diff --git a/unit2/README.md b/unit2/README.md
index 4fc6892..2f59224 100644
--- a/unit2/README.md
+++ b/unit2/README.md
@@ -48,7 +48,9 @@ Are you new to Discord? Check our **discord 101 to get the best practices** 👉
5️⃣ 📖 **Read An [Introduction to Q-Learning Part 2](https://huggingface.co/blog/deep-rl-q-part2)**.
-6️⃣ 👩💻 Then dive on the hands-on, where **you’ll implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
+6️⃣ 📝 Take a piece of paper and **check your knowledge with this series of questions** ❔ 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/quiz2.md
+
+7️⃣ 👩💻 Then dive on the hands-on, where **you’ll implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
1. Frozen Lake v1 ❄️: where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. An autonomous taxi 🚕: where the agent will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
@@ -60,7 +62,7 @@ The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-L
You can work directly **with the colab notebook, which allows you not to have to install everything on your machine (and it’s free)**.
-7️⃣ The best way to learn **is to try things on your own**. That’s why we have a challenges section in the colab where we give you some ideas on how you can go further: using another environment, using another model etc.
+8️⃣ The best way to learn **is to try things on your own**. That’s why we have a challenges section in the colab where we give you some ideas on how you can go further: using another environment, using another model etc.
## Additional readings 📚
- [Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7](http://incompleteideas.net/book/RLbook2020.pdf)
diff --git a/unit2/assets/img/q-update-ex.jpg.jpg b/unit2/assets/img/q-update-ex.jpg.jpg
new file mode 100644
index 0000000..7f7c954
Binary files /dev/null and b/unit2/assets/img/q-update-ex.jpg.jpg differ
diff --git a/unit2/assets/img/q-update-solution.jpg.jpg b/unit2/assets/img/q-update-solution.jpg.jpg
new file mode 100644
index 0000000..0f761eb
Binary files /dev/null and b/unit2/assets/img/q-update-solution.jpg.jpg differ
diff --git a/unit2/quiz1.md b/unit2/quiz1.md
index 2075759..abe899b 100644
--- a/unit2/quiz1.md
+++ b/unit2/quiz1.md
@@ -91,9 +91,8 @@ There are two types of methods to learn a policy or a value function:
📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part1#monte-carlo-learning-at-the-end-of-the-episode
-
---
-Congrats on **finishing this Quiz** 🥳, if you missed some elements, take time to [read again the chapter](https://huggingface.co/blog/deep-rl-q-part1) to reinforce (😏) your knowledge.
+Congrats on **finishing this Quiz** 🥳, if you missed some elements, take time to [read the chapter again](https://huggingface.co/blog/deep-rl-q-part1) to reinforce (😏) your knowledge.
**Keep Learning, Stay Awesome**
diff --git a/unit2/quiz2.md b/unit2/quiz2.md
new file mode 100644
index 0000000..af45d32
--- /dev/null
+++ b/unit2/quiz2.md
@@ -0,0 +1,81 @@
+# Knowledge Check ✔️
+
+The best way to learn and [avoid the illusion of competence](https://fr.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+📝 Take a piece of paper and try to answer by writing, **then check the solutions**.
+
+### Q1: What is Q-Learning?
+
+
+Solution
+
+Q-Learning is **the algorithm we use to train our Q-Function**, an action-value function that determines the value of being at a particular state and taking a specific action at that state.
+
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#what-is-q-learning
+
+
+### Q2: What is a Q-Table?
+
+
+Solution
+
+ Q-table is the "internal memory" of our agent where each cell corresponds to a state-action value pair value. Think of this Q-table as the memory or cheat sheet of our Q-function.
+
+
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#what-is-q-learning
+
+
+### Q3: Why if we have an optimal Q-function Q* we have an optimal policy?
+
+
+Solution
+
+Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.
+
+ +
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#what-is-q-learning
+
+
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#what-is-q-learning
+
+
+### Q4: Can you explain what is Epsilon-Greedy Strategy?
+
+
+Solution
+Epsilon Greedy Strategy is a **policy that handles the exploration/exploitation trade-off**.
+
+The idea is that we define epsilon ɛ = 1.0:
+
+- With *probability 1 — ɛ* : we do exploitation (aka our agent selects the action with the highest state-action pair value).
+- With *probability ɛ* : we do exploration (trying random action).
+
+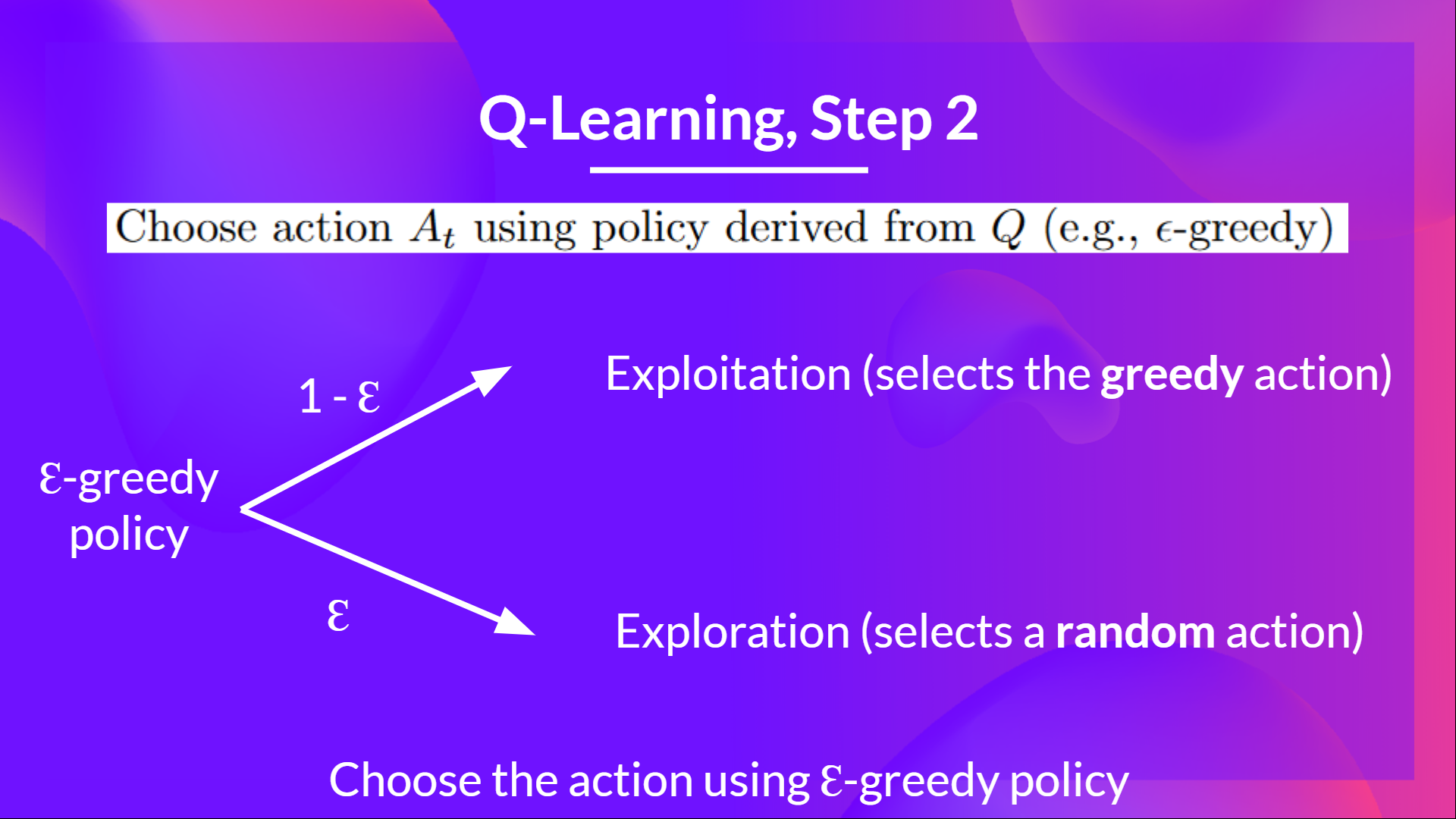 +
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#the-q-learning-algorithm
+
+
+
+📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#the-q-learning-algorithm
+
+
+
+### Q5: How do we update the Q value of a state, action pair?
+ +
+
+
+
+Solution
+  + 📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#the-q-learning-algorithm
+
+ 📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#the-q-learning-algorithm
+
+
+### Q6: What's the difference between on-policy and off-policy
+
+
+Solution
+  + 📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#off-policy-vs-on-policy
+
+ 📖 If you don't remember, check 👉 https://huggingface.co/blog/deep-rl-q-part2#off-policy-vs-on-policy
+
+
+
+---
+
+Congrats on **finishing this Quiz** 🥳, if you missed some elements, take time to [read the chapter again](https://huggingface.co/blog/deep-rl-q-part2) to reinforce (😏) your knowledge.
+
+**Keep Learning, Stay Awesome**
+
+