diff --git a/units/en/unit3/hands-on.mdx b/units/en/unit3/hands-on.mdx
index 26c7ad0..90108ce 100644
--- a/units/en/unit3/hands-on.mdx
+++ b/units/en/unit3/hands-on.mdx
@@ -4,7 +4,7 @@
@@ -14,7 +14,7 @@ Now that you've studied the theory behind Deep Q-Learning, **you’re ready to t
 -We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, or Prioritized Experience Replay.
To validate this hands-on for the certification process, you need to push your trained model to the Hub and **get a result of >= 500**.
@@ -113,7 +113,7 @@ virtual_display.start()
```
## Clone RL-Baselines3 Zoo Repo 📚
-You can now directly install from python package `pip install rl_zoo3` but since we want **the full installation with extra environments and dependencies** we're going to clone `RL-Baselines3-Zoo` repository and install from source.
+You could directly install from the Python package (`pip install rl_zoo3`), but since we want **the full installation with extra environments and dependencies**, we're going to clone the `RL-Baselines3-Zoo` repository and install from source.
```bash
git clone https://github.com/DLR-RM/rl-baselines3-zoo
@@ -146,10 +146,10 @@ To train an agent with RL-Baselines3-Zoo, we just need to do two things:
Here we see that:
-- We use the `Atari Wrapper` that preprocess the input (Frame reduction ,grayscale, stack 4 frames)
-- We use `CnnPolicy`, since we use Convolutional layers to process the frames
-- We train it for 10 million `n_timesteps`
-- Memory (Experience Replay) size is 100000, aka the amount of experience steps you saved to train again your agent with.
+- We use the `Atari Wrapper` that does the pre-processing (Frame reduction, grayscale, stack four frames frames),
+- We use `CnnPolicy`, since we use Convolutional layers to process the frames.
+- We train the model for 10 million `n_timesteps`.
+- Memory (Experience Replay) size is 100000, i.e. the number of experience steps you saved to train again your agent with.
💡 My advice is to **reduce the training timesteps to 1M,** which will take about 90 minutes on a P100. `!nvidia-smi` will tell you what GPU you're using. At 10 million steps, this will take about 9 hours, which could likely result in Colab timing out. I recommend running this on your local computer (or somewhere else). Just click on: `File>Download`.
@@ -189,11 +189,11 @@ python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n
```
## Publish our trained model on the Hub 🚀
-Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
-We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
+We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, or Prioritized Experience Replay.
To validate this hands-on for the certification process, you need to push your trained model to the Hub and **get a result of >= 500**.
@@ -113,7 +113,7 @@ virtual_display.start()
```
## Clone RL-Baselines3 Zoo Repo 📚
-You can now directly install from python package `pip install rl_zoo3` but since we want **the full installation with extra environments and dependencies** we're going to clone `RL-Baselines3-Zoo` repository and install from source.
+You could directly install from the Python package (`pip install rl_zoo3`), but since we want **the full installation with extra environments and dependencies**, we're going to clone the `RL-Baselines3-Zoo` repository and install from source.
```bash
git clone https://github.com/DLR-RM/rl-baselines3-zoo
@@ -146,10 +146,10 @@ To train an agent with RL-Baselines3-Zoo, we just need to do two things:
Here we see that:
-- We use the `Atari Wrapper` that preprocess the input (Frame reduction ,grayscale, stack 4 frames)
-- We use `CnnPolicy`, since we use Convolutional layers to process the frames
-- We train it for 10 million `n_timesteps`
-- Memory (Experience Replay) size is 100000, aka the amount of experience steps you saved to train again your agent with.
+- We use the `Atari Wrapper` that does the pre-processing (Frame reduction, grayscale, stack four frames frames),
+- We use `CnnPolicy`, since we use Convolutional layers to process the frames.
+- We train the model for 10 million `n_timesteps`.
+- Memory (Experience Replay) size is 100000, i.e. the number of experience steps you saved to train again your agent with.
💡 My advice is to **reduce the training timesteps to 1M,** which will take about 90 minutes on a P100. `!nvidia-smi` will tell you what GPU you're using. At 10 million steps, this will take about 9 hours, which could likely result in Colab timing out. I recommend running this on your local computer (or somewhere else). Just click on: `File>Download`.
@@ -189,11 +189,11 @@ python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n
```
## Publish our trained model on the Hub 🚀
-Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
+Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
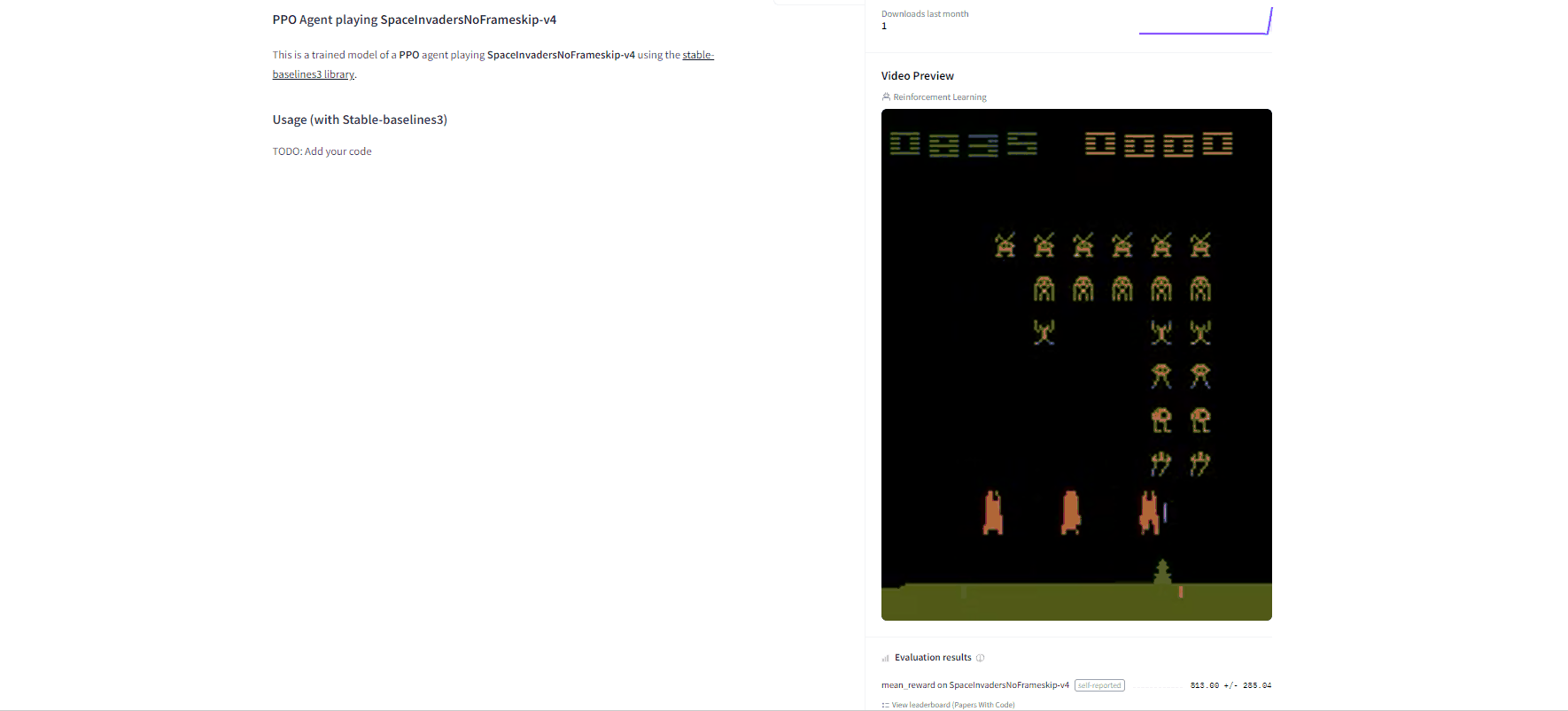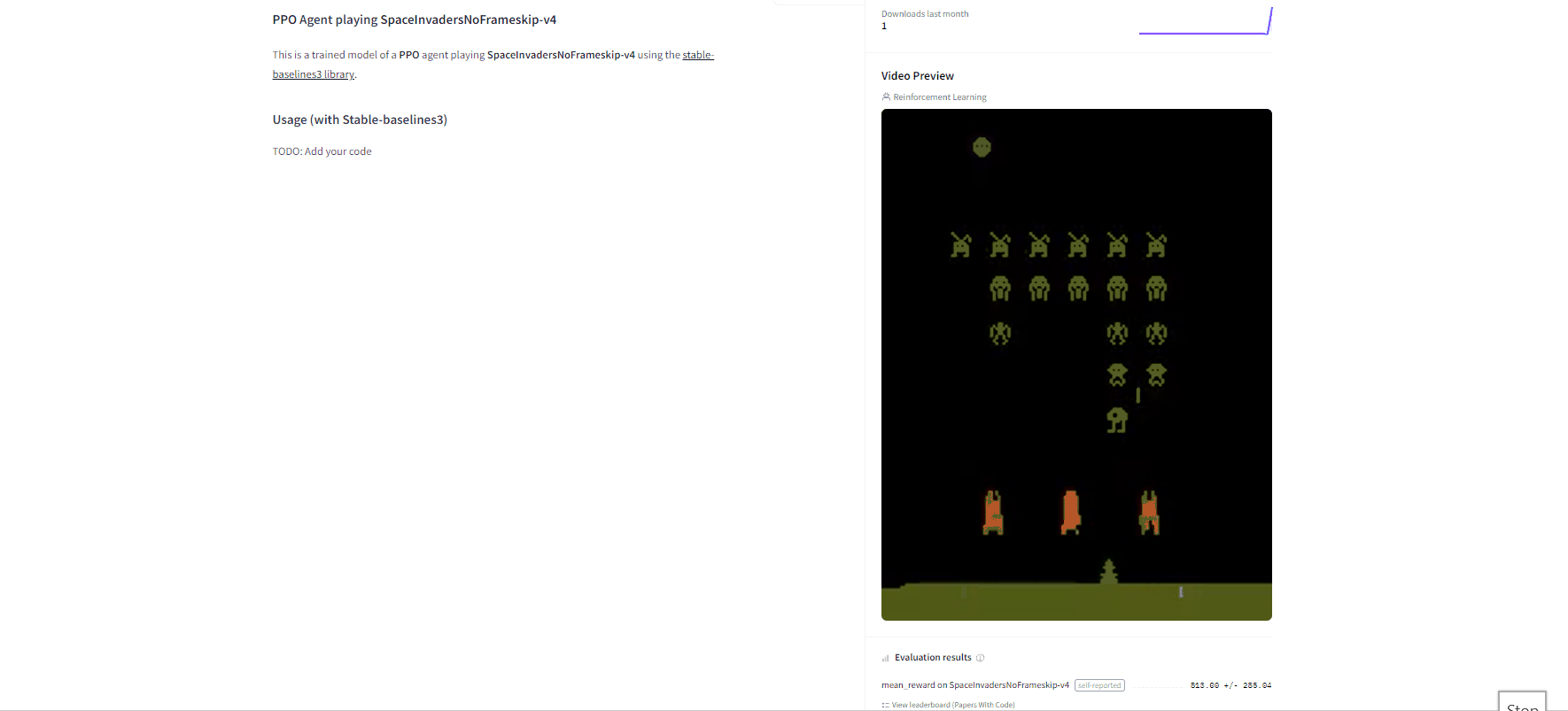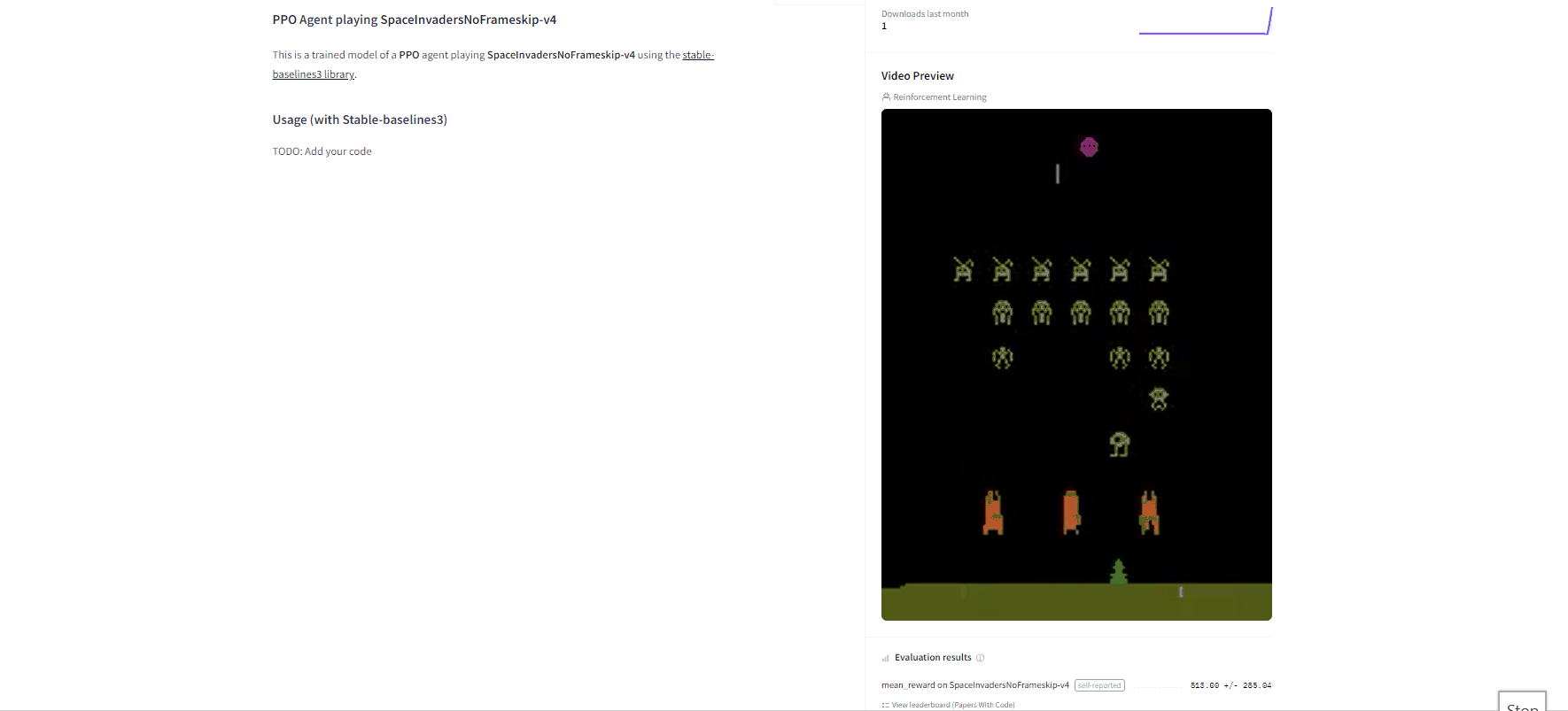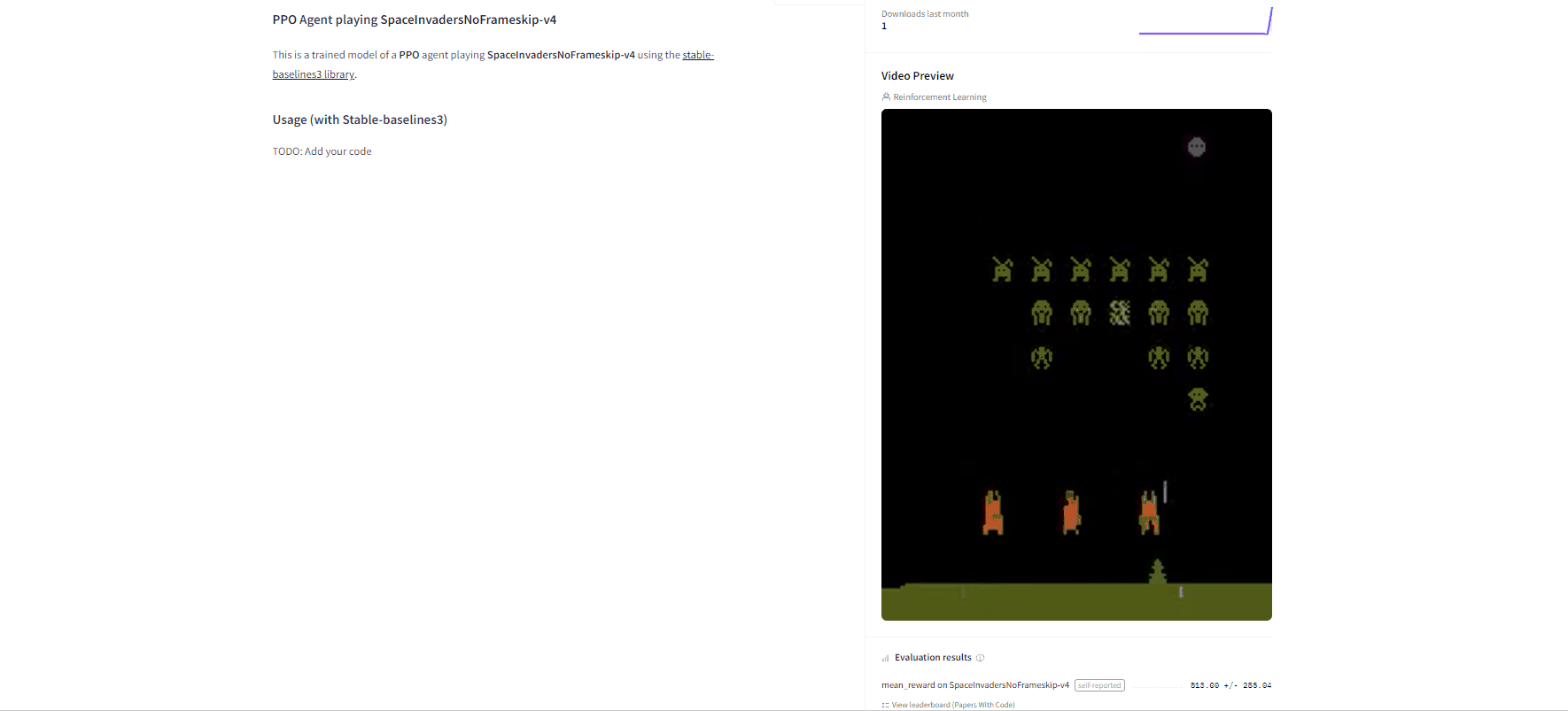 -By using `rl_zoo3.push_to_hub.py` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
+By using `rl_zoo3.push_to_hub.py`, **you evaluate, record a replay, generate a model card of your agent, and push it to the Hub**.
This way:
- You can **showcase our work** 🔥
@@ -201,9 +201,9 @@ This way:
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
-To be able to share your model with the community there are three more steps to follow:
+To be able to share your model with the community, there are three more steps to follow:
-1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+1️⃣ (If it's not already done) create an account in HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
@@ -221,13 +221,12 @@ git config --global credential.helper store
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥
+3️⃣ We're now ready to push our trained agent to the Hub 🔥
-Let's run push_to_hub.py file to upload our trained agent to the Hub.
+Let's run `push_to_hub.py` file to upload our trained agent to the Hub. There are two important parameters:
-`--repo-name `: The name of the repo
-
-`-orga`: Your Hugging Face username
+* `--repo-name `: The name of the repo
+* `-orga`: Your Hugging Face username
-By using `rl_zoo3.push_to_hub.py` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
+By using `rl_zoo3.push_to_hub.py`, **you evaluate, record a replay, generate a model card of your agent, and push it to the Hub**.
This way:
- You can **showcase our work** 🔥
@@ -201,9 +201,9 @@ This way:
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
-To be able to share your model with the community there are three more steps to follow:
+To be able to share your model with the community, there are three more steps to follow:
-1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+1️⃣ (If it's not already done) create an account in HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
@@ -221,13 +221,12 @@ git config --global credential.helper store
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥
+3️⃣ We're now ready to push our trained agent to the Hub 🔥
-Let's run push_to_hub.py file to upload our trained agent to the Hub.
+Let's run `push_to_hub.py` file to upload our trained agent to the Hub. There are two important parameters:
-`--repo-name `: The name of the repo
-
-`-orga`: Your Hugging Face username
+* `--repo-name `: The name of the repo
+* `-orga`: Your Hugging Face username
 @@ -254,7 +253,7 @@ Under the hood, the Hub uses git-based repositories (don't worry if you don't kn
## Load a powerful trained model 🔥
-- The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**.
+The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**. You can download them and use them to see how they perform!
You can find them here: 👉 https://huggingface.co/sb3
@@ -285,9 +284,9 @@ python enjoy.py --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/
Why not trying to train your own **Deep Q-Learning Agent playing BeamRiderNoFrameskip-v4? 🏆.**
-If you want to try, check https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters **in the model card, you have the hyperparameters of the trained agent.**
+If you want to try, check https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters. There, **in the model card, you have the hyperparameters of the trained agent.**
-But finding hyperparameters can be a daunting task. Fortunately, we'll see in the next Unit, how we can **use Optuna for optimizing the Hyperparameters 🔥.**
+But finding hyperparameters can be a daunting task. Fortunately, we'll see in the next bonus Unit, how we can **use Optuna for optimizing the Hyperparameters 🔥.**
## Some additional challenges 🏆
@@ -254,7 +253,7 @@ Under the hood, the Hub uses git-based repositories (don't worry if you don't kn
## Load a powerful trained model 🔥
-- The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**.
+The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**. You can download them and use them to see how they perform!
You can find them here: 👉 https://huggingface.co/sb3
@@ -285,9 +284,9 @@ python enjoy.py --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/
Why not trying to train your own **Deep Q-Learning Agent playing BeamRiderNoFrameskip-v4? 🏆.**
-If you want to try, check https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters **in the model card, you have the hyperparameters of the trained agent.**
+If you want to try, check https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters. There, **in the model card, you have the hyperparameters of the trained agent.**
-But finding hyperparameters can be a daunting task. Fortunately, we'll see in the next Unit, how we can **use Optuna for optimizing the Hyperparameters 🔥.**
+But finding hyperparameters can be a daunting task. Fortunately, we'll see in the next bonus Unit, how we can **use Optuna for optimizing the Hyperparameters 🔥.**
## Some additional challenges 🏆