diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index 605f506..48f01d2 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -73,7 +73,7 @@ This is the Q-Learning pseudocode; let's study each part and **see how it works
We need to initialize the Q-table for each state-action pair. **Most of the time, we initialize with values of 0.**
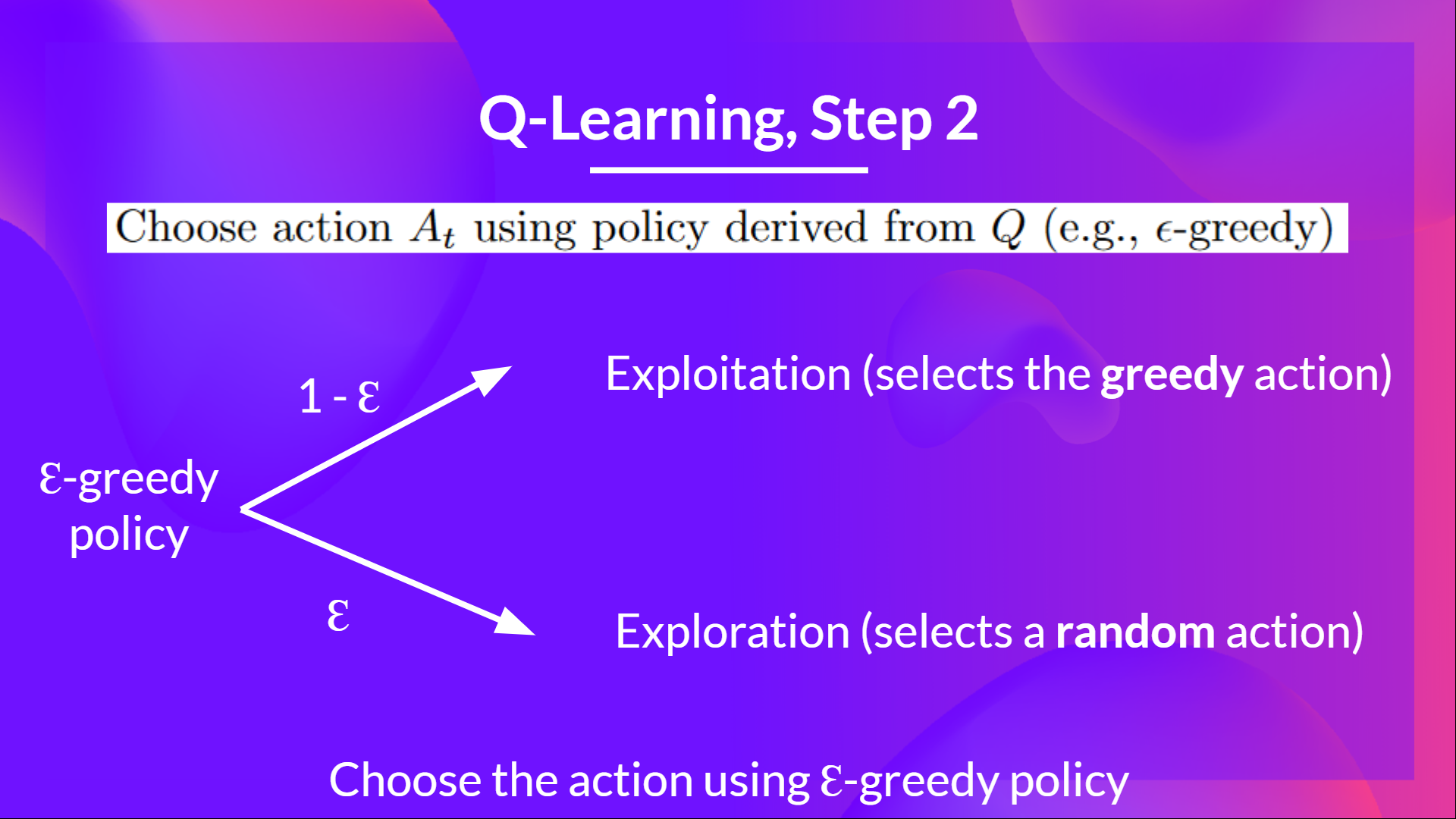
-### Step 2: Choose action using epsilon greedy strategy [[step2]]
+### Step 2: Choose action using epsilon-greedy strategy [[step2]]
@@ -114,7 +114,7 @@ It means that to update our \\(Q(S_t, A_t)\\):
How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
-2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
@@ -126,7 +126,7 @@ The difference is subtle:
- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
-For instance, with Q-Learning, the epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
@@ -144,7 +144,7 @@ Is different from the policy we use during the training part:
- *On-policy:* using the **same policy for acting and updating.**
-For instance, with Sarsa, another value-based algorithm, **the epsilon greedy Policy selects the next state-action pair, not a greedy policy.**
+For instance, with Sarsa, another value-based algorithm, **the epsilon-greedy Policy selects the next state-action pair, not a greedy policy.**
 @@ -114,7 +114,7 @@ It means that to update our \\(Q(S_t, A_t)\\):
How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
-2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
@@ -126,7 +126,7 @@ The difference is subtle:
- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
-For instance, with Q-Learning, the epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
@@ -114,7 +114,7 @@ It means that to update our \\(Q(S_t, A_t)\\):
How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
-2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
@@ -126,7 +126,7 @@ The difference is subtle:
- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
-For instance, with Q-Learning, the epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**