diff --git a/units/en/unit4/policy-gradient.mdx b/units/en/unit4/policy-gradient.mdx
index dc17db5..fbd0740 100644
--- a/units/en/unit4/policy-gradient.mdx
+++ b/units/en/unit4/policy-gradient.mdx
@@ -2,7 +2,7 @@
## Getting the big picture
-We just learned that policy-gradient methods aim to find parameters ////theta //) that **maximize the expected return**.
+We just learned that policy-gradient methods aim to find parameters (\\ \theta \\) that **maximize the expected return**.
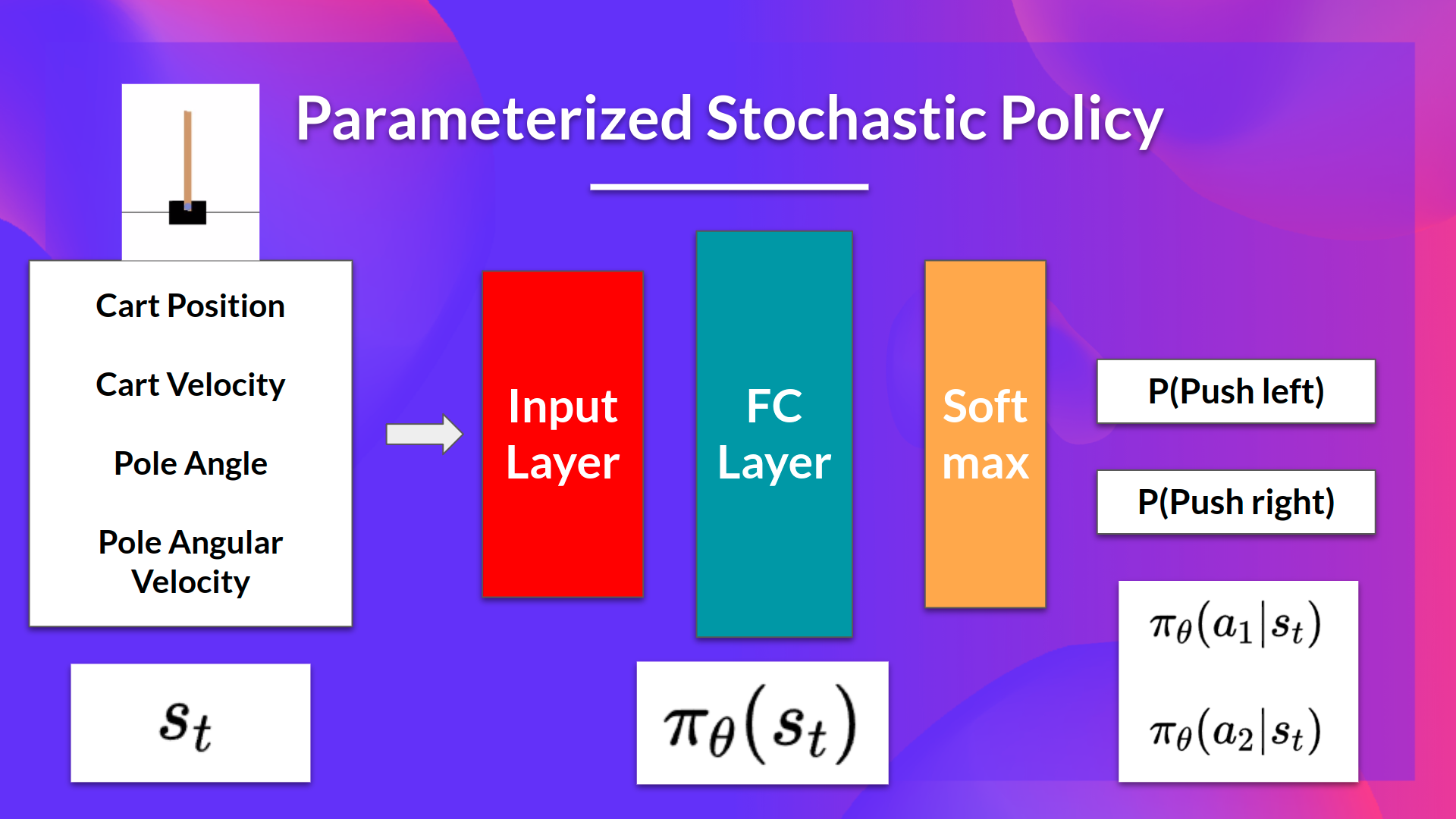
The idea is that we have a *parameterized stochastic policy*. In our case, a neural network outputs a probability distribution over actions. The probability of taking each action is also called *action preference*.
@@ -10,7 +10,7 @@ If we take the example of CartPole-v1:
- As input, we have a state.
- As output, we have a probability distribution over actions at that state.
-
+
Our goal with policy-gradient is to **control the probability distribution of actions** by tuning the policy such that **good actions (that maximize the return) are sampled more frequently in the future.**
Each time the agent interacts with the environment, we tweak the parameters such that good actions will be sampled more likely in the future.
@@ -20,7 +20,7 @@ But **how we're going to optimize the weights using the expected return**?
The idea is that we're going to **let the agent interact during an episode**. And if we win the episode, we consider that each action taken was good and must be more sampled in the future
since they lead to win.
-So for each state-action pair, we want to increase the //(P(a|s)//): the probability of taking that action at that state. Or decrease if we lost.
+So for each state-action pair, we want to increase the \\(P(a|s)\\): the probability of taking that action at that state. Or decrease if we lost.
The Policy-gradient algorithm (simplified) looks like this:
@@ -55,6 +55,9 @@ Let's detail a little bit more this formula:
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(tau\\) (that probability depends on (\\theta\\) since it defines the policy that it uses to select the actions of the trajectory which as an impact of the states visited).
+
+
+
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given $\theta$, and the return of this trajectory.
Our objective then is to maximize the expected cumulative rewards by finding \\(\theta \\) that will output the best action probability distributions:
@@ -68,9 +71,10 @@ Our objective then is to maximize the expected cumulative rewards by finding \\(
Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
Our update step for gradient-ascent is:
-\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\J(\theta)\\).
+(\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
+
+We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\(J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it would imply calculating the probability of each possible trajectory which is computationally super expensive.
@@ -78,8 +82,7 @@ We want then to **calculate a gradient estimation with a sample-based estimate (
2. We have another problem that I detail in the optional next section. That is, to differentiate this objective function, we need to differentiate the state distribution, also called Markov Decision Process dynamics. This is attached to the environment. It gives us the probability of the environment going into the next state, given the current state and the action taken by the agent. The problem is that we can't differentiate it because we might not know about it.
-TODO: add maths of jtheta
-TODO: Add markov decision dynamics
+
Fortunately we're going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
diff --git a/units/en/unit4/what-are-policy-based-methods.mdx b/units/en/unit4/what-are-policy-based-methods.mdx
index 5f0fa4e..2ebed11 100644
--- a/units/en/unit4/what-are-policy-based-methods.mdx
+++ b/units/en/unit4/what-are-policy-based-methods.mdx
@@ -14,7 +14,7 @@ We studied in the first unit, that we had two methods to find (most of the time
- In *value-Based methods*, we learn a value function.
- The idea then is that an optimal value function leads to an optimal policy \\(\pi^{*}\\).
- - Our objective is to **minimize the loss between the predicted and target value to approximate the true action-value function.
+ - Our objective is to **minimize the loss between the predicted and target value** to approximate the true action-value function.
- We have a policy, but it's implicit since it **was generated directly from the Value function**. For instance, in Q-Learning, we defined an epsilon-greedy policy.
- On the other hand, in *policy-based methods*, we directly learn to approximate \\(\pi^{*}\\) without having to learn a value function.
@@ -27,18 +27,18 @@ We studied in the first unit, that we had two methods to find (most of the time
- Finally, we'll study the next time *actor-critic* which is a combination of value-based and policy-based methods.
-
+
-Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
+Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_\theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
To do that, we define an objective function \\(J(\theta)\\), that is, the expected cumulative reward, and we **want to find \\(\theta\\) that maximizes this objective function**.
## The difference between policy-based and policy-gradient methods
Policy-gradient methods, what we're going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time *on-policy* since for each update, we only use data (trajectories) collected **by our most recent version of** \\(\pi_\theta\\).
-The difference between these two methods **lies on how we optimize the parameter** //(/theta//):
+The difference between these two methods **lies on how we optimize the parameter** \\(\theta\\):
-- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter //(/theta//) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
-- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter //(/theta//) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
+- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter \\(\theta\\) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
+- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter \\(\theta\\) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
Before diving more into how works policy-gradient methods (the objective function, policy gradient theorem, gradient ascent, etc.), let's study the advantages and disadvantages of policy-based methods.
 +
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given $\theta$, and the return of this trajectory.
Our objective then is to maximize the expected cumulative rewards by finding \\(\theta \\) that will output the best action probability distributions:
@@ -68,9 +71,10 @@ Our objective then is to maximize the expected cumulative rewards by finding \\(
Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
Our update step for gradient-ascent is:
-\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\J(\theta)\\).
+(\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
+
+We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\(J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it would imply calculating the probability of each possible trajectory which is computationally super expensive.
@@ -78,8 +82,7 @@ We want then to **calculate a gradient estimation with a sample-based estimate (
2. We have another problem that I detail in the optional next section. That is, to differentiate this objective function, we need to differentiate the state distribution, also called Markov Decision Process dynamics. This is attached to the environment. It gives us the probability of the environment going into the next state, given the current state and the action taken by the agent. The problem is that we can't differentiate it because we might not know about it.
-TODO: add maths of jtheta
-TODO: Add markov decision dynamics
+
+
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given $\theta$, and the return of this trajectory.
Our objective then is to maximize the expected cumulative rewards by finding \\(\theta \\) that will output the best action probability distributions:
@@ -68,9 +71,10 @@ Our objective then is to maximize the expected cumulative rewards by finding \\(
Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
Our update step for gradient-ascent is:
-\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
-We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\J(\theta)\\).
+(\\ \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
+
+We can repeatedly apply this update state in the hope that \\(\theta)\\ converges to the value that maximizes \\(J(\theta)\\).
However, we have two problems to derivate \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it would imply calculating the probability of each possible trajectory which is computationally super expensive.
@@ -78,8 +82,7 @@ We want then to **calculate a gradient estimation with a sample-based estimate (
2. We have another problem that I detail in the optional next section. That is, to differentiate this objective function, we need to differentiate the state distribution, also called Markov Decision Process dynamics. This is attached to the environment. It gives us the probability of the environment going into the next state, given the current state and the action taken by the agent. The problem is that we can't differentiate it because we might not know about it.
-TODO: add maths of jtheta
-TODO: Add markov decision dynamics
+ +
+ -Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
+Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_\theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
To do that, we define an objective function \\(J(\theta)\\), that is, the expected cumulative reward, and we **want to find \\(\theta\\) that maximizes this objective function**.
## The difference between policy-based and policy-gradient methods
Policy-gradient methods, what we're going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time *on-policy* since for each update, we only use data (trajectories) collected **by our most recent version of** \\(\pi_\theta\\).
-The difference between these two methods **lies on how we optimize the parameter** //(/theta//):
+The difference between these two methods **lies on how we optimize the parameter** \\(\theta\\):
-- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter //(/theta//) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
-- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter //(/theta//) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
+- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter \\(\theta\\) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
+- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter \\(\theta\\) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
Before diving more into how works policy-gradient methods (the objective function, policy gradient theorem, gradient ascent, etc.), let's study the advantages and disadvantages of policy-based methods.
-Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
+Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_\theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
To do that, we define an objective function \\(J(\theta)\\), that is, the expected cumulative reward, and we **want to find \\(\theta\\) that maximizes this objective function**.
## The difference between policy-based and policy-gradient methods
Policy-gradient methods, what we're going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time *on-policy* since for each update, we only use data (trajectories) collected **by our most recent version of** \\(\pi_\theta\\).
-The difference between these two methods **lies on how we optimize the parameter** //(/theta//):
+The difference between these two methods **lies on how we optimize the parameter** \\(\theta\\):
-- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter //(/theta//) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
-- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter //(/theta//) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
+- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter \\(\theta\\) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
+- In *policy-gradient methods*, because we're a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter \\(\theta\\) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
Before diving more into how works policy-gradient methods (the objective function, policy gradient theorem, gradient ascent, etc.), let's study the advantages and disadvantages of policy-based methods.