From a31043822e7f23d4f55df549b1b9896e2c56f29d Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Sun, 3 Dec 2023 18:58:37 +0000
Subject: [PATCH 1/6] Create quiz for unit 6
---
units/en/unit6/quiz.mdx | 119 ++++++++++++++++++++++++++++++++++++++++
1 file changed, 119 insertions(+)
create mode 100644 units/en/unit6/quiz.mdx
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
new file mode 100644
index 0000000..f9832a9
--- /dev/null
+++ b/units/en/unit6/quiz.mdx
@@ -0,0 +1,119 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: What of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
+
+
+
+### Q2: Which of the following statements are correct?
+
+
+
+### Q3: Which of the following statements are true about Monte-carlo method?
+
+
+### Q4: What is the Advanced Actor-Critic Method (A2C)?
+
+Solution
+
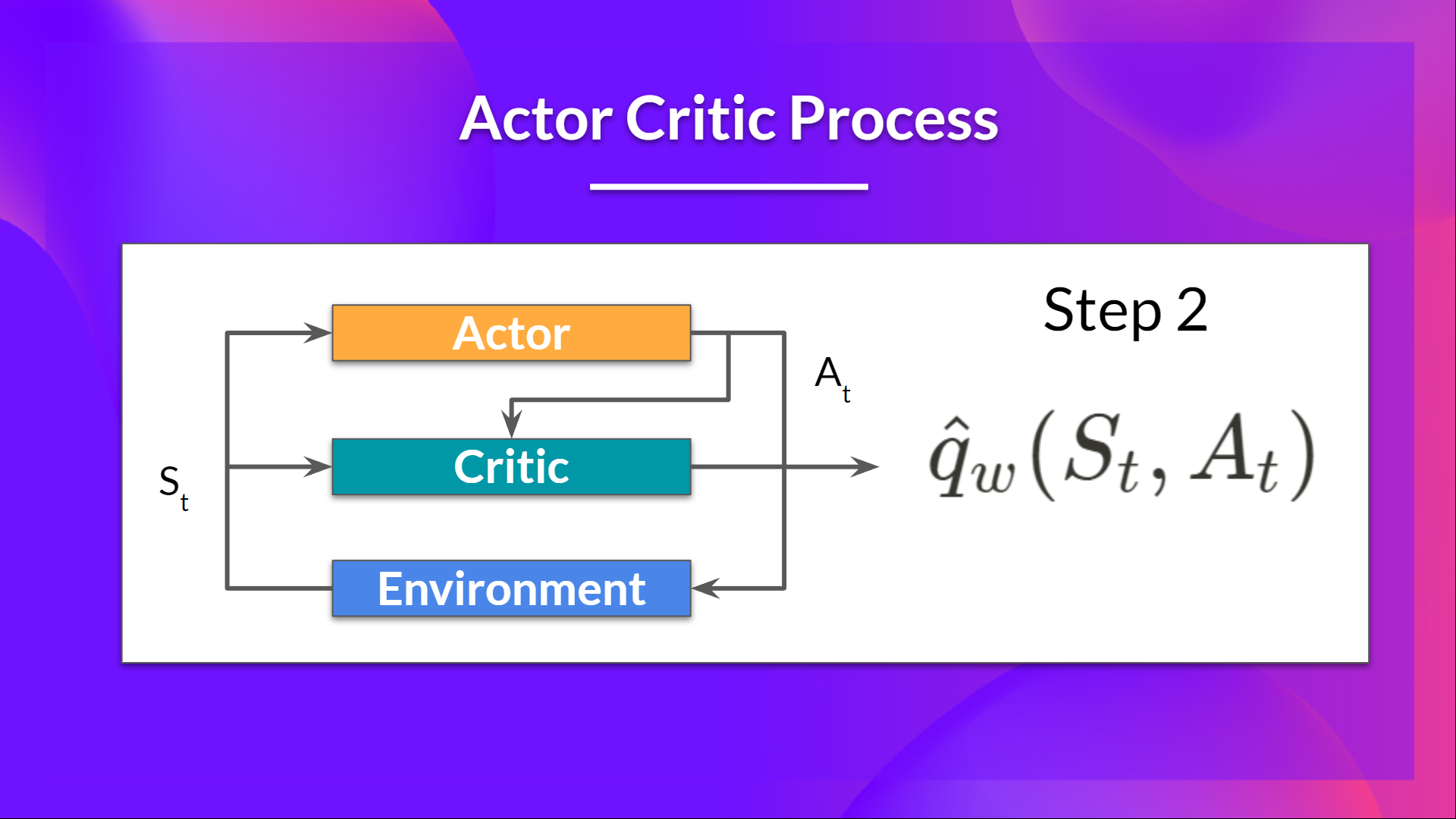
+The idea behind Actor-Critic is the following - we learn two function approximations:
+1. A policy that controls how our agent acts (π)
+2. A value function to assist the policy update by measuring how good the action taken is (q)
+
+ +
+
+
+
+
+### Q5: Which of the following statemets are True about the Actor-Critic Method?
+
+
+
+
+### Q6: What is Advantege in the A2C method?
+
+Solution
+
+Instead of using directly the Action-Value function of the Critic as it is, we calculate an Advantage function, the relative advantage of an action compared to the others possible at a state.
+In other words: how taking that action at a state is better compared to the average value of the state
+
+ +
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
From 57678da563ef761e8a00fdfbab7e0b632d3d2b9e Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Sun, 3 Dec 2023 19:16:18 +0000
Subject: [PATCH 2/6] Update quiz.mdx
---
units/en/unit6/quiz.mdx | 33 +++++++++++++++++----------------
1 file changed, 17 insertions(+), 16 deletions(-)
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
index f9832a9..b53a5ef 100644
--- a/units/en/unit6/quiz.mdx
+++ b/units/en/unit6/quiz.mdx
@@ -8,29 +8,29 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
-### Q2: Which of the following statements are correct?
+### Q2: Which of the following statements are True, when talking about models with bias and/or variance in RL?
@@ -63,7 +63,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
},
,
{
- text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take n strategies and average them, reducing their impact impact in case of noise"
+ text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take `n` strategies and average them, reducing their impact impact in case of noise"
explain: "",
correct: true,
},
@@ -74,9 +74,9 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
Solution
-The idea behind Actor-Critic is the following - we learn two function approximations:
-1. A policy that controls how our agent acts (π)
-2. A value function to assist the policy update by measuring how good the action taken is (q)
+The idea behind Actor-Critic is that we learn two function approximations:
+1. A `policy` that controls how our agent acts (π)
+2. A `value` function to assist the policy update by measuring how good the action taken is (q)
@@ -97,7 +97,7 @@ The idea behind Actor-Critic is the following - we learn two function approximat
},
{
text: "It adds resistance to stochasticity and reduces high variance",
- explain: "Monte-carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
+ explain: "",
correct: true,
},
]}
@@ -105,11 +105,12 @@ The idea behind Actor-Critic is the following - we learn two function approximat
-### Q6: What is Advantege in the A2C method?
+### Q6: What is `Advantege` in the A2C method?
Solution
-Instead of using directly the Action-Value function of the Critic as it is, we calculate an Advantage function, the relative advantage of an action compared to the others possible at a state.
+Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
+
In other words: how taking that action at a state is better compared to the average value of the state
From 306d4084c21c959f3997c3857a88da90a2628b94 Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Mon, 4 Dec 2023 16:32:22 +0000
Subject: [PATCH 3/6] Update _toctree.yml
---
units/en/_toctree.yml | 2 ++
1 file changed, 2 insertions(+)
diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 704be13..cc96faf 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -160,6 +160,8 @@
title: Advantage Actor Critic (A2C)
- local: unit6/hands-on
title: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
+ - local: unit6/quiz
+ title: Quiz
- local: unit6/conclusion
title: Conclusion
- local: unit6/additional-readings
From 40cf7684e51765267c7c6f20f7da8b9858769780 Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Wed, 6 Dec 2023 11:10:43 +0000
Subject: [PATCH 4/6] Fixes typo and comma(s)
---
units/en/unit6/quiz.mdx | 44 ++++++++++++++++++++---------------------
1 file changed, 21 insertions(+), 23 deletions(-)
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
index b53a5ef..0fc9b38 100644
--- a/units/en/unit6/quiz.mdx
+++ b/units/en/unit6/quiz.mdx
@@ -10,12 +10,12 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
{
text: "The bias-variance tradeoff reflects how my model is able to generalize the knowledge to previously tagged data we give to the model during training time.",
explain: "This is the traditional bias-variance tradeoff in Machine Learning. In our specific case of Reinforcement Learning, we don't have previously tagged data, but only a reward signal.",
- correct: false,
+ correct: false,
},
- {
+ {
text: "The bias-variance tradeoff reflects how well the reinforcement signal reflects the true reward the agent should get from the enviromment",
explain: "",
- correct: true,
+ correct: true,
},
]}
/>
@@ -26,23 +26,22 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
{
text: "An unbiased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "",
- correct: true,
+ correct: true,
},
- {
+ {
text: "A biased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "If a reward signal is biased, it means the reward signal we get differs from the real reward we should be getting from an environment",
- correct: false,
+ correct: false,
},
- ,
- {
+ {
text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment"
explain: "",
- correct: true,
+ correct: true,
},
- {
+ {
text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment"
explain: "If a reward signal has low variance, then it's less affected by the noise of the environment and produce similar values regardless the random elements in the environment",
- correct: false,
+ correct: false,
},
]}
/>
@@ -54,18 +53,17 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
{
text: "It's a sampling mechanism, which means we don't consider analyze all the possible states, but a sample of those",
explain: "",
- correct: true,
+ correct: true,
},
- {
+ {
text: "It's very resistant to stochasticity (random elements in the trajectory)",
explain: "Monte-carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
- correct: false,
+ correct: false,
},
- ,
- {
+ {
text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take `n` strategies and average them, reducing their impact impact in case of noise"
explain: "",
- correct: true,
+ correct: true,
},
]}
/>
@@ -85,27 +83,27 @@ The idea behind Actor-Critic is that we learn two function approximations:
### Q5: Which of the following statemets are True about the Actor-Critic Method?
-### Q6: What is `Advantege` in the A2C method?
+### Q6: What is `Advantage` in the A2C method?
Solution
From f7c510a063f9fb68f85fcafb60e6e42b9870b42f Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Wed, 6 Dec 2023 11:12:38 +0000
Subject: [PATCH 5/6] Adds newline after ###
---
units/en/unit6/quiz.mdx | 5 +++++
1 file changed, 5 insertions(+)
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
index 0fc9b38..2a5797e 100644
--- a/units/en/unit6/quiz.mdx
+++ b/units/en/unit6/quiz.mdx
@@ -21,6 +21,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
/>
### Q2: Which of the following statements are True, when talking about models with bias and/or variance in RL?
+
### Q4: What is the Advanced Actor-Critic Method (A2C)?
+
Solution
@@ -81,6 +84,7 @@ The idea behind Actor-Critic is that we learn two function approximations:
### Q5: Which of the following statemets are True about the Actor-Critic Method?
+
Solution
From f41bf2c5fb50a5200d63a68250586ad568dfa45c Mon Sep 17 00:00:00 2001
From: Juan Martinez <36634572+josejuanmartinez@users.noreply.github.com>
Date: Wed, 6 Dec 2023 11:36:29 +0000
Subject: [PATCH 6/6] Fixes missing commas
---
units/en/unit6/quiz.mdx | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
index 2a5797e..0c49305 100644
--- a/units/en/unit6/quiz.mdx
+++ b/units/en/unit6/quiz.mdx
@@ -35,12 +35,12 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
correct: false,
},
{
- text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment"
+ text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "",
correct: true,
},
{
- text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment"
+ text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "If a reward signal has low variance, then it's less affected by the noise of the environment and produce similar values regardless the random elements in the environment",
correct: false,
},
@@ -63,7 +63,7 @@ The best way to learn and [to avoid the illusion of competence](https://www.cour
correct: false,
},
{
- text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take `n` strategies and average them, reducing their impact impact in case of noise"
+ text: "To reduce the impact of stochastic elements in Monte-Carlo, we can take `n` strategies and average them, reducing their impact impact in case of noise",
explain: "",
correct: true,
},