diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index 51a136a..7aae384 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -126,7 +126,7 @@ Which is equivalent to:
However, in reality, **we can’t just add them like that.** The rewards that come sooner (at the beginning of the game) **are more likely to happen** since they are more predictable than the long-term future reward.
-Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). Your goal is **to eat the maximum amount of cheese before being eaten by the cat.**
+Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse's goal is **to eat the maximum amount of cheese before being eaten by the cat.**
 @@ -142,5 +142,5 @@ To discount the rewards, we proceed like this:
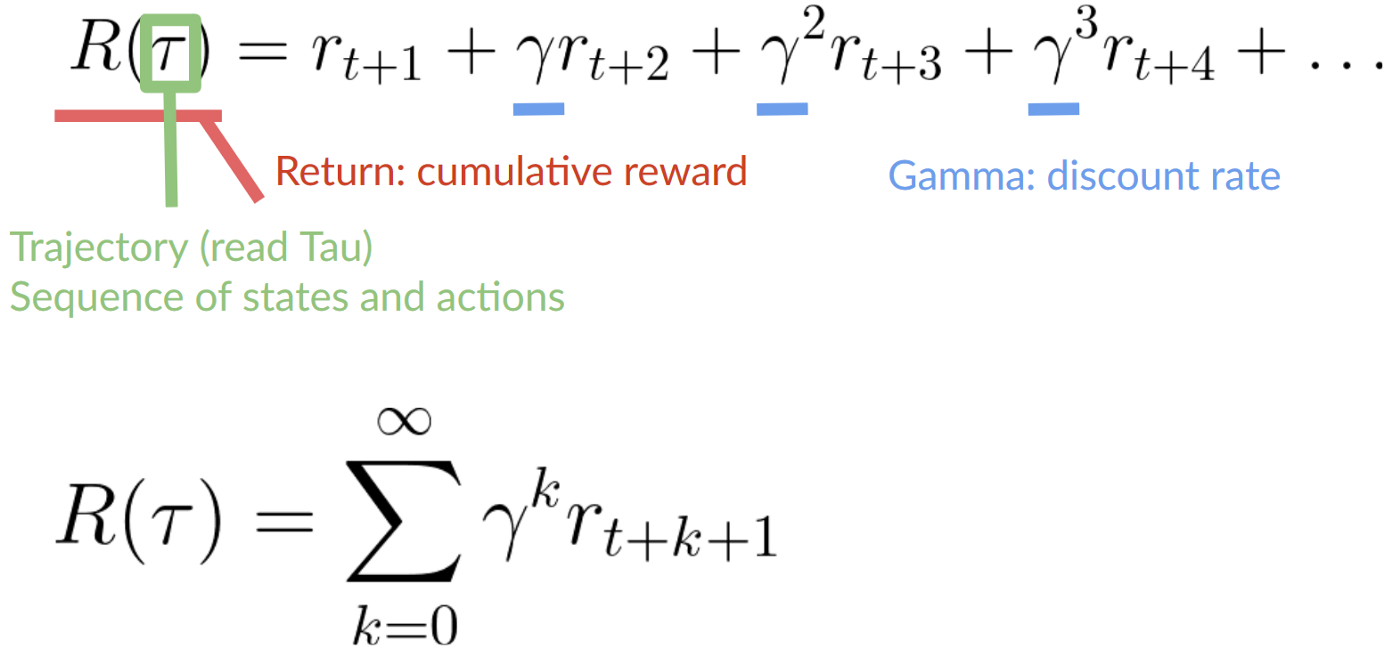
2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
-Our discounted cumulative expected rewards is:
+Our discounted expected cumulative reward is:
@@ -142,5 +142,5 @@ To discount the rewards, we proceed like this:
2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
-Our discounted cumulative expected rewards is:
+Our discounted expected cumulative reward is:
 diff --git a/units/en/unit1/summary.mdx b/units/en/unit1/summary.mdx
index eab64a9..5f835d6 100644
--- a/units/en/unit1/summary.mdx
+++ b/units/en/unit1/summary.mdx
@@ -1,6 +1,6 @@
# Summary [[summary]]
-That was a lot of information, if we summarize:
+That was a lot of information! Let's summarize:
- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
diff --git a/units/en/unit1/summary.mdx b/units/en/unit1/summary.mdx
index eab64a9..5f835d6 100644
--- a/units/en/unit1/summary.mdx
+++ b/units/en/unit1/summary.mdx
@@ -1,6 +1,6 @@
# Summary [[summary]]
-That was a lot of information, if we summarize:
+That was a lot of information! Let's summarize:
- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.