diff --git a/units/en/unit7/introduction.mdx b/units/en/unit7/introduction.mdx
index ead04df..92be024 100644
--- a/units/en/unit7/introduction.mdx
+++ b/units/en/unit7/introduction.mdx
@@ -14,7 +14,7 @@ This worked great, and the single-agent system is useful for many applications.
A patchwork of all the environments you’ve trained your agents on since the beginning of the course
-
+
But, as humans, **we live in a multi-agent world**. Our intelligence comes from interaction with other agents. And so, our **goal is to create agents that can interact with other humans and other agents**.
diff --git a/units/en/unit7/multi-agent-setting.mdx b/units/en/unit7/multi-agent-setting.mdx
index 83f670d..6185df4 100644
--- a/units/en/unit7/multi-agent-setting.mdx
+++ b/units/en/unit7/multi-agent-setting.mdx
@@ -11,7 +11,12 @@ To design this multi-agents reinforcement learning system (MARL), we have two so
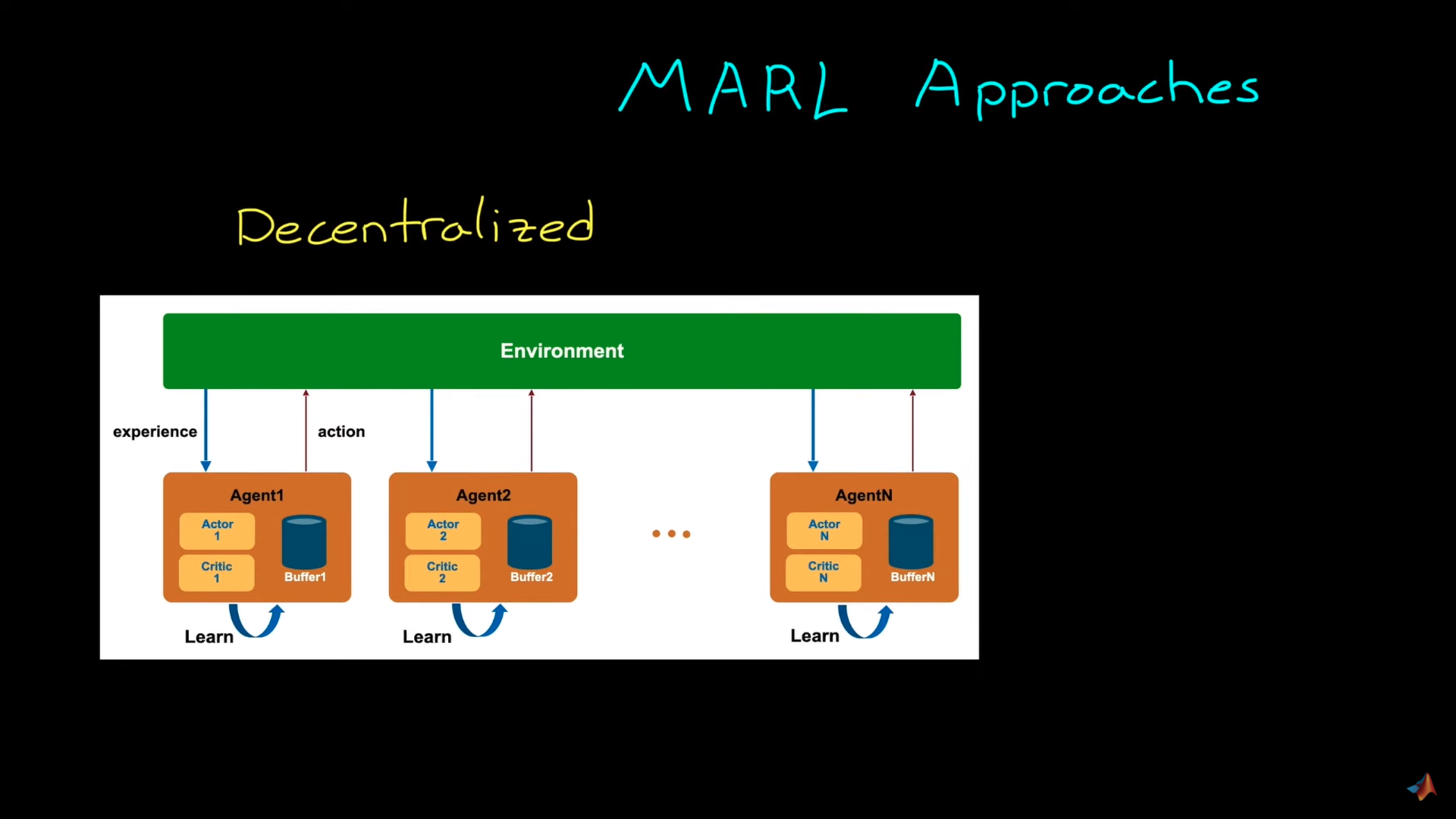
## Decentralized system
-[ADD illustration decentralized approach]
+
+
+
+Source: Introduction to Multi-Agent Reinforcement Learning
+
+
In decentralized learning, **each agent is trained independently from others**. In the example given each vacuum learns to clean as much place it can **without caring about what other vacuums (agents) are doing**.
@@ -24,7 +29,12 @@ And this is problematic for many reinforcement Learning algorithms **that can't
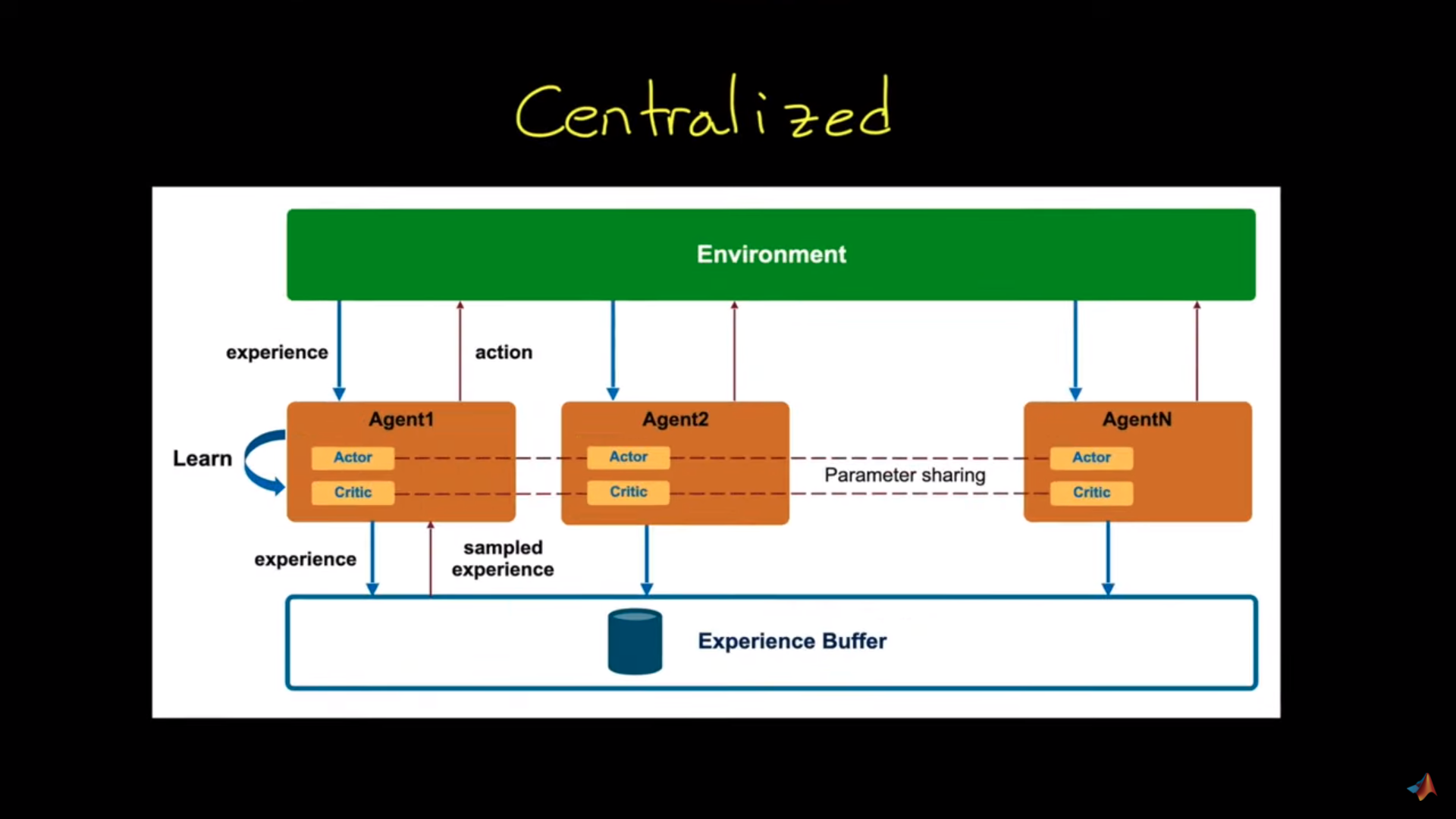
## Centralized approach
-[ADD illustration centralized approach]
+
+
+
+Source: Introduction to Multi-Agent Reinforcement Learning
+
+
In this architecture, **we have a high level process that collect agents experiences**: experience buffer. And we'll use these experience **to learn a common policy**.
diff --git a/units/en/unit7/self-play.mdx b/units/en/unit7/self-play.mdx
index f553432..4d5ac48 100644
--- a/units/en/unit7/self-play.mdx
+++ b/units/en/unit7/self-play.mdx
@@ -1,11 +1,11 @@
# Self-Play: a classic technique to train competitive agents in adversarial games
-Now that we studied the basics of multi-agents. We're ready to go deeper. As mentioned in the introduction, we're going to train agents in an adversarial games a Soccer 2vs2 game.
+Now that we studied the basics of multi-agents. We're ready to go deeper. As mentioned in the introduction, we're going **to train agents in an adversarial games with SoccerTwos a 2vs2 game.
-
+
-This environment was made by the Unity MLAgents Team
+This environment was made by the Unity MLAgents Team
@@ -80,7 +80,7 @@ After every game:
So if A and B have rating Ra, and Rb, then the **expected scores are** given by:
-
+
Then, at the end of the game, we need to update the player’s actual Elo score, we use a linear adjustment **proportional to the amount by which the player over-performed or under-performed.**
@@ -91,7 +91,7 @@ We also define a maximum adjustment rating per game: K-factor.
If Player A has Ea points but scored Sa points, then the player’s rating is updated using the formula:
-
+
### Example
 +
+ +
+ +
+ -
- +
+ Then, at the end of the game, we need to update the player’s actual Elo score, we use a linear adjustment **proportional to the amount by which the player over-performed or under-performed.**
@@ -91,7 +91,7 @@ We also define a maximum adjustment rating per game: K-factor.
If Player A has Ea points but scored Sa points, then the player’s rating is updated using the formula:
-
Then, at the end of the game, we need to update the player’s actual Elo score, we use a linear adjustment **proportional to the amount by which the player over-performed or under-performed.**
@@ -91,7 +91,7 @@ We also define a maximum adjustment rating per game: K-factor.
If Player A has Ea points but scored Sa points, then the player’s rating is updated using the formula:
- +
+ ### Example
### Example