diff --git a/notebooks/unit1/requirements-unit1.txt b/notebooks/unit1/requirements-unit1.txt
index cfb6770..fd27dfc 100644
--- a/notebooks/unit1/requirements-unit1.txt
+++ b/notebooks/unit1/requirements-unit1.txt
@@ -1,3 +1,4 @@
stable-baselines3==2.0.0a5
+swig
gymnasium[box2d]
huggingface_sb3
diff --git a/notebooks/unit6/unit6.ipynb b/notebooks/unit6/unit6.ipynb
index b797060..01b6802 100644
--- a/notebooks/unit6/unit6.ipynb
+++ b/notebooks/unit6/unit6.ipynb
@@ -5,7 +5,6 @@
"colab": {
"provenance": [],
"private_outputs": true,
- "authorship_tag": "ABX9TyPDFLK3trc6MCLJLqUUuAbl",
"include_colab_link": true
},
"kernelspec": {
@@ -36,7 +35,7 @@
"\n",
"\n",
"\n",
- "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments. \n",
+ "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments.\n",
"\n",
"With [PyBullet](https://github.com/bulletphysics/bullet3), you're going to **train a robot to move**:\n",
"- `AntBulletEnv-v0` 🕸️ More precisely, a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
@@ -62,12 +61,12 @@
{
"cell_type": "markdown",
"source": [
- "### 🎮 Environments: \n",
+ "### 🎮 Environments:\n",
"\n",
"- [PyBullet](https://github.com/bulletphysics/bullet3)\n",
"- [Panda-Gym](https://github.com/qgallouedec/panda-gym)\n",
"\n",
- "###📚 RL-Library: \n",
+ "###📚 RL-Library:\n",
"\n",
"- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)"
],
@@ -112,7 +111,7 @@
"\n",
"- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
"- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
- "- 🤖 Train **agents in unique environments** \n",
+ "- 🤖 Train **agents in unique environments**\n",
"\n",
"And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
"\n",
@@ -192,7 +191,7 @@
"source": [
"## Create a virtual display 🔽\n",
"\n",
- "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).\n",
"\n",
"Hence the following cell will install the librairies and create and run a virtual screen 🖥"
],
@@ -266,7 +265,10 @@
},
"outputs": [],
"source": [
- "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt"
+ "!pip install stable-baselines3[extra]==1.8.0\n",
+ "!pip install huggingface_sb3\n",
+ "!pip install panda_gym==2.0.0\n",
+ "!pip install pyglet==1.5.1"
]
},
{
@@ -403,7 +405,7 @@
{
"cell_type": "markdown",
"source": [
- "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html). \n",
+ "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).\n",
"\n",
"For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.\n",
"\n",
@@ -630,7 +632,7 @@
"\n",
"\n",
"\n",
- "- Copy the token \n",
+ "- Copy the token\n",
"- Run the cell below and paste the token"
]
},
@@ -855,7 +857,7 @@
"cell_type": "code",
"source": [
"# 6\n",
- "model_name = \"a2c-PandaReachDense-v2\"; \n",
+ "model_name = \"a2c-PandaReachDense-v2\";\n",
"model.save(model_name)\n",
"env.save(\"vec_normalize.pkl\")\n",
"\n",
@@ -927,4 +929,4 @@
}
}
]
-}
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part2.ipynb b/notebooks/unit8/unit8_part2.ipynb
index 51819df..4a41921 100644
--- a/notebooks/unit8/unit8_part2.ipynb
+++ b/notebooks/unit8/unit8_part2.ipynb
@@ -41,7 +41,7 @@
"from IPython.display import HTML\n",
"\n",
"HTML(''''''\n",
")"
]
@@ -124,15 +124,15 @@
"\n",
"### How sample-factory works\n",
"\n",
- "Sample-factory is one of the **most highly optimized RL implementations available to the community**. \n",
+ "Sample-factory is one of the **most highly optimized RL implementations available to the community**.\n",
"\n",
- "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**. \n",
+ "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.\n",
"\n",
- "The *workers* **communicate through shared memory, which lowers the communication cost between processes**. \n",
+ "The *workers* **communicate through shared memory, which lowers the communication cost between processes**.\n",
"\n",
- "The *rollout workers* interact with the environment and send observations to the *inference workers*. \n",
+ "The *rollout workers* interact with the environment and send observations to the *inference workers*.\n",
"\n",
- "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**. \n",
+ "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.\n",
"\n",
"After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.\n",
"\n",
@@ -164,9 +164,9 @@
"source": [
"## ViZDoom\n",
"\n",
- "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**. \n",
+ "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.\n",
"\n",
- "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland. \n",
+ "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.\n",
"\n",
"The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.\n",
"\n",
@@ -195,7 +195,7 @@
"source": [
"## We first need to install some dependencies that are required for the ViZDoom environment\n",
"\n",
- "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux. \n",
+ "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.\n",
"\n",
"If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)."
]
@@ -210,7 +210,7 @@
"source": [
"%%capture\n",
"%%bash\n",
- "# Install ViZDoom deps from \n",
+ "# Install ViZDoom deps from\n",
"# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux\n",
"\n",
"apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \\\n",
@@ -244,11 +244,21 @@
"source": [
"# install python libraries\n",
"# thanks toinsson\n",
- "!pip install sample-factory==2.0.2\n",
"!pip install faster-fifo==1.4.2\n",
"!pip install vizdoom"
]
},
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install sample-factory==2.0.2"
+ ],
+ "metadata": {
+ "id": "alxUt7Au-O8e"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -330,7 +340,7 @@
"- 1 available game variable: HEALTH\n",
"- death penalty = 100\n",
"\n",
- "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios). \n",
+ "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).\n",
"\n",
"There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).\n",
"\n"
@@ -451,7 +461,7 @@
"\n",
"\n",
"\n",
- "- Copy the token \n",
+ "- Copy the token\n",
"- Run the cell below and paste the token"
]
},
@@ -571,7 +581,7 @@
"source": [
"## Some additional challenges 🏆: Doom Deathmatch\n",
"\n",
- "Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**. \n",
+ "Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**.\n",
"\n",
"Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance."
],
diff --git a/units/en/communication/certification.mdx b/units/en/communication/certification.mdx
index 6d7ab34..bf836f8 100644
--- a/units/en/communication/certification.mdx
+++ b/units/en/communication/certification.mdx
@@ -3,8 +3,8 @@
The certification process is **completely free**:
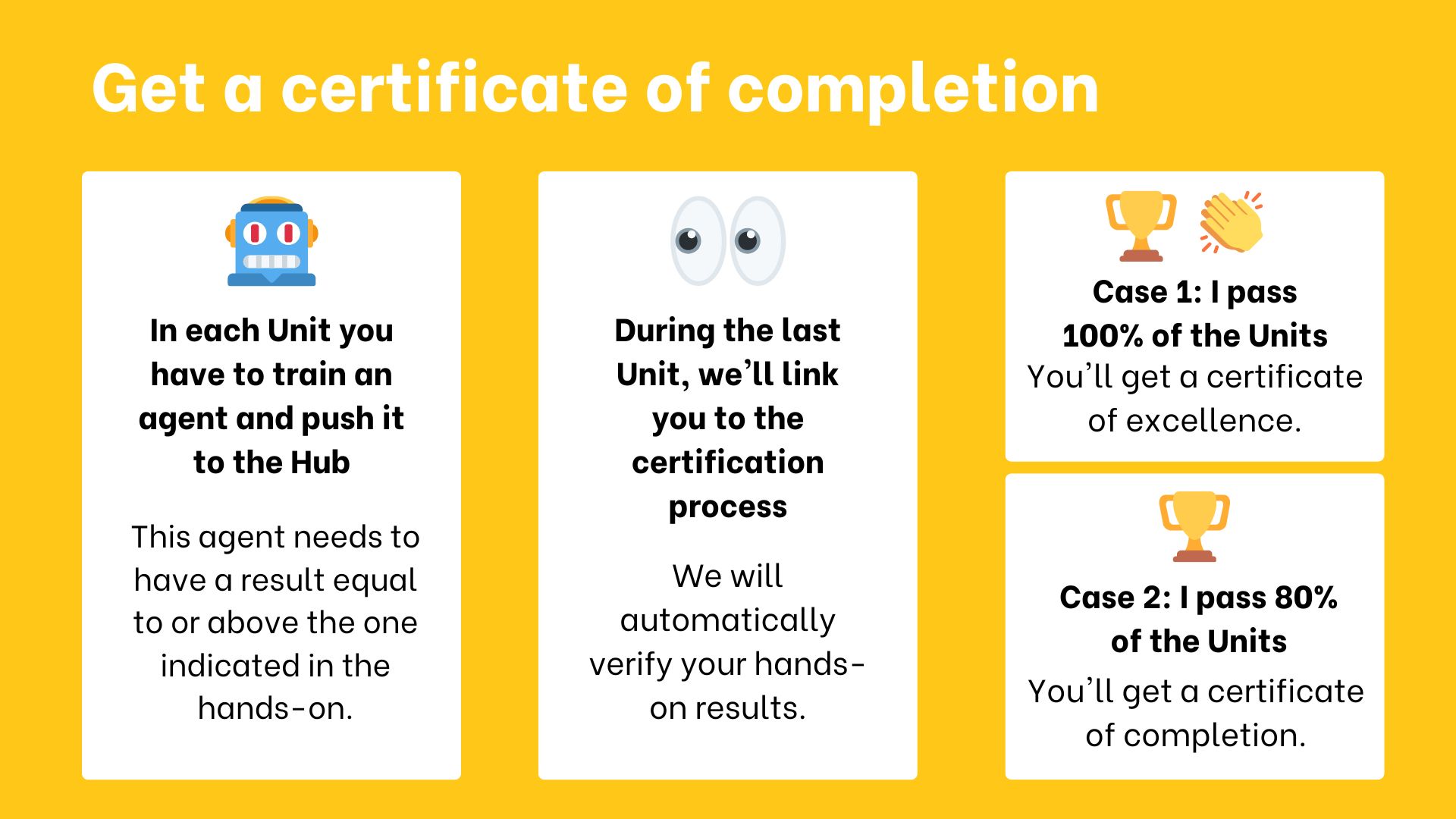
-- To get a *certificate of completion*: you need **to pass 80% of the assignments** before the end of July 2023.
-- To get a *certificate of excellence*: you need **to pass 100% of the assignments** before the end of July 2023.
+- To get a *certificate of completion*: you need **to pass 80% of the assignments** before the end of September 2023.
+- To get a *certificate of excellence*: you need **to pass 100% of the assignments** before the end of September 2023.
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index e3f3212..9ff4770 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -716,13 +716,10 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
- ```python
-
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
- ```
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 9d34e59..b6c063b 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -108,7 +108,10 @@ The first step is to install the dependencies, we’ll install multiple ones:
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]==1.8.0
+!pip install huggingface_sb3
+!pip install panda_gym==2.0.0
+!pip install pyglet==1.5.1
```
## Import the packages 📦
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index c65fb12..94b16d1 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -88,7 +88,7 @@ Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
-At the end your executable should be in `mlagents/training-envs-executables/SoccerTwos`
+At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
 \n",
"\n",
- "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments. \n",
+ "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments.\n",
"\n",
"With [PyBullet](https://github.com/bulletphysics/bullet3), you're going to **train a robot to move**:\n",
"- `AntBulletEnv-v0` 🕸️ More precisely, a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
@@ -62,12 +61,12 @@
{
"cell_type": "markdown",
"source": [
- "### 🎮 Environments: \n",
+ "### 🎮 Environments:\n",
"\n",
"- [PyBullet](https://github.com/bulletphysics/bullet3)\n",
"- [Panda-Gym](https://github.com/qgallouedec/panda-gym)\n",
"\n",
- "###📚 RL-Library: \n",
+ "###📚 RL-Library:\n",
"\n",
"- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)"
],
@@ -112,7 +111,7 @@
"\n",
"- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
"- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
- "- 🤖 Train **agents in unique environments** \n",
+ "- 🤖 Train **agents in unique environments**\n",
"\n",
"And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
"\n",
@@ -192,7 +191,7 @@
"source": [
"## Create a virtual display 🔽\n",
"\n",
- "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).\n",
"\n",
"Hence the following cell will install the librairies and create and run a virtual screen 🖥"
],
@@ -266,7 +265,10 @@
},
"outputs": [],
"source": [
- "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt"
+ "!pip install stable-baselines3[extra]==1.8.0\n",
+ "!pip install huggingface_sb3\n",
+ "!pip install panda_gym==2.0.0\n",
+ "!pip install pyglet==1.5.1"
]
},
{
@@ -403,7 +405,7 @@
{
"cell_type": "markdown",
"source": [
- "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html). \n",
+ "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).\n",
"\n",
"For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.\n",
"\n",
@@ -630,7 +632,7 @@
"\n",
"
\n",
"\n",
- "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments. \n",
+ "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments.\n",
"\n",
"With [PyBullet](https://github.com/bulletphysics/bullet3), you're going to **train a robot to move**:\n",
"- `AntBulletEnv-v0` 🕸️ More precisely, a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
@@ -62,12 +61,12 @@
{
"cell_type": "markdown",
"source": [
- "### 🎮 Environments: \n",
+ "### 🎮 Environments:\n",
"\n",
"- [PyBullet](https://github.com/bulletphysics/bullet3)\n",
"- [Panda-Gym](https://github.com/qgallouedec/panda-gym)\n",
"\n",
- "###📚 RL-Library: \n",
+ "###📚 RL-Library:\n",
"\n",
"- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)"
],
@@ -112,7 +111,7 @@
"\n",
"- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
"- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
- "- 🤖 Train **agents in unique environments** \n",
+ "- 🤖 Train **agents in unique environments**\n",
"\n",
"And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
"\n",
@@ -192,7 +191,7 @@
"source": [
"## Create a virtual display 🔽\n",
"\n",
- "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).\n",
"\n",
"Hence the following cell will install the librairies and create and run a virtual screen 🖥"
],
@@ -266,7 +265,10 @@
},
"outputs": [],
"source": [
- "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt"
+ "!pip install stable-baselines3[extra]==1.8.0\n",
+ "!pip install huggingface_sb3\n",
+ "!pip install panda_gym==2.0.0\n",
+ "!pip install pyglet==1.5.1"
]
},
{
@@ -403,7 +405,7 @@
{
"cell_type": "markdown",
"source": [
- "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html). \n",
+ "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).\n",
"\n",
"For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.\n",
"\n",
@@ -630,7 +632,7 @@
"\n",
" \n",
"\n",
- "- Copy the token \n",
+ "- Copy the token\n",
"- Run the cell below and paste the token"
]
},
@@ -855,7 +857,7 @@
"cell_type": "code",
"source": [
"# 6\n",
- "model_name = \"a2c-PandaReachDense-v2\"; \n",
+ "model_name = \"a2c-PandaReachDense-v2\";\n",
"model.save(model_name)\n",
"env.save(\"vec_normalize.pkl\")\n",
"\n",
@@ -927,4 +929,4 @@
}
}
]
-}
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part2.ipynb b/notebooks/unit8/unit8_part2.ipynb
index 51819df..4a41921 100644
--- a/notebooks/unit8/unit8_part2.ipynb
+++ b/notebooks/unit8/unit8_part2.ipynb
@@ -41,7 +41,7 @@
"from IPython.display import HTML\n",
"\n",
"HTML(''''''\n",
")"
]
@@ -124,15 +124,15 @@
"\n",
"### How sample-factory works\n",
"\n",
- "Sample-factory is one of the **most highly optimized RL implementations available to the community**. \n",
+ "Sample-factory is one of the **most highly optimized RL implementations available to the community**.\n",
"\n",
- "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**. \n",
+ "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.\n",
"\n",
- "The *workers* **communicate through shared memory, which lowers the communication cost between processes**. \n",
+ "The *workers* **communicate through shared memory, which lowers the communication cost between processes**.\n",
"\n",
- "The *rollout workers* interact with the environment and send observations to the *inference workers*. \n",
+ "The *rollout workers* interact with the environment and send observations to the *inference workers*.\n",
"\n",
- "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**. \n",
+ "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.\n",
"\n",
"After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.\n",
"\n",
@@ -164,9 +164,9 @@
"source": [
"## ViZDoom\n",
"\n",
- "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**. \n",
+ "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.\n",
"\n",
- "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland. \n",
+ "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.\n",
"\n",
"The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.\n",
"\n",
@@ -195,7 +195,7 @@
"source": [
"## We first need to install some dependencies that are required for the ViZDoom environment\n",
"\n",
- "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux. \n",
+ "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.\n",
"\n",
"If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)."
]
@@ -210,7 +210,7 @@
"source": [
"%%capture\n",
"%%bash\n",
- "# Install ViZDoom deps from \n",
+ "# Install ViZDoom deps from\n",
"# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux\n",
"\n",
"apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \\\n",
@@ -244,11 +244,21 @@
"source": [
"# install python libraries\n",
"# thanks toinsson\n",
- "!pip install sample-factory==2.0.2\n",
"!pip install faster-fifo==1.4.2\n",
"!pip install vizdoom"
]
},
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install sample-factory==2.0.2"
+ ],
+ "metadata": {
+ "id": "alxUt7Au-O8e"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -330,7 +340,7 @@
"- 1 available game variable: HEALTH\n",
"- death penalty = 100\n",
"\n",
- "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios). \n",
+ "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).\n",
"\n",
"There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).\n",
"\n"
@@ -451,7 +461,7 @@
"\n",
"
\n",
"\n",
- "- Copy the token \n",
+ "- Copy the token\n",
"- Run the cell below and paste the token"
]
},
@@ -855,7 +857,7 @@
"cell_type": "code",
"source": [
"# 6\n",
- "model_name = \"a2c-PandaReachDense-v2\"; \n",
+ "model_name = \"a2c-PandaReachDense-v2\";\n",
"model.save(model_name)\n",
"env.save(\"vec_normalize.pkl\")\n",
"\n",
@@ -927,4 +929,4 @@
}
}
]
-}
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part2.ipynb b/notebooks/unit8/unit8_part2.ipynb
index 51819df..4a41921 100644
--- a/notebooks/unit8/unit8_part2.ipynb
+++ b/notebooks/unit8/unit8_part2.ipynb
@@ -41,7 +41,7 @@
"from IPython.display import HTML\n",
"\n",
"HTML(''''''\n",
")"
]
@@ -124,15 +124,15 @@
"\n",
"### How sample-factory works\n",
"\n",
- "Sample-factory is one of the **most highly optimized RL implementations available to the community**. \n",
+ "Sample-factory is one of the **most highly optimized RL implementations available to the community**.\n",
"\n",
- "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**. \n",
+ "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.\n",
"\n",
- "The *workers* **communicate through shared memory, which lowers the communication cost between processes**. \n",
+ "The *workers* **communicate through shared memory, which lowers the communication cost between processes**.\n",
"\n",
- "The *rollout workers* interact with the environment and send observations to the *inference workers*. \n",
+ "The *rollout workers* interact with the environment and send observations to the *inference workers*.\n",
"\n",
- "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**. \n",
+ "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.\n",
"\n",
"After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.\n",
"\n",
@@ -164,9 +164,9 @@
"source": [
"## ViZDoom\n",
"\n",
- "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**. \n",
+ "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.\n",
"\n",
- "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland. \n",
+ "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.\n",
"\n",
"The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.\n",
"\n",
@@ -195,7 +195,7 @@
"source": [
"## We first need to install some dependencies that are required for the ViZDoom environment\n",
"\n",
- "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux. \n",
+ "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.\n",
"\n",
"If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)."
]
@@ -210,7 +210,7 @@
"source": [
"%%capture\n",
"%%bash\n",
- "# Install ViZDoom deps from \n",
+ "# Install ViZDoom deps from\n",
"# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux\n",
"\n",
"apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \\\n",
@@ -244,11 +244,21 @@
"source": [
"# install python libraries\n",
"# thanks toinsson\n",
- "!pip install sample-factory==2.0.2\n",
"!pip install faster-fifo==1.4.2\n",
"!pip install vizdoom"
]
},
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install sample-factory==2.0.2"
+ ],
+ "metadata": {
+ "id": "alxUt7Au-O8e"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -330,7 +340,7 @@
"- 1 available game variable: HEALTH\n",
"- death penalty = 100\n",
"\n",
- "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios). \n",
+ "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).\n",
"\n",
"There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).\n",
"\n"
@@ -451,7 +461,7 @@
"\n",
" diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index e3f3212..9ff4770 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -716,13 +716,10 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
- ```python
-
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
- ```
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 9d34e59..b6c063b 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -108,7 +108,10 @@ The first step is to install the dependencies, we’ll install multiple ones:
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]==1.8.0
+!pip install huggingface_sb3
+!pip install panda_gym==2.0.0
+!pip install pyglet==1.5.1
```
## Import the packages 📦
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index c65fb12..94b16d1 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -88,7 +88,7 @@ Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
-At the end your executable should be in `mlagents/training-envs-executables/SoccerTwos`
+At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index e3f3212..9ff4770 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -716,13 +716,10 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
- ```python
-
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
- ```
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 9d34e59..b6c063b 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -108,7 +108,10 @@ The first step is to install the dependencies, we’ll install multiple ones:
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]==1.8.0
+!pip install huggingface_sb3
+!pip install panda_gym==2.0.0
+!pip install pyglet==1.5.1
```
## Import the packages 📦
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index c65fb12..94b16d1 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -88,7 +88,7 @@ Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
-At the end your executable should be in `mlagents/training-envs-executables/SoccerTwos`
+At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)