diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index a46425e..2843096 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -104,8 +104,21 @@
title: Optuna
- local: unitbonus2/hands-on
title: Hands-on
+- title: Unit 6. Actor Crtic methods with Robotics environments
+ sections:
+ - local: unit6/introduction
+ title: Introduction
+ - local: unit6/variance-problem
+ title: The Problem of Variance in Reinforce
+ - local: unit6/advantage-actor-critic
+ title: Advantage Actor-Critic (A2C)
+ - local: unit6/hands-on
+ title: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+ - local: unit6/conclusion
+ title: Conclusion
+ - local: unit6/additional-readings
+ title: Additional Readings
- title: What's next? New Units Publishing Schedule
sections:
- local: communication/publishing-schedule
title: Publishing Schedule
-
diff --git a/units/en/unit6/additional-readings.mdx b/units/en/unit6/additional-readings.mdx
new file mode 100644
index 0000000..4361839
--- /dev/null
+++ b/units/en/unit6/additional-readings.mdx
@@ -0,0 +1,9 @@
+# Additional Readings [[additional-readings]]
+
+## Bias-variance tradeoff in Reinforcement Learning
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+
+## Advantage Functions
+- [Advantage Functions, SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
new file mode 100644
index 0000000..d0731f0
--- /dev/null
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -0,0 +1,68 @@
+# Advantage Actor-Critic (A2C) [[advantage-actor-critic-a2c]]
+## Reducing variance with Actor-Critic methods
+The solution to reducing the variance of Reinforce algorithm and training our agent faster and better is to use a combination of policy-based and value-based methods: *the Actor-Critic method*.
+
+To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor, and your friend is the Critic.
+
+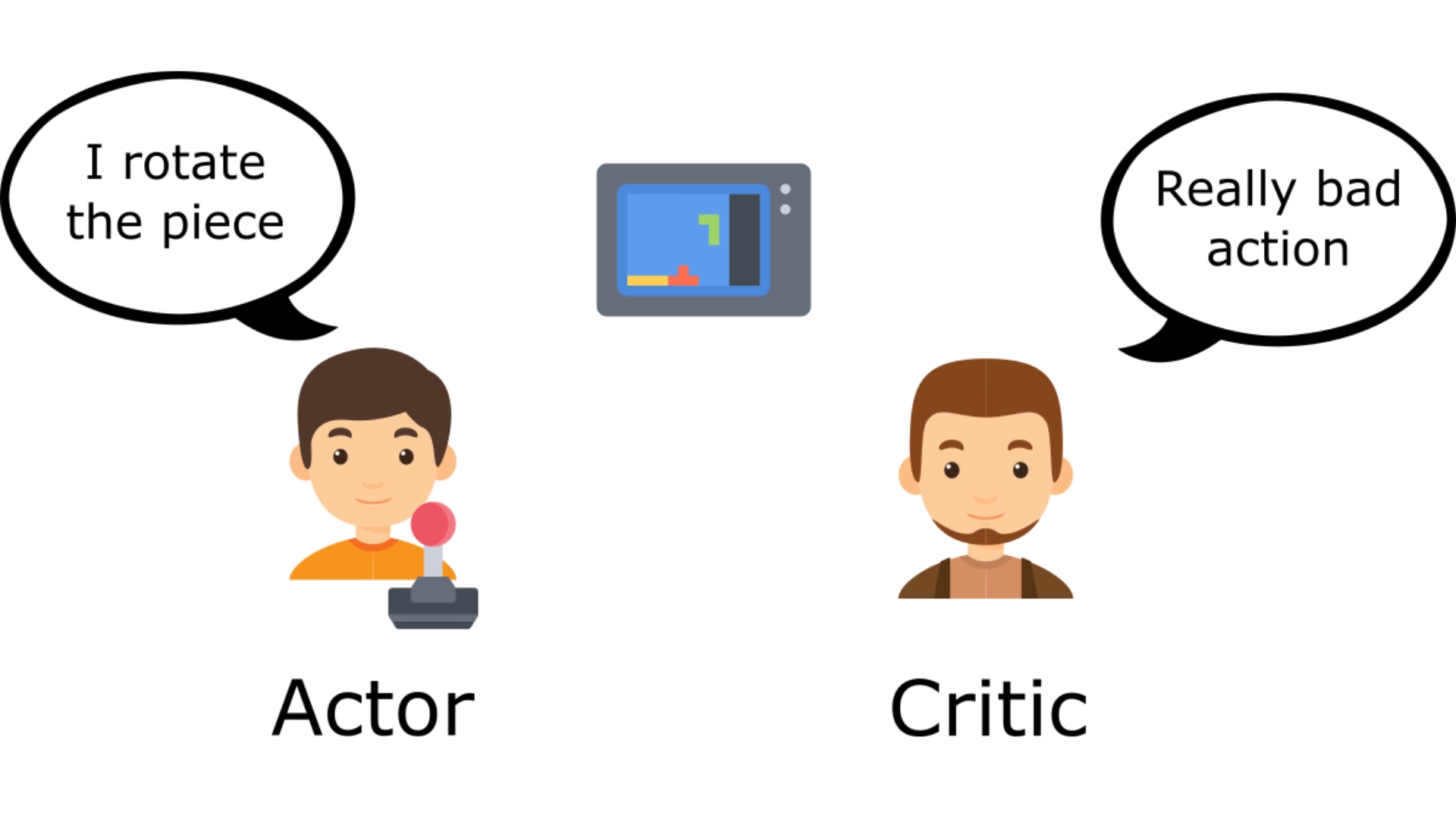 +
+You don't know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
+
+Learning from this feedback, **you'll update your policy and be better at playing that game.**
+
+On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
+
+This is the idea behind Actor-Critic. We learn two function approximations:
+
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+
+- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
+
+## The Actor-Critic Process
+Now that we have seen the Actor Critic's big picture let's dive deeper to understand how Actor and Critic improve together during the training.
+
+As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
+
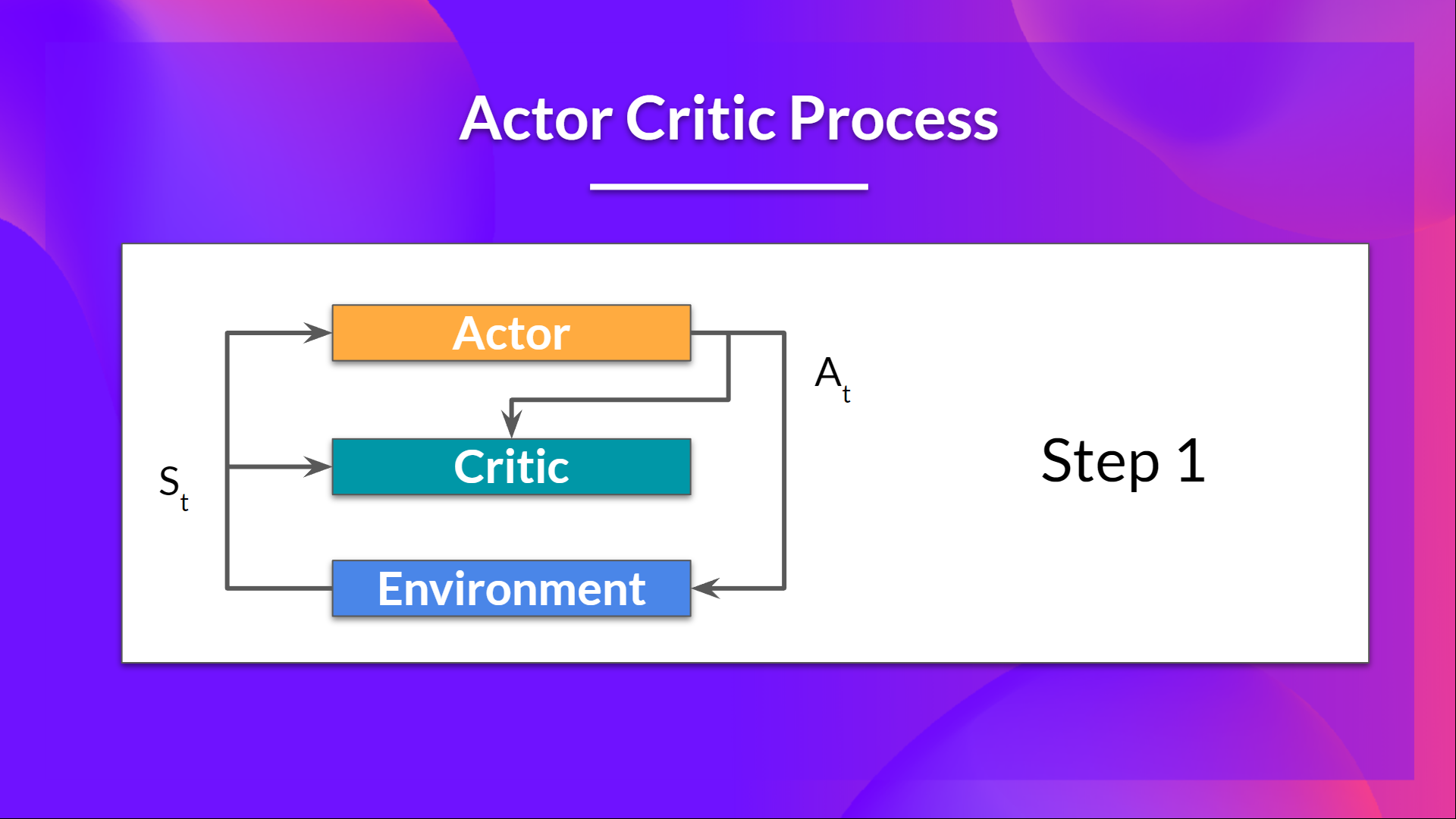
+Let's see the training process to understand how Actor and Critic are optimized:
+- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
+
+- Our Policy takes the state and **outputs an action** \\( A_t \\).
+
+
+
+You don't know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
+
+Learning from this feedback, **you'll update your policy and be better at playing that game.**
+
+On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
+
+This is the idea behind Actor-Critic. We learn two function approximations:
+
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+
+- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
+
+## The Actor-Critic Process
+Now that we have seen the Actor Critic's big picture let's dive deeper to understand how Actor and Critic improve together during the training.
+
+As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
+
+Let's see the training process to understand how Actor and Critic are optimized:
+- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
+
+- Our Policy takes the state and **outputs an action** \\( A_t \\).
+
+ +
+- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
+
+
+
+- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
+
+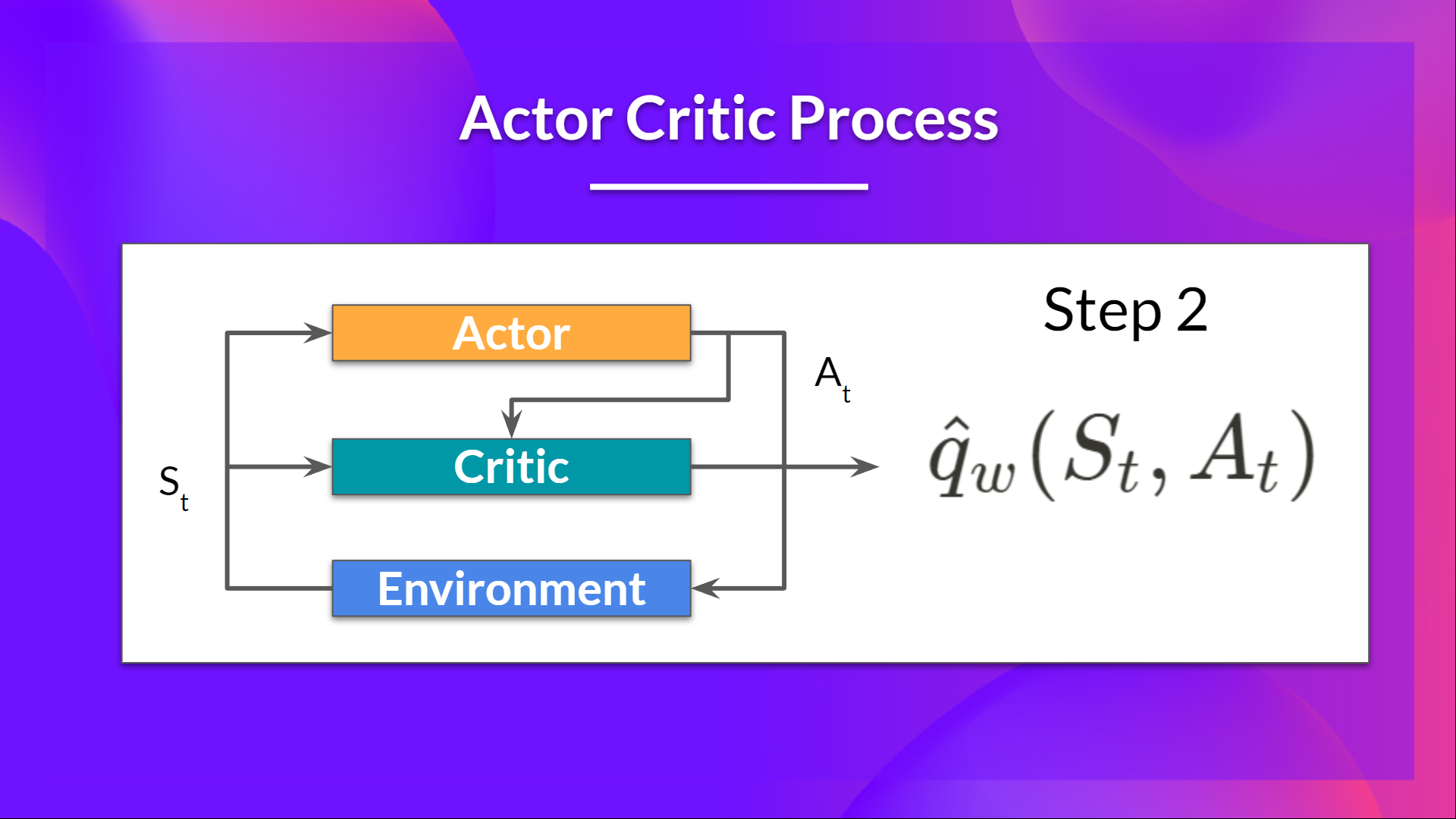 +
+- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
+
+
+
+- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
+
+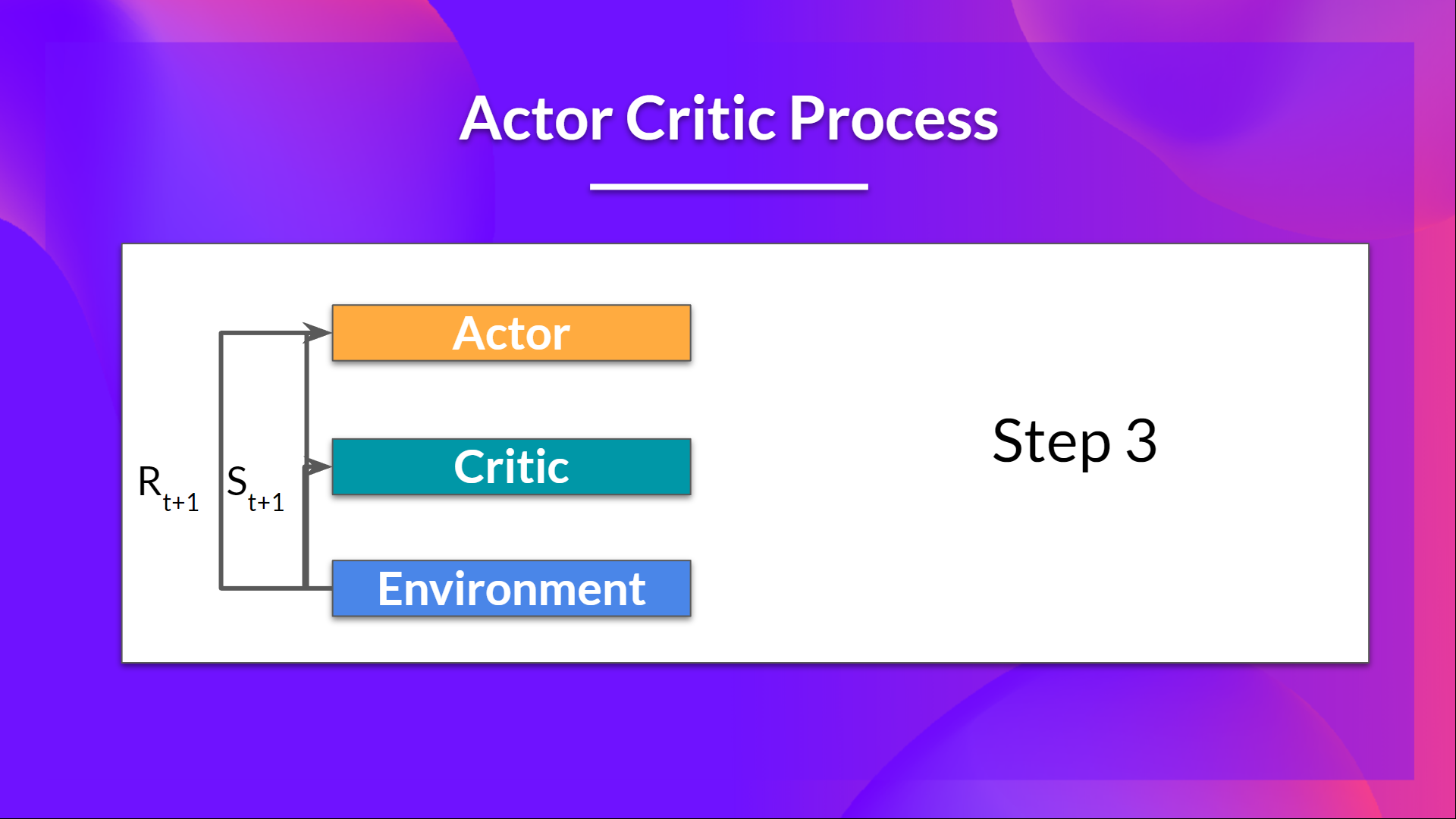 +
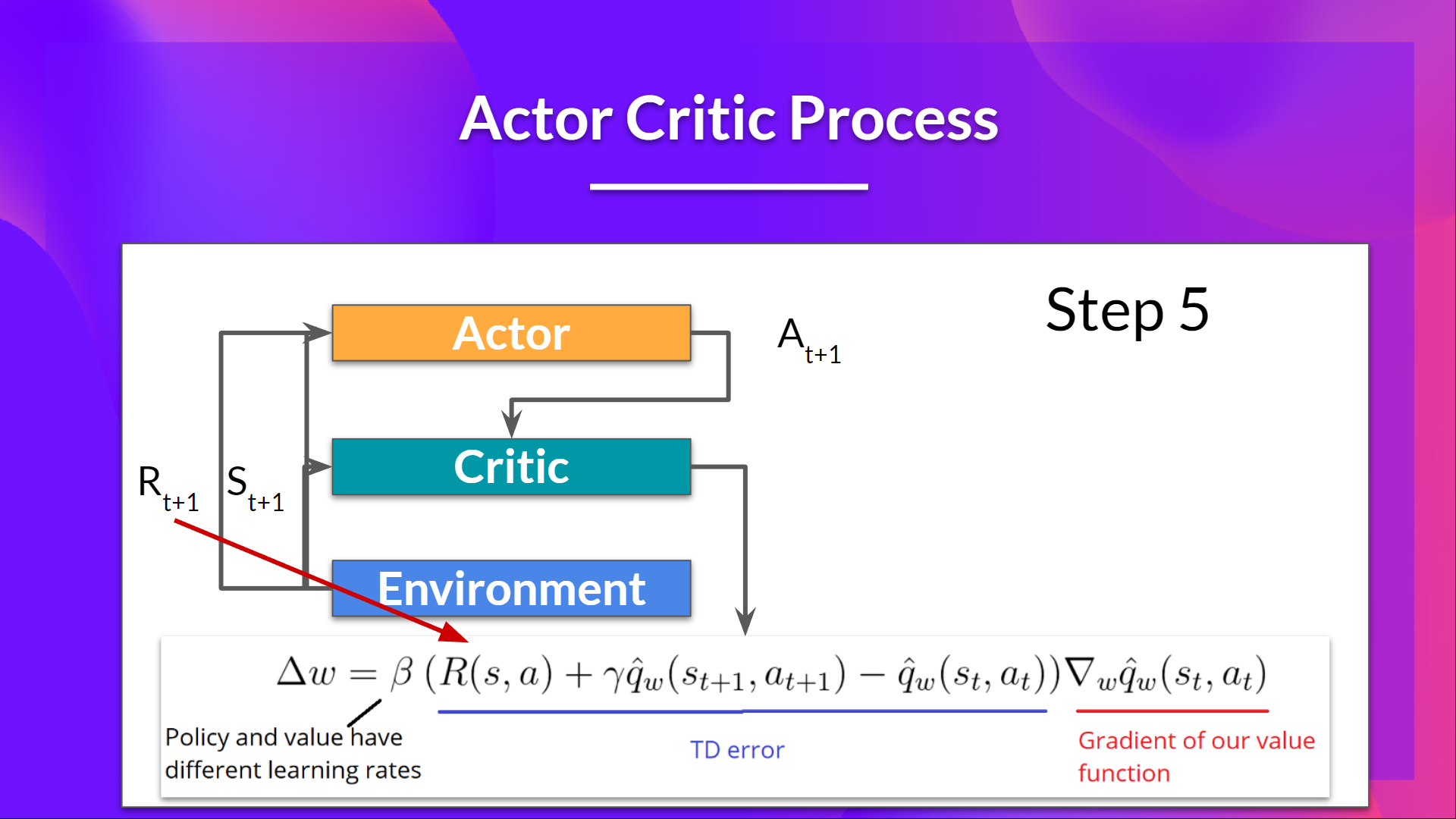
+- The Actor updates its policy parameters using the Q value.
+
+
+
+- The Actor updates its policy parameters using the Q value.
+
+ +
+- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
+
+- The Critic then updates its value parameters.
+
+
+
+- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
+
+- The Critic then updates its value parameters.
+
+ +
+## Adding "Advantage" in Actor Critic (A2C)
+We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
+
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how better taking that action at a state is compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+
+
+
+## Adding "Advantage" in Actor Critic (A2C)
+We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
+
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how better taking that action at a state is compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+
+ +
+In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
+
+The extra reward is what's beyond the expected value of that state.
+- If A(s,a) > 0: our gradient is **pushed in that direction**.
+- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
+
+The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
+
+
+
+In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
+
+The extra reward is what's beyond the expected value of that state.
+- If A(s,a) > 0: our gradient is **pushed in that direction**.
+- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
+
+The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
+
+ diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
new file mode 100644
index 0000000..5502e31
--- /dev/null
+++ b/units/en/unit6/conclusion.mdx
@@ -0,0 +1,15 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this unit and the tutorial. You've just trained your first virtual robots 🥳.
+
+**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
+
+Feel free to train your agent in other environments. The **best way to learn is to try things on your own!** For instance, what about teaching your robot [to stack objects](https://panda-gym.readthedocs.io/en/latest/usage/environments.html#sparce-reward-end-effector-control-default-setting)?
+
+In the next unit, we will learn to improve Actor-Critic Methods with Proximal Policy Optimization using the [CleanRL library](https://github.com/vwxyzjn/cleanrl). Then we'll study how to speed up the process with the [Sample Factory library](https://samplefactory.dev/). You'll train your PPO agents in these environments: VizDoom, Racing Car, and a 3D FPS.
+
+TODO: IMAGE of the environment Vizdoom + ED
+
+Finally, with your feedback, we want **to improve and update the course iteratively**. If you have some, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep learning, stay awesome 🤗,
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
new file mode 100644
index 0000000..28ca5c7
--- /dev/null
+++ b/units/en/unit6/hands-on.mdx
@@ -0,0 +1,35 @@
+# Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖 [[hands-on]]
+
+
+
+
+
+Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train three robots:
+
+- A bipedal walker 🚶 to learn to walk.
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move objects in the correct position.
+
+We're going to use two Robotics environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+TODO: ADD IMAGE OF THREE
+
+
+To validate this hands-on for the certification process, you need to push your three trained model to the Hub and get:
+
+TODO ADD CERTIFICATION ELEMENTS
+
+To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
new file mode 100644
index 0000000..8d3e6a6
--- /dev/null
+++ b/units/en/unit6/introduction.mdx
@@ -0,0 +1,25 @@
+# Introduction [[introduction]]
+
+TODO: ADD THUMBNAIL
+
+In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
+
+In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
+
+We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
+
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. Aka, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (policy-based method)
+- *A Critic* that measures **how good the action taken is** (value-based method)
+
+
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. Where we'll train three robots:
+- A bipedal walker 🚶 to learn to walk.
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move objects in the correct position.
+
+TODO: ADD IMAGE OF THREE
+
+Sounds exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
new file mode 100644
index 0000000..bb8df6a
--- /dev/null
+++ b/units/en/unit6/variance-problem.mdx
@@ -0,0 +1,30 @@
+# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
+
+In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+
+
+
diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
new file mode 100644
index 0000000..5502e31
--- /dev/null
+++ b/units/en/unit6/conclusion.mdx
@@ -0,0 +1,15 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this unit and the tutorial. You've just trained your first virtual robots 🥳.
+
+**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
+
+Feel free to train your agent in other environments. The **best way to learn is to try things on your own!** For instance, what about teaching your robot [to stack objects](https://panda-gym.readthedocs.io/en/latest/usage/environments.html#sparce-reward-end-effector-control-default-setting)?
+
+In the next unit, we will learn to improve Actor-Critic Methods with Proximal Policy Optimization using the [CleanRL library](https://github.com/vwxyzjn/cleanrl). Then we'll study how to speed up the process with the [Sample Factory library](https://samplefactory.dev/). You'll train your PPO agents in these environments: VizDoom, Racing Car, and a 3D FPS.
+
+TODO: IMAGE of the environment Vizdoom + ED
+
+Finally, with your feedback, we want **to improve and update the course iteratively**. If you have some, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep learning, stay awesome 🤗,
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
new file mode 100644
index 0000000..28ca5c7
--- /dev/null
+++ b/units/en/unit6/hands-on.mdx
@@ -0,0 +1,35 @@
+# Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖 [[hands-on]]
+
+
+
+
+
+Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train three robots:
+
+- A bipedal walker 🚶 to learn to walk.
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move objects in the correct position.
+
+We're going to use two Robotics environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+TODO: ADD IMAGE OF THREE
+
+
+To validate this hands-on for the certification process, you need to push your three trained model to the Hub and get:
+
+TODO ADD CERTIFICATION ELEMENTS
+
+To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
new file mode 100644
index 0000000..8d3e6a6
--- /dev/null
+++ b/units/en/unit6/introduction.mdx
@@ -0,0 +1,25 @@
+# Introduction [[introduction]]
+
+TODO: ADD THUMBNAIL
+
+In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
+
+In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
+
+We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
+
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. Aka, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (policy-based method)
+- *A Critic* that measures **how good the action taken is** (value-based method)
+
+
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. Where we'll train three robots:
+- A bipedal walker 🚶 to learn to walk.
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move objects in the correct position.
+
+TODO: ADD IMAGE OF THREE
+
+Sounds exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
new file mode 100644
index 0000000..bb8df6a
--- /dev/null
+++ b/units/en/unit6/variance-problem.mdx
@@ -0,0 +1,30 @@
+# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
+
+In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+
+
+ +
+- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
+- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. Indeed, we collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
+
+But the problem is that **the variance is high, since trajectories can lead to different returns** due to stochasticity of the environment (random events during episode) and stochasticity of the policy. Consequently, the same starting state can lead to very different returns.
+Because of this, **the return starting at the same state can vary significantly across episodes**.
+
+
+
+- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
+- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. Indeed, we collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
+
+But the problem is that **the variance is high, since trajectories can lead to different returns** due to stochasticity of the environment (random events during episode) and stochasticity of the policy. Consequently, the same starting state can lead to very different returns.
+Because of this, **the return starting at the same state can vary significantly across episodes**.
+
+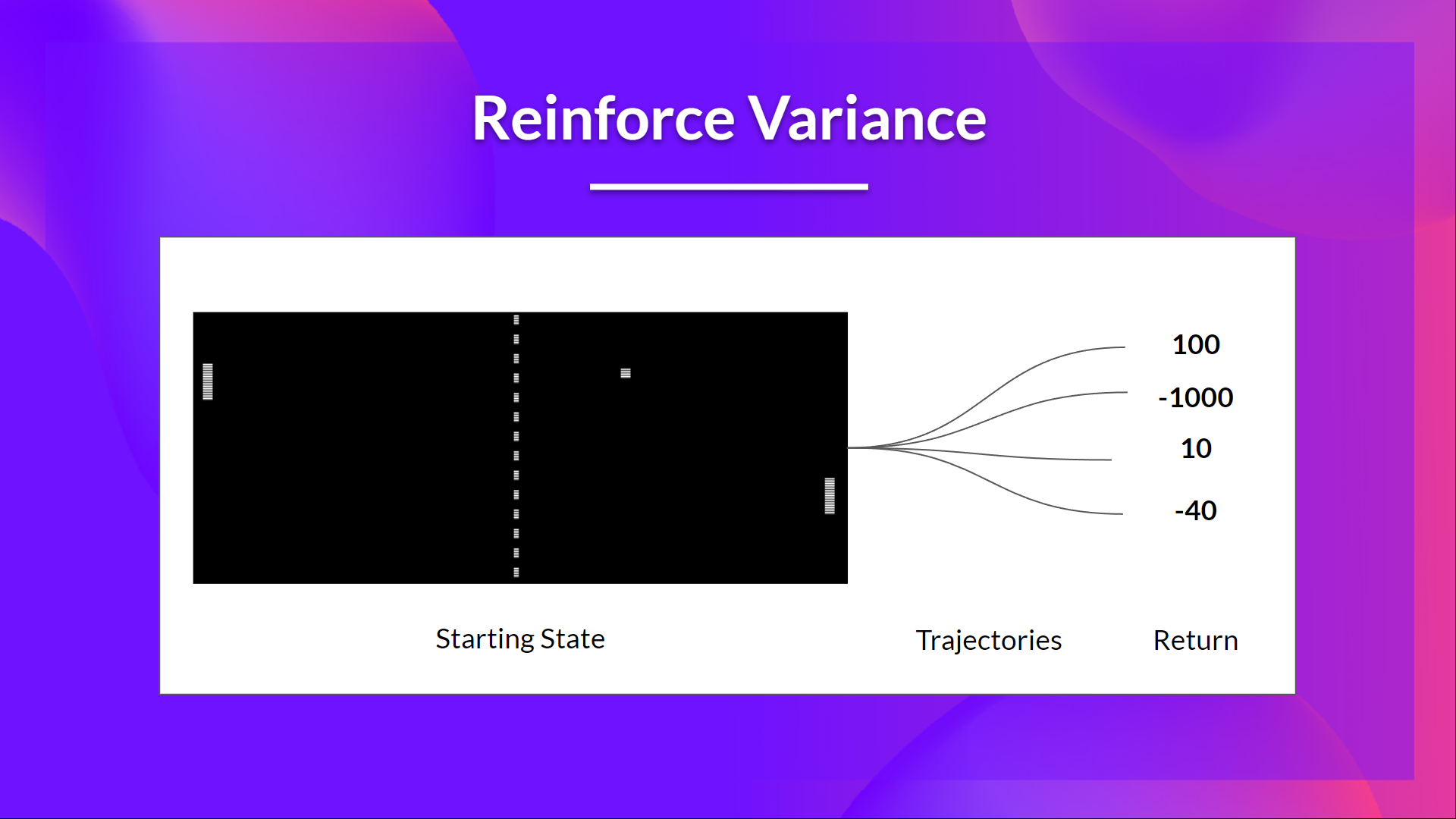 +
+The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
+
+However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
+
+---
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+---
+
+The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
+
+However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
+
+---
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+---