diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index 4f3d8a8..e6459c2 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -11,17 +11,13 @@ In other terms, how to build an RL agent that can **select the actions that ma
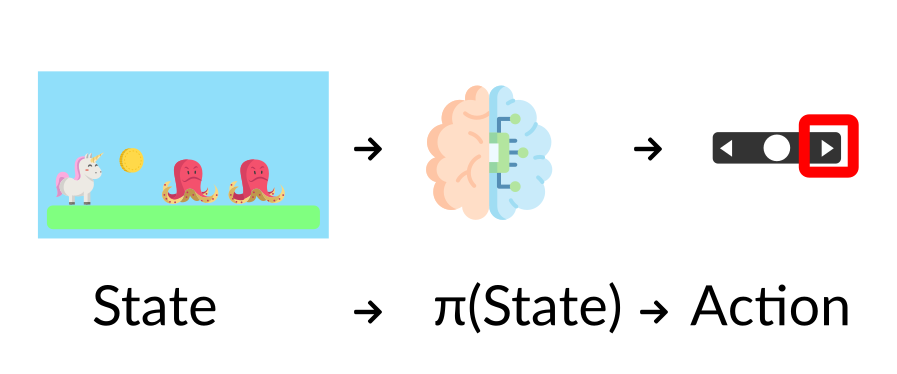
The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are.** So it **defines the agent’s behavior** at a given time.
-
-Think of policy as the brain of our agent, the function that will tell us the action to take given a state
-
-
+
+Think of policy as the brain of our agent, the function that will tell us the action to take given a state
-Think of policy as the brain of our agent, the function that will tells us the action to take given a state
+This Policy **is the function we want to learn**, our goal is to find the optimal policy π\*, the policy that **maximizes expected return** when the agent acts according to it. We find this π\* **through training.**
-This Policy **is the function we want to learn**, our goal is to find the optimal policy π*, the policy that** maximizes **expected return** when the agent acts according to it. We find this *π through training.**
-
-There are two approaches to train our agent to find this optimal policy π*:
+There are two approaches to train our agent to find this optimal policy π\*:
- **Directly,** by teaching the agent to learn which **action to take,** given the current state: **Policy-Based Methods.**
- Indirectly, **teach the agent to learn which state is more valuable** and then take the action that **leads to the more valuable states**: Value-Based Methods.
@@ -33,9 +29,8 @@ In Policy-Based methods, **we learn a policy function directly.**
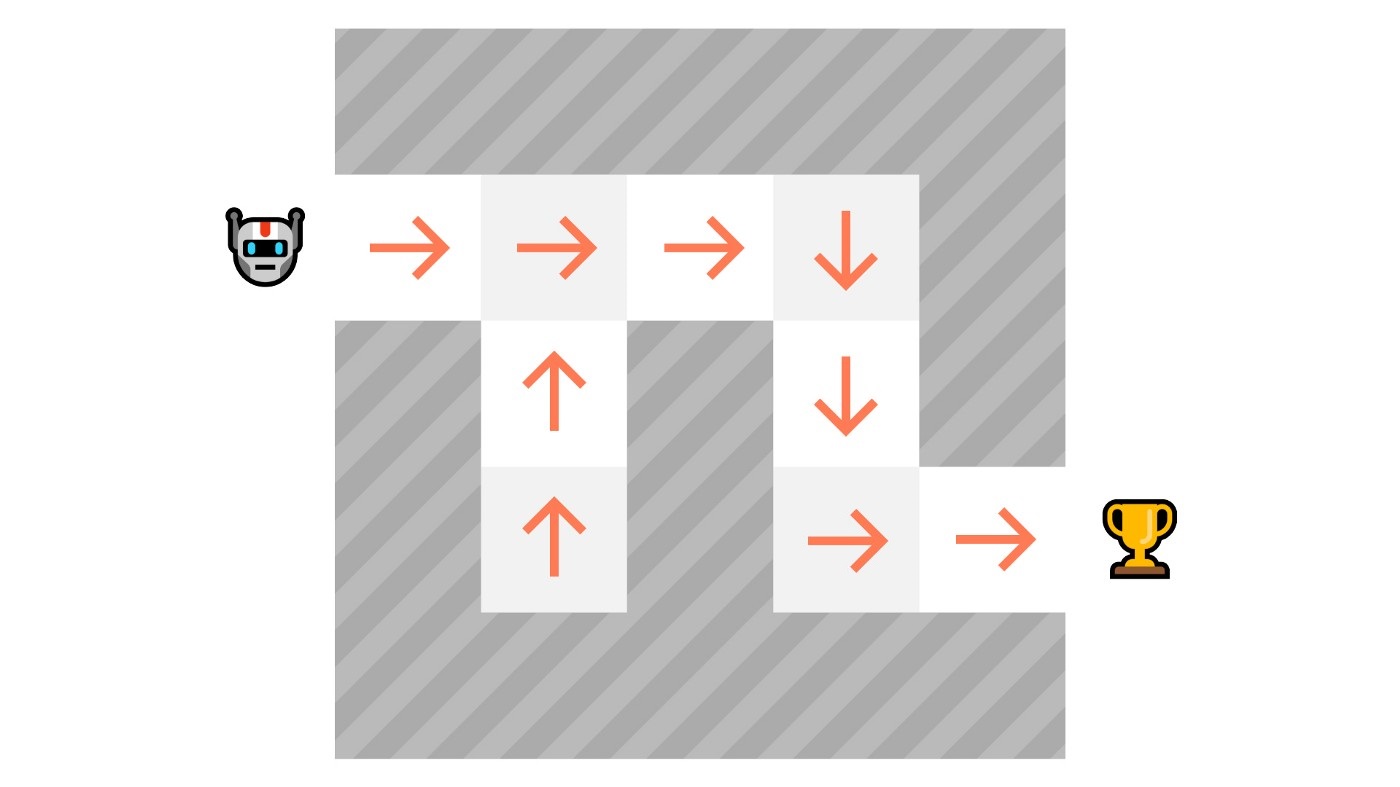
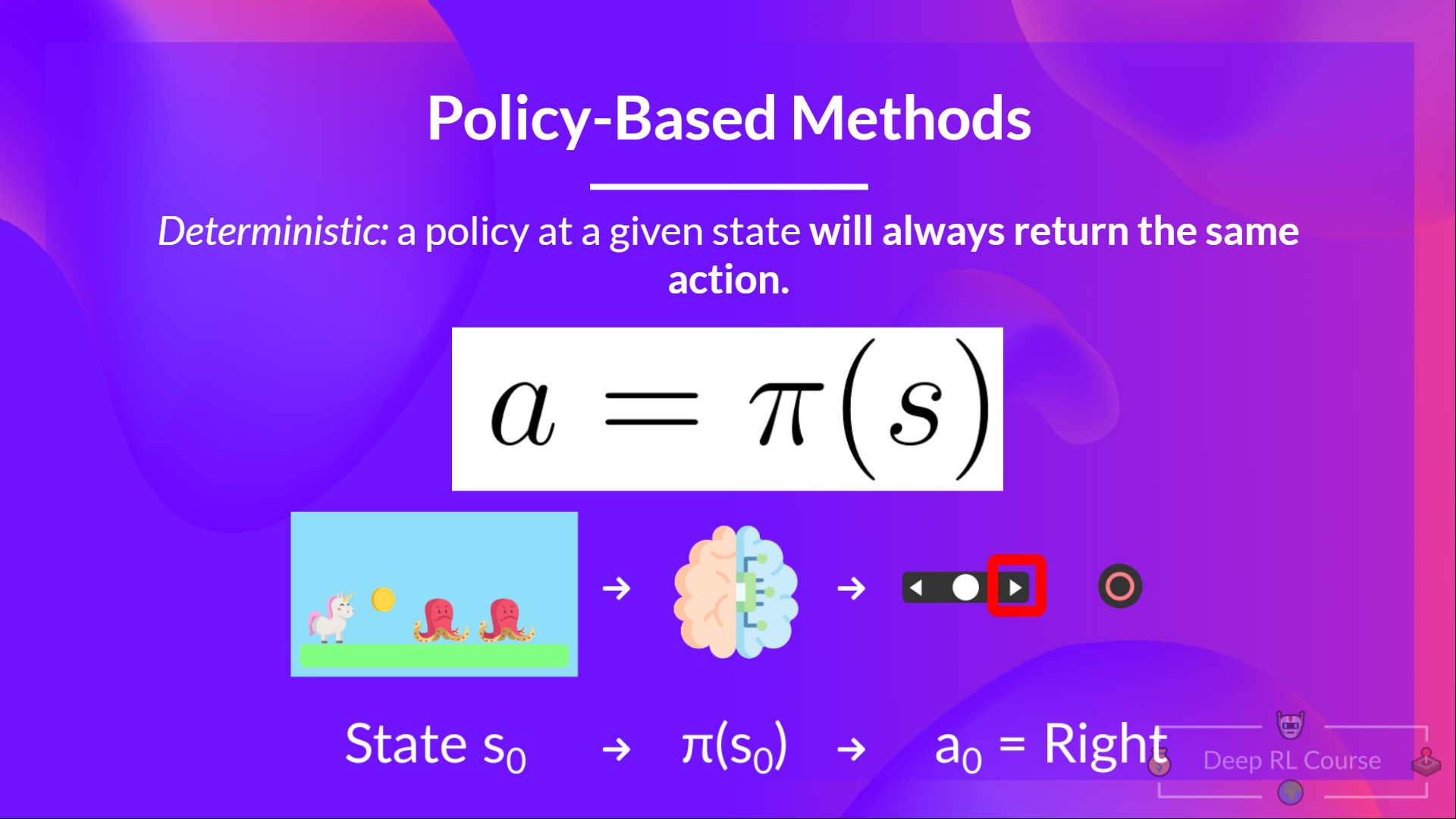
This function will define a mapping between each state and the best corresponding action. We can also say that it'll define **a probability distribution over the set of possible actions at that state.**
-
-As we can see here, the policy (deterministic) directly indicates the action to take for each step.
-
+
+As we can see here, the policy (deterministic) directly indicates the action to take for each step.
@@ -46,8 +41,7 @@ We have two types of policies:
-action = policy(state)
-
+action = policy(state)
@@ -56,21 +50,19 @@ We have two types of policies:
-policy(actions | state) = probability distribution over the set of actions given the current state
-
+policy(actions | state) = probability distribution over the set of actions given the current state
-Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
-
+Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
If we recap:
-
-
+
+
## Value-based methods [[value-based]]
@@ -81,19 +73,18 @@ The value of a state is the **expected discounted return** the agent can get i
“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
-
+
Here we see that our value function **defined value for each possible state.**
-Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
-
+Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
If we recap:
-
-
+
+
 -
- -
-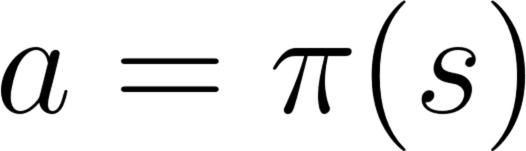 -
- @@ -56,21 +50,19 @@ We have two types of policies:
@@ -56,21 +50,19 @@ We have two types of policies:
 -
- -
- -
- +
+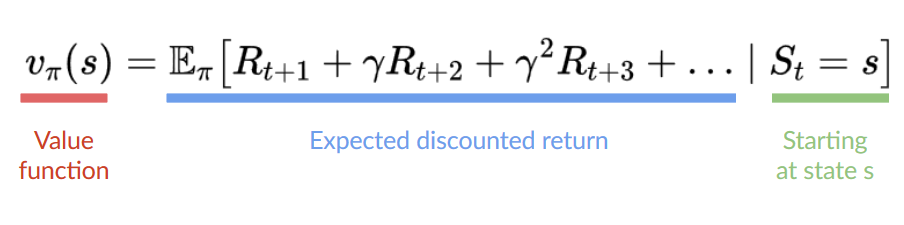 +
+ -
- -
- +
+