diff --git a/units/en/unit1/conclusion.mdx b/units/en/unit1/conclusion.mdx
index e1d8b56..fd280e0 100644
--- a/units/en/unit1/conclusion.mdx
+++ b/units/en/unit1/conclusion.mdx
@@ -1,16 +1,16 @@
# Conclusion [[conclusion]]
-Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared it with the community! 🥳
+Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared them with the community! 🥳
-It's **normal if you still feel confused with some of these elements**. This was the same for me and for all people who studied RL.
+It's **normal if you still feel confused by some of these elements**. This was the same for me and for all people who studied RL.
-**Take time to really grasp the material** before continuing. It’s important to master these elements and having a solid foundations before entering the fun part.
+**Take time to really grasp the material** before continuing. It’s important to master these elements and have a solid foundation before entering the fun part.
Naturally, during the course, we’re going to use and explain these terms again, but it’s better to understand them before diving into the next units.
-In the next (bonus) unit, we’re going to reinforce what we just learned by **training Huggy the Dog to fetch the stick**.
+In the next (bonus) unit, we’re going to reinforce what we just learned by **training Huggy the Dog to fetch a stick**.
-You will be able then to play with him 🤗.
+You will then be able to play with him 🤗.
diff --git a/units/en/unit1/deep-rl.mdx b/units/en/unit1/deep-rl.mdx
index b448d6f..acbbac1 100644
--- a/units/en/unit1/deep-rl.mdx
+++ b/units/en/unit1/deep-rl.mdx
@@ -8,7 +8,7 @@ Deep Reinforcement Learning introduces **deep neural networks to solve Reinforc
For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
-You’ll see the difference is that in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
+You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
In the second approach, **we will use a Neural Network** (to approximate the Q value).
@@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the Q
-If you are not familiar with Deep Learning you definitely should watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
+If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
diff --git a/units/en/unit1/exp-exp-tradeoff.mdx b/units/en/unit1/exp-exp-tradeoff.mdx
index 451adde..1c2778f 100644
--- a/units/en/unit1/exp-exp-tradeoff.mdx
+++ b/units/en/unit1/exp-exp-tradeoff.mdx
@@ -30,7 +30,7 @@ If it’s still confusing, **think of a real problem: the choice of picking a re
-- *Exploitation*: You go every day to the same one that you know is good and **take the risk to miss another better restaurant.**
+- *Exploitation*: You go to the same one that you know is good every day and **take the risk to miss another better restaurant.**
- *Exploration*: Try restaurants you never went to before, with the risk of having a bad experience **but the probable opportunity of a fantastic experience.**
To recap:
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 5c181a0..737fbb4 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -34,7 +34,7 @@ So let's get started! 🚀
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
-You can either do this hands-on by reading the notebook or following it with the video tutorial 📹 :
+You can either do this hands-on by reading the notebook or following along with the video tutorial 📹 :
@@ -75,7 +75,7 @@ In this free course, you will:
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
- 🤖 Train **agents in unique environments**
-And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
+And more: check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
@@ -85,17 +85,17 @@ The best way to keep in touch and ask questions is to join our discord server to
## Prerequisites 🏗️
Before diving into the notebook, you need to:
-🔲 📝 **Read Unit 0** that gives you all the **information about the course and help you to onboard** 🤗
+🔲 📝 **Read Unit 0** that gives you all the **information about the course and helps you to onboard** 🤗
🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** by reading Unit 1
-## A small recap of what is Deep Reinforcement Learning 📚
+## A small recap of Deep Reinforcement Learning 📚
Let's do a small recap on what we learned in the first Unit:
-- Reinforcement Learning is a **computational approach to learning from action**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+- Reinforcement Learning is a **computational approach to learning from actions**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
-- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of the expected cumulative reward.
+- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of an expected cumulative reward.
- The RL process is a **loop that outputs a sequence of state, action, reward, and next state**.
@@ -151,7 +151,7 @@ Hence the following cell will install virtual screen libraries and create and ru
!pip3 install pyvirtualdisplay
```
-To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
@@ -175,7 +175,7 @@ One additional library we import is huggingface_hub **to be able to upload and d
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
-You can see here all the Deep reinforcement Learning models available 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
+You can see all the Deep reinforcement Learning models available here 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
@@ -192,7 +192,7 @@ from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.env_util import make_vec_env
```
-## Understand what is Gym and how it works 🤖
+## Understand Gym and how it works 🤖
🏋 The library containing our environment is called Gym.
**You'll use Gym a lot in Deep Reinforcement Learning.**
@@ -201,15 +201,15 @@ The Gym library provides two things:
- An interface that allows you to **create RL environments**.
- A **collection of environments** (gym-control, atari, box2D...).
-Let's look at an example, but first let's remember what's the RL Loop.
+Let's look at an example, but first let's recall the RL loop.
At each step:
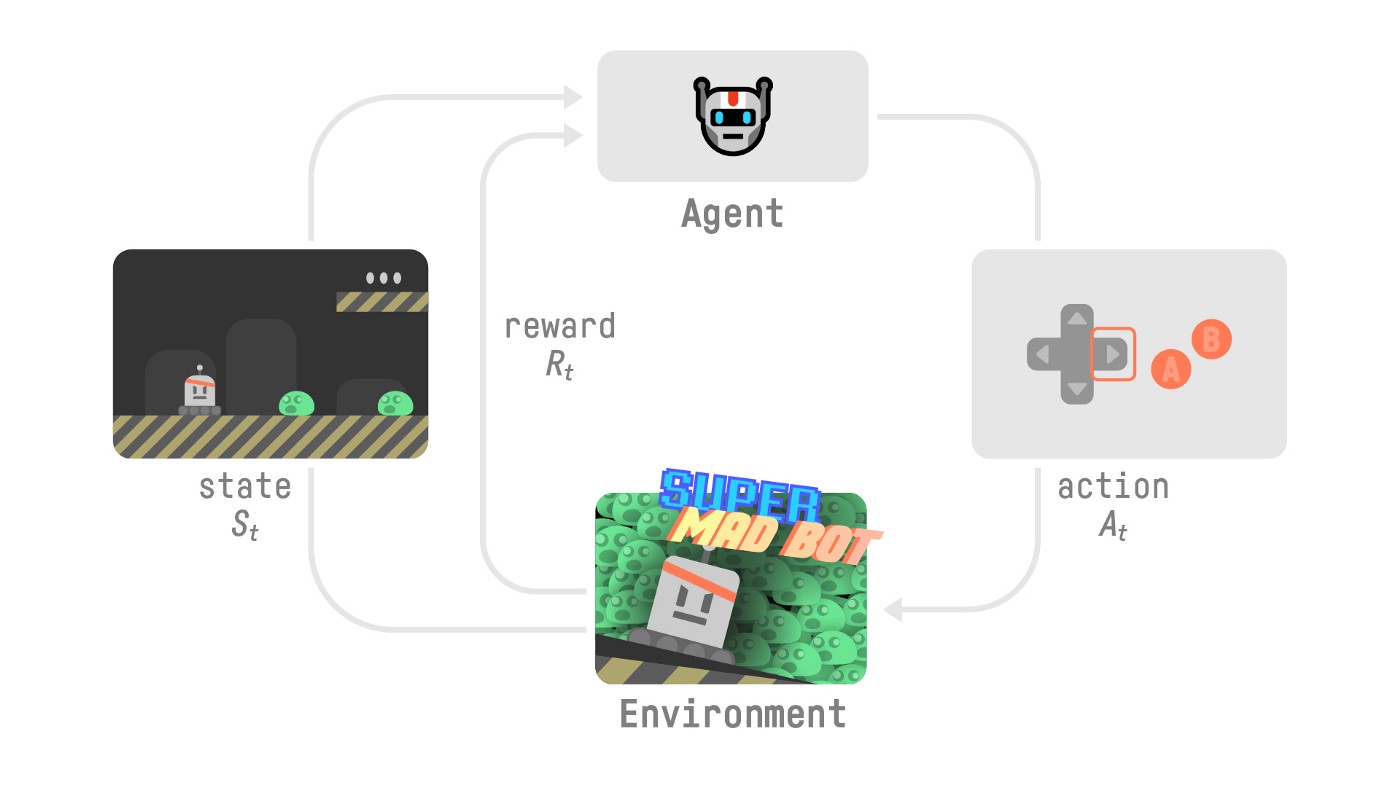
-- Our Agent receives **state S0** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state S0,** the Agent takes **action A0** — our Agent will move to the right.
-- Environment to a **new** **state S1** — new frame.
-- The environment gives some **reward R1** to the Agent — we’re not dead *(Positive Reward +1)*.
+- Our Agent receives a **state (S0)** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state (S0),** the Agent takes an **action (A0)** — our Agent will move to the right.
+- The environment transitions to a **new** **state (S1)** — new frame.
+- The environment gives some **reward (R1)** to the Agent — we’re not dead *(Positive Reward +1)*.
With Gym:
@@ -263,7 +263,7 @@ for _ in range(20):
### The environment 🎮
-In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://www.gymlibrary.dev/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position(horizontal, vertical, and angular) to land correctly.**
+In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://www.gymlibrary.dev/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position (horizontal, vertical, and angular) to land correctly.**
---
@@ -295,8 +295,8 @@ We see with `Observation Space Shape (8,)` that the observation is a vector of s
- Vertical speed (y)
- Angle
- Angular speed
-- If the left leg has contact point touched the land
-- If the right leg has contact point touched the land
+- If the left leg contact point has touched the land
+- If the right leg contact point has touched the land
```python
@@ -316,12 +316,12 @@ Reward function (the function that will gives a reward at each timestep) 💰:
- Moving from the top of the screen to the landing pad and zero speed is about 100~140 points.
- Firing main engine is -0.3 each frame
-- Each leg ground contact is +10 points
-- Episode finishes if the lander crashes (additional - 100 points) or come to rest (+100 points)
+- Each leg making ground contact is +10 points
+- Episode finishes if the lander crashes (additional - 100 points) or comes to rest (+100 points)
#### Vectorized Environment
-- We create a vectorized environment (method for stacking multiple independent environments into a single environment) of 16 environments, this way, **we'll have more diverse experiences during the training.**
+- We create a vectorized environment (a method for stacking multiple independent environments into a single environment) of 16 environments, this way, **we'll have more diverse experiences during the training.**
```python
# Create the environment
@@ -330,7 +330,7 @@ env = make_vec_env("LunarLander-v2", n_envs=16)
## Create the Model 🤖
-- Now that we studied our environment and we understood the problem: **being able to land correctly the Lunar Lander to the Landing Pad by controlling left, right and main orientation engine**. Let's build the algorithm we're going to use to solve this Problem 🚀.
+- We have studied our environment and we understood the problem: **being able to land the Lunar Lander to the Landing Pad correctly by controlling left, right and main orientation engine**. Now let's build the algorithm we're going to use to solve this Problem 🚀.
- To do so, we're going to use our first Deep RL library, [Stable Baselines3 (SB3)](https://stable-baselines3.readthedocs.io/en/master/).
@@ -344,12 +344,12 @@ env = make_vec_env("LunarLander-v2", n_envs=16)

-To solve this problem, we're going to use SB3 **PPO**. [PPO (aka Proximal Policy Optimization) is one of the of the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
+To solve this problem, we're going to use SB3 **PPO**. [PPO (aka Proximal Policy Optimization) is one of the the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
PPO is a combination of:
-- *Value-based reinforcement learning method*: learning an action-value function that will tell us what's the **most valuable action to take given a state and action**.
-- *Policy-based reinforcement learning method*: learning a policy that will **gives us a probability distribution over actions**.
+- *Value-based reinforcement learning method*: learning an action-value function that will tell us the **most valuable action to take given a state and action**.
+- *Policy-based reinforcement learning method*: learning a policy that will **give us a probability distribution over actions**.
Stable-Baselines3 is easy to set up:
@@ -401,7 +401,7 @@ model = PPO(
## Train the PPO agent 🏃
-- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use less timesteps if you just want to try it out.
+- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use fewer timesteps if you just want to try it out.
- During the training, take a ☕ break you deserved it 🤗
```python
@@ -452,7 +452,7 @@ mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, d
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
-- In my case, I got a mean reward is `200.20 +/- 20.80` after training for 1 million steps, which means that our lunar lander agent is ready to land on the moon 🌛🥳.
+- In my case, I got a mean reward of `200.20 +/- 20.80` after training for 1 million steps, which means that our lunar lander agent is ready to land on the moon 🌛🥳.
## Publish our trained model on the Hub 🔥
Now that we saw we got good results after the training, we can publish our trained model on the Hub 🤗 with one line of code.
@@ -472,9 +472,9 @@ This way:
To be able to share your model with the community there are three more steps to follow:
-1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+1️⃣ (If it's not already done) create an account on HF ➡ https://huggingface.co/join
-2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+2️⃣ Sign in and then you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
@@ -494,7 +494,7 @@ If you don't want to use a Google Colab or a Jupyter Notebook, you need to use t
Let's fill the `package_to_hub` function:
- `model`: our trained model.
- `model_name`: the name of the trained model that we defined in `model_save`
-- `model_architecture`: the model architecture we used: in our case PPO
+- `model_architecture`: the model architecture we used, in our case PPO
- `env_id`: the name of the environment, in our case `LunarLander-v2`
- `eval_env`: the evaluation environment defined in eval_env
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `(repo_id = {username}/{repo_name})`
@@ -598,7 +598,7 @@ Thanks to [ironbar](https://github.com/ironbar) for the contribution.
Loading a saved model from the Hub is really easy.
-You go https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
+You go to https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
1. You select one and copy its repo_id
@@ -644,20 +644,20 @@ In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Rei
Here are some ideas to achieve so:
* Train more steps
-* Try different hyperparameters of `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
-* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another models such as DQN.
+* Try different hyperparameters for `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
+* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another model such as DQN.
* **Push your new trained model** on the Hub 🔥
**Compare the results of your LunarLander-v2 with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
-Is moon landing too boring to you? Try to **change the environment**, why not using MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they works [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+Is moon landing too boring for you? Try to **change the environment**, why not use MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
________________________________________________________________________
Congrats on finishing this chapter! That was the biggest one, **and there was a lot of information.**
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
-Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
+Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and have a solid foundations.
Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d5d62ab..cf155e7 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -12,9 +12,9 @@ To understand the RL process, let’s imagine an agent learning to play a platfo
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
+- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment goes to a **new** **state \\(S_1\\)** — new frame.
- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
This RL loop outputs a sequence of **state, action, reward and next state.**
@@ -34,7 +34,7 @@ That’s why in Reinforcement Learning, **to have the best behavior,** we aim
## Markov Property [[markov-property]]
-In papers, you’ll see that the RL process is called the **Markov Decision Process** (MDP).
+In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
@@ -58,10 +58,10 @@ In a chess game, we have access to the whole board information, so we receive a
-In Super Mario Bros, we only see a part of the level close to the player, so we receive an observation.
+In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
-In Super Mario Bros, we only see a part of the level close to the player, so we receive an observation.
+In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
@@ -110,7 +110,7 @@ The cumulative reward at each time step **t** can be written as:
-The cumulative reward equals to the sum of all rewards of the sequence.
+The cumulative reward equals the sum of all rewards in the sequence.
@@ -134,7 +134,7 @@ Consequently, **the reward near the cat, even if it is bigger (more cheese), wi
To discount the rewards, we proceed like this:
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.99 and 0.95**.
+1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
diff --git a/units/en/unit1/summary.mdx b/units/en/unit1/summary.mdx
index 05c57ff..3462ef3 100644
--- a/units/en/unit1/summary.mdx
+++ b/units/en/unit1/summary.mdx
@@ -2,7 +2,7 @@
That was a lot of information! Let's summarize:
-- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+- Reinforcement Learning is a computational approach of learning from actions. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
- The goal of any RL agent is to maximize its expected cumulative reward (also called expected return) because RL is based on the **reward hypothesis**, which is that **all goals can be described as the maximization of the expected cumulative reward.**
diff --git a/units/en/unit1/tasks.mdx b/units/en/unit1/tasks.mdx
index 9eb83a2..a5e7e05 100644
--- a/units/en/unit1/tasks.mdx
+++ b/units/en/unit1/tasks.mdx
@@ -6,7 +6,7 @@ A task is an **instance** of a Reinforcement Learning problem. We can have two t
In this case, we have a starting point and an ending point **(a terminal state). This creates an episode**: a list of States, Actions, Rewards, and new States.
-For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ending **when you’re killed or you reached the end of the level.**
+For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ends **when you’re killed or you reached the end of the level.**
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index 5818e5e..44ce264 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -4,7 +4,7 @@
Now that we learned the RL framework, how do we solve the RL problem?
-In other terms, how to build an RL agent that can **select the actions that maximize its expected cumulative reward?**
+In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
## The Policy π: the agent’s brain [[policy]]
@@ -26,7 +26,7 @@ There are two approaches to train our agent to find this optimal policy π\*:
In Policy-Based methods, **we learn a policy function directly.**
-This function will define a mapping between each state and the best corresponding action. We can also say that it'll define **a probability distribution over the set of possible actions at that state.**
+This function will define a mapping from each state to the best corresponding action. Alternatively, it could define **a probability distribution over the set of possible actions at that state.**
@@ -69,13 +69,13 @@ If we recap:
In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
-Here we see that our value function **defined value for each possible state.**
+Here we see that our value function **defined values for each possible state.**
diff --git a/units/en/unit1/what-is-rl.mdx b/units/en/unit1/what-is-rl.mdx
index 410569c..ba63f92 100644
--- a/units/en/unit1/what-is-rl.mdx
+++ b/units/en/unit1/what-is-rl.mdx
@@ -17,12 +17,12 @@ Your brother will interact with the environment (the video game) by pressing the
-But then, **he presses right again** and he touches an enemy. He just died, so that's a -1 reward.
+But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
-By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
+By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
**Without any supervision**, the child will get better and better at playing the game.
@@ -31,7 +31,7 @@ That’s how humans and animals learn, **through interaction.** Reinforcement
### A formal definition [[a-formal-definition]]
-If we take now a formal definition:
+We can now make a formal definition:
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
 -
- diff --git a/units/en/unit1/deep-rl.mdx b/units/en/unit1/deep-rl.mdx
index b448d6f..acbbac1 100644
--- a/units/en/unit1/deep-rl.mdx
+++ b/units/en/unit1/deep-rl.mdx
@@ -8,7 +8,7 @@ Deep Reinforcement Learning introduces **deep neural networks to solve Reinforc
For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
-You’ll see the difference is that in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
+You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
In the second approach, **we will use a Neural Network** (to approximate the Q value).
@@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the Q
-If you are not familiar with Deep Learning you definitely should watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
+If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
diff --git a/units/en/unit1/exp-exp-tradeoff.mdx b/units/en/unit1/exp-exp-tradeoff.mdx
index 451adde..1c2778f 100644
--- a/units/en/unit1/exp-exp-tradeoff.mdx
+++ b/units/en/unit1/exp-exp-tradeoff.mdx
@@ -30,7 +30,7 @@ If it’s still confusing, **think of a real problem: the choice of picking a re
-- *Exploitation*: You go every day to the same one that you know is good and **take the risk to miss another better restaurant.**
+- *Exploitation*: You go to the same one that you know is good every day and **take the risk to miss another better restaurant.**
- *Exploration*: Try restaurants you never went to before, with the risk of having a bad experience **but the probable opportunity of a fantastic experience.**
To recap:
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 5c181a0..737fbb4 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -34,7 +34,7 @@ So let's get started! 🚀
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
-You can either do this hands-on by reading the notebook or following it with the video tutorial 📹 :
+You can either do this hands-on by reading the notebook or following along with the video tutorial 📹 :
diff --git a/units/en/unit1/deep-rl.mdx b/units/en/unit1/deep-rl.mdx
index b448d6f..acbbac1 100644
--- a/units/en/unit1/deep-rl.mdx
+++ b/units/en/unit1/deep-rl.mdx
@@ -8,7 +8,7 @@ Deep Reinforcement Learning introduces **deep neural networks to solve Reinforc
For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
-You’ll see the difference is that in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
+You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
In the second approach, **we will use a Neural Network** (to approximate the Q value).
@@ -18,4 +18,4 @@ In the second approach, **we will use a Neural Network** (to approximate the Q
-If you are not familiar with Deep Learning you definitely should watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
+If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
diff --git a/units/en/unit1/exp-exp-tradeoff.mdx b/units/en/unit1/exp-exp-tradeoff.mdx
index 451adde..1c2778f 100644
--- a/units/en/unit1/exp-exp-tradeoff.mdx
+++ b/units/en/unit1/exp-exp-tradeoff.mdx
@@ -30,7 +30,7 @@ If it’s still confusing, **think of a real problem: the choice of picking a re
-- *Exploitation*: You go every day to the same one that you know is good and **take the risk to miss another better restaurant.**
+- *Exploitation*: You go to the same one that you know is good every day and **take the risk to miss another better restaurant.**
- *Exploration*: Try restaurants you never went to before, with the risk of having a bad experience **but the probable opportunity of a fantastic experience.**
To recap:
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 5c181a0..737fbb4 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -34,7 +34,7 @@ So let's get started! 🚀
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
-You can either do this hands-on by reading the notebook or following it with the video tutorial 📹 :
+You can either do this hands-on by reading the notebook or following along with the video tutorial 📹 :
 Let's do a small recap on what we learned in the first Unit:
-- Reinforcement Learning is a **computational approach to learning from action**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+- Reinforcement Learning is a **computational approach to learning from actions**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
-- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of the expected cumulative reward.
+- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of an expected cumulative reward.
- The RL process is a **loop that outputs a sequence of state, action, reward, and next state**.
@@ -151,7 +151,7 @@ Hence the following cell will install virtual screen libraries and create and ru
!pip3 install pyvirtualdisplay
```
-To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
@@ -175,7 +175,7 @@ One additional library we import is huggingface_hub **to be able to upload and d
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
-You can see here all the Deep reinforcement Learning models available 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
+You can see all the Deep reinforcement Learning models available here 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
@@ -192,7 +192,7 @@ from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.env_util import make_vec_env
```
-## Understand what is Gym and how it works 🤖
+## Understand Gym and how it works 🤖
🏋 The library containing our environment is called Gym.
**You'll use Gym a lot in Deep Reinforcement Learning.**
@@ -201,15 +201,15 @@ The Gym library provides two things:
- An interface that allows you to **create RL environments**.
- A **collection of environments** (gym-control, atari, box2D...).
-Let's look at an example, but first let's remember what's the RL Loop.
+Let's look at an example, but first let's recall the RL loop.
Let's do a small recap on what we learned in the first Unit:
-- Reinforcement Learning is a **computational approach to learning from action**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
+- Reinforcement Learning is a **computational approach to learning from actions**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
-- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of the expected cumulative reward.
+- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of an expected cumulative reward.
- The RL process is a **loop that outputs a sequence of state, action, reward, and next state**.
@@ -151,7 +151,7 @@ Hence the following cell will install virtual screen libraries and create and ru
!pip3 install pyvirtualdisplay
```
-To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
@@ -175,7 +175,7 @@ One additional library we import is huggingface_hub **to be able to upload and d
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
-You can see here all the Deep reinforcement Learning models available 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
+You can see all the Deep reinforcement Learning models available here 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
@@ -192,7 +192,7 @@ from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.env_util import make_vec_env
```
-## Understand what is Gym and how it works 🤖
+## Understand Gym and how it works 🤖
🏋 The library containing our environment is called Gym.
**You'll use Gym a lot in Deep Reinforcement Learning.**
@@ -201,15 +201,15 @@ The Gym library provides two things:
- An interface that allows you to **create RL environments**.
- A **collection of environments** (gym-control, atari, box2D...).
-Let's look at an example, but first let's remember what's the RL Loop.
+Let's look at an example, but first let's recall the RL loop.
 @@ -494,7 +494,7 @@ If you don't want to use a Google Colab or a Jupyter Notebook, you need to use t
Let's fill the `package_to_hub` function:
- `model`: our trained model.
- `model_name`: the name of the trained model that we defined in `model_save`
-- `model_architecture`: the model architecture we used: in our case PPO
+- `model_architecture`: the model architecture we used, in our case PPO
- `env_id`: the name of the environment, in our case `LunarLander-v2`
- `eval_env`: the evaluation environment defined in eval_env
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `(repo_id = {username}/{repo_name})`
@@ -598,7 +598,7 @@ Thanks to [ironbar](https://github.com/ironbar) for the contribution.
Loading a saved model from the Hub is really easy.
-You go https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
+You go to https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
1. You select one and copy its repo_id
@@ -494,7 +494,7 @@ If you don't want to use a Google Colab or a Jupyter Notebook, you need to use t
Let's fill the `package_to_hub` function:
- `model`: our trained model.
- `model_name`: the name of the trained model that we defined in `model_save`
-- `model_architecture`: the model architecture we used: in our case PPO
+- `model_architecture`: the model architecture we used, in our case PPO
- `env_id`: the name of the environment, in our case `LunarLander-v2`
- `eval_env`: the evaluation environment defined in eval_env
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `(repo_id = {username}/{repo_name})`
@@ -598,7 +598,7 @@ Thanks to [ironbar](https://github.com/ironbar) for the contribution.
Loading a saved model from the Hub is really easy.
-You go https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
+You go to https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
1. You select one and copy its repo_id
 @@ -644,20 +644,20 @@ In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Rei
Here are some ideas to achieve so:
* Train more steps
-* Try different hyperparameters of `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
-* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another models such as DQN.
+* Try different hyperparameters for `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
+* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another model such as DQN.
* **Push your new trained model** on the Hub 🔥
**Compare the results of your LunarLander-v2 with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
-Is moon landing too boring to you? Try to **change the environment**, why not using MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they works [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+Is moon landing too boring for you? Try to **change the environment**, why not use MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
________________________________________________________________________
Congrats on finishing this chapter! That was the biggest one, **and there was a lot of information.**
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
-Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
+Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and have a solid foundations.
Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d5d62ab..cf155e7 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -12,9 +12,9 @@ To understand the RL process, let’s imagine an agent learning to play a platfo
@@ -644,20 +644,20 @@ In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Rei
Here are some ideas to achieve so:
* Train more steps
-* Try different hyperparameters of `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
-* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another models such as DQN.
+* Try different hyperparameters for `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
+* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another model such as DQN.
* **Push your new trained model** on the Hub 🔥
**Compare the results of your LunarLander-v2 with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
-Is moon landing too boring to you? Try to **change the environment**, why not using MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they works [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+Is moon landing too boring for you? Try to **change the environment**, why not use MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
________________________________________________________________________
Congrats on finishing this chapter! That was the biggest one, **and there was a lot of information.**
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
-Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
+Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and have a solid foundations.
Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index d5d62ab..cf155e7 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -12,9 +12,9 @@ To understand the RL process, let’s imagine an agent learning to play a platfo
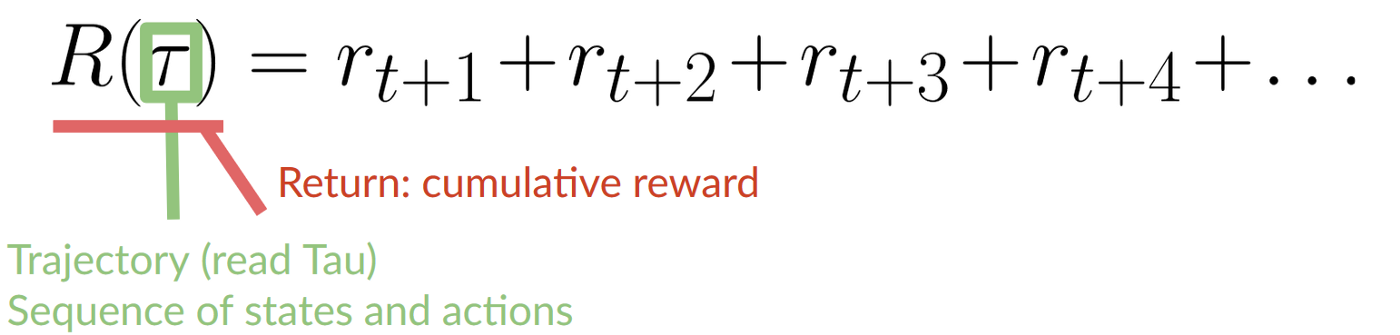 -
-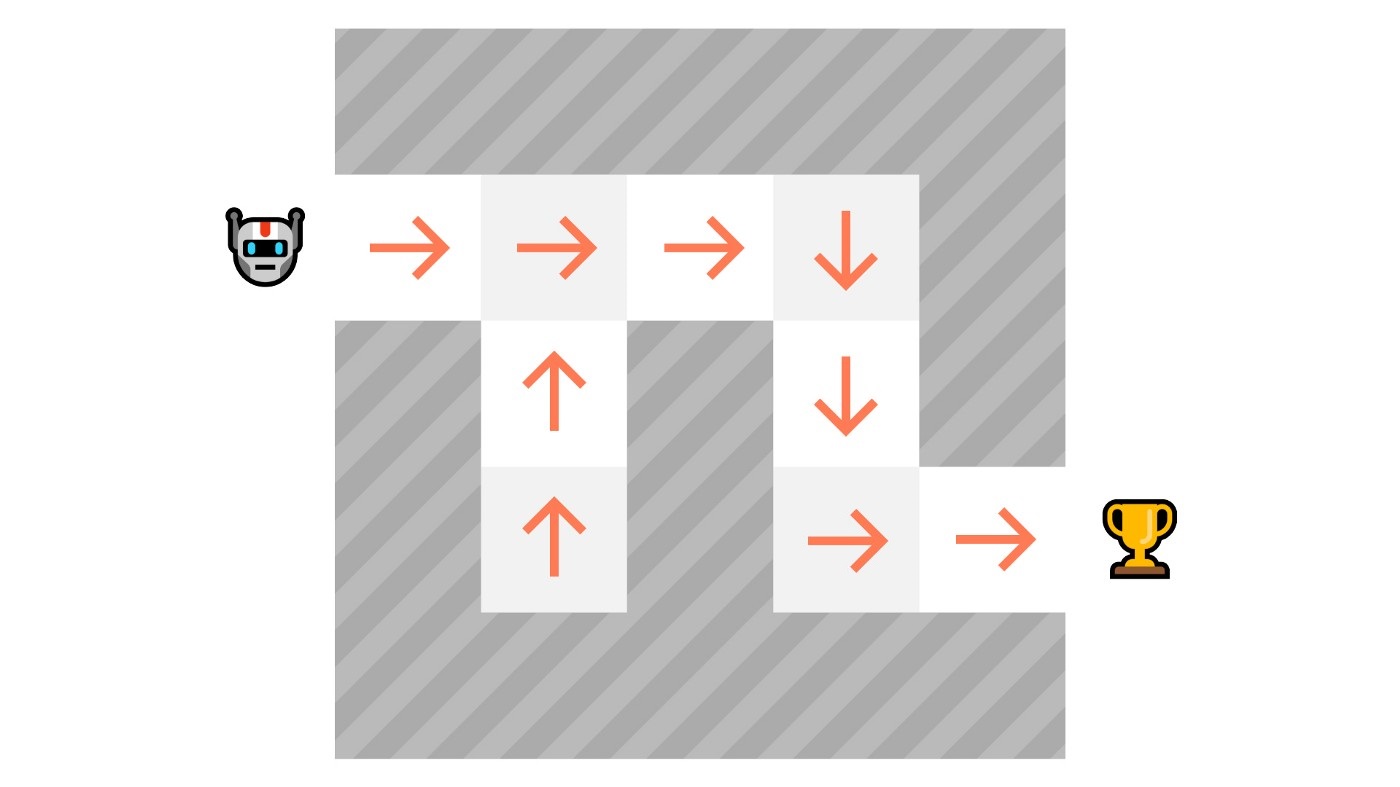 @@ -69,13 +69,13 @@ If we recap:
In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
@@ -69,13 +69,13 @@ If we recap:
In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
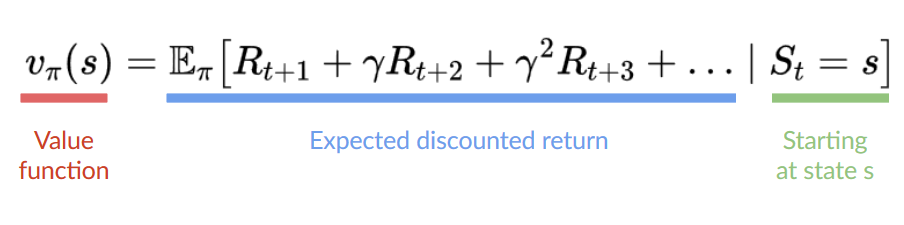 -Here we see that our value function **defined value for each possible state.**
+Here we see that our value function **defined values for each possible state.**
-Here we see that our value function **defined value for each possible state.**
+Here we see that our value function **defined values for each possible state.**
 diff --git a/units/en/unit1/what-is-rl.mdx b/units/en/unit1/what-is-rl.mdx
index 410569c..ba63f92 100644
--- a/units/en/unit1/what-is-rl.mdx
+++ b/units/en/unit1/what-is-rl.mdx
@@ -17,12 +17,12 @@ Your brother will interact with the environment (the video game) by pressing the
diff --git a/units/en/unit1/what-is-rl.mdx b/units/en/unit1/what-is-rl.mdx
index 410569c..ba63f92 100644
--- a/units/en/unit1/what-is-rl.mdx
+++ b/units/en/unit1/what-is-rl.mdx
@@ -17,12 +17,12 @@ Your brother will interact with the environment (the video game) by pressing the
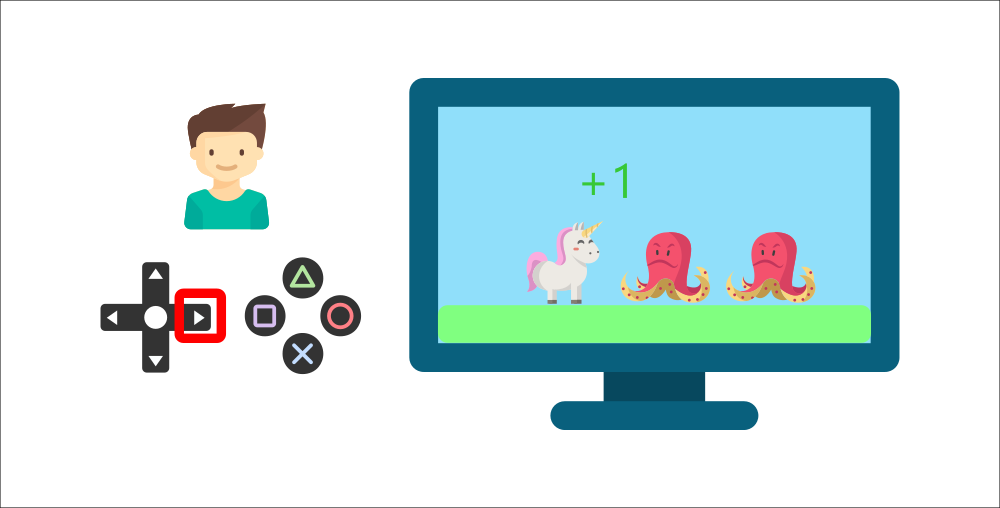 -But then, **he presses right again** and he touches an enemy. He just died, so that's a -1 reward.
+But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
-But then, **he presses right again** and he touches an enemy. He just died, so that's a -1 reward.
+But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
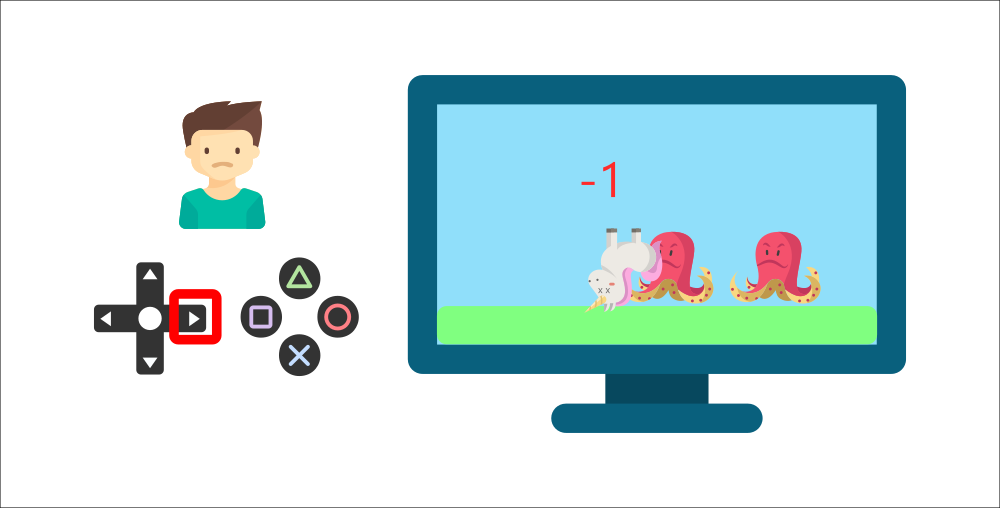 -By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
+By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
**Without any supervision**, the child will get better and better at playing the game.
@@ -31,7 +31,7 @@ That’s how humans and animals learn, **through interaction.** Reinforcement
### A formal definition [[a-formal-definition]]
-If we take now a formal definition:
+We can now make a formal definition:
-By interacting with his environment through trial and error, your little brother understood that **he needed to get coins in this environment but avoid the enemies.**
+By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
**Without any supervision**, the child will get better and better at playing the game.
@@ -31,7 +31,7 @@ That’s how humans and animals learn, **through interaction.** Reinforcement
### A formal definition [[a-formal-definition]]
-If we take now a formal definition:
+We can now make a formal definition: