diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
index 78ef297..be9a44a 100644
--- a/units/en/unit2/mc-vs-td.mdx
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -57,18 +57,25 @@ For instance, if we train a state-value function using Monte Carlo:
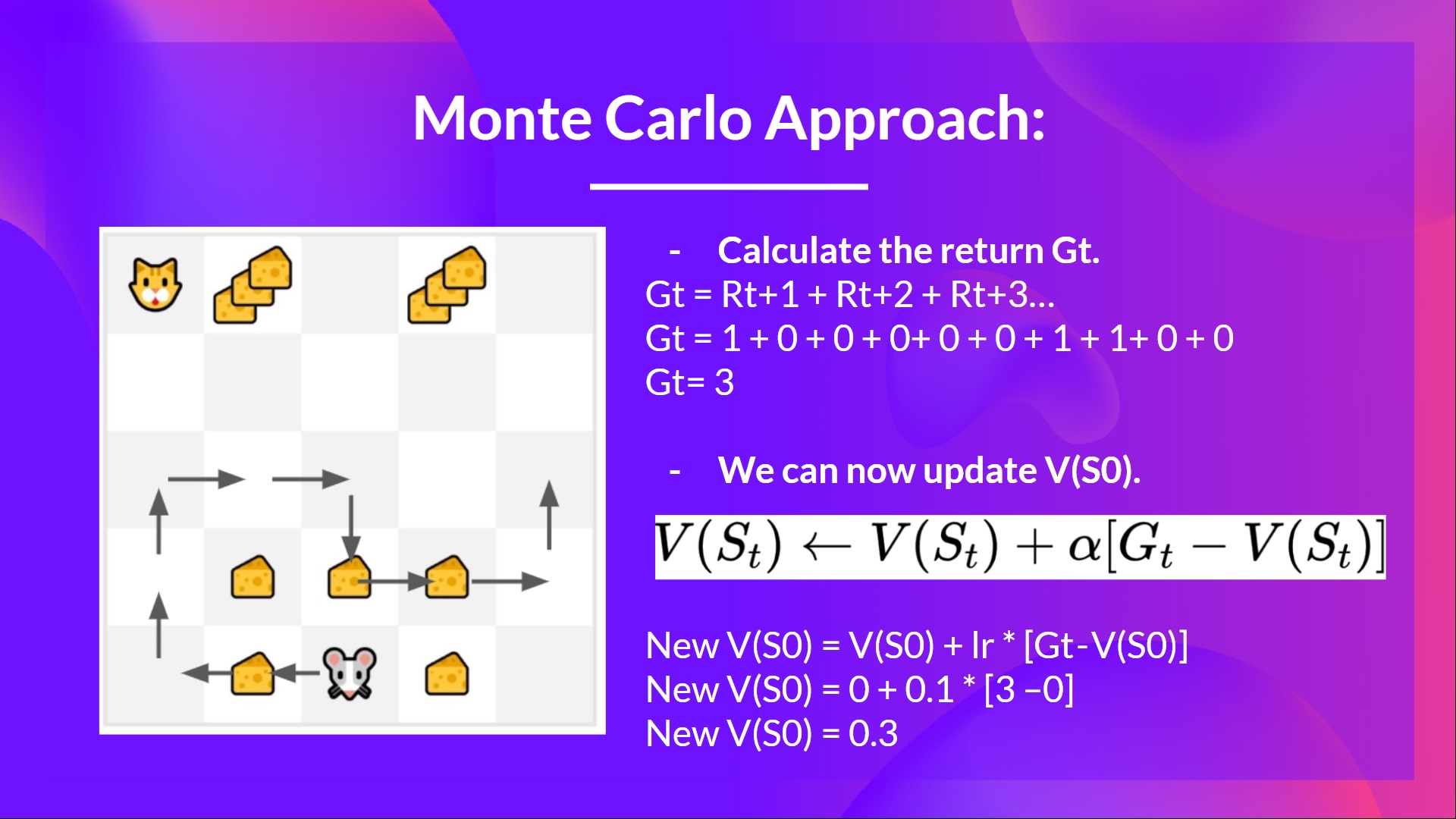
 -- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
-- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
-- \\(G_t= 3\\)
-- We can now update \\(V(S_0)\\):
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\) (for simplicity, we don't discount the rewards)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- We can now compute the **new** \\(V(S_0)\\):
-- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
-- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
-- \\(G_t= 3\\)
-- We can now update \\(V(S_0)\\):
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\) (for simplicity, we don't discount the rewards)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- We can now compute the **new** \\(V(S_0)\\):
 -- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
-- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
-- New \\(V(S_0) = 0.3\\)
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)
-- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
-- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
-- New \\(V(S_0) = 0.3\\)
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)