diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
index f9832a9..b53a5ef 100644
--- a/units/en/unit6/quiz.mdx
+++ b/units/en/unit6/quiz.mdx
@@ -8,29 +8,29 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
-### Q2: Which of the following statements are correct?
+### Q2: Which of the following statements are True, when talking about models with bias and/or variance in RL?
@@ -63,7 +63,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
},
,
{
- text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take n strategies and average them, reducing their impact impact in case of noise"
+ text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take `n` strategies and average them, reducing their impact impact in case of noise"
explain: "",
correct: true,
},
@@ -74,9 +74,9 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
Solution
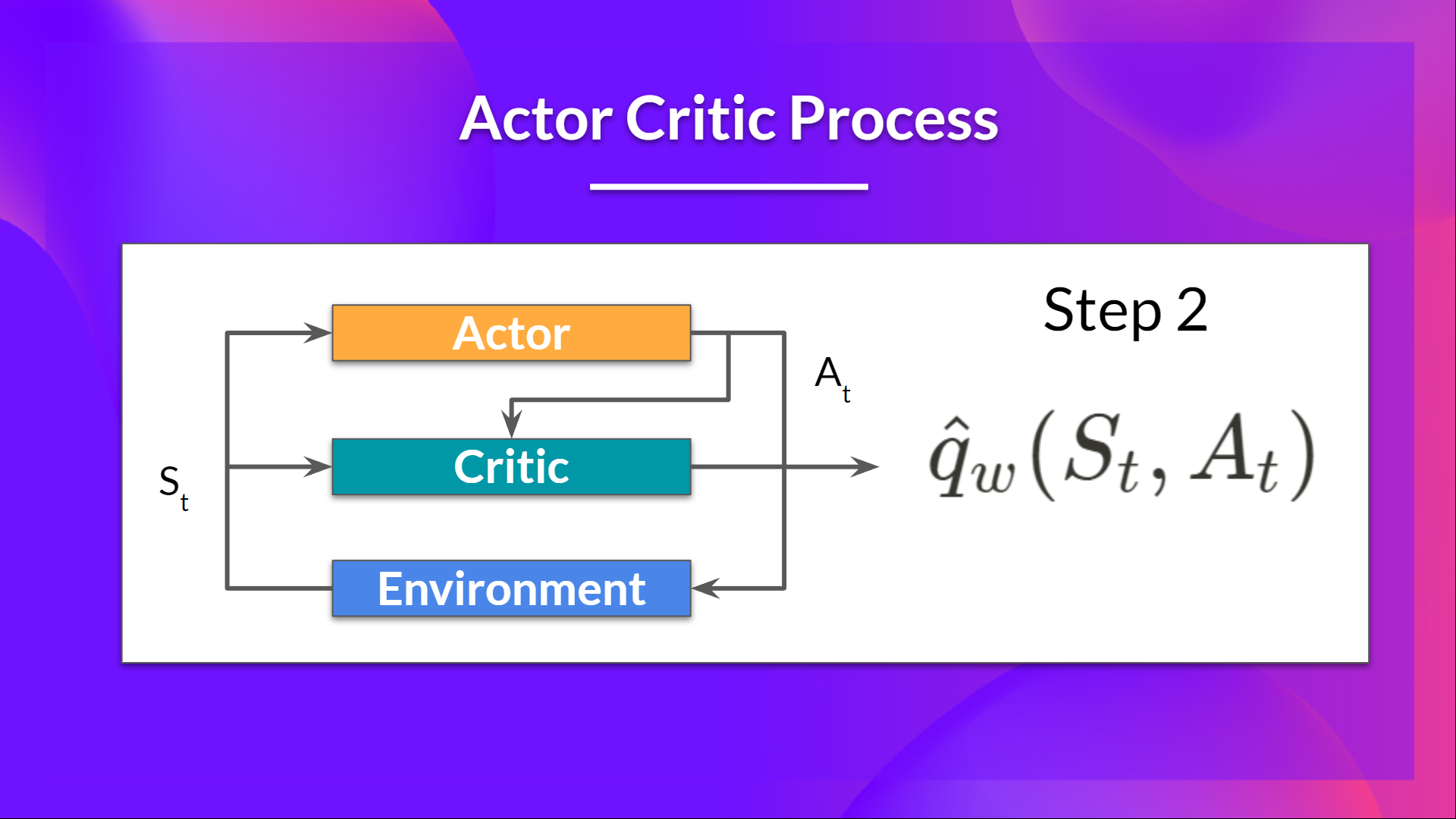
-The idea behind Actor-Critic is the following - we learn two function approximations:
-1. A policy that controls how our agent acts (π)
-2. A value function to assist the policy update by measuring how good the action taken is (q)
+The idea behind Actor-Critic is that we learn two function approximations:
+1. A `policy` that controls how our agent acts (π)
+2. A `value` function to assist the policy update by measuring how good the action taken is (q)
 @@ -97,7 +97,7 @@ The idea behind Actor-Critic is the following - we learn two function approximat
},
{
text: "It adds resistance to stochasticity and reduces high variance",
- explain: "Monte-carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
+ explain: "",
correct: true,
},
]}
@@ -105,11 +105,12 @@ The idea behind Actor-Critic is the following - we learn two function approximat
-### Q6: What is Advantege in the A2C method?
+### Q6: What is `Advantege` in the A2C method?
@@ -97,7 +97,7 @@ The idea behind Actor-Critic is the following - we learn two function approximat
},
{
text: "It adds resistance to stochasticity and reduces high variance",
- explain: "Monte-carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
+ explain: "",
correct: true,
},
]}
@@ -105,11 +105,12 @@ The idea behind Actor-Critic is the following - we learn two function approximat
-### Q6: What is Advantege in the A2C method?
+### Q6: What is `Advantege` in the A2C method?
Solution
-Instead of using directly the Action-Value function of the Critic as it is, we calculate an Advantage function, the relative advantage of an action compared to the others possible at a state.
+Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
+
In other words: how taking that action at a state is better compared to the average value of the state
