diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 2c1e2fd..ac63d1e 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -202,6 +202,28 @@
title: PPO with Sample Factory and Doom
- local: unit8/conclusion-sf
title: Conclusion
+- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ sections:
+ - local: unitbonus3/introduction
+ title: Introduction
+ - local: unitbonus3/model-based
+ title: Model-Based Reinforcement Learning
+ - local: unitbonus3/offline-online
+ title: Offline vs. Online Reinforcement Learning
+ - local: unitbonus3/rlhf
+ title: Reinforcement Learning from Human Feedback
+ - local: unitbonus3/decision-transformers
+ title: Decision Transformers and Offline RL
+ - local: unitbonus3/language-models
+ title: Language models in RL
+ - local: unitbonus3/curriculum-learning
+ title: (Automatic) Curriculum Learning for RL
+ - local: unitbonus3/envs-to-try
+ title: Interesting environments to try
+ - local: unitbonus3/godotrl
+ title: An Introduction to Godot RL
+ - local: unitbonus3/rl-documentation
+ title: Brief introduction to RL documentation
- title: What's next? New Units Publishing Schedule
sections:
- local: communication/publishing-schedule
diff --git a/units/en/unitbonus3/curriculum-learning.mdx b/units/en/unitbonus3/curriculum-learning.mdx
new file mode 100644
index 0000000..dbe8e64
--- /dev/null
+++ b/units/en/unitbonus3/curriculum-learning.mdx
@@ -0,0 +1,54 @@
+# (Automatic) Curriculum Learning for RL
+
+While most of the RL methods seen in this course work well in practice, there are some cases where using them alone fails. It is for instance the case where:
+
+- the task to learn is hard and requires an **incremental acquisition of skills** (for instance when one wants to make a bipedal agent learn to go through hard obstacles, it must first learn to stand, then walk, then maybe jump…)
+- there are variations in the environment (that affect the difficulty) and one wants its agent to be **robust** to them
+
+
+
+
+TeachMyAgent
+
+
+In such cases, it seems needed to propose different tasks to our RL agent and organize them such that it allows the agent to progressively acquire skills. This approach is called **Curriculum Learning** and usually implies a hand-designed curriculum (or set of tasks organized in a specific order). In practice, one can for instance control the generation of the environment, the initial states, or use Self-Play an control the level of opponents proposed to the RL agent.
+
+As designing such a curriculum is not always trivial, the field of **Automatic Curriculum Learning (ACL) proposes to design approaches that learn to create such and organization of tasks in order to maximize the RL agent’s performances**. Portelas et al. proposed to define ACL as:
+
+> … a family of mechanisms that automatically adapt the distribution of training data by learning to adjust the selection of learning situations to the capabilities of RL agents.
+>
+
+As an example, OpenAI used **Domain Randomization** (they applied random variations on the environment) to make a robot hand solve Rubik’s Cubes.
+
+
+
+
+OpenAI - Solving Rubik’s Cube with a Robot Hand
+
+
+Finally, you can play with the robustness of agents trained in the TeachMyAgent benchmark by controlling environment variations or even drawing the terrain 👇
+
+
+
+https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
+
+
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+### Overview of the field
+
+- [Automatic Curriculum Learning For Deep RL: A Short Survey](https://arxiv.org/pdf/2003.04664.pdf)
+- [Curriculum for Reinforcement Learning](https://lilianweng.github.io/posts/2020-01-29-curriculum-rl/)
+
+### Recent methods
+
+- [Evolving Curricula with Regret-Based Environment Design](https://arxiv.org/abs/2203.01302)
+- [Curriculum Reinforcement Learning via Constrained Optimal Transport](https://proceedings.mlr.press/v162/klink22a.html)
+- [Prioritized Level Replay](https://arxiv.org/abs/2010.03934)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/decision-transformers.mdx b/units/en/unitbonus3/decision-transformers.mdx
new file mode 100644
index 0000000..737564e
--- /dev/null
+++ b/units/en/unitbonus3/decision-transformers.mdx
@@ -0,0 +1,31 @@
+# Decision Transformers
+
+The Decision Transformer model was introduced by ["Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a conditional-sequence modeling problem.
+
+The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), **we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return**.
+It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
+
+This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
+
+The 🤗 Transformers team integrated the Decision Transformer, an Offline Reinforcement Learning method, into the library as well as the Hugging Face Hub.
+
+## Learn about Decision Transformers
+
+To learn more about Decision Transformers, you should read the blogpost we wrote about it [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers)
+
+## Train your first Decision Transformers
+
+Now that you understand how Decision Transformers work thanks to [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers). You’re ready to learn to train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
+
+Start the tutorial here 👉 https://huggingface.co/blog/train-decision-transformers
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+- [Online Decision Transformer](https://arxiv.org/abs/2202.05607)
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
new file mode 100644
index 0000000..404e038
--- /dev/null
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -0,0 +1,49 @@
+# Interesting Environments to try
+
+We provide here a list of interesting environments you can try to train your agents on:
+
+## MineRL
+
+
+
+
+MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
+Every year, there are challenges with this library. Check the [website](https://minerl.io/)
+
+To start using this environment, check these resources:
+- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar Simulator
+
+
+Donkey is a Self Driving Car Platform for hobby remote control cars.
+This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
+
+
+To start using this environment, check these resources:
+- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- Pretrained agents:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## Starcraft II
+
+
+
+Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+To start using this environment, check these resources:
+- [Starcraft gym](http://starcraftgym.com/)
+- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
new file mode 100644
index 0000000..8e993a3
--- /dev/null
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -0,0 +1,208 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
+
+The library provides:
+
+- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
+- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- Support for memory-based agents with LSTM or attention based interfaces
+- Support for *2D and 3D games*
+- A suite of *AI sensors* to augment your agent's capacity to observe the game world
+- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
+
+You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
+
+## Create a custom RL environment with Godot RL Agents
+
+In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
+
+The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**.You can then dive into the examples for more complex environments and behaviors.
+
+The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
+
+
+
+### Installing the Godot Game Engine
+
+The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
+
+Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
+
+While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
+
+In order to create games in Godot, **you must first download the editor**. The latest version Godot RL agents was updated to use Godot 4 beta, as we are expecting this to be released in the next few months.
+
+At the time of writing the latest beta version was beta 14 which can be downloaded at the following links:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_linux.x86_64.zip)
+
+### Loading the starter project
+
+We provide two versions of the codebase:
+- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
+
+If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
+
+### Installing the Godot RL Agents plugin
+
+The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
+
+First click on the AssetLib and search for “rl”
+
+
+
+Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+
+
+
+
+The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+
+
+
+
+### Adding the AI controller
+
+We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
+
+
+
+Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
+
+
+
+The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
+
+Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+We will now implement the 4 missing methods, delete this code and replace it with the following:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
+
+You can run training live in the the editor, but first launching the python training with `python examples/clean_rl_example.py —env-id=debug`
+
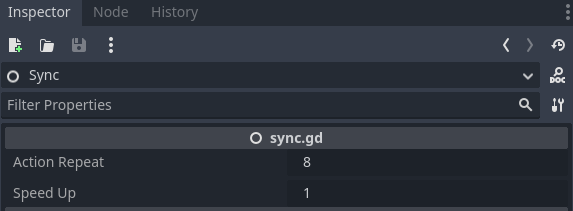
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+
+
+
+Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
+
+### There’s more!
+
+We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/introduction.mdx b/units/en/unitbonus3/introduction.mdx
new file mode 100644
index 0000000..50b4bd0
--- /dev/null
+++ b/units/en/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# Introduction
+
+
+
+
+Congratulations on finishing this course! **You now have a solid background in Deep Reinforcement Learning**.
+But this course was just the beginning of your Deep Reinforcement Learning journey, there are so many subsections to discover. In this optional unit, we **give you resources to explore multiple concepts and research topics in Reinforcement Learning**.
+
+Contrary to other units, this unit is a collective work of multiple people from Hugging Face. We mention the author for each unit.
+
+Sounds fun? Let's get started 🔥,
diff --git a/units/en/unitbonus3/language-models.mdx b/units/en/unitbonus3/language-models.mdx
new file mode 100644
index 0000000..0fffc19
--- /dev/null
+++ b/units/en/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# Language models in RL
+## LMs encode useful knowledge for agents
+
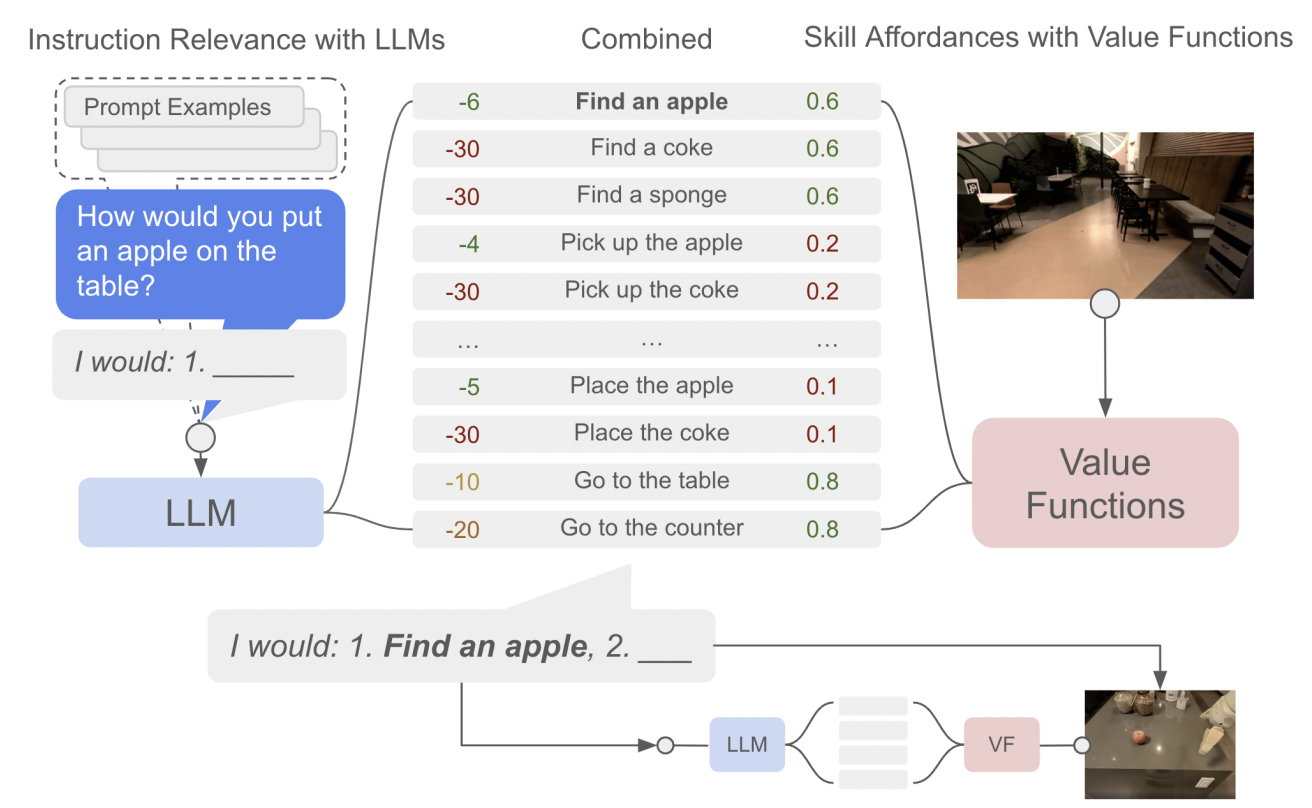
+**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
+
+A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
+
+
+
+Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+## LMs and RL
+
+There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct these knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the **Tabula-rasa** setup where everything is learned from scratch by agent leading to:
+
+1) Sample inefficiency
+
+2) Unexpected behaviors from humans’ eyes
+
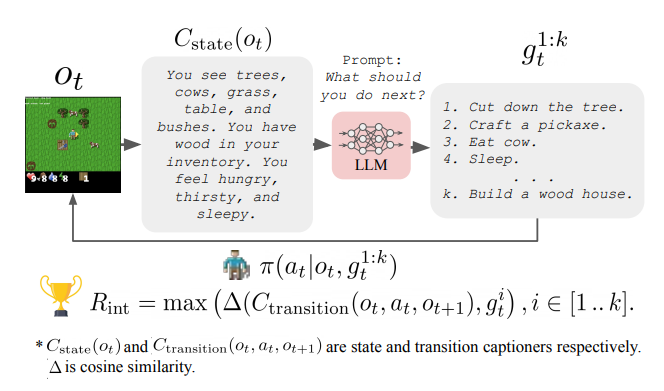
+As a first attempt, the paper [“Grounding Large Language Models with Online Reinforcement Learning”](https://arxiv.org/abs/2302.02662v1) tackled the problem of **adapting or aligning a LM to a textual environment using PPO**. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenue for sample efficiency RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
+
+
+
+Another direction studied in [“Guiding Pretraining in Reinforcement Learning with Large Language Models”](https://arxiv.org/abs/2302.06692) was to keep the LM frozen but leverage its knowledge to **guide an RL agent’s exploration**. Such method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
+
+
+
+ Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+Several limitations make these works still very preliminary such as the need to convert the agent's observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
+
+## Further reading
+
+For more information we recommend you check out the following resources:
+
+- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
+- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
+- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
+- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/model-based.mdx b/units/en/unitbonus3/model-based.mdx
new file mode 100644
index 0000000..9983a01
--- /dev/null
+++ b/units/en/unitbonus3/model-based.mdx
@@ -0,0 +1,32 @@
+# Model Based Reinforcement Learning (MBRL)
+
+Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
+
+The dynamics models usually model the environment transition dynamics, \\( s_{t+1} = f_\theta (s_t, a_t) \\), but things like inverse dynamics models (mapping from states to actions) or reward models (predicting rewards) can be used in this framework.
+
+
+## Simple definition
+
+- There is an agent that repeatedly tries to solve a problem, **accumulating state and action data**.
+- With that data, the agent creates a structured learning tool, *a dynamics model*, to reason about the world.
+- With the dynamics model, the agent **decides how to act by predicting the future**.
+- With those actions, **the agent collects more data, improves said model, and hopefully improves future actions**.
+
+## Academic definition
+
+Model-based reinforcement learning (MBRL) follows the framework of an agent interacting in an environment, **learning a model of said environment**, and then **leveraging the model for control (making decisions).
+
+Specifically, the agent acts in a Markov Decision Process (MDP) governed by a transition function \\( s_{t+1} = f (s_t , a_t) \\) and returns a reward at each step \\( r(s_t, a_t) \\). With a collected dataset \\( D :={ s_i, a_i, s_{i+1}, r_i} \\), the agent learns a model, \\( s_{t+1} = f_\theta (s_t , a_t) \\) **to minimize the negative log-likelihood of the transitions**.
+
+We employ sample-based model-predictive control (MPC) using the learned dynamics model, which optimizes the expected reward over a finite, recursively predicted horizon, \\( \tau \\), from a set of actions sampled from a uniform distribution \\( U(a) \\), (see [paper](https://arxiv.org/pdf/2002.04523) or [paper](https://arxiv.org/pdf/2012.09156.pdf) or [paper](https://arxiv.org/pdf/2009.01221.pdf)).
+
+## Further reading
+
+For more information on MBRL, we recommend you check out the following resources:
+
+- A [blog post on debugging MBRL](https://www.natolambert.com/writing/debugging-mbrl).
+- A [recent review paper on MBRL](https://arxiv.org/abs/2006.16712),
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/offline-online.mdx b/units/en/unitbonus3/offline-online.mdx
new file mode 100644
index 0000000..be6fa37
--- /dev/null
+++ b/units/en/unitbonus3/offline-online.mdx
@@ -0,0 +1,37 @@
+# Offline vs. Online Reinforcement Learning
+
+Deep Reinforcement Learning (RL) is a framework **to build decision-making agents**. These agents aim to learn optimal behavior (policy) by interacting with the environment through **trial and error and receiving rewards as unique feedback**.
+
+The agent’s goal **is to maximize its cumulative reward**, called return. Because RL is based on the *reward hypothesis*: all goals can be described as the **maximization of the expected cumulative reward**.
+
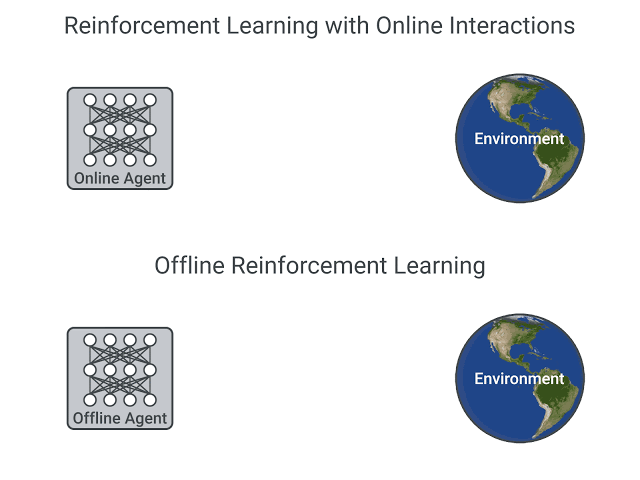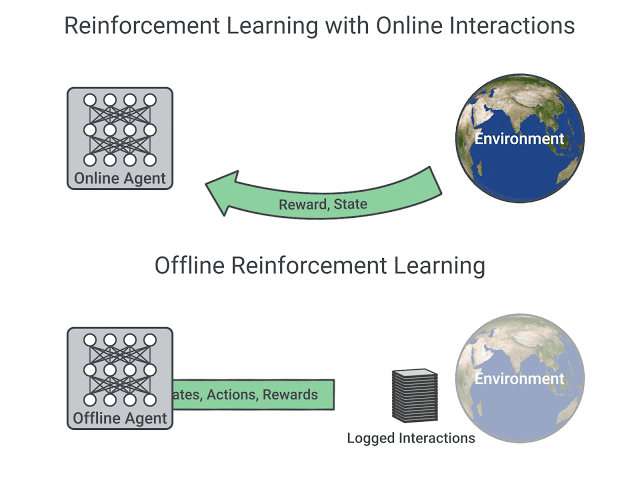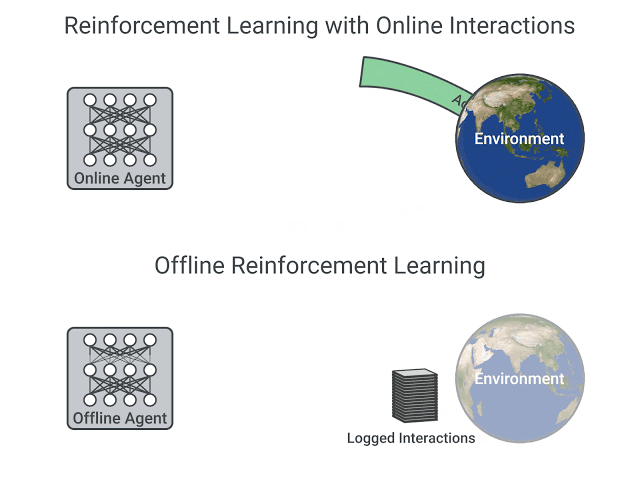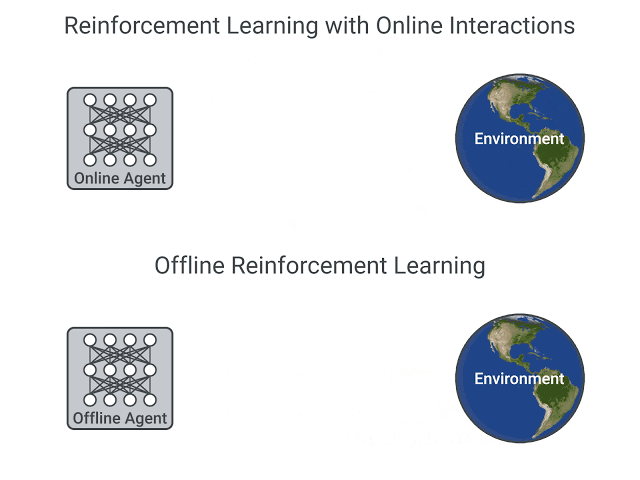
+Deep Reinforcement Learning agents **learn with batches of experience**. The question is, how do they collect it?:
+
+
+
+A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from this post
+
+
+- In *online reinforcement learning*, which is what we've learned during this course, the agent **gathers data directly**: it collects a batch of experience by **interacting with the environment**. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
+
+But this implies that either you **train your agent directly in the real world or have a simulator**. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure (if the simulator has flaws that may provide a competitive advantage, the agent will exploit them).
+
+- On the other hand, in *offline reinforcement learning*, the agent only **uses data collected from other agents or human demonstrations**. It does **not interact with the environment**.
+
+The process is as follows:
+- **Create a dataset** using one or more policies and/or human interactions.
+- Run **offline RL on this dataset** to learn a policy
+
+This method has one drawback: the *counterfactual queries problem*. What do we do if our agent **decides to do something for which we don’t have the data?** For instance, turning right on an intersection but we don’t have this trajectory.
+
+There exist some solutions on this topic, but if you want to know more about offline reinforcement learning, you can [watch this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Offline Reinforcement Learning, Talk by Sergei Levine](https://www.youtube.com/watch?v=qgZPZREor5I)
+- [Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems](https://arxiv.org/abs/2005.01643)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/rl-documentation.mdx b/units/en/unitbonus3/rl-documentation.mdx
new file mode 100644
index 0000000..dc4a661
--- /dev/null
+++ b/units/en/unitbonus3/rl-documentation.mdx
@@ -0,0 +1,56 @@
+# Brief introduction to RL documentation
+
+In this advanced topic, we address the question: **how should we monitor and keep track of powerful reinforcement learning agents that we are training in the real world and
+interfacing with humans?**
+
+As machine learning systems have increasingly impacted modern life, **call for documentation of these systems has grown**.
+
+Such documentation can cover aspects such as the training data used — where it is stored, when it was collected, who was involved, etc.
+— or the model optimization framework — the architecture, evaluation metrics, relevant papers, etc. — and more.
+
+Today, model cards and datasheets are becoming increasingly available. For example, on the Hub
+(see documentation [here](https://huggingface.co/docs/hub/model-cards)).
+
+If you click on a [popular model on the Hub](https://huggingface.co/models), you can learn about its creation process.
+
+These model and data specific logs are designed to be completed when the model or dataset are created, leaving them to go un-updated when these models are built into evolving systems in the future.
+
+## Motivating Reward Reports
+
+Reinforcement learning systems are fundamentally designed to optimize based on measurements of reward and time.
+While the notion of a reward function can be mapped nicely to many well-understood fields of supervised learning (via a loss function),
+understanding how machine learning systems evolve over time is limited.
+
+To that end, the authors introduce [*Reward Reports for Reinforcement Learning*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4) (the pithy naming is designed to mirror the popular papers *Model Cards for Model Reporting* and *Datasheets for Datasets*).
+The goal is to propose a type of documentation focused on the **human factors of reward** and **time-varying feedback systems**.
+
+Building on the documentation frameworks for [model cards](https://arxiv.org/abs/1810.03993) and [datasheets](https://arxiv.org/abs/1803.09010) proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems.
+
+**Reward Reports** are living documents for proposed RL deployments that demarcate design choices.
+
+However, many questions remain about the applicability of this framework to different RL applications, roadblocks to system interpretability,
+and the resonances between deployed supervised machine learning systems and the sequential decision-making utilized in RL.
+
+At a minimum, Reward Reports are an opportunity for RL practitioners to deliberate on these questions and begin the work of deciding how to resolve them in practice.
+
+## Capturing temporal behavior with documentation
+
+The core piece specific to documentation designed for RL and feedback-driven ML systems is a *change-log*. The change-log updates information
+from the designer (changed training parameters, data, etc.) along with noticed changes from the user (harmful behavior, unexpected responses, etc.).
+
+The change log is accompanied by update triggers that encourage monitoring these effects.
+
+## Contributing
+
+Some of the most impactful RL-driven systems are multi-stakeholder in nature and behind closed doors of private corporations.
+These corporations are largely without regulation, so the burden of documentation falls on the public.
+
+If you are interested in contributing, we are building Reward Reports for popular machine learning systems on a public
+record on [GitHub](https://github.com/RewardReports/reward-reports).
+
+For further reading, you can visit the Reward Reports [paper](https://arxiv.org/abs/2204.10817)
+or look [an example report](https://github.com/RewardReports/reward-reports/tree/main/examples).
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/rlhf.mdx b/units/en/unitbonus3/rlhf.mdx
new file mode 100644
index 0000000..7c473d1
--- /dev/null
+++ b/units/en/unitbonus3/rlhf.mdx
@@ -0,0 +1,50 @@
+# RLHF
+
+Reinforcement learning from human feedback (RLHF) is a **methodology for integrating human data labels into a RL-based optimization process**.
+It is motivated by the **challenge of modeling human preferences**.
+
+For many questions, even if you could try and write down an equation for one ideal, humans differ on their preferences.
+
+Updating models **based on measured data is an avenue to try and alleviate these inherently human ML problems**.
+
+## Start Learning about RLHF
+
+To start learning about RLHF:
+
+1. Read this introduction: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf).
+
+2. Watch the recorded live we did some weeks ago, where Nathan covered the basics of Reinforcement Learning from Human Feedback (RLHF) and how this technology is being used to enable state-of-the-art ML tools like ChatGPT.
+Most of the talk is an overview of the interconnected ML models. It covers the basics of Natural Language Processing and RL and how RLHF is used on large language models. We then conclude with the open question in RLHF.
+
+
+
+3. Read other blogs on this topic, such as [Closed-API vs Open-source continues: RLHF, ChatGPT, data moats](https://robotic.substack.com/p/rlhf-chatgpt-data-moats). Let us know if there are more you like!
+
+
+## Additional readings
+
+*Note, this is copied from the Illustrating RLHF blog post above*.
+Here is a list of the most prevalent papers on RLHF to date. The field was recently popularized with the emergence of DeepRL (around 2017) and has grown into a broader study of the applications of LLMs from many large technology companies.
+Here are some papers on RLHF that pre-date the LM focus:
+- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008): Proposed a learned agent where humans provided scores on the actions taken iteratively to learn a reward model.
+- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017): Proposed an actor-critic algorithm, COACH, where human feedback (both positive and negative) is used to tune the advantage function.
+- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017): RLHF applied on preferences between Atari trajectories.
+- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485) (Warnell et al. 2018): Extends the TAMER framework where a deep neural network is used to model the reward prediction.
+
+And here is a snapshot of the growing set of papers that show RLHF's performance for LMs:
+- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
+- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021), follow on work summarizing books.
+- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
+- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022): RLHF applied to a general language model [[Blog post](https://openai.com/blog/instruction-following/) on InstructGPT].
+- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
+- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
+- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
+- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
+- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
+- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
+- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
+- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
+
+## Author
+
+This section was written by Nathan Lambert
 +
+ +
+ +
+ +
+ +
+
+MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
+Every year, there are challenges with this library. Check the [website](https://minerl.io/)
+
+To start using this environment, check these resources:
+- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar Simulator
+
+
+
+
+MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
+Every year, there are challenges with this library. Check the [website](https://minerl.io/)
+
+To start using this environment, check these resources:
+- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar Simulator
+
+ +Donkey is a Self Driving Car Platform for hobby remote control cars.
+This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
+
+
+To start using this environment, check these resources:
+- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- Pretrained agents:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## Starcraft II
+
+
+Donkey is a Self Driving Car Platform for hobby remote control cars.
+This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
+
+
+To start using this environment, check these resources:
+- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- Pretrained agents:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## Starcraft II
+
+ +
+Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+To start using this environment, check these resources:
+- [Starcraft gym](http://starcraftgym.com/)
+- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
new file mode 100644
index 0000000..8e993a3
--- /dev/null
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -0,0 +1,208 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
+
+The library provides:
+
+- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
+- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- Support for memory-based agents with LSTM or attention based interfaces
+- Support for *2D and 3D games*
+- A suite of *AI sensors* to augment your agent's capacity to observe the game world
+- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
+
+You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
+
+## Create a custom RL environment with Godot RL Agents
+
+In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
+
+The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**.You can then dive into the examples for more complex environments and behaviors.
+
+The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
+
+
+
+Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+To start using this environment, check these resources:
+- [Starcraft gym](http://starcraftgym.com/)
+- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
new file mode 100644
index 0000000..8e993a3
--- /dev/null
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -0,0 +1,208 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
+
+The library provides:
+
+- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
+- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- Support for memory-based agents with LSTM or attention based interfaces
+- Support for *2D and 3D games*
+- A suite of *AI sensors* to augment your agent's capacity to observe the game world
+- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
+
+You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
+
+## Create a custom RL environment with Godot RL Agents
+
+In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
+
+The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**.You can then dive into the examples for more complex environments and behaviors.
+
+The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
+
+ +
+### Installing the Godot Game Engine
+
+The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
+
+Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
+
+While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
+
+In order to create games in Godot, **you must first download the editor**. The latest version Godot RL agents was updated to use Godot 4 beta, as we are expecting this to be released in the next few months.
+
+At the time of writing the latest beta version was beta 14 which can be downloaded at the following links:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_linux.x86_64.zip)
+
+### Loading the starter project
+
+We provide two versions of the codebase:
+- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
+
+If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
+
+### Installing the Godot RL Agents plugin
+
+The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
+
+First click on the AssetLib and search for “rl”
+
+
+
+### Installing the Godot Game Engine
+
+The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
+
+Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
+
+While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
+
+In order to create games in Godot, **you must first download the editor**. The latest version Godot RL agents was updated to use Godot 4 beta, as we are expecting this to be released in the next few months.
+
+At the time of writing the latest beta version was beta 14 which can be downloaded at the following links:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_linux.x86_64.zip)
+
+### Loading the starter project
+
+We provide two versions of the codebase:
+- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
+
+If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
+
+### Installing the Godot RL Agents plugin
+
+The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
+
+First click on the AssetLib and search for “rl”
+
+ +
+Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+
+
+
+Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+
+ +
+
+The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+
+
+
+
+The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+
+ +
+
+### Adding the AI controller
+
+We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
+
+
+
+
+### Adding the AI controller
+
+We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
+
+ +
+Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
+
+
+
+Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
+
+ +
+The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
+
+Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+We will now implement the 4 missing methods, delete this code and replace it with the following:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
+
+You can run training live in the the editor, but first launching the python training with `python examples/clean_rl_example.py —env-id=debug`
+
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+
+
+
+The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
+
+Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+We will now implement the 4 missing methods, delete this code and replace it with the following:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
+
+You can run training live in the the editor, but first launching the python training with `python examples/clean_rl_example.py —env-id=debug`
+
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+
+ +
+Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
+
+### There’s more!
+
+We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/introduction.mdx b/units/en/unitbonus3/introduction.mdx
new file mode 100644
index 0000000..50b4bd0
--- /dev/null
+++ b/units/en/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# Introduction
+
+
+
+Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
+
+### There’s more!
+
+We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/introduction.mdx b/units/en/unitbonus3/introduction.mdx
new file mode 100644
index 0000000..50b4bd0
--- /dev/null
+++ b/units/en/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# Introduction
+
+ +
+
+Congratulations on finishing this course! **You now have a solid background in Deep Reinforcement Learning**.
+But this course was just the beginning of your Deep Reinforcement Learning journey, there are so many subsections to discover. In this optional unit, we **give you resources to explore multiple concepts and research topics in Reinforcement Learning**.
+
+Contrary to other units, this unit is a collective work of multiple people from Hugging Face. We mention the author for each unit.
+
+Sounds fun? Let's get started 🔥,
diff --git a/units/en/unitbonus3/language-models.mdx b/units/en/unitbonus3/language-models.mdx
new file mode 100644
index 0000000..0fffc19
--- /dev/null
+++ b/units/en/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# Language models in RL
+## LMs encode useful knowledge for agents
+
+**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
+
+A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
+
+
+
+
+Congratulations on finishing this course! **You now have a solid background in Deep Reinforcement Learning**.
+But this course was just the beginning of your Deep Reinforcement Learning journey, there are so many subsections to discover. In this optional unit, we **give you resources to explore multiple concepts and research topics in Reinforcement Learning**.
+
+Contrary to other units, this unit is a collective work of multiple people from Hugging Face. We mention the author for each unit.
+
+Sounds fun? Let's get started 🔥,
diff --git a/units/en/unitbonus3/language-models.mdx b/units/en/unitbonus3/language-models.mdx
new file mode 100644
index 0000000..0fffc19
--- /dev/null
+++ b/units/en/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# Language models in RL
+## LMs encode useful knowledge for agents
+
+**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
+
+A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
+
+ +
+ +
+ +
+