diff --git a/units/en/unit6/additional-readings.mdx b/units/en/unit6/additional-readings.mdx
index 07d80fb..1f91af4 100644
--- a/units/en/unit6/additional-readings.mdx
+++ b/units/en/unit6/additional-readings.mdx
@@ -2,7 +2,7 @@
## Bias-variance tradeoff in Reinforcement Learning
-If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
index 64f07fc..0c455a0 100644
--- a/units/en/unit6/advantage-actor-critic.mdx
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -4,7 +4,7 @@
The solution to reducing the variance of the Reinforce algorithm and training our agent faster and better is to use a combination of Policy-Based and Value-Based methods: *the Actor-Critic method*.
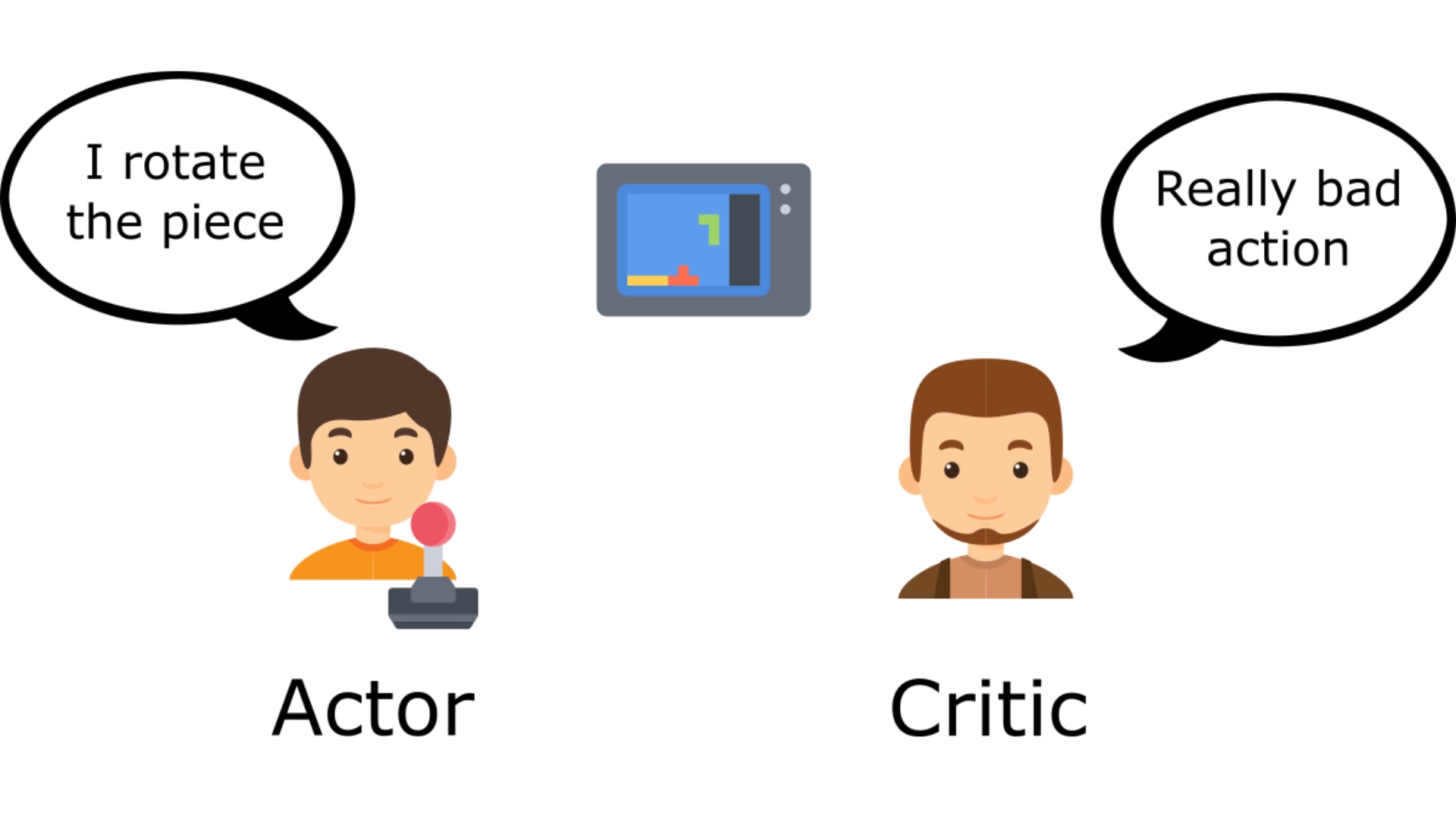
-To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
+To understand the Actor-Critic, imagine you're playing a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
 @@ -21,13 +21,13 @@ This is the idea behind Actor-Critic. We learn two function approximations:
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
## The Actor-Critic Process
-Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how the Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
-Let's see the training process to understand how Actor and Critic are optimized:
+Let's see the training process to understand how the Actor and Critic are optimized:
- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
- Our Policy takes the state and **outputs an action** \\( A_t \\).
diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
index 85d0229..557b159 100644
--- a/units/en/unit6/conclusion.mdx
+++ b/units/en/unit6/conclusion.mdx
@@ -4,8 +4,8 @@ Congrats on finishing this unit and the tutorial. You've just trained your first
**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
-Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill out this form](https://forms.gle/BzKXWzLAGZESGNaE9)
-See you in next unit,
+See you in next unit!
-### Keep learning, stay awesome 🤗,
+### Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 4a52152..9d34e59 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -11,7 +11,7 @@
Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train two robots:
- A spider 🕷️ to learn to move.
-- A robotic arm 🦾 to move in the correct position.
+- A robotic arm 🦾 to move to the correct position.
We're going to use two Robotics environments:
@@ -54,7 +54,7 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.
+- Be able to use the environment librairies **PyBullet** and **Panda-Gym**.
- Be able to **train robots using A2C**.
- Understand why **we need to normalize the input**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
@@ -80,7 +80,7 @@ Before diving into the notebook, you need to:
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
-Hence the following cell will install the librairies and create and run a virtual screen 🖥
+The following cell will install the librairies and create and run a virtual screen 🖥
```python
%%capture
@@ -135,7 +135,7 @@ from huggingface_hub import notebook_login
### Create the AntBulletEnv-v0
#### The environment 🎮
-In this environment, the agent needs to use correctly its different joints to walk correctly.
+In this environment, the agent needs to use its different joints correctly in order to walk.
You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
```python
@@ -231,7 +231,7 @@ model = A2C(
### Train the A2C agent 🏃
-- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
+- Let's train our agent for 2,000,000 timesteps. Don't forget to use GPU on Colab. It will take approximately ~25-40min
```python
model.learn(2_000_000)
@@ -244,7 +244,7 @@ env.save("vec_normalize.pkl")
```
### Evaluate the agent 📈
-- Now that's our agent is trained, we need to **check its performance**.
+- Now that our agent is trained, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`
- In my case, I got a mean reward of `2371.90 +/- 16.50`
@@ -282,7 +282,7 @@ By using `package_to_hub`, as we already mentionned in the former units, **you e
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share with the community an agent that others can use** 💾
+- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
@@ -290,7 +290,7 @@ To be able to share your model with the community there are three more steps to
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
-2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+2️⃣ Sign in and then you need to get your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
@@ -21,13 +21,13 @@ This is the idea behind Actor-Critic. We learn two function approximations:
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
## The Actor-Critic Process
-Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how the Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
-Let's see the training process to understand how Actor and Critic are optimized:
+Let's see the training process to understand how the Actor and Critic are optimized:
- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
- Our Policy takes the state and **outputs an action** \\( A_t \\).
diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
index 85d0229..557b159 100644
--- a/units/en/unit6/conclusion.mdx
+++ b/units/en/unit6/conclusion.mdx
@@ -4,8 +4,8 @@ Congrats on finishing this unit and the tutorial. You've just trained your first
**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
-Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill out this form](https://forms.gle/BzKXWzLAGZESGNaE9)
-See you in next unit,
+See you in next unit!
-### Keep learning, stay awesome 🤗,
+### Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 4a52152..9d34e59 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -11,7 +11,7 @@
Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train two robots:
- A spider 🕷️ to learn to move.
-- A robotic arm 🦾 to move in the correct position.
+- A robotic arm 🦾 to move to the correct position.
We're going to use two Robotics environments:
@@ -54,7 +54,7 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.
+- Be able to use the environment librairies **PyBullet** and **Panda-Gym**.
- Be able to **train robots using A2C**.
- Understand why **we need to normalize the input**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
@@ -80,7 +80,7 @@ Before diving into the notebook, you need to:
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
-Hence the following cell will install the librairies and create and run a virtual screen 🖥
+The following cell will install the librairies and create and run a virtual screen 🖥
```python
%%capture
@@ -135,7 +135,7 @@ from huggingface_hub import notebook_login
### Create the AntBulletEnv-v0
#### The environment 🎮
-In this environment, the agent needs to use correctly its different joints to walk correctly.
+In this environment, the agent needs to use its different joints correctly in order to walk.
You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
```python
@@ -231,7 +231,7 @@ model = A2C(
### Train the A2C agent 🏃
-- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
+- Let's train our agent for 2,000,000 timesteps. Don't forget to use GPU on Colab. It will take approximately ~25-40min
```python
model.learn(2_000_000)
@@ -244,7 +244,7 @@ env.save("vec_normalize.pkl")
```
### Evaluate the agent 📈
-- Now that's our agent is trained, we need to **check its performance**.
+- Now that our agent is trained, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`
- In my case, I got a mean reward of `2371.90 +/- 16.50`
@@ -282,7 +282,7 @@ By using `package_to_hub`, as we already mentionned in the former units, **you e
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share with the community an agent that others can use** 💾
+- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
@@ -290,7 +290,7 @@ To be able to share your model with the community there are three more steps to
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
-2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+2️⃣ Sign in and then you need to get your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
 @@ -303,7 +303,7 @@ notebook_login()
!git config --global credential.helper store
```
-If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
@@ -332,9 +332,9 @@ In robotics, the *end-effector* is the device at the end of a robotic arm design
In `PandaReach`, the robot must place its end-effector at a target position (green ball).
-We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+We're going to use the dense version of this environment. This means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). This is in contrast to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
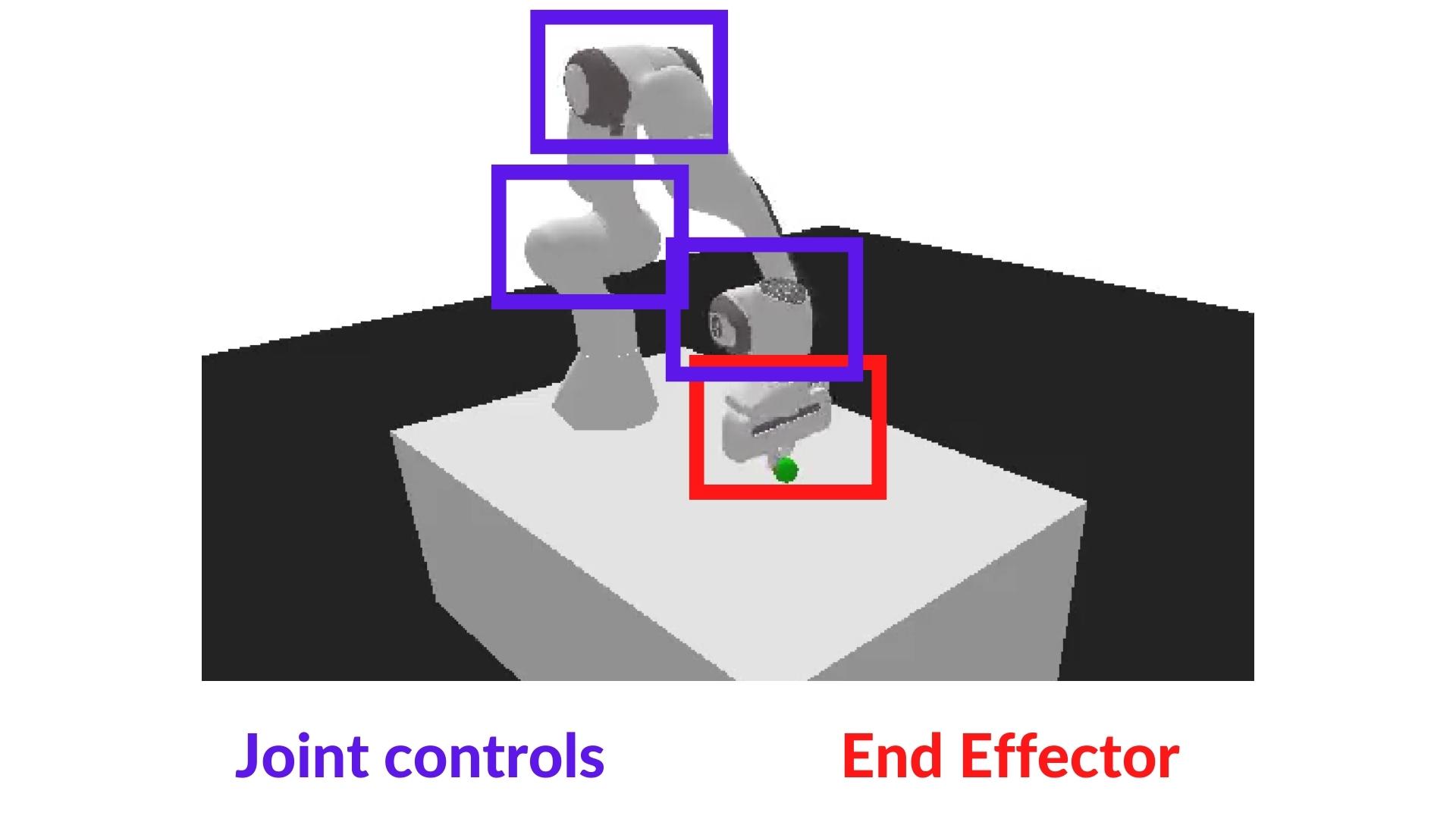
-Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+Also, we're going to use the *End-effector displacement control*, which means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
@@ -303,7 +303,7 @@ notebook_login()
!git config --global credential.helper store
```
-If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
@@ -332,9 +332,9 @@ In robotics, the *end-effector* is the device at the end of a robotic arm design
In `PandaReach`, the robot must place its end-effector at a target position (green ball).
-We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+We're going to use the dense version of this environment. This means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). This is in contrast to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
-Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+Also, we're going to use the *End-effector displacement control*, which means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
 @@ -384,14 +384,14 @@ The action space is a vector with 3 values:
Now it's your turn:
-1. Define the environment called "PandaReachDense-v2"
-2. Make a vectorized environment
+1. Define the environment called "PandaReachDense-v2".
+2. Make a vectorized environment.
3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. Create the A2C Model (don't forget verbose=1 to print the training logs).
-5. Train it for 1M Timesteps
-6. Save the model and VecNormalize statistics when saving the agent
-7. Evaluate your agent
-8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+5. Train it for 1M Timesteps.
+6. Save the model and VecNormalize statistics when saving the agent.
+7. Evaluate your agent.
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`.
### Solution (fill the todo)
@@ -448,7 +448,7 @@ package_to_hub(
## Some additional challenges 🏆
-The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
+The best way to learn **is to try things on your own**! Why not try `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
@@ -456,7 +456,7 @@ PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-Here are some ideas to achieve so:
+Here are some ideas to go further:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
* **Push your new trained model** on the Hub 🔥
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index d85281d..4be735f 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -11,15 +11,15 @@ We saw that Reinforce worked well. However, because we use Monte-Carlo sampling
Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
-So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+So today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that helps to stabilize the training by reducing the variance using:
- *An Actor* that controls **how our agent behaves** (Policy-Based method)
- *A Critic* that measures **how good the taken action is** (Value-Based method)
We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
- A spider 🕷️ to learn to move.
-- A robotic arm 🦾 to move in the correct position.
+- A robotic arm 🦾 to move to the correct position.
@@ -384,14 +384,14 @@ The action space is a vector with 3 values:
Now it's your turn:
-1. Define the environment called "PandaReachDense-v2"
-2. Make a vectorized environment
+1. Define the environment called "PandaReachDense-v2".
+2. Make a vectorized environment.
3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. Create the A2C Model (don't forget verbose=1 to print the training logs).
-5. Train it for 1M Timesteps
-6. Save the model and VecNormalize statistics when saving the agent
-7. Evaluate your agent
-8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+5. Train it for 1M Timesteps.
+6. Save the model and VecNormalize statistics when saving the agent.
+7. Evaluate your agent.
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`.
### Solution (fill the todo)
@@ -448,7 +448,7 @@ package_to_hub(
## Some additional challenges 🏆
-The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
+The best way to learn **is to try things on your own**! Why not try `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
@@ -456,7 +456,7 @@ PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-Here are some ideas to achieve so:
+Here are some ideas to go further:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
* **Push your new trained model** on the Hub 🔥
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index d85281d..4be735f 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -11,15 +11,15 @@ We saw that Reinforce worked well. However, because we use Monte-Carlo sampling
Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
-So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+So today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that helps to stabilize the training by reducing the variance using:
- *An Actor* that controls **how our agent behaves** (Policy-Based method)
- *A Critic* that measures **how good the taken action is** (Value-Based method)
We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
- A spider 🕷️ to learn to move.
-- A robotic arm 🦾 to move in the correct position.
+- A robotic arm 🦾 to move to the correct position.
 -Sounds exciting? Let's get started!
+Sound exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
index 9eb1888..9ce3d8e 100644
--- a/units/en/unit6/variance-problem.mdx
+++ b/units/en/unit6/variance-problem.mdx
@@ -1,12 +1,12 @@
# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
-In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+In Reinforce, we want to **increase the probability of actions in a trajectory proportionally to how high the return is**.
-Sounds exciting? Let's get started!
+Sound exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
index 9eb1888..9ce3d8e 100644
--- a/units/en/unit6/variance-problem.mdx
+++ b/units/en/unit6/variance-problem.mdx
@@ -1,12 +1,12 @@
# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
-In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+In Reinforce, we want to **increase the probability of actions in a trajectory proportionally to how high the return is**.
 - If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
-- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+- Otherwise, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
@@ -24,7 +24,7 @@ The solution is to mitigate the variance by **using a large number of trajectori
However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
---
-If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
---
- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
-- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+- Otherwise, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
@@ -24,7 +24,7 @@ The solution is to mitigate the variance by **using a large number of trajectori
However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
---
-If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
---