diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
index d6ccbda..e771af9 100644
--- a/units/en/unit2/q-learning-example.mdx
+++ b/units/en/unit2/q-learning-example.mdx
@@ -25,11 +25,11 @@ The reward function goes like this:
To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
-## Step 1: We initialize the Q-Table [[step1]]
+## Step 1: We initialize the Q-table [[step1]]
 -So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+So, for now, **our Q-table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
Let's do it for 2 training timesteps:
@@ -80,4 +80,4 @@ Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
-As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-function.**
diff --git a/units/en/unit2/q-learning-recap.mdx b/units/en/unit2/q-learning-recap.mdx
index 55c66bf..ab3b974 100644
--- a/units/en/unit2/q-learning-recap.mdx
+++ b/units/en/unit2/q-learning-recap.mdx
@@ -3,20 +3,20 @@
The *Q-Learning* **is the RL algorithm that** :
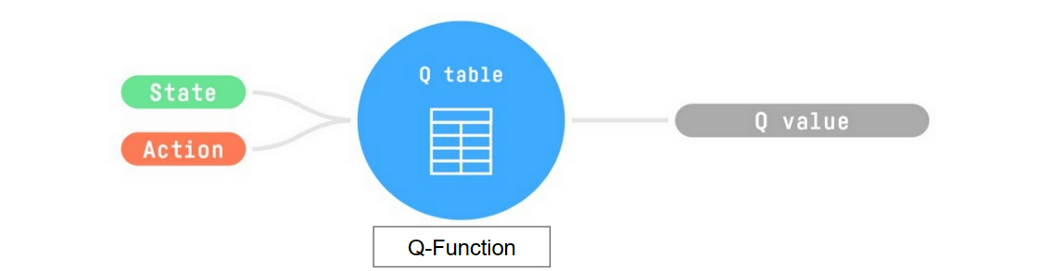
-- Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
-- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+- Given a state and action, our Q-function **will search into its Q-table the corresponding value.**
-So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+So, for now, **our Q-table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
Let's do it for 2 training timesteps:
@@ -80,4 +80,4 @@ Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
-As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-function.**
diff --git a/units/en/unit2/q-learning-recap.mdx b/units/en/unit2/q-learning-recap.mdx
index 55c66bf..ab3b974 100644
--- a/units/en/unit2/q-learning-recap.mdx
+++ b/units/en/unit2/q-learning-recap.mdx
@@ -3,20 +3,20 @@
The *Q-Learning* **is the RL algorithm that** :
-- Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
-- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+- Given a state and action, our Q-function **will search into its Q-table the corresponding value.**
 -- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done,**we have an optimal Q-function, so an optimal Q-table.**
- And if we **have an optimal Q-function**, we
have an optimal policy,since we **know for each state, what is the best action to take.**
-- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done,**we have an optimal Q-function, so an optimal Q-table.**
- And if we **have an optimal Q-function**, we
have an optimal policy,since we **know for each state, what is the best action to take.**
 -But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+But, in the beginning, our **Q-table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-table to 0 values)**. But, as we’ll explore the environment and update our Q-table it will give us better and better approximations
-But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+But, in the beginning, our **Q-table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-table to 0 values)**. But, as we’ll explore the environment and update our Q-table it will give us better and better approximations
 diff --git a/units/en/unit2/quiz2.mdx b/units/en/unit2/quiz2.mdx
index 9d96d74..961d477 100644
--- a/units/en/unit2/quiz2.mdx
+++ b/units/en/unit2/quiz2.mdx
@@ -9,7 +9,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
-### Q2: What is a Q-Table?
+### Q2: What is a Q-table?
diff --git a/units/en/unit2/quiz2.mdx b/units/en/unit2/quiz2.mdx
index 9d96d74..961d477 100644
--- a/units/en/unit2/quiz2.mdx
+++ b/units/en/unit2/quiz2.mdx
@@ -9,7 +9,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
-### Q2: What is a Q-Table?
+### Q2: What is a Q-table?