diff --git a/notebooks/unit8/unit8_part1.ipynb b/notebooks/unit8/unit8_part1.ipynb
new file mode 100644
index 0000000..a1862c8
--- /dev/null
+++ b/notebooks/unit8/unit8_part1.ipynb
@@ -0,0 +1,1357 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-cf5-oDPjwf8"
+ },
+ "source": [
+ "# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-cf5-oDPjwf8"
+ },
+ "source": [
+ "# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.\n",
+ "\n",
+ "To test its robustness, we're going to train it in:\n",
+ "\n",
+ "- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2Fl6Rxt0lc0O"
+ },
+ "source": [
+ "⬇️ Here is an example of what you will achieve. ⬇️"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DbKfCj5ilgqT"
+ },
+ "outputs": [],
+ "source": [
+ "%%html\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YcOFdWpnlxNf"
+ },
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to **code your PPO agent from scratch using PyTorch**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "T6lIPYFghhYL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ "
\n",
+ "\n",
+ "\n",
+ "In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.\n",
+ "\n",
+ "To test its robustness, we're going to train it in:\n",
+ "\n",
+ "- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2Fl6Rxt0lc0O"
+ },
+ "source": [
+ "⬇️ Here is an example of what you will achieve. ⬇️"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DbKfCj5ilgqT"
+ },
+ "outputs": [],
+ "source": [
+ "%%html\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YcOFdWpnlxNf"
+ },
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to **code your PPO agent from scratch using PyTorch**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "T6lIPYFghhYL"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ " \n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "Wp-rD6Fuhq31"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "rasqqGQlhujA"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "PUFfMGOih3CW"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "Wp-rD6Fuhq31"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "rasqqGQlhujA"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "PUFfMGOih3CW"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip install pyglet==1.5\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ncIgfNf3mOtc"
+ },
+ "source": [
+ "## Install dependencies 🔽\n",
+ "For this exercise, we use `gym==0.21`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install gym==0.21\n",
+ "!pip install imageio-ffmpeg\n",
+ "!pip install huggingface_hub\n",
+ "!pip install box2d"
+ ],
+ "metadata": {
+ "id": "9xZQFTPcsKUK"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oDkUufewmq6v"
+ },
+ "source": [
+ "## Let's code PPO from scratch with Costa Huang tutorial\n",
+ "- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.\n",
+ "- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/\n",
+ "\n",
+ "👉 The video tutorial: https://youtu.be/MEt6rrxH8W4"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aNgEL1_uvhaq"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML('')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f34ILn7AvTbt"
+ },
+ "source": [
+ "- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_bE708C6mhE7"
+ },
+ "outputs": [],
+ "source": [
+ "### Your code here:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mk-a9CmNuS2W"
+ },
+ "source": [
+ "## Add the Hugging Face Integration 🤗\n",
+ "- In order to push our model to the Hub, we need to define a function `package_to_hub`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TPi1Nme-oGWd"
+ },
+ "source": [
+ "- Add dependencies we need to push our model to the Hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Sj8bz-AmoNVj"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5rDr8-lWn0zi"
+ },
+ "source": [
+ "- Add new argument in `parse_args()` function to define the repo-id where we want to push the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iHQiqQEFn0QH"
+ },
+ "outputs": [],
+ "source": [
+ "# Adding HuggingFace argument\n",
+ "parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "blLZMiBAoUVT"
+ },
+ "source": [
+ "- Next, we add the methods needed to push the model to the Hub\n",
+ "\n",
+ "- These methods will:\n",
+ " - `_evalutate_agent()`: evaluate the agent.\n",
+ " - `_generate_model_card()`: generate the model card of your agent.\n",
+ " - `_record_video()`: record a video of your agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WlLcz4L9odXs"
+ },
+ "outputs": [],
+ "source": [
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TqX8z8_rooD6"
+ },
+ "source": [
+ "- Finally, we call this function at the end of the PPO training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I8V1vNiTo2hL"
+ },
+ "outputs": [],
+ "source": [
+ "# Create the evaluation environment\n",
+ "eval_env = gym.make(args.env_id)\n",
+ "\n",
+ "package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "muCCzed4o5TC"
+ },
+ "source": [
+ "- Here's what look the ppo.py final file"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LviRdtXgo7kF"
+ },
+ "outputs": [],
+ "source": [
+ "# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy\n",
+ "\n",
+ "import argparse\n",
+ "import os\n",
+ "import random\n",
+ "import time\n",
+ "from distutils.util import strtobool\n",
+ "\n",
+ "import gym\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.optim as optim\n",
+ "from torch.distributions.categorical import Categorical\n",
+ "from torch.utils.tensorboard import SummaryWriter\n",
+ "\n",
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()\n",
+ "\n",
+ "def parse_args():\n",
+ " # fmt: off\n",
+ " parser = argparse.ArgumentParser()\n",
+ " parser.add_argument(\"--exp-name\", type=str, default=os.path.basename(__file__).rstrip(\".py\"),\n",
+ " help=\"the name of this experiment\")\n",
+ " parser.add_argument(\"--seed\", type=int, default=1,\n",
+ " help=\"seed of the experiment\")\n",
+ " parser.add_argument(\"--torch-deterministic\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, `torch.backends.cudnn.deterministic=False`\")\n",
+ " parser.add_argument(\"--cuda\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, cuda will be enabled by default\")\n",
+ " parser.add_argument(\"--track\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, this experiment will be tracked with Weights and Biases\")\n",
+ " parser.add_argument(\"--wandb-project-name\", type=str, default=\"cleanRL\",\n",
+ " help=\"the wandb's project name\")\n",
+ " parser.add_argument(\"--wandb-entity\", type=str, default=None,\n",
+ " help=\"the entity (team) of wandb's project\")\n",
+ " parser.add_argument(\"--capture-video\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"weather to capture videos of the agent performances (check out `videos` folder)\")\n",
+ "\n",
+ " # Algorithm specific arguments\n",
+ " parser.add_argument(\"--env-id\", type=str, default=\"CartPole-v1\",\n",
+ " help=\"the id of the environment\")\n",
+ " parser.add_argument(\"--total-timesteps\", type=int, default=50000,\n",
+ " help=\"total timesteps of the experiments\")\n",
+ " parser.add_argument(\"--learning-rate\", type=float, default=2.5e-4,\n",
+ " help=\"the learning rate of the optimizer\")\n",
+ " parser.add_argument(\"--num-envs\", type=int, default=4,\n",
+ " help=\"the number of parallel game environments\")\n",
+ " parser.add_argument(\"--num-steps\", type=int, default=128,\n",
+ " help=\"the number of steps to run in each environment per policy rollout\")\n",
+ " parser.add_argument(\"--anneal-lr\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggle learning rate annealing for policy and value networks\")\n",
+ " parser.add_argument(\"--gae\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Use GAE for advantage computation\")\n",
+ " parser.add_argument(\"--gamma\", type=float, default=0.99,\n",
+ " help=\"the discount factor gamma\")\n",
+ " parser.add_argument(\"--gae-lambda\", type=float, default=0.95,\n",
+ " help=\"the lambda for the general advantage estimation\")\n",
+ " parser.add_argument(\"--num-minibatches\", type=int, default=4,\n",
+ " help=\"the number of mini-batches\")\n",
+ " parser.add_argument(\"--update-epochs\", type=int, default=4,\n",
+ " help=\"the K epochs to update the policy\")\n",
+ " parser.add_argument(\"--norm-adv\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles advantages normalization\")\n",
+ " parser.add_argument(\"--clip-coef\", type=float, default=0.2,\n",
+ " help=\"the surrogate clipping coefficient\")\n",
+ " parser.add_argument(\"--clip-vloss\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles whether or not to use a clipped loss for the value function, as per the paper.\")\n",
+ " parser.add_argument(\"--ent-coef\", type=float, default=0.01,\n",
+ " help=\"coefficient of the entropy\")\n",
+ " parser.add_argument(\"--vf-coef\", type=float, default=0.5,\n",
+ " help=\"coefficient of the value function\")\n",
+ " parser.add_argument(\"--max-grad-norm\", type=float, default=0.5,\n",
+ " help=\"the maximum norm for the gradient clipping\")\n",
+ " parser.add_argument(\"--target-kl\", type=float, default=None,\n",
+ " help=\"the target KL divergence threshold\")\n",
+ " \n",
+ " # Adding HuggingFace argument\n",
+ " parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")\n",
+ "\n",
+ " args = parser.parse_args()\n",
+ " args.batch_size = int(args.num_envs * args.num_steps)\n",
+ " args.minibatch_size = int(args.batch_size // args.num_minibatches)\n",
+ " # fmt: on\n",
+ " return args\n",
+ "\n",
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)\n",
+ "\n",
+ "def make_env(env_id, seed, idx, capture_video, run_name):\n",
+ " def thunk():\n",
+ " env = gym.make(env_id)\n",
+ " env = gym.wrappers.RecordEpisodeStatistics(env)\n",
+ " if capture_video:\n",
+ " if idx == 0:\n",
+ " env = gym.wrappers.RecordVideo(env, f\"videos/{run_name}\")\n",
+ " env.seed(seed)\n",
+ " env.action_space.seed(seed)\n",
+ " env.observation_space.seed(seed)\n",
+ " return env\n",
+ "\n",
+ " return thunk\n",
+ "\n",
+ "\n",
+ "def layer_init(layer, std=np.sqrt(2), bias_const=0.0):\n",
+ " torch.nn.init.orthogonal_(layer.weight, std)\n",
+ " torch.nn.init.constant_(layer.bias, bias_const)\n",
+ " return layer\n",
+ "\n",
+ "\n",
+ "class Agent(nn.Module):\n",
+ " def __init__(self, envs):\n",
+ " super().__init__()\n",
+ " self.critic = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 1), std=1.0),\n",
+ " )\n",
+ " self.actor = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),\n",
+ " )\n",
+ "\n",
+ " def get_value(self, x):\n",
+ " return self.critic(x)\n",
+ "\n",
+ " def get_action_and_value(self, x, action=None):\n",
+ " logits = self.actor(x)\n",
+ " probs = Categorical(logits=logits)\n",
+ " if action is None:\n",
+ " action = probs.sample()\n",
+ " return action, probs.log_prob(action), probs.entropy(), self.critic(x)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " args = parse_args()\n",
+ " run_name = f\"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}\"\n",
+ " if args.track:\n",
+ " import wandb\n",
+ "\n",
+ " wandb.init(\n",
+ " project=args.wandb_project_name,\n",
+ " entity=args.wandb_entity,\n",
+ " sync_tensorboard=True,\n",
+ " config=vars(args),\n",
+ " name=run_name,\n",
+ " monitor_gym=True,\n",
+ " save_code=True,\n",
+ " )\n",
+ " writer = SummaryWriter(f\"runs/{run_name}\")\n",
+ " writer.add_text(\n",
+ " \"hyperparameters\",\n",
+ " \"|param|value|\\n|-|-|\\n%s\" % (\"\\n\".join([f\"|{key}|{value}|\" for key, value in vars(args).items()])),\n",
+ " )\n",
+ "\n",
+ " # TRY NOT TO MODIFY: seeding\n",
+ " random.seed(args.seed)\n",
+ " np.random.seed(args.seed)\n",
+ " torch.manual_seed(args.seed)\n",
+ " torch.backends.cudnn.deterministic = args.torch_deterministic\n",
+ "\n",
+ " device = torch.device(\"cuda\" if torch.cuda.is_available() and args.cuda else \"cpu\")\n",
+ "\n",
+ " # env setup\n",
+ " envs = gym.vector.SyncVectorEnv(\n",
+ " [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]\n",
+ " )\n",
+ " assert isinstance(envs.single_action_space, gym.spaces.Discrete), \"only discrete action space is supported\"\n",
+ "\n",
+ " agent = Agent(envs).to(device)\n",
+ " optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)\n",
+ "\n",
+ " # ALGO Logic: Storage setup\n",
+ " obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)\n",
+ " actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)\n",
+ " logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " dones = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " values = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ "\n",
+ " # TRY NOT TO MODIFY: start the game\n",
+ " global_step = 0\n",
+ " start_time = time.time()\n",
+ " next_obs = torch.Tensor(envs.reset()).to(device)\n",
+ " next_done = torch.zeros(args.num_envs).to(device)\n",
+ " num_updates = args.total_timesteps // args.batch_size\n",
+ "\n",
+ " for update in range(1, num_updates + 1):\n",
+ " # Annealing the rate if instructed to do so.\n",
+ " if args.anneal_lr:\n",
+ " frac = 1.0 - (update - 1.0) / num_updates\n",
+ " lrnow = frac * args.learning_rate\n",
+ " optimizer.param_groups[0][\"lr\"] = lrnow\n",
+ "\n",
+ " for step in range(0, args.num_steps):\n",
+ " global_step += 1 * args.num_envs\n",
+ " obs[step] = next_obs\n",
+ " dones[step] = next_done\n",
+ "\n",
+ " # ALGO LOGIC: action logic\n",
+ " with torch.no_grad():\n",
+ " action, logprob, _, value = agent.get_action_and_value(next_obs)\n",
+ " values[step] = value.flatten()\n",
+ " actions[step] = action\n",
+ " logprobs[step] = logprob\n",
+ "\n",
+ " # TRY NOT TO MODIFY: execute the game and log data.\n",
+ " next_obs, reward, done, info = envs.step(action.cpu().numpy())\n",
+ " rewards[step] = torch.tensor(reward).to(device).view(-1)\n",
+ " next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)\n",
+ "\n",
+ " for item in info:\n",
+ " if \"episode\" in item.keys():\n",
+ " print(f\"global_step={global_step}, episodic_return={item['episode']['r']}\")\n",
+ " writer.add_scalar(\"charts/episodic_return\", item[\"episode\"][\"r\"], global_step)\n",
+ " writer.add_scalar(\"charts/episodic_length\", item[\"episode\"][\"l\"], global_step)\n",
+ " break\n",
+ "\n",
+ " # bootstrap value if not done\n",
+ " with torch.no_grad():\n",
+ " next_value = agent.get_value(next_obs).reshape(1, -1)\n",
+ " if args.gae:\n",
+ " advantages = torch.zeros_like(rewards).to(device)\n",
+ " lastgaelam = 0\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " nextvalues = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " nextvalues = values[t + 1]\n",
+ " delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]\n",
+ " advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam\n",
+ " returns = advantages + values\n",
+ " else:\n",
+ " returns = torch.zeros_like(rewards).to(device)\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " next_return = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " next_return = returns[t + 1]\n",
+ " returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return\n",
+ " advantages = returns - values\n",
+ "\n",
+ " # flatten the batch\n",
+ " b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)\n",
+ " b_logprobs = logprobs.reshape(-1)\n",
+ " b_actions = actions.reshape((-1,) + envs.single_action_space.shape)\n",
+ " b_advantages = advantages.reshape(-1)\n",
+ " b_returns = returns.reshape(-1)\n",
+ " b_values = values.reshape(-1)\n",
+ "\n",
+ " # Optimizing the policy and value network\n",
+ " b_inds = np.arange(args.batch_size)\n",
+ " clipfracs = []\n",
+ " for epoch in range(args.update_epochs):\n",
+ " np.random.shuffle(b_inds)\n",
+ " for start in range(0, args.batch_size, args.minibatch_size):\n",
+ " end = start + args.minibatch_size\n",
+ " mb_inds = b_inds[start:end]\n",
+ "\n",
+ " _, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])\n",
+ " logratio = newlogprob - b_logprobs[mb_inds]\n",
+ " ratio = logratio.exp()\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " # calculate approx_kl http://joschu.net/blog/kl-approx.html\n",
+ " old_approx_kl = (-logratio).mean()\n",
+ " approx_kl = ((ratio - 1) - logratio).mean()\n",
+ " clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]\n",
+ "\n",
+ " mb_advantages = b_advantages[mb_inds]\n",
+ " if args.norm_adv:\n",
+ " mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)\n",
+ "\n",
+ " # Policy loss\n",
+ " pg_loss1 = -mb_advantages * ratio\n",
+ " pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)\n",
+ " pg_loss = torch.max(pg_loss1, pg_loss2).mean()\n",
+ "\n",
+ " # Value loss\n",
+ " newvalue = newvalue.view(-1)\n",
+ " if args.clip_vloss:\n",
+ " v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2\n",
+ " v_clipped = b_values[mb_inds] + torch.clamp(\n",
+ " newvalue - b_values[mb_inds],\n",
+ " -args.clip_coef,\n",
+ " args.clip_coef,\n",
+ " )\n",
+ " v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2\n",
+ " v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)\n",
+ " v_loss = 0.5 * v_loss_max.mean()\n",
+ " else:\n",
+ " v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()\n",
+ "\n",
+ " entropy_loss = entropy.mean()\n",
+ " loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef\n",
+ "\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ " nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)\n",
+ " optimizer.step()\n",
+ "\n",
+ " if args.target_kl is not None:\n",
+ " if approx_kl > args.target_kl:\n",
+ " break\n",
+ "\n",
+ " y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()\n",
+ " var_y = np.var(y_true)\n",
+ " explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y\n",
+ "\n",
+ " # TRY NOT TO MODIFY: record rewards for plotting purposes\n",
+ " writer.add_scalar(\"charts/learning_rate\", optimizer.param_groups[0][\"lr\"], global_step)\n",
+ " writer.add_scalar(\"losses/value_loss\", v_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/policy_loss\", pg_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/entropy\", entropy_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/old_approx_kl\", old_approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/approx_kl\", approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/clipfrac\", np.mean(clipfracs), global_step)\n",
+ " writer.add_scalar(\"losses/explained_variance\", explained_var, global_step)\n",
+ " print(\"SPS:\", int(global_step / (time.time() - start_time)))\n",
+ " writer.add_scalar(\"charts/SPS\", int(global_step / (time.time() - start_time)), global_step)\n",
+ "\n",
+ " envs.close()\n",
+ " writer.close()\n",
+ "\n",
+ " # Create the evaluation environment\n",
+ " eval_env = gym.make(args.env_id)\n",
+ "\n",
+ " package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip install pyglet==1.5\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ncIgfNf3mOtc"
+ },
+ "source": [
+ "## Install dependencies 🔽\n",
+ "For this exercise, we use `gym==0.21`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install gym==0.21\n",
+ "!pip install imageio-ffmpeg\n",
+ "!pip install huggingface_hub\n",
+ "!pip install box2d"
+ ],
+ "metadata": {
+ "id": "9xZQFTPcsKUK"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oDkUufewmq6v"
+ },
+ "source": [
+ "## Let's code PPO from scratch with Costa Huang tutorial\n",
+ "- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.\n",
+ "- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/\n",
+ "\n",
+ "👉 The video tutorial: https://youtu.be/MEt6rrxH8W4"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aNgEL1_uvhaq"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import HTML\n",
+ "\n",
+ "HTML('')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f34ILn7AvTbt"
+ },
+ "source": [
+ "- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_bE708C6mhE7"
+ },
+ "outputs": [],
+ "source": [
+ "### Your code here:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mk-a9CmNuS2W"
+ },
+ "source": [
+ "## Add the Hugging Face Integration 🤗\n",
+ "- In order to push our model to the Hub, we need to define a function `package_to_hub`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TPi1Nme-oGWd"
+ },
+ "source": [
+ "- Add dependencies we need to push our model to the Hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Sj8bz-AmoNVj"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5rDr8-lWn0zi"
+ },
+ "source": [
+ "- Add new argument in `parse_args()` function to define the repo-id where we want to push the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iHQiqQEFn0QH"
+ },
+ "outputs": [],
+ "source": [
+ "# Adding HuggingFace argument\n",
+ "parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "blLZMiBAoUVT"
+ },
+ "source": [
+ "- Next, we add the methods needed to push the model to the Hub\n",
+ "\n",
+ "- These methods will:\n",
+ " - `_evalutate_agent()`: evaluate the agent.\n",
+ " - `_generate_model_card()`: generate the model card of your agent.\n",
+ " - `_record_video()`: record a video of your agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WlLcz4L9odXs"
+ },
+ "outputs": [],
+ "source": [
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TqX8z8_rooD6"
+ },
+ "source": [
+ "- Finally, we call this function at the end of the PPO training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I8V1vNiTo2hL"
+ },
+ "outputs": [],
+ "source": [
+ "# Create the evaluation environment\n",
+ "eval_env = gym.make(args.env_id)\n",
+ "\n",
+ "package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "muCCzed4o5TC"
+ },
+ "source": [
+ "- Here's what look the ppo.py final file"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LviRdtXgo7kF"
+ },
+ "outputs": [],
+ "source": [
+ "# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy\n",
+ "\n",
+ "import argparse\n",
+ "import os\n",
+ "import random\n",
+ "import time\n",
+ "from distutils.util import strtobool\n",
+ "\n",
+ "import gym\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.optim as optim\n",
+ "from torch.distributions.categorical import Categorical\n",
+ "from torch.utils.tensorboard import SummaryWriter\n",
+ "\n",
+ "from huggingface_hub import HfApi, upload_folder\n",
+ "from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
+ "\n",
+ "from pathlib import Path\n",
+ "import datetime\n",
+ "import tempfile\n",
+ "import json\n",
+ "import shutil\n",
+ "import imageio\n",
+ "\n",
+ "from wasabi import Printer\n",
+ "msg = Printer()\n",
+ "\n",
+ "def parse_args():\n",
+ " # fmt: off\n",
+ " parser = argparse.ArgumentParser()\n",
+ " parser.add_argument(\"--exp-name\", type=str, default=os.path.basename(__file__).rstrip(\".py\"),\n",
+ " help=\"the name of this experiment\")\n",
+ " parser.add_argument(\"--seed\", type=int, default=1,\n",
+ " help=\"seed of the experiment\")\n",
+ " parser.add_argument(\"--torch-deterministic\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, `torch.backends.cudnn.deterministic=False`\")\n",
+ " parser.add_argument(\"--cuda\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, cuda will be enabled by default\")\n",
+ " parser.add_argument(\"--track\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"if toggled, this experiment will be tracked with Weights and Biases\")\n",
+ " parser.add_argument(\"--wandb-project-name\", type=str, default=\"cleanRL\",\n",
+ " help=\"the wandb's project name\")\n",
+ " parser.add_argument(\"--wandb-entity\", type=str, default=None,\n",
+ " help=\"the entity (team) of wandb's project\")\n",
+ " parser.add_argument(\"--capture-video\", type=lambda x: bool(strtobool(x)), default=False, nargs=\"?\", const=True,\n",
+ " help=\"weather to capture videos of the agent performances (check out `videos` folder)\")\n",
+ "\n",
+ " # Algorithm specific arguments\n",
+ " parser.add_argument(\"--env-id\", type=str, default=\"CartPole-v1\",\n",
+ " help=\"the id of the environment\")\n",
+ " parser.add_argument(\"--total-timesteps\", type=int, default=50000,\n",
+ " help=\"total timesteps of the experiments\")\n",
+ " parser.add_argument(\"--learning-rate\", type=float, default=2.5e-4,\n",
+ " help=\"the learning rate of the optimizer\")\n",
+ " parser.add_argument(\"--num-envs\", type=int, default=4,\n",
+ " help=\"the number of parallel game environments\")\n",
+ " parser.add_argument(\"--num-steps\", type=int, default=128,\n",
+ " help=\"the number of steps to run in each environment per policy rollout\")\n",
+ " parser.add_argument(\"--anneal-lr\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggle learning rate annealing for policy and value networks\")\n",
+ " parser.add_argument(\"--gae\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Use GAE for advantage computation\")\n",
+ " parser.add_argument(\"--gamma\", type=float, default=0.99,\n",
+ " help=\"the discount factor gamma\")\n",
+ " parser.add_argument(\"--gae-lambda\", type=float, default=0.95,\n",
+ " help=\"the lambda for the general advantage estimation\")\n",
+ " parser.add_argument(\"--num-minibatches\", type=int, default=4,\n",
+ " help=\"the number of mini-batches\")\n",
+ " parser.add_argument(\"--update-epochs\", type=int, default=4,\n",
+ " help=\"the K epochs to update the policy\")\n",
+ " parser.add_argument(\"--norm-adv\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles advantages normalization\")\n",
+ " parser.add_argument(\"--clip-coef\", type=float, default=0.2,\n",
+ " help=\"the surrogate clipping coefficient\")\n",
+ " parser.add_argument(\"--clip-vloss\", type=lambda x: bool(strtobool(x)), default=True, nargs=\"?\", const=True,\n",
+ " help=\"Toggles whether or not to use a clipped loss for the value function, as per the paper.\")\n",
+ " parser.add_argument(\"--ent-coef\", type=float, default=0.01,\n",
+ " help=\"coefficient of the entropy\")\n",
+ " parser.add_argument(\"--vf-coef\", type=float, default=0.5,\n",
+ " help=\"coefficient of the value function\")\n",
+ " parser.add_argument(\"--max-grad-norm\", type=float, default=0.5,\n",
+ " help=\"the maximum norm for the gradient clipping\")\n",
+ " parser.add_argument(\"--target-kl\", type=float, default=None,\n",
+ " help=\"the target KL divergence threshold\")\n",
+ " \n",
+ " # Adding HuggingFace argument\n",
+ " parser.add_argument(\"--repo-id\", type=str, default=\"ThomasSimonini/ppo-CartPole-v1\", help=\"id of the model repository from the Hugging Face Hub {username/repo_name}\")\n",
+ "\n",
+ " args = parser.parse_args()\n",
+ " args.batch_size = int(args.num_envs * args.num_steps)\n",
+ " args.minibatch_size = int(args.batch_size // args.num_minibatches)\n",
+ " # fmt: on\n",
+ " return args\n",
+ "\n",
+ "def package_to_hub(repo_id, \n",
+ " model,\n",
+ " hyperparameters,\n",
+ " eval_env,\n",
+ " video_fps=30,\n",
+ " commit_message=\"Push agent to the Hub\",\n",
+ " token= None,\n",
+ " logs=None\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the hub\n",
+ " :param repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param model: trained model\n",
+ " :param eval_env: environment used to evaluate the agent\n",
+ " :param fps: number of fps for rendering the video\n",
+ " :param commit_message: commit message\n",
+ " :param logs: directory on local machine of tensorboard logs you'd like to upload\n",
+ " \"\"\"\n",
+ " msg.info(\n",
+ " \"This function will save, evaluate, generate a video of your agent, \"\n",
+ " \"create a model card and push everything to the hub. \"\n",
+ " \"It might take up to 1min. \\n \"\n",
+ " \"This is a work in progress: if you encounter a bug, please open an issue.\"\n",
+ " )\n",
+ " # Step 1: Clone or create the repo\n",
+ " repo_url = HfApi().create_repo(\n",
+ " repo_id=repo_id,\n",
+ " token=token,\n",
+ " private=False,\n",
+ " exist_ok=True,\n",
+ " )\n",
+ " \n",
+ " with tempfile.TemporaryDirectory() as tmpdirname:\n",
+ " tmpdirname = Path(tmpdirname)\n",
+ "\n",
+ " # Step 2: Save the model\n",
+ " torch.save(model.state_dict(), tmpdirname / \"model.pt\")\n",
+ " \n",
+ " # Step 3: Evaluate the model and build JSON\n",
+ " mean_reward, std_reward = _evaluate_agent(eval_env, \n",
+ " 10, \n",
+ " model)\n",
+ "\n",
+ " # First get datetime\n",
+ " eval_datetime = datetime.datetime.now()\n",
+ " eval_form_datetime = eval_datetime.isoformat()\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": hyperparameters.env_id, \n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"std_reward\": std_reward,\n",
+ " \"n_evaluation_episodes\": 10,\n",
+ " \"eval_datetime\": eval_form_datetime,\n",
+ " }\n",
+ " \n",
+ " # Write a JSON file\n",
+ " with open(tmpdirname / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 4: Generate a video\n",
+ " video_path = tmpdirname / \"replay.mp4\"\n",
+ " record_video(eval_env, model, video_path, video_fps)\n",
+ " \n",
+ " # Step 5: Generate the model card\n",
+ " generated_model_card, metadata = _generate_model_card(\"PPO\", hyperparameters.env_id, mean_reward, std_reward, hyperparameters)\n",
+ " _save_model_card(tmpdirname, generated_model_card, metadata)\n",
+ "\n",
+ " # Step 6: Add logs if needed\n",
+ " if logs:\n",
+ " _add_logdir(tmpdirname, Path(logs))\n",
+ " \n",
+ " msg.info(f\"Pushing repo {repo_id} to the Hugging Face Hub\")\n",
+ " \n",
+ " repo_url = upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=tmpdirname,\n",
+ " path_in_repo=\"\",\n",
+ " commit_message=commit_message,\n",
+ " token=token,\n",
+ " )\n",
+ "\n",
+ " msg.info(f\"Your model is pushed to the Hub. You can view your model here: {repo_url}\")\n",
+ " return repo_url\n",
+ "\n",
+ "def _evaluate_agent(env, n_eval_episodes, policy):\n",
+ " \"\"\"\n",
+ " Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
+ " :param env: The evaluation environment\n",
+ " :param n_eval_episodes: Number of episode to evaluate the agent\n",
+ " :param policy: The agent\n",
+ " \"\"\"\n",
+ " episode_rewards = []\n",
+ " for episode in range(n_eval_episodes):\n",
+ " state = env.reset()\n",
+ " step = 0\n",
+ " done = False\n",
+ " total_rewards_ep = 0\n",
+ " \n",
+ " while done is False:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " new_state, reward, done, info = env.step(action.cpu().numpy())\n",
+ " total_rewards_ep += reward \n",
+ " if done:\n",
+ " break\n",
+ " state = new_state\n",
+ " episode_rewards.append(total_rewards_ep)\n",
+ " mean_reward = np.mean(episode_rewards)\n",
+ " std_reward = np.std(episode_rewards)\n",
+ "\n",
+ " return mean_reward, std_reward\n",
+ "\n",
+ "\n",
+ "def record_video(env, policy, out_directory, fps=30):\n",
+ " images = [] \n",
+ " done = False\n",
+ " state = env.reset()\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " while not done:\n",
+ " state = torch.Tensor(state).to(device)\n",
+ " # Take the action (index) that have the maximum expected future reward given that state\n",
+ " action, _, _, _ = policy.get_action_and_value(state)\n",
+ " state, reward, done, info = env.step(action.cpu().numpy()) # We directly put next_state = state for recording logic\n",
+ " img = env.render(mode='rgb_array')\n",
+ " images.append(img)\n",
+ " imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)\n",
+ "\n",
+ "\n",
+ "def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):\n",
+ " \"\"\"\n",
+ " Generate the model card for the Hub\n",
+ " :param model_name: name of the model\n",
+ " :env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " :hyperparameters: training arguments\n",
+ " \"\"\"\n",
+ " # Step 1: Select the tags\n",
+ " metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)\n",
+ "\n",
+ " # Transform the hyperparams namespace to string\n",
+ " converted_dict = vars(hyperparameters)\n",
+ " converted_str = str(converted_dict)\n",
+ " converted_str = converted_str.split(\", \")\n",
+ " converted_str = '\\n'.join(converted_str)\n",
+ " \n",
+ " # Step 2: Generate the model card\n",
+ " model_card = f\"\"\"\n",
+ " # PPO Agent Playing {env_id}\n",
+ "\n",
+ " This is a trained model of a PPO agent playing {env_id}.\n",
+ " \n",
+ " # Hyperparameters\n",
+ " ```python\n",
+ " {converted_str}\n",
+ " ```\n",
+ " \"\"\"\n",
+ " return model_card, metadata\n",
+ "\n",
+ "def generate_metadata(model_name, env_id, mean_reward, std_reward):\n",
+ " \"\"\"\n",
+ " Define the tags for the model card\n",
+ " :param model_name: name of the model\n",
+ " :param env_id: name of the environment\n",
+ " :mean_reward: mean reward of the agent\n",
+ " :std_reward: standard deviation of the mean reward of the agent\n",
+ " \"\"\"\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [\n",
+ " env_id,\n",
+ " \"ppo\",\n",
+ " \"deep-reinforcement-learning\",\n",
+ " \"reinforcement-learning\",\n",
+ " \"custom-implementation\",\n",
+ " \"deep-rl-course\"\n",
+ " ]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=model_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_id,\n",
+ " dataset_id=env_id,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " return metadata\n",
+ "\n",
+ "def _save_model_card(local_path, generated_model_card, metadata):\n",
+ " \"\"\"Saves a model card for the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param generated_model_card: model card generated by _generate_model_card()\n",
+ " :param metadata: metadata\n",
+ " \"\"\"\n",
+ " readme_path = local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = generated_model_card\n",
+ "\n",
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ "def _add_logdir(local_path: Path, logdir: Path):\n",
+ " \"\"\"Adds a logdir to the repository.\n",
+ " :param local_path: repository directory\n",
+ " :param logdir: logdir directory\n",
+ " \"\"\"\n",
+ " if logdir.exists() and logdir.is_dir():\n",
+ " # Add the logdir to the repository under new dir called logs\n",
+ " repo_logdir = local_path / \"logs\"\n",
+ " \n",
+ " # Delete current logs if they exist\n",
+ " if repo_logdir.exists():\n",
+ " shutil.rmtree(repo_logdir)\n",
+ "\n",
+ " # Copy logdir into repo logdir\n",
+ " shutil.copytree(logdir, repo_logdir)\n",
+ "\n",
+ "def make_env(env_id, seed, idx, capture_video, run_name):\n",
+ " def thunk():\n",
+ " env = gym.make(env_id)\n",
+ " env = gym.wrappers.RecordEpisodeStatistics(env)\n",
+ " if capture_video:\n",
+ " if idx == 0:\n",
+ " env = gym.wrappers.RecordVideo(env, f\"videos/{run_name}\")\n",
+ " env.seed(seed)\n",
+ " env.action_space.seed(seed)\n",
+ " env.observation_space.seed(seed)\n",
+ " return env\n",
+ "\n",
+ " return thunk\n",
+ "\n",
+ "\n",
+ "def layer_init(layer, std=np.sqrt(2), bias_const=0.0):\n",
+ " torch.nn.init.orthogonal_(layer.weight, std)\n",
+ " torch.nn.init.constant_(layer.bias, bias_const)\n",
+ " return layer\n",
+ "\n",
+ "\n",
+ "class Agent(nn.Module):\n",
+ " def __init__(self, envs):\n",
+ " super().__init__()\n",
+ " self.critic = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 1), std=1.0),\n",
+ " )\n",
+ " self.actor = nn.Sequential(\n",
+ " layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, 64)),\n",
+ " nn.Tanh(),\n",
+ " layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),\n",
+ " )\n",
+ "\n",
+ " def get_value(self, x):\n",
+ " return self.critic(x)\n",
+ "\n",
+ " def get_action_and_value(self, x, action=None):\n",
+ " logits = self.actor(x)\n",
+ " probs = Categorical(logits=logits)\n",
+ " if action is None:\n",
+ " action = probs.sample()\n",
+ " return action, probs.log_prob(action), probs.entropy(), self.critic(x)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " args = parse_args()\n",
+ " run_name = f\"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}\"\n",
+ " if args.track:\n",
+ " import wandb\n",
+ "\n",
+ " wandb.init(\n",
+ " project=args.wandb_project_name,\n",
+ " entity=args.wandb_entity,\n",
+ " sync_tensorboard=True,\n",
+ " config=vars(args),\n",
+ " name=run_name,\n",
+ " monitor_gym=True,\n",
+ " save_code=True,\n",
+ " )\n",
+ " writer = SummaryWriter(f\"runs/{run_name}\")\n",
+ " writer.add_text(\n",
+ " \"hyperparameters\",\n",
+ " \"|param|value|\\n|-|-|\\n%s\" % (\"\\n\".join([f\"|{key}|{value}|\" for key, value in vars(args).items()])),\n",
+ " )\n",
+ "\n",
+ " # TRY NOT TO MODIFY: seeding\n",
+ " random.seed(args.seed)\n",
+ " np.random.seed(args.seed)\n",
+ " torch.manual_seed(args.seed)\n",
+ " torch.backends.cudnn.deterministic = args.torch_deterministic\n",
+ "\n",
+ " device = torch.device(\"cuda\" if torch.cuda.is_available() and args.cuda else \"cpu\")\n",
+ "\n",
+ " # env setup\n",
+ " envs = gym.vector.SyncVectorEnv(\n",
+ " [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]\n",
+ " )\n",
+ " assert isinstance(envs.single_action_space, gym.spaces.Discrete), \"only discrete action space is supported\"\n",
+ "\n",
+ " agent = Agent(envs).to(device)\n",
+ " optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)\n",
+ "\n",
+ " # ALGO Logic: Storage setup\n",
+ " obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)\n",
+ " actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)\n",
+ " logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " dones = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ " values = torch.zeros((args.num_steps, args.num_envs)).to(device)\n",
+ "\n",
+ " # TRY NOT TO MODIFY: start the game\n",
+ " global_step = 0\n",
+ " start_time = time.time()\n",
+ " next_obs = torch.Tensor(envs.reset()).to(device)\n",
+ " next_done = torch.zeros(args.num_envs).to(device)\n",
+ " num_updates = args.total_timesteps // args.batch_size\n",
+ "\n",
+ " for update in range(1, num_updates + 1):\n",
+ " # Annealing the rate if instructed to do so.\n",
+ " if args.anneal_lr:\n",
+ " frac = 1.0 - (update - 1.0) / num_updates\n",
+ " lrnow = frac * args.learning_rate\n",
+ " optimizer.param_groups[0][\"lr\"] = lrnow\n",
+ "\n",
+ " for step in range(0, args.num_steps):\n",
+ " global_step += 1 * args.num_envs\n",
+ " obs[step] = next_obs\n",
+ " dones[step] = next_done\n",
+ "\n",
+ " # ALGO LOGIC: action logic\n",
+ " with torch.no_grad():\n",
+ " action, logprob, _, value = agent.get_action_and_value(next_obs)\n",
+ " values[step] = value.flatten()\n",
+ " actions[step] = action\n",
+ " logprobs[step] = logprob\n",
+ "\n",
+ " # TRY NOT TO MODIFY: execute the game and log data.\n",
+ " next_obs, reward, done, info = envs.step(action.cpu().numpy())\n",
+ " rewards[step] = torch.tensor(reward).to(device).view(-1)\n",
+ " next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)\n",
+ "\n",
+ " for item in info:\n",
+ " if \"episode\" in item.keys():\n",
+ " print(f\"global_step={global_step}, episodic_return={item['episode']['r']}\")\n",
+ " writer.add_scalar(\"charts/episodic_return\", item[\"episode\"][\"r\"], global_step)\n",
+ " writer.add_scalar(\"charts/episodic_length\", item[\"episode\"][\"l\"], global_step)\n",
+ " break\n",
+ "\n",
+ " # bootstrap value if not done\n",
+ " with torch.no_grad():\n",
+ " next_value = agent.get_value(next_obs).reshape(1, -1)\n",
+ " if args.gae:\n",
+ " advantages = torch.zeros_like(rewards).to(device)\n",
+ " lastgaelam = 0\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " nextvalues = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " nextvalues = values[t + 1]\n",
+ " delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]\n",
+ " advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam\n",
+ " returns = advantages + values\n",
+ " else:\n",
+ " returns = torch.zeros_like(rewards).to(device)\n",
+ " for t in reversed(range(args.num_steps)):\n",
+ " if t == args.num_steps - 1:\n",
+ " nextnonterminal = 1.0 - next_done\n",
+ " next_return = next_value\n",
+ " else:\n",
+ " nextnonterminal = 1.0 - dones[t + 1]\n",
+ " next_return = returns[t + 1]\n",
+ " returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return\n",
+ " advantages = returns - values\n",
+ "\n",
+ " # flatten the batch\n",
+ " b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)\n",
+ " b_logprobs = logprobs.reshape(-1)\n",
+ " b_actions = actions.reshape((-1,) + envs.single_action_space.shape)\n",
+ " b_advantages = advantages.reshape(-1)\n",
+ " b_returns = returns.reshape(-1)\n",
+ " b_values = values.reshape(-1)\n",
+ "\n",
+ " # Optimizing the policy and value network\n",
+ " b_inds = np.arange(args.batch_size)\n",
+ " clipfracs = []\n",
+ " for epoch in range(args.update_epochs):\n",
+ " np.random.shuffle(b_inds)\n",
+ " for start in range(0, args.batch_size, args.minibatch_size):\n",
+ " end = start + args.minibatch_size\n",
+ " mb_inds = b_inds[start:end]\n",
+ "\n",
+ " _, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])\n",
+ " logratio = newlogprob - b_logprobs[mb_inds]\n",
+ " ratio = logratio.exp()\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " # calculate approx_kl http://joschu.net/blog/kl-approx.html\n",
+ " old_approx_kl = (-logratio).mean()\n",
+ " approx_kl = ((ratio - 1) - logratio).mean()\n",
+ " clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]\n",
+ "\n",
+ " mb_advantages = b_advantages[mb_inds]\n",
+ " if args.norm_adv:\n",
+ " mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)\n",
+ "\n",
+ " # Policy loss\n",
+ " pg_loss1 = -mb_advantages * ratio\n",
+ " pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)\n",
+ " pg_loss = torch.max(pg_loss1, pg_loss2).mean()\n",
+ "\n",
+ " # Value loss\n",
+ " newvalue = newvalue.view(-1)\n",
+ " if args.clip_vloss:\n",
+ " v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2\n",
+ " v_clipped = b_values[mb_inds] + torch.clamp(\n",
+ " newvalue - b_values[mb_inds],\n",
+ " -args.clip_coef,\n",
+ " args.clip_coef,\n",
+ " )\n",
+ " v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2\n",
+ " v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)\n",
+ " v_loss = 0.5 * v_loss_max.mean()\n",
+ " else:\n",
+ " v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()\n",
+ "\n",
+ " entropy_loss = entropy.mean()\n",
+ " loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef\n",
+ "\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ " nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)\n",
+ " optimizer.step()\n",
+ "\n",
+ " if args.target_kl is not None:\n",
+ " if approx_kl > args.target_kl:\n",
+ " break\n",
+ "\n",
+ " y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()\n",
+ " var_y = np.var(y_true)\n",
+ " explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y\n",
+ "\n",
+ " # TRY NOT TO MODIFY: record rewards for plotting purposes\n",
+ " writer.add_scalar(\"charts/learning_rate\", optimizer.param_groups[0][\"lr\"], global_step)\n",
+ " writer.add_scalar(\"losses/value_loss\", v_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/policy_loss\", pg_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/entropy\", entropy_loss.item(), global_step)\n",
+ " writer.add_scalar(\"losses/old_approx_kl\", old_approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/approx_kl\", approx_kl.item(), global_step)\n",
+ " writer.add_scalar(\"losses/clipfrac\", np.mean(clipfracs), global_step)\n",
+ " writer.add_scalar(\"losses/explained_variance\", explained_var, global_step)\n",
+ " print(\"SPS:\", int(global_step / (time.time() - start_time)))\n",
+ " writer.add_scalar(\"charts/SPS\", int(global_step / (time.time() - start_time)), global_step)\n",
+ "\n",
+ " envs.close()\n",
+ " writer.close()\n",
+ "\n",
+ " # Create the evaluation environment\n",
+ " eval_env = gym.make(args.env_id)\n",
+ "\n",
+ " package_to_hub(repo_id = args.repo_id,\n",
+ " model = agent, # The model we want to save\n",
+ " hyperparameters = args,\n",
+ " eval_env = gym.make(args.env_id),\n",
+ " logs= f\"runs/{run_name}\",\n",
+ " )\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ " \n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jRqkGvk7pFQ6"
+ },
+ "source": [
+ "## Let's start the training 🔥\n",
+ "- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0tmEArP8ug2l"
+ },
+ "source": [
+ "- First, you need to copy all your code to a file you create called `ppo.py`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "
\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login\n",
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jRqkGvk7pFQ6"
+ },
+ "source": [
+ "## Let's start the training 🔥\n",
+ "- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0tmEArP8ug2l"
+ },
+ "source": [
+ "- First, you need to copy all your code to a file you create called `ppo.py`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ " "
+ ],
+ "metadata": {
+ "id": "Sq0My0LOjPYR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "
"
+ ],
+ "metadata": {
+ "id": "Sq0My0LOjPYR"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ " "
+ ],
+ "metadata": {
+ "id": "A8C-Q5ZyjUe3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VrS80GmMu_j5"
+ },
+ "source": [
+ "- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`\n",
+ "\n",
+ "- You should modify more hyperparameters otherwise the training will not be super stable."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!python ppo.py --env-id=\"LunarLander-v2\" --repo-id=\"YOUR_REPO_ID\" --total-timesteps=50000"
+ ],
+ "metadata": {
+ "id": "KXLih6mKseBs"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eVsVJ5AdqLE7"
+ },
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying another environment?\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nYdl758GqLXT"
+ },
+ "source": [
+ "See you on Unit 8, part 2 where we going to train agents to play Doom 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "accelerator": "GPU"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part1.mdx b/notebooks/unit8/unit8_part1.mdx
new file mode 100644
index 0000000..0606dac
--- /dev/null
+++ b/notebooks/unit8/unit8_part1.mdx
@@ -0,0 +1,1068 @@
+
"
+ ],
+ "metadata": {
+ "id": "A8C-Q5ZyjUe3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VrS80GmMu_j5"
+ },
+ "source": [
+ "- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`\n",
+ "\n",
+ "- You should modify more hyperparameters otherwise the training will not be super stable."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!python ppo.py --env-id=\"LunarLander-v2\" --repo-id=\"YOUR_REPO_ID\" --total-timesteps=50000"
+ ],
+ "metadata": {
+ "id": "KXLih6mKseBs"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eVsVJ5AdqLE7"
+ },
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying another environment?\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nYdl758GqLXT"
+ },
+ "source": [
+ "See you on Unit 8, part 2 where we going to train agents to play Doom 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "accelerator": "GPU"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/unit8/unit8_part1.mdx b/notebooks/unit8/unit8_part1.mdx
new file mode 100644
index 0000000..0606dac
--- /dev/null
+++ b/notebooks/unit8/unit8_part1.mdx
@@ -0,0 +1,1068 @@
+ +
+# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖
+
+
+
+# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖
+
+ +
+
+In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.
+
+To test its robustness, we're going to train it in:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+
+⬇️ Here is an example of what you will achieve. ⬇️
+
+```python
+%%html
+
+```
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to **code your PPO agent from scratch using PyTorch**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+
+
+## This notebook is from the Deep Reinforcement Learning Course
+
+
+
+In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.
+
+To test its robustness, we're going to train it in:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+
+⬇️ Here is an example of what you will achieve. ⬇️
+
+```python
+%%html
+
+```
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to **code your PPO agent from scratch using PyTorch**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+
+
+## This notebook is from the Deep Reinforcement Learning Course
+ +
+In this free course, you will:
+
+- 📖 Study Deep Reinforcement Learning in **theory and practice**.
+- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
+- 🤖 Train **agents in unique environments**
+
+Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
+
+
+The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+In this free course, you will:
+
+- 📖 Study Deep Reinforcement Learning in **theory and practice**.
+- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
+- 🤖 Train **agents in unique environments**
+
+Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
+
+
+The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+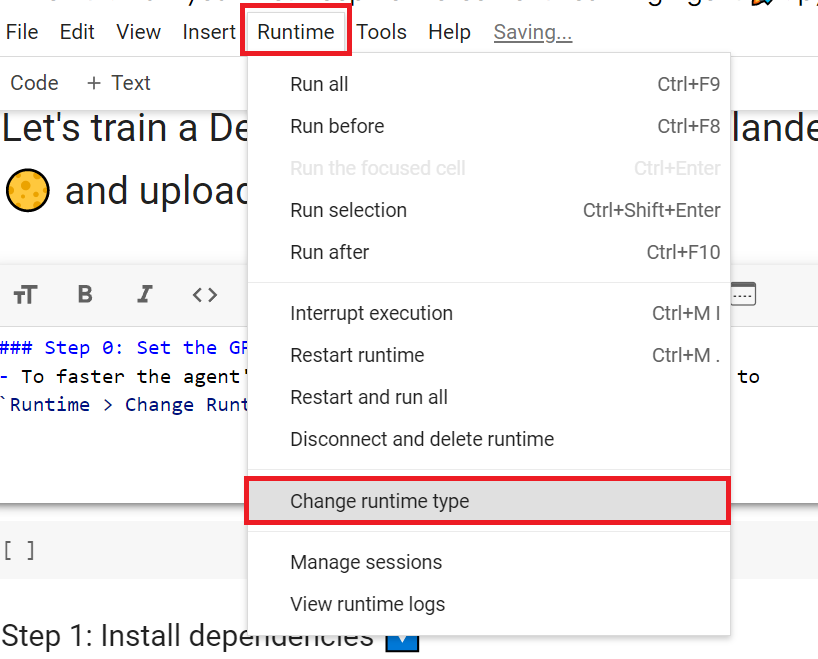 +
+- `Hardware Accelerator > GPU`
+
+
+
+- `Hardware Accelerator > GPU`
+
+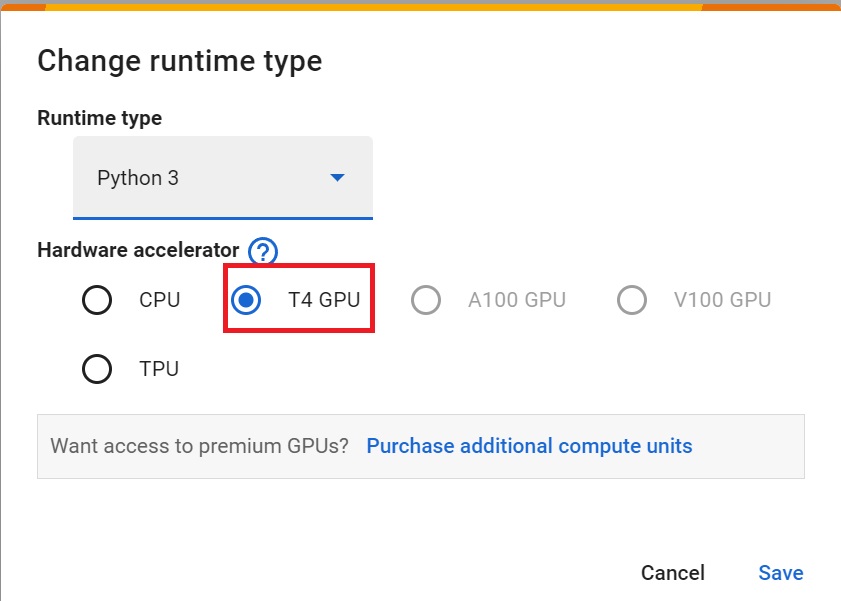 +
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip install pyglet==1.5
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Install dependencies 🔽
+For this exercise, we use `gym==0.21`
+
+
+```python
+!pip install gym==0.21
+!pip install imageio-ffmpeg
+!pip install huggingface_hub
+!pip install box2d
+```
+
+## Let's code PPO from scratch with Costa Huang tutorial
+- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.
+- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 The video tutorial: https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**.
+
+```python
+### Your code here:
+```
+
+## Add the Hugging Face Integration 🤗
+- In order to push our model to the Hub, we need to define a function `package_to_hub`
+
+- Add dependencies we need to push our model to the Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ ```python
+ {converted_str}
+ ```
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what look the ppo.py final file
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ ```python
+ {converted_str}
+ ```
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip install pyglet==1.5
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Install dependencies 🔽
+For this exercise, we use `gym==0.21`
+
+
+```python
+!pip install gym==0.21
+!pip install imageio-ffmpeg
+!pip install huggingface_hub
+!pip install box2d
+```
+
+## Let's code PPO from scratch with Costa Huang tutorial
+- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.
+- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 The video tutorial: https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+- The best is to code first on the cell below, this way, if you kill the machine **you don't loose the implementation**.
+
+```python
+### Your code here:
+```
+
+## Add the Hugging Face Integration 🤗
+- In order to push our model to the Hub, we need to define a function `package_to_hub`
+
+- Add dependencies we need to push our model to the Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ ```python
+ {converted_str}
+ ```
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what look the ppo.py final file
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ ```python
+ {converted_str}
+ ```
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+ +
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+## Let's start the training 🔥
+- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥
+
+- First, you need to copy all your code to a file you create called `ppo.py`
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+## Let's start the training 🔥
+- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥
+
+- First, you need to copy all your code to a file you create called `ppo.py`
+
+ +
+
+
+ +
+- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`
+
+- You should modify more hyperparameters otherwise the training will not be super stable.
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## Some additional challenges 🏆
+The best way to learn **is to try things by your own**! Why not trying another environment?
+
+
+See you on Unit 8, part 2 where we going to train agents to play Doom 🔥
+## Keep learning, stay awesome 🤗
\ No newline at end of file
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index e3be1cd..6d3483b 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -178,6 +178,22 @@
title: Conclusion
- local: unit7/additional-readings
title: Additional Readings
+- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ sections:
+ - local: unit8/introduction
+ title: Introduction
+ - local: unit8/intuition-behind-ppo
+ title: The intuition behind PPO
+ - local: unit8/clipped-surrogate-objective
+ title: Introducing the Clipped Surrogate Objective Function
+ - local: unit8/visualize
+ title: Visualize the Clipped Surrogate Objective Function
+ - local: unit8/hands-on-cleanrl
+ title: PPO with CleanRL
+ - local: unit8/conclusion
+ title: Conclusion
+ - local: unit8/additional-readings
+ title: Additional Readings
- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
sections:
- local: unitbonus3/introduction
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 5e4c164..473047b 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -369,7 +369,7 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+The exploration related hyperparameters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
diff --git a/units/en/unit8/additional-readings.mdx b/units/en/unit8/additional-readings.mdx
new file mode 100644
index 0000000..89196f9
--- /dev/null
+++ b/units/en/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## PPO Explained
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [Paper Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347)
+
+## PPO Implementation details
+
+- [The 37 Implementation Details of Proximal Policy Optimization](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [Part 1 of 3 — Proximal Policy Optimization Implementation: 11 Core Implementation Details](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## Importance Sampling
+
+- [Importance Sampling Explained](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/en/unit8/clipped-surrogate-objective.mdx b/units/en/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 0000000..9319b3e
--- /dev/null
+++ b/units/en/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# Introducing the Clipped Surrogate Objective Function
+## Recap: The Policy Objective Function
+
+Let’s remember what is the objective to optimize in Reinforce:
+
+
+- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`
+
+- You should modify more hyperparameters otherwise the training will not be super stable.
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## Some additional challenges 🏆
+The best way to learn **is to try things by your own**! Why not trying another environment?
+
+
+See you on Unit 8, part 2 where we going to train agents to play Doom 🔥
+## Keep learning, stay awesome 🤗
\ No newline at end of file
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index e3be1cd..6d3483b 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -178,6 +178,22 @@
title: Conclusion
- local: unit7/additional-readings
title: Additional Readings
+- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ sections:
+ - local: unit8/introduction
+ title: Introduction
+ - local: unit8/intuition-behind-ppo
+ title: The intuition behind PPO
+ - local: unit8/clipped-surrogate-objective
+ title: Introducing the Clipped Surrogate Objective Function
+ - local: unit8/visualize
+ title: Visualize the Clipped Surrogate Objective Function
+ - local: unit8/hands-on-cleanrl
+ title: PPO with CleanRL
+ - local: unit8/conclusion
+ title: Conclusion
+ - local: unit8/additional-readings
+ title: Additional Readings
- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
sections:
- local: unitbonus3/introduction
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 5e4c164..473047b 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -369,7 +369,7 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+The exploration related hyperparameters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
diff --git a/units/en/unit8/additional-readings.mdx b/units/en/unit8/additional-readings.mdx
new file mode 100644
index 0000000..89196f9
--- /dev/null
+++ b/units/en/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## PPO Explained
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [What is the way to understand Proximal Policy Optimization Algorithm in RL?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO Blogpost](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [Paper Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347)
+
+## PPO Implementation details
+
+- [The 37 Implementation Details of Proximal Policy Optimization](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [Part 1 of 3 — Proximal Policy Optimization Implementation: 11 Core Implementation Details](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## Importance Sampling
+
+- [Importance Sampling Explained](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/en/unit8/clipped-surrogate-objective.mdx b/units/en/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 0000000..9319b3e
--- /dev/null
+++ b/units/en/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# Introducing the Clipped Surrogate Objective Function
+## Recap: The Policy Objective Function
+
+Let’s remember what is the objective to optimize in Reinforce:
+ +
+The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
+
+However, the problem comes from the step size:
+- Too small, **the training process was too slow**
+- Too high, **there was too much variability in the training**
+
+Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
+
+This new function **is designed to avoid destructive large weights updates** :
+
+
+
+The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
+
+However, the problem comes from the step size:
+- Too small, **the training process was too slow**
+- Too high, **there was too much variability in the training**
+
+Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
+
+This new function **is designed to avoid destructive large weights updates** :
+
+ +
+Let’s study each part to understand how it works.
+
+## The Ratio Function
+
+
+Let’s study each part to understand how it works.
+
+## The Ratio Function
+ +
+This ratio is calculated this way:
+
+
+
+This ratio is calculated this way:
+
+ +
+It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
+
+As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
+
+- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
+- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
+
+So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
+
+## The unclipped part of the Clipped Surrogate Objective function
+
+
+It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
+
+As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
+
+- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
+- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
+
+So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
+
+## The unclipped part of the Clipped Surrogate Objective function
+ +
+This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
+
+
+
+This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
+
+  + Proximal Policy Optimization Algorithms
+
+
+However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
+
+## The clipped Part of the Clipped Surrogate Objective function
+
+
+ Proximal Policy Optimization Algorithms
+
+
+However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
+
+## The clipped Part of the Clipped Surrogate Objective function
+
+ +
+Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
+
+**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
+
+To do that, we have two solutions:
+
+- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
+- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
+
+
+
+This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+
+With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
+
+Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
+
+Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
diff --git a/units/en/unit8/conclusion.mdx b/units/en/unit8/conclusion.mdx
new file mode 100644
index 0000000..7dc56e6
--- /dev/null
+++ b/units/en/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# Conclusion [[Conclusion]]
+
+That’s all for today. Congrats on finishing this unit and the tutorial!
+
+The best way to learn is to practice and try stuff. **Why not improving the implementation to handle frames as input?**.
+
+See you on second part of this Unit 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/hands-on-cleanrl.mdx b/units/en/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 0000000..65a1270
--- /dev/null
+++ b/units/en/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1076 @@
+# Hands-on
+
+
+
+
+
+
+Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
+
+Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
+
+So, to be able to code it, we're going to use two resources:
+- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
+- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+Then, to test its robustness, we're going to train it in:
+
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
+
+LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
+
+
+
+Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
+
+**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
+
+To do that, we have two solutions:
+
+- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
+- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
+
+
+
+This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+
+With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
+
+Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
+
+Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
diff --git a/units/en/unit8/conclusion.mdx b/units/en/unit8/conclusion.mdx
new file mode 100644
index 0000000..7dc56e6
--- /dev/null
+++ b/units/en/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# Conclusion [[Conclusion]]
+
+That’s all for today. Congrats on finishing this unit and the tutorial!
+
+The best way to learn is to practice and try stuff. **Why not improving the implementation to handle frames as input?**.
+
+See you on second part of this Unit 🔥,
+
+## Keep Learning, Stay awesome 🤗
diff --git a/units/en/unit8/hands-on-cleanrl.mdx b/units/en/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 0000000..65a1270
--- /dev/null
+++ b/units/en/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1076 @@
+# Hands-on
+
+
+
+
+
+
+Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
+
+Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
+
+So, to be able to code it, we're going to use two resources:
+- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
+- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+Then, to test its robustness, we're going to train it in:
+
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
+
+LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
+
+via GIPHY
+
+Let's get started! 🚀
+
+
+
+
+# Unit 8: Proximal Policy Gradient (PPO) with PyTorch 🤖
+
+
+
+
+In this notebook, you'll learn to **code your PPO agent from scratch with PyTorch using CleanRL implementation as model**.
+
+To test its robustness, we're going to train it in:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to **code your PPO agent from scratch using PyTorch**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+## Prerequisites 🏗️
+
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [PPO by reading Unit 8](https://huggingface.co/deep-rl-course/unit8/introduction) 🤗
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model, we don't ask for a minimal result but we **advise you to try different hyperparameters settings to get better results**.
+
+If you don't find your model, **go to the bottom of the page and click on the refresh button**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip install pyglet==1.5
+pip install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Install dependencies 🔽
+For this exercise, we use `gym==0.21`
+
+```python
+pip install gym==0.21
+pip install imageio-ffmpeg
+pip install huggingface_hub
+pip install box2d
+```
+
+## Let's code PPO from scratch with Costa Huang tutorial
+- For the core implementation of PPO we're going to use the excellent [Costa Huang](https://costa.sh/) tutorial.
+- In addition to the tutorial, to go deeper you can read the 37 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 The video tutorial: https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+## Add the Hugging Face Integration 🤗
+- In order to push our model to the Hub, we need to define a function `package_to_hub`
+
+- Add dependencies we need to push our model to the Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what look the ppo.py final file
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+## Let's start the training 🔥
+
+- Now that you've coded from scratch PPO and added the Hugging Face Integration, we're ready to start the training 🔥
+
+- First, you need to copy all your code to a file you create called `ppo.py`
+
+
+
+
+
+- Now we just need to run this python script using `python .py` with the additional parameters we defined with `argparse`
+
+- You should modify more hyperparameters otherwise the training will not be super stable.
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## Some additional challenges 🏆
+
+The best way to learn **is to try things by your own**! Why not trying another environment?
+
+See you on Unit 8, part 2 where we going to train agents to play Doom 🔥
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit8/introduction.mdx b/units/en/unit8/introduction.mdx
new file mode 100644
index 0000000..7c74578
--- /dev/null
+++ b/units/en/unit8/introduction.mdx
@@ -0,0 +1,23 @@
+# Introduction [[introduction]]
+
+
+
+In Unit 6, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
+
+- *An Actor* that controls **how our agent behaves** (policy-based method).
+- *A Critic* that measures **how good the action taken is** (value-based method).
+
+Today we'll learn about Proximal Policy Optimization (PPO), an architecture that **improves our agent's training stability by avoiding too large policy updates**. To do that, we use a ratio that indicates the difference between our current and old policy and clip this ratio from a specific range \\( [1 - \epsilon, 1 + \epsilon] \\) .
+
+Doing this will ensure **that our policy update will not be too large and that the training is more stable.**
+
+This Unit is in two parts:
+- In this first part, you'll learn the theory behind PPO and code your PPO agent from scratch using [CleanRL](https://github.com/vwxyzjn/cleanrl) implementation. To test its robustness with LunarLander-v2. LunarLander-v2 **is the first environment you used when you started this course**. At that time, you didn't know how PPO worked, and now, **you can code it from scratch and train it. How incredible is that 🤩**.
+- In the second part, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/) and train an agent playing vizdoom (an open source version of Doom).
+
+
+ +This is the environments you're going to use to train your agents: VizDoom and GodotRL environments
+
+
+Sounds exciting? Let's get started! 🚀
diff --git a/units/en/unit8/intuition-behind-ppo.mdx b/units/en/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 0000000..921fed1
--- /dev/null
+++ b/units/en/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# The intuition behind PPO [[the-intuition-behind-ppo]]
+
+
+The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
+
+For two reasons:
+- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
+- A too-big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
+
+
+
+This is the environments you're going to use to train your agents: VizDoom and GodotRL environments
+
+
+Sounds exciting? Let's get started! 🚀
diff --git a/units/en/unit8/intuition-behind-ppo.mdx b/units/en/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 0000000..921fed1
--- /dev/null
+++ b/units/en/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# The intuition behind PPO [[the-intuition-behind-ppo]]
+
+
+The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
+
+For two reasons:
+- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
+- A too-big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
+
+
+  + Taking smaller policy updates to improve the training stability
+ Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui
+
+
+**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
new file mode 100644
index 0000000..958b61c
--- /dev/null
+++ b/units/en/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# Visualize the Clipped Surrogate Objective Function
+
+Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
+
+
+
+ Taking smaller policy updates to improve the training stability
+ Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui
+
+
+**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
new file mode 100644
index 0000000..958b61c
--- /dev/null
+++ b/units/en/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# Visualize the Clipped Surrogate Objective Function
+
+Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
+
+
+ 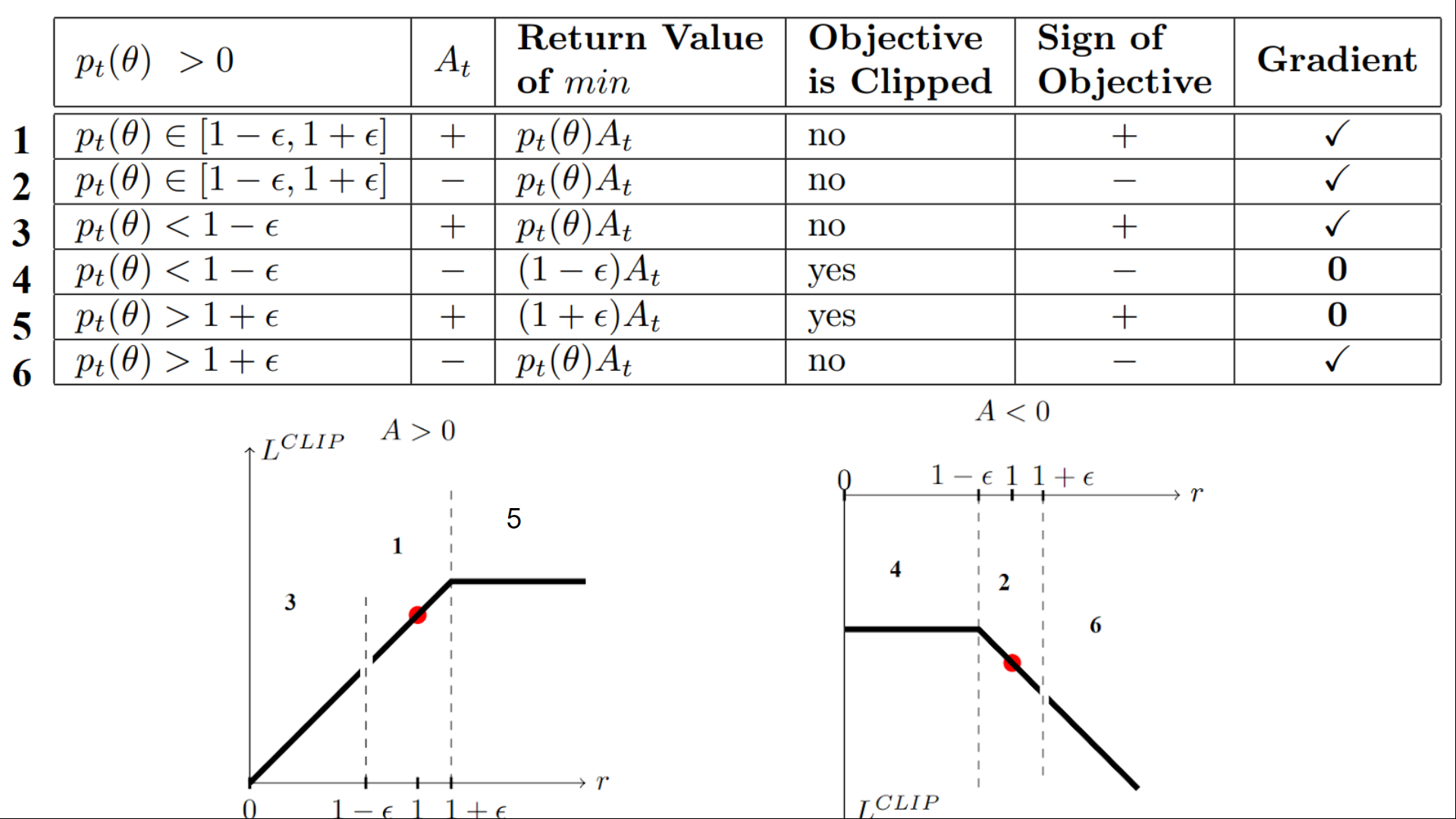 + Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
+
+## Case 1 and 2: the ratio is between the range
+
+In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
+
+In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
+
+Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
+
+In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
+
+Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
+
+## Case 3 and 4: the ratio is below the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
+
+If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
+
+But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+## Case 5 and 6: the ratio is above the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
+
+If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
+
+So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
+
+So we update our policy only if:
+- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
+- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
+ - Being below the ratio but the advantage is > 0
+ - Being above the ratio but the advantage is < 0
+
+**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
+
+
+To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
+
+The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
+
+## Case 1 and 2: the ratio is between the range
+
+In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
+
+In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
+
+Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
+
+In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
+
+Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
+
+## Case 3 and 4: the ratio is below the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
+
+If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
+
+But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+## Case 5 and 6: the ratio is above the range
+
+
+ Table from "Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization" by Daniel Bick
+
+
+If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
+
+If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
+
+If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
+
+So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
+
+So we update our policy only if:
+- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
+- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
+ - Being below the ratio but the advantage is > 0
+ - Being above the ratio but the advantage is < 0
+
+**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
+
+
+To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
+
+The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
+
+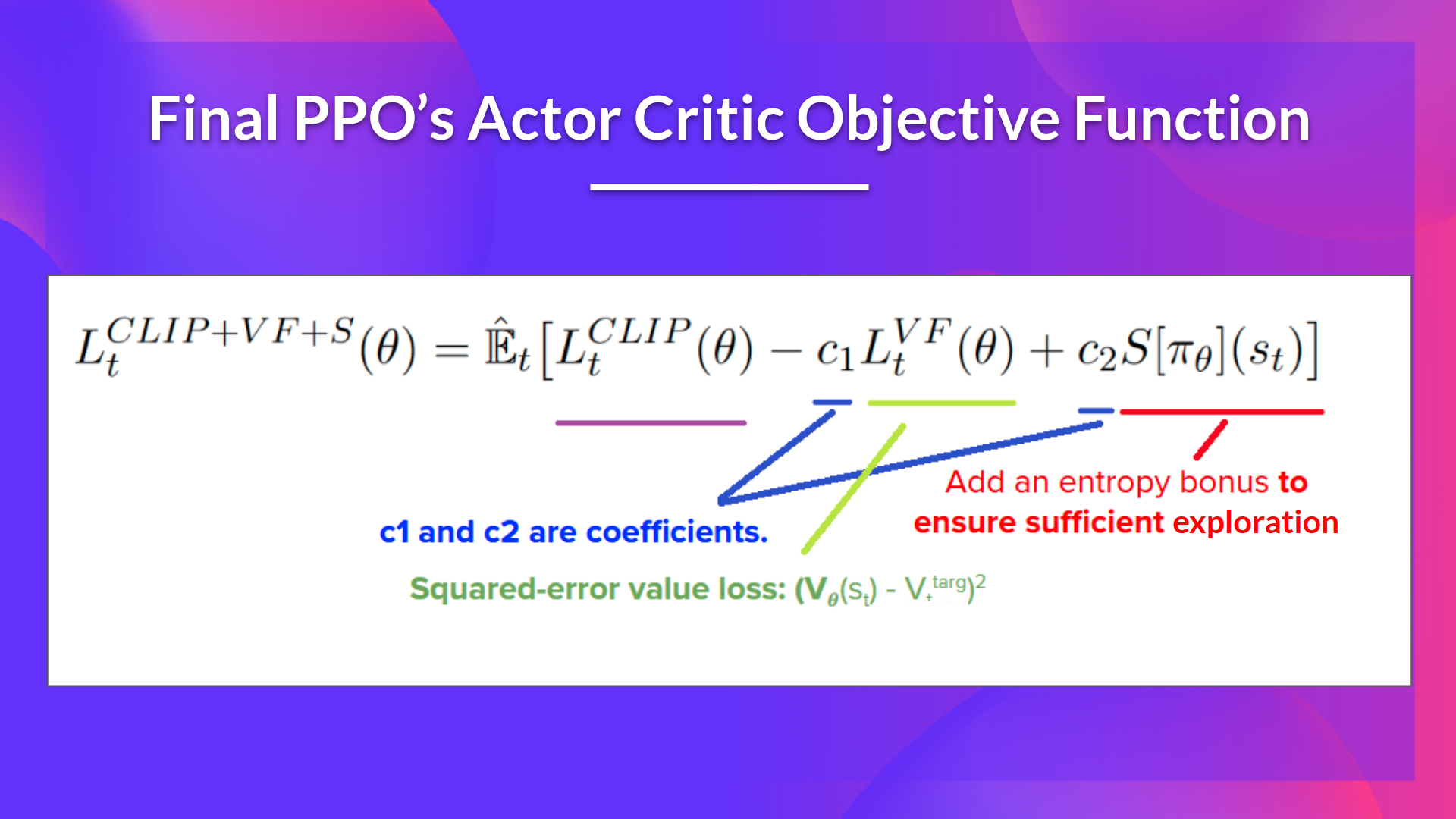 +
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
+
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).