diff --git a/units/en/unit5/bonus.mdx b/units/en/unit5/bonus.mdx
index 81301fd..f4607f6 100644
--- a/units/en/unit5/bonus.mdx
+++ b/units/en/unit5/bonus.mdx
@@ -1,6 +1,6 @@
# Bonus: Learn to create your own environments with Unity and MLAgents
-**You can create your own reinforcement learning environments with Unity and MLAgents**. But, using a game engine such as Unity, can be intimidating at first but here are the steps you can do to learn smoothly.
+**You can create your own reinforcement learning environments with Unity and MLAgents**. Using a game engine such as Unity can be intimidating at first, but here are the steps you can take to learn smoothly.
## Step 1: Know how to use Unity
@@ -12,8 +12,8 @@
## Step 3: Iterate and create nice environments
-- Now that you've created a first simple environment you can iterate in more complex one using the [MLAgents documentation (especially Designing Agents and Agent part)](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/)
-- In addition, you can follow this free course ["Create a hummingbird environment"](https://learn.unity.com/course/ml-agents-hummingbirds) by [Adam Kelly](https://twitter.com/aktwelve)
+- Now that you've created your first simple environment you can iterate to more complex ones using the [MLAgents documentation (especially Designing Agents and Agent part)](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/)
+- In addition, you can take this free course ["Create a hummingbird environment"](https://learn.unity.com/course/ml-agents-hummingbirds) by [Adam Kelly](https://twitter.com/aktwelve)
-Have fun! And if you create custom environments don't hesitate to share them to `#rl-i-made-this` discord channel.
+Have fun! And if you create custom environments don't hesitate to share them to the `#rl-i-made-this` discord channel.
diff --git a/units/en/unit5/conclusion.mdx b/units/en/unit5/conclusion.mdx
index 339336a..b0d8056 100644
--- a/units/en/unit5/conclusion.mdx
+++ b/units/en/unit5/conclusion.mdx
@@ -6,17 +6,17 @@ The best way to learn is to **practice and try stuff**. Why not try another envi
For instance:
- [Worm](https://singularite.itch.io/worm), where you teach a worm to crawl.
-- [Walker](https://singularite.itch.io/walker): teach an agent to walk towards a goal.
+- [Walker](https://singularite.itch.io/walker), where you teach an agent to walk towards a goal.
-Check the documentation to find how to train them and the list of already integrated MLAgents environments on the Hub: https://github.com/huggingface/ml-agents#getting-started
+Check the documentation to find out how to train them and to see the list of already integrated MLAgents environments on the Hub: https://github.com/huggingface/ml-agents#getting-started
 -In the next unit, we're going to learn about multi-agents. And you're going to train your first multi-agents to compete in Soccer and Snowball fight against other classmate's agents.
+In the next unit, we're going to learn about multi-agents. You're going to train your first multi-agents to compete in Soccer and Snowball fight against other classmate's agents.
-In the next unit, we're going to learn about multi-agents. And you're going to train your first multi-agents to compete in Soccer and Snowball fight against other classmate's agents.
+In the next unit, we're going to learn about multi-agents. You're going to train your first multi-agents to compete in Soccer and Snowball fight against other classmate's agents.
 -Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit5/curiosity.mdx b/units/en/unit5/curiosity.mdx
index b8dfb9f..a1aed85 100644
--- a/units/en/unit5/curiosity.mdx
+++ b/units/en/unit5/curiosity.mdx
@@ -7,7 +7,7 @@ This is an (optional) introduction to Curiosity. If you want to learn more, you
## Two Major Problems in Modern RL
-To understand what is Curiosity, we need first to understand the two major problems with RL:
+To understand what Curiosity is, we first need to understand the two major problems with RL:
First, the *sparse rewards problem:* that is, **most rewards do not contain information, and hence are set to zero**.
@@ -33,7 +33,7 @@ A solution to these problems is **to develop a reward function intrinsic to the
**This intrinsic reward mechanism is known as Curiosity** because this reward pushes the agent to explore states that are novel/unfamiliar. To achieve that, our agent will receive a high reward when exploring new trajectories.
-This reward is inspired by how human acts. ** we naturally have an intrinsic desire to explore environments and discover new things**.
+This reward is inspired by how humans act. ** We naturally have an intrinsic desire to explore environments and discover new things**.
There are different ways to calculate this intrinsic reward. The classical approach (Curiosity through next-state prediction) is to calculate Curiosity **as the error of our agent in predicting the next state, given the current state and action taken**.
@@ -41,7 +41,7 @@ There are different ways to calculate this intrinsic reward. The classical appro
Because the idea of Curiosity is to **encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequences of its actions** (uncertainty will be higher in areas where the agent has spent less time or in areas with complex dynamics).
-If the agent spends a lot of time on these states, it will be good to predict the next state (low Curiosity). On the other hand, if it’s a new state unexplored, it will be hard to predict the following state (high Curiosity).
+If the agent spends a lot of time on these states, it will be good at predicting the next state (low Curiosity). On the other hand, if it’s in a new, unexplored state, it will be hard to predict the following state (high Curiosity).
-Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit5/curiosity.mdx b/units/en/unit5/curiosity.mdx
index b8dfb9f..a1aed85 100644
--- a/units/en/unit5/curiosity.mdx
+++ b/units/en/unit5/curiosity.mdx
@@ -7,7 +7,7 @@ This is an (optional) introduction to Curiosity. If you want to learn more, you
## Two Major Problems in Modern RL
-To understand what is Curiosity, we need first to understand the two major problems with RL:
+To understand what Curiosity is, we first need to understand the two major problems with RL:
First, the *sparse rewards problem:* that is, **most rewards do not contain information, and hence are set to zero**.
@@ -33,7 +33,7 @@ A solution to these problems is **to develop a reward function intrinsic to the
**This intrinsic reward mechanism is known as Curiosity** because this reward pushes the agent to explore states that are novel/unfamiliar. To achieve that, our agent will receive a high reward when exploring new trajectories.
-This reward is inspired by how human acts. ** we naturally have an intrinsic desire to explore environments and discover new things**.
+This reward is inspired by how humans act. ** We naturally have an intrinsic desire to explore environments and discover new things**.
There are different ways to calculate this intrinsic reward. The classical approach (Curiosity through next-state prediction) is to calculate Curiosity **as the error of our agent in predicting the next state, given the current state and action taken**.
@@ -41,7 +41,7 @@ There are different ways to calculate this intrinsic reward. The classical appro
Because the idea of Curiosity is to **encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequences of its actions** (uncertainty will be higher in areas where the agent has spent less time or in areas with complex dynamics).
-If the agent spends a lot of time on these states, it will be good to predict the next state (low Curiosity). On the other hand, if it’s a new state unexplored, it will be hard to predict the following state (high Curiosity).
+If the agent spends a lot of time on these states, it will be good at predicting the next state (low Curiosity). On the other hand, if it’s in a new, unexplored state, it will be hard to predict the following state (high Curiosity).
 diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index a5c867e..ac85f71 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -11,8 +11,8 @@ We learned what ML-Agents is and how it works. We also studied the two environme
diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index a5c867e..ac85f71 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -11,8 +11,8 @@ We learned what ML-Agents is and how it works. We also studied the two environme
 -The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
-There are no minimum results to attain to validate this Hands On. But if you want to get nice results, you can try to reach the following:
+The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But, for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
+There are no minimum results to attain in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
- For [Pyramids](https://singularite.itch.io/pyramids): Mean Reward = 1.75
- For [SnowballTarget](https://singularite.itch.io/snowballtarget): Mean Reward = 15 or 30 targets shoot in an episode.
@@ -30,7 +30,7 @@ For more information about the certification process, check this section 👉 ht
In this notebook, you'll learn about ML-Agents and train two agents.
- The first one will learn to **shoot snowballs onto spawning targets**.
-- The second need to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, **and move to the gold brick at the top**. To do that, it will need to explore its environment, and we will use a technique called curiosity.
+- The second needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, **and move to the gold brick at the top**. To do that, it will need to explore its environment, and we will use a technique called curiosity.
After that, you'll be able **to watch your agents playing directly on your browser**.
@@ -59,13 +59,13 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Understand how works **ML-Agents**, the environment library.
+- Understand how **ML-Agents** works and the environment library.
- Be able to **train agents in Unity Environments**.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
-🔲 📚 **Study [what is ML-Agents and how it works by reading Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
+🔲 📚 **Study [what ML-Agents is and how it works by reading Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
# Let's train our agents 🚀
@@ -101,7 +101,7 @@ Before diving into the notebook, you need to:
If you need a refresher on how this environment works check this section 👉
https://huggingface.co/deep-rl-course/unit5/snowball-target
-### Download and move the environm ent zip file in `./training-envs-executables/linux/`
+### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it to `./training-envs-executables/linux/`
- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
@@ -134,14 +134,14 @@ Make sure your file is accessible
```
### Define the SnowballTarget config file
-- In ML-Agents, you define the **training hyperparameters into config.yaml files.**
+- In ML-Agents, you define the **training hyperparameters in config.yaml files.**
-There are multiple hyperparameters. To know them better, you should check for each explanation with [the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)
+There are multiple hyperparameters. To understand them better, you should read the explanation for each one in [the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)
You need to create a `SnowballTarget.yaml` config file in ./content/ml-agents/config/ppo/
-We'll give you here a first version of this config (to copy and paste into your `SnowballTarget.yaml file`), **but you should modify it**.
+We'll give you a preliminary version of this config (to copy and paste into your `SnowballTarget.yaml file`), **but you should modify it**.
```yaml
behaviors:
@@ -197,7 +197,7 @@ Train the model and use the `--resume` flag to continue training in case of inte
> It will fail the first time if and when you use `--resume`. Try rerunning the block to bypass the error.
-The training will take 10 to 35min depending on your config. Go take a ☕️you deserve it 🤗.
+The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
```bash
!mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
@@ -205,7 +205,7 @@ The training will take 10 to 35min depending on your config. Go take a ☕️you
### Push the agent to the Hugging Face Hub
-- Now that we trained our agent, we’re **ready to push it to the Hub to be able to visualize it playing on your browser🔥.**
+- Now that we've trained our agent, we’re **ready to push it to the Hub and visualize it playing on your browser🔥.**
To be able to share your model with the community, there are three more steps to follow:
@@ -225,9 +225,9 @@ from huggingface_hub import notebook_login
notebook_login()
```
-If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-Then, we need to run `mlagents-push-to-hf`.
+Then we need to run `mlagents-push-to-hf`.
And we define four parameters:
@@ -235,7 +235,7 @@ And we define four parameters:
2. `--local-dir`: where the agent was saved, it’s results/, so in my case results/First Training.
3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always /
If the repo does not exist **it will be created automatically**
-4. `--commit-message`: since HF repos are git repository you need to define a commit message.
+4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
-The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
-There are no minimum results to attain to validate this Hands On. But if you want to get nice results, you can try to reach the following:
+The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But, for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
+There are no minimum results to attain in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
- For [Pyramids](https://singularite.itch.io/pyramids): Mean Reward = 1.75
- For [SnowballTarget](https://singularite.itch.io/snowballtarget): Mean Reward = 15 or 30 targets shoot in an episode.
@@ -30,7 +30,7 @@ For more information about the certification process, check this section 👉 ht
In this notebook, you'll learn about ML-Agents and train two agents.
- The first one will learn to **shoot snowballs onto spawning targets**.
-- The second need to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, **and move to the gold brick at the top**. To do that, it will need to explore its environment, and we will use a technique called curiosity.
+- The second needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, **and move to the gold brick at the top**. To do that, it will need to explore its environment, and we will use a technique called curiosity.
After that, you'll be able **to watch your agents playing directly on your browser**.
@@ -59,13 +59,13 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Understand how works **ML-Agents**, the environment library.
+- Understand how **ML-Agents** works and the environment library.
- Be able to **train agents in Unity Environments**.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
-🔲 📚 **Study [what is ML-Agents and how it works by reading Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
+🔲 📚 **Study [what ML-Agents is and how it works by reading Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
# Let's train our agents 🚀
@@ -101,7 +101,7 @@ Before diving into the notebook, you need to:
If you need a refresher on how this environment works check this section 👉
https://huggingface.co/deep-rl-course/unit5/snowball-target
-### Download and move the environm ent zip file in `./training-envs-executables/linux/`
+### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it to `./training-envs-executables/linux/`
- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
@@ -134,14 +134,14 @@ Make sure your file is accessible
```
### Define the SnowballTarget config file
-- In ML-Agents, you define the **training hyperparameters into config.yaml files.**
+- In ML-Agents, you define the **training hyperparameters in config.yaml files.**
-There are multiple hyperparameters. To know them better, you should check for each explanation with [the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)
+There are multiple hyperparameters. To understand them better, you should read the explanation for each one in [the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)
You need to create a `SnowballTarget.yaml` config file in ./content/ml-agents/config/ppo/
-We'll give you here a first version of this config (to copy and paste into your `SnowballTarget.yaml file`), **but you should modify it**.
+We'll give you a preliminary version of this config (to copy and paste into your `SnowballTarget.yaml file`), **but you should modify it**.
```yaml
behaviors:
@@ -197,7 +197,7 @@ Train the model and use the `--resume` flag to continue training in case of inte
> It will fail the first time if and when you use `--resume`. Try rerunning the block to bypass the error.
-The training will take 10 to 35min depending on your config. Go take a ☕️you deserve it 🤗.
+The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
```bash
!mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
@@ -205,7 +205,7 @@ The training will take 10 to 35min depending on your config. Go take a ☕️you
### Push the agent to the Hugging Face Hub
-- Now that we trained our agent, we’re **ready to push it to the Hub to be able to visualize it playing on your browser🔥.**
+- Now that we've trained our agent, we’re **ready to push it to the Hub and visualize it playing on your browser🔥.**
To be able to share your model with the community, there are three more steps to follow:
@@ -225,9 +225,9 @@ from huggingface_hub import notebook_login
notebook_login()
```
-If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-Then, we need to run `mlagents-push-to-hf`.
+Then we need to run `mlagents-push-to-hf`.
And we define four parameters:
@@ -235,7 +235,7 @@ And we define four parameters:
2. `--local-dir`: where the agent was saved, it’s results/, so in my case results/First Training.
3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always /
If the repo does not exist **it will be created automatically**
-4. `--commit-message`: since HF repos are git repository you need to define a commit message.
+4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
 @@ -247,7 +247,7 @@ For instance:
!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
-Else, if everything worked you should have this at the end of the process(but with a different url 😆) :
+If everything worked you should see this at the end of the process (but with a different url 😆) :
@@ -277,18 +277,18 @@ This step it's simple:
- I have multiple ones since we saved a model every 500000 timesteps.
- But if I want the more recent I choose `SnowballTarget.onnx`
-👉 What's nice **is to try different models steps to see the improvement of the agent.**
+👉 It's nice to **try different model stages to see the improvement of the agent.**
-And don't hesitate to share the best score your agent gets on discord in #rl-i-made-this channel 🔥
+And don't hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
-Let's now try a more challenging environment called Pyramids.
+Now let's try a more challenging environment called Pyramids.
## Pyramids 🏆
### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
-- We need to download it and place it to `./training-envs-executables/linux/`
-- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
+- We need to download it and place it into `./training-envs-executables/linux/`
+- We use a linux executable because we're using colab, and the colab machine's OS is Ubuntu (linux)
Download the file Pyramids.zip from https://drive.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
@@ -316,7 +316,7 @@ Make sure your file is accessible
For this training, we’ll modify one thing:
- The total training steps hyperparameter is too high since we can hit the benchmark (mean reward = 1.75) in only 1M training steps.
-👉 To do that, we go to config/ppo/PyramidsRND.yaml,**and modify these to max_steps to 1000000.**
+👉 To do that, we go to config/ppo/PyramidsRND.yaml,**and change max_steps to 1000000.**
@@ -247,7 +247,7 @@ For instance:
!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
-Else, if everything worked you should have this at the end of the process(but with a different url 😆) :
+If everything worked you should see this at the end of the process (but with a different url 😆) :
@@ -277,18 +277,18 @@ This step it's simple:
- I have multiple ones since we saved a model every 500000 timesteps.
- But if I want the more recent I choose `SnowballTarget.onnx`
-👉 What's nice **is to try different models steps to see the improvement of the agent.**
+👉 It's nice to **try different model stages to see the improvement of the agent.**
-And don't hesitate to share the best score your agent gets on discord in #rl-i-made-this channel 🔥
+And don't hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
-Let's now try a more challenging environment called Pyramids.
+Now let's try a more challenging environment called Pyramids.
## Pyramids 🏆
### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
-- We need to download it and place it to `./training-envs-executables/linux/`
-- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
+- We need to download it and place it into `./training-envs-executables/linux/`
+- We use a linux executable because we're using colab, and the colab machine's OS is Ubuntu (linux)
Download the file Pyramids.zip from https://drive.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
@@ -316,7 +316,7 @@ Make sure your file is accessible
For this training, we’ll modify one thing:
- The total training steps hyperparameter is too high since we can hit the benchmark (mean reward = 1.75) in only 1M training steps.
-👉 To do that, we go to config/ppo/PyramidsRND.yaml,**and modify these to max_steps to 1000000.**
+👉 To do that, we go to config/ppo/PyramidsRND.yaml,**and change max_steps to 1000000.**
 @@ -326,7 +326,7 @@ We’re now ready to train our agent 🔥.
### Train the agent
-The training will take 30 to 45min depending on your machine, go take a ☕️you deserve it 🤗.
+The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
```python
!mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
@@ -347,13 +347,13 @@ The temporary link for the Pyramids demo is: https://singularite.itch.io/pyramid
### 🎁 Bonus: Why not train on another environment?
Now that you know how to train an agent using MLAgents, **why not try another environment?**
-MLAgents provides 18 different and we’re building some custom ones. The best way to learn is to try things of your own, have fun.
+MLAgents provides 18 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

-You have the full list of the one currently available on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
+You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
-For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Space)
+For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Spaces)
For now we have integrated:
- [Worm](https://singularite.itch.io/worm) demo where you teach a **worm to crawl**.
@@ -363,7 +363,7 @@ If you want new demos to be added, please open an issue: https://github.com/hugg
That’s all for today. Congrats on finishing this tutorial!
-The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own? Check the documentation and have fun!
+The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own. Check the documentation and have fun!
See you on Unit 6 🔥,
diff --git a/units/en/unit5/how-mlagents-works.mdx b/units/en/unit5/how-mlagents-works.mdx
index 86661f9..12acede 100644
--- a/units/en/unit5/how-mlagents-works.mdx
+++ b/units/en/unit5/how-mlagents-works.mdx
@@ -26,14 +26,14 @@ With Unity ML-Agents, you have six essential components:
- The second is the *Python Low-level API*, which contains **the low-level Python interface for interacting and manipulating the environment**. It’s the API we use to launch the training.
- Then, we have the *External Communicator* that **connects the Learning Environment (made with C#) with the low level Python API (Python)**.
- The *Python trainers*: the **Reinforcement algorithms made with PyTorch (PPO, SAC…)**.
-- The *Gym wrapper*: to encapsulate RL environment in a gym wrapper.
-- The *PettingZoo wrapper*: PettingZoo is the multi-agents of gym wrapper.
+- The *Gym wrapper*: to encapsulate the RL environment in a gym wrapper.
+- The *PettingZoo wrapper*: PettingZoo is the multi-agents version of the gym wrapper.
## Inside the Learning Component [[inside-learning-component]]
Inside the Learning Component, we have **three important elements**:
-- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called *Brain*.
+- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called the *Brain*.
- Finally, there is the *Academy*. This component **orchestrates agents and their decision-making processes**. Think of this Academy as a teacher who handles Python API requests.
To better understand its role, let’s remember the RL process. This can be modeled as a loop that works like this:
@@ -50,7 +50,7 @@ Now, let’s imagine an agent learning to play a platform game. The RL process l
- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment goes to a **new** **state \\(S_1\\)** — new frame.
- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
diff --git a/units/en/unit5/introduction.mdx b/units/en/unit5/introduction.mdx
index 05f877f..8997f47 100644
--- a/units/en/unit5/introduction.mdx
+++ b/units/en/unit5/introduction.mdx
@@ -2,7 +2,7 @@
@@ -326,7 +326,7 @@ We’re now ready to train our agent 🔥.
### Train the agent
-The training will take 30 to 45min depending on your machine, go take a ☕️you deserve it 🤗.
+The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
```python
!mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
@@ -347,13 +347,13 @@ The temporary link for the Pyramids demo is: https://singularite.itch.io/pyramid
### 🎁 Bonus: Why not train on another environment?
Now that you know how to train an agent using MLAgents, **why not try another environment?**
-MLAgents provides 18 different and we’re building some custom ones. The best way to learn is to try things of your own, have fun.
+MLAgents provides 18 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

-You have the full list of the one currently available on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
+You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
-For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Space)
+For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Spaces)
For now we have integrated:
- [Worm](https://singularite.itch.io/worm) demo where you teach a **worm to crawl**.
@@ -363,7 +363,7 @@ If you want new demos to be added, please open an issue: https://github.com/hugg
That’s all for today. Congrats on finishing this tutorial!
-The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own? Check the documentation and have fun!
+The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own. Check the documentation and have fun!
See you on Unit 6 🔥,
diff --git a/units/en/unit5/how-mlagents-works.mdx b/units/en/unit5/how-mlagents-works.mdx
index 86661f9..12acede 100644
--- a/units/en/unit5/how-mlagents-works.mdx
+++ b/units/en/unit5/how-mlagents-works.mdx
@@ -26,14 +26,14 @@ With Unity ML-Agents, you have six essential components:
- The second is the *Python Low-level API*, which contains **the low-level Python interface for interacting and manipulating the environment**. It’s the API we use to launch the training.
- Then, we have the *External Communicator* that **connects the Learning Environment (made with C#) with the low level Python API (Python)**.
- The *Python trainers*: the **Reinforcement algorithms made with PyTorch (PPO, SAC…)**.
-- The *Gym wrapper*: to encapsulate RL environment in a gym wrapper.
-- The *PettingZoo wrapper*: PettingZoo is the multi-agents of gym wrapper.
+- The *Gym wrapper*: to encapsulate the RL environment in a gym wrapper.
+- The *PettingZoo wrapper*: PettingZoo is the multi-agents version of the gym wrapper.
## Inside the Learning Component [[inside-learning-component]]
Inside the Learning Component, we have **three important elements**:
-- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called *Brain*.
+- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called the *Brain*.
- Finally, there is the *Academy*. This component **orchestrates agents and their decision-making processes**. Think of this Academy as a teacher who handles Python API requests.
To better understand its role, let’s remember the RL process. This can be modeled as a loop that works like this:
@@ -50,7 +50,7 @@ Now, let’s imagine an agent learning to play a platform game. The RL process l
- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment goes to a **new** **state \\(S_1\\)** — new frame.
- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
diff --git a/units/en/unit5/introduction.mdx b/units/en/unit5/introduction.mdx
index 05f877f..8997f47 100644
--- a/units/en/unit5/introduction.mdx
+++ b/units/en/unit5/introduction.mdx
@@ -2,7 +2,7 @@
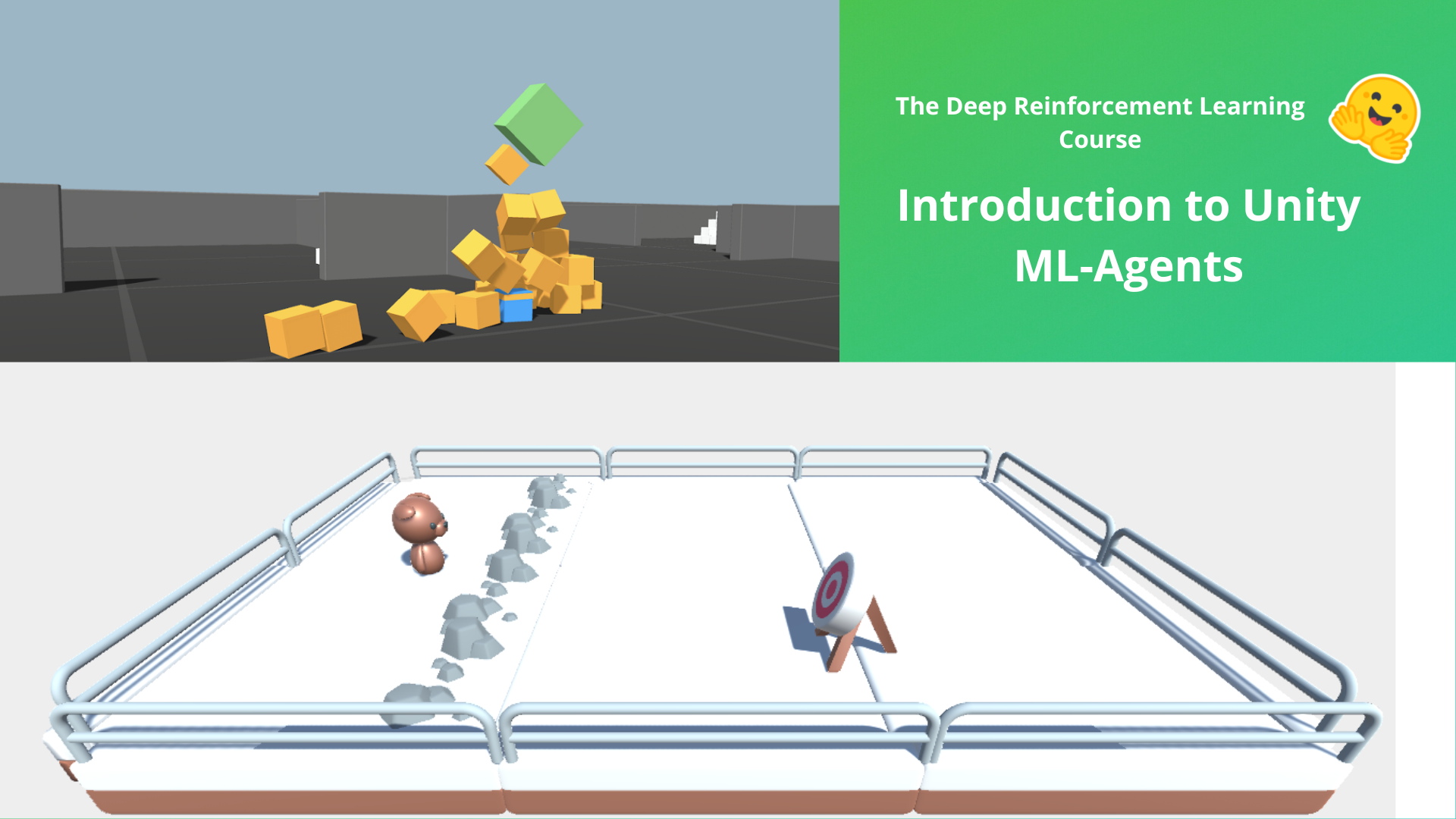 -One of the challenges in Reinforcement Learning is **creating environments**. Fortunately for us, we can use game engines to achieve so.
+One of the challenges in Reinforcement Learning is **creating environments**. Fortunately for us, we can use game engines to do so.
These engines, such as [Unity](https://unity.com/), [Godot](https://godotengine.org/) or [Unreal Engine](https://www.unrealengine.com/), are programs made to create video games. They are perfectly suited
for creating environments: they provide physics systems, 2D/3D rendering, and more.
@@ -14,18 +14,18 @@ One of them, [Unity](https://unity.com/), created the [Unity ML-Agents Toolkit](
Source: ML-Agents documentation
-Unity ML-Agents Toolkit provides many exceptional pre-made environments, from playing football (soccer), learning to walk, and jumping big walls.
+Unity ML-Agents Toolkit provides many exceptional pre-made environments, from playing football (soccer), learning to walk, and jumping over big walls.
In this Unit, we'll learn to use ML-Agents, but **don't worry if you don't know how to use the Unity Game Engine**: you don't need to use it to train your agents.
So, today, we're going to train two agents:
-- The first one will learn to **shoot snowballs onto spawning target**.
-- The second needs to **press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top**. To do that, it will need to explore its environment, which will be achieved using a technique called curiosity.
+- The first one will learn to **shoot snowballs onto a spawning target**.
+- The second needs to **press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top**. To do that, it will need to explore its environment, which will be done using a technique called curiosity.
-Then, after training, **you'll push the trained agents to the Hugging Face Hub**, and you'll be able to **visualize it playing directly on your browser without having to use the Unity Editor**.
+Then, after training, **you'll push the trained agents to the Hugging Face Hub**, and you'll be able to **visualize them playing directly on your browser without having to use the Unity Editor**.
Doing this Unit will **prepare you for the next challenge: AI vs. AI where you will train agents in multi-agents environments and compete against your classmates' agents**.
-Sounds exciting? Let's get started!
+Sound exciting? Let's get started!
diff --git a/units/en/unit5/snowball-target.mdx b/units/en/unit5/snowball-target.mdx
index f44865f..fc89101 100644
--- a/units/en/unit5/snowball-target.mdx
+++ b/units/en/unit5/snowball-target.mdx
@@ -8,7 +8,7 @@ SnowballTarget is an environment we created at Hugging Face using assets from [K
The first agent you're going to train is called Julien the bear 🐻. Julien is trained **to hit targets with snowballs**.
-The Goal in this environment is that Julien **hits as many targets as possible in the limited time** (1000 timesteps). It will need **to place itself correctly from the target and shoot**to do that.
+The Goal in this environment is that Julien **hits as many targets as possible in the limited time** (1000 timesteps). It will need **to place itself correctly in relation to the target and shoot**to do that.
In addition, to avoid "snowball spamming" (aka shooting a snowball every timestep), **Julien has a "cool off" system** (it needs to wait 0.5 seconds after a shoot to be able to shoot again).
-One of the challenges in Reinforcement Learning is **creating environments**. Fortunately for us, we can use game engines to achieve so.
+One of the challenges in Reinforcement Learning is **creating environments**. Fortunately for us, we can use game engines to do so.
These engines, such as [Unity](https://unity.com/), [Godot](https://godotengine.org/) or [Unreal Engine](https://www.unrealengine.com/), are programs made to create video games. They are perfectly suited
for creating environments: they provide physics systems, 2D/3D rendering, and more.
@@ -14,18 +14,18 @@ One of them, [Unity](https://unity.com/), created the [Unity ML-Agents Toolkit](
Source: ML-Agents documentation
-Unity ML-Agents Toolkit provides many exceptional pre-made environments, from playing football (soccer), learning to walk, and jumping big walls.
+Unity ML-Agents Toolkit provides many exceptional pre-made environments, from playing football (soccer), learning to walk, and jumping over big walls.
In this Unit, we'll learn to use ML-Agents, but **don't worry if you don't know how to use the Unity Game Engine**: you don't need to use it to train your agents.
So, today, we're going to train two agents:
-- The first one will learn to **shoot snowballs onto spawning target**.
-- The second needs to **press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top**. To do that, it will need to explore its environment, which will be achieved using a technique called curiosity.
+- The first one will learn to **shoot snowballs onto a spawning target**.
+- The second needs to **press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top**. To do that, it will need to explore its environment, which will be done using a technique called curiosity.
-Then, after training, **you'll push the trained agents to the Hugging Face Hub**, and you'll be able to **visualize it playing directly on your browser without having to use the Unity Editor**.
+Then, after training, **you'll push the trained agents to the Hugging Face Hub**, and you'll be able to **visualize them playing directly on your browser without having to use the Unity Editor**.
Doing this Unit will **prepare you for the next challenge: AI vs. AI where you will train agents in multi-agents environments and compete against your classmates' agents**.
-Sounds exciting? Let's get started!
+Sound exciting? Let's get started!
diff --git a/units/en/unit5/snowball-target.mdx b/units/en/unit5/snowball-target.mdx
index f44865f..fc89101 100644
--- a/units/en/unit5/snowball-target.mdx
+++ b/units/en/unit5/snowball-target.mdx
@@ -8,7 +8,7 @@ SnowballTarget is an environment we created at Hugging Face using assets from [K
The first agent you're going to train is called Julien the bear 🐻. Julien is trained **to hit targets with snowballs**.
-The Goal in this environment is that Julien **hits as many targets as possible in the limited time** (1000 timesteps). It will need **to place itself correctly from the target and shoot**to do that.
+The Goal in this environment is that Julien **hits as many targets as possible in the limited time** (1000 timesteps). It will need **to place itself correctly in relation to the target and shoot**to do that.
In addition, to avoid "snowball spamming" (aka shooting a snowball every timestep), **Julien has a "cool off" system** (it needs to wait 0.5 seconds after a shoot to be able to shoot again).