diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 1ce98b5..3138949 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -76,3 +76,9 @@
title: Conclusion
- local: unit2/additional-readings
title: Additional Readings
+- title: Unit 4. Introduction to ML-Agents
+ sections:
+ - local: unit4/introduction
+ title: Introduction
+ - local: unit4/how-mlagents-works
+ title: How ML-Agents works?
diff --git a/units/en/unit4/how-mlagents-works.mdx b/units/en/unit4/how-mlagents-works.mdx
new file mode 100644
index 0000000..68d357c
--- /dev/null
+++ b/units/en/unit4/how-mlagents-works.mdx
@@ -0,0 +1,66 @@
+# How do Unity ML-Agents work? [[how-mlagents-works]]
+
+Before training our agent, we need to understand what is ML-Agents and how it works.
+
+## What is Unity ML-Agents? [[what-is-mlagents]]
+
+[Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents) is a toolkit for the game engine Unity that **allows us to create environments using Unity or use pre-made environments to train our agents**.
+
+It’s developed by [Unity Technologies](https://unity.com/), the developers of Unity, one of the most famous Game Engines used by the creators of Firewatch, Cuphead, and Cities: Skylines.
+
+
+
+Firewatch was made with Unity
+
+
+## The four components [[four-components]]
+
+With Unity ML-Agents, you have four essential components:
+
+
+
+Source: Unity ML-Agents Documentation
+
+
+- The first is the *Learning Environment*, which contains **the Unity scene (the environment) and the environment elements** (game characters).
+- The second is the *Python API* which contains **the low-level Python interface for interacting and manipulating the environment**. It’s the API we use to launch the training.
+- Then, we have the *Communicator* that **connects the environment (C#) with the Python API (Python)**.
+- Finally, we have the *Python trainers**: the **Reinforcement algorithms made with PyTorch (PPO, SAC…)**.
+
+## Inside the Learning Component [[inside-learning-component]]
+
+Inside the Learning Component, we have **three important elements**:
+
+- The first is the *agent*, the actor of the scene. We’ll **train the agent by optimizing his policy** (which will tell us what action to take in each state). The policy is called *Brain*.
+- Finally, there is the *Academy*. This element **orchestrates agents and their decision-making process**. Think of this Academy as a maestro that handles the requests from the python API.
+
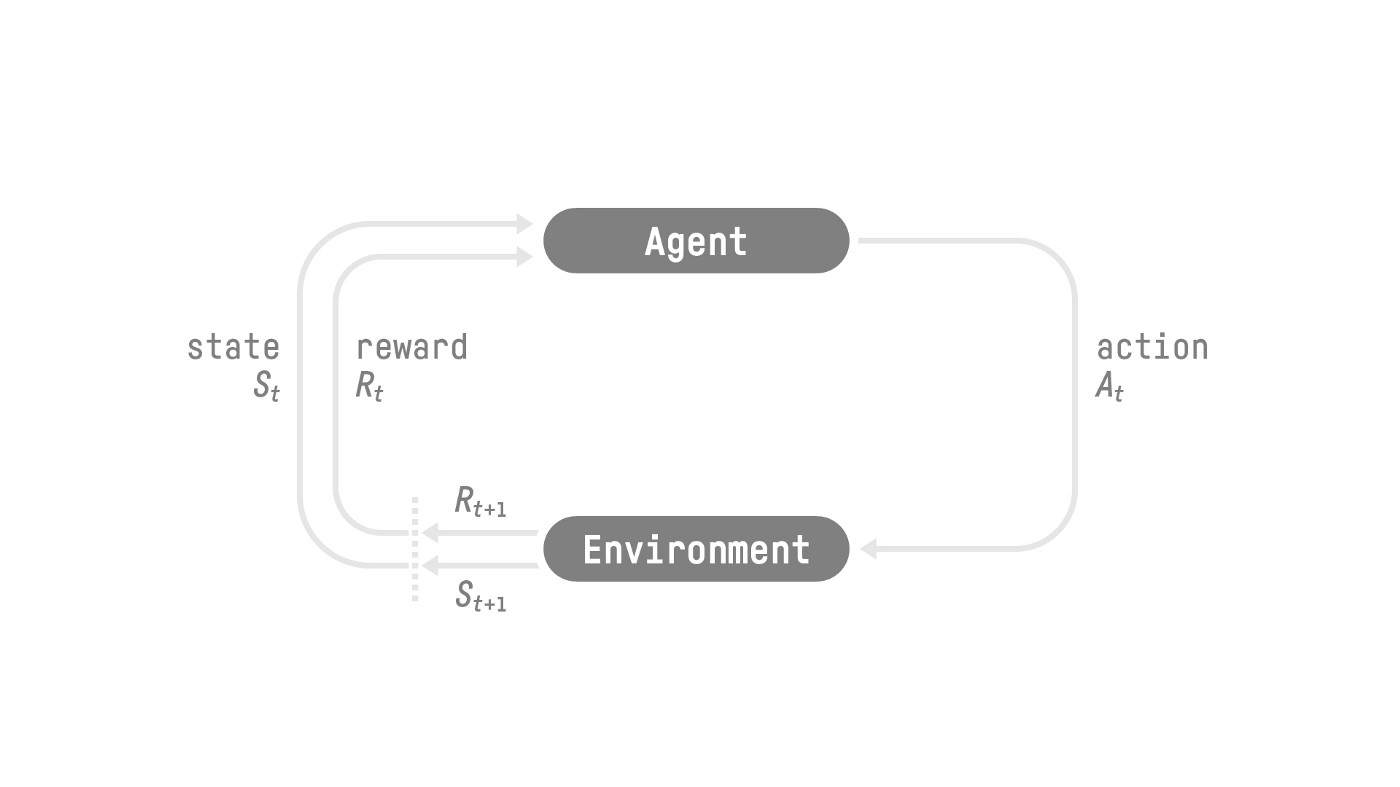
+To better understand its role, let’s remember the RL process. This can be modeled as a loop that works like this:
+
+
+
+The RL Process: a loop of state, action, reward and next state
+Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
+
+
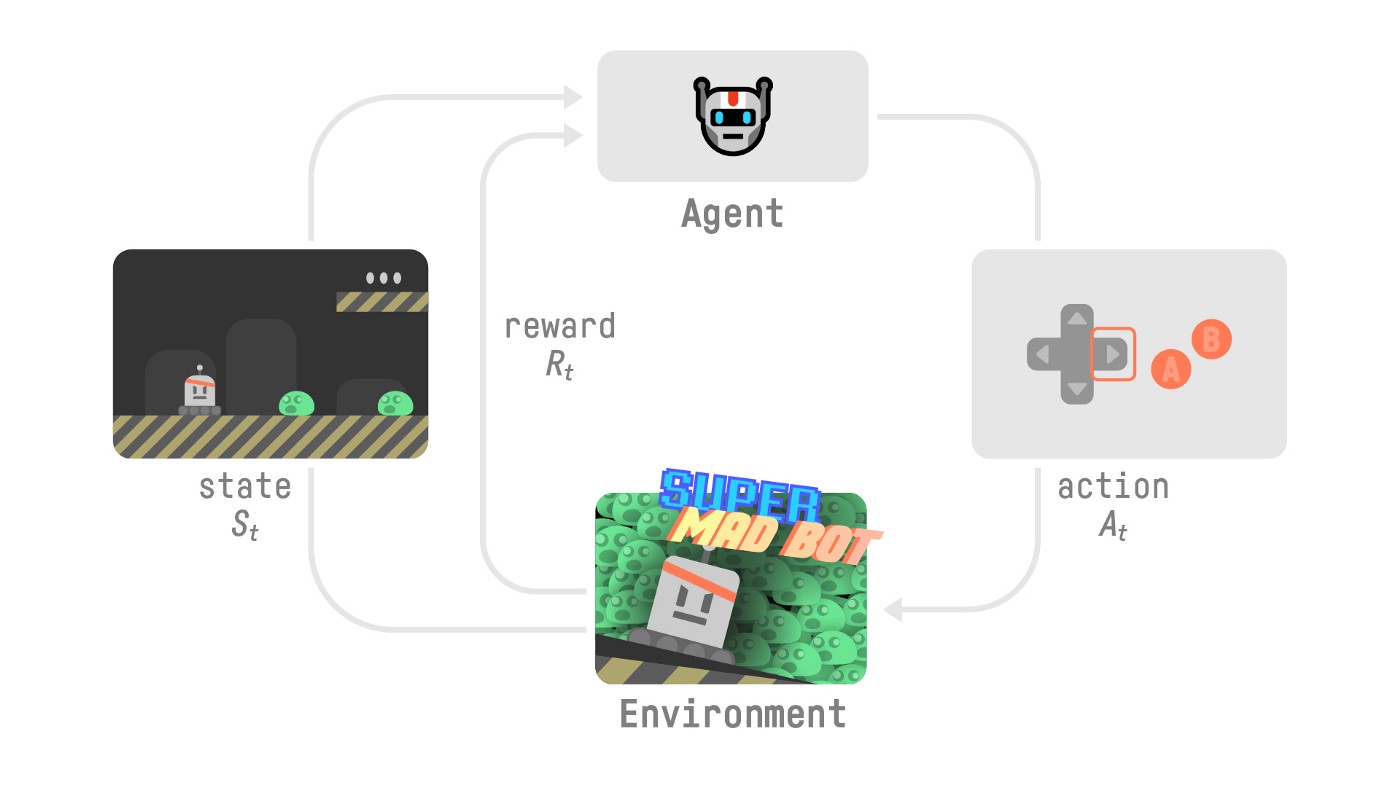
+Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
+
+
+
+- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
+
+The Academy will be the one that will **send the order to our Agents and ensure that agents are in sync**:
+
+- Collect Observations
+- Select your action using your policy
+- Take the Action
+- Reset if you reached the max step or if you’re done.
+
+
+
+
+Now that we understand how ML-Agents works, **we’re ready to train our agent** TODO add a phrase about our agent (snowball target)
diff --git a/units/en/unit4/introduction.mdx b/units/en/unit4/introduction.mdx
new file mode 100644
index 0000000..7fd9354
--- /dev/null
+++ b/units/en/unit4/introduction.mdx
@@ -0,0 +1,3 @@
+# An Introduction to Unity ML-Agents [[introduction-to-ml-agents]]
+
+Environment: Snowball target
 +
+ +
+ +
+ +
+- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
+
+The Academy will be the one that will **send the order to our Agents and ensure that agents are in sync**:
+
+- Collect Observations
+- Select your action using your policy
+- Take the Action
+- Reset if you reached the max step or if you’re done.
+
+
+
+- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- Environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
+
+The Academy will be the one that will **send the order to our Agents and ensure that agents are in sync**:
+
+- Collect Observations
+- Select your action using your policy
+- Take the Action
+- Reset if you reached the max step or if you’re done.
+
+ +
+
+Now that we understand how ML-Agents works, **we’re ready to train our agent** TODO add a phrase about our agent (snowball target)
diff --git a/units/en/unit4/introduction.mdx b/units/en/unit4/introduction.mdx
new file mode 100644
index 0000000..7fd9354
--- /dev/null
+++ b/units/en/unit4/introduction.mdx
@@ -0,0 +1,3 @@
+# An Introduction to Unity ML-Agents [[introduction-to-ml-agents]]
+
+Environment: Snowball target
+
+
+Now that we understand how ML-Agents works, **we’re ready to train our agent** TODO add a phrase about our agent (snowball target)
diff --git a/units/en/unit4/introduction.mdx b/units/en/unit4/introduction.mdx
new file mode 100644
index 0000000..7fd9354
--- /dev/null
+++ b/units/en/unit4/introduction.mdx
@@ -0,0 +1,3 @@
+# An Introduction to Unity ML-Agents [[introduction-to-ml-agents]]
+
+Environment: Snowball target