diff --git a/notebooks/unit2/unit2.ipynb b/notebooks/unit2/unit2.ipynb
index c9fa7ca..c7477e6 100644
--- a/notebooks/unit2/unit2.ipynb
+++ b/notebooks/unit2/unit2.ipynb
@@ -926,6 +926,7 @@
" \"\"\"\n",
" Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.\n",
" :param env: The evaluation environment\n",
+ " :param max_steps: Maximum number of steps per episode\n",
" :param n_eval_episodes: Number of episode to evaluate the agent\n",
" :param Q: The Q-table\n",
" :param seed: The evaluation seed array (for taxi-v3)\n",
@@ -966,7 +967,7 @@
"## Evaluate our Q-Learning agent 📈\n",
"\n",
"- Usually, you should have a mean reward of 1.0\n",
- "- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex."
+ "- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://gymnasium.farama.org/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex."
]
},
{
diff --git a/units/en/unit2/glossary.mdx b/units/en/unit2/glossary.mdx
index b44d40f..f76ea52 100644
--- a/units/en/unit2/glossary.mdx
+++ b/units/en/unit2/glossary.mdx
@@ -11,7 +11,7 @@ This is a community-created glossary. Contributions are welcomed!
### Among the value-based methods, we can find two main strategies
- **The state-value function.** For each state, the state-value function is the expected return if the agent starts in that state and follows the policy until the end.
-- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state and takes an action. Then it follows the policy forever after.
+- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
### Epsilon-greedy strategy:
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index 6661341..7207c79 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -93,16 +93,16 @@ Before diving into the notebook, you need to:
*Q-Learning* **is the RL algorithm that**:
-- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
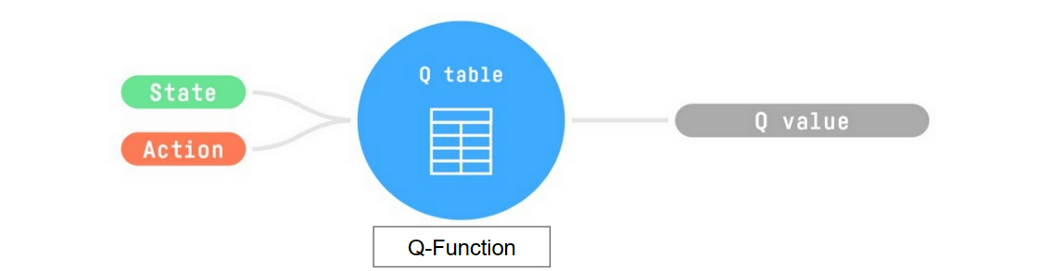 -- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
-- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
 diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec32172..5f46722 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -113,7 +113,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec32172..5f46722 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -113,7 +113,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**