diff --git a/units/en/unit4/introduction.mdx b/units/en/unit4/introduction.mdx
index 5495901..8f63e49 100644
--- a/units/en/unit4/introduction.mdx
+++ b/units/en/unit4/introduction.mdx
@@ -1,5 +1,7 @@
# Introduction [[introduction]]
+
+
In the last unit, we learned about Deep Q-Learning. In this value-based deep reinforcement learning algorithm, we **used a deep neural network to approximate the different Q-values for each possible action at a state.**
Indeed, since the beginning of the course, we only studied value-based methods, **where we estimate a value function as an intermediate step towards finding an optimal policy.**
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index 532bbee..b9ea7db 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -34,7 +34,7 @@ Now that we got the big picture, let's dive deeper into policy-gradient.
We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
-
+
Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action at from state st, given our policy.
@@ -67,15 +67,13 @@ Our objective then is to maximize the expected cumulative rewards by finding \\(
## Gradient Ascent and the Policy-gradient Theorem
Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
-
-
Our update step for gradient-ascent is:
\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
We can repeatidly apply this update state in the hope that \\(\theta)\\ converges to the value that maximize \\J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
-1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computatially super expensive.
+1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computotially super expensive.
We want then to **calculate an estimation of the gradient with a sample-based estimate (collect some trajectories)**.
2. We have another problem, that I detail in the optional next section. That is to differentiate this objective function we need to differentiate the state distribution (attached to the environment it gives us the probability of the environment goes into next state given the current state and the action taken) but we might not know about it.
@@ -83,18 +81,17 @@ We want then to **calculate an estimation of the gradient with a sample-based es
Fortunately we're going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
-
+
## The policy-gradient algorithm
-
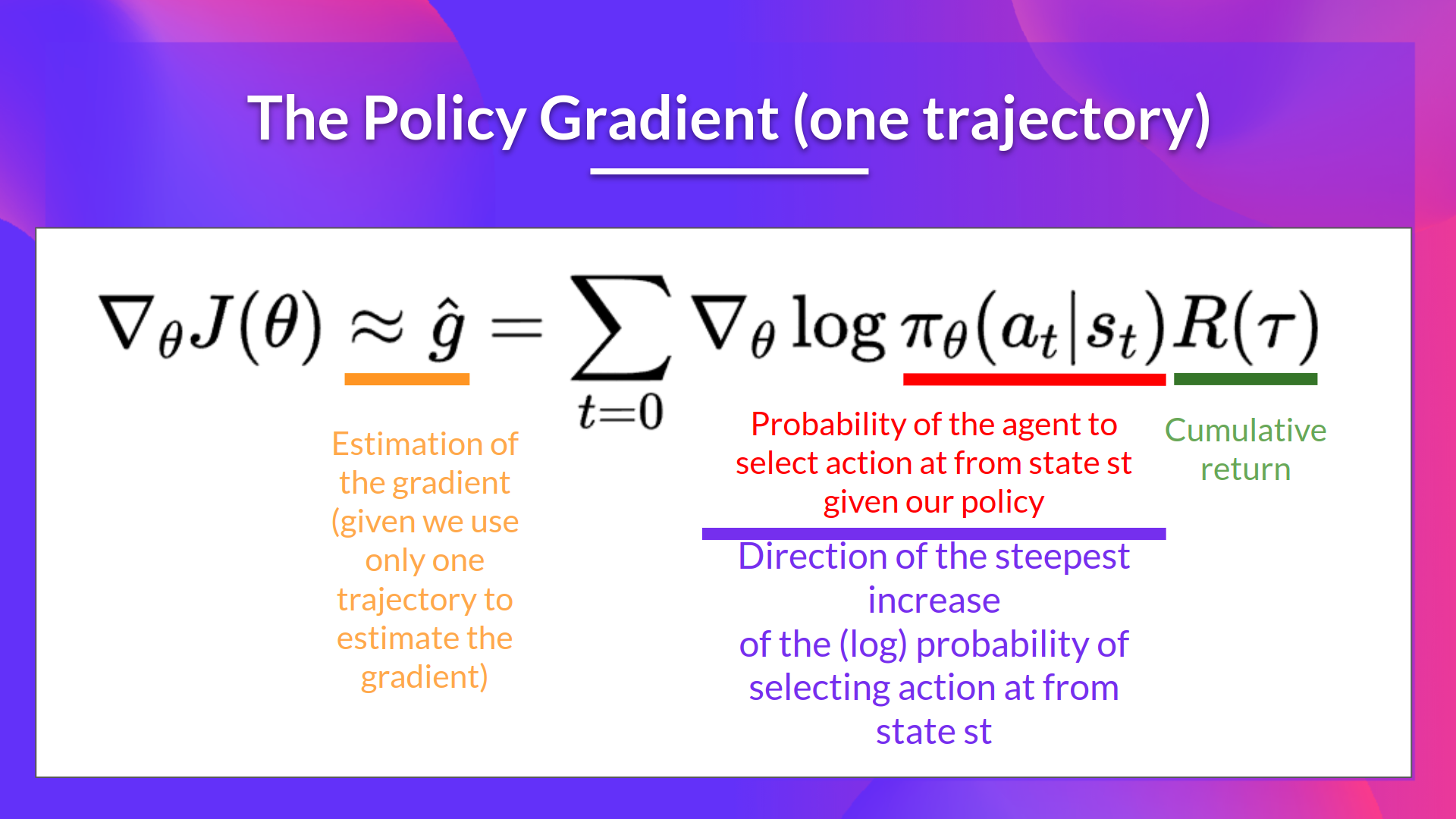
The Reinforce algorithm works like this:
Loop:
- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
-
+
- Update the weights of the policy: \\(\theta \leftarrow \theta + \alpha \hat{g}\\)
@@ -105,3 +102,9 @@ The interpretation we can make is this one:
- \\(R(\tau)\\): is the scoring function:
- If the return is high, it will push up the probabilities of the (state, action) combinations.
- Else, if the return is low, it will push down the probabilities of the (state, action) combinations.
+
+
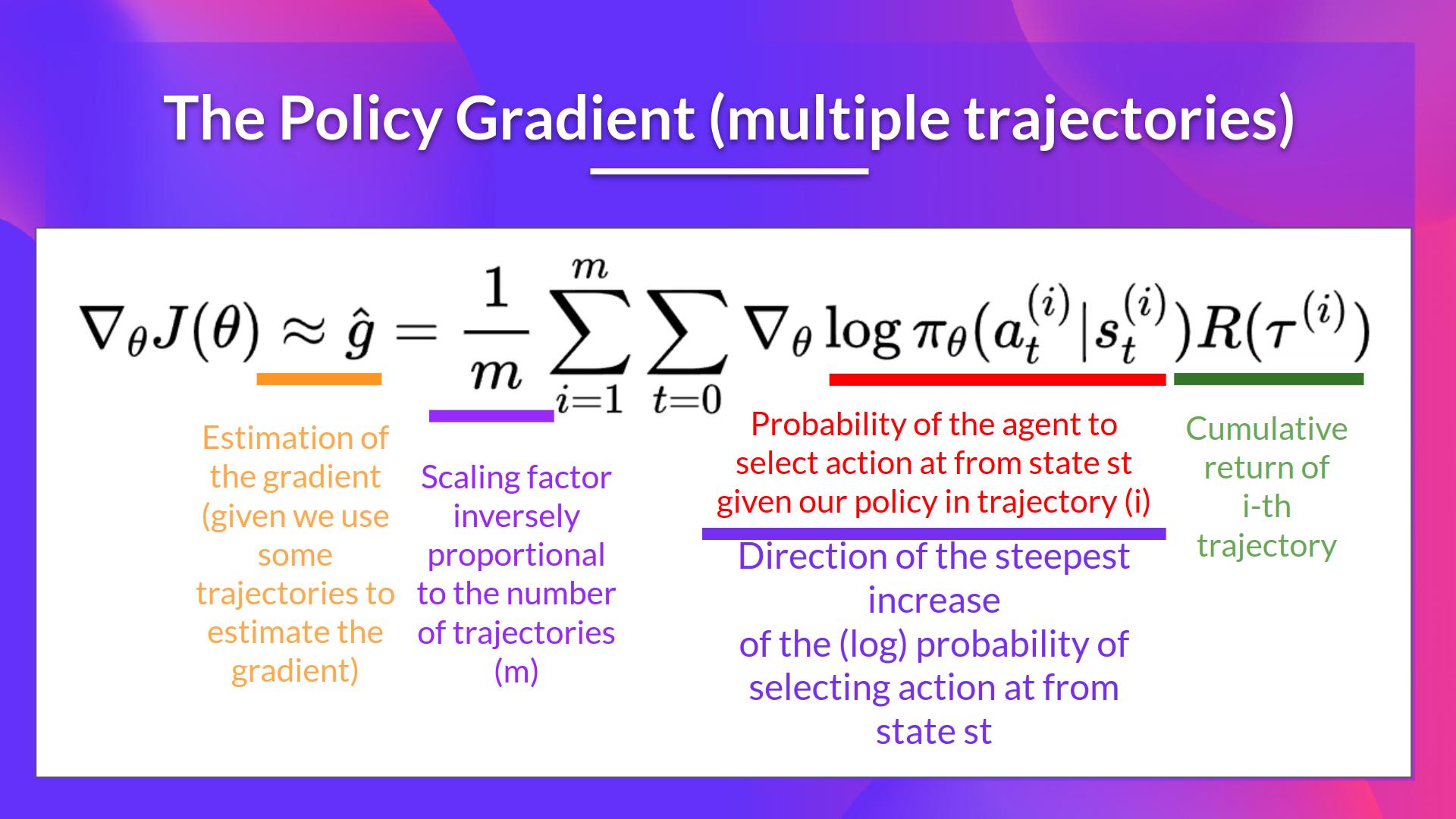
+We can also collect multiple episodes to estimate the gradient:
+
+
+
diff --git a/units/en/unit4/what-are-policy-based-methods.mdx b/units/en/unit4/what-are-policy-based-methods.mdx
index b8d8299..b86e647 100644
--- a/units/en/unit4/what-are-policy-based-methods.mdx
+++ b/units/en/unit4/what-are-policy-based-methods.mdx
@@ -19,6 +19,9 @@ We studied in the Unit 1, that we had two methods to find (most of the time appr
- On the other hand, in *policy-based methods*, we directly learn to approximate \\(\pi*\\) without having to learn a value function.
- The idea then is to parameterize policy, for instance using a neural network \\(\pi_\theta\\), this policy will output a probability distribution over actions (stochastic policy).
+
+
+
- Our objective then is *to maximize the performance of the parameterized policy using gradient ascent*.
- To do that we control the parameter \\(\theta\\) that will affect the distribution of actions over a state.
 +
+ 
 +
In the last unit, we learned about Deep Q-Learning. In this value-based deep reinforcement learning algorithm, we **used a deep neural network to approximate the different Q-values for each possible action at a state.**
Indeed, since the beginning of the course, we only studied value-based methods, **where we estimate a value function as an intermediate step towards finding an optimal policy.**
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index 532bbee..b9ea7db 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -34,7 +34,7 @@ Now that we got the big picture, let's dive deeper into policy-gradient.
We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
+
In the last unit, we learned about Deep Q-Learning. In this value-based deep reinforcement learning algorithm, we **used a deep neural network to approximate the different Q-values for each possible action at a state.**
Indeed, since the beginning of the course, we only studied value-based methods, **where we estimate a value function as an intermediate step towards finding an optimal policy.**
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index 532bbee..b9ea7db 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -34,7 +34,7 @@ Now that we got the big picture, let's dive deeper into policy-gradient.
We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
 -
Our update step for gradient-ascent is:
\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
We can repeatidly apply this update state in the hope that \\(\theta)\\ converges to the value that maximize \\J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
-1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computatially super expensive.
+1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computotially super expensive.
We want then to **calculate an estimation of the gradient with a sample-based estimate (collect some trajectories)**.
2. We have another problem, that I detail in the optional next section. That is to differentiate this objective function we need to differentiate the state distribution (attached to the environment it gives us the probability of the environment goes into next state given the current state and the action taken) but we might not know about it.
@@ -83,18 +81,17 @@ We want then to **calculate an estimation of the gradient with a sample-based es
Fortunately we're going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
-
-
Our update step for gradient-ascent is:
\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
We can repeatidly apply this update state in the hope that \\(\theta)\\ converges to the value that maximize \\J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
-1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computatially super expensive.
+1. We can't calculate the true gradient of the objective function, since it would imply to calculate the probability of each possible trajectory which is computotially super expensive.
We want then to **calculate an estimation of the gradient with a sample-based estimate (collect some trajectories)**.
2. We have another problem, that I detail in the optional next section. That is to differentiate this objective function we need to differentiate the state distribution (attached to the environment it gives us the probability of the environment goes into next state given the current state and the action taken) but we might not know about it.
@@ -83,18 +81,17 @@ We want then to **calculate an estimation of the gradient with a sample-based es
Fortunately we're going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
- +
+ ## The policy-gradient algorithm
-
The Reinforce algorithm works like this:
Loop:
- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
## The policy-gradient algorithm
-
The Reinforce algorithm works like this:
Loop:
- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
 +
+ 
 +
+