diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 45f4925..f2fbe2a 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -44,3 +44,29 @@
title: Play with Huggy
- local: unitbonus1/conclusion
title: Conclusion
+- title: Unit 3. Deep Q-Learning with Atari Games
+ sections:
+ - local: unit3/introduction
+ title: Introduction
+ - local: unit3/from-q-to-dqn
+ title: From Q-Learning to Deep Q-Learning
+ - local: unit3/deep-q-network
+ title: The Deep Q-Network (DQN)
+ - local: unit3/deep-q-algorithm
+ title: The Deep Q Algorithm
+ - local: unit3/hands-on
+ title: Hands-on
+ - local: unit3/quiz
+ title: Quiz
+ - local: unit3/conclusion
+ title: Conclusion
+ - local: unit3/additional-readings
+ title: Additional Readings
+- title: Unit Bonus 2. Automatic Hyperparameter Tuning with Optuna
+ sections:
+ - local: unitbonus2/introduction
+ title: Introduction
+ - local: unitbonus2/optuna
+ title: Optuna
+ - local: unitbonus2/hands-on
+ title: Hands-on
\ No newline at end of file
diff --git a/units/en/unit3/additional-readings.mdx b/units/en/unit3/additional-readings.mdx
new file mode 100644
index 0000000..9c615fc
--- /dev/null
+++ b/units/en/unit3/additional-readings.mdx
@@ -0,0 +1,8 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
+- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
+- [Double Deep Q-Learning](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [Prioritized Experience Replay](https://arxiv.org/abs/1511.05952)
diff --git a/units/en/unit3/conclusion.mdx b/units/en/unit3/conclusion.mdx
new file mode 100644
index 0000000..1e3592d
--- /dev/null
+++ b/units/en/unit3/conclusion.mdx
@@ -0,0 +1,14 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
+
+Take time to really grasp the material before continuing.
+
+Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
+
+ +
+
+In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+
+### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit3/deep-q-algorithm.mdx b/units/en/unit3/deep-q-algorithm.mdx
new file mode 100644
index 0000000..d8dd604
--- /dev/null
+++ b/units/en/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,102 @@
+# The Deep Q-Learning Algorithm [[deep-q-algorithm]]
+
+We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
+
+The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
+
+
+
+
+In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+
+### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit3/deep-q-algorithm.mdx b/units/en/unit3/deep-q-algorithm.mdx
new file mode 100644
index 0000000..d8dd604
--- /dev/null
+++ b/units/en/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,102 @@
+# The Deep Q-Learning Algorithm [[deep-q-algorithm]]
+
+We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
+
+The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
+
+ +
+In Deep Q-Learning, we create a **Loss function between our Q-value prediction and the Q-target and use Gradient Descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
+
+
+
+In Deep Q-Learning, we create a **Loss function between our Q-value prediction and the Q-target and use Gradient Descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
+
+ +
+The Deep Q-Learning training algorithm has *two phases*:
+
+- **Sampling**: we perform actions and **store the observed experiences tuples in a replay memory**.
+- **Training**: Select the **small batch of tuple randomly and learn from it using a gradient descent update step**.
+
+
+
+The Deep Q-Learning training algorithm has *two phases*:
+
+- **Sampling**: we perform actions and **store the observed experiences tuples in a replay memory**.
+- **Training**: Select the **small batch of tuple randomly and learn from it using a gradient descent update step**.
+
+ +
+But, this is not the only change compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
+
+To help us stabilize the training, we implement three different solutions:
+1. *Experience Replay*, to make more **efficient use of experiences**.
+2. *Fixed Q-Target* **to stabilize the training**.
+3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
+
+
+## Experience Replay to make more efficient use of experiences [[exp-replay]]
+
+Why do we create a replay memory?
+
+Experience Replay in Deep Q-Learning has two functions:
+
+1. **Make more efficient use of the experiences during the training**.
+- Experience replay helps us **make more efficient use of the experiences during the training.** Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
+- But with experience replay, we create a replay buffer that saves experience samples **that we can reuse during the training.**
+
+
+
+But, this is not the only change compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
+
+To help us stabilize the training, we implement three different solutions:
+1. *Experience Replay*, to make more **efficient use of experiences**.
+2. *Fixed Q-Target* **to stabilize the training**.
+3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
+
+
+## Experience Replay to make more efficient use of experiences [[exp-replay]]
+
+Why do we create a replay memory?
+
+Experience Replay in Deep Q-Learning has two functions:
+
+1. **Make more efficient use of the experiences during the training**.
+- Experience replay helps us **make more efficient use of the experiences during the training.** Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
+- But with experience replay, we create a replay buffer that saves experience samples **that we can reuse during the training.**
+
+ +
+⇒ This allows us to **learn from individual experiences multiple times**.
+
+2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
+- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it overwrites new experiences.** For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
+
+The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has immediately done.**
+
+Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
+
+In the Deep Q-Learning pseudocode, we see that we **initialize a replay memory buffer D from capacity N** (N is an hyperparameter that you can define). We then store experiences in the memory and sample a minibatch of experiences to feed the Deep Q-Network during the training phase.
+
+
+
+⇒ This allows us to **learn from individual experiences multiple times**.
+
+2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
+- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it overwrites new experiences.** For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
+
+The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has immediately done.**
+
+Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
+
+In the Deep Q-Learning pseudocode, we see that we **initialize a replay memory buffer D from capacity N** (N is an hyperparameter that you can define). We then store experiences in the memory and sample a minibatch of experiences to feed the Deep Q-Network during the training phase.
+
+ +
+## Fixed Q-Target to stabilize the training [[fixed-q]]
+
+When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
+
+But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
+
+
+
+However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
+
+Therefore, it means that at every step of training, **our Q values shift but also the target value shifts.** So, we’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This led to a significant oscillation in training.
+
+It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target), you must get closer (reduce the error).
+
+
+
+## Fixed Q-Target to stabilize the training [[fixed-q]]
+
+When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
+
+But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
+
+
+
+However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
+
+Therefore, it means that at every step of training, **our Q values shift but also the target value shifts.** So, we’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This led to a significant oscillation in training.
+
+It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target), you must get closer (reduce the error).
+
+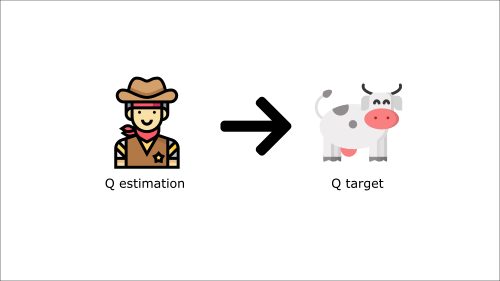 +
+At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
+
+
+
+At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
+
+ +
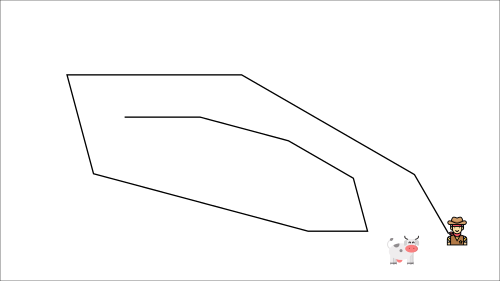
+ +This leads to a bizarre path of chasing (a significant oscillation in training).
+
+This leads to a bizarre path of chasing (a significant oscillation in training).
+ +
+Instead, what we see in the pseudo-code is that we:
+- Use a **separate network with a fixed parameter** for estimating the TD Target
+- **Copy the parameters from our Deep Q-Network at every C step** to update the target network.
+
+
+
+Instead, what we see in the pseudo-code is that we:
+- Use a **separate network with a fixed parameter** for estimating the TD Target
+- **Copy the parameters from our Deep Q-Network at every C step** to update the target network.
+
+ +
+
+
+## Double DQN [[double-dqn]]
+
+Double DQNs, or Double Learning, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
+
+To understand this problem, remember how we calculate the TD Target:
+
+We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
+
+We know that the accuracy of Q values depends on what action we tried **and** what neighboring states we explored.
+
+Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
+
+The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
+- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q value).
+- Use our **Target network** to calculate the target Q value of taking that action at the next state.
+
+Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
+
+Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list.
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
new file mode 100644
index 0000000..2a2c5c5
--- /dev/null
+++ b/units/en/unit3/deep-q-network.mdx
@@ -0,0 +1,39 @@
+# The Deep Q-Network (DQN) [[deep-q-network]]
+This is the architecture of our Deep Q-Learning network:
+
+
+
+
+
+## Double DQN [[double-dqn]]
+
+Double DQNs, or Double Learning, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
+
+To understand this problem, remember how we calculate the TD Target:
+
+We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
+
+We know that the accuracy of Q values depends on what action we tried **and** what neighboring states we explored.
+
+Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
+
+The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
+- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q value).
+- Use our **Target network** to calculate the target Q value of taking that action at the next state.
+
+Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
+
+Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list.
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
new file mode 100644
index 0000000..2a2c5c5
--- /dev/null
+++ b/units/en/unit3/deep-q-network.mdx
@@ -0,0 +1,39 @@
+# The Deep Q-Network (DQN) [[deep-q-network]]
+This is the architecture of our Deep Q-Learning network:
+
+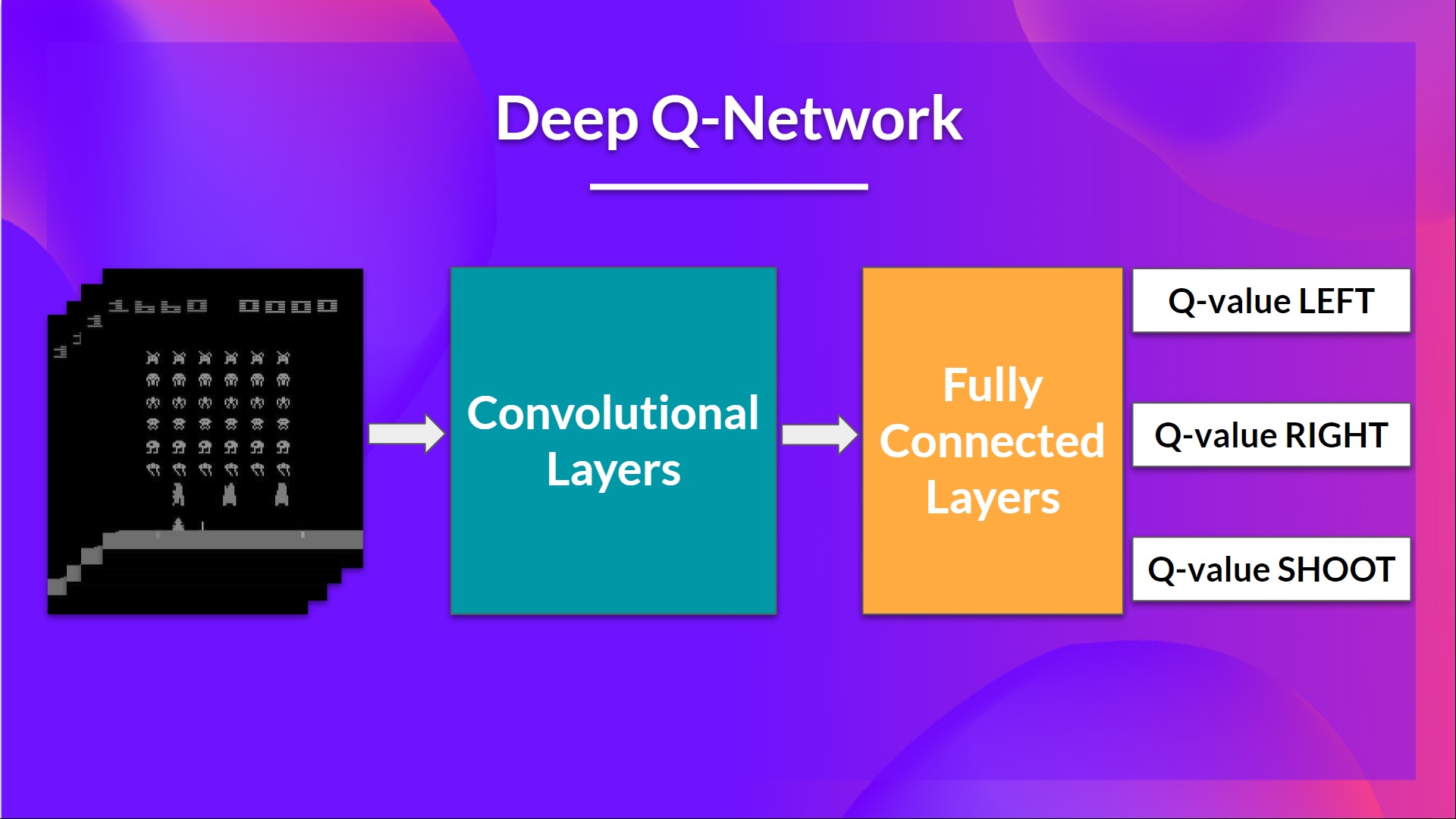 +
+As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
+
+When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with appropriate action and **learn to play the game well**.
+
+## Preprocessing the input and temporal limitation [[preprocessing]]
+
+We mentioned that we preprocess the input. It’s an essential step since we want to **reduce the complexity of our state to reduce the computation time needed for training**.
+
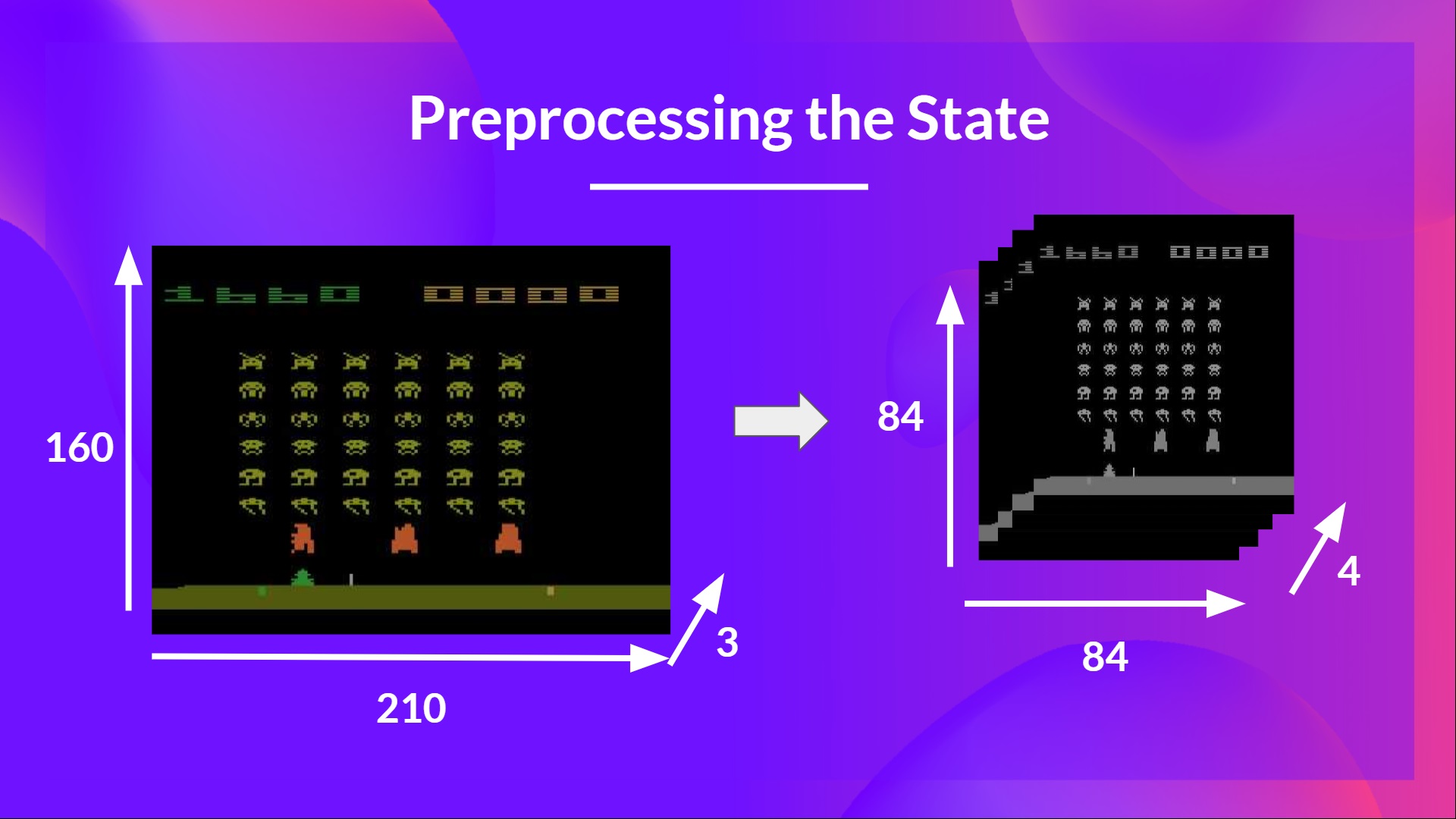
+So what we do is **reduce the state space to 84x84 and grayscale it** (since the colors in Atari environments don't add important information).
+This is an essential saving since we **reduce our three color channels (RGB) to 1**.
+
+We can also **crop a part of the screen in some games** if it does not contain important information.
+Then we stack four frames together.
+
+
+
+As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
+
+When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with appropriate action and **learn to play the game well**.
+
+## Preprocessing the input and temporal limitation [[preprocessing]]
+
+We mentioned that we preprocess the input. It’s an essential step since we want to **reduce the complexity of our state to reduce the computation time needed for training**.
+
+So what we do is **reduce the state space to 84x84 and grayscale it** (since the colors in Atari environments don't add important information).
+This is an essential saving since we **reduce our three color channels (RGB) to 1**.
+
+We can also **crop a part of the screen in some games** if it does not contain important information.
+Then we stack four frames together.
+
+ +
+**Why do we stack four frames together?**
+We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
+
+
+
+**Why do we stack four frames together?**
+We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
+
+ +
+Can you tell me where the ball is going?
+No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
+
+
+
+Can you tell me where the ball is going?
+No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
+
+ +That’s why, to capture temporal information, we stack four frames together.
+
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+
+Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
+
+
+
+So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
diff --git a/units/en/unit3/from-q-to-dqn.mdx b/units/en/unit3/from-q-to-dqn.mdx
new file mode 100644
index 0000000..33d2ba4
--- /dev/null
+++ b/units/en/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,33 @@
+# From Q-Learning to Deep Q-Learning [[from-q-to-dqn]]
+
+We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+
+That’s why, to capture temporal information, we stack four frames together.
+
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+
+Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
+
+
+
+So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
diff --git a/units/en/unit3/from-q-to-dqn.mdx b/units/en/unit3/from-q-to-dqn.mdx
new file mode 100644
index 0000000..33d2ba4
--- /dev/null
+++ b/units/en/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,33 @@
+# From Q-Learning to Deep Q-Learning [[from-q-to-dqn]]
+
+We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+ 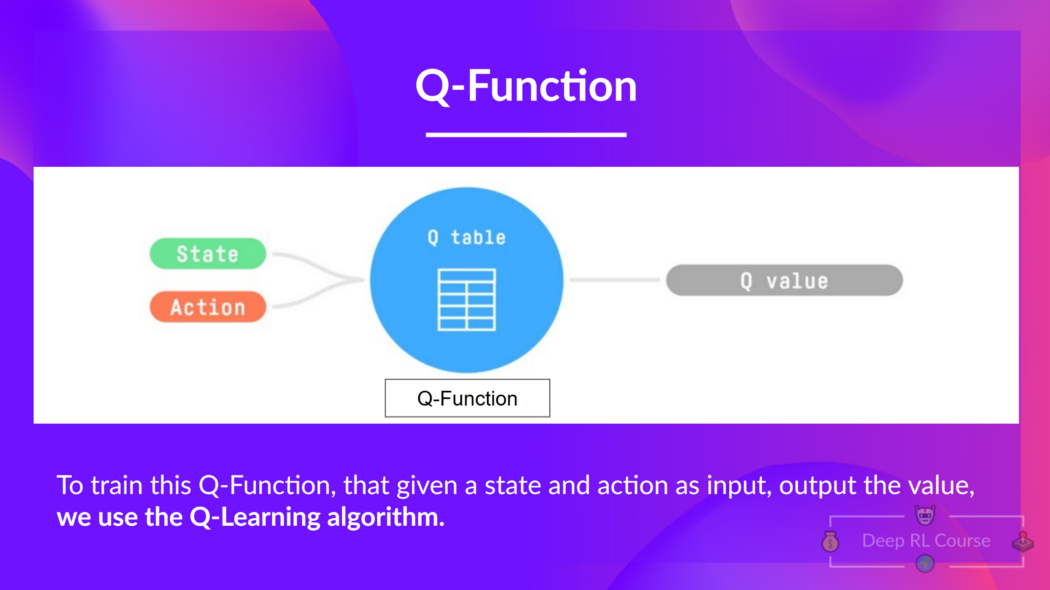 + Given a state and action, our Q Function outputs a state-action value (also called Q-value)
+
+
+The **Q comes from "the Quality" of that action at that state.**
+
+Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
+
+The problem is that Q-Learning is a *tabular method*. This raises a problem in which the states and actions spaces **are small enough to approximate value functions to be represented as arrays and tables**. Also, this is **not scalable**.
+Q-Learning worked well with small state space environments like:
+
+- FrozenLake, we had 14 states.
+- Taxi-v3, we had 500 states.
+
+But think of what we're going to do today: we will train an agent to learn to play Space Invaders a more complex game, using the frames as input.
+
+As **[Nikita Melkozerov mentioned](https://twitter.com/meln1k), Atari environments** have an observation space with a shape of (210, 160, 3), containing values ranging from 0 to 255 so that gives us 256^(210x160x3) = 256^100800 (for comparison, we have approximately 10^80 atoms in the observable universe).
+
+
+ Given a state and action, our Q Function outputs a state-action value (also called Q-value)
+
+
+The **Q comes from "the Quality" of that action at that state.**
+
+Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
+
+The problem is that Q-Learning is a *tabular method*. This raises a problem in which the states and actions spaces **are small enough to approximate value functions to be represented as arrays and tables**. Also, this is **not scalable**.
+Q-Learning worked well with small state space environments like:
+
+- FrozenLake, we had 14 states.
+- Taxi-v3, we had 500 states.
+
+But think of what we're going to do today: we will train an agent to learn to play Space Invaders a more complex game, using the frames as input.
+
+As **[Nikita Melkozerov mentioned](https://twitter.com/meln1k), Atari environments** have an observation space with a shape of (210, 160, 3), containing values ranging from 0 to 255 so that gives us 256^(210x160x3) = 256^100800 (for comparison, we have approximately 10^80 atoms in the observable universe).
+
+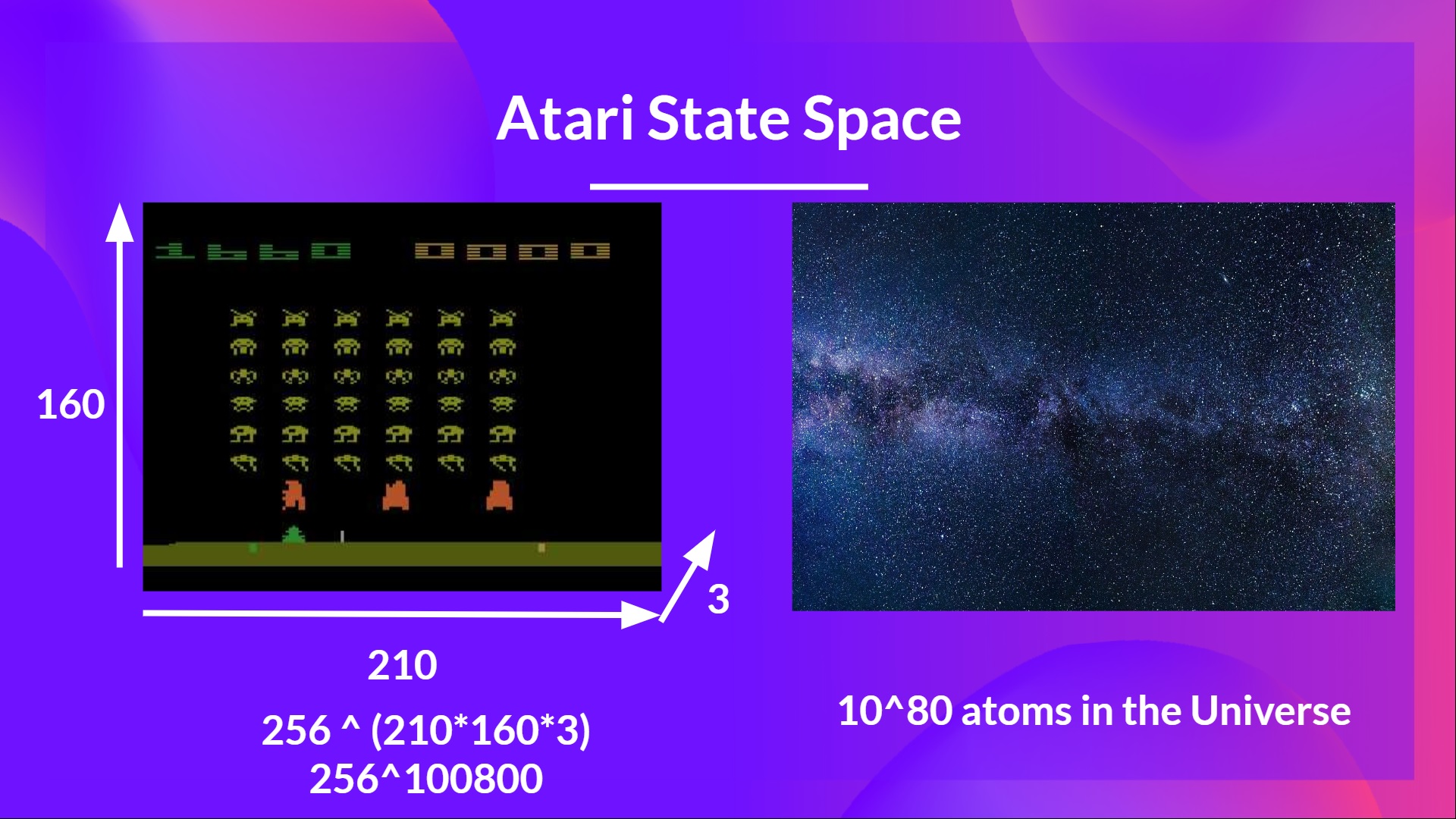 +
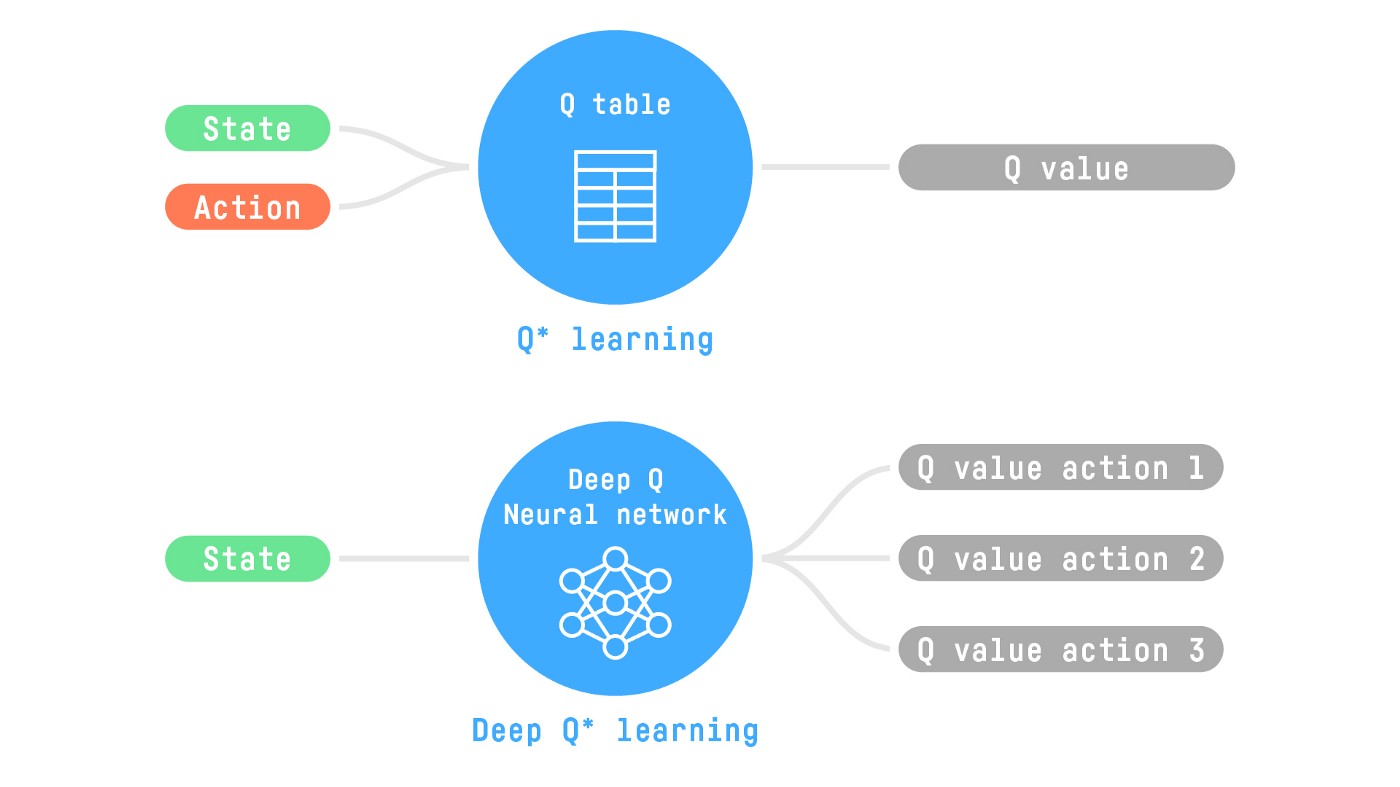
+Therefore, the state space is gigantic; hence creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values instead of a Q-table using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
+
+This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
+
+
+
+Therefore, the state space is gigantic; hence creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values instead of a Q-table using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
+
+This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
+
+ +
+
+Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
new file mode 100644
index 0000000..4b73137
--- /dev/null
+++ b/units/en/unit3/hands-on.mdx
@@ -0,0 +1,13 @@
+# Hands-on [[hands-on]]
+
+Now that you've studied the theory behind Deep Q-Learning, **you’re ready to train your Deep Q-Learning agent to play Atari Games**. We'll start with Space Invaders, but you'll be able to use any Atari game you want 🔥
+
+
+
+
+We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unit3/introduction.mdx b/units/en/unit3/introduction.mdx
new file mode 100644
index 0000000..366286d
--- /dev/null
+++ b/units/en/unit3/introduction.mdx
@@ -0,0 +1,19 @@
+# Deep Q-Learning [[deep-q-learning]]
+
+
+
+
+Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
new file mode 100644
index 0000000..4b73137
--- /dev/null
+++ b/units/en/unit3/hands-on.mdx
@@ -0,0 +1,13 @@
+# Hands-on [[hands-on]]
+
+Now that you've studied the theory behind Deep Q-Learning, **you’re ready to train your Deep Q-Learning agent to play Atari Games**. We'll start with Space Invaders, but you'll be able to use any Atari game you want 🔥
+
+
+
+
+We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[]()
diff --git a/units/en/unit3/introduction.mdx b/units/en/unit3/introduction.mdx
new file mode 100644
index 0000000..366286d
--- /dev/null
+++ b/units/en/unit3/introduction.mdx
@@ -0,0 +1,19 @@
+# Deep Q-Learning [[deep-q-learning]]
+
+ +
+
+
+In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
+
+We got excellent results with this simple algorithm. But these environments were relatively simple because the **state space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3).
+
+But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
+
+So in this unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning. Instead of using a Q-table, Deep Q-Learning uses a Neural Network that takes a state and approximates Q-values for each action based on that state.
+
+And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
+
+
+
+So let’s get started! 🚀
diff --git a/units/en/unit3/quiz.mdx b/units/en/unit3/quiz.mdx
new file mode 100644
index 0000000..cefffa6
--- /dev/null
+++ b/units/en/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What are tabular methods?
+
+
+
+
+
+In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
+
+We got excellent results with this simple algorithm. But these environments were relatively simple because the **state space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3).
+
+But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
+
+So in this unit, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning. Instead of using a Q-table, Deep Q-Learning uses a Neural Network that takes a state and approximates Q-values for each action based on that state.
+
+And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
+
+
+
+So let’s get started! 🚀
diff --git a/units/en/unit3/quiz.mdx b/units/en/unit3/quiz.mdx
new file mode 100644
index 0000000..cefffa6
--- /dev/null
+++ b/units/en/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# Quiz [[quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: What are tabular methods?
+
+
+Solution
+
+*Tabular methods* are a type of problems in which the state and actions spaces are small enough to approximate value functions to be **represented as arrays and tables**. For instance, **Q-Learning is a tabular method** since we use a table to represent the state,action value pairs.
+
+
+
+
+### Q2: Why we can't use a classical Q-Learning to solve an Atari Game?
+
+
+
+
+### Q3: Why do we stack four frames together when we use frames as input in Deep Q-Learning?
+
+
+Solution
+
+We stack frames together because it helps us **handle the problem of temporal limitation**. Since one frame is not enough to capture temporal information.
+For instance, in pong, our agent **will be unable to know the ball direction if it gets only one frame**.
+
+
+
+
+
+
+
+
+### Q4: What are the two phases of Deep Q-Learning?
+
+
+
+### Q5: Why do we create a replay memory in Deep Q-Learning?
+
+
+ Solution
+
+**1. Make more efficient use of the experiences during the training**
+
+Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
+But with experience replay, **we create a replay buffer that saves experience samples that we can reuse during the training**.
+
+**2. Avoid forgetting previous experiences and reduce the correlation between experiences**
+
+ The problem we get if we give sequential samples of experiences to our neural network is that it **tends to forget the previous experiences as it overwrites new experiences**. For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
+
+
+
+
+### Q6: How do we use Double Deep Q-Learning?
+
+
+
+ Solution
+
+ When we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
+
+ - Use our *DQN network* to **select the best action to take for the next state** (the action with the highest Q value).
+
+ - Use our *Target network* to calculate **the target Q value of taking that action at the next state**.
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/units/en/unitbonus2/hands-on.mdx b/units/en/unitbonus2/hands-on.mdx
new file mode 100644
index 0000000..ac942a5
--- /dev/null
+++ b/units/en/unitbonus2/hands-on.mdx
@@ -0,0 +1,3 @@
+# Hands-on [[hands-on]]
+
+Now that you've learned to use Optuna, **why not going back to our Deep Q-Learning hands-on and implement Optuna to find the best training hyperparameters?**
diff --git a/units/en/unitbonus2/introduction.mdx b/units/en/unitbonus2/introduction.mdx
new file mode 100644
index 0000000..05c881e
--- /dev/null
+++ b/units/en/unitbonus2/introduction.mdx
@@ -0,0 +1,7 @@
+# Introduction [[introduction]]
+
+One of the most critical task in Deep Reinforcement Learning is to **find a good set of training hyperparameters**.
+
+ +
+[Optuna](https://optuna.org/) is a library that helps you to automate the search. In this Unit, we'll study a **little bit of the theory behind automatic hyperparameter tuning**. We'll first try to optimize the parameters of the DQN studied in the last unit manually. We'll then **learn how to automate the search using Optuna**.
diff --git a/units/en/unitbonus2/optuna.mdx b/units/en/unitbonus2/optuna.mdx
new file mode 100644
index 0000000..d01d8cc
--- /dev/null
+++ b/units/en/unitbonus2/optuna.mdx
@@ -0,0 +1,12 @@
+# Optuna Tutorial [[optuna]]
+
+The content below comes from [Antonin's Raffin ICRA 2022 presentations](https://araffin.github.io/tools-for-robotic-rl-icra2022/), he's one of the founders of Stable-Baselines and RL-Baselines3-Zoo.
+
+
+## The theory behind Hyperparameter tuning
+
+
+
+## Optuna Tutorial
+
+The notebook 👉 https://colab.research.google.com/github/araffin/tools-for-robotic-rl-icra2022/blob/main/notebooks/optuna_lab.ipynb
+
+[Optuna](https://optuna.org/) is a library that helps you to automate the search. In this Unit, we'll study a **little bit of the theory behind automatic hyperparameter tuning**. We'll first try to optimize the parameters of the DQN studied in the last unit manually. We'll then **learn how to automate the search using Optuna**.
diff --git a/units/en/unitbonus2/optuna.mdx b/units/en/unitbonus2/optuna.mdx
new file mode 100644
index 0000000..d01d8cc
--- /dev/null
+++ b/units/en/unitbonus2/optuna.mdx
@@ -0,0 +1,12 @@
+# Optuna Tutorial [[optuna]]
+
+The content below comes from [Antonin's Raffin ICRA 2022 presentations](https://araffin.github.io/tools-for-robotic-rl-icra2022/), he's one of the founders of Stable-Baselines and RL-Baselines3-Zoo.
+
+
+## The theory behind Hyperparameter tuning
+
+
+
+## Optuna Tutorial
+
+The notebook 👉 https://colab.research.google.com/github/araffin/tools-for-robotic-rl-icra2022/blob/main/notebooks/optuna_lab.ipynb