diff --git a/notebooks/unit6/requirements-unit6.txt b/notebooks/unit6/requirements-unit6.txt
new file mode 100644
index 0000000..1c8ffaa
--- /dev/null
+++ b/notebooks/unit6/requirements-unit6.txt
@@ -0,0 +1,4 @@
+stable-baselines3[extra]
+huggingface_sb3
+panda_gym==2.0.0
+pyglet==1.5.1
diff --git a/notebooks/unit6/unit6.ipynb b/notebooks/unit6/unit6.ipynb
new file mode 100644
index 0000000..95056b5
--- /dev/null
+++ b/notebooks/unit6/unit6.ipynb
@@ -0,0 +1,918 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "provenance": [],
+ "private_outputs": true,
+ "authorship_tag": "ABX9TyMm2AvQJHZiNbxotv6J/Rf+",
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "accelerator": "GPU",
+ "gpuClass": "standard"
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖\n",
+ "\n",
+ " \n",
+ "\n",
+ "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments. \n",
+ "\n",
+ "With [PyBullet](https://github.com/bulletphysics/bullet3), you're going to **train a robot to move**:\n",
+ "- `AntBulletEnv-v0` 🕸️ More precisely, a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
+ "\n",
+ "Then, with [Panda-Gym](https://github.com/qgallouedec/panda-gym), you're going **to train a robotic arm** (Franka Emika Panda robot) to perform a task:\n",
+ "- `Reach`: the robot must place its end-effector at a target position.\n",
+ "\n",
+ "After that, you'll be able **to train in other robotics environments**.\n"
+ ],
+ "metadata": {
+ "id": "-PTReiOw-RAN"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "
\n",
+ "\n",
+ "In this notebook, you'll learn to use A2C with PyBullet and Panda-Gym, two set of robotics environments. \n",
+ "\n",
+ "With [PyBullet](https://github.com/bulletphysics/bullet3), you're going to **train a robot to move**:\n",
+ "- `AntBulletEnv-v0` 🕸️ More precisely, a spider (they say Ant but come on... it's a spider 😆) 🕸️\n",
+ "\n",
+ "Then, with [Panda-Gym](https://github.com/qgallouedec/panda-gym), you're going **to train a robotic arm** (Franka Emika Panda robot) to perform a task:\n",
+ "- `Reach`: the robot must place its end-effector at a target position.\n",
+ "\n",
+ "After that, you'll be able **to train in other robotics environments**.\n"
+ ],
+ "metadata": {
+ "id": "-PTReiOw-RAN"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ " "
+ ],
+ "metadata": {
+ "id": "2VGL_0ncoAJI"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### 🎮 Environments: \n",
+ "\n",
+ "- [PyBullet](https://github.com/bulletphysics/bullet3)\n",
+ "- [Panda-Gym](https://github.com/qgallouedec/panda-gym)\n",
+ "\n",
+ "###📚 RL-Library: \n",
+ "\n",
+ "- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)"
+ ],
+ "metadata": {
+ "id": "QInFitfWno1Q"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ],
+ "metadata": {
+ "id": "2CcdX4g3oFlp"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.\n",
+ "- Be able to **train robots using A2C**.\n",
+ "- Understand why **we need to normalize the input**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "MoubJX20oKaQ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "2VGL_0ncoAJI"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### 🎮 Environments: \n",
+ "\n",
+ "- [PyBullet](https://github.com/bulletphysics/bullet3)\n",
+ "- [Panda-Gym](https://github.com/qgallouedec/panda-gym)\n",
+ "\n",
+ "###📚 RL-Library: \n",
+ "\n",
+ "- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)"
+ ],
+ "metadata": {
+ "id": "QInFitfWno1Q"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ ],
+ "metadata": {
+ "id": "2CcdX4g3oFlp"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Objectives of this notebook 🏆\n",
+ "\n",
+ "At the end of the notebook, you will:\n",
+ "\n",
+ "- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.\n",
+ "- Be able to **train robots using A2C**.\n",
+ "- Understand why **we need to normalize the input**.\n",
+ "- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
+ "\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "MoubJX20oKaQ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
+ " \n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "DoUNkTExoUED"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "BTuQAUAPoa5E"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Let's train our first robots 🤖"
+ ],
+ "metadata": {
+ "id": "iajHvVDWoo01"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your two trained models to the Hub and get the following results:\n",
+ "\n",
+ "- `AntBulletEnv-v0` get a result of >= 650.\n",
+ "- `PandaReachDense-v2` get a result of >= -3.5.\n",
+ "\n",
+ "To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "zbOENTE2os_D"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In this free course, you will:\n",
+ "\n",
+ "- 📖 Study Deep Reinforcement Learning in **theory and practice**.\n",
+ "- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.\n",
+ "- 🤖 Train **agents in unique environments** \n",
+ "\n",
+ "And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course\n",
+ "\n",
+ "Don’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**\n",
+ "\n",
+ "\n",
+ "The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5"
+ ],
+ "metadata": {
+ "id": "DoUNkTExoUED"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Prerequisites 🏗️\n",
+ "Before diving into the notebook, you need to:\n",
+ "\n",
+ "🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗 "
+ ],
+ "metadata": {
+ "id": "BTuQAUAPoa5E"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Let's train our first robots 🤖"
+ ],
+ "metadata": {
+ "id": "iajHvVDWoo01"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your two trained models to the Hub and get the following results:\n",
+ "\n",
+ "- `AntBulletEnv-v0` get a result of >= 650.\n",
+ "- `PandaReachDense-v2` get a result of >= -3.5.\n",
+ "\n",
+ "To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**\n",
+ "\n",
+ "If you don't find your model, **go to the bottom of the page and click on the refresh button**\n",
+ "\n",
+ "For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process"
+ ],
+ "metadata": {
+ "id": "zbOENTE2os_D"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Set the GPU 💪\n",
+ "- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "PU4FVzaoM6fC"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "- `Hardware Accelerator > GPU`\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Install dependencies 🔽\n",
+ "The first step is to install the dependencies, we’ll install multiple ones:\n",
+ "\n",
+ "- `pybullet`: Contains the walking robots environments.\n",
+ "- `panda-gym`: Contains the robotics arm environments.\n",
+ "- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.\n",
+ "- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.\n",
+ "- `huggingface_hub`: Library allowing anyone to work with the Hub repositories."
+ ],
+ "metadata": {
+ "id": "e1obkbdJ_KnG"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2yZRi_0bQGPM"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Import the packages 📦"
+ ],
+ "metadata": {
+ "id": "QTep3PQQABLr"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import pybullet_envs\n",
+ "import panda_gym\n",
+ "import gym\n",
+ "\n",
+ "import os\n",
+ "\n",
+ "from huggingface_sb3 import load_from_hub, package_to_hub\n",
+ "\n",
+ "from stable_baselines3 import A2C\n",
+ "from stable_baselines3.common.evaluation import evaluate_policy\n",
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "from stable_baselines3.common.env_util import make_vec_env\n",
+ "\n",
+ "from huggingface_hub import notebook_login"
+ ],
+ "metadata": {
+ "id": "HpiB8VdnQ7Bk"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Environment 1: AntBulletEnv-v0 🕸\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "lfBwIS_oAVXI"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Create the AntBulletEnv-v0\n",
+ "#### The environment 🎮\n",
+ "In this environment, the agent needs to use correctly its different joints to walk correctly.\n",
+ "You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet"
+ ],
+ "metadata": {
+ "id": "frVXOrnlBerQ"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env_id = \"AntBulletEnv-v0\"\n",
+ "# Create the env\n",
+ "env = gym.make(env_id)\n",
+ "\n",
+ "# Get the state space and action space\n",
+ "s_size = env.observation_space.shape[0]\n",
+ "a_size = env.action_space"
+ ],
+ "metadata": {
+ "id": "JpU-JCDQYYax"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"_____OBSERVATION SPACE_____ \\n\")\n",
+ "print(\"The State Space is: \", s_size)\n",
+ "print(\"Sample observation\", env.observation_space.sample()) # Get a random observation"
+ ],
+ "metadata": {
+ "id": "2ZfvcCqEYgrg"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):\n",
+ "\n",
+ "The difference is that our observation space is 28 not 29.\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "KV0NyFdQM9ZG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Create a virtual display 🔽\n",
+ "\n",
+ "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "\n",
+ "Hence the following cell will install the librairies and create and run a virtual screen 🖥"
+ ],
+ "metadata": {
+ "id": "bTpYcVZVMzUI"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jV6wjQ7Be7p5"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "!apt install python-opengl\n",
+ "!apt install ffmpeg\n",
+ "!apt install xvfb\n",
+ "!pip3 install pyvirtualdisplay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Virtual display\n",
+ "from pyvirtualdisplay import Display\n",
+ "\n",
+ "virtual_display = Display(visible=0, size=(1400, 900))\n",
+ "virtual_display.start()"
+ ],
+ "metadata": {
+ "id": "ww5PQH1gNLI4"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Install dependencies 🔽\n",
+ "The first step is to install the dependencies, we’ll install multiple ones:\n",
+ "\n",
+ "- `pybullet`: Contains the walking robots environments.\n",
+ "- `panda-gym`: Contains the robotics arm environments.\n",
+ "- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.\n",
+ "- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.\n",
+ "- `huggingface_hub`: Library allowing anyone to work with the Hub repositories."
+ ],
+ "metadata": {
+ "id": "e1obkbdJ_KnG"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2yZRi_0bQGPM"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Import the packages 📦"
+ ],
+ "metadata": {
+ "id": "QTep3PQQABLr"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import pybullet_envs\n",
+ "import panda_gym\n",
+ "import gym\n",
+ "\n",
+ "import os\n",
+ "\n",
+ "from huggingface_sb3 import load_from_hub, package_to_hub\n",
+ "\n",
+ "from stable_baselines3 import A2C\n",
+ "from stable_baselines3.common.evaluation import evaluate_policy\n",
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "from stable_baselines3.common.env_util import make_vec_env\n",
+ "\n",
+ "from huggingface_hub import notebook_login"
+ ],
+ "metadata": {
+ "id": "HpiB8VdnQ7Bk"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Environment 1: AntBulletEnv-v0 🕸\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "lfBwIS_oAVXI"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Create the AntBulletEnv-v0\n",
+ "#### The environment 🎮\n",
+ "In this environment, the agent needs to use correctly its different joints to walk correctly.\n",
+ "You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet"
+ ],
+ "metadata": {
+ "id": "frVXOrnlBerQ"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env_id = \"AntBulletEnv-v0\"\n",
+ "# Create the env\n",
+ "env = gym.make(env_id)\n",
+ "\n",
+ "# Get the state space and action space\n",
+ "s_size = env.observation_space.shape[0]\n",
+ "a_size = env.action_space"
+ ],
+ "metadata": {
+ "id": "JpU-JCDQYYax"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"_____OBSERVATION SPACE_____ \\n\")\n",
+ "print(\"The State Space is: \", s_size)\n",
+ "print(\"Sample observation\", env.observation_space.sample()) # Get a random observation"
+ ],
+ "metadata": {
+ "id": "2ZfvcCqEYgrg"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):\n",
+ "\n",
+ "The difference is that our observation space is 28 not 29.\n",
+ "\n",
+ " \n"
+ ],
+ "metadata": {
+ "id": "QzMmsdMJS7jh"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"\\n _____ACTION SPACE_____ \\n\")\n",
+ "print(\"The Action Space is: \", a_size)\n",
+ "print(\"Action Space Sample\", env.action_space.sample()) # Take a random action"
+ ],
+ "metadata": {
+ "id": "Tc89eLTYYkK2"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):\n",
+ "\n",
+ "
\n"
+ ],
+ "metadata": {
+ "id": "QzMmsdMJS7jh"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"\\n _____ACTION SPACE_____ \\n\")\n",
+ "print(\"The Action Space is: \", a_size)\n",
+ "print(\"Action Space Sample\", env.action_space.sample()) # Take a random action"
+ ],
+ "metadata": {
+ "id": "Tc89eLTYYkK2"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):\n",
+ "\n",
+ " \n"
+ ],
+ "metadata": {
+ "id": "3RfsHhzZS9Pw"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Normalize observation and rewards"
+ ],
+ "metadata": {
+ "id": "S5sXcg469ysB"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html). \n",
+ "\n",
+ "For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.\n",
+ "\n",
+ "We also normalize rewards with this same wrapper by adding `norm_reward = True`\n",
+ "\n",
+ "[You should check the documentation to fill this cell](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)"
+ ],
+ "metadata": {
+ "id": "1ZyX6qf3Zva9"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "# Adding this wrapper to normalize the observation and the reward\n",
+ "env = # TODO: Add the wrapper"
+ ],
+ "metadata": {
+ "id": "1RsDtHHAQ9Ie"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "#### Solution"
+ ],
+ "metadata": {
+ "id": "tF42HvI7-gs5"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)"
+ ],
+ "metadata": {
+ "id": "2O67mqgC-hol"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Create the A2C Model 🤖\n",
+ "\n",
+ "In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.\n",
+ "\n",
+ "For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes\n",
+ "\n",
+ "To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3)."
+ ],
+ "metadata": {
+ "id": "4JmEVU6z1ZA-"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model = # Create the A2C model and try to find the best parameters"
+ ],
+ "metadata": {
+ "id": "vR3T4qFt164I"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "#### Solution"
+ ],
+ "metadata": {
+ "id": "nWAuOOLh-oQf"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model = A2C(policy = \"MlpPolicy\",\n",
+ " env = env,\n",
+ " gae_lambda = 0.9,\n",
+ " gamma = 0.99,\n",
+ " learning_rate = 0.00096,\n",
+ " max_grad_norm = 0.5,\n",
+ " n_steps = 8,\n",
+ " vf_coef = 0.4,\n",
+ " ent_coef = 0.0,\n",
+ " policy_kwargs=dict(\n",
+ " log_std_init=-2, ortho_init=False),\n",
+ " normalize_advantage=False,\n",
+ " use_rms_prop= True,\n",
+ " use_sde= True,\n",
+ " verbose=1)"
+ ],
+ "metadata": {
+ "id": "FKFLY54T-pU1"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Train the A2C agent 🏃\n",
+ "- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min"
+ ],
+ "metadata": {
+ "id": "opyK3mpJ1-m9"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model.learn(2_000_000)"
+ ],
+ "metadata": {
+ "id": "4TuGHZD7RF1G"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Save the model and VecNormalize statistics when saving the agent\n",
+ "model.save(\"a2c-AntBulletEnv-v0\")\n",
+ "env.save(\"vec_normalize.pkl\")"
+ ],
+ "metadata": {
+ "id": "MfYtjj19cKFr"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Evaluate the agent 📈\n",
+ "- Now that's our agent is trained, we need to **check its performance**.\n",
+ "- Stable-Baselines3 provides a method to do that: `evaluate_policy`\n",
+ "- In my case, I got a mean reward of `2371.90 +/- 16.50`"
+ ],
+ "metadata": {
+ "id": "01M9GCd32Ig-"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "\n",
+ "# Load the saved statistics\n",
+ "eval_env = DummyVecEnv([lambda: gym.make(\"AntBulletEnv-v0\")])\n",
+ "eval_env = VecNormalize.load(\"vec_normalize.pkl\", eval_env)\n",
+ "\n",
+ "# do not update them at test time\n",
+ "eval_env.training = False\n",
+ "# reward normalization is not needed at test time\n",
+ "eval_env.norm_reward = False\n",
+ "\n",
+ "# Load the agent\n",
+ "model = A2C.load(\"a2c-AntBulletEnv-v0\")\n",
+ "\n",
+ "mean_reward, std_reward = evaluate_policy(model, env)\n",
+ "\n",
+ "print(f\"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}\")"
+ ],
+ "metadata": {
+ "id": "liirTVoDkHq3"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Publish your trained model on the Hub 🔥\n",
+ "Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.\n",
+ "\n",
+ "📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20\n",
+ "\n",
+ "Here's an example of a Model Card (with a PyBullet environment):\n",
+ "\n",
+ "
\n"
+ ],
+ "metadata": {
+ "id": "3RfsHhzZS9Pw"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Normalize observation and rewards"
+ ],
+ "metadata": {
+ "id": "S5sXcg469ysB"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html). \n",
+ "\n",
+ "For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.\n",
+ "\n",
+ "We also normalize rewards with this same wrapper by adding `norm_reward = True`\n",
+ "\n",
+ "[You should check the documentation to fill this cell](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)"
+ ],
+ "metadata": {
+ "id": "1ZyX6qf3Zva9"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "# Adding this wrapper to normalize the observation and the reward\n",
+ "env = # TODO: Add the wrapper"
+ ],
+ "metadata": {
+ "id": "1RsDtHHAQ9Ie"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "#### Solution"
+ ],
+ "metadata": {
+ "id": "tF42HvI7-gs5"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)"
+ ],
+ "metadata": {
+ "id": "2O67mqgC-hol"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Create the A2C Model 🤖\n",
+ "\n",
+ "In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.\n",
+ "\n",
+ "For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes\n",
+ "\n",
+ "To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3)."
+ ],
+ "metadata": {
+ "id": "4JmEVU6z1ZA-"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model = # Create the A2C model and try to find the best parameters"
+ ],
+ "metadata": {
+ "id": "vR3T4qFt164I"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "#### Solution"
+ ],
+ "metadata": {
+ "id": "nWAuOOLh-oQf"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model = A2C(policy = \"MlpPolicy\",\n",
+ " env = env,\n",
+ " gae_lambda = 0.9,\n",
+ " gamma = 0.99,\n",
+ " learning_rate = 0.00096,\n",
+ " max_grad_norm = 0.5,\n",
+ " n_steps = 8,\n",
+ " vf_coef = 0.4,\n",
+ " ent_coef = 0.0,\n",
+ " policy_kwargs=dict(\n",
+ " log_std_init=-2, ortho_init=False),\n",
+ " normalize_advantage=False,\n",
+ " use_rms_prop= True,\n",
+ " use_sde= True,\n",
+ " verbose=1)"
+ ],
+ "metadata": {
+ "id": "FKFLY54T-pU1"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Train the A2C agent 🏃\n",
+ "- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min"
+ ],
+ "metadata": {
+ "id": "opyK3mpJ1-m9"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "model.learn(2_000_000)"
+ ],
+ "metadata": {
+ "id": "4TuGHZD7RF1G"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Save the model and VecNormalize statistics when saving the agent\n",
+ "model.save(\"a2c-AntBulletEnv-v0\")\n",
+ "env.save(\"vec_normalize.pkl\")"
+ ],
+ "metadata": {
+ "id": "MfYtjj19cKFr"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Evaluate the agent 📈\n",
+ "- Now that's our agent is trained, we need to **check its performance**.\n",
+ "- Stable-Baselines3 provides a method to do that: `evaluate_policy`\n",
+ "- In my case, I got a mean reward of `2371.90 +/- 16.50`"
+ ],
+ "metadata": {
+ "id": "01M9GCd32Ig-"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "\n",
+ "# Load the saved statistics\n",
+ "eval_env = DummyVecEnv([lambda: gym.make(\"AntBulletEnv-v0\")])\n",
+ "eval_env = VecNormalize.load(\"vec_normalize.pkl\", eval_env)\n",
+ "\n",
+ "# do not update them at test time\n",
+ "eval_env.training = False\n",
+ "# reward normalization is not needed at test time\n",
+ "eval_env.norm_reward = False\n",
+ "\n",
+ "# Load the agent\n",
+ "model = A2C.load(\"a2c-AntBulletEnv-v0\")\n",
+ "\n",
+ "mean_reward, std_reward = evaluate_policy(model, env)\n",
+ "\n",
+ "print(f\"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}\")"
+ ],
+ "metadata": {
+ "id": "liirTVoDkHq3"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Publish your trained model on the Hub 🔥\n",
+ "Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.\n",
+ "\n",
+ "📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20\n",
+ "\n",
+ "Here's an example of a Model Card (with a PyBullet environment):\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "44L9LVQaavR8"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.\n",
+ "\n",
+ "This way:\n",
+ "- You can **showcase our work** 🔥\n",
+ "- You can **visualize your agent playing** 👀\n",
+ "- You can **share with the community an agent that others can use** 💾\n",
+ "- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard\n"
+ ],
+ "metadata": {
+ "id": "MkMk99m8bgaQ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "44L9LVQaavR8"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.\n",
+ "\n",
+ "This way:\n",
+ "- You can **showcase our work** 🔥\n",
+ "- You can **visualize your agent playing** 👀\n",
+ "- You can **share with the community an agent that others can use** 💾\n",
+ "- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard\n"
+ ],
+ "metadata": {
+ "id": "MkMk99m8bgaQ"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JquRrWytA6eo"
+ },
+ "source": [
+ "To be able to share your model with the community there are three more steps to follow:\n",
+ "\n",
+ "1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join\n",
+ "\n",
+ "2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.\n",
+ "- Create a new token (https://huggingface.co/settings/tokens) **with write role**\n",
+ "\n",
+ " \n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FGNh9VsZok0i"
+ },
+ "source": [
+ "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "package_to_hub(\n",
+ " model=model,\n",
+ " model_name=f\"a2c-{env_id}\",\n",
+ " model_architecture=\"A2C\",\n",
+ " env_id=env_id,\n",
+ " eval_env=eval_env,\n",
+ " repo_id=f\"ThomasSimonini/a2c-{env_id}\", # Change the username\n",
+ " commit_message=\"Initial commit\",\n",
+ ")"
+ ],
+ "metadata": {
+ "id": "ueuzWVCUTkfS"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Take a coffee break ☕\n",
+ "- You already trained your first robot that learned to move congratutlations 🥳!\n",
+ "- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.\n"
+ ],
+ "metadata": {
+ "id": "Qk9ykOk9D6Qh"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Environment 2: PandaReachDense-v2 🦾\n",
+ "\n",
+ "The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).\n",
+ "\n",
+ "In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.\n",
+ "\n",
+ "In `PandaReach`, the robot must place its end-effector at a target position (green ball).\n",
+ "\n",
+ "We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.\n",
+ "\n",
+ "Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).\n",
+ "\n",
+ "
\n",
+ "\n",
+ "- Copy the token \n",
+ "- Run the cell below and paste the token"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZiFBBlzxzxY"
+ },
+ "outputs": [],
+ "source": [
+ "notebook_login()\n",
+ "!git config --global credential.helper store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_tsf2uv0g_4p"
+ },
+ "source": [
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FGNh9VsZok0i"
+ },
+ "source": [
+ "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "package_to_hub(\n",
+ " model=model,\n",
+ " model_name=f\"a2c-{env_id}\",\n",
+ " model_architecture=\"A2C\",\n",
+ " env_id=env_id,\n",
+ " eval_env=eval_env,\n",
+ " repo_id=f\"ThomasSimonini/a2c-{env_id}\", # Change the username\n",
+ " commit_message=\"Initial commit\",\n",
+ ")"
+ ],
+ "metadata": {
+ "id": "ueuzWVCUTkfS"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Take a coffee break ☕\n",
+ "- You already trained your first robot that learned to move congratutlations 🥳!\n",
+ "- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.\n"
+ ],
+ "metadata": {
+ "id": "Qk9ykOk9D6Qh"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Environment 2: PandaReachDense-v2 🦾\n",
+ "\n",
+ "The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).\n",
+ "\n",
+ "In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.\n",
+ "\n",
+ "In `PandaReach`, the robot must place its end-effector at a target position (green ball).\n",
+ "\n",
+ "We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.\n",
+ "\n",
+ "Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "This way **the training will be easier**.\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "5VWfwAA7EJg7"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "\n",
+ "In `PandaReachDense-v2` the robotic arm must place its end-effector at a target position (green ball).\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "oZ7FyDEi7G3T"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import gym\n",
+ "\n",
+ "env_id = \"PandaPushDense-v2\"\n",
+ "\n",
+ "# Create the env\n",
+ "env = gym.make(env_id)\n",
+ "\n",
+ "# Get the state space and action space\n",
+ "s_size = env.observation_space.shape\n",
+ "a_size = env.action_space"
+ ],
+ "metadata": {
+ "id": "zXzAu3HYF1WD"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"_____OBSERVATION SPACE_____ \\n\")\n",
+ "print(\"The State Space is: \", s_size)\n",
+ "print(\"Sample observation\", env.observation_space.sample()) # Get a random observation"
+ ],
+ "metadata": {
+ "id": "E-U9dexcF-FB"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The observation space **is a dictionary with 3 different elements**:\n",
+ "- `achieved_goal`: (x,y,z) position of the goal.\n",
+ "- `desired_goal`: (x,y,z) distance between the goal position and the current object position.\n",
+ "- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).\n",
+ "\n",
+ "Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**."
+ ],
+ "metadata": {
+ "id": "g_JClfElGFnF"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"\\n _____ACTION SPACE_____ \\n\")\n",
+ "print(\"The Action Space is: \", a_size)\n",
+ "print(\"Action Space Sample\", env.action_space.sample()) # Take a random action"
+ ],
+ "metadata": {
+ "id": "ib1Kxy4AF-FC"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The action space is a vector with 3 values:\n",
+ "- Control x, y, z movement"
+ ],
+ "metadata": {
+ "id": "5MHTHEHZS4yp"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Now it's your turn:\n",
+ "\n",
+ "1. Define the environment called \"PandaReachDense-v2\"\n",
+ "2. Make a vectorized environment\n",
+ "3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)\n",
+ "4. Create the A2C Model (don't forget verbose=1 to print the training logs).\n",
+ "5. Train it for 1M Timesteps\n",
+ "6. Save the model and VecNormalize statistics when saving the agent\n",
+ "7. Evaluate your agent\n",
+ "8. Publish your trained model on the Hub 🔥 with `package_to_hub`"
+ ],
+ "metadata": {
+ "id": "nIhPoc5t9HjG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Solution (fill the todo)"
+ ],
+ "metadata": {
+ "id": "sKGbFXZq9ikN"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# 1 - 2\n",
+ "env_id = \"PandaReachDense-v2\"\n",
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "# 3\n",
+ "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)\n",
+ "\n",
+ "# 4\n",
+ "model = A2C(policy = \"MultiInputPolicy\",\n",
+ " env = env,\n",
+ " verbose=1)\n",
+ "# 5\n",
+ "model.learn(1_000_000)"
+ ],
+ "metadata": {
+ "id": "J-cC-Feg9iMm"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# 6\n",
+ "model_name = \"a2c-PandaReachDense-v2\"; \n",
+ "model.save(model_name)\n",
+ "env.save(\"vec_normalize.pkl\")\n",
+ "\n",
+ "# 7\n",
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "\n",
+ "# Load the saved statistics\n",
+ "eval_env = DummyVecEnv([lambda: gym.make(\"PandaReachDense-v2\")])\n",
+ "eval_env = VecNormalize.load(\"vec_normalize.pkl\", eval_env)\n",
+ "\n",
+ "# do not update them at test time\n",
+ "eval_env.training = False\n",
+ "# reward normalization is not needed at test time\n",
+ "eval_env.norm_reward = False\n",
+ "\n",
+ "# Load the agent\n",
+ "model = A2C.load(model_name)\n",
+ "\n",
+ "mean_reward, std_reward = evaluate_policy(model, env)\n",
+ "\n",
+ "print(f\"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}\")\n",
+ "\n",
+ "# 8\n",
+ "package_to_hub(\n",
+ " model=model,\n",
+ " model_name=f\"a2c-{env_id}\",\n",
+ " model_architecture=\"A2C\",\n",
+ " env_id=env_id,\n",
+ " eval_env=eval_env,\n",
+ " repo_id=f\"ThomasSimonini/a2c-{env_id}\", # TODO: Change the username\n",
+ " commit_message=\"Initial commit\",\n",
+ ")"
+ ],
+ "metadata": {
+ "id": "-UnlKLmpg80p"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?\n",
+ "\n",
+ "If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.\n",
+ "\n",
+ "PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1\n",
+ "\n",
+ "And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html\n",
+ "\n",
+ "Here are some ideas to achieve so:\n",
+ "* Train more steps\n",
+ "* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0\n",
+ "* **Push your new trained model** on the Hub 🔥\n"
+ ],
+ "metadata": {
+ "id": "G3xy3Nf3c2O1"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "See you on Unit 7! 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "usatLaZ8dM4P"
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 8d1b138..3b6f440 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -148,6 +148,20 @@
title: Bonus. Learn to create your own environments with Unity and MLAgents
- local: unit5/conclusion
title: Conclusion
+- title: Unit 6. Actor Critic methods with Robotics environments
+ sections:
+ - local: unit6/introduction
+ title: Introduction
+ - local: unit6/variance-problem
+ title: The Problem of Variance in Reinforce
+ - local: unit6/advantage-actor-critic
+ title: Advantage Actor Critic (A2C)
+ - local: unit6/hands-on
+ title: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+ - local: unit6/conclusion
+ title: Conclusion
+ - local: unit6/additional-readings
+ title: Additional Readings
- title: What's next? New Units Publishing Schedule
sections:
- local: communication/publishing-schedule
diff --git a/units/en/unit6/additional-readings.mdx b/units/en/unit6/additional-readings.mdx
new file mode 100644
index 0000000..07d80fb
--- /dev/null
+++ b/units/en/unit6/additional-readings.mdx
@@ -0,0 +1,17 @@
+# Additional Readings [[additional-readings]]
+
+## Bias-variance tradeoff in Reinforcement Learning
+
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+
+## Advantage Functions
+
+- [Advantage Functions, SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
+
+## Actor Critic
+
+- [Foundations of Deep RL Series, L3 Policy Gradients and Advantage Estimation by Pieter Abbeel](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
+- [A2C Paper: Asynchronous Methods for Deep Reinforcement Learning](https://arxiv.org/abs/1602.01783v2)
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
new file mode 100644
index 0000000..8b7863c
--- /dev/null
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -0,0 +1,70 @@
+# Advantage Actor-Critic (A2C) [[advantage-actor-critic]]
+
+## Reducing variance with Actor-Critic methods
+
+The solution to reducing the variance of the Reinforce algorithm and training our agent faster and better is to use a combination of Policy-Based and Value-Based methods: *the Actor-Critic method*.
+
+To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
+
+
\n",
+ "\n",
+ "\n",
+ "This way **the training will be easier**.\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "5VWfwAA7EJg7"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "\n",
+ "In `PandaReachDense-v2` the robotic arm must place its end-effector at a target position (green ball).\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "oZ7FyDEi7G3T"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import gym\n",
+ "\n",
+ "env_id = \"PandaPushDense-v2\"\n",
+ "\n",
+ "# Create the env\n",
+ "env = gym.make(env_id)\n",
+ "\n",
+ "# Get the state space and action space\n",
+ "s_size = env.observation_space.shape\n",
+ "a_size = env.action_space"
+ ],
+ "metadata": {
+ "id": "zXzAu3HYF1WD"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"_____OBSERVATION SPACE_____ \\n\")\n",
+ "print(\"The State Space is: \", s_size)\n",
+ "print(\"Sample observation\", env.observation_space.sample()) # Get a random observation"
+ ],
+ "metadata": {
+ "id": "E-U9dexcF-FB"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The observation space **is a dictionary with 3 different elements**:\n",
+ "- `achieved_goal`: (x,y,z) position of the goal.\n",
+ "- `desired_goal`: (x,y,z) distance between the goal position and the current object position.\n",
+ "- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).\n",
+ "\n",
+ "Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**."
+ ],
+ "metadata": {
+ "id": "g_JClfElGFnF"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print(\"\\n _____ACTION SPACE_____ \\n\")\n",
+ "print(\"The Action Space is: \", a_size)\n",
+ "print(\"Action Space Sample\", env.action_space.sample()) # Take a random action"
+ ],
+ "metadata": {
+ "id": "ib1Kxy4AF-FC"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "The action space is a vector with 3 values:\n",
+ "- Control x, y, z movement"
+ ],
+ "metadata": {
+ "id": "5MHTHEHZS4yp"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "Now it's your turn:\n",
+ "\n",
+ "1. Define the environment called \"PandaReachDense-v2\"\n",
+ "2. Make a vectorized environment\n",
+ "3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)\n",
+ "4. Create the A2C Model (don't forget verbose=1 to print the training logs).\n",
+ "5. Train it for 1M Timesteps\n",
+ "6. Save the model and VecNormalize statistics when saving the agent\n",
+ "7. Evaluate your agent\n",
+ "8. Publish your trained model on the Hub 🔥 with `package_to_hub`"
+ ],
+ "metadata": {
+ "id": "nIhPoc5t9HjG"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Solution (fill the todo)"
+ ],
+ "metadata": {
+ "id": "sKGbFXZq9ikN"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# 1 - 2\n",
+ "env_id = \"PandaReachDense-v2\"\n",
+ "env = make_vec_env(env_id, n_envs=4)\n",
+ "\n",
+ "# 3\n",
+ "env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)\n",
+ "\n",
+ "# 4\n",
+ "model = A2C(policy = \"MultiInputPolicy\",\n",
+ " env = env,\n",
+ " verbose=1)\n",
+ "# 5\n",
+ "model.learn(1_000_000)"
+ ],
+ "metadata": {
+ "id": "J-cC-Feg9iMm"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# 6\n",
+ "model_name = \"a2c-PandaReachDense-v2\"; \n",
+ "model.save(model_name)\n",
+ "env.save(\"vec_normalize.pkl\")\n",
+ "\n",
+ "# 7\n",
+ "from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize\n",
+ "\n",
+ "# Load the saved statistics\n",
+ "eval_env = DummyVecEnv([lambda: gym.make(\"PandaReachDense-v2\")])\n",
+ "eval_env = VecNormalize.load(\"vec_normalize.pkl\", eval_env)\n",
+ "\n",
+ "# do not update them at test time\n",
+ "eval_env.training = False\n",
+ "# reward normalization is not needed at test time\n",
+ "eval_env.norm_reward = False\n",
+ "\n",
+ "# Load the agent\n",
+ "model = A2C.load(model_name)\n",
+ "\n",
+ "mean_reward, std_reward = evaluate_policy(model, env)\n",
+ "\n",
+ "print(f\"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}\")\n",
+ "\n",
+ "# 8\n",
+ "package_to_hub(\n",
+ " model=model,\n",
+ " model_name=f\"a2c-{env_id}\",\n",
+ " model_architecture=\"A2C\",\n",
+ " env_id=env_id,\n",
+ " eval_env=eval_env,\n",
+ " repo_id=f\"ThomasSimonini/a2c-{env_id}\", # TODO: Change the username\n",
+ " commit_message=\"Initial commit\",\n",
+ ")"
+ ],
+ "metadata": {
+ "id": "-UnlKLmpg80p"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Some additional challenges 🏆\n",
+ "The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?\n",
+ "\n",
+ "If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.\n",
+ "\n",
+ "PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1\n",
+ "\n",
+ "And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html\n",
+ "\n",
+ "Here are some ideas to achieve so:\n",
+ "* Train more steps\n",
+ "* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0\n",
+ "* **Push your new trained model** on the Hub 🔥\n"
+ ],
+ "metadata": {
+ "id": "G3xy3Nf3c2O1"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "See you on Unit 7! 🔥\n",
+ "## Keep learning, stay awesome 🤗"
+ ],
+ "metadata": {
+ "id": "usatLaZ8dM4P"
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 8d1b138..3b6f440 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -148,6 +148,20 @@
title: Bonus. Learn to create your own environments with Unity and MLAgents
- local: unit5/conclusion
title: Conclusion
+- title: Unit 6. Actor Critic methods with Robotics environments
+ sections:
+ - local: unit6/introduction
+ title: Introduction
+ - local: unit6/variance-problem
+ title: The Problem of Variance in Reinforce
+ - local: unit6/advantage-actor-critic
+ title: Advantage Actor Critic (A2C)
+ - local: unit6/hands-on
+ title: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+ - local: unit6/conclusion
+ title: Conclusion
+ - local: unit6/additional-readings
+ title: Additional Readings
- title: What's next? New Units Publishing Schedule
sections:
- local: communication/publishing-schedule
diff --git a/units/en/unit6/additional-readings.mdx b/units/en/unit6/additional-readings.mdx
new file mode 100644
index 0000000..07d80fb
--- /dev/null
+++ b/units/en/unit6/additional-readings.mdx
@@ -0,0 +1,17 @@
+# Additional Readings [[additional-readings]]
+
+## Bias-variance tradeoff in Reinforcement Learning
+
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+
+## Advantage Functions
+
+- [Advantage Functions, SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
+
+## Actor Critic
+
+- [Foundations of Deep RL Series, L3 Policy Gradients and Advantage Estimation by Pieter Abbeel](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
+- [A2C Paper: Asynchronous Methods for Deep Reinforcement Learning](https://arxiv.org/abs/1602.01783v2)
diff --git a/units/en/unit6/advantage-actor-critic.mdx b/units/en/unit6/advantage-actor-critic.mdx
new file mode 100644
index 0000000..8b7863c
--- /dev/null
+++ b/units/en/unit6/advantage-actor-critic.mdx
@@ -0,0 +1,70 @@
+# Advantage Actor-Critic (A2C) [[advantage-actor-critic]]
+
+## Reducing variance with Actor-Critic methods
+
+The solution to reducing the variance of the Reinforce algorithm and training our agent faster and better is to use a combination of Policy-Based and Value-Based methods: *the Actor-Critic method*.
+
+To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
+
+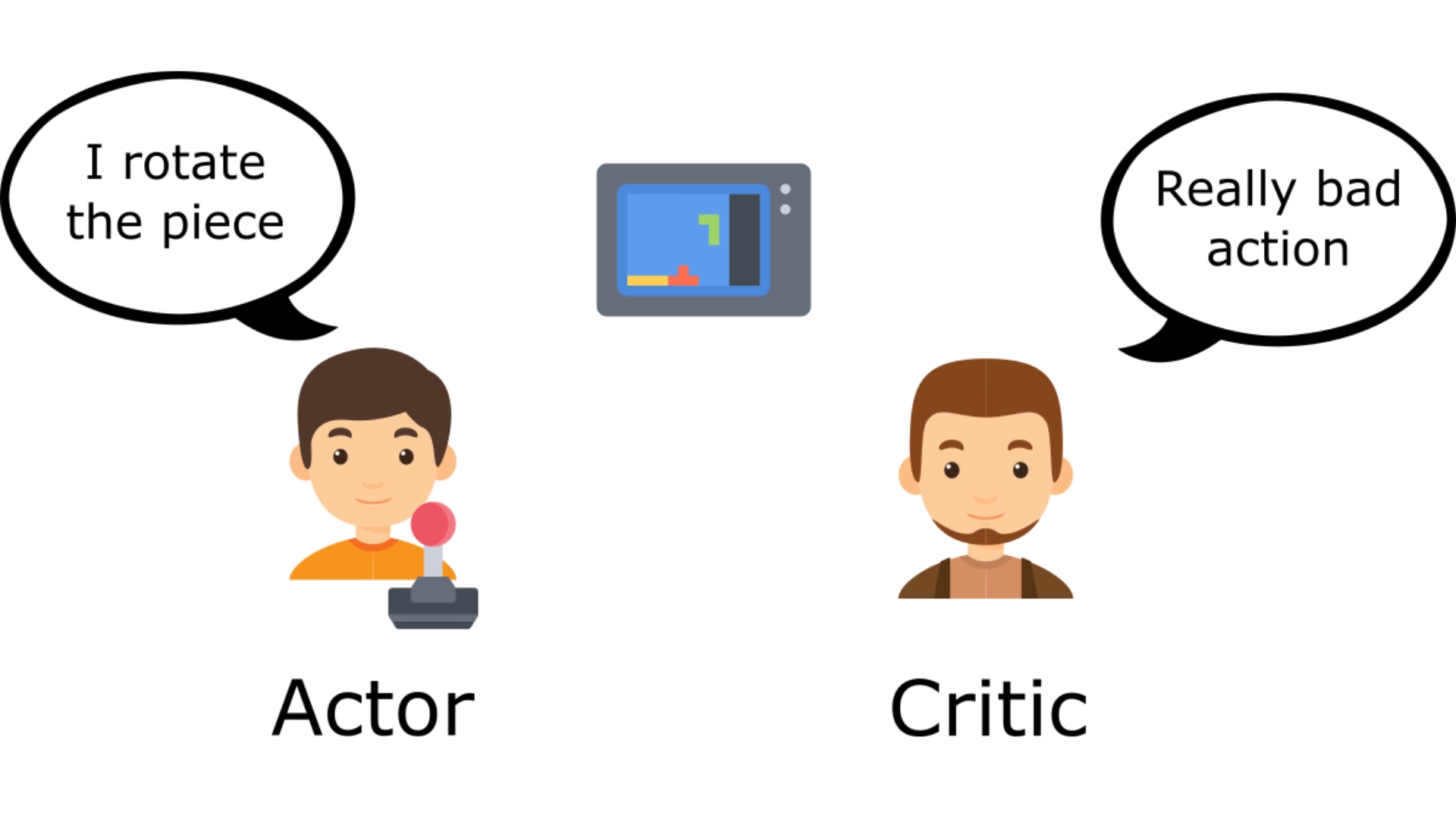 +
+You don't know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
+
+Learning from this feedback, **you'll update your policy and be better at playing that game.**
+
+On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
+
+This is the idea behind Actor-Critic. We learn two function approximations:
+
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+
+- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
+
+## The Actor-Critic Process
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
+
+As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
+
+Let's see the training process to understand how Actor and Critic are optimized:
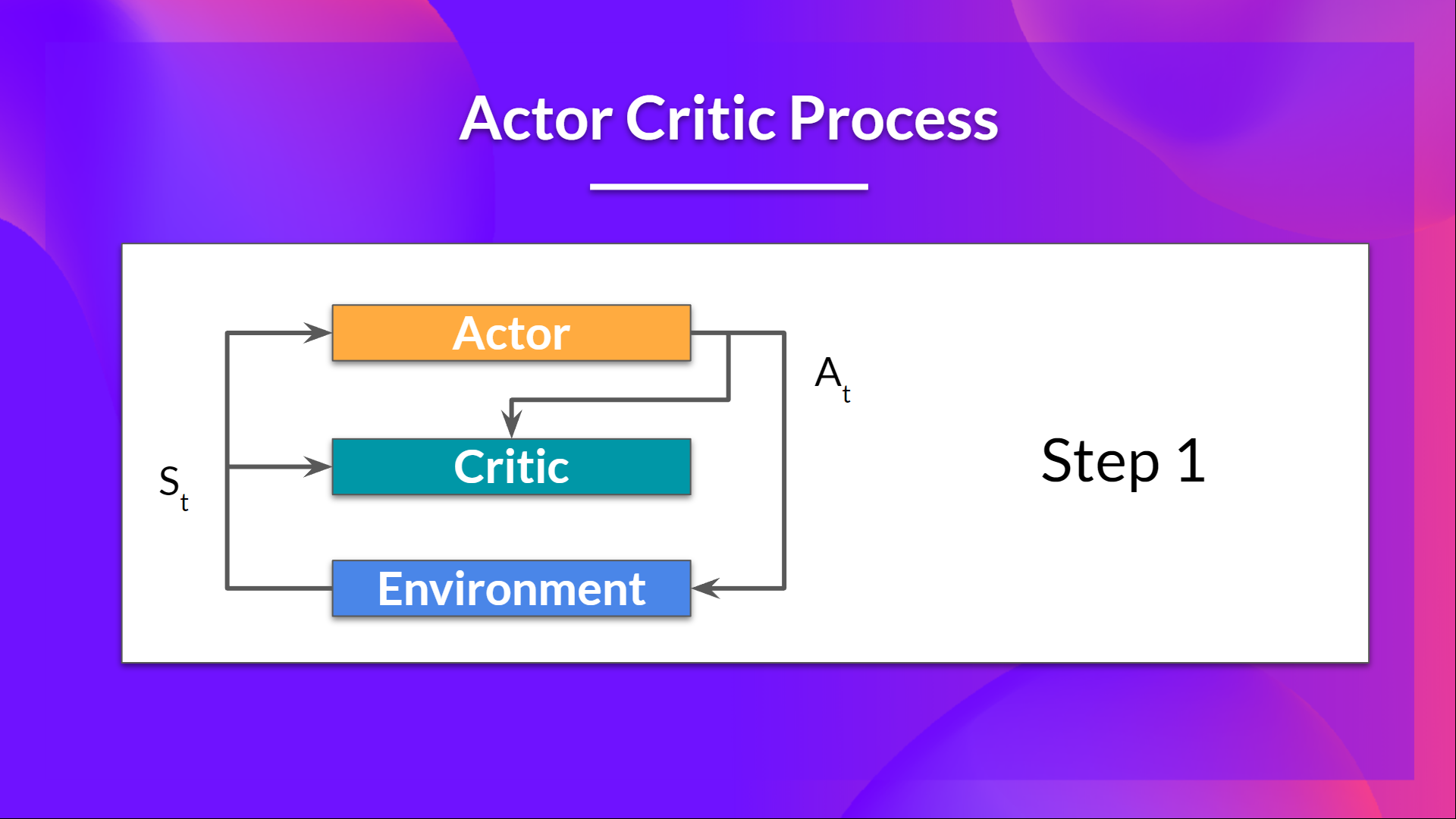
+- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
+
+- Our Policy takes the state and **outputs an action** \\( A_t \\).
+
+
+
+You don't know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
+
+Learning from this feedback, **you'll update your policy and be better at playing that game.**
+
+On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
+
+This is the idea behind Actor-Critic. We learn two function approximations:
+
+- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
+
+- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
+
+## The Actor-Critic Process
+Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
+
+As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
+- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
+- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
+
+Let's see the training process to understand how Actor and Critic are optimized:
+- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
+
+- Our Policy takes the state and **outputs an action** \\( A_t \\).
+
+ +
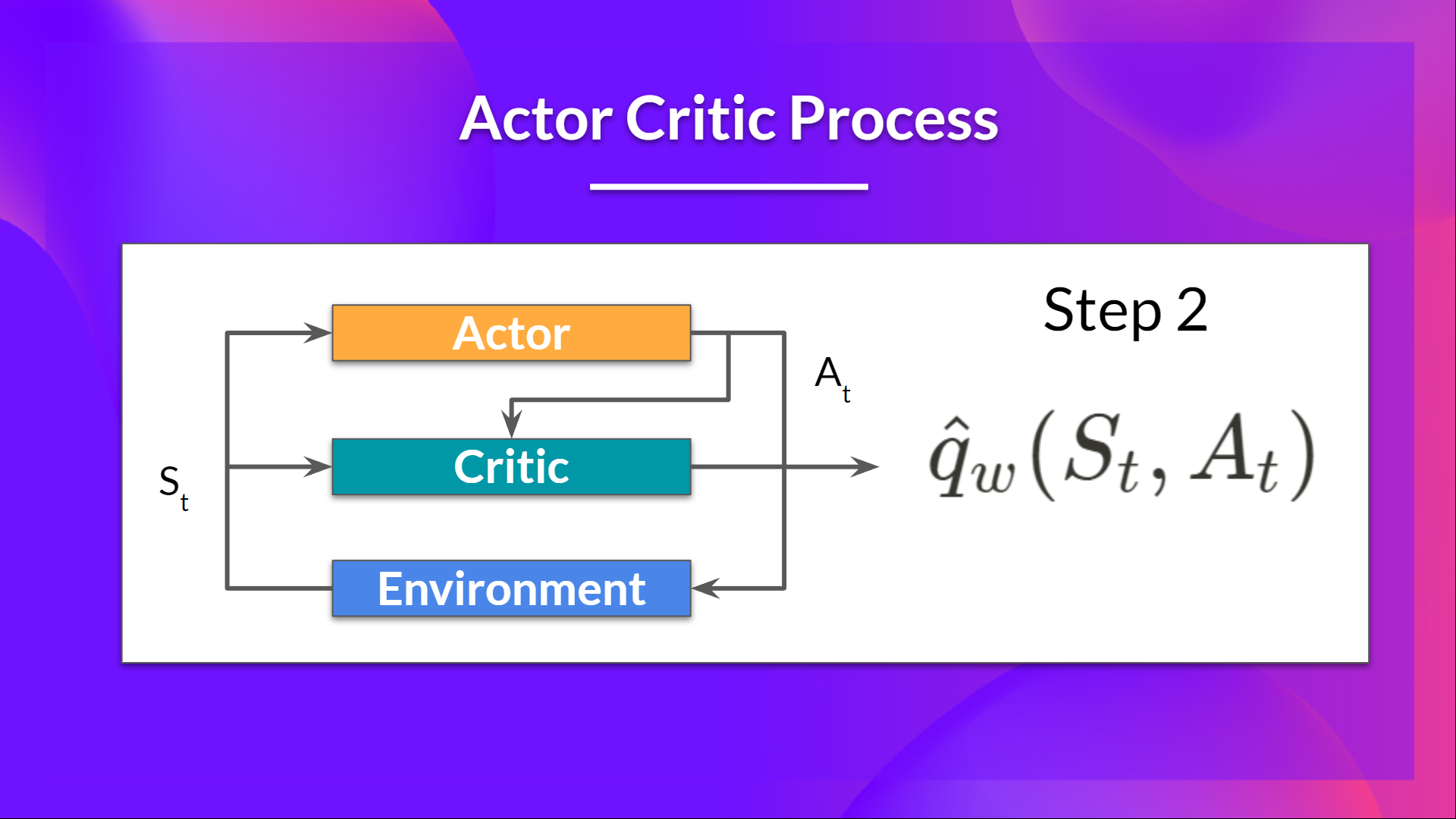
+- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
+
+
+
+- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
+
+ +
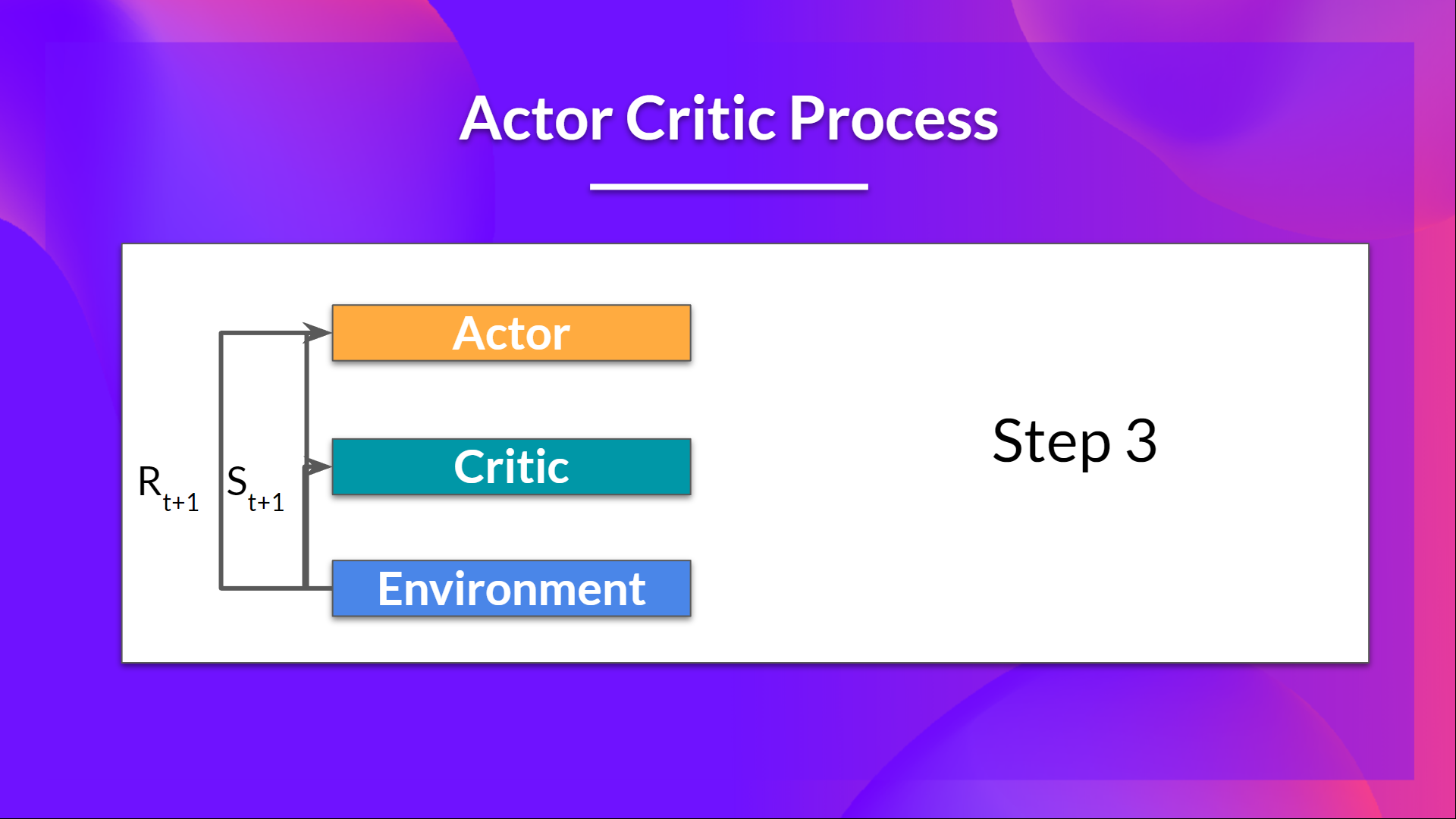
+- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
+
+
+
+- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
+
+ +
+- The Actor updates its policy parameters using the Q value.
+
+
+
+- The Actor updates its policy parameters using the Q value.
+
+ +
+- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
+
+- The Critic then updates its value parameters.
+
+
+
+- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
+
+- The Critic then updates its value parameters.
+
+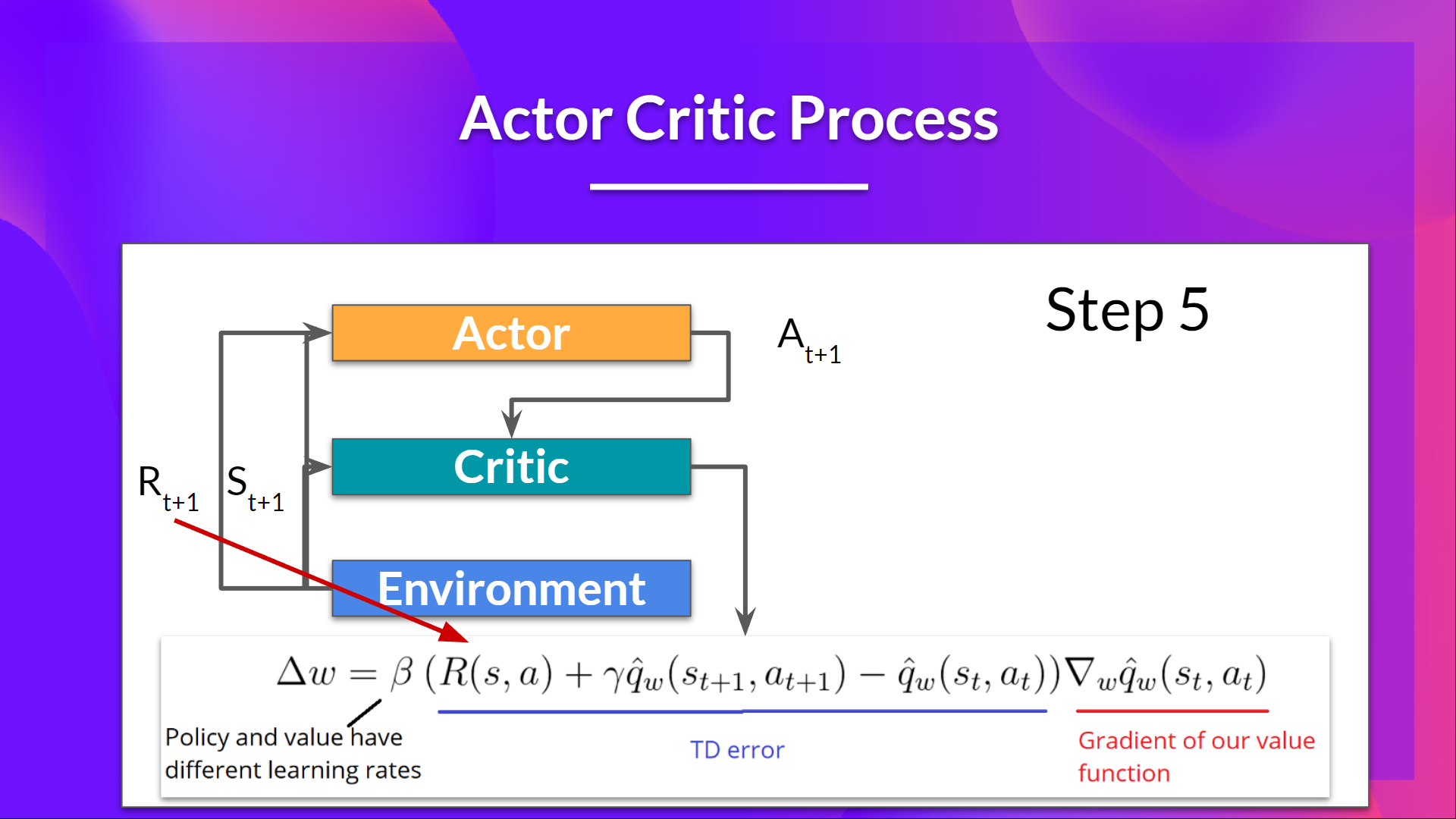 +
+## Adding Advantage in Actor-Critic (A2C)
+We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
+
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how taking that action at a state is better compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+
+
+
+## Adding Advantage in Actor-Critic (A2C)
+We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
+
+The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how taking that action at a state is better compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
+
+ +
+In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
+
+The extra reward is what's beyond the expected value of that state.
+- If A(s,a) > 0: our gradient is **pushed in that direction**.
+- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
+
+The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
+
+
+
+In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
+
+The extra reward is what's beyond the expected value of that state.
+- If A(s,a) > 0: our gradient is **pushed in that direction**.
+- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
+
+The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
+
+ diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
new file mode 100644
index 0000000..85d0229
--- /dev/null
+++ b/units/en/unit6/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this unit and the tutorial. You've just trained your first virtual robots 🥳.
+
+**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+See you in next unit,
+
+### Keep learning, stay awesome 🤗,
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
new file mode 100644
index 0000000..37a0d93
--- /dev/null
+++ b/units/en/unit6/hands-on.mdx
@@ -0,0 +1,464 @@
+# Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖 [[hands-on]]
+
+
+
+
+
+Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train two robots:
+
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move in the correct position.
+
+We're going to use two Robotics environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+
diff --git a/units/en/unit6/conclusion.mdx b/units/en/unit6/conclusion.mdx
new file mode 100644
index 0000000..85d0229
--- /dev/null
+++ b/units/en/unit6/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusion [[conclusion]]
+
+Congrats on finishing this unit and the tutorial. You've just trained your first virtual robots 🥳.
+
+**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
+
+Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+See you in next unit,
+
+### Keep learning, stay awesome 🤗,
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
new file mode 100644
index 0000000..37a0d93
--- /dev/null
+++ b/units/en/unit6/hands-on.mdx
@@ -0,0 +1,464 @@
+# Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖 [[hands-on]]
+
+
+
+
+
+Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train two robots:
+
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move in the correct position.
+
+We're going to use two Robotics environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+ +
+
+To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
+
+- `AntBulletEnv-v0` get a result of >= 650.
+- `PandaReachDense-v2` get a result of >= -3.5.
+
+To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
+
+
+# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+
+### 🎮 Environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
+
+### 📚 RL-Library:
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.
+- Be able to **train robots using A2C**.
+- Understand why **we need to normalize the input**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗
+
+# Let's train our first robots 🤖
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+
+
+
+To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
+
+- `AntBulletEnv-v0` get a result of >= 650.
+- `PandaReachDense-v2` get a result of >= -3.5.
+
+To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
+
+
+# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+
+### 🎮 Environments:
+
+- [PyBullet](https://github.com/bulletphysics/bullet3)
+- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
+
+### 📚 RL-Library:
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to use **PyBullet** and **Panda-Gym**, the environment libraries.
+- Be able to **train robots using A2C**.
+- Understand why **we need to normalize the input**.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗
+
+# Let's train our first robots 🤖
+
+## Set the GPU 💪
+
+- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
+
+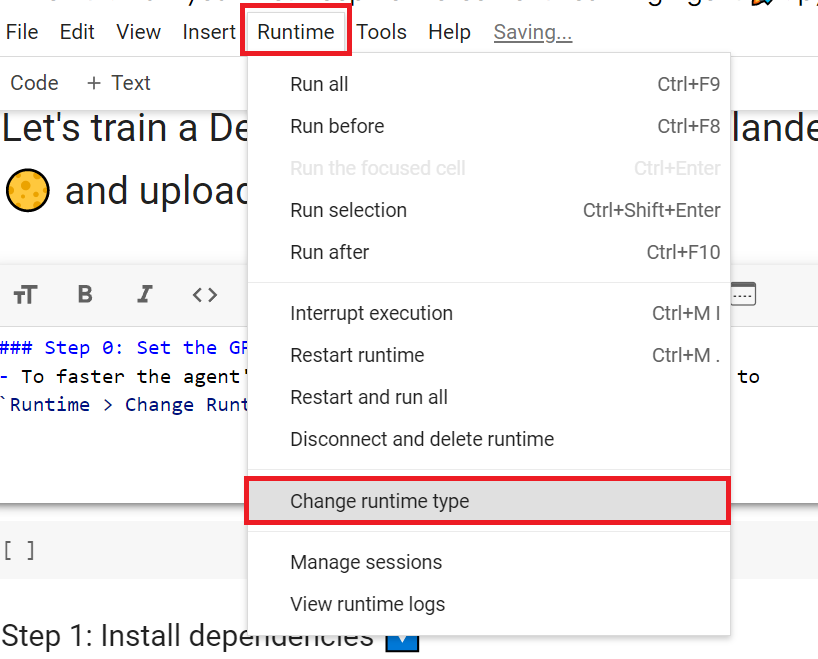 +
+- `Hardware Accelerator > GPU`
+
+
+
+- `Hardware Accelerator > GPU`
+
+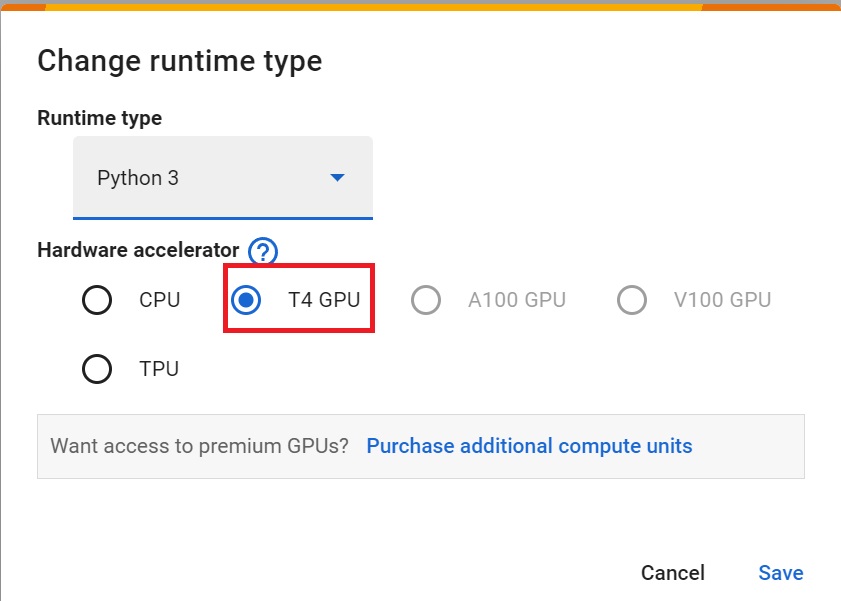 +
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+### Install dependencies 🔽
+The first step is to install the dependencies, we’ll install multiple ones:
+
+- `pybullet`: Contains the walking robots environments.
+- `panda-gym`: Contains the robotics arm environments.
+- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.
+- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
+- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
+
+```bash
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+```
+
+## Import the packages 📦
+
+```python
+import pybullet_envs
+import panda_gym
+import gym
+
+import os
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+
+from stable_baselines3 import A2C
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_hub import notebook_login
+```
+
+## Environment 1: AntBulletEnv-v0 🕸
+
+### Create the AntBulletEnv-v0
+#### The environment 🎮
+
+In this environment, the agent needs to use correctly its different joints to walk correctly.
+You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
+
+```python
+env_id = "AntBulletEnv-v0"
+# Create the env
+env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape[0]
+a_size = env.action_space
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
+The difference is that our observation space is 28 not 29.
+
+
+
+## Create a virtual display 🔽
+
+During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
+
+Hence the following cell will install the librairies and create and run a virtual screen 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+### Install dependencies 🔽
+The first step is to install the dependencies, we’ll install multiple ones:
+
+- `pybullet`: Contains the walking robots environments.
+- `panda-gym`: Contains the robotics arm environments.
+- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.
+- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
+- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
+
+```bash
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+```
+
+## Import the packages 📦
+
+```python
+import pybullet_envs
+import panda_gym
+import gym
+
+import os
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+
+from stable_baselines3 import A2C
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_hub import notebook_login
+```
+
+## Environment 1: AntBulletEnv-v0 🕸
+
+### Create the AntBulletEnv-v0
+#### The environment 🎮
+
+In this environment, the agent needs to use correctly its different joints to walk correctly.
+You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
+
+```python
+env_id = "AntBulletEnv-v0"
+# Create the env
+env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape[0]
+a_size = env.action_space
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
+The difference is that our observation space is 28 not 29.
+
+ +
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
+
+
+
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
+
+ +
+
+### Normalize observation and rewards
+
+A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).
+
+For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
+
+We also normalize rewards with this same wrapper by adding `norm_reward = True`
+
+[You should check the documentation to fill this cell](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+# Adding this wrapper to normalize the observation and the reward
+env = # TODO: Add the wrapper
+```
+
+#### Solution
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+```
+
+### Create the A2C Model 🤖
+
+In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.
+
+For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
+
+To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
+
+```python
+model = # Create the A2C model and try to find the best parameters
+```
+
+#### Solution
+
+```python
+model = A2C(
+ policy="MlpPolicy",
+ env=env,
+ gae_lambda=0.9,
+ gamma=0.99,
+ learning_rate=0.00096,
+ max_grad_norm=0.5,
+ n_steps=8,
+ vf_coef=0.4,
+ ent_coef=0.0,
+ policy_kwargs=dict(log_std_init=-2, ortho_init=False),
+ normalize_advantage=False,
+ use_rms_prop=True,
+ use_sde=True,
+ verbose=1,
+)
+```
+
+### Train the A2C agent 🏃
+
+- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
+
+```python
+model.learn(2_000_000)
+```
+
+```python
+# Save the model and VecNormalize statistics when saving the agent
+model.save("a2c-AntBulletEnv-v0")
+env.save("vec_normalize.pkl")
+```
+
+### Evaluate the agent 📈
+- Now that's our agent is trained, we need to **check its performance**.
+- Stable-Baselines3 provides a method to do that: `evaluate_policy`
+- In my case, I got a mean reward of `2371.90 +/- 16.50`
+
+```python
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# Load the saved statistics
+eval_env = DummyVecEnv([lambda: gym.make("AntBulletEnv-v0")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# do not update them at test time
+eval_env.training = False
+# reward normalization is not needed at test time
+eval_env.norm_reward = False
+
+# Load the agent
+model = A2C.load("a2c-AntBulletEnv-v0")
+
+mean_reward, std_reward = evaluate_policy(model, env)
+
+print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+### Publish your trained model on the Hub 🔥
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
+
+📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+Here's an example of a Model Card (with a PyBullet environment):
+
+
+
+
+### Normalize observation and rewards
+
+A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).
+
+For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
+
+We also normalize rewards with this same wrapper by adding `norm_reward = True`
+
+[You should check the documentation to fill this cell](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+# Adding this wrapper to normalize the observation and the reward
+env = # TODO: Add the wrapper
+```
+
+#### Solution
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+```
+
+### Create the A2C Model 🤖
+
+In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.
+
+For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
+
+To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
+
+```python
+model = # Create the A2C model and try to find the best parameters
+```
+
+#### Solution
+
+```python
+model = A2C(
+ policy="MlpPolicy",
+ env=env,
+ gae_lambda=0.9,
+ gamma=0.99,
+ learning_rate=0.00096,
+ max_grad_norm=0.5,
+ n_steps=8,
+ vf_coef=0.4,
+ ent_coef=0.0,
+ policy_kwargs=dict(log_std_init=-2, ortho_init=False),
+ normalize_advantage=False,
+ use_rms_prop=True,
+ use_sde=True,
+ verbose=1,
+)
+```
+
+### Train the A2C agent 🏃
+
+- Let's train our agent for 2,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
+
+```python
+model.learn(2_000_000)
+```
+
+```python
+# Save the model and VecNormalize statistics when saving the agent
+model.save("a2c-AntBulletEnv-v0")
+env.save("vec_normalize.pkl")
+```
+
+### Evaluate the agent 📈
+- Now that's our agent is trained, we need to **check its performance**.
+- Stable-Baselines3 provides a method to do that: `evaluate_policy`
+- In my case, I got a mean reward of `2371.90 +/- 16.50`
+
+```python
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# Load the saved statistics
+eval_env = DummyVecEnv([lambda: gym.make("AntBulletEnv-v0")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# do not update them at test time
+eval_env.training = False
+# reward normalization is not needed at test time
+eval_env.norm_reward = False
+
+# Load the agent
+model = A2C.load("a2c-AntBulletEnv-v0")
+
+mean_reward, std_reward = evaluate_policy(model, env)
+
+print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+### Publish your trained model on the Hub 🔥
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
+
+📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+Here's an example of a Model Card (with a PyBullet environment):
+
+ +
+By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
+
+This way:
+- You can **showcase our work** 🔥
+- You can **visualize your agent playing** 👀
+- You can **share with the community an agent that others can use** 💾
+- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
+
+This way:
+- You can **showcase our work** 🔥
+- You can **visualize your agent playing** 👀
+- You can **share with the community an agent that others can use** 💾
+- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+ +
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
+
+```python
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
+ commit_message="Initial commit",
+)
+```
+
+## Take a coffee break ☕
+- You already trained your first robot that learned to move congratutlations 🥳!
+- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.
+
+
+## Environment 2: PandaReachDense-v2 🦾
+
+The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
+
+In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
+
+In `PandaReach`, the robot must place its end-effector at a target position (green ball).
+
+We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+
+Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+
+
+
+- Copy the token
+- Run the cell below and paste the token
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
+
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
+
+```python
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
+ commit_message="Initial commit",
+)
+```
+
+## Take a coffee break ☕
+- You already trained your first robot that learned to move congratutlations 🥳!
+- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.
+
+
+## Environment 2: PandaReachDense-v2 🦾
+
+The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
+
+In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
+
+In `PandaReach`, the robot must place its end-effector at a target position (green ball).
+
+We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+
+Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+
+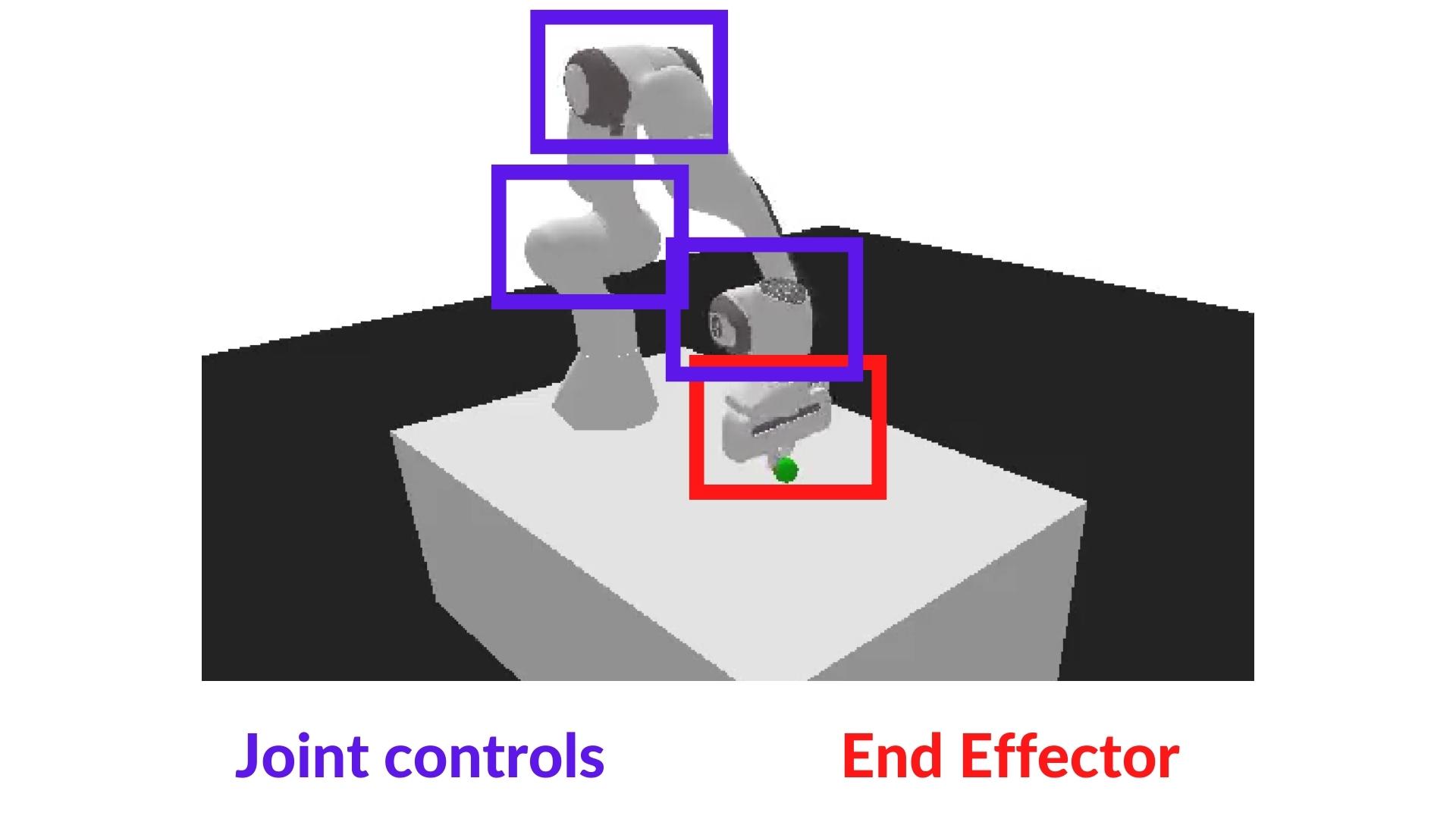 +
+
+This way **the training will be easier**.
+
+
+
+In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
+
+
+
+```python
+import gym
+
+env_id = "PandaPushDense-v2"
+
+# Create the env
+env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape
+a_size = env.action_space
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+The observation space **is a dictionary with 3 different elements**:
+- `achieved_goal`: (x,y,z) position of the goal.
+- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
+- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+
+Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action space is a vector with 3 values:
+- Control x, y, z movement
+
+Now it's your turn:
+
+1. Define the environment called "PandaReachDense-v2"
+2. Make a vectorized environment
+3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+4. Create the A2C Model (don't forget verbose=1 to print the training logs).
+5. Train it for 1M Timesteps
+6. Save the model and VecNormalize statistics when saving the agent
+7. Evaluate your agent
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+
+### Solution (fill the todo)
+
+```python
+# 1 - 2
+env_id = "PandaReachDense-v2"
+env = make_vec_env(env_id, n_envs=4)
+
+# 3
+env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+
+# 4
+model = A2C(policy="MultiInputPolicy", env=env, verbose=1)
+# 5
+model.learn(1_000_000)
+```
+
+```python
+# 6
+model_name = "a2c-PandaReachDense-v2"
+model.save(model_name)
+env.save("vec_normalize.pkl")
+
+# 7
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# Load the saved statistics
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v2")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# do not update them at test time
+eval_env.training = False
+# reward normalization is not needed at test time
+eval_env.norm_reward = False
+
+# Load the agent
+model = A2C.load(model_name)
+
+mean_reward, std_reward = evaluate_policy(model, env)
+
+print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
+
+# 8
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
+ commit_message="Initial commit",
+)
+```
+
+## Some additional challenges 🏆
+
+The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
+
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
+
+PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
+
+And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
+
+Here are some ideas to achieve so:
+* Train more steps
+* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
+* **Push your new trained model** on the Hub 🔥
+
+
+See you on Unit 7! 🔥
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
new file mode 100644
index 0000000..d85281d
--- /dev/null
+++ b/units/en/unit6/introduction.mdx
@@ -0,0 +1,25 @@
+# Introduction [[introduction]]
+
+
+
+
+
+This way **the training will be easier**.
+
+
+
+In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
+
+
+
+```python
+import gym
+
+env_id = "PandaPushDense-v2"
+
+# Create the env
+env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape
+a_size = env.action_space
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+The observation space **is a dictionary with 3 different elements**:
+- `achieved_goal`: (x,y,z) position of the goal.
+- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
+- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+
+Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action space is a vector with 3 values:
+- Control x, y, z movement
+
+Now it's your turn:
+
+1. Define the environment called "PandaReachDense-v2"
+2. Make a vectorized environment
+3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+4. Create the A2C Model (don't forget verbose=1 to print the training logs).
+5. Train it for 1M Timesteps
+6. Save the model and VecNormalize statistics when saving the agent
+7. Evaluate your agent
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+
+### Solution (fill the todo)
+
+```python
+# 1 - 2
+env_id = "PandaReachDense-v2"
+env = make_vec_env(env_id, n_envs=4)
+
+# 3
+env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+
+# 4
+model = A2C(policy="MultiInputPolicy", env=env, verbose=1)
+# 5
+model.learn(1_000_000)
+```
+
+```python
+# 6
+model_name = "a2c-PandaReachDense-v2"
+model.save(model_name)
+env.save("vec_normalize.pkl")
+
+# 7
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# Load the saved statistics
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v2")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# do not update them at test time
+eval_env.training = False
+# reward normalization is not needed at test time
+eval_env.norm_reward = False
+
+# Load the agent
+model = A2C.load(model_name)
+
+mean_reward, std_reward = evaluate_policy(model, env)
+
+print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
+
+# 8
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
+ commit_message="Initial commit",
+)
+```
+
+## Some additional challenges 🏆
+
+The best way to learn **is to try things by your own**! Why not trying `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
+
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
+
+PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
+
+And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
+
+Here are some ideas to achieve so:
+* Train more steps
+* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
+* **Push your new trained model** on the Hub 🔥
+
+
+See you on Unit 7! 🔥
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
new file mode 100644
index 0000000..d85281d
--- /dev/null
+++ b/units/en/unit6/introduction.mdx
@@ -0,0 +1,25 @@
+# Introduction [[introduction]]
+
+
+ +
+In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
+
+In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
+
+We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
+
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (Policy-Based method)
+- *A Critic* that measures **how good the taken action is** (Value-Based method)
+
+
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move in the correct position.
+
+
+
+Sounds exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
new file mode 100644
index 0000000..9eb1888
--- /dev/null
+++ b/units/en/unit6/variance-problem.mdx
@@ -0,0 +1,30 @@
+# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
+
+In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+
+
+
+
+In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
+
+In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
+
+We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
+
+Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
+
+So, today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that help to stabilize the training by reducing the variance:
+- *An Actor* that controls **how our agent behaves** (Policy-Based method)
+- *A Critic* that measures **how good the taken action is** (Value-Based method)
+
+
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
+- A spider 🕷️ to learn to move.
+- A robotic arm 🦾 to move in the correct position.
+
+
+
+Sounds exciting? Let's get started!
diff --git a/units/en/unit6/variance-problem.mdx b/units/en/unit6/variance-problem.mdx
new file mode 100644
index 0000000..9eb1888
--- /dev/null
+++ b/units/en/unit6/variance-problem.mdx
@@ -0,0 +1,30 @@
+# The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
+
+In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
+
+
+ +
+- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
+- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
+
+Given the stochasticity of the environment (random events during an episode) and stochasticity of the policy, **trajectories can lead to different returns, which can lead to high variance**. Consequently, the same starting state can lead to very different returns.
+Because of this, **the return starting at the same state can vary significantly across episodes**.
+
+
+
+- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
+- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
+
+This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
+
+Given the stochasticity of the environment (random events during an episode) and stochasticity of the policy, **trajectories can lead to different returns, which can lead to high variance**. Consequently, the same starting state can lead to very different returns.
+Because of this, **the return starting at the same state can vary significantly across episodes**.
+
+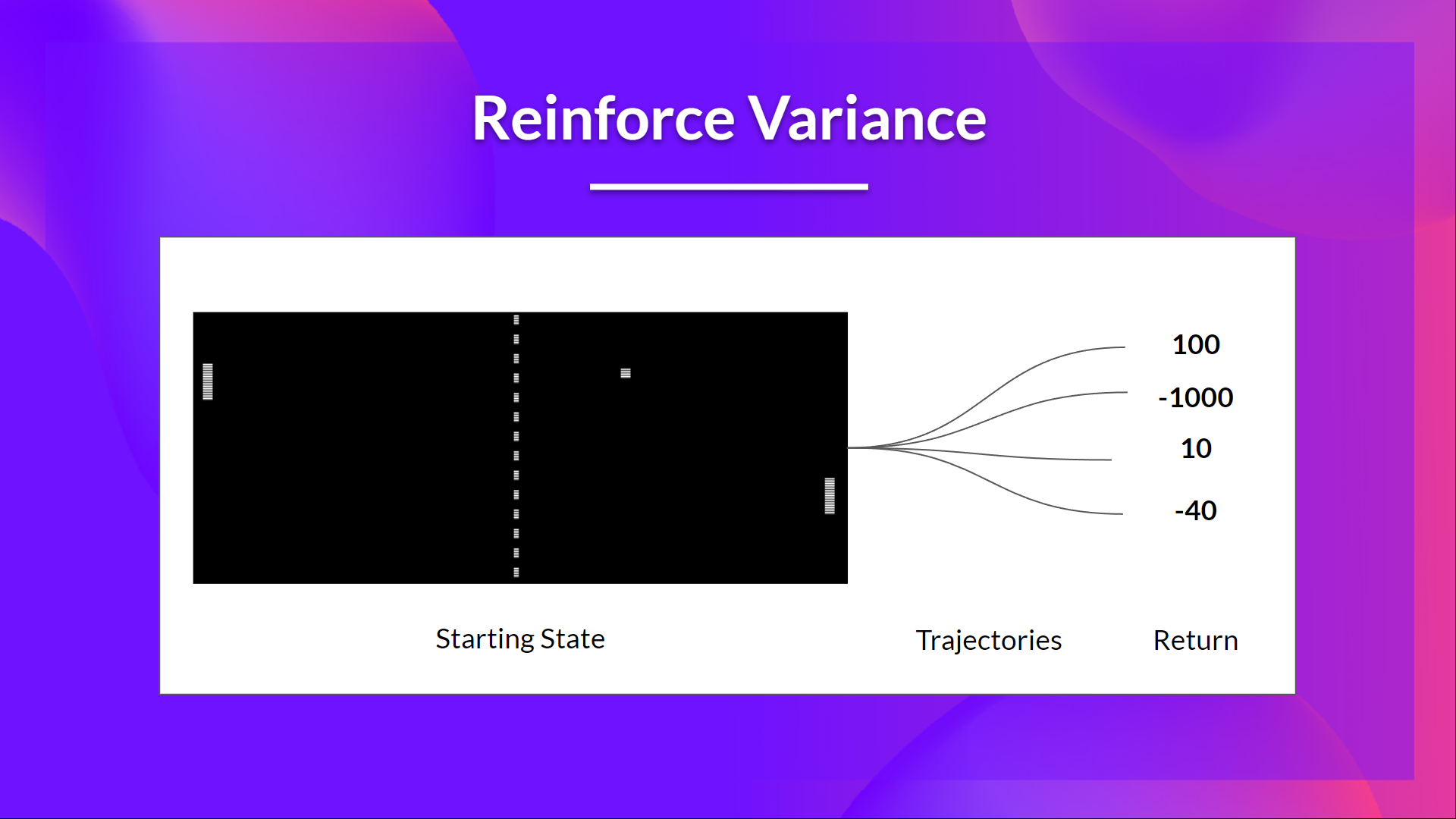 +
+The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
+
+However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
+
+---
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+---
+
+The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
+
+However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
+
+---
+If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
+- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+---