From 59bce06bea7a92529088db5404c5b991420c27d0 Mon Sep 17 00:00:00 2001
From: fzyzcjy <5236035+fzyzcjy@users.noreply.github.com>
Date: Wed, 8 Nov 2023 12:49:55 +0800
Subject: [PATCH 01/23] Update policy-gradient.mdx
---
units/en/unit4/policy-gradient.mdx | 1 +
1 file changed, 1 insertion(+)
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index 1a178d6..ccc34cb 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -54,6 +54,7 @@ Let's give some more details on this formula:
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
+
- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\( \theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
From 5d6a4065894f6669e2db7627aa04f38dc859a969 Mon Sep 17 00:00:00 2001
From: Pierre Counathe
Date: Fri, 9 Feb 2024 19:15:15 -0800
Subject: [PATCH 02/23] nits
---
units/en/unit5/quiz.mdx | 10 ++++++----
1 file changed, 6 insertions(+), 4 deletions(-)
diff --git a/units/en/unit5/quiz.mdx b/units/en/unit5/quiz.mdx
index 7b9ec0c..ccb8f40 100644
--- a/units/en/unit5/quiz.mdx
+++ b/units/en/unit5/quiz.mdx
@@ -78,13 +78,15 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
### Q3: Fill the missing letters
-- In Unity ML-Agents, the Policy of an Agent is called a b _ _ _ n
-- The component in charge of orchestrating the agents is called the _ c _ _ _ m _
+- In Unity ML-Agents, the Policy of an Agent is called a b \_ \_ \_ n
+- The component in charge of orchestrating the agents is called the \_ c \_ \_ \_ m \_
Solution
-- b r a i n
-- a c a d e m y
+
+
b r a i n
+
a c a d e m y
+
### Q4: Define with your own words what is a `raycast`
From 62183fd456a23b513b3b63f4cfb20e83e9d34745 Mon Sep 17 00:00:00 2001
From: Bagas N <80507232+MrPuppeteer@users.noreply.github.com>
Date: Mon, 12 Feb 2024 12:52:59 +0700
Subject: [PATCH 03/23] Fix typo in discord101.mdx
---
units/en/unit0/discord101.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index 962c766..1c3d440 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -17,7 +17,7 @@ Then click next, you'll then get to **introduce yourself in the `#introduce-your
They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
-- `rl-announcements`: where we give the **lastest information about the course**.
+- `rl-announcements`: where we give the **latest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
- `rl-i-made-this`: where you can **share your projects and models**.
From 6ab84a4e8e8586e836766e433e9844baa225ae99 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Fri, 16 Feb 2024 17:35:15 +0100
Subject: [PATCH 04/23] Using wget instead
---
notebooks/bonus-unit1/bonus-unit1.ipynb | 26 ++++++++++++-------------
1 file changed, 13 insertions(+), 13 deletions(-)
diff --git a/notebooks/bonus-unit1/bonus-unit1.ipynb b/notebooks/bonus-unit1/bonus-unit1.ipynb
index 58f20cf..39e32cb 100644
--- a/notebooks/bonus-unit1/bonus-unit1.ipynb
+++ b/notebooks/bonus-unit1/bonus-unit1.ipynb
@@ -217,25 +217,25 @@
]
},
{
- "cell_type": "code",
+ "cell_type": "markdown",
"source": [
- "!wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF\" -O ./trained-envs-executables/linux/Huggy.zip && rm -rf /tmp/cookies.txt"
+ "We downloaded the file Huggy.zip from https://github.com/huggingface/Huggy using `wget`"
],
"metadata": {
- "id": "EB-G-80GsxYN"
+ "id": "IHh_LXsRrrbM"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!wget \"https://github.com/huggingface/Huggy/raw/main/Huggy.zip\" -O ./trained-envs-executables/linux/Huggy.zip"
+ ],
+ "metadata": {
+ "id": "8xNAD1tRpy0_"
},
"execution_count": null,
"outputs": []
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "jsoZGxr1MIXY"
- },
- "source": [
- "Download the file Huggy.zip from https://drive.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -441,7 +441,7 @@
},
"outputs": [],
"source": [
- "!mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id=\"Huggy\" --no-graphics"
+ "!mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id=\"Huggy2\" --no-graphics"
]
},
{
From 87fcfeb9bbc8baeb579e2cf1ddd2fa2de804902c Mon Sep 17 00:00:00 2001
From: Balaji Varatharajan
Date: Sat, 17 Feb 2024 15:16:29 +0530
Subject: [PATCH 05/23] Update variance-problem.mdx
Hi, I've a blog titled [High Variance in Policy gradients](https://balajiai.github.io/high_variance_in_policy_gradients) which also explains about the variance problem in policy gradient and techniques for variance reduction such as baseline and actor-critics method.
I think, it would be valuable to this course readers. So I'm adding it to the reading-list.
Thanks!
---
units/en/unit6/variance-problem.mdx | 1 +
1 file changed, 1 insertion(+)
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
index 9ce3d8e..1fbbe9c 100644
--- a/units/en/unit6/variance-problem.mdx
+++ b/units/en/unit6/variance-problem.mdx
@@ -27,4 +27,5 @@ However, increasing the batch size significantly **reduces sample efficiency**.
If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+- [High Variance in Policy gradients](https://balajiai.github.io/high_variance_in_policy_gradients)
---
From 7bf227dea26bce04960ae463894f4be7a6c3ff14 Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Thu, 22 Feb 2024 23:53:50 -0500
Subject: [PATCH 06/23] Add DIAMBRA to envs to try
---
units/en/unitbonus3/envs-to-try.mdx | 39 +++++++++++++++++++++++++++++
1 file changed, 39 insertions(+)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index 6bc4ba9..62d3183 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -2,6 +2,45 @@
Here we provide a list of interesting environments you can try to train your agents on:
+## DIAMBRA Arena
+
+
+
+
+DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
+
+It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via Python PIP. It is completely free to use, the user only needs to register on the official website.
+
+In addition, its [GitHub repository](https://github.com/diambra/) provides a collection of examples covering main use cases of interest that can be run in just a few steps.
+
+#### Main Features
+
+All environments are episodic Reinforcement Learning tasks, with discrete actions (gamepad buttons) and observations composed by screen pixels plus additional numerical data (RAM values like characters health bars or characters stage side).
+
+They all support both single player (1P) as well as two players (2P) mode, making them the perfect resource to explore Standard RL, Competitive Multi-Agent, Competitive Human-Agent, Self-Play, Imitation Learning and Human-in-the-Loop.
+
+Interfaced games have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
+
+DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most import packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
+
+### Competition Platform
+
+DIAMBRA also provides a competition platform fully integrated with Hugging Face, on which you can submit your trained agents and compete with other coders around the globe in epic video games tournaments!
+
+It features a public leaderboard where users are ranked by the best score achieved by their agents in our different environments.
+
+It also offers the possibility to unlock cool achievements depending on the performances of your agent.
+
+Submitted agents are evaluated and their episodes are streamed on [DIAMBRA Twitch channel](https://www.twitch.tv/diambra_ai).
+
+#### References
+
+To start using this environment, check these resources:
+- [Official Docs](https://docs.diambra.ai/)
+- [Competition Platform](https://diambra.ai)
+- [GitHub](https://github.com/diambra/)
+- [Discord](https://diambra.ai/discord)
+
## MineRL
From f4e21ebc8d785a88d4bba4efa451446e303c16bb Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Fri, 23 Feb 2024 00:10:43 -0500
Subject: [PATCH 07/23] Add some links
---
units/en/unitbonus3/envs-to-try.mdx | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index 62d3183..e342bcb 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -4,12 +4,12 @@ Here we provide a list of interesting environments you can try to train your age
## DIAMBRA Arena
-
+
DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
-It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via Python PIP. It is completely free to use, the user only needs to register on the official website.
+It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via [Python PIP](https://pypi.org/project/diambra-arena/). It is completely free to use, the user only needs to register on the official website.
In addition, its [GitHub repository](https://github.com/diambra/) provides a collection of examples covering main use cases of interest that can be run in just a few steps.
@@ -19,9 +19,9 @@ All environments are episodic Reinforcement Learning tasks, with discrete action
They all support both single player (1P) as well as two players (2P) mode, making them the perfect resource to explore Standard RL, Competitive Multi-Agent, Competitive Human-Agent, Self-Play, Imitation Learning and Human-in-the-Loop.
-Interfaced games have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
+[Interfaced games](https://docs.diambra.ai/envs/games/) have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
-DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most import packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
+DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most important packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents examples repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
### Competition Platform
From 5e5ea78e639bb87d21fed668614f643d0a8d46fb Mon Sep 17 00:00:00 2001
From: SNORLAX
Date: Sat, 24 Feb 2024 20:37:58 +0800
Subject: [PATCH 08/23] fix error in quiz2.mdx
---
units/en/unit2/quiz2.mdx | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/units/en/unit2/quiz2.mdx b/units/en/unit2/quiz2.mdx
index 961d477..3ab4f51 100644
--- a/units/en/unit2/quiz2.mdx
+++ b/units/en/unit2/quiz2.mdx
@@ -19,12 +19,11 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
},
{
text: "An algorithm that determines the value of being at a particular state and taking a specific action at that state",
- explain: "",
- correct: true
+ explain: "Q-function is the function that determines the value of being at a particular state and taking a specific action at that state.",
},
{
text: "A table",
- explain: "Q-function is not a Q-table. The Q-function is the algorithm that will feed the Q-table."
+ explain: "Q-learning is not a Q-table. The Q-function is the algorithm that will feed the Q-table."
}
]}
/>
From 89f68ae039ef9169814f4cd33d5a0da423e45a46 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Mon, 26 Feb 2024 09:57:41 +0100
Subject: [PATCH 09/23] Update Pyramids download
---
notebooks/unit5/unit5.ipynb | 64 +++++++++++++------------------------
1 file changed, 22 insertions(+), 42 deletions(-)
diff --git a/notebooks/unit5/unit5.ipynb b/notebooks/unit5/unit5.ipynb
index cef401d..622960e 100644
--- a/notebooks/unit5/unit5.ipynb
+++ b/notebooks/unit5/unit5.ipynb
@@ -206,7 +206,7 @@
},
"outputs": [],
"source": [
- "%%capture\n",
+ "\n",
"# Go inside the repository and install the package\n",
"%cd ml-agents\n",
"!pip3 install -e ./ml-agents-envs\n",
@@ -600,58 +600,38 @@
},
{
"cell_type": "markdown",
- "metadata": {
- "id": "NyqYYkLyAVMK"
- },
"source": [
- "Download the file Pyramids.zip from https://drive.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)"
- ]
+ "We downloaded the file Pyramids-linux.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids-linux.zip using `wget`"
+ ],
+ "metadata": {
+ "id": "x2C48SGZjZYw"
+ }
},
{
"cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "AxojCsSVAVMP"
- },
- "outputs": [],
"source": [
- "!wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H\" -O ./training-envs-executables/linux/Pyramids.zip && rm -rf /tmp/cookies.txt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "bfs6CTJ1AVMP"
- },
- "source": [
- "**OR** Download directly to local machine and then drag and drop the file from local machine to `./training-envs-executables/linux`"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "H7JmgOwcSSmF"
- },
- "source": [
- "Wait for the upload to finish and then run the command below.\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "source": [
- "Unzip it"
+ "!wget \"https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip\" -O ./training-envs-executables/linux/Pyramids.zip"
],
"metadata": {
- "id": "iWUUcs0_794U"
+ "id": "eWh8Pl3sjZY2"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We unzip the executable.zip file"
+ ],
+ "metadata": {
+ "id": "V5LXPOPujZY3"
}
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "i2E3K4V2AVMP"
+ "id": "SmNgFdXhjZY3"
},
"outputs": [],
"source": [
@@ -662,7 +642,7 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "KmKYBgHTAVMP"
+ "id": "T1jxwhrJjZY3"
},
"source": [
"Make sure your file is accessible"
@@ -672,7 +652,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "Im-nwvLPAVMP"
+ "id": "6fDd03btjZY3"
},
"outputs": [],
"source": [
From 0535a45230d4b6c976f12693cae70eb9fd86e814 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Mon, 26 Feb 2024 09:59:54 +0100
Subject: [PATCH 10/23] Update hands-on.mdx
* Change pyramids environment
---
units/en/unit5/hands-on.mdx | 7 +++----
1 file changed, 3 insertions(+), 4 deletions(-)
diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index cd4a157..15c70ef 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -288,17 +288,16 @@ Now let's try a more challenging environment called Pyramids.
- We need to download it and place it into `./training-envs-executables/linux/`
- We use a linux executable because we're using colab, and the colab machine's OS is Ubuntu (linux)
-Download the file Pyramids.zip from https://drive.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
+We downloaded the file Pyramids-linux.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip using `wget`
```python
-!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H" -O ./training-envs-executables/linux/Pyramids.zip && rm -rf /tmp/cookies.txt
+wget "https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip" -O ./training-envs-executables/linux/Pyramids.zip
```
Unzip it
```python
-%%capture
-!unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zip
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zip
```
Make sure your file is accessible
From 8cde698f60850bdddd782ebd961de8233d6a1c07 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Mon, 26 Feb 2024 10:02:14 +0100
Subject: [PATCH 11/23] Update unit5.ipynb
---
notebooks/unit5/unit5.ipynb | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/notebooks/unit5/unit5.ipynb b/notebooks/unit5/unit5.ipynb
index 622960e..633d204 100644
--- a/notebooks/unit5/unit5.ipynb
+++ b/notebooks/unit5/unit5.ipynb
@@ -601,7 +601,7 @@
{
"cell_type": "markdown",
"source": [
- "We downloaded the file Pyramids-linux.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids-linux.zip using `wget`"
+ "We downloaded the file Pyramids.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip using `wget`"
],
"metadata": {
"id": "x2C48SGZjZYw"
@@ -814,4 +814,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From 00c6120fe67dde9fed96c2cbd6ff34b46adb6f14 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Mon, 26 Feb 2024 10:10:56 +0100
Subject: [PATCH 12/23] Update hands-on.mdx
---
units/en/unit5/hands-on.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index 15c70ef..1b9dfc3 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -288,7 +288,7 @@ Now let's try a more challenging environment called Pyramids.
- We need to download it and place it into `./training-envs-executables/linux/`
- We use a linux executable because we're using colab, and the colab machine's OS is Ubuntu (linux)
-We downloaded the file Pyramids-linux.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip using `wget`
+We downloaded the file Pyramids.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip using `wget`
```python
wget "https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip" -O ./training-envs-executables/linux/Pyramids.zip
From 74ce0e458fbc0aee95c87d48a71bae092986195f Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Fri, 1 Mar 2024 16:19:10 +0100
Subject: [PATCH 13/23] Delete .github/workflows/delete_doc_comment.yml
---
.github/workflows/delete_doc_comment.yml | 13 -------------
1 file changed, 13 deletions(-)
delete mode 100644 .github/workflows/delete_doc_comment.yml
diff --git a/.github/workflows/delete_doc_comment.yml b/.github/workflows/delete_doc_comment.yml
deleted file mode 100644
index 72801c8..0000000
--- a/.github/workflows/delete_doc_comment.yml
+++ /dev/null
@@ -1,13 +0,0 @@
-name: Delete doc comment
-
-on:
- workflow_run:
- workflows: ["Delete doc comment trigger"]
- types:
- - completed
-
-jobs:
- delete:
- uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
- secrets:
- comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
\ No newline at end of file
From c43bad97b7fd798842ef45910f71cba7db7b27d1 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Fri, 1 Mar 2024 16:22:39 +0100
Subject: [PATCH 14/23] Delete .github/workflows/delete_doc_comment_trigger.yml
---
.github/workflows/delete_doc_comment_trigger.yml | 12 ------------
1 file changed, 12 deletions(-)
delete mode 100644 .github/workflows/delete_doc_comment_trigger.yml
diff --git a/.github/workflows/delete_doc_comment_trigger.yml b/.github/workflows/delete_doc_comment_trigger.yml
deleted file mode 100644
index 5e39e25..0000000
--- a/.github/workflows/delete_doc_comment_trigger.yml
+++ /dev/null
@@ -1,12 +0,0 @@
-name: Delete doc comment trigger
-
-on:
- pull_request:
- types: [ closed ]
-
-
-jobs:
- delete:
- uses: huggingface/doc-builder/.github/workflows/delete_doc_comment_trigger.yml@main
- with:
- pr_number: ${{ github.event.number }}
\ No newline at end of file
From cd30c90961cfec1252a90500a5c98a71847e90bb Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Fri, 1 Mar 2024 23:28:19 -0500
Subject: [PATCH 15/23] Updated page
---
units/en/unitbonus3/envs-to-try.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index e342bcb..3e33ccc 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -9,7 +9,7 @@ Here we provide a list of interesting environments you can try to train your age
DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
-It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via [Python PIP](https://pypi.org/project/diambra-arena/). It is completely free to use, the user only needs to register on the official website.
+It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via [Python PIP](https://pypi.org/project/diambra-arena/). It is completely free to use, the user only needs to register on the [official website](https://diambra.ai/register/).
In addition, its [GitHub repository](https://github.com/diambra/) provides a collection of examples covering main use cases of interest that can be run in just a few steps.
From 2db3b14f4a598ac8a133990a430db2c72c7ffd6b Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Fri, 1 Mar 2024 23:32:13 -0500
Subject: [PATCH 16/23] Update diambra arena image
---
units/en/unitbonus3/envs-to-try.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index 3e33ccc..2d10c81 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -4,7 +4,7 @@ Here we provide a list of interesting environments you can try to train your age
## DIAMBRA Arena
-
+
DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
From 311e125d067c8422284db78220f570bf0e105507 Mon Sep 17 00:00:00 2001
From: Ivan <34917945+Croolch@users.noreply.github.com>
Date: Sat, 2 Mar 2024 14:13:20 +0800
Subject: [PATCH 17/23] Update unit1.ipynb
---
notebooks/unit1/unit1.ipynb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index eb02ad4..858fe5a 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -115,7 +115,7 @@
"\n",
"🔲 📝 **[Read Unit 0](https://huggingface.co/deep-rl-course/unit0/introduction)** that gives you all the **information about the course and helps you to onboard** 🤗\n",
"\n",
- "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (RL process, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
]
},
{
From e8b6db8a326805265bc0ea9daacd4bb55217d8cd Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Sat, 2 Mar 2024 14:58:10 -0500
Subject: [PATCH 18/23] Update units/en/unitbonus3/envs-to-try.mdx
Co-authored-by: Thomas Simonini
---
units/en/unitbonus3/envs-to-try.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index 2d10c81..ea2ee6d 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -21,7 +21,7 @@ They all support both single player (1P) as well as two players (2P) mode, makin
[Interfaced games](https://docs.diambra.ai/envs/games/) have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
-DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most important packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents examples repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
+DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most important packages: [Stable Baselines 3](https://stable-baselines3.readthedocs.io/en/master/) and [Ray RLlib](https://docs.ray.io/en/latest/rllib/index.html), while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents examples repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
### Competition Platform
From 382c69caa48054fa322196f54847115289dcdedb Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
Date: Sat, 2 Mar 2024 14:59:06 -0500
Subject: [PATCH 19/23] Update units/en/unitbonus3/envs-to-try.mdx
Co-authored-by: Thomas Simonini
---
units/en/unitbonus3/envs-to-try.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
index ea2ee6d..ce372e5 100644
--- a/units/en/unitbonus3/envs-to-try.mdx
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -25,7 +25,7 @@ DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Le
### Competition Platform
-DIAMBRA also provides a competition platform fully integrated with Hugging Face, on which you can submit your trained agents and compete with other coders around the globe in epic video games tournaments!
+DIAMBRA also provides a competition platform fully integrated with the Hugging Face Hub, on which you can submit your trained agents and compete with other coders around the globe in epic video games tournaments!
It features a public leaderboard where users are ranked by the best score achieved by their agents in our different environments.
From 9d777a01b0fa94d5492dc8ca350162e64cb3bfb8 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Tue, 5 Mar 2024 10:40:03 +0100
Subject: [PATCH 20/23] Update pg-theorem.mdx
---
units/en/unit4/pg-theorem.mdx | 8 ++++++--
1 file changed, 6 insertions(+), 2 deletions(-)
diff --git a/units/en/unit4/pg-theorem.mdx b/units/en/unit4/pg-theorem.mdx
index 9db62d9..dc7a320 100644
--- a/units/en/unit4/pg-theorem.mdx
+++ b/units/en/unit4/pg-theorem.mdx
@@ -27,9 +27,13 @@ We then multiply every term in the sum by \\(\frac{P(\tau;\theta)}{P(\tau;\theta
\\( = \sum_{\tau} \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta)R(\tau) \\)
-We can simplify further this since \\( \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\)
+We can simplify further this since
-\\(= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
+\\( \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\)
+
+
+
+\\ (P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
We can then use the *derivative log trick* (also called *likelihood ratio trick* or *REINFORCE trick*), a simple rule in calculus that implies that \\( \nabla_x log f(x) = \frac{\nabla_x f(x)}{f(x)} \\)
From 72473f08a804333e01160ec62136e8635bd97412 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
Date: Tue, 5 Mar 2024 10:45:12 +0100
Subject: [PATCH 21/23] Update pg-theorem.mdx
---
units/en/unit4/pg-theorem.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/units/en/unit4/pg-theorem.mdx b/units/en/unit4/pg-theorem.mdx
index dc7a320..602ff69 100644
--- a/units/en/unit4/pg-theorem.mdx
+++ b/units/en/unit4/pg-theorem.mdx
@@ -33,7 +33,7 @@ We can simplify further this since
-\\ (P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
+\\( P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
We can then use the *derivative log trick* (also called *likelihood ratio trick* or *REINFORCE trick*), a simple rule in calculus that implies that \\( \nabla_x log f(x) = \frac{\nabla_x f(x)}{f(x)} \\)
From f123308a28cc3ee9d96b47a704d3af89c69d928f Mon Sep 17 00:00:00 2001
From: S-N-O-R-L-A-X
Date: Thu, 4 Apr 2024 19:33:25 +0800
Subject: [PATCH 22/23] fix: fix doc equations
---
units/en/unit2/bellman-equation.mdx | 2 +-
units/en/unit4/policy-gradient.mdx | 26 ++++++++++++++------------
2 files changed, 15 insertions(+), 13 deletions(-)
diff --git a/units/en/unit2/bellman-equation.mdx b/units/en/unit2/bellman-equation.mdx
index f401ccc..6f85eed 100644
--- a/units/en/unit2/bellman-equation.mdx
+++ b/units/en/unit2/bellman-equation.mdx
@@ -27,7 +27,7 @@ Instead of calculating the expected return for each state or each state-action p
The Bellman equation is a recursive equation that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as:
-**The immediate reward \\(R_{t+1}\\) + the discounted value of the state that follows ( \\(gamma * V(S_{t+1}) \\) ) .**
+**The immediate reward \\(R_{t+1}\\) + the discounted value of the state that follows ( \\(\gamma * V(S_{t+1}) \\) ) .**
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index ccc34cb..7406e7f 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -37,9 +37,9 @@ We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This
-Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action \\(a_t\\) from state \\(s_t\\) given our policy.
+Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action \\(a_t\\) from state \\(s_t\\) given our policy.
-**But how do we know if our policy is good?** We need to have a way to measure it. To know that, we define a score/objective function called \\(J(\theta)\\).
+**But how do we know if our policy is good?** We need to have a way to measure it. To know that, we define a score/objective function called \\(J(\theta)\\).
### The objective function
@@ -48,20 +48,20 @@ The *objective function* gives us the **performance of the agent** given a traje
Let's give some more details on this formula:
-- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
+- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
-- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\( \theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
+- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\(\theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
-Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
+Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
@@ -69,7 +69,7 @@ Our objective then is to maximize the expected cumulative reward by finding the
## Gradient Ascent and the Policy-gradient Theorem
-Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
+Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
(If you need a refresher on the difference between gradient descent and gradient ascent [check this](https://www.baeldung.com/cs/gradient-descent-vs-ascent) and [this](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression)).
@@ -77,9 +77,9 @@ Our update step for gradient-ascent is:
\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
+We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
-However, there are two problems with computing the derivative of \\(J(\theta)\\):
+However, there are two problems with computing the derivative of \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it requires calculating the probability of each possible trajectory, which is computationally super expensive.
So we want to **calculate a gradient estimation with a sample-based estimate (collect some trajectories)**.
@@ -98,18 +98,20 @@ If you want to understand how we derive this formula for approximating the gradi
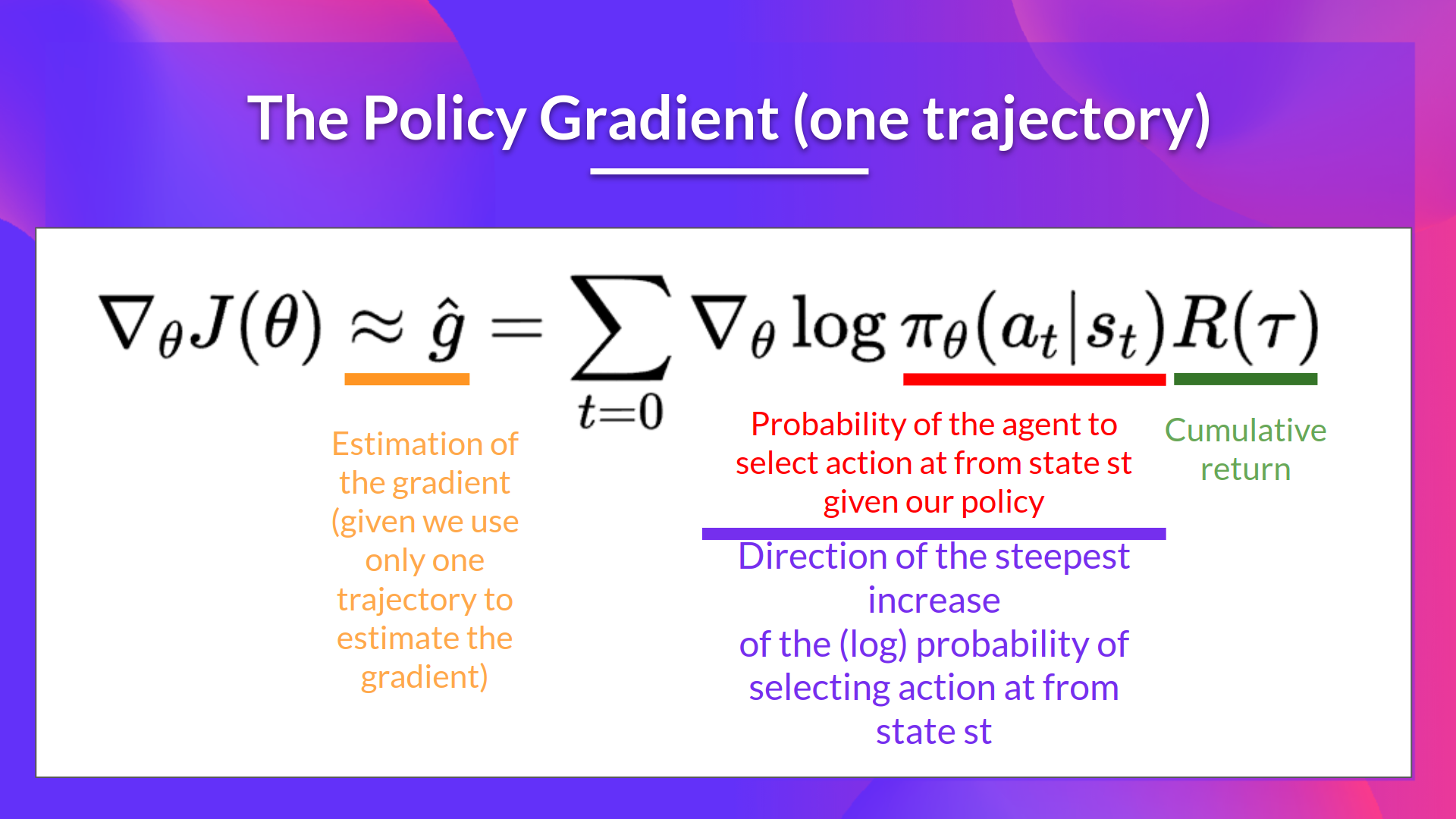
The Reinforce algorithm, also called Monte-Carlo policy-gradient, is a policy-gradient algorithm that **uses an estimated return from an entire episode to update the policy parameter** \\(\theta\\):
In a loop:
-- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
-- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
+- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
+- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
-- Update the weights of the policy: \\(\theta \leftarrow \theta + \alpha \hat{g}\\)
+- Update the weights of the policy: \\(\theta \leftarrow \theta + \alpha \hat{g}\\)
We can interpret this update as follows:
+
- \\(\nabla_\theta log \pi_\theta(a_t|s_t)\\) is the direction of **steepest increase of the (log) probability** of selecting action at from state st.
-This tells us **how we should change the weights of policy** if we want to increase/decrease the log probability of selecting action \\(a_t\\) at state \\(s_t\\).
+This tells us **how we should change the weights of policy** if we want to increase/decrease the log probability of selecting action \\(a_t\\) at state \\(s_t\\).
+
- \\(R(\tau)\\): is the scoring function:
- If the return is high, it will **push up the probabilities** of the (state, action) combinations.
- Otherwise, if the return is low, it will **push down the probabilities** of the (state, action) combinations.
From ddcdc8cd3a6282509b92eb756e2194d807578289 Mon Sep 17 00:00:00 2001
From: S-N-O-R-L-A-X
Date: Sun, 7 Apr 2024 16:10:57 +0800
Subject: [PATCH 23/23] fix: fix gap between math signs and text
---
units/en/unit4/policy-gradient.mdx | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index 7406e7f..10439b1 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -2,7 +2,7 @@
## Getting the big picture
-We just learned that policy-gradient methods aim to find parameters \\( \theta \\) that **maximize the expected return**.
+We just learned that policy-gradient methods aim to find parameters \\( \theta \\) that **maximize the expected return**.
The idea is that we have a *parameterized stochastic policy*. In our case, a neural network outputs a probability distribution over actions. The probability of taking each action is also called the *action preference*.
@@ -20,7 +20,7 @@ But **how are we going to optimize the weights using the expected return**?
The idea is that we're going to **let the agent interact during an episode**. And if we win the episode, we consider that each action taken was good and must be more sampled in the future
since they lead to win.
-So for each state-action pair, we want to increase the \\(P(a|s)\\): the probability of taking that action at that state. Or decrease if we lost.
+So for each state-action pair, we want to increase the \\(P(a|s)\\): the probability of taking that action at that state. Or decrease if we lost.
The Policy-gradient algorithm (simplified) looks like this:
@@ -31,13 +31,13 @@ Now that we got the big picture, let's dive deeper into policy-gradient methods.
## Diving deeper into policy-gradient methods
-We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
+We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
-Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action \\(a_t\\) from state \\(s_t\\) given our policy.
+Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action \\(a_t\\) from state \\(s_t\\) given our policy.
**But how do we know if our policy is good?** We need to have a way to measure it. To know that, we define a score/objective function called \\(J(\theta)\\).
@@ -55,11 +55,11 @@ Let's give some more details on this formula:
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
-- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\(\theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
+- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\(\theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
-- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
+- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
 They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
-- `rl-announcements`: where we give the **lastest information about the course**.
+- `rl-announcements`: where we give the **latest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
- `rl-i-made-this`: where you can **share your projects and models**.
From 6ab84a4e8e8586e836766e433e9844baa225ae99 Mon Sep 17 00:00:00 2001
From: Thomas Simonini
They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
-- `rl-announcements`: where we give the **lastest information about the course**.
+- `rl-announcements`: where we give the **latest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
- `rl-i-made-this`: where you can **share your projects and models**.
From 6ab84a4e8e8586e836766e433e9844baa225ae99 Mon Sep 17 00:00:00 2001
From: Thomas Simonini  +
+
+DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
+
+It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via Python PIP. It is completely free to use, the user only needs to register on the official website.
+
+In addition, its [GitHub repository](https://github.com/diambra/) provides a collection of examples covering main use cases of interest that can be run in just a few steps.
+
+#### Main Features
+
+All environments are episodic Reinforcement Learning tasks, with discrete actions (gamepad buttons) and observations composed by screen pixels plus additional numerical data (RAM values like characters health bars or characters stage side).
+
+They all support both single player (1P) as well as two players (2P) mode, making them the perfect resource to explore Standard RL, Competitive Multi-Agent, Competitive Human-Agent, Self-Play, Imitation Learning and Human-in-the-Loop.
+
+Interfaced games have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
+
+DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most import packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
+
+### Competition Platform
+
+DIAMBRA also provides a competition platform fully integrated with Hugging Face, on which you can submit your trained agents and compete with other coders around the globe in epic video games tournaments!
+
+It features a public leaderboard where users are ranked by the best score achieved by their agents in our different environments.
+
+It also offers the possibility to unlock cool achievements depending on the performances of your agent.
+
+Submitted agents are evaluated and their episodes are streamed on [DIAMBRA Twitch channel](https://www.twitch.tv/diambra_ai).
+
+#### References
+
+To start using this environment, check these resources:
+- [Official Docs](https://docs.diambra.ai/)
+- [Competition Platform](https://diambra.ai)
+- [GitHub](https://github.com/diambra/)
+- [Discord](https://diambra.ai/discord)
+
## MineRL
+
+
+DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
+
+It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via Python PIP. It is completely free to use, the user only needs to register on the official website.
+
+In addition, its [GitHub repository](https://github.com/diambra/) provides a collection of examples covering main use cases of interest that can be run in just a few steps.
+
+#### Main Features
+
+All environments are episodic Reinforcement Learning tasks, with discrete actions (gamepad buttons) and observations composed by screen pixels plus additional numerical data (RAM values like characters health bars or characters stage side).
+
+They all support both single player (1P) as well as two players (2P) mode, making them the perfect resource to explore Standard RL, Competitive Multi-Agent, Competitive Human-Agent, Self-Play, Imitation Learning and Human-in-the-Loop.
+
+Interfaced games have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
+
+DIAMBRA Arena is built to maximize compatibility will all major Reinforcement Learning libraries. It natively provides interfaces with the two most import packages: Stable Baselines 3 and Ray RLlib, while Stable Baselines is also available but deprecated. Their usage is illustrated in the [official documentation](https://docs.diambra.ai/) and in the [DIAMBRA Agents repository](https://github.com/diambra/agents). It can easily be interfaced with any other package in a similar way.
+
+### Competition Platform
+
+DIAMBRA also provides a competition platform fully integrated with Hugging Face, on which you can submit your trained agents and compete with other coders around the globe in epic video games tournaments!
+
+It features a public leaderboard where users are ranked by the best score achieved by their agents in our different environments.
+
+It also offers the possibility to unlock cool achievements depending on the performances of your agent.
+
+Submitted agents are evaluated and their episodes are streamed on [DIAMBRA Twitch channel](https://www.twitch.tv/diambra_ai).
+
+#### References
+
+To start using this environment, check these resources:
+- [Official Docs](https://docs.diambra.ai/)
+- [Competition Platform](https://diambra.ai)
+- [GitHub](https://github.com/diambra/)
+- [Discord](https://diambra.ai/discord)
+
## MineRL
 DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
From 311e125d067c8422284db78220f570bf0e105507 Mon Sep 17 00:00:00 2001
From: Ivan <34917945+Croolch@users.noreply.github.com>
Date: Sat, 2 Mar 2024 14:13:20 +0800
Subject: [PATCH 17/23] Update unit1.ipynb
---
notebooks/unit1/unit1.ipynb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index eb02ad4..858fe5a 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -115,7 +115,7 @@
"\n",
"🔲 📝 **[Read Unit 0](https://huggingface.co/deep-rl-course/unit0/introduction)** that gives you all the **information about the course and helps you to onboard** 🤗\n",
"\n",
- "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (RL process, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
]
},
{
From e8b6db8a326805265bc0ea9daacd4bb55217d8cd Mon Sep 17 00:00:00 2001
From: Alessandro Palmas
DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
From 311e125d067c8422284db78220f570bf0e105507 Mon Sep 17 00:00:00 2001
From: Ivan <34917945+Croolch@users.noreply.github.com>
Date: Sat, 2 Mar 2024 14:13:20 +0800
Subject: [PATCH 17/23] Update unit1.ipynb
---
notebooks/unit1/unit1.ipynb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index eb02ad4..858fe5a 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -115,7 +115,7 @@
"\n",
"🔲 📝 **[Read Unit 0](https://huggingface.co/deep-rl-course/unit0/introduction)** that gives you all the **information about the course and helps you to onboard** 🤗\n",
"\n",
- "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (RL process, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction)."
]
},
{
From e8b6db8a326805265bc0ea9daacd4bb55217d8cd Mon Sep 17 00:00:00 2001
From: Alessandro Palmas  diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index ccc34cb..7406e7f 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -37,9 +37,9 @@ We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This
diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index ccc34cb..7406e7f 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -37,9 +37,9 @@ We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This

 Let's give some more details on this formula:
-- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
+- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
Let's give some more details on this formula:
-- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
+- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
 - \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
-- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\( \theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
+- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\(\theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
-- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\( \theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
+- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\(\theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
 - \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
-Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
+Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
-Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
+Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
 @@ -69,7 +69,7 @@ Our objective then is to maximize the expected cumulative reward by finding the
## Gradient Ascent and the Policy-gradient Theorem
-Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
+Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
(If you need a refresher on the difference between gradient descent and gradient ascent [check this](https://www.baeldung.com/cs/gradient-descent-vs-ascent) and [this](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression)).
@@ -77,9 +77,9 @@ Our update step for gradient-ascent is:
\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
+We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
-However, there are two problems with computing the derivative of \\(J(\theta)\\):
+However, there are two problems with computing the derivative of \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it requires calculating the probability of each possible trajectory, which is computationally super expensive.
So we want to **calculate a gradient estimation with a sample-based estimate (collect some trajectories)**.
@@ -98,18 +98,20 @@ If you want to understand how we derive this formula for approximating the gradi
The Reinforce algorithm, also called Monte-Carlo policy-gradient, is a policy-gradient algorithm that **uses an estimated return from an entire episode to update the policy parameter** \\(\theta\\):
In a loop:
-- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
-- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
+- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
+- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
@@ -69,7 +69,7 @@ Our objective then is to maximize the expected cumulative reward by finding the
## Gradient Ascent and the Policy-gradient Theorem
-Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
+Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
(If you need a refresher on the difference between gradient descent and gradient ascent [check this](https://www.baeldung.com/cs/gradient-descent-vs-ascent) and [this](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression)).
@@ -77,9 +77,9 @@ Our update step for gradient-ascent is:
\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
+We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
-However, there are two problems with computing the derivative of \\(J(\theta)\\):
+However, there are two problems with computing the derivative of \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it requires calculating the probability of each possible trajectory, which is computationally super expensive.
So we want to **calculate a gradient estimation with a sample-based estimate (collect some trajectories)**.
@@ -98,18 +98,20 @@ If you want to understand how we derive this formula for approximating the gradi
The Reinforce algorithm, also called Monte-Carlo policy-gradient, is a policy-gradient algorithm that **uses an estimated return from an entire episode to update the policy parameter** \\(\theta\\):
In a loop:
-- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
-- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
+- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
+- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)