# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
### Q3: Which of the following statements are true about Monte Carlo method?
### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
Solution
The idea behind Actor-Critic is that we learn two function approximations:
1. A `policy` that controls how our agent acts (π)
2. A `value` function to assist the policy update by measuring how good the action taken is (q)
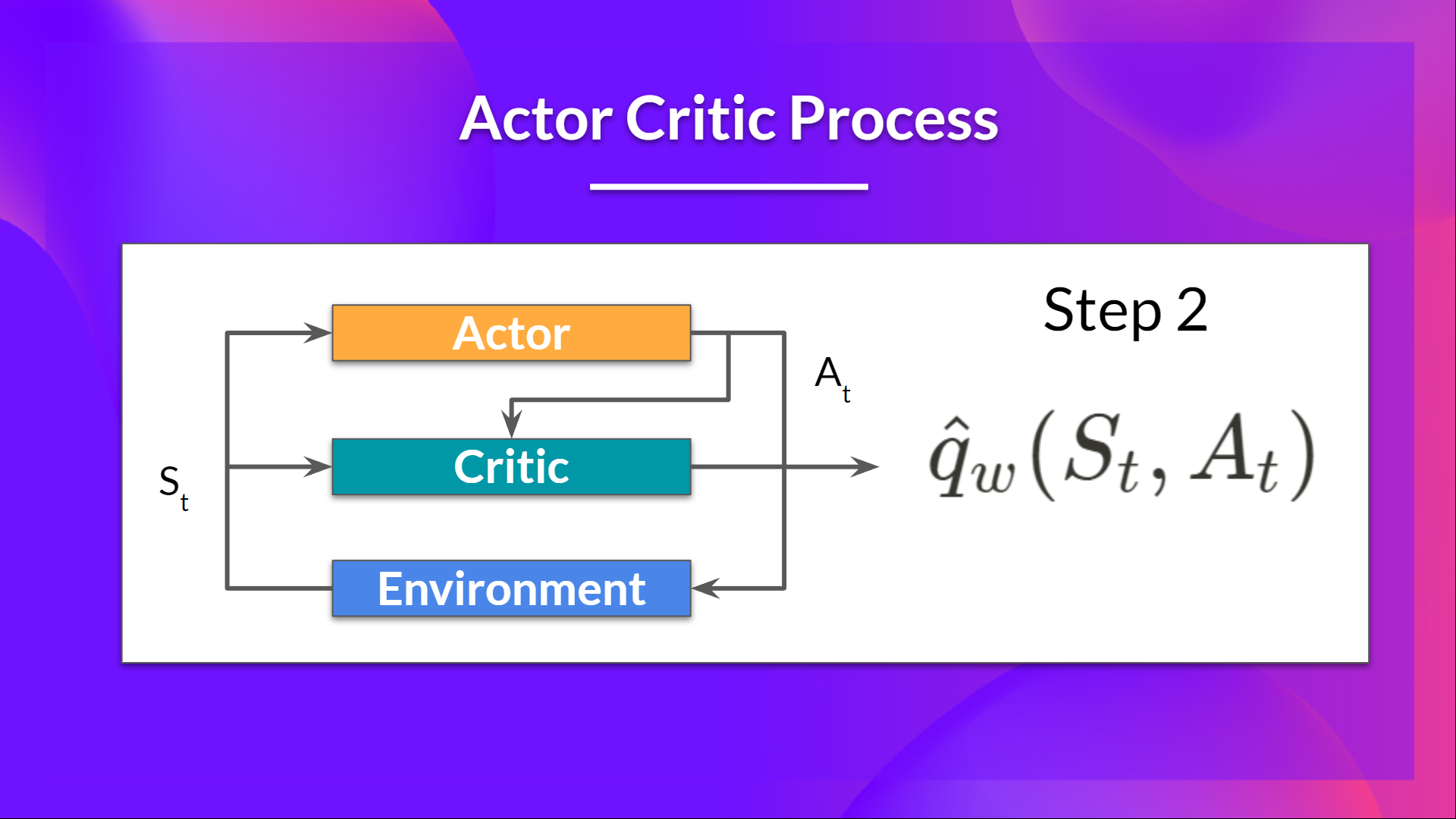
### Q5: Which of the following statements are true about the Actor-Critic Method?
### Q6: What is `Advantage` in the A2C method?
Solution
Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
In other words: how taking that action at a state is better compared to the average value of the state

Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.