diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 244ce11..7a043a4 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -21,7 +21,7 @@ We're going to use two Robotics environments:
 -To validate this hands-on for the certification process, you need to push your three trained model to the Hub and get:
+To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
- `AntBulletEnv-v0` get a result of >= 650.
- `PandaReachDense-v2` get a result of >= -3.5.
@@ -172,7 +172,7 @@ The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyB
A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).
-For that, a wrapper exists and will compute a running average and standard deviation of input features.
+For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
We also normalize rewards with this same wrapper by adding `norm_reward = True`
@@ -242,8 +242,8 @@ env.save("vec_normalize.pkl")
### Evaluate the agent 📈
- Now that's our agent is trained, we need to **check its performance**.
-- Stable-Baselines3 provides a method to do that `evaluate_policy`
-- In my case, I've got a mean reward of `2371.90 +/- 16.50`
+- Stable-Baselines3 provides a method to do that: `evaluate_policy`
+- In my case, I got a mean reward of `2371.90 +/- 16.50`
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
@@ -266,7 +266,7 @@ print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
### Publish your trained model on the Hub 🔥
-Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
@@ -336,11 +336,11 @@ Also, we're going to use the *End-effector displacement control*, it means the *
-To validate this hands-on for the certification process, you need to push your three trained model to the Hub and get:
+To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
- `AntBulletEnv-v0` get a result of >= 650.
- `PandaReachDense-v2` get a result of >= -3.5.
@@ -172,7 +172,7 @@ The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyB
A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).
-For that, a wrapper exists and will compute a running average and standard deviation of input features.
+For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
We also normalize rewards with this same wrapper by adding `norm_reward = True`
@@ -242,8 +242,8 @@ env.save("vec_normalize.pkl")
### Evaluate the agent 📈
- Now that's our agent is trained, we need to **check its performance**.
-- Stable-Baselines3 provides a method to do that `evaluate_policy`
-- In my case, I've got a mean reward of `2371.90 +/- 16.50`
+- Stable-Baselines3 provides a method to do that: `evaluate_policy`
+- In my case, I got a mean reward of `2371.90 +/- 16.50`
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
@@ -266,7 +266,7 @@ print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
### Publish your trained model on the Hub 🔥
-Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
@@ -336,11 +336,11 @@ Also, we're going to use the *End-effector displacement control*, it means the *
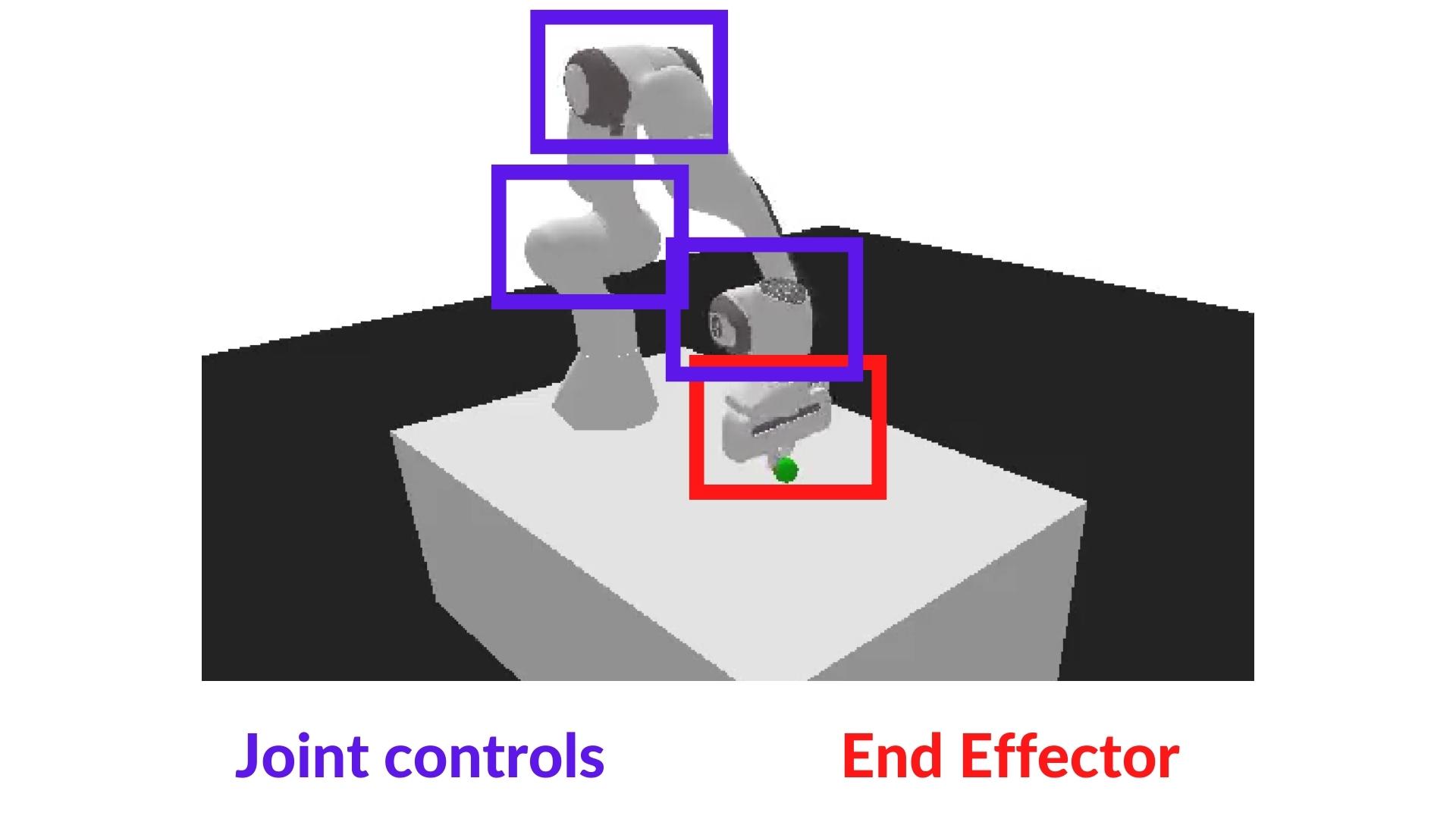 -This way, **the training will be easier**.
+This way **the training will be easier**.
-In `PandaReachDense-v2` the robotic arm must place its end-effector at a target position (green ball).
+In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
@@ -363,7 +363,7 @@ print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-The observation space **is a dictionary with 3 different element**:
+The observation space **is a dictionary with 3 different elements**:
- `achieved_goal`: (x,y,z) position of the goal.
- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
@@ -447,7 +447,7 @@ package_to_hub(
The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet?
-If you want to try more advanced tasks for panda-gym you need to check what was done using **TQC or SAC** (a more sample efficient algorithm suited for robotics tasks). In real robotics, you'll use more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much you have a risk to break it**.
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-This way, **the training will be easier**.
+This way **the training will be easier**.
-In `PandaReachDense-v2` the robotic arm must place its end-effector at a target position (green ball).
+In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
@@ -363,7 +363,7 @@ print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-The observation space **is a dictionary with 3 different element**:
+The observation space **is a dictionary with 3 different elements**:
- `achieved_goal`: (x,y,z) position of the goal.
- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
@@ -447,7 +447,7 @@ package_to_hub(
The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet?
-If you want to try more advanced tasks for panda-gym you need to check what was done using **TQC or SAC** (a more sample efficient algorithm suited for robotics tasks). In real robotics, you'll use more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much you have a risk to break it**.
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1