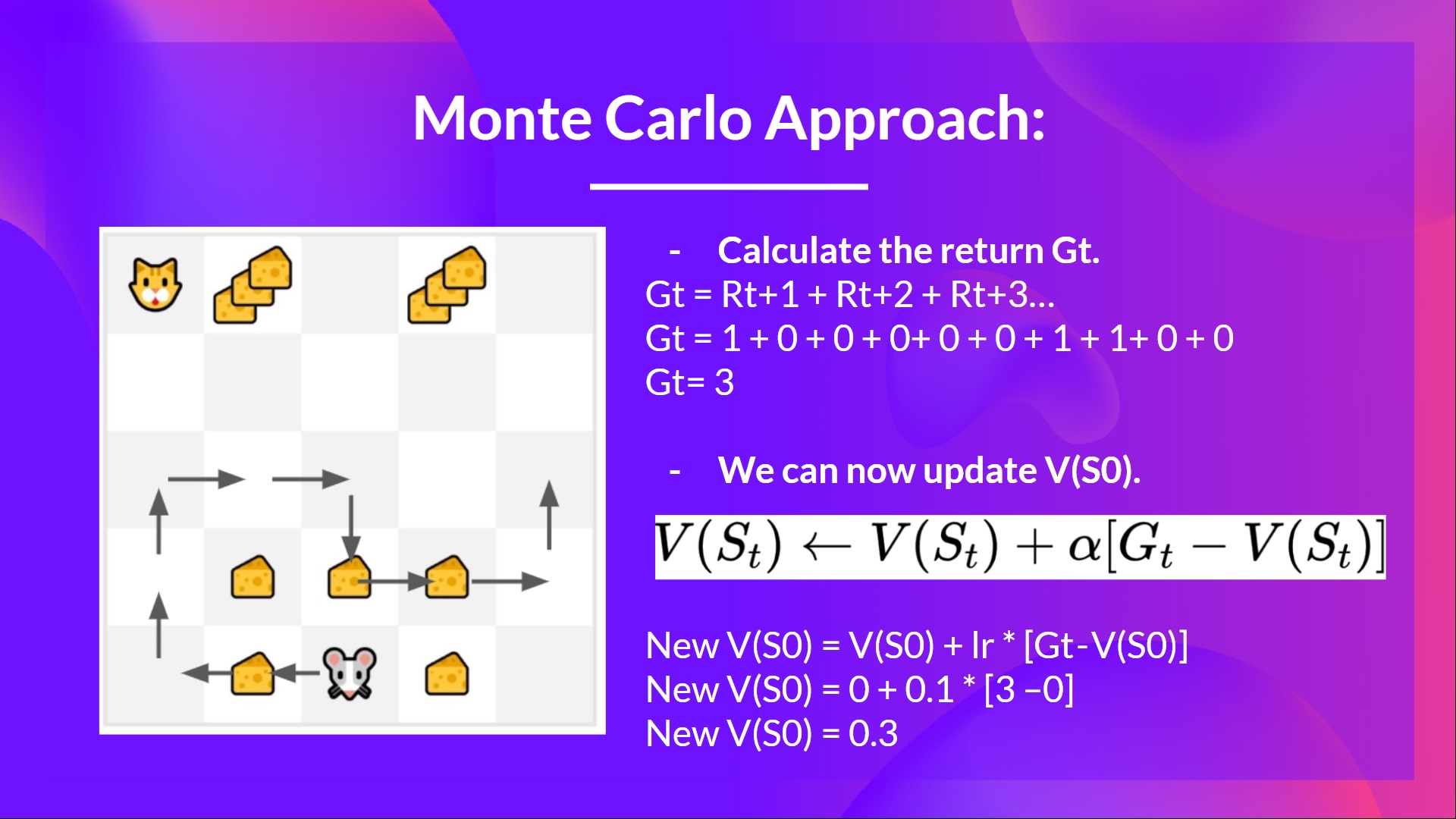
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
+- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
+- \\(G_t= 3\\)
+- We can now update \\(V(S_0)\\):
+
+
+
+
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
+- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
+- \\(G_t= 3\\)
+- We can now update \\(V(S_0)\\):
+
+  +
+- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
+- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+- New \\(V(S_0) = 0.3\\)
+
+
+
+
+- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
+- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+- New \\(V(S_0) = 0.3\\)
+
+
+  +
+
+## Temporal Difference Learning: learning at each step [[td-learning]]
+
+- **Temporal difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\(gamma * V(S_{t+1})\\).
+
+The idea with **TD is to update the \\(V(S_t)\\) at each step.**
+
+But because we didn't play during an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+
+This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
+
+
+
+
+## Temporal Difference Learning: learning at each step [[td-learning]]
+
+- **Temporal difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\(gamma * V(S_{t+1})\\).
+
+The idea with **TD is to update the \\(V(S_t)\\) at each step.**
+
+But because we didn't play during an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+
+This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
+
+  +
+
+This method is called TD(0) or **one-step TD (update the value function after any individual step).**
+
+
+
+
+This method is called TD(0) or **one-step TD (update the value function after any individual step).**
+
+  +
+If we take the same example,
+
+
+
+If we take the same example,
+
+  +
+- We just started to train our Value function, so it returns 0 value for each state.
+- Our learning rate (lr) is 0.1, and our discount rate is 1 (no discount).
+- Our mouse explore the environment and take a random action: **going to the left**
+- It gets a reward \\(R_{t+1} = 1\\) since **it eats a piece of cheese**
+
+
+
+- We just started to train our Value function, so it returns 0 value for each state.
+- Our learning rate (lr) is 0.1, and our discount rate is 1 (no discount).
+- Our mouse explore the environment and take a random action: **going to the left**
+- It gets a reward \\(R_{t+1} = 1\\) since **it eats a piece of cheese**
+
+ 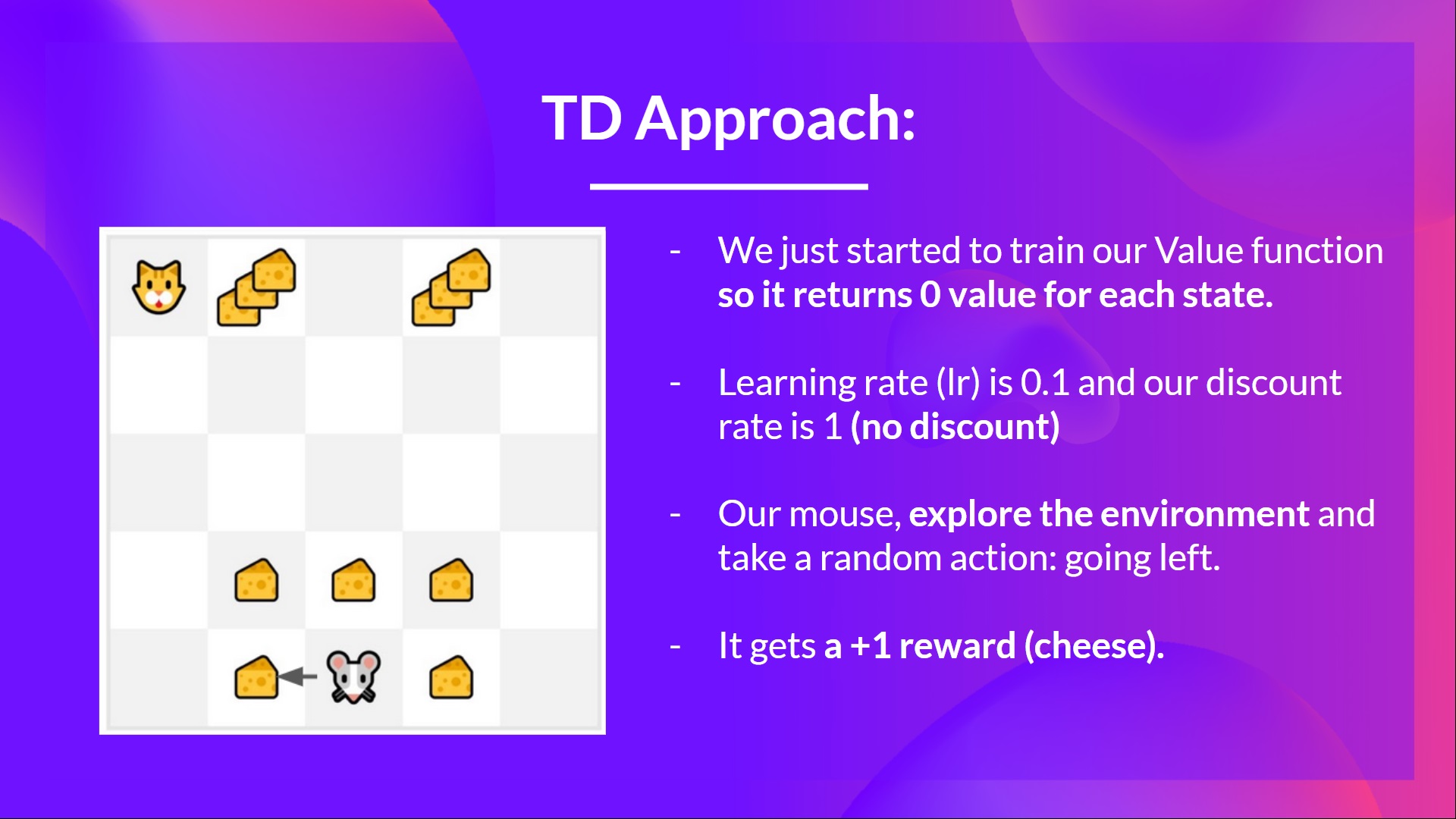 +
+
+
+
+
+ 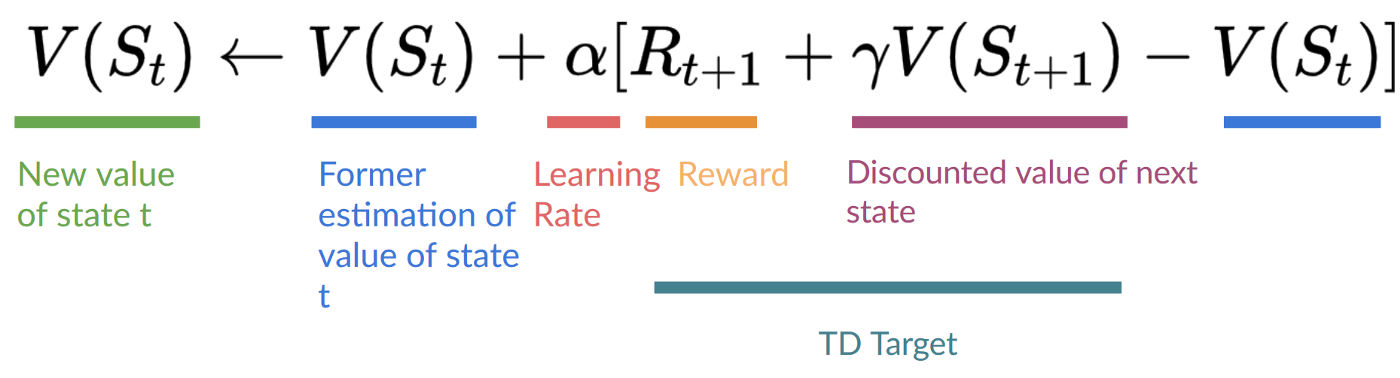 +
+We can now update \\(V(S_0)\\):
+
+New \\(V(S_0) = V(S_0) + lr * [R_1 + gamma * V(S_1) - V(S_0)]\\)
+
+New \\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+New \\(V(S_0) = 0.1\\)
+
+So we just updated our value function for State 0.
+
+Now we **continue to interact with this environment with our updated value function.**
+
+
+
+We can now update \\(V(S_0)\\):
+
+New \\(V(S_0) = V(S_0) + lr * [R_1 + gamma * V(S_1) - V(S_0)]\\)
+
+New \\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+New \\(V(S_0) = 0.1\\)
+
+So we just updated our value function for State 0.
+
+Now we **continue to interact with this environment with our updated value function.**
+
+  +
+ If we summarize:
+
+ - With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+ - With *TD learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+
+
+
+ If we summarize:
+
+ - With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+ - With *TD learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+
+ 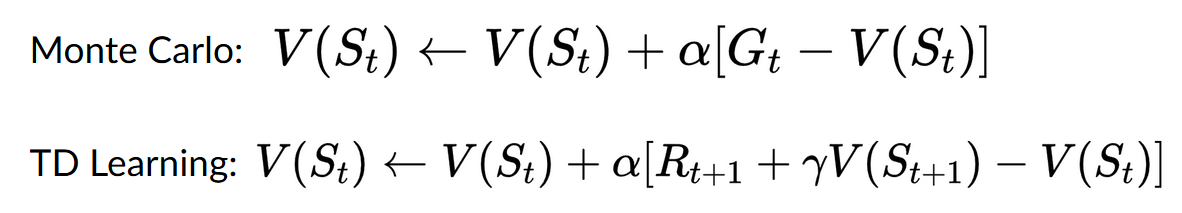 diff --git a/chapters/en/unit2/q-learning-example.mdx b/chapters/en/unit2/q-learning-example.mdx
new file mode 100644
index 0000000..62e9be3
--- /dev/null
+++ b/chapters/en/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# A Q-Learning example [[q-learning-example]]
+
+To better understand Q-Learning, let's take a simple example:
+
+
diff --git a/chapters/en/unit2/q-learning-example.mdx b/chapters/en/unit2/q-learning-example.mdx
new file mode 100644
index 0000000..62e9be3
--- /dev/null
+++ b/chapters/en/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# A Q-Learning example [[q-learning-example]]
+
+To better understand Q-Learning, let's take a simple example:
+
+ +
+- You're a mouse in this tiny maze. You always **start at the same starting point.**
+- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
+- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
+- The learning rate is 0.1
+- The gamma (discount rate) is 0.99
+
+
+
+- You're a mouse in this tiny maze. You always **start at the same starting point.**
+- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
+- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
+- The learning rate is 0.1
+- The gamma (discount rate) is 0.99
+
+ +
+
+The reward function goes like this:
+
+- **+0:** Going to a state with no cheese in it.
+- **+1:** Going to a state with a small cheese in it.
+- **+10:** Going to the state with the big pile of cheese.
+- **-10:** Going to the state with the poison and thus die.
+- **+0** If we spend more than five steps.
+
+
+
+
+The reward function goes like this:
+
+- **+0:** Going to a state with no cheese in it.
+- **+1:** Going to a state with a small cheese in it.
+- **+10:** Going to the state with the big pile of cheese.
+- **-10:** Going to the state with the poison and thus die.
+- **+0** If we spend more than five steps.
+
+ +
+To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
+
+## Step 1: We initialize the Q-Table [[step1]]
+
+
+
+To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
+
+## Step 1: We initialize the Q-Table [[step1]]
+
+ +
+So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+
+Let's do it for 2 training timesteps:
+
+Training timestep 1:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+Because epsilon is big = 1.0, I take a random action, in this case, I go right.
+
+
+
+So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+
+Let's do it for 2 training timesteps:
+
+Training timestep 1:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+Because epsilon is big = 1.0, I take a random action, in this case, I go right.
+
+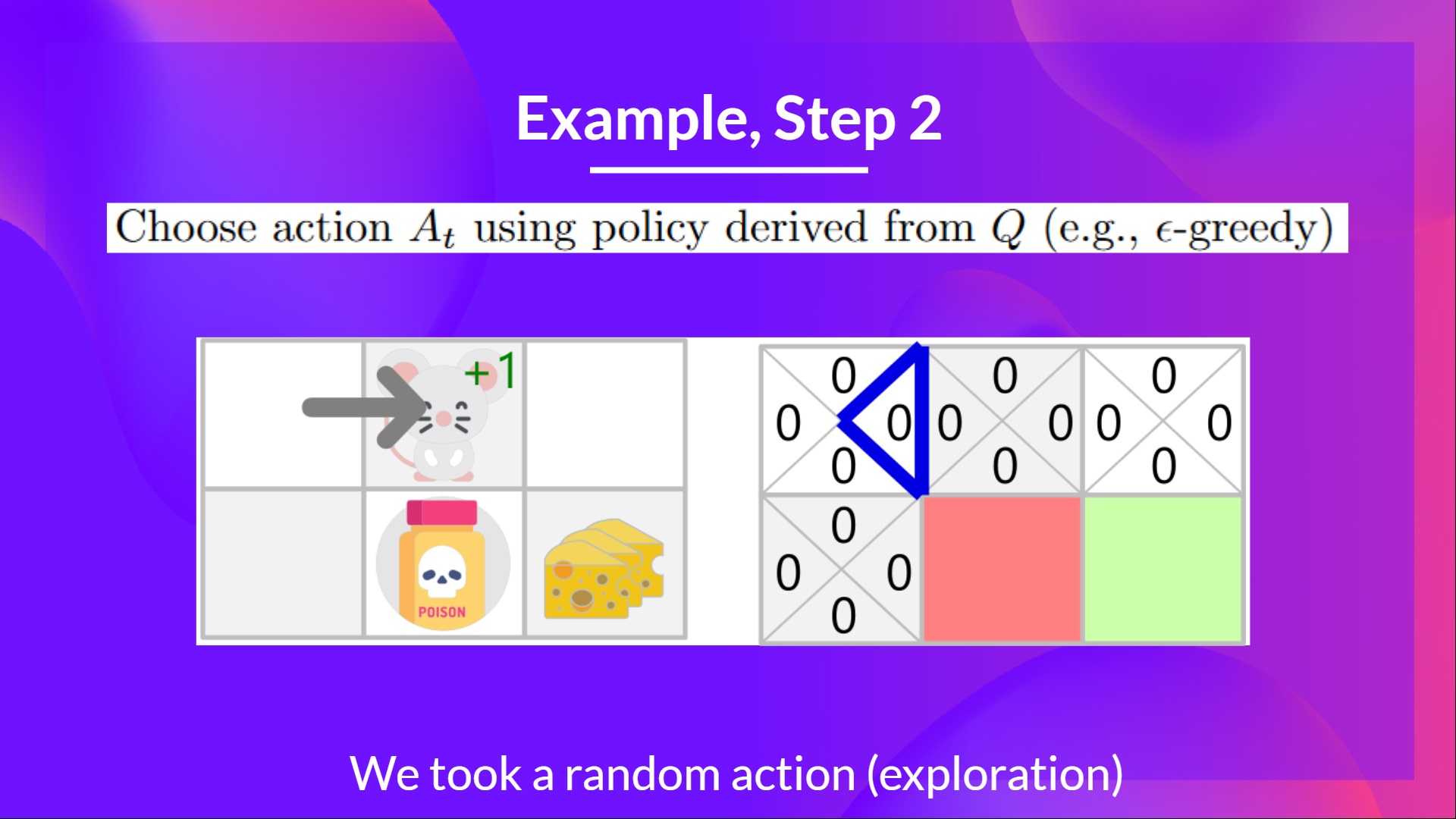 +
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3]]
+
+By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
+
+
+
+
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3]]
+
+By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
+
+
+ +
+
+## Step 4: Update Q(St, At) [[step4]]
+
+We can now update \\(Q(S_t, A_t)\\) using our formula.
+
+
+
+
+## Step 4: Update Q(St, At) [[step4]]
+
+We can now update \\(Q(S_t, A_t)\\) using our formula.
+
+ +
+ +
+Training timestep 2:
+
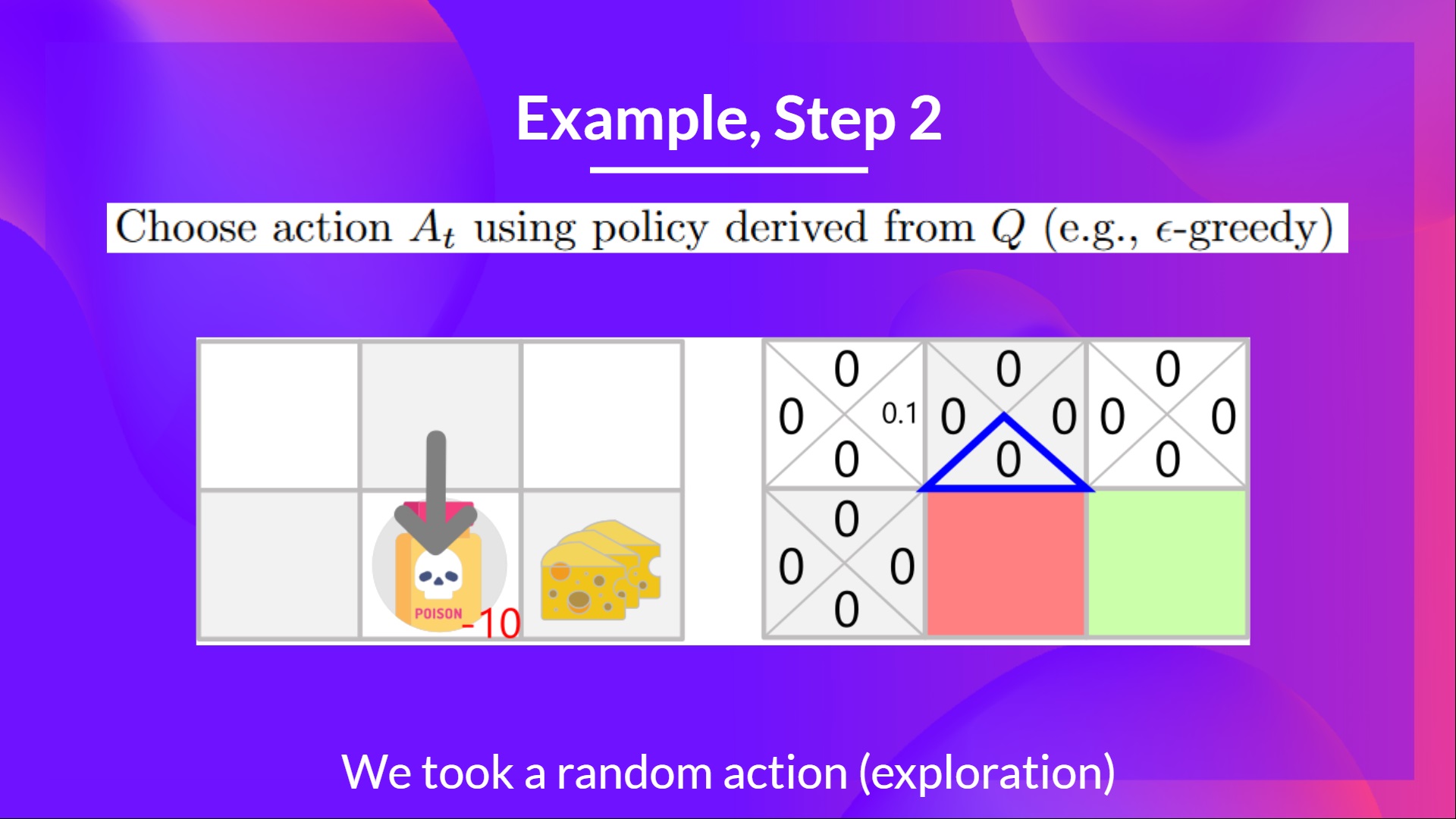
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2-2]]
+
+**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
+
+I took action down. **Not a good action since it leads me to the poison.**
+
+
+
+Training timestep 2:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2-2]]
+
+**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
+
+I took action down. **Not a good action since it leads me to the poison.**
+
+ +
+
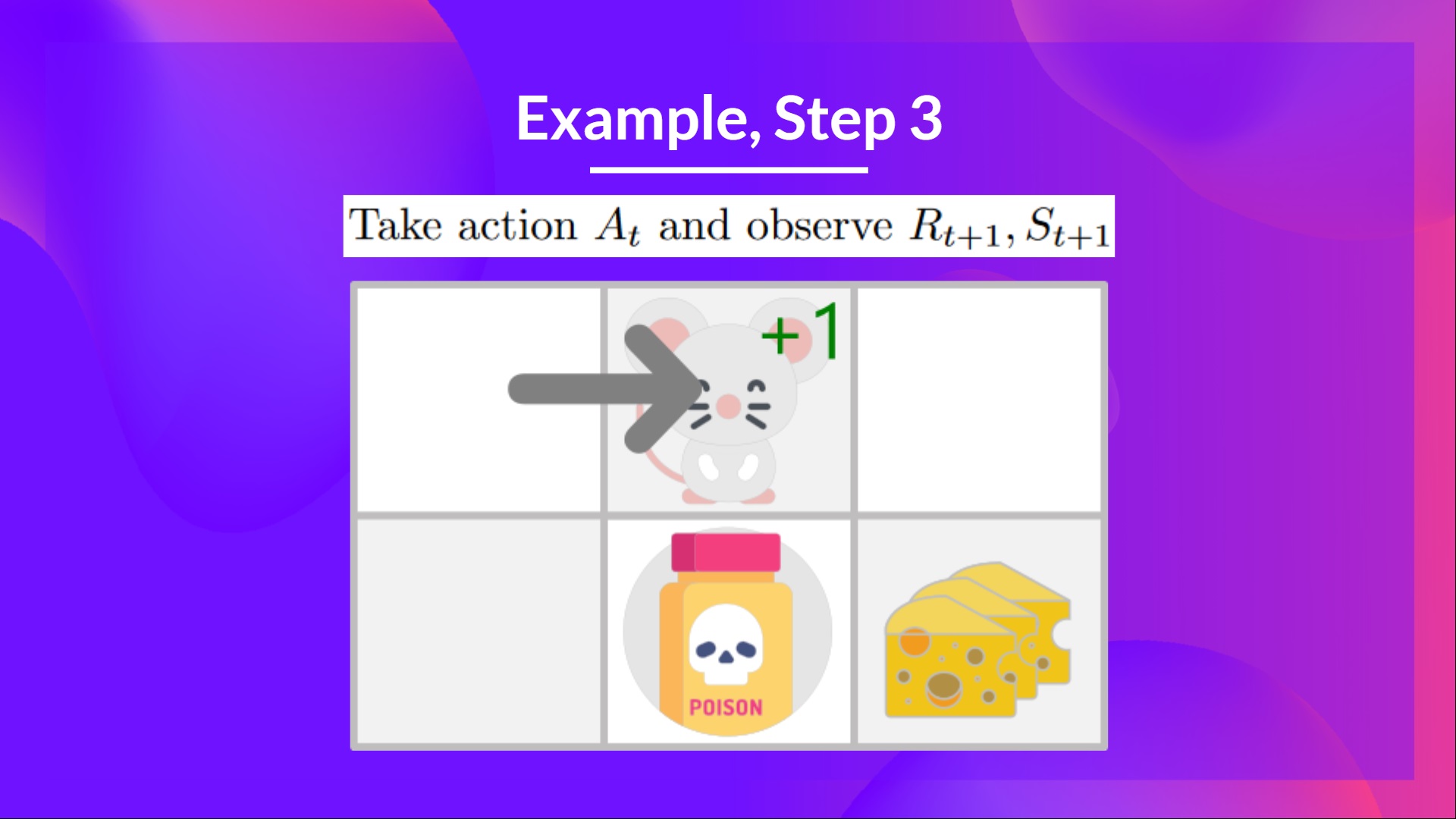
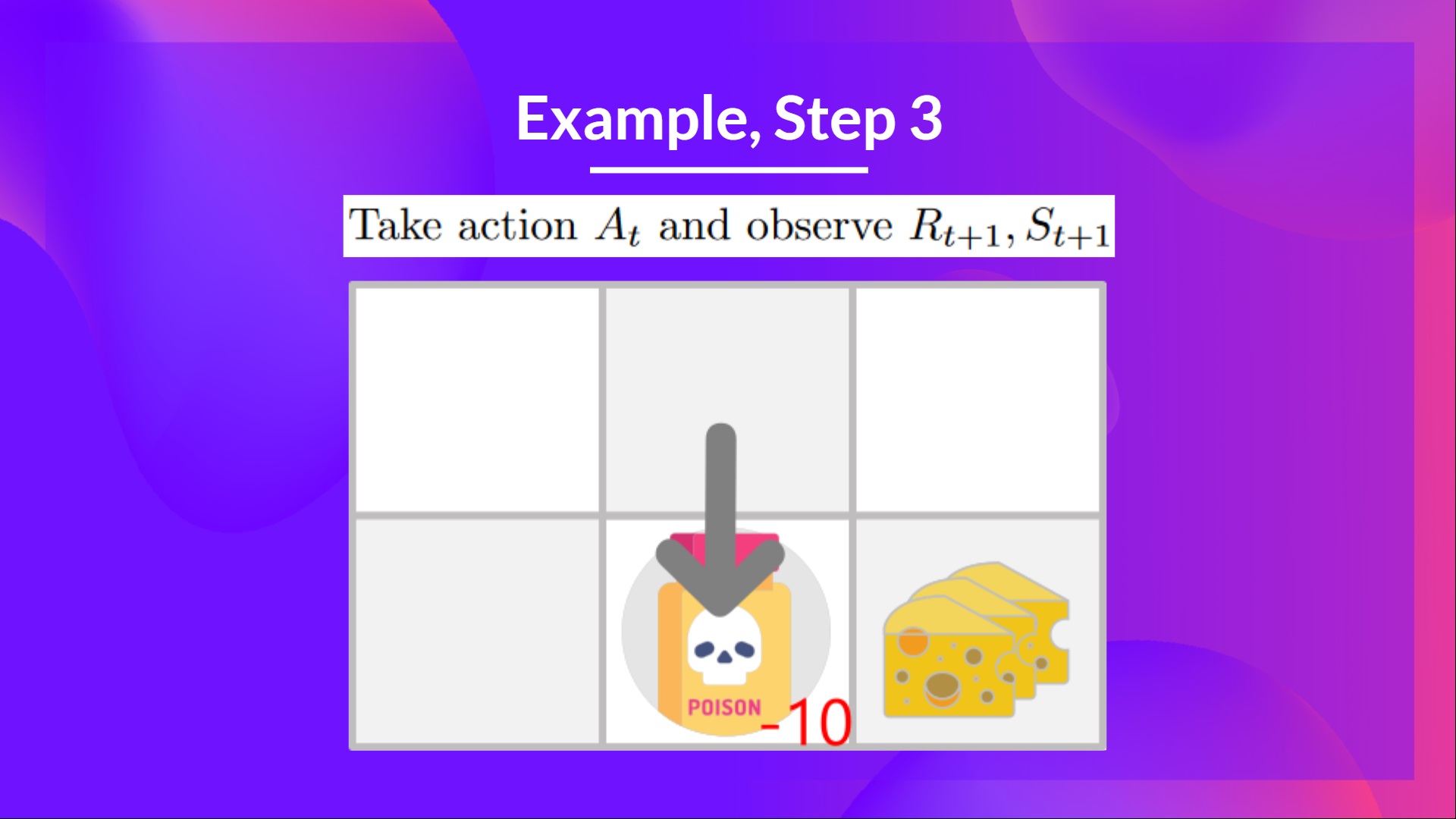
+## Step 3: Perform action At, gets \Rt+1 and St+1 [[step3-3]]
+
+Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
+
+
+
+
+## Step 3: Perform action At, gets \Rt+1 and St+1 [[step3-3]]
+
+Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
+
+ +
+## Step 4: Update Q(St, At) [[step4-4]]
+
+
+
+## Step 4: Update Q(St, At) [[step4-4]]
+
+ +
+Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
+
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
diff --git a/chapters/en/unit2/q-learning.mdx b/chapters/en/unit2/q-learning.mdx
new file mode 100644
index 0000000..8447e4c
--- /dev/null
+++ b/chapters/en/unit2/q-learning.mdx
@@ -0,0 +1,153 @@
+# Introducing Q-Learning [[q-learning]]
+## What is Q-Learning? [[what-is-q-learning]]
+
+Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
+
+- *Off-policy*: we'll talk about that at the end of this chapter.
+- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
+- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
+
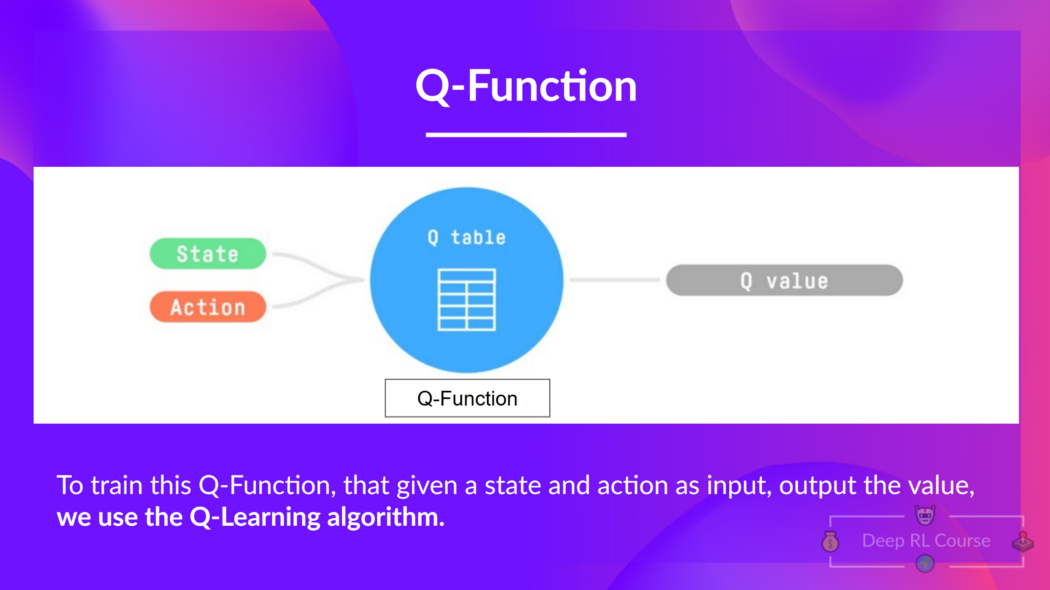
+**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+
+Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
+
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
diff --git a/chapters/en/unit2/q-learning.mdx b/chapters/en/unit2/q-learning.mdx
new file mode 100644
index 0000000..8447e4c
--- /dev/null
+++ b/chapters/en/unit2/q-learning.mdx
@@ -0,0 +1,153 @@
+# Introducing Q-Learning [[q-learning]]
+## What is Q-Learning? [[what-is-q-learning]]
+
+Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
+
+- *Off-policy*: we'll talk about that at the end of this chapter.
+- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
+- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
+
+**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+ +
+  +
+The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
+
+
+
+The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
+
+ +
+Here we see that the **state-action value of the initial state and going up is 0:**
+
+
+
+Here we see that the **state-action value of the initial state and going up is 0:**
+
+ +
+Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
+
+
+
+Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
+
+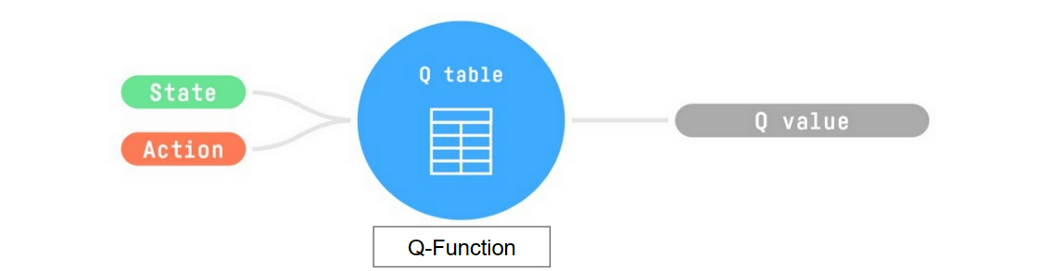 +
+  +
+
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
+
+
+
+
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
+
+ +
+  +
+### Step 1: We initialize the Q-Table [[step1]]
+
+
+
+### Step 1: We initialize the Q-Table [[step1]]
+
+ +
+
+We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
+
+### Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+
+
+
+We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
+
+### Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+ +
+
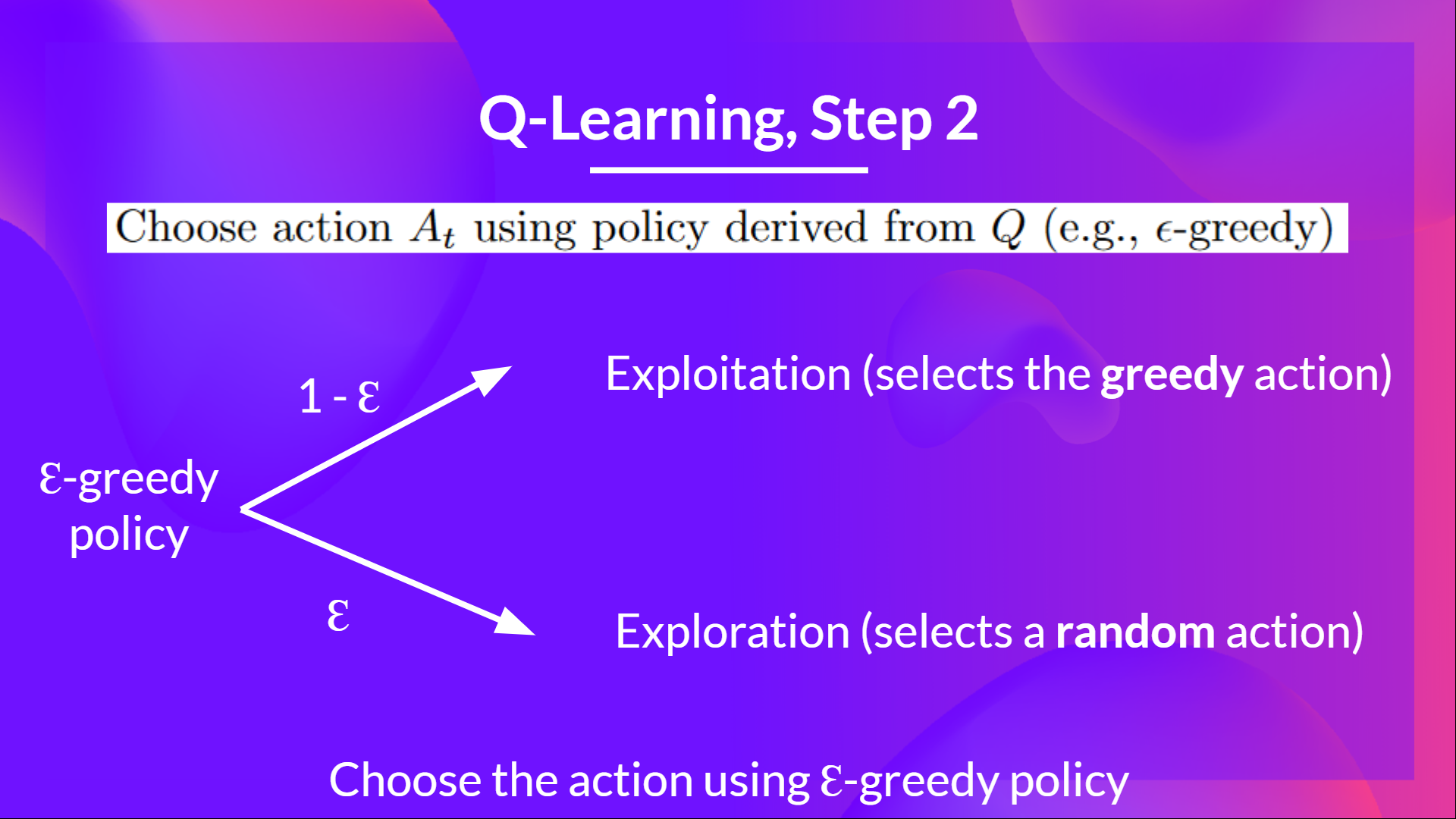
+Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
+
+The idea is that we define epsilon ɛ = 1.0:
+
+- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
+- With probability ɛ: **we do exploration** (trying random action).
+
+At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
+
+
+
+
+Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
+
+The idea is that we define epsilon ɛ = 1.0:
+
+- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
+- With probability ɛ: **we do exploration** (trying random action).
+
+At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
+
+ +
+
+### Step 3: Perform action At, gets reward Rt+1 and next state St+1 [[step3]]
+
+
+
+
+### Step 3: Perform action At, gets reward Rt+1 and next state St+1 [[step3]]
+
+ +
+### Step 4: Update Q(St, At) [[step4]]
+
+Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
+
+To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
+
+
+
+### Step 4: Update Q(St, At) [[step4]]
+
+Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
+
+To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
+
+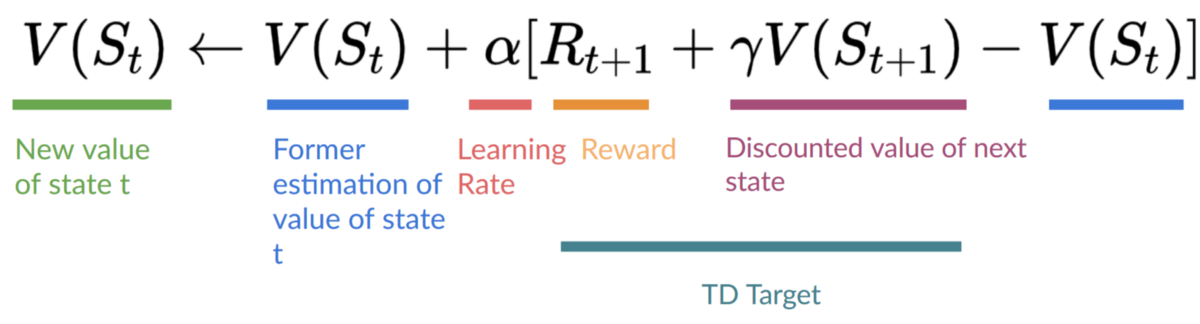 +
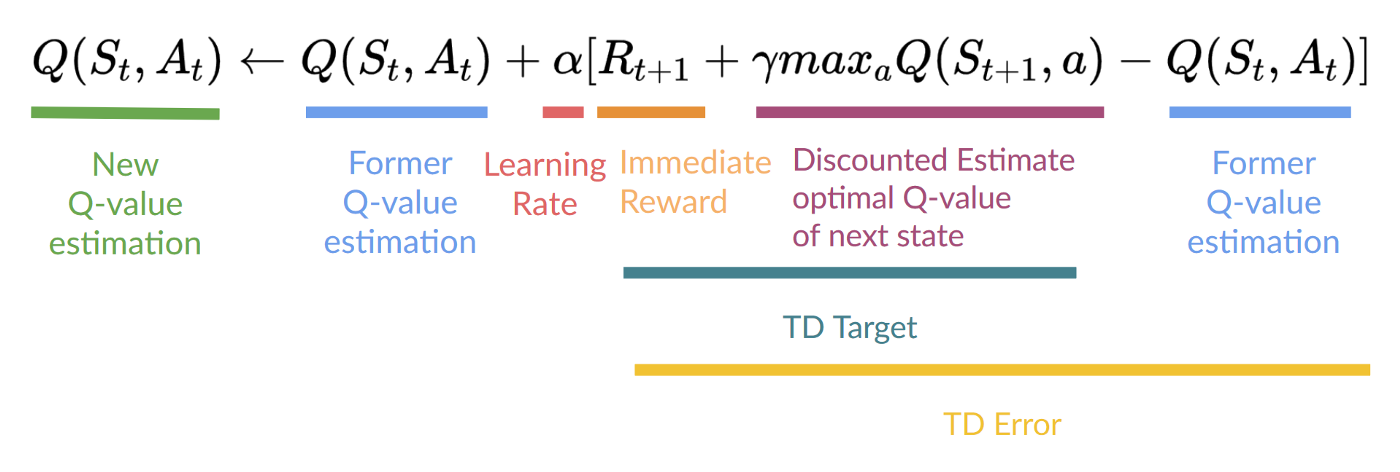
+Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
+
+
+
+Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
+
+ +
+
+It means that to update our \\(Q(S_t, A_t)\\):
+
+- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
+- To update our Q-value at a given state-action pair, we use the TD target.
+
+How do we form the TD target?
+1. We obtain the reward after taking the action \\(R_{t+1}\\).
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+
+Then when the update of this Q-value is done. We start in a new_state and select our action **using our epsilon-greedy policy again.**
+
+**It's why we say that this is an off-policy algorithm.**
+
+## Off-policy vs On-policy [[off-vs-on]]
+
+The difference is subtle:
+
+- *Off-policy*: using **a different policy for acting and updating.**
+
+For instance, with Q-Learning, the Epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+
+
+
+
+
+It means that to update our \\(Q(S_t, A_t)\\):
+
+- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
+- To update our Q-value at a given state-action pair, we use the TD target.
+
+How do we form the TD target?
+1. We obtain the reward after taking the action \\(R_{t+1}\\).
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+
+Then when the update of this Q-value is done. We start in a new_state and select our action **using our epsilon-greedy policy again.**
+
+**It's why we say that this is an off-policy algorithm.**
+
+## Off-policy vs On-policy [[off-vs-on]]
+
+The difference is subtle:
+
+- *Off-policy*: using **a different policy for acting and updating.**
+
+For instance, with Q-Learning, the Epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+
+
+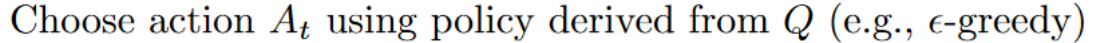 +
+ 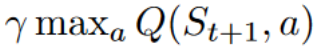 +
+  +
+  +
+
+
+
+### Q3: Define each part of the Bellman Equation
+
+Solution
+ +**The Bellman equation is a recursive equation** that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as: + +Rt+1 + (gamma * V(St+1)) +The immediate reward + the discounted value of the state that follows + + +
+
+
+
+
+
+
+
+
+
+### Q4: What is the difference between Monte Carlo and Temporal Difference learning methods?
+
+Solution
+ +
+
+ +
+
+
+
+
+
+
+
+
+### Q6: Define each part of Monte Carlo learning formula
+
+Solution
+ +
+
+ +
+
+
+
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/chapters/en/unit2/quiz2.mdx b/chapters/en/unit2/quiz2.mdx
new file mode 100644
index 0000000..73fe187
--- /dev/null
+++ b/chapters/en/unit2/quiz2.mdx
@@ -0,0 +1,97 @@
+# Second Quiz [[quiz2]]
+
+The best way to learn and [to avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: What is Q-Learning?
+
+
+Solution
+ +
+
+
+
+
+
+
+### Q4: Can you explain what is Epsilon-Greedy Strategy?
+
+Solution
+ +Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take. + +
+
+
+
+
+
+
+
+### Q5: How do we update the Q value of a state, action pair?
+Solution
+Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off. + +The idea is that we define epsilon ɛ = 1.0: + +- With *probability 1 — ɛ* : we do exploitation (aka our agent selects the action with the highest state-action pair value). +- With *probability ɛ* : we do exploration (trying random action). + +
+
+
+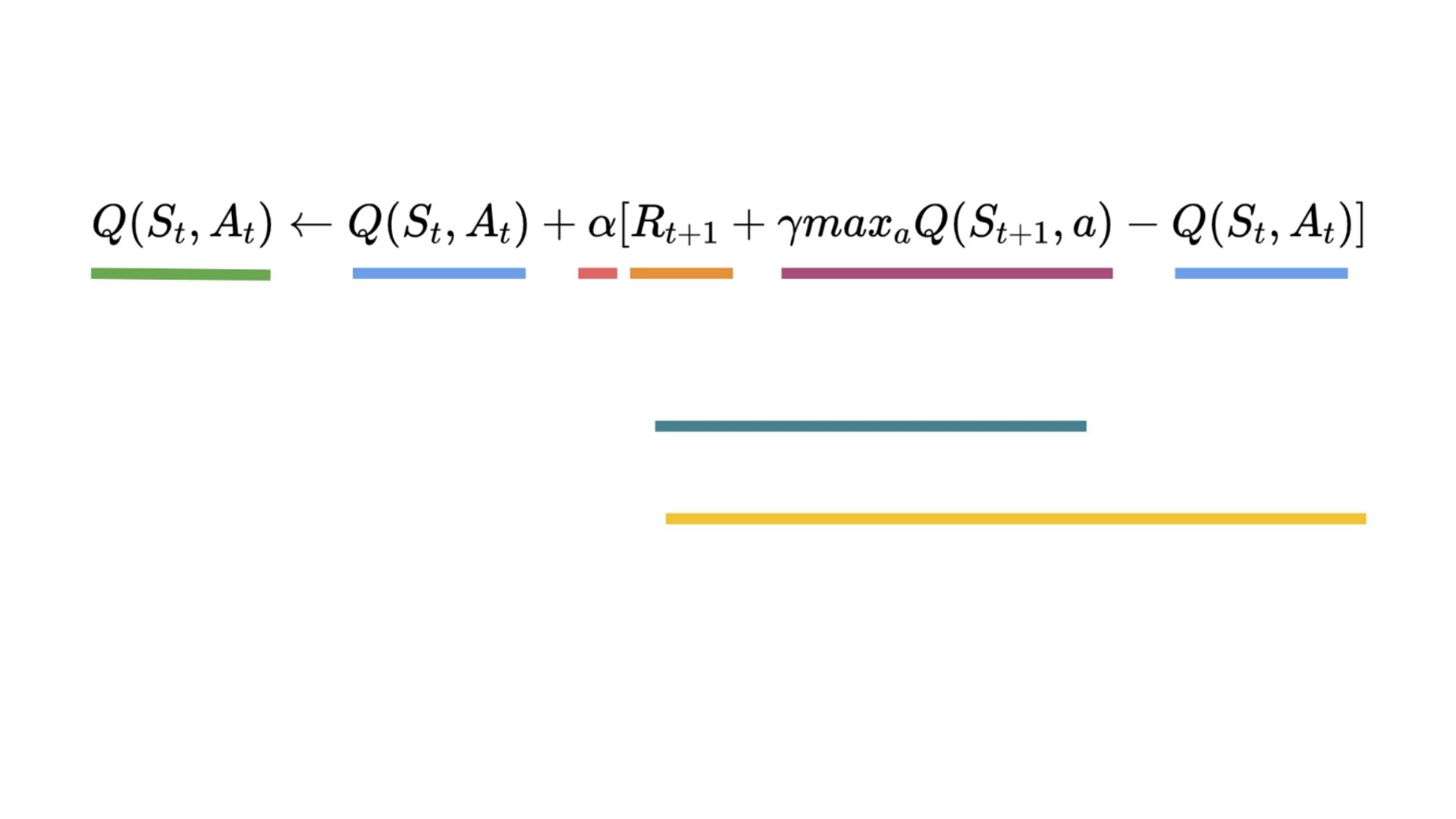 +
+
+
+
+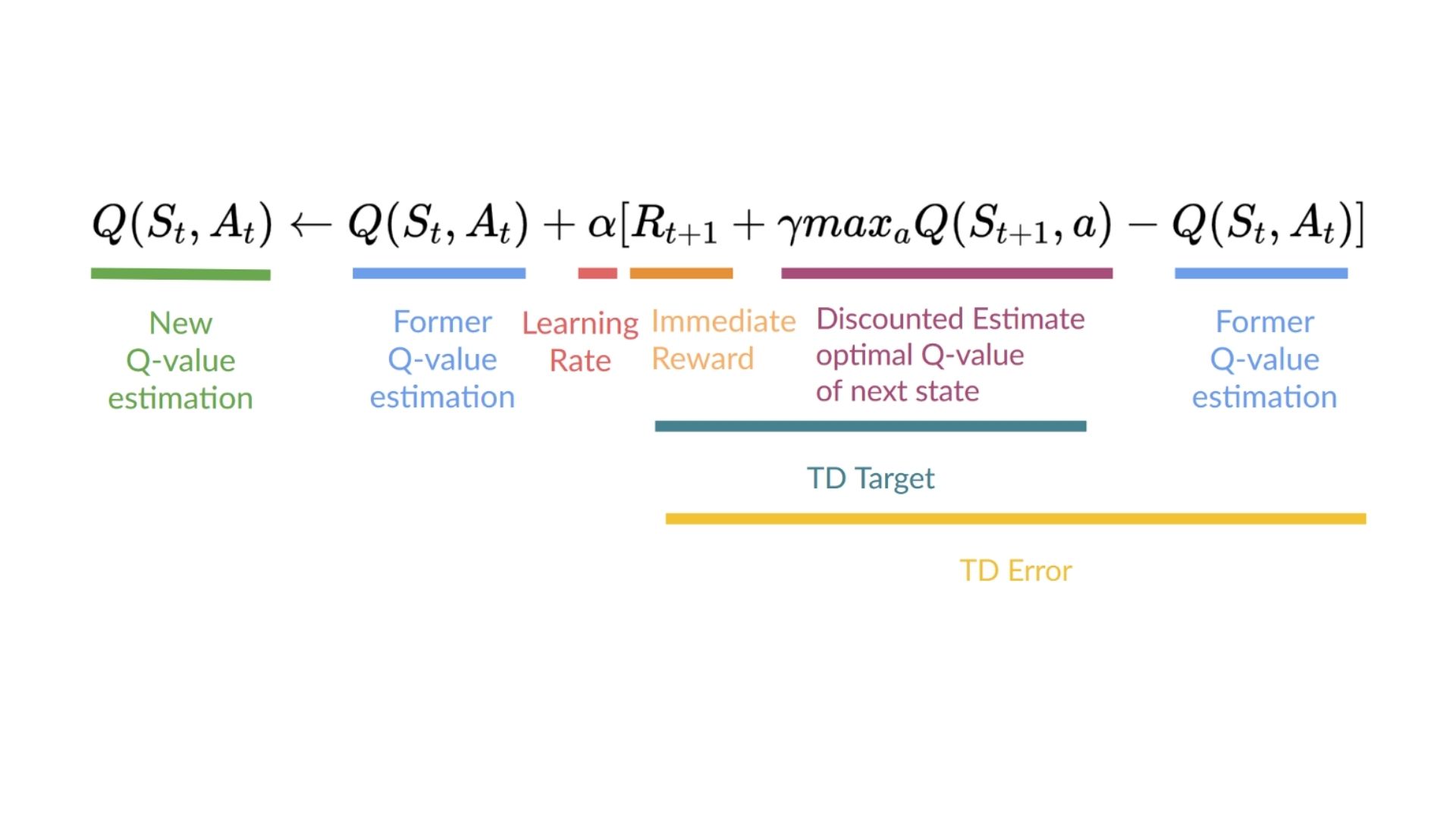 +
+
+
+
+
+
+
+### Q6: What's the difference between on-policy and off-policy
+
+Solution
+
+
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/chapters/en/unit2/summary1.mdx b/chapters/en/unit2/summary1.mdx
new file mode 100644
index 0000000..3a19d86
--- /dev/null
+++ b/chapters/en/unit2/summary1.mdx
@@ -0,0 +1,17 @@
+# Summary [[summary1]]
+
+Before diving on Q-Learning, let's summarize what we just learned.
+
+We have two types of value-based functions:
+
+- State-Value function: outputs the expected return if **the agent starts at a given state and acts accordingly to the policy forever after.**
+- Action-Value function: outputs the expected return if **the agent starts in a given state, takes a given action at that state** and then acts accordingly to the policy forever after.
+- In value-based methods, **we define the policy by hand** because we don't train it, we train a value function. The idea is that if we have an optimal value function, we **will have an optimal policy.**
+
+There are two types of methods to learn a policy for a value function:
+
+- With *the Monte Carlo method*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+- With *the TD Learning method,* we update the value function from a step, so we replace Gt that we don't have with **an estimated return called TD target.**
+
+
+Solution
+
+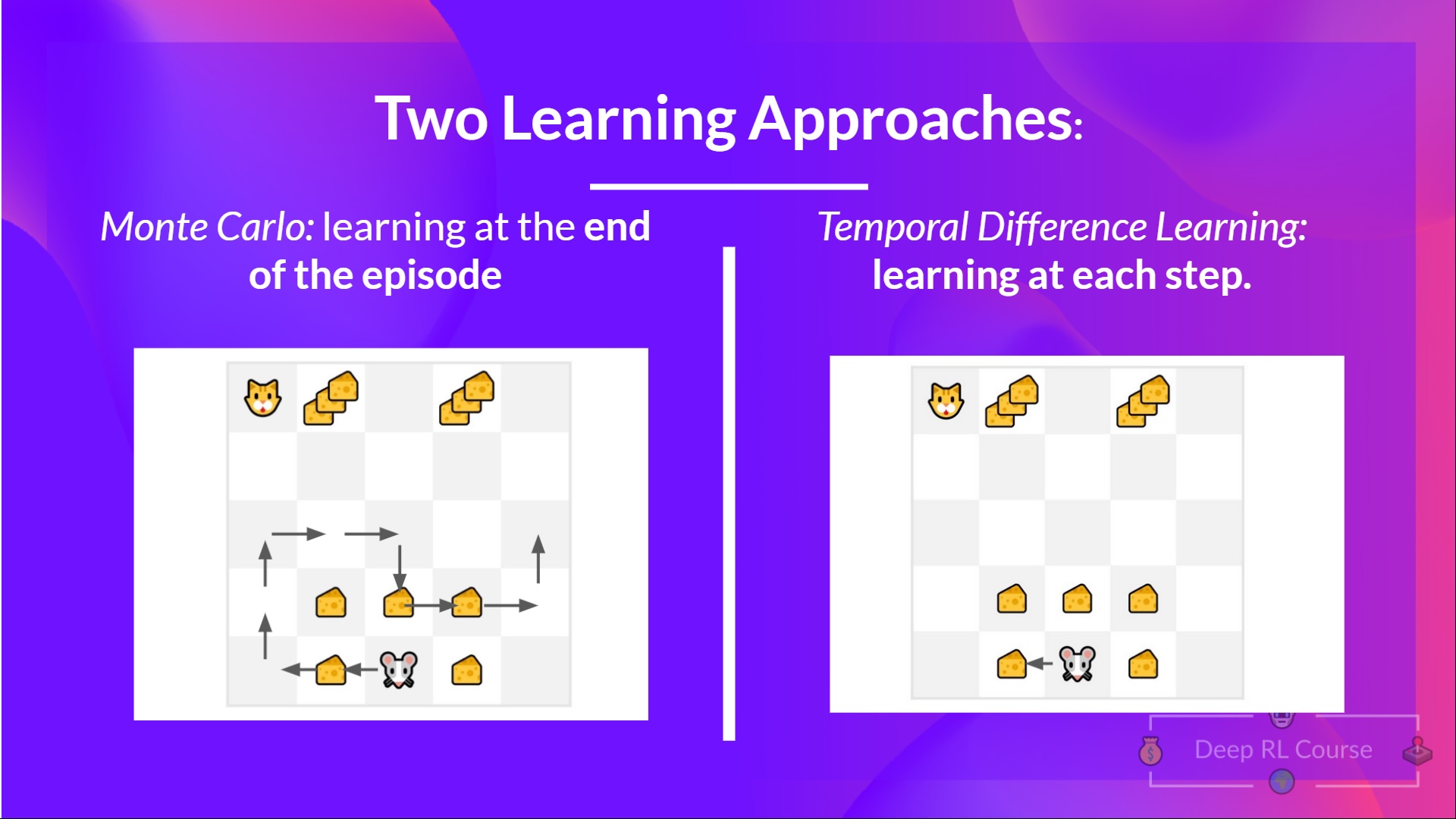 diff --git a/chapters/en/unit2/two-types-value-based-methods.mdx b/chapters/en/unit2/two-types-value-based-methods.mdx
new file mode 100644
index 0000000..5cf12da
--- /dev/null
+++ b/chapters/en/unit2/two-types-value-based-methods.mdx
@@ -0,0 +1,86 @@
+# The two types of value-based methods [[two-types-value-based-methods]]
+
+In value-based methods, **we learn a value function** that **maps a state to the expected value of being at that state.**
+
+
diff --git a/chapters/en/unit2/two-types-value-based-methods.mdx b/chapters/en/unit2/two-types-value-based-methods.mdx
new file mode 100644
index 0000000..5cf12da
--- /dev/null
+++ b/chapters/en/unit2/two-types-value-based-methods.mdx
@@ -0,0 +1,86 @@
+# The two types of value-based methods [[two-types-value-based-methods]]
+
+In value-based methods, **we learn a value function** that **maps a state to the expected value of being at that state.**
+
+ +
+The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
+
+
+
+The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
+
+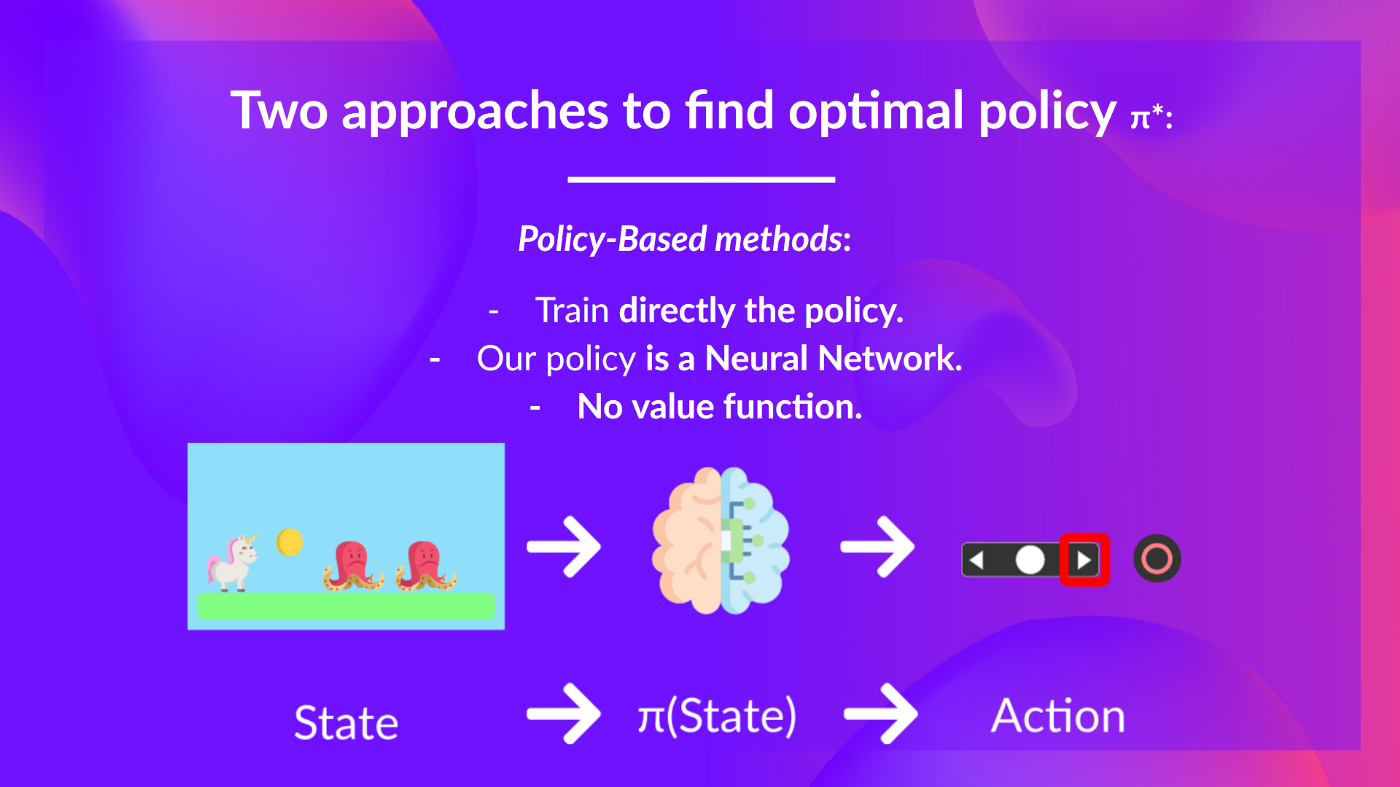 +
+The policy takes a state as input and outputs what action to take at that state (deterministic policy).
+
+And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
+
+- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take action.**
+
+But, because we didn't train our policy, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
+
+
+
+The policy takes a state as input and outputs what action to take at that state (deterministic policy).
+
+And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
+
+- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take action.**
+
+But, because we didn't train our policy, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
+
+ +
+
+In fact, most of the time, in value-based methods, you'll use **an Epsilon-Greedy Policy** that handles the exploration/exploitation trade-off; we'll talk about it when we talk about Q-Learning in the second part of this unit.
+
+
+So, we have two types of value-based functions:
+
+## The State-Value function [[state-value-function]]
+
+We write the state value function under a policy π like this:
+
+
+
+
+In fact, most of the time, in value-based methods, you'll use **an Epsilon-Greedy Policy** that handles the exploration/exploitation trade-off; we'll talk about it when we talk about Q-Learning in the second part of this unit.
+
+
+So, we have two types of value-based functions:
+
+## The State-Value function [[state-value-function]]
+
+We write the state value function under a policy π like this:
+
+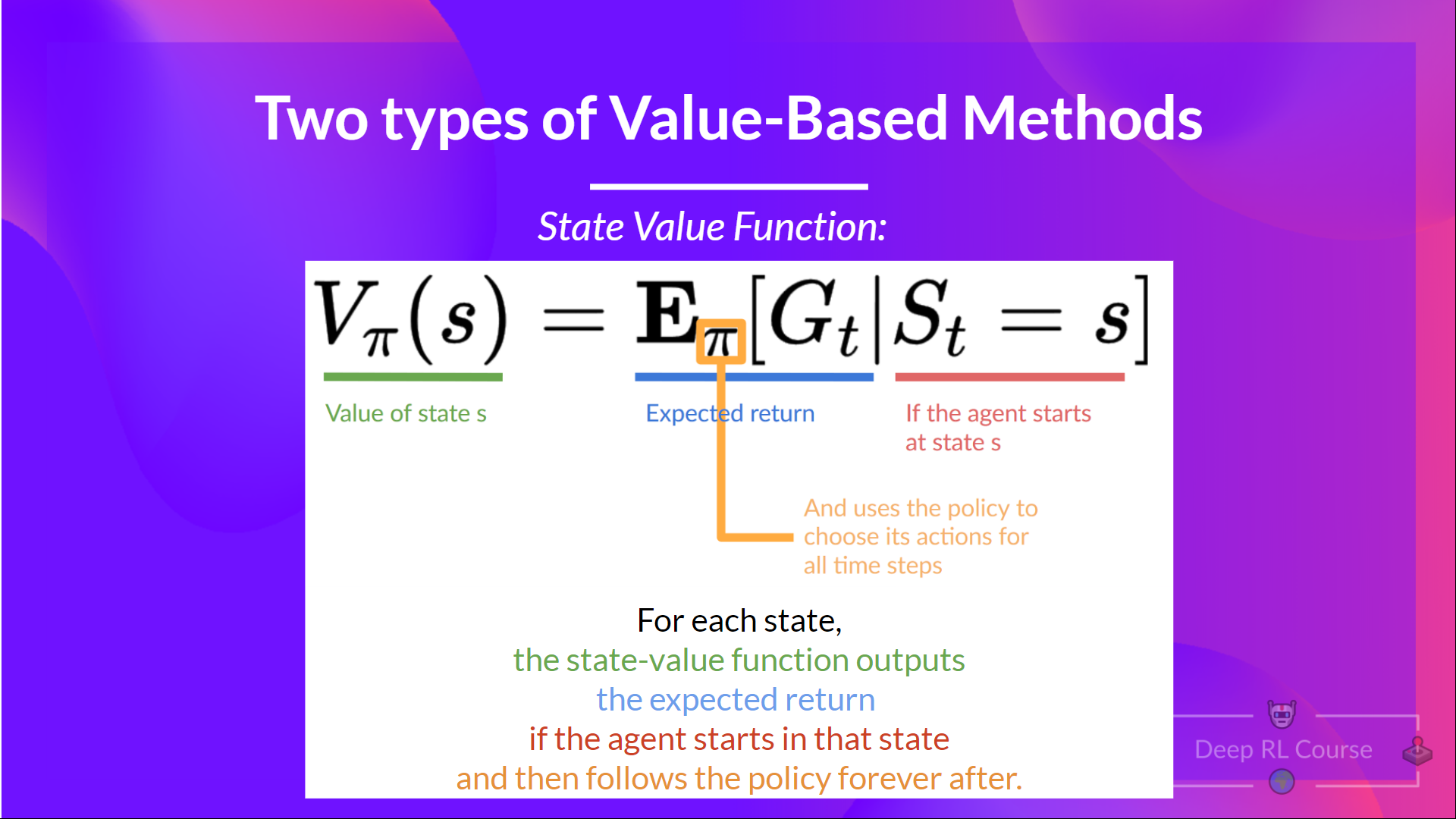 +
+For each state, the state-value function outputs the expected return if the agent **starts at that state,** and then follow the policy forever after (for all future timesteps if you prefer).
+
+
+
+For each state, the state-value function outputs the expected return if the agent **starts at that state,** and then follow the policy forever after (for all future timesteps if you prefer).
+
+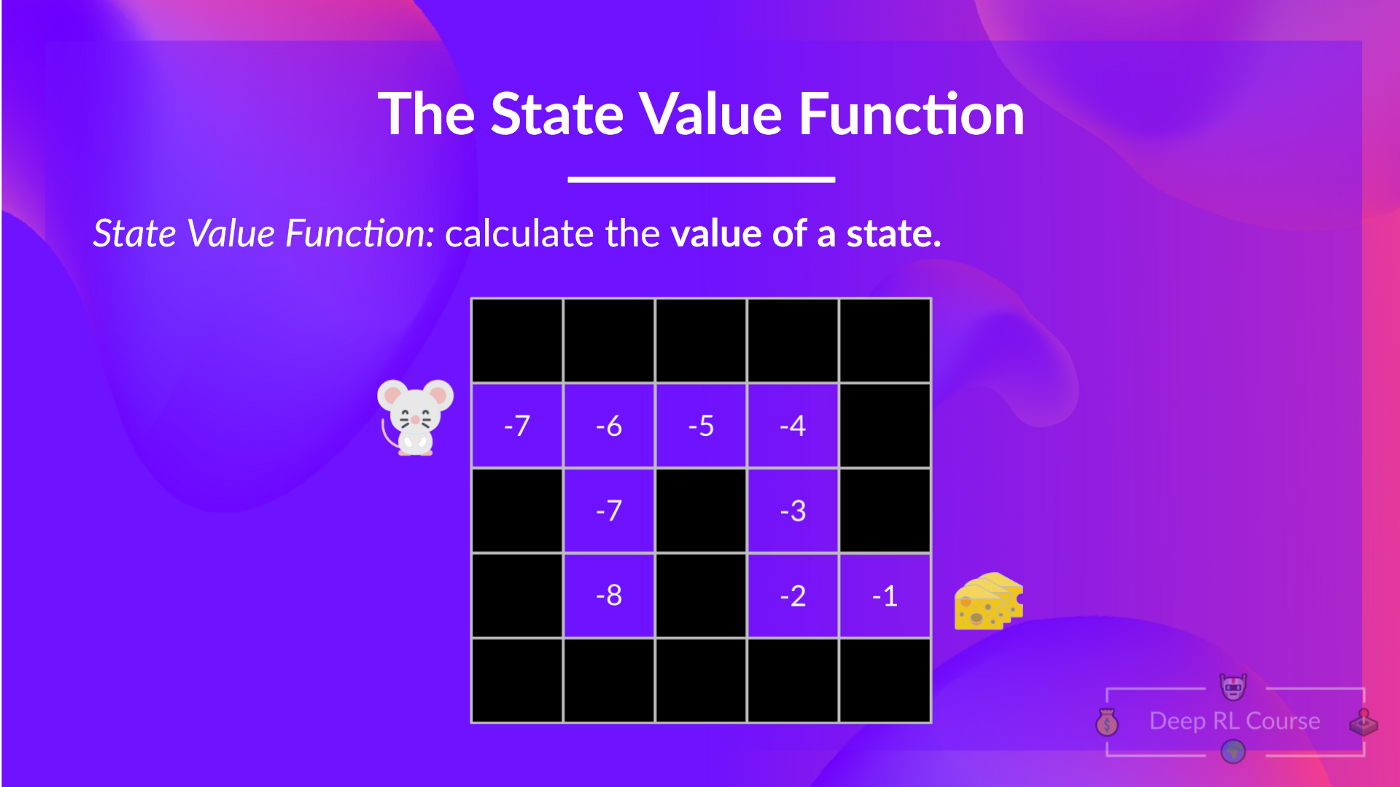 +
+  +
+ +
+
+We see that the difference is:
+
+- In state-value function, we calculate **the value of a state \\(S_t\\)**
+- In action-value function, we calculate **the value of the state-action pair ( \\(S_t, A_t\\) ) hence the value of taking that action at that state.**
+
+
+
+
+We see that the difference is:
+
+- In state-value function, we calculate **the value of a state \\(S_t\\)**
+- In action-value function, we calculate **the value of the state-action pair ( \\(S_t, A_t\\) ) hence the value of taking that action at that state.**
+
+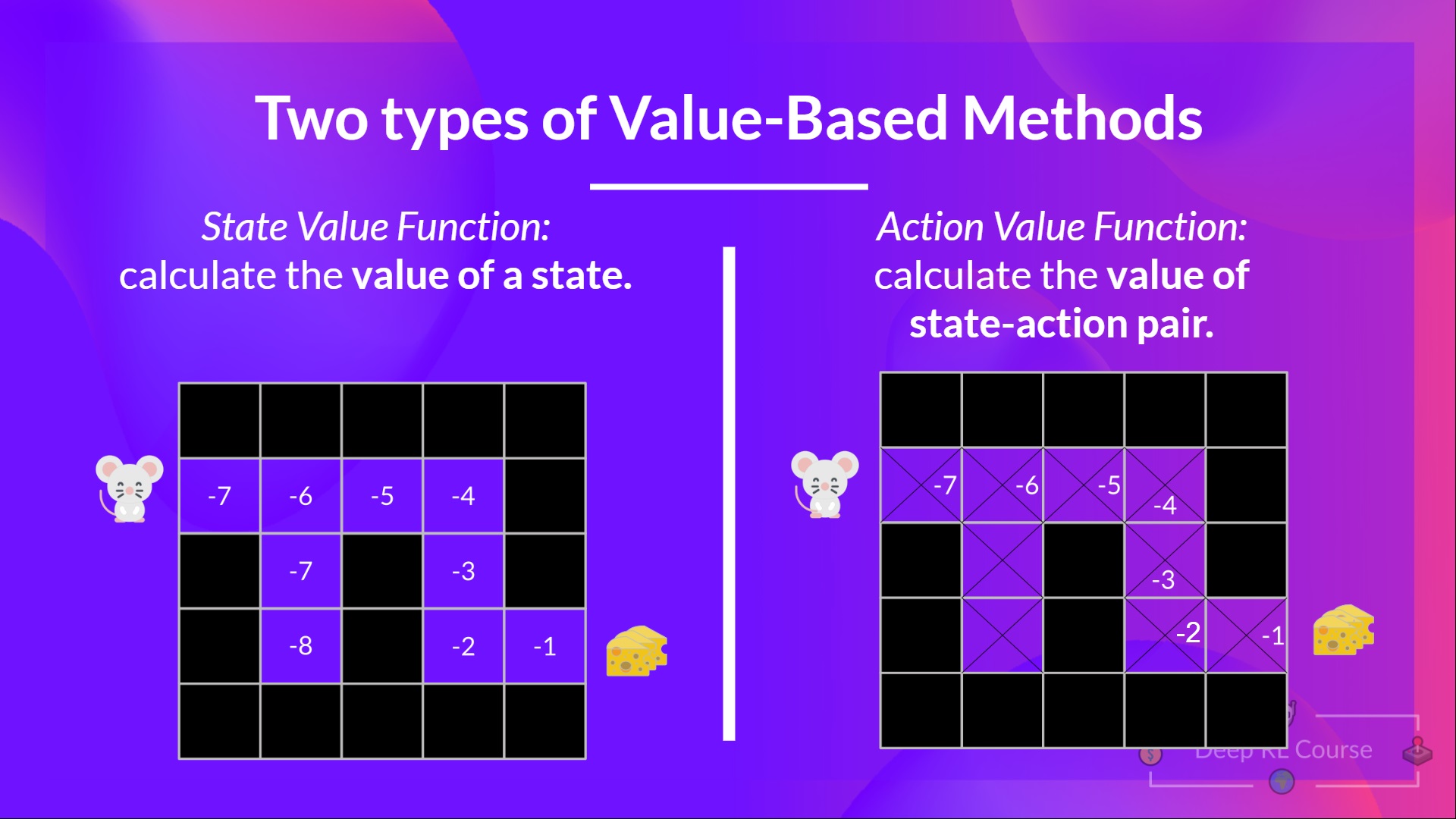 +
+ 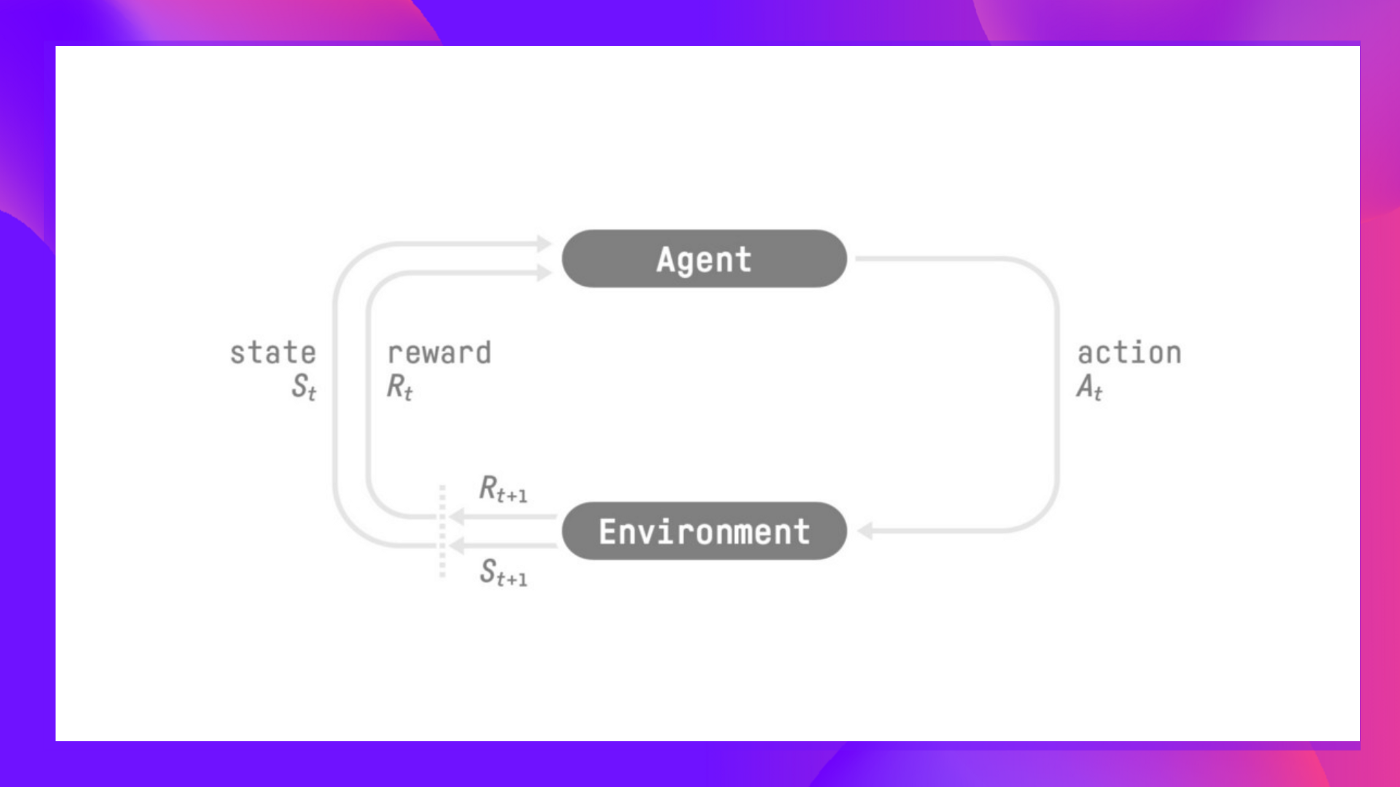 +
+
+But, to make intelligent decisions, our agent will learn from the environment by **interacting with it through trial and error** and receiving rewards (positive or negative) **as unique feedback.**
+
+Its goal **is to maximize its expected cumulative reward** (because of the reward hypothesis).
+
+**The agent's decision-making process is called the policy π:** given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
+
+
+
+
+But, to make intelligent decisions, our agent will learn from the environment by **interacting with it through trial and error** and receiving rewards (positive or negative) **as unique feedback.**
+
+Its goal **is to maximize its expected cumulative reward** (because of the reward hypothesis).
+
+**The agent's decision-making process is called the policy π:** given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
+
+ +
+**Our goal is to find an optimal policy π* **, aka., a policy that leads to the best expected cumulative reward.
+
+And to find this optimal policy (hence solving the RL problem), there **are two main types of RL methods**:
+
+- *Policy-based methods*: **Train the policy directly** to learn which action to take given a state.
+- *Value-based methods*: **Train a value function** to learn **which state is more valuable** and use this value function **to take the action that leads to it.**
+
+
+
+**Our goal is to find an optimal policy π* **, aka., a policy that leads to the best expected cumulative reward.
+
+And to find this optimal policy (hence solving the RL problem), there **are two main types of RL methods**:
+
+- *Policy-based methods*: **Train the policy directly** to learn which action to take given a state.
+- *Value-based methods*: **Train a value function** to learn **which state is more valuable** and use this value function **to take the action that leads to it.**
+
+ +
+And in this unit, **we'll dive deeper into the Value-based methods.**
diff --git a/chapters/en/unit3/additional-reading.mdx b/chapters/en/unit3/additional-reading.mdx
new file mode 100644
index 0000000..46a60ee
--- /dev/null
+++ b/chapters/en/unit3/additional-reading.mdx
@@ -0,0 +1 @@
+# Additional Reading [[additional-reading]]
diff --git a/chapters/en/unit3/conclusion.mdx b/chapters/en/unit3/conclusion.mdx
new file mode 100644
index 0000000..8a1f9a6
--- /dev/null
+++ b/chapters/en/unit3/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
+
+Take time to really grasp the material before continuing.
+
+Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
+
+In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+
+### Keep Learning, stay awesome 🤗
diff --git a/chapters/en/unit3/deep-q-algorithm.mdx b/chapters/en/unit3/deep-q-algorithm.mdx
new file mode 100644
index 0000000..cc6889a
--- /dev/null
+++ b/chapters/en/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,102 @@
+# The Deep Q-Learning Algorithm [[deep-q-algorithm]]
+
+We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
+
+The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
+
+
+
+In Deep Q-Learning, we create a **Loss function between our Q-value prediction and the Q-target and use Gradient Descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
+
+
+
+And in this unit, **we'll dive deeper into the Value-based methods.**
diff --git a/chapters/en/unit3/additional-reading.mdx b/chapters/en/unit3/additional-reading.mdx
new file mode 100644
index 0000000..46a60ee
--- /dev/null
+++ b/chapters/en/unit3/additional-reading.mdx
@@ -0,0 +1 @@
+# Additional Reading [[additional-reading]]
diff --git a/chapters/en/unit3/conclusion.mdx b/chapters/en/unit3/conclusion.mdx
new file mode 100644
index 0000000..8a1f9a6
--- /dev/null
+++ b/chapters/en/unit3/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
+
+Take time to really grasp the material before continuing.
+
+Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
+
+In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+
+### Keep Learning, stay awesome 🤗
diff --git a/chapters/en/unit3/deep-q-algorithm.mdx b/chapters/en/unit3/deep-q-algorithm.mdx
new file mode 100644
index 0000000..cc6889a
--- /dev/null
+++ b/chapters/en/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,102 @@
+# The Deep Q-Learning Algorithm [[deep-q-algorithm]]
+
+We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
+
+The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
+
+
+
+In Deep Q-Learning, we create a **Loss function between our Q-value prediction and the Q-target and use Gradient Descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
+
+ +
+The Deep Q-Learning training algorithm has *two phases*:
+
+- **Sampling**: we perform actions and **store the observed experiences tuples in a replay memory**.
+- **Training**: Select the **small batch of tuple randomly and learn from it using a gradient descent update step**.
+
+
+
+The Deep Q-Learning training algorithm has *two phases*:
+
+- **Sampling**: we perform actions and **store the observed experiences tuples in a replay memory**.
+- **Training**: Select the **small batch of tuple randomly and learn from it using a gradient descent update step**.
+
+ +
+But, this is not the only change compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
+
+To help us stabilize the training, we implement three different solutions:
+1. *Experience Replay*, to make more **efficient use of experiences**.
+2. *Fixed Q-Target* **to stabilize the training**.
+3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
+
+
+## Experience Replay to make more efficient use of experiences [[exp-replay]]
+
+Why do we create a replay memory?
+
+Experience Replay in Deep Q-Learning has two functions:
+
+1. **Make more efficient use of the experiences during the training**.
+- Experience replay helps us **make more efficient use of the experiences during the training.** Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
+- But with experience replay, we create a replay buffer that saves experience samples **that we can reuse during the training.**
+
+
+
+But, this is not the only change compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
+
+To help us stabilize the training, we implement three different solutions:
+1. *Experience Replay*, to make more **efficient use of experiences**.
+2. *Fixed Q-Target* **to stabilize the training**.
+3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
+
+
+## Experience Replay to make more efficient use of experiences [[exp-replay]]
+
+Why do we create a replay memory?
+
+Experience Replay in Deep Q-Learning has two functions:
+
+1. **Make more efficient use of the experiences during the training**.
+- Experience replay helps us **make more efficient use of the experiences during the training.** Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
+- But with experience replay, we create a replay buffer that saves experience samples **that we can reuse during the training.**
+
+ +
+⇒ This allows us to **learn from individual experiences multiple times**.
+
+2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
+- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it overwrites new experiences.** For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
+
+The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has immediately done.**
+
+Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
+
+In the Deep Q-Learning pseudocode, we see that we **initialize a replay memory buffer D from capacity N** (N is an hyperparameter that you can define). We then store experiences in the memory and sample a minibatch of experiences to feed the Deep Q-Network during the training phase.
+
+
+
+⇒ This allows us to **learn from individual experiences multiple times**.
+
+2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
+- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it overwrites new experiences.** For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
+
+The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has immediately done.**
+
+Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
+
+In the Deep Q-Learning pseudocode, we see that we **initialize a replay memory buffer D from capacity N** (N is an hyperparameter that you can define). We then store experiences in the memory and sample a minibatch of experiences to feed the Deep Q-Network during the training phase.
+
+ +
+## Fixed Q-Target to stabilize the training [[fixed-q]]
+
+When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
+
+But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
+
+
+
+However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
+
+Therefore, it means that at every step of training, **our Q values shift but also the target value shifts.** So, we’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This led to a significant oscillation in training.
+
+It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target), you must get closer (reduce the error).
+
+
+
+## Fixed Q-Target to stabilize the training [[fixed-q]]
+
+When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
+
+But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
+
+
+
+However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
+
+Therefore, it means that at every step of training, **our Q values shift but also the target value shifts.** So, we’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This led to a significant oscillation in training.
+
+It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target), you must get closer (reduce the error).
+
+ +
+At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
+
+
+
+At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
+
+ +
+ +This leads to a bizarre path of chasing (a significant oscillation in training).
+
+This leads to a bizarre path of chasing (a significant oscillation in training).
+ +
+Instead, what we see in the pseudo-code is that we:
+- Use a **separate network with a fixed parameter** for estimating the TD Target
+- **Copy the parameters from our Deep Q-Network at every C step** to update the target network.
+
+
+
+Instead, what we see in the pseudo-code is that we:
+- Use a **separate network with a fixed parameter** for estimating the TD Target
+- **Copy the parameters from our Deep Q-Network at every C step** to update the target network.
+
+ +
+
+
+## Double DQN [[double-dqn]]
+
+Double DQNs, or Double Learning, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
+
+To understand this problem, remember how we calculate the TD Target:
+
+We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
+
+We know that the accuracy of Q values depends on what action we tried **and** what neighboring states we explored.
+
+Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
+
+The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
+- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q value).
+- Use our **Target network** to calculate the target Q value of taking that action at the next state.
+
+Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
+
+Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list. TODO Add reading list
diff --git a/chapters/en/unit3/deep-q-network.mdx b/chapters/en/unit3/deep-q-network.mdx
new file mode 100644
index 0000000..6e24a3a
--- /dev/null
+++ b/chapters/en/unit3/deep-q-network.mdx
@@ -0,0 +1,39 @@
+# The Deep Q-Network (DQN) [[deep-q-network]]
+This is the architecture of our Deep Q-Learning network:
+
+
+
+
+
+## Double DQN [[double-dqn]]
+
+Double DQNs, or Double Learning, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
+
+To understand this problem, remember how we calculate the TD Target:
+
+We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
+
+We know that the accuracy of Q values depends on what action we tried **and** what neighboring states we explored.
+
+Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
+
+The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
+- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q value).
+- Use our **Target network** to calculate the target Q value of taking that action at the next state.
+
+Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
+
+Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list. TODO Add reading list
diff --git a/chapters/en/unit3/deep-q-network.mdx b/chapters/en/unit3/deep-q-network.mdx
new file mode 100644
index 0000000..6e24a3a
--- /dev/null
+++ b/chapters/en/unit3/deep-q-network.mdx
@@ -0,0 +1,39 @@
+# The Deep Q-Network (DQN) [[deep-q-network]]
+This is the architecture of our Deep Q-Learning network:
+
+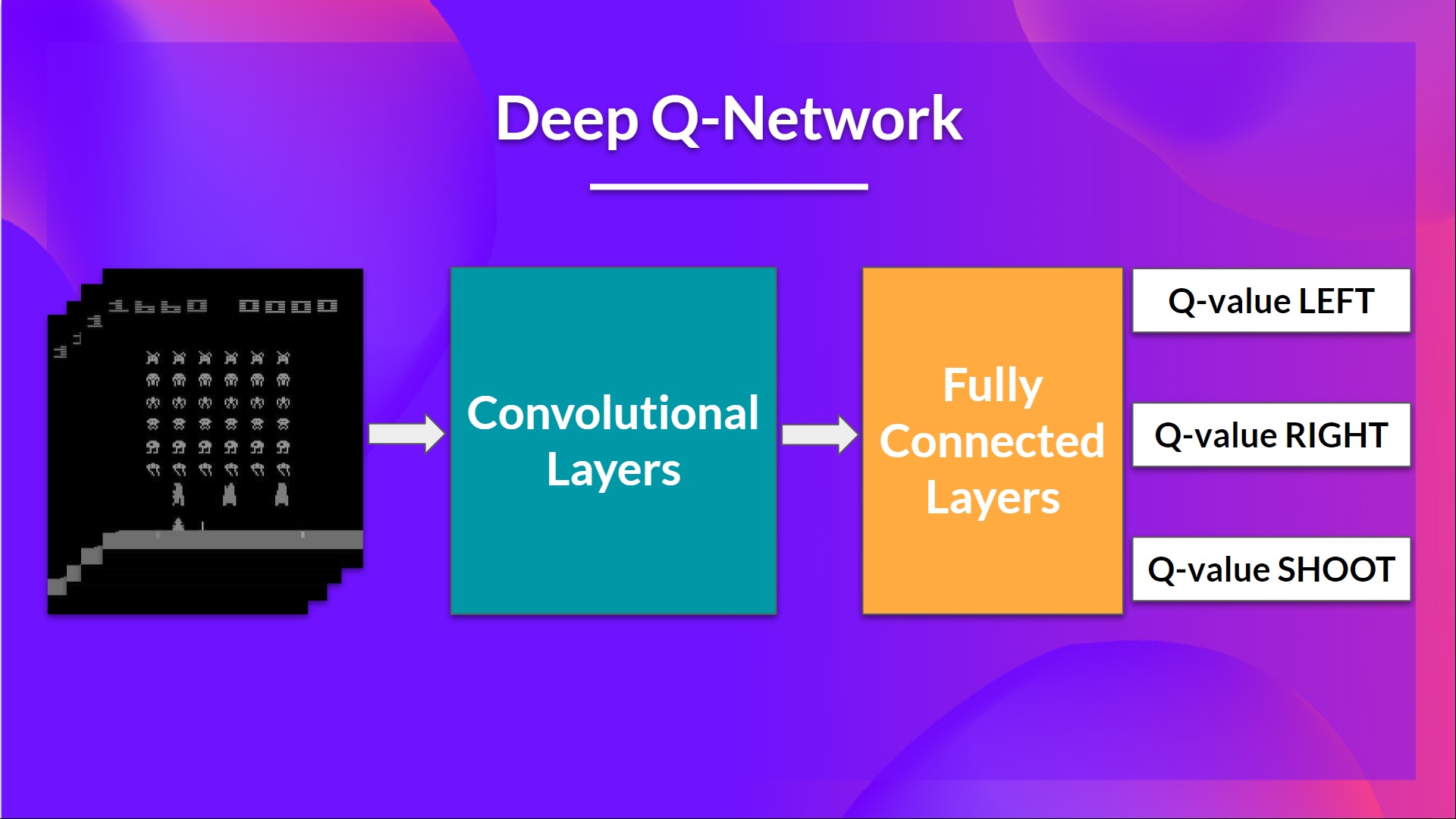 +
+As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
+
+When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with appropriate action and **learn to play the game well**.
+
+## Preprocessing the input and temporal limitation [[preprocessing]]
+
+We mentioned that we preprocess the input. It’s an essential step since we want to **reduce the complexity of our state to reduce the computation time needed for training**.
+
+So what we do is **reduce the state space to 84x84 and grayscale it** (since the colors in Atari environments don't add important information).
+This is an essential saving since we **reduce our three color channels (RGB) to 1**.
+
+We can also **crop a part of the screen in some games** if it does not contain important information.
+Then we stack four frames together.
+
+
+
+As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
+
+When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with appropriate action and **learn to play the game well**.
+
+## Preprocessing the input and temporal limitation [[preprocessing]]
+
+We mentioned that we preprocess the input. It’s an essential step since we want to **reduce the complexity of our state to reduce the computation time needed for training**.
+
+So what we do is **reduce the state space to 84x84 and grayscale it** (since the colors in Atari environments don't add important information).
+This is an essential saving since we **reduce our three color channels (RGB) to 1**.
+
+We can also **crop a part of the screen in some games** if it does not contain important information.
+Then we stack four frames together.
+
+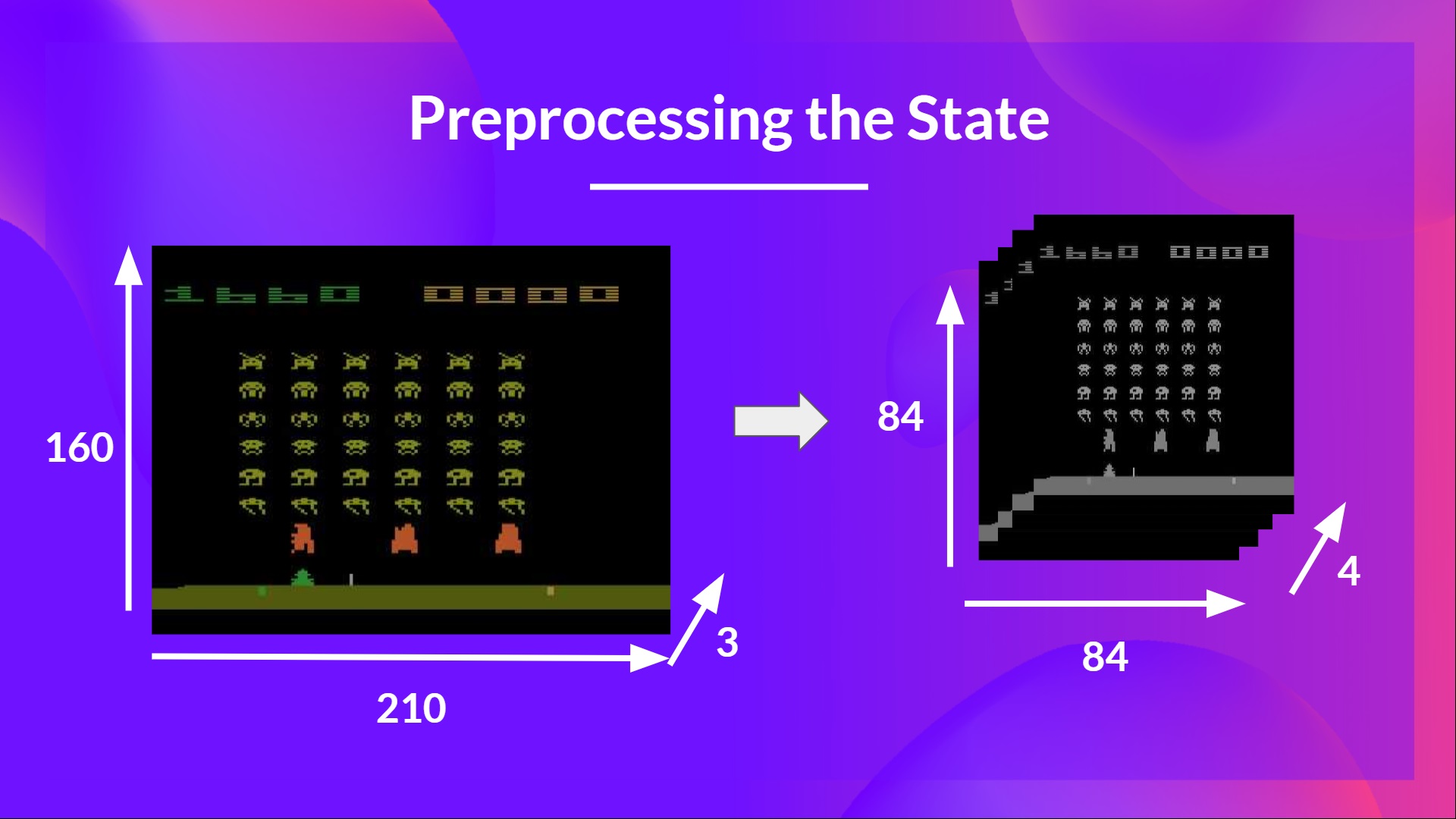 +
+Why do we stack four frames together?
+We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
+
+
+
+Why do we stack four frames together?
+We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
+
+ +
+Can you tell me where the ball is going?
+No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
+
+
+
+Can you tell me where the ball is going?
+No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
+
+ +That’s why, to capture temporal information, we stack four frames together.
+
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+
+Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
+
+
+
+So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
diff --git a/chapters/en/unit3/from-q-to-dqn.mdx b/chapters/en/unit3/from-q-to-dqn.mdx
new file mode 100644
index 0000000..b65ca0f
--- /dev/null
+++ b/chapters/en/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,34 @@
+# From Q-Learning to Deep Q-Learning [[from-q-to-dqn]]
+
+We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+
+That’s why, to capture temporal information, we stack four frames together.
+
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+
+Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
+
+
+
+So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
diff --git a/chapters/en/unit3/from-q-to-dqn.mdx b/chapters/en/unit3/from-q-to-dqn.mdx
new file mode 100644
index 0000000..b65ca0f
--- /dev/null
+++ b/chapters/en/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,34 @@
+# From Q-Learning to Deep Q-Learning [[from-q-to-dqn]]
+
+We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+ 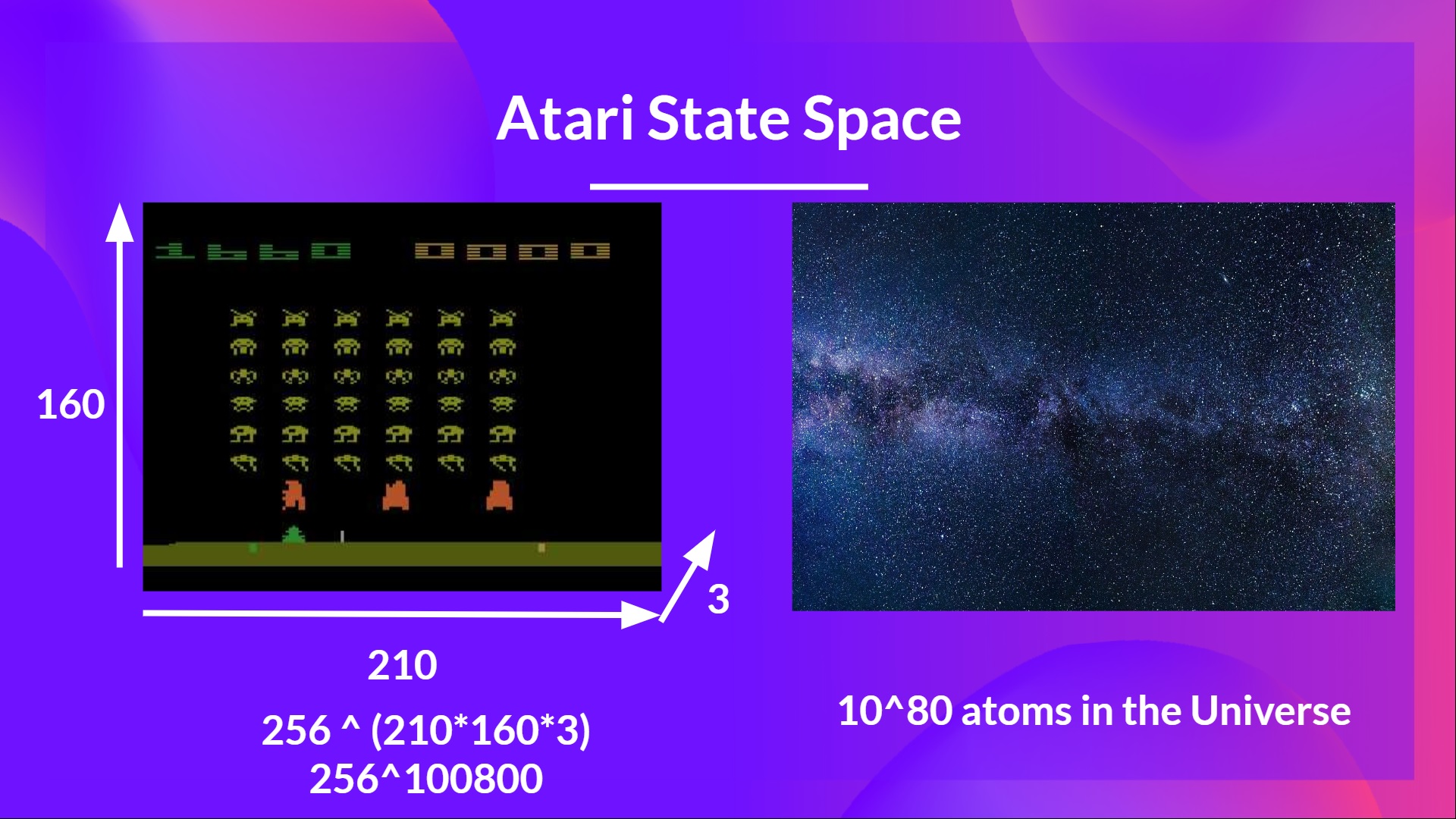 +
+Therefore, the state space is gigantic; hence creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values instead of a Q-table using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
+
+This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
+
+
+
+
+Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
diff --git a/chapters/en/unit3/hands-on.mdx b/chapters/en/unit3/hands-on.mdx
new file mode 100644
index 0000000..ef7c709
--- /dev/null
+++ b/chapters/en/unit3/hands-on.mdx
@@ -0,0 +1 @@
+# Hands-on [[hands-on]]
diff --git a/chapters/en/unit3/introduction.mdx b/chapters/en/unit3/introduction.mdx
new file mode 100644
index 0000000..3752bc8
--- /dev/null
+++ b/chapters/en/unit3/introduction.mdx
@@ -0,0 +1,15 @@
+# Deep Q-Learning [[deep-q-learning]]
+
+In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
+
+We got excellent results with this simple algorithm. But these environments were relatively simple because the **State Space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3).
+
+But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
+
+So in this unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning. Instead of using a Q-table, Deep Q-Learning uses a Neural Network that takes a state and approximates Q-values for each action based on that state.
+
+And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
+
+
+
+So let’s get started! 🚀
diff --git a/chapters/en/unit3/quiz.mdx b/chapters/en/unit3/quiz.mdx
new file mode 100644
index 0000000..bde7e78
--- /dev/null
+++ b/chapters/en/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What are tabular methods?
+
+
+
+Therefore, the state space is gigantic; hence creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values instead of a Q-table using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
+
+This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
+
+
+
+
+Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
diff --git a/chapters/en/unit3/hands-on.mdx b/chapters/en/unit3/hands-on.mdx
new file mode 100644
index 0000000..ef7c709
--- /dev/null
+++ b/chapters/en/unit3/hands-on.mdx
@@ -0,0 +1 @@
+# Hands-on [[hands-on]]
diff --git a/chapters/en/unit3/introduction.mdx b/chapters/en/unit3/introduction.mdx
new file mode 100644
index 0000000..3752bc8
--- /dev/null
+++ b/chapters/en/unit3/introduction.mdx
@@ -0,0 +1,15 @@
+# Deep Q-Learning [[deep-q-learning]]
+
+In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
+
+We got excellent results with this simple algorithm. But these environments were relatively simple because the **State Space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3).
+
+But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
+
+So in this unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning. Instead of using a Q-table, Deep Q-Learning uses a Neural Network that takes a state and approximates Q-values for each action based on that state.
+
+And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
+
+
+
+So let’s get started! 🚀
diff --git a/chapters/en/unit3/quiz.mdx b/chapters/en/unit3/quiz.mdx
new file mode 100644
index 0000000..bde7e78
--- /dev/null
+++ b/chapters/en/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What are tabular methods?
+
+
+
+
+### Q2: Why we can't use a classical Q-Learning to solve an Atari Game?
+
+Solution
+ +*Tabular methods* are a type of problems in which the state and actions spaces are small enough to approximate value functions to be **represented as arrays and tables**. For instance, **Q-Learning is a tabular method** since we use a table to represent the state,action value pairs. + + +
+
+
+
+
+
+
+
+### Q4: What are the two phases of Deep Q-Learning?
+
+Solution
+ +We stack frames together because it helps us **handle the problem of temporal limitation**. Since one frame is not enough to capture temporal information. +For instance, in pong, our agent **will be unable to know the ball direction if it gets only one frame**. + +
+
+
+
+
+
+
+### Q6: How do we use Double Deep Q-Learning?
+
+
+Solution
+ +**1. Make more efficient use of the experiences during the training** + +Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them. +But with experience replay, **we create a replay buffer that saves experience samples that we can reuse during the training**. + +**2. Avoid forgetting previous experiences and reduce the correlation between experiences** + + The problem we get if we give sequential samples of experiences to our neural network is that it **tends to forget the previous experiences as it overwrites new experiences**. For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level. + + +
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/chapters/en/unitbonus1/introduction.mdx b/chapters/en/unitbonus1/introduction.mdx
new file mode 100644
index 0000000..93600af
--- /dev/null
+++ b/chapters/en/unitbonus1/introduction.mdx
@@ -0,0 +1 @@
+# Introduction [[introduction]]
diff --git a/chapters/en/unitbonus2/hands-on.mdx b/chapters/en/unitbonus2/hands-on.mdx
new file mode 100644
index 0000000..ef7c709
--- /dev/null
+++ b/chapters/en/unitbonus2/hands-on.mdx
@@ -0,0 +1 @@
+# Hands-on [[hands-on]]
diff --git a/chapters/en/unitbonus2/introduction.mdx b/chapters/en/unitbonus2/introduction.mdx
new file mode 100644
index 0000000..e3bb200
--- /dev/null
+++ b/chapters/en/unitbonus2/introduction.mdx
@@ -0,0 +1,7 @@
+# Introduction [[introduction]]
+
+One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters.
+
+Solution
+ + When we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We: + + - Use our *DQN network* to **select the best action to take for the next state** (the action with the highest Q value). + + - Use our *Target network* to calculate **the target Q value of taking that action at the next state**. + +
-
-Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
-
-
-
-But then, **he presses right again** and he touches an enemy, he just died -1 reward.
-
-
-
-By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
-
-**Without any supervision**, the child will get better and better at playing the game.
-
-That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from action.**
-
-### A formal definition [[formal-definition]]
-
-If we take now a formal definition:
-
-
-
-
-
-
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- Environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
-
-This RL loop outputs a sequence of **state, action, reward and next state.**
-
- -
- -
- -
- -
-
-
- -
- -
-
-
- -
- -
- -
- -
-
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-
-
- -
- -
- -
- -
- -
- -
- -
-