 "
]
},
- {
- "cell_type": "markdown",
- "source": [
- "TODO: ADD TEXT LIVE INFO"
- ],
- "metadata": {
- "id": "yaBKcncmYku4"
- }
- },
- {
- "cell_type": "markdown",
- "source": [
- "TODO: ADD IF YOU HAVE QUESTIONS\n"
- ],
- "metadata": {
- "id": "hz5KE5HjYlRh"
- }
- },
{
"cell_type": "markdown",
"source": [
"###🎮 Environments: \n",
+ "\n",
"- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)\n",
"- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)\n",
"\n",
"###📚 RL-Library: \n",
- "- Python and Numpy"
+ "\n",
+ "- Python and NumPy\n",
+ "- [Gym](https://www.gymlibrary.dev/)"
],
"metadata": {
"id": "DPTBOv9HYLZ2"
@@ -60,7 +45,7 @@
{
"cell_type": "markdown",
"source": [
- "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
],
"metadata": {
"id": "3iaIxM_TwklQ"
@@ -73,7 +58,9 @@
},
"source": [
"## Objectives of this notebook 🏆\n",
+ "\n",
"At the end of the notebook, you will:\n",
+ "\n",
"- Be able to use **Gym**, the environment library.\n",
"- Be able to code from scratch a Q-Learning agent.\n",
"- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
@@ -84,7 +71,7 @@
{
"cell_type": "markdown",
"source": [
- "## This notebook is from Deep Reinforcement Learning Course\n",
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
"
"
]
},
- {
- "cell_type": "markdown",
- "source": [
- "TODO: ADD TEXT LIVE INFO"
- ],
- "metadata": {
- "id": "yaBKcncmYku4"
- }
- },
- {
- "cell_type": "markdown",
- "source": [
- "TODO: ADD IF YOU HAVE QUESTIONS\n"
- ],
- "metadata": {
- "id": "hz5KE5HjYlRh"
- }
- },
{
"cell_type": "markdown",
"source": [
"###🎮 Environments: \n",
+ "\n",
"- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)\n",
"- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)\n",
"\n",
"###📚 RL-Library: \n",
- "- Python and Numpy"
+ "\n",
+ "- Python and NumPy\n",
+ "- [Gym](https://www.gymlibrary.dev/)"
],
"metadata": {
"id": "DPTBOv9HYLZ2"
@@ -60,7 +45,7 @@
{
"cell_type": "markdown",
"source": [
- "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues)."
+ "We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues)."
],
"metadata": {
"id": "3iaIxM_TwklQ"
@@ -73,7 +58,9 @@
},
"source": [
"## Objectives of this notebook 🏆\n",
+ "\n",
"At the end of the notebook, you will:\n",
+ "\n",
"- Be able to use **Gym**, the environment library.\n",
"- Be able to code from scratch a Q-Learning agent.\n",
"- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.\n",
@@ -84,7 +71,7 @@
{
"cell_type": "markdown",
"source": [
- "## This notebook is from Deep Reinforcement Learning Course\n",
+ "## This notebook is from the Deep Reinforcement Learning Course\n",
" "
],
"metadata": {
@@ -120,7 +107,7 @@
"## Prerequisites 🏗️\n",
"Before diving into the notebook, you need to:\n",
"\n",
- "🔲 📚 **Study Q-Learning by reading Unit 2** 🤗 ADD LINK "
+ "🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗 "
]
},
{
@@ -139,6 +126,7 @@
},
"source": [
"- The *Q-Learning* **is the RL algorithm that** \n",
+ "\n",
" - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**\n",
" \n",
" - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**\n",
@@ -176,33 +164,24 @@
"source": [
"## Install dependencies and create a virtual display 🔽\n",
"\n",
- "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).\n",
"\n",
- "Hence the following cell will install the librairies and create and run a virtual screen 🖥\n",
+ "Hence the following cell will install the libraries and create and run a virtual screen 🖥\n",
"\n",
"We’ll install multiple ones:\n",
"\n",
"- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.\n",
"- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.\n",
- "- `numPy`: Used for handling our Q-table.\n",
+ "- `numpy`: Used for handling our Q-table.\n",
"\n",
"The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.\n",
"\n",
- "You can see here all the Deep reinforcement Learning models available 👉 https://huggingface.co/models?other=q-learning\n"
+ "You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning"
],
"metadata": {
"id": "4gpxC1_kqUYe"
}
},
- {
- "cell_type": "markdown",
- "source": [
- "TODO CHANGE LINK OF THE REQUIREMENTS"
- ],
- "metadata": {
- "id": "32e3NPYgH5ET"
- }
- },
{
"cell_type": "code",
"execution_count": null,
@@ -211,17 +190,15 @@
},
"outputs": [],
"source": [
- "!pip install -r https://huggingface.co/spaces/ThomasSimonini/temp-space-requirements/raw/main/requirements/requirements-unit2.txt"
+ "!pip install -r pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt"
]
},
{
"cell_type": "code",
"source": [
- "%capture\n",
+ "%%capture\n",
"!sudo apt-get update\n",
- "!apt install python-opengl\n",
- "!apt install ffmpeg\n",
- "!apt install xvfb\n",
+ "!apt install python-opengl ffmpeg xvfb\n",
"!pip3 install pyvirtualdisplay"
],
"metadata": {
@@ -230,6 +207,27 @@
"execution_count": null,
"outputs": []
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**"
+ ],
+ "metadata": {
+ "id": "K6XC13pTfFiD"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import os\n",
+ "os.kill(os.getpid(), 9)"
+ ],
+ "metadata": {
+ "id": "3kuZbWAkfHdg"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "code",
"source": [
@@ -255,12 +253,8 @@
"\n",
"In addition to the installed libraries, we also use:\n",
"\n",
- "- `random`: To generate random numbers (that will be useful for Epsilon-Greedy Policy).\n",
- "- `imageio`: To generate a replay video\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).\n",
+ "- `imageio`: To generate a replay video."
]
},
{
@@ -317,13 +311,15 @@
"We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.\n",
"\n",
"We can have two sizes of environment:\n",
+ "\n",
"- `map_name=\"4x4\"`: a 4x4 grid version\n",
"- `map_name=\"8x8\"`: a 8x8 grid version\n",
"\n",
"\n",
"The environment has two modes:\n",
- "- `is_slippery=False`: The agent always move in the intended direction due to the non-slippery nature of the frozen lake.\n",
- "- `is_slippery=True`: The agent may not always move in the intended direction due to the slippery nature of the frozen lake (stochastic)."
+ "\n",
+ "- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).\n",
+ "- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic)."
]
},
{
@@ -400,8 +396,7 @@
},
"outputs": [],
"source": [
- "# We create our environment with gym.make(\"
"
],
"metadata": {
@@ -120,7 +107,7 @@
"## Prerequisites 🏗️\n",
"Before diving into the notebook, you need to:\n",
"\n",
- "🔲 📚 **Study Q-Learning by reading Unit 2** 🤗 ADD LINK "
+ "🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗 "
]
},
{
@@ -139,6 +126,7 @@
},
"source": [
"- The *Q-Learning* **is the RL algorithm that** \n",
+ "\n",
" - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**\n",
" \n",
" - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**\n",
@@ -176,33 +164,24 @@
"source": [
"## Install dependencies and create a virtual display 🔽\n",
"\n",
- "During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). \n",
+ "In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).\n",
"\n",
- "Hence the following cell will install the librairies and create and run a virtual screen 🖥\n",
+ "Hence the following cell will install the libraries and create and run a virtual screen 🖥\n",
"\n",
"We’ll install multiple ones:\n",
"\n",
"- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.\n",
"- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.\n",
- "- `numPy`: Used for handling our Q-table.\n",
+ "- `numpy`: Used for handling our Q-table.\n",
"\n",
"The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.\n",
"\n",
- "You can see here all the Deep reinforcement Learning models available 👉 https://huggingface.co/models?other=q-learning\n"
+ "You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning"
],
"metadata": {
"id": "4gpxC1_kqUYe"
}
},
- {
- "cell_type": "markdown",
- "source": [
- "TODO CHANGE LINK OF THE REQUIREMENTS"
- ],
- "metadata": {
- "id": "32e3NPYgH5ET"
- }
- },
{
"cell_type": "code",
"execution_count": null,
@@ -211,17 +190,15 @@
},
"outputs": [],
"source": [
- "!pip install -r https://huggingface.co/spaces/ThomasSimonini/temp-space-requirements/raw/main/requirements/requirements-unit2.txt"
+ "!pip install -r pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt"
]
},
{
"cell_type": "code",
"source": [
- "%capture\n",
+ "%%capture\n",
"!sudo apt-get update\n",
- "!apt install python-opengl\n",
- "!apt install ffmpeg\n",
- "!apt install xvfb\n",
+ "!apt install python-opengl ffmpeg xvfb\n",
"!pip3 install pyvirtualdisplay"
],
"metadata": {
@@ -230,6 +207,27 @@
"execution_count": null,
"outputs": []
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**"
+ ],
+ "metadata": {
+ "id": "K6XC13pTfFiD"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "import os\n",
+ "os.kill(os.getpid(), 9)"
+ ],
+ "metadata": {
+ "id": "3kuZbWAkfHdg"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "code",
"source": [
@@ -255,12 +253,8 @@
"\n",
"In addition to the installed libraries, we also use:\n",
"\n",
- "- `random`: To generate random numbers (that will be useful for Epsilon-Greedy Policy).\n",
- "- `imageio`: To generate a replay video\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).\n",
+ "- `imageio`: To generate a replay video."
]
},
{
@@ -317,13 +311,15 @@
"We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.\n",
"\n",
"We can have two sizes of environment:\n",
+ "\n",
"- `map_name=\"4x4\"`: a 4x4 grid version\n",
"- `map_name=\"8x8\"`: a 8x8 grid version\n",
"\n",
"\n",
"The environment has two modes:\n",
- "- `is_slippery=False`: The agent always move in the intended direction due to the non-slippery nature of the frozen lake.\n",
- "- `is_slippery=True`: The agent may not always move in the intended direction due to the slippery nature of the frozen lake (stochastic)."
+ "\n",
+ "- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).\n",
+ "- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic)."
]
},
{
@@ -400,8 +396,7 @@
},
"outputs": [],
"source": [
- "# We create our environment with gym.make(\" \n",
"\n",
"\n",
- "It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. OpenAI Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`\n"
+ "It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`\n"
]
},
{
@@ -558,6 +553,62 @@
"Qtable_frozenlake = initialize_q_table(state_space, action_space)"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Atll4Z774gri"
+ },
+ "source": [
+ "## Define the greedy policy 🤖\n",
+ "Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.\n",
+ "\n",
+ "- Epsilon-greedy policy (acting policy)\n",
+ "- Greedy-policy (updating policy)\n",
+ "\n",
+ "Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.\n",
+ "\n",
+ "
\n",
"\n",
"\n",
- "It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. OpenAI Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`\n"
+ "It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`\n"
]
},
{
@@ -558,6 +553,62 @@
"Qtable_frozenlake = initialize_q_table(state_space, action_space)"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Atll4Z774gri"
+ },
+ "source": [
+ "## Define the greedy policy 🤖\n",
+ "Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.\n",
+ "\n",
+ "- Epsilon-greedy policy (acting policy)\n",
+ "- Greedy-policy (updating policy)\n",
+ "\n",
+ "Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "E3SCLmLX5bWG"
+ },
+ "outputs": [],
+ "source": [
+ "def greedy_policy(Qtable, state):\n",
+ " # Exploitation: take the action with the highest state, action value\n",
+ " action = \n",
+ " \n",
+ " return action"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "B2_-8b8z5k54"
+ },
+ "source": [
+ "#### Solution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "se2OzWGW5kYJ"
+ },
+ "outputs": [],
+ "source": [
+ "def greedy_policy(Qtable, state):\n",
+ " # Exploitation: take the action with the highest state, action value\n",
+ " action = np.argmax(Qtable[state][:])\n",
+ " \n",
+ " return action"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -566,11 +617,11 @@
"source": [
"##Define the epsilon-greedy policy 🤖\n",
"\n",
- "Epsilon-Greedy is the training policy that handles the exploration/exploitation trade-off.\n",
+ "Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.\n",
"\n",
- "The idea with Epsilon Greedy:\n",
+ "The idea with epsilon-greedy:\n",
"\n",
- "- With *probability 1 - ɛ* : **we do exploitation** (aka our agent selects the action with the highest state-action pair value).\n",
+ "- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).\n",
"\n",
"- With *probability ɛ*: we do **exploration** (trying random action).\n",
"\n",
@@ -579,15 +630,6 @@
"
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "E3SCLmLX5bWG"
+ },
+ "outputs": [],
+ "source": [
+ "def greedy_policy(Qtable, state):\n",
+ " # Exploitation: take the action with the highest state, action value\n",
+ " action = \n",
+ " \n",
+ " return action"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "B2_-8b8z5k54"
+ },
+ "source": [
+ "#### Solution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "se2OzWGW5kYJ"
+ },
+ "outputs": [],
+ "source": [
+ "def greedy_policy(Qtable, state):\n",
+ " # Exploitation: take the action with the highest state, action value\n",
+ " action = np.argmax(Qtable[state][:])\n",
+ " \n",
+ " return action"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -566,11 +617,11 @@
"source": [
"##Define the epsilon-greedy policy 🤖\n",
"\n",
- "Epsilon-Greedy is the training policy that handles the exploration/exploitation trade-off.\n",
+ "Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.\n",
"\n",
- "The idea with Epsilon Greedy:\n",
+ "The idea with epsilon-greedy:\n",
"\n",
- "- With *probability 1 - ɛ* : **we do exploitation** (aka our agent selects the action with the highest state-action pair value).\n",
+ "- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).\n",
"\n",
"- With *probability ɛ*: we do **exploration** (trying random action).\n",
"\n",
@@ -579,15 +630,6 @@
" \n"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LjZSvhsD7_52"
- },
- "source": [
- "Thanks to Sambit for finding a bug on the epsilon function 🤗"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -635,7 +677,7 @@
" if random_int > epsilon:\n",
" # Take the action with the highest value given a state\n",
" # np.argmax can be useful here\n",
- " action = np.argmax(Qtable[state])\n",
+ " action = greedy_policy(Qtable, state)\n",
" # else --> exploration\n",
" else:\n",
" action = env.action_space.sample()\n",
@@ -643,62 +685,6 @@
" return action"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Atll4Z774gri"
- },
- "source": [
- "## Define the greedy policy 🤖\n",
- "Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.\n",
- "\n",
- "- Epsilon greedy policy (acting policy)\n",
- "- Greedy policy (updating policy)\n",
- "\n",
- "Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "E3SCLmLX5bWG"
- },
- "outputs": [],
- "source": [
- "def greedy_policy(Qtable, state):\n",
- " # Exploitation: take the action with the highest state, action value\n",
- " action = \n",
- " \n",
- " return action"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "B2_-8b8z5k54"
- },
- "source": [
- "#### Solution"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "se2OzWGW5kYJ"
- },
- "outputs": [],
- "source": [
- "def greedy_policy(Qtable, state):\n",
- " # Exploitation: take the action with the highest state, action value\n",
- " action = np.argmax(Qtable[state])\n",
- " \n",
- " return action"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -708,8 +694,8 @@
"## Define the hyperparameters ⚙️\n",
"The exploration related hyperparamters are some of the most important ones. \n",
"\n",
- "- We need to make sure that our agent **explores enough the state space** in order to learn a good value approximation, in order to do that we need to have progressive decay of the epsilon.\n",
- "- If you decrease too fast epsilon (too high decay_rate), **you take the risk that your agent is stuck**, since your agent didn't explore enough the state space and hence can't solve the problem."
+ "- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.\n",
+ "- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem."
]
},
{
@@ -745,7 +731,25 @@
"id": "cDb7Tdx8atfL"
},
"source": [
- "## Step 6: Create the training loop method"
+ "## Create the training loop method\n",
+ "\n",
+ "\n",
+ "\n",
+ "The training loop goes like this:\n",
+ "\n",
+ "```\n",
+ "For episode in the total of training episodes:\n",
+ "\n",
+ "Reduce epsilon (since we need less and less exploration)\n",
+ "Reset the environment\n",
+ "\n",
+ " For step in max timesteps: \n",
+ " Choose the action At using epsilon greedy policy\n",
+ " Take the action (a) and observe the outcome state(s') and reward (r)\n",
+ " Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]\n",
+ " If done, finish the episode\n",
+ " Our next state is the new state\n",
+ "```"
]
},
{
@@ -781,7 +785,7 @@
" if done:\n",
" break\n",
" \n",
- " # Our state is the new state\n",
+ " # Our next state is the new state\n",
" state = new_state\n",
" return Qtable"
]
@@ -828,7 +832,7 @@
" if done:\n",
" break\n",
" \n",
- " # Our state is the new state\n",
+ " # Our next state is the new state\n",
" state = new_state\n",
" return Qtable"
]
@@ -879,7 +883,9 @@
"id": "pUrWkxsHccXD"
},
"source": [
- "## Define the evaluation method 📝"
+ "## The evaluation method 📝\n",
+ "\n",
+ "- We defined the evaluation method that we're going to use to test our Q-Learning agent."
]
},
{
@@ -910,7 +916,7 @@
" \n",
" for step in range(max_steps):\n",
" # Take the action (index) that have the maximum expected future reward given that state\n",
- " action = np.argmax(Q[state][:])\n",
+ " action = greedy_policy(Q, state)\n",
" new_state, reward, done, info = env.step(action)\n",
" total_rewards_ep += reward\n",
" \n",
@@ -931,8 +937,9 @@
},
"source": [
"## Evaluate our Q-Learning agent 📈\n",
- "- Normally you should have mean reward of 1.0\n",
- "- It's relatively easy since the state space is really small (16). What you can try to do is [to replace with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)."
+ "\n",
+ "- Usually, you should have a mean reward of 1.0\n",
+ "- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex."
]
},
{
@@ -954,8 +961,9 @@
"id": "yxaP3bPdg1DV"
},
"source": [
- "## Publish our trained model on the Hub 🔥\n",
- "Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.\n",
+ "## Publish our trained model to the Hub 🔥\n",
+ "\n",
+ "Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.\n",
"\n",
"Here's an example of a Model Card:\n",
"\n",
@@ -988,8 +996,7 @@
},
"outputs": [],
"source": [
- "%%capture\n",
- "from huggingface_hub import HfApi, HfFolder, Repository\n",
+ "from huggingface_hub import HfApi, snapshot_download\n",
"from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
"\n",
"from pathlib import Path\n",
@@ -1006,6 +1013,13 @@
"outputs": [],
"source": [
"def record_video(env, Qtable, out_directory, fps=1):\n",
+ " \"\"\"\n",
+ " Generate a replay video of the agent\n",
+ " :param env\n",
+ " :param Qtable: Qtable of our agent\n",
+ " :param out_directory\n",
+ " :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)\n",
+ " \"\"\"\n",
" images = [] \n",
" done = False\n",
" state = env.reset(seed=random.randint(0,500))\n",
@@ -1022,149 +1036,141 @@
},
{
"cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pwsNrzB339aF"
- },
- "outputs": [],
"source": [
- "def push_to_hub(repo_id, \n",
- " model,\n",
- " env,\n",
- " video_fps=1,\n",
- " local_repo_path=\"hub\",\n",
- " commit_message=\"Push Q-Learning agent to Hub\",\n",
- " token= None\n",
- " ):\n",
- " _, repo_name = repo_id.split(\"/\")\n",
+ "def push_to_hub(\n",
+ " repo_id, model, env, video_fps=1, local_repo_path=\"hub\"\n",
+ "):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the Hub\n",
"\n",
- " eval_env = env\n",
- " \n",
- " # Step 1: Clone or create the repo\n",
- " # Create the repo (or clone its content if it's nonempty)\n",
- " api = HfApi()\n",
- " \n",
- " repo_url = api.create_repo(\n",
+ " :param repo_id: repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param env\n",
+ " :param video_fps: how many frame per seconds to record our video replay \n",
+ " (with taxi-v3 and frozenlake-v1 we use 1)\n",
+ " :param local_repo_path: where the local repository is\n",
+ " \"\"\"\n",
+ " _, repo_name = repo_id.split(\"/\")\n",
+ "\n",
+ " eval_env = env\n",
+ " api = HfApi()\n",
+ "\n",
+ " # Step 1: Create the repo\n",
+ " repo_url = api.create_repo(\n",
" repo_id=repo_id,\n",
- " token=token,\n",
- " private=False,\n",
- " exist_ok=True,)\n",
- " \n",
- " # Git pull\n",
- " repo_local_path = Path(local_repo_path) / repo_name\n",
- " repo = Repository(repo_local_path, clone_from=repo_url, use_auth_token=True)\n",
- " repo.git_pull()\n",
- " \n",
- " repo.lfs_track([\"*.mp4\"])\n",
- "\n",
- " # Step 1: Save the model\n",
- " if env.spec.kwargs.get(\"map_name\"):\n",
- " model[\"map_name\"] = env.spec.kwargs.get(\"map_name\")\n",
- " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
- " model[\"slippery\"] = False\n",
- "\n",
- " print(model)\n",
- " \n",
- " \n",
- " # Pickle the model\n",
- " with open(Path(repo_local_path)/'q-learning.pkl', 'wb') as f:\n",
- " pickle.dump(model, f)\n",
- " \n",
- " # Step 2: Evaluate the model and build JSON\n",
- " mean_reward, std_reward = evaluate_agent(eval_env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
- "\n",
- " # First get datetime\n",
- " eval_datetime = datetime.datetime.now()\n",
- " eval_form_datetime = eval_datetime.isoformat()\n",
- "\n",
- " evaluate_data = {\n",
- " \"env_id\": model[\"env_id\"], \n",
- " \"mean_reward\": mean_reward,\n",
- " \"n_eval_episodes\": model[\"n_eval_episodes\"],\n",
- " \"eval_datetime\": eval_form_datetime,\n",
- " }\n",
- " # Write a JSON file\n",
- " with open(Path(repo_local_path) / \"results.json\", \"w\") as outfile:\n",
- " json.dump(evaluate_data, outfile)\n",
- "\n",
- " # Step 3: Create the model card\n",
- " # Env id\n",
- " env_name = model[\"env_id\"]\n",
- " if env.spec.kwargs.get(\"map_name\"):\n",
- " env_name += \"-\" + env.spec.kwargs.get(\"map_name\")\n",
- "\n",
- " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
- " env_name += \"-\" + \"no_slippery\"\n",
- "\n",
- " metadata = {}\n",
- " metadata[\"tags\"] = [\n",
- " env_name,\n",
- " \"q-learning\",\n",
- " \"reinforcement-learning\",\n",
- " \"custom-implementation\"\n",
- " ]\n",
- "\n",
- " # Add metrics\n",
- " eval = metadata_eval_result(\n",
- " model_pretty_name=repo_name,\n",
- " task_pretty_name=\"reinforcement-learning\",\n",
- " task_id=\"reinforcement-learning\",\n",
- " metrics_pretty_name=\"mean_reward\",\n",
- " metrics_id=\"mean_reward\",\n",
- " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
- " dataset_pretty_name=env_name,\n",
- " dataset_id=env_name,\n",
+ " exist_ok=True,\n",
" )\n",
"\n",
- " # Merges both dictionaries\n",
- " metadata = {**metadata, **eval}\n",
+ " # Step 2: Download files\n",
+ " repo_local_path = Path(snapshot_download(repo_id=repo_id))\n",
"\n",
- " model_card = f\"\"\"\n",
- " # **Q-Learning** Agent playing **{env_id}**\n",
+ " # Step 3: Save the model\n",
+ " if env.spec.kwargs.get(\"map_name\"):\n",
+ " model[\"map_name\"] = env.spec.kwargs.get(\"map_name\")\n",
+ " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
+ " model[\"slippery\"] = False\n",
+ "\n",
+ " # Pickle the model\n",
+ " with open((repo_local_path) / \"q-learning.pkl\", \"wb\") as f:\n",
+ " pickle.dump(model, f)\n",
+ "\n",
+ " # Step 4: Evaluate the model and build JSON with evaluation metrics\n",
+ " mean_reward, std_reward = evaluate_agent(\n",
+ " eval_env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"]\n",
+ " )\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": model[\"env_id\"],\n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"n_eval_episodes\": model[\"n_eval_episodes\"],\n",
+ " \"eval_datetime\": datetime.datetime.now().isoformat()\n",
+ " }\n",
+ "\n",
+ " # Write a JSON file called \"results.json\" that will contain the\n",
+ " # evaluation results\n",
+ " with open(repo_local_path / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 5: Create the model card\n",
+ " env_name = model[\"env_id\"]\n",
+ " if env.spec.kwargs.get(\"map_name\"):\n",
+ " env_name += \"-\" + env.spec.kwargs.get(\"map_name\")\n",
+ "\n",
+ " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
+ " env_name += \"-\" + \"no_slippery\"\n",
+ "\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [env_name, \"q-learning\", \"reinforcement-learning\", \"custom-implementation\"]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=repo_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_name,\n",
+ " dataset_id=env_name,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " model_card = f\"\"\"\n",
+ " # **Q-Learning** Agent playing1 **{env_id}**\n",
" This is a trained model of a **Q-Learning** agent playing **{env_id}** .\n",
- " \"\"\"\n",
"\n",
- " model_card += \"\"\"\n",
" ## Usage\n",
- " ```python\n",
- " \"\"\"\n",
"\n",
- " model_card += f\"\"\"model = load_from_hub(repo_id=\"{repo_id}\", filename=\"q-learning.pkl\")\n",
+ " ```python\n",
+ " \n",
+ " model = load_from_hub(repo_id=\"{repo_id}\", filename=\"q-learning.pkl\")\n",
"\n",
" # Don't forget to check if you need to add additional attributes (is_slippery=False etc)\n",
" env = gym.make(model[\"env_id\"])\n",
- "\n",
- " evaluate_agent(env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
- " \"\"\"\n",
- "\n",
- " model_card +=\"\"\"\n",
" ```\n",
" \"\"\"\n",
"\n",
- " readme_path = repo_local_path / \"README.md\"\n",
- " readme = \"\"\n",
- " if readme_path.exists():\n",
- " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
- " readme = f.read()\n",
- " else:\n",
- " readme = model_card\n",
- "\n",
- " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
- " f.write(readme)\n",
- "\n",
- " # Save our metrics to Readme metadata\n",
- " metadata_save(readme_path, metadata)\n",
- "\n",
- " # Step 4: Record a video\n",
- " video_path = repo_local_path / \"replay.mp4\"\n",
- " record_video(env, model[\"qtable\"], video_path, video_fps)\n",
+ " evaluate_agent(env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
" \n",
- " # Push everything to hub\n",
- " print(f\"Pushing repo {repo_name} to the Hugging Face Hub\")\n",
- " repo.push_to_hub(commit_message=commit_message)\n",
+ " readme_path = repo_local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " print(readme_path.exists())\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = model_card\n",
"\n",
- " print(f\"Your model is pushed to the hub. You can view your model here: {repo_url}\")"
- ]
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ " # Step 6: Record a video\n",
+ " video_path = repo_local_path / \"replay.mp4\"\n",
+ " record_video(env, model[\"qtable\"], video_path, video_fps)\n",
+ "\n",
+ " # Step 7. Push everything to the Hub\n",
+ " api.upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=repo_local_path,\n",
+ " path_in_repo=\".\",\n",
+ " )\n",
+ "\n",
+ " print(\"Your model is pushed to the Hub. You can view your model here: \", repo_url)"
+ ],
+ "metadata": {
+ "id": "U4mdUTKkGnUd"
+ },
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -1173,7 +1179,8 @@
},
"source": [
"### .\n",
- "By using `package_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.\n",
+ "\n",
+ "By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.\n",
"\n",
"This way:\n",
"- You can **showcase our work** 🔥\n",
@@ -1217,7 +1224,7 @@
"id": "GyWc1x3-o3xG"
},
"source": [
- "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)"
]
},
{
@@ -1226,7 +1233,7 @@
"id": "Gc5AfUeFo3xH"
},
"source": [
- "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function\n",
+ "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function\n",
"\n",
"- Let's create **the model dictionary that contains the hyperparameters and the Q_table**."
]
@@ -1263,10 +1270,11 @@
"id": "9kld-AEso3xH"
},
"source": [
- "Let's fill the `package_to_hub` function:\n",
+ "Let's fill the `push_to_hub` function:\n",
+ "\n",
"- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `\n",
"(repo_id = {username}/{repo_name})`\n",
- "💡 **A good name is {username}/q-{env_id}**\n",
+ "💡 A good `repo_id` is `{username}/q-{env_id}`\n",
"- `model`: our model dictionary containing the hyperparameters and the Qtable.\n",
"- `env`: the environment.\n",
"- `commit_message`: message of the commit"
@@ -1326,7 +1334,9 @@
"\n",
"---\n",
"\n",
- "In Taxi-v3 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue). When the episode starts, the taxi starts off at a random square and the passenger is at a random location. The taxi drives to the passenger’s location, picks up the passenger, drives to the passenger’s destination (another one of the four specified locations), and then drops off the passenger. Once the passenger is dropped off, the episode ends.\n",
+ "In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue). \n",
+ "\n",
+ "When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.\n",
"\n",
"\n",
"
\n"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LjZSvhsD7_52"
- },
- "source": [
- "Thanks to Sambit for finding a bug on the epsilon function 🤗"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -635,7 +677,7 @@
" if random_int > epsilon:\n",
" # Take the action with the highest value given a state\n",
" # np.argmax can be useful here\n",
- " action = np.argmax(Qtable[state])\n",
+ " action = greedy_policy(Qtable, state)\n",
" # else --> exploration\n",
" else:\n",
" action = env.action_space.sample()\n",
@@ -643,62 +685,6 @@
" return action"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Atll4Z774gri"
- },
- "source": [
- "## Define the greedy policy 🤖\n",
- "Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.\n",
- "\n",
- "- Epsilon greedy policy (acting policy)\n",
- "- Greedy policy (updating policy)\n",
- "\n",
- "Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "E3SCLmLX5bWG"
- },
- "outputs": [],
- "source": [
- "def greedy_policy(Qtable, state):\n",
- " # Exploitation: take the action with the highest state, action value\n",
- " action = \n",
- " \n",
- " return action"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "B2_-8b8z5k54"
- },
- "source": [
- "#### Solution"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "se2OzWGW5kYJ"
- },
- "outputs": [],
- "source": [
- "def greedy_policy(Qtable, state):\n",
- " # Exploitation: take the action with the highest state, action value\n",
- " action = np.argmax(Qtable[state])\n",
- " \n",
- " return action"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -708,8 +694,8 @@
"## Define the hyperparameters ⚙️\n",
"The exploration related hyperparamters are some of the most important ones. \n",
"\n",
- "- We need to make sure that our agent **explores enough the state space** in order to learn a good value approximation, in order to do that we need to have progressive decay of the epsilon.\n",
- "- If you decrease too fast epsilon (too high decay_rate), **you take the risk that your agent is stuck**, since your agent didn't explore enough the state space and hence can't solve the problem."
+ "- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.\n",
+ "- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem."
]
},
{
@@ -745,7 +731,25 @@
"id": "cDb7Tdx8atfL"
},
"source": [
- "## Step 6: Create the training loop method"
+ "## Create the training loop method\n",
+ "\n",
+ "\n",
+ "\n",
+ "The training loop goes like this:\n",
+ "\n",
+ "```\n",
+ "For episode in the total of training episodes:\n",
+ "\n",
+ "Reduce epsilon (since we need less and less exploration)\n",
+ "Reset the environment\n",
+ "\n",
+ " For step in max timesteps: \n",
+ " Choose the action At using epsilon greedy policy\n",
+ " Take the action (a) and observe the outcome state(s') and reward (r)\n",
+ " Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]\n",
+ " If done, finish the episode\n",
+ " Our next state is the new state\n",
+ "```"
]
},
{
@@ -781,7 +785,7 @@
" if done:\n",
" break\n",
" \n",
- " # Our state is the new state\n",
+ " # Our next state is the new state\n",
" state = new_state\n",
" return Qtable"
]
@@ -828,7 +832,7 @@
" if done:\n",
" break\n",
" \n",
- " # Our state is the new state\n",
+ " # Our next state is the new state\n",
" state = new_state\n",
" return Qtable"
]
@@ -879,7 +883,9 @@
"id": "pUrWkxsHccXD"
},
"source": [
- "## Define the evaluation method 📝"
+ "## The evaluation method 📝\n",
+ "\n",
+ "- We defined the evaluation method that we're going to use to test our Q-Learning agent."
]
},
{
@@ -910,7 +916,7 @@
" \n",
" for step in range(max_steps):\n",
" # Take the action (index) that have the maximum expected future reward given that state\n",
- " action = np.argmax(Q[state][:])\n",
+ " action = greedy_policy(Q, state)\n",
" new_state, reward, done, info = env.step(action)\n",
" total_rewards_ep += reward\n",
" \n",
@@ -931,8 +937,9 @@
},
"source": [
"## Evaluate our Q-Learning agent 📈\n",
- "- Normally you should have mean reward of 1.0\n",
- "- It's relatively easy since the state space is really small (16). What you can try to do is [to replace with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)."
+ "\n",
+ "- Usually, you should have a mean reward of 1.0\n",
+ "- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex."
]
},
{
@@ -954,8 +961,9 @@
"id": "yxaP3bPdg1DV"
},
"source": [
- "## Publish our trained model on the Hub 🔥\n",
- "Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.\n",
+ "## Publish our trained model to the Hub 🔥\n",
+ "\n",
+ "Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.\n",
"\n",
"Here's an example of a Model Card:\n",
"\n",
@@ -988,8 +996,7 @@
},
"outputs": [],
"source": [
- "%%capture\n",
- "from huggingface_hub import HfApi, HfFolder, Repository\n",
+ "from huggingface_hub import HfApi, snapshot_download\n",
"from huggingface_hub.repocard import metadata_eval_result, metadata_save\n",
"\n",
"from pathlib import Path\n",
@@ -1006,6 +1013,13 @@
"outputs": [],
"source": [
"def record_video(env, Qtable, out_directory, fps=1):\n",
+ " \"\"\"\n",
+ " Generate a replay video of the agent\n",
+ " :param env\n",
+ " :param Qtable: Qtable of our agent\n",
+ " :param out_directory\n",
+ " :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)\n",
+ " \"\"\"\n",
" images = [] \n",
" done = False\n",
" state = env.reset(seed=random.randint(0,500))\n",
@@ -1022,149 +1036,141 @@
},
{
"cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pwsNrzB339aF"
- },
- "outputs": [],
"source": [
- "def push_to_hub(repo_id, \n",
- " model,\n",
- " env,\n",
- " video_fps=1,\n",
- " local_repo_path=\"hub\",\n",
- " commit_message=\"Push Q-Learning agent to Hub\",\n",
- " token= None\n",
- " ):\n",
- " _, repo_name = repo_id.split(\"/\")\n",
+ "def push_to_hub(\n",
+ " repo_id, model, env, video_fps=1, local_repo_path=\"hub\"\n",
+ "):\n",
+ " \"\"\"\n",
+ " Evaluate, Generate a video and Upload a model to Hugging Face Hub.\n",
+ " This method does the complete pipeline:\n",
+ " - It evaluates the model\n",
+ " - It generates the model card\n",
+ " - It generates a replay video of the agent\n",
+ " - It pushes everything to the Hub\n",
"\n",
- " eval_env = env\n",
- " \n",
- " # Step 1: Clone or create the repo\n",
- " # Create the repo (or clone its content if it's nonempty)\n",
- " api = HfApi()\n",
- " \n",
- " repo_url = api.create_repo(\n",
+ " :param repo_id: repo_id: id of the model repository from the Hugging Face Hub\n",
+ " :param env\n",
+ " :param video_fps: how many frame per seconds to record our video replay \n",
+ " (with taxi-v3 and frozenlake-v1 we use 1)\n",
+ " :param local_repo_path: where the local repository is\n",
+ " \"\"\"\n",
+ " _, repo_name = repo_id.split(\"/\")\n",
+ "\n",
+ " eval_env = env\n",
+ " api = HfApi()\n",
+ "\n",
+ " # Step 1: Create the repo\n",
+ " repo_url = api.create_repo(\n",
" repo_id=repo_id,\n",
- " token=token,\n",
- " private=False,\n",
- " exist_ok=True,)\n",
- " \n",
- " # Git pull\n",
- " repo_local_path = Path(local_repo_path) / repo_name\n",
- " repo = Repository(repo_local_path, clone_from=repo_url, use_auth_token=True)\n",
- " repo.git_pull()\n",
- " \n",
- " repo.lfs_track([\"*.mp4\"])\n",
- "\n",
- " # Step 1: Save the model\n",
- " if env.spec.kwargs.get(\"map_name\"):\n",
- " model[\"map_name\"] = env.spec.kwargs.get(\"map_name\")\n",
- " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
- " model[\"slippery\"] = False\n",
- "\n",
- " print(model)\n",
- " \n",
- " \n",
- " # Pickle the model\n",
- " with open(Path(repo_local_path)/'q-learning.pkl', 'wb') as f:\n",
- " pickle.dump(model, f)\n",
- " \n",
- " # Step 2: Evaluate the model and build JSON\n",
- " mean_reward, std_reward = evaluate_agent(eval_env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
- "\n",
- " # First get datetime\n",
- " eval_datetime = datetime.datetime.now()\n",
- " eval_form_datetime = eval_datetime.isoformat()\n",
- "\n",
- " evaluate_data = {\n",
- " \"env_id\": model[\"env_id\"], \n",
- " \"mean_reward\": mean_reward,\n",
- " \"n_eval_episodes\": model[\"n_eval_episodes\"],\n",
- " \"eval_datetime\": eval_form_datetime,\n",
- " }\n",
- " # Write a JSON file\n",
- " with open(Path(repo_local_path) / \"results.json\", \"w\") as outfile:\n",
- " json.dump(evaluate_data, outfile)\n",
- "\n",
- " # Step 3: Create the model card\n",
- " # Env id\n",
- " env_name = model[\"env_id\"]\n",
- " if env.spec.kwargs.get(\"map_name\"):\n",
- " env_name += \"-\" + env.spec.kwargs.get(\"map_name\")\n",
- "\n",
- " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
- " env_name += \"-\" + \"no_slippery\"\n",
- "\n",
- " metadata = {}\n",
- " metadata[\"tags\"] = [\n",
- " env_name,\n",
- " \"q-learning\",\n",
- " \"reinforcement-learning\",\n",
- " \"custom-implementation\"\n",
- " ]\n",
- "\n",
- " # Add metrics\n",
- " eval = metadata_eval_result(\n",
- " model_pretty_name=repo_name,\n",
- " task_pretty_name=\"reinforcement-learning\",\n",
- " task_id=\"reinforcement-learning\",\n",
- " metrics_pretty_name=\"mean_reward\",\n",
- " metrics_id=\"mean_reward\",\n",
- " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
- " dataset_pretty_name=env_name,\n",
- " dataset_id=env_name,\n",
+ " exist_ok=True,\n",
" )\n",
"\n",
- " # Merges both dictionaries\n",
- " metadata = {**metadata, **eval}\n",
+ " # Step 2: Download files\n",
+ " repo_local_path = Path(snapshot_download(repo_id=repo_id))\n",
"\n",
- " model_card = f\"\"\"\n",
- " # **Q-Learning** Agent playing **{env_id}**\n",
+ " # Step 3: Save the model\n",
+ " if env.spec.kwargs.get(\"map_name\"):\n",
+ " model[\"map_name\"] = env.spec.kwargs.get(\"map_name\")\n",
+ " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
+ " model[\"slippery\"] = False\n",
+ "\n",
+ " # Pickle the model\n",
+ " with open((repo_local_path) / \"q-learning.pkl\", \"wb\") as f:\n",
+ " pickle.dump(model, f)\n",
+ "\n",
+ " # Step 4: Evaluate the model and build JSON with evaluation metrics\n",
+ " mean_reward, std_reward = evaluate_agent(\n",
+ " eval_env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"]\n",
+ " )\n",
+ "\n",
+ " evaluate_data = {\n",
+ " \"env_id\": model[\"env_id\"],\n",
+ " \"mean_reward\": mean_reward,\n",
+ " \"n_eval_episodes\": model[\"n_eval_episodes\"],\n",
+ " \"eval_datetime\": datetime.datetime.now().isoformat()\n",
+ " }\n",
+ "\n",
+ " # Write a JSON file called \"results.json\" that will contain the\n",
+ " # evaluation results\n",
+ " with open(repo_local_path / \"results.json\", \"w\") as outfile:\n",
+ " json.dump(evaluate_data, outfile)\n",
+ "\n",
+ " # Step 5: Create the model card\n",
+ " env_name = model[\"env_id\"]\n",
+ " if env.spec.kwargs.get(\"map_name\"):\n",
+ " env_name += \"-\" + env.spec.kwargs.get(\"map_name\")\n",
+ "\n",
+ " if env.spec.kwargs.get(\"is_slippery\", \"\") == False:\n",
+ " env_name += \"-\" + \"no_slippery\"\n",
+ "\n",
+ " metadata = {}\n",
+ " metadata[\"tags\"] = [env_name, \"q-learning\", \"reinforcement-learning\", \"custom-implementation\"]\n",
+ "\n",
+ " # Add metrics\n",
+ " eval = metadata_eval_result(\n",
+ " model_pretty_name=repo_name,\n",
+ " task_pretty_name=\"reinforcement-learning\",\n",
+ " task_id=\"reinforcement-learning\",\n",
+ " metrics_pretty_name=\"mean_reward\",\n",
+ " metrics_id=\"mean_reward\",\n",
+ " metrics_value=f\"{mean_reward:.2f} +/- {std_reward:.2f}\",\n",
+ " dataset_pretty_name=env_name,\n",
+ " dataset_id=env_name,\n",
+ " )\n",
+ "\n",
+ " # Merges both dictionaries\n",
+ " metadata = {**metadata, **eval}\n",
+ "\n",
+ " model_card = f\"\"\"\n",
+ " # **Q-Learning** Agent playing1 **{env_id}**\n",
" This is a trained model of a **Q-Learning** agent playing **{env_id}** .\n",
- " \"\"\"\n",
"\n",
- " model_card += \"\"\"\n",
" ## Usage\n",
- " ```python\n",
- " \"\"\"\n",
"\n",
- " model_card += f\"\"\"model = load_from_hub(repo_id=\"{repo_id}\", filename=\"q-learning.pkl\")\n",
+ " ```python\n",
+ " \n",
+ " model = load_from_hub(repo_id=\"{repo_id}\", filename=\"q-learning.pkl\")\n",
"\n",
" # Don't forget to check if you need to add additional attributes (is_slippery=False etc)\n",
" env = gym.make(model[\"env_id\"])\n",
- "\n",
- " evaluate_agent(env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
- " \"\"\"\n",
- "\n",
- " model_card +=\"\"\"\n",
" ```\n",
" \"\"\"\n",
"\n",
- " readme_path = repo_local_path / \"README.md\"\n",
- " readme = \"\"\n",
- " if readme_path.exists():\n",
- " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
- " readme = f.read()\n",
- " else:\n",
- " readme = model_card\n",
- "\n",
- " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
- " f.write(readme)\n",
- "\n",
- " # Save our metrics to Readme metadata\n",
- " metadata_save(readme_path, metadata)\n",
- "\n",
- " # Step 4: Record a video\n",
- " video_path = repo_local_path / \"replay.mp4\"\n",
- " record_video(env, model[\"qtable\"], video_path, video_fps)\n",
+ " evaluate_agent(env, model[\"max_steps\"], model[\"n_eval_episodes\"], model[\"qtable\"], model[\"eval_seed\"])\n",
" \n",
- " # Push everything to hub\n",
- " print(f\"Pushing repo {repo_name} to the Hugging Face Hub\")\n",
- " repo.push_to_hub(commit_message=commit_message)\n",
+ " readme_path = repo_local_path / \"README.md\"\n",
+ " readme = \"\"\n",
+ " print(readme_path.exists())\n",
+ " if readme_path.exists():\n",
+ " with readme_path.open(\"r\", encoding=\"utf8\") as f:\n",
+ " readme = f.read()\n",
+ " else:\n",
+ " readme = model_card\n",
"\n",
- " print(f\"Your model is pushed to the hub. You can view your model here: {repo_url}\")"
- ]
+ " with readme_path.open(\"w\", encoding=\"utf-8\") as f:\n",
+ " f.write(readme)\n",
+ "\n",
+ " # Save our metrics to Readme metadata\n",
+ " metadata_save(readme_path, metadata)\n",
+ "\n",
+ " # Step 6: Record a video\n",
+ " video_path = repo_local_path / \"replay.mp4\"\n",
+ " record_video(env, model[\"qtable\"], video_path, video_fps)\n",
+ "\n",
+ " # Step 7. Push everything to the Hub\n",
+ " api.upload_folder(\n",
+ " repo_id=repo_id,\n",
+ " folder_path=repo_local_path,\n",
+ " path_in_repo=\".\",\n",
+ " )\n",
+ "\n",
+ " print(\"Your model is pushed to the Hub. You can view your model here: \", repo_url)"
+ ],
+ "metadata": {
+ "id": "U4mdUTKkGnUd"
+ },
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -1173,7 +1179,8 @@
},
"source": [
"### .\n",
- "By using `package_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.\n",
+ "\n",
+ "By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.\n",
"\n",
"This way:\n",
"- You can **showcase our work** 🔥\n",
@@ -1217,7 +1224,7 @@
"id": "GyWc1x3-o3xG"
},
"source": [
- "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`"
+ "If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)"
]
},
{
@@ -1226,7 +1233,7 @@
"id": "Gc5AfUeFo3xH"
},
"source": [
- "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function\n",
+ "3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function\n",
"\n",
"- Let's create **the model dictionary that contains the hyperparameters and the Q_table**."
]
@@ -1263,10 +1270,11 @@
"id": "9kld-AEso3xH"
},
"source": [
- "Let's fill the `package_to_hub` function:\n",
+ "Let's fill the `push_to_hub` function:\n",
+ "\n",
"- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `\n",
"(repo_id = {username}/{repo_name})`\n",
- "💡 **A good name is {username}/q-{env_id}**\n",
+ "💡 A good `repo_id` is `{username}/q-{env_id}`\n",
"- `model`: our model dictionary containing the hyperparameters and the Qtable.\n",
"- `env`: the environment.\n",
"- `commit_message`: message of the commit"
@@ -1326,7 +1334,9 @@
"\n",
"---\n",
"\n",
- "In Taxi-v3 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue). When the episode starts, the taxi starts off at a random square and the passenger is at a random location. The taxi drives to the passenger’s location, picks up the passenger, drives to the passenger’s destination (another one of the four specified locations), and then drops off the passenger. Once the passenger is dropped off, the episode ends.\n",
+ "In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue). \n",
+ "\n",
+ "When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.\n",
"\n",
"\n",
" \n"
@@ -1383,6 +1393,7 @@
},
"source": [
"The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:\n",
+ "\n",
"- 0: move south\n",
"- 1: move north\n",
"- 2: move east\n",
@@ -1391,6 +1402,7 @@
"- 5: drop off passenger\n",
"\n",
"Reward function 💰:\n",
+ "\n",
"- -1 per step unless other reward is triggered.\n",
"- +20 delivering passenger.\n",
"- -10 executing “pickup” and “drop-off” actions illegally."
@@ -1461,17 +1473,6 @@
"## Train our Q-Learning agent 🏃"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MLNwkNDb14h2"
- },
- "outputs": [],
- "source": [
- "Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1480,6 +1481,7 @@
},
"outputs": [],
"source": [
+ "Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)\n",
"Qtable_taxi"
]
},
@@ -1489,7 +1491,7 @@
"id": "wPdu0SueLVl2"
},
"source": [
- "## Create a model dictionary 💾 and publish our trained model on the Hub 🔥\n",
+ "## Create a model dictionary 💾 and publish our trained model to the Hub 🔥\n",
"- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.\n"
]
},
@@ -1528,7 +1530,7 @@
"outputs": [],
"source": [
"username = \"\" # FILL THIS\n",
- "repo_name = \"q-Taxi-v3\"\n",
+ "repo_name = \"\"\n",
"push_to_hub(\n",
" repo_id=f\"{username}/{repo_name}\",\n",
" model=model,\n",
@@ -1543,6 +1545,8 @@
"source": [
"Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard\n",
"\n",
+ "⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠\n",
+ "\n",
"
\n"
@@ -1383,6 +1393,7 @@
},
"source": [
"The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:\n",
+ "\n",
"- 0: move south\n",
"- 1: move north\n",
"- 2: move east\n",
@@ -1391,6 +1402,7 @@
"- 5: drop off passenger\n",
"\n",
"Reward function 💰:\n",
+ "\n",
"- -1 per step unless other reward is triggered.\n",
"- +20 delivering passenger.\n",
"- -10 executing “pickup” and “drop-off” actions illegally."
@@ -1461,17 +1473,6 @@
"## Train our Q-Learning agent 🏃"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MLNwkNDb14h2"
- },
- "outputs": [],
- "source": [
- "Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1480,6 +1481,7 @@
},
"outputs": [],
"source": [
+ "Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)\n",
"Qtable_taxi"
]
},
@@ -1489,7 +1491,7 @@
"id": "wPdu0SueLVl2"
},
"source": [
- "## Create a model dictionary 💾 and publish our trained model on the Hub 🔥\n",
+ "## Create a model dictionary 💾 and publish our trained model to the Hub 🔥\n",
"- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.\n"
]
},
@@ -1528,7 +1530,7 @@
"outputs": [],
"source": [
"username = \"\" # FILL THIS\n",
- "repo_name = \"q-Taxi-v3\"\n",
+ "repo_name = \"\"\n",
"push_to_hub(\n",
" repo_id=f\"{username}/{repo_name}\",\n",
" model=model,\n",
@@ -1543,6 +1545,8 @@
"source": [
"Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard\n",
"\n",
+ "⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠\n",
+ "\n",
" "
]
},
@@ -1556,7 +1560,8 @@
"\n",
"What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.\n",
"\n",
- "Loading a saved model from the Hub is really easy.\n",
+ "Loading a saved model from the Hub is really easy:\n",
+ "\n",
"1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.\n",
"2. You select one and copy its repo_id\n",
"\n",
@@ -1602,14 +1607,6 @@
" :param repo_id: id of the model repository from the Hugging Face Hub\n",
" :param filename: name of the model zip file from the repository\n",
" \"\"\"\n",
- " try:\n",
- " from huggingface_hub import cached_download, hf_hub_url\n",
- " except ImportError:\n",
- " raise ImportError(\n",
- " \"You need to install huggingface_hub to use `load_from_hub`. \"\n",
- " \"See https://pypi.org/project/huggingface-hub/ for installation.\"\n",
- " )\n",
- "\n",
" # Get the model from the Hub, download and cache the model on your local disk\n",
" pickle_model = hf_hub_download(\n",
" repo_id=repo_id,\n",
@@ -1671,9 +1668,10 @@
"## Some additional challenges 🏆\n",
"The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results! \n",
"\n",
- "In the [Leaderboard](https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?\n",
+ "In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?\n",
"\n",
"Here are some ideas to achieve so:\n",
+ "\n",
"* Train more steps\n",
"* Try different hyperparameters by looking at what your classmates have done.\n",
"* **Push your new trained model** on the Hub 🔥\n",
@@ -1711,8 +1709,8 @@
"id": "BjLhT70TEZIn"
},
"source": [
- "See you on [Unit 3](https://github.com/huggingface/deep-rl-class/tree/main/unit2#unit-2-introduction-to-q-learning)! 🔥\n",
- "TODO CHANGE LINK\n",
+ "See you on Unit 3! 🔥\n",
+ "\n",
"## Keep learning, stay awesome 🤗"
]
}
@@ -1720,14 +1718,13 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [
- "4i6tjI2tHQ8j",
- "Y-mo_6rXIjRi",
- "EtrfoTaBoNrd",
- "BjLhT70TEZIn"
- ],
"private_outputs": true,
- "provenance": []
+ "provenance": [],
+ "collapsed_sections": [
+ "Ji_UrI5l2zzn",
+ "67OdoKL63eDD",
+ "B2_-8b8z5k54"
+ ]
},
"gpuClass": "standard",
"kernelspec": {
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 07eecd3..1ce98b5 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -46,3 +46,33 @@
title: Play with Huggy
- local: unitbonus1/conclusion
title: Conclusion
+- title: Unit 2. Introduction to Q-Learning
+ sections:
+ - local: unit2/introduction
+ title: Introduction
+ - local: unit2/what-is-rl
+ title: What is RL? A short recap
+ - local: unit2/two-types-value-based-methods
+ title: The two types of value-based methods
+ - local: unit2/bellman-equation
+ title: The Bellman Equation, simplify our value estimation
+ - local: unit2/mc-vs-td
+ title: Monte Carlo vs Temporal Difference Learning
+ - local: unit2/mid-way-recap
+ title: Mid-way Recap
+ - local: unit2/mid-way-quiz
+ title: Mid-way Quiz
+ - local: unit2/q-learning
+ title: Introducing Q-Learning
+ - local: unit2/q-learning-example
+ title: A Q-Learning example
+ - local: unit2/q-learning-recap
+ title: Q-Learning Recap
+ - local: unit2/hands-on
+ title: Hands-on
+ - local: unit2/quiz2
+ title: Q-Learning Quiz
+ - local: unit2/conclusion
+ title: Conclusion
+ - local: unit2/additional-readings
+ title: Additional Readings
diff --git a/units/en/unit2/additional-readings.mdx b/units/en/unit2/additional-readings.mdx
new file mode 100644
index 0000000..9a14724
--- /dev/null
+++ b/units/en/unit2/additional-readings.mdx
@@ -0,0 +1,15 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## Monte Carlo and TD Learning [[mc-td]]
+
+To dive deeper on Monte Carlo and Temporal Difference Learning:
+
+- Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?
+- When are Monte Carlo methods preferred over temporal difference ones?
+
+## Q-Learning [[q-learning]]
+
+- Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7
+- Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel
diff --git a/units/en/unit2/bellman-equation.mdx b/units/en/unit2/bellman-equation.mdx
new file mode 100644
index 0000000..577c6bb
--- /dev/null
+++ b/units/en/unit2/bellman-equation.mdx
@@ -0,0 +1,63 @@
+# The Bellman Equation: simplify our value estimation [[bellman-equation]]
+
+The Bellman equation **simplifies our state value or state-action value calculation.**
+
+
+
"
]
},
@@ -1556,7 +1560,8 @@
"\n",
"What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.\n",
"\n",
- "Loading a saved model from the Hub is really easy.\n",
+ "Loading a saved model from the Hub is really easy:\n",
+ "\n",
"1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.\n",
"2. You select one and copy its repo_id\n",
"\n",
@@ -1602,14 +1607,6 @@
" :param repo_id: id of the model repository from the Hugging Face Hub\n",
" :param filename: name of the model zip file from the repository\n",
" \"\"\"\n",
- " try:\n",
- " from huggingface_hub import cached_download, hf_hub_url\n",
- " except ImportError:\n",
- " raise ImportError(\n",
- " \"You need to install huggingface_hub to use `load_from_hub`. \"\n",
- " \"See https://pypi.org/project/huggingface-hub/ for installation.\"\n",
- " )\n",
- "\n",
" # Get the model from the Hub, download and cache the model on your local disk\n",
" pickle_model = hf_hub_download(\n",
" repo_id=repo_id,\n",
@@ -1671,9 +1668,10 @@
"## Some additional challenges 🏆\n",
"The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results! \n",
"\n",
- "In the [Leaderboard](https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?\n",
+ "In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?\n",
"\n",
"Here are some ideas to achieve so:\n",
+ "\n",
"* Train more steps\n",
"* Try different hyperparameters by looking at what your classmates have done.\n",
"* **Push your new trained model** on the Hub 🔥\n",
@@ -1711,8 +1709,8 @@
"id": "BjLhT70TEZIn"
},
"source": [
- "See you on [Unit 3](https://github.com/huggingface/deep-rl-class/tree/main/unit2#unit-2-introduction-to-q-learning)! 🔥\n",
- "TODO CHANGE LINK\n",
+ "See you on Unit 3! 🔥\n",
+ "\n",
"## Keep learning, stay awesome 🤗"
]
}
@@ -1720,14 +1718,13 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [
- "4i6tjI2tHQ8j",
- "Y-mo_6rXIjRi",
- "EtrfoTaBoNrd",
- "BjLhT70TEZIn"
- ],
"private_outputs": true,
- "provenance": []
+ "provenance": [],
+ "collapsed_sections": [
+ "Ji_UrI5l2zzn",
+ "67OdoKL63eDD",
+ "B2_-8b8z5k54"
+ ]
},
"gpuClass": "standard",
"kernelspec": {
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 07eecd3..1ce98b5 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -46,3 +46,33 @@
title: Play with Huggy
- local: unitbonus1/conclusion
title: Conclusion
+- title: Unit 2. Introduction to Q-Learning
+ sections:
+ - local: unit2/introduction
+ title: Introduction
+ - local: unit2/what-is-rl
+ title: What is RL? A short recap
+ - local: unit2/two-types-value-based-methods
+ title: The two types of value-based methods
+ - local: unit2/bellman-equation
+ title: The Bellman Equation, simplify our value estimation
+ - local: unit2/mc-vs-td
+ title: Monte Carlo vs Temporal Difference Learning
+ - local: unit2/mid-way-recap
+ title: Mid-way Recap
+ - local: unit2/mid-way-quiz
+ title: Mid-way Quiz
+ - local: unit2/q-learning
+ title: Introducing Q-Learning
+ - local: unit2/q-learning-example
+ title: A Q-Learning example
+ - local: unit2/q-learning-recap
+ title: Q-Learning Recap
+ - local: unit2/hands-on
+ title: Hands-on
+ - local: unit2/quiz2
+ title: Q-Learning Quiz
+ - local: unit2/conclusion
+ title: Conclusion
+ - local: unit2/additional-readings
+ title: Additional Readings
diff --git a/units/en/unit2/additional-readings.mdx b/units/en/unit2/additional-readings.mdx
new file mode 100644
index 0000000..9a14724
--- /dev/null
+++ b/units/en/unit2/additional-readings.mdx
@@ -0,0 +1,15 @@
+# Additional Readings [[additional-readings]]
+
+These are **optional readings** if you want to go deeper.
+
+## Monte Carlo and TD Learning [[mc-td]]
+
+To dive deeper on Monte Carlo and Temporal Difference Learning:
+
+- Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?
+- When are Monte Carlo methods preferred over temporal difference ones?
+
+## Q-Learning [[q-learning]]
+
+- Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7
+- Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel
diff --git a/units/en/unit2/bellman-equation.mdx b/units/en/unit2/bellman-equation.mdx
new file mode 100644
index 0000000..577c6bb
--- /dev/null
+++ b/units/en/unit2/bellman-equation.mdx
@@ -0,0 +1,63 @@
+# The Bellman Equation: simplify our value estimation [[bellman-equation]]
+
+The Bellman equation **simplifies our state value or state-action value calculation.**
+
+
+ +
+With what we have learned so far, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(The policy we defined in the following example is a Greedy Policy; for simplification, we don't discount the reward).**
+
+So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
+
+
+
+With what we have learned so far, we know that if we calculate the \\(V(S_t)\\) (value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(The policy we defined in the following example is a Greedy Policy; for simplification, we don't discount the reward).**
+
+So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
+
+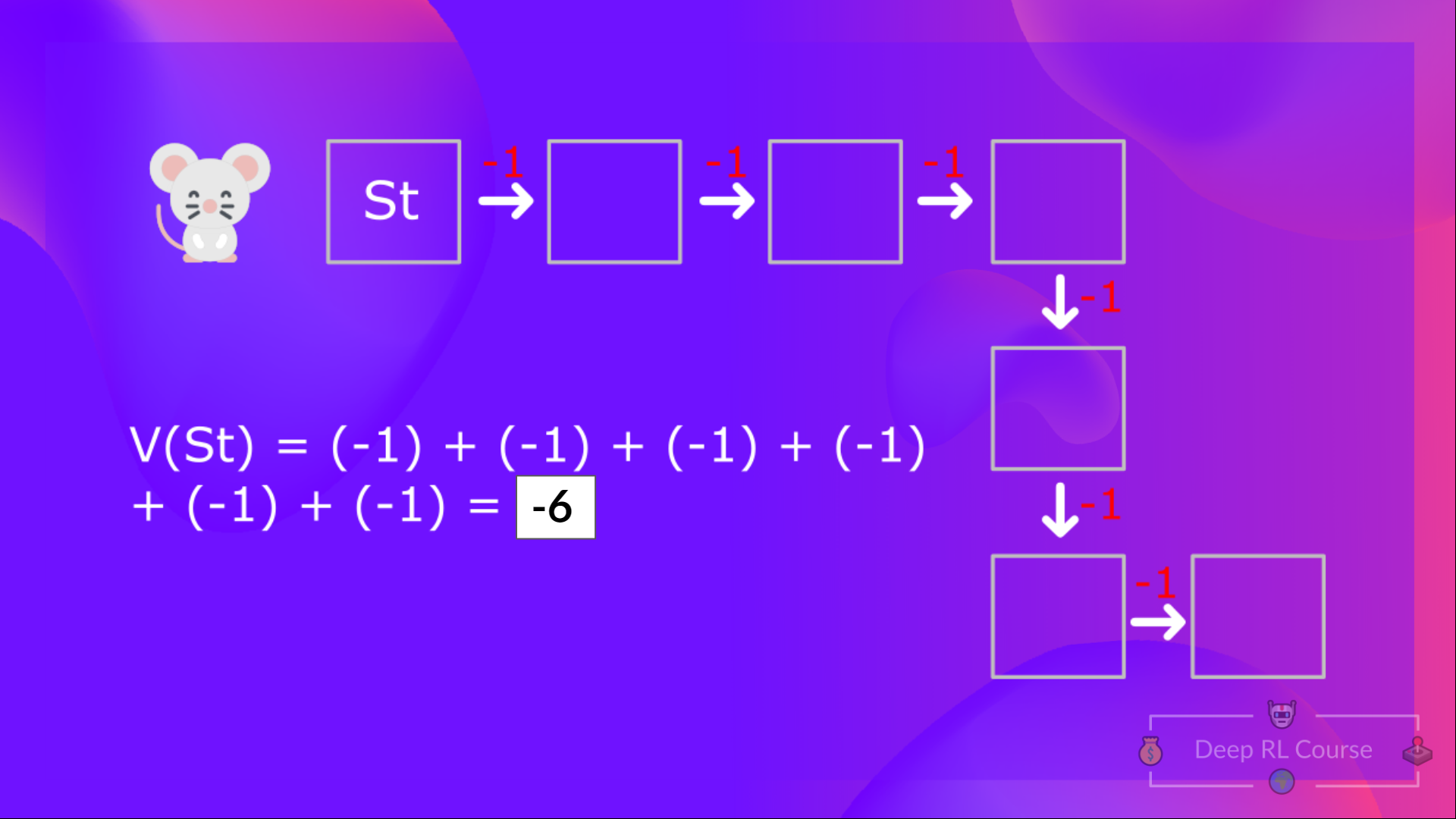 +
+ 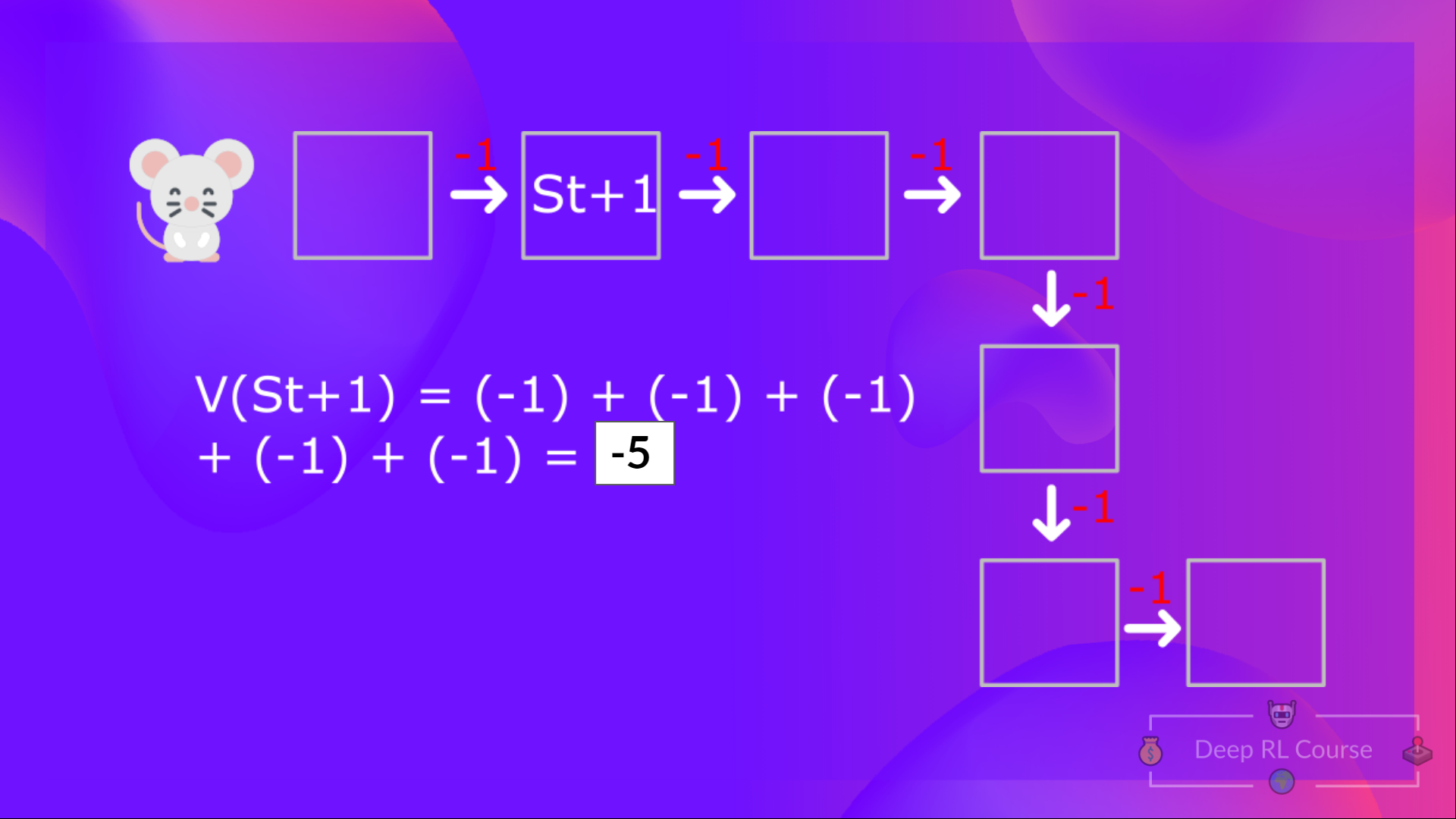 +
+  +
+
+
+To calculate the value of State 1: the sum of rewards **if the agent started in that state 1** and then followed the **policy for all the time steps.**
+
+This is equivalent to \\(V(S_{t})\\) = Immediate reward \\(R_{t+1}\\) + Discounted value of the next state \\(\gamma * V(S_{t+1})\\)
+
+
+
+
+
+To calculate the value of State 1: the sum of rewards **if the agent started in that state 1** and then followed the **policy for all the time steps.**
+
+This is equivalent to \\(V(S_{t})\\) = Immediate reward \\(R_{t+1}\\) + Discounted value of the next state \\(\gamma * V(S_{t+1})\\)
+
+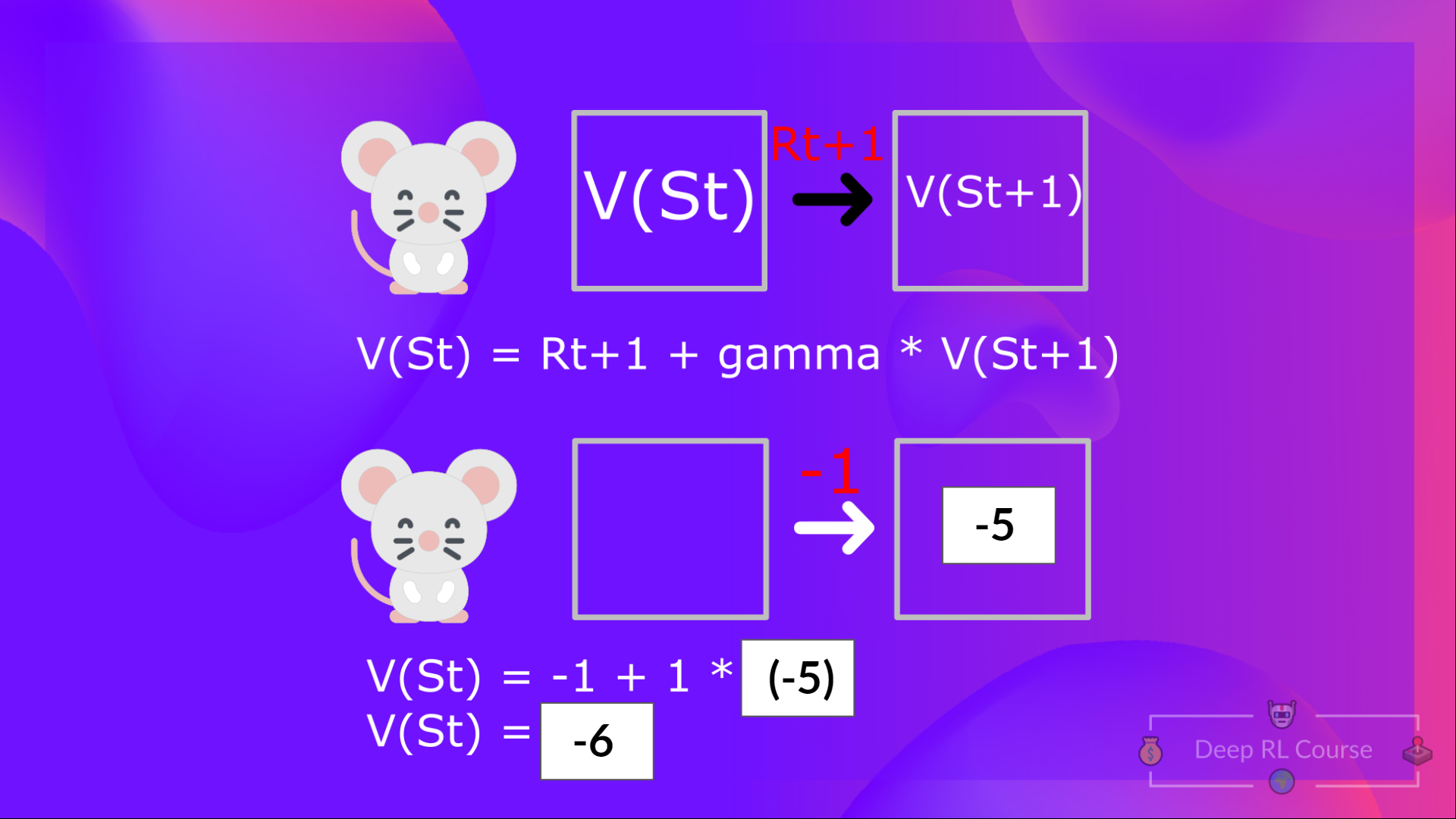 +
+  +
+
+
+### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
new file mode 100644
index 0000000..58a2a57
--- /dev/null
+++ b/units/en/unit2/hands-on.mdx
@@ -0,0 +1,1098 @@
+# Hands-on [[hands-on]]
+
+
+
+
+
+### Keep Learning, stay awesome 🤗
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
new file mode 100644
index 0000000..58a2a57
--- /dev/null
+++ b/units/en/unit2/hands-on.mdx
@@ -0,0 +1,1098 @@
+# Hands-on [[hands-on]]
+
+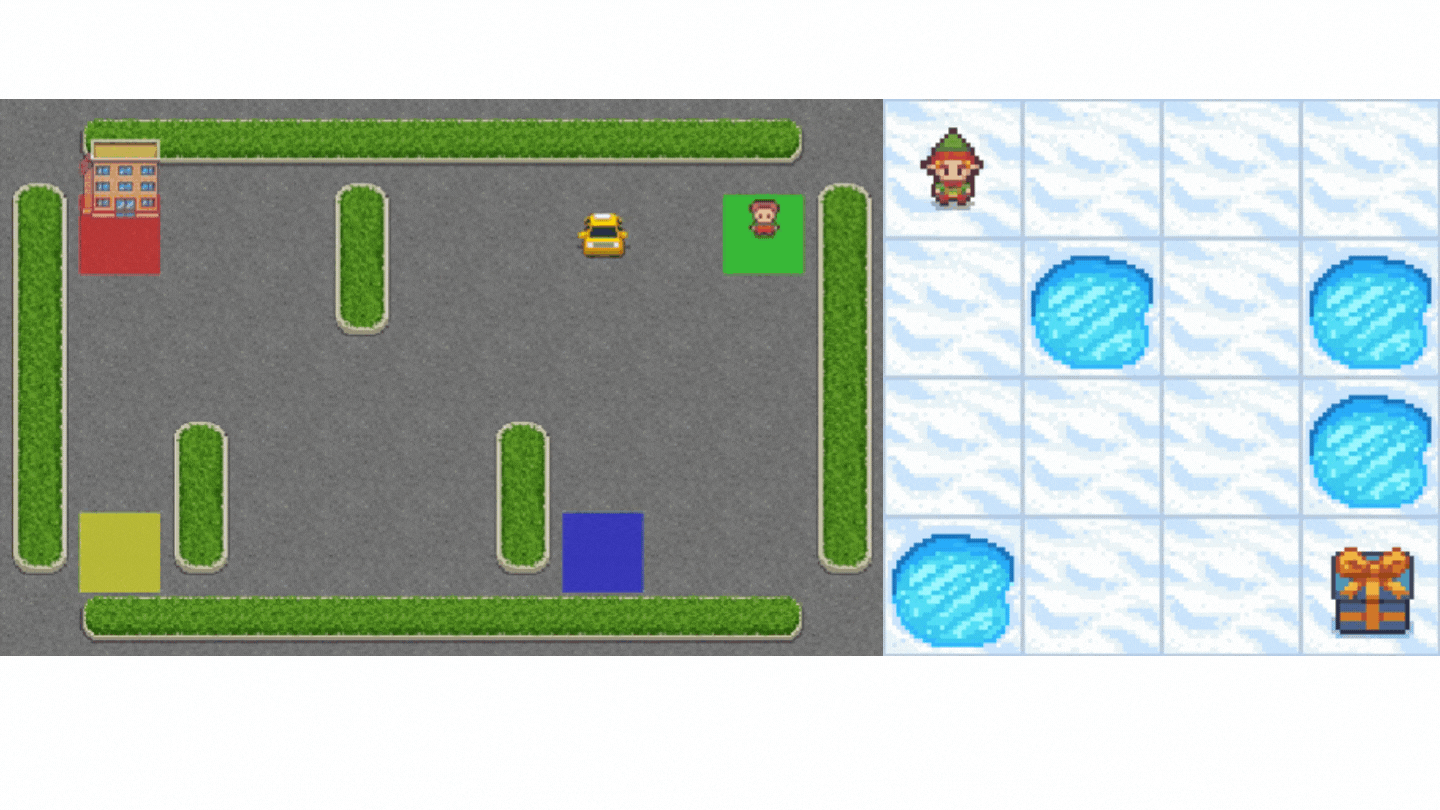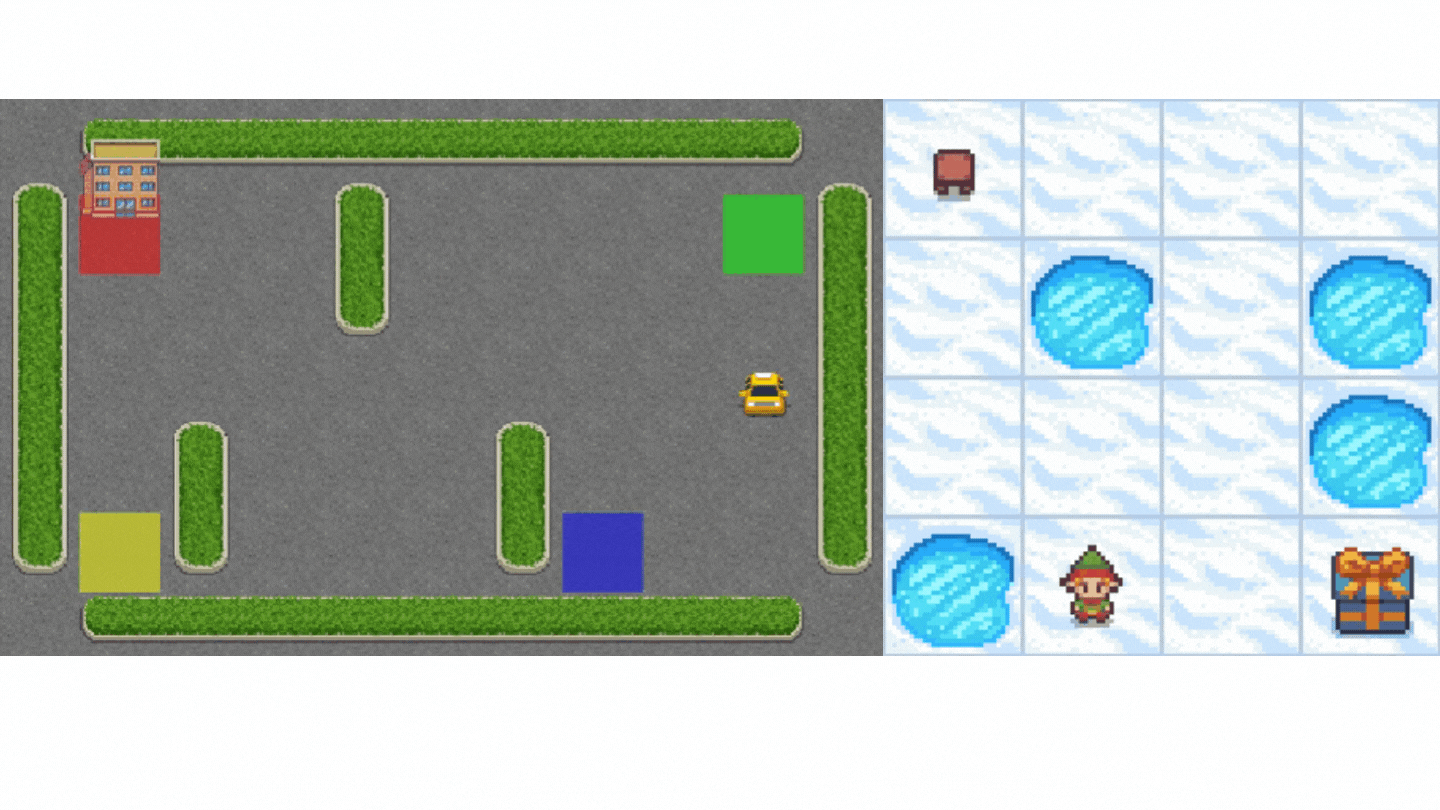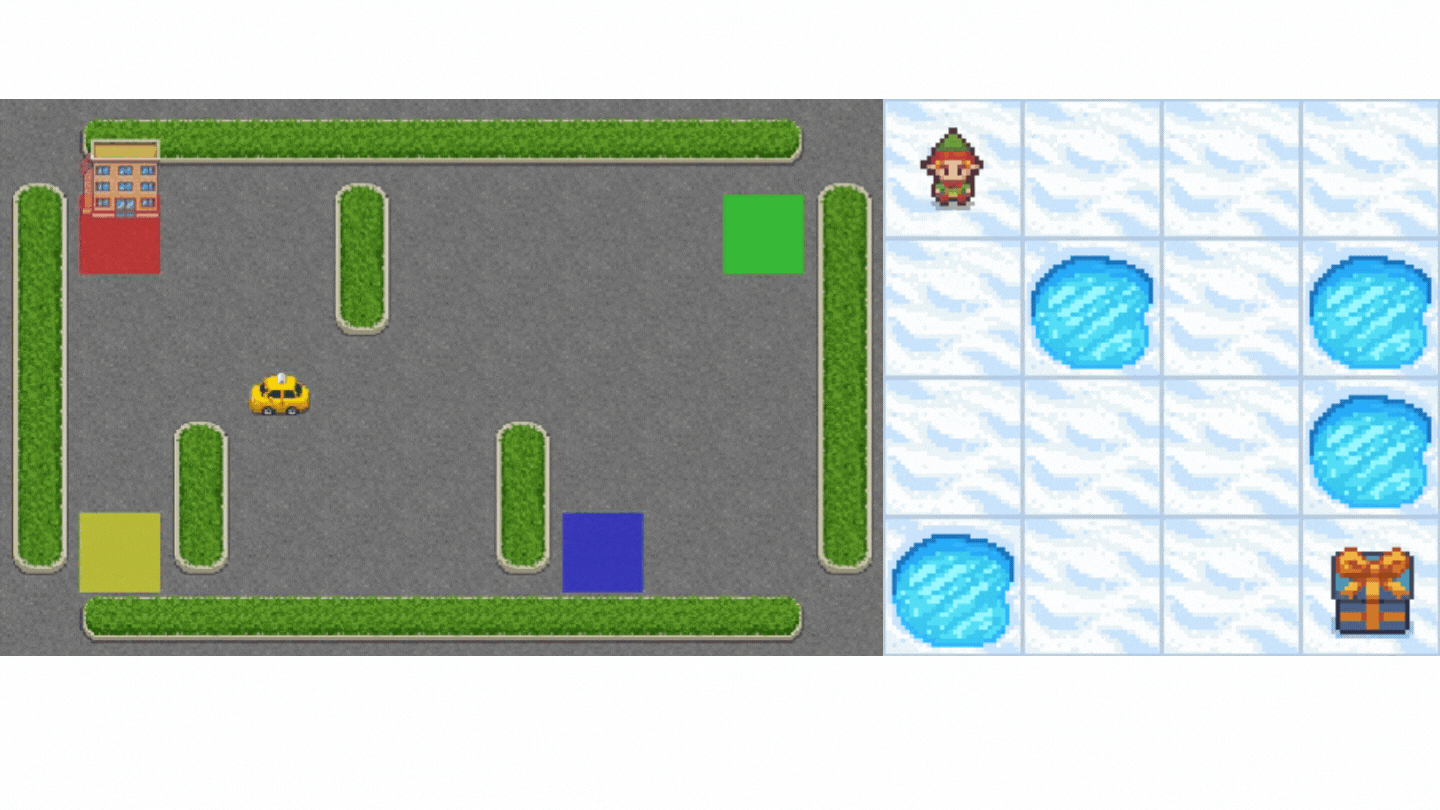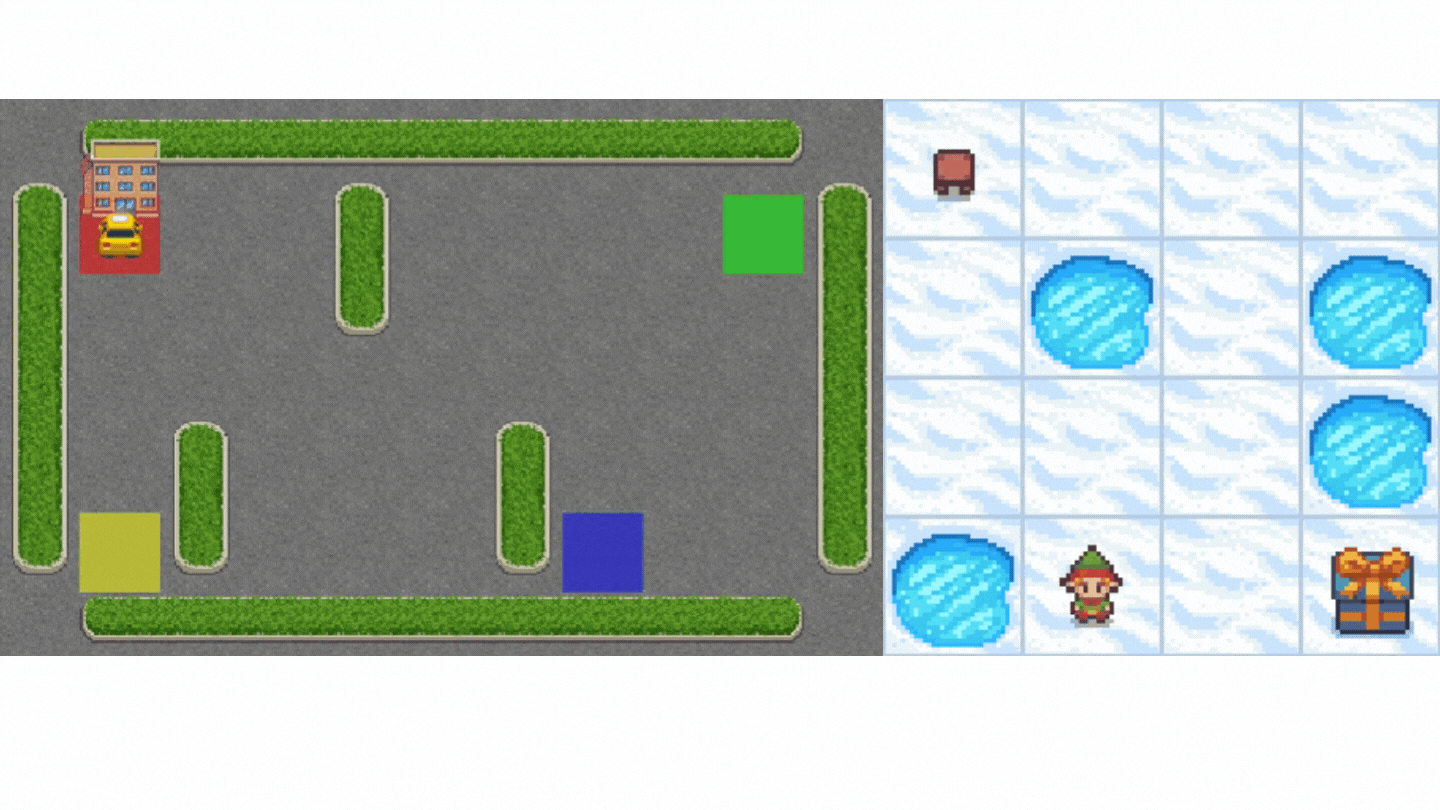 +
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
+
+
+
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+
+
+**To start the hands-on click on Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
+
+ +
+In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations.
+
+
+⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
+
+
+
+
+### 🎮 Environments:
+
+- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+
+### 📚 RL-Library:
+
+- Python and NumPy
+- [Gym](https://www.gymlibrary.dev/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to use **Gym**, the environment library.
+- Be able to code from scratch a Q-Learning agent.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
+
+## A small recap of Q-Learning
+
+- The *Q-Learning* **is the RL algorithm that**
+
+ - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+
+ - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+
+
+
+In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations.
+
+
+⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
+
+
+
+
+### 🎮 Environments:
+
+- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+
+### 📚 RL-Library:
+
+- Python and NumPy
+- [Gym](https://www.gymlibrary.dev/)
+
+We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
+
+## Objectives of this notebook 🏆
+
+At the end of the notebook, you will:
+
+- Be able to use **Gym**, the environment library.
+- Be able to code from scratch a Q-Learning agent.
+- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
+
+
+## Prerequisites 🏗️
+Before diving into the notebook, you need to:
+
+🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
+
+## A small recap of Q-Learning
+
+- The *Q-Learning* **is the RL algorithm that**
+
+ - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+
+ - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+
+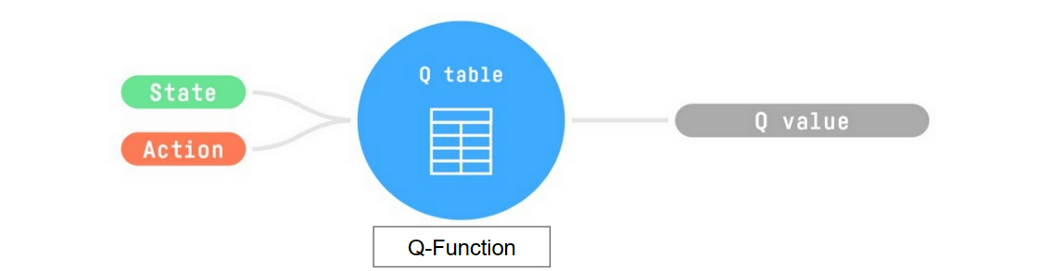 +
+- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+
+- And if we **have an optimal Q-function**, we
+have an optimal policy,since we **know for each state, what is the best action to take.**
+
+
+
+- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+
+- And if we **have an optimal Q-function**, we
+have an optimal policy,since we **know for each state, what is the best action to take.**
+
+ +
+
+But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+
+
+
+
+But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+
+ +
+This is the Q-Learning pseudocode:
+
+
+
+This is the Q-Learning pseudocode:
+
+ +
+
+# Let's code our first Reinforcement Learning algorithm 🚀
+
+## Install dependencies and create a virtual display 🔽
+
+In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).
+
+Hence the following cell will install the libraries and create and run a virtual screen 🖥
+
+We’ll install multiple ones:
+
+- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.
+- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
+- `numpy`: Used for handling our Q-table.
+
+The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
+
+You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```
+
+```bash
+sudo apt-get update
+apt install python-opengl ffmpeg xvfb
+pip3 install pyvirtualdisplay
+```
+
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Import the packages 📦
+
+In addition to the installed libraries, we also use:
+
+- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).
+- `imageio`: To generate a replay video.
+
+```python
+import numpy as np
+import gym
+import random
+import imageio
+import os
+
+import pickle5 as pickle
+from tqdm.notebook import tqdm
+```
+
+We're now ready to code our Q-Learning algorithm 🔥
+
+# Part 1: Frozen Lake ⛄ (non slippery version)
+
+## Create and understand [FrozenLake environment ⛄](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+---
+
+💡 A good habit when you start to use an environment is to check its documentation
+
+👉 https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
+
+---
+
+We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.
+
+We can have two sizes of environment:
+
+- `map_name="4x4"`: a 4x4 grid version
+- `map_name="8x8"`: a 8x8 grid version
+
+
+The environment has two modes:
+
+- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
+- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
+
+For now let's keep it simple with the 4x4 map and non-slippery
+
+```python
+# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version
+env = gym.make() # TODO use the correct parameters
+```
+
+### Solution
+
+```python
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
+```
+
+You can create your own custom grid like this:
+
+```python
+desc=["SFFF", "FHFH", "FFFH", "HFFG"]
+gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
+```
+
+but we'll use the default environment for now.
+
+### Let's see what the Environment looks like:
+
+
+```python
+# We create our environment with gym.make("
+
+
+# Let's code our first Reinforcement Learning algorithm 🚀
+
+## Install dependencies and create a virtual display 🔽
+
+In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).
+
+Hence the following cell will install the libraries and create and run a virtual screen 🖥
+
+We’ll install multiple ones:
+
+- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.
+- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
+- `numpy`: Used for handling our Q-table.
+
+The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
+
+You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```
+
+```bash
+sudo apt-get update
+apt install python-opengl ffmpeg xvfb
+pip3 install pyvirtualdisplay
+```
+
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## Import the packages 📦
+
+In addition to the installed libraries, we also use:
+
+- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).
+- `imageio`: To generate a replay video.
+
+```python
+import numpy as np
+import gym
+import random
+import imageio
+import os
+
+import pickle5 as pickle
+from tqdm.notebook import tqdm
+```
+
+We're now ready to code our Q-Learning algorithm 🔥
+
+# Part 1: Frozen Lake ⛄ (non slippery version)
+
+## Create and understand [FrozenLake environment ⛄](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+---
+
+💡 A good habit when you start to use an environment is to check its documentation
+
+👉 https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
+
+---
+
+We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.
+
+We can have two sizes of environment:
+
+- `map_name="4x4"`: a 4x4 grid version
+- `map_name="8x8"`: a 8x8 grid version
+
+
+The environment has two modes:
+
+- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
+- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
+
+For now let's keep it simple with the 4x4 map and non-slippery
+
+```python
+# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version
+env = gym.make() # TODO use the correct parameters
+```
+
+### Solution
+
+```python
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
+```
+
+You can create your own custom grid like this:
+
+```python
+desc=["SFFF", "FHFH", "FFFH", "HFFG"]
+gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
+```
+
+but we'll use the default environment for now.
+
+### Let's see what the Environment looks like:
+
+
+```python
+# We create our environment with gym.make(" +
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("Action Space Shape", env.action_space.n)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
+- 0: GO LEFT
+- 1: GO DOWN
+- 2: GO RIGHT
+- 3: GO UP
+
+Reward function 💰:
+- Reach goal: +1
+- Reach hole: 0
+- Reach frozen: 0
+
+## Create and Initialize the Q-table 🗄️
+(👀 Step 1 of the pseudocode)
+
+
+
+
+It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`
+
+
+```python
+state_space =
+print("There are ", state_space, " possible states")
+
+action_space =
+print("There are ", action_space, " possible actions")
+```
+
+```python
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+def initialize_q_table(state_space, action_space):
+ Qtable =
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+### Solution
+
+```python
+state_space = env.observation_space.n
+print("There are ", state_space, " possible states")
+
+action_space = env.action_space.n
+print("There are ", action_space, " possible actions")
+```
+
+```python
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+def initialize_q_table(state_space, action_space):
+ Qtable = np.zeros((state_space, action_space))
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+## Define the greedy policy 🤖
+Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
+
+- Epsilon-greedy policy (acting policy)
+- Greedy-policy (updating policy)
+
+Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.
+
+
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("Action Space Shape", env.action_space.n)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
+- 0: GO LEFT
+- 1: GO DOWN
+- 2: GO RIGHT
+- 3: GO UP
+
+Reward function 💰:
+- Reach goal: +1
+- Reach hole: 0
+- Reach frozen: 0
+
+## Create and Initialize the Q-table 🗄️
+(👀 Step 1 of the pseudocode)
+
+
+
+
+It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`
+
+
+```python
+state_space =
+print("There are ", state_space, " possible states")
+
+action_space =
+print("There are ", action_space, " possible actions")
+```
+
+```python
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+def initialize_q_table(state_space, action_space):
+ Qtable =
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+### Solution
+
+```python
+state_space = env.observation_space.n
+print("There are ", state_space, " possible states")
+
+action_space = env.action_space.n
+print("There are ", action_space, " possible actions")
+```
+
+```python
+# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
+def initialize_q_table(state_space, action_space):
+ Qtable = np.zeros((state_space, action_space))
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+## Define the greedy policy 🤖
+Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
+
+- Epsilon-greedy policy (acting policy)
+- Greedy-policy (updating policy)
+
+Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.
+
+ +
+
+```python
+def greedy_policy(Qtable, state):
+ # Exploitation: take the action with the highest state, action value
+ action =
+
+ return action
+```
+
+#### Solution
+
+```python
+def greedy_policy(Qtable, state):
+ # Exploitation: take the action with the highest state, action value
+ action = np.argmax(Qtable[state][:])
+
+ return action
+```
+
+##Define the epsilon-greedy policy 🤖
+
+Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
+
+The idea with epsilon-greedy:
+
+- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
+
+- With *probability ɛ*: we do **exploration** (trying random action).
+
+And as the training goes, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
+
+
+
+
+```python
+def greedy_policy(Qtable, state):
+ # Exploitation: take the action with the highest state, action value
+ action =
+
+ return action
+```
+
+#### Solution
+
+```python
+def greedy_policy(Qtable, state):
+ # Exploitation: take the action with the highest state, action value
+ action = np.argmax(Qtable[state][:])
+
+ return action
+```
+
+##Define the epsilon-greedy policy 🤖
+
+Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
+
+The idea with epsilon-greedy:
+
+- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
+
+- With *probability ɛ*: we do **exploration** (trying random action).
+
+And as the training goes, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
+
+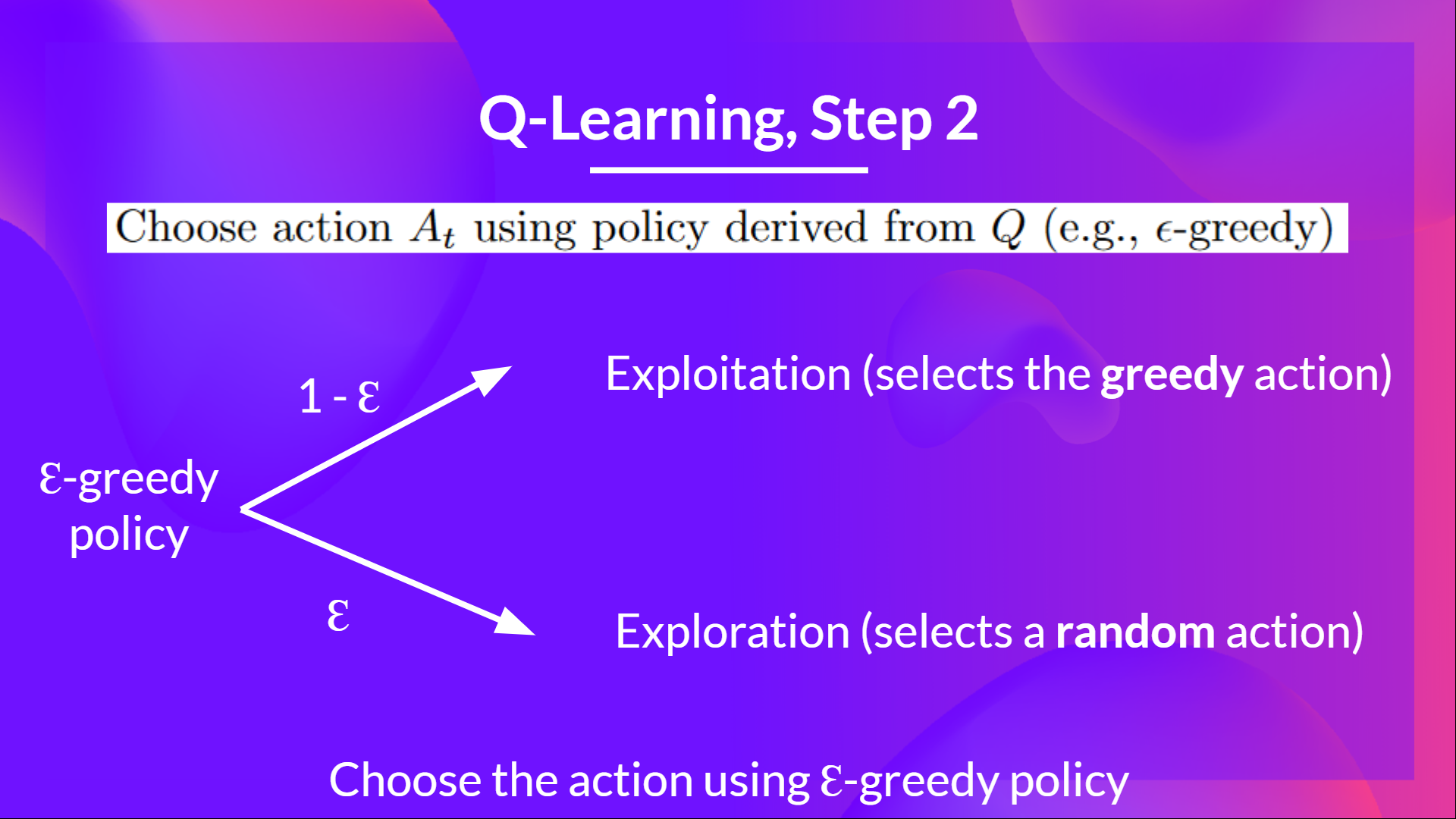 +
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # Randomly generate a number between 0 and 1
+ random_num =
+ # if random_num > greater than epsilon --> exploitation
+ if random_num > epsilon:
+ # Take the action with the highest value given a state
+ # np.argmax can be useful here
+ action =
+ # else --> exploration
+ else:
+ action = # Take a random action
+
+ return action
+```
+
+#### Solution
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # Randomly generate a number between 0 and 1
+ random_int = random.uniform(0, 1)
+ # if random_int > greater than epsilon --> exploitation
+ if random_int > epsilon:
+ # Take the action with the highest value given a state
+ # np.argmax can be useful here
+ action = greedy_policy(Qtable, state)
+ # else --> exploration
+ else:
+ action = env.action_space.sample()
+
+ return action
+```
+
+## Define the hyperparameters ⚙️
+The exploration related hyperparamters are some of the most important ones.
+
+- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
+- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
+
+```python
+# Training parameters
+n_training_episodes = 10000 # Total training episodes
+learning_rate = 0.7 # Learning rate
+
+# Evaluation parameters
+n_eval_episodes = 100 # Total number of test episodes
+
+# Environment parameters
+env_id = "FrozenLake-v1" # Name of the environment
+max_steps = 99 # Max steps per episode
+gamma = 0.95 # Discounting rate
+eval_seed = [] # The evaluation seed of the environment
+
+# Exploration parameters
+max_epsilon = 1.0 # Exploration probability at start
+min_epsilon = 0.05 # Minimum exploration probability
+decay_rate = 0.0005 # Exponential decay rate for exploration prob
+```
+
+## Create the training loop method
+
+
+
+The training loop goes like this:
+
+```
+For episode in the total of training episodes:
+
+Reduce epsilon (since we need less and less exploration)
+Reset the environment
+
+ For step in max timesteps:
+ Choose the action At using epsilon greedy policy
+ Take the action (a) and observe the outcome state(s') and reward (r)
+ Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ If done, finish the episode
+ Our next state is the new state
+```
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in range(n_training_episodes):
+ # Reduce epsilon (because we need less and less exploration)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
+ # Reset the environment
+ state = env.reset()
+ step = 0
+ done = False
+
+ # repeat
+ for step in range(max_steps):
+ # Choose the action At using epsilon greedy policy
+ action =
+
+ # Take action At and observe Rt+1 and St+1
+ # Take the action (a) and observe the outcome state(s') and reward (r)
+ new_state, reward, done, info =
+
+ # Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] =
+
+ # If done, finish the episode
+ if done:
+ break
+
+ # Our next state is the new state
+ state = new_state
+ return Qtable
+```
+
+#### Solution
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # Reduce epsilon (because we need less and less exploration)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
+ # Reset the environment
+ state = env.reset()
+ step = 0
+ done = False
+
+ # repeat
+ for step in range(max_steps):
+ # Choose the action At using epsilon greedy policy
+ action = epsilon_greedy_policy(Qtable, state, epsilon)
+
+ # Take action At and observe Rt+1 and St+1
+ # Take the action (a) and observe the outcome state(s') and reward (r)
+ new_state, reward, done, info = env.step(action)
+
+ # Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] = Qtable[state][action] + learning_rate * (
+ reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
+ )
+
+ # If done, finish the episode
+ if done:
+ break
+
+ # Our next state is the new state
+ state = new_state
+ return Qtable
+```
+
+## Train the Q-Learning agent 🏃
+
+```python
+Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
+```
+
+## Let's see what our Q-Learning table looks like now 👀
+
+```python
+Qtable_frozenlake
+```
+
+## The evaluation method 📝
+
+- We defined the evaluation method that we're going to use to test our Q-Learning agent.
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param Q: The Q-table
+ :param seed: The evaluation seed array (for taxi-v3)
+ """
+ episode_rewards = []
+ for episode in tqdm(range(n_eval_episodes)):
+ if seed:
+ state = env.reset(seed=seed[episode])
+ else:
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ # Take the action (index) that have the maximum expected future reward given that state
+ action = greedy_policy(Q, state)
+ new_state, reward, done, info = env.step(action)
+ total_rewards_ep += reward
+
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## Evaluate our Q-Learning agent 📈
+
+- Usually, you should have a mean reward of 1.0
+- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex.
+
+```python
+# Evaluate our Agent
+mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
+print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+## Publish our trained model to the Hub 🔥
+
+Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.
+
+Here's an example of a Model Card:
+
+
+
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # Randomly generate a number between 0 and 1
+ random_num =
+ # if random_num > greater than epsilon --> exploitation
+ if random_num > epsilon:
+ # Take the action with the highest value given a state
+ # np.argmax can be useful here
+ action =
+ # else --> exploration
+ else:
+ action = # Take a random action
+
+ return action
+```
+
+#### Solution
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # Randomly generate a number between 0 and 1
+ random_int = random.uniform(0, 1)
+ # if random_int > greater than epsilon --> exploitation
+ if random_int > epsilon:
+ # Take the action with the highest value given a state
+ # np.argmax can be useful here
+ action = greedy_policy(Qtable, state)
+ # else --> exploration
+ else:
+ action = env.action_space.sample()
+
+ return action
+```
+
+## Define the hyperparameters ⚙️
+The exploration related hyperparamters are some of the most important ones.
+
+- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
+- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
+
+```python
+# Training parameters
+n_training_episodes = 10000 # Total training episodes
+learning_rate = 0.7 # Learning rate
+
+# Evaluation parameters
+n_eval_episodes = 100 # Total number of test episodes
+
+# Environment parameters
+env_id = "FrozenLake-v1" # Name of the environment
+max_steps = 99 # Max steps per episode
+gamma = 0.95 # Discounting rate
+eval_seed = [] # The evaluation seed of the environment
+
+# Exploration parameters
+max_epsilon = 1.0 # Exploration probability at start
+min_epsilon = 0.05 # Minimum exploration probability
+decay_rate = 0.0005 # Exponential decay rate for exploration prob
+```
+
+## Create the training loop method
+
+
+
+The training loop goes like this:
+
+```
+For episode in the total of training episodes:
+
+Reduce epsilon (since we need less and less exploration)
+Reset the environment
+
+ For step in max timesteps:
+ Choose the action At using epsilon greedy policy
+ Take the action (a) and observe the outcome state(s') and reward (r)
+ Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ If done, finish the episode
+ Our next state is the new state
+```
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in range(n_training_episodes):
+ # Reduce epsilon (because we need less and less exploration)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
+ # Reset the environment
+ state = env.reset()
+ step = 0
+ done = False
+
+ # repeat
+ for step in range(max_steps):
+ # Choose the action At using epsilon greedy policy
+ action =
+
+ # Take action At and observe Rt+1 and St+1
+ # Take the action (a) and observe the outcome state(s') and reward (r)
+ new_state, reward, done, info =
+
+ # Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] =
+
+ # If done, finish the episode
+ if done:
+ break
+
+ # Our next state is the new state
+ state = new_state
+ return Qtable
+```
+
+#### Solution
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # Reduce epsilon (because we need less and less exploration)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
+ # Reset the environment
+ state = env.reset()
+ step = 0
+ done = False
+
+ # repeat
+ for step in range(max_steps):
+ # Choose the action At using epsilon greedy policy
+ action = epsilon_greedy_policy(Qtable, state, epsilon)
+
+ # Take action At and observe Rt+1 and St+1
+ # Take the action (a) and observe the outcome state(s') and reward (r)
+ new_state, reward, done, info = env.step(action)
+
+ # Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] = Qtable[state][action] + learning_rate * (
+ reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
+ )
+
+ # If done, finish the episode
+ if done:
+ break
+
+ # Our next state is the new state
+ state = new_state
+ return Qtable
+```
+
+## Train the Q-Learning agent 🏃
+
+```python
+Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
+```
+
+## Let's see what our Q-Learning table looks like now 👀
+
+```python
+Qtable_frozenlake
+```
+
+## The evaluation method 📝
+
+- We defined the evaluation method that we're going to use to test our Q-Learning agent.
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param Q: The Q-table
+ :param seed: The evaluation seed array (for taxi-v3)
+ """
+ episode_rewards = []
+ for episode in tqdm(range(n_eval_episodes)):
+ if seed:
+ state = env.reset(seed=seed[episode])
+ else:
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ # Take the action (index) that have the maximum expected future reward given that state
+ action = greedy_policy(Q, state)
+ new_state, reward, done, info = env.step(action)
+ total_rewards_ep += reward
+
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## Evaluate our Q-Learning agent 📈
+
+- Usually, you should have a mean reward of 1.0
+- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex.
+
+```python
+# Evaluate our Agent
+mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
+print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+## Publish our trained model to the Hub 🔥
+
+Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.
+
+Here's an example of a Model Card:
+
+ +
+
+Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
+
+#### Do not modify this code
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+```
+
+```python
+def record_video(env, Qtable, out_directory, fps=1):
+ """
+ Generate a replay video of the agent
+ :param env
+ :param Qtable: Qtable of our agent
+ :param out_directory
+ :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
+ """
+ images = []
+ done = False
+ state = env.reset(seed=random.randint(0, 500))
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ # Take the action (index) that have the maximum expected future reward given that state
+ action = np.argmax(Qtable[state][:])
+ state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the Hub
+
+ :param repo_id: repo_id: id of the model repository from the Hugging Face Hub
+ :param env
+ :param video_fps: how many frame per seconds to record our video replay
+ (with taxi-v3 and frozenlake-v1 we use 1)
+ :param local_repo_path: where the local repository is
+ """
+ _, repo_name = repo_id.split("/")
+
+ eval_env = env
+ api = HfApi()
+
+ # Step 1: Create the repo
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ # Step 2: Download files
+ repo_local_path = Path(snapshot_download(repo_id=repo_id))
+
+ # Step 3: Save the model
+ if env.spec.kwargs.get("map_name"):
+ model["map_name"] = env.spec.kwargs.get("map_name")
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ model["slippery"] = False
+
+ # Pickle the model
+ with open((repo_local_path) / "q-learning.pkl", "wb") as f:
+ pickle.dump(model, f)
+
+ # Step 4: Evaluate the model and build JSON with evaluation metrics
+ mean_reward, std_reward = evaluate_agent(
+ eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
+ )
+
+ evaluate_data = {
+ "env_id": model["env_id"],
+ "mean_reward": mean_reward,
+ "n_eval_episodes": model["n_eval_episodes"],
+ "eval_datetime": datetime.datetime.now().isoformat(),
+ }
+
+ # Write a JSON file called "results.json" that will contain the
+ # evaluation results
+ with open(repo_local_path / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 5: Create the model card
+ env_name = model["env_id"]
+ if env.spec.kwargs.get("map_name"):
+ env_name += "-" + env.spec.kwargs.get("map_name")
+
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ env_name += "-" + "no_slippery"
+
+ metadata = {}
+ metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ model_card = f"""
+ # **Q-Learning** Agent playing1 **{env_id}**
+ This is a trained model of a **Q-Learning** agent playing **{env_id}** .
+
+ ## Usage
+
+ ```python
+
+ model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
+
+ # Don't forget to check if you need to add additional attributes (is_slippery=False etc)
+ env = gym.make(model["env_id"])
+ ```
+ """
+
+ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+
+ readme_path = repo_local_path / "README.md"
+ readme = ""
+ print(readme_path.exists())
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+ # Step 6: Record a video
+ video_path = repo_local_path / "replay.mp4"
+ record_video(env, model["qtable"], video_path, video_fps)
+
+ # Step 7. Push everything to the Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=repo_local_path,
+ path_in_repo=".",
+ )
+
+ print("Your model is pushed to the Hub. You can view your model here: ", repo_url)
+```
+
+### .
+
+By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.
+
+This way:
+- You can **showcase our work** 🔥
+- You can **visualize your agent playing** 👀
+- You can **share with the community an agent that others can use** 💾
+- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+
+
+
+Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
+
+#### Do not modify this code
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+```
+
+```python
+def record_video(env, Qtable, out_directory, fps=1):
+ """
+ Generate a replay video of the agent
+ :param env
+ :param Qtable: Qtable of our agent
+ :param out_directory
+ :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
+ """
+ images = []
+ done = False
+ state = env.reset(seed=random.randint(0, 500))
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ # Take the action (index) that have the maximum expected future reward given that state
+ action = np.argmax(Qtable[state][:])
+ state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the Hub
+
+ :param repo_id: repo_id: id of the model repository from the Hugging Face Hub
+ :param env
+ :param video_fps: how many frame per seconds to record our video replay
+ (with taxi-v3 and frozenlake-v1 we use 1)
+ :param local_repo_path: where the local repository is
+ """
+ _, repo_name = repo_id.split("/")
+
+ eval_env = env
+ api = HfApi()
+
+ # Step 1: Create the repo
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ # Step 2: Download files
+ repo_local_path = Path(snapshot_download(repo_id=repo_id))
+
+ # Step 3: Save the model
+ if env.spec.kwargs.get("map_name"):
+ model["map_name"] = env.spec.kwargs.get("map_name")
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ model["slippery"] = False
+
+ # Pickle the model
+ with open((repo_local_path) / "q-learning.pkl", "wb") as f:
+ pickle.dump(model, f)
+
+ # Step 4: Evaluate the model and build JSON with evaluation metrics
+ mean_reward, std_reward = evaluate_agent(
+ eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
+ )
+
+ evaluate_data = {
+ "env_id": model["env_id"],
+ "mean_reward": mean_reward,
+ "n_eval_episodes": model["n_eval_episodes"],
+ "eval_datetime": datetime.datetime.now().isoformat(),
+ }
+
+ # Write a JSON file called "results.json" that will contain the
+ # evaluation results
+ with open(repo_local_path / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 5: Create the model card
+ env_name = model["env_id"]
+ if env.spec.kwargs.get("map_name"):
+ env_name += "-" + env.spec.kwargs.get("map_name")
+
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ env_name += "-" + "no_slippery"
+
+ metadata = {}
+ metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ model_card = f"""
+ # **Q-Learning** Agent playing1 **{env_id}**
+ This is a trained model of a **Q-Learning** agent playing **{env_id}** .
+
+ ## Usage
+
+ ```python
+
+ model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
+
+ # Don't forget to check if you need to add additional attributes (is_slippery=False etc)
+ env = gym.make(model["env_id"])
+ ```
+ """
+
+ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+
+ readme_path = repo_local_path / "README.md"
+ readme = ""
+ print(readme_path.exists())
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+ # Step 6: Record a video
+ video_path = repo_local_path / "replay.mp4"
+ record_video(env, model["qtable"], video_path, video_fps)
+
+ # Step 7. Push everything to the Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=repo_local_path,
+ path_in_repo=".",
+ )
+
+ print("Your model is pushed to the Hub. You can view your model here: ", repo_url)
+```
+
+### .
+
+By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.
+
+This way:
+- You can **showcase our work** 🔥
+- You can **visualize your agent playing** 👀
+- You can **share with the community an agent that others can use** 💾
+- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+To be able to share your model with the community there are three more steps to follow:
+
+1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
+
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
+- Create a new token (https://huggingface.co/settings/tokens) **with write role**
+
+
+ +
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)
+
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function
+
+- Let's create **the model dictionary that contains the hyperparameters and the Q_table**.
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_frozenlake,
+}
+```
+
+Let's fill the `push_to_hub` function:
+
+- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `
+(repo_id = {username}/{repo_name})`
+💡 A good `repo_id` is `{username}/q-{env_id}`
+- `model`: our model dictionary containing the hyperparameters and the Qtable.
+- `env`: the environment.
+- `commit_message`: message of the commit
+
+```python
+model
+```
+
+```python
+username = "" # FILL THIS
+repo_name = "q-FrozenLake-v1-4x4-noSlippery"
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+Congrats 🥳 you've just implemented from scratch, trained and uploaded your first Reinforcement Learning agent.
+FrozenLake-v1 no_slippery is very simple environment, let's try an harder one 🔥.
+
+# Part 2: Taxi-v3 🚖
+
+## Create and understand [Taxi-v3 🚕](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+---
+
+💡 A good habit when you start to use an environment is to check its documentation
+
+👉 https://www.gymlibrary.dev/environments/toy_text/taxi/
+
+---
+
+In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
+
+When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
+
+
+
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)
+
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function
+
+- Let's create **the model dictionary that contains the hyperparameters and the Q_table**.
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_frozenlake,
+}
+```
+
+Let's fill the `push_to_hub` function:
+
+- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `
+(repo_id = {username}/{repo_name})`
+💡 A good `repo_id` is `{username}/q-{env_id}`
+- `model`: our model dictionary containing the hyperparameters and the Qtable.
+- `env`: the environment.
+- `commit_message`: message of the commit
+
+```python
+model
+```
+
+```python
+username = "" # FILL THIS
+repo_name = "q-FrozenLake-v1-4x4-noSlippery"
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+Congrats 🥳 you've just implemented from scratch, trained and uploaded your first Reinforcement Learning agent.
+FrozenLake-v1 no_slippery is very simple environment, let's try an harder one 🔥.
+
+# Part 2: Taxi-v3 🚖
+
+## Create and understand [Taxi-v3 🚕](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+---
+
+💡 A good habit when you start to use an environment is to check its documentation
+
+👉 https://www.gymlibrary.dev/environments/toy_text/taxi/
+
+---
+
+In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
+
+When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
+
+
+ +
+
+```python
+env = gym.make("Taxi-v3")
+```
+
+There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
+
+
+```python
+state_space = env.observation_space.n
+print("There are ", state_space, " possible states")
+```
+
+```python
+action_space = env.action_space.n
+print("There are ", action_space, " possible actions")
+```
+
+The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:
+
+- 0: move south
+- 1: move north
+- 2: move east
+- 3: move west
+- 4: pickup passenger
+- 5: drop off passenger
+
+Reward function 💰:
+
+- -1 per step unless other reward is triggered.
+- +20 delivering passenger.
+- -10 executing “pickup” and “drop-off” actions illegally.
+
+```python
+# Create our Q table with state_size rows and action_size columns (500x6)
+Qtable_taxi = initialize_q_table(state_space, action_space)
+print(Qtable_taxi)
+print("Q-table shape: ", Qtable_taxi.shape)
+```
+
+## Define the hyperparameters ⚙️
+⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
+
+```python
+# Training parameters
+n_training_episodes = 25000 # Total training episodes
+learning_rate = 0.7 # Learning rate
+
+# Evaluation parameters
+n_eval_episodes = 100 # Total number of test episodes
+
+# DO NOT MODIFY EVAL_SEED
+eval_seed = [
+ 16,
+ 54,
+ 165,
+ 177,
+ 191,
+ 191,
+ 120,
+ 80,
+ 149,
+ 178,
+ 48,
+ 38,
+ 6,
+ 125,
+ 174,
+ 73,
+ 50,
+ 172,
+ 100,
+ 148,
+ 146,
+ 6,
+ 25,
+ 40,
+ 68,
+ 148,
+ 49,
+ 167,
+ 9,
+ 97,
+ 164,
+ 176,
+ 61,
+ 7,
+ 54,
+ 55,
+ 161,
+ 131,
+ 184,
+ 51,
+ 170,
+ 12,
+ 120,
+ 113,
+ 95,
+ 126,
+ 51,
+ 98,
+ 36,
+ 135,
+ 54,
+ 82,
+ 45,
+ 95,
+ 89,
+ 59,
+ 95,
+ 124,
+ 9,
+ 113,
+ 58,
+ 85,
+ 51,
+ 134,
+ 121,
+ 169,
+ 105,
+ 21,
+ 30,
+ 11,
+ 50,
+ 65,
+ 12,
+ 43,
+ 82,
+ 145,
+ 152,
+ 97,
+ 106,
+ 55,
+ 31,
+ 85,
+ 38,
+ 112,
+ 102,
+ 168,
+ 123,
+ 97,
+ 21,
+ 83,
+ 158,
+ 26,
+ 80,
+ 63,
+ 5,
+ 81,
+ 32,
+ 11,
+ 28,
+ 148,
+] # Evaluation seed, this ensures that all classmates agents are trained on the same taxi starting position
+# Each seed has a specific starting state
+
+# Environment parameters
+env_id = "Taxi-v3" # Name of the environment
+max_steps = 99 # Max steps per episode
+gamma = 0.95 # Discounting rate
+
+# Exploration parameters
+max_epsilon = 1.0 # Exploration probability at start
+min_epsilon = 0.05 # Minimum exploration probability
+decay_rate = 0.005 # Exponential decay rate for exploration prob
+```
+
+## Train our Q-Learning agent 🏃
+
+```python
+Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
+Qtable_taxi
+```
+
+## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
+- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
+
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_taxi,
+}
+```
+
+```python
+username = "" # FILL THIS
+repo_name = ""
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠
+
+
+
+
+```python
+env = gym.make("Taxi-v3")
+```
+
+There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
+
+
+```python
+state_space = env.observation_space.n
+print("There are ", state_space, " possible states")
+```
+
+```python
+action_space = env.action_space.n
+print("There are ", action_space, " possible actions")
+```
+
+The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:
+
+- 0: move south
+- 1: move north
+- 2: move east
+- 3: move west
+- 4: pickup passenger
+- 5: drop off passenger
+
+Reward function 💰:
+
+- -1 per step unless other reward is triggered.
+- +20 delivering passenger.
+- -10 executing “pickup” and “drop-off” actions illegally.
+
+```python
+# Create our Q table with state_size rows and action_size columns (500x6)
+Qtable_taxi = initialize_q_table(state_space, action_space)
+print(Qtable_taxi)
+print("Q-table shape: ", Qtable_taxi.shape)
+```
+
+## Define the hyperparameters ⚙️
+⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
+
+```python
+# Training parameters
+n_training_episodes = 25000 # Total training episodes
+learning_rate = 0.7 # Learning rate
+
+# Evaluation parameters
+n_eval_episodes = 100 # Total number of test episodes
+
+# DO NOT MODIFY EVAL_SEED
+eval_seed = [
+ 16,
+ 54,
+ 165,
+ 177,
+ 191,
+ 191,
+ 120,
+ 80,
+ 149,
+ 178,
+ 48,
+ 38,
+ 6,
+ 125,
+ 174,
+ 73,
+ 50,
+ 172,
+ 100,
+ 148,
+ 146,
+ 6,
+ 25,
+ 40,
+ 68,
+ 148,
+ 49,
+ 167,
+ 9,
+ 97,
+ 164,
+ 176,
+ 61,
+ 7,
+ 54,
+ 55,
+ 161,
+ 131,
+ 184,
+ 51,
+ 170,
+ 12,
+ 120,
+ 113,
+ 95,
+ 126,
+ 51,
+ 98,
+ 36,
+ 135,
+ 54,
+ 82,
+ 45,
+ 95,
+ 89,
+ 59,
+ 95,
+ 124,
+ 9,
+ 113,
+ 58,
+ 85,
+ 51,
+ 134,
+ 121,
+ 169,
+ 105,
+ 21,
+ 30,
+ 11,
+ 50,
+ 65,
+ 12,
+ 43,
+ 82,
+ 145,
+ 152,
+ 97,
+ 106,
+ 55,
+ 31,
+ 85,
+ 38,
+ 112,
+ 102,
+ 168,
+ 123,
+ 97,
+ 21,
+ 83,
+ 158,
+ 26,
+ 80,
+ 63,
+ 5,
+ 81,
+ 32,
+ 11,
+ 28,
+ 148,
+] # Evaluation seed, this ensures that all classmates agents are trained on the same taxi starting position
+# Each seed has a specific starting state
+
+# Environment parameters
+env_id = "Taxi-v3" # Name of the environment
+max_steps = 99 # Max steps per episode
+gamma = 0.95 # Discounting rate
+
+# Exploration parameters
+max_epsilon = 1.0 # Exploration probability at start
+min_epsilon = 0.05 # Minimum exploration probability
+decay_rate = 0.005 # Exponential decay rate for exploration prob
+```
+
+## Train our Q-Learning agent 🏃
+
+```python
+Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
+Qtable_taxi
+```
+
+## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
+- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
+
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_taxi,
+}
+```
+
+```python
+username = "" # FILL THIS
+repo_name = ""
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠
+
+ +
+# Part 3: Load from Hub 🔽
+
+What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.
+
+Loading a saved model from the Hub is really easy:
+
+1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.
+2. You select one and copy its repo_id
+
+
+
+# Part 3: Load from Hub 🔽
+
+What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.
+
+Loading a saved model from the Hub is really easy:
+
+1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.
+2. You select one and copy its repo_id
+
+ +
+3. Then we just need to use `load_from_hub` with:
+- The repo_id
+- The filename: the saved model inside the repo.
+
+#### Do not modify this code
+
+```python
+from urllib.error import HTTPError
+
+from huggingface_hub import hf_hub_download
+
+
+def load_from_hub(repo_id: str, filename: str) -> str:
+ """
+ Download a model from Hugging Face Hub.
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param filename: name of the model zip file from the repository
+ """
+ # Get the model from the Hub, download and cache the model on your local disk
+ pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
+
+ with open(pickle_model, "rb") as f:
+ downloaded_model_file = pickle.load(f)
+
+ return downloaded_model_file
+```
+
+### .
+
+```python
+model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # Try to use another model
+
+print(model)
+env = gym.make(model["env_id"])
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+```python
+model = load_from_hub(
+ repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
+) # Try to use another model
+
+env = gym.make(model["env_id"], is_slippery=False)
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+## Some additional challenges 🏆
+The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
+
+In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
+
+Here are some ideas to achieve so:
+
+* Train more steps
+* Try different hyperparameters by looking at what your classmates have done.
+* **Push your new trained model** on the Hub 🔥
+
+Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not using FrozenLake-v1 slippery version? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+
+_____________________________________________________________________
+Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
+
+Understanding Q-Learning is an **important step to understanding value-based methods.**
+
+In the next Unit with Deep Q-Learning, we'll see that creating and updating a Q-table was a good strategy — **however, this is not scalable.**
+
+For instance, imagine you create an agent that learns to play Doom.
+
+
+
+3. Then we just need to use `load_from_hub` with:
+- The repo_id
+- The filename: the saved model inside the repo.
+
+#### Do not modify this code
+
+```python
+from urllib.error import HTTPError
+
+from huggingface_hub import hf_hub_download
+
+
+def load_from_hub(repo_id: str, filename: str) -> str:
+ """
+ Download a model from Hugging Face Hub.
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param filename: name of the model zip file from the repository
+ """
+ # Get the model from the Hub, download and cache the model on your local disk
+ pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
+
+ with open(pickle_model, "rb") as f:
+ downloaded_model_file = pickle.load(f)
+
+ return downloaded_model_file
+```
+
+### .
+
+```python
+model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # Try to use another model
+
+print(model)
+env = gym.make(model["env_id"])
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+```python
+model = load_from_hub(
+ repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
+) # Try to use another model
+
+env = gym.make(model["env_id"], is_slippery=False)
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+## Some additional challenges 🏆
+The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
+
+In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
+
+Here are some ideas to achieve so:
+
+* Train more steps
+* Try different hyperparameters by looking at what your classmates have done.
+* **Push your new trained model** on the Hub 🔥
+
+Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not using FrozenLake-v1 slippery version? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+
+_____________________________________________________________________
+Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
+
+Understanding Q-Learning is an **important step to understanding value-based methods.**
+
+In the next Unit with Deep Q-Learning, we'll see that creating and updating a Q-table was a good strategy — **however, this is not scalable.**
+
+For instance, imagine you create an agent that learns to play Doom.
+
+ +
+Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
+
+That's why we'll study, in the next unit, Deep Q-Learning, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
+
+
+
+
+See you on Unit 3! 🔥
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
new file mode 100644
index 0000000..e465f45
--- /dev/null
+++ b/units/en/unit2/introduction.mdx
@@ -0,0 +1,26 @@
+# Introduction to Q-Learning [[introduction-q-learning]]
+
+
+
+
+In the first unit of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
+
+In this unit, we're going to **dive deeper into one of the Reinforcement Learning methods: value-based methods** and study our first RL algorithm: **Q-Learning.**
+
+We'll also **implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
+
+1. Frozen-Lake-v1 (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. An autonomous taxi: where our agent will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+
+
+Concretely, we will:
+
+- Learn about **value-based methods**.
+- Learn about the **differences between Monte Carlo and Temporal Difference Learning**.
+- Study and implement **our first RL algorithm**: Q-Learning.
+
+This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that played Atari games and beat the human level on some of them (breakout, space invaders, etc).
+
+So let's get started! 🚀
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
new file mode 100644
index 0000000..1d3517f
--- /dev/null
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -0,0 +1,128 @@
+# Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
+
+The last thing we need to discuss before diving into Q-Learning is the two learning strategies.
+
+Remember that an RL agent **learns by interacting with its environment.** The idea is that **given the experience and the received reward, the agent will update its value function or policy.**
+
+Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
+
+On one hand, Monte Carlo uses **an entire episode of experience before learning.** On the other hand, Temporal Difference uses **only a step ( \\(S_t, A_t, R_{t+1}, S_{t+1}\\) ) to learn.**
+
+We'll explain both of them **using a value-based method example.**
+
+## Monte Carlo: learning at the end of the episode [[monte-carlo]]
+
+Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
+
+So it requires a **complete episode of interaction before updating our value function.**
+
+
+
+Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
+
+That's why we'll study, in the next unit, Deep Q-Learning, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
+
+
+
+
+See you on Unit 3! 🔥
+
+## Keep learning, stay awesome 🤗
diff --git a/units/en/unit2/introduction.mdx b/units/en/unit2/introduction.mdx
new file mode 100644
index 0000000..e465f45
--- /dev/null
+++ b/units/en/unit2/introduction.mdx
@@ -0,0 +1,26 @@
+# Introduction to Q-Learning [[introduction-q-learning]]
+
+
+
+
+In the first unit of this class, we learned about Reinforcement Learning (RL), the RL process, and the different methods to solve an RL problem. We also **trained our first agents and uploaded them to the Hugging Face Hub.**
+
+In this unit, we're going to **dive deeper into one of the Reinforcement Learning methods: value-based methods** and study our first RL algorithm: **Q-Learning.**
+
+We'll also **implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
+
+1. Frozen-Lake-v1 (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. An autonomous taxi: where our agent will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+
+
+Concretely, we will:
+
+- Learn about **value-based methods**.
+- Learn about the **differences between Monte Carlo and Temporal Difference Learning**.
+- Study and implement **our first RL algorithm**: Q-Learning.
+
+This unit is **fundamental if you want to be able to work on Deep Q-Learning**: the first Deep RL algorithm that played Atari games and beat the human level on some of them (breakout, space invaders, etc).
+
+So let's get started! 🚀
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
new file mode 100644
index 0000000..1d3517f
--- /dev/null
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -0,0 +1,128 @@
+# Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
+
+The last thing we need to discuss before diving into Q-Learning is the two learning strategies.
+
+Remember that an RL agent **learns by interacting with its environment.** The idea is that **given the experience and the received reward, the agent will update its value function or policy.**
+
+Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
+
+On one hand, Monte Carlo uses **an entire episode of experience before learning.** On the other hand, Temporal Difference uses **only a step ( \\(S_t, A_t, R_{t+1}, S_{t+1}\\) ) to learn.**
+
+We'll explain both of them **using a value-based method example.**
+
+## Monte Carlo: learning at the end of the episode [[monte-carlo]]
+
+Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
+
+So it requires a **complete episode of interaction before updating our value function.**
+
+  +
+
+If we take an example:
+
+
+
+
+If we take an example:
+
+  +
+
+- We always start the episode **at the same starting point.**
+- **The agent takes actions using the policy**. For instance, using an Epsilon Greedy Strategy, a policy that alternates between exploration (random actions) and exploitation.
+- We get **the reward and the next state.**
+- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
+
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
+For instance [[State tile 3 bottom, Go Left, +1, State tile 2 bottom], [State tile 2 bottom, Go Left, +0, State tile 1 bottom]...]
+
+- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
+- It will then **update \\(V(s_t)\\) based on the formula**
+
+
+
+
+- We always start the episode **at the same starting point.**
+- **The agent takes actions using the policy**. For instance, using an Epsilon Greedy Strategy, a policy that alternates between exploration (random actions) and exploitation.
+- We get **the reward and the next state.**
+- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
+
+- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
+For instance [[State tile 3 bottom, Go Left, +1, State tile 2 bottom], [State tile 2 bottom, Go Left, +0, State tile 1 bottom]...]
+
+- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
+- It will then **update \\(V(s_t)\\) based on the formula**
+
+  +
+- Then **start a new game with this new knowledge**
+
+By running more and more episodes, **the agent will learn to play better and better.**
+
+
+
+- Then **start a new game with this new knowledge**
+
+By running more and more episodes, **the agent will learn to play better and better.**
+
+  +
+For instance, if we train a state-value function using Monte Carlo:
+
+- We just started to train our value function, **so it returns 0 value for each state**
+- Our learning rate (lr) is 0.1 and our discount rate is 1 (= no discount)
+- Our mouse **explores the environment and takes random actions**
+
+
+
+For instance, if we train a state-value function using Monte Carlo:
+
+- We just started to train our value function, **so it returns 0 value for each state**
+- Our learning rate (lr) is 0.1 and our discount rate is 1 (= no discount)
+- Our mouse **explores the environment and takes random actions**
+
+ 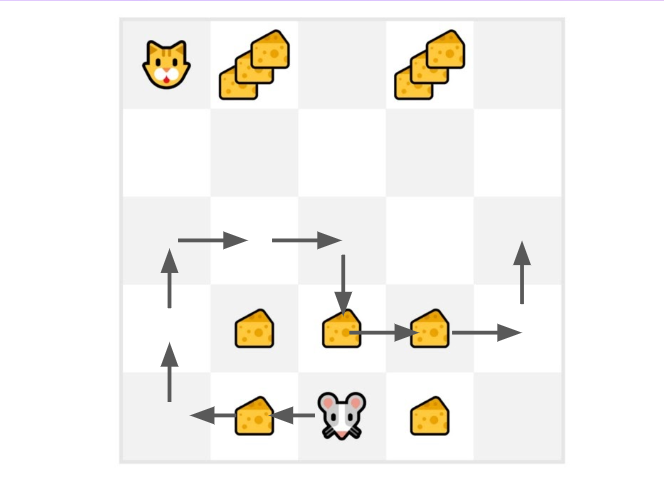 +
+
+- The mouse made more than 10 steps, so the episode ends .
+
+
+
+
+- The mouse made more than 10 steps, so the episode ends .
+
+ 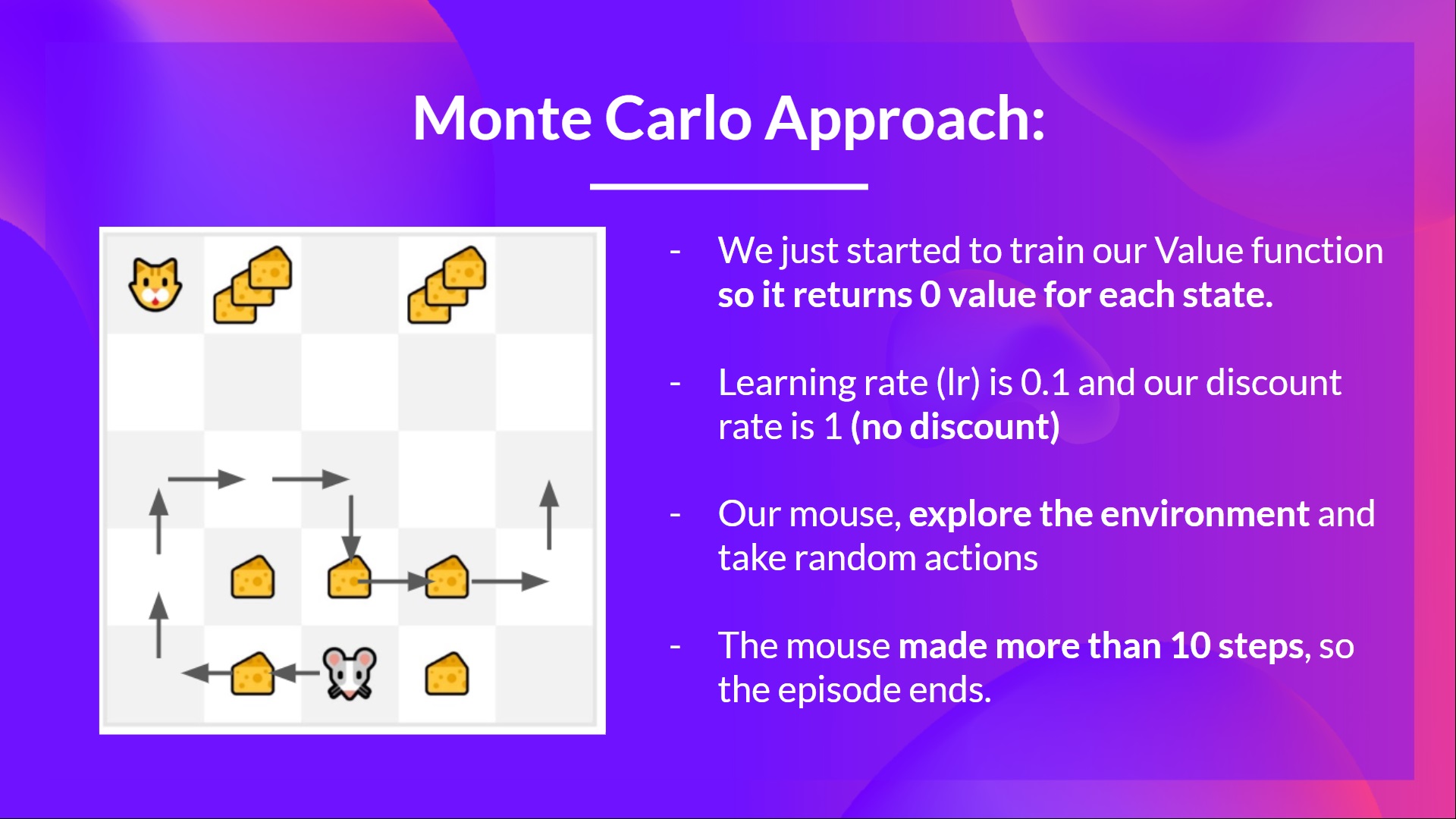 +
+
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
+- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
+- \\(G_t= 3\\)
+- We can now update \\(V(S_0)\\):
+
+
+
+
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
+- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
+- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
+- \\(G_t= 3\\)
+- We can now update \\(V(S_0)\\):
+
+  +
+- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
+- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+- New \\(V(S_0) = 0.3\\)
+
+
+
+
+- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
+- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+- New \\(V(S_0) = 0.3\\)
+
+
+ 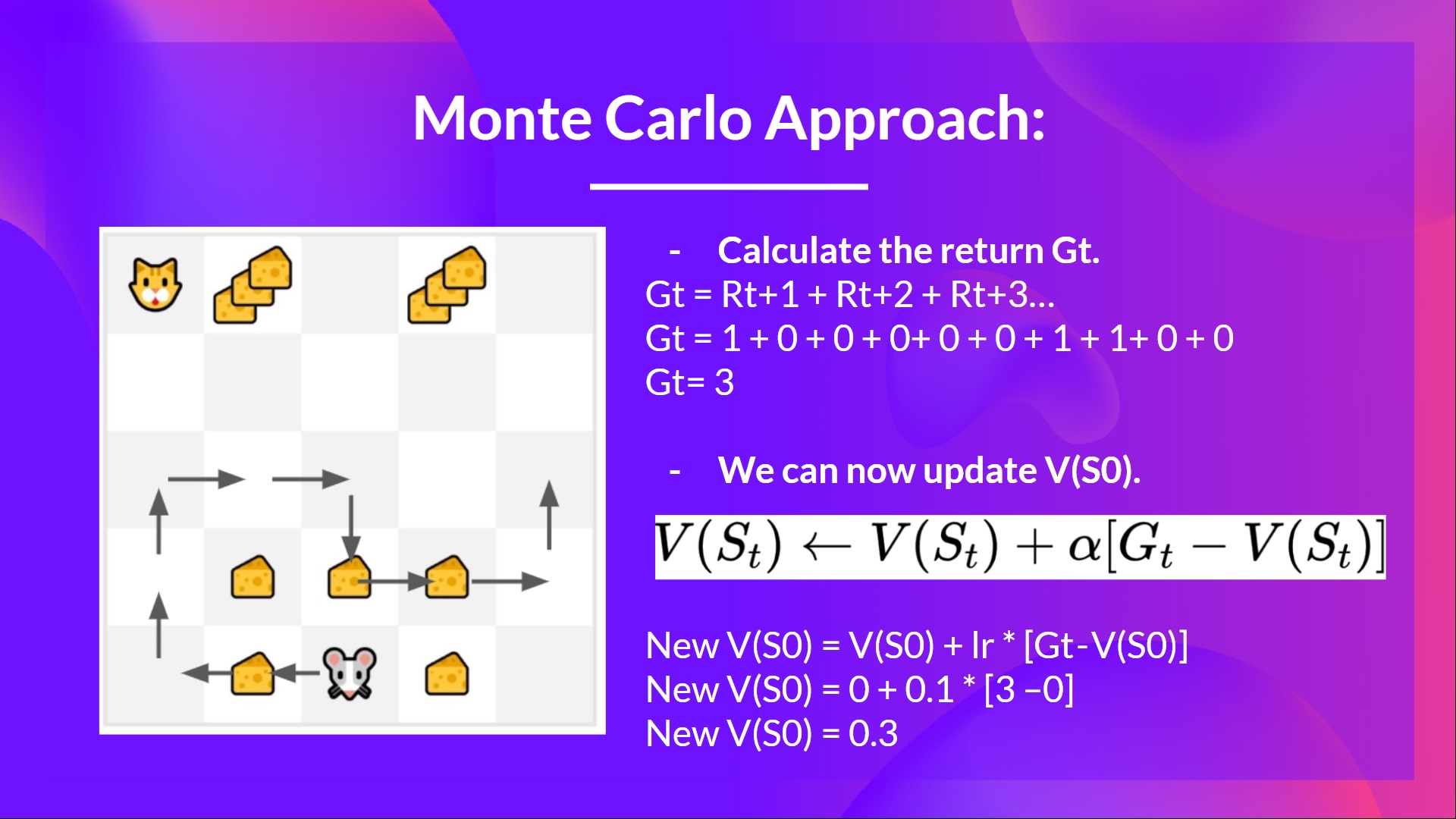 +
+
+## Temporal Difference Learning: learning at each step [[td-learning]]
+
+- **Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\( \gamma * V(S_{t+1})\\).
+
+The idea with **TD is to update the \\(V(S_t)\\) at each step.**
+
+But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+
+This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
+
+
+
+
+## Temporal Difference Learning: learning at each step [[td-learning]]
+
+- **Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)**
+- to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\( \gamma * V(S_{t+1})\\).
+
+The idea with **TD is to update the \\(V(S_t)\\) at each step.**
+
+But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
+
+This is called bootstrapping. It's called this **because TD bases its update part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
+
+  +
+
+This method is called TD(0) or **one-step TD (update the value function after any individual step).**
+
+
+
+
+This method is called TD(0) or **one-step TD (update the value function after any individual step).**
+
+  +
+If we take the same example,
+
+
+
+If we take the same example,
+
+  +
+- We just started to train our value function, so it returns 0 value for each state.
+- Our learning rate (lr) is 0.1, and our discount rate is 1 (no discount).
+- Our mouse explore the environment and take a random action: **going to the left**
+- It gets a reward \\(R_{t+1} = 1\\) since **it eats a piece of cheese**
+
+
+
+- We just started to train our value function, so it returns 0 value for each state.
+- Our learning rate (lr) is 0.1, and our discount rate is 1 (no discount).
+- Our mouse explore the environment and take a random action: **going to the left**
+- It gets a reward \\(R_{t+1} = 1\\) since **it eats a piece of cheese**
+
+ 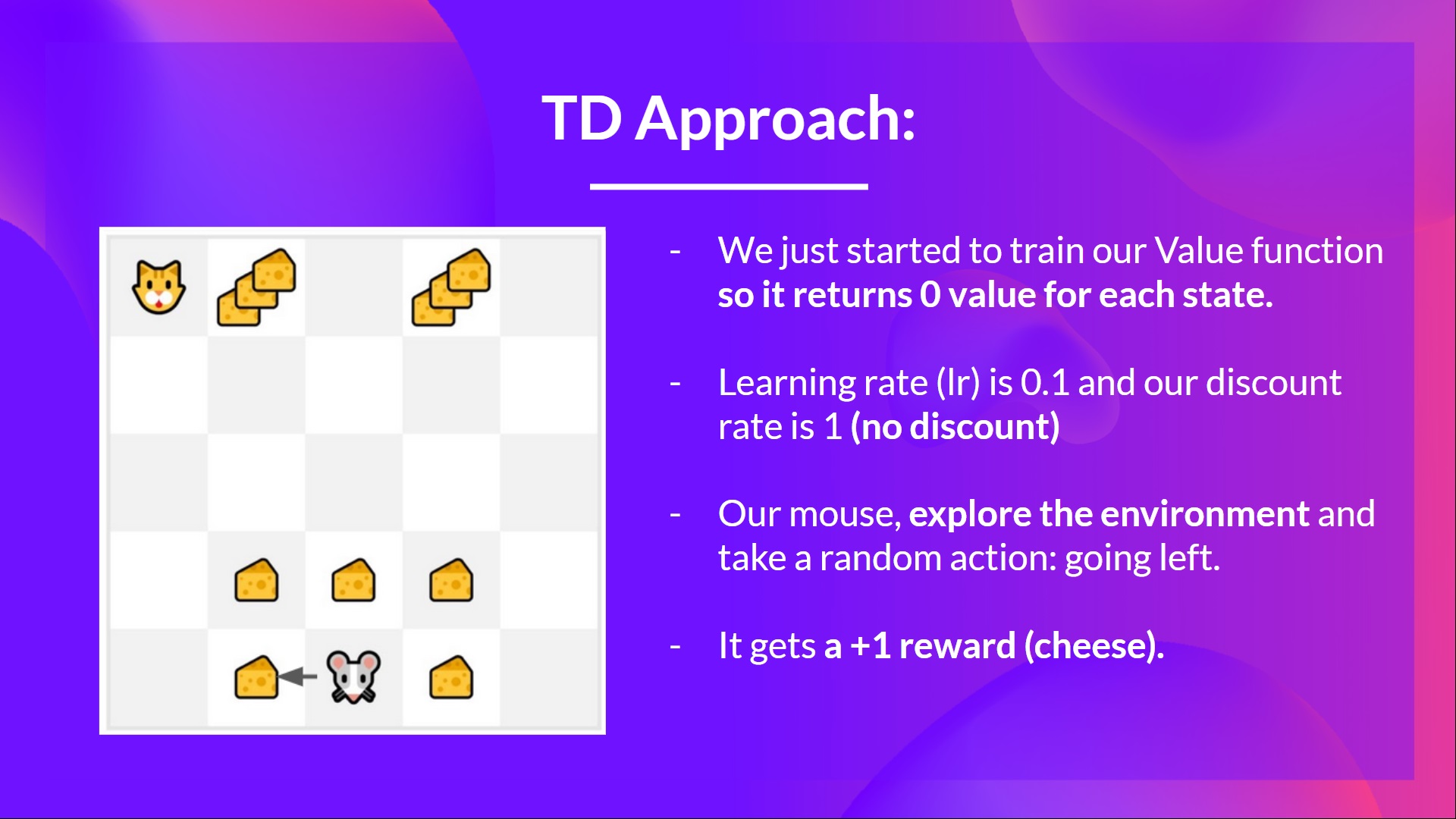 +
+
+
+
+
+ 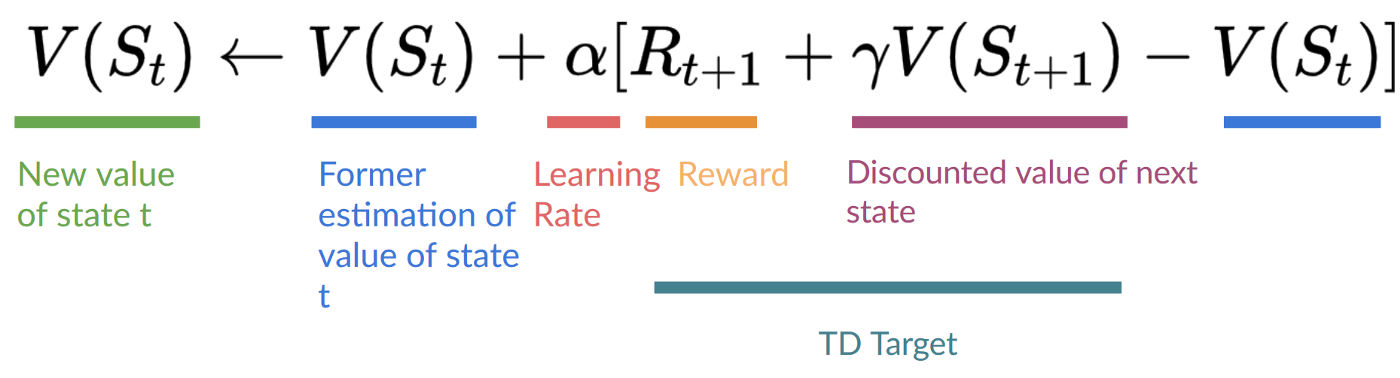 +
+We can now update \\(V(S_0)\\):
+
+New \\(V(S_0) = V(S_0) + lr * [R_1 + \gamma * V(S_1) - V(S_0)]\\)
+
+New \\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+New \\(V(S_0) = 0.1\\)
+
+So we just updated our value function for State 0.
+
+Now we **continue to interact with this environment with our updated value function.**
+
+
+
+We can now update \\(V(S_0)\\):
+
+New \\(V(S_0) = V(S_0) + lr * [R_1 + \gamma * V(S_1) - V(S_0)]\\)
+
+New \\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+New \\(V(S_0) = 0.1\\)
+
+So we just updated our value function for State 0.
+
+Now we **continue to interact with this environment with our updated value function.**
+
+  +
+ If we summarize:
+
+ - With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+ - With *TD Learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+
+
+
+ If we summarize:
+
+ - With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+ - With *TD Learning*, we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+
+ 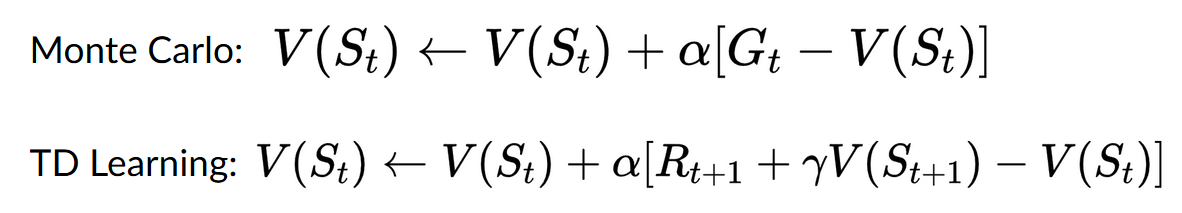 diff --git a/units/en/unit2/mid-way-quiz.mdx b/units/en/unit2/mid-way-quiz.mdx
new file mode 100644
index 0000000..b1ffe3a
--- /dev/null
+++ b/units/en/unit2/mid-way-quiz.mdx
@@ -0,0 +1,105 @@
+# Mid-way Quiz [[mid-way-quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: What are the two main approaches to find optimal policy?
+
+
+
diff --git a/units/en/unit2/mid-way-quiz.mdx b/units/en/unit2/mid-way-quiz.mdx
new file mode 100644
index 0000000..b1ffe3a
--- /dev/null
+++ b/units/en/unit2/mid-way-quiz.mdx
@@ -0,0 +1,105 @@
+# Mid-way Quiz [[mid-way-quiz]]
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: What are the two main approaches to find optimal policy?
+
+
+
+
+
+### Q3: Define each part of the Bellman Equation
+
+Solution
+ +**The Bellman equation is a recursive equation** that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as: + +\\(Rt+1 + (\gamma * V(St+1)))\\ +The immediate reward + the discounted value of the state that follows + + +
+
+
+
+
+
+
+
+
+
+### Q4: What is the difference between Monte Carlo and Temporal Difference learning methods?
+
+Solution
+ +
+
+ +
+
+
+
+
+
+
+
+
+### Q6: Define each part of Monte Carlo learning formula
+
+Solution
+ +
+
+ +
+
+
+
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the previous sections to reinforce (😏) your knowledge.
diff --git a/units/en/unit2/mid-way-recap.mdx b/units/en/unit2/mid-way-recap.mdx
new file mode 100644
index 0000000..0bae566
--- /dev/null
+++ b/units/en/unit2/mid-way-recap.mdx
@@ -0,0 +1,17 @@
+# Mid-way Recap [[mid-way-recap]]
+
+Before diving into Q-Learning, let's summarize what we just learned.
+
+We have two types of value-based functions:
+
+- State-value function: outputs the expected return if **the agent starts at a given state and acts accordingly to the policy forever after.**
+- Action-value function: outputs the expected return if **the agent starts in a given state, takes a given action at that state** and then acts accordingly to the policy forever after.
+- In value-based methods, rather than learning the policy, **we define the policy by hand** and we learn a value function. If we have an optimal value function, we **will have an optimal policy.**
+
+There are two types of methods to learn a policy for a value function:
+
+- With *the Monte Carlo method*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
+- With *the TD Learning method,* we update the value function from a step, so we replace \\(G_t\\) that we don't have with **an estimated return called TD target.**
+
+
+Solution
+ +
+
+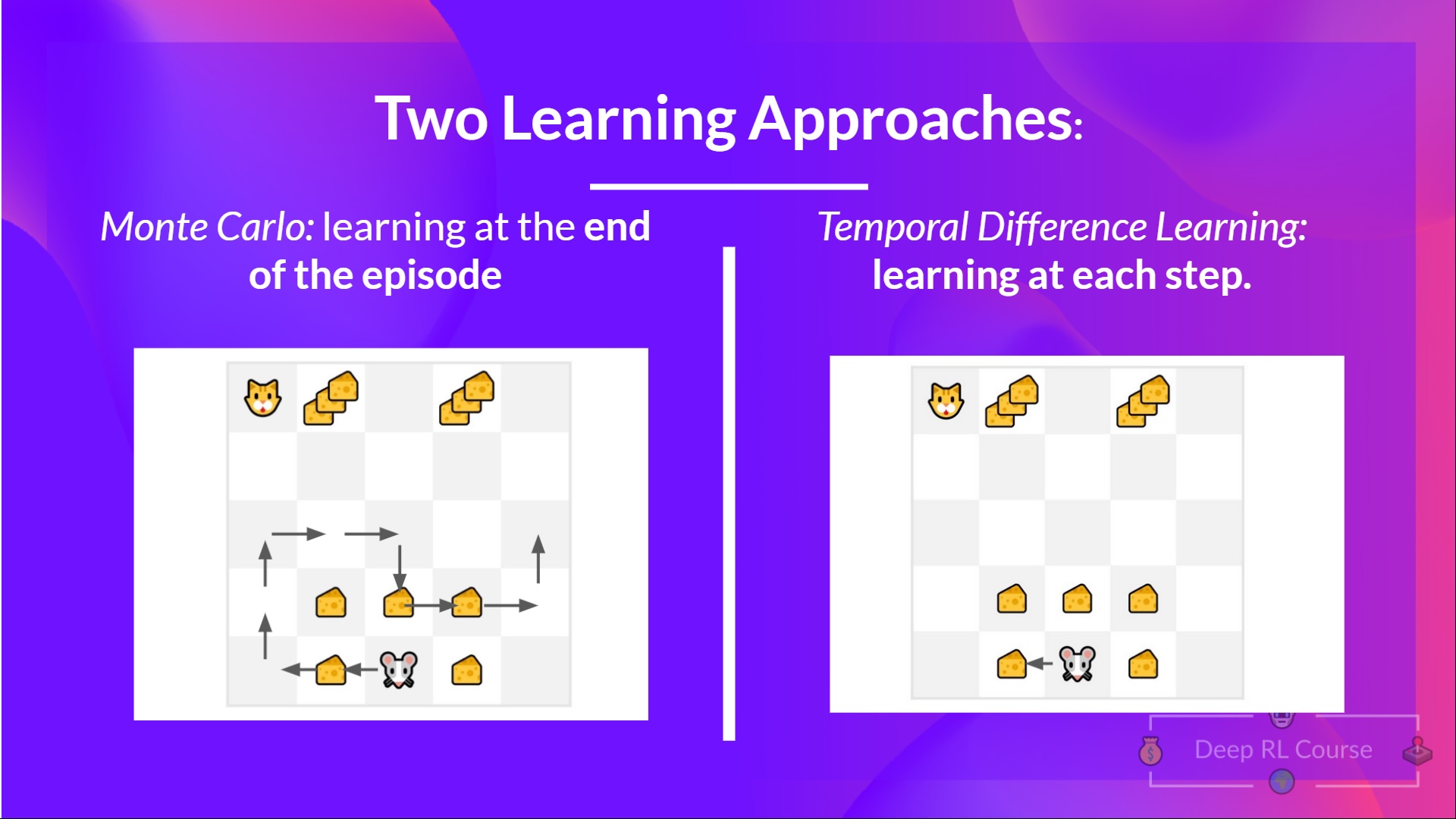 diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
new file mode 100644
index 0000000..d6ccbda
--- /dev/null
+++ b/units/en/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# A Q-Learning example [[q-learning-example]]
+
+To better understand Q-Learning, let's take a simple example:
+
+
diff --git a/units/en/unit2/q-learning-example.mdx b/units/en/unit2/q-learning-example.mdx
new file mode 100644
index 0000000..d6ccbda
--- /dev/null
+++ b/units/en/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# A Q-Learning example [[q-learning-example]]
+
+To better understand Q-Learning, let's take a simple example:
+
+ +
+- You're a mouse in this tiny maze. You always **start at the same starting point.**
+- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
+- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
+- The learning rate is 0.1
+- The gamma (discount rate) is 0.99
+
+
+
+- You're a mouse in this tiny maze. You always **start at the same starting point.**
+- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
+- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
+- The learning rate is 0.1
+- The gamma (discount rate) is 0.99
+
+ +
+
+The reward function goes like this:
+
+- **+0:** Going to a state with no cheese in it.
+- **+1:** Going to a state with a small cheese in it.
+- **+10:** Going to the state with the big pile of cheese.
+- **-10:** Going to the state with the poison and thus die.
+- **+0** If we spend more than five steps.
+
+
+
+
+The reward function goes like this:
+
+- **+0:** Going to a state with no cheese in it.
+- **+1:** Going to a state with a small cheese in it.
+- **+10:** Going to the state with the big pile of cheese.
+- **-10:** Going to the state with the poison and thus die.
+- **+0** If we spend more than five steps.
+
+ +
+To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
+
+## Step 1: We initialize the Q-Table [[step1]]
+
+
+
+To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
+
+## Step 1: We initialize the Q-Table [[step1]]
+
+ +
+So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+
+Let's do it for 2 training timesteps:
+
+Training timestep 1:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+Because epsilon is big = 1.0, I take a random action, in this case, I go right.
+
+
+
+So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
+
+Let's do it for 2 training timesteps:
+
+Training timestep 1:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2]]
+
+Because epsilon is big = 1.0, I take a random action, in this case, I go right.
+
+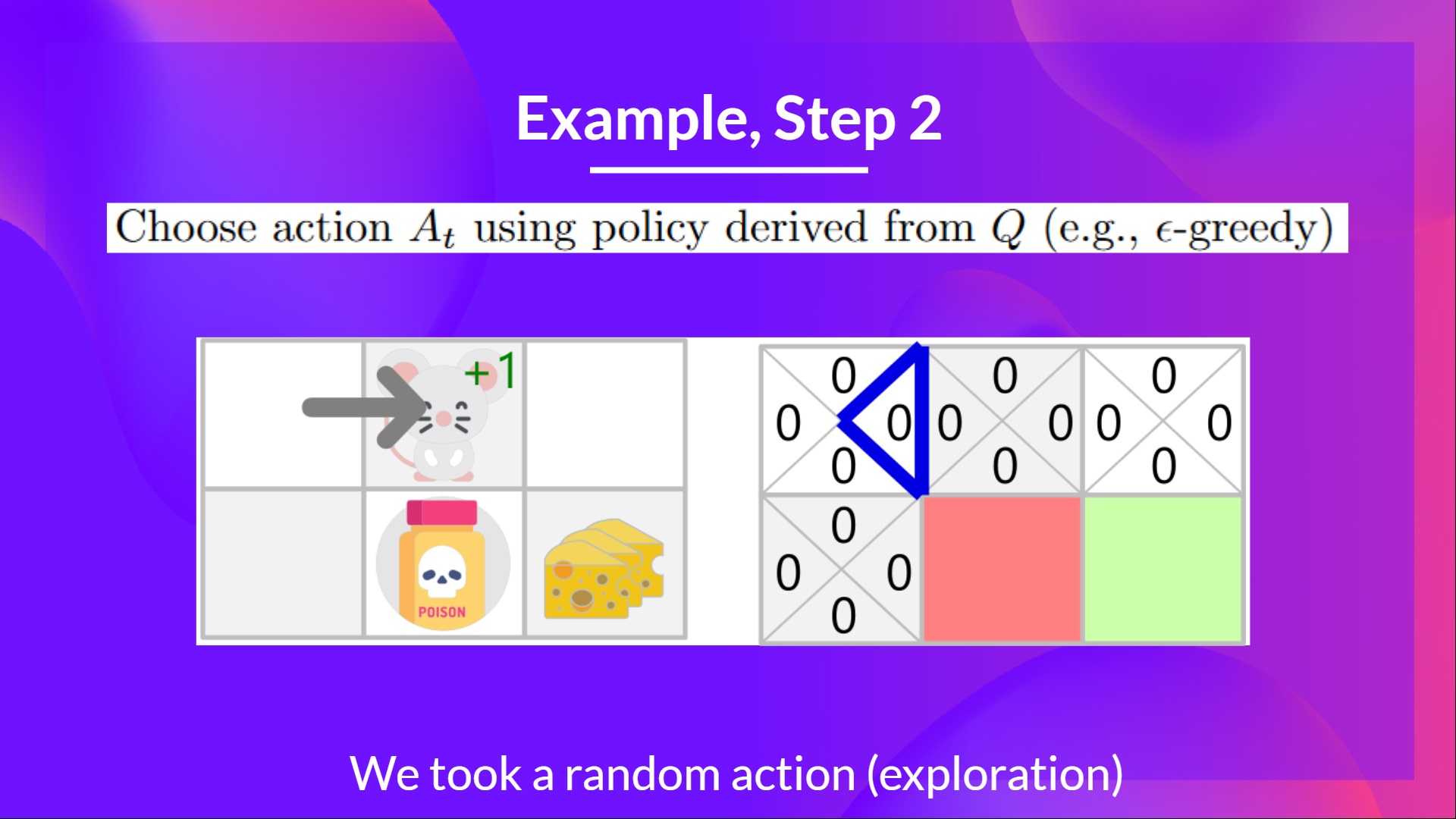 +
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3]]
+
+By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
+
+
+
+
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3]]
+
+By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
+
+
+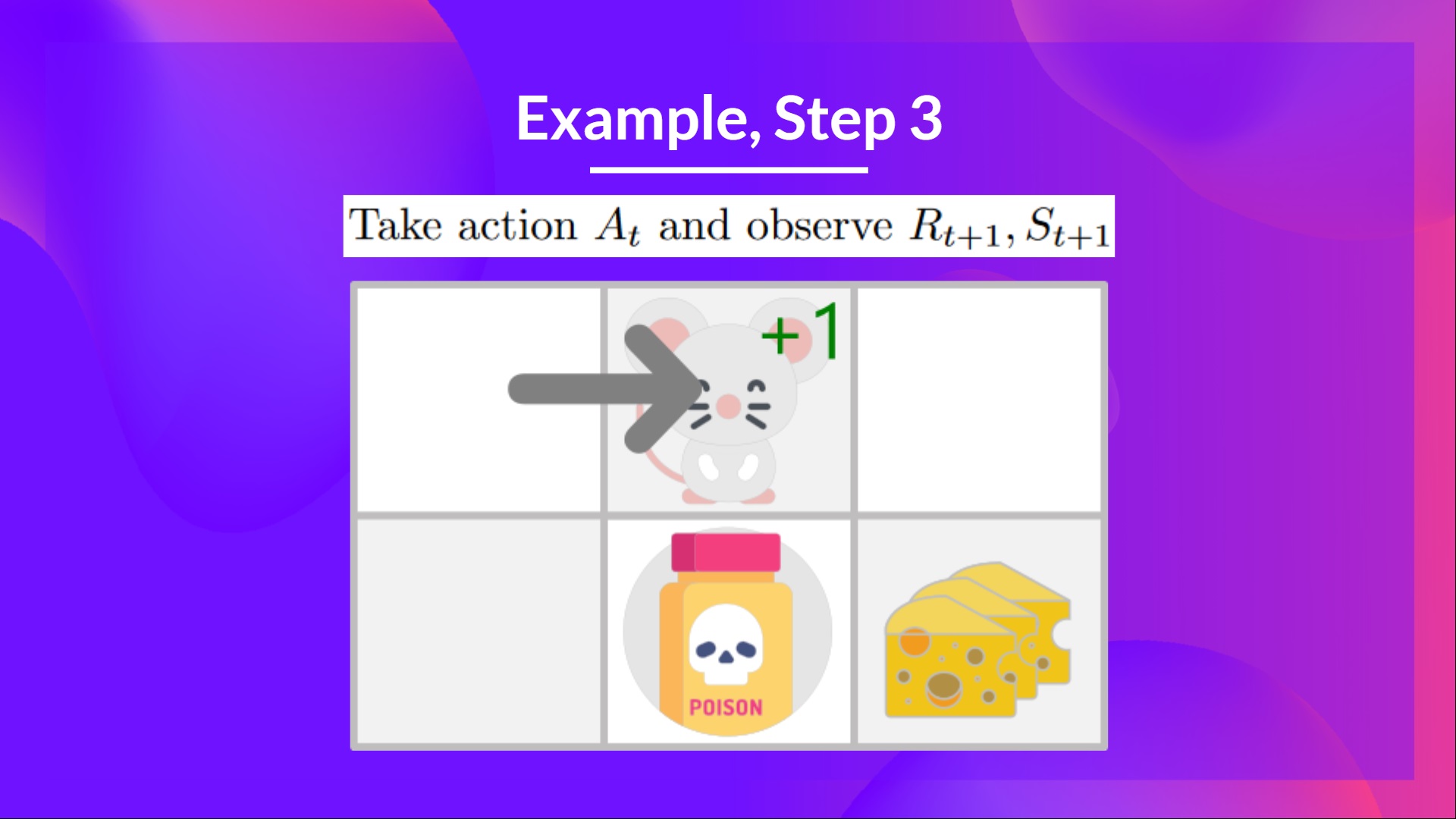 +
+
+## Step 4: Update Q(St, At) [[step4]]
+
+We can now update \\(Q(S_t, A_t)\\) using our formula.
+
+
+
+
+## Step 4: Update Q(St, At) [[step4]]
+
+We can now update \\(Q(S_t, A_t)\\) using our formula.
+
+ +
+ +
+Training timestep 2:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2-2]]
+
+**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
+
+I took action down. **Not a good action since it leads me to the poison.**
+
+
+
+Training timestep 2:
+
+## Step 2: Choose action using Epsilon Greedy Strategy [[step2-2]]
+
+**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
+
+I took action down. **Not a good action since it leads me to the poison.**
+
+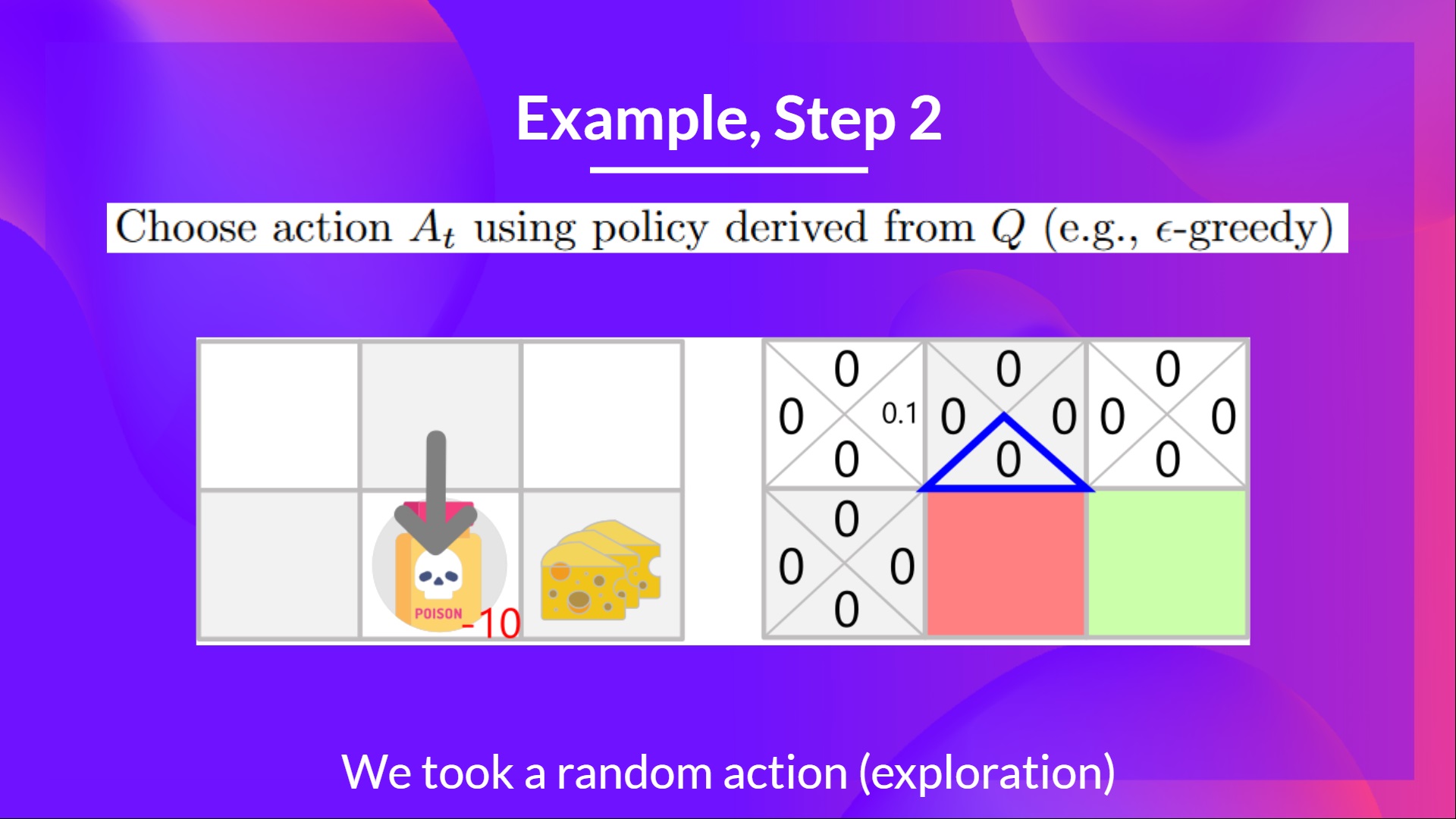 +
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3-3]]
+
+Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
+
+
+
+
+## Step 3: Perform action At, gets Rt+1 and St+1 [[step3-3]]
+
+Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
+
+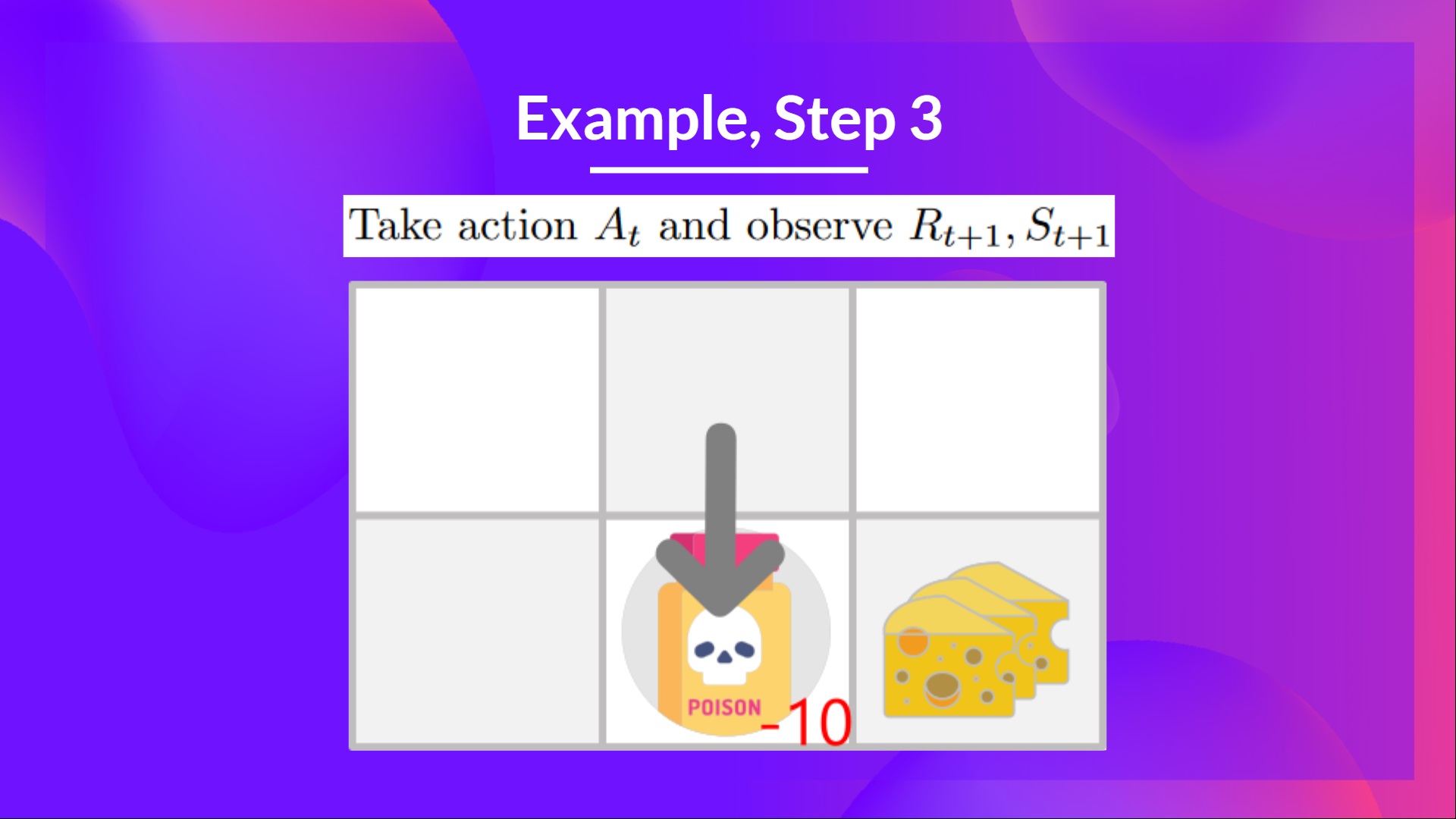 +
+## Step 4: Update Q(St, At) [[step4-4]]
+
+
+
+## Step 4: Update Q(St, At) [[step4-4]]
+
+ +
+Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
+
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
diff --git a/units/en/unit2/q-learning-recap.mdx b/units/en/unit2/q-learning-recap.mdx
new file mode 100644
index 0000000..55c66bf
--- /dev/null
+++ b/units/en/unit2/q-learning-recap.mdx
@@ -0,0 +1,25 @@
+# Q-Learning Recap [[q-learning-recap]]
+
+
+The *Q-Learning* **is the RL algorithm that** :
+
+- Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+
+- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+
+
+
+- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+
+- And if we **have an optimal Q-function**, we
+have an optimal policy,since we **know for each state, what is the best action to take.**
+
+
+
+But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+
+
+
+This is the Q-Learning pseudocode:
+
+
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
new file mode 100644
index 0000000..52e744a
--- /dev/null
+++ b/units/en/unit2/q-learning.mdx
@@ -0,0 +1,157 @@
+# Introducing Q-Learning [[q-learning]]
+## What is Q-Learning? [[what-is-q-learning]]
+
+Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
+
+- *Off-policy*: we'll talk about that at the end of this unit.
+- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
+- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
+
+**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+
+
+Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
+
+As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
diff --git a/units/en/unit2/q-learning-recap.mdx b/units/en/unit2/q-learning-recap.mdx
new file mode 100644
index 0000000..55c66bf
--- /dev/null
+++ b/units/en/unit2/q-learning-recap.mdx
@@ -0,0 +1,25 @@
+# Q-Learning Recap [[q-learning-recap]]
+
+
+The *Q-Learning* **is the RL algorithm that** :
+
+- Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
+
+- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
+
+
+
+- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+
+- And if we **have an optimal Q-function**, we
+have an optimal policy,since we **know for each state, what is the best action to take.**
+
+
+
+But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
+
+
+
+This is the Q-Learning pseudocode:
+
+
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
new file mode 100644
index 0000000..52e744a
--- /dev/null
+++ b/units/en/unit2/q-learning.mdx
@@ -0,0 +1,157 @@
+# Introducing Q-Learning [[q-learning]]
+## What is Q-Learning? [[what-is-q-learning]]
+
+Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
+
+- *Off-policy*: we'll talk about that at the end of this unit.
+- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
+- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
+
+**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
+
+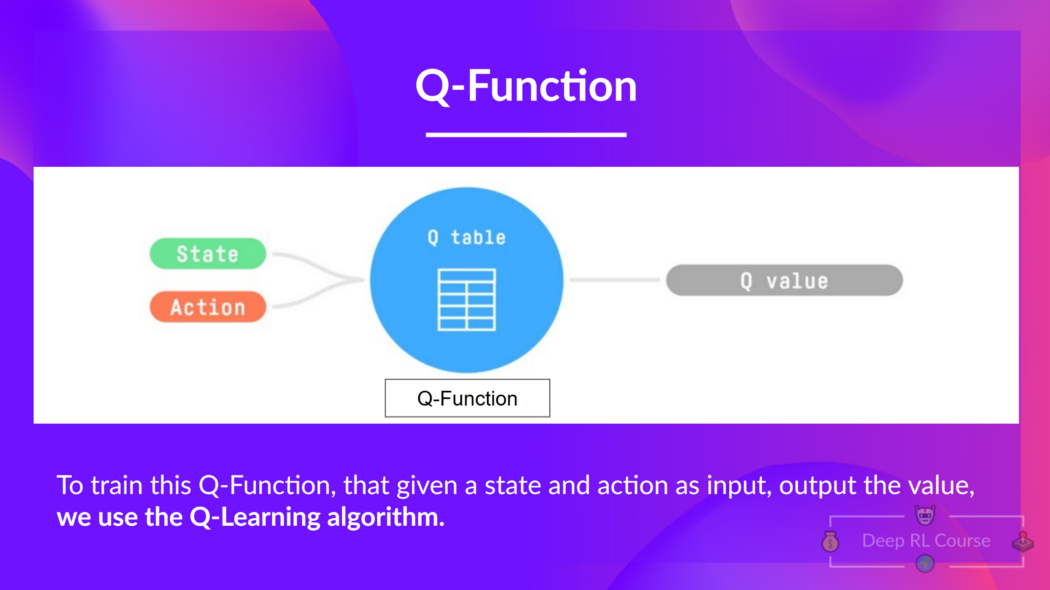 +
+  +
+The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
+
+
+
+The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
+
+ +
+Here we see that the **state-action value of the initial state and going up is 0:**
+
+
+
+Here we see that the **state-action value of the initial state and going up is 0:**
+
+ +
+Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
+
+
+
+
+
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0). As the agent **explores the environment and we update the Q-Table, it will give us better and better approximations** to the optimal policy.
+
+
+
+Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
+
+
+
+
+
+But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0). As the agent **explores the environment and we update the Q-Table, it will give us better and better approximations** to the optimal policy.
+
+ +
+
+### Step 1: We initialize the Q-Table [[step1]]
+
+
+
+
+### Step 1: We initialize the Q-Table [[step1]]
+
+ +
+
+We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
+
+### Step 2: Choose action using epsilon greedy strategy [[step2]]
+
+
+
+
+Epsilon greedy strategy is a policy that handles the exploration/exploitation trade-off.
+
+The idea is that we define epsilon ɛ = 1.0:
+
+- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
+- With probability ɛ: **we do exploration** (trying random action).
+
+At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
+
+
+
+
+We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
+
+### Step 2: Choose action using epsilon greedy strategy [[step2]]
+
+
+
+
+Epsilon greedy strategy is a policy that handles the exploration/exploitation trade-off.
+
+The idea is that we define epsilon ɛ = 1.0:
+
+- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
+- With probability ɛ: **we do exploration** (trying random action).
+
+At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
+
+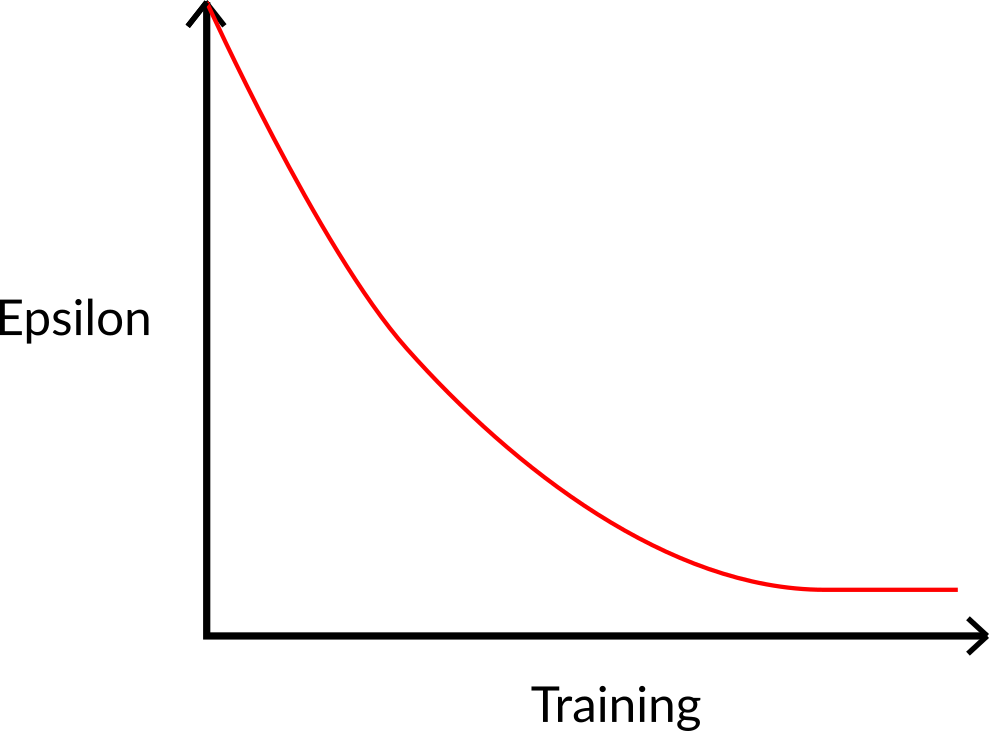 +
+
+### Step 3: Perform action At, gets reward Rt+1 and next state St+1 [[step3]]
+
+
+
+
+### Step 3: Perform action At, gets reward Rt+1 and next state St+1 [[step3]]
+
+ +
+### Step 4: Update Q(St, At) [[step4]]
+
+Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
+
+To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
+
+
+
+### Step 4: Update Q(St, At) [[step4]]
+
+Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
+
+To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
+
+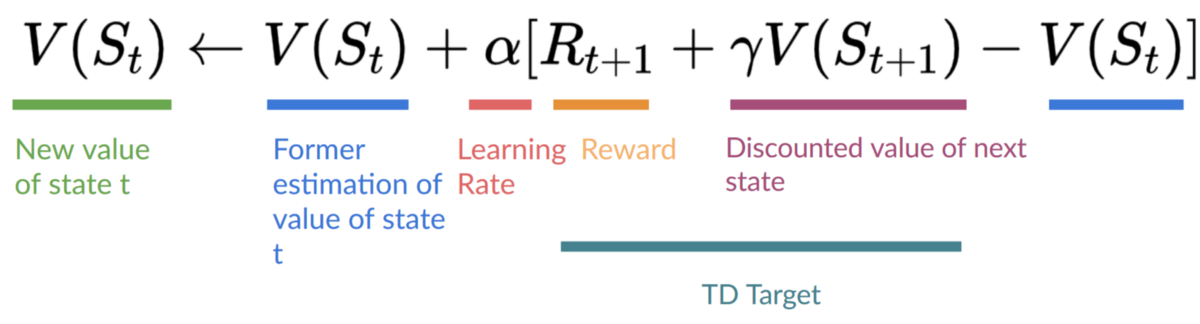 +
+Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
+
+
+
+Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
+
+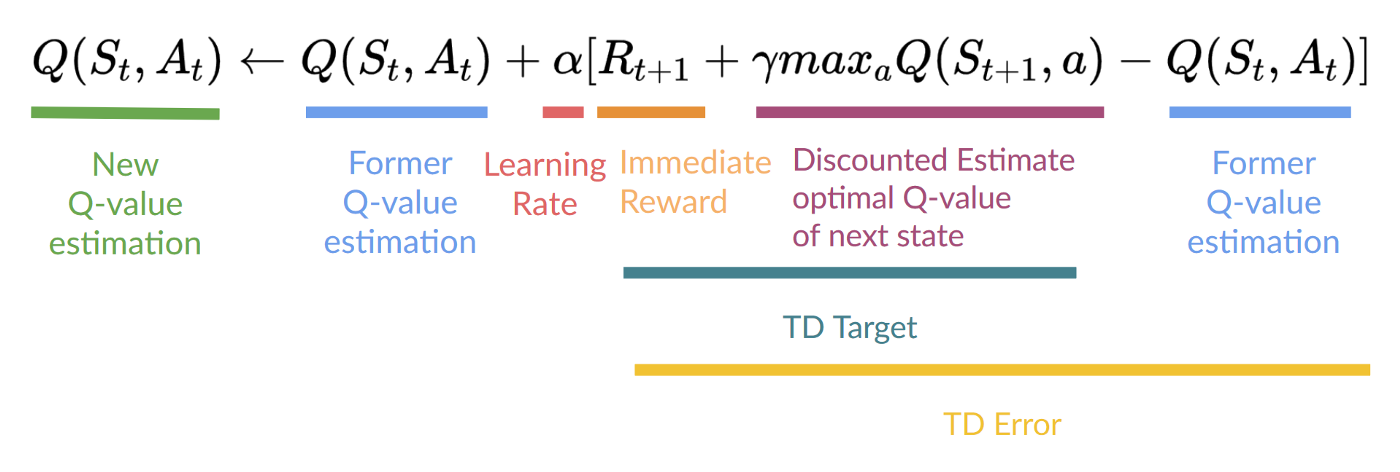 +
+
+It means that to update our \\(Q(S_t, A_t)\\):
+
+- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
+- To update our Q-value at a given state-action pair, we use the TD target.
+
+How do we form the TD target?
+1. We obtain the reward after taking the action \\(R_{t+1}\\).
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+
+Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
+
+**This is why we say that Q Learning is an off-policy algorithm.**
+
+## Off-policy vs On-policy [[off-vs-on]]
+
+The difference is subtle:
+
+- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
+
+For instance, with Q-Learning, the epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+
+
+
+
+
+It means that to update our \\(Q(S_t, A_t)\\):
+
+- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
+- To update our Q-value at a given state-action pair, we use the TD target.
+
+How do we form the TD target?
+1. We obtain the reward after taking the action \\(R_{t+1}\\).
+2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
+
+Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
+
+**This is why we say that Q Learning is an off-policy algorithm.**
+
+## Off-policy vs On-policy [[off-vs-on]]
+
+The difference is subtle:
+
+- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
+
+For instance, with Q-Learning, the epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
+
+
+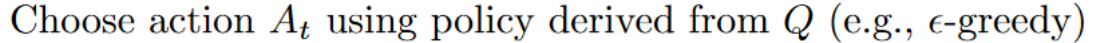 +
+ 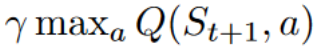 +
+  +
+
+
+
+
+
+
+
+### Q4: Can you explain what is Epsilon-Greedy Strategy?
+
+Solution
+ +Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take. + +
+
+
+
+
+
+
+
+### Q5: How do we update the Q value of a state, action pair?
+Solution
+Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off. + +The idea is that we define epsilon ɛ = 1.0: + +- With *probability 1 — ɛ* : we do exploitation (aka our agent selects the action with the highest state-action pair value). +- With *probability ɛ* : we do exploration (trying random action). + +
+
+
+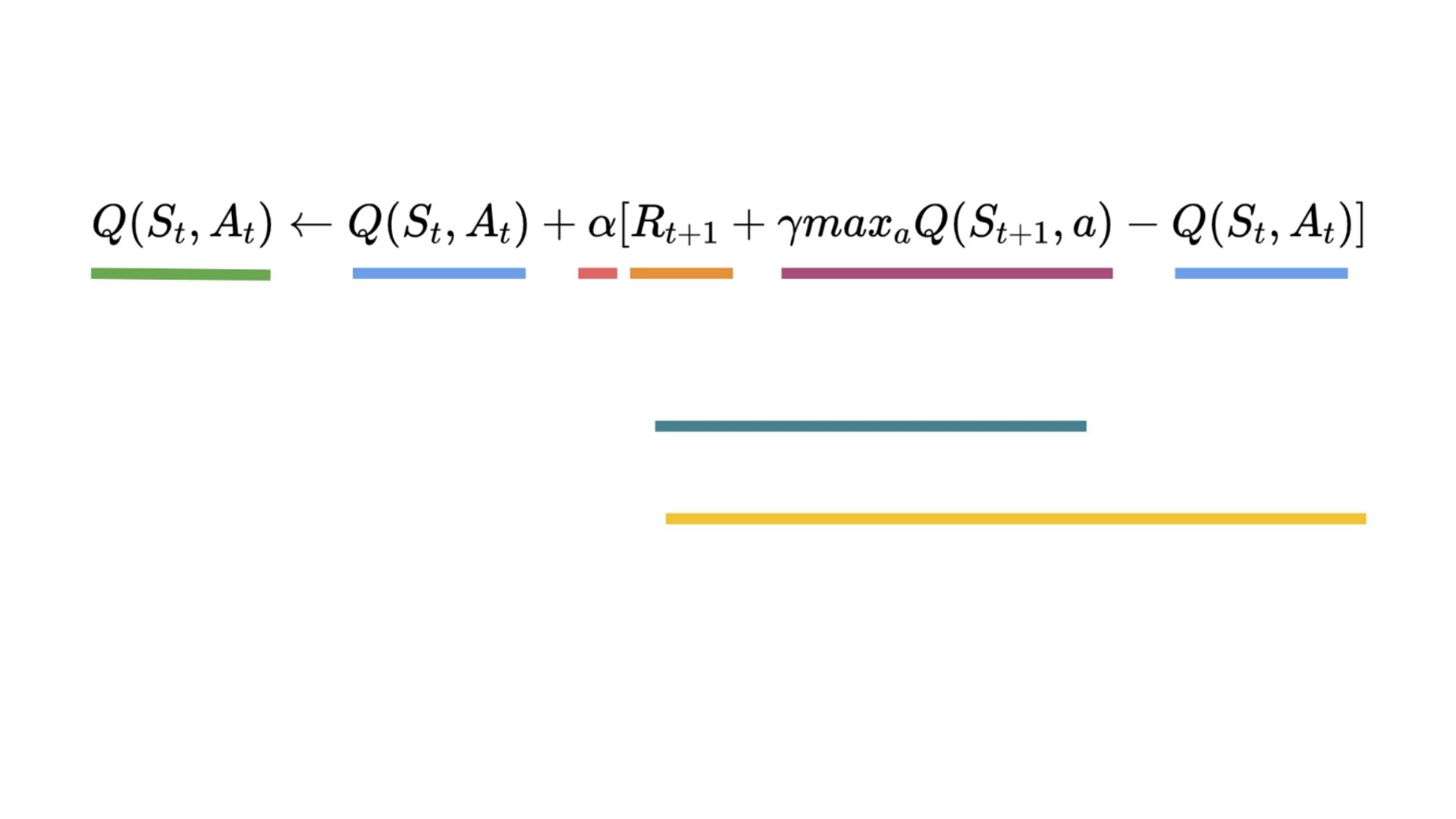 +
+
+
+
+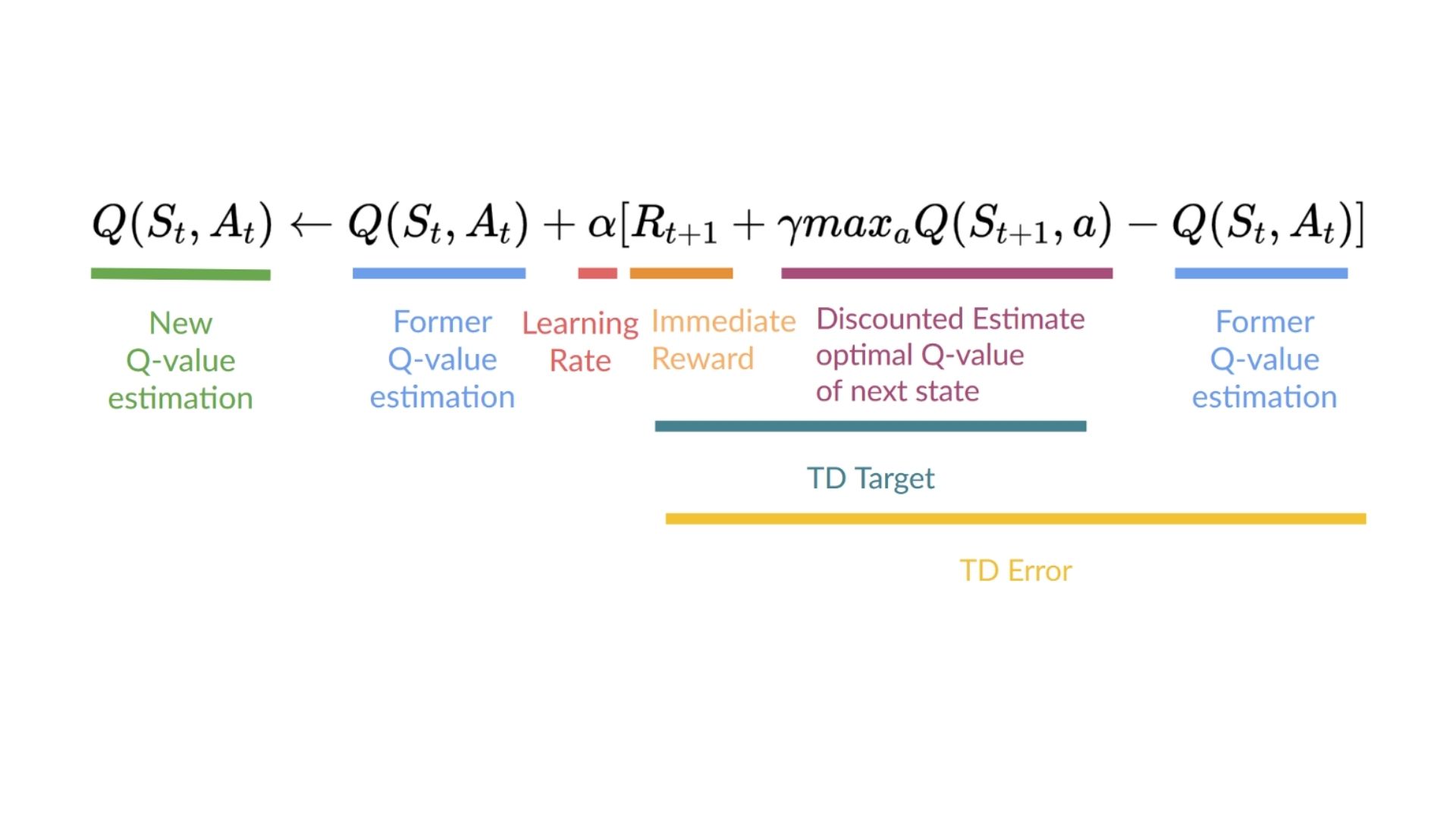 +
+
+
+
+
+
+
+### Q6: What's the difference between on-policy and off-policy
+
+Solution
+
+
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
diff --git a/units/en/unit2/two-types-value-based-methods.mdx b/units/en/unit2/two-types-value-based-methods.mdx
new file mode 100644
index 0000000..47a17e2
--- /dev/null
+++ b/units/en/unit2/two-types-value-based-methods.mdx
@@ -0,0 +1,86 @@
+# Two types of value-based methods [[two-types-value-based-methods]]
+
+In value-based methods, **we learn a value function** that **maps a state to the expected value of being at that state.**
+
+Solution
+
+ +
+The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
+
+
+
+The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
+
+ +
+The policy takes a state as input and outputs what action to take at that state (deterministic policy: a policy that output one action given a state, contrary to stochastic policy that output a probability distribution over actions).
+
+And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
+
+- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take an action.**
+
+Since the policy is not trained/learned, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
+
+
+
+The policy takes a state as input and outputs what action to take at that state (deterministic policy: a policy that output one action given a state, contrary to stochastic policy that output a probability distribution over actions).
+
+And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
+
+- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take an action.**
+
+Since the policy is not trained/learned, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
+
+ +
+
+In fact, most of the time, in value-based methods, you'll use **an Epsilon-Greedy Policy** that handles the exploration/exploitation trade-off; we'll talk about it when we talk about Q-Learning in the second part of this unit.
+
+
+So, we have two types of value-based functions:
+
+## The state-value function [[state-value-function]]
+
+We write the state value function under a policy π like this:
+
+
+
+
+In fact, most of the time, in value-based methods, you'll use **an Epsilon-Greedy Policy** that handles the exploration/exploitation trade-off; we'll talk about it when we talk about Q-Learning in the second part of this unit.
+
+
+So, we have two types of value-based functions:
+
+## The state-value function [[state-value-function]]
+
+We write the state value function under a policy π like this:
+
+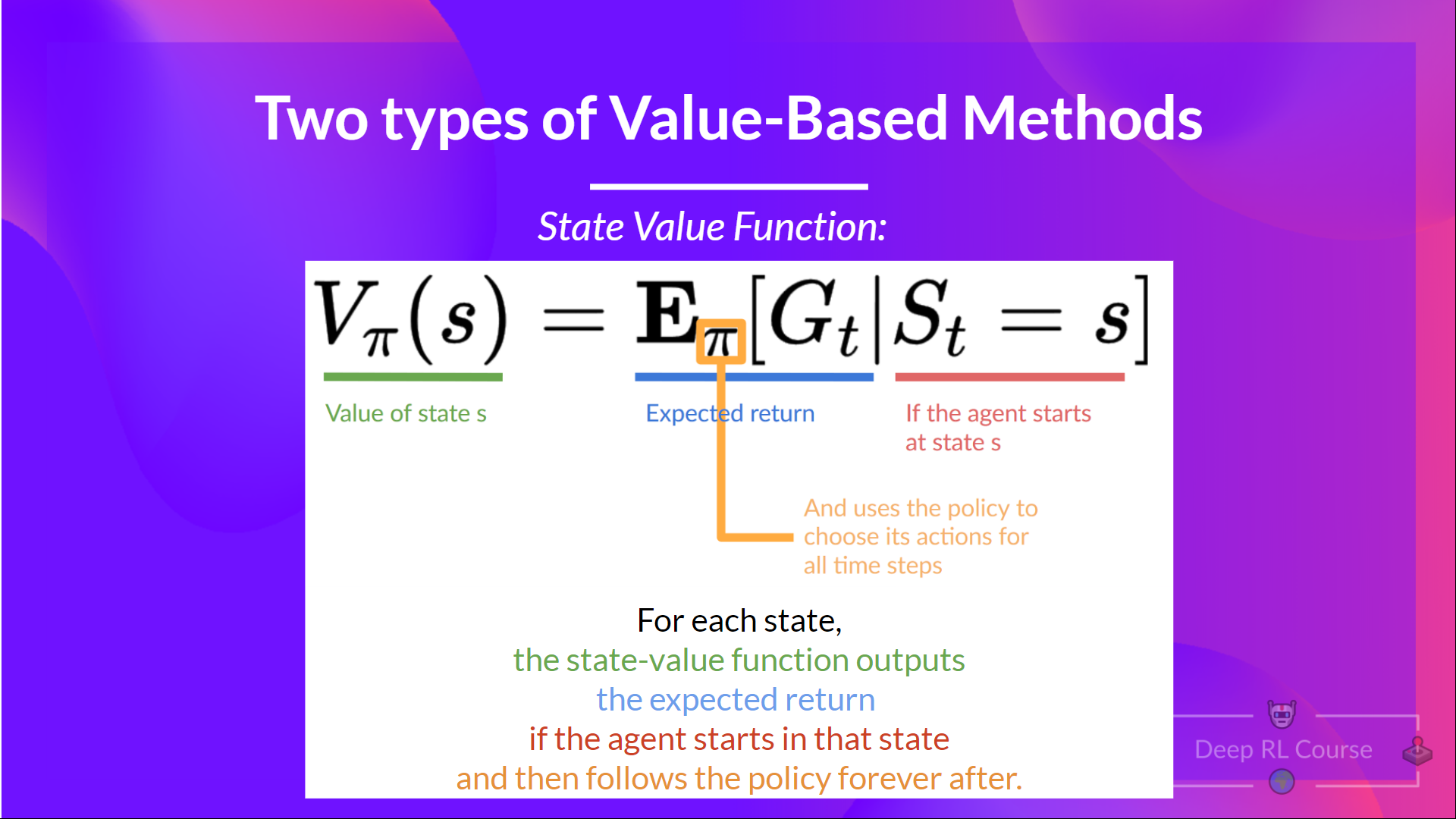 +
+For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
+
+
+
+For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
+
+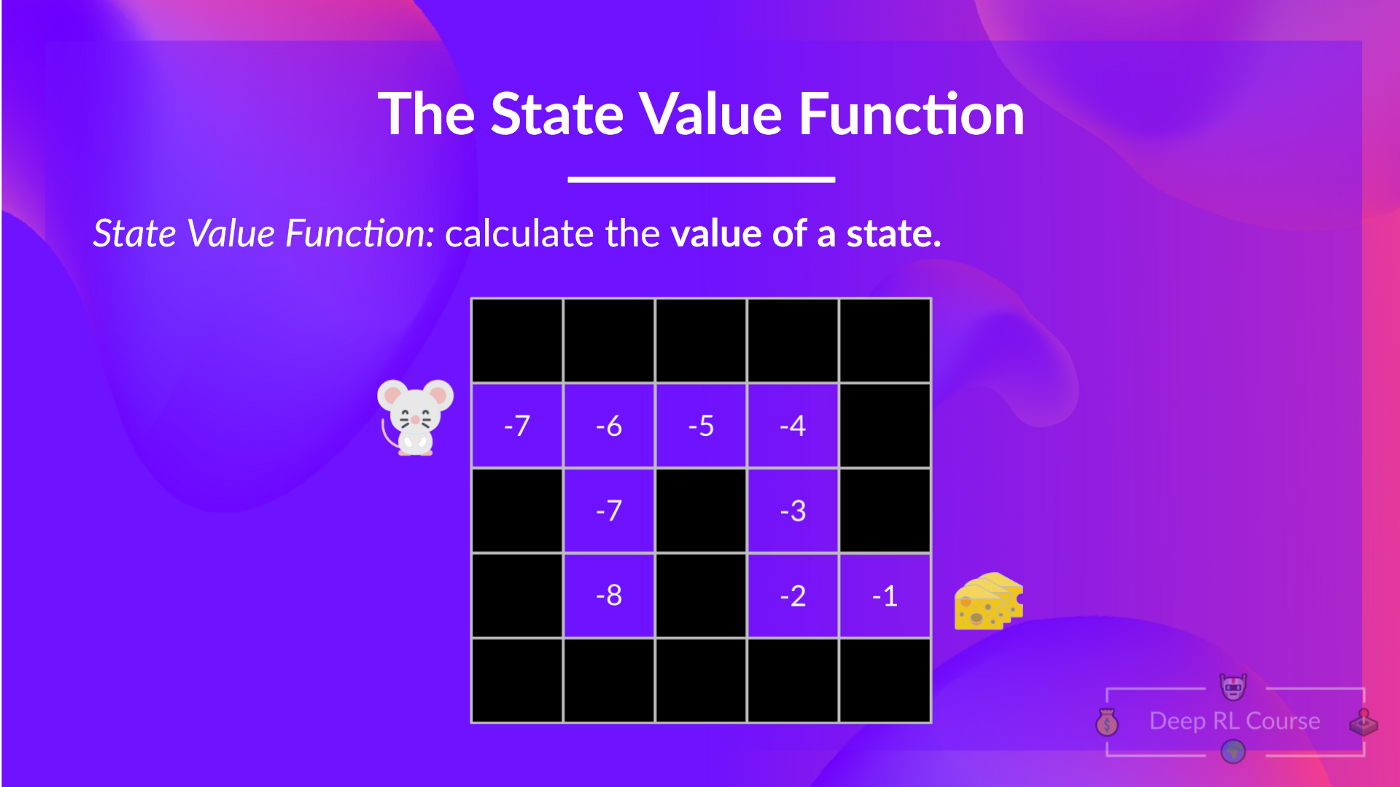 +
+  +
+ +
+
+We see that the difference is:
+
+- In state-value function, we calculate **the value of a state \\(S_t\\)**
+- In action-value function, we calculate **the value of the state-action pair ( \\(S_t, A_t\\) ) hence the value of taking that action at that state.**
+
+
+
+
+We see that the difference is:
+
+- In state-value function, we calculate **the value of a state \\(S_t\\)**
+- In action-value function, we calculate **the value of the state-action pair ( \\(S_t, A_t\\) ) hence the value of taking that action at that state.**
+
+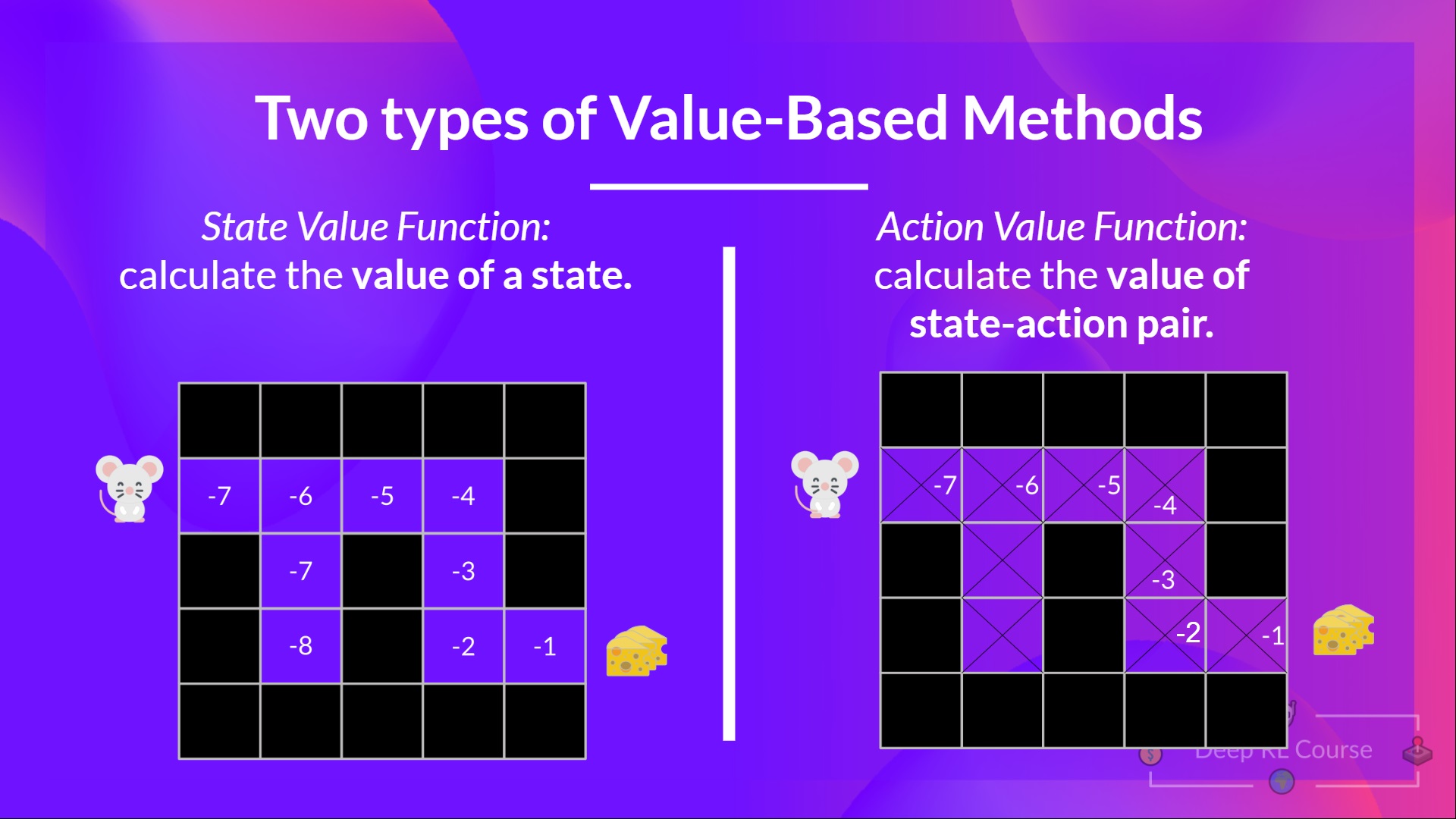 +
+  +
+
+But, to make intelligent decisions, our agent will learn from the environment by **interacting with it through trial and error** and receiving rewards (positive or negative) **as unique feedback.**
+
+Its goal **is to maximize its expected cumulative reward** (because of the reward hypothesis).
+
+**The agent's decision-making process is called the policy π:** given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
+
+
+
+
+But, to make intelligent decisions, our agent will learn from the environment by **interacting with it through trial and error** and receiving rewards (positive or negative) **as unique feedback.**
+
+Its goal **is to maximize its expected cumulative reward** (because of the reward hypothesis).
+
+**The agent's decision-making process is called the policy π:** given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
+
+ +
+**Our goal is to find an optimal policy π* **, aka., a policy that leads to the best expected cumulative reward.
+
+And to find this optimal policy (hence solving the RL problem), there **are two main types of RL methods**:
+
+- *Policy-based methods*: **Train the policy directly** to learn which action to take given a state.
+- *Value-based methods*: **Train a value function** to learn **which state is more valuable** and use this value function **to take the action that leads to it.**
+
+
+
+**Our goal is to find an optimal policy π* **, aka., a policy that leads to the best expected cumulative reward.
+
+And to find this optimal policy (hence solving the RL problem), there **are two main types of RL methods**:
+
+- *Policy-based methods*: **Train the policy directly** to learn which action to take given a state.
+- *Value-based methods*: **Train a value function** to learn **which state is more valuable** and use this value function **to take the action that leads to it.**
+
+ +
+And in this unit, **we'll dive deeper into the value-based methods.**
+
+And in this unit, **we'll dive deeper into the value-based methods.**