diff --git a/notebooks/unit1/requirements-unit1.txt b/notebooks/unit1/requirements-unit1.txt
new file mode 100644
index 0000000..b67799f
--- /dev/null
+++ b/notebooks/unit1/requirements-unit1.txt
@@ -0,0 +1,5 @@
+stable-baselines3[extra]
+box2d
+box2d-kengz
+huggingface_sb3
+pyglet==1.5.1
\ No newline at end of file
diff --git a/notebooks/unit1/unit1.ipynb b/notebooks/unit1/unit1.ipynb
index e3af2df..fff439e 100644
--- a/notebooks/unit1/unit1.ipynb
+++ b/notebooks/unit1/unit1.ipynb
@@ -247,7 +247,7 @@
},
"outputs": [],
"source": [
- "!pip install -r https://huggingface.co/spaces/ThomasSimonini/temp-space-requirements/raw/main/requirements/requirements-unit1.txt"
+ "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt"
]
},
{
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index a46425e..d7772a7 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -46,6 +46,10 @@
title: Play with Huggy
- local: unitbonus1/conclusion
title: Conclusion
+- title: Live 1. How the course work, Q&A, and playing with Huggy
+ sections:
+ - local: live1/live1
+ title: Live 1. How the course work, Q&A, and playing with Huggy 🐶
- title: Unit 2. Introduction to Q-Learning
sections:
- local: unit2/introduction
@@ -96,7 +100,7 @@
title: Conclusion
- local: unit3/additional-readings
title: Additional Readings
-- title: Unit Bonus 2. Automatic Hyperparameter Tuning with Optuna
+- title: Bonus Unit 2. Automatic Hyperparameter Tuning with Optuna
sections:
- local: unitbonus2/introduction
title: Introduction
diff --git a/units/en/communication/publishing-schedule.mdx b/units/en/communication/publishing-schedule.mdx
index fe24045..c4fa7a7 100644
--- a/units/en/communication/publishing-schedule.mdx
+++ b/units/en/communication/publishing-schedule.mdx
@@ -1,6 +1,6 @@
# Publishing Schedule [[publishing-schedule]]
-We publish a **new unit every Monday** (except Monday, the 26th of December).
+We publish a **new unit every Tuesday**.
If you don't want to miss any of the updates, don't forget to:
diff --git a/units/en/live1/live1.mdx b/units/en/live1/live1.mdx
new file mode 100644
index 0000000..624365d
--- /dev/null
+++ b/units/en/live1/live1.mdx
@@ -0,0 +1,9 @@
+# Live 1: How the course work, Q&A, and playing with Huggy
+
+In this first live stream, we explained how the course work (scope, units, challenges, and more) and answered your questions.
+
+And finally, we saw some LunarLander agents you've trained and play with your Huggies 🐶
+
+
+
+To know when the next live is scheduled **check the discord server**. We will also send **you an email**. If you can't participate, don't worry, we record the live sessions.
\ No newline at end of file
diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index f970432..9904168 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -9,7 +9,13 @@ Discord is a free chat platform. If you've used Slack, **it's quite similar**. T
Starting in Discord can be a bit intimidating, so let me take you through it.
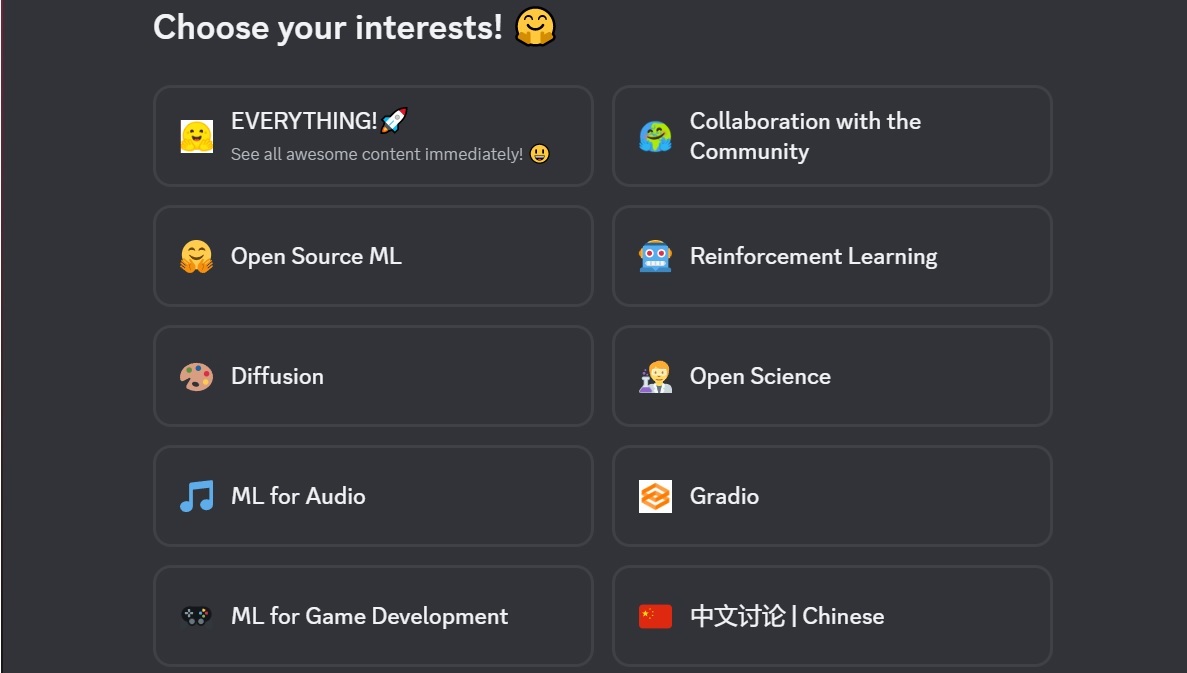
-When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**. Here, you can pick different categories. Make sure to **click "Reinforcement Learning"**! :fire:. You'll then get to **introduce yourself in the `#introduction-yourself` channel**.
+When you sign-up to our Discord server, you'll need to specify which topics you're interested in by **clicking #role-assignment at the left**.
+
+ +
+In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduction-yourself` channel**.
+
+
+
+In #role-assignment, you can pick different categories. Make sure to **click "Reinforcement Learning"**. You'll then get to **introduce yourself in the `#introduction-yourself` channel**.
+
+ ## So which channels are interesting to me? [[channels]]
diff --git a/units/en/unit0/introduction.mdx b/units/en/unit0/introduction.mdx
index 3118d0d..aba76dd 100644
--- a/units/en/unit0/introduction.mdx
+++ b/units/en/unit0/introduction.mdx
@@ -23,7 +23,7 @@ In this course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice.**
- 🧑💻 Learn to **use famous Deep RL libraries** such as [Stable Baselines3](https://stable-baselines3.readthedocs.io/en/master/), [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), [Sample Factory](https://samplefactory.dev/) and [CleanRL](https://github.com/vwxyzjn/cleanrl).
-- 🤖 **Train agents in unique environments** such as [SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight), [Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy), [MineRL (Minecraft ⛏️)](https://minerl.io/), [VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/) and classical ones such as [Space Invaders](https://www.gymlibrary.dev/environments/atari/) and [PyBullet](https://pybullet.org/wordpress/).
+- 🤖 **Train agents in unique environments** such as [SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight), [Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy), [VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/) and classical ones such as [Space Invaders](https://www.gymlibrary.dev/environments/atari/), [PyBullet](https://pybullet.org/wordpress/) and more.
- 💾 Share your **trained agents with one line of code to the Hub** and also download powerful agents from the community.
- 🏆 Participate in challenges where you will **evaluate your agents against other teams. You'll also get to play against the agents you'll train.**
@@ -58,7 +58,8 @@ You can choose to follow this course either:
Both paths **are completely free**.
Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with your fellow classmates.**
-You don't need to tell us which path you choose. At the end of March, when we verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
+
+You don't need to tell us which path you choose. At the end of March, when we will verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
## The Certification Process [[certification-process]]
@@ -92,7 +93,7 @@ You need only 3 things:
## What is the publishing schedule? [[publishing-schedule]]
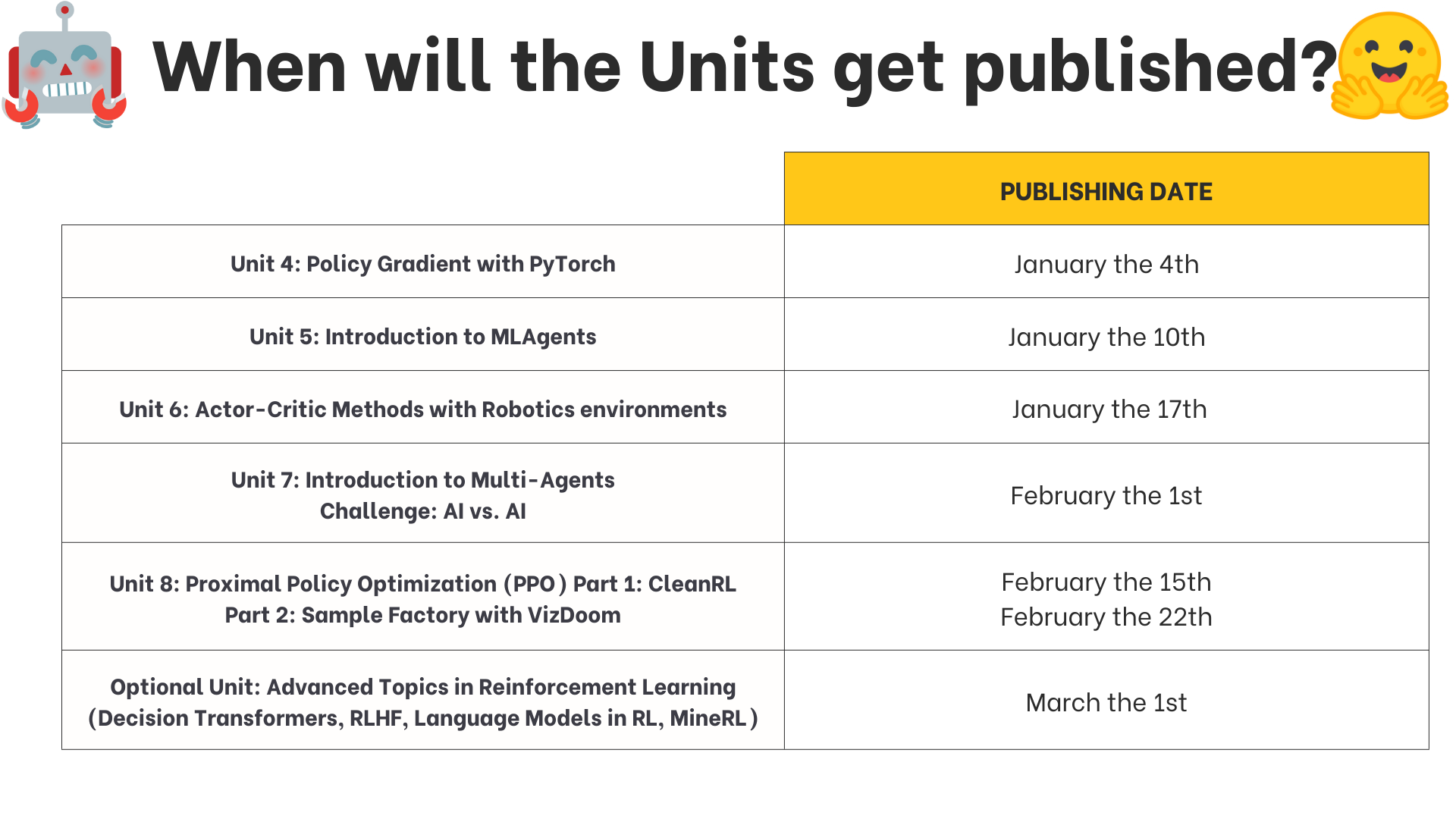
-We publish **a new unit every Monday** (except Monday, the 26th of December).
+We publish **a new unit every Tuesday**.
## So which channels are interesting to me? [[channels]]
diff --git a/units/en/unit0/introduction.mdx b/units/en/unit0/introduction.mdx
index 3118d0d..aba76dd 100644
--- a/units/en/unit0/introduction.mdx
+++ b/units/en/unit0/introduction.mdx
@@ -23,7 +23,7 @@ In this course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice.**
- 🧑💻 Learn to **use famous Deep RL libraries** such as [Stable Baselines3](https://stable-baselines3.readthedocs.io/en/master/), [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), [Sample Factory](https://samplefactory.dev/) and [CleanRL](https://github.com/vwxyzjn/cleanrl).
-- 🤖 **Train agents in unique environments** such as [SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight), [Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy), [MineRL (Minecraft ⛏️)](https://minerl.io/), [VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/) and classical ones such as [Space Invaders](https://www.gymlibrary.dev/environments/atari/) and [PyBullet](https://pybullet.org/wordpress/).
+- 🤖 **Train agents in unique environments** such as [SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight), [Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy), [VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/) and classical ones such as [Space Invaders](https://www.gymlibrary.dev/environments/atari/), [PyBullet](https://pybullet.org/wordpress/) and more.
- 💾 Share your **trained agents with one line of code to the Hub** and also download powerful agents from the community.
- 🏆 Participate in challenges where you will **evaluate your agents against other teams. You'll also get to play against the agents you'll train.**
@@ -58,7 +58,8 @@ You can choose to follow this course either:
Both paths **are completely free**.
Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with your fellow classmates.**
-You don't need to tell us which path you choose. At the end of March, when we verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
+
+You don't need to tell us which path you choose. At the end of March, when we will verify the assignments **if you get more than 80% of the assignments done, you'll get a certificate.**
## The Certification Process [[certification-process]]
@@ -92,7 +93,7 @@ You need only 3 things:
## What is the publishing schedule? [[publishing-schedule]]
-We publish **a new unit every Monday** (except Monday, the 26th of December).
+We publish **a new unit every Tuesday**.

 @@ -128,7 +129,7 @@ In this new version of the course, you have two types of challenges:
@@ -128,7 +129,7 @@ In this new version of the course, you have two types of challenges:
 -These AI vs.AI challenges will be announced **later in December**.
+These AI vs.AI challenges will be announced **in January**.
## I found a bug, or I want to improve the course [[contribute]]
diff --git a/units/en/unit0/setup.mdx b/units/en/unit0/setup.mdx
index 4fc55bb..d02fd75 100644
--- a/units/en/unit0/setup.mdx
+++ b/units/en/unit0/setup.mdx
@@ -21,6 +21,7 @@ We have multiple RL-related channels:
- `rl-announcements`: where we give the last information about the course.
- `rl-discussions`: where you can exchange about RL and share information.
- `rl-study-group`: where you can create and join study groups.
+- `rl-i-made-this`: where you can share your projects and models.
If this is your first time using Discord, we wrote a Discord 101 to get the best practices. Check the next section.
diff --git a/units/en/unit1/conclusion.mdx b/units/en/unit1/conclusion.mdx
index de31951..504c1c0 100644
--- a/units/en/unit1/conclusion.mdx
+++ b/units/en/unit1/conclusion.mdx
@@ -12,5 +12,10 @@ In the next (bonus) unit, we’re going to reinforce what we just learned by **t
You will be able then to play with him 🤗.
-
+
-These AI vs.AI challenges will be announced **later in December**.
+These AI vs.AI challenges will be announced **in January**.
## I found a bug, or I want to improve the course [[contribute]]
diff --git a/units/en/unit0/setup.mdx b/units/en/unit0/setup.mdx
index 4fc55bb..d02fd75 100644
--- a/units/en/unit0/setup.mdx
+++ b/units/en/unit0/setup.mdx
@@ -21,6 +21,7 @@ We have multiple RL-related channels:
- `rl-announcements`: where we give the last information about the course.
- `rl-discussions`: where you can exchange about RL and share information.
- `rl-study-group`: where you can create and join study groups.
+- `rl-i-made-this`: where you can share your projects and models.
If this is your first time using Discord, we wrote a Discord 101 to get the best practices. Check the next section.
diff --git a/units/en/unit1/conclusion.mdx b/units/en/unit1/conclusion.mdx
index de31951..504c1c0 100644
--- a/units/en/unit1/conclusion.mdx
+++ b/units/en/unit1/conclusion.mdx
@@ -12,5 +12,10 @@ In the next (bonus) unit, we’re going to reinforce what we just learned by **t
You will be able then to play with him 🤗.
-
+ +
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
+
+
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index d3645de..0d5732d 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -139,7 +139,7 @@ To make things easier, we created a script to install all these dependencies.
```
```python
-!pip install -r https://huggingface.co/spaces/ThomasSimonini/temp-space-requirements/raw/main/requirements/requirements-unit1.txt
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
```
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index 660ec20..f8017cd 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -22,7 +22,6 @@ It's essential **to master these elements** before diving into implementing Dee
After this unit, in a bonus unit, you'll be **able to train Huggy the Dog 🐶 to fetch the stick and play with him 🤗**.
-
+
So let's get started! 🚀
diff --git a/units/en/unit2/conclusion.mdx b/units/en/unit2/conclusion.mdx
index f271ce0..42ad84e 100644
--- a/units/en/unit2/conclusion.mdx
+++ b/units/en/unit2/conclusion.mdx
@@ -15,5 +15,7 @@ In the next chapter, we’re going to dive deeper by studying our first Deep Rei
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
+
+
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index d3645de..0d5732d 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -139,7 +139,7 @@ To make things easier, we created a script to install all these dependencies.
```
```python
-!pip install -r https://huggingface.co/spaces/ThomasSimonini/temp-space-requirements/raw/main/requirements/requirements-unit1.txt
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
```
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
diff --git a/units/en/unit1/introduction.mdx b/units/en/unit1/introduction.mdx
index 660ec20..f8017cd 100644
--- a/units/en/unit1/introduction.mdx
+++ b/units/en/unit1/introduction.mdx
@@ -22,7 +22,6 @@ It's essential **to master these elements** before diving into implementing Dee
After this unit, in a bonus unit, you'll be **able to train Huggy the Dog 🐶 to fetch the stick and play with him 🤗**.
-
+
So let's get started! 🚀
diff --git a/units/en/unit2/conclusion.mdx b/units/en/unit2/conclusion.mdx
index f271ce0..42ad84e 100644
--- a/units/en/unit2/conclusion.mdx
+++ b/units/en/unit2/conclusion.mdx
@@ -15,5 +15,7 @@ In the next chapter, we’re going to dive deeper by studying our first Deep Rei
 +Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
+
diff --git a/units/en/unit2/two-types-value-based-methods.mdx b/units/en/unit2/two-types-value-based-methods.mdx
index df83311..5ceb191 100644
--- a/units/en/unit2/two-types-value-based-methods.mdx
+++ b/units/en/unit2/two-types-value-based-methods.mdx
@@ -62,7 +62,7 @@ For each state, the state-value function outputs the expected return if the agen
In the action-value function, for each state and action pair, the action-value function **outputs the expected return** if the agent starts in that state and takes action, and then follows the policy forever after.
-The value of taking action an in state \\(s\\) under a policy \\(π\\) is:
+The value of taking action \\(a\\) in state \\(s\\) under a policy \\(π\\) is:
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
+
diff --git a/units/en/unit2/two-types-value-based-methods.mdx b/units/en/unit2/two-types-value-based-methods.mdx
index df83311..5ceb191 100644
--- a/units/en/unit2/two-types-value-based-methods.mdx
+++ b/units/en/unit2/two-types-value-based-methods.mdx
@@ -62,7 +62,7 @@ For each state, the state-value function outputs the expected return if the agen
In the action-value function, for each state and action pair, the action-value function **outputs the expected return** if the agent starts in that state and takes action, and then follows the policy forever after.
-The value of taking action an in state \\(s\\) under a policy \\(π\\) is:
+The value of taking action \\(a\\) in state \\(s\\) under a policy \\(π\\) is:

 diff --git a/units/en/unit3/conclusion.mdx b/units/en/unit3/conclusion.mdx
index 1e3592d..5b9754d 100644
--- a/units/en/unit3/conclusion.mdx
+++ b/units/en/unit3/conclusion.mdx
@@ -11,4 +11,7 @@ Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert,
In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
### Keep Learning, stay awesome 🤗
+
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
index 75c66d3..b69dc58 100644
--- a/units/en/unit3/deep-q-network.mdx
+++ b/units/en/unit3/deep-q-network.mdx
@@ -30,7 +30,7 @@ No, because one frame is not enough to have a sense of motion! But what if I add
diff --git a/units/en/unit3/conclusion.mdx b/units/en/unit3/conclusion.mdx
index 1e3592d..5b9754d 100644
--- a/units/en/unit3/conclusion.mdx
+++ b/units/en/unit3/conclusion.mdx
@@ -11,4 +11,7 @@ Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert,
In the next unit, **we're going to learn about Optuna**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
### Keep Learning, stay awesome 🤗
+
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
index 75c66d3..b69dc58 100644
--- a/units/en/unit3/deep-q-network.mdx
+++ b/units/en/unit3/deep-q-network.mdx
@@ -30,7 +30,7 @@ No, because one frame is not enough to have a sense of motion! But what if I add
 That’s why, to capture temporal information, we stack four frames together.
-Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some temporal properties across those frames**.
If you don't know what are convolutional layers, don't worry. You can check the [Lesson 4 of this free Deep Reinforcement Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
diff --git a/units/en/unit3/from-q-to-dqn.mdx b/units/en/unit3/from-q-to-dqn.mdx
index d4f77a8..5b119c2 100644
--- a/units/en/unit3/from-q-to-dqn.mdx
+++ b/units/en/unit3/from-q-to-dqn.mdx
@@ -13,7 +13,7 @@ Internally, our Q-function has **a Q-table, a table where each cell corresponds
The problem is that Q-Learning is a *tabular method*. This raises a problem in which the states and actions spaces **are small enough to approximate value functions to be represented as arrays and tables**. Also, this is **not scalable**.
Q-Learning worked well with small state space environments like:
-- FrozenLake, we had 14 states.
+- FrozenLake, we had 16 states.
- Taxi-v3, we had 500 states.
But think of what we're going to do today: we will train an agent to learn to play Space Invaders a more complex game, using the frames as input.
diff --git a/units/en/unitbonus1/conclusion.mdx b/units/en/unitbonus1/conclusion.mdx
index 57cd254..d715edc 100644
--- a/units/en/unitbonus1/conclusion.mdx
+++ b/units/en/unitbonus1/conclusion.mdx
@@ -6,5 +6,7 @@ You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to sp
That’s why, to capture temporal information, we stack four frames together.
-Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
+Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some temporal properties across those frames**.
If you don't know what are convolutional layers, don't worry. You can check the [Lesson 4 of this free Deep Reinforcement Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
diff --git a/units/en/unit3/from-q-to-dqn.mdx b/units/en/unit3/from-q-to-dqn.mdx
index d4f77a8..5b119c2 100644
--- a/units/en/unit3/from-q-to-dqn.mdx
+++ b/units/en/unit3/from-q-to-dqn.mdx
@@ -13,7 +13,7 @@ Internally, our Q-function has **a Q-table, a table where each cell corresponds
The problem is that Q-Learning is a *tabular method*. This raises a problem in which the states and actions spaces **are small enough to approximate value functions to be represented as arrays and tables**. Also, this is **not scalable**.
Q-Learning worked well with small state space environments like:
-- FrozenLake, we had 14 states.
+- FrozenLake, we had 16 states.
- Taxi-v3, we had 500 states.
But think of what we're going to do today: we will train an agent to learn to play Space Invaders a more complex game, using the frames as input.
diff --git a/units/en/unitbonus1/conclusion.mdx b/units/en/unitbonus1/conclusion.mdx
index 57cd254..d715edc 100644
--- a/units/en/unitbonus1/conclusion.mdx
+++ b/units/en/unitbonus1/conclusion.mdx
@@ -6,5 +6,7 @@ You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to sp
 +Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
-### Keep Learning, Stay Awesome 🤗
diff --git a/units/en/unitbonus2/hands-on.mdx b/units/en/unitbonus2/hands-on.mdx
index 4130e38..a49dcf7 100644
--- a/units/en/unitbonus2/hands-on.mdx
+++ b/units/en/unitbonus2/hands-on.mdx
@@ -9,3 +9,8 @@ Now that you've learned to use Optuna, we give you some ideas to apply what you'
By doing that, you're going to see how Optuna is valuable and powerful in training better agents,
Have fun,
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
-### Keep Learning, Stay Awesome 🤗
diff --git a/units/en/unitbonus2/hands-on.mdx b/units/en/unitbonus2/hands-on.mdx
index 4130e38..a49dcf7 100644
--- a/units/en/unitbonus2/hands-on.mdx
+++ b/units/en/unitbonus2/hands-on.mdx
@@ -9,3 +9,8 @@ Now that you've learned to use Optuna, we give you some ideas to apply what you'
By doing that, you're going to see how Optuna is valuable and powerful in training better agents,
Have fun,
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### Keep Learning, stay awesome 🤗
+