diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
index d0731f0..6544eb3 100644
--- a/units/en/unit6/advantage-actor-critic.mdx
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -1,8 +1,8 @@
# Advantage Actor-Critic (A2C) [[advantage-actor-critic-a2c]]
## Reducing variance with Actor-Critic methods
-The solution to reducing the variance of Reinforce algorithm and training our agent faster and better is to use a combination of policy-based and value-based methods: *the Actor-Critic method*.
+The solution to reducing the variance of the Reinforce algorithm and training our agent faster and better is to use a combination of Policy-Based and Value-Based methods: *the Actor-Critic method*.
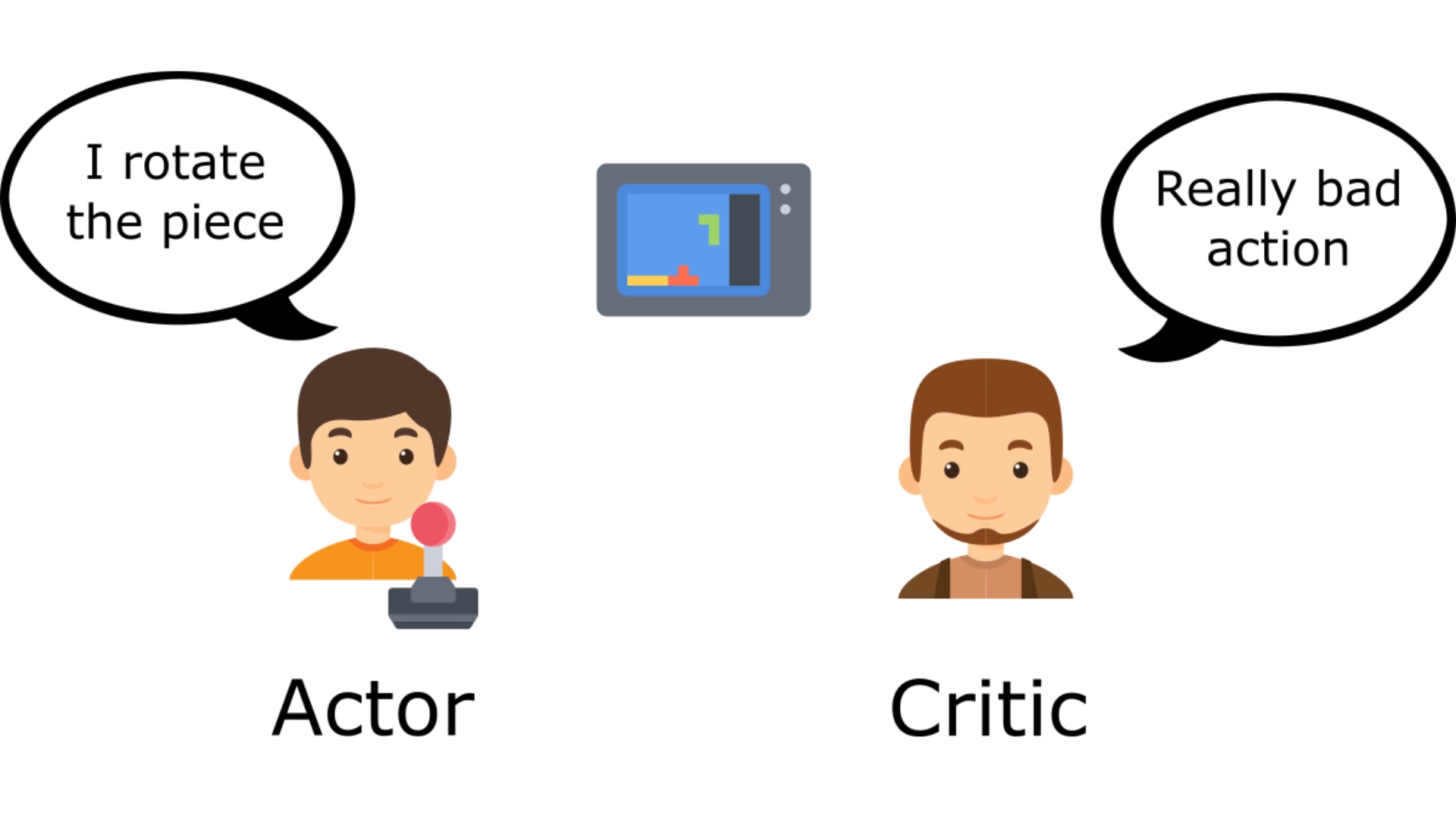
-To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor, and your friend is the Critic.
+To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
 @@ -19,7 +19,7 @@ This is the idea behind Actor-Critic. We learn two function approximations:
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
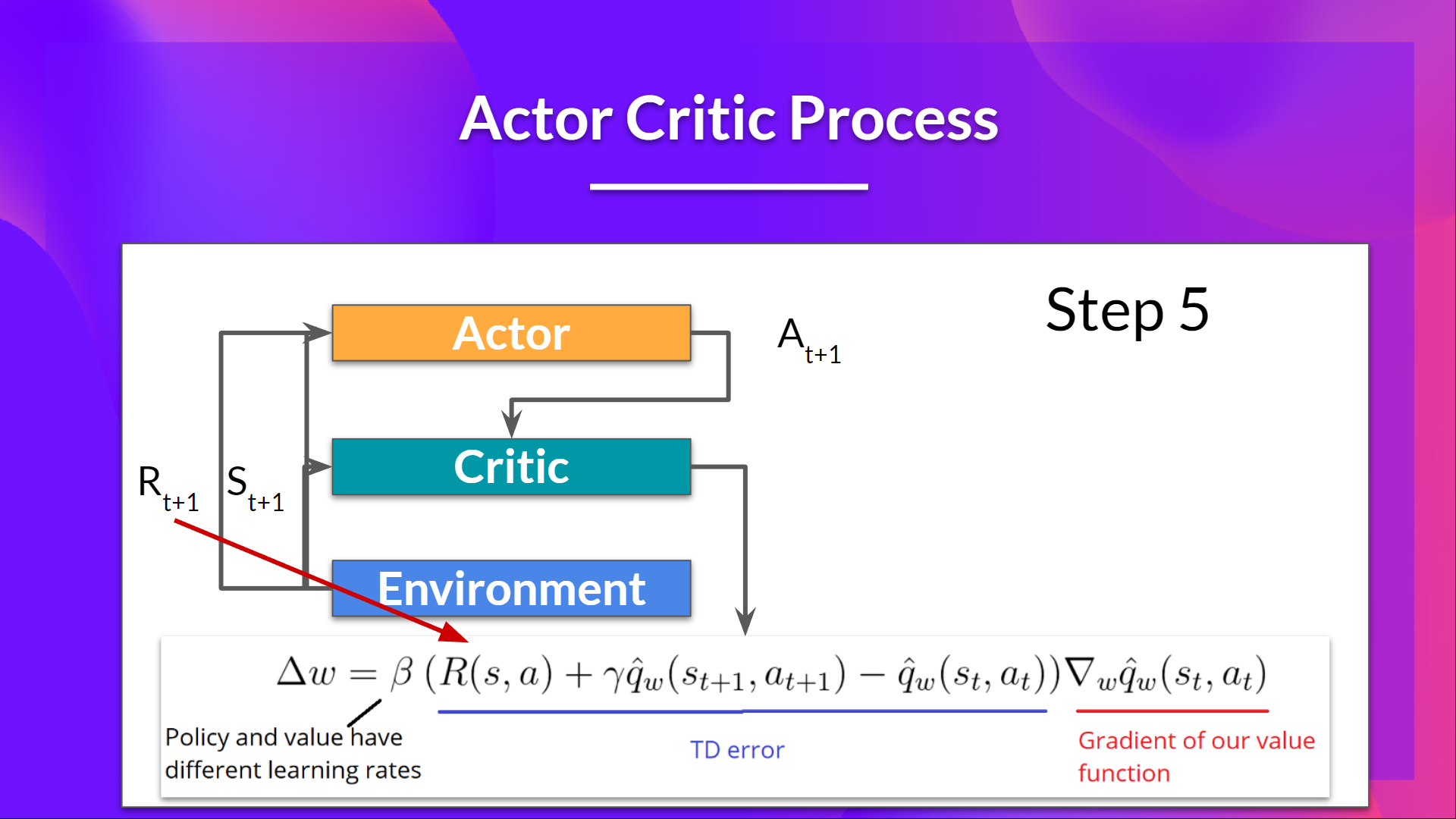
## The Actor-Critic Process
-Now that we have seen the Actor Critic's big picture let's dive deeper to understand how Actor and Critic improve together during the training.
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
@@ -50,10 +50,10 @@ Let's see the training process to understand how Actor and Critic are optimized:
@@ -19,7 +19,7 @@ This is the idea behind Actor-Critic. We learn two function approximations:
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
## The Actor-Critic Process
-Now that we have seen the Actor Critic's big picture let's dive deeper to understand how Actor and Critic improve together during the training.
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
@@ -50,10 +50,10 @@ Let's see the training process to understand how Actor and Critic are optimized:
 -## Adding "Advantage" in Actor Critic (A2C)
+## Adding "Advantage" in Actor-Critic (A2C)
We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
-The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how better taking that action at a state is compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how taking that action at a state is better compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
-## Adding "Advantage" in Actor Critic (A2C)
+## Adding "Advantage" in Actor-Critic (A2C)
We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
-The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how better taking that action at a state is compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how taking that action at a state is better compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
 diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index 64b8605..b96ba39 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -9,14 +9,14 @@ In Policy-Based methods, **we aim to optimize the policy directly without using
We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
-Remember that the policy gradient estimation is **the direction of the steepest increase in return**. Aka, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
-So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance:
-- *An Actor* that controls **how our agent behaves** (policy-based method)
-- *A Critic* that measures **how good the action taken is** (value-based method)
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (Policy-Based method)
+- *A Critic* that measures **how good the taken action is** (Value-Based method)
-We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. Where we'll train three robots:
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train three robots:
- A bipedal walker 🚶 to learn to walk.
- A spider 🕷️ to learn to move.
- A robotic arm 🦾 to move objects in the correct position.
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
index bb8df6a..9eb1888 100644
--- a/units/en/unit6/variance-problem.mdx
+++ b/units/en/unit6/variance-problem.mdx
@@ -8,13 +8,13 @@ In Reinforce, we want to **increase the probability of actions in a trajectory p
- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
-This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. Indeed, we collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
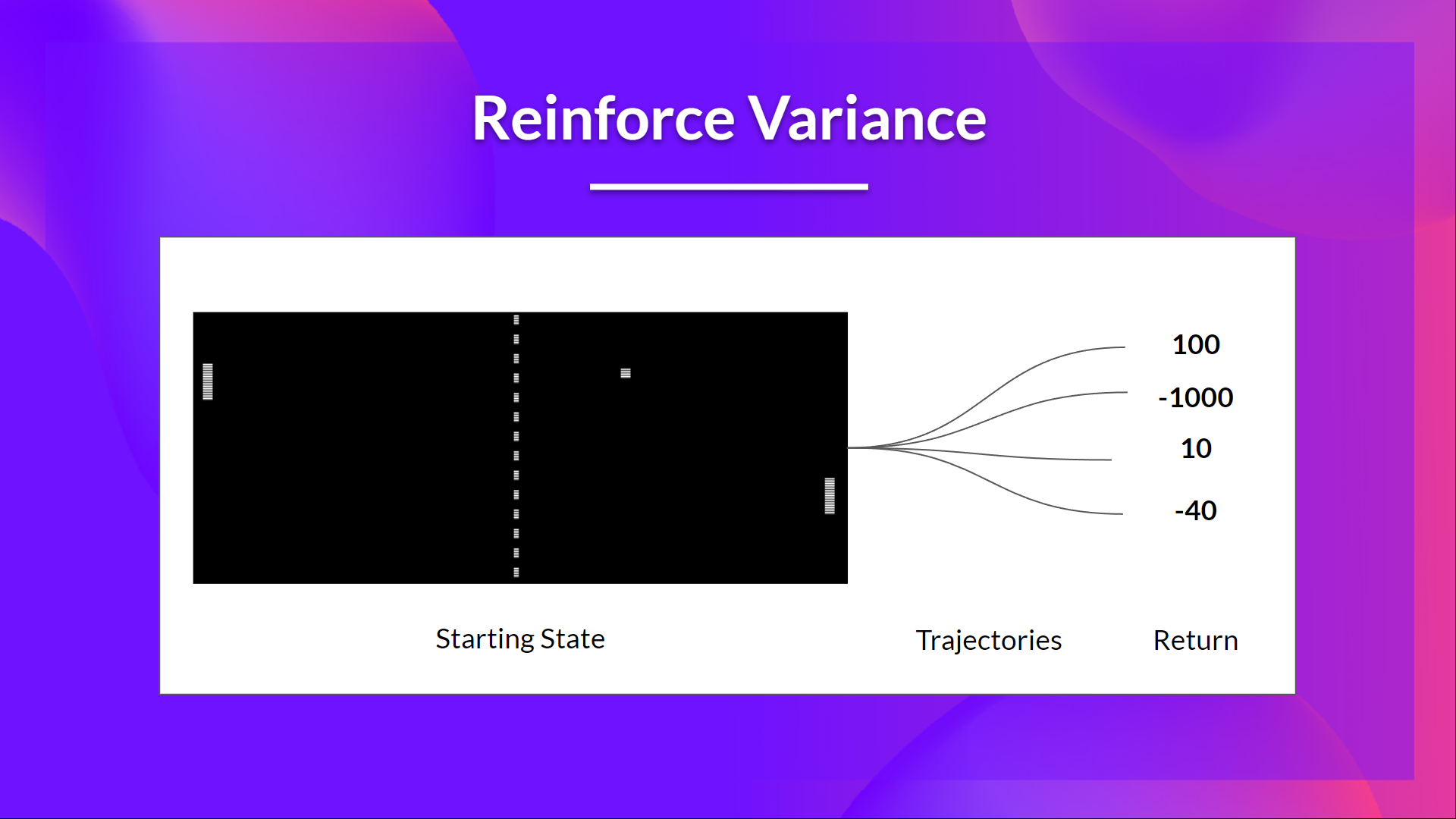
-But the problem is that **the variance is high, since trajectories can lead to different returns** due to stochasticity of the environment (random events during episode) and stochasticity of the policy. Consequently, the same starting state can lead to very different returns.
+Given the stochasticity of the environment (random events during an episode) and stochasticity of the policy, **trajectories can lead to different returns, which can lead to high variance**. Consequently, the same starting state can lead to very different returns.
Because of this, **the return starting at the same state can vary significantly across episodes**.
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index 64b8605..b96ba39 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -9,14 +9,14 @@ In Policy-Based methods, **we aim to optimize the policy directly without using
We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
-Remember that the policy gradient estimation is **the direction of the steepest increase in return**. Aka, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
-So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance:
-- *An Actor* that controls **how our agent behaves** (policy-based method)
-- *A Critic* that measures **how good the action taken is** (value-based method)
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (Policy-Based method)
+- *A Critic* that measures **how good the taken action is** (Value-Based method)
-We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. Where we'll train three robots:
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train three robots:
- A bipedal walker 🚶 to learn to walk.
- A spider 🕷️ to learn to move.
- A robotic arm 🦾 to move objects in the correct position.
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
index bb8df6a..9eb1888 100644
--- a/units/en/unit6/variance-problem.mdx
+++ b/units/en/unit6/variance-problem.mdx
@@ -8,13 +8,13 @@ In Reinforce, we want to **increase the probability of actions in a trajectory p
- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
-This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. Indeed, we collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
-But the problem is that **the variance is high, since trajectories can lead to different returns** due to stochasticity of the environment (random events during episode) and stochasticity of the policy. Consequently, the same starting state can lead to very different returns.
+Given the stochasticity of the environment (random events during an episode) and stochasticity of the policy, **trajectories can lead to different returns, which can lead to high variance**. Consequently, the same starting state can lead to very different returns.
Because of this, **the return starting at the same state can vary significantly across episodes**.