diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index d5541fc..f75636e 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -30,6 +30,8 @@
title: Quiz
- local: unit1/conclusion
title: Conclusion
+ - local: unit1/additional-readings
+ title: Additional Readings
- title: Bonus Unit 1. Introduction to Deep Reinforcement Learning with Huggy
sections:
- local: unitbonus1/introduction
@@ -60,8 +62,8 @@
title: Second Quiz
- local: unit2/conclusion
title: Conclusion
- - local: unit2/additional-reading
- title: Additional Reading
+ - local: unit2/additional-readings
+ title: Additional Readings
- title: Unit 3. Deep Q-Learning with Atari Games
sections:
- local: unit3/introduction
@@ -78,8 +80,8 @@
title: Quiz
- local: unit3/conclusion
title: Conclusion
- - local: unit3/additional-reading
- title: Additional Reading
+ - local: unit3/additional-readings
+ title: Additional Readings
- title: Unit Bonus 2. Automatic Hyperparameter Tuning with Optuna
sections:
- local: unitbonus2/introduction
diff --git a/units/en/unit1/additional-readings.mdx b/units/en/unit1/additional-readings.mdx
new file mode 100644
index 0000000..73e6a1e
--- /dev/null
+++ b/units/en/unit1/additional-readings.mdx
@@ -0,0 +1,11 @@
+# Additional Readings [[additional-readings]]
+
+## Deep Reinforcement Learning [[deep-rl]]
+
+- [Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 1, 2 and 3](http://incompleteideas.net/book/RLbook2020.pdf)
+- [Foundations of Deep RL Series, L1 MDPs, Exact Solution Methods, Max-ent RL by Pieter Abbeel](https://youtu.be/2GwBez0D20A)
+- [Spinning Up RL by OpenAI Part 1: Key concepts of RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html)
+
+## Gym [[gym]]
+
+- [Getting Started With OpenAI Gym: The Basic Building Blocks](https://blog.paperspace.com/getting-started-with-openai-gym/)
diff --git a/units/en/unit2/additional-reading.mdx b/units/en/unit2/additional-reading.mdx
deleted file mode 100644
index 46a60ee..0000000
--- a/units/en/unit2/additional-reading.mdx
+++ /dev/null
@@ -1 +0,0 @@
-# Additional Reading [[additional-reading]]
diff --git a/units/en/unit2/additional-readings.mdx b/units/en/unit2/additional-readings.mdx
new file mode 100644
index 0000000..ebc3fa9
--- /dev/null
+++ b/units/en/unit2/additional-readings.mdx
@@ -0,0 +1,13 @@
+# Additional Readings [[additional-readings]]
+
+## Monte Carlo and TD Learning [[mc-td]]
+
+To dive deeper on Monte Carlo and Temporal Difference Learning:
+
+- Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?
+- When are Monte Carlo methods preferred over temporal difference ones?
+
+## Q-Learning [[q-learning]]
+
+- Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7
+- Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel
diff --git a/units/en/unit2/bellman-equation.mdx b/units/en/unit2/bellman-equation.mdx
index 27c7d35..9e3753f 100644
--- a/units/en/unit2/bellman-equation.mdx
+++ b/units/en/unit2/bellman-equation.mdx
@@ -5,9 +5,9 @@ The Bellman equation **simplifies our state value or state-action value calcula
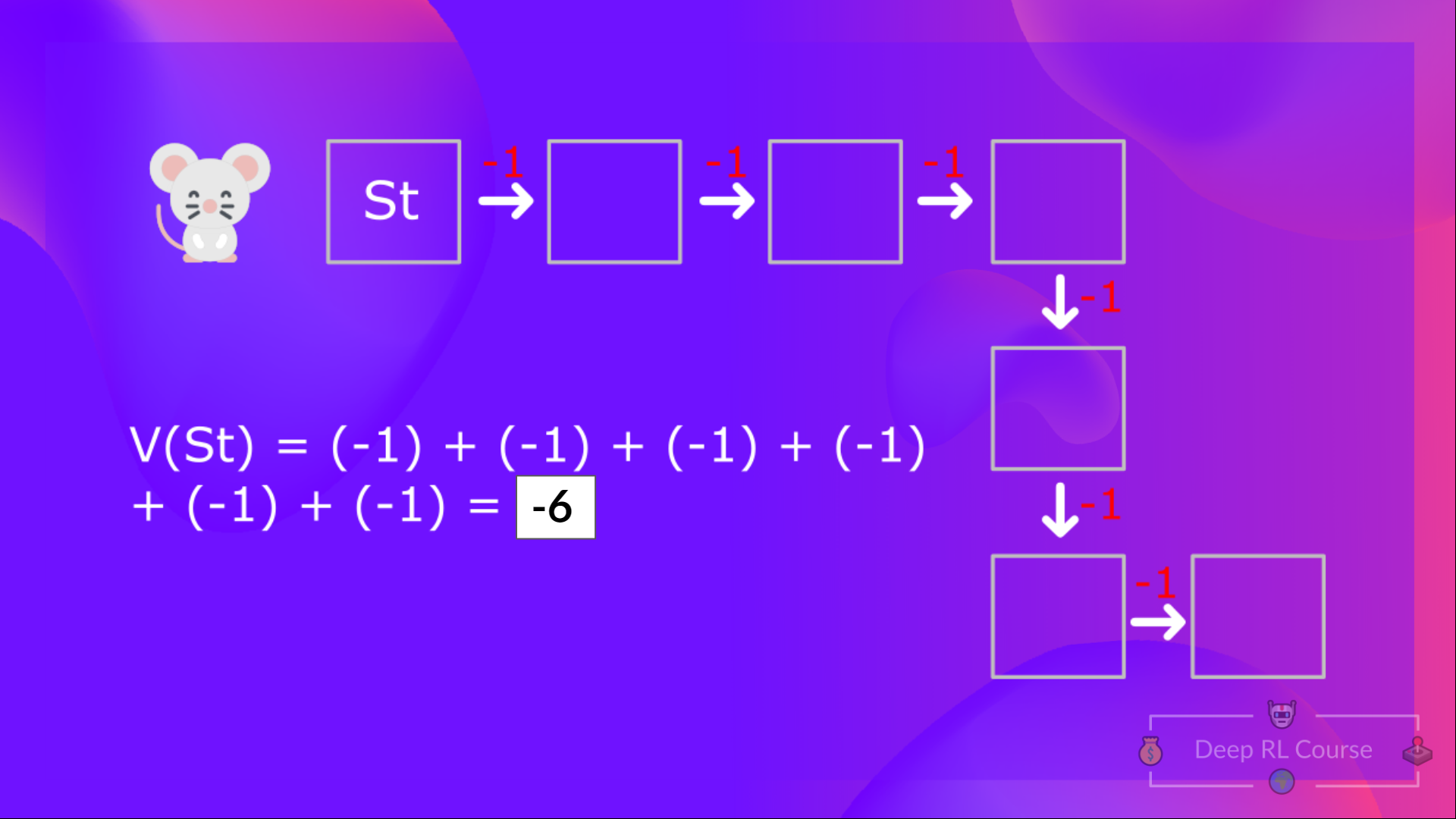
-With what we learned from now, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
+With what we learned so far, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
-So to calculate \\(V(S_t)\\), we need to make the sum of the expected rewards. Hence:
+So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
@@ -35,7 +35,7 @@ The Bellman equation is a recursive equation that works like this: instead of st
-If we go back to our example, the value of State 1= expected cumulative return if we start at that state.
+If we go back to our example, we can say that the value of State 1 is equal to the expected cumulative return if we start at that state.
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index a9f9bb1..7d4365c 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -1,2 +1,9 @@
# Hands-on [[hands-on]]
-n
+
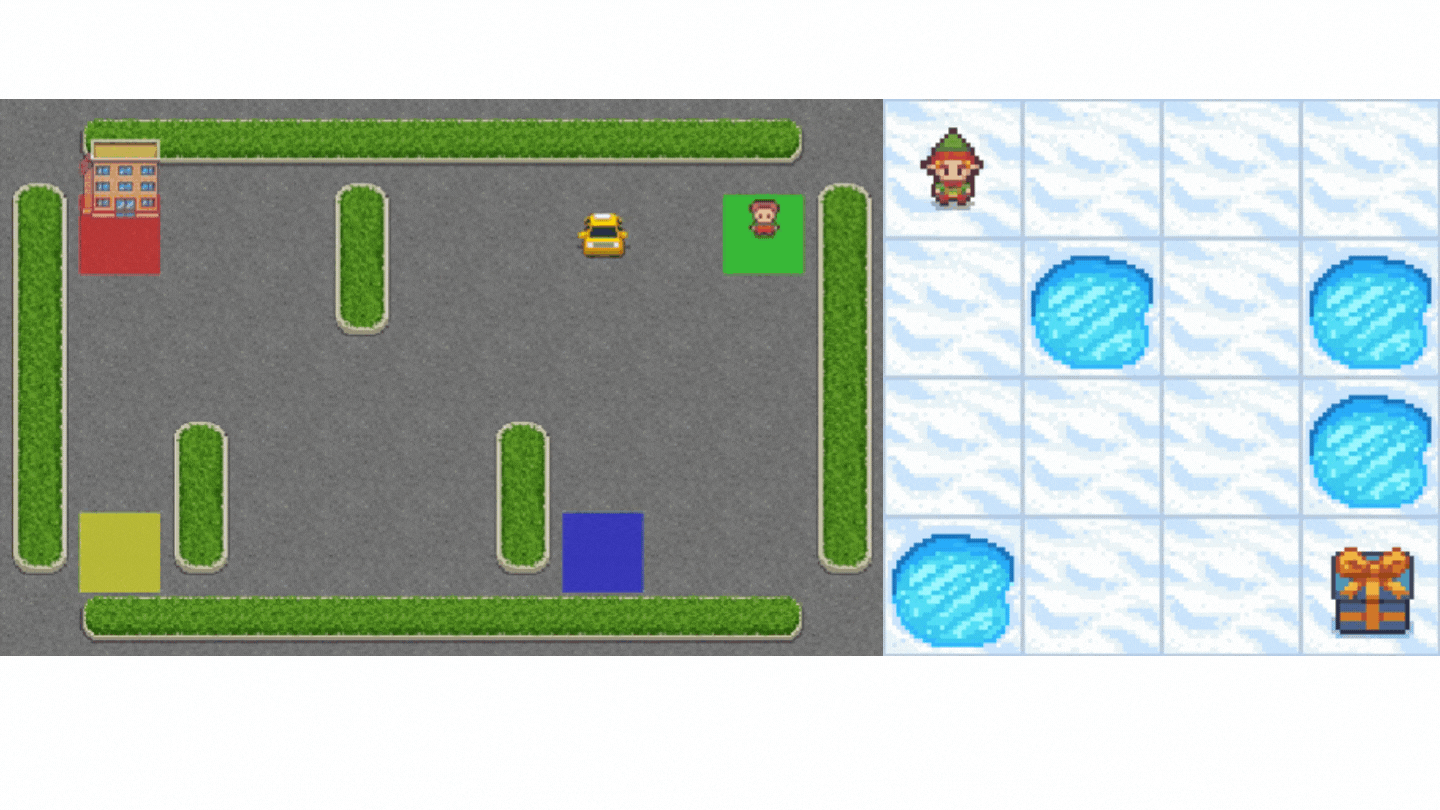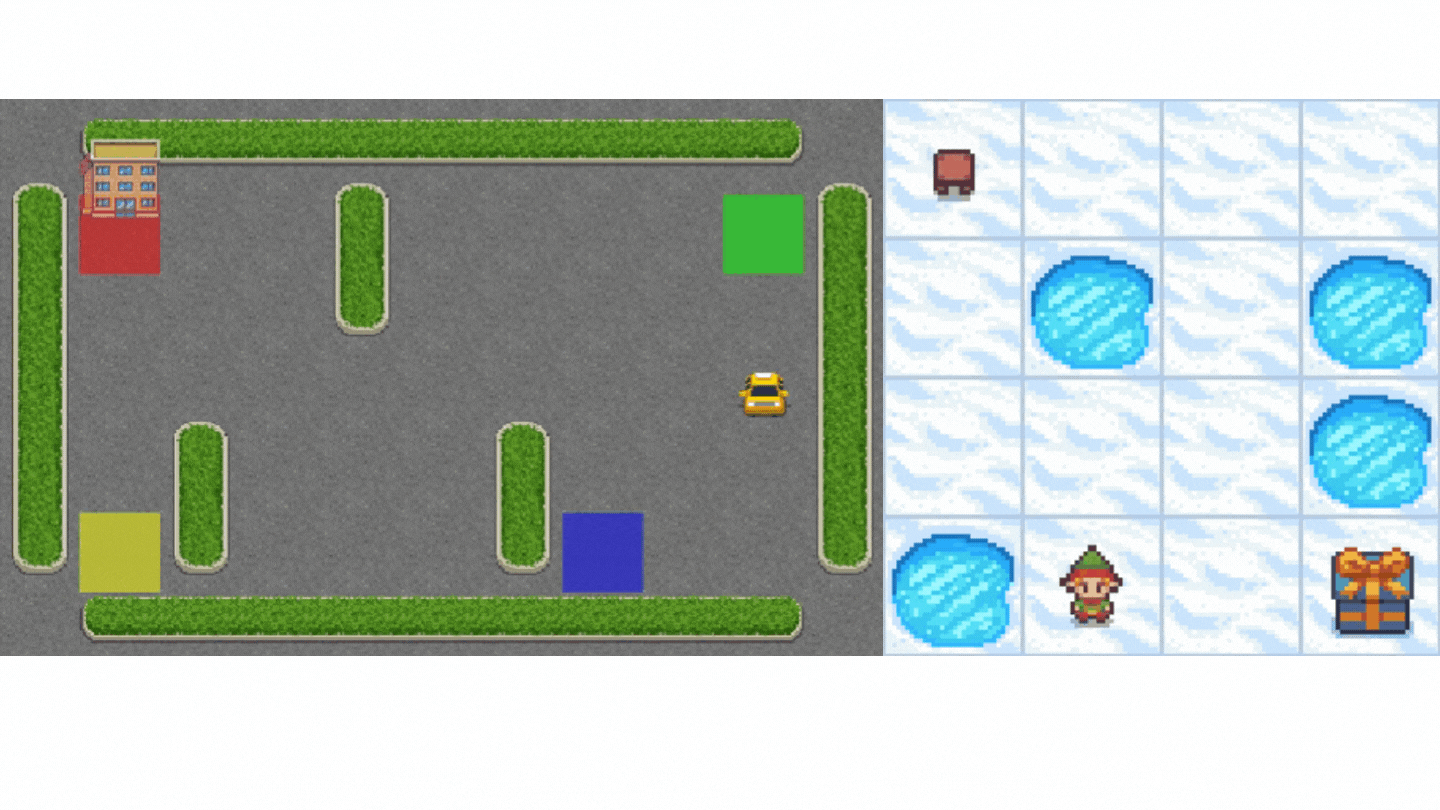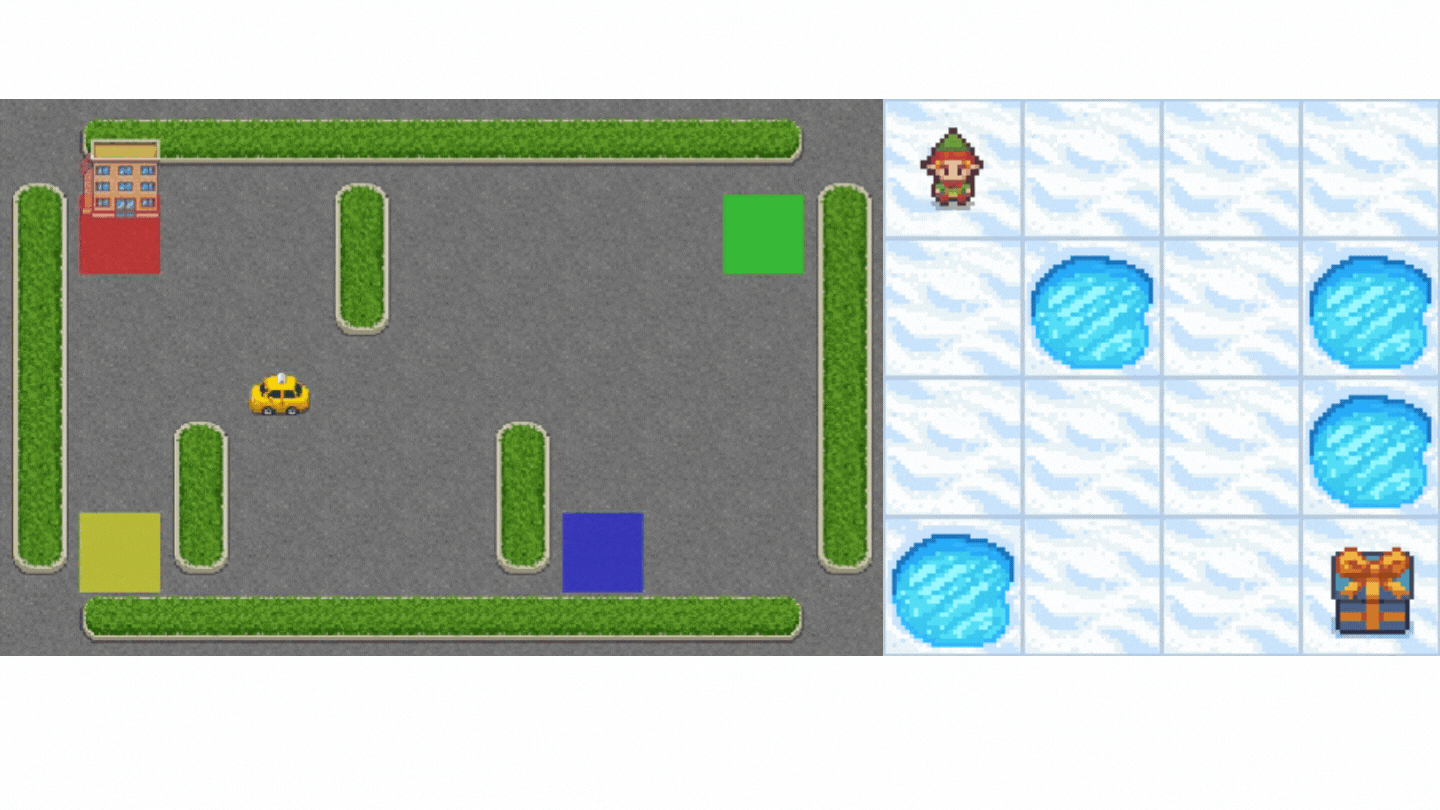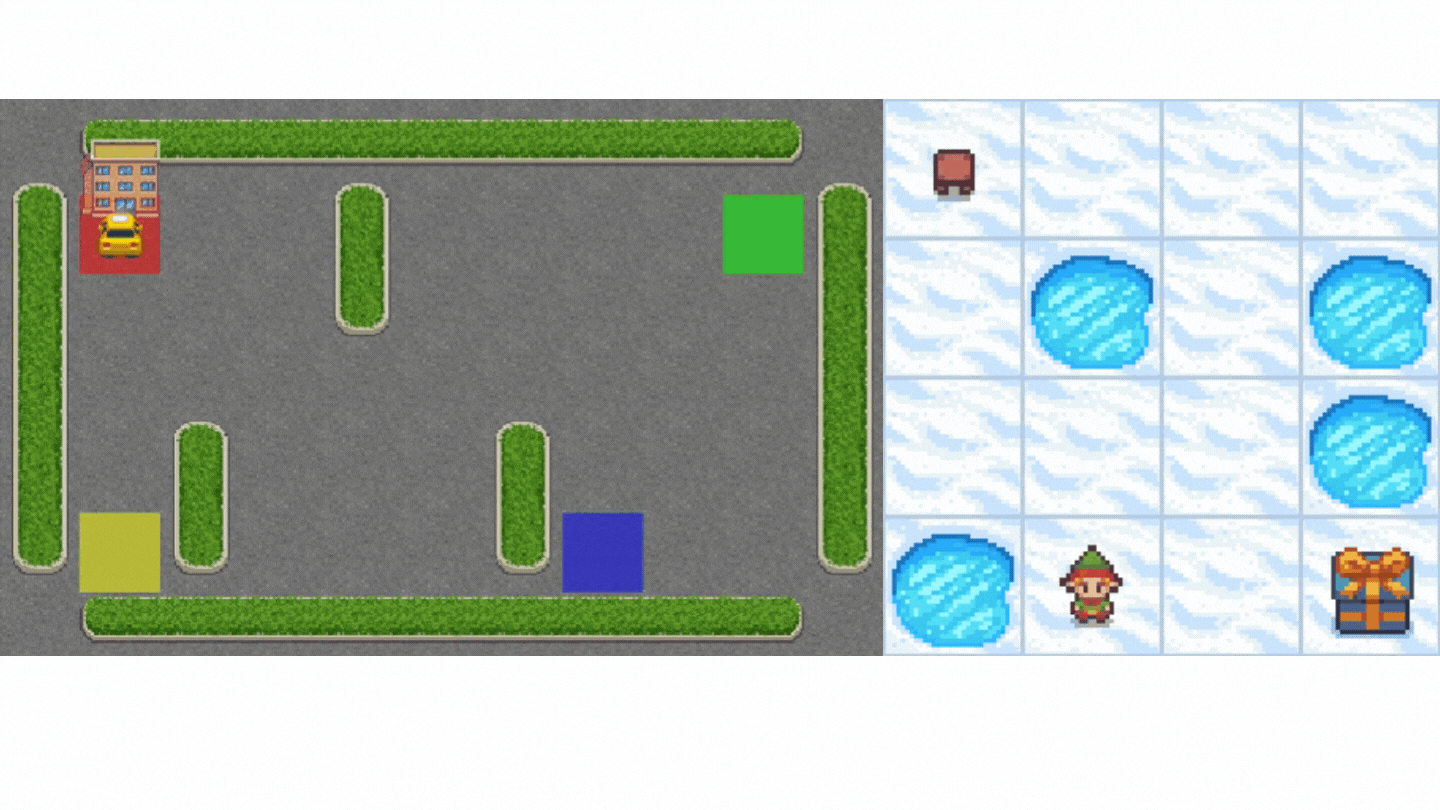
+Now that we studied the Q-Learning algorithm, let's implement it from scratch and train our Q-Learning agent in two environments:
+1. [Frozen-Lake-v1 (non-slippery and slippery version)](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/) ☃️ : where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. [An autonomous taxi](https://www.gymlibrary.dev/environments/toy_text/taxi/) 🚖 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
index a05b237..98c56d5 100644
--- a/units/en/unit2/introduction.mdx
+++ b/units/en/unit2/introduction.mdx
@@ -1,6 +1,7 @@
# Introduction to Q-Learning [[introduction-q-learning]]
-ADD THUMBNAIL
+
+
In the first chapter of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
@@ -14,13 +15,11 @@ We'll also **implement our first RL agent from scratch**: a Q-Learning agent an
+Concretely, we will:
-Concretely, we'll:
-
-* learn about value-based methods
-* learn about the differences between Monte Carlo and Temporal Difference Learning
-* study and implement our first RL algorithm: Q-Learning
-* implement our first RL agent
+- Learn about **value-based methods**.
+- Learn about the **differences between Monte Carlo and Temporal Difference Learning**.
+- Study and implement **our first RL algorithm**: Q-Learning.s
This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that played Atari games and beat the human level on some of them (breakout, space invaders…).
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
index 5410237..e78ee78 100644
--- a/units/en/unit2/mc-vs-td.mdx
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -121,6 +121,6 @@ Now we **continue to interact with this environment with our updated value func
If we summarize:
- With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
- - With *TD learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+ - With *TD Learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
diff --git a/units/en/unit2/what-is-rl.mdx b/units/en/unit2/what-is-rl.mdx
index fef3e96..2c31486 100644
--- a/units/en/unit2/what-is-rl.mdx
+++ b/units/en/unit2/what-is-rl.mdx
@@ -22,4 +22,4 @@ And to find this optimal policy (hence solving the RL problem), there **are two
-And in this unit, **we'll dive deeper into the Value-based methods.**
+And in this unit, **we'll dive deeper into the value-based methods.**
diff --git a/units/en/unit3/additional-reading.mdx b/units/en/unit3/additional-reading.mdx
deleted file mode 100644
index 46a60ee..0000000
--- a/units/en/unit3/additional-reading.mdx
+++ /dev/null
@@ -1 +0,0 @@
-# Additional Reading [[additional-reading]]
diff --git a/units/en/unit3/additional-readings.mdx b/units/en/unit3/additional-readings.mdx
new file mode 100644
index 0000000..1c91b69
--- /dev/null
+++ b/units/en/unit3/additional-readings.mdx
@@ -0,0 +1,6 @@
+# Additional Readings [[additional-readings]]
+
+- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
+- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
+- [Double Deep Q-Learning](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [Prioritized Experience Replay](https://arxiv.org/abs/1511.05952)
 @@ -35,7 +35,7 @@ The Bellman equation is a recursive equation that works like this: instead of st
@@ -35,7 +35,7 @@ The Bellman equation is a recursive equation that works like this: instead of st
 -With what we learned from now, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
+With what we learned so far, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
-So to calculate \\(V(S_t)\\), we need to make the sum of the expected rewards. Hence:
+So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
-With what we learned from now, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
+With what we learned so far, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(Our policy that we defined in the following example is a Greedy Policy, and for simplification, we don't discount the reward).**
-So to calculate \\(V(S_t)\\), we need to make the sum of the expected rewards. Hence:
+So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
 +
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
index a05b237..98c56d5 100644
--- a/units/en/unit2/introduction.mdx
+++ b/units/en/unit2/introduction.mdx
@@ -1,6 +1,7 @@
# Introduction to Q-Learning [[introduction-q-learning]]
-ADD THUMBNAIL
+
+
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
index a05b237..98c56d5 100644
--- a/units/en/unit2/introduction.mdx
+++ b/units/en/unit2/introduction.mdx
@@ -1,6 +1,7 @@
# Introduction to Q-Learning [[introduction-q-learning]]
-ADD THUMBNAIL
+ +
In the first chapter of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
@@ -14,13 +15,11 @@ We'll also **implement our first RL agent from scratch**: a Q-Learning agent an
+
In the first chapter of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
@@ -14,13 +15,11 @@ We'll also **implement our first RL agent from scratch**: a Q-Learning agent an
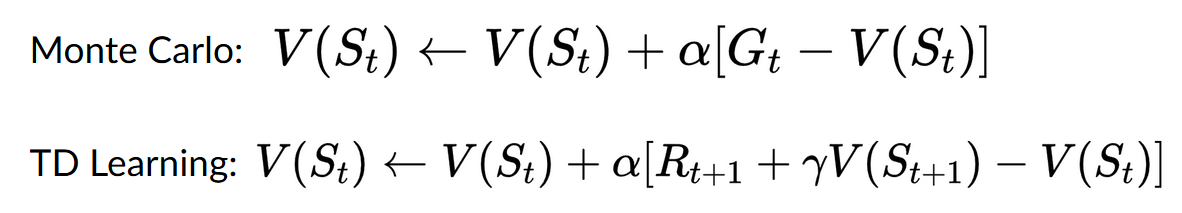 diff --git a/units/en/unit2/what-is-rl.mdx b/units/en/unit2/what-is-rl.mdx
index fef3e96..2c31486 100644
--- a/units/en/unit2/what-is-rl.mdx
+++ b/units/en/unit2/what-is-rl.mdx
@@ -22,4 +22,4 @@ And to find this optimal policy (hence solving the RL problem), there **are two
diff --git a/units/en/unit2/what-is-rl.mdx b/units/en/unit2/what-is-rl.mdx
index fef3e96..2c31486 100644
--- a/units/en/unit2/what-is-rl.mdx
+++ b/units/en/unit2/what-is-rl.mdx
@@ -22,4 +22,4 @@ And to find this optimal policy (hence solving the RL problem), there **are two
 -And in this unit, **we'll dive deeper into the Value-based methods.**
+And in this unit, **we'll dive deeper into the value-based methods.**
diff --git a/units/en/unit3/additional-reading.mdx b/units/en/unit3/additional-reading.mdx
deleted file mode 100644
index 46a60ee..0000000
--- a/units/en/unit3/additional-reading.mdx
+++ /dev/null
@@ -1 +0,0 @@
-# Additional Reading [[additional-reading]]
diff --git a/units/en/unit3/additional-readings.mdx b/units/en/unit3/additional-readings.mdx
new file mode 100644
index 0000000..1c91b69
--- /dev/null
+++ b/units/en/unit3/additional-readings.mdx
@@ -0,0 +1,6 @@
+# Additional Readings [[additional-readings]]
+
+- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
+- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
+- [Double Deep Q-Learning](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [Prioritized Experience Replay](https://arxiv.org/abs/1511.05952)
-And in this unit, **we'll dive deeper into the Value-based methods.**
+And in this unit, **we'll dive deeper into the value-based methods.**
diff --git a/units/en/unit3/additional-reading.mdx b/units/en/unit3/additional-reading.mdx
deleted file mode 100644
index 46a60ee..0000000
--- a/units/en/unit3/additional-reading.mdx
+++ /dev/null
@@ -1 +0,0 @@
-# Additional Reading [[additional-reading]]
diff --git a/units/en/unit3/additional-readings.mdx b/units/en/unit3/additional-readings.mdx
new file mode 100644
index 0000000..1c91b69
--- /dev/null
+++ b/units/en/unit3/additional-readings.mdx
@@ -0,0 +1,6 @@
+# Additional Readings [[additional-readings]]
+
+- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
+- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
+- [Double Deep Q-Learning](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [Prioritized Experience Replay](https://arxiv.org/abs/1511.05952)