diff --git a/README.md b/README.md
index ee3f53c..d9cd483 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,8 @@
# [The Hugging Face Deep Reinforcement Learning Course 🤗 (v2.0)](https://huggingface.co/deep-rl-course/unit0/introduction)
-This repository contains the Deep Reinforcement Learning Course mdx files and notebooks. The website is here: https://huggingface.co/deep-rl-course/unit0/introduction?fw=pt
+If you like the course, don't hesitate to **⭐ star this repository. This helps us 🤗**.
+
+This repository contains the Deep Reinforcement Learning Course mdx files and notebooks. **The website is here**: https://huggingface.co/deep-rl-course/unit0/introduction?fw=pt
- The syllabus 📚: https://simoninithomas.github.io/deep-rl-course
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index ec814b0..0e7b4f1 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -1099,7 +1099,7 @@
"\n",
"Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.\n",
"\n",
- "Naturally, during the course, we’re going to use and deeper explain again these terms but **it’s better to have a good understanding of them now before diving into the next chapters.**\n"
+ "Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**\n\n"
]
},
{
diff --git a/notebooks/unit2/unit2.ipynb b/notebooks/unit2/unit2.ipynb
index 90baea8..13a86f0 100644
--- a/notebooks/unit2/unit2.ipynb
+++ b/notebooks/unit2/unit2.ipynb
@@ -511,7 +511,7 @@
},
"outputs": [],
"source": [
- "# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros\n",
+ "# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)\n",
"def initialize_q_table(state_space, action_space):\n",
" Qtable = \n",
" return Qtable"
diff --git a/notebooks/unit3/unit3.ipynb b/notebooks/unit3/unit3.ipynb
index e776208..5c21dca 100644
--- a/notebooks/unit3/unit3.ipynb
+++ b/notebooks/unit3/unit3.ipynb
@@ -301,7 +301,7 @@
"## Train our Deep Q-Learning Agent to Play Space Invaders 👾\n",
"\n",
"To train an agent with RL-Baselines3-Zoo, we just need to do two things:\n",
- "1. We define the hyperparameters in `rl-baselines3-zoo/hyperparams/dqn.yml`\n",
+ "1. We define the hyperparameters in `/content/rl-baselines3-zoo/hyperparams/dqn.yml`\n",
"\n",
" \n"
]
diff --git a/notebooks/unit6/unit6.ipynb b/notebooks/unit6/unit6.ipynb
index 0ca054e..28f8a5c 100644
--- a/notebooks/unit6/unit6.ipynb
+++ b/notebooks/unit6/unit6.ipynb
@@ -431,7 +431,7 @@
"source": [
"env = make_vec_env(env_id, n_envs=4)\n",
"\n",
- "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)"
+ "env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)"
],
"metadata": {
"id": "2O67mqgC-hol"
diff --git a/notebooks/unit8/unit8_part1.ipynb b/notebooks/unit8/unit8_part1.ipynb
new file mode 100644
index 0000000..a1862c8
--- /dev/null
+++ b/notebooks/unit8/unit8_part1.ipynb
@@ -0,0 +1,1357 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ "
\n"
]
diff --git a/notebooks/unit6/unit6.ipynb b/notebooks/unit6/unit6.ipynb
index 0ca054e..28f8a5c 100644
--- a/notebooks/unit6/unit6.ipynb
+++ b/notebooks/unit6/unit6.ipynb
@@ -431,7 +431,7 @@
"source": [
"env = make_vec_env(env_id, n_envs=4)\n",
"\n",
- "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)"
+ "env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)"
],
"metadata": {
"id": "2O67mqgC-hol"
diff --git a/notebooks/unit8/unit8_part1.ipynb b/notebooks/unit8/unit8_part1.ipynb
new file mode 100644
index 0000000..a1862c8
--- /dev/null
+++ b/notebooks/unit8/unit8_part1.ipynb
@@ -0,0 +1,1357 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-cf5-oDPjwf8"
+ },
+ "source": [
+ "# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-cf5-oDPjwf8"
+ },
+ "source": [
+ "# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.\n",
+ "\n",
+ "To test its robustness, we're going to train it in:\n",
+ "\n",
+ "- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2Fl6Rxt0lc0O"
+ },
+ "source": [
+ "⬇️ Here is an example of what you will achieve. ⬇️"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DbKfCj5ilgqT"
+ },
+ "outputs": [],
+ "source": [
+ "%%html\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YcOFdWpnlxNf"
+ },
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to **code your PPO agent from scratch using PyTorch**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "T6lIPYFghhYL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ "
\n",
+ "\n",
+ "\n",
+ "In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.\n",
+ "\n",
+ "To test its robustness, we're going to train it in:\n",
+ "\n",
+ "- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2Fl6Rxt0lc0O"
+ },
+ "source": [
+ "⬇️ Here is an example of what you will achieve. ⬇️"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DbKfCj5ilgqT"
+ },
+ "outputs": [],
+ "source": [
+ "%%html\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YcOFdWpnlxNf"
+ },
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to **code your PPO agent from scratch using PyTorch**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "T6lIPYFghhYL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ " \n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "Wp-rD6Fuhq31"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "rasqqGQlhujA"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "PUFfMGOih3CW"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "Wp-rD6Fuhq31"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "rasqqGQlhujA"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "PUFfMGOih3CW"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip install pyglet==1.5\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ncIgfNf3mOtc"
+ },
+ "source": [
+ "## Install dependencies 🔽\n",
+ "For this exercise, we use `gym==0.21`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install gym==0.21\n",
+ "!pip install imageio-ffmpeg\n",
+ "!pip install huggingface_hub\n",
+ "!pip install box2d"
+ ],
+ "metadata": {
+ "id": "9xZQFTPcsKUK"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oDkUufewmq6v"
+ },
+ "source": [
+ "## Let's code PPO from scratch with Costa Huang tutorial\n",
+ "- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.\n",
+ "- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/\n",
+ "\n",
+ "👉 The video tutorial: https://youtu.be/MEt6rrxH8W4"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aNgEL1_uvhaq"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML('')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f34ILn7AvTbt"
+ },
+ "source": [
+ "- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_bE708C6mhE7"
+ },
+ "outputs": [],
+ "source": [
+ "### Your code here:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mk-a9CmNuS2W"
+ },
+ "source": [
+ "## Add the Hugging Face Integration 🤗\n",
+ "- In order to push our model to the Hub, we need to define a function `package_to_hub`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TPi1Nme-oGWd"
+ },
+ "source": [
+ "- Add dependencies we need to push our model to the Hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Sj8bz-AmoNVj"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5rDr8-lWn0zi"
+ },
+ "source": [
+ "- Add new argument in `parse_args()` function to define the repo-id where we want to push the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iHQiqQEFn0QH"
+ },
+ "outputs": [],
+ "source": [
+ "# Adding HuggingFace argument\n",
+ "parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "blLZMiBAoUVT"
+ },
+ "source": [
+ "- Next, we add the methods needed to push the model to the Hub\n",
+ "\n",
+ "- These methods will:\n",
+ " - `_evalutate_agent()`: evaluate the agent.\n",
+ " - `_generate_model_card()`: generate the model card of your agent.\n",
+ " - `_record_video()`: record a video of your agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WlLcz4L9odXs"
+ },
+ "outputs": [],
+ "source": [
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TqX8z8_rooD6"
+ },
+ "source": [
+ "- Finally, we call this function at the end of the PPO training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I8V1vNiTo2hL"
+ },
+ "outputs": [],
+ "source": [
+ "# Create the evaluation environment\n",
+ "eval_env = gym.make(args.env_id)\n",
+ "\n",
+ "package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "muCCzed4o5TC"
+ },
+ "source": [
+ "- Here's what look the ppo.py final file"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LviRdtXgo7kF"
+ },
+ "outputs": [],
+ "source": [
+ "# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy\n",
+ "\n",
+ "import argparse\n",
+ "import os\n",
+ "import random\n",
+ "import time\n",
+ "from distutils.util import strtobool\n",
+ "\n",
+ "import gym\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.optim as optim\n",
+ "from torch.distributions.categorical import Categorical\n",
+ "from torch.utils.tensorboard import SummaryWriter\n",
+ "\n",
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()\n",
+ "\n",
+ "def parse_args():\n",
+ " # fmt: off\n",
+ " parser = argparse.ArgumentParser()\n",
+ " parser.add_argument(\"--exp-name\", type=str, default=os.path.basename(__file__).rstrip(\".py\"),\n",
+ " help=\"the name of this experiment\")\n",
+ " parser.add_argument(\"--seed\", type=int, default=1,\n",
+ " help=\"seed of the experiment\")\n",
+ " parser.add_argument(\"--torch-deterministic\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, `torch.backends.cudnn.deterministic=False`\")\n",
+ " parser.add_argument(\"--cuda\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, cuda will be enabled by default\")\n",
+ " parser.add_argument(\"--track\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, this experiment will be tracked with Weights and Biases\")\n",
+ " parser.add_argument(\"--wandb-project-name\", type=str, default=\"cleanRL\",\n",
+ " help=\"the wandb's project name\")\n",
+ " parser.add_argument(\"--wandb-entity\", type=str, default=None,\n",
+ " help=\"the entity (team) of wandb's project\")\n",
+ " parser.add_argument(\"--capture-video\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"weather to capture videos of the agent performances (check out `videos` folder)\")\n",
+ "\n",
+ " # Algorithm specific arguments\n",
+ " parser.add_argument(\"--env-id\", type=str, default=\"CartPole-v1\",\n",
+ " help=\"the id of the environment\")\n",
+ " parser.add_argument(\"--total-timesteps\", type=int, default=50000,\n",
+ " help=\"total timesteps of the experiments\")\n",
+ " parser.add_argument(\"--learning-rate\", type=float, default=2.5e-4,\n",
+ " help=\"the learning rate of the optimizer\")\n",
+ " parser.add_argument(\"--num-envs\", type=int, default=4,\n",
+ " help=\"the number of parallel game environments\")\n",
+ " parser.add_argument(\"--num-steps\", type=int, default=128,\n",
+ " help=\"the number of steps to run in each environment per policy rollout\")\n",
+ " parser.add_argument(\"--anneal-lr\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggle learning rate annealing for policy and value networks\")\n",
+ " parser.add_argument(\"--gae\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Use GAE for advantage computation\")\n",
+ " parser.add_argument(\"--gamma\", type=float, default=0.99,\n",
+ " help=\"the discount factor gamma\")\n",
+ " parser.add_argument(\"--gae-lambda\", type=float, default=0.95,\n",
+ " help=\"the lambda for the general advantage estimation\")\n",
+ " parser.add_argument(\"--num-minibatches\", type=int, default=4,\n",
+ " help=\"the number of mini-batches\")\n",
+ " parser.add_argument(\"--update-epochs\", type=int, default=4,\n",
+ " help=\"the K epochs to update the policy\")\n",
+ " parser.add_argument(\"--norm-adv\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles advantages normalization\")\n",
+ " parser.add_argument(\"--clip-coef\", type=float, default=0.2,\n",
+ " help=\"the surrogate clipping coefficient\")\n",
+ " parser.add_argument(\"--clip-vloss\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles whether or not to use a clipped loss for the value function, as per the paper.\")\n",
+ " parser.add_argument(\"--ent-coef\", type=float, default=0.01,\n",
+ " help=\"coefficient of the entropy\")\n",
+ " parser.add_argument(\"--vf-coef\", type=float, default=0.5,\n",
+ " help=\"coefficient of the value function\")\n",
+ " parser.add_argument(\"--max-grad-norm\", type=float, default=0.5,\n",
+ " help=\"the maximum norm for the gradient clipping\")\n",
+ " parser.add_argument(\"--target-kl\", type=float, default=None,\n",
+ " help=\"the target KL divergence threshold\")\n",
+ " \n",
+ " # Adding HuggingFace argument\n",
+ " parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")\n",
+ "\n",
+ " args = parser.parse_args()\n",
+ " args.batch_size = int(args.num_envs * args.num_steps)\n",
+ " args.minibatch_size = int(args.batch_size // args.num_minibatches)\n",
+ " # fmt: on\n",
+ " return args\n",
+ "\n",
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)\n",
+ "\n",
+ "def make_env(env_id, seed, idx, capture_video, run_name):\n",
+ " def thunk():\n",
+ " env = gym.make(env_id)\n",
+ " env = gym.wrappers.RecordEpisodeStatistics(env)\n",
+ " if capture_video:\n",
+ " if idx == 0:\n",
+ " env = gym.wrappers.RecordVideo(env, f\"videos/{run_name}\")\n",
+ " env.seed(seed)\n",
+ " env.action_space.seed(seed)\n",
+ " env.observation_space.seed(seed)\n",
+ " return env\n",
+ "\n",
+ " return thunk\n",
+ "\n",
+ "\n",
+ "def layer_init(layer, std=np.sqrt(2), bias_const=0.0):\n",
+ " torch.nn.init.orthogonal_(layer.weight, std)\n",
+ " torch.nn.init.constant_(layer.bias, bias_const)\n",
+ " return layer\n",
+ "\n",
+ "\n",
+ "class Agent(nn.Module):\n",
+ " def __init__(self, envs):\n",
+ " super().__init__()\n",
+ " self.critic = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 1), std=1.0),\n",
+ " )\n",
+ " self.actor = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),\n",
+ " )\n",
+ "\n",
+ " def get_value(self, x):\n",
+ " return self.critic(x)\n",
+ "\n",
+ " def get_action_and_value(self, x, action=None):\n",
+ " logits = self.actor(x)\n",
+ " probs = Categorical(logits=logits)\n",
+ " if action is None:\n",
+ " action = probs.sample()\n",
+ " return action, probs.log_prob(action), probs.entropy(), self.critic(x)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " args = parse_args()\n",
+ " run_name = f\"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}\"\n",
+ " if args.track:\n",
+ " import wandb\n",
+ "\n",
+ " wandb.init(\n",
+ " project=args.wandb_project_name,\n",
+ " entity=args.wandb_entity,\n",
+ " sync_tensorboard=True,\n",
+ " config=vars(args),\n",
+ " name=run_name,\n",
+ " monitor_gym=True,\n",
+ " save_code=True,\n",
+ " )\n",
+ " writer = SummaryWriter(f\"runs/{run_name}\")\n",
+ " writer.add_text(\n",
+ " \"hyperparameters\",\n",
+ " \"|param|value|\\n|-|-|\\n%s\" % (\"\\n\".join([f\"|{key}|{value}|\" for key, value in vars(args).items()])),\n",
+ " )\n",
+ "\n",
+ " # TRY NOT TO MODIFY: seeding\n",
+ " random.seed(args.seed)\n",
+ " np.random.seed(args.seed)\n",
+ " torch.manual_seed(args.seed)\n",
+ " torch.backends.cudnn.deterministic = args.torch_deterministic\n",
+ "\n",
+ " device = torch.device(\"cuda\" if torch.cuda.is_available() and args.cuda else \"cpu\")\n",
+ "\n",
+ " # env setup\n",
+ " envs = gym.vector.SyncVectorEnv(\n",
+ " [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]\n",
+ " )\n",
+ " assert isinstance(envs.single_action_space, gym.spaces.Discrete), \"only discrete action space is supported\"\n",
+ "\n",
+ " agent = Agent(envs).to(device)\n",
+ " optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)\n",
+ "\n",
+ " # ALGO Logic: Storage setup\n",
+ " obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)\n",
+ " actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)\n",
+ " logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " dones = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " values = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ "\n",
+ " # TRY NOT TO MODIFY: start the game\n",
+ " global_step = 0\n",
+ " start_time = time.time()\n",
+ " next_obs = torch.Tensor(envs.reset()).to(device)\n",
+ " next_done = torch.zeros(args.num_envs).to(device)\n",
+ " num_updates = args.total_timesteps // args.batch_size\n",
+ "\n",
+ " for update in range(1, num_updates + 1):\n",
+ " # Annealing the rate if instructed to do so.\n",
+ " if args.anneal_lr:\n",
+ " frac = 1.0 - (update - 1.0) / num_updates\n",
+ " lrnow = frac * args.learning_rate\n",
+ " optimizer.param_groups[0][\"lr\"] = lrnow\n",
+ "\n",
+ " for step in range(0, args.num_steps):\n",
+ " global_step += 1 * args.num_envs\n",
+ " obs[step] = next_obs\n",
+ " dones[step] = next_done\n",
+ "\n",
+ " # ALGO LOGIC: action logic\n",
+ " with torch.no_grad():\n",
+ " action, logprob, _, value = agent.get_action_and_value(next_obs)\n",
+ " values[step] = value.flatten()\n",
+ " actions[step] = action\n",
+ " logprobs[step] = logprob\n",
+ "\n",
+ " # TRY NOT TO MODIFY: execute the game and log data.\n",
+ " next_obs, reward, done, info = envs.step(action.cpu().numpy())\n",
+ " rewards[step] = torch.tensor(reward).to(device).view(-1)\n",
+ " next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)\n",
+ "\n",
+ " for item in info:\n",
+ " if \"episode\" in item.keys():\n",
+ " print(f\"global_step={global_step}, episodic_return={item['episode']['r']}\")\n",
+ " writer.add_scalar(\"charts/episodic_return\", item[\"episode\"][\"r\"], global_step)\n",
+ " writer.add_scalar(\"charts/episodic_length\", item[\"episode\"][\"l\"], global_step)\n",
+ " break\n",
+ "\n",
+ " # bootstrap value if not done\n",
+ " with torch.no_grad():\n",
+ " next_value = agent.get_value(next_obs).reshape(1, -1)\n",
+ " if args.gae:\n",
+ " advantages = torch.zeros_like(rewards).to(device)\n",
+ " lastgaelam = 0\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " nextvalues = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " nextvalues = values[t + 1]\n",
+ " delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]\n",
+ " advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam\n",
+ " returns = advantages + values\n",
+ " else:\n",
+ " returns = torch.zeros_like(rewards).to(device)\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " next_return = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " next_return = returns[t + 1]\n",
+ " returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return\n",
+ " advantages = returns - values\n",
+ "\n",
+ " # flatten the batch\n",
+ " b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)\n",
+ " b_logprobs = logprobs.reshape(-1)\n",
+ " b_actions = actions.reshape((-1,) + envs.single_action_space.shape)\n",
+ " b_advantages = advantages.reshape(-1)\n",
+ " b_returns = returns.reshape(-1)\n",
+ " b_values = values.reshape(-1)\n",
+ "\n",
+ " # Optimizing the policy and value network\n",
+ " b_inds = np.arange(args.batch_size)\n",
+ " clipfracs = []\n",
+ " for epoch in range(args.update_epochs):\n",
+ " np.random.shuffle(b_inds)\n",
+ " for start in range(0, args.batch_size, args.minibatch_size):\n",
+ " end = start + args.minibatch_size\n",
+ " mb_inds = b_inds[start:end]\n",
+ "\n",
+ " _, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])\n",
+ " logratio = newlogprob - b_logprobs[mb_inds]\n",
+ " ratio = logratio.exp()\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " # calculate approx_kl http://joschu.net/blog/kl-approx.html\n",
+ " old_approx_kl = (-logratio).mean()\n",
+ " approx_kl = ((ratio - 1) - logratio).mean()\n",
+ " clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]\n",
+ "\n",
+ " mb_advantages = b_advantages[mb_inds]\n",
+ " if args.norm_adv:\n",
+ " mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)\n",
+ "\n",
+ " # Policy loss\n",
+ " pg_loss1 = -mb_advantages * ratio\n",
+ " pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)\n",
+ " pg_loss = torch.max(pg_loss1, pg_loss2).mean()\n",
+ "\n",
+ " # Value loss\n",
+ " newvalue = newvalue.view(-1)\n",
+ " if args.clip_vloss:\n",
+ " v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2\n",
+ " v_clipped = b_values[mb_inds] + torch.clamp(\n",
+ " newvalue - b_values[mb_inds],\n",
+ " -args.clip_coef,\n",
+ " args.clip_coef,\n",
+ " )\n",
+ " v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2\n",
+ " v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)\n",
+ " v_loss = 0.5 * v_loss_max.mean()\n",
+ " else:\n",
+ " v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()\n",
+ "\n",
+ " entropy_loss = entropy.mean()\n",
+ " loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef\n",
+ "\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ " nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)\n",
+ " optimizer.step()\n",
+ "\n",
+ " if args.target_kl is not None:\n",
+ " if approx_kl > args.target_kl:\n",
+ " break\n",
+ "\n",
+ " y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()\n",
+ " var_y = np.var(y_true)\n",
+ " explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y\n",
+ "\n",
+ " # TRY NOT TO MODIFY: record rewards for plotting purposes\n",
+ " writer.add_scalar(\"charts/learning_rate\", optimizer.param_groups[0][\"lr\"], global_step)\n",
+ " writer.add_scalar(\"losses/value_loss\", v_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/policy_loss\", pg_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/entropy\", entropy_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/old_approx_kl\", old_approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/approx_kl\", approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/clipfrac\", np.mean(clipfracs), global_step)\n",
+ " writer.add_scalar(\"losses/explained_variance\", explained_var, global_step)\n",
+ " print(\"SPS:\", int(global_step / (time.time() - start_time)))\n",
+ " writer.add_scalar(\"charts/SPS\", int(global_step / (time.time() - start_time)), global_step)\n",
+ "\n",
+ " envs.close()\n",
+ " writer.close()\n",
+ "\n",
+ " # Create the evaluation environment\n",
+ " eval_env = gym.make(args.env_id)\n",
+ "\n",
+ " package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip install pyglet==1.5\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ncIgfNf3mOtc"
+ },
+ "source": [
+ "## Install dependencies 🔽\n",
+ "For this exercise, we use `gym==0.21`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install gym==0.21\n",
+ "!pip install imageio-ffmpeg\n",
+ "!pip install huggingface_hub\n",
+ "!pip install box2d"
+ ],
+ "metadata": {
+ "id": "9xZQFTPcsKUK"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oDkUufewmq6v"
+ },
+ "source": [
+ "## Let's code PPO from scratch with Costa Huang tutorial\n",
+ "- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.\n",
+ "- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/\n",
+ "\n",
+ "👉 The video tutorial: https://youtu.be/MEt6rrxH8W4"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aNgEL1_uvhaq"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML('')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f34ILn7AvTbt"
+ },
+ "source": [
+ "- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_bE708C6mhE7"
+ },
+ "outputs": [],
+ "source": [
+ "### Your code here:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mk-a9CmNuS2W"
+ },
+ "source": [
+ "## Add the Hugging Face Integration 🤗\n",
+ "- In order to push our model to the Hub, we need to define a function `package_to_hub`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TPi1Nme-oGWd"
+ },
+ "source": [
+ "- Add dependencies we need to push our model to the Hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Sj8bz-AmoNVj"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5rDr8-lWn0zi"
+ },
+ "source": [
+ "- Add new argument in `parse_args()` function to define the repo-id where we want to push the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iHQiqQEFn0QH"
+ },
+ "outputs": [],
+ "source": [
+ "# Adding HuggingFace argument\n",
+ "parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "blLZMiBAoUVT"
+ },
+ "source": [
+ "- Next, we add the methods needed to push the model to the Hub\n",
+ "\n",
+ "- These methods will:\n",
+ " - `_evalutate_agent()`: evaluate the agent.\n",
+ " - `_generate_model_card()`: generate the model card of your agent.\n",
+ " - `_record_video()`: record a video of your agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WlLcz4L9odXs"
+ },
+ "outputs": [],
+ "source": [
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TqX8z8_rooD6"
+ },
+ "source": [
+ "- Finally, we call this function at the end of the PPO training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I8V1vNiTo2hL"
+ },
+ "outputs": [],
+ "source": [
+ "# Create the evaluation environment\n",
+ "eval_env = gym.make(args.env_id)\n",
+ "\n",
+ "package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "muCCzed4o5TC"
+ },
+ "source": [
+ "- Here's what look the ppo.py final file"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LviRdtXgo7kF"
+ },
+ "outputs": [],
+ "source": [
+ "# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy\n",
+ "\n",
+ "import argparse\n",
+ "import os\n",
+ "import random\n",
+ "import time\n",
+ "from distutils.util import strtobool\n",
+ "\n",
+ "import gym\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.optim as optim\n",
+ "from torch.distributions.categorical import Categorical\n",
+ "from torch.utils.tensorboard import SummaryWriter\n",
+ "\n",
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()\n",
+ "\n",
+ "def parse_args():\n",
+ " # fmt: off\n",
+ " parser = argparse.ArgumentParser()\n",
+ " parser.add_argument(\"--exp-name\", type=str, default=os.path.basename(__file__).rstrip(\".py\"),\n",
+ " help=\"the name of this experiment\")\n",
+ " parser.add_argument(\"--seed\", type=int, default=1,\n",
+ " help=\"seed of the experiment\")\n",
+ " parser.add_argument(\"--torch-deterministic\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, `torch.backends.cudnn.deterministic=False`\")\n",
+ " parser.add_argument(\"--cuda\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, cuda will be enabled by default\")\n",
+ " parser.add_argument(\"--track\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, this experiment will be tracked with Weights and Biases\")\n",
+ " parser.add_argument(\"--wandb-project-name\", type=str, default=\"cleanRL\",\n",
+ " help=\"the wandb's project name\")\n",
+ " parser.add_argument(\"--wandb-entity\", type=str, default=None,\n",
+ " help=\"the entity (team) of wandb's project\")\n",
+ " parser.add_argument(\"--capture-video\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"weather to capture videos of the agent performances (check out `videos` folder)\")\n",
+ "\n",
+ " # Algorithm specific arguments\n",
+ " parser.add_argument(\"--env-id\", type=str, default=\"CartPole-v1\",\n",
+ " help=\"the id of the environment\")\n",
+ " parser.add_argument(\"--total-timesteps\", type=int, default=50000,\n",
+ " help=\"total timesteps of the experiments\")\n",
+ " parser.add_argument(\"--learning-rate\", type=float, default=2.5e-4,\n",
+ " help=\"the learning rate of the optimizer\")\n",
+ " parser.add_argument(\"--num-envs\", type=int, default=4,\n",
+ " help=\"the number of parallel game environments\")\n",
+ " parser.add_argument(\"--num-steps\", type=int, default=128,\n",
+ " help=\"the number of steps to run in each environment per policy rollout\")\n",
+ " parser.add_argument(\"--anneal-lr\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggle learning rate annealing for policy and value networks\")\n",
+ " parser.add_argument(\"--gae\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Use GAE for advantage computation\")\n",
+ " parser.add_argument(\"--gamma\", type=float, default=0.99,\n",
+ " help=\"the discount factor gamma\")\n",
+ " parser.add_argument(\"--gae-lambda\", type=float, default=0.95,\n",
+ " help=\"the lambda for the general advantage estimation\")\n",
+ " parser.add_argument(\"--num-minibatches\", type=int, default=4,\n",
+ " help=\"the number of mini-batches\")\n",
+ " parser.add_argument(\"--update-epochs\", type=int, default=4,\n",
+ " help=\"the K epochs to update the policy\")\n",
+ " parser.add_argument(\"--norm-adv\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles advantages normalization\")\n",
+ " parser.add_argument(\"--clip-coef\", type=float, default=0.2,\n",
+ " help=\"the surrogate clipping coefficient\")\n",
+ " parser.add_argument(\"--clip-vloss\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles whether or not to use a clipped loss for the value function, as per the paper.\")\n",
+ " parser.add_argument(\"--ent-coef\", type=float, default=0.01,\n",
+ " help=\"coefficient of the entropy\")\n",
+ " parser.add_argument(\"--vf-coef\", type=float, default=0.5,\n",
+ " help=\"coefficient of the value function\")\n",
+ " parser.add_argument(\"--max-grad-norm\", type=float, default=0.5,\n",
+ " help=\"the maximum norm for the gradient clipping\")\n",
+ " parser.add_argument(\"--target-kl\", type=float, default=None,\n",
+ " help=\"the target KL divergence threshold\")\n",
+ " \n",
+ " # Adding HuggingFace argument\n",
+ " parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")\n",
+ "\n",
+ " args = parser.parse_args()\n",
+ " args.batch_size = int(args.num_envs * args.num_steps)\n",
+ " args.minibatch_size = int(args.batch_size // args.num_minibatches)\n",
+ " # fmt: on\n",
+ " return args\n",
+ "\n",
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)\n",
+ "\n",
+ "def make_env(env_id, seed, idx, capture_video, run_name):\n",
+ " def thunk():\n",
+ " env = gym.make(env_id)\n",
+ " env = gym.wrappers.RecordEpisodeStatistics(env)\n",
+ " if capture_video:\n",
+ " if idx == 0:\n",
+ " env = gym.wrappers.RecordVideo(env, f\"videos/{run_name}\")\n",
+ " env.seed(seed)\n",
+ " env.action_space.seed(seed)\n",
+ " env.observation_space.seed(seed)\n",
+ " return env\n",
+ "\n",
+ " return thunk\n",
+ "\n",
+ "\n",
+ "def layer_init(layer, std=np.sqrt(2), bias_const=0.0):\n",
+ " torch.nn.init.orthogonal_(layer.weight, std)\n",
+ " torch.nn.init.constant_(layer.bias, bias_const)\n",
+ " return layer\n",
+ "\n",
+ "\n",
+ "class Agent(nn.Module):\n",
+ " def __init__(self, envs):\n",
+ " super().__init__()\n",
+ " self.critic = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 1), std=1.0),\n",
+ " )\n",
+ " self.actor = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),\n",
+ " )\n",
+ "\n",
+ " def get_value(self, x):\n",
+ " return self.critic(x)\n",
+ "\n",
+ " def get_action_and_value(self, x, action=None):\n",
+ " logits = self.actor(x)\n",
+ " probs = Categorical(logits=logits)\n",
+ " if action is None:\n",
+ " action = probs.sample()\n",
+ " return action, probs.log_prob(action), probs.entropy(), self.critic(x)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " args = parse_args()\n",
+ " run_name = f\"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}\"\n",
+ " if args.track:\n",
+ " import wandb\n",
+ "\n",
+ " wandb.init(\n",
+ " project=args.wandb_project_name,\n",
+ " entity=args.wandb_entity,\n",
+ " sync_tensorboard=True,\n",
+ " config=vars(args),\n",
+ " name=run_name,\n",
+ " monitor_gym=True,\n",
+ " save_code=True,\n",
+ " )\n",
+ " writer = SummaryWriter(f\"runs/{run_name}\")\n",
+ " writer.add_text(\n",
+ " \"hyperparameters\",\n",
+ " \"|param|value|\\n|-|-|\\n%s\" % (\"\\n\".join([f\"|{key}|{value}|\" for key, value in vars(args).items()])),\n",
+ " )\n",
+ "\n",
+ " # TRY NOT TO MODIFY: seeding\n",
+ " random.seed(args.seed)\n",
+ " np.random.seed(args.seed)\n",
+ " torch.manual_seed(args.seed)\n",
+ " torch.backends.cudnn.deterministic = args.torch_deterministic\n",
+ "\n",
+ " device = torch.device(\"cuda\" if torch.cuda.is_available() and args.cuda else \"cpu\")\n",
+ "\n",
+ " # env setup\n",
+ " envs = gym.vector.SyncVectorEnv(\n",
+ " [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]\n",
+ " )\n",
+ " assert isinstance(envs.single_action_space, gym.spaces.Discrete), \"only discrete action space is supported\"\n",
+ "\n",
+ " agent = Agent(envs).to(device)\n",
+ " optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)\n",
+ "\n",
+ " # ALGO Logic: Storage setup\n",
+ " obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)\n",
+ " actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)\n",
+ " logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " dones = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " values = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ "\n",
+ " # TRY NOT TO MODIFY: start the game\n",
+ " global_step = 0\n",
+ " start_time = time.time()\n",
+ " next_obs = torch.Tensor(envs.reset()).to(device)\n",
+ " next_done = torch.zeros(args.num_envs).to(device)\n",
+ " num_updates = args.total_timesteps // args.batch_size\n",
+ "\n",
+ " for update in range(1, num_updates + 1):\n",
+ " # Annealing the rate if instructed to do so.\n",
+ " if args.anneal_lr:\n",
+ " frac = 1.0 - (update - 1.0) / num_updates\n",
+ " lrnow = frac * args.learning_rate\n",
+ " optimizer.param_groups[0][\"lr\"] = lrnow\n",
+ "\n",
+ " for step in range(0, args.num_steps):\n",
+ " global_step += 1 * args.num_envs\n",
+ " obs[step] = next_obs\n",
+ " dones[step] = next_done\n",
+ "\n",
+ " # ALGO LOGIC: action logic\n",
+ " with torch.no_grad():\n",
+ " action, logprob, _, value = agent.get_action_and_value(next_obs)\n",
+ " values[step] = value.flatten()\n",
+ " actions[step] = action\n",
+ " logprobs[step] = logprob\n",
+ "\n",
+ " # TRY NOT TO MODIFY: execute the game and log data.\n",
+ " next_obs, reward, done, info = envs.step(action.cpu().numpy())\n",
+ " rewards[step] = torch.tensor(reward).to(device).view(-1)\n",
+ " next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)\n",
+ "\n",
+ " for item in info:\n",
+ " if \"episode\" in item.keys():\n",
+ " print(f\"global_step={global_step}, episodic_return={item['episode']['r']}\")\n",
+ " writer.add_scalar(\"charts/episodic_return\", item[\"episode\"][\"r\"], global_step)\n",
+ " writer.add_scalar(\"charts/episodic_length\", item[\"episode\"][\"l\"], global_step)\n",
+ " break\n",
+ "\n",
+ " # bootstrap value if not done\n",
+ " with torch.no_grad():\n",
+ " next_value = agent.get_value(next_obs).reshape(1, -1)\n",
+ " if args.gae:\n",
+ " advantages = torch.zeros_like(rewards).to(device)\n",
+ " lastgaelam = 0\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " nextvalues = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " nextvalues = values[t + 1]\n",
+ " delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]\n",
+ " advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam\n",
+ " returns = advantages + values\n",
+ " else:\n",
+ " returns = torch.zeros_like(rewards).to(device)\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " next_return = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " next_return = returns[t + 1]\n",
+ " returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return\n",
+ " advantages = returns - values\n",
+ "\n",
+ " # flatten the batch\n",
+ " b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)\n",
+ " b_logprobs = logprobs.reshape(-1)\n",
+ " b_actions = actions.reshape((-1,) + envs.single_action_space.shape)\n",
+ " b_advantages = advantages.reshape(-1)\n",
+ " b_returns = returns.reshape(-1)\n",
+ " b_values = values.reshape(-1)\n",
+ "\n",
+ " # Optimizing the policy and value network\n",
+ " b_inds = np.arange(args.batch_size)\n",
+ " clipfracs = []\n",
+ " for epoch in range(args.update_epochs):\n",
+ " np.random.shuffle(b_inds)\n",
+ " for start in range(0, args.batch_size, args.minibatch_size):\n",
+ " end = start + args.minibatch_size\n",
+ " mb_inds = b_inds[start:end]\n",
+ "\n",
+ " _, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])\n",
+ " logratio = newlogprob - b_logprobs[mb_inds]\n",
+ " ratio = logratio.exp()\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " # calculate approx_kl http://joschu.net/blog/kl-approx.html\n",
+ " old_approx_kl = (-logratio).mean()\n",
+ " approx_kl = ((ratio - 1) - logratio).mean()\n",
+ " clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]\n",
+ "\n",
+ " mb_advantages = b_advantages[mb_inds]\n",
+ " if args.norm_adv:\n",
+ " mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)\n",
+ "\n",
+ " # Policy loss\n",
+ " pg_loss1 = -mb_advantages * ratio\n",
+ " pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)\n",
+ " pg_loss = torch.max(pg_loss1, pg_loss2).mean()\n",
+ "\n",
+ " # Value loss\n",
+ " newvalue = newvalue.view(-1)\n",
+ " if args.clip_vloss:\n",
+ " v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2\n",
+ " v_clipped = b_values[mb_inds] + torch.clamp(\n",
+ " newvalue - b_values[mb_inds],\n",
+ " -args.clip_coef,\n",
+ " args.clip_coef,\n",
+ " )\n",
+ " v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2\n",
+ " v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)\n",
+ " v_loss = 0.5 * v_loss_max.mean()\n",
+ " else:\n",
+ " v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()\n",
+ "\n",
+ " entropy_loss = entropy.mean()\n",
+ " loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef\n",
+ "\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ " nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)\n",
+ " optimizer.step()\n",
+ "\n",
+ " if args.target_kl is not None:\n",
+ " if approx_kl > args.target_kl:\n",
+ " break\n",
+ "\n",
+ " y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()\n",
+ " var_y = np.var(y_true)\n",
+ " explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y\n",
+ "\n",
+ " # TRY NOT TO MODIFY: record rewards for plotting purposes\n",
+ " writer.add_scalar(\"charts/learning_rate\", optimizer.param_groups[0][\"lr\"], global_step)\n",
+ " writer.add_scalar(\"losses/value_loss\", v_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/policy_loss\", pg_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/entropy\", entropy_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/old_approx_kl\", old_approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/approx_kl\", approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/clipfrac\", np.mean(clipfracs), global_step)\n",
+ " writer.add_scalar(\"losses/explained_variance\", explained_var, global_step)\n",
+ " print(\"SPS:\", int(global_step / (time.time() - start_time)))\n",
+ " writer.add_scalar(\"charts/SPS\", int(global_step / (time.time() - start_time)), global_step)\n",
+ "\n",
+ " envs.close()\n",
+ " writer.close()\n",
+ "\n",
+ " # Create the evaluation environment\n",
+ " eval_env = gym.make(args.env_id)\n",
+ "\n",
+ " package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ " \n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jRqkGvk7pFQ6"
+ },
+ "source": [
+ "## Let's start the training 🔥\n",
+ "- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0tmEArP8ug2l"
+ },
+ "source": [
+ "- First, you need to copy all your code to a file you create called `ppo.py`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "
\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jRqkGvk7pFQ6"
+ },
+ "source": [
+ "## Let's start the training 🔥\n",
+ "- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0tmEArP8ug2l"
+ },
+ "source": [
+ "- First, you need to copy all your code to a file you create called `ppo.py`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ " "
+ ],
+ "metadata": {
+ "id": "Sq0My0LOjPYR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "
"
+ ],
+ "metadata": {
+ "id": "Sq0My0LOjPYR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ " "
+ ],
+ "metadata": {
+ "id": "A8C-Q5ZyjUe3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VrS80GmMu_j5"
+ },
+ "source": [
+ "- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`\n",
+ "\n",
+ "- You should modify more hyperparameters otherwise the training will not be super stable."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!python ppo.py --env-id=\"LunarLander-v2\" --repo-id=\"YOUR_REPO_ID\" --total-timesteps=50000"
+ ],
+ "metadata": {
+ "id": "KXLih6mKseBs"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eVsVJ5AdqLE7"
+ },
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying another environment?\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nYdl758GqLXT"
+ },
+ "source": [
+ "See you on Unit 8, part 2 where we going to train agents to play Doom 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "accelerator": "GPU"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part2.ipynb b/notebooks/unit8/unit8_part2.ipynb
new file mode 100644
index 0000000..51819df
--- /dev/null
+++ b/notebooks/unit8/unit8_part2.ipynb
@@ -0,0 +1,680 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "OVx1gdg9wt9t"
+ },
+ "source": [
+ "# Unit 8 Part 2: Advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "A8C-Q5ZyjUe3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VrS80GmMu_j5"
+ },
+ "source": [
+ "- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`\n",
+ "\n",
+ "- You should modify more hyperparameters otherwise the training will not be super stable."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!python ppo.py --env-id=\"LunarLander-v2\" --repo-id=\"YOUR_REPO_ID\" --total-timesteps=50000"
+ ],
+ "metadata": {
+ "id": "KXLih6mKseBs"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eVsVJ5AdqLE7"
+ },
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying another environment?\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nYdl758GqLXT"
+ },
+ "source": [
+ "See you on Unit 8, part 2 where we going to train agents to play Doom 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "accelerator": "GPU"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part2.ipynb b/notebooks/unit8/unit8_part2.ipynb
new file mode 100644
index 0000000..51819df
--- /dev/null
+++ b/notebooks/unit8/unit8_part2.ipynb
@@ -0,0 +1,680 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "OVx1gdg9wt9t"
+ },
+ "source": [
+ "# Unit 8 Part 2: Advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels\n",
+ "\n",
+ " \n",
+ "\n",
+ "In this notebook, we will learn how to train a Deep Neural Network to collect objects in a 3D environment based on the game of Doom, a video of the resulting policy is shown below. We train this policy using [Sample Factory](https://www.samplefactory.dev/), an asynchronous implementation of the PPO algorithm.\n",
+ "\n",
+ "Please note the following points:\n",
+ "\n",
+ "* [Sample Factory](https://www.samplefactory.dev/) is an advanced RL framework and **only functions on Linux and Mac** (not Windows).\n",
+ "\n",
+ "* The framework performs best on a **GPU machine with many CPU cores**, where it can achieve speeds of 100k interactions per second. The resources available on a standard Colab notebook **limit the performance of this library**. So the speed in this setting **does not reflect the real-world performance**.\n",
+ "* Benchmarks for Sample Factory are available in a number of settings, check out the [examples](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples) if you want to find out more.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I6_67HfI1CKg"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML(''''''\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DgHRAsYEXdyw"
+ },
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model:\n",
+ "\n",
+ "- `doom_health_gathering_supreme` get a result of >= 5.\n",
+ "\n",
+ "To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ },
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ },
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-fSy5HzUcMWB"
+ },
+ "source": [
+ "Before starting to train our agent, let's **study the library and environments we're going to use**.\n",
+ "\n",
+ "## Sample Factory\n",
+ "\n",
+ "[Sample Factory](https://www.samplefactory.dev/) is one of the **fastest RL libraries focused on very efficient synchronous and asynchronous implementations of policy gradients (PPO)**.\n",
+ "\n",
+ "Sample Factory is thoroughly **tested, used by many researchers and practitioners**, and is actively maintained. Our implementation is known to **reach SOTA performance in a variety of domains while minimizing RL experiment training time and hardware requirements**.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In this notebook, we will learn how to train a Deep Neural Network to collect objects in a 3D environment based on the game of Doom, a video of the resulting policy is shown below. We train this policy using [Sample Factory](https://www.samplefactory.dev/), an asynchronous implementation of the PPO algorithm.\n",
+ "\n",
+ "Please note the following points:\n",
+ "\n",
+ "* [Sample Factory](https://www.samplefactory.dev/) is an advanced RL framework and **only functions on Linux and Mac** (not Windows).\n",
+ "\n",
+ "* The framework performs best on a **GPU machine with many CPU cores**, where it can achieve speeds of 100k interactions per second. The resources available on a standard Colab notebook **limit the performance of this library**. So the speed in this setting **does not reflect the real-world performance**.\n",
+ "* Benchmarks for Sample Factory are available in a number of settings, check out the [examples](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples) if you want to find out more.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I6_67HfI1CKg"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML(''''''\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DgHRAsYEXdyw"
+ },
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model:\n",
+ "\n",
+ "- `doom_health_gathering_supreme` get a result of >= 5.\n",
+ "\n",
+ "To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ },
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ },
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-fSy5HzUcMWB"
+ },
+ "source": [
+ "Before starting to train our agent, let's **study the library and environments we're going to use**.\n",
+ "\n",
+ "## Sample Factory\n",
+ "\n",
+ "[Sample Factory](https://www.samplefactory.dev/) is one of the **fastest RL libraries focused on very efficient synchronous and asynchronous implementations of policy gradients (PPO)**.\n",
+ "\n",
+ "Sample Factory is thoroughly **tested, used by many researchers and practitioners**, and is actively maintained. Our implementation is known to **reach SOTA performance in a variety of domains while minimizing RL experiment training time and hardware requirements**.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Key features\n",
+ "\n",
+ "- Highly optimized algorithm [architecture](https://www.samplefactory.dev/06-architecture/overview/) for maximum learning throughput\n",
+ "- [Synchronous and asynchronous](https://www.samplefactory.dev/07-advanced-topics/sync-async/) training regimes\n",
+ "- [Serial (single-process) mode](https://www.samplefactory.dev/07-advanced-topics/serial-mode/) for easy debugging\n",
+ "- Optimal performance in both CPU-based and [GPU-accelerated environments](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)\n",
+ "- Single- & multi-agent training, self-play, supports [training multiple policies](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/) at once on one or many GPUs\n",
+ "- Population-Based Training ([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))\n",
+ "- Discrete, continuous, hybrid action spaces\n",
+ "- Vector-based, image-based, dictionary observation spaces\n",
+ "- Automatically creates a model architecture by parsing action/observation space specification. Supports [custom model architectures](https://www.samplefactory.dev/03-customization/custom-models/)\n",
+ "- Designed to be imported into other projects, [custom environments](https://www.samplefactory.dev/03-customization/custom-environments/) are first-class citizens\n",
+ "- Detailed [WandB and Tensorboard summaries](https://www.samplefactory.dev/05-monitoring/metrics-reference/), [custom metrics](https://www.samplefactory.dev/05-monitoring/custom-metrics/)\n",
+ "- [HuggingFace 🤗 integration](https://www.samplefactory.dev/10-huggingface/huggingface/) (upload trained models and metrics to the Hub)\n",
+ "- [Multiple](https://www.samplefactory.dev/09-environment-integrations/mujoco/) [example](https://www.samplefactory.dev/09-environment-integrations/atari/) [environment](https://www.samplefactory.dev/09-environment-integrations/vizdoom/) [integrations](https://www.samplefactory.dev/09-environment-integrations/dmlab/) with tuned parameters and trained models\n",
+ "\n",
+ "All of the above policies are available on the 🤗 hub. Search for the tag [sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)\n",
+ "\n",
+ "### How sample-factory works\n",
+ "\n",
+ "Sample-factory is one of the **most highly optimized RL implementations available to the community**. \n",
+ "\n",
+ "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**. \n",
+ "\n",
+ "The *workers* **communicate through shared memory, which lowers the communication cost between processes**. \n",
+ "\n",
+ "The *rollout workers* interact with the environment and send observations to the *inference workers*. \n",
+ "\n",
+ "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**. \n",
+ "\n",
+ "After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Key features\n",
+ "\n",
+ "- Highly optimized algorithm [architecture](https://www.samplefactory.dev/06-architecture/overview/) for maximum learning throughput\n",
+ "- [Synchronous and asynchronous](https://www.samplefactory.dev/07-advanced-topics/sync-async/) training regimes\n",
+ "- [Serial (single-process) mode](https://www.samplefactory.dev/07-advanced-topics/serial-mode/) for easy debugging\n",
+ "- Optimal performance in both CPU-based and [GPU-accelerated environments](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)\n",
+ "- Single- & multi-agent training, self-play, supports [training multiple policies](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/) at once on one or many GPUs\n",
+ "- Population-Based Training ([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))\n",
+ "- Discrete, continuous, hybrid action spaces\n",
+ "- Vector-based, image-based, dictionary observation spaces\n",
+ "- Automatically creates a model architecture by parsing action/observation space specification. Supports [custom model architectures](https://www.samplefactory.dev/03-customization/custom-models/)\n",
+ "- Designed to be imported into other projects, [custom environments](https://www.samplefactory.dev/03-customization/custom-environments/) are first-class citizens\n",
+ "- Detailed [WandB and Tensorboard summaries](https://www.samplefactory.dev/05-monitoring/metrics-reference/), [custom metrics](https://www.samplefactory.dev/05-monitoring/custom-metrics/)\n",
+ "- [HuggingFace 🤗 integration](https://www.samplefactory.dev/10-huggingface/huggingface/) (upload trained models and metrics to the Hub)\n",
+ "- [Multiple](https://www.samplefactory.dev/09-environment-integrations/mujoco/) [example](https://www.samplefactory.dev/09-environment-integrations/atari/) [environment](https://www.samplefactory.dev/09-environment-integrations/vizdoom/) [integrations](https://www.samplefactory.dev/09-environment-integrations/dmlab/) with tuned parameters and trained models\n",
+ "\n",
+ "All of the above policies are available on the 🤗 hub. Search for the tag [sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)\n",
+ "\n",
+ "### How sample-factory works\n",
+ "\n",
+ "Sample-factory is one of the **most highly optimized RL implementations available to the community**. \n",
+ "\n",
+ "It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**. \n",
+ "\n",
+ "The *workers* **communicate through shared memory, which lowers the communication cost between processes**. \n",
+ "\n",
+ "The *rollout workers* interact with the environment and send observations to the *inference workers*. \n",
+ "\n",
+ "The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**. \n",
+ "\n",
+ "After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nB68Eb9UgC94"
+ },
+ "source": [
+ "### Actor Critic models in Sample-factory\n",
+ "\n",
+ "Actor Critic models in Sample Factory are composed of three components:\n",
+ "\n",
+ "- **Encoder** - Process input observations (images, vectors) and map them to a vector. This is the part of the model you will most likely want to customize.\n",
+ "- **Core** - Intergrate vectors from one or more encoders, can optionally include a single- or multi-layer LSTM/GRU in a memory-based agent.\n",
+ "- **Decoder** - Apply additional layers to the output of the model core before computing the policy and value outputs.\n",
+ "\n",
+ "The library has been designed to automatically support any observation and action spaces. Users can easily add their custom models. You can find out more in the [documentation](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ez5UhUtYcWXF"
+ },
+ "source": [
+ "## ViZDoom\n",
+ "\n",
+ "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**. \n",
+ "\n",
+ "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland. \n",
+ "\n",
+ "The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.\n",
+ "\n",
+ "The library includes feature such as:\n",
+ "\n",
+ "- Multi-platform (Linux, macOS, Windows),\n",
+ "- API for Python and C++,\n",
+ "- [OpenAI Gym](https://www.gymlibrary.dev/) environment wrappers\n",
+ "- Easy-to-create custom scenarios (visual editors, scripting language, and examples available),\n",
+ "- Async and sync single-player and multiplayer modes,\n",
+ "- Lightweight (few MBs) and fast (up to 7000 fps in sync mode, single-threaded),\n",
+ "- Customizable resolution and rendering parameters,\n",
+ "- Access to the depth buffer (3D vision),\n",
+ "- Automatic labeling of game objects visible in the frame,\n",
+ "- Access to the audio buffer\n",
+ "- Access to the list of actors/objects and map geometry,\n",
+ "- Off-screen rendering and episode recording,\n",
+ "- Time scaling in async mode."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wAMwza0d5QVj"
+ },
+ "source": [
+ "## We first need to install some dependencies that are required for the ViZDoom environment\n",
+ "\n",
+ "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux. \n",
+ "\n",
+ "If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RJMxkaldwIVx"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "%%bash\n",
+ "# Install ViZDoom deps from \n",
+ "# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux\n",
+ "\n",
+ "apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \\\n",
+ "nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \\\n",
+ "libopenal-dev timidity libwildmidi-dev unzip ffmpeg\n",
+ "\n",
+ "# Boost libraries\n",
+ "apt-get install libboost-all-dev\n",
+ "\n",
+ "# Lua binding dependencies\n",
+ "apt-get install liblua5.1-dev"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JT4att2c57MW"
+ },
+ "source": [
+ "## Then we can install Sample Factory and ViZDoom\n",
+ "- This can take 7min"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bbqfPZnIsvA6"
+ },
+ "outputs": [],
+ "source": [
+ "# install python libraries\n",
+ "# thanks toinsson\n",
+ "!pip install sample-factory==2.0.2\n",
+ "!pip install faster-fifo==1.4.2\n",
+ "!pip install vizdoom"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1jizouGpghUZ"
+ },
+ "source": [
+ "## Setting up the Doom Environment in sample-factory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bCgZbeiavcDU"
+ },
+ "outputs": [],
+ "source": [
+ "import functools\n",
+ "\n",
+ "from sample_factory.algo.utils.context import global_model_factory\n",
+ "from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args\n",
+ "from sample_factory.envs.env_utils import register_env\n",
+ "from sample_factory.train import run_rl\n",
+ "\n",
+ "from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder\n",
+ "from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults\n",
+ "from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec\n",
+ "\n",
+ "\n",
+ "# Registers all the ViZDoom environments\n",
+ "def register_vizdoom_envs():\n",
+ " for env_spec in DOOM_ENVS:\n",
+ " make_env_func = functools.partial(make_doom_env_from_spec, env_spec)\n",
+ " register_env(env_spec.name, make_env_func)\n",
+ "\n",
+ "# Sample Factory allows the registration of a custom Neural Network architecture\n",
+ "# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details\n",
+ "def register_vizdoom_models():\n",
+ " global_model_factory().register_encoder_factory(make_vizdoom_encoder)\n",
+ "\n",
+ "\n",
+ "def register_vizdoom_components():\n",
+ " register_vizdoom_envs()\n",
+ " register_vizdoom_models()\n",
+ "\n",
+ "# parse the command line args and create a config\n",
+ "def parse_vizdoom_cfg(argv=None, evaluation=False):\n",
+ " parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)\n",
+ " # parameters specific to Doom envs\n",
+ " add_doom_env_args(parser)\n",
+ " # override Doom default values for algo parameters\n",
+ " doom_override_defaults(parser)\n",
+ " # second parsing pass yields the final configuration\n",
+ " final_cfg = parse_full_cfg(parser, argv)\n",
+ " return final_cfg"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "sgRy6wnrgnij"
+ },
+ "source": [
+ "Now that the setup if complete, we can train the agent. We have chosen here to learn a ViZDoom task called `Health Gathering Supreme`.\n",
+ "\n",
+ "### The scenario: Health Gathering Supreme\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nB68Eb9UgC94"
+ },
+ "source": [
+ "### Actor Critic models in Sample-factory\n",
+ "\n",
+ "Actor Critic models in Sample Factory are composed of three components:\n",
+ "\n",
+ "- **Encoder** - Process input observations (images, vectors) and map them to a vector. This is the part of the model you will most likely want to customize.\n",
+ "- **Core** - Intergrate vectors from one or more encoders, can optionally include a single- or multi-layer LSTM/GRU in a memory-based agent.\n",
+ "- **Decoder** - Apply additional layers to the output of the model core before computing the policy and value outputs.\n",
+ "\n",
+ "The library has been designed to automatically support any observation and action spaces. Users can easily add their custom models. You can find out more in the [documentation](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ez5UhUtYcWXF"
+ },
+ "source": [
+ "## ViZDoom\n",
+ "\n",
+ "[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**. \n",
+ "\n",
+ "The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland. \n",
+ "\n",
+ "The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.\n",
+ "\n",
+ "The library includes feature such as:\n",
+ "\n",
+ "- Multi-platform (Linux, macOS, Windows),\n",
+ "- API for Python and C++,\n",
+ "- [OpenAI Gym](https://www.gymlibrary.dev/) environment wrappers\n",
+ "- Easy-to-create custom scenarios (visual editors, scripting language, and examples available),\n",
+ "- Async and sync single-player and multiplayer modes,\n",
+ "- Lightweight (few MBs) and fast (up to 7000 fps in sync mode, single-threaded),\n",
+ "- Customizable resolution and rendering parameters,\n",
+ "- Access to the depth buffer (3D vision),\n",
+ "- Automatic labeling of game objects visible in the frame,\n",
+ "- Access to the audio buffer\n",
+ "- Access to the list of actors/objects and map geometry,\n",
+ "- Off-screen rendering and episode recording,\n",
+ "- Time scaling in async mode."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wAMwza0d5QVj"
+ },
+ "source": [
+ "## We first need to install some dependencies that are required for the ViZDoom environment\n",
+ "\n",
+ "Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux. \n",
+ "\n",
+ "If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RJMxkaldwIVx"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "%%bash\n",
+ "# Install ViZDoom deps from \n",
+ "# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux\n",
+ "\n",
+ "apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \\\n",
+ "nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \\\n",
+ "libopenal-dev timidity libwildmidi-dev unzip ffmpeg\n",
+ "\n",
+ "# Boost libraries\n",
+ "apt-get install libboost-all-dev\n",
+ "\n",
+ "# Lua binding dependencies\n",
+ "apt-get install liblua5.1-dev"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JT4att2c57MW"
+ },
+ "source": [
+ "## Then we can install Sample Factory and ViZDoom\n",
+ "- This can take 7min"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bbqfPZnIsvA6"
+ },
+ "outputs": [],
+ "source": [
+ "# install python libraries\n",
+ "# thanks toinsson\n",
+ "!pip install sample-factory==2.0.2\n",
+ "!pip install faster-fifo==1.4.2\n",
+ "!pip install vizdoom"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1jizouGpghUZ"
+ },
+ "source": [
+ "## Setting up the Doom Environment in sample-factory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bCgZbeiavcDU"
+ },
+ "outputs": [],
+ "source": [
+ "import functools\n",
+ "\n",
+ "from sample_factory.algo.utils.context import global_model_factory\n",
+ "from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args\n",
+ "from sample_factory.envs.env_utils import register_env\n",
+ "from sample_factory.train import run_rl\n",
+ "\n",
+ "from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder\n",
+ "from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults\n",
+ "from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec\n",
+ "\n",
+ "\n",
+ "# Registers all the ViZDoom environments\n",
+ "def register_vizdoom_envs():\n",
+ " for env_spec in DOOM_ENVS:\n",
+ " make_env_func = functools.partial(make_doom_env_from_spec, env_spec)\n",
+ " register_env(env_spec.name, make_env_func)\n",
+ "\n",
+ "# Sample Factory allows the registration of a custom Neural Network architecture\n",
+ "# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details\n",
+ "def register_vizdoom_models():\n",
+ " global_model_factory().register_encoder_factory(make_vizdoom_encoder)\n",
+ "\n",
+ "\n",
+ "def register_vizdoom_components():\n",
+ " register_vizdoom_envs()\n",
+ " register_vizdoom_models()\n",
+ "\n",
+ "# parse the command line args and create a config\n",
+ "def parse_vizdoom_cfg(argv=None, evaluation=False):\n",
+ " parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)\n",
+ " # parameters specific to Doom envs\n",
+ " add_doom_env_args(parser)\n",
+ " # override Doom default values for algo parameters\n",
+ " doom_override_defaults(parser)\n",
+ " # second parsing pass yields the final configuration\n",
+ " final_cfg = parse_full_cfg(parser, argv)\n",
+ " return final_cfg"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "sgRy6wnrgnij"
+ },
+ "source": [
+ "Now that the setup if complete, we can train the agent. We have chosen here to learn a ViZDoom task called `Health Gathering Supreme`.\n",
+ "\n",
+ "### The scenario: Health Gathering Supreme\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "The objective of this scenario is to **teach the agent how to survive without knowing what makes him survive**. Agent know only that **life is precious** and death is bad so **it must learn what prolongs his existence and that his health is connected with it**.\n",
+ "\n",
+ "Map is a rectangle containing walls and with a green, acidic floor which **hurts the player periodically**. Initially there are some medkits spread uniformly over the map. A new medkit falls from the skies every now and then. **Medkits heal some portions of player's health** - to survive agent needs to pick them up. Episode finishes after player's death or on timeout.\n",
+ "\n",
+ "Further configuration:\n",
+ "- Living_reward = 1\n",
+ "- 3 available buttons: turn left, turn right, move forward\n",
+ "- 1 available game variable: HEALTH\n",
+ "- death penalty = 100\n",
+ "\n",
+ "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios). \n",
+ "\n",
+ "There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "siHZZ34DiZEp"
+ },
+ "source": [
+ "## Training the agent\n",
+ "- We're going to train the agent for 4000000 steps it will take approximately 20min"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "y_TeicMvyKHP"
+ },
+ "outputs": [],
+ "source": [
+ "## Start the training, this should take around 15 minutes\n",
+ "register_vizdoom_components()\n",
+ "\n",
+ "# The scenario we train on today is health gathering\n",
+ "# other scenarios include \"doom_basic\", \"doom_two_colors_easy\", \"doom_dm\", \"doom_dwango5\", \"doom_my_way_home\", \"doom_deadly_corridor\", \"doom_defend_the_center\", \"doom_defend_the_line\"\n",
+ "env = \"doom_health_gathering_supreme\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=8\", \"--num_envs_per_worker=4\", \"--train_for_env_steps=4000000\"])\n",
+ "\n",
+ "status = run_rl(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5L0nBS9e_jqC"
+ },
+ "source": [
+ "## Let's take a look at the performance of the trained policy and output a video of the agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "MGSA4Kg5_i0j"
+ },
+ "outputs": [],
+ "source": [
+ "from sample_factory.enjoy import enjoy\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lj5L1x0WLxwB"
+ },
+ "source": [
+ "## Now lets visualize the performance of the agent"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WsXhBY7JNOdJ"
+ },
+ "outputs": [],
+ "source": [
+ "from base64 import b64encode\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "mp4 = open('/content/train_dir/default_experiment/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The agent has learned something, but its performance could be better. We would clearly need to train for longer. But let's upload this model to the Hub."
+ ],
+ "metadata": {
+ "id": "2A4pf_1VwPqR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CSQVWF0kNuy9"
+ },
+ "source": [
+ "## Now lets upload your checkpoint and video to the Hugging Face Hub\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GoQm_jYSOts0"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "sEawW_i0OvJV"
+ },
+ "outputs": [],
+ "source": [
+ "from sample_factory.enjoy import enjoy\n",
+ "\n",
+ "hf_username = \"ThomasSimonini\" # insert your HuggingFace username here\n",
+ "\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\", \"--max_num_frames=100000\", \"--push_to_hub\", f\"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Let's load another model\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "9PzeXx-qxVvw"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mHZAWSgL5F7P"
+ },
+ "source": [
+ "This agent's performance was good, but can do better! Let's download and visualize an agent trained for 10B timesteps from the hub."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Ud6DwAUl5S-l"
+ },
+ "outputs": [],
+ "source": [
+ "#download the agent from the hub\n",
+ "!python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qoUJhL6x6sY5"
+ },
+ "outputs": [],
+ "source": [
+ "!ls train_dir/doom_health_gathering_supreme_2222"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lZskc8LG8qr8"
+ },
+ "outputs": [],
+ "source": [
+ "env = \"doom_health_gathering_supreme\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\", \"--experiment=doom_health_gathering_supreme_2222\", \"--train_dir=train_dir\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BtzXBoj65Wmq"
+ },
+ "outputs": [],
+ "source": [
+ "mp4 = open('/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Some additional challenges 🏆: Doom Deathmatch\n",
+ "\n",
+ "Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**. \n",
+ "\n",
+ "Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance."
+ ],
+ "metadata": {
+ "id": "ie5YWC3NyKO8"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fq3WFeus81iI"
+ },
+ "outputs": [],
+ "source": [
+ "# Download the agent from the hub\n",
+ "!python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Given the agent plays for a long time the video generation can take **10 minutes**."
+ ],
+ "metadata": {
+ "id": "7AX_LwxR2FQ0"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "0hq6XL__85Bv"
+ },
+ "outputs": [],
+ "source": [
+ "\n",
+ "from sample_factory.enjoy import enjoy\n",
+ "register_vizdoom_components()\n",
+ "env = \"doom_deathmatch_bots\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=1\", \"--experiment=doom_deathmatch_bots_2222\", \"--train_dir=train_dir\"], evaluation=True)\n",
+ "status = enjoy(cfg)\n",
+ "mp4 = open('/content/train_dir/doom_deathmatch_bots_2222/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "You **can try to train your agent in this environment** using the code above, but not on colab.\n",
+ "**Good luck 🤞**"
+ ],
+ "metadata": {
+ "id": "N6mEC-4zyihx"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "If you prefer an easier scenario, **why not try training in another ViZDoom scenario such as `doom_deadly_corridor` or `doom_defend_the_center`.**\n",
+ "\n",
+ "\n",
+ "\n",
+ "---\n",
+ "\n",
+ "\n",
+ "This concludes the last unit. But we are not finished yet! 🤗 The following **bonus section include some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.\n",
+ "\n",
+ "## Keep learning, stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "YnDAngN6zeeI"
+ }
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": [],
+ "collapsed_sections": [
+ "PU4FVzaoM6fC",
+ "nB68Eb9UgC94",
+ "ez5UhUtYcWXF",
+ "sgRy6wnrgnij"
+ ],
+ "private_outputs": true,
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/unit1/README.md b/unit1/README.md
index 32cbb03..a6d2acb 100644
--- a/unit1/README.md
+++ b/unit1/README.md
@@ -1,4 +1,8 @@
-# Unit 1: Introduction to Deep Reinforcement Learning 🚀
+# DEPRECIATED THE NEW UNIT 1 IS HERE: https://huggingface.co/deep-rl-course/unit1/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit1/introduction
+
+
+# Unit 1: Introduction to Deep Reinforcement Learning 🚀 (DEPRECIATED)

diff --git a/unit1/unit1.ipynb b/unit1/unit1.ipynb
index a333c08..49eb1b0 100644
--- a/unit1/unit1.ipynb
+++ b/unit1/unit1.ipynb
@@ -16,6 +16,11 @@
"id": "njb_ProuHiOe"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 1 IS HERE: https://huggingface.co/deep-rl-course/unit1/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit1/introduction",
+ "\n",
+ "\n",
"# Unit 1: Train your first Deep Reinforcement Learning Agent 🚀\n",
"\n",
"\n",
diff --git a/unit2/README.md b/unit2/README.md
index 677e655..ff6682d 100644
--- a/unit2/README.md
+++ b/unit2/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED UNIT, THE NEW UNIT 2 IS HERE: https://huggingface.co/deep-rl-course/unit2/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit2/introduction"
+
+
# Unit 2: Introduction to Q-Learning
In this Unit, we're going to dive deeper into one of the Reinforcement Learning methods: value-based methods and **study our first RL algorithm: Q-Learning**.
@@ -70,7 +74,7 @@ You can work directly **with the colab notebook, which allows you not to have to
- To dive deeper on Monte Carlo and Temporal Difference Learning:
- [Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?](https://stats.stackexchange.com/questions/355820/why-do-temporal-difference-td-methods-have-lower-variance-than-monte-carlo-met)
- [When are Monte Carlo methods preferred over temporal difference ones?](https://stats.stackexchange.com/questions/336974/when-are-monte-carlo-methods-preferred-over-temporal-difference-ones)
-
+
## How to make the most of this course
To make the most of the course, my advice is to:
diff --git a/unit2/unit2.ipynb b/unit2/unit2.ipynb
index 803db1c..c6119cb 100644
--- a/unit2/unit2.ipynb
+++ b/unit2/unit2.ipynb
@@ -16,6 +16,11 @@
"id": "njb_ProuHiOe"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 2 IS HERE: https://huggingface.co/deep-rl-course/unit2/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit2/introduction",
+ "\n",
+ "\n",
"# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕\n",
"\n",
"In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations\n",
diff --git a/unit3/README.md b/unit3/README.md
index 07f17c3..897d8f5 100644
--- a/unit3/README.md
+++ b/unit3/README.md
@@ -1,6 +1,10 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit3/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit3/introduction
+
+
# Unit 3: Deep Q-Learning with Atari Games 👾
-In this Unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning.
+In this Unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning.
And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
diff --git a/unit3/unit3.ipynb b/unit3/unit3.ipynb
index 9657cce..fead1ad 100644
--- a/unit3/unit3.ipynb
+++ b/unit3/unit3.ipynb
@@ -16,6 +16,11 @@
"id": "k7xBVPzoXxOg"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 3 IS HERE: https://huggingface.co/deep-rl-course/unit3/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit3/introduction",
+ "\n",
+ "\n",
"# Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 Zoo\n",
"\n",
"In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.\n",
diff --git a/unit4/README.md b/unit4/README.md
index 2de68c8..9bf4fca 100644
--- a/unit4/README.md
+++ b/unit4/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit5/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit5/introduction
+
+
# Unit 4: An Introduction to Unity MLAgents with Hugging Face 🤗

diff --git a/unit4/unit4.ipynb b/unit4/unit4.ipynb
index 79e53aa..9232ad6 100644
--- a/unit4/unit4.ipynb
+++ b/unit4/unit4.ipynb
@@ -16,6 +16,11 @@
"id": "2D3NL_e4crQv"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit5/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit5/introduction",
+ "\n",
+ "\n",
"# Unit 4: Let's learn about Unity ML-Agents with Hugging Face 🤗\n",
"\n"
]
@@ -561,4 +566,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/unit5/README.md b/unit5/README.md
index 2b50dbe..757f089 100644
--- a/unit5/README.md
+++ b/unit5/README.md
@@ -1,6 +1,10 @@
-# Unit 5: Policy Gradient with PyTorch
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit4/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit4/introduction
-In this Unit, **we'll study Policy Gradient Methods**.
+
+# Unit 5: Policy Gradient with PyTorch
+
+In this Unit, **we'll study Policy Gradient Methods**.
And we'll **implement Reinforce (a policy gradient method) from scratch using PyTorch**. Before testing its robustness using CartPole-v1, PixelCopter, and Pong.
diff --git a/unit5/unit5.ipynb b/unit5/unit5.ipynb
index b23e2e5..85de7b5 100644
--- a/unit5/unit5.ipynb
+++ b/unit5/unit5.ipynb
@@ -16,6 +16,11 @@
"id": "CjRWziAVU2lZ"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit4/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit4/introduction",
+ "\n",
+ "\n",
"# Unit 5: Code your first Deep Reinforcement Learning Algorithm with PyTorch: Reinforce. And test its robustness 💪\n",
"In this notebook, you'll code your first Deep Reinforcement Learning algorithm from scratch: Reinforce (also called Monte Carlo Policy Gradient).\n",
"\n",
diff --git a/unit7/README.md b/unit7/README.md
index ded4fdc..d09bbdb 100644
--- a/unit7/README.md
+++ b/unit7/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit6/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit6/introduction
+
+
# Unit 7: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖
One of the major industries that use Reinforcement Learning is robotics. Unfortunately, **having access to robot equipment is very expensive**. Fortunately, some simulations exist to train Robots:
@@ -32,7 +36,7 @@ Thanks to a leaderboard, you'll be able to compare your results with other class
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
## Additional readings 📚
-- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
- [Foundations of Deep RL Series, L3 Policy Gradients and Advantage Estimation by Pieter Abbeel](https://youtu.be/AKbX1Zvo7r8)
diff --git a/unit7/unit7.ipynb b/unit7/unit7.ipynb
index 31e9f2e..f87fa02 100644
--- a/unit7/unit7.ipynb
+++ b/unit7/unit7.ipynb
@@ -34,6 +34,11 @@
{
"cell_type": "markdown",
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit6/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit6/introduction",
+ "\n",
+ "\n",
"# Unit 7: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖\n",
"In this small notebook you'll learn to use A2C with PyBullet. And train an agent to walk. More precisely a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
"\n",
@@ -533,4 +538,4 @@
}
}
]
-}
\ No newline at end of file
+}
diff --git a/unit8/README.md b/unit8/README.md
index 61664da..1280536 100644
--- a/unit8/README.md
+++ b/unit8/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit8/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit8/introduction
+
+
# Unit 8: Proximal Policy Optimization (PPO) with PyTorch
Today we'll learn about Proximal Policy Optimization (PPO), an architecture that improves our agent's training stability by avoiding too large policy updates. To do that, we use a ratio that will indicates the difference between our current and old policy and clip this ratio from a specific range $[1 - \epsilon, 1 + \epsilon]$. Doing this will ensure that our policy update will not be too large and that the training is more stable.
@@ -29,7 +33,7 @@ Thanks to a leaderboard, you'll be able to compare your results with other class
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
## Additional readings 📚
-- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
diff --git a/unit8/unit8.ipynb b/unit8/unit8.ipynb
index 2bbd7e1..5a177dd 100644
--- a/unit8/unit8.ipynb
+++ b/unit8/unit8.ipynb
@@ -16,6 +16,11 @@
"id": "-cf5-oDPjwf8"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit8/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit8/introduction",
+ "\n",
+ "\n",
"# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
"\n",
"In this unit, you'll learn to **code your PPO agent from scratch with PyTorch**.\n",
diff --git a/unit9/README.md b/unit9/README.md
index 051fe94..7770e3c 100644
--- a/unit9/README.md
+++ b/unit9/README.md
@@ -1,8 +1,13 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unitbonus3/decision-transformers
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unitbonus3/decision-transformers
+
+
+
# Unit 9: Decision Transformers and offline Reinforcement Learning 🤖

-In this Unit, you'll learn what is Decision Transformer and Offline Reinforcement Learning. And then, you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
+In this Unit, you'll learn what is Decision Transformer and Offline Reinforcement Learning. And then, you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
This course is **self-paced**, you can start whenever you want.
@@ -18,12 +23,12 @@ Here are the steps for this Unit:
2️⃣ 👩💻 Then dive on the first hands-on.
👩💻 The hands-on 👉 [](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing)
-
+
3️⃣ 📖 Read [Train your first Decision Transformer](https://huggingface.co/blog/train-decision-transformers)
-4️⃣ 👩💻 Then dive on the hands-on, where **you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run**.
+4️⃣ 👩💻 Then dive on the hands-on, where **you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run**.
👩💻 The hands-on 👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb
-
+
## How to make the most of this course
To make the most of the course, my advice is to:
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 99b3d94..040e10a 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -178,6 +178,52 @@
title: Conclusion
- local: unit7/additional-readings
title: Additional Readings
+- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ sections:
+ - local: unit8/introduction
+ title: Introduction
+ - local: unit8/intuition-behind-ppo
+ title: The intuition behind PPO
+ - local: unit8/clipped-surrogate-objective
+ title: Introducing the Clipped Surrogate Objective Function
+ - local: unit8/visualize
+ title: Visualize the Clipped Surrogate Objective Function
+ - local: unit8/hands-on-cleanrl
+ title: PPO with CleanRL
+ - local: unit8/conclusion
+ title: Conclusion
+ - local: unit8/additional-readings
+ title: Additional Readings
+- title: Unit 8. Part 2 Proximal Policy Optimization (PPO) with Doom
+ sections:
+ - local: unit8/introduction-sf
+ title: Introduction
+ - local: unit8/hands-on-sf
+ title: PPO with Sample Factory and Doom
+ - local: unit8/conclusion-sf
+ title: Conclusion
+- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ sections:
+ - local: unitbonus3/introduction
+ title: Introduction
+ - local: unitbonus3/model-based
+ title: Model-Based Reinforcement Learning
+ - local: unitbonus3/offline-online
+ title: Offline vs. Online Reinforcement Learning
+ - local: unitbonus3/rlhf
+ title: Reinforcement Learning from Human Feedback
+ - local: unitbonus3/decision-transformers
+ title: Decision Transformers and Offline RL
+ - local: unitbonus3/language-models
+ title: Language models in RL
+ - local: unitbonus3/curriculum-learning
+ title: (Automatic) Curriculum Learning for RL
+ - local: unitbonus3/envs-to-try
+ title: Interesting environments to try
+ - local: unitbonus3/godotrl
+ title: An Introduction to Godot RL
+ - local: unitbonus3/rl-documentation
+ title: Brief introduction to RL documentation
- title: Certification and congratulations
sections:
- local: communication/conclusion
diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index 9904168..e3bda2c 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -9,11 +9,11 @@ Discord is a free chat platform. If you've used Slack, **it's quite similar**. T
Starting in Discord can be a bit intimidating, so let me take you through it.
-When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**.
+When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**.
\n",
+ "\n",
+ "\n",
+ "\n",
+ "The objective of this scenario is to **teach the agent how to survive without knowing what makes him survive**. Agent know only that **life is precious** and death is bad so **it must learn what prolongs his existence and that his health is connected with it**.\n",
+ "\n",
+ "Map is a rectangle containing walls and with a green, acidic floor which **hurts the player periodically**. Initially there are some medkits spread uniformly over the map. A new medkit falls from the skies every now and then. **Medkits heal some portions of player's health** - to survive agent needs to pick them up. Episode finishes after player's death or on timeout.\n",
+ "\n",
+ "Further configuration:\n",
+ "- Living_reward = 1\n",
+ "- 3 available buttons: turn left, turn right, move forward\n",
+ "- 1 available game variable: HEALTH\n",
+ "- death penalty = 100\n",
+ "\n",
+ "You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios). \n",
+ "\n",
+ "There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "siHZZ34DiZEp"
+ },
+ "source": [
+ "## Training the agent\n",
+ "- We're going to train the agent for 4000000 steps it will take approximately 20min"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "y_TeicMvyKHP"
+ },
+ "outputs": [],
+ "source": [
+ "## Start the training, this should take around 15 minutes\n",
+ "register_vizdoom_components()\n",
+ "\n",
+ "# The scenario we train on today is health gathering\n",
+ "# other scenarios include \"doom_basic\", \"doom_two_colors_easy\", \"doom_dm\", \"doom_dwango5\", \"doom_my_way_home\", \"doom_deadly_corridor\", \"doom_defend_the_center\", \"doom_defend_the_line\"\n",
+ "env = \"doom_health_gathering_supreme\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=8\", \"--num_envs_per_worker=4\", \"--train_for_env_steps=4000000\"])\n",
+ "\n",
+ "status = run_rl(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5L0nBS9e_jqC"
+ },
+ "source": [
+ "## Let's take a look at the performance of the trained policy and output a video of the agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "MGSA4Kg5_i0j"
+ },
+ "outputs": [],
+ "source": [
+ "from sample_factory.enjoy import enjoy\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lj5L1x0WLxwB"
+ },
+ "source": [
+ "## Now lets visualize the performance of the agent"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WsXhBY7JNOdJ"
+ },
+ "outputs": [],
+ "source": [
+ "from base64 import b64encode\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "mp4 = open('/content/train_dir/default_experiment/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The agent has learned something, but its performance could be better. We would clearly need to train for longer. But let's upload this model to the Hub."
+ ],
+ "metadata": {
+ "id": "2A4pf_1VwPqR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CSQVWF0kNuy9"
+ },
+ "source": [
+ "## Now lets upload your checkpoint and video to the Hugging Face Hub\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GoQm_jYSOts0"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "sEawW_i0OvJV"
+ },
+ "outputs": [],
+ "source": [
+ "from sample_factory.enjoy import enjoy\n",
+ "\n",
+ "hf_username = \"ThomasSimonini\" # insert your HuggingFace username here\n",
+ "\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\", \"--max_num_frames=100000\", \"--push_to_hub\", f\"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Let's load another model\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "9PzeXx-qxVvw"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mHZAWSgL5F7P"
+ },
+ "source": [
+ "This agent's performance was good, but can do better! Let's download and visualize an agent trained for 10B timesteps from the hub."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Ud6DwAUl5S-l"
+ },
+ "outputs": [],
+ "source": [
+ "#download the agent from the hub\n",
+ "!python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qoUJhL6x6sY5"
+ },
+ "outputs": [],
+ "source": [
+ "!ls train_dir/doom_health_gathering_supreme_2222"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lZskc8LG8qr8"
+ },
+ "outputs": [],
+ "source": [
+ "env = \"doom_health_gathering_supreme\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=10\", \"--experiment=doom_health_gathering_supreme_2222\", \"--train_dir=train_dir\"], evaluation=True)\n",
+ "status = enjoy(cfg)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BtzXBoj65Wmq"
+ },
+ "outputs": [],
+ "source": [
+ "mp4 = open('/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Some additional challenges 🏆: Doom Deathmatch\n",
+ "\n",
+ "Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**. \n",
+ "\n",
+ "Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance."
+ ],
+ "metadata": {
+ "id": "ie5YWC3NyKO8"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fq3WFeus81iI"
+ },
+ "outputs": [],
+ "source": [
+ "# Download the agent from the hub\n",
+ "!python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Given the agent plays for a long time the video generation can take **10 minutes**."
+ ],
+ "metadata": {
+ "id": "7AX_LwxR2FQ0"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "0hq6XL__85Bv"
+ },
+ "outputs": [],
+ "source": [
+ "\n",
+ "from sample_factory.enjoy import enjoy\n",
+ "register_vizdoom_components()\n",
+ "env = \"doom_deathmatch_bots\"\n",
+ "cfg = parse_vizdoom_cfg(argv=[f\"--env={env}\", \"--num_workers=1\", \"--save_video\", \"--no_render\", \"--max_num_episodes=1\", \"--experiment=doom_deathmatch_bots_2222\", \"--train_dir=train_dir\"], evaluation=True)\n",
+ "status = enjoy(cfg)\n",
+ "mp4 = open('/content/train_dir/doom_deathmatch_bots_2222/replay.mp4','rb').read()\n",
+ "data_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\" % data_url)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "You **can try to train your agent in this environment** using the code above, but not on colab.\n",
+ "**Good luck 🤞**"
+ ],
+ "metadata": {
+ "id": "N6mEC-4zyihx"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "If you prefer an easier scenario, **why not try training in another ViZDoom scenario such as `doom_deadly_corridor` or `doom_defend_the_center`.**\n",
+ "\n",
+ "\n",
+ "\n",
+ "---\n",
+ "\n",
+ "\n",
+ "This concludes the last unit. But we are not finished yet! 🤗 The following **bonus section include some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.\n",
+ "\n",
+ "## Keep learning, stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "YnDAngN6zeeI"
+ }
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": [],
+ "collapsed_sections": [
+ "PU4FVzaoM6fC",
+ "nB68Eb9UgC94",
+ "ez5UhUtYcWXF",
+ "sgRy6wnrgnij"
+ ],
+ "private_outputs": true,
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/unit1/README.md b/unit1/README.md
index 32cbb03..a6d2acb 100644
--- a/unit1/README.md
+++ b/unit1/README.md
@@ -1,4 +1,8 @@
-# Unit 1: Introduction to Deep Reinforcement Learning 🚀
+# DEPRECIATED THE NEW UNIT 1 IS HERE: https://huggingface.co/deep-rl-course/unit1/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit1/introduction
+
+
+# Unit 1: Introduction to Deep Reinforcement Learning 🚀 (DEPRECIATED)

diff --git a/unit1/unit1.ipynb b/unit1/unit1.ipynb
index a333c08..49eb1b0 100644
--- a/unit1/unit1.ipynb
+++ b/unit1/unit1.ipynb
@@ -16,6 +16,11 @@
"id": "njb_ProuHiOe"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 1 IS HERE: https://huggingface.co/deep-rl-course/unit1/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit1/introduction",
+ "\n",
+ "\n",
"# Unit 1: Train your first Deep Reinforcement Learning Agent 🚀\n",
"\n",
"\n",
diff --git a/unit2/README.md b/unit2/README.md
index 677e655..ff6682d 100644
--- a/unit2/README.md
+++ b/unit2/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED UNIT, THE NEW UNIT 2 IS HERE: https://huggingface.co/deep-rl-course/unit2/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit2/introduction"
+
+
# Unit 2: Introduction to Q-Learning
In this Unit, we're going to dive deeper into one of the Reinforcement Learning methods: value-based methods and **study our first RL algorithm: Q-Learning**.
@@ -70,7 +74,7 @@ You can work directly **with the colab notebook, which allows you not to have to
- To dive deeper on Monte Carlo and Temporal Difference Learning:
- [Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?](https://stats.stackexchange.com/questions/355820/why-do-temporal-difference-td-methods-have-lower-variance-than-monte-carlo-met)
- [When are Monte Carlo methods preferred over temporal difference ones?](https://stats.stackexchange.com/questions/336974/when-are-monte-carlo-methods-preferred-over-temporal-difference-ones)
-
+
## How to make the most of this course
To make the most of the course, my advice is to:
diff --git a/unit2/unit2.ipynb b/unit2/unit2.ipynb
index 803db1c..c6119cb 100644
--- a/unit2/unit2.ipynb
+++ b/unit2/unit2.ipynb
@@ -16,6 +16,11 @@
"id": "njb_ProuHiOe"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 2 IS HERE: https://huggingface.co/deep-rl-course/unit2/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit2/introduction",
+ "\n",
+ "\n",
"# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕\n",
"\n",
"In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations\n",
diff --git a/unit3/README.md b/unit3/README.md
index 07f17c3..897d8f5 100644
--- a/unit3/README.md
+++ b/unit3/README.md
@@ -1,6 +1,10 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit3/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit3/introduction
+
+
# Unit 3: Deep Q-Learning with Atari Games 👾
-In this Unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning.
+In this Unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning.
And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
diff --git a/unit3/unit3.ipynb b/unit3/unit3.ipynb
index 9657cce..fead1ad 100644
--- a/unit3/unit3.ipynb
+++ b/unit3/unit3.ipynb
@@ -16,6 +16,11 @@
"id": "k7xBVPzoXxOg"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW UNIT 3 IS HERE: https://huggingface.co/deep-rl-course/unit3/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit3/introduction",
+ "\n",
+ "\n",
"# Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 Zoo\n",
"\n",
"In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.\n",
diff --git a/unit4/README.md b/unit4/README.md
index 2de68c8..9bf4fca 100644
--- a/unit4/README.md
+++ b/unit4/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit5/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit5/introduction
+
+
# Unit 4: An Introduction to Unity MLAgents with Hugging Face 🤗

diff --git a/unit4/unit4.ipynb b/unit4/unit4.ipynb
index 79e53aa..9232ad6 100644
--- a/unit4/unit4.ipynb
+++ b/unit4/unit4.ipynb
@@ -16,6 +16,11 @@
"id": "2D3NL_e4crQv"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit5/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit5/introduction",
+ "\n",
+ "\n",
"# Unit 4: Let's learn about Unity ML-Agents with Hugging Face 🤗\n",
"\n"
]
@@ -561,4 +566,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/unit5/README.md b/unit5/README.md
index 2b50dbe..757f089 100644
--- a/unit5/README.md
+++ b/unit5/README.md
@@ -1,6 +1,10 @@
-# Unit 5: Policy Gradient with PyTorch
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit4/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit4/introduction
-In this Unit, **we'll study Policy Gradient Methods**.
+
+# Unit 5: Policy Gradient with PyTorch
+
+In this Unit, **we'll study Policy Gradient Methods**.
And we'll **implement Reinforce (a policy gradient method) from scratch using PyTorch**. Before testing its robustness using CartPole-v1, PixelCopter, and Pong.
diff --git a/unit5/unit5.ipynb b/unit5/unit5.ipynb
index b23e2e5..85de7b5 100644
--- a/unit5/unit5.ipynb
+++ b/unit5/unit5.ipynb
@@ -16,6 +16,11 @@
"id": "CjRWziAVU2lZ"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit4/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit4/introduction",
+ "\n",
+ "\n",
"# Unit 5: Code your first Deep Reinforcement Learning Algorithm with PyTorch: Reinforce. And test its robustness 💪\n",
"In this notebook, you'll code your first Deep Reinforcement Learning algorithm from scratch: Reinforce (also called Monte Carlo Policy Gradient).\n",
"\n",
diff --git a/unit7/README.md b/unit7/README.md
index ded4fdc..d09bbdb 100644
--- a/unit7/README.md
+++ b/unit7/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit6/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit6/introduction
+
+
# Unit 7: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖
One of the major industries that use Reinforcement Learning is robotics. Unfortunately, **having access to robot equipment is very expensive**. Fortunately, some simulations exist to train Robots:
@@ -32,7 +36,7 @@ Thanks to a leaderboard, you'll be able to compare your results with other class
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
## Additional readings 📚
-- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
- [Foundations of Deep RL Series, L3 Policy Gradients and Advantage Estimation by Pieter Abbeel](https://youtu.be/AKbX1Zvo7r8)
diff --git a/unit7/unit7.ipynb b/unit7/unit7.ipynb
index 31e9f2e..f87fa02 100644
--- a/unit7/unit7.ipynb
+++ b/unit7/unit7.ipynb
@@ -34,6 +34,11 @@
{
"cell_type": "markdown",
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit6/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit6/introduction",
+ "\n",
+ "\n",
"# Unit 7: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖\n",
"In this small notebook you'll learn to use A2C with PyBullet. And train an agent to walk. More precisely a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
"\n",
@@ -533,4 +538,4 @@
}
}
]
-}
\ No newline at end of file
+}
diff --git a/unit8/README.md b/unit8/README.md
index 61664da..1280536 100644
--- a/unit8/README.md
+++ b/unit8/README.md
@@ -1,3 +1,7 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit8/introduction
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit8/introduction
+
+
# Unit 8: Proximal Policy Optimization (PPO) with PyTorch
Today we'll learn about Proximal Policy Optimization (PPO), an architecture that improves our agent's training stability by avoiding too large policy updates. To do that, we use a ratio that will indicates the difference between our current and old policy and clip this ratio from a specific range $[1 - \epsilon, 1 + \epsilon]$. Doing this will ensure that our policy update will not be too large and that the training is more stable.
@@ -29,7 +33,7 @@ Thanks to a leaderboard, you'll be able to compare your results with other class
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
## Additional readings 📚
-- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
diff --git a/unit8/unit8.ipynb b/unit8/unit8.ipynb
index 2bbd7e1..5a177dd 100644
--- a/unit8/unit8.ipynb
+++ b/unit8/unit8.ipynb
@@ -16,6 +16,11 @@
"id": "-cf5-oDPjwf8"
},
"source": [
+ "# DEPRECIATED NOTEBOOK, THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unit8/introduction",
+ "\n",
+ "**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unit8/introduction",
+ "\n",
+ "\n",
"# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
"\n",
"In this unit, you'll learn to **code your PPO agent from scratch with PyTorch**.\n",
diff --git a/unit9/README.md b/unit9/README.md
index 051fe94..7770e3c 100644
--- a/unit9/README.md
+++ b/unit9/README.md
@@ -1,8 +1,13 @@
+# DEPRECIATED THE NEW VERSION OF THIS UNIT IS HERE: https://huggingface.co/deep-rl-course/unitbonus3/decision-transformers
+**Everything under is depreciated** 👇, the new version of the course is here: https://huggingface.co/deep-rl-course/unitbonus3/decision-transformers
+
+
+
# Unit 9: Decision Transformers and offline Reinforcement Learning 🤖

-In this Unit, you'll learn what is Decision Transformer and Offline Reinforcement Learning. And then, you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
+In this Unit, you'll learn what is Decision Transformer and Offline Reinforcement Learning. And then, you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
This course is **self-paced**, you can start whenever you want.
@@ -18,12 +23,12 @@ Here are the steps for this Unit:
2️⃣ 👩💻 Then dive on the first hands-on.
👩💻 The hands-on 👉 [](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing)
-
+
3️⃣ 📖 Read [Train your first Decision Transformer](https://huggingface.co/blog/train-decision-transformers)
-4️⃣ 👩💻 Then dive on the hands-on, where **you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run**.
+4️⃣ 👩💻 Then dive on the hands-on, where **you’ll train your first Offline Decision Transformer model from scratch to make a half-cheetah run**.
👩💻 The hands-on 👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb
-
+
## How to make the most of this course
To make the most of the course, my advice is to:
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 99b3d94..040e10a 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -178,6 +178,52 @@
title: Conclusion
- local: unit7/additional-readings
title: Additional Readings
+- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ sections:
+ - local: unit8/introduction
+ title: Introduction
+ - local: unit8/intuition-behind-ppo
+ title: The intuition behind PPO
+ - local: unit8/clipped-surrogate-objective
+ title: Introducing the Clipped Surrogate Objective Function
+ - local: unit8/visualize
+ title: Visualize the Clipped Surrogate Objective Function
+ - local: unit8/hands-on-cleanrl
+ title: PPO with CleanRL
+ - local: unit8/conclusion
+ title: Conclusion
+ - local: unit8/additional-readings
+ title: Additional Readings
+- title: Unit 8. Part 2 Proximal Policy Optimization (PPO) with Doom
+ sections:
+ - local: unit8/introduction-sf
+ title: Introduction
+ - local: unit8/hands-on-sf
+ title: PPO with Sample Factory and Doom
+ - local: unit8/conclusion-sf
+ title: Conclusion
+- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ sections:
+ - local: unitbonus3/introduction
+ title: Introduction
+ - local: unitbonus3/model-based
+ title: Model-Based Reinforcement Learning
+ - local: unitbonus3/offline-online
+ title: Offline vs. Online Reinforcement Learning
+ - local: unitbonus3/rlhf
+ title: Reinforcement Learning from Human Feedback
+ - local: unitbonus3/decision-transformers
+ title: Decision Transformers and Offline RL
+ - local: unitbonus3/language-models
+ title: Language models in RL
+ - local: unitbonus3/curriculum-learning
+ title: (Automatic) Curriculum Learning for RL
+ - local: unitbonus3/envs-to-try
+ title: Interesting environments to try
+ - local: unitbonus3/godotrl
+ title: An Introduction to Godot RL
+ - local: unitbonus3/rl-documentation
+ title: Brief introduction to RL documentation
- title: Certification and congratulations
sections:
- local: communication/conclusion
diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index 9904168..e3bda2c 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -9,11 +9,11 @@ Discord is a free chat platform. If you've used Slack, **it's quite similar**. T
Starting in Discord can be a bit intimidating, so let me take you through it.
-When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**.
+When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**.
 -In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduction-yourself` channel**.
+In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduce-yourself` channel**.
-In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduction-yourself` channel**.
+In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduce-yourself` channel**.
 diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index c2dc4cd..5c181a0 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -22,6 +22,8 @@ To validate this hands-on for the [certification process](https://huggingface.co
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -43,13 +45,6 @@ You can either do this hands-on by reading the notebook or following it with the
In this notebook, you'll train your **first Deep Reinforcement Learning agent** a Lunar Lander agent that will learn to **land correctly on the Moon 🌕**. Using [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) a Deep Reinforcement Learning library, share them with the community, and experiment with different configurations
-⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
-
-```python
-%%html
-
-```
-
### The environment 🎮
- [LunarLander-v2](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
@@ -92,7 +87,7 @@ Before diving into the notebook, you need to:
🔲 📝 **Read Unit 0** that gives you all the **information about the course and help you to onboard** 🤗
-🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1
+🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** by reading Unit 1
## A small recap of what is Deep Reinforcement Learning 📚
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index c2dc4cd..5c181a0 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -22,6 +22,8 @@ To validate this hands-on for the [certification process](https://huggingface.co
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -43,13 +45,6 @@ You can either do this hands-on by reading the notebook or following it with the
In this notebook, you'll train your **first Deep Reinforcement Learning agent** a Lunar Lander agent that will learn to **land correctly on the Moon 🌕**. Using [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) a Deep Reinforcement Learning library, share them with the community, and experiment with different configurations
-⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
-
-```python
-%%html
-
-```
-
### The environment 🎮
- [LunarLander-v2](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
@@ -92,7 +87,7 @@ Before diving into the notebook, you need to:
🔲 📝 **Read Unit 0** that gives you all the **information about the course and help you to onboard** 🤗
-🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1
+🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** by reading Unit 1
## A small recap of what is Deep Reinforcement Learning 📚
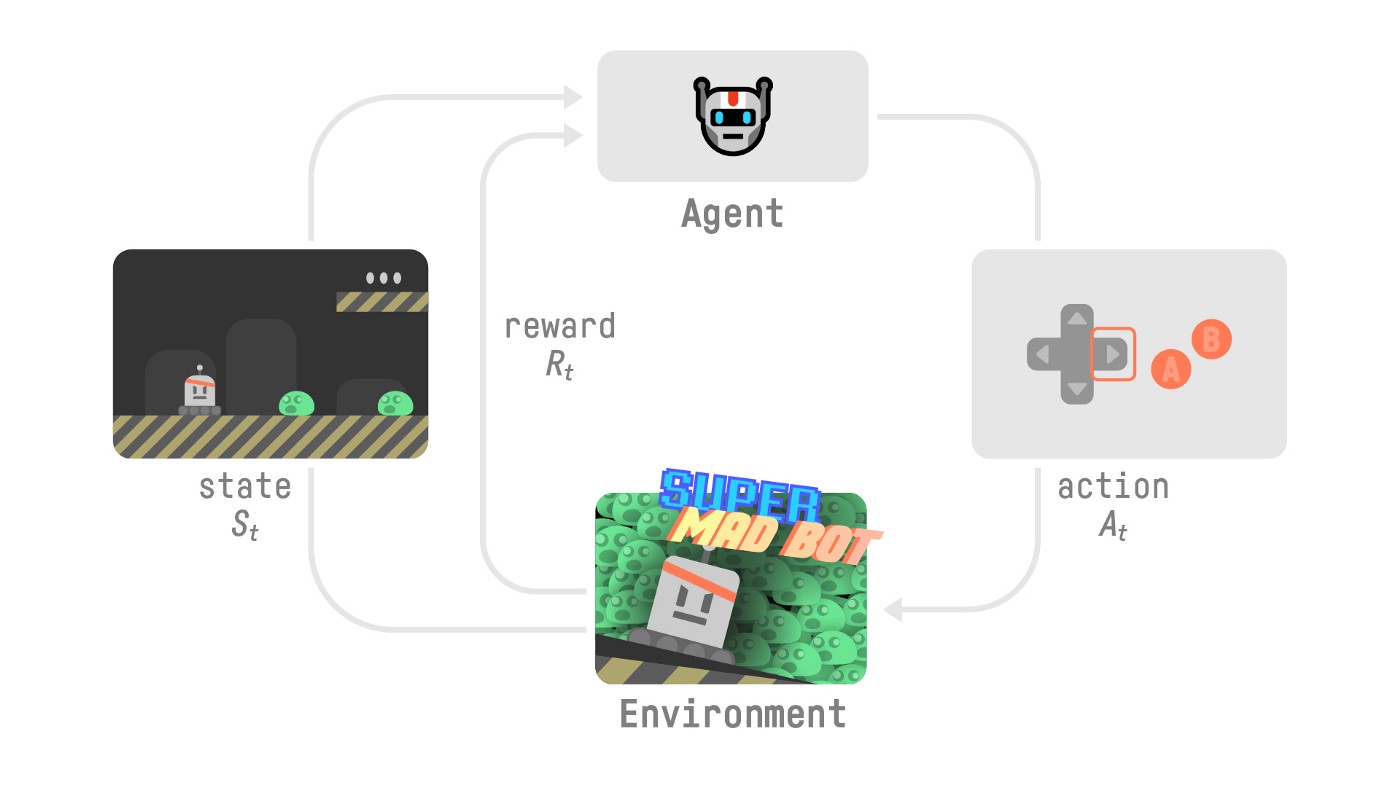 @@ -664,8 +659,7 @@ If you’re still feel confused with all these elements...it's totally normal! *
Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
-Naturally, during the course, we’re going to use and deeper explain again these terms but **it’s better to have a good understanding of them now before diving into the next chapters.**
-
+Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
Next time, in the bonus unit 1, you'll train Huggy the Dog to fetch the stick.
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index f8017cd..e1ebd76 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -22,6 +22,6 @@ It's essential **to master these elements** before diving into implementing Dee
After this unit, in a bonus unit, you'll be **able to train Huggy the Dog 🐶 to fetch the stick and play with him 🤗**.
-
@@ -664,8 +659,7 @@ If you’re still feel confused with all these elements...it's totally normal! *
Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
-Naturally, during the course, we’re going to use and deeper explain again these terms but **it’s better to have a good understanding of them now before diving into the next chapters.**
-
+Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
Next time, in the bonus unit 1, you'll train Huggy the Dog to fetch the stick.
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index f8017cd..e1ebd76 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -22,6 +22,6 @@ It's essential **to master these elements** before diving into implementing Dee
After this unit, in a bonus unit, you'll be **able to train Huggy the Dog 🐶 to fetch the stick and play with him 🤗**.
- +
So let's get started! 🚀
diff --git a/units/en/unit1/tasks.mdx b/units/en/unit1/tasks.mdx
index 1be4fea..9eb83a2 100644
--- a/units/en/unit1/tasks.mdx
+++ b/units/en/unit1/tasks.mdx
@@ -17,7 +17,7 @@ For instance, think about Super Mario Bros: an episode begin at the launch of a
## Continuing tasks [[continuing-tasks]]
-These are tasks that continue forever (no terminal state). In this case, the agent must **learn how to choose the best actions and simultaneously interact with the environment.**
+These are tasks that continue forever (**no terminal state**). In this case, the agent must **learn how to choose the best actions and simultaneously interact with the environment.**
For instance, an agent that does automated stock trading. For this task, there is no starting point and terminal state. **The agent keeps running until we decide to stop it.**
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index e6459c2..5818e5e 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -8,7 +8,7 @@ In other terms, how to build an RL agent that can **select the actions that ma
## The Policy π: the agent’s brain [[policy]]
-The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are.** So it **defines the agent’s behavior** at a given time.
+The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
+
So let's get started! 🚀
diff --git a/units/en/unit1/tasks.mdx b/units/en/unit1/tasks.mdx
index 1be4fea..9eb83a2 100644
--- a/units/en/unit1/tasks.mdx
+++ b/units/en/unit1/tasks.mdx
@@ -17,7 +17,7 @@ For instance, think about Super Mario Bros: an episode begin at the launch of a
## Continuing tasks [[continuing-tasks]]
-These are tasks that continue forever (no terminal state). In this case, the agent must **learn how to choose the best actions and simultaneously interact with the environment.**
+These are tasks that continue forever (**no terminal state**). In this case, the agent must **learn how to choose the best actions and simultaneously interact with the environment.**
For instance, an agent that does automated stock trading. For this task, there is no starting point and terminal state. **The agent keeps running until we decide to stop it.**
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index e6459c2..5818e5e 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -8,7 +8,7 @@ In other terms, how to build an RL agent that can **select the actions that ma
## The Policy π: the agent’s brain [[policy]]
-The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are.** So it **defines the agent’s behavior** at a given time.
+The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
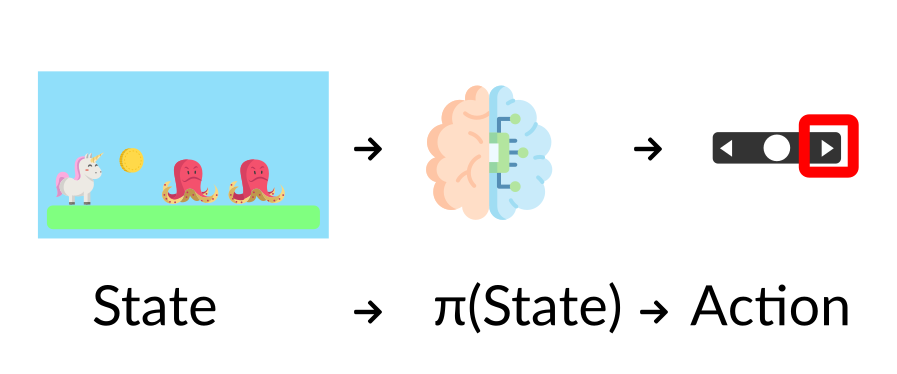 @@ -67,7 +67,7 @@ If we recap:
## Value-based methods [[value-based]]
-In value-based methods, instead of training a policy function, we **train a value function** that maps a state to the expected value **of being at that state.**
+In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 5e4c164..4c201a2 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -16,6 +16,8 @@ Now that we studied the Q-Learning algorithm, let's implement it from scratch an
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
@@ -259,7 +261,8 @@ print("There are ", action_space, " possible actions")
```
```python
-# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
+
def initialize_q_table(state_space, action_space):
Qtable =
return Qtable
@@ -369,7 +372,7 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+The exploration related hyperparameters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 118d913..409d410 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -22,6 +22,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -36,7 +38,7 @@ And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSi
@@ -67,7 +67,7 @@ If we recap:
## Value-based methods [[value-based]]
-In value-based methods, instead of training a policy function, we **train a value function** that maps a state to the expected value **of being at that state.**
+In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then act according to our policy.**
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 5e4c164..4c201a2 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -16,6 +16,8 @@ Now that we studied the Q-Learning algorithm, let's implement it from scratch an
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
@@ -259,7 +261,8 @@ print("There are ", action_space, " possible actions")
```
```python
-# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
+
def initialize_q_table(state_space, action_space):
Qtable =
return Qtable
@@ -369,7 +372,7 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+The exploration related hyperparameters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 118d913..409d410 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -22,6 +22,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -36,7 +38,7 @@ And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSi
 -In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.
+In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning arameters, plotting results and recording videos.
We're using the [RL-Baselines-3 Zoo integration, a vanilla version of Deep Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
@@ -131,7 +133,7 @@ pip install -r requirements.txt
## Train our Deep Q-Learning Agent to Play Space Invaders 👾
To train an agent with RL-Baselines3-Zoo, we just need to do two things:
-1. We define the hyperparameters in `rl-baselines3-zoo/hyperparams/dqn.yml`
+1. We define the hyperparameters in `/content/rl-baselines3-zoo/hyperparams/dqn.yml`
-In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.
+In this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning arameters, plotting results and recording videos.
We're using the [RL-Baselines-3 Zoo integration, a vanilla version of Deep Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
@@ -131,7 +133,7 @@ pip install -r requirements.txt
## Train our Deep Q-Learning Agent to Play Space Invaders 👾
To train an agent with RL-Baselines3-Zoo, we just need to do two things:
-1. We define the hyperparameters in `rl-baselines3-zoo/hyperparams/dqn.yml`
+1. We define the hyperparameters in `/content/rl-baselines3-zoo/hyperparams/dqn.yml`
 diff --git a/units/en/unit4/hands-on.mdx b/units/en/unit4/hands-on.mdx
index e4deb34..857887e 100644
--- a/units/en/unit4/hands-on.mdx
+++ b/units/en/unit4/hands-on.mdx
@@ -26,6 +26,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**. **If you don't see your model on the leaderboard, go at the bottom of the leaderboard page and click on the refresh button**.
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -373,11 +375,11 @@ The second question you may ask is **why do we minimize the loss**? Did you talk
- We want to maximize our utility function $J(\theta)$, but in PyTorch and TensorFlow, it's better to **minimize an objective function.**
- So let's say we want to reinforce action 3 at a certain timestep. Before training this action P is 0.25.
- - So we want to modify $\theta$ such that $\pi_\theta(a_3|s; \theta) > 0.25$
- - Because all P must sum to 1, max $\pi_\theta(a_3|s; \theta)$ will **minimize other action probability.**
- - So we should tell PyTorch **to min $1 - \pi_\theta(a_3|s; \theta)$.**
- - This loss function approaches 0 as $\pi_\theta(a_3|s; \theta)$ nears 1.
- - So we are encouraging the gradient to max $\pi_\theta(a_3|s; \theta)$
+ - So we want to modify \\(theta \\) such that \\(\pi_\theta(a_3|s; \theta) > 0.25 \\)
+ - Because all P must sum to 1, max \\(pi_\theta(a_3|s; \theta)\\) will **minimize other action probability.**
+ - So we should tell PyTorch **to min \\(1 - \pi_\theta(a_3|s; \theta)\\).**
+ - This loss function approaches 0 as \\(\pi_\theta(a_3|s; \theta)\\) nears 1.
+ - So we are encouraging the gradient to max \\(\pi_\theta(a_3|s; \theta)\\)
```python
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
index 8b7863c..64f07fc 100644
--- a/units/en/unit6/advantage-actor-critic.mdx
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -16,7 +16,7 @@ On the other hand, your friend (Critic) will also update their way to provide fe
This is the idea behind Actor-Critic. We learn two function approximations:
-- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s) \\)
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
@@ -24,7 +24,7 @@ This is the idea behind Actor-Critic. We learn two function approximations:
Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
-- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
Let's see the training process to understand how Actor and Critic are optimized:
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 37a0d93..50c3e45 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -28,6 +28,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on click on Open In Colab button** 👇 :
@@ -191,7 +193,7 @@ env = # TODO: Add the wrapper
```python
env = make_vec_env(env_id, n_envs=4)
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.0)
```
### Create the A2C Model 🤖
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index 7b07bba..42d6af6 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -24,6 +24,8 @@ More precisely, AI vs. AI is three tools:
- A *leaderboard* getting the match history results and displaying the models’ ELO ratings: [https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
- A *Space demo* to visualize your agents playing against others: [https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
+In addition to these three tools, your classmate cyllum created a 🤗 SoccerTwos Challenge Analytics where you can check the detailed match results of a model: [https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
+
We're going to write a blog post to explain this AI vs. AI tool in detail, but to give you the big picture it works this way:
- Every four hours, our algorithm **fetches all the available models for a given environment (in our case ML-Agents-SoccerTwos).**
diff --git a/units/en/unit8/additional-readings.mdx b/units/en/unit8/additional-readings.mdx
new file mode 100644
index 0000000..89196f9
--- /dev/null
+++ b/units/en/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## PPO Explained
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [Paper Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347)
+
+## PPO Implementation details
+
+- [The 37 Implementation Details of Proximal Policy Optimization](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [Part 1 of 3 — Proximal Policy Optimization Implementation: 11 Core Implementation Details](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## Importance Sampling
+
+- [Importance Sampling Explained](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/en/unit8/clipped-surrogate-objective.mdx b/units/en/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 0000000..9319b3e
--- /dev/null
+++ b/units/en/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# Introducing the Clipped Surrogate Objective Function
+## Recap: The Policy Objective Function
+
+Let’s remember what is the objective to optimize in Reinforce:
+
diff --git a/units/en/unit4/hands-on.mdx b/units/en/unit4/hands-on.mdx
index e4deb34..857887e 100644
--- a/units/en/unit4/hands-on.mdx
+++ b/units/en/unit4/hands-on.mdx
@@ -26,6 +26,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**. **If you don't see your model on the leaderboard, go at the bottom of the leaderboard page and click on the refresh button**.
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
@@ -373,11 +375,11 @@ The second question you may ask is **why do we minimize the loss**? Did you talk
- We want to maximize our utility function $J(\theta)$, but in PyTorch and TensorFlow, it's better to **minimize an objective function.**
- So let's say we want to reinforce action 3 at a certain timestep. Before training this action P is 0.25.
- - So we want to modify $\theta$ such that $\pi_\theta(a_3|s; \theta) > 0.25$
- - Because all P must sum to 1, max $\pi_\theta(a_3|s; \theta)$ will **minimize other action probability.**
- - So we should tell PyTorch **to min $1 - \pi_\theta(a_3|s; \theta)$.**
- - This loss function approaches 0 as $\pi_\theta(a_3|s; \theta)$ nears 1.
- - So we are encouraging the gradient to max $\pi_\theta(a_3|s; \theta)$
+ - So we want to modify \\(theta \\) such that \\(\pi_\theta(a_3|s; \theta) > 0.25 \\)
+ - Because all P must sum to 1, max \\(pi_\theta(a_3|s; \theta)\\) will **minimize other action probability.**
+ - So we should tell PyTorch **to min \\(1 - \pi_\theta(a_3|s; \theta)\\).**
+ - This loss function approaches 0 as \\(\pi_\theta(a_3|s; \theta)\\) nears 1.
+ - So we are encouraging the gradient to max \\(\pi_\theta(a_3|s; \theta)\\)
```python
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
index 8b7863c..64f07fc 100644
--- a/units/en/unit6/advantage-actor-critic.mdx
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -16,7 +16,7 @@ On the other hand, your friend (Critic) will also update their way to provide fe
This is the idea behind Actor-Critic. We learn two function approximations:
-- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s) \\)
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
@@ -24,7 +24,7 @@ This is the idea behind Actor-Critic. We learn two function approximations:
Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
-- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
Let's see the training process to understand how Actor and Critic are optimized:
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 37a0d93..50c3e45 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -28,6 +28,8 @@ To validate this hands-on for the certification process, you need to push your t
To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+**If you don't find your model, go to the bottom of the page and click on the refresh button.**
+
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on click on Open In Colab button** 👇 :
@@ -191,7 +193,7 @@ env = # TODO: Add the wrapper
```python
env = make_vec_env(env_id, n_envs=4)
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.0)
```
### Create the A2C Model 🤖
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index 7b07bba..42d6af6 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -24,6 +24,8 @@ More precisely, AI vs. AI is three tools:
- A *leaderboard* getting the match history results and displaying the models’ ELO ratings: [https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
- A *Space demo* to visualize your agents playing against others: [https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
+In addition to these three tools, your classmate cyllum created a 🤗 SoccerTwos Challenge Analytics where you can check the detailed match results of a model: [https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
+
We're going to write a blog post to explain this AI vs. AI tool in detail, but to give you the big picture it works this way:
- Every four hours, our algorithm **fetches all the available models for a given environment (in our case ML-Agents-SoccerTwos).**
diff --git a/units/en/unit8/additional-readings.mdx b/units/en/unit8/additional-readings.mdx
new file mode 100644
index 0000000..89196f9
--- /dev/null
+++ b/units/en/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## PPO Explained
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [Paper Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347)
+
+## PPO Implementation details
+
+- [The 37 Implementation Details of Proximal Policy Optimization](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [Part 1 of 3 — Proximal Policy Optimization Implementation: 11 Core Implementation Details](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## Importance Sampling
+
+- [Importance Sampling Explained](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/en/unit8/clipped-surrogate-objective.mdx b/units/en/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 0000000..9319b3e
--- /dev/null
+++ b/units/en/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# Introducing the Clipped Surrogate Objective Function
+## Recap: The Policy Objective Function
+
+Let’s remember what is the objective to optimize in Reinforce:
+ +
+The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
+
+However, the problem comes from the step size:
+- Too small, **the training process was too slow**
+- Too high, **there was too much variability in the training**
+
+Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
+
+This new function **is designed to avoid destructive large weights updates** :
+
+
+
+The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
+
+However, the problem comes from the step size:
+- Too small, **the training process was too slow**
+- Too high, **there was too much variability in the training**
+
+Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
+
+This new function **is designed to avoid destructive large weights updates** :
+
+ +
+Let’s study each part to understand how it works.
+
+## The Ratio Function
+
+
+Let’s study each part to understand how it works.
+
+## The Ratio Function
+ +
+This ratio is calculated this way:
+
+
+
+This ratio is calculated this way:
+
+ +
+It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
+
+As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
+
+- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
+- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
+
+So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
+
+## The unclipped part of the Clipped Surrogate Objective function
+
+
+It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
+
+As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
+
+- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
+- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
+
+So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
+
+## The unclipped part of the Clipped Surrogate Objective function
+ +
+This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
+
+
+
+This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
+
+  + Proximal Policy Optimization Algorithms
+
+
+However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
+
+## The clipped Part of the Clipped Surrogate Objective function
+
+
+ Proximal Policy Optimization Algorithms
+
+
+However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
+
+## The clipped Part of the Clipped Surrogate Objective function
+
+ +
+Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
+
+**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
+
+To do that, we have two solutions:
+
+- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
+- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
+
+
+
+This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+
+With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
+
+Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
+
+Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
diff --git a/units/en/unit8/conclusion-sf.mdx b/units/en/unit8/conclusion-sf.mdx
new file mode 100644
index 0000000..34c85df
--- /dev/null
+++ b/units/en/unit8/conclusion-sf.mdx
@@ -0,0 +1,13 @@
+# Conclusion
+
+That's all for today. Congrats on finishing this Unit and the tutorial! ⭐️
+
+Now that you've successfully trained your Doom agent, why not try deathmatch? Remember, that's a much more complex level than the one you've just trained, **but it's a nice experiment and I advise you to try it.**
+
+If you do it, don't hesitate to share your model in the `#rl-i-made-this` channel in our [discord server](https://www.hf.co/join/discord).
+
+This concludes the last unit, but we are not finished yet! 🤗 The following **bonus unit includes some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.
+
+See you next time 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/conclusion.mdx b/units/en/unit8/conclusion.mdx
new file mode 100644
index 0000000..7dc56e6
--- /dev/null
+++ b/units/en/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# Conclusion [[Conclusion]]
+
+That’s all for today. Congrats on finishing this unit and the tutorial!
+
+The best way to learn is to practice and try stuff. **Why not improving the implementation to handle frames as input?**.
+
+See you on second part of this Unit 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/hands-on-cleanrl.mdx b/units/en/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 0000000..88d1033
--- /dev/null
+++ b/units/en/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1077 @@
+# Hands-on
+
+
+
+
+
+
+Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
+
+Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
+
+So, to be able to code it, we're going to use two resources:
+- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
+- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+Then, to test its robustness, we're going to train it in:
+
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
+
+LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
+
+
+
+Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
+
+**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
+
+To do that, we have two solutions:
+
+- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
+- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
+
+
+
+This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+
+With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
+
+Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
+
+Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
diff --git a/units/en/unit8/conclusion-sf.mdx b/units/en/unit8/conclusion-sf.mdx
new file mode 100644
index 0000000..34c85df
--- /dev/null
+++ b/units/en/unit8/conclusion-sf.mdx
@@ -0,0 +1,13 @@
+# Conclusion
+
+That's all for today. Congrats on finishing this Unit and the tutorial! ⭐️
+
+Now that you've successfully trained your Doom agent, why not try deathmatch? Remember, that's a much more complex level than the one you've just trained, **but it's a nice experiment and I advise you to try it.**
+
+If you do it, don't hesitate to share your model in the `#rl-i-made-this` channel in our [discord server](https://www.hf.co/join/discord).
+
+This concludes the last unit, but we are not finished yet! 🤗 The following **bonus unit includes some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.
+
+See you next time 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/conclusion.mdx b/units/en/unit8/conclusion.mdx
new file mode 100644
index 0000000..7dc56e6
--- /dev/null
+++ b/units/en/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# Conclusion [[Conclusion]]
+
+That’s all for today. Congrats on finishing this unit and the tutorial!
+
+The best way to learn is to practice and try stuff. **Why not improving the implementation to handle frames as input?**.
+
+See you on second part of this Unit 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/hands-on-cleanrl.mdx b/units/en/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 0000000..88d1033
--- /dev/null
+++ b/units/en/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1077 @@
+# Hands-on
+
+
+
+
+
+
+Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
+
+Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
+
+So, to be able to code it, we're going to use two resources:
+- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
+- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+Then, to test its robustness, we're going to train it in:
+
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
+
+LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
+
+via GIPHY
+
+Let's get started! 🚀
+
+The colab notebook:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part1.ipynb)
+
+# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖
+
+ +
+
+In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.
+
+To test its robustness, we're going to train it in:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to **code your PPO agent from scratch using PyTorch**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+## Prerequisites 🏗️
+
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+
+In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.
+
+To test its robustness, we're going to train it in:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to **code your PPO agent from scratch using PyTorch**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+## Prerequisites 🏗️
+
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+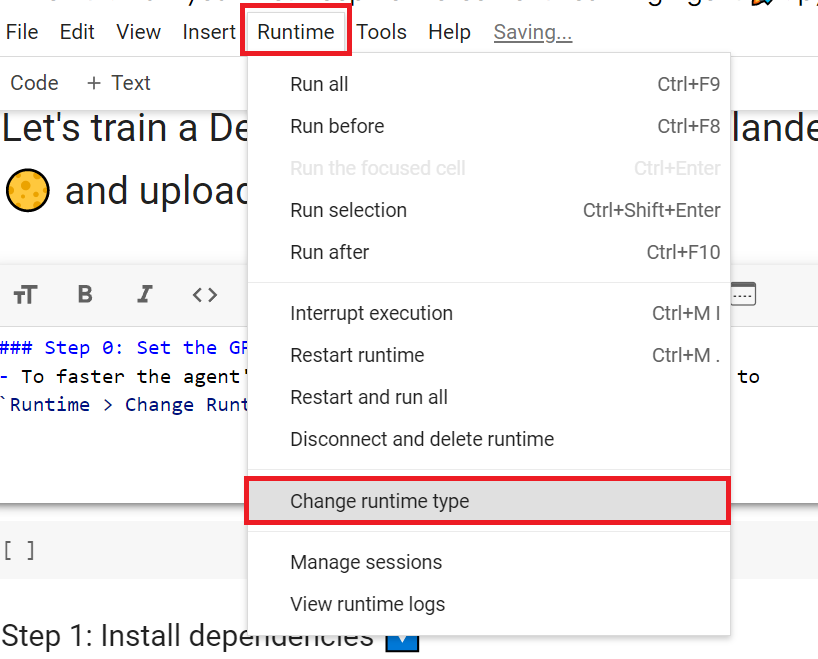 +
+- `Hardware Accelerator > GPU`
+
+
+
+- `Hardware Accelerator > GPU`
+
+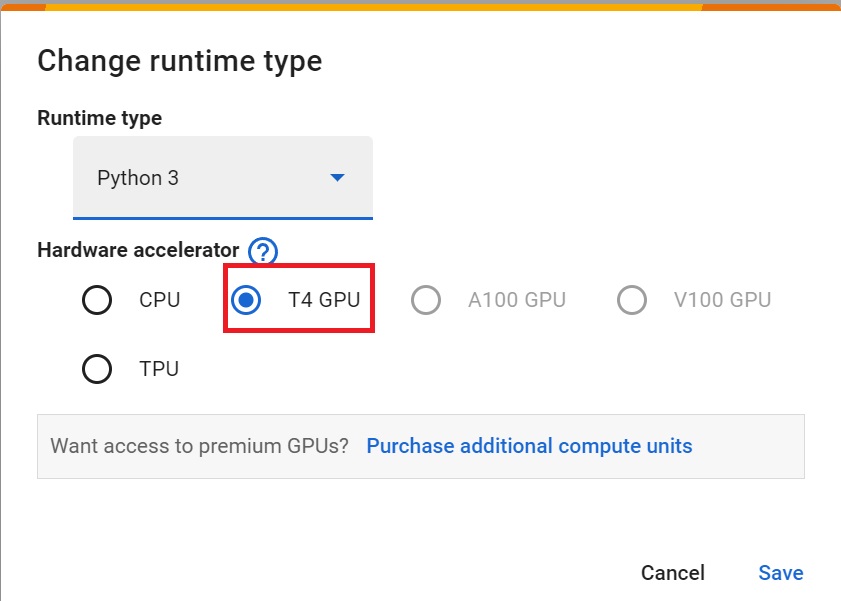 +
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip install pyglet==1.5
+pip install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Install dependencies 🔽
+For this exercise, we use `gym==0.21`
+
+```python
+pip install gym==0.21
+pip install imageio-ffmpeg
+pip install huggingface_hub
+pip install box2d
+```
+
+## Let's code PPO from scratch with Costa Huang tutorial
+- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.
+- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 The video tutorial: https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+## Add the Hugging Face Integration 🤗
+- In order to push our model to the Hub, we need to define a function `package_to_hub`
+
+- Add dependencies we need to push our model to the Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what look the ppo.py final file
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip install pyglet==1.5
+pip install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Install dependencies 🔽
+For this exercise, we use `gym==0.21`
+
+```python
+pip install gym==0.21
+pip install imageio-ffmpeg
+pip install huggingface_hub
+pip install box2d
+```
+
+## Let's code PPO from scratch with Costa Huang tutorial
+- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.
+- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 The video tutorial: https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+## Add the Hugging Face Integration 🤗
+- In order to push our model to the Hub, we need to define a function `package_to_hub`
+
+- Add dependencies we need to push our model to the Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what look the ppo.py final file
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+ +
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+## Let's start the training 🔥
+
+- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥
+
+- First, you need to copy all your code to a file you create called `ppo.py`
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+## Let's start the training 🔥
+
+- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥
+
+- First, you need to copy all your code to a file you create called `ppo.py`
+
+ +
+
+
+ +
+- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`
+
+- You should modify more hyperparameters otherwise the training will not be super stable.
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## Some additional challenges 🏆
+
+The best way to learn **is to try things by your own**! Why not trying another environment?
+
+See you on Unit 8, part 2 where we going to train agents to play Doom 🔥
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit8/hands-on-sf.mdx b/units/en/unit8/hands-on-sf.mdx
new file mode 100644
index 0000000..1a71f2f
--- /dev/null
+++ b/units/en/unit8/hands-on-sf.mdx
@@ -0,0 +1,430 @@
+# Hands-on: advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
+
+
+
+The colab notebook:
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part2.ipynb)
+
+# Unit 8 Part 2: Advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
+
+
+
+- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`
+
+- You should modify more hyperparameters otherwise the training will not be super stable.
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## Some additional challenges 🏆
+
+The best way to learn **is to try things by your own**! Why not trying another environment?
+
+See you on Unit 8, part 2 where we going to train agents to play Doom 🔥
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit8/hands-on-sf.mdx b/units/en/unit8/hands-on-sf.mdx
new file mode 100644
index 0000000..1a71f2f
--- /dev/null
+++ b/units/en/unit8/hands-on-sf.mdx
@@ -0,0 +1,430 @@
+# Hands-on: advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
+
+
+
+The colab notebook:
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part2.ipynb)
+
+# Unit 8 Part 2: Advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
+
+ +
+In this notebook, we will learn how to train a Deep Neural Network to collect objects in a 3D environment based on the game of Doom, a video of the resulting policy is shown below. We train this policy using [Sample Factory](https://www.samplefactory.dev/), an asynchronous implementation of the PPO algorithm.
+
+Please note the following points:
+
+* [Sample Factory](https://www.samplefactory.dev/) is an advanced RL framework and **only functions on Linux and Mac** (not Windows).
+
+* The framework performs best on a **GPU machine with many CPU cores**, where it can achieve speeds of 100k interactions per second. The resources available on a standard Colab notebook **limit the performance of this library**. So the speed in this setting **does not reflect the real-world performance**.
+* Benchmarks for Sample Factory are available in a number of settings, check out the [examples](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples) if you want to find out more.
+
+
+```python
+from IPython.display import HTML
+
+HTML(
+ """"""
+)
+```
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model:
+
+- `doom_health_gathering_supreme` get a result of >= 5.
+
+To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+Before starting to train our agent, let's **study the library and environments we're going to use**.
+
+## Sample Factory
+
+[Sample Factory](https://www.samplefactory.dev/) is one of the **fastest RL libraries focused on very efficient synchronous and asynchronous implementations of policy gradients (PPO)**.
+
+Sample Factory is thoroughly **tested, used by many researchers and practitioners**, and is actively maintained. Our implementation is known to **reach SOTA performance in a variety of domains while minimizing RL experiment training time and hardware requirements**.
+
+
+
+In this notebook, we will learn how to train a Deep Neural Network to collect objects in a 3D environment based on the game of Doom, a video of the resulting policy is shown below. We train this policy using [Sample Factory](https://www.samplefactory.dev/), an asynchronous implementation of the PPO algorithm.
+
+Please note the following points:
+
+* [Sample Factory](https://www.samplefactory.dev/) is an advanced RL framework and **only functions on Linux and Mac** (not Windows).
+
+* The framework performs best on a **GPU machine with many CPU cores**, where it can achieve speeds of 100k interactions per second. The resources available on a standard Colab notebook **limit the performance of this library**. So the speed in this setting **does not reflect the real-world performance**.
+* Benchmarks for Sample Factory are available in a number of settings, check out the [examples](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples) if you want to find out more.
+
+
+```python
+from IPython.display import HTML
+
+HTML(
+ """"""
+)
+```
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model:
+
+- `doom_health_gathering_supreme` get a result of >= 5.
+
+To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+Before starting to train our agent, let's **study the library and environments we're going to use**.
+
+## Sample Factory
+
+[Sample Factory](https://www.samplefactory.dev/) is one of the **fastest RL libraries focused on very efficient synchronous and asynchronous implementations of policy gradients (PPO)**.
+
+Sample Factory is thoroughly **tested, used by many researchers and practitioners**, and is actively maintained. Our implementation is known to **reach SOTA performance in a variety of domains while minimizing RL experiment training time and hardware requirements**.
+
+ +
+### Key features
+
+- Highly optimized algorithm [architecture](https://www.samplefactory.dev/06-architecture/overview/) for maximum learning throughput
+- [Synchronous and asynchronous](https://www.samplefactory.dev/07-advanced-topics/sync-async/) training regimes
+- [Serial (single-process) mode](https://www.samplefactory.dev/07-advanced-topics/serial-mode/) for easy debugging
+- Optimal performance in both CPU-based and [GPU-accelerated environments](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)
+- Single- & multi-agent training, self-play, supports [training multiple policies](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/) at once on one or many GPUs
+- Population-Based Training ([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))
+- Discrete, continuous, hybrid action spaces
+- Vector-based, image-based, dictionary observation spaces
+- Automatically creates a model architecture by parsing action/observation space specification. Supports [custom model architectures](https://www.samplefactory.dev/03-customization/custom-models/)
+- Designed to be imported into other projects, [custom environments](https://www.samplefactory.dev/03-customization/custom-environments/) are first-class citizens
+- Detailed [WandB and Tensorboard summaries](https://www.samplefactory.dev/05-monitoring/metrics-reference/), [custom metrics](https://www.samplefactory.dev/05-monitoring/custom-metrics/)
+- [HuggingFace 🤗 integration](https://www.samplefactory.dev/10-huggingface/huggingface/) (upload trained models and metrics to the Hub)
+- [Multiple](https://www.samplefactory.dev/09-environment-integrations/mujoco/) [example](https://www.samplefactory.dev/09-environment-integrations/atari/) [environment](https://www.samplefactory.dev/09-environment-integrations/vizdoom/) [integrations](https://www.samplefactory.dev/09-environment-integrations/dmlab/) with tuned parameters and trained models
+
+All of the above policies are available on the 🤗 hub. Search for the tag [sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)
+
+### How sample-factory works
+
+Sample-factory is one of the **most highly optimized RL implementations available to the community**.
+
+It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.
+
+The *workers* **communicate through shared memory, which lowers the communication cost between processes**.
+
+The *rollout workers* interact with the environment and send observations to the *inference workers*.
+
+The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.
+
+After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.
+
+
+
+### Key features
+
+- Highly optimized algorithm [architecture](https://www.samplefactory.dev/06-architecture/overview/) for maximum learning throughput
+- [Synchronous and asynchronous](https://www.samplefactory.dev/07-advanced-topics/sync-async/) training regimes
+- [Serial (single-process) mode](https://www.samplefactory.dev/07-advanced-topics/serial-mode/) for easy debugging
+- Optimal performance in both CPU-based and [GPU-accelerated environments](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)
+- Single- & multi-agent training, self-play, supports [training multiple policies](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/) at once on one or many GPUs
+- Population-Based Training ([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))
+- Discrete, continuous, hybrid action spaces
+- Vector-based, image-based, dictionary observation spaces
+- Automatically creates a model architecture by parsing action/observation space specification. Supports [custom model architectures](https://www.samplefactory.dev/03-customization/custom-models/)
+- Designed to be imported into other projects, [custom environments](https://www.samplefactory.dev/03-customization/custom-environments/) are first-class citizens
+- Detailed [WandB and Tensorboard summaries](https://www.samplefactory.dev/05-monitoring/metrics-reference/), [custom metrics](https://www.samplefactory.dev/05-monitoring/custom-metrics/)
+- [HuggingFace 🤗 integration](https://www.samplefactory.dev/10-huggingface/huggingface/) (upload trained models and metrics to the Hub)
+- [Multiple](https://www.samplefactory.dev/09-environment-integrations/mujoco/) [example](https://www.samplefactory.dev/09-environment-integrations/atari/) [environment](https://www.samplefactory.dev/09-environment-integrations/vizdoom/) [integrations](https://www.samplefactory.dev/09-environment-integrations/dmlab/) with tuned parameters and trained models
+
+All of the above policies are available on the 🤗 hub. Search for the tag [sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)
+
+### How sample-factory works
+
+Sample-factory is one of the **most highly optimized RL implementations available to the community**.
+
+It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.
+
+The *workers* **communicate through shared memory, which lowers the communication cost between processes**.
+
+The *rollout workers* interact with the environment and send observations to the *inference workers*.
+
+The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.
+
+After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.
+
+ +
+### Actor Critic models in Sample-factory
+
+Actor Critic models in Sample Factory are composed of three components:
+
+- **Encoder** - Process input observations (images, vectors) and map them to a vector. This is the part of the model you will most likely want to customize.
+- **Core** - Intergrate vectors from one or more encoders, can optionally include a single- or multi-layer LSTM/GRU in a memory-based agent.
+- **Decoder** - Apply additional layers to the output of the model core before computing the policy and value outputs.
+
+The library has been designed to automatically support any observation and action spaces. Users can easily add their custom models. You can find out more in the [documentation](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory).
+
+## ViZDoom
+
+[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.
+
+The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.
+
+The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.
+
+The library includes feature such as:
+
+- Multi-platform (Linux, macOS, Windows),
+- API for Python and C++,
+- [OpenAI Gym](https://www.gymlibrary.dev/) environment wrappers
+- Easy-to-create custom scenarios (visual editors, scripting language, and examples available),
+- Async and sync single-player and multiplayer modes,
+- Lightweight (few MBs) and fast (up to 7000 fps in sync mode, single-threaded),
+- Customizable resolution and rendering parameters,
+- Access to the depth buffer (3D vision),
+- Automatic labeling of game objects visible in the frame,
+- Access to the audio buffer
+- Access to the list of actors/objects and map geometry,
+- Off-screen rendering and episode recording,
+- Time scaling in async mode.
+
+## We first need to install some dependencies that are required for the ViZDoom environment
+
+Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.
+
+If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36).
+
+```python
+# Install ViZDoom deps from
+# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux
+
+apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \
+nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \
+libopenal-dev timidity libwildmidi-dev unzip ffmpeg
+
+# Boost libraries
+apt-get install libboost-all-dev
+
+# Lua binding dependencies
+apt-get install liblua5.1-dev
+```
+
+## Then we can install Sample Factory and ViZDoom
+
+- This can take 7min
+
+```bash
+pip install sample-factory
+pip install vizdoom
+```
+
+## Setting up the Doom Environment in sample-factory
+
+```python
+import functools
+
+from sample_factory.algo.utils.context import global_model_factory
+from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args
+from sample_factory.envs.env_utils import register_env
+from sample_factory.train import run_rl
+
+from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder
+from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults
+from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec
+
+
+# Registers all the ViZDoom environments
+def register_vizdoom_envs():
+ for env_spec in DOOM_ENVS:
+ make_env_func = functools.partial(make_doom_env_from_spec, env_spec)
+ register_env(env_spec.name, make_env_func)
+
+
+# Sample Factory allows the registration of a custom Neural Network architecture
+# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details
+def register_vizdoom_models():
+ global_model_factory().register_encoder_factory(make_vizdoom_encoder)
+
+
+def register_vizdoom_components():
+ register_vizdoom_envs()
+ register_vizdoom_models()
+
+
+# parse the command line args and create a config
+def parse_vizdoom_cfg(argv=None, evaluation=False):
+ parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)
+ # parameters specific to Doom envs
+ add_doom_env_args(parser)
+ # override Doom default values for algo parameters
+ doom_override_defaults(parser)
+ # second parsing pass yields the final configuration
+ final_cfg = parse_full_cfg(parser, argv)
+ return final_cfg
+```
+
+Now that the setup if complete, we can train the agent. We have chosen here to learn a ViZDoom task called `Health Gathering Supreme`.
+
+### The scenario: Health Gathering Supreme
+
+
+
+### Actor Critic models in Sample-factory
+
+Actor Critic models in Sample Factory are composed of three components:
+
+- **Encoder** - Process input observations (images, vectors) and map them to a vector. This is the part of the model you will most likely want to customize.
+- **Core** - Intergrate vectors from one or more encoders, can optionally include a single- or multi-layer LSTM/GRU in a memory-based agent.
+- **Decoder** - Apply additional layers to the output of the model core before computing the policy and value outputs.
+
+The library has been designed to automatically support any observation and action spaces. Users can easily add their custom models. You can find out more in the [documentation](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory).
+
+## ViZDoom
+
+[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.
+
+The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.
+
+The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.
+
+The library includes feature such as:
+
+- Multi-platform (Linux, macOS, Windows),
+- API for Python and C++,
+- [OpenAI Gym](https://www.gymlibrary.dev/) environment wrappers
+- Easy-to-create custom scenarios (visual editors, scripting language, and examples available),
+- Async and sync single-player and multiplayer modes,
+- Lightweight (few MBs) and fast (up to 7000 fps in sync mode, single-threaded),
+- Customizable resolution and rendering parameters,
+- Access to the depth buffer (3D vision),
+- Automatic labeling of game objects visible in the frame,
+- Access to the audio buffer
+- Access to the list of actors/objects and map geometry,
+- Off-screen rendering and episode recording,
+- Time scaling in async mode.
+
+## We first need to install some dependencies that are required for the ViZDoom environment
+
+Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.
+
+If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36).
+
+```python
+# Install ViZDoom deps from
+# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux
+
+apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \
+nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \
+libopenal-dev timidity libwildmidi-dev unzip ffmpeg
+
+# Boost libraries
+apt-get install libboost-all-dev
+
+# Lua binding dependencies
+apt-get install liblua5.1-dev
+```
+
+## Then we can install Sample Factory and ViZDoom
+
+- This can take 7min
+
+```bash
+pip install sample-factory
+pip install vizdoom
+```
+
+## Setting up the Doom Environment in sample-factory
+
+```python
+import functools
+
+from sample_factory.algo.utils.context import global_model_factory
+from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args
+from sample_factory.envs.env_utils import register_env
+from sample_factory.train import run_rl
+
+from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder
+from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults
+from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec
+
+
+# Registers all the ViZDoom environments
+def register_vizdoom_envs():
+ for env_spec in DOOM_ENVS:
+ make_env_func = functools.partial(make_doom_env_from_spec, env_spec)
+ register_env(env_spec.name, make_env_func)
+
+
+# Sample Factory allows the registration of a custom Neural Network architecture
+# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details
+def register_vizdoom_models():
+ global_model_factory().register_encoder_factory(make_vizdoom_encoder)
+
+
+def register_vizdoom_components():
+ register_vizdoom_envs()
+ register_vizdoom_models()
+
+
+# parse the command line args and create a config
+def parse_vizdoom_cfg(argv=None, evaluation=False):
+ parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)
+ # parameters specific to Doom envs
+ add_doom_env_args(parser)
+ # override Doom default values for algo parameters
+ doom_override_defaults(parser)
+ # second parsing pass yields the final configuration
+ final_cfg = parse_full_cfg(parser, argv)
+ return final_cfg
+```
+
+Now that the setup if complete, we can train the agent. We have chosen here to learn a ViZDoom task called `Health Gathering Supreme`.
+
+### The scenario: Health Gathering Supreme
+
+ +
+
+
+The objective of this scenario is to **teach the agent how to survive without knowing what makes him survive**. Agent know only that **life is precious** and death is bad so **it must learn what prolongs his existence and that his health is connected with it**.
+
+Map is a rectangle containing walls and with a green, acidic floor which **hurts the player periodically**. Initially there are some medkits spread uniformly over the map. A new medkit falls from the skies every now and then. **Medkits heal some portions of player's health** - to survive agent needs to pick them up. Episode finishes after player's death or on timeout.
+
+Further configuration:
+- Living_reward = 1
+- 3 available buttons: turn left, turn right, move forward
+- 1 available game variable: HEALTH
+- death penalty = 100
+
+You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).
+
+There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).
+
+
+
+## Training the agent
+
+- We're going to train the agent for 4000000 steps it will take approximately 20min
+
+```python
+## Start the training, this should take around 15 minutes
+register_vizdoom_components()
+
+# The scenario we train on today is health gathering
+# other scenarios include "doom_basic", "doom_two_colors_easy", "doom_dm", "doom_dwango5", "doom_my_way_home", "doom_deadly_corridor", "doom_defend_the_center", "doom_defend_the_line"
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=8", "--num_envs_per_worker=4", "--train_for_env_steps=4000000"]
+)
+
+status = run_rl(cfg)
+```
+
+## Let's take a look at the performance of the trained policy and output a video of the agent.
+
+```python
+from sample_factory.enjoy import enjoy
+
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=1", "--save_video", "--no_render", "--max_num_episodes=10"], evaluation=True
+)
+status = enjoy(cfg)
+```
+
+## Now lets visualize the performance of the agent
+
+```python
+from base64 import b64encode
+from IPython.display import HTML
+
+mp4 = open("/content/train_dir/default_experiment/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+The agent has learned something, but its performance could be better. We would clearly need to train for longer. But let's upload this model to the Hub.
+
+## Now lets upload your checkpoint and video to the Hugging Face Hub
+
+
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+```python
+from sample_factory.enjoy import enjoy
+
+hf_username = "ThomasSimonini" # insert your HuggingFace username here
+
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--max_num_frames=100000",
+ "--push_to_hub",
+ f"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+## Let's load another model
+
+
+
+
+This agent's performance was good, but can do better! Let's download and visualize an agent trained for 10B timesteps from the hub.
+
+```bash
+#download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir
+```
+
+```bash
+ls train_dir/doom_health_gathering_supreme_2222
+```
+
+```python
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--experiment=doom_health_gathering_supreme_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+```python
+mp4 = open("/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+## Some additional challenges 🏆: Doom Deathmatch
+
+Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**.
+
+Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance.
+
+```python
+# Download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir
+```
+
+Given the agent plays for a long time the video generation can take **10 minutes**.
+
+```python
+from sample_factory.enjoy import enjoy
+
+register_vizdoom_components()
+env = "doom_deathmatch_bots"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=1",
+ "--experiment=doom_deathmatch_bots_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+mp4 = open("/content/train_dir/doom_deathmatch_bots_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+
+You **can try to train your agent in this environment** using the code above, but not on colab.
+**Good luck 🤞**
+
+If you prefer an easier scenario, **why not try training in another ViZDoom scenario such as `doom_deadly_corridor` or `doom_defend_the_center`.**
+
+
+
+---
+
+
+This concludes the last unit. But we are not finished yet! 🤗 The following **bonus section include some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit8/introduction-sf.mdx b/units/en/unit8/introduction-sf.mdx
new file mode 100644
index 0000000..9250cf4
--- /dev/null
+++ b/units/en/unit8/introduction-sf.mdx
@@ -0,0 +1,13 @@
+# Introduction to PPO with Sample-Factory
+
+
+
+In this second part of Unit 8, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/), an **asynchronous implementation of the PPO algorithm**, to train our agent playing [vizdoom](https://vizdoom.cs.put.edu.pl/) (an open source version of Doom).
+
+In the notebook, **you'll train your agent to play the Health Gathering level**, where the agent must collect health packs to avoid dying. After that, you can **train your agent to play more complex levels, such as Deathmatch**.
+
+
+
+
+
+The objective of this scenario is to **teach the agent how to survive without knowing what makes him survive**. Agent know only that **life is precious** and death is bad so **it must learn what prolongs his existence and that his health is connected with it**.
+
+Map is a rectangle containing walls and with a green, acidic floor which **hurts the player periodically**. Initially there are some medkits spread uniformly over the map. A new medkit falls from the skies every now and then. **Medkits heal some portions of player's health** - to survive agent needs to pick them up. Episode finishes after player's death or on timeout.
+
+Further configuration:
+- Living_reward = 1
+- 3 available buttons: turn left, turn right, move forward
+- 1 available game variable: HEALTH
+- death penalty = 100
+
+You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).
+
+There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).
+
+
+
+## Training the agent
+
+- We're going to train the agent for 4000000 steps it will take approximately 20min
+
+```python
+## Start the training, this should take around 15 minutes
+register_vizdoom_components()
+
+# The scenario we train on today is health gathering
+# other scenarios include "doom_basic", "doom_two_colors_easy", "doom_dm", "doom_dwango5", "doom_my_way_home", "doom_deadly_corridor", "doom_defend_the_center", "doom_defend_the_line"
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=8", "--num_envs_per_worker=4", "--train_for_env_steps=4000000"]
+)
+
+status = run_rl(cfg)
+```
+
+## Let's take a look at the performance of the trained policy and output a video of the agent.
+
+```python
+from sample_factory.enjoy import enjoy
+
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=1", "--save_video", "--no_render", "--max_num_episodes=10"], evaluation=True
+)
+status = enjoy(cfg)
+```
+
+## Now lets visualize the performance of the agent
+
+```python
+from base64 import b64encode
+from IPython.display import HTML
+
+mp4 = open("/content/train_dir/default_experiment/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+The agent has learned something, but its performance could be better. We would clearly need to train for longer. But let's upload this model to the Hub.
+
+## Now lets upload your checkpoint and video to the Hugging Face Hub
+
+
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+```python
+from sample_factory.enjoy import enjoy
+
+hf_username = "ThomasSimonini" # insert your HuggingFace username here
+
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--max_num_frames=100000",
+ "--push_to_hub",
+ f"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+## Let's load another model
+
+
+
+
+This agent's performance was good, but can do better! Let's download and visualize an agent trained for 10B timesteps from the hub.
+
+```bash
+#download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir
+```
+
+```bash
+ls train_dir/doom_health_gathering_supreme_2222
+```
+
+```python
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--experiment=doom_health_gathering_supreme_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+```python
+mp4 = open("/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+## Some additional challenges 🏆: Doom Deathmatch
+
+Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**.
+
+Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance.
+
+```python
+# Download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir
+```
+
+Given the agent plays for a long time the video generation can take **10 minutes**.
+
+```python
+from sample_factory.enjoy import enjoy
+
+register_vizdoom_components()
+env = "doom_deathmatch_bots"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=1",
+ "--experiment=doom_deathmatch_bots_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+mp4 = open("/content/train_dir/doom_deathmatch_bots_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+
+You **can try to train your agent in this environment** using the code above, but not on colab.
+**Good luck 🤞**
+
+If you prefer an easier scenario, **why not try training in another ViZDoom scenario such as `doom_deadly_corridor` or `doom_defend_the_center`.**
+
+
+
+---
+
+
+This concludes the last unit. But we are not finished yet! 🤗 The following **bonus section include some of the most interesting, advanced and cutting edge work in Deep Reinforcement Learning**.
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit8/introduction-sf.mdx b/units/en/unit8/introduction-sf.mdx
new file mode 100644
index 0000000..9250cf4
--- /dev/null
+++ b/units/en/unit8/introduction-sf.mdx
@@ -0,0 +1,13 @@
+# Introduction to PPO with Sample-Factory
+
+
+
+In this second part of Unit 8, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/), an **asynchronous implementation of the PPO algorithm**, to train our agent playing [vizdoom](https://vizdoom.cs.put.edu.pl/) (an open source version of Doom).
+
+In the notebook, **you'll train your agent to play the Health Gathering level**, where the agent must collect health packs to avoid dying. After that, you can **train your agent to play more complex levels, such as Deathmatch**.
+
+ +
+Sounds exciting? Let's get started! 🚀
+
+The hands-on is made by [Edward Beeching](https://twitter.com/edwardbeeching), a Machine Learning Research Scientist at Hugging Face. He worked on Godot Reinforcement Learning Agents, an open-source interface for developing environments and agents in the Godot Game Engine.
diff --git a/units/en/unit8/introduction.mdx b/units/en/unit8/introduction.mdx
new file mode 100644
index 0000000..6e8645d
--- /dev/null
+++ b/units/en/unit8/introduction.mdx
@@ -0,0 +1,23 @@
+# Introduction [[introduction]]
+
+
+
+In Unit 6, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
+
+- *An Actor* that controls **how our agent behaves** (policy-based method).
+- *A Critic* that measures **how good the action taken is** (value-based method).
+
+Today we'll learn about Proximal Policy Optimization (PPO), an architecture that **improves our agent's training stability by avoiding too large policy updates**. To do that, we use a ratio that indicates the difference between our current and old policy and clip this ratio from a specific range \\( [1 - \epsilon, 1 + \epsilon] \\) .
+
+Doing this will ensure **that our policy update will not be too large and that the training is more stable.**
+
+This Unit is in two parts:
+- In this first part, you'll learn the theory behind PPO and code your PPO agent from scratch using [CleanRL](https://github.com/vwxyzjn/cleanrl) implementation. To test its robustness with LunarLander-v2. LunarLander-v2 **is the first environment you used when you started this course**. At that time, you didn't know how PPO worked, and now, **you can code it from scratch and train it. How incredible is that 🤩**.
+- In the second part, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/) and train an agent playing vizdoom (an open source version of Doom).
+
+
+
+These are the environments you're going to use to train your agents: VizDoom environments
+
+
+Sounds exciting? Let's get started! 🚀
diff --git a/units/en/unit8/intuition-behind-ppo.mdx b/units/en/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 0000000..921fed1
--- /dev/null
+++ b/units/en/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# The intuition behind PPO [[the-intuition-behind-ppo]]
+
+
+The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
+
+For two reasons:
+- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
+- A too-big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
+
+
+
+
+Sounds exciting? Let's get started! 🚀
+
+The hands-on is made by [Edward Beeching](https://twitter.com/edwardbeeching), a Machine Learning Research Scientist at Hugging Face. He worked on Godot Reinforcement Learning Agents, an open-source interface for developing environments and agents in the Godot Game Engine.
diff --git a/units/en/unit8/introduction.mdx b/units/en/unit8/introduction.mdx
new file mode 100644
index 0000000..6e8645d
--- /dev/null
+++ b/units/en/unit8/introduction.mdx
@@ -0,0 +1,23 @@
+# Introduction [[introduction]]
+
+
+
+In Unit 6, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
+
+- *An Actor* that controls **how our agent behaves** (policy-based method).
+- *A Critic* that measures **how good the action taken is** (value-based method).
+
+Today we'll learn about Proximal Policy Optimization (PPO), an architecture that **improves our agent's training stability by avoiding too large policy updates**. To do that, we use a ratio that indicates the difference between our current and old policy and clip this ratio from a specific range \\( [1 - \epsilon, 1 + \epsilon] \\) .
+
+Doing this will ensure **that our policy update will not be too large and that the training is more stable.**
+
+This Unit is in two parts:
+- In this first part, you'll learn the theory behind PPO and code your PPO agent from scratch using [CleanRL](https://github.com/vwxyzjn/cleanrl) implementation. To test its robustness with LunarLander-v2. LunarLander-v2 **is the first environment you used when you started this course**. At that time, you didn't know how PPO worked, and now, **you can code it from scratch and train it. How incredible is that 🤩**.
+- In the second part, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/) and train an agent playing vizdoom (an open source version of Doom).
+
+
+
+These are the environments you're going to use to train your agents: VizDoom environments
+
+
+Sounds exciting? Let's get started! 🚀
diff --git a/units/en/unit8/intuition-behind-ppo.mdx b/units/en/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 0000000..921fed1
--- /dev/null
+++ b/units/en/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# The intuition behind PPO [[the-intuition-behind-ppo]]
+
+
+The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
+
+For two reasons:
+- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
+- A too-big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
+
+
+  + Taking smaller policy updates to improve the training stability
+ Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui
+
+
+**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
new file mode 100644
index 0000000..958b61c
--- /dev/null
+++ b/units/en/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# Visualize the Clipped Surrogate Objective Function
+
+Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
+
+
+
+ Taking smaller policy updates to improve the training stability
+ Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui
+
+
+**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
new file mode 100644
index 0000000..958b61c
--- /dev/null
+++ b/units/en/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# Visualize the Clipped Surrogate Objective Function
+
+Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
+
+
+ 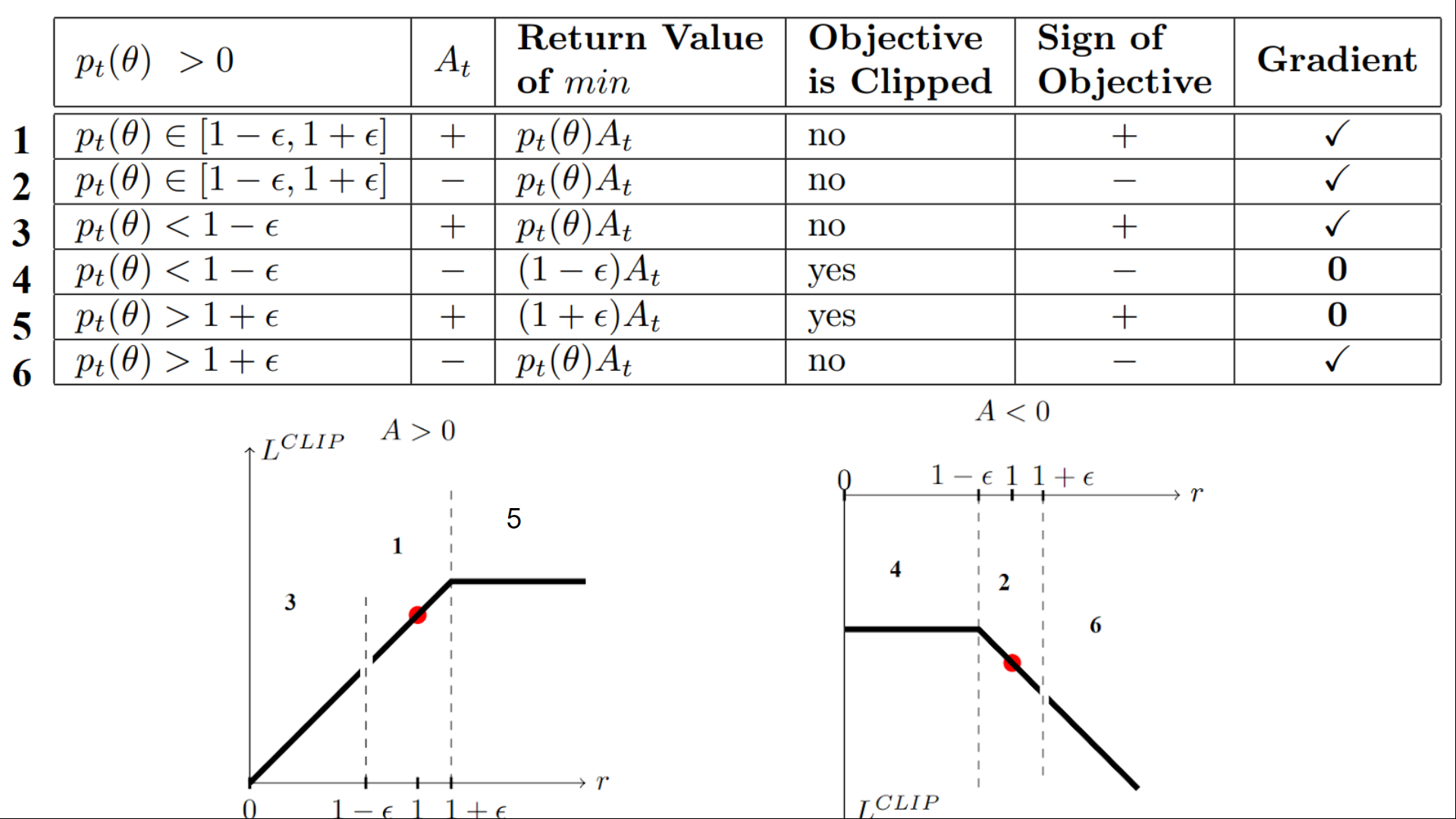 + Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
+
+## Case 1 and 2: the ratio is between the range
+
+In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
+
+In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
+
+Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
+
+In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
+
+Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
+
+## Case 3 and 4: the ratio is below the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
+
+If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
+
+But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+## Case 5 and 6: the ratio is above the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
+
+If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
+
+So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
+
+So we update our policy only if:
+- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
+- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
+ - Being below the ratio but the advantage is > 0
+ - Being above the ratio but the advantage is < 0
+
+**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
+
+
+To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
+
+The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
+
+## Case 1 and 2: the ratio is between the range
+
+In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
+
+In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
+
+Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
+
+In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
+
+Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
+
+## Case 3 and 4: the ratio is below the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
+
+If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
+
+But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+## Case 5 and 6: the ratio is above the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
+
+If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
+
+So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
+
+So we update our policy only if:
+- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
+- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
+ - Being below the ratio but the advantage is > 0
+ - Being above the ratio but the advantage is < 0
+
+**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
+
+
+To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
+
+The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
+
+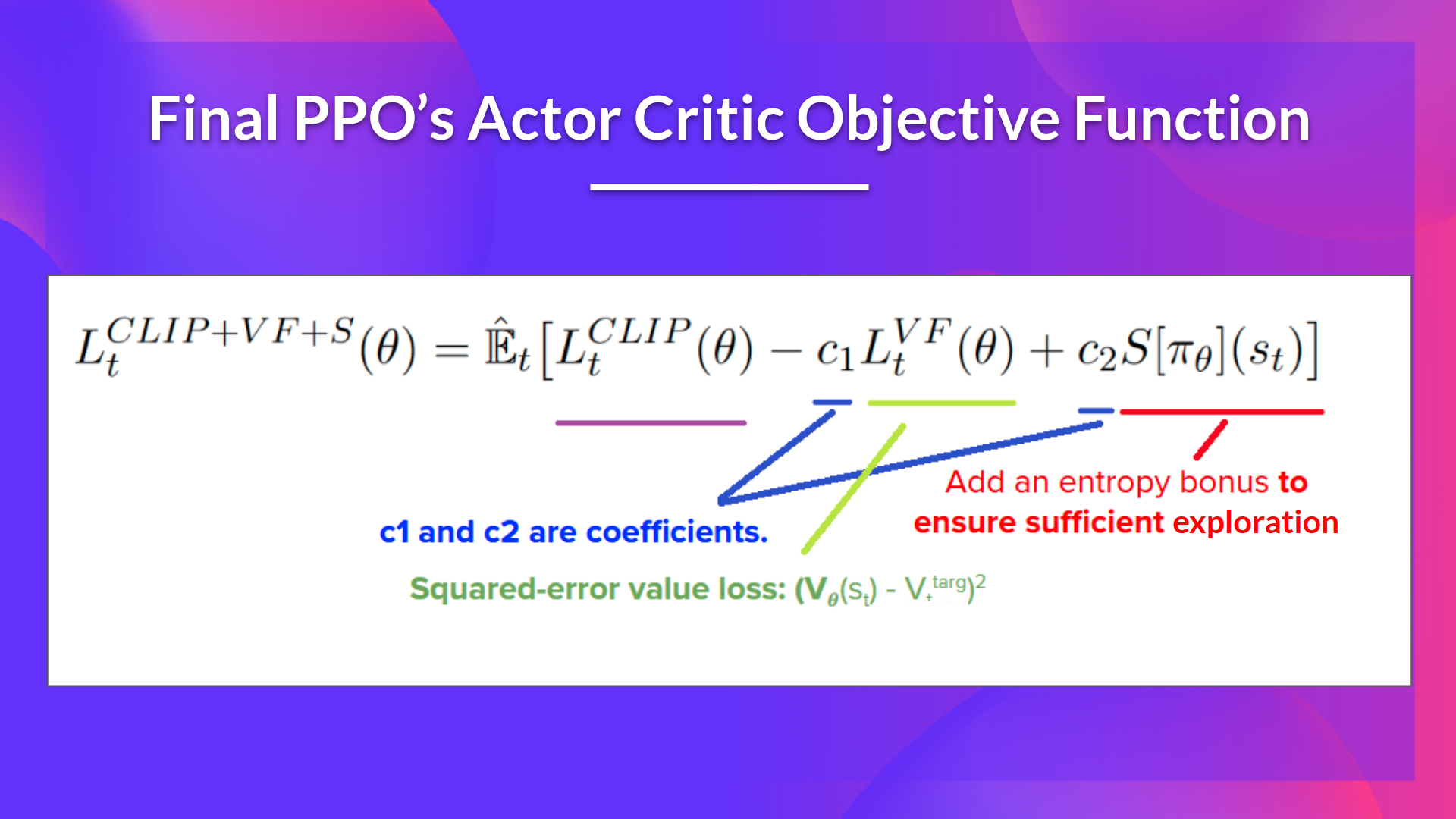 +
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
diff --git a/units/en/unitbonus3/curriculum-learning.mdx b/units/en/unitbonus3/curriculum-learning.mdx
new file mode 100644
index 0000000..dbe8e64
--- /dev/null
+++ b/units/en/unitbonus3/curriculum-learning.mdx
@@ -0,0 +1,54 @@
+# (Automatic) Curriculum Learning for RL
+
+While most of the RL methods seen in this course work well in practice, there are some cases where using them alone fails. It is for instance the case where:
+
+- the task to learn is hard and requires an **incremental acquisition of skills** (for instance when one wants to make a bipedal agent learn to go through hard obstacles, it must first learn to stand, then walk, then maybe jump…)
+- there are variations in the environment (that affect the difficulty) and one wants its agent to be **robust** to them
+
+
+
+
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
diff --git a/units/en/unitbonus3/curriculum-learning.mdx b/units/en/unitbonus3/curriculum-learning.mdx
new file mode 100644
index 0000000..dbe8e64
--- /dev/null
+++ b/units/en/unitbonus3/curriculum-learning.mdx
@@ -0,0 +1,54 @@
+# (Automatic) Curriculum Learning for RL
+
+While most of the RL methods seen in this course work well in practice, there are some cases where using them alone fails. It is for instance the case where:
+
+- the task to learn is hard and requires an **incremental acquisition of skills** (for instance when one wants to make a bipedal agent learn to go through hard obstacles, it must first learn to stand, then walk, then maybe jump…)
+- there are variations in the environment (that affect the difficulty) and one wants its agent to be **robust** to them
+
+
+ +
+ + TeachMyAgent
+
+
+In such cases, it seems needed to propose different tasks to our RL agent and organize them such that it allows the agent to progressively acquire skills. This approach is called **Curriculum Learning** and usually implies a hand-designed curriculum (or set of tasks organized in a specific order). In practice, one can for instance control the generation of the environment, the initial states, or use Self-Play an control the level of opponents proposed to the RL agent.
+
+As designing such a curriculum is not always trivial, the field of **Automatic Curriculum Learning (ACL) proposes to design approaches that learn to create such and organization of tasks in order to maximize the RL agent’s performances**. Portelas et al. proposed to define ACL as:
+
+> … a family of mechanisms that automatically adapt the distribution of training data by learning to adjust the selection of learning situations to the capabilities of RL agents.
+>
+
+As an example, OpenAI used **Domain Randomization** (they applied random variations on the environment) to make a robot hand solve Rubik’s Cubes.
+
+
+
+
+ TeachMyAgent
+
+
+In such cases, it seems needed to propose different tasks to our RL agent and organize them such that it allows the agent to progressively acquire skills. This approach is called **Curriculum Learning** and usually implies a hand-designed curriculum (or set of tasks organized in a specific order). In practice, one can for instance control the generation of the environment, the initial states, or use Self-Play an control the level of opponents proposed to the RL agent.
+
+As designing such a curriculum is not always trivial, the field of **Automatic Curriculum Learning (ACL) proposes to design approaches that learn to create such and organization of tasks in order to maximize the RL agent’s performances**. Portelas et al. proposed to define ACL as:
+
+> … a family of mechanisms that automatically adapt the distribution of training data by learning to adjust the selection of learning situations to the capabilities of RL agents.
+>
+
+As an example, OpenAI used **Domain Randomization** (they applied random variations on the environment) to make a robot hand solve Rubik’s Cubes.
+
+
+
+ + OpenAI - Solving Rubik’s Cube with a Robot Hand
+
+
+Finally, you can play with the robustness of agents trained in the TeachMyAgent benchmark by controlling environment variations or even drawing the terrain 👇
+
+
+
+ OpenAI - Solving Rubik’s Cube with a Robot Hand
+
+
+Finally, you can play with the robustness of agents trained in the TeachMyAgent benchmark by controlling environment variations or even drawing the terrain 👇
+
+
+ + https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
+
+
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+### Overview of the field
+
+- [Automatic Curriculum Learning For Deep RL: A Short Survey](https://arxiv.org/pdf/2003.04664.pdf)
+- [Curriculum for Reinforcement Learning](https://lilianweng.github.io/posts/2020-01-29-curriculum-rl/)
+
+### Recent methods
+
+- [Evolving Curricula with Regret-Based Environment Design](https://arxiv.org/abs/2203.01302)
+- [Curriculum Reinforcement Learning via Constrained Optimal Transport](https://proceedings.mlr.press/v162/klink22a.html)
+- [Prioritized Level Replay](https://arxiv.org/abs/2010.03934)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/decision-transformers.mdx b/units/en/unitbonus3/decision-transformers.mdx
new file mode 100644
index 0000000..737564e
--- /dev/null
+++ b/units/en/unitbonus3/decision-transformers.mdx
@@ -0,0 +1,31 @@
+# Decision Transformers
+
+The Decision Transformer model was introduced by ["Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a conditional-sequence modeling problem.
+
+The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), **we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return**.
+It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
+
+This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
+
+The 🤗 Transformers team integrated the Decision Transformer, an Offline Reinforcement Learning method, into the library as well as the Hugging Face Hub.
+
+## Learn about Decision Transformers
+
+To learn more about Decision Transformers, you should read the blogpost we wrote about it [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers)
+
+## Train your first Decision Transformers
+
+Now that you understand how Decision Transformers work thanks to [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers). You’re ready to learn to train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
+
+Start the tutorial here 👉 https://huggingface.co/blog/train-decision-transformers
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+- [Online Decision Transformer](https://arxiv.org/abs/2202.05607)
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
new file mode 100644
index 0000000..404e038
--- /dev/null
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -0,0 +1,49 @@
+# Interesting Environments to try
+
+We provide here a list of interesting environments you can try to train your agents on:
+
+## MineRL
+
+
+ https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
+
+
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+### Overview of the field
+
+- [Automatic Curriculum Learning For Deep RL: A Short Survey](https://arxiv.org/pdf/2003.04664.pdf)
+- [Curriculum for Reinforcement Learning](https://lilianweng.github.io/posts/2020-01-29-curriculum-rl/)
+
+### Recent methods
+
+- [Evolving Curricula with Regret-Based Environment Design](https://arxiv.org/abs/2203.01302)
+- [Curriculum Reinforcement Learning via Constrained Optimal Transport](https://proceedings.mlr.press/v162/klink22a.html)
+- [Prioritized Level Replay](https://arxiv.org/abs/2010.03934)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/decision-transformers.mdx b/units/en/unitbonus3/decision-transformers.mdx
new file mode 100644
index 0000000..737564e
--- /dev/null
+++ b/units/en/unitbonus3/decision-transformers.mdx
@@ -0,0 +1,31 @@
+# Decision Transformers
+
+The Decision Transformer model was introduced by ["Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a conditional-sequence modeling problem.
+
+The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), **we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return**.
+It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
+
+This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
+
+The 🤗 Transformers team integrated the Decision Transformer, an Offline Reinforcement Learning method, into the library as well as the Hugging Face Hub.
+
+## Learn about Decision Transformers
+
+To learn more about Decision Transformers, you should read the blogpost we wrote about it [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers)
+
+## Train your first Decision Transformers
+
+Now that you understand how Decision Transformers work thanks to [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers). You’re ready to learn to train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
+
+Start the tutorial here 👉 https://huggingface.co/blog/train-decision-transformers
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+- [Online Decision Transformer](https://arxiv.org/abs/2202.05607)
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/envs-to-try.mdx b/units/en/unitbonus3/envs-to-try.mdx
new file mode 100644
index 0000000..404e038
--- /dev/null
+++ b/units/en/unitbonus3/envs-to-try.mdx
@@ -0,0 +1,49 @@
+# Interesting Environments to try
+
+We provide here a list of interesting environments you can try to train your agents on:
+
+## MineRL
+
+ +
+
+MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
+Every year, there are challenges with this library. Check the [website](https://minerl.io/)
+
+To start using this environment, check these resources:
+- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar Simulator
+
+
+
+
+MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
+Every year, there are challenges with this library. Check the [website](https://minerl.io/)
+
+To start using this environment, check these resources:
+- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar Simulator
+
+ +Donkey is a Self Driving Car Platform for hobby remote control cars.
+This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
+
+
+To start using this environment, check these resources:
+- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- Pretrained agents:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## Starcraft II
+
+
+Donkey is a Self Driving Car Platform for hobby remote control cars.
+This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
+
+
+To start using this environment, check these resources:
+- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- Pretrained agents:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## Starcraft II
+
+ +
+Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+To start using this environment, check these resources:
+- [Starcraft gym](http://starcraftgym.com/)
+- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
new file mode 100644
index 0000000..8e993a3
--- /dev/null
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -0,0 +1,208 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
+
+The library provides:
+
+- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
+- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- Support for memory-based agents with LSTM or attention based interfaces
+- Support for *2D and 3D games*
+- A suite of *AI sensors* to augment your agent's capacity to observe the game world
+- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
+
+You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
+
+## Create a custom RL environment with Godot RL Agents
+
+In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
+
+The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**.You can then dive into the examples for more complex environments and behaviors.
+
+The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
+
+
+
+Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+To start using this environment, check these resources:
+- [Starcraft gym](http://starcraftgym.com/)
+- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
new file mode 100644
index 0000000..8e993a3
--- /dev/null
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -0,0 +1,208 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
+
+The library provides:
+
+- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
+- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- Support for memory-based agents with LSTM or attention based interfaces
+- Support for *2D and 3D games*
+- A suite of *AI sensors* to augment your agent's capacity to observe the game world
+- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
+
+You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
+
+## Create a custom RL environment with Godot RL Agents
+
+In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
+
+The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**.You can then dive into the examples for more complex environments and behaviors.
+
+The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
+
+ +
+### Installing the Godot Game Engine
+
+The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
+
+Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
+
+While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
+
+In order to create games in Godot, **you must first download the editor**. The latest version Godot RL agents was updated to use Godot 4 beta, as we are expecting this to be released in the next few months.
+
+At the time of writing the latest beta version was beta 14 which can be downloaded at the following links:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_linux.x86_64.zip)
+
+### Loading the starter project
+
+We provide two versions of the codebase:
+- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
+
+If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
+
+### Installing the Godot RL Agents plugin
+
+The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
+
+First click on the AssetLib and search for “rl”
+
+
+
+### Installing the Godot Game Engine
+
+The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
+
+Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
+
+While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
+
+In order to create games in Godot, **you must first download the editor**. The latest version Godot RL agents was updated to use Godot 4 beta, as we are expecting this to be released in the next few months.
+
+At the time of writing the latest beta version was beta 14 which can be downloaded at the following links:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0/beta14/Godot_v4.0-beta14_linux.x86_64.zip)
+
+### Loading the starter project
+
+We provide two versions of the codebase:
+- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
+
+If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
+
+### Installing the Godot RL Agents plugin
+
+The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
+
+First click on the AssetLib and search for “rl”
+
+ +
+Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+
+
+
+Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+
+ +
+
+The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+
+
+
+
+The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+
+ +
+
+### Adding the AI controller
+
+We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
+
+
+
+
+### Adding the AI controller
+
+We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
+
+ +
+Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
+
+
+
+Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
+
+ +
+The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
+
+Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+We will now implement the 4 missing methods, delete this code and replace it with the following:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
+
+You can run training live in the the editor, but first launching the python training with `python examples/clean_rl_example.py —env-id=debug`
+
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+
+
+
+The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
+
+Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+We will now implement the 4 missing methods, delete this code and replace it with the following:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
+
+You can run training live in the the editor, but first launching the python training with `python examples/clean_rl_example.py —env-id=debug`
+
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+
+ +
+Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
+
+### There’s more!
+
+We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/introduction.mdx b/units/en/unitbonus3/introduction.mdx
new file mode 100644
index 0000000..50b4bd0
--- /dev/null
+++ b/units/en/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# Introduction
+
+
+
+Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
+
+### There’s more!
+
+We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+
+## Author
+
+This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/introduction.mdx b/units/en/unitbonus3/introduction.mdx
new file mode 100644
index 0000000..50b4bd0
--- /dev/null
+++ b/units/en/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# Introduction
+
+ +
+
+Congratulations on finishing this course! **You now have a solid background in Deep Reinforcement Learning**.
+But this course was just the beginning of your Deep Reinforcement Learning journey, there are so many subsections to discover. In this optional unit, we **give you resources to explore multiple concepts and research topics in Reinforcement Learning**.
+
+Contrary to other units, this unit is a collective work of multiple people from Hugging Face. We mention the author for each unit.
+
+Sounds fun? Let's get started 🔥,
diff --git a/units/en/unitbonus3/language-models.mdx b/units/en/unitbonus3/language-models.mdx
new file mode 100644
index 0000000..0fffc19
--- /dev/null
+++ b/units/en/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# Language models in RL
+## LMs encode useful knowledge for agents
+
+**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
+
+A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
+
+
+
+
+
+Congratulations on finishing this course! **You now have a solid background in Deep Reinforcement Learning**.
+But this course was just the beginning of your Deep Reinforcement Learning journey, there are so many subsections to discover. In this optional unit, we **give you resources to explore multiple concepts and research topics in Reinforcement Learning**.
+
+Contrary to other units, this unit is a collective work of multiple people from Hugging Face. We mention the author for each unit.
+
+Sounds fun? Let's get started 🔥,
diff --git a/units/en/unitbonus3/language-models.mdx b/units/en/unitbonus3/language-models.mdx
new file mode 100644
index 0000000..0fffc19
--- /dev/null
+++ b/units/en/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# Language models in RL
+## LMs encode useful knowledge for agents
+
+**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
+
+A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
+
+
+ +Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+## LMs and RL
+
+There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct these knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the **Tabula-rasa** setup where everything is learned from scratch by agent leading to:
+
+1) Sample inefficiency
+
+2) Unexpected behaviors from humans’ eyes
+
+As a first attempt, the paper [“Grounding Large Language Models with Online Reinforcement Learning”](https://arxiv.org/abs/2302.02662v1) tackled the problem of **adapting or aligning a LM to a textual environment using PPO**. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenue for sample efficiency RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
+
+
+
+Another direction studied in [“Guiding Pretraining in Reinforcement Learning with Large Language Models”](https://arxiv.org/abs/2302.06692) was to keep the LM frozen but leverage its knowledge to **guide an RL agent’s exploration**. Such method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
+
+
+
+Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+## LMs and RL
+
+There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct these knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the **Tabula-rasa** setup where everything is learned from scratch by agent leading to:
+
+1) Sample inefficiency
+
+2) Unexpected behaviors from humans’ eyes
+
+As a first attempt, the paper [“Grounding Large Language Models with Online Reinforcement Learning”](https://arxiv.org/abs/2302.02662v1) tackled the problem of **adapting or aligning a LM to a textual environment using PPO**. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenue for sample efficiency RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
+
+
+
+Another direction studied in [“Guiding Pretraining in Reinforcement Learning with Large Language Models”](https://arxiv.org/abs/2302.06692) was to keep the LM frozen but leverage its knowledge to **guide an RL agent’s exploration**. Such method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
+
+
+ + Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+Several limitations make these works still very preliminary such as the need to convert the agent's observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
+
+## Further reading
+
+For more information we recommend you check out the following resources:
+
+- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
+- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
+- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
+- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/model-based.mdx b/units/en/unitbonus3/model-based.mdx
new file mode 100644
index 0000000..9983a01
--- /dev/null
+++ b/units/en/unitbonus3/model-based.mdx
@@ -0,0 +1,32 @@
+# Model Based Reinforcement Learning (MBRL)
+
+Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
+
+The dynamics models usually model the environment transition dynamics, \\( s_{t+1} = f_\theta (s_t, a_t) \\), but things like inverse dynamics models (mapping from states to actions) or reward models (predicting rewards) can be used in this framework.
+
+
+## Simple definition
+
+- There is an agent that repeatedly tries to solve a problem, **accumulating state and action data**.
+- With that data, the agent creates a structured learning tool, *a dynamics model*, to reason about the world.
+- With the dynamics model, the agent **decides how to act by predicting the future**.
+- With those actions, **the agent collects more data, improves said model, and hopefully improves future actions**.
+
+## Academic definition
+
+Model-based reinforcement learning (MBRL) follows the framework of an agent interacting in an environment, **learning a model of said environment**, and then **leveraging the model for control (making decisions).
+
+Specifically, the agent acts in a Markov Decision Process (MDP) governed by a transition function \\( s_{t+1} = f (s_t , a_t) \\) and returns a reward at each step \\( r(s_t, a_t) \\). With a collected dataset \\( D :={ s_i, a_i, s_{i+1}, r_i} \\), the agent learns a model, \\( s_{t+1} = f_\theta (s_t , a_t) \\) **to minimize the negative log-likelihood of the transitions**.
+
+We employ sample-based model-predictive control (MPC) using the learned dynamics model, which optimizes the expected reward over a finite, recursively predicted horizon, \\( \tau \\), from a set of actions sampled from a uniform distribution \\( U(a) \\), (see [paper](https://arxiv.org/pdf/2002.04523) or [paper](https://arxiv.org/pdf/2012.09156.pdf) or [paper](https://arxiv.org/pdf/2009.01221.pdf)).
+
+## Further reading
+
+For more information on MBRL, we recommend you check out the following resources:
+
+- A [blog post on debugging MBRL](https://www.natolambert.com/writing/debugging-mbrl).
+- A [recent review paper on MBRL](https://arxiv.org/abs/2006.16712),
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/offline-online.mdx b/units/en/unitbonus3/offline-online.mdx
new file mode 100644
index 0000000..be6fa37
--- /dev/null
+++ b/units/en/unitbonus3/offline-online.mdx
@@ -0,0 +1,37 @@
+# Offline vs. Online Reinforcement Learning
+
+Deep Reinforcement Learning (RL) is a framework **to build decision-making agents**. These agents aim to learn optimal behavior (policy) by interacting with the environment through **trial and error and receiving rewards as unique feedback**.
+
+The agent’s goal **is to maximize its cumulative reward**, called return. Because RL is based on the *reward hypothesis*: all goals can be described as the **maximization of the expected cumulative reward**.
+
+Deep Reinforcement Learning agents **learn with batches of experience**. The question is, how do they collect it?:
+
+
+
+ Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+Several limitations make these works still very preliminary such as the need to convert the agent's observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
+
+## Further reading
+
+For more information we recommend you check out the following resources:
+
+- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
+- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
+- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
+- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
+
+## Author
+
+This section was written by Clément Romac
diff --git a/units/en/unitbonus3/model-based.mdx b/units/en/unitbonus3/model-based.mdx
new file mode 100644
index 0000000..9983a01
--- /dev/null
+++ b/units/en/unitbonus3/model-based.mdx
@@ -0,0 +1,32 @@
+# Model Based Reinforcement Learning (MBRL)
+
+Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
+
+The dynamics models usually model the environment transition dynamics, \\( s_{t+1} = f_\theta (s_t, a_t) \\), but things like inverse dynamics models (mapping from states to actions) or reward models (predicting rewards) can be used in this framework.
+
+
+## Simple definition
+
+- There is an agent that repeatedly tries to solve a problem, **accumulating state and action data**.
+- With that data, the agent creates a structured learning tool, *a dynamics model*, to reason about the world.
+- With the dynamics model, the agent **decides how to act by predicting the future**.
+- With those actions, **the agent collects more data, improves said model, and hopefully improves future actions**.
+
+## Academic definition
+
+Model-based reinforcement learning (MBRL) follows the framework of an agent interacting in an environment, **learning a model of said environment**, and then **leveraging the model for control (making decisions).
+
+Specifically, the agent acts in a Markov Decision Process (MDP) governed by a transition function \\( s_{t+1} = f (s_t , a_t) \\) and returns a reward at each step \\( r(s_t, a_t) \\). With a collected dataset \\( D :={ s_i, a_i, s_{i+1}, r_i} \\), the agent learns a model, \\( s_{t+1} = f_\theta (s_t , a_t) \\) **to minimize the negative log-likelihood of the transitions**.
+
+We employ sample-based model-predictive control (MPC) using the learned dynamics model, which optimizes the expected reward over a finite, recursively predicted horizon, \\( \tau \\), from a set of actions sampled from a uniform distribution \\( U(a) \\), (see [paper](https://arxiv.org/pdf/2002.04523) or [paper](https://arxiv.org/pdf/2012.09156.pdf) or [paper](https://arxiv.org/pdf/2009.01221.pdf)).
+
+## Further reading
+
+For more information on MBRL, we recommend you check out the following resources:
+
+- A [blog post on debugging MBRL](https://www.natolambert.com/writing/debugging-mbrl).
+- A [recent review paper on MBRL](https://arxiv.org/abs/2006.16712),
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/offline-online.mdx b/units/en/unitbonus3/offline-online.mdx
new file mode 100644
index 0000000..be6fa37
--- /dev/null
+++ b/units/en/unitbonus3/offline-online.mdx
@@ -0,0 +1,37 @@
+# Offline vs. Online Reinforcement Learning
+
+Deep Reinforcement Learning (RL) is a framework **to build decision-making agents**. These agents aim to learn optimal behavior (policy) by interacting with the environment through **trial and error and receiving rewards as unique feedback**.
+
+The agent’s goal **is to maximize its cumulative reward**, called return. Because RL is based on the *reward hypothesis*: all goals can be described as the **maximization of the expected cumulative reward**.
+
+Deep Reinforcement Learning agents **learn with batches of experience**. The question is, how do they collect it?:
+
+
+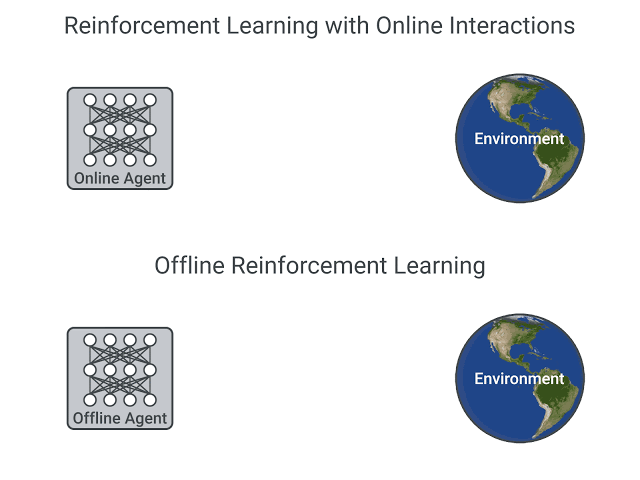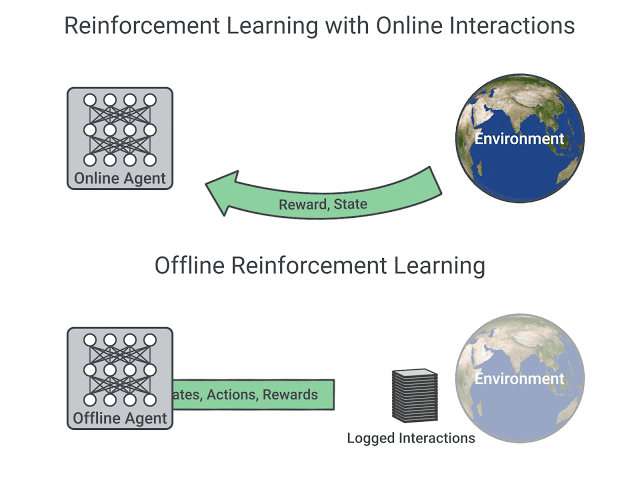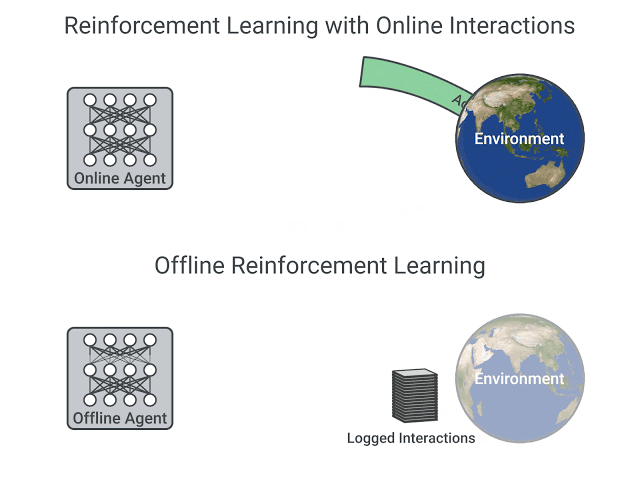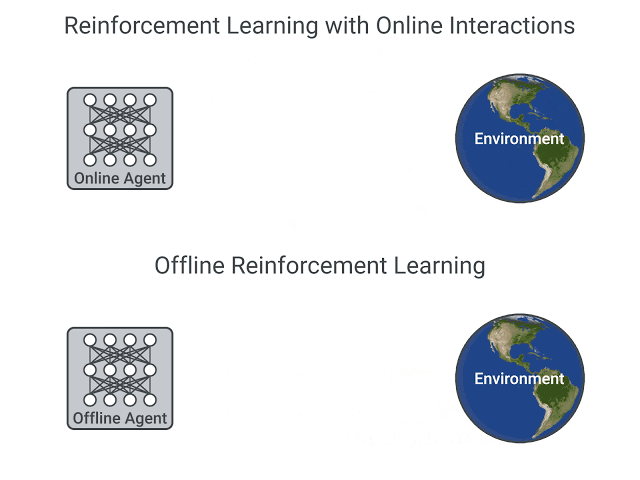 +A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from this post
+
+
+- In *online reinforcement learning*, which is what we've learned during this course, the agent **gathers data directly**: it collects a batch of experience by **interacting with the environment**. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
+
+But this implies that either you **train your agent directly in the real world or have a simulator**. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure (if the simulator has flaws that may provide a competitive advantage, the agent will exploit them).
+
+- On the other hand, in *offline reinforcement learning*, the agent only **uses data collected from other agents or human demonstrations**. It does **not interact with the environment**.
+
+The process is as follows:
+- **Create a dataset** using one or more policies and/or human interactions.
+- Run **offline RL on this dataset** to learn a policy
+
+This method has one drawback: the *counterfactual queries problem*. What do we do if our agent **decides to do something for which we don’t have the data?** For instance, turning right on an intersection but we don’t have this trajectory.
+
+There exist some solutions on this topic, but if you want to know more about offline reinforcement learning, you can [watch this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Offline Reinforcement Learning, Talk by Sergei Levine](https://www.youtube.com/watch?v=qgZPZREor5I)
+- [Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems](https://arxiv.org/abs/2005.01643)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/rl-documentation.mdx b/units/en/unitbonus3/rl-documentation.mdx
new file mode 100644
index 0000000..dc4a661
--- /dev/null
+++ b/units/en/unitbonus3/rl-documentation.mdx
@@ -0,0 +1,56 @@
+# Brief introduction to RL documentation
+
+In this advanced topic, we address the question: **how should we monitor and keep track of powerful reinforcement learning agents that we are training in the real world and
+interfacing with humans?**
+
+As machine learning systems have increasingly impacted modern life, **call for documentation of these systems has grown**.
+
+Such documentation can cover aspects such as the training data used — where it is stored, when it was collected, who was involved, etc.
+— or the model optimization framework — the architecture, evaluation metrics, relevant papers, etc. — and more.
+
+Today, model cards and datasheets are becoming increasingly available. For example, on the Hub
+(see documentation [here](https://huggingface.co/docs/hub/model-cards)).
+
+If you click on a [popular model on the Hub](https://huggingface.co/models), you can learn about its creation process.
+
+These model and data specific logs are designed to be completed when the model or dataset are created, leaving them to go un-updated when these models are built into evolving systems in the future.
+
+## Motivating Reward Reports
+
+Reinforcement learning systems are fundamentally designed to optimize based on measurements of reward and time.
+While the notion of a reward function can be mapped nicely to many well-understood fields of supervised learning (via a loss function),
+understanding how machine learning systems evolve over time is limited.
+
+To that end, the authors introduce [*Reward Reports for Reinforcement Learning*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4) (the pithy naming is designed to mirror the popular papers *Model Cards for Model Reporting* and *Datasheets for Datasets*).
+The goal is to propose a type of documentation focused on the **human factors of reward** and **time-varying feedback systems**.
+
+Building on the documentation frameworks for [model cards](https://arxiv.org/abs/1810.03993) and [datasheets](https://arxiv.org/abs/1803.09010) proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems.
+
+**Reward Reports** are living documents for proposed RL deployments that demarcate design choices.
+
+However, many questions remain about the applicability of this framework to different RL applications, roadblocks to system interpretability,
+and the resonances between deployed supervised machine learning systems and the sequential decision-making utilized in RL.
+
+At a minimum, Reward Reports are an opportunity for RL practitioners to deliberate on these questions and begin the work of deciding how to resolve them in practice.
+
+## Capturing temporal behavior with documentation
+
+The core piece specific to documentation designed for RL and feedback-driven ML systems is a *change-log*. The change-log updates information
+from the designer (changed training parameters, data, etc.) along with noticed changes from the user (harmful behavior, unexpected responses, etc.).
+
+The change log is accompanied by update triggers that encourage monitoring these effects.
+
+## Contributing
+
+Some of the most impactful RL-driven systems are multi-stakeholder in nature and behind closed doors of private corporations.
+These corporations are largely without regulation, so the burden of documentation falls on the public.
+
+If you are interested in contributing, we are building Reward Reports for popular machine learning systems on a public
+record on [GitHub](https://github.com/RewardReports/reward-reports).
+
+For further reading, you can visit the Reward Reports [paper](https://arxiv.org/abs/2204.10817)
+or look [an example report](https://github.com/RewardReports/reward-reports/tree/main/examples).
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/rlhf.mdx b/units/en/unitbonus3/rlhf.mdx
new file mode 100644
index 0000000..7c473d1
--- /dev/null
+++ b/units/en/unitbonus3/rlhf.mdx
@@ -0,0 +1,50 @@
+# RLHF
+
+Reinforcement learning from human feedback (RLHF) is a **methodology for integrating human data labels into a RL-based optimization process**.
+It is motivated by the **challenge of modeling human preferences**.
+
+For many questions, even if you could try and write down an equation for one ideal, humans differ on their preferences.
+
+Updating models **based on measured data is an avenue to try and alleviate these inherently human ML problems**.
+
+## Start Learning about RLHF
+
+To start learning about RLHF:
+
+1. Read this introduction: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf).
+
+2. Watch the recorded live we did some weeks ago, where Nathan covered the basics of Reinforcement Learning from Human Feedback (RLHF) and how this technology is being used to enable state-of-the-art ML tools like ChatGPT.
+Most of the talk is an overview of the interconnected ML models. It covers the basics of Natural Language Processing and RL and how RLHF is used on large language models. We then conclude with the open question in RLHF.
+
+
+
+3. Read other blogs on this topic, such as [Closed-API vs Open-source continues: RLHF, ChatGPT, data moats](https://robotic.substack.com/p/rlhf-chatgpt-data-moats). Let us know if there are more you like!
+
+
+## Additional readings
+
+*Note, this is copied from the Illustrating RLHF blog post above*.
+Here is a list of the most prevalent papers on RLHF to date. The field was recently popularized with the emergence of DeepRL (around 2017) and has grown into a broader study of the applications of LLMs from many large technology companies.
+Here are some papers on RLHF that pre-date the LM focus:
+- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008): Proposed a learned agent where humans provided scores on the actions taken iteratively to learn a reward model.
+- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017): Proposed an actor-critic algorithm, COACH, where human feedback (both positive and negative) is used to tune the advantage function.
+- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017): RLHF applied on preferences between Atari trajectories.
+- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485) (Warnell et al. 2018): Extends the TAMER framework where a deep neural network is used to model the reward prediction.
+
+And here is a snapshot of the growing set of papers that show RLHF's performance for LMs:
+- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
+- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021), follow on work summarizing books.
+- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
+- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022): RLHF applied to a general language model [[Blog post](https://openai.com/blog/instruction-following/) on InstructGPT].
+- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
+- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
+- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
+- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
+- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
+- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
+- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
+- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
+
+## Author
+
+This section was written by Nathan Lambert
+A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from this post
+
+
+- In *online reinforcement learning*, which is what we've learned during this course, the agent **gathers data directly**: it collects a batch of experience by **interacting with the environment**. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
+
+But this implies that either you **train your agent directly in the real world or have a simulator**. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure (if the simulator has flaws that may provide a competitive advantage, the agent will exploit them).
+
+- On the other hand, in *offline reinforcement learning*, the agent only **uses data collected from other agents or human demonstrations**. It does **not interact with the environment**.
+
+The process is as follows:
+- **Create a dataset** using one or more policies and/or human interactions.
+- Run **offline RL on this dataset** to learn a policy
+
+This method has one drawback: the *counterfactual queries problem*. What do we do if our agent **decides to do something for which we don’t have the data?** For instance, turning right on an intersection but we don’t have this trajectory.
+
+There exist some solutions on this topic, but if you want to know more about offline reinforcement learning, you can [watch this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
+
+## Further reading
+
+For more information, we recommend you check out the following resources:
+
+- [Offline Reinforcement Learning, Talk by Sergei Levine](https://www.youtube.com/watch?v=qgZPZREor5I)
+- [Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems](https://arxiv.org/abs/2005.01643)
+
+## Author
+
+This section was written by Thomas Simonini
diff --git a/units/en/unitbonus3/rl-documentation.mdx b/units/en/unitbonus3/rl-documentation.mdx
new file mode 100644
index 0000000..dc4a661
--- /dev/null
+++ b/units/en/unitbonus3/rl-documentation.mdx
@@ -0,0 +1,56 @@
+# Brief introduction to RL documentation
+
+In this advanced topic, we address the question: **how should we monitor and keep track of powerful reinforcement learning agents that we are training in the real world and
+interfacing with humans?**
+
+As machine learning systems have increasingly impacted modern life, **call for documentation of these systems has grown**.
+
+Such documentation can cover aspects such as the training data used — where it is stored, when it was collected, who was involved, etc.
+— or the model optimization framework — the architecture, evaluation metrics, relevant papers, etc. — and more.
+
+Today, model cards and datasheets are becoming increasingly available. For example, on the Hub
+(see documentation [here](https://huggingface.co/docs/hub/model-cards)).
+
+If you click on a [popular model on the Hub](https://huggingface.co/models), you can learn about its creation process.
+
+These model and data specific logs are designed to be completed when the model or dataset are created, leaving them to go un-updated when these models are built into evolving systems in the future.
+
+## Motivating Reward Reports
+
+Reinforcement learning systems are fundamentally designed to optimize based on measurements of reward and time.
+While the notion of a reward function can be mapped nicely to many well-understood fields of supervised learning (via a loss function),
+understanding how machine learning systems evolve over time is limited.
+
+To that end, the authors introduce [*Reward Reports for Reinforcement Learning*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4) (the pithy naming is designed to mirror the popular papers *Model Cards for Model Reporting* and *Datasheets for Datasets*).
+The goal is to propose a type of documentation focused on the **human factors of reward** and **time-varying feedback systems**.
+
+Building on the documentation frameworks for [model cards](https://arxiv.org/abs/1810.03993) and [datasheets](https://arxiv.org/abs/1803.09010) proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems.
+
+**Reward Reports** are living documents for proposed RL deployments that demarcate design choices.
+
+However, many questions remain about the applicability of this framework to different RL applications, roadblocks to system interpretability,
+and the resonances between deployed supervised machine learning systems and the sequential decision-making utilized in RL.
+
+At a minimum, Reward Reports are an opportunity for RL practitioners to deliberate on these questions and begin the work of deciding how to resolve them in practice.
+
+## Capturing temporal behavior with documentation
+
+The core piece specific to documentation designed for RL and feedback-driven ML systems is a *change-log*. The change-log updates information
+from the designer (changed training parameters, data, etc.) along with noticed changes from the user (harmful behavior, unexpected responses, etc.).
+
+The change log is accompanied by update triggers that encourage monitoring these effects.
+
+## Contributing
+
+Some of the most impactful RL-driven systems are multi-stakeholder in nature and behind closed doors of private corporations.
+These corporations are largely without regulation, so the burden of documentation falls on the public.
+
+If you are interested in contributing, we are building Reward Reports for popular machine learning systems on a public
+record on [GitHub](https://github.com/RewardReports/reward-reports).
+
+For further reading, you can visit the Reward Reports [paper](https://arxiv.org/abs/2204.10817)
+or look [an example report](https://github.com/RewardReports/reward-reports/tree/main/examples).
+
+## Author
+
+This section was written by Nathan Lambert
diff --git a/units/en/unitbonus3/rlhf.mdx b/units/en/unitbonus3/rlhf.mdx
new file mode 100644
index 0000000..7c473d1
--- /dev/null
+++ b/units/en/unitbonus3/rlhf.mdx
@@ -0,0 +1,50 @@
+# RLHF
+
+Reinforcement learning from human feedback (RLHF) is a **methodology for integrating human data labels into a RL-based optimization process**.
+It is motivated by the **challenge of modeling human preferences**.
+
+For many questions, even if you could try and write down an equation for one ideal, humans differ on their preferences.
+
+Updating models **based on measured data is an avenue to try and alleviate these inherently human ML problems**.
+
+## Start Learning about RLHF
+
+To start learning about RLHF:
+
+1. Read this introduction: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf).
+
+2. Watch the recorded live we did some weeks ago, where Nathan covered the basics of Reinforcement Learning from Human Feedback (RLHF) and how this technology is being used to enable state-of-the-art ML tools like ChatGPT.
+Most of the talk is an overview of the interconnected ML models. It covers the basics of Natural Language Processing and RL and how RLHF is used on large language models. We then conclude with the open question in RLHF.
+
+
+
+3. Read other blogs on this topic, such as [Closed-API vs Open-source continues: RLHF, ChatGPT, data moats](https://robotic.substack.com/p/rlhf-chatgpt-data-moats). Let us know if there are more you like!
+
+
+## Additional readings
+
+*Note, this is copied from the Illustrating RLHF blog post above*.
+Here is a list of the most prevalent papers on RLHF to date. The field was recently popularized with the emergence of DeepRL (around 2017) and has grown into a broader study of the applications of LLMs from many large technology companies.
+Here are some papers on RLHF that pre-date the LM focus:
+- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008): Proposed a learned agent where humans provided scores on the actions taken iteratively to learn a reward model.
+- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017): Proposed an actor-critic algorithm, COACH, where human feedback (both positive and negative) is used to tune the advantage function.
+- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017): RLHF applied on preferences between Atari trajectories.
+- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485) (Warnell et al. 2018): Extends the TAMER framework where a deep neural network is used to model the reward prediction.
+
+And here is a snapshot of the growing set of papers that show RLHF's performance for LMs:
+- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
+- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021), follow on work summarizing books.
+- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
+- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022): RLHF applied to a general language model [[Blog post](https://openai.com/blog/instruction-following/) on InstructGPT].
+- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
+- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
+- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
+- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
+- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
+- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
+- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
+- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
+
+## Author
+
+This section was written by Nathan Lambert