diff --git a/notebooks/bonus-unit1/bonus-unit1.ipynb b/notebooks/bonus-unit1/bonus-unit1.ipynb
new file mode 100644
index 0000000..522ec13
--- /dev/null
+++ b/notebooks/bonus-unit1/bonus-unit1.ipynb
@@ -0,0 +1,537 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2D3NL_e4crQv"
+ },
+ "source": [
+ "# Bonus Unit 1: Let's train Huggy the Dog 🐶 to fetch a stick"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "\n",
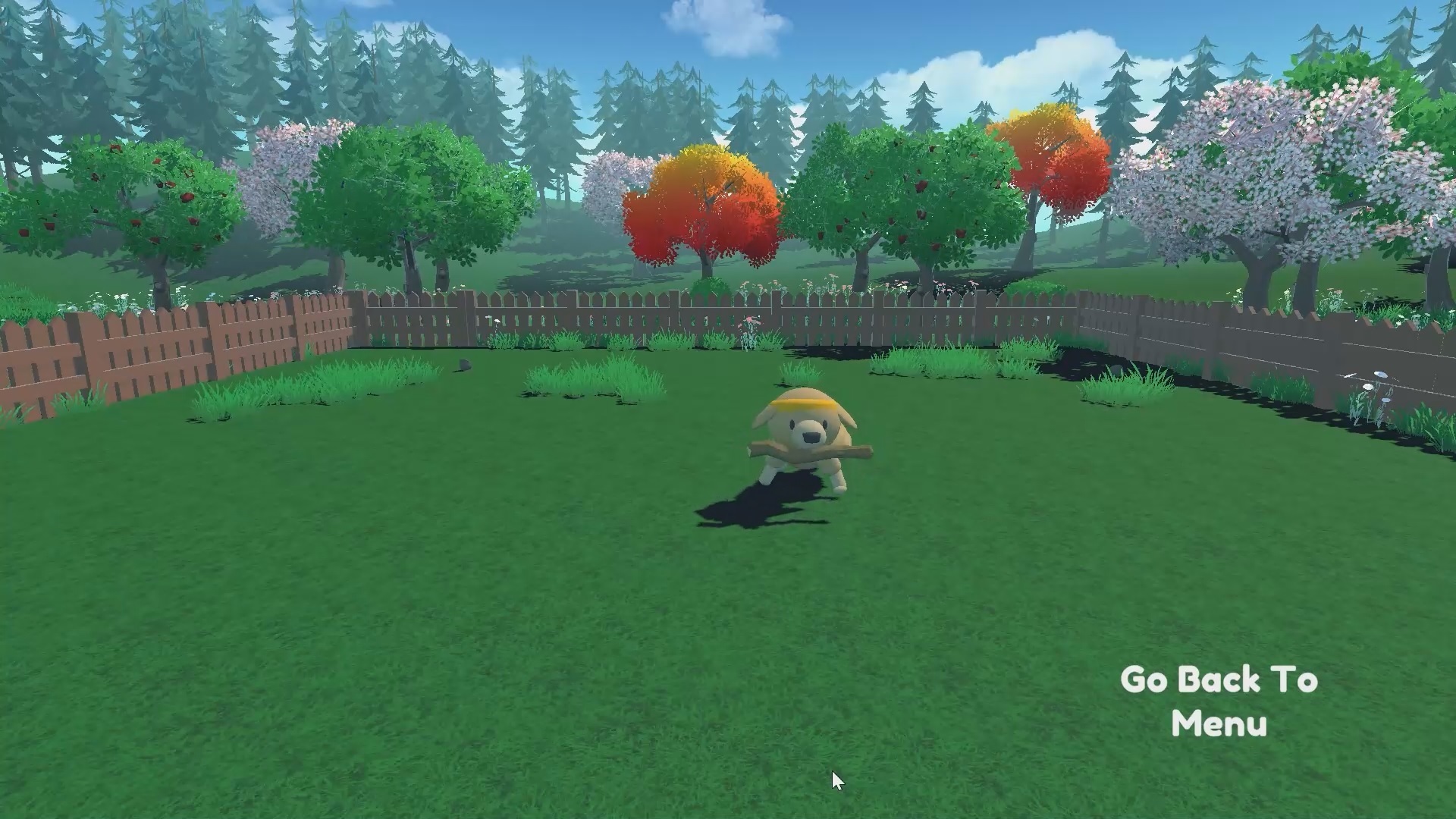
+ "In this notebook, we'll reinforce what we learn in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**\n",
+ "\n",
+ "⬇️ Here is an example of what **you will achieve at the end of the unit.** ⬇️ (launch ▶ to see)"
+ ],
+ "metadata": {
+ "id": "FMYrDriDujzX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "%%html\n",
+ ""
+ ],
+ "metadata": {
+ "id": "PnVhs1yYNyUF"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD TEXT LIVE INFO"
+ ],
+ "metadata": {
+ "id": "QQnzAjfcIO2z"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD IF YOU HAVE QUESTIONS\n",
+ "\n",
+ "\n",
+ "### The environment 🎮\n",
+ "- Huggy the Dog, an environment created by [Thomas Simonini](https://twitter.com/ThomasSimonini) based on [Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)\n",
+ "\n",
+ "### The library used 📚\n",
+ "- [MLAgents (Hugging Face version)](https://github.com/huggingface/ml-agents)"
+ ],
+ "metadata": {
+ "id": "x7oR6R-ZIbeS"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ],
+ "metadata": {
+ "id": "60yACvZwO0Cy"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "At the end of the notebook, you will:\n",
+ "- Understand **the state space, action space and reward function used to train Huggy**.\n",
+ "- **Train your own Huggy** to fetch the stick.\n",
+ "- Be able to play **with your trained Huggy directly in your browser**.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "Oks-ETYdO2Dc"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from Deep Reinforcement Learning Course\n",
+ ""
+ ],
+ "metadata": {
+ "id": "mUlVrqnBv2o1"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "pAMjaQpHwB_s"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1 👉 ADD LINK\n",
+ "\n",
+ "🔲 📚 **Read the introduction to Huggy** by doing Bonus Unit 1 👉 ADD LINK\n"
+ ],
+ "metadata": {
+ "id": "6r7Hl0uywFSO"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "an3ByrXYQ4iK"
+ },
+ "source": [
+ "## Clone the repository and install the dependencies 🔽\n",
+ "- We need to clone the repository, that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6WNoL04M7rTa"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Clone this specific repository (can take 3min)\n",
+ "!git clone https://github.com/huggingface/ml-agents/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "d8wmVcMk7xKo"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Go inside the repository and install the package (can take 3min)\n",
+ "%cd ml-agents\n",
+ "!pip3 install -e ./ml-agents-envs\n",
+ "!pip3 install -e ./ml-agents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HRY5ufKUKfhI"
+ },
+ "source": [
+ "## Download and move the environment zip file in `./trained-envs-executables/linux/`\n",
+ "- Our environment executable is in a zip file.\n",
+ "- We need to download it and place it to `./trained-envs-executables/linux/`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C9Ls6_6eOKiA"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir ./trained-envs-executables\n",
+ "!mkdir ./trained-envs-executables/linux"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF\" -O ./trained-envs-executables/linux/Huggy.zip && rm -rf /tmp/cookies.txt"
+ ],
+ "metadata": {
+ "id": "EB-G-80GsxYN"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jsoZGxr1MIXY"
+ },
+ "source": [
+ "Download the file Huggy.zip from https://drive.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8FPx0an9IAwO"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nyumV5XfPKzu"
+ },
+ "source": [
+ "Make sure your file is accessible "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EdFsLJ11JvQf"
+ },
+ "outputs": [],
+ "source": [
+ "!chmod -R 755 ./trained-envs-executables/linux/Huggy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Let's recap how this environment works\n",
+ "### The State Space: what Huggy \"perceives.\"\n",
+ "\n",
+ "Huggy doesn't \"see\" his environment. Instead, we provide him information about the environment:\n",
+ "- The target (stick) position\n",
+ "- The relative position between himself and the target\n",
+ "- The orientation of his legs.\n",
+ "\n",
+ "Given all this information, Huggy **can decide which action to take next to fulfill his goal**.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### The Action Space: what moves Huggy can do\n",
+ "\n",
+ "\n",
+ "**Joint motors drive huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.\n",
+ "\n",
+ "### The Reward Function\n",
+ "\n",
+ "The reward function is designed so that **Huggy will fulfill his goal** : fetch the stick.\n",
+ "\n",
+ "Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.\n",
+ "\n",
+ "Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.\n",
+ "\n",
+ "Our reward function:\n",
+ "\n",
+ "\n",
+ "\n",
+ "- *Orientation bonus*: we **reward him for getting close to the target**.\n",
+ "- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.\n",
+ "- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.\n",
+ "- *Getting to the target reward*: we reward Huggy for **reaching the target**."
+ ],
+ "metadata": {
+ "id": "dYKVj8yUvj55"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Check the Huggy config file\n",
+ "- In ML-Agents, you define the **training hyperparameters into config.yaml files.**\n",
+ "For this first training, we’ll modify one thing:\n",
+ "- The total training steps hyperparameter is too 2M that's enough for having very good results.\n",
+ "\n",
+ "- For the scope of this notebook, we're not going to modify the hyperparameters but if you want to try as an experimentation, you should also try to modify some other hyperparameters, Unity provides a very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)."
+ ],
+ "metadata": {
+ "id": "NAuEq32Mwvtz"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- Click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`\n",
+ "\n",
+ "\n",
+ "We’re now ready to train our agent 🔥."
+ ],
+ "metadata": {
+ "id": "r9wv5NYGw-05"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f9fI555bO12v"
+ },
+ "source": [
+ "## Train our agent\n",
+ "\n",
+ "To train our agent, we just need to **launch mlagents-learn and select the executable containing the environment.**\n",
+ "\n",
+ "\n",
+ "\n",
+ "We define four parameters:\n",
+ "\n",
+ "1. `mlagents-learn `: the path where the hyperparameter config file is.\n",
+ "2. `--env`: where the environment executable is.\n",
+ "3. `--run_id`: the name you want to give to your training run id.\n",
+ "4. `--no-graphics`: to not launch the visualization during the training.\n",
+ "\n",
+ "Train the model and use the `--resume` flag to continue training in case of interruption. \n",
+ "\n",
+ "> It will fail first time when you use `--resume`, try running the block again to bypass the error. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The training will take 30 to 45min depending on your machine, go take a ☕️you deserve it 🤗."
+ ],
+ "metadata": {
+ "id": "lN32oWF8zPjs"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bS-Yh1UdHfzy"
+ },
+ "outputs": [],
+ "source": [
+ "!mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id=\"Huggy\" --no-graphics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5Vue94AzPy1t"
+ },
+ "source": [
+ "## Push the agent to the 🤗 Hub\n",
+ "- Now that we trained our agent, we’re **ready to push it to the Hub to be able to play with Huggy on your browser🔥.**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ],
+ "metadata": {
+ "id": "izT6FpgNzZ6R"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rKt2vsYoK56o"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ],
+ "metadata": {
+ "id": "ew59mK19zjtN"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Xi0y_VASRzJU"
+ },
+ "source": [
+ "Then, we simply need to run `mlagents-push-to-hf`.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "And we define 4 parameters:\n",
+ "\n",
+ "1. `--run-id`: the name of the training run id.\n",
+ "2. `--local-dir`: where the agent was saved, it’s results/, so in my case results/First Training.\n",
+ "3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always /\n",
+ "If the repo does not exist **it will be created automatically**\n",
+ "4. `--commit-message`: since HF repos are git repository you need to define a commit message."
+ ],
+ "metadata": {
+ "id": "KK4fPfnczunT"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dGEFAIboLVc6"
+ },
+ "outputs": [],
+ "source": [
+ "!mlagents-push-to-hf --run-id=\"HuggyTraining\" --local-dir=\"./results/Huggy\" --repo-id=\"ThomasSimonini/ppo-Huggy\" --commit-message=\"Huggy\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Else, if everything worked you should have this at the end of the process(but with a different url 😆) :\n",
+ "\n",
+ "\n",
+ "\n",
+ "```\n",
+ "Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-Huggy\n",
+ "```\n",
+ "\n",
+ "It’s the link to your model, it contains a model card that explains how to use it, your Tensorboard and your config file. **What’s awesome is that it’s a git repository, that means you can have different commits, update your repository with a new push etc.**\n",
+ "\n",
+ ""
+ ],
+ "metadata": {
+ "id": "yborB0850FTM"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "But now comes the best: **being able to play with Huggy online 👀.**"
+ ],
+ "metadata": {
+ "id": "5Uaon2cg0NrL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Play with your Huggy 🐕\n",
+ "\n",
+ "For this step it’s simple:\n",
+ "\n",
+ "- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy\n",
+ "\n",
+ "- Click on Play with my Huggy model\n",
+ "\n",
+ ""
+ ],
+ "metadata": {
+ "id": "VMc4oOsE0QiZ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).\n",
+ "\n",
+ "2. In step 2, **choose what model you want to replay**:\n",
+ " - I have multiple one, since we saved a model every 500000 timesteps. \n",
+ " - But if I want the more recent I choose Huggy.onnx\n",
+ "\n",
+ "👉 What’s nice **is to try with different models step to see the improvement of the agent.**"
+ ],
+ "metadata": {
+ "id": "Djs8c5rR0Z8a"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Congrats on finishing this bonus unit!\n",
+ "\n",
+ "You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "## Keep Learning, Stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "PI6dPWmh064H"
+ }
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": [],
+ "private_outputs": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index d6e6d54..58aea61 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -295,7 +295,7 @@
"id": "wrgpVFqyENVf"
},
"source": [
- "## Step 2: Import the packages 📦\n",
+ "## Import the packages 📦\n",
"\n",
"One additional library we import is huggingface_hub **to be able to upload and download trained models from the hub**.\n",
"\n",
@@ -330,7 +330,7 @@
"id": "MRqRuRUl8CsB"
},
"source": [
- "## Step 3: Understand what is Gym and how it works? 🤖\n",
+ "## Understand what is Gym and how it works 🤖\n",
"\n",
"🏋 The library containing our environment is called Gym.\n",
"**You'll use Gym a lot in Deep Reinforcement Learning.**\n",
@@ -649,8 +649,8 @@
"id": "ClJJk88yoBUi"
},
"source": [
- "### Train the PPO agent 🏃\n",
- "- Let's train our agent for 500,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~10min, but you can use less timesteps if you just want to try it out.\n",
+ "## Train the PPO agent 🏃\n",
+ "- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use less timesteps if you just want to try it out.\n",
"- During the training, take a ☕ break you deserved it 🤗"
]
},
@@ -662,7 +662,7 @@
},
"outputs": [],
"source": [
- "# TODO: Train it for 500,000 timesteps\n",
+ "# TODO: Train it for 1,000,000 timesteps\n",
"\n",
"# TODO: Specify file name for model and save the model to file\n",
"model_name = \"\"\n"
@@ -686,8 +686,8 @@
"outputs": [],
"source": [
"# SOLUTION\n",
- "# Train it for 500,000 timesteps\n",
- "model.learn(total_timesteps=500000)\n",
+ "# Train it for 1,000,000 timesteps\n",
+ "model.learn(total_timesteps=1000000)\n",
"# Save the model\n",
"model_name = \"ppo-LunarLander-v2\"\n",
"model.save(model_name)"
@@ -699,7 +699,7 @@
"id": "BY_HuedOoISR"
},
"source": [
- "### Evaluate the agent 📈\n",
+ "## Evaluate the agent 📈\n",
"- Now that our Lunar Lander agent is trained 🚀, we need to **check its performance**.\n",
"- Stable-Baselines3 provides a method to do that: `evaluate_policy`.\n",
"- To fill that part you need to [check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)\n",
@@ -766,7 +766,7 @@
"id": "IK_kR78NoNb2"
},
"source": [
- "### Publish our trained model on the Hub 🔥\n",
+ "## Publish our trained model on the Hub 🔥\n",
"Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.\n",
"\n",
"📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20\n",
@@ -1016,8 +1016,8 @@
"outputs": [],
"source": [
"from huggingface_sb3 import load_from_hub\n",
- "repo_id = \"\" # The repo_id\n",
- "filename = \"\" # The model filename.zip\n",
+ "repo_id = \"Classroom-workshop/assignment2-omar\" # The repo_id\n",
+ "filename = \"ppo-LunarLander-v2.zip\" # The model filename.zip\n",
"\n",
"# When the model was trained on Python 3.8 the pickle protocol is 5\n",
"# But Python 3.6, 3.7 use protocol 4\n",
@@ -1120,9 +1120,6 @@
"collapsed_sections": [
"dFD9RAFjG8aq",
"QAN7B0_HCVZC",
- "ClJJk88yoBUi",
- "1bQzQ-QcE3zo",
- "BY_HuedOoISR",
"BqPKw3jt_pG5",
"IK_kR78NoNb2",
"Avf6gufJBGMw"
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 506f858..c8a1b8e 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -11,3 +11,7 @@ And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a
Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
+
+To start the hands-on click on Open In Colab button 👇 :
+
+[]()
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 7d4365c..d683cac 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -7,3 +7,8 @@ Now that we studied the Q-Learning algorithm, let's implement it from scratch an
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 51a5b7e..4b73137 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -6,3 +6,8 @@ Now that you've studied the theory behind Deep Q-Learning, **you’re ready to t
We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unitbonus1/how-huggy-works.mdx b/units/en/unitbonus1/how-huggy-works.mdx
index 3887a7e..3c695c3 100644
--- a/units/en/unitbonus1/how-huggy-works.mdx
+++ b/units/en/unitbonus1/how-huggy-works.mdx
@@ -7,17 +7,15 @@ This environment was created using the [Unity game engine](https://unity.com/) a
In this environment we aim to train Huggy to **fetch the stick we throw at him. It means he needs to move correctly toward the stick**.
-## The State Space: what Huggy "perceives." [[state-space]]
+## The State Space, what Huggy "perceives." [[state-space]]
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
* The target (stick) position
* The relative position between himself and the target
* The orientation of his legs.
-Given all this information, Huggy can use his policy to determine which action to take next to fulfill his goal.
-
+Given all this information, Huggy can **use his policy to determine which action to take next to fulfill his goal**.
-
-## The Action Space: what moves Huggy can perform [[action-space]]
+## The Action Space, what moves Huggy can perform [[action-space]]
**Joint motors drive Huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
@@ -52,7 +50,8 @@ The training loop looks like this:
The training environment looks like this:
-ADD IMAGE TRAINING ENVIRONMENT
+
+
It's a place where a **stick is spawned randomly**. When Huggy reaches it, the stick get spawned somewhere else.
We built **multiple copies of the environment for the training**. This helps speed up the training by providing more diverse experiences.
diff --git a/units/en/unitbonus1/train-play.mdx b/units/en/unitbonus1/train-play.mdx
index 3aa2670..21cf139 100644
--- a/units/en/unitbonus1/train-play.mdx
+++ b/units/en/unitbonus1/train-play.mdx
@@ -2,14 +2,27 @@
## Let's train Huggy 🐶
-Open this colab:
+**To start to train Huggy, click on Open In Colab button** 👇 :
+
+[]()
## Play with Huggy
+
Now that you've trained Huggy and pushed it to the Hub. **You will be able to play with him ❤️**
-Just launch this game:
+For this step it’s simple:
-CLic
+- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
-ADD STEPS
+- Click on Play with my Huggy model
+
+
+
+1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).
+
+2. In step 2, **choose what model you want to replay**:
+ - I have multiple one, since we saved a model every 500000 timesteps.
+ - But if I want the more recent I choose Huggy.onnx
+
+👉 What’s nice **is to try with different models step to see the improvement of the agent.**
 \n",
+ "\n",
+ "In this notebook, we'll reinforce what we learn in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**\n",
+ "\n",
+ "⬇️ Here is an example of what **you will achieve at the end of the unit.** ⬇️ (launch ▶ to see)"
+ ],
+ "metadata": {
+ "id": "FMYrDriDujzX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "%%html\n",
+ ""
+ ],
+ "metadata": {
+ "id": "PnVhs1yYNyUF"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD TEXT LIVE INFO"
+ ],
+ "metadata": {
+ "id": "QQnzAjfcIO2z"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD IF YOU HAVE QUESTIONS\n",
+ "\n",
+ "\n",
+ "### The environment 🎮\n",
+ "- Huggy the Dog, an environment created by [Thomas Simonini](https://twitter.com/ThomasSimonini) based on [Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)\n",
+ "\n",
+ "### The library used 📚\n",
+ "- [MLAgents (Hugging Face version)](https://github.com/huggingface/ml-agents)"
+ ],
+ "metadata": {
+ "id": "x7oR6R-ZIbeS"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ],
+ "metadata": {
+ "id": "60yACvZwO0Cy"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "At the end of the notebook, you will:\n",
+ "- Understand **the state space, action space and reward function used to train Huggy**.\n",
+ "- **Train your own Huggy** to fetch the stick.\n",
+ "- Be able to play **with your trained Huggy directly in your browser**.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "Oks-ETYdO2Dc"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from Deep Reinforcement Learning Course\n",
+ "
\n",
+ "\n",
+ "In this notebook, we'll reinforce what we learn in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**\n",
+ "\n",
+ "⬇️ Here is an example of what **you will achieve at the end of the unit.** ⬇️ (launch ▶ to see)"
+ ],
+ "metadata": {
+ "id": "FMYrDriDujzX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "%%html\n",
+ ""
+ ],
+ "metadata": {
+ "id": "PnVhs1yYNyUF"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD TEXT LIVE INFO"
+ ],
+ "metadata": {
+ "id": "QQnzAjfcIO2z"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "TODO: ADD IF YOU HAVE QUESTIONS\n",
+ "\n",
+ "\n",
+ "### The environment 🎮\n",
+ "- Huggy the Dog, an environment created by [Thomas Simonini](https://twitter.com/ThomasSimonini) based on [Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)\n",
+ "\n",
+ "### The library used 📚\n",
+ "- [MLAgents (Hugging Face version)](https://github.com/huggingface/ml-agents)"
+ ],
+ "metadata": {
+ "id": "x7oR6R-ZIbeS"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ],
+ "metadata": {
+ "id": "60yACvZwO0Cy"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "At the end of the notebook, you will:\n",
+ "- Understand **the state space, action space and reward function used to train Huggy**.\n",
+ "- **Train your own Huggy** to fetch the stick.\n",
+ "- Be able to play **with your trained Huggy directly in your browser**.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "Oks-ETYdO2Dc"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from Deep Reinforcement Learning Course\n",
+ " "
+ ],
+ "metadata": {
+ "id": "mUlVrqnBv2o1"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "pAMjaQpHwB_s"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1 👉 ADD LINK\n",
+ "\n",
+ "🔲 📚 **Read the introduction to Huggy** by doing Bonus Unit 1 👉 ADD LINK\n"
+ ],
+ "metadata": {
+ "id": "6r7Hl0uywFSO"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "an3ByrXYQ4iK"
+ },
+ "source": [
+ "## Clone the repository and install the dependencies 🔽\n",
+ "- We need to clone the repository, that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6WNoL04M7rTa"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Clone this specific repository (can take 3min)\n",
+ "!git clone https://github.com/huggingface/ml-agents/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "d8wmVcMk7xKo"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Go inside the repository and install the package (can take 3min)\n",
+ "%cd ml-agents\n",
+ "!pip3 install -e ./ml-agents-envs\n",
+ "!pip3 install -e ./ml-agents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HRY5ufKUKfhI"
+ },
+ "source": [
+ "## Download and move the environment zip file in `./trained-envs-executables/linux/`\n",
+ "- Our environment executable is in a zip file.\n",
+ "- We need to download it and place it to `./trained-envs-executables/linux/`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C9Ls6_6eOKiA"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir ./trained-envs-executables\n",
+ "!mkdir ./trained-envs-executables/linux"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF\" -O ./trained-envs-executables/linux/Huggy.zip && rm -rf /tmp/cookies.txt"
+ ],
+ "metadata": {
+ "id": "EB-G-80GsxYN"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jsoZGxr1MIXY"
+ },
+ "source": [
+ "Download the file Huggy.zip from https://drive.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8FPx0an9IAwO"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nyumV5XfPKzu"
+ },
+ "source": [
+ "Make sure your file is accessible "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EdFsLJ11JvQf"
+ },
+ "outputs": [],
+ "source": [
+ "!chmod -R 755 ./trained-envs-executables/linux/Huggy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Let's recap how this environment works\n",
+ "### The State Space: what Huggy \"perceives.\"\n",
+ "\n",
+ "Huggy doesn't \"see\" his environment. Instead, we provide him information about the environment:\n",
+ "- The target (stick) position\n",
+ "- The relative position between himself and the target\n",
+ "- The orientation of his legs.\n",
+ "\n",
+ "Given all this information, Huggy **can decide which action to take next to fulfill his goal**.\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "mUlVrqnBv2o1"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "pAMjaQpHwB_s"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1 👉 ADD LINK\n",
+ "\n",
+ "🔲 📚 **Read the introduction to Huggy** by doing Bonus Unit 1 👉 ADD LINK\n"
+ ],
+ "metadata": {
+ "id": "6r7Hl0uywFSO"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "an3ByrXYQ4iK"
+ },
+ "source": [
+ "## Clone the repository and install the dependencies 🔽\n",
+ "- We need to clone the repository, that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6WNoL04M7rTa"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Clone this specific repository (can take 3min)\n",
+ "!git clone https://github.com/huggingface/ml-agents/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "d8wmVcMk7xKo"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "# Go inside the repository and install the package (can take 3min)\n",
+ "%cd ml-agents\n",
+ "!pip3 install -e ./ml-agents-envs\n",
+ "!pip3 install -e ./ml-agents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HRY5ufKUKfhI"
+ },
+ "source": [
+ "## Download and move the environment zip file in `./trained-envs-executables/linux/`\n",
+ "- Our environment executable is in a zip file.\n",
+ "- We need to download it and place it to `./trained-envs-executables/linux/`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C9Ls6_6eOKiA"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir ./trained-envs-executables\n",
+ "!mkdir ./trained-envs-executables/linux"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF\" -O ./trained-envs-executables/linux/Huggy.zip && rm -rf /tmp/cookies.txt"
+ ],
+ "metadata": {
+ "id": "EB-G-80GsxYN"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jsoZGxr1MIXY"
+ },
+ "source": [
+ "Download the file Huggy.zip from https://drive.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8FPx0an9IAwO"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nyumV5XfPKzu"
+ },
+ "source": [
+ "Make sure your file is accessible "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EdFsLJ11JvQf"
+ },
+ "outputs": [],
+ "source": [
+ "!chmod -R 755 ./trained-envs-executables/linux/Huggy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Let's recap how this environment works\n",
+ "### The State Space: what Huggy \"perceives.\"\n",
+ "\n",
+ "Huggy doesn't \"see\" his environment. Instead, we provide him information about the environment:\n",
+ "- The target (stick) position\n",
+ "- The relative position between himself and the target\n",
+ "- The orientation of his legs.\n",
+ "\n",
+ "Given all this information, Huggy **can decide which action to take next to fulfill his goal**.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "### The Action Space: what moves Huggy can do\n",
+ "
\n",
+ "\n",
+ "\n",
+ "### The Action Space: what moves Huggy can do\n",
+ " \n",
+ "\n",
+ "**Joint motors drive huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.\n",
+ "\n",
+ "### The Reward Function\n",
+ "\n",
+ "The reward function is designed so that **Huggy will fulfill his goal** : fetch the stick.\n",
+ "\n",
+ "Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.\n",
+ "\n",
+ "Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.\n",
+ "\n",
+ "Our reward function:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "**Joint motors drive huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.\n",
+ "\n",
+ "### The Reward Function\n",
+ "\n",
+ "The reward function is designed so that **Huggy will fulfill his goal** : fetch the stick.\n",
+ "\n",
+ "Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.\n",
+ "\n",
+ "Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.\n",
+ "\n",
+ "Our reward function:\n",
+ "\n",
+ " \n",
+ "\n",
+ "- *Orientation bonus*: we **reward him for getting close to the target**.\n",
+ "- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.\n",
+ "- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.\n",
+ "- *Getting to the target reward*: we reward Huggy for **reaching the target**."
+ ],
+ "metadata": {
+ "id": "dYKVj8yUvj55"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Check the Huggy config file\n",
+ "- In ML-Agents, you define the **training hyperparameters into config.yaml files.**\n",
+ "For this first training, we’ll modify one thing:\n",
+ "- The total training steps hyperparameter is too 2M that's enough for having very good results.\n",
+ "\n",
+ "- For the scope of this notebook, we're not going to modify the hyperparameters but if you want to try as an experimentation, you should also try to modify some other hyperparameters, Unity provides a very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)."
+ ],
+ "metadata": {
+ "id": "NAuEq32Mwvtz"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- Click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`\n",
+ "\n",
+ "\n",
+ "We’re now ready to train our agent 🔥."
+ ],
+ "metadata": {
+ "id": "r9wv5NYGw-05"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f9fI555bO12v"
+ },
+ "source": [
+ "## Train our agent\n",
+ "\n",
+ "To train our agent, we just need to **launch mlagents-learn and select the executable containing the environment.**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "- *Orientation bonus*: we **reward him for getting close to the target**.\n",
+ "- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.\n",
+ "- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.\n",
+ "- *Getting to the target reward*: we reward Huggy for **reaching the target**."
+ ],
+ "metadata": {
+ "id": "dYKVj8yUvj55"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Check the Huggy config file\n",
+ "- In ML-Agents, you define the **training hyperparameters into config.yaml files.**\n",
+ "For this first training, we’ll modify one thing:\n",
+ "- The total training steps hyperparameter is too 2M that's enough for having very good results.\n",
+ "\n",
+ "- For the scope of this notebook, we're not going to modify the hyperparameters but if you want to try as an experimentation, you should also try to modify some other hyperparameters, Unity provides a very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)."
+ ],
+ "metadata": {
+ "id": "NAuEq32Mwvtz"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- Click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`\n",
+ "\n",
+ "\n",
+ "We’re now ready to train our agent 🔥."
+ ],
+ "metadata": {
+ "id": "r9wv5NYGw-05"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f9fI555bO12v"
+ },
+ "source": [
+ "## Train our agent\n",
+ "\n",
+ "To train our agent, we just need to **launch mlagents-learn and select the executable containing the environment.**\n",
+ "\n",
+ " \n",
+ "\n",
+ "We define four parameters:\n",
+ "\n",
+ "1. `mlagents-learn
\n",
+ "\n",
+ "We define four parameters:\n",
+ "\n",
+ "1. `mlagents-learn  \n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ],
+ "metadata": {
+ "id": "izT6FpgNzZ6R"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rKt2vsYoK56o"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ],
+ "metadata": {
+ "id": "ew59mK19zjtN"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Xi0y_VASRzJU"
+ },
+ "source": [
+ "Then, we simply need to run `mlagents-push-to-hf`.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ],
+ "metadata": {
+ "id": "izT6FpgNzZ6R"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rKt2vsYoK56o"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ],
+ "metadata": {
+ "id": "ew59mK19zjtN"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Xi0y_VASRzJU"
+ },
+ "source": [
+ "Then, we simply need to run `mlagents-push-to-hf`.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "And we define 4 parameters:\n",
+ "\n",
+ "1. `--run-id`: the name of the training run id.\n",
+ "2. `--local-dir`: where the agent was saved, it’s results/
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "And we define 4 parameters:\n",
+ "\n",
+ "1. `--run-id`: the name of the training run id.\n",
+ "2. `--local-dir`: where the agent was saved, it’s results/ "
+ ],
+ "metadata": {
+ "id": "yborB0850FTM"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "But now comes the best: **being able to play with Huggy online 👀.**"
+ ],
+ "metadata": {
+ "id": "5Uaon2cg0NrL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Play with your Huggy 🐕\n",
+ "\n",
+ "For this step it’s simple:\n",
+ "\n",
+ "- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy\n",
+ "\n",
+ "- Click on Play with my Huggy model\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "yborB0850FTM"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "But now comes the best: **being able to play with Huggy online 👀.**"
+ ],
+ "metadata": {
+ "id": "5Uaon2cg0NrL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Play with your Huggy 🐕\n",
+ "\n",
+ "For this step it’s simple:\n",
+ "\n",
+ "- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy\n",
+ "\n",
+ "- Click on Play with my Huggy model\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "VMc4oOsE0QiZ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).\n",
+ "\n",
+ "2. In step 2, **choose what model you want to replay**:\n",
+ " - I have multiple one, since we saved a model every 500000 timesteps. \n",
+ " - But if I want the more recent I choose Huggy.onnx\n",
+ "\n",
+ "👉 What’s nice **is to try with different models step to see the improvement of the agent.**"
+ ],
+ "metadata": {
+ "id": "Djs8c5rR0Z8a"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Congrats on finishing this bonus unit!\n",
+ "\n",
+ "You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "VMc4oOsE0QiZ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).\n",
+ "\n",
+ "2. In step 2, **choose what model you want to replay**:\n",
+ " - I have multiple one, since we saved a model every 500000 timesteps. \n",
+ " - But if I want the more recent I choose Huggy.onnx\n",
+ "\n",
+ "👉 What’s nice **is to try with different models step to see the improvement of the agent.**"
+ ],
+ "metadata": {
+ "id": "Djs8c5rR0Z8a"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Congrats on finishing this bonus unit!\n",
+ "\n",
+ "You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "## Keep Learning, Stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "PI6dPWmh064H"
+ }
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": [],
+ "private_outputs": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index d6e6d54..58aea61 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -295,7 +295,7 @@
"id": "wrgpVFqyENVf"
},
"source": [
- "## Step 2: Import the packages 📦\n",
+ "## Import the packages 📦\n",
"\n",
"One additional library we import is huggingface_hub **to be able to upload and download trained models from the hub**.\n",
"\n",
@@ -330,7 +330,7 @@
"id": "MRqRuRUl8CsB"
},
"source": [
- "## Step 3: Understand what is Gym and how it works? 🤖\n",
+ "## Understand what is Gym and how it works 🤖\n",
"\n",
"🏋 The library containing our environment is called Gym.\n",
"**You'll use Gym a lot in Deep Reinforcement Learning.**\n",
@@ -649,8 +649,8 @@
"id": "ClJJk88yoBUi"
},
"source": [
- "### Train the PPO agent 🏃\n",
- "- Let's train our agent for 500,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~10min, but you can use less timesteps if you just want to try it out.\n",
+ "## Train the PPO agent 🏃\n",
+ "- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use less timesteps if you just want to try it out.\n",
"- During the training, take a ☕ break you deserved it 🤗"
]
},
@@ -662,7 +662,7 @@
},
"outputs": [],
"source": [
- "# TODO: Train it for 500,000 timesteps\n",
+ "# TODO: Train it for 1,000,000 timesteps\n",
"\n",
"# TODO: Specify file name for model and save the model to file\n",
"model_name = \"\"\n"
@@ -686,8 +686,8 @@
"outputs": [],
"source": [
"# SOLUTION\n",
- "# Train it for 500,000 timesteps\n",
- "model.learn(total_timesteps=500000)\n",
+ "# Train it for 1,000,000 timesteps\n",
+ "model.learn(total_timesteps=1000000)\n",
"# Save the model\n",
"model_name = \"ppo-LunarLander-v2\"\n",
"model.save(model_name)"
@@ -699,7 +699,7 @@
"id": "BY_HuedOoISR"
},
"source": [
- "### Evaluate the agent 📈\n",
+ "## Evaluate the agent 📈\n",
"- Now that our Lunar Lander agent is trained 🚀, we need to **check its performance**.\n",
"- Stable-Baselines3 provides a method to do that: `evaluate_policy`.\n",
"- To fill that part you need to [check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)\n",
@@ -766,7 +766,7 @@
"id": "IK_kR78NoNb2"
},
"source": [
- "### Publish our trained model on the Hub 🔥\n",
+ "## Publish our trained model on the Hub 🔥\n",
"Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.\n",
"\n",
"📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20\n",
@@ -1016,8 +1016,8 @@
"outputs": [],
"source": [
"from huggingface_sb3 import load_from_hub\n",
- "repo_id = \"\" # The repo_id\n",
- "filename = \"\" # The model filename.zip\n",
+ "repo_id = \"Classroom-workshop/assignment2-omar\" # The repo_id\n",
+ "filename = \"ppo-LunarLander-v2.zip\" # The model filename.zip\n",
"\n",
"# When the model was trained on Python 3.8 the pickle protocol is 5\n",
"# But Python 3.6, 3.7 use protocol 4\n",
@@ -1120,9 +1120,6 @@
"collapsed_sections": [
"dFD9RAFjG8aq",
"QAN7B0_HCVZC",
- "ClJJk88yoBUi",
- "1bQzQ-QcE3zo",
- "BY_HuedOoISR",
"BqPKw3jt_pG5",
"IK_kR78NoNb2",
"Avf6gufJBGMw"
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 506f858..c8a1b8e 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -11,3 +11,7 @@ And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a
Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
+
+To start the hands-on click on Open In Colab button 👇 :
+
+[]()
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 7d4365c..d683cac 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -7,3 +7,8 @@ Now that we studied the Q-Learning algorithm, let's implement it from scratch an
\n",
+ "\n",
+ "\n",
+ "## Keep Learning, Stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "PI6dPWmh064H"
+ }
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": [],
+ "private_outputs": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index d6e6d54..58aea61 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -295,7 +295,7 @@
"id": "wrgpVFqyENVf"
},
"source": [
- "## Step 2: Import the packages 📦\n",
+ "## Import the packages 📦\n",
"\n",
"One additional library we import is huggingface_hub **to be able to upload and download trained models from the hub**.\n",
"\n",
@@ -330,7 +330,7 @@
"id": "MRqRuRUl8CsB"
},
"source": [
- "## Step 3: Understand what is Gym and how it works? 🤖\n",
+ "## Understand what is Gym and how it works 🤖\n",
"\n",
"🏋 The library containing our environment is called Gym.\n",
"**You'll use Gym a lot in Deep Reinforcement Learning.**\n",
@@ -649,8 +649,8 @@
"id": "ClJJk88yoBUi"
},
"source": [
- "### Train the PPO agent 🏃\n",
- "- Let's train our agent for 500,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~10min, but you can use less timesteps if you just want to try it out.\n",
+ "## Train the PPO agent 🏃\n",
+ "- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use less timesteps if you just want to try it out.\n",
"- During the training, take a ☕ break you deserved it 🤗"
]
},
@@ -662,7 +662,7 @@
},
"outputs": [],
"source": [
- "# TODO: Train it for 500,000 timesteps\n",
+ "# TODO: Train it for 1,000,000 timesteps\n",
"\n",
"# TODO: Specify file name for model and save the model to file\n",
"model_name = \"\"\n"
@@ -686,8 +686,8 @@
"outputs": [],
"source": [
"# SOLUTION\n",
- "# Train it for 500,000 timesteps\n",
- "model.learn(total_timesteps=500000)\n",
+ "# Train it for 1,000,000 timesteps\n",
+ "model.learn(total_timesteps=1000000)\n",
"# Save the model\n",
"model_name = \"ppo-LunarLander-v2\"\n",
"model.save(model_name)"
@@ -699,7 +699,7 @@
"id": "BY_HuedOoISR"
},
"source": [
- "### Evaluate the agent 📈\n",
+ "## Evaluate the agent 📈\n",
"- Now that our Lunar Lander agent is trained 🚀, we need to **check its performance**.\n",
"- Stable-Baselines3 provides a method to do that: `evaluate_policy`.\n",
"- To fill that part you need to [check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)\n",
@@ -766,7 +766,7 @@
"id": "IK_kR78NoNb2"
},
"source": [
- "### Publish our trained model on the Hub 🔥\n",
+ "## Publish our trained model on the Hub 🔥\n",
"Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.\n",
"\n",
"📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20\n",
@@ -1016,8 +1016,8 @@
"outputs": [],
"source": [
"from huggingface_sb3 import load_from_hub\n",
- "repo_id = \"\" # The repo_id\n",
- "filename = \"\" # The model filename.zip\n",
+ "repo_id = \"Classroom-workshop/assignment2-omar\" # The repo_id\n",
+ "filename = \"ppo-LunarLander-v2.zip\" # The model filename.zip\n",
"\n",
"# When the model was trained on Python 3.8 the pickle protocol is 5\n",
"# But Python 3.6, 3.7 use protocol 4\n",
@@ -1120,9 +1120,6 @@
"collapsed_sections": [
"dFD9RAFjG8aq",
"QAN7B0_HCVZC",
- "ClJJk88yoBUi",
- "1bQzQ-QcE3zo",
- "BY_HuedOoISR",
"BqPKw3jt_pG5",
"IK_kR78NoNb2",
"Avf6gufJBGMw"
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 506f858..c8a1b8e 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -11,3 +11,7 @@ And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a
Thanks to our leaderboard, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
So let's get started! 🚀
+
+To start the hands-on click on Open In Colab button 👇 :
+
+[]()
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 7d4365c..d683cac 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -7,3 +7,8 @@ Now that we studied the Q-Learning algorithm, let's implement it from scratch an
 Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 51a5b7e..4b73137 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -6,3 +6,8 @@ Now that you've studied the theory behind Deep Q-Learning, **you’re ready to t
We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unitbonus1/how-huggy-works.mdx b/units/en/unitbonus1/how-huggy-works.mdx
index 3887a7e..3c695c3 100644
--- a/units/en/unitbonus1/how-huggy-works.mdx
+++ b/units/en/unitbonus1/how-huggy-works.mdx
@@ -7,17 +7,15 @@ This environment was created using the [Unity game engine](https://unity.com/) a
In this environment we aim to train Huggy to **fetch the stick we throw at him. It means he needs to move correctly toward the stick**.
-## The State Space: what Huggy "perceives." [[state-space]]
+## The State Space, what Huggy "perceives." [[state-space]]
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
* The target (stick) position
* The relative position between himself and the target
* The orientation of his legs.
-Given all this information, Huggy can use his policy to determine which action to take next to fulfill his goal.
-
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores Who will win the challenge for Unit 2?
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 51a5b7e..4b73137 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -6,3 +6,8 @@ Now that you've studied the theory behind Deep Q-Learning, **you’re ready to t
We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unitbonus1/how-huggy-works.mdx b/units/en/unitbonus1/how-huggy-works.mdx
index 3887a7e..3c695c3 100644
--- a/units/en/unitbonus1/how-huggy-works.mdx
+++ b/units/en/unitbonus1/how-huggy-works.mdx
@@ -7,17 +7,15 @@ This environment was created using the [Unity game engine](https://unity.com/) a
In this environment we aim to train Huggy to **fetch the stick we throw at him. It means he needs to move correctly toward the stick**.
-## The State Space: what Huggy "perceives." [[state-space]]
+## The State Space, what Huggy "perceives." [[state-space]]
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
* The target (stick) position
* The relative position between himself and the target
* The orientation of his legs.
-Given all this information, Huggy can use his policy to determine which action to take next to fulfill his goal.
- +Given all this information, Huggy can **use his policy to determine which action to take next to fulfill his goal**.
-
-## The Action Space: what moves Huggy can perform [[action-space]]
+## The Action Space, what moves Huggy can perform [[action-space]]
+Given all this information, Huggy can **use his policy to determine which action to take next to fulfill his goal**.
-
-## The Action Space: what moves Huggy can perform [[action-space]]
+## The Action Space, what moves Huggy can perform [[action-space]]
 **Joint motors drive Huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
@@ -52,7 +50,8 @@ The training loop looks like this:
The training environment looks like this:
-ADD IMAGE TRAINING ENVIRONMENT
+
**Joint motors drive Huggy legs**. It means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
@@ -52,7 +50,8 @@ The training loop looks like this:
The training environment looks like this:
-ADD IMAGE TRAINING ENVIRONMENT
+ +
It's a place where a **stick is spawned randomly**. When Huggy reaches it, the stick get spawned somewhere else.
We built **multiple copies of the environment for the training**. This helps speed up the training by providing more diverse experiences.
diff --git a/units/en/unitbonus1/train-play.mdx b/units/en/unitbonus1/train-play.mdx
index 3aa2670..21cf139 100644
--- a/units/en/unitbonus1/train-play.mdx
+++ b/units/en/unitbonus1/train-play.mdx
@@ -2,14 +2,27 @@
## Let's train Huggy 🐶
-Open this colab:
+**To start to train Huggy, click on Open In Colab button** 👇 :
+
+[]()
## Play with Huggy
+
Now that you've trained Huggy and pushed it to the Hub. **You will be able to play with him ❤️**
-Just launch this game:
+For this step it’s simple:
-CLic
+- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
-ADD STEPS
+- Click on Play with my Huggy model
+
+
+
It's a place where a **stick is spawned randomly**. When Huggy reaches it, the stick get spawned somewhere else.
We built **multiple copies of the environment for the training**. This helps speed up the training by providing more diverse experiences.
diff --git a/units/en/unitbonus1/train-play.mdx b/units/en/unitbonus1/train-play.mdx
index 3aa2670..21cf139 100644
--- a/units/en/unitbonus1/train-play.mdx
+++ b/units/en/unitbonus1/train-play.mdx
@@ -2,14 +2,27 @@
## Let's train Huggy 🐶
-Open this colab:
+**To start to train Huggy, click on Open In Colab button** 👇 :
+
+[]()
## Play with Huggy
+
Now that you've trained Huggy and pushed it to the Hub. **You will be able to play with him ❤️**
-Just launch this game:
+For this step it’s simple:
-CLic
+- Open the game Huggy in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
-ADD STEPS
+- Click on Play with my Huggy model
+
+ +
+1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).
+
+2. In step 2, **choose what model you want to replay**:
+ - I have multiple one, since we saved a model every 500000 timesteps.
+ - But if I want the more recent I choose Huggy.onnx
+
+👉 What’s nice **is to try with different models step to see the improvement of the agent.**
+
+1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).
+
+2. In step 2, **choose what model you want to replay**:
+ - I have multiple one, since we saved a model every 500000 timesteps.
+ - But if I want the more recent I choose Huggy.onnx
+
+👉 What’s nice **is to try with different models step to see the improvement of the agent.**