diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 1202432..79fa795 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -1,26 +1,60 @@
- +# Hands-on [[hands-on]]
+
+
+
+
+
+Now that we studied the Q-Learning algorithm, let's implement it from scratch and train our Q-Learning agent in two environments:
+1. [Frozen-Lake-v1 (non-slippery and slippery version)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️ : where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. [An autonomous taxi](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+
+# Hands-on [[hands-on]]
+
+
+
+
+
+Now that we studied the Q-Learning algorithm, let's implement it from scratch and train our Q-Learning agent in two environments:
+1. [Frozen-Lake-v1 (non-slippery and slippery version)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️ : where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
+2. [An autonomous taxi](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
+
+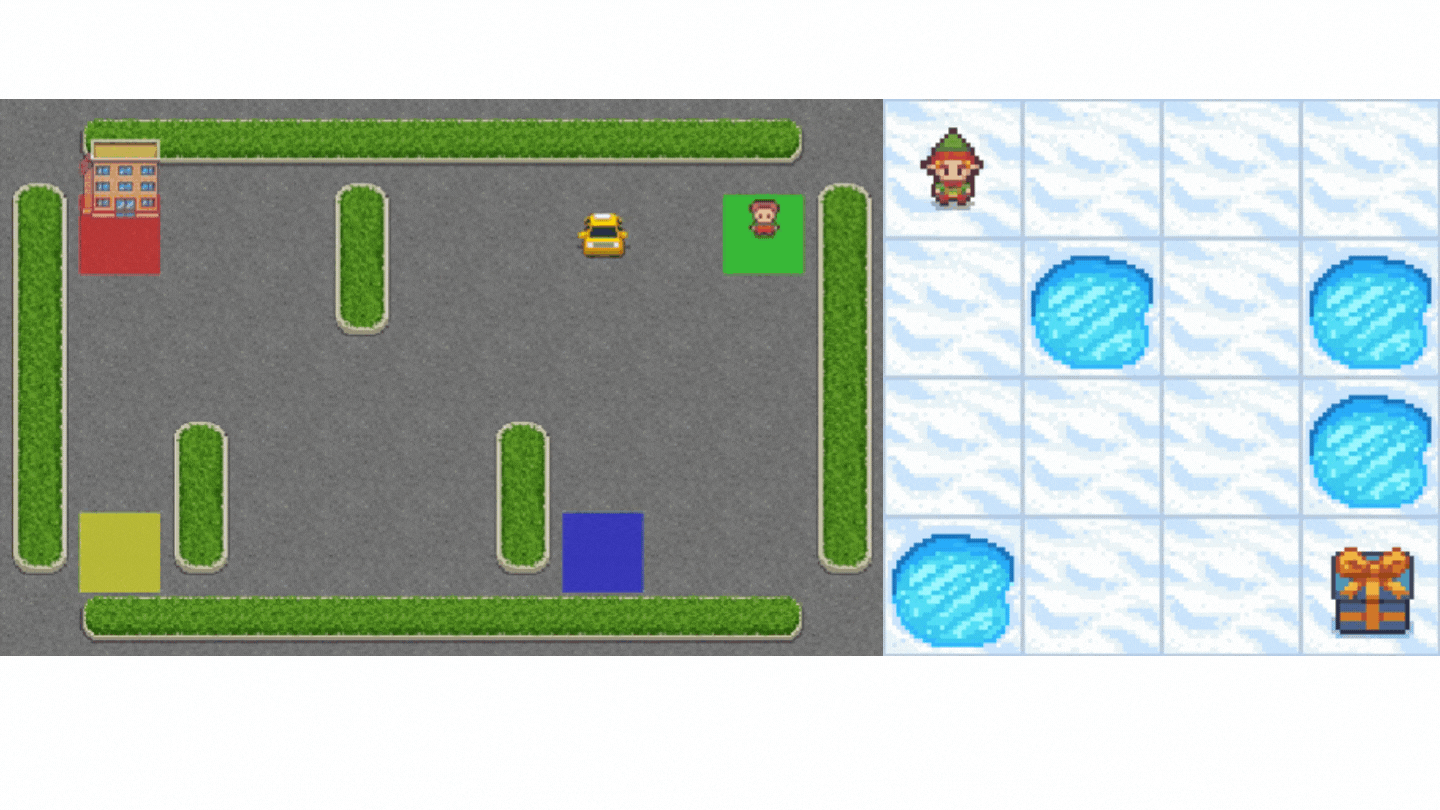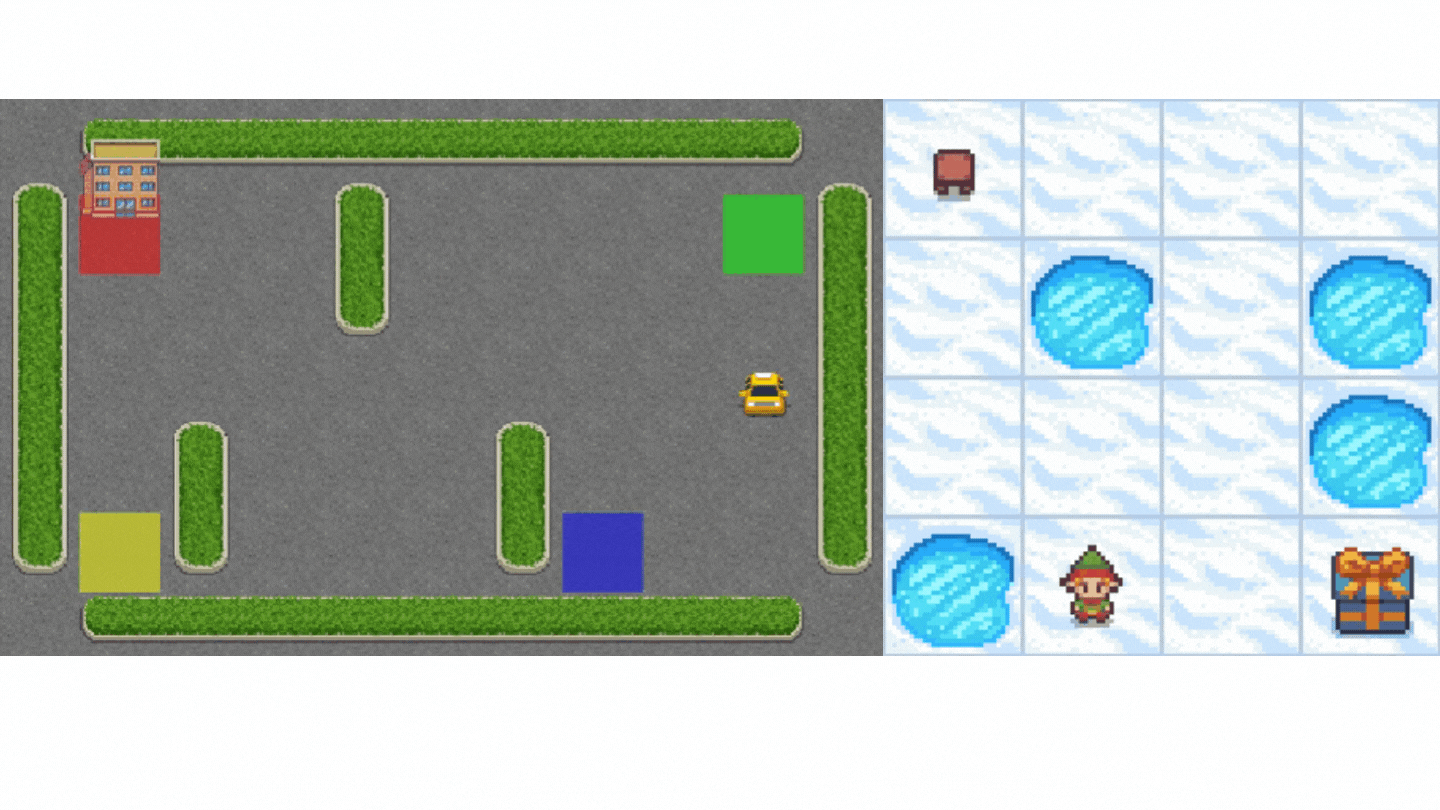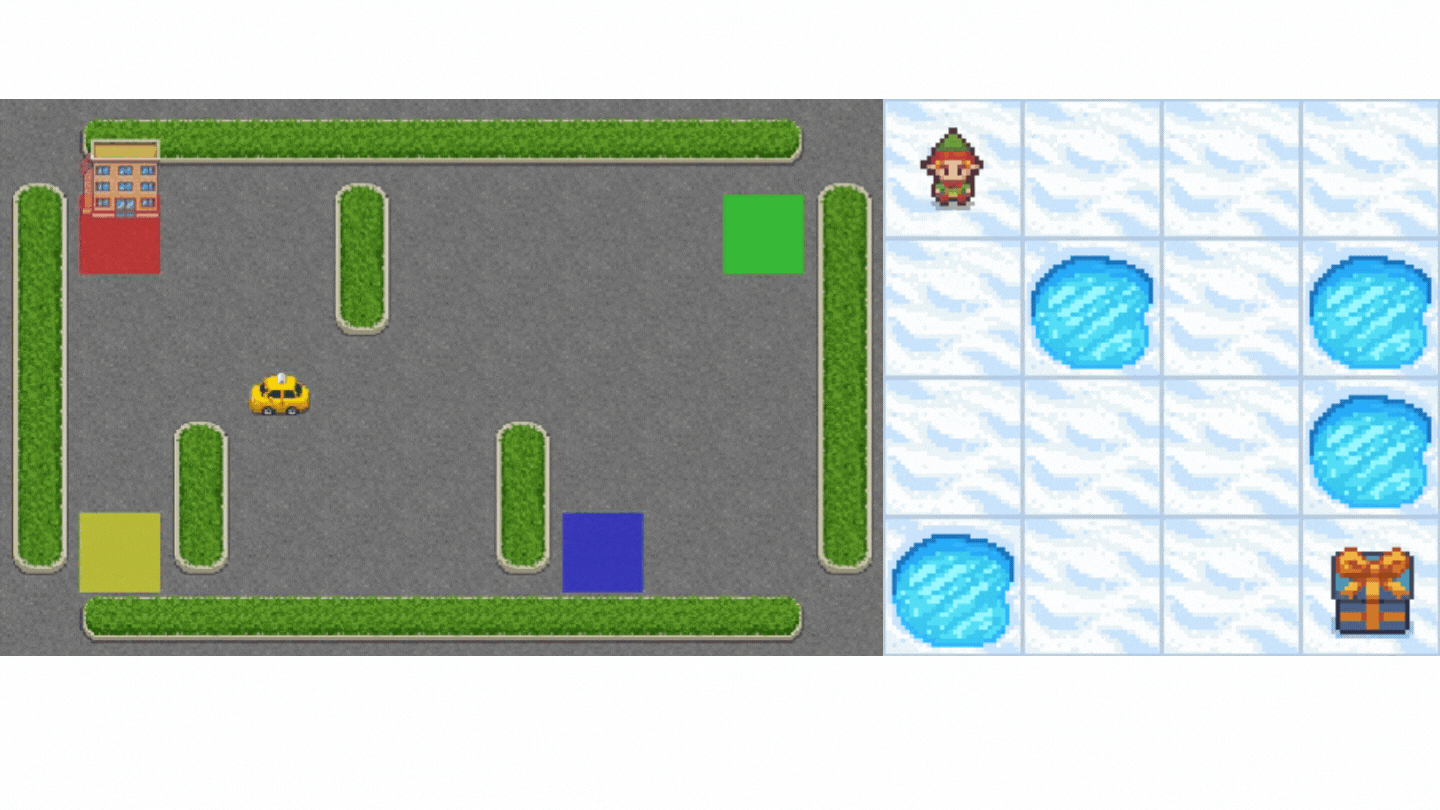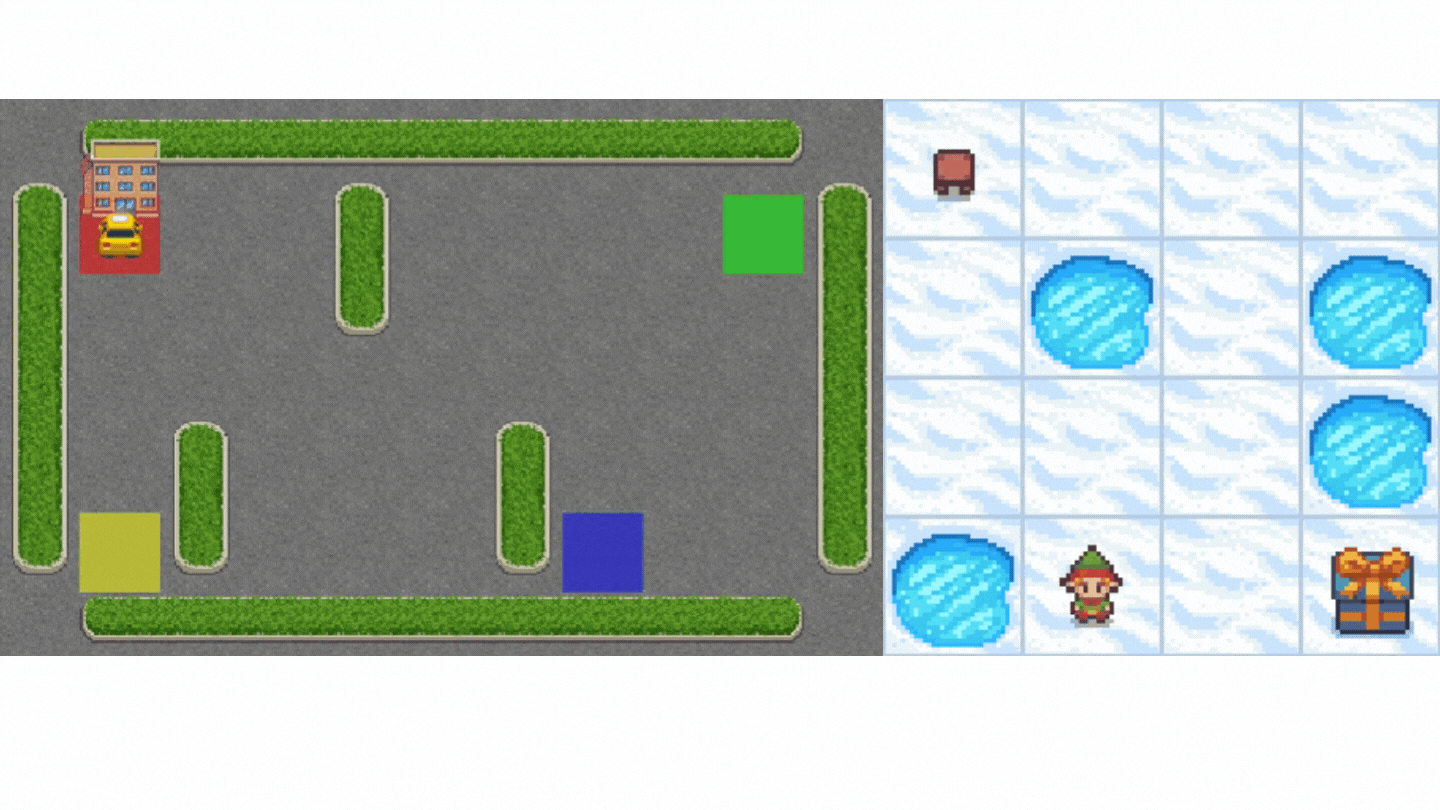 +
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
+
+To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**To start the hands-on click on the Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+
+We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
+
+By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
+
# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
+
+Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
+
+To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
+
+To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
+
+For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**To start the hands-on click on the Open In Colab button** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+
+We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
+
+By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
+
# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
 -In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations.
-
+In this notebook, **you'll code your first Reinforcement Learning agent from scratch** to play FrozenLake ❄️ using Q-Learning, share it with the community, and experiment with different configurations.
⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
-###🎮 Environments:
+###🎮 Environments:
-- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
-- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
-###📚 RL-Library:
+###📚 RL-Library:
- Python and NumPy
-- [Gym](https://www.gymlibrary.dev/)
+- [Gymnasium](https://gymnasium.farama.org/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -28,21 +62,19 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use **Gym**, the environment library.
-- Be able to code from scratch a Q-Learning agent.
+- Be able to use **Gymnasium**, the environment library.
+- Be able to code a Q-Learning agent from scratch.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
-
-
-
## This notebook is from the Deep Reinforcement Learning Course
+
-In this notebook, **you'll code from scratch your first Reinforcement Learning agent** playing FrozenLake ❄️ using Q-Learning, share it to the community, and experiment with different configurations.
-
+In this notebook, **you'll code your first Reinforcement Learning agent from scratch** to play FrozenLake ❄️ using Q-Learning, share it with the community, and experiment with different configurations.
⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
-###🎮 Environments:
+###🎮 Environments:
-- [FrozenLake-v1](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
-- [Taxi-v3](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
-###📚 RL-Library:
+###📚 RL-Library:
- Python and NumPy
-- [Gym](https://www.gymlibrary.dev/)
+- [Gymnasium](https://gymnasium.farama.org/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -28,21 +62,19 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use **Gym**, the environment library.
-- Be able to code from scratch a Q-Learning agent.
+- Be able to use **Gymnasium**, the environment library.
+- Be able to code a Q-Learning agent from scratch.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
-
-
-
## This notebook is from the Deep Reinforcement Learning Course
+
 In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
-- 🤖 Train **agents in unique environments**
+- 🤖 Train **agents in unique environments**
And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
@@ -52,24 +84,25 @@ Don’t forget to **sign up to the course
The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
+
Before diving into the notebook, you need to:
-🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
+🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
## A small recap of Q-Learning
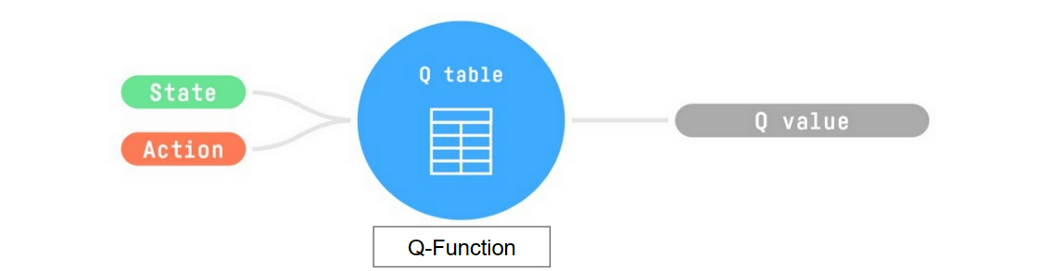
-- The *Q-Learning* **is the RL algorithm that**
+*Q-Learning* **is the RL algorithm that**:
+
+- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+
+- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
- - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
-
- - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
-
In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
-- 🤖 Train **agents in unique environments**
+- 🤖 Train **agents in unique environments**
And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
@@ -52,24 +84,25 @@ Don’t forget to **sign up to the course
The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
+
Before diving into the notebook, you need to:
-🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
+🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
## A small recap of Q-Learning
-- The *Q-Learning* **is the RL algorithm that**
+*Q-Learning* **is the RL algorithm that**:
+
+- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+
+- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
- - Trains *Q-Function*, an **action-value function** that contains, as internal memory, a *Q-table* **that contains all the state-action pair values.**
-
- - Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
-
 - When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
-
+
- And if we **have an optimal Q-function**, we
-have an optimal policy,since we **know for each state, what is the best action to take.**
+have an optimal policy, since we **know for, each state, the best action to take.**
- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
-
+
- And if we **have an optimal Q-function**, we
-have an optimal policy,since we **know for each state, what is the best action to take.**
+have an optimal policy, since we **know for, each state, the best action to take.**
 @@ -85,7 +118,6 @@ This is the Q-Learning pseudocode:
# Let's code our first Reinforcement Learning algorithm 🚀
-
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
@@ -100,26 +132,25 @@ Hence the following cell will install the libraries and create and run a virtual
We’ll install multiple ones:
-- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.
+- `gymnasium`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments.
- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
- `numpy`: Used for handling our Q-table.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
-You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning
+You can see here all the Deep RL models available (if they use Q Learning) here 👉 https://huggingface.co/models?other=q-learning
-```python
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
```
-```python
-%%capture
-!sudo apt-get update
-!apt install python-opengl ffmpeg xvfb
-!pip3 install pyvirtualdisplay
+```bash
+sudo apt-get update
+apt install python-opengl ffmpeg xvfb
+pip3 install pyvirtualdisplay
```
-To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
@@ -144,7 +175,7 @@ In addition to the installed libraries, we also use:
```python
import numpy as np
-import gym
+import gymnasium as gym
import random
import imageio
import os
@@ -158,12 +189,12 @@ We're now ready to code our Q-Learning algorithm 🔥
# Part 1: Frozen Lake ⛄ (non slippery version)
-## Create and understand [FrozenLake environment ⛄]((https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+## Create and understand [FrozenLake environment ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
---
-💡 A good habit when you start to use an environment is to check its documentation
+💡 A good habit when you start to use an environment is to check its documentation
-👉 https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
+👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
---
@@ -180,17 +211,20 @@ The environment has two modes:
- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
-For now let's keep it simple with the 4x4 map and non-slippery
+For now let's keep it simple with the 4x4 map and non-slippery.
+We add a parameter called `render_mode` that specifies how the environment should be visualised. In our case because we **want to record a video of the environment at the end, we need to set render_mode to rgb_array**.
+
+As [explained in the documentation](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) “rgb_array”: Return a single frame representing the current state of the environment. A frame is a np.ndarray with shape (x, y, 3) representing RGB values for an x-by-y pixel image.
```python
-# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version
+# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version and render_mode="rgb_array"
env = gym.make() # TODO use the correct parameters
```
### Solution
```python
-env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
```
You can create your own custom grid like this:
@@ -212,7 +246,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
+We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
@@ -239,6 +273,7 @@ Reward function 💰:
- Reach frozen: 0
## Create and Initialize the Q-table 🗄️
+
(👀 Step 1 of the pseudocode)
@@ -85,7 +118,6 @@ This is the Q-Learning pseudocode:
# Let's code our first Reinforcement Learning algorithm 🚀
-
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
@@ -100,26 +132,25 @@ Hence the following cell will install the libraries and create and run a virtual
We’ll install multiple ones:
-- `gym`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments. We use `gym==0.24` since it contains a nice Taxi-v3 UI version.
+- `gymnasium`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments.
- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
- `numpy`: Used for handling our Q-table.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
-You can see here all the Deep RL models available (if they use Q Learning) 👉 https://huggingface.co/models?other=q-learning
+You can see here all the Deep RL models available (if they use Q Learning) here 👉 https://huggingface.co/models?other=q-learning
-```python
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
```
-```python
-%%capture
-!sudo apt-get update
-!apt install python-opengl ffmpeg xvfb
-!pip3 install pyvirtualdisplay
+```bash
+sudo apt-get update
+apt install python-opengl ffmpeg xvfb
+pip3 install pyvirtualdisplay
```
-To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks for this trick, **we will be able to run our virtual screen.**
+To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
@@ -144,7 +175,7 @@ In addition to the installed libraries, we also use:
```python
import numpy as np
-import gym
+import gymnasium as gym
import random
import imageio
import os
@@ -158,12 +189,12 @@ We're now ready to code our Q-Learning algorithm 🔥
# Part 1: Frozen Lake ⛄ (non slippery version)
-## Create and understand [FrozenLake environment ⛄]((https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
+## Create and understand [FrozenLake environment ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
---
-💡 A good habit when you start to use an environment is to check its documentation
+💡 A good habit when you start to use an environment is to check its documentation
-👉 https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
+👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
---
@@ -180,17 +211,20 @@ The environment has two modes:
- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
-For now let's keep it simple with the 4x4 map and non-slippery
+For now let's keep it simple with the 4x4 map and non-slippery.
+We add a parameter called `render_mode` that specifies how the environment should be visualised. In our case because we **want to record a video of the environment at the end, we need to set render_mode to rgb_array**.
+
+As [explained in the documentation](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) “rgb_array”: Return a single frame representing the current state of the environment. A frame is a np.ndarray with shape (x, y, 3) representing RGB values for an x-by-y pixel image.
```python
-# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version
+# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version and render_mode="rgb_array"
env = gym.make() # TODO use the correct parameters
```
### Solution
```python
-env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
```
You can create your own custom grid like this:
@@ -212,7 +246,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
+We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
@@ -239,6 +273,7 @@ Reward function 💰:
- Reach frozen: 0
## Create and Initialize the Q-table 🗄️
+
(👀 Step 1 of the pseudocode)
 @@ -248,17 +283,17 @@ It's time to initialize our Q-table! To know how many rows (states) and columns
```python
-state_space =
+state_space =
print("There are ", state_space, " possible states")
-action_space =
+action_space =
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
def initialize_q_table(state_space, action_space):
- Qtable =
+ Qtable =
return Qtable
```
@@ -288,12 +323,13 @@ Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
## Define the greedy policy 🤖
+
Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
- Epsilon-greedy policy (acting policy)
- Greedy-policy (updating policy)
-Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.
+The greedy policy will also be the final policy we'll have when the Q-learning agent completes training. The greedy policy is used to select an action using the Q-table.
@@ -248,17 +283,17 @@ It's time to initialize our Q-table! To know how many rows (states) and columns
```python
-state_space =
+state_space =
print("There are ", state_space, " possible states")
-action_space =
+action_space =
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
def initialize_q_table(state_space, action_space):
- Qtable =
+ Qtable =
return Qtable
```
@@ -288,12 +323,13 @@ Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
## Define the greedy policy 🤖
+
Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
- Epsilon-greedy policy (acting policy)
- Greedy-policy (updating policy)
-Greedy policy will also be the final policy we'll have when the Q-learning agent will be trained. The greedy policy is used to select an action from the Q-table.
+The greedy policy will also be the final policy we'll have when the Q-learning agent completes training. The greedy policy is used to select an action using the Q-table.
 @@ -301,8 +337,8 @@ Greedy policy will also be the final policy we'll have when the Q-learning agent
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
- action =
-
+ action =
+
return action
```
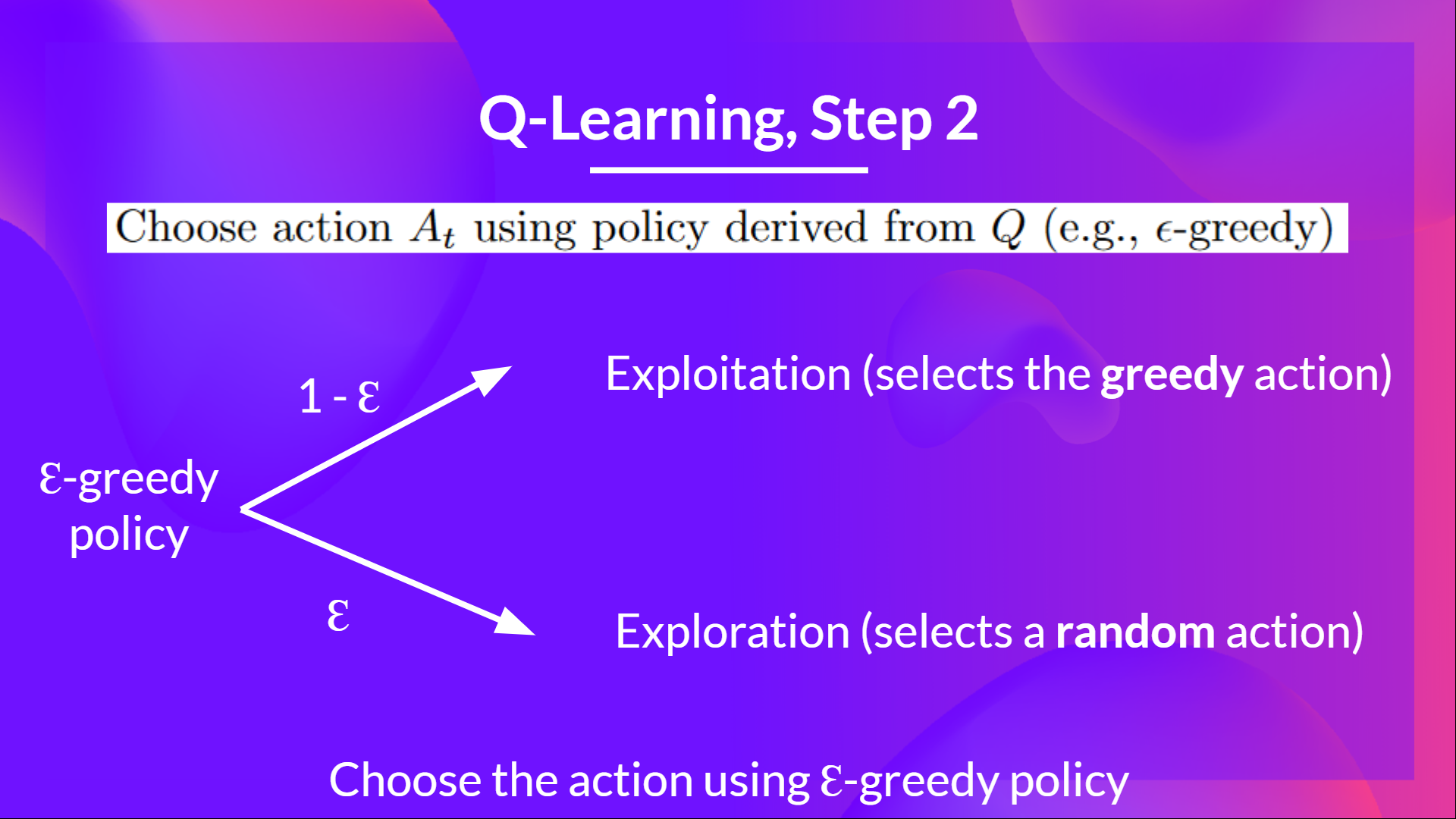
@@ -324,9 +360,9 @@ The idea with epsilon-greedy:
- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
-- With *probability ɛ*: we do **exploration** (trying random action).
+- With *probability ɛ*: we do **exploration** (trying a random action).
-And as the training goes, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
+As the training continues, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
@@ -301,8 +337,8 @@ Greedy policy will also be the final policy we'll have when the Q-learning agent
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
- action =
-
+ action =
+
return action
```
@@ -324,9 +360,9 @@ The idea with epsilon-greedy:
- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
-- With *probability ɛ*: we do **exploration** (trying random action).
+- With *probability ɛ*: we do **exploration** (trying a random action).
-And as the training goes, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
+As the training continues, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
 @@ -334,16 +370,16 @@ And as the training goes, we progressively **reduce the epsilon value since we w
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
- random_num =
+ random_num =
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
- action =
+ action =
# else --> exploration
else:
action = # Take a random action
-
+
return action
```
@@ -366,7 +402,8 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+
+The exploration related hyperparamters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
@@ -403,7 +440,7 @@ For episode in the total of training episodes:
Reduce epsilon (since we need less and less exploration)
Reset the environment
- For step in max timesteps:
+ For step in max timesteps:
Choose the action At using epsilon greedy policy
Take the action (a) and observe the outcome state(s') and reward (r)
Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
@@ -417,26 +454,27 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ terminated = False
+ truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
- action =
+ action =
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
- new_state, reward, done, info =
+ new_state, reward, terminated, truncated, info =
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
- Qtable[state][action] =
+ Qtable[state][action] =
- # If done, finish the episode
- if done:
+ # If terminated or truncated finish the episode
+ if terminated or truncated:
break
-
+
# Our next state is the new state
state = new_state
return Qtable
@@ -450,9 +488,10 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
# Reset the environment
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ terminated = False
+ truncated = False
# repeat
for step in range(max_steps):
@@ -461,15 +500,15 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
- new_state, reward, done, info = env.step(action)
+ new_state, reward, terminated, truncated, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] = Qtable[state][action] + learning_rate * (
reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
)
- # If done, finish the episode
- if done:
+ # If terminated or truncated finish the episode
+ if terminated or truncated:
break
# Our next state is the new state
@@ -505,20 +544,21 @@ def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in tqdm(range(n_eval_episodes)):
if seed:
- state = env.reset(seed=seed[episode])
+ state, info = env.reset(seed=seed[episode])
else:
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ truncated = False
+ terminated = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum expected future reward given that state
action = greedy_policy(Q, state)
- new_state, reward, done, info = env.step(action)
+ new_state, reward, terminated, truncated, info = env.step(action)
total_rewards_ep += reward
- if done:
+ if terminated or truncated:
break
state = new_state
episode_rewards.append(total_rewards_ep)
@@ -571,15 +611,18 @@ def record_video(env, Qtable, out_directory, fps=1):
:param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
"""
images = []
- done = False
- state = env.reset(seed=random.randint(0, 500))
- img = env.render(mode="rgb_array")
+ terminated = False
+ truncated = False
+ state, info = env.reset(seed=random.randint(0, 500))
+ img = env.render()
images.append(img)
- while not done:
+ while not terminated or truncated:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
- state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
- img = env.render(mode="rgb_array")
+ state, reward, terminated, truncated, info = env.step(
+ action
+ ) # We directly put next_state = state for recording logic
+ img = env.render()
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
```
@@ -674,7 +717,7 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
```python
-
+
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
@@ -720,7 +763,7 @@ By using `push_to_hub` **you evaluate, record a replay, generate a model card of
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share with the community an agent that others can use** 💾
+- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
@@ -782,21 +825,21 @@ repo_name = "q-FrozenLake-v1-4x4-noSlippery"
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
-Congrats 🥳 you've just implemented from scratch, trained and uploaded your first Reinforcement Learning agent.
-FrozenLake-v1 no_slippery is very simple environment, let's try an harder one 🔥.
+Congrats 🥳 you've just implemented from scratch, trained, and uploaded your first Reinforcement Learning agent.
+FrozenLake-v1 no_slippery is very simple environment, let's try a harder one 🔥.
# Part 2: Taxi-v3 🚖
-## Create and understand [Taxi-v3 🚕](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+## Create and understand [Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
---
-💡 A good habit when you start to use an environment is to check its documentation
+💡 A good habit when you start to use an environment is to check its documentation
-👉 https://www.gymlibrary.dev/environments/toy_text/taxi/
+👉 https://gymnasium.farama.org/environments/toy_text/taxi/
---
-In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
+In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
@@ -805,7 +848,7 @@ When the episode starts, **the taxi starts off at a random square** and the pass
```python
-env = gym.make("Taxi-v3")
+env = gym.make("Taxi-v3", render_mode="rgb_array")
```
There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
@@ -844,6 +887,7 @@ print("Q-table shape: ", Qtable_taxi.shape)
```
## Define the hyperparameters ⚙️
+
⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
```python
@@ -978,6 +1022,7 @@ Qtable_taxi
```
## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
+
- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
@@ -999,13 +1044,12 @@ model = {
```python
username = "" # FILL THIS
-repo_name = ""
+repo_name = "" # FILL THIS
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
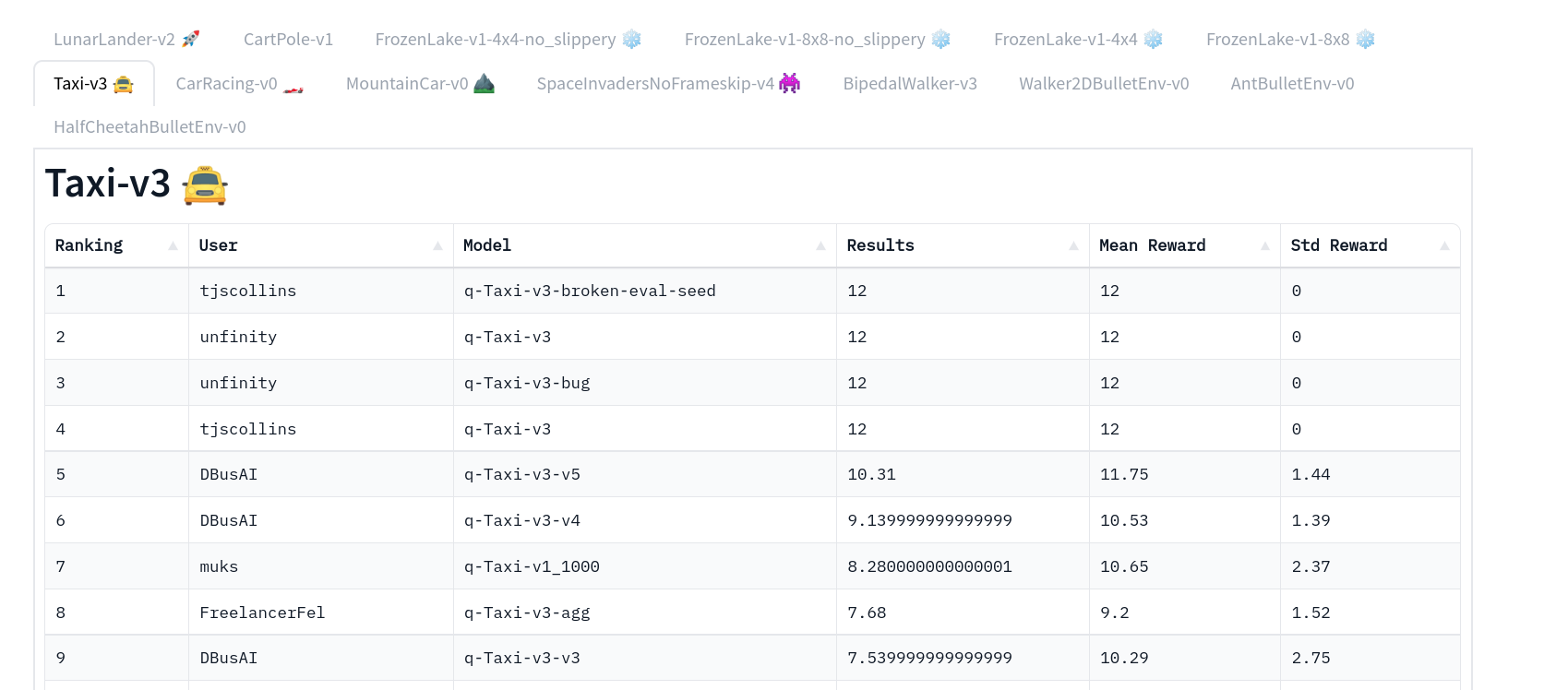
-Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+Now that it's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
-⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠
@@ -334,16 +370,16 @@ And as the training goes, we progressively **reduce the epsilon value since we w
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
- random_num =
+ random_num =
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
- action =
+ action =
# else --> exploration
else:
action = # Take a random action
-
+
return action
```
@@ -366,7 +402,8 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```
## Define the hyperparameters ⚙️
-The exploration related hyperparamters are some of the most important ones.
+
+The exploration related hyperparamters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
@@ -403,7 +440,7 @@ For episode in the total of training episodes:
Reduce epsilon (since we need less and less exploration)
Reset the environment
- For step in max timesteps:
+ For step in max timesteps:
Choose the action At using epsilon greedy policy
Take the action (a) and observe the outcome state(s') and reward (r)
Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
@@ -417,26 +454,27 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ terminated = False
+ truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
- action =
+ action =
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
- new_state, reward, done, info =
+ new_state, reward, terminated, truncated, info =
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
- Qtable[state][action] =
+ Qtable[state][action] =
- # If done, finish the episode
- if done:
+ # If terminated or truncated finish the episode
+ if terminated or truncated:
break
-
+
# Our next state is the new state
state = new_state
return Qtable
@@ -450,9 +488,10 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
# Reset the environment
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ terminated = False
+ truncated = False
# repeat
for step in range(max_steps):
@@ -461,15 +500,15 @@ def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_st
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
- new_state, reward, done, info = env.step(action)
+ new_state, reward, terminated, truncated, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] = Qtable[state][action] + learning_rate * (
reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
)
- # If done, finish the episode
- if done:
+ # If terminated or truncated finish the episode
+ if terminated or truncated:
break
# Our next state is the new state
@@ -505,20 +544,21 @@ def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in tqdm(range(n_eval_episodes)):
if seed:
- state = env.reset(seed=seed[episode])
+ state, info = env.reset(seed=seed[episode])
else:
- state = env.reset()
+ state, info = env.reset()
step = 0
- done = False
+ truncated = False
+ terminated = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum expected future reward given that state
action = greedy_policy(Q, state)
- new_state, reward, done, info = env.step(action)
+ new_state, reward, terminated, truncated, info = env.step(action)
total_rewards_ep += reward
- if done:
+ if terminated or truncated:
break
state = new_state
episode_rewards.append(total_rewards_ep)
@@ -571,15 +611,18 @@ def record_video(env, Qtable, out_directory, fps=1):
:param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
"""
images = []
- done = False
- state = env.reset(seed=random.randint(0, 500))
- img = env.render(mode="rgb_array")
+ terminated = False
+ truncated = False
+ state, info = env.reset(seed=random.randint(0, 500))
+ img = env.render()
images.append(img)
- while not done:
+ while not terminated or truncated:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
- state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
- img = env.render(mode="rgb_array")
+ state, reward, terminated, truncated, info = env.step(
+ action
+ ) # We directly put next_state = state for recording logic
+ img = env.render()
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
```
@@ -674,7 +717,7 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
```python
-
+
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
@@ -720,7 +763,7 @@ By using `push_to_hub` **you evaluate, record a replay, generate a model card of
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share with the community an agent that others can use** 💾
+- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
@@ -782,21 +825,21 @@ repo_name = "q-FrozenLake-v1-4x4-noSlippery"
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
-Congrats 🥳 you've just implemented from scratch, trained and uploaded your first Reinforcement Learning agent.
-FrozenLake-v1 no_slippery is very simple environment, let's try an harder one 🔥.
+Congrats 🥳 you've just implemented from scratch, trained, and uploaded your first Reinforcement Learning agent.
+FrozenLake-v1 no_slippery is very simple environment, let's try a harder one 🔥.
# Part 2: Taxi-v3 🚖
-## Create and understand [Taxi-v3 🚕](https://www.gymlibrary.dev/environments/toy_text/taxi/)
+## Create and understand [Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
---
-💡 A good habit when you start to use an environment is to check its documentation
+💡 A good habit when you start to use an environment is to check its documentation
-👉 https://www.gymlibrary.dev/environments/toy_text/taxi/
+👉 https://gymnasium.farama.org/environments/toy_text/taxi/
---
-In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
+In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
@@ -805,7 +848,7 @@ When the episode starts, **the taxi starts off at a random square** and the pass
```python
-env = gym.make("Taxi-v3")
+env = gym.make("Taxi-v3", render_mode="rgb_array")
```
There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
@@ -844,6 +887,7 @@ print("Q-table shape: ", Qtable_taxi.shape)
```
## Define the hyperparameters ⚙️
+
⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
```python
@@ -978,6 +1022,7 @@ Qtable_taxi
```
## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
+
- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
@@ -999,13 +1044,12 @@ model = {
```python
username = "" # FILL THIS
-repo_name = ""
+repo_name = "" # FILL THIS
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
-Now that's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+Now that it's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
-⚠ To see your entry, you need to go to the bottom of the leaderboard page and **click on refresh** ⚠
 @@ -1069,36 +1113,37 @@ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"
```
## Some additional challenges 🏆
-The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
+
+The best way to learn **is to try things on your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
-Here are some ideas to achieve so:
+Here are some ideas to climb up the leaderboard:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done.
* **Push your new trained model** on the Hub 🔥
-Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not using FrozenLake-v1 slippery version? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not use FrozenLake-v1 slippery version? Check how they work [using the gymnasium documentation](https://gymnasium.farama.org/) and have fun 🎉.
_____________________________________________________________________
Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
Understanding Q-Learning is an **important step to understanding value-based methods.**
-In the next Unit with Deep Q-Learning, we'll see that creating and updating a Q-table was a good strategy — **however, this is not scalable.**
+In the next Unit with Deep Q-Learning, we'll see that while creating and updating a Q-table was a good strategy — **however, it is not scalable.**
-For instance, imagine you create an agent that learns to play Doom.
+For instance, imagine you create an agent that learns to play Doom.
@@ -1069,36 +1113,37 @@ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"
```
## Some additional challenges 🏆
-The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
+
+The best way to learn **is to try things on your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
-Here are some ideas to achieve so:
+Here are some ideas to climb up the leaderboard:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done.
* **Push your new trained model** on the Hub 🔥
-Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not using FrozenLake-v1 slippery version? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
+Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not use FrozenLake-v1 slippery version? Check how they work [using the gymnasium documentation](https://gymnasium.farama.org/) and have fun 🎉.
_____________________________________________________________________
Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
Understanding Q-Learning is an **important step to understanding value-based methods.**
-In the next Unit with Deep Q-Learning, we'll see that creating and updating a Q-table was a good strategy — **however, this is not scalable.**
+In the next Unit with Deep Q-Learning, we'll see that while creating and updating a Q-table was a good strategy — **however, it is not scalable.**
-For instance, imagine you create an agent that learns to play Doom.
+For instance, imagine you create an agent that learns to play Doom.
 -Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
+Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
-That's why we'll study, in the next unit, Deep Q-Learning, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
+That's why we'll study Deep Q-Learning in the next unit, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
-Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
+Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
-That's why we'll study, in the next unit, Deep Q-Learning, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
+That's why we'll study Deep Q-Learning in the next unit, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
 -See you on Unit 3! 🔥
+See you in Unit 3! 🔥
-## Keep learning, stay awesome 🤗
\ No newline at end of file
+## Keep learning, stay awesome 🤗
-See you on Unit 3! 🔥
+See you in Unit 3! 🔥
-## Keep learning, stay awesome 🤗
\ No newline at end of file
+## Keep learning, stay awesome 🤗